Sequential-Scanning Dual-Energy CT Imaging Using High Temporal Resolution Image Reconstruction and Error-Compensated Material Basis Image Generation
Abstract
Dual-energy computed tomography (DECT) has been widely used to obtain quantitative elemental composition of imaged subjects for personalized and precise medical diagnosis. Compared with DECT leveraging advanced X-ray source and/or detector technologies, the use of the sequential-scanning data acquisition scheme to implement DECT may make a broader impact on clinical practice because this scheme requires no specialized hardware designs and can be directly implemented into conventional CT systems. However, since the concentration of iodinated contrast agent in the imaged subject varies over time, sequentially scanned data sets acquired at two tube potentials are temporally inconsistent. As existing material basis image reconstruction approaches assume that the data sets acquired at two tube potentials are temporally consistent, the violation of this assumption results in inaccurate quantification of material concentration. In this work, we developed sequential-scanning DECT imaging using high temporal resolution image reconstruction and error-compensated material basis image generation, ACCELERATION in short, to address the technical challenge induced by temporal inconsistency of sequentially scanned data sets and improve quantification accuracy of material concentration in sequential-scanning DECT. ACCELERATION has been validated and evaluated using numerical simulation data sets generated from clinical human subject exams and experimental human subject studies. Results demonstrated the improvement of quantification accuracy and image quality using ACCELERATION.
Index Terms:
Multi-detector-row CT; Dual-Energy CT; Temporal Resolution Improvement; Deep Learning; Material QuantificationI Introduction
Dual-energy computed tomography (DECT) has been widely used to obtain quantitative elemental composition of imaged subjects for personalized and precise medical diagnosis. Significant efforts have been made to implement DECT, such that, temporally consistent data sets at two different tube potentials can be acquired [1]. These DECT technologies can be broadly classified as two categories: advanced X-ray source-based technologies and detector-based technologies. X-ray source-based DECT equipped with two pairs of sources and detectors acquire data sets corresponding to two different spectrum at the same time [2]. Leveraging advanced source and detector technologies, tube potential can be switched from one to another at the speed in sub-millisecond level to acquire nearly consistent data sets [3]. Two different beam filters are applied to split the X-ray beam into two halves along the longitudinal direction with different spectrum [4, 5]. Detector-based DECT equipped with energy-discriminating photon counting detectors acquire temporally consistent data sets with different spectrum [6]. Two different scintillation materials are manufactured along the depth direction of the detector to form the dual-layered detector, such that, two temporally consistent data sets, each with a different spectrum associated with the scintillation material can be readout [7].
Although significant efforts have been made to implement DECT leveraging advanced X-ray source and/or detector technologies, the number of patients who can benefit from DECT may be limited partially because these high-end DECT may be limited to major clinical centers or research institutes in first-tier cities. To broaden the impact of DECT on clinical practice, DECT implemented with sequential-scanning data acquisition scheme may be a promising alternative because this scheme requires no specialized hardware designs and can be directly implemented into conventional CT systems. The feasibility of sequential-scanning DECT has been validated in static non-contrast CT imaging for the diagnosis of renal stones [8].
I-A Technical Challenges in Sequential-Scanning Contrast-Enhanced DECT
In sequential-scanning contrast-enhanced DECT, data sets corresponding to two different tube potentials are acquired separately. Since the concentration of iodinated contrast agent in the imaged subject varies over time, sequentially scanned data sets acquired at two tube potentials are temporally inconsistent. As existing material basis image reconstruction approaches for DECT assume that the data sets acquired at two tube potentials are temporally consistent, the violation of this assumption results in inaccurate quantification accuracy of material concentration and much degraded image quality.
I-B Purpose and Innovation of This Work
To address the technical challenge induced by temporal inconsistency of sequentially scanned data sets and improve quantification accuracy of material concentration in sequential-scanning contrast-enhanced DECT, in this work, we developed sequential-scanning contrast-enhanced DECT imaging using high temporal resolution image reconstruction and error-compensated material basis image generation, ACCELERATION in short.
ACCELERATION first reconstructs several time-resolved images, each corresponding to an improved temporal resolution and lower temporal-averaging error, to resolve the temporal variation of the imaged subject using the short-scan data acquired at the first tube potential. Then, ACCELERATION resolves the temporal variation of the imaged subject using the short-scan data acquired at the second tube potential. The imaged subject corresponding to the selected reference time can be obtained via temporally extrapolating the time-resolved images corresponding to the first and second tube potentials.
To improve the quantitative accuracy and image quality of material basis images, material concentration can be quantified at the reference time using the pair of calculated temporally consistent images at two tube potentials and the developed error-compensated material basis image generation technique. The error-compensated material basis image generation models the degradation process into the forward model to train the generator using the data acquired for each individual subject. The degradation process includes the beam hardening effect due to polychromatic spectrum and structural error in the dual-energy images obtained from the developed high temporal resolution image reconstruction plus temporal extrapolation. Via properly modeling the degradation process, the forward model can maximally approximate the obtained dual-energy images, such that, the structural error in the obtained dual-energy images can be compensated for the improvement of accuracy in the obtained material basis images.
