2Department of Computer Science and Engineering
Chittagong University of Engineering and Technology
Chittagong-4349, Bangladesh
11email: {eftekhar.hossain, omar.sharif, moshiul_240∗, iqbal}@cuet.ac.bd
SentiLSTM: A Deep Learning Approach for Sentiment Analysis of Restaurant Reviews
Abstract
The amount of textual data generation has increased enor-mously due to the effortless access of the Internet and the evolution of various web 2.0 applications. These textual data productions resulted because of the people express their opinion, emotion or sentiment about any product or service in the form of tweets, Facebook post or status, blog write up, and reviews. Sentiment analysis deals with the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer’s attitude toward a particular topic is positive, negative, or neutral. The impact of customer review is significant to perceive the customer attitude towards a restaurant. Thus, the automatic detection of sentiment from reviews is advantageous for the restaurant owners, or service providers and customers to make their decisions or services more satisfactory. This paper proposes, a deep learning-based technique (i.e., BiLSTM) to classify the reviews provided by the clients of the restaurant into positive and negative polarities. A corpus consists of 8435 reviews is constructed to evaluate the proposed technique. In addition, a comparative analysis of the proposed technique with other machine learning algorithms presented. The results of the evaluation on test dataset show that BiLSTM technique produced in the highest accuracy of 91.35%.
Keywords:
Natural language processing Opinion mining Embedding features Deep learning Sentiment classification Sentiment corpus.1 Introduction
Sentiment polarity detection regarded as one of the significant research problems for opinion extraction in natural language processing (NLP). In recent years, the plenteous growth of the internet and the random access of e-devices facilitate the generation of voluminous reviews or opinions in textual form on social media or online platforms. Most of these reviews express the consumers feedback toward the products and services that they received. Several business companies, as well as online marketers, take advantage of these feedbacks to provide praiseworthy services to the consumers. In addition to that customer makes a perfect decision based on the previous reviews before receiving products or services.
Sentiment detection is a computational technique that attempts to uncover the viewpoint of a user towards a specific entity. It aims to identify the contextual polarity of the text contents (such as comments, reviews, tweets or posts) as the positive, neutral and negative [20]. Sentiment analysis or detection has shown a remarkable impact in the business community, whereby taking into account the user opinions the communities can ensure the sustainability of their product or services. The restaurant is one such business, where customers opinions can be utilized to improve their quality of foods, environments, and services. Pompous lifestyle and assorted food habits led to a significant increase in the number of people in restaurants. To collect the excellence of services, customers instinct to look through the restaurant reviews before visit it. Therefore, reviewing a restaurant via the internet has become an ecumenical trend. Besides, an abundant amount of positive reviews can make a restaurant as a symbol of faith towards the customers. Also, it can assist a restaurant to reach the pinnacle of success. In contrast, without a sufficient amount of positive reviews, it becomes difficult to gain the attention of new customers by a restaurant. Sometimes, a restaurant with negative reviews loses the trustworthiness of the customers, which turned into reducing the profit.
Straightforwardly, users opinions on specific criteria such as food quality, ambience and service standards of a restaurant can have enough influence on the customers liking. However, it would not be wrong to say that customers inclination or reluctance towards a restaurant depends on the amount of positive and negative reviews. Therefore, the restaurants should appreciate the consents as well as the opinions of the customers. Nevertheless, scrutinizing every reviews one by one is a very time consuming as well as cumbersome task. Further, to govern such surveys, it requires plenty amount of investment in both money and human resources. Considering the fact of the explosive growth of the visitors as well as user preferences, it requires an automatic system that can comprehend the contextual polarity of reviewer opinions posted in different online platforms including Facebook, Twitter, company website, and blogs. Nevertheless, sentiment classification is a challenging research issue in a resource-poor language like Bengali. The inadequacy of benchmark dataset and the limited amount of e-textual contents or reviews in the Bengali language resulted in the sentiment classification task complicated. Deep learning algorithms are very effective to tackle such complications and classify the sentiments correctly [1, 19]. One main advantage of these algorithms are their ability to capture the semantic information in long texts. This paper proposed a deep learning-based sentiment classification technique to classify sentiment form reviews. By taking into consideration the current constraints of sentiment analysis in low resource languages, this paper contributions illustrate in the following:
-
•
Develop a corpus consisting of Bengali restaurant reviews which are labelled either positive or negative sentiment polarities.
