Set-based Value Operators for Non-stationary and Uncertain Markov Decision Processes
Abstract
This paper analyzes finite state Markov Decision Processes (MDPs) with uncertain parameters in compact sets and re-examines results from robust MDP via set-based fixed point theory. To this end, we generalize the Bellman and policy evaluation operators to contracting operators on the value function space and denote them as value operators. We lift these value operators to act on sets of value functions and denote them as set-based value operators. We prove that the set-based value operators are contractions in the space of compact value function sets. Leveraging insights from set theory, we generalize the rectangularity condition in classic robust MDP literature to a containment condition for all value operators, which is weaker and can be applied to a larger set of parameter-uncertain MDPs and contracting operators in dynamic programming. We prove that both the rectangularity condition and the containment condition sufficiently ensure that the set-based value operator’s fixed point set contains its own extrema elements. For convex and compact sets of uncertain MDP parameters, we show equivalence between the classic robust value function and the supremum of the fixed point set of the set-based Bellman operator. Under dynamically changing MDP parameters in compact sets, we prove a set convergence result for value iteration, which otherwise may not converge to a single value function. Finally, we derive novel guarantees for probabilistic path planning problems in planet exploration and stratospheric station-keeping.
keywords:
Markov decision process, contraction operator, stochastic control, decision making and autonomy, , ,
1 Introduction
Markov decision process (MDP) is a versatile model for decision making in stochastic environments and is widely used in trajectory planning [1], robotics [20], and operations research [4]. Given state-action costs and transition probabilities, finding an optimal policy of the MDP is equivalent to solving for the fixed point value function of the corresponding Bellman operator.
Many application settings of MDPs, including traffic light control, motion planning, and dexterous manipulation, deal with environmental non-stationarity—dynamically changing MDP cost and transition probabilities due to external factors or the presence of interfering decision makers. This environmental non-stationarity corresponds to uncertainty in the MDP transition and cost parameters and differs from an MDP’s internal stochasticity, which is modeled by stationary stochastic dynamics whose probability distributions do not change over time.
Example 1 (Navigating in changing wind).
An autonomous aircraft navigates in a two-dimensional and time-varying wind field towards a non-stationary target, where the wind field varies between major patterns over time. The aircraft’s transition probabilities are constructed from global averages of local wind observations, and the aircraft’s objective is to reach the location of the non-stationary target, which is also affected by wind. If the wind pattern strictly switches between the discrete wind trends, then the transition uncertainty at state is given by the set . Similarly, the reachability cost of each state-action is also given by . Collectively, we say that the MDP has time-varying parameters at each state , where .
Environmental non-stationarity differs from parameter uncertainty and yet is closely related. Parameter-uncertain dynamic programming assumes that the MDP has stationary yet unknown stochastic dynamics within a bounded set, and its performance can be bounded via worst-case performance in robust MDP, risk-sensitive reinforcement learning, and zero-sum stochastic games—value functions that result from adversarial selections of the MDP parameters. Under environmental non-stationarity, we assume that at every time instance, the MDP parameters are known but will vary in time unpredictably. Environmental non-stationarity is a better assumption than parameter uncertainty for scenarios such as Example 1, where the dynamics are stochastic, observable, non-adversarial, yet time-varying.
Consider dynamic programming under environmental non-stationarity: at every time instance, the dynamic program is updated with respect to known but time-varying MDP parameters. Although interesting and highly relevant to many trajectory planning problems, this setting has no convergence guarantees. In fact, value iteration will most definitely diverge and can be demonstrated using simple examples. Does this mean that dynamic program has no convergence guarantees under environmental non-stationarity?
In this paper, we introduce a set-based framework to non-stationary MDPs that provides convergence guarantees under Hausdorff distance, and demonstrate that this set-based convergence also applies to parameter-uncertain MDPs and is related to dynamic programming robust dynamic programming.
Contributions. For environmental nonstationarity bounded by compact sets, we propose the set-extensions of value operators: a general class of contraction operators that extends the Bellman operator and the policy evaluation operator. We prove the existence of compact fixed point sets of the set-based value operators and show that the set-based value iteration converges. In a non-stationary Markovian environment, standard value iteration may not converge. However, we can show that the point-to-set distance of the resulting value function trajectory to the fixed point set always goes to zero in the limit. We derive a containment condition that is sufficient for the fixed point sets to contain their own extremal elements. Within robust MDPs, we show that the containment condition generalizes the rectangularity condition, such that the optimal worst-case policy, or the robust policy, exists when the containment condition is satisfied. We then derive the relationship between the fixed point sets of 1) the set-based optimistic policy evaluation operator, 2) the set-based robust policy evaluation operator, and 3) the set-based Bellman operator. Given a value operator and a compact MDP parameter uncertainty set, we present an algorithm that computes the bounds of the corresponding fixed point set and derive its convergence guarantees. Finally, we apply our results to the wind-assisted navigation of high altitude platform systems relevant to space exploration [22] and show that our algorithms can be used to derive policies with better guarantees.