The innovation in ACCELERATION is summarized as follows:
-
•
It achieves sequential-scanning dual-energy CT for contrast-enhanced imaging;
-
•
It mitigates temporal inconsistency in terms of concentration of iodinated contrast agent;
-
•
It explicitly models the degradation process into the forward model of the material basis image generation to properly compensate the structural error in the dual-energy images obtained from the developed high temporal resolution image reconstruction plus temporal extrapolation;
-
•
It explicitly leverages the measured data of each individual subject to guarantee the accuracy of temporal matching and material basis image reconstruction for each individual subject.
In this work, we demonstrated that, a low-cost sequential-scanning data acquisition scheme to implement DECT has been achieved for contrast-enhanced imaging using the developed ACCELERATION technique. Results shown in this paper demonstrated the improvement of quantification accuracy and image quality using ACCELERATION.
II ACCELERATION: Sequential-Scanning Dual-Energy CT Imaging Using Temporal Matching and Error-Compensated Material Basis Image Generation
II-A Overall Framework
Our goal is to address the technical challenge induced by temporal inconsistency of sequentially scanned data sets and improve quantification accuracy of material concentration in sequential-scanning DECT. The developed ACCELERATION includes two major techniques: (i) temporal matching using high temporal resolution image reconstruction and temporal extrapolation and (ii) material quantification using error-compensated material basis image generation. The temporal matching technique addresses the technical challenge induced by temporal inconsistency of sequentially scanned data sets in sequential-scanning DECT. The error-compensated material basis image generation improves material quantification accuracy and image quality of material basis images.
To make the subject temporally consistent, one has to first resolve the temporal variation of the subject using the data acquired at one of the tube potentials. To achieve this purpose, we developed a subject-specific deep time-resolved image representation to resolve the temporal variation of the subject during the time window to acquire the data at one of the tube potentials. The imaged subject corresponding to the selected reference time can be obtained via temporally extrapolating the time-resolved images corresponding to the data acquired at two tube potentials. To improve the quantitative accuracy and image quality of material basis images, material concentration can be quantified at the selected reference time using the pair of calculated temporally consistent images at two tube potentials and the developed error-compensated material basis image generation network. Fig. 1 shows the overall framework of ACCELERATION.
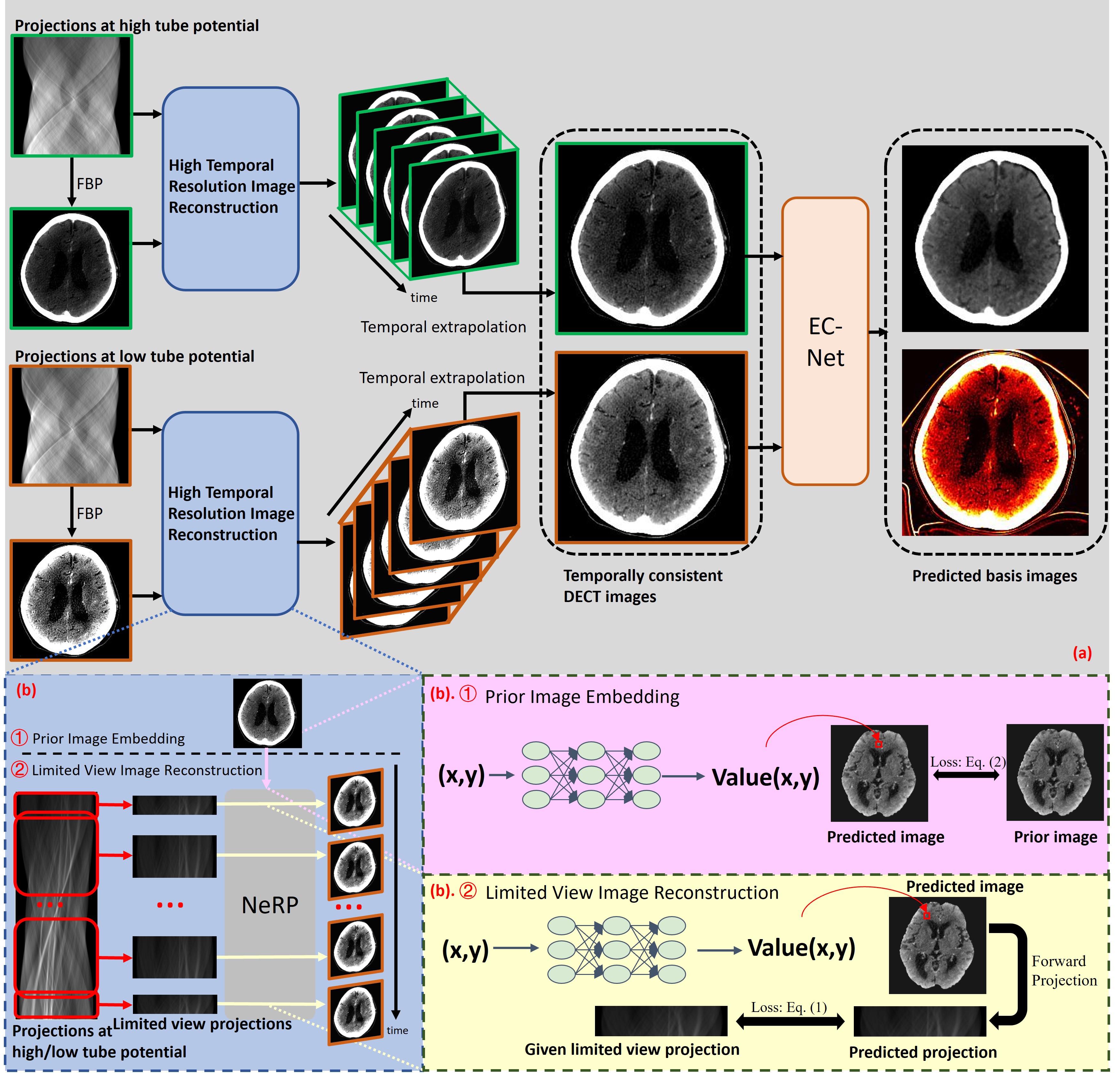
II-B High Temporal Resolution Image Reconstruction Using Data Acquired Over the Short-Scan Range
For a system with a fixed gantry rotation speed, the only way to improve its temporal resolution is to use data acquired over a narrower angular range that violates the data sufficiency condition. For FBP, the data sufficiency condition specifies the minimal angular range as the short-scan angular range. Severe data-insufficiency-induced errors (a.k.a. limited view artifacts), can be observed using FBP from the data acquired over shorter than the short-scan range. Model-based iterative image reconstruction approaches leveraging prior image and sparsity [9], the low rankness of the spatial-temporal image matrix [10, 11] can be applied to reconstruct the entire imaged object without severe data-insufficiency-induced errors using a data sub-set acquired over up to one-fourth of the short-scan range. The four-dimensional digital subtraction angiography method reconstructs a three-dimensional image volume from the data acquired at a single projection view [12] using both a pre-contrast scan (the one without contrast injection) and a post-contrast scan (the one with contrast injection). By incorporating the prior knowledge of the periodicity of the data-insufficiency-induced errors, eSMART-RECON further improves temporal resolution to 4-7.5 fps [13]. To leverage the prior knowledge of the periodicity, eSMART-RECON requires that the acquired data set covers at least four scans (i.e. two forward scans plus two backward scans). By recasting the temporal resolution improvement task as a temporal extrapolation task, AIRPORT [14] improves the temporal resolution to 40 fps, the time window needed to acquire a single projection view data using a typical C-arm CBCT and the data acquired over the short-scan range.