-
•
Develop a deep learning-based framework using LSTM for classifying the sentiment expressed in the Bengali reviews.
-
•
Perform hyperparameters tuning to settle the suitable parameters for better performance.
-
•
Presents a comparative performance analysis among baseline models, including the proposed technique.
2 Related Work
Although substantial data on sentiment analysis is available in various languages, most of the research conducted on high resource languages (such as English, Chinese) [4]. Siqi Liu et al. [14] presented a comprehensive study of sentiment analysis on yelp restaurant reviews. They experimented different machine learning (ML) and deep learning algorithms to predict whether the sentiment of a review is positive or negative. Their work concluded that simpler models of ML more suitable than complex deep learning algorithms to predict sentiment. Minaee et al. [16] combined CNN and bidirectional long short term memory (BiLSTM) for sentiment analysis using IMDB movie reviews. A cloud-based deep learning technique introduced by Ghorbani et al. [7] to identify the polarity of movie reviews. This work combined CNN and LSTM technique which achieved of 89.02% accuracy. An integrated CNN-LSTM approach presented for sentiment analysis from the Arabic text using FastText embedding model [18] using. Smadi et al. [2] developed CNN-LSTM based technique to classify the sentiment of Arabic tweets which obtained about 64.46% F_1-score. A CNN with gated recurrent mechanism was introduced in [27] to find both sentiment and aspect from restaurant review dataset. A stacked BiLSTM model proposed that incorporates continuous bag of words (CBOW) technique to determine the polarity of Chinese microblog text [26]. Zhou et al. [30] introduced a sentiment classification model based on improved word vector representation aggregated with BiLSTM. This work classifies the positive and negative sentiment of Chinese hotel reviews. Furthermore, Rani et al. [21] performed sentiment analysis on Hindi movie reviews using CNN which achieved 95% accuracy for positive, negative and neutral classes.
Although sentiment analysis on resource-poor languages such as Bengali is in the preliminary stage till to date, few studies already conducted using ML and deep learning techniques. Rumman et al. [5] presented a sentiment analysis model for Bengali movie reviews. They have experimented with different ML and deep learning algorithms on a dataset consisting of 4000 Bengali reviews and obtained accuracy of (for SVM) and (for LSTM). Eftekhar et al. [11] proposed multinomial Naive Bayes model to classify sentiment polarities into the positive and negative using 2000 Bengali book reviews, which achieved accuracy. An LSTM-based sentiment analysis model is proposed by Hassan et al. [10] for classifying Bengali text into positive and negative sentiments which achieved accuracy on 9337 reviews. Kamal et al. [22] proposed an LSTM based sentiment analysis to classify Bengali 1500 tweets into positive, negative, and neutral categories with an accuracy of . Wahid et al. [25] proposed a sentiment analysis model using LSTM to classify the Bengali text into positive, negative, and neutral classes with an accuracy of accuracy over a dataset consists of 10,000 Facebook comments. A BiLSTM based sentiment detection method classify sentiment from Facebook tweets [23]. This method obtained about accuracy on a Bengali tweet dataset consisting of 10000 tweets. Rahman et al. [20] introduced a sentiment analysis model for extracting positive and negative aspect category from 2000 Bengali reviews. Their system applied CNN and achieved an accuracy of .
It is observed that most of the previous studies on sentiment analysis in the Bengali language conducted with various datasets, including Facebook tweets, book reviews, and movie reviews. However, the size of the dataset relatively was small in most recent studies. As far as we concern, there is no work except [24] has explicitly done on sentiment analysis in the Bengali language that considers restaurant reviews. Though this work achieved a reasonable accuracy of , there exist some notable drawbacks. Firstly, the model was trained and evaluated on a relatively tiny dataset consists of reviews. Secondly, this work used the word frequency (TF-idf) feature extraction technique that cannot handle the disambiguation problem and thus in most of the cases the trained ML models failed to distinguish the actual sentiment of a review from an unseen data. To address these drawbacks, we proposed a deep learning-based sentiment analysis technique (Bi-LSTM) along with word2vec [15] word representation algorithm to classify the sentiment polarity into positive and negative based on our developed corpus of restaurant reviews.