Related research. MDP with parameter uncertainty is well studied in robust control and reinforcement learning. In control theory, the worst-case cost-to-go with respect to state-decoupled parameter uncertainties is derived via a minmax variation of the Bellman operator in [5, 8, 15, 21]. The cost-to-go under parameter uncertainty with coupling between states and time steps is similarly bounded in [12, 6]. The effect of statistical uncertainty on the optimal cost-to-go is studied in [15, 12, 21, 23]. Recently, MDP with parameter uncertainty has gained traction in the reinforcement learning community due to the presence of uncertainty in real world problems such as traffic signal control and multi-agent coordination [9, 10, 16]. Most RL research extends the minmax worst-case analysis to methods such as Q-learning and SARSA. Recently, methods for value-based RL using non-contracting operators have been investigated in [3].
As opposed to the worst-case approach to analyzing MDPs under parameter uncertainty, we do not assume adversarial MDP parameter selection. Instead, we derive a set of cost-to-gos that is invariant with respect to the compact parameter uncertainty sets for order-preserving, -contracting operators, a class that the Bellman operator belongs to. We continue from our previous work [11], in which we analyzed the set-based Bellman operator for cost uncertainty only.
Notation: A set of elements is given by . We denote the set of matrices of rows and columns with real (non-negative) entries as (), respectively. Matrices and some integers are denoted by capital letters, , while sets are denoted by cursive typeset . The set of all compact subsets of is denoted by . The column vector of ones of size is denoted by . The identity matrix of size is denoted by . The simplex of dimension is denoted by
| (1) |
A vector has equivalent notation , where is the value of in the coordinate, . Throughout the paper, denotes the infinity norm in .
2 Discounted infinite-horizon MDP
A discounted infinite-horizon finite state MDP is given by , where is the discount factor, is the finite set of states and is the finite set of actions. Without loss of generality, assume that each action is admissible from each state .
MDP Costs. is the matrix encoding the MDP cost. Each is the cost of taking action from state . We also denote the cost of all actions at state by , such that .
MDP Transition Dynamics. The transition probabilities when action is taken from state are given by . Collectively, all possible transition probabilities from state are given by the matrix , and all possible transition probabilities in the MDP are given by the matrix .
MDP Objective. We want to minimize the expected cost-to-go, or the value vector , defined per state as
| (2) |
where is the expected value of the input with respect to initial state , and () are the state and action at time .
Remark 2.
Although value function is the standard term for the expected cost-to-go, we use value vector in this paper to emphasize that the cost-to-go values of finite MDPs belong in a finite dimensional space.
MDP Policy. The decision maker controls the policy, denoted as , where the element of is the conditional probability of action being chosen from state . Using the policy, we can minimize the value vector (2) in a closed-loop fashion.
| (3) |
Under policy , the expected immediate cost at is given by and the expected transition probabilities from is given by .
2.1 Value operators
Solving an MDP is equivalent to finding the value vector and the associated policy that minimizes the objective (3). Typical solution methods utilize order preserving [19, Def.3.1], -contractive operators whose fixed points are the optimal value vectors (e.g. Bellman operator [17, Thm.6.2.3], -value operator [13]).
Definition 3 (-Contraction).
Let be a metric space with metric . The operator is an -contraction if and only if there exists such that
| (4) |
Definition 4 (Order Preservation).
Let be an ordered space with partial order . The operator is order preserving if for all such that , .
These operators are typically locally Lipschitz in MDP parameter space.
Definition 5 (-Lipschitz).
Let be a metric space with metric and be a metric space with metric . The operator is -Lipschitz with respect to if for all , there exists such that
| (5) |
Remark 6.
The property -contraction is a special case of Lipschitz continuity when the input and output spaces are identical and the Lipschitz constant is less than .
To capture operators with these properties, we define a value operator that takes inputs: value vector, MDP cost, and MDP transition probability. The MDP cost and transition probability are selected from an MDP parameter set .
Definition 7 (Value operator).
Consider the operator ,
| (6) |
We say (6) is a value operator on if
-
1.
For all , is an -contraction in .
-
2.
For all , is order preserving in .
-
3.
For all , is -Lipschitz on .
Remark 8.

An immediate consequence of the value operator being an -contractive and order-preserving operator on is that is continuous on .
Lemma 9 (Continuity).
If (6) is a value operator on , is continuous on .
See App. B for proof. Examples of value operators include the Bellman operator and the policy evaluation operators when the MDP cost and transition probability are input parameters rather than fixed parameters.
Definition 10 (Policy evaluation operator).
Given a policy , the vector-valued operator is defined per state as
| (7) |
Given , is a vector-valued operator whose fixed point is the expected cost-to-go of the MDP under , denoted as [17, Thm.6.2.5].
| (8) |
When the context is clear, we denote as .
Definition 11 (Bellman operator).
The vector-valued operator is defined per each state as
| (9) |
The corresponding optimal policy is defined per state as (9). One such policy is defined for all by
| (10) |
where is the set of minimizing actions for the function . An optimal policy in the form (10) always exists for a discounted infinite horizon MDP [17, Thm 6.2.10]. Given parameters , is a vector operator whose fixed point is the optimal cost-to-go for the MDP , denoted as .
| (11) |
When the context is clear, we denote as
Lemma 12.