CT image reconstruction using data acquired from a limited view range violates the data sufficiency condition and hence results in images with severe limited view artifacts unless appropriate regularization can be incorporated to constrain the otherwise ill-posed problem. However, it remains a technical challenge to appropriately design the regularization for better solving the limited view image reconstruction problem. Inappropriate regularization may lead to degraded quantitative accuracy (such as biased CT values) and/or image quality (degraded image sharpness, unnatural noise texture, image artifacts etc.).
Instead of solving the CT value for each individual image voxel, one can also represent the image-to-be-reconstructed as a deep convolutional neural network [15, 16, 17] or a deep fully connected network [18, 19, 20, 21, 22, 23, 24] with learnable parameters to regularize the image reconstruction problem using the architecture of the deep neural network. The network parameters can then be determined by best fitting the forward model of the image estimation to the measured data corresponding to a limited view range. After training the network using the data corresponding to the imaged subject, the deep neural networks with fully connected layers learns a smooth mapping from the image voxel coordinates domain to the corresponding intensity value domain. As the smoothness has been implicitly enforced from one image voxel to other nearby voxels, CT image noise and artifacts can be effectively mitigated in the reconstructed image represented by the learned smooth mapping, such that, CT image reconstruction problems under nonideal data acquisition conditions can be effectively solved. The high temporal resolution image reconstruction using deep neural networks with fully connected layers includes two steps: prior image embedding (see in Fig. 1 (b). ①) and limited view image reconstruction (see in Fig. 1 (b). ②).
II-B1 Prior Image Embedding
In the prior image embedding step, a deep neural network with multiple fully connected layers is trained to express the mapping from image voxel coordinates to intensity values associated with the image voxel, that is, , where denotes the coordinate index in the image spatial domain. The optimization problem in the prior image embedding step can be formulated as follows:
| (1) |
where denotes the total number of voxels in the CT image. The anatomical structure of the temporally averaging image over the short-scan range (a.k.a. prior image) can be implicitly embedded into the network parameters which can be considered as a warm initialization to represent the imaged subject associated to a limited view range in the next limited view image reconstruction step.
II-B2 Limited View Image Reconstruction
The optimization problem in the limited view image reconstruction step can be formulated as follows:
| (2) |
where denotes the network parameters corresponding to the -th time frame, namely a sub-set of measured data corresponding to a limited view range, . denotes the set of measurement corresponding to the -th time frame. The detailed implementation of is specified in Sec. II-E2. denotes the number of elements in the set, and denotes the number of reconstructed time frames which is a hyper-parameter to be optimized for the best reconstruction accuracy. Note that, the learned network parameters in the prior image embedding (Eq. (1)) are used as the initialization in solving these optimization problems defined in Eq. (2) for each time frame.