3 Corpora Development
As Bengali is a limited resource language, it is a challenging task to accumulate a large amount of data/reviews related to the restaurant. We collect 6625 Bengali restaurant reviews from various online platforms. Among these reviews 1763, 1940 and 2922 reviews collected from restaurant pages, groups, Facebook comments respectively. We also collected 2000 restaurant reviews from the Yelp dataset [3], which is manually translated into Bengali by following the method described in [20]. Data collection is performed between February 2020 to June 2020.
Accumulated raw data contains many inconsistent reviews. To mitigate the annotation efforts, we designed a filter to remove the inconsistencies form the collected dataset by ensuing the following steps: (i) Duplicate reviews are discarded (ii) If a review consists of less than three words, it is discarded, (iii) If a review was written in a mixture of Bengali and non-Bengali language, then it is discarded (iv) A review containing neutral sentiment is discarded, and (v) Punctuation marks, numbers, and emojis are removed from the reviews. Inconsistencies detected by the designed filter were taken care of, and a cleaned corpus is prepared for manual annotation.
After data collection and cleaning, we performed manual annotation of the 6435 reviews and did not alter the label of 2000 reviews that were collected from Yelp dataset. For annotation, we assigned three annotators having 12-18 months experience in NLP domain. For the purpose of annotation, we follow the techniques presented by Mohammad [17]. Annotators are asked to label a review either positive or negative. To clear the understanding of the annotators, we provide some restaurant reviews to them prior labelling. In order to check the quality of the annotation, we measure the inter-rater agreement between the annotators using Cohen’s Kappa [6]. The average Kappa score is of 0.81 in our corpus, which indicates that data are of acceptable quality. Finally, the label of a review is decided based on majority voting among the annotators. We developed the Bengali Restaurant Review Corpus (BRRC) containing 4865 positive and 3570 negative reviews. Some statistics of the BRRC summarized in Table 1.
| Dataset attributes | Positive | Negative |
|---|---|---|
| Number of documents | 4 865 | 3 570 |
| Number of words | 85 956 | 270 613 |
| Total unique words | 11 295 | 5 470 |
| Size (in bytes) | 8 974 848 | 579 872 |
| Number of sentences | 15 081 | 40 710 |
4 Methodology
The main objective of our work is to develop a sentiment classifier using deep learning approach (i.e Bi-LSTM) that can classify restaurant reviews into positive or negative sentiment categories. An abstract view of the proposed framework is depicted in Fig. 1. The proposed framework consists of three main constituents: text to vector representation module, model architecture module, and sentiment prediction module.
