Separating the Effects of Batch Normalization on CNN Training Speed and Stability Using Classical Adaptive Filter Theory
Abstract
Batch Normalization (BatchNorm) is commonly used in Convolutional Neural Networks (CNNs) to improve training speed and stability. However, there is still limited consensus on why this technique is effective. This paper uses concepts from the traditional adaptive filter domain to provide insight into the dynamics and inner workings of BatchNorm. First, we show that the convolution weight updates have natural modes whose stability and convergence speed are tied to the eigenvalues of the input autocorrelation matrices, which are controlled by BatchNorm through the convolution layers’ channel-wise structure. Furthermore, our experiments demonstrate that the speed and stability benefits are distinct effects. At low learning rates, it is BatchNorm’s amplification of the smallest eigenvalues that improves convergence speed, while at high learning rates, it is BatchNorm’s suppression of the largest eigenvalues that ensures stability. Lastly, we prove that in the first training step, when normalization is needed most, BatchNorm satisfies the same optimization as Normalized Least Mean Square (NLMS), while it continues to approximate this condition in subsequent steps. The analyses provided in this paper lay the groundwork for gaining further insight into the operation of modern neural network structures using adaptive filter theory.
Index Terms:
BatchNorm, Natural Modes, NLMS, whiteningI Introduction
The Deep Neural Network (DNN) community is split into two groups. One group drives progress empirically and has delivered innovations in new network architectures such as Residual Networks (ResNets) [1] and training techniques such as Batch Normalization (BatchNorm) [2]. The other group focuses on understanding why these contributions work [3] [4]. However, experiment-driven research has become the prevailing paradigm due to widespread access to large datasets and GPU-accelerated frameworks [5], resulting in a growing gap between DNN innovations and their theoretical understanding.
An example of where this gap exists is BatchNorm, a channel-wise normalization technique popular in CNN training. The primary benefit is in maintaining network stability at higher learning rates. At lower learning rates, BatchNorm increases training speed. In networks such as ResNet [1], BatchNorm is critical to convergence. The creators of BatchNorm theorized that BatchNorm reduces the effect of Internal Covariate Shift (ICS) [2]. Later publications have since disproved the impact of ICS. For example, the authors of [6] demonstrated that they could deliberately induce ICS without affecting convergence speed. Works such as [7] and [8] experimentally demonstrated that BatchNorm helps control exploding gradients but ultimately provide conflicting hypotheses. These works show that despite BatchNorm’s popularity, there is still a debate on why BatchNorm helps training.
This work focuses on improving our theoretical understanding of BatchNorm. Unlike prior work in this area, we leverage insight from the traditional adaptive filter domain. Although modern DNNs are considered a separate field, there are reasons to expect similarities between classical adaptive filter theory and modern DNN techniques. Neural networks originated from the signal processing community in the early 1960s [9] and were treated as a particular form of an adaptive filter. Like modern DNNs, adaptive filters are trained using gradient descent to minimize a loss function such as Least Mean Squares (LMS) [10]. Additionally, BatchNorm bears a strong resemblance to Normalized LMS (NLMS), a variant of LMS that reduces its sensitivity to the learning rate and increases convergence speed. Thus, it is reasonable to expect that classical adaptive filters can provide insight into understanding BatchNorm. We explore the similarities and differences in this paper. More concretely, this work:
-
•
restructures CNNs to follow the traditional adaptive filter notation (Section II). We address the handling of CNN nonlinearities and the global cost function over multiple layers. This explicit recasting is necessary to reconcile the differences between CNNs and adaptive filters.
-
•
demonstrates that CNNs, similar to adaptive filters, have natural modes, stability bounds, and training speeds that are controlled by the input autocorrelation matrix’s eigenvalues (Section III). We demonstrate how the sliding convolution mechanisms create uniform statistics within channels, leading to pseudo-whitening effects via channel-wise normalization. This results in better-conditioned eigenvalues.