II-C Temporal Matching by Extrapolation
Suppose that scanning at the first tube potential is performed during , the tube potential is changed during , and scanning at the second tube potential is performed during . The variation of iodine concentration of the imaged subject underwent intravenous contrast injection at each image voxel can be approximately considered as general Gamma-Variate functions [25] over a relatively long duration (normally longer than 30 seconds). Given the short duration of data acquisition (e.g. about 0.2 seconds to acquire a short-scan data set using a state-of-the-art multi-detector-row CT scanners), the variation of iodine concentration and CT attenuation values within such short duration can be legitimately assumed as linear variation.
Based on the time-resolved CT images obtained by solving Eq. (2), for each voxel in the image, a linear least squares fitting is used to find a linear representation of the temporal variation of intensity value at the given image voxel. CT images corresponding to (the midpoint of ) and the first tube potential can then be determined by linear extrapolation of each linear representation of the temporal variation of intensity value at the each image voxel corresponding to time-resolved images during . Similarly, CT images corresponding to and the second tube potential can then be determined by linear extrapolation of each linear representation of the temporal variation of intensity value at the each image voxel corresponding to time-resolved images during . Then, temporal inconsistency in CT images corresponding to both the first and the second tube potentials are maximally mitigated at . Material quantification can then be performed to obtain quantitative material concentration using the above extrapolated dual-energy images at .
II-D Material Quantification Using Error-Compensated Material Basis Image Generation
Through the developed high temporal resolution image reconstruction and temporal extrapolation, we can obtain CT images at two tube potentials with the nearly consistent iodine concentration, which can be used for material quantification. Due to the instability of material quantification, structural errors in the reconstructed dual-energy CT images obtained from high temporal resolution image reconstruction plus temporal extrapolation developed in Sec. II-B and Sec. II-C will be greatly amplified [26], resulting in erroneous material basis images.
To mitigate the errors in the material basis image, in this paper, instead of applying conventional image-domain material quantification procedure to obtain material basis images, an error-compensated material basis image generation network, EC-Net, has been designed and properly trained to improve quantitative accuracy and image quality of material basis images for each individual subject. The error-compensated material basis image generation models the degradation process into the forward model to train the generator using the data acquired for each individual subject. The degradation process includes the beam hardening effect due to polychromatic spectrum and structural error in the dual-energy images obtained from the developed high temporal resolution image reconstruction plus temporal extrapolation. Via properly modeling the degradation process, the forward model can maximally approximate the obtained dual-energy images, such that, the structural error in the obtained dual-energy images can be properly compensated to further improve the accuracy of the obtained material basis images.
EC-Net is trained to learn the subject-specific material quantification mapping including two sub-mappings . Here denotes the material basis image generation mapping from randomly sampled noise image to ideal material basis images. denotes the dual-energy CT image degradation mapping from ideal material basis images to dual-energy CT images from the developed high temporal resolution image reconstruction plus temporal extrapolation. The material basis image generation mapping is learned for each subject individually to maximally avoid the generalizability error induced by a model trained using a relative large data cohort. The dual-energy CT image degradation mapping , on the other hand, can be trained using a relative large data cohort to represent the features of structural errors represented in a large group of dual-energy CT images. To implement this idea, model parameters are determined by solving the following problem using a relatively large training data set and will be frozen during the training of the material basis image generation mapping .
The optimization problem for determining can be formulated as follows:
| (3) | ||||
where and denote the simulated dual-energy CT images using ideal material basis images at the low and high tube potentials respectively, and denote the reconstructed dual-energy CT images using the high temporal resolution image reconstruction and temporal extrapolation developed in Sec. II-B and Sec. II-C respectively.
The optimization problem for determining can be formulated as follows:
| (4) |
where denotes the random values sampled from the uniform distribution. Once the material basis image generation mapping has been trained for each individual subject, the optimal material basis images can be obtained via .
represents the operator for synthesizing DECT images showing as follows:
| (5) | ||||
where denotes the modeled dual-energy post-log sinogram data, denotes the normalized photon number corresponding to -th tube potential at the -th energy index, denotes the mass attenuation coefficient of -th basis material at -th energy index, denotes -, -th element of the system matrix , denotes -, -th element of which represents the pseudo inverse of . Here we used the standard FBP algorithm to implement .
II-E Implementation Details
All our experimental implementations are based on PyTorch, and the differentiable forward projection operators in neural network are based on LEAP in [27]. All computations were performed on a workstation equipped with an Intel(R) Xeon(R) Platinum 8160 CPU @ 2.10GHz and an RTX 3090 GPU with 24GB of memory.
II-E1 Data Pre-processing
To decouple the interference between static bony structures (such as skull) and temporal varying contrast-enhanced structures (such as iodinated cerebral tissues or vessels) in the sinogram domain, the contribution of static bony structures in the sinogram domain has been subtracted from the measured data prior to the following high temporal resolution image reconstruction. To achieve this purpose, we first applied FBP to reconstruct the measured data acquired at two tube potentials. We then applied a thresholding-based segmentation approach to discriminate bony structures from other tissues. After forward projecting the segmented bony structures, we subtracted the contribution of static bony structures in the sinogram domain from the measured data.
II-E2 High Temporal Resolution Image Reconstruction
The input of the high temporal resolution image reconstruction is the short-scan range data at one of the tube potentials acquired during or , and its output corresponds to time frames at equally spaced intervals within the time intervals or . In this phase, the consists of a Fourier feature embedding layer [21] and an eight fully-connected layers. The width of fully-connected layers is 256 and the activation function is sinusoidal activation functions [18]. For prior image embedding, we used Adam optimizer with an initial learning rate of , and the maximum number of training iterations is set to 1500. For limited view image reconstruction, the initial learning rate of Adam optimizer is set to for the first and last time frames, and for the middle time frames, linearly decreasing from peripheral to middle frames. The maximum number of training iterations is set to 2000.