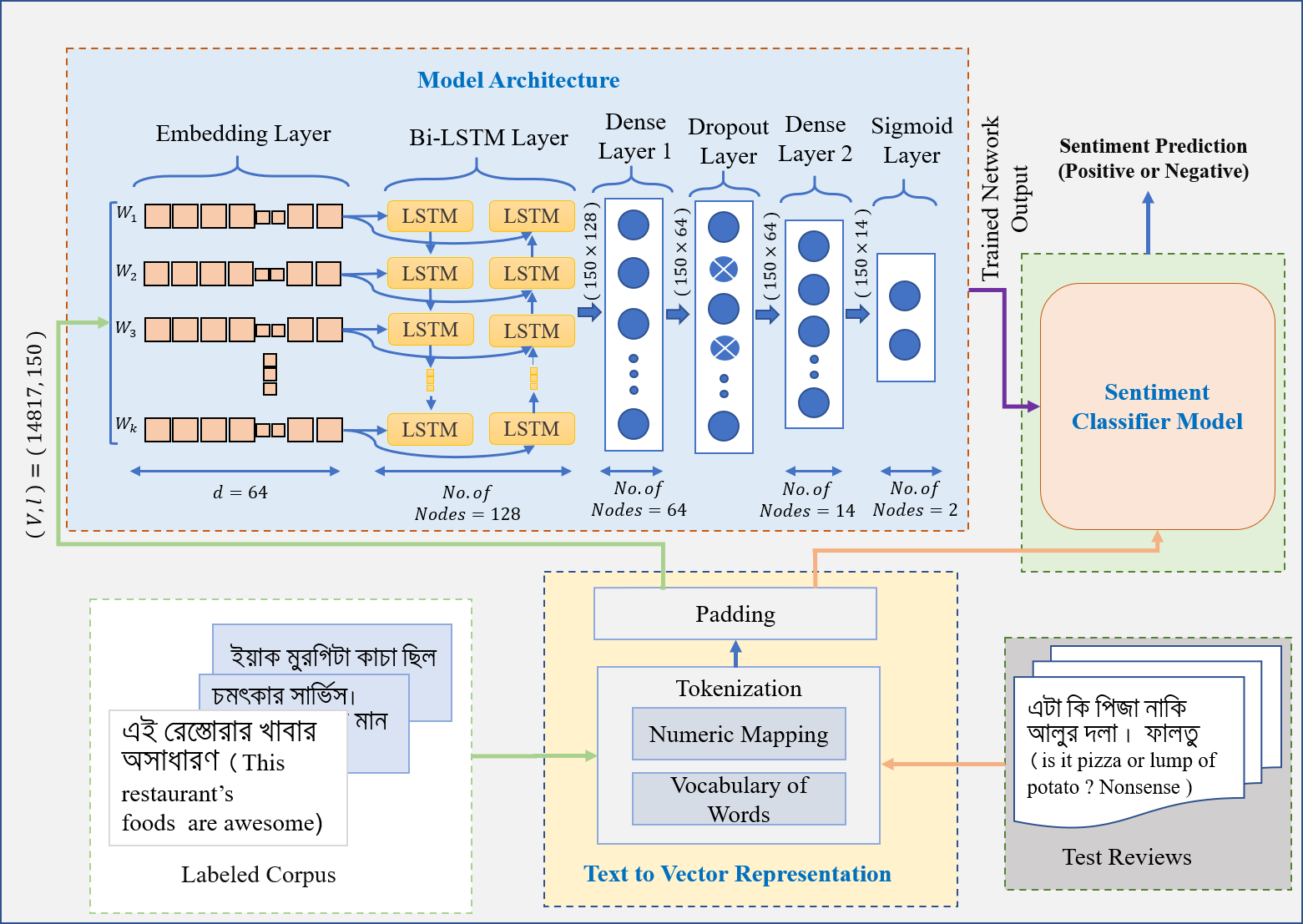
4.1 Text to Vector Representation
Success of any deep learning algorithm heavily depends on the features applied during training. As deep learning algorithms are unable to learn from raw reviews, we have to create a numeric mapping of the reviews, . To get this numeric mapping, a vocabulary of unique words is created, . Words in a review replaced by the index value of the words in . Thus we get converted vector sequence () from a review (), . At this stage we get variable length sequences, } which are not suitable for feature extraction and training. By applying pad sequence method transformed into fixed length sequences, . Each sequence () of is a fixed length vector of size . To reduce computational cost, optimal sequence length is chosen by analyzing the length distribution of the reviews. We observe that most of the reviews are shorter than . Hence, is chosen as optimal review length to keep the useful information intact as well as develop the system with minimal computation. Extra words discarded form long reviews and a zero vector padded with short reviews to maintain the length .
4.2 Model Architecture
The model architecture comprises three major blocks: embedding layer, Bi-LSTM layer and classification layer.
4.2.1 Embedding Layer
To extract the feature, we used word2vec [15] embedding technique that is a way of mapping integer indices of textual data into the dense vector. We used entire BRRC to train word2vec using Keras embedding layer. Embedding layer takes three inputs where = size of vocabulary, embedding dimension, length of a review. Embedding dimension is a hyper-parameter which determines the length of the vector representation of a word. Embedding layer converted a review into a 2D vector of dimension . Thus, for the number of reviews, we obtained a feature vector of dimension .
4.2.2 LSTM Layer
Long short-term memory (LSTM) network is a commonly used variant of recurrent neural network (RNN) which used as a solution of exploding and vanishing gradient problem. Particularly, LSTM are proved [28] effective to capture the long term dependencies in a text. We applied bidirectional LSTM (BiLSTM) to keep the contextual information form previous as well as next word [12, 8]. Word embedding values of the embedding layer passed to each of the LSTM where each LSTM consists hidden units of size . For BiLSTM, after the concatenation of each LSTM output we obtained a vector representation of length . LSTM process a input sequence of embedding vector as a pair . For each pair and each time step , a hidden vector and a remember vector is preserved by a LSTM. This vectors are responsible for regulating the updates and outputs of states. This helps to produce target output based on the past states of the input. The processing steps at time executed by the Eqs. 1-6.