-
•
analyzes two BatchNorm variants to explore their impact on the eigenvalues. We show how the pseudo-whitening effects lead to improved bounds and study the effects on training speed and network stability (Section IV).
-
•
proves that the Principle of Minimum Disturbance (PMD) can be applied to CNNs and that under certain conditions, BatchNorm placed before the convolution operation is equivalent to NLMS (Section V).
II Casting CNN Features as Adaptive Filters
II-A Adaptive Filter Definitions
II-A1 Variables
At time step for adaptive filters with vector weights and scalar outputs, we use the following variables:
-
•
: column vector input
-
•
: column vector weight
-
•
: scalar desired response
-
•
: scalar output
-
•
: scalar error
-
•
II-A2 Convolution
We use convolution to refer to the CNN’s spatial convolutions instead of the temporal convolution typical in signal processing.
II-B The Convolution Layer as an Adaptive Filter
II-B1 Restructuring the CNN Convolution Layer
For CNNs with image inputs, tensors are the default structures for the weights, inputs, and outputs, with the following dimensions:
-
•
Weight dimensions input channel output channel height width:
-
•
Input activations input height input width input channels:
-
•
Output activations output height output width output channels:
We restructure the 4D spatial convolution into a matrix-vector multiplication, as shown in Fig. 1. Without loss of generality, we restrict the analysis to a single output channel and single batch because operations along the output channels and batches are independent of one another. For brevity, we drop references to the time step .


II-B2 Variables
Given this restructured form, we adapt the framework from Section II-A to describe the CNN layer components for a given convolution layer :
-
•
: filter weight vector of size . is the th element in . When there are multiple output channels, the weight array is the matrix .
-
•
: unrolled local error vector of length . is the th element in .
-
•
: unrolled local desired response vector of length . is the th element in .
-
•
: input vector of size . It is the unrolled patch of the spatial input map that is convolved with the filter. is the th element in this vector.
-
•
: input matrix of size . It is the input when is expanded along the spatial convolution strides. Each stride, indexed by , corresponds to a vector and a new output pixel.
-
•
: unrolled output vector of length . is the th element in .
As in the adaptive filter format, the goal of CNN training is to update for all so that the desired response eventually matches the local error vector . Fig. 2 shows the recast convolution layer with these terms, the ReLU nonlinearity, and the backpropagation path.


II-B3 The Restructured Loss Function
To make the natural modes analysis of Section III-A tractable, we transform the global loss function (defined over the entire network architecture) into , which is a function of only terms available in the current layer . We start with as a function of only the layer input , the layer weights and the downstream weights (where ). At time step , since the downstream updates do not affect the update at layer until time step , we safely fix all downstream weights as constants, leaving and as the only variables in . , where is the local gradient calculated using the chain rule. For the th element in :
| (1) |
is the th row of . We now have an expression for that is usable in the derivation of the natural modes.
III Natural Modes and Normalization Effects
This section shows that the restructured CNN layer has natural modes similar to adaptive filters [11][12].
III-A Derivation of the Natural Modes
To begin this analysis, we define the following terms. is the cross-correlation vector between the input and the desired response. is the unrolled local error vector (Section II-B). is the autocorrelation matrix. is the mean along the rows of .111In the adaptive filter setting, we estimate the autocorrelation matrix by averaging the input vector’s outer product with itself over many time steps, i.e., strides in time. In the restructured CNN, these strides are spatial. Therefore, we average over both the columns of and a randomly sampled batch. We use these terms to expand (1):
| (2) |
Let us apply the principle of orthogonality to the CNN layer: when the estimation error vector, , is orthogonal to the input (and by extension, all rows of ), then the weights are at their optimum value, . At this point, the error vector is at its minimum, denoted as , . In summary, applying the principle of orthogonality to (1) results in . This gives the Wiener-Hopf equations. We introduce the time step, , and as the learning rate and apply the Wiener-Hopf equations and (2) to the weight update equation, : .