During limited view image reconstruction, elements in the set of are determined flexibly, allowing for an overlapped data usage in the reconstruction of different time frames. For any specific value of , total number of central views can be identified. The set of projection in the reconstruction of -th frame was determined by maximally utilizing all available data equally distributed around the central view of -th frame. For the time frames close to the boundaries of the total angular range, fewer data were used, while for those in the middle, more data were used. Obviously, this scheme can reduce limited view artifacts in middle time frames but introduces temporal-averaging errors [10].
is empirically designed to solve the high temporal resolution image reconstruction problem. The specific implementation of is not necessary to be generalizable to solve other image reconstruction problems in other imaging tasks, therefore, it should be optimized for each individual image reconstruction problem or imaging task. In this work, was empirically selected.

II-E3 Temporal Extrapolation
Based on the reconstructed time-resolved CT images obtained from the high temporal resolution image reconstruction, temporal variation of each pixel’s attenuation values is linearly fitted using the least square method. The value at is calculated from the fitted line, representing the temporally extrapolated attenuation value at . After temporal extrapolation, temporally consistent CT images under different tube potentials were obtained.
II-E4 EC-Net
The EC-Net consists of an encoder-decoder convolutional neural network (the pink section in Fig. 2) and a traditional seven-layer convolutional neural network (the purple section in Fig. 2). The model parameters of is pre-trained using 3000 samples and the model parameters of are frozen in solving Eq. (4).
For , the network structure is shown in Fig. 2 and hyperparameters follow the image denoising settings in [15]. The maximum number of training iterations is set to 1500, and the learning rate of Adam optimizer is set to . For , the number of convolutional kernels per layer is specified in the figure. Each layer includes a batch normalization operation and uses ReLU as the activation function.
III Materials and Methods to Validate and Evaluate ACCELERATION
To validate the proposed ACCELERATION, we employed numerical simulations with known ground truth to assess its performance and accuracy. Additionally, data acquired from human subjects were introduced to verify the clinical feasibility of ACCELERATION. ACCELERATION was compared against several baseline methods.
III-A Numerical Simulation Studies with Known Ground Truth

III-A1 Data Collection
To obtain numerical simulation data with known ground truth, a pair of cerebral water and iodine basis images was used as the ground true material basis images for the simulation experiments. The ground true material basis images were obtained using a clinical high-end DECT and a clinical contrast-enhanced cerebral CT angiography data acquisition protocol. The 512512 CT images were simulated using a fan-beam CT scanner with 384 detectors, 1000 views, 210 degrees for a short-scan range, and data acquisition time of 1 second.
III-A2 Training and Validation Data Generation
To simulate the variation of iodine contrast agent in the brain of the subject, we set that the concentration of the iodine contrast agent in blood vessels linearly increased to 2.5 times the basis image in the interval , while the soft tissue increased to 1.5 times the basis image. In CT images at 140 kV, vascular changes are approximately 80 HU, while soft tissue changes are about 20-30 HU.
The details of data generation in numerical simulation studies are shown in Fig. 3. Based on the simulated variation of iodine concentration, we obtained iodine basis images corresponding to each view angle during the short scans and , and performed forward projection for iodine basis images corresponding to each view angle using the forward projection operator in [27]. We performed forward projection for water basis images and assumed that the water basis image remains unchanged. Note that it is a legitimate assumption because in contrast-enhanced CT imaging tasks, the variation of iodine concentration takes solo responsibility for the variation of attenuation values. Based on the energy-dependent attenuation coefficients of basis materials and simulated X-ray spectrum, line integrals corresponding to each view angle under 80/140 kV were simulated. By performing filtered back projection (FBP) on each short-scan line integral data, the ground truth CT images at each time point (corresponding to a short-scan angule range) under 80/140 kV can be obtained. The sequential-scanning DECT data in and can be constructed by extracting the line integral data corresponding to each view angle and combining them into two short-scan sinogram data under 80/140 kV.
We used 150 samples to generate the training data to learn the dual-energy CT image degradation mapping . For each sample, 20 values were randomly sampled from a uniform distribution over . These sampled values represented the variation in iodine concentration within the interval . We generated the corresponding training data for high temporal resolution reconstruction. After high temporal resolution image reconstruction and temporal extrapolation, reconstructed CT images at with structural errors are paired with the ground truth, and were used for training the degradation mapping .
III-B Experimental Human Subject Studies
In addition to numerical simulations studies, in vivo human subject studies have been conducted to further demonstrate the technical feasibility of ACCELERATION. Data sets of one human subject (male, 44 years old) acquired with an institutional review board approval and written informed consent at Shanghai Jiading Central Hospital were retrospectively analyzed. The data were acquired using a MDCT system (uCT 960+, United Imaging Healthcare, Shanghai, China). Both the data acquisition and contrast agent injection protocols were approved by the institution. Projection data were processed with the needed data correction using the proprietary software toolkit provided by the vendor.