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
| (6) |
Here, represents the sigmoid activation function, correspondingly , and are weight matrices and projection matrices of the recurrent units. The computed gates of LSTM cells play pivotal role in attaining significant attributes from the computed vector by storing in the remember vector as long as needed. The forget gate decides the amount of information to be dumped from the previous remember vector , on the contrary the update gate use input gate and previous remember vector to write updated information in the new remember vector . Finally, output gate monitors which information goes from new memory vector to the hidden vector .
4.2.3 Classification Layer
This step includes an two dense layer followed by a sigmoid layer. For the input sequence, BiLSTM layer takes input of size and transformed into output vector of size . This vector is propagated through the first dense layer and generates a new vector of shape with the help of rectified linear unit (Relu) activation function. To avoid over-fitting a dropout layer introduced between two dense layer with dropout ratio of 26% [9]. At every iteration 74% neurons are randomly chosen to pass their output form first dense layer to second dense layer which further generates a new vector of size . Noted that the and correspondingly represents number of hidden neurons in first and second dense layer. By applying flattening to output vector of the second dense layer we got an one dimensional vector of size . Finally, the last layer output vector passed into a sigmoid [9] layer. The sentiment of the input sequence of reviews is calculated by using the equation 7 and 8.
| (7) |
| (8) |
The equation 9 corresponds to the cross entropy loss function [9] that we used to train the model. Here, subscript indicates the input review and indicates the true sentiment class of review.
| (9) |
4.3 Sentiment Classifier Model
The purpose of this module is to determine the sentiment of reviews that the model never seen before. For classification at first, an unlabeled review is feed into the text to vector representation module, where it is gone through the tokenization and padding steps. Then, the trained sentiment classifier model takes this transformed vector as an input and predicts the sentiment of that review.
5 Experiments
The goal of this experiment is to find out the appropriate hyperparameter combination as well as analyze the effectiveness of the proposed model over other machine learning algorithms. We used Google Colaboratory to conduct experiments which widely used for building deep learning applications. Pandas == 1.0.5 data frame used to prepare data. Deep learning model developed on Keras == 2.3.0 and TensorFlow == 2.2.0 framework. Training, validation, and testing sets are consist of 72% (6072 reviews), 18% (1519 reviews), 10% (844 reviews) of total reviews, respectively. Training set used to train the model while validation samples help to tune the hyper-parameters (i.e. learning rate, batch size) of the model. Finally, the trained model evaluated with the test set.
5.1 Hyperparameter Optimization
Model hyperparameters are the parameters that directly governs the training process of a model. These parameters determine the network architecture (i.e. number of layers, number of hidden units) and how the network is trained (i.e. batch size, learning rate). Two hidden layers respectively with and hidden units have used. The hyperparameter settings for the proposed model such as embedding dimension, batch size, dropout rate, optimizer, learning rate and the number of epochs are specified in Table 2. We arbitrarily choose an initial value for each hyperparameter except embedding dimension. To find the optimum value of a hyperparameter, we iterate through the hyperparameter space. The proposed model is trained with these optimum hyperparameter settings.
| Hyperparameters | Initial value | Hyperparameter space | Optimal value |
|---|---|---|---|
| Embedding Dimension | - | , , , , , , , , , , , , , | |
| Batch Size | ,,, , , , , | ||
| Dropout | , , , , , , , , , , , , , , , , , , , | ||
| Optimizer | |||
| Learning Rate | , , , , , , , , , , , , , , , , , | ||
| Number of Epochs | , , , , , ,, , , , , , , , |
5.2 Results


Fig. 2 shows the accuracy and loss variation over the number of epochs for training and validation data. Initially, the validation accuracy is greater than the training accuracy, but after ten epochs, training accuracy keeps increasing while the validation accuracy stands at a flat line. Similarly, the validation loss also keeps decreasing with the training loss. At epoch ten, the validation accuracy reaches its maximum value of . That is why we choose as the optimum value of the epoch number.