Define the weight error vector, and substitute into this new weight update equation to obtain:
| (3) |
Define . Substituting the eigendecomposition , where is the diagonal matrix containing the eigenvalues of , and into (3) gives the transformed set of weight update equations: . The natural modes are the elements in . Let be a single element in , indexed by , such that for eigenvalues and assume an initial starting point . Then the natural modes are as follows:
| (4) |
III-B Bounds of the Natural Modes
The exponential form of (4) enables us to derive explicit bounds on stability and error decay rate. Training is stable when , indicating that any CNN architecture that uses a technique to suppress the largest eigenvalues is stable at comparatively higher . Assuming all modes have the same , the largest eigenvalue of all the modes sets the stability bound:
| (5) |
The time constant of the modes determine the speed of weight error decay, and by extension, the speed of training. Each entry in the weight error matrix decays via an exponential , where . The bound on the training speed is set by the largest time constant, or the smallest eigenvalue:
| (6) |
Equation (6) shows that training converges faster when using techniques that boost the smallest eigenvalues without compromising stability.
Increased stability and training speed are well-established benefits of whitening. True matrix whitening is not typically performed in both the traditional adaptive filter domain and the forward path of CNNs, because the whitening matrix calculation is cost-prohibitive. BatchNorm improves stability and increases training speed because BatchNorm is a cost-effective approximation of whitening.
III-C CNN Spatial Strides and Intra-Channel Statistics
BatchNorm is a pseudo-whitening operation because it partially decorrelates the input without an explicit calculation of the whitening matrix. Fig. 3 illustrates this effect. A realistic set of input activations (not statistically white) is generated from ResNet18 [1] trained on CIFAR-10 [13] without BatchNorm and shown in Fig. 3(a). These activations have strong off-diagonal values and weak main diagonal values and show a block pattern. Each block’s side-length is equal to the number of vector elements corresponding to a single channel. This pattern emerges from the uniformity of the intra-channel statistics and wide variation in inter-channel statistics (Fig. 4). The row-wise blocking (illustrated in Fig. 5) and overlapping strides result in elements of the same block row having similar statistics. BatchNorm, at the granularity of blocks, transforms the activations to resemble a whitened input by strengthening the blocks along the main diagonal while weakening the off-diagonal blocks (Fig. 3(b)).




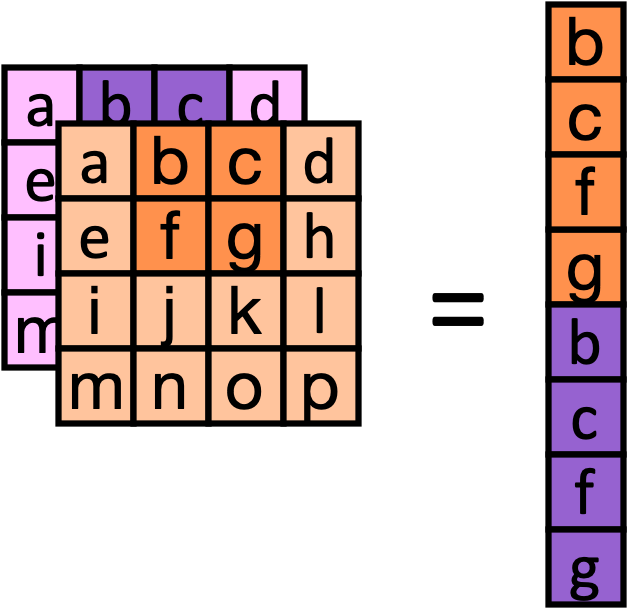
The matrix is the concatenation of block matrices, where each block matrix is the autocorrelation matrix of block rows. In the extreme case where there is no correlation between channels, each block is responsible for a different set of eigenvalues. Entire groups of eigenvalues can be scaled by scaling their associated channel.