See App. C for proof.
Remark 13.
Beyond the policy evaluation operator and the Bellman operator, many algorithms in reinforcement learning can be reformulated using value operators. For example, it’s not difficult to show that the Q-learning operator [13] is a value operator on the vector space .
3 Set-based value operators
Motivated by stochastic and time-varying Markovian dynamics, we now consider set-based value operators with respect to a compact set of MDP parameters. We first introduce Hausdorff-type set distances.
Definition 14 (Point-to-set Distance).
The distance between a value vector and a set is given by
| (12) |
On the space of compact subsets of , given by , the distance between value vector sets extends (12) and is given by the Hausdorff distance [7].
Definition 15 (Set-to-set Distance).
The Hausdorff distance between two value vector sets is given by
| (13) |
We use to denote the metric space formed by the set of all compact subsets of under the Hausdorff distance . The induced Hausdorff space is complete if and only if the original metric space is complete [7, Thm 3.3]. Therefore, is a complete metric space.
For a value operator (6), we ask the following question: what is the set of possible value vectors when the MDP has parameter non-stationarity given by ? To resolve this, we define the set-based value operator .
Definition 16 (Set-based Value Operator).
The set-valued operator is induced by on (6) and is defined as
| (14) |
where is a subset of the value vector space.

We denote the set-based value operator induced by the Bellman operator (9) and policy evaluation operators (7) as and , respectively, such that for any value vector set ,
| (15) |
| (16) |
The set-based Bellman operator is the union over all one-step optimal value vectors, which may result from different policies, while is the union over all value vectors that result from the same policy .
We can ask the following question: is there a set of value vectors that is invariant with respect to ? Similar to the value operators from Definition 7, we can affirmatively answer this question by showing that is -contractive on .
Theorem 17.
If is a value operator on (6) and is compact, then the induced set value operator (14) satisfies
-
1.
For all , ;
-
2.
is an -contractive on (13) with a unique fixed point set given by
(17) -
3.
The sequence where converges to for any .
In particular, these hold for (15) and (16), whose fixed point sets are denoted as and , respectively.
| (18) |
The first statement follows from Lemma 9, since the image of a compact set by a continuous function is compact [18]. Let us prove the second statement: for some , for all, :
Take , then holds from the -contractive property of . Finally,
We use the same technique to prove that
Finally, . From the Banach fixed point theorem and the completeness of [7, Thm 3.3], has a unique fixed point in .
The third point is a consequence of the Banach fixed point theorem. Finally, and are value operators (6) on , therefore this theorem’s statements apply. ∎
4 Properties of the fixed point set
For the MDP parameters , the fixed point of is typically meaningful for the corresponding MDP. For example, the fixed point of a policy evaluation operator (7) is the expected cost-to-go under policy , and the fixed point of the Bellman operator (9) is the minimum cost-to-go when can be freely chosen. In this section, we derive properties of the fixed point set of (14) in the context of non-stationary value iteration.
4.1 Non-stationary value iteration
Given a value operator on , we consider value iteration under a dynamic parameter uncertainty model discussed in [15], where at every iteration, a new set of MDP parameters is chosen from as
| (20) |
In robust MDP literature [8, 15], is modified by an adversarial opponent of the MDP decision maker such that (20) converges to a worst-case value vector. We consider a more general scenario in which is chosen from the closed and bounded set without any probabilistic prior. In this scenario, convergence of in will not occur for all possible sequences of . However, we can show convergence results on the set domain by leveraging our fixed point analysis of the set-based operator (14).
Proposition 19.
Let be a sequence defined by and , where (14) is the set operator induced by on . We first show statement 1). From Theorem 17, converges to in . Therefore, as tends to .
Next, for all , there exists such that for all , . We define the strictly increasing function , such that and for all , . Then, for all , there exists such that . As is compact, there exists strictly increasing such that converges to some [18, Thm 3.6]. Finally, let , there exist such that for all , and for all , . So, taking , we have and converges to . ∎ In addition to containing all asymptotic behavior of value vector trajectories under time-varying value iteration, the fixed point set also contains all fixed points of the value operator when (6) are fixed.
Corollary 20.
We construct sequence where and . Then for all . From the second point of Proposition 19, follows. ∎ Going further, we can bound the transient behavior of (20) when is an element of the fixed point set .
Corollary 21 (Transient behavior).
As a fixed point set of (14), (17) satisfies , then the following is true by definition of : if , then . If , then follows by induction. ∎
Remark 22.
4.2 Bounds of the fixed point set
In Theorem 17, the compactness of implied the compactness of . This relationship carries over to the supremum and infimum elements of and —i.e., if satisfies Assumption 30 with respect to , then contains its own supremum and infimum elements.