Furthermore, the performance of the proposed model is assessed on the test set by using various evaluation metrics such as accuracy, precision, recall and f1-score are noteworthy. On the other hand, the precision-recall (PR) curve and receiver operating characteristics (ROC) curve taken as the graphical evaluation metric. Apart from that, to analyze the effectiveness of the model, we compared its performance with different machine learning (ML) models. Logistic regression (LR), decision tree (DT), random forest (RF), Naive Bayes (NB) and support vector machine (SVM) [13] taken as the baseline models for comparison. Term frequency-inverse document frequency [24] (TF-IDF) feature representation tech-nique employed to train the ML algorithms on the same corpus. Finally, the similar test set used to evaluate all the models. The performance comparison of the models listed in Table 3.
| Approach | Accuracy | Precision | Recall | F1-score |
| Logistic Regression | ||||
| Decision Tree | ||||
| Random Forest | ||||
| Naive Bayes | ||||
| Support Vector Machine | ||||
| Proposed (BiLSTM) |

From the table, it observed that SVM and NB provide pretty good accuracy of and respectively. Besides, they also give acceptable f1-scores of and respectively. Among the models, decision tree performs poorly compared to others. The proposed model outperforms all the ML models by achieving maximum accuracy of and f1-score of .


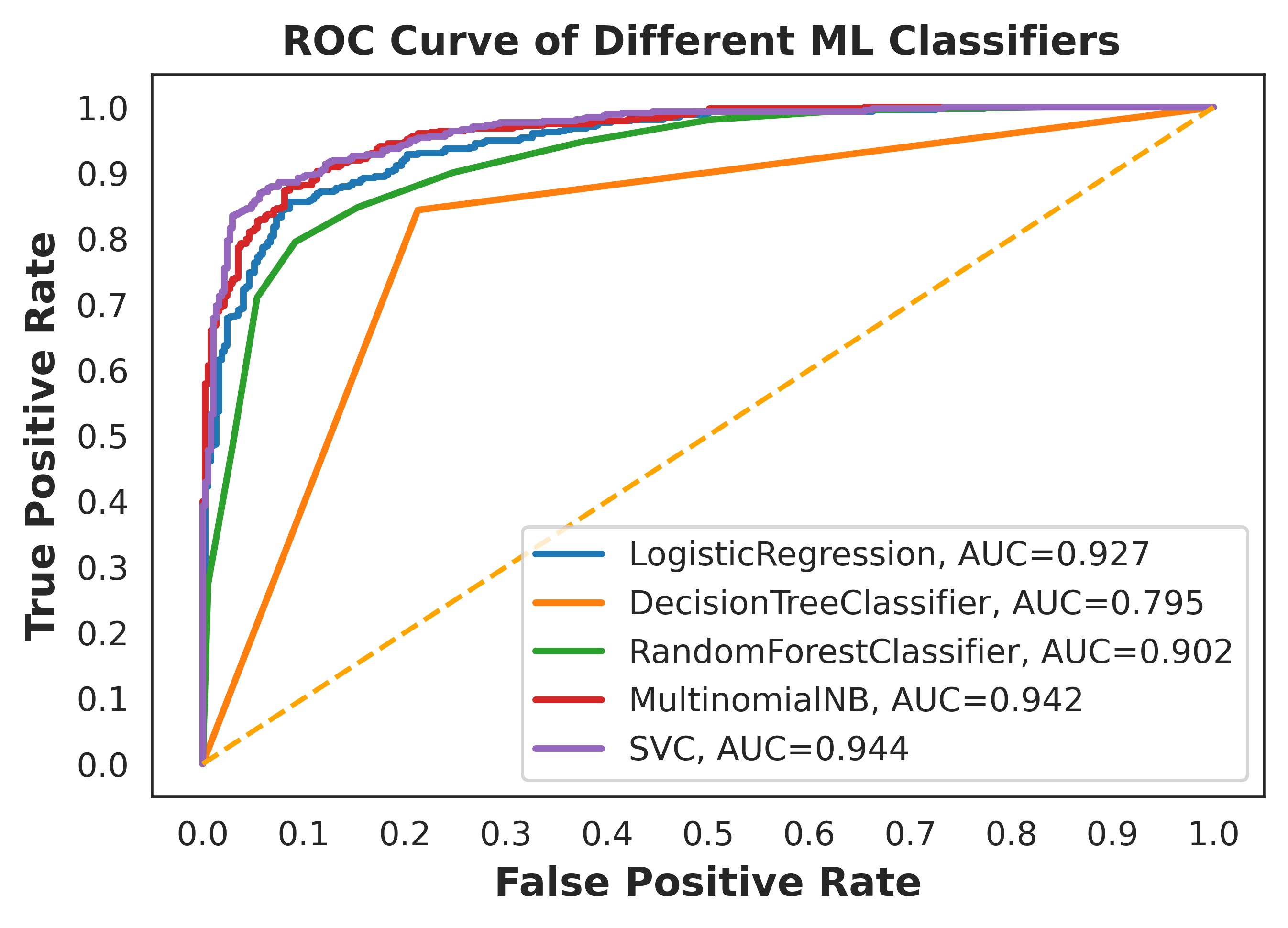
Fig. 3 presents the ROC curve analysis of the proposed and baseline ML models. Among the ML models, SVM provides the highest area under the curve (AUC) value of approximately and DT provides the lowest AUC value of approximately . On the contrary, the proposed BiLSTM model outperforms all the baseline models by acquiring AUC value of . PR curve analysis of the models depicted in Fig. 4. The proposed model outdoes all the baseline models by achieving average precision (AP) score. Therefore, after analyzing the results, it is needless to say that the proposed model acquired the highest value for all the evaluation parameters.
To verify the assessment of the proposed method, we compared it with other techniques accomplished on similar tasks. We applied existing techniques on our developed corpus and compared the outcomes with the proposed approach. Table 4 shows the comparative analysis of the adopted techniques and their obtained accuracy on BRRC. The result indicates that the proposed approach performs better than other techniques. To sum up, it revealed that the proposed model shows outstanding result compared to the baseline models as well as the existing techniques.
6 Conclusion