III-C Baseline Methods for Performance Comparison
In the high temporal resolution reconstruction phase, we selected FBP, SIRT [28], PICCS [9], and SMART [10] as baseline methods. We provided the SIRT, PICCS, and SMART methods with the same prior image as the initial images for iteration as used in the proposed method, and the same projection selection method and CT image reconstruction frame count were used for fair comparison. We optimized the hyperparameters of the baseline methods as much as possible under our imaging conditions. In PICCS, was set to 0.91, and was set to 0.09. In SMART, singular values greater than 5% of the maximum singular value were retained. Other hyperparameters for each method were set according to the recommendations in the reference articles. In the material quantification phase, we introduced the direct inversion method [26] after FBP reconstruction of DECT images and direct inversion with the proposed high temporal resolution reconstruction and temporal extrapolation to demonstrate the effectiveness of the proposed workflow.
III-D Metrics for Quantitative Performance Assessment
The normalized root mean square error (nrMSE) was used to quantitatively assess the similarity between the reconstructed image and the ground truth.
where is the pixel value of the reconstructed image, is the pixel value of the ground truth image, and is the total number of pixels, and the denominator is the root mean square value of the ground truth image. Additionally, we subtracted 1000 mg/ml from the water basis image to amplify the nrMSE, thereby more effectively reflecting the error between the reconstructed water basis image and the ground truth.
IV Results
IV-A Numerical Simulation Studies
IV-A1 Validation of Numerical Optimization
Empirical convergence of the optimization process of ACCELERATION is shown in the change of loss function value of the corresponding prediction with respect to each epoch in Fig. 4. As shown in Fig. 4, the loss function value quasi-monotonically decreases during the optimization. The plateau of the total loss values indicates the empirical convergence of the numerical optimization process.

IV-A2 Assessment of High Temporal Resolution Image Reconstruction

Projections at 80/140 kV generated from numerical simulation studies were used to evaluate the algorithms in the high temporal resolution image reconstruction. The ground true images at different time points are shown in the first row of Fig. 5. The baseline methods, SIRT, PICCS, and SMART, are shown in the 2nd, 3rd, and 4th rows, respectively. Clearly, FBP exhibits severe artifacts for limited view reconstruction. By using prior images as the initial image, SIRT shows some alleviation of artifacts compared with FBP but still presents noticeable limited view artifacts. PICCS algorithm introduces compressed sensing based on sparse-promoting regularization, significantly reducing limited view artifacts in most time frames. However, it exhibits notable errors as shown in the difference images and fails to clearly depict the temporal variation of the imaged object. SMART algorithm leverages low rank regularization on the spatial-temporal image matrix, nearly eliminating limited view artifacts and qualitatively depict the temporal variation of the imaged object. However, it underestimates attenuation values, resulting in quantitative errors that will be further amplified during temporal extrapolation and material quantification. The proposed high temporal resolution image reconstruction, HRT in short, resolves the temporal variation of the imaged object with sufficient quantitative accuracy and image quality.
To evaluate the reconstruction accuracy statistically, we performed 200 rounds of data generation and high temporal resolution image reconstruction under the condition of an 80% change in iodine concentration. For the blood vessel region, the absolute error is 7.6 [0, 15.9] HU (mean value and 95% confidence interval respectively). For the cerebral tissue region, the absolute error is 2.4 [0, 6.2] HU.

Fig. 6 shows the comparison of the accuracy of high temporal image resolution reconstruction and linear extrapolation for baseline methods and the proposed method. Results shown in the figure demonstrate that the proposed method achieves high reconstruction accuracy in both vascular regions (subfig. b, c) and cerebral tissue regions (subfig. d, e, f).
IV-A3 Performance Dependence of High Temporal Resolution Image Reconstruction on the Variation Rate of Contrast Concentration

The variation rate of contrast agent concentration within the brain affects the accuracy and feasibility of the proposed method. We investigated how the accuracy of our method changes with respect to different variation rates of contrast agent concentration. Fig. 7 shows the accuracy (quantified by nrMSE) of our method when the average iodine concentration changes by 10% - 300% during the scan duration of 1000 ms. It can be observed that when the variation rate of contrast agent concentration is less than 60%, the quantitative error of our method remains within 5%. For variation rates between 60% and 150%, the error remains within 10%. Even with very drastic changes in contrast agent concentration (e.g. peak CT values caused by the injection of contrast agent in proximal arteries), the error remains within 15%.
IV-A4 Assessment of Material Quantification

Material basis images obtained in the numerical simulation studies have been shown in Fig. 8. In the second column, without using the proposed HTR and temporal extrapolation, material basis images obtained by the direct image-domain inversion are completely incorrect. In the third column, material basis images obtained by HTR, temporal extrapolation, and direct image-domain inversion, demonstrated amplified noise level, biased quantification of material concentration, and substantial loss of details partially due to the illness of the direct image-domain inversion. In the fourth column, material basis images obtained by HTR, temporal extrapolation and EC-Net, material basis images are reconstructed with sufficient quantitative accuracy and image quality. Note that we did not present material basis images obtained from other baseline methods for temporal matching partially because high temporal resolution image reconstruction using baseline methods are not sufficiently accurate (as shown in Fig. 5 and Fig. 6), resulting in inaccurate material basis images.
