Sensor Control for Information Gain in Dynamic, Sparse and Partially Observed Environments
Abstract
We present an approach for autonomous sensor control for information gathering under partially observable, dynamic and sparsely sampled environments that maximizes information about entities present in that space. We describe our approach for the task of Radio-Frequency (RF) spectrum monitoring, where the goal is to search for and track unknown, dynamic signals in the environment. To this end, we extend the Deep Anticipatory Network (DAN) Reinforcement Learning (RL) framework by (1) improving exploration in sparse, non-stationary environments using a novel information gain reward, and (2) scaling up the control space and enabling the monitoring of complex, dynamic activity patterns using hybrid convolutional-recurrent neural layers. We also extend this problem to situations in which sampling from the intended RF spectrum/field is limited and propose a model-based version of the original RL algorithm that fine-tunes the controller via a model that is iteratively improved from the limited field sampling. Results in simulated RF environments of differing complexity show that our system outperforms the standard DAN architecture and is more flexible and robust than baseline expert-designed agents. We also show that it is adaptable to non-stationary emission environments.
Keywords Reinforcement Learning Partial Observability Dynamic Environment Sparse Rewards Sensor Control Information Gain
1 Introduction
Overview. Sensor control that maximizes information gain under partially observable and dynamic environments is an important problem that has several applications (Satsangi et al., 2020). For example, consider the problems of tracking widespread activity from a limited, but controllable field of view, or tracking carbon monoxide levels over a geographic area with the minimum number of sample sites. A relevant problem, which we study in this work, is Radio Frequency (RF) spectrum monitoring, which involves detecting and tracking multiple dynamic signals in a potentially large RF spectrum using an RF receiver (sensor) with only a limited, but tunable, reception band. All these problems require a sequential decision making approach that selects the sensor(s) or sensor settings for each time instant, based on past observation history, to maximize information gain e.g., knowledge about signal activity.
Challenges. The above tasks present several challenges: (i) partial observability: each sensor (or sensor band) can only provide partial observations of the underlying state; (ii) dynamic environments: the underlying environment is stochastic and could be non-stationary, making it hard to track its state over time; (iii) sparse environments: it is possible that useful information may only be infrequently collected, meaning that the majority of observations are mostly non-informative; (iv) costly samples: taking samples from an actual fielded sensor is costly and so interactions with it are restricted according to some budget.
Approach. In this paper, we study and evaluate our approach for an abstracted RF spectrum monitoring task. In particular, the goal is to control a band-limited RF receiver to optimize multi-signal detection and tracking throughout an extensive RF environment. The autonomous controller is given a range of the spectrum (discretized into several frequency bands) within which to operate. However, it is not given information about the specific frequencies, densities or distributions of the signals within this range. For purposes of experimentation, we developed an RF simulator on which a controller is trained to decide which band to sample at each instant to accomplish the goal of tracking/predicting the signals in the spectrum. During the training process, the controller learns the general behavior of the signals, such as frequency switching patterns and typical durations, and learns how to use this knowledge to search for and track these types of signals in novel situations.
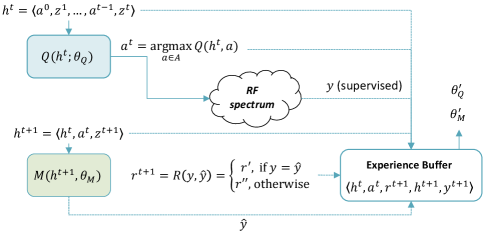
Towards this goal, we propose an approach based on the Deep Anticipatory Network (DAN) (Satsangi et al., 2020) framework for optimal sensor control in information gathering tasks. DAN uses deep Reinforcement Learning (RL) with prediction rewards, where the action suggested by a value-network, that implements the value function, is rewarded whenever a separate model-network makes a correct prediction of the true state based on observations that are the result of the action. In order to scale to large problem spaces, e.g., large spectrum and/or small reception bandwidth, and to efficiently learn and process signals with potentially complex frequency-time patterns, we extended the DAN approach by implementing the prediction and control functions using neural networks with hybrid convolutional-recurrent layers, such as the ConvLSTM layer (Xingjian et al., 2015). Additionally, as the environment is dynamic and sparse, we propose novel information-gain rewards for our RL approach to encourage exploration thereby avoiding sampling regions of spectrum where signals were already identified.