While in reality, there is some correlation between channels, large eigenvalues primarily result from the channels with larger power, and small eigenvalues result from the channels with smaller power. Therefore, there exists the possibility that we can independently tune the large and small eigenvalues by normalizing only the largest and smallest channels, respectively. This ability allows us to delineate the effects of the bounds proposed in Section III-A. Therefore, we propose two BatchNorm variants: BN_Amplify and BN_Suppress. BN_Amplify amplifies channels using normalization only on channels above a power threshold of 1.0. BN_Suppress suppresses channels using normalization only on channels below a power threshold of 1.0 (Fig. 6).



IV Experiments
IV-A MNIST
The networks are based on LeNet [14] with one FC layer removed (to reduce memory requirements for saving activations from multiple training steps). We compare four networks:
-
•
Baseline: Described in Table I
-
•
BatchNorm: BatchNorm layer after each conv layer
-
•
BN_Amplify: BN_Amplify layer after each conv layer
-
•
BN_Suppress: BN_Suppress layer after each conv layer
All networks are trained with five seeds, starting with the same set of random weights on the MNIST dataset [15]. for the convolution weights is swept over 20 epochs. We capture the minimum and maximum eigenvalues after the five steps across various . All other parameters are trained at without dropout. The training algorithm uses stochastic gradient descent and cross-entropy loss.
| Layer | Type | Filter Size | Stride |
|---|---|---|---|
| 1 | Conv | 1655 | 1 |
| 2 | ReLU | - | - |
| 3 | Avg Pool | 22 | 2 |
| 4 | Conv | 61655 | 1 |
| 5 | ReLU | - | - |
| 6 | Avg Pool | 22 | 2 |
| 7 | Fully Connected | 40010 | - |






IV-A1 Results for Training Convergence Speed Measurements on MNIST
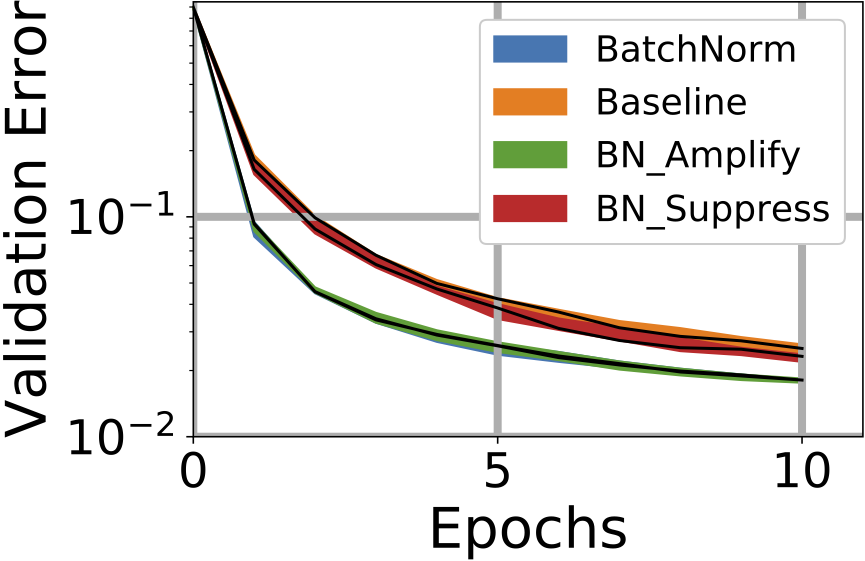
The nearly indistinguishable BatchNorm and BN_Amplify curves in Fig. 8(a) and Fig. 8(b) show that at low , BatchNorm is amplifying the weaker channels. In Fig. 7 below , the minimum eigenvalues of BatchNorm and BN_Amplify not only match, but they are higher than the minimum eigenvalues of the other curves.
Amplification did not affect the final validation error for . Even though we plot up to 20 epochs, all networks eventually reached the same validation error in all cases for . This observation reinforces the observation that at these lower , the amplification of the smallest eigenvalues benefits primarily speed rather than absolute validation error.