In this paper, we presented a deep learning-based scheme to analyze the sentiment on Bengali restaurant reviews. Word2vec embedding technique is used to consider the semantic meaning of the Bengali reviews. BiLSTM network tuned to find out the optimal hyperparameter combination. A corpus of 8435 Bengali restaurant reviews is developed to evaluate the performance of the proposed system. The outcome of the experimentation exhibits that the proposed system outperforms the baseline ML algorithms and previous techniques on a holdout dataset. Though our approach acquires satisfactory results compared to other works, some improv-ements are still required to take this system in production level. Thus, in future, we will try to add reviews with more classes and conjoin the aspect of the reviews as well.
References
- [1] Akhtar, M.S., Kumar, A., Ekbal, A., Bhattacharyya, P.: A hybrid deep learning architecture for sentiment analysis. In: Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. pp. 482–493 (2016)
- [2] Al-Smadi, M., Talafha, B., Al-Ayyoub, M., Jararweh, Y.: Using long short-term memory deep neural networks for aspect-based sentiment analysis of arabic reviews. Int. J. Mac. Learn. & Cybern. 10(8), 2163–2175 (2019)
- [3] Asghar, N.: Yelp dataset challenge: Review rating prediction. arXiv preprint arXiv:1605.05362 (2016)
- [4] Bautin, M., Vijayarenu, L., Skiena, S.: International sentiment analysis for news and blogs. In: ICWSM (2008)
- [5] Chowdhury, R.R., Hossain, M.S., Hossain, S., Andersson, K.: Analyzing sentiment of movie reviews in bangla by applying machine learning techniques. In: Int. Con. on Bangla Speech & Lan. Proc. (ICBSLP). pp. 1–6. IEEE (2019)
- [6] Cohen, J.: A coefficient of agreement for nominal scales. Educational and psychological measurement 20(1), 37–46 (1960)
- [7] Ghorbani, M., Bahaghighat, M., Xin, Q., Özen, F.: Convlstmconv network: a deep learning approach for sentiment analysis in cloud computing. Journal of Cloud Computing 9(1), 1–12 (2020)
- [8] Graves, A.: Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850 (2013)
- [9] Gulli, A., Pal, S.: Deep learning with Keras. Packt Publishing Ltd (2017)
- [10] Hassan, A., Amin, M.R., Mohammed, N., Azad, A.: Sentiment analysis on bangla and romanized bangla text (brbt) using deep recurrent models. arXiv preprint arXiv:1610.00369 (2016)
- [11] Hossain, E., Sharif, O., Hoque, M.M.: Sentiment polarity detection on bengali book reviews using multinomial naive bayes. arXiv preprint arXiv:2007.02758 (2020)
- [12] Kalchbrenner, N., Danihelka, I., Graves, A.: Grid long short-term memory. arXiv preprint arXiv:1507.01526 (2015)
- [13] Kowsari, K., Jafari Meimandi, K., Heidarysafa, M., Mendu, S., Barnes, L., Brown, D.: Text classification algorithms: A survey. Information 10(4), 150 (2019)
- [14] Liu, S.: Sentiment analysis of yelp reviews: A comparison of techniques and models. arXiv preprint arXiv:2004.13851 (2020)
- [15] Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Advances in neural information processing systems. pp. 3111–3119 (2013)