Another important aspect of our approach, that was not considered in the original DAN work, is the use of potentially limited data from a fielded controller (referred to as experience feedback) to update the RF simulator used for training.In particular, a controller is trained in simulated RF environments by using a simulator that parameterizes a distribution over several aspects controlling the dynamics of the RF spectrum, e.g., the number of emitting signals, the frequency at which they emit, different communication patterns, etc. We refer to this as the lab simulator. Using it, the controller can train on many and diverse samples of environments — far more than can be sampled out in the actual field environments over a reasonable training period. However, in a real-world situation, the distribution over the actual field RF environments of interest may be non-stationary, which can make theconditions in which the controller was trained obsolete and consequently the controller sub-optimal. In this work, we investigate how the lab simulator can be updated using field experience data gathered by deploying the trained controller in the field for a limited amount — the interactions are restricted according to some budget. These field samples are used to adjust the lab simulator’s parameters such that the generated environments closely match those encountered in the field, and the controller’s policy can be fine-tuned by RL-based retraining on the updated lab simulator. We study this problem by using an additional field simulator — one that holds the ground-truth of the distribution over the environment parameters — to simulate the collection of limited field data and to test the retrained system.
In this work, we will refer to a stochastic model of an RF environment, which determines its dynamics, as a spec. The field simulator will have a field spec, which is hidden to the system, and during any given training iteration, the lab simulator will have a lab spec that is used to train the controller. In addition to estimating the field parameters/spec using field samples, we study an alternative approach of learning the field state dynamics model directly using field samples. We then use this field state model in the lab as an environment to train a controller using model-based RL.
Contributions. Our contributions in this paper are as follows:
-
•
Extending the DAN framework to handle the challenging problem of monitoring an RF spectrum.
-
•
Scaling up the control space and enabling the monitoring of complex, dynamic activity patterns using hybrid convolutional-recurrent processing steps.
-
•
Improving exploration in sparse, non-stationary environments using novel information gain rewards.
-
•
A supervised learning variant that is shown to perform better than RL approaches in certain environments.
-
•
Two model-based RL approaches capable of model updating using experience feedback from limited field deployment.
-
•
An evaluation of the the proposed approaches using various architectural configurations showing their benefit over baseline controllers in different environments.
2 Related Work
General approaches. Information gathering under partial observability, which is related to Partially Observable Markov Decision Processes (POMDPs) (Kaelbling et al., 1998), has been explored in several domains. For example, Satsangi et al. (2020), present a technique (our baseline approach) for information gathering using Deep Anticipatory Network (DAN) that decides which camera to switch on to track people in a mall. They also applied a related approach to active perception in robotics (Satsangi et al., 2018). Wang et al. (2018) propose an RL technique for information gathering using sparse mobile crowd-sensing that tells which cell to collect data from to minimize the uncertainty in state estimation. Mnih et al. (2014) and Haque et al. (2016) present an image classifier that adaptively selects regions for processing at high resolution. Most of these techniques do not address our problem combining dynamic environment, reward sparsity and limited field experience. In the domain of generic POMDP solutions, James and Singh (2009) present an algorithm for learning in POMDPs assuming availability of ‘landmarks’ or special states that are not hidden to the agent, but not available in our domain. Katt et al. (2017) present an approach based on Monte-Carlo tree search and look-ahead planning for solving POMDP problems in an online manner. However, due to large dimensional state space, such an approach is not scalable to our domain.
RF domain. In the domain of RF spectrum monitoring, most of the existing work is on signal detection and identification (SDI) rather than tracking. Franco et al. (2020) present a hierarchical two-step approach for SDI. At a finer scale, they first use a sweeping window to detect the local presence of signals, and at a larger scale, these local detections are integrated using a frequency-time region proposal network. Kulin et al. (2018) present a single-step, an end-to-end deep learning approach for wireless signal detection. Mendis et al. (2019) present an attention-driven RL technique for signal detection in a wide-band spectrum. The proposed method consists of two main components: a spectral correlation function (SCF) based spectral visualization scheme and a spectral attention-driven RL mechanism that adaptively selects the spectrum range and implements the intelligent signal detection. This approach however assumes that the modulation technique is known a priori.