IV-A2 Stability Analysis on MNIST
At high , the primary benefit of BatchNorm is in suppressing the largest eigenvalue. In Fig. 8(d), the validation errors of BatchNorm and BN_Suppress are nearly indistinguishable, indicating at these high , the primary benefit of BatchNorm is in suppression. Indeed, in Fig. 9(b) at , the maximum eigenvalue of BatchNorm and BN_Suppress is nearly indistinguishable from that of BN_Suppress. In contrast, BN_Amplify and Baseline cannot to suppress the largest eigenvalues and therefore become unstable.
Figs. 8 and 9(a) show that there is a crossover point between and . In this range, the stability bound begins to dominate training performance over the slowest mode bound, and for BN_Amplify and Baseline, the validation error starts increasing. This growing instability is marked in Fig. 8(c) and 8(d) by an increase in the error bands.
The toy network described in Table I provides a controlled environment to disentangle the dynamics of BatchNorm and its effects on the bounds of the natural modes. However, due to the strong dependence modern neural networks have on BatchNorm, we expand this analysis to ResNet20.
IV-B ResNet20 on CIFAR-10
ResNet20 [1], featuring residual connections that allows for much deeper networks, is difficult to train without BatchNorm. To stably train the BatchNorm variants of interest, we use the core portion of Fix-Up initialization [7] which applies depth-wise layer scaling of the weights to our ResNet models. We call this ”FixupCore” in our experiments. This scaling removes the exponential scaling effect of depth on the variances and allows the more detailed study of the impact of channel-wise scaling of BatchNorm on the bounds provided by the Natural Modes analysis (Fig. 10(b)). We compare five networks:
-
•
FixupCore: ResNet20 with FixupCore
-
•
BN_Suppress: ResNet20 with BN_Suppress
-
•
BN_Suppress_FixupCore: ResNet20 with BN_Suppress, FixupCore initialization
-
•
BatchNorm: ResNet20 with BatchNorm
-
•
BN_Amplify_FixupCore: ResNet20 with BN_Amplify, FixupCore initialization
All networks are trained with 20 seeds for 20 epochs without dropout. We sweep for the convolution weights, but fix for all other parameters.
IV-B1 Training Without BatchNorm: The Connection to Initialization
Prior to BatchNorm, CNNs were deemed very sensitive to initialization. Networks such as AlexNet [16] and VGG [17] were developed before the introduction of BatchNorm but were sensitive to the selection of and weight initialization. Works studying neural network initialization [18][19] aim to reduce this sensitivity by using the heuristics of the layer-wise variance of activations and gradients to set the weights during initialization. The authors hoped to strike a balance between the problems of exploding and vanishing gradients. BatchNorm reduces CNNs’ reliance on these methods.
Natural mode analysis presents a more concrete interpretation of the initialization story. The analysis shows that the stability bound is set by the largest eigenvalue and . Since the common method for training neural networks is to set all layers of the network to have the same , the maximum allowed eigenvalue must also be the same for all layers of the network. Limiting the variance is a very coarse method to limit the maximum eigenvalue because the maximum eigenvalue is upper-bounded by the variance. Indeed, in Fig. 10(a), the maximum eigenvalue exponentially increases with depth without Fixup or normalization.



IV-B2 Training Speed Experiments
We plot the training curves at different (Fig. 11). For low , BN_Amplify_FixupCore trains the fastest. However, since BatchNorm could not match the performance of BN_Amplify, we cannot conclude that for residual networks that BatchNorm’s primary function at low is to amplify weak channels. Further work is needed to understand BatchNorm’s effect on the minimum eigenvalues at these low learning rates.



IV-B3 Stability
We explore the stability of the network at different (Fig. 12). At , the two networks without active suppression via normalization become unstable. Fixup does not help because it is an initialization technique. Fig. 12 shows how the eigenvalues rapidly increase before the network fails to train completely.


V NLMS and the Principle of Minimum Disturbance
This section details the similarities and differences between NLMS and BatchNorm. We formally introduce NLMS as a result of an optimization problem based on the Principle of Minimum Disturbance (PMD) [11]. We demonstrate how to apply PMD to CNNs, and that BatchNorm placed before the convolution operation most closely matches NLMS. We conclude with noise injection experiments to validate the theoretical results.