- [16] Minaee, S., Azimi, E., Abdolrashidi, A.: Deep-sentiment: Sentiment analysis using ensemble of cnn and bi-lstm models. arXiv preprint arXiv:1904.04206 (2019)
- [17] Mohammad, S.: A practical guide to sentiment annotation: Challenges and solutions. In: Proceedings of the 7th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis. pp. 174–179 (2016)
- [18] Ombabi, A.H., Ouarda, W., Alimi, A.M.: Deep learning cnn–lstm framework for arabic sentiment analysis using textual information shared in social networks. Social Network Analysis and Mining 10(1), 1–13 (2020)
- [19] Poria, S., Hazarika, D., Majumder, N., Mihalcea, R.: Beneath the tip of the iceberg: Current challenges and new directions in sentiment analysis research. arXiv preprint arXiv:2005.00357 (2020)
- [20] Rahman, M.A., Dey, E.K.: Aspect extraction from bangla reviews using convolutional neural network. In: Int. Conf. on Info., Elect. & Vision (ICIEV). pp. 262–267. IEEE (2018)
- [21] Rani, S., Kumar, P.: Deep learning based sentiment analysis using convolution neural network. A. J. for Sci. & Eng. 44(4), 3305–3314 (2019)
- [22] Sarkar, K.: Sentiment polarity detection in bengali tweets using lstm recurrent neural networks. In: 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP). pp. 1–6. IEEE (2019)
- [23] Sharfuddin, A.A., Tihami, M.N., Islam, M.S.: A deep recurrent neural network with bilstm model for sentiment classification. In: 2018 International Conference on Bangla Speech and Language Processing (ICBSLP). pp. 1–4. IEEE (2018)
- [24] Sharif, O., Hoque, M.M., Hossain, E.: Sentiment analysis of bengali texts on online restaurant reviews using multinomial naïve bayes. In: Int. Conf. on Advances in Sci., Eng. & Robo. Tech. (ICASERT). pp. 1–6. IEEE (2019)
- [25] Wahid, M.F., Hasan, M.J., Alom, M.S.: Cricket sentiment analysis from bangla text using recurrent neural network with long short term memory model. In: Int. Con. on Bangla Speech & Lang. Proc. (ICBSLP). pp. 1–4. IEEE (2019)
- [26] Xu, G., Meng, Y., Qiu, X., Yu, Z., Wu, X.: Sentiment analysis of comment texts based on bilstm. Ieee Access 7, 51522–51532 (2019)
- [27] Xue, W., Li, T.: Aspect based sentiment analysis with gated convolutional networks. arXiv preprint arXiv:1805.07043 (2018)
- [28] Yenter, A., Verma, A.: Deep cnn-lstm with combined kernels from multiple branches for imdb review sentiment analysis. In: IEEE A. Ubi. Comp., Elect. & Mob. Com. Conf. (UEMCON). pp. 540–546. IEEE (2017)
- [29] Yu, B., Zhou, J., Zhang, Y., Cao, Y.: Identifying restaurant features via sentiment analysis on yelp reviews. arXiv preprint arXiv:1709.08698 (2017)
- [30] Zhou, J., Lu, Y., Dai, H.N., Wang, H., Xiao, H.: Sentiment analysis of chinese microblog based on stacked bidirectional lstm. IEEE Access 7, 38856–38866 (2019)