Greatest and least elements. We define the supremum and infimum elements of a value vector set element-wise as follows,
| (21) |

If a set is compact, the projection of on each state is compact. Then, the coordinate-wise supremum and infimum values for each state are achieved by . However in general, no single element of the set may simultaneously achieve the minimum over all states—i.e., may not be an element of . This is illustrated in Figure 3.
Given and parameter uncertainty set , we wish to 1) bound the supremum and infimum elements of the fixed point set (17) and 2) derive sufficient conditions for when they are elements of . To facilitate bounding , we introduce the following bound operators.
Definition 24 (Bound Operators).
The bound operators induced by the value operator on are coordinate-wise defined at each as
| (22) |

We want to bound the fixed point set of the set-based value operator (14) by the bound operators (22). First we show that are themselves -contractive and order preserving on .
Lemma 25 (-Contraction).
From Lemma 9, is continuous and is compact, then for all , there exists such that and . We upper-bound by , and use the -contraction property of to derive
Since and are arbitrarily ordered, we conclude that . The proof for follows a similar reasoning and takes . The existence of follows from applying Banach’s fixed point theorem. ∎
The lemma statement follows directly from the fact that order preservation is conserved through composition with and . If , then . A similar argument follows for . ∎ We show that the fixed points and bounds the fixed point set of the set-based value operator (14).
Theorem 27 (Bounding fixed point sets).
For and (19), we first show
| (25) |
via induction. Suppose that (25) is satisfied for . The order preserving property of implies that holds for all . We take the infimum and supremum over and , respectively, to show that for all and ,
Since and are the fixed points of and for all , respectively, we conclude that (25) holds for .
Next, we show that and bounds the fixed point set for the -induced operator (14). From Lemma 45, we know that for all , there exists a strictly increasing sequence and corresponding value vectors such that and for the sequence of value vector sets generated from . Since holds for all , we conclude (24) holds. ∎
5 Revisiting robust MDP
We re-examine robust MDP with the set-theoretical analysis in this section, and show that Assumption 30 generalizes the rectangularity assumption made in robust MDPs, thus enabling robust dynamic programming techniques to be available to a wider class of MDP problems and contraction operators.
Recall the optimistic value vector and robust value vectors of a discounted MDP from [8, 15] as the fixed points of the following operators.
| (26) |
| (27) |
The optimistic policy and robust policy are the optimal policies corresponding to (26) and (27), respectively.
| (28) |
| (29) |
For readability, we denote the policy evaluation operator (7) under as and the policy evaluation operator (7) under as .
When is -rectangular (39), the set of policies satisfying (28) and (29) are non-empty and includes deterministic policies [8, Thm 3.1]. When is -rectangular and convex, the set of policies satisfying (29) is non-empty but may be mixed [21, Thm 4]. When is convex, we show that policies (28) and (29) exist.
Proposition 28.
Recall the Bellman operator (9). When is compact, the formulation of the fixed point of (22) is equivalently given by
| (30) |
We note that (30) is identical to the formulation of (26). Therefore, is the fixed point of . When is compact, exists due to Lemma 25. From (28), is the optimal argument of , a continuous function in minimized over compact sets for all . Therefore exists. Since , the optimal exists.
For the robust scenario: when is compact, the fixed point of (22), , exists from Lemma 25 and is given by
| (31) |
The function is concave in and convex in . If is convex, then we apply the minimax theorem [14] to switch the order of and in (31) to derive
| (32) |
Equation (32) is identical to (27), therefore and exists by Lemma 25. In (32), is piece-wise linear in and is compact for all , thus is non-empty. Finally, since , exists. ∎
Remark 29.
Since is piecewise linear in , the optimal is mixed policy in general. This is consistent with the results in [21].
Proposition 28 generalizes the results from [21] to show that (27) exists when is compact and convex instead of -rectangular and convex. From Theorem 27, and are the fixed points of the bound operators and (24), respectively. They become infimum and supremum elements when satisfies Assumption 30 with respect to and . We explicitly derive this result next. First, we introduce some notations: let , the fixed point of be , , and the fixed point of be .
| (33) |
| (34) |
Additionally, the supremum elements of and are and respectively and the infimum elements are and , respectively.
| (35) |
| (36) |
We compare these with the fixed point set of the Bellman operator, (17), denoted by and as
| (37) |
6 Fixed-point set containing its infimum/supremum
We make the following assumption on the MDP parameter set with respect to .
Assumption 30 (Containment condition).
The MDP parameter set satisfies the containment condition with respect to if is compact and for all ,
| (38) |

Remark 31.
Assumption 30 is an -dependent condition imposed on the structure of , and is independent of ’s convexity and connectivity.
6.1 Containment-satisfying MDP parameter sets
Assumption 30 restricts the structure of with respect to the value operator . Thus whether or not satisfies Assumption 30 must always be determined with respect to the operator . With respect to the Bellman operator (9) and the policy evaluation operators (7), the following conditions in robust MDP are sufficient to satisfy Assumption 30.
Intuitively, -rectangularity implies that the MDP parameter uncertainty is decoupled between each state-action. A more general condition is if the parameter uncertainty is decoupled between different states but not between different actions within the same state.