LMS is a popular stochastic gradient algorithm used to find the filter weights of an adaptive filter based on just the current input and current error [10]: . A well-known problem with LMS is its sensitivity to the input size, where large inputs amplify gradient noise. As a result of this sensitivity, when the input power fluctuates, it becomes hard to maintain stability at high . Normalized LMS (NLMS) is a technique that resolves this sensitivity by dividing the weight update by the input power: .
NLMS is derived using the Principle of Minimum Disturbance. PMD is the idea that while there are many ways to update the weights to reach the desired output, the best collection of updates is the one that disturbs the weights the least. For a traditional adaptive filter with a scalar output and vector weights and inputs, one should minimize subject to the constraint .
We now prove that PMD can be applied to the CNN weight update. Since we cannot derive directly from the global CNN loss function , we derive from the local error provided by backpropagation. Because we are constraining our analysis to the components and operations in a single layer, there is no need to explicitly index by layer. Therefore, we drop references to the layer index .
V-1 The Scalar Output Case
Constrain the analysis to a single pixel in a given output feature map, indexed by . Then the output is scalar, and the weight update can be expressed using ordinary LMS. The output pixel at location is given by at time step .
To apply the PMD to the convolution layer, we need the desired output . For a traditional adaptive filter, the desired response is provided externally by the system that the filter is trying to model. In the convolution layer case, internal layers do not have a local desired response directly provided. Instead, they have the local error . Therefore, we assume the following relationship to derive the desired response: . Using , NLMS can be derived for this scalar case.
V-2 Multiple Input Channels
Recall that for every output pixel , where , there is an unrolled input patch , with size . However, there is a distinct set of weights for the block row of weights corresponding to channel . Using the components defined in Section II-B, and notation developed in Section III-A for block rows in , we can index into this patch and the associated weight element with , where for input channel :
| (7) |
V-3 The Array Output Case
For a convolution layer, any given single weight value is used in the calculation of output pixels. Therefore, in a single time step, has weights updates from M sources. Because the weight update contributions from each output pixel are summed together to create the total weight update for , these updates are operationally independent of each other. Therefore, instead of a single optimization with M constraints, there are M separate optimization problems, each with a scalar Lagrangian multiplier. Therefore, to extend (7) over an array of output pixels, we sum over all constraint equations. Starting with (7), sum over M:
| (8) |
V-4 Normalized Inputs
The explicit normalization by the input power in the weight update equation can be removed if the input is normalized to zero mean and unit variance. To do so, assume that within each feature map patch with dimensions HxW, the pixels locally have the same statistics and therefore have the same variance. Then the variance for is the same for all and , and is indicated by .
Let us introduce the learning parameter , and roll into . Assume that the input along channel is zero mean, denoted by . Then can replace :
| (9) |
V-5 The Role of Batches
In Section V-4, the variance is estimated over a single input feature map. For many CNNs, the number of pixels can be as small as 7x7, making it difficult to estimate the variance. However, if weight updates are calculated across input batches, the channel variances are now estimated from a size of , and the channel statistics estimate becomes more accurate. In the limit of large , it is safe to replace with its normalized version, . Then and can be removed:
| (10) |
V-A BatchNorm and NLMS
In this section, we analyze how BatchNorm deviates from the prior analysis. To do so, we must start with defining the location of BatchNorm and NLMS in the forward and backward pass of CNN operations.







V-A1 BatchNorm Before or After the Convolution
Fig. 13(a) gives the base arrangement of a convolution layer followed by a ReLU nonlinearity. Fig. 13(b) illustrates how NLMS operates on the weight update during the backward pass. Fig. 13(c) and 13(d) show the two possible placements of BatchNorm, either before or after the convolution layer. It is not clear from [2] which placement of the BatchNorm layer is better. Work such as [20] found that the networks performed slightly better when the BatchNorm layer is placed before the convolution layer. Despite these findings, the standard convention is to place BatchNorm after the convolution layer.