Experience Feedback. This problem is related to other types of machine learning tasks. In transfer learning for RL, (Taylor and Stone (2009) and Zhu et al. (2020)) there is a source (lab spec) and target (field spec) population; however, partial observability is not addressed. In model-based value expansion (imagination rollouts), the number of real (field) interactions is reduced by doing additional training with updated simulator (Feinberg et al. (2018)). Kalweit and Boedecker (2017) and Hafner et al. (2020) discuss RL imagination rollout approaches based on uncertainty and latent space. However, unlike our problem, most of these works deal with continuous actions. Model-based RL traditionally involves interactions between a planning module and RL training (Moerland et al. (2020)); Li et al. (2020) discuss a technique for accelerating model-free RL using imperfect models for the related application of spectrum access. Hua et al. (2019) present a GAN-based method to learn the state-action values for resource management in network slicing. Huang et al. (2021) present a Generative Adversarial Interactive Reinforcement Learning that combines the advantages of GAN-based learning and interactive RL. In our problem, the field state to be learned is a time-series system and most existing approaches do not handle this case.
3 Proposed Solution
3.1 State Estimation and Tracking
The problem involves finding and tracking multiple signals that have activity patterns of varying complexity involving several unknown parameters. A controller agent is trained and tested using multiple episodes (trials), where each episode has a new signal environment sampled from the same stochastic environment model (spec), and the episode involves a sequence of control (frequency selection) and observation (signal detection) steps. The specific signal patterns of each new environment are unknown to the agent and must be inferred through tracking and monitoring during the interaction. To solve this problem, we extend the original DAN architecture and rewards.
Problem Formulation. Following the DAN approach in (Satsangi et al., 2020), we consider a Partially Observable Markov Decision Process (POMDP) (Kaelbling et al., 1998) to model the dynamics of our RF environment. We denote to represent the hidden state of the environment, to denote a target variable of interest that depends only on , to denote a partial observation that is correlated with and to denote the action taken by the agent. At each discrete timestep, , the agent takes an action , the environment transitions to state and the agent receives an observation . The goal of the agent is to correctly predict the target variable given the history of previous actions and observations denoted by . We denote by the agent’s prediction of . At each step, the agent receives a reward, denoted by , that indicates how similar and are.
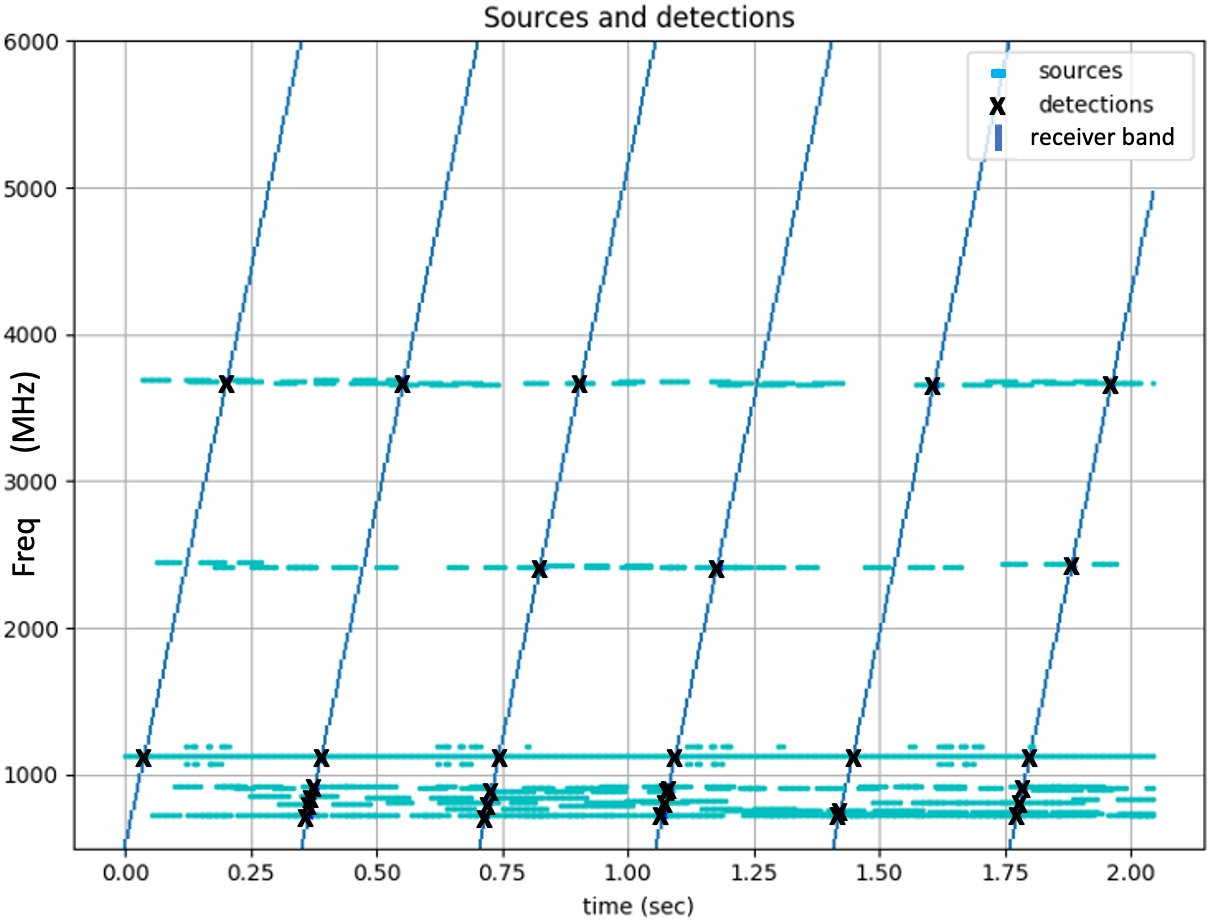