Definition 33 (-rectangular sets).
The uncertainty set is -rectangular if
| (40) |
-rectangularity generalizes -rectangularity—i.e. -rectangularity implies -rectangularity.
Example 34 (Wind uncertainty).
Consider the navigation problem presented in Example 1. If the wind pattern strictly switches between the discrete wind trends, then the transition uncertainty at state is . If the wind pattern is a mixture of the discrete wind trends, the transition uncertainty at state is . Both wind patterns lead to -rectangular uncertainty, given by .
We show that the rectangularity conditions indeed are sufficient for satisfying Assumption 30 with respect to (9) and (7).
Proposition 35.
We first show that satisfies Assumption 30 with respect to the Bellman operator. Given , only depends on the component of and . From Lemma 9, is continuous in . Let be the solution to for all . If is compact, . We can construct and . If is -rectangular, then and for all . We conclude that satisfies Assumption 30.
Given and , only depends on and as well. We can similarly show that there exists an optimal parameter for all such that . ∎ Beyond -rectangularity, there are sets that satisfy Assumption 30 with respect to specific value operators.
Example 36 (Beyond rectangularity).
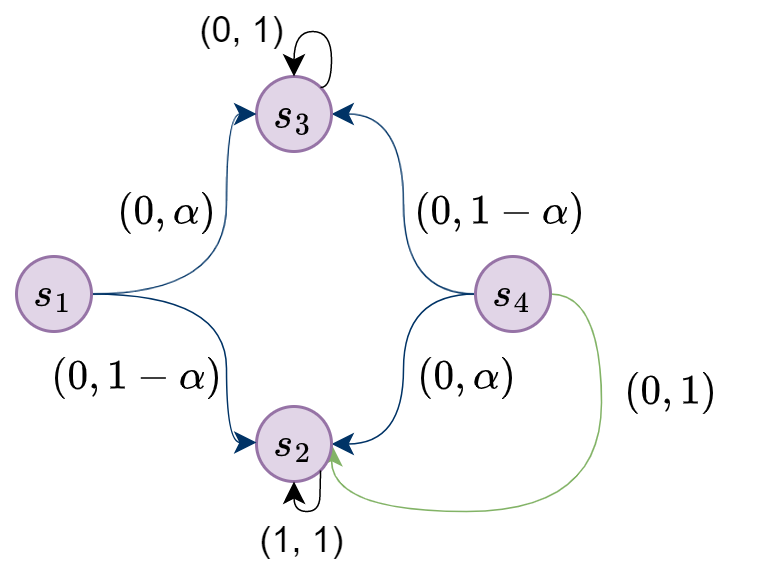
In Figure 6, we visualize a four state MDP with transition uncertainty parameterized by . MDP states are the nodes and MDP actions are the arrows. Actions that transition to multiple states are visualized by multi-headed arrows. Each head has an associated tuple denoting its state-action cost and transition probability. All states have a single action except for state , where two actions exist and are distinguished by different colors. Both and are absorbing states with a unique action, such that and for both and for all , where is the discount factor.
The states and have transition uncertainty parametrized by . Therefore, violates -rectangularity (Definition 33). The optimal cost-to-go values and occur at different ’s. Therefore, violates Assumption 30 with respect to . However, suppose that at , we only consider policies that exclusively choose the action colored green in Fig. 6. Then the expected cost-to-go at , , is independent of . The minimum and maximum values of under occur at and , respectively. Therefore, satisfies Assumption 30 with respect to operator for all where .
Theorem 37.
From Theorem 27, and are the lower and upper bounds on the fixed point set . We show that these are the infimum and supremum elements of by showing that they are also elements of . From Assumption 30, there exists such that and for all . Since and are fixed points of and , we apply Corollary 20 to conclude that . ∎ Our next result proves the relationship between when , and on satisfy Assumption 30.
Theorem 38.
Since is the infimum element for the fixed point set (36), we can apply Theorem 37 to derive
| (43) |
By definition of (28), . As the two minima commute,
| (44) |
Combining (43) and (44), is exactly the unique fixed point of . However, by applying Theorem 37 to on , is also the unique fixed point of . Therefore .
From (35), , we can minimize over the policy space to lower bound as
| (45) |
Since the right hand side of (45) is equivalent to , (45) is equivalent to . From Lemma 26, is order-preserving in , we conclude that .
From Theorem 37, is the fixed point of , such that
| (46) |
We apply to both sides of (46) and use the definition of to derive that is the fixed point of . From Assumption 30, there exists that maximizes , so equivalently satisfies
From Corollary 20, this implies that and therefore . Next we show . From Theorem 37, is the fixed point of , such that , From the min-max inequality,
Since ,
| (47) |
The right-hand side of (47) is (22), such that (47) is equivalent to . We consider the sequence where . Since is a contraction, , the fixed point of . From Lemma 26, is order preserving. Therefore .
Finally, Theorem 37 implies that is the fixed point of : . By construction, . From the min-max inequality,
such that the right hand side of the inequality is equivalent to . Following the monotonicity properties of the Bellman operator [17, Thm.6.2.2], we conclude that . ∎
Remark 39.