We can only remove the explicit normalization term and still satisfy PMD if the inputs are already normalized. Assuming the learned parameters of BatchNorm are close to their initial values, BatchNorm placed before the convolution layer more closely satisfies PMD. From Fig. 13, it is clear that BatchNorm has no chance of normalizing the inputs of that particular layer if placed after a given convolution layer, and thus cannot meet the conditions outlined in Section V-4. We do not expect it to match the performance of NLMS.
V-A2 The Role of Learned Parameters
A key difference between BatchNorm and the normalization requirements of PMD are the BatchNorm channel-wise scale and shift parameters, and , respectively. These parameters change the channel-wise mean from 0 to and the variance from 1 to .
To follow PMD exactly, the common CNN update equation needs the following change:
| (11) |
where and are usually initialized to 1 and 0, respectively. This means that in the first training step, the CNN update follows PMD exactly. The first training step is arguably the point in training when NLMS is most needed. During the first training steps, when the weights have not settled, the input power is still wildly fluctuating. Recall that the original motivation behind NLMS was that it enables designers to pick a high when the input power is strongly fluctuating.
Even though and allow deviations from the weight update size mandated by PMD, as long as they do not deviate too far from their initial values, we expect BatchNorm placed before the convolution layer to come close to satisfying PMD.
V-B Experiments with NLMS
Here, we quantify the effect of NLMS on gradient noise, and compare NLMS to BatchNorm before and after the convolution operation. The network variants (Fig. 13) are:
-
•
Baseline: Network in Table I
-
•
BatchNorm: BatchNorm layer after the convolution
-
•
NLMS_L1: NLMS, with L1 norm
-
•
NLMS_L2: NLMS, with L2 norm
-
•
BN_Prior: BatchNorm layer before the convolution
To isolate the effects of NLMS on the convolution layers and not have the FC layers’ learning power compensate for the impact of noise in the weight updates, we leave the FC layer as untrained. We only apply BatchNorm and NLMS to the second convolution layer. This results in BatchNorm having a higher validation error, dropping the baseline’s accuracy from 99% to 95%. This is acceptable for our analysis because we are only interested in the validation error variance due to noise injection. To measure the effect of NLMS in a controlled manner, we inject noise into the local error (before weight gradient calculation). The noise is drawn from a Gaussian and scaled according to the local error variance. We train with stochastic gradient descent, no dropout, and no weight decay or momentum over 40 epochs (Fig. 14).
Fig. 14 shows that NLMS, which satisfies PMD exactly, has the least amount of noise amplification, resulting in the smoothest curve in the presence of noise. NLMS_L2 has the smallest band and shows the greatest resilience to noise. BN_Prior, which comes close to satisfying PMD, performs similar to NLMS_L2. Other networks, including both BatchNorm and Baseline, are sensitive to injected noise. As a result of leaving the FC layer untrained, the variant with BatchNorm placed after the convolution layer settles at a higher error.
VI Related Works
Our work is similar to others that focus on the Hessian matrix because the input autocorrelation matrix is the expectation of the local Hessian of the layer weights. Reference [21] studies the relationship between the local Hessian and backpropagation and similarly proposed that BatchNorm applied to an FC layer controls the spectrum of the local Hessian eigenvalues, which can lead to better training speed. In this work, we study BatchNorm applied to convolution layers and separate the amplification and suppression effects of BatchNorm to demonstrate that it is the amplification of the smallest eigenvalues that leads to increased training speed. The works of [22][23] derive the Hessian and draw conclusions similar to our work. They extend the findings to Hessian-free techniques for determining an adaptive learning rate. We derive the relationship between BatchNorm and the eigenvalues of by applying adaptive filter ideas (principle of orthogonality and Wiener-Hopf equations).