RF Environment. In the context of RF spectrum monitoring, represents the state of the whole RF spectrum, that contains a set of unknown entities interacting with each other and transmitting signals spread across frequency and varying in time. Further, is the vector representing signal activity ( for none and for activity) at all frequency bands, represents the frequency band(s) that the agent samples, and represents observed detections (the presence/absence of signals at the sampled bands); is the history of sampled frequencies and observations. The agent’s actions can only sub-sample the spectrum at specific frequencies. The goal of the agent is to select actions at each timestep in order to accurately report the presence/absence of signals in all frequency bands at that timestep. Fig. 1 shows an example of a partially observed RF environment. One or more bands can be active (contain signals) at any given time. Here, a sequential scan is performed across the spectrum, which misses the short signal bursts around MHz.
Environment Spec Details. An environment spec defines an environment population model as a range of possible values for the following parameters: (i) number: number of interacting signal pairs; (ii) width: total number of spectral bands spanned by the pairs; (iii) period: period of the signal pair interaction; (iv) duty cycle: duration of one signal over the other during an interaction cycle; (v) frequency: the frequency of the lowest of the signal pair; (vi) start: timestep when signal pair appears in spectrum. Table 1 lists some of the environment specs used in our experiments.
3.2 DAN framework
Deep Anticipatory Networks (DANs) (Satsangi et al., 2020) were developed for information-gathering tasks under partial observability e.g., tracking people using cameras. A DAN makes control decisions that maximize the information gathered (minimize the uncertainty) about a target variable of interest that cannot be fully-observed. The key point is that, for this type of task, DAN avoids complex belief state updating and instead uses state prediction rewards to guide the agent behavior.111This has been demonstrated in Satsangi et al. (2020) to be equivalent in effect to belief updating. DAN uses two neural networks to train a policy, as shown in Fig. 2. The first, , takes the history of previous actions and observations, , and produces -values for the different actions. A second network, , takes the history plus the last action and observation to predict , i.e., an estimate of target variable . is trained in a supervised manner with ground truth data, i.e., using the actual target values . is a standard value function network trained using RL but here it is rewarded when ’s predictions are accurate, i.e., when is similar to . is trained to maximize cumulative discounted reward, . The and networks are trained simultaneously and, after training, only is used for autonomous control for information gain. In all of our DAN variants, is trained using weighted binary cross entropy (WBCE) as a loss, weighted to emphasize our metrics; see the discussion on rewards and metrics in Sec. 3.2.2.
3.2.1 ConvLSTM, Predictive and InfoMax DAN Architectures
The problem of RF spectrum monitoring presents several challenges, including: being able to scale to large discrete frequency and time domains, identifying repeating signal patterns in frequency-time space and coping with non-stationary nature of the environment. The original DAN does not address these challenges; we propose various architectural and reward modifications to address them.