Through our fixed-point analysis, we see that in addition to having the best worst-case performance among , also has the smallest variation in performance for the same uncertainty set .
Finally, we generalize the -rectangularity condition by showing that the optimistic and robust policies exist when the MDP parameter set satisfies Assumption 30.
Corollary 40 (Robust MDP under Assumption 30).
When satisfies Assumption 30 on , Theorem 37 shows that If and also satisfies Assumption 30 on , then we apply Theorem 38 to derive and . This proves the corollary statement. ∎
Remark 41.

7 Value iteration for fixed point set computation
In the previous sections, we proved the existence of a fixed point set for value operators with compact parameter uncertainty sets and re-interpreted robust control through our techniques. Next, we derive an iterative algorithm for computing the bounds of the fixed point set given a value operator and parameter uncertainty set .
Algorithm Sketch. Based on the set-based value iteration (19), we iteratively find the one-step bounds of to converge the bounds of the fixed point set.
For any compact set , the one step bounds of are equivalent to the one-step output of the bound operators and (22) applied to the extremal points of .
Theorem 42 (One step bounds).
Consider a set operator (14) and its bound operators and (22) induced by on (6). For a compact set , is bounded by and (22) as
| (49) |
where and (21) are the extremal elements of . If satisfies Assumption 30 on and , then and are the supremum and infimum elements of , respectively— for all , and satisfy
| (50) |
For all , for all . If is -Lipschitz and -contractions in , then is order-preserving (Lemma 26) such that for all . We conclude that
| (51) |
Since is an upper bound, and is the least upper bound, it holds that . We use the definition of (14) to conclude that for all . The inequality can be similarly proved.
If satisfies Assumption 30 on and , Assumption 30 states that there exists such that . Therefore, . Since also lower bounds all the elements of , it is the infimum element of . The fact that the greatest element of is can be similarly proved. ∎ Based on Theorem 42, we propose the following bound approximation algorithm of the fixed point set (17) for a set-valued operator (6). {algorithm} Bound approximation of the fixed point set
7.1 Computing one-step optimal parameters
Algorithm 7 is stated for a general MDP parameter set and does not specify how to compute lines 6 and 7. Here we discuss solution methods for different shapes of .
- 1.
-
2.
Convex . When is a convex set, the computation depends on . If is the policy operator, lines 6 and 7 can be solved as convex optimization problems. If is the Bellman operator , lines 6 and 7 take on min-max formulation and is NP-hard to solve in the general form [21]. When can be characterized by an ellipsoidal set of parameters, the solutions to lines 6 and 7 is given in [21].
We recall the stochastic path planning problem from Example 1 with the two different parameter uncertainty scenarios. When the wind field uncertainty is discrete, is finite, when wind field is a combination of the major wind trends, is convex.
7.2 Algorithm Convergence Rate
When lines 6 and 7 are solvable, Algorithm 7 asymptotically converges to approximations of the bounding elements of . If satisfies Assumption 30 with respect to , Algorithm 7 derives the exact bounds of . Algorithm 7 has similar rates of convergence in Hausdorff distance as standard value iteration using on .
Theorem 43.
Consider the value operator , compact uncertainty set , and the fixed point set of the set-based operator (14) induced by on . If satisfies Assumption 30 with respect to , then at each iteration ,
| (53) |
where all norms are infinity norms, and are the infimum and supremum bounds of , respectively. At Algorithm 7’s termination, satisfies
| (54) |
From Algorithm 7, . From Lemma 25, is an -contraction. We obtain and note that (53) holds by induction. Next, we apply triangle inequality to to derive
| (55) |
We can then use to bound (55) as . A similar argument can show that . When Algorithm 7’s while condition is satisfied, This concludes our proof. ∎ In particular, the Bellman operator and policy operator are -contractive on , where is the discount factor, therefore, Theorem 42 applies with .
8 Path Planning in Time-varying Wind Fields
We apply set-based value iteration to wind-assisted probabilistic path planning of a balloon in strong, uncertain wind fields [22]. MDP as a model for wind-assisted path planning of balloons in the stratosphere and exoplanets has recently gained traction [22, 2]. Discrete state-action MDPs have been shown to be a viable high-level path planning model [22] for such applications.
Mission Objective. In the two dimensional wind-field, we assume that the wind-assisted balloon is tasked with reaching target state in Figure 8 using minimum fuel.
Uncertain Wind Fields. By collecting a set of wind data on the environment’s wind field, an MDP can be created and a policy that handles stochastic planning can be deployed. However, wind can be a time-varying factor that causes the expected optimal policy to have worse-than-expected worst-case performance. We built an ideal uncertain wind field to demonstrate how the set Bellman operator can be used to predict the best and worst-case behavior of a robust policy.
MDP Modeling Assumptions. Following the framework described in [22], we model the path planning problem in an uncertain wind field as an infinite horizon, discounted MDP with discrete state-actions in a two-dimensional space. While balloons typically traverse in three dimensions, we assume that the wind is consistent in the vertical direction and that the final target is any vertical position along the given two-dimensional coordinates. As a result, we can disregard the vertical position during planning.