VII Conclusion
This work uses the lens of classical adaptive filters to analyze BatchNorm. We showed that CNN weight updates have natural modes, whose bounds control stability and training speed dynamics. We explored these connections with experiments on LeNet/MNIST and ResNet20/CIFAR10. For small LeNet-like networks, the experiments match the theoretical results. For ResNet, the stability behavior provides an explanation of how BatchNorm stabilizes networks with residual connections. The ResNet experiments demonstrate that amplification at low learning rates is critical for fast convergence. BatchNorm does not demonstrate similar amplification results at low learning rates, and this holds back training. Further work is needed to fully understand the role of BatchNorm in ResNets at low . Finally, we derived NLMS for CNNs and showed how BatchNorm placed before the convolution operation is closest to NLMS and demonstrates similar gradient noise suppression.
References
- [1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 770–778, 2016.
- [2] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Proceedings of the 32nd International Conference on Machine Learning, pp. 448–456, 2015.
- [3] B. Hanin, “Which neural net architectures give rise to exploding and vanishing gradients?,” in Advances in Neural Information Processing Systems 32, pp. 582–591, 2018.
- [4] Y. Greg, J. Pennington, V. Rao, J. Sohl-Dickstein, and S. Schoenholz, “A mean field theory of batch normalization,” in 7th International Conference on Learning Representations, 2019.
- [5] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 33, pp. 8024–8035, 2019.
- [6] S. Santurkar, D. Tsipras, A. Ilyas, and A. Madry, “How does batch normalization help optimization?,” in Advances in Neural Information Processing Systems 32, pp. 2488–2498, 2018.
- [7] H. Zhang, Y. Dauphin, and T. Ma, “Fixup initialization: Residual learning without normalization,” in 7th International Conference on Learning Representations, 2019.
- [8] D. Balduzzi, M. Frean, L. Leary, J. Lewis, K. Ma, and B. McWilliams, “The shattered gradients problem: If resnets are the answer, then what is the question?,” in Proceedings of the 34th International Conference on Machine Learning, pp. 536–549, 2017.
- [9] B. Widrow, “An adaptive adaline neuron using chemical memistors,” Tech. Rep. TR-1553-2, Stanford Electronics Labs, Stanford, CA, Oct. 1960.
- [10] B. Widrow and M. Hoff, “Adaptive switching circuits,” Tech. Rep. TR-1553-1, Stanford Electronics Labs, Stanford, CA, June 1960.
- [11] S. Haykin, Adaptive Filter Theory. Upper Saddle River, NJ: Prentice Hall, 4th ed., 2002.
- [12] B. Widrow, “Adaptive filters,” in Aspects of Network and System Theory (R. Kalman and N. DeClaris, eds.), pp. 563–587, New York: Holt, Rinehart, and Winston, 1971.
- [13] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” 2009.
- [14] Y. LeCun, L. Jackel, B. Boser, J. Denker, H. Graf, I. Guyon, D. Henderson, R. Howard, and W. Hubbard, “Handwritten digit recognition: Applications of neural network chips and automatic learning,” IEEE Communications Magazine, vol. 27, no. 11, pp. 41–46, 1989.
- [15] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [16] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems 25, (Red Hook, NY, USA), p. 1097–1105, Curran Associates Inc., 2012.
- [17] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [18] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, pp. 249–256, 2010.
- [19] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 1026–1034, 2015.
- [20] D. Mishkin and J. Matas, “All you need is a good init,” in 4th International Conference on Learning Representations, pp. 1–13, 2016.
- [21] H. Zhang, W. Chen, and T. Liu, “On the local hessian in back-propagation,” in Advances in Neural Information Processing Systems 32, pp. 6520–6530, 2018.
- [22] Y. LeCun, P. Simard, and B. Pearlmutter, “Automatic learning rate maximization by on-line estimation of the hessian’s eigenvectors,” in Advances in Neural Information Processing Systems 7, pp. 156–163, 1993.
- [23] Y. LeCun, L. Bottou, G. Orr, and K. Müller, “Efficient BackProp,” in Neural Networks: Tricks of the Trade, pp. 9–48, Springer, 2012.