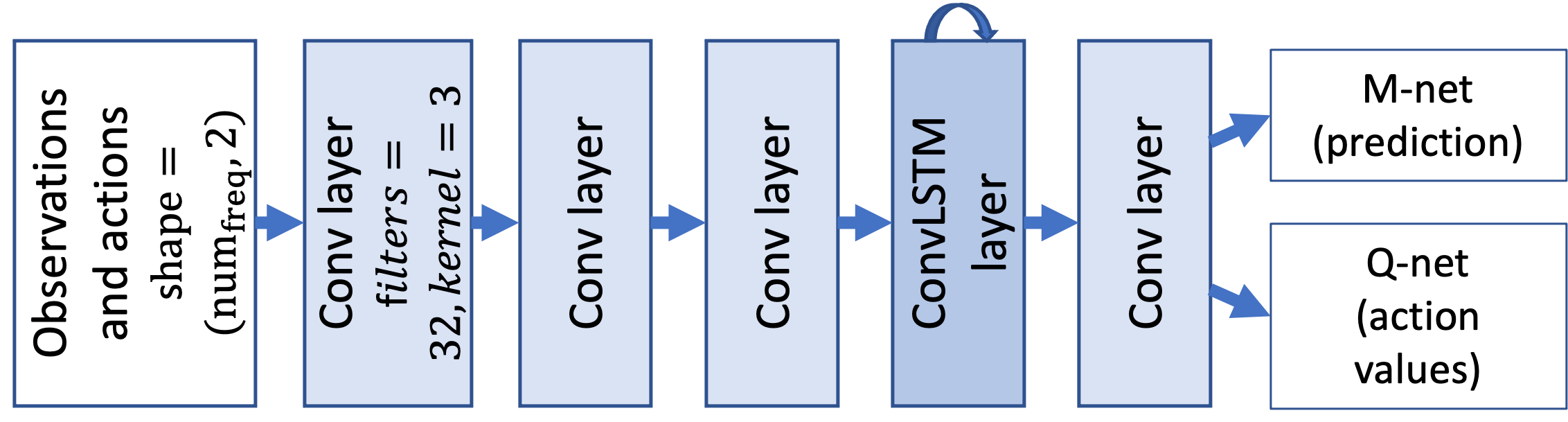
ConvLSTM-DAN. The baseline DAN uses fully connected/dense layers for both and networks with Rectified Linear Unit (ReLU) activation, which doesn’t scale well and makes learning of frequency-invariant activity patterns difficult. We address the scalability of the problem space by using convolutional layers (convolution in frequency). We also introduce hybrid convolutional-LSTM (Long Short Term Memory) / ConvLSTM layers (Xingjian et al., 2015), which combine convolution in frequency dimension and recurrence/memory in time dimension for learning translation-invariant frequency-time activity patterns. This architecture is shown in Fig. 3. For ConvLSTM training, we use a reward that is a function of the intersection over union (IoU) of the predicted output from and the ground truth; see the discussion on rewards and metrics in Sec. 3.2.2. As the input to both and networks are similar, and action selection and state prediction are related tasks, the layers used to compute features can be shared to reduce the training space. We call this enhanced framework ConvLSTM-DAN, which has two outputs, one for and the other for . (All of our DAN variants discussed in this paper use a shared architecture.) After studying the effect of different well-known DQN/RL enhancements, we found that Dueling DQN (Wang et al., 2016) improved results across the board. Therefore, our standard ConvLSTM-DAN framework incorporates it (not shown in Fig. 3): for , the output of the last convolutional layer is split into two streams—Value and Advantage—which are then combined to give the output. Double DQN (van Hasselt et al., 2015) was not considered as useful and was not incorporated.
Predictive DAN. If the environment spec defines a variable number of signals it introduces an interesting exploration / exploitation challenge with subtle differences in the payoff odds between carefully tracking the signal found vs. finding a new one.This problem is exacerbated in reward-sparse scenarios (with an empty spectrum most of the time). In order to encourage exploring an unknown state space and at the same time exploit the known state space, we propose an enhancement over the ConvLSTM-DAN that provides an auxiliary predictive reward, which we refer to as the Predictive-DAN. This is similar to the Intrinsic Curiosity Module (Pathak et al., 2017). In Predictive-DAN, the shared network in Fig. 3 has 3 outputs: -output, (the current state given current observation history), -output, (next action to take given current observation history) and a predictive output, (the next state given current observation history). Here, state refers to target variable, . When the next action, is actually taken, then the m-network estimates the current state given current information: , where . We can denote the information gained from this action as , which is used as an auxiliary reward to train the Predictive-DAN -network: . In practice, typically only the observed ‘band’ will change if at all, but if the network has learned relations between signals in other bands, that could be affected too. This is similar to the reward that can be used when there is no ground-truth (the difference being that this is only computed for the observed state and not full state).