States. A total of states represent the two-dimensional space, composed of three different regions characterized by their wind variability as shown in Figure 8.
-
1.
Calm wind. In calm states , the wind magnitude varies uniformly between , and the wind direction is uniformly sampled between .
-
2.
Gusty wind. In states with gusts , wind magnitude is consistently , while the wind direction is uniformly sampled between . .
-
3.
Unreliable wind. In unreliable states , a predictable wind front occasionally moves across an otherwise windless region. In other words, the wind magnitude is either or and the wind direction varies uniformly between .
Actions. The balloon is equipped with an actuator that provides a constant thrust of in discretized directions shown in Figure 8b. The only stationary action vector with zero magnitude is highlighted in blue in the center of Figure 8b. We assume that the actuation force is enough to move the balloon across one state in wind with magnitude , and is otherwise not strong enough to overcome wind effects.



Transition Probabilities. The transition probabilities are region-dependent. In the states and , the transition dynamics are stochastic but stationary in time. In the states , the transition dynamics are stochastic but change over time. We define the following neighboring states for each state .
-
1.
: all neighboring states of state .
-
2.
: the neighboring state of in the direction of .
-
3.
: the neighboring state of in the direction of plus the two adjacent states as shown in Figure 9a.
-
4.
: the up and upper-right neighbors of , as shown in Figure 9b.
In the calm wind region, the transition probabilities are given by
| (56) |
In the gusty wind region, the transition probabilities are given by
| (57) |
In the unreliable wind region, the transition probabilities vary between transition dynamics and .
| (58) |
| (59) |
Collectively, and collectively form the uncertainty set defined at each state.
| (60) |
Cost. We define the following state-action cost to achieve the mission objective: at each state-action, the cost is the sum of the current distance from target position , as well as the fuel expended by given action.
We take for all actions except for the staying still action, where .
8.1 Bellman, optimistic policy, and robust policy
We first compute the optimistic and robust bounds of the MDP with parameter uncertainty in when by running Algorithm 7. The results are shown in Figure 10.


We denote the optimistic policy as and the robust policy as , and derive the bounds of their respective value vector sets (33) and (34) using Algorithm 7. The output is compared against the bounds of the set-based Bellman operator’s fixed point set in Table 1.
| Set | Maximum value | Minimum value |
|---|---|---|
| 70.61 | 62.25 | |
| 101.58 | 62.25 | |
| 70.63 | 70.52 |
Time-varying wind field Next, we consider a time-varying wind field: at each time step , the transition probability is chosen at random from (60). In this time-varying wind field, we compare three different policy deployments: 1) stationary optimistic policy as policy operator (33), 2) stationary robust policy as policy operator (34), and 3) dynamically changing policy that is optimal for the MDP as (9). These three different policy deployments are given by
| (61) | ||||
| (62) | ||||
| (63) |
The resulting cost-to-go at state is plotted in Figure 11. Here, we see that the optimistic policy deployment (61) has the greatest variation in value over the course of MDP time steps. Both the robust policy deployment (62) and the dynamically changing policy deployment (63) achieve better upper-bound at each MDP iteration. The dynamically changing policy deployment (63) achieves less than in cost-to-go on average, which is the best among all three deployments. As we discussed in Remark 39, the robust policy deployment has the smallest variance in value in the presence of wind uncertainty, achieving a value difference of less than .



Sampled solutions. We can compute a sampled MDP model based on samples of wind vectors for each state. Based on these samples, we add the action vector and compute the statistical distribution of state transitions. We then compute the value of these stationary sampled MDPs, and compare randomly selected states’ values. The resulting scatter plot is shown in Figure 12.

9 Conclusion
In this paper, we categorized a class of operators utilized to solve Markov decision processes as value operators and lifted their input space from vectors to compact sets of vectors. We showed using fixed point analysis that the set extensions of value operators have fixed point sets that remain invariant given a compact set of MDP parameter uncertainties. These sets were applied to robust dynamic programming to further enrich existing results and generalize the -rectangularity assumption for robust MDPs. Finally, we applied our results to a path planning problem for time-varying wind fields. For future work, we plan on applying set-based value operators to stochastic games in the presence of uncoordinated players such as humans, as well as applying value operators to reinforcement learning to synthesize robust learning algorithms.
References
- [1] Wesam H Al-Sabban, Luis F Gonzalez, and Ryan N Smith. Wind-energy based path planning for unmanned aerial vehicles using markov decision processes. In 2013 IEEE International Conference on Robotics and Automation, pages 784–789. IEEE, 2013.
- [2] Marc G Bellemare, Salvatore Candido, Pablo Samuel Castro, Jun Gong, Marlos C Machado, Subhodeep Moitra, Sameera S Ponda, and Ziyu Wang. Autonomous navigation of stratospheric balloons using reinforcement learning. Nature, 588:77–82, 2020.