IV-B Experimental Human Subject Studies
Results generated from human subject studies were also used to assess the overall qualitative image quality for imaged objects with complex anatomy and realistic temporal dynamics. Direct material quantification without and with HTR and temporal extrapolation were used as the baseline methods and the results were shown in the first and second columns of Fig. 9. ACCELERATION images are shown in the third row of the figure. As demonstrated by the figure, intensity values of iodinated vessels in the obtained water basis images are mitigated using ACCELERATION while other baseline methods cannot. As shown in the figure, iodinated vessels are erroneously enhanced in the water basis image using HRT and direct inversion (the second column of the figure). The image-domain direct inversion cannot produce accurate water basis image partially because the direct inversion does not incorporate the full X-ray spectrum into the physical forward model of the material decomposition process. Note that, in Fig. 9, the material basis images of baseline methods (No Extrapolation and HTR + Extrapolation + Direct Inversion) were reconstructed using in-house implementation. It is necessary to emphasize that the in-house implementation of these baseline methods is different from the reconstruction algorithms implemented in the commercial workstation provided by the vendor.

V Discussion and Conclusion
V-A Potential Limitations and Future Work
This work has several potential limitations which need further investigations in future studies.
First, there is no proprietary hyperparameter to control the trade-off between reconstruction accuracy and noise level of the reconstructed images in HTR or EC-Net. To control the trade-off, one must empirically stop the optimization process at an early stage. The immediate future work is to develop a new optimization framework to solve the optimization problem of HTR and EC-Net with theoretical convergence, explicit hyperparameters to control the trade-off between reconstruction accuracy and noise level, and other flexibilities to obtain imaging-task-specific image quality control.
Second, the data acquisition and contrast injection protocol in the human subject study presented in the paper were not designed and optimized for time-resolved angiography imaging task. To apply ACCELERATION to this imaging task, the data acquisition and contrast injection protocols such as the injection rate, volume and concentration of contrast agent, the rate and volume of saline chasing, the timing of data acquisition, etc., need to be specifically optimized to maximally benefit from ACCELERATION for the time-resolved angiography imaging task.
Third, the performance of HTR depends on the detailed implementation of data classification, , and the selection of the number of time frames, , in Eq. (2). Currently, empirical implementations of and have been applied in solving Eq. (2). The immediate future work is to systematically investigate the performance dependence of the quantitative accuracy of the reconstructed time-resolved images on different implementations of , , or the combination of both of them.
Fourth, the sensitivity and specificity of ACCELERATION in resolving temporal dynamics induced by realistic diseases are under investigation. In our future studies, we will rely on in vivo animal studies involving stroke models with different severity levels to systematically show the potential clinical benefits of ACCELERATION.
V-B Conclusion
In this work, it has been demonstrated that using ACCELERATION, a low-cost sequential-scanning data acquisition scheme to implement DECT has been achieved for contrast-enhanced imaging. Results shown in this paper demonstrated the improvement of quantification accuracy and image quality using ACCELERATION.
References
- [1] C. H. McCollough, K. Boedeker, D. Cody, X. Duan, T. Flohr, S. S. Halliburton, J. Hsieh, R. R. Layman, and N. J. Pelc, “Principles and applications of multienergy ct: Report of aapm task group 291,” Medical physics, vol. 47, no. 7, pp. e881–e912, 2020.
- [2] T. G. Flohr, C. H. McCollough, H. Bruder, M. Petersilka, K. Gruber, C. Sü, M. Grasruck, K. Stierstorfer, B. Krauss, R. Raupach et al., “First performance evaluation of a dual-source ct (dsct) system,” European radiology, vol. 16, pp. 256–268, 2006.
- [3] D. Zhang, X. Li, and B. Liu, “Objective characterization of ge discovery ct750 hd scanner: gemstone spectral imaging mode,” Medical physics, vol. 38, no. 3, pp. 1178–1188, 2011.
- [4] I. P. Almeida, L. E. Schyns, M. C. Öllers, W. van Elmpt, K. Parodi, G. Landry, and F. Verhaegen, “Dual-energy ct quantitative imaging: a comparison study between twin-beam and dual-source ct scanners,” Medical physics, vol. 44, no. 1, pp. 171–179, 2017.
- [5] D. Lee, J. Lee, H. Kim, T. Lee, J. Soh, M. Park, C. Kim, Y. J. Lee, and S. Cho, “A feasibility study of low-dose single-scan dual-energy cone-beam ct in many-view under-sampling framework,” IEEE Transactions on Medical Imaging, vol. 36, no. 12, pp. 2578–2587, 2017.
- [6] R. Symons, B. Krauss, P. Sahbaee, T. E. Cork, M. N. Lakshmanan, D. A. Bluemke, and A. Pourmorteza, “Photon-counting ct for simultaneous imaging of multiple contrast agents in the abdomen: an in vivo study,” Medical physics, vol. 44, no. 10, pp. 5120–5127, 2017.
- [7] S. Lennartz, K. R. Laukamp, V. Neuhaus, N. G. Hokamp, M. Le Blanc, V. Maus, C. Kabbasch, A. Mpotsaris, D. Maintz, and J. Borggrefe, “Dual-layer detector ct of the head: initial experience in visualization of intracranial hemorrhage and hypodense brain lesions using virtual monoenergetic images,” European Journal of Radiology, vol. 108, pp. 177–183, 2018.