InfoMax-DAN. While in above architectures, we compute and use information gain only for the executed action, it is also possible to compute the information gained for all actions instead of just the action taken. We use this idea to train -net in a fully supervised manner without using RL. This approach maximizes information gained in a single step (with no cumulative reward). We refer to this alternative approach as InfoMax-DAN, which is fully supervised version of Predictive-DAN.
3.2.2 Rewards and Metrics
Since the goal in our control problem is to maximize information about signal presence, it seems reasonable to start with the commonly used detection/localization metric Intersection over Union (IoU). In our case, intersection is the count of (time, frequency) positions where true signals coincide with predicted ones, and union is the total count of true positions plus the total for predicted ones (where predictions can either be probabilities or thresholded, binary states). We use the following variants of IoU for rewards and metrics in our experiments: Instantaneous IoU is IoU for one slice of time; Cumulative IoU is cumulative IoU up to a given time; Block IoU is cumulative for the last timesteps. The Instantaneous IoU can provide frequent rewards but is unstable in sparse environments, which be can addressed using a differential reward: Differential Block IoU , where the are block IoU, for blocks of fixed . For losses to train prediction, we use weighted binary cross entropy (WBCE), which is an effort to tilt the commonly used BCE more towards the IoU-based reward functions: the error for existing signals is weighted more than the error for non-existing signals. (The weight for positions without signals is set to the expected signal density, . ) In experiments, we have noticed that WBCE is qualitatively better than BCE or IoU.
3.3 Experience-feedback via Model-based RL
Often, the lab spec used for training does not entirely cover the field (ground-truth) population of environments — for example, the domain knowledge employed may be outdated. To address this challenge, we introduce an experience feedback loop. Once trained on the lab spec, the agent is then deployed in field environments (here, simulated by a field spec) for a limited time, during which it collects samples that might be sparse. In this fielded phase, unlike the lab training, the agent does not have access to the underlying full state required to train the network via prediction loss. Rather, these experiences are used to estimate the environments’ dynamics, which are then used to update a lab spec/model. The agent is then retrained using the updated spec/model and re-deployed for more samples, and the process repeats for a number of times. We develop two model-based RL approaches to implement this feedback loop: (i) field spec estimation uses collected experiences to estimate the field spec parameters directly , which is then sampled to retrain the controller; (ii) field state estimation uses them to build a deep, generative model of the field state sequence population, from which we sample to retrain the controller.
3.3.1 Field Spec Estimation
Experience feedback using field spec estimation uses the following basic loop: (i) deploy a controller in the field (simulator with field spec), (ii) use an expert system to estimate the field parameters from the resulting samples (Sec. 4.1), (iii) add the resulting estimated field spec to a pool of training specs (including original lab spec), (iv) train the DAN controller using samples from the training pool of specs, and (v) deploy the resulting trained DAN. We studied three different variations of these steps. Estimating Spec from Feedback: in step (i), deploy our expert controller (Sec. 4.1), and in step (iv), train from only the estimated field spec. Estimating Spec for Retraining: in step (i), deploy a DAN controller trained on a general lab spec, and in step (iv), train from the spec pool with sample rates: estimated field spec=, lab spec= (to avoid forgetting). Bootstrapping: do multiple iterations of the latter scheme, varying the field spec each deployment and training from all previously estimated specs.
3.3.2 Field State Estimation
One drawback of the Field Spec Estimation approach is that it assumes that observed dynamics in the field can be modeled by fitting a predetermined set of (known) simulator parameters. In realistic settings, we cannot anticipate all parameters governing the observed behavior in the RF spectrum — e.g., what if the entities are using a different communication protocol? To address this challenge, we follow a different approach to experience feedback that retrains the agent using Machine Learning (ML)-based methods that do not rely on parameterized environment specifications. Instead, the approach discussed here trains the controller on full, extended state sequences reconstructed and extrapolated from partially observed field samples. This will be evaluated against one that directly does controller fine-tuning on the raw, partially observed samples.