- [3] Marc G Bellemare, Georg Ostrovski, Arthur Guez, Philip Thomas, and Rémi Munos. Increasing the action gap: New operators for reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30, 2016.
- [4] Prashant Doshi, Richard Goodwin, Rama Akkiraju, and Kunal Verma. Dynamic workflow composition: Using markov decision processes. International Journal of Web Services Research (IJWSR), 2(1):1–17, 2005.
- [5] Robert Givan, Sonia Leach, and Thomas Dean. Bounded-parameter markov decision processes. Artificial Intelligence, 122(1-2):71–109, 2000.
- [6] Vineet Goyal and Julien Grand-Clement. Robust markov decision processes: Beyond rectangularity. Mathematics of Operations Research, 2022.
- [7] Jeff Henrikson. Completeness and total boundedness of the hausdorff metric. In MIT Undergraduate Journal of Mathematics. Citeseer, 1999.
- [8] Garud N Iyengar. Robust dynamic programming. Mathematics of Operations Research, 30(2):257–280, 2005.
- [9] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. Advances in Neural Information Processing Systems, 33:1179–1191, 2020.
- [10] Erwan Lecarpentier and Emmanuel Rachelson. Non-stationary markov decision processes, a worst-case approach using model-based reinforcement learning. Advances in neural information processing systems, 32, 2019.
- [11] Sarah HQ Li, Assalé Adjé, Pierre-Loïc Garoche, and Behçet Açıkmeşe. Bounding fixed points of set-based bellman operator and nash equilibria of stochastic games. Automatica, 130:109685, 2021.
- [12] Shie Mannor, Ofir Mebel, and Huan Xu. Robust mdps with k-rectangular uncertainty. Mathematics of Operations Research, 41(4):1484–1509, 2016.
- [13] Francisco S Melo. Convergence of q-learning: A simple proof. Institute Of Systems and Robotics, Tech. Rep, pages 1–4, 2001.
- [14] J v Neumann. Zur theorie der gesellschaftsspiele. Mathematische annalen, 100(1):295–320, 1928.
- [15] Arnab Nilim and Laurent El Ghaoui. Robust control of markov decision processes with uncertain transition matrices. Operations Research, 53(5):780–798, 2005.
- [16] Sindhu Padakandla, Prabuchandran KJ, and Shalabh Bhatnagar. Reinforcement learning algorithm for non-stationary environments. Applied Intelligence, 50(11):3590–3606, 2020.
- [17] Martin L Puterman. Markov Decision Processes.: Discrete Stochastic Dynamic Programming. John Wiley & Sons, 2014.
- [18] Walter Rudin et al. Principles of mathematical analysis, volume 3. McGraw-hill New York, 1964.
- [19] Bernd SW Schröder. Ordered sets. Springer, 29:30, 2003.
- [20] Herke Van Hoof, Tucker Hermans, Gerhard Neumann, and Jan Peters. Learning robot in-hand manipulation with tactile features. In 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), pages 121–127. IEEE, 2015.
- [21] Wolfram Wiesemann, Daniel Kuhn, and Berç Rustem. Robust markov decision processes. Mathematics of Operations Research, 38(1):153–183, 2013.
- [22] Michael T Wolf, Lars Blackmore, Yoshiaki Kuwata, Nanaz Fathpour, Alberto Elfes, and Claire Newman. Probabilistic motion planning of balloons in strong, uncertain wind fields. In 2010 IEEE International Conference on Robotics and Automation, pages 1123–1129. IEEE, 2010.
- [23] Insoon Yang. A convex optimization approach to distributionally robust markov decision processes with wasserstein distance. IEEE control systems letters, 1(1):164–169, 2017.
Appendix A Set sequence convergence
Lemma 45.
Let be a converging sequence for with as . For all , there exists a converging subsequence whose limit is for .
Let . We can define the strictly increasing function on as follows: and for all , . Finally, as for all , , the result holds. ∎
Appendix B Proof of Lemma 9
Let and consider a sequence that converges to . It holds that , where from the -contractive property of , . From the -Lipschitz property of ,
As both and , and is continuous. ∎
Appendix C Proof of Lemma 25
We show that both the Bellman operator and the policy evaluation operator satisfy the contractive, order preserving, and Lipschitz properties given in Definition 7. Contraction: given , and are both -contractions [17, Prop.6.2.4] on the complete metric space , where is the discount factor.
Order preservation: given , the operator is order preserving [17, Lem.6.1.2]. Consider where . If is order-preserving, for all . Taking the infimum over , we have .
-Lipschitz: given and , we prove the following for each ,
| (64) |
We prove (64) for each of the following cases: 1) , and 2) . For case 1), let (10) be the optimal policy for and be the optimal policy for . For , suppose , then . Since is sub-optimal for , we can upper bound . Since , . We conclude that (64) holds when . For case 2), , (64) also holds by similar arguments.
Letting and , we can upper bound as
| (65) | ||||
| (66) |
The policy evaluation operator satisfies (64) if is replaced by . Since , is -Lipschitz. ∎