- [8] S. Leng, M. Shiung, S. Ai, M. Qu, T. Vrtiska, K. Grant, B. Krauss, B. Schmidt, J. Lieske, and C. McCollough, “Feasibility of discriminating uric acid from non-uric acid renal stones using consecutive spatially registered low-and high-energy scans obtained on a conventional ct scanner,” American Journal of Roentgenology, vol. 204, no. 1, pp. 92–97, Jan. 2015, publisher Copyright: © American Roentgen Ray Society.
- [9] J. Tang, J. Hsieh, and G.-H. Chen, “Temporal resolution improvement in cardiac ct using piccs (tri-piccs): Performance studies,” Medical physics, vol. 37, no. 8, pp. 4377–4388, 2010.
- [10] G.-H. Chen and Y. Li, “Synchronized multiartifact reduction with tomographic reconstruction (SMART-RECON): A statistical model based iterative image reconstruction method to eliminate limited-view artifacts and to mitigate the temporal-average artifacts in time-resolved CT,” Medical physics, vol. 42, no. 8, pp. 4698–4707, 2015.
- [11] Y. Li and et al., “Time-resolved C-arm cone beam CT angiography (TR-CBCTA) imaging from a single short-scan C-arm cone beam CT acquisition with intra-arterial contrast injection,” Physics in Medicine & Biology, vol. 63, no. 7, p. 075001, 2018.
- [12] B. Davis and et al., “4D digital subtraction angiography: implementation and demonstration of feasibility,” American Journal of Neuroradiology, vol. 34, no. 10, pp. 1914–1921, 2013.
- [13] Y. Li, J. W. Garrett, K. Li, C. Strother, and G.-H. Chen, “An Enhanced SMART-RECON Algorithm for Time-Resolved C-arm Cone-Beam CT Imaging,” IEEE transactions on medical imaging, vol. 39, no. 6, pp. 1894–1905, 2019.
- [14] Y. Li, J. Feng, J. Xiang, Z. Li, and D. Liang, “Airport: A data consistency constrained deep temporal extrapolation method to improve temporal resolution in contrast enhanced ct imaging,” IEEE transactions on medical imaging, 2023.
- [15] D. Ulyanov, A. Vedaldi, and V. Lempitsky, “Deep image prior,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 9446–9454.
- [16] R. Barbano, J. Leuschner, M. Schmidt, A. Denker, A. Hauptmann, P. Maass, and B. Jin, “An educated warm start for deep image prior-based micro ct reconstruction,” IEEE Transactions on Computational Imaging, vol. 8, pp. 1210–1222, 2022.
- [17] Z. Shu and A. Entezari, “Sparse-view and limited-angle ct reconstruction with untrained networks and deep image prior,” Computer Methods and Programs in Biomedicine, vol. 226, p. 107167, 2022.
- [18] V. Sitzmann, J. Martel, A. Bergman, D. Lindell, and G. Wetzstein, “Implicit neural representations with periodic activation functions,” Advances in neural information processing systems, vol. 33, pp. 7462–7473, 2020.
- [19] A. Molaei, A. Aminimehr, A. Tavakoli, A. Kazerouni, B. Azad, R. Azad, and D. Merhof, “Implicit neural representation in medical imaging: A comparative survey,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2381–2391.
- [20] A. W. Reed, H. Kim, R. Anirudh, K. A. Mohan, K. Champley, J. Kang, and S. Jayasuriya, “Dynamic ct reconstruction from limited views with implicit neural representations and parametric motion fields,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2021, pp. 2258–2268.
- [21] L. Shen, J. Pauly, and L. Xing, “Nerp: implicit neural representation learning with prior embedding for sparsely sampled image reconstruction,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [22] Y. Zhang, H.-C. Shao, T. Pan, and T. Mengke, “Dynamic cone-beam ct reconstruction using spatial and temporal implicit neural representation learning (stinr),” Physics in Medicine & Biology, vol. 68, no. 4, p. 045005, 2023.
- [23] B. Song, L. Shen, and L. Xing, “Piner: Prior-informed implicit neural representation learning for test-time adaptation in sparse-view ct reconstruction,” in Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2023, pp. 1928–1938.
- [24] J. Lee and J. Baek, “Iterative reconstruction for limited-angle ct using implicit neural representation,” Physics in Medicine & Biology, vol. 69, no. 10, p. 105008, 2024.
- [25] J. Preslar, M. Madsen, and E. Argenyi, “A new method for determination of left-to-right cardiac shunts,” Journal of nuclear medicine technology, vol. 19, no. 4, pp. 216–219, 1991.
- [26] R. E. Alvarez and A. Macovski, “Energy-selective reconstructions in x-ray computerised tomography,” Physics in Medicine & Biology, vol. 21, no. 5, p. 733, 1976.
- [27] H. Kim and K. Champley, “Differentiable forward projector for x-ray computed tomography,” arXiv preprint arXiv:2307.05801, 2023.
- [28] J. Trampert and J.-J. Leveque, “Simultaneous iterative reconstruction technique: Physical interpretation based on the generalized least squares solution,” Journal of Geophysical Research: Solid Earth, vol. 95, no. B8, pp. 12 553–12 559, 1990.