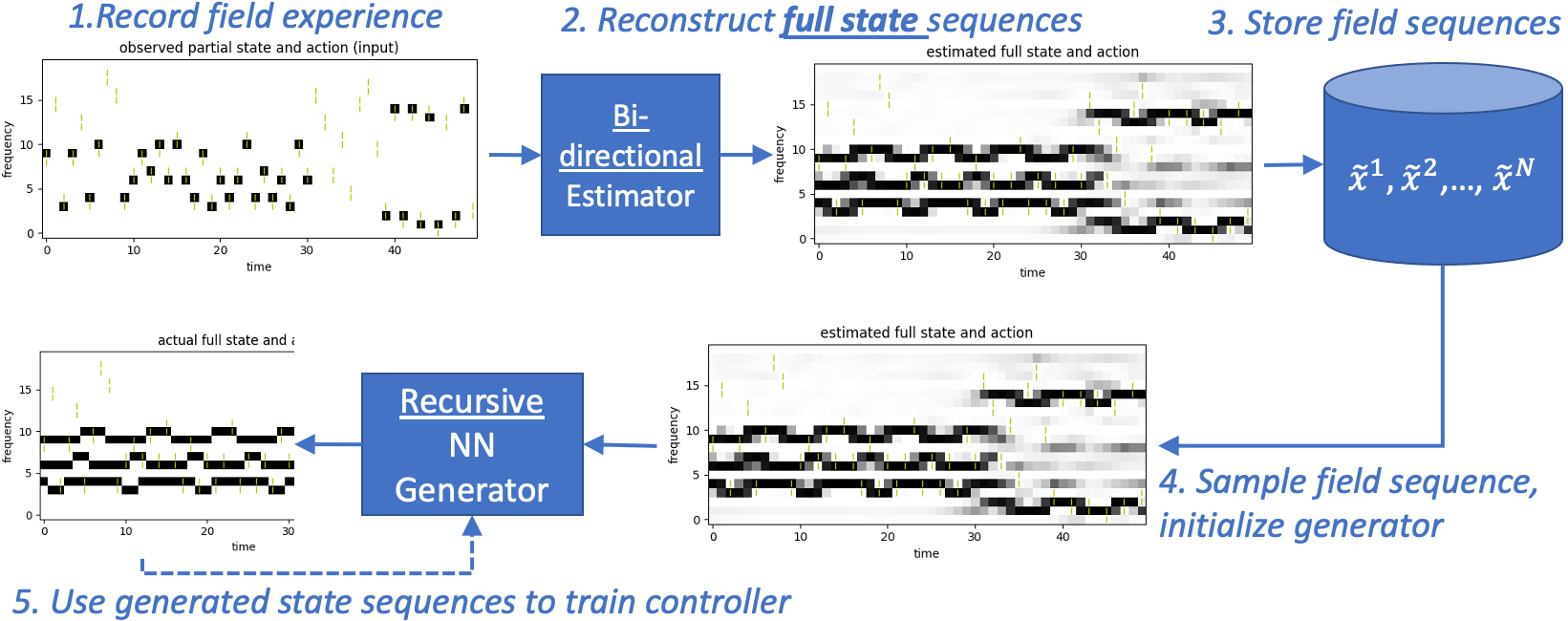
In field state estimation, we first train our DAN controller using a generic Lab Spec. We then adopt the following procedure (Fig. 4): (i) deploy and collect field experiences, which are sequences of partially observed states; (ii) reconstruct full state sequences from the partially observed samples using a bidirectional Recurrent Neural Network (RNN) or U-net architecture (Ronneberger et al., 2015); (iii) store reconstructed field sequences in a database; (iv) sample these stored sequences and use to initialize an RNN-based generator that then emits extended sequences; (v) binarize the generated sequences (=signal, =none); (vi) use these to train the controller, instead of a parameterized spec.
This will be compared to a DAN controller that is fine-tuned in the field directly (no lab retraining) using the available partially observed field states (see 1. in Fig. 4). As we have ground truth only in the particular band sampled, the reward obtained by the -network was modified to be only the prediction in this band.
4 Performance Evaluation
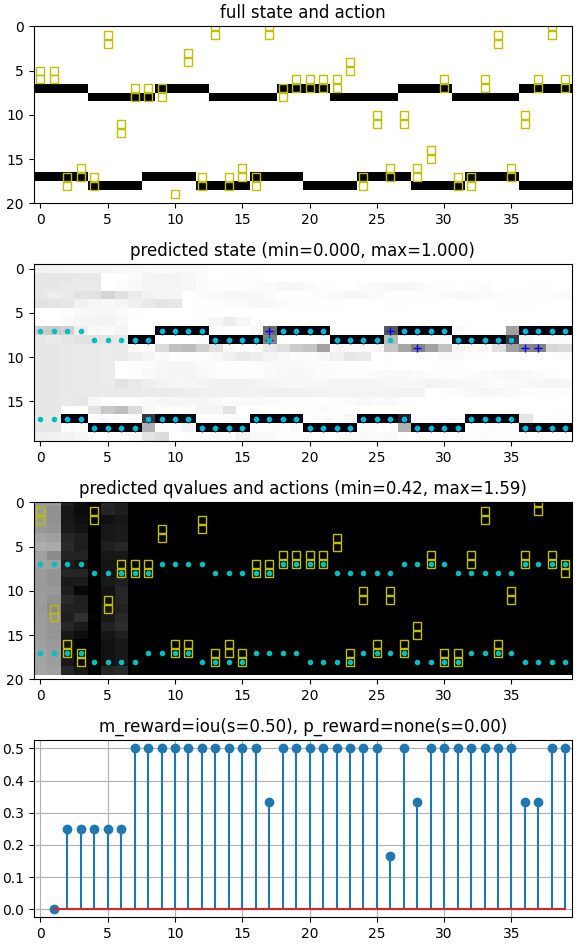
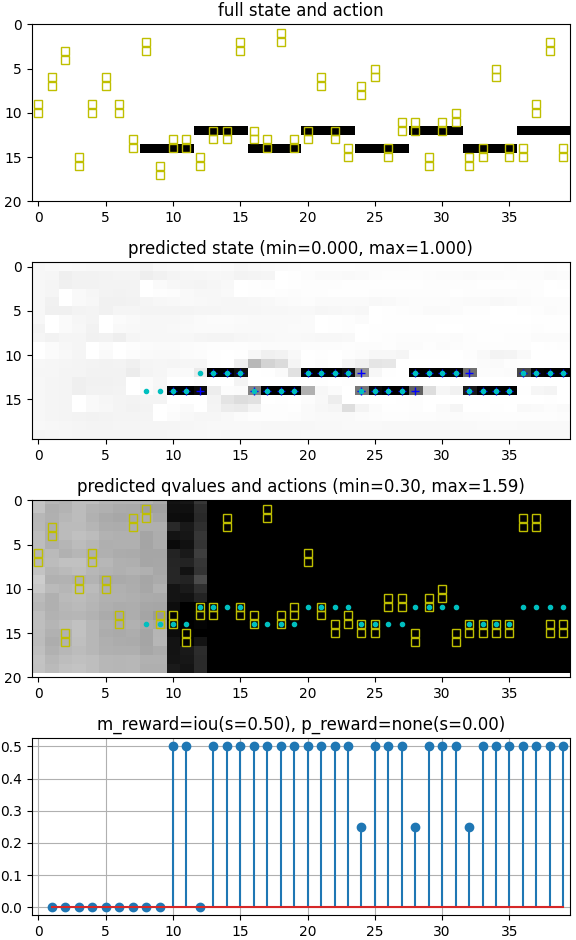
Experimental Setup. In order to have sufficient complexity in environment and control space to test our proposed approach, we considered environments that vary in terms of the number of communicating signal pairs and their properties; Table 1 shows some of the environment specs studied. We will start in Section 4.1 by comparing our DAN controller with expert-designed systems and study their adaptability using SpecA as the environment for which the expert-designed systems are optimized, while SpecB1 and SpecB2 – environments with increased variation and complexity – are used to test the adaptability. Example episodes from SpecA and SpecB2 are shown in Fig. 5. Then, in Sec. 4.2, we will extend the study to include non-stationary, semi-periodic and wider spectrum environments with multiple signal classes, such as in Fig. 1.
| Params | A | B1 | B2 | C1 | C2 | F1 | F2 | F3 |
|---|---|---|---|---|---|---|---|---|
| Number | ||||||||
| Width | ||||||||
| Period | ||||||||
| Dutycyc | ||||||||
| Freq | Rand | Rand | Rand | Rand | Rand | Rand | Rand | Rand |
| Start |
4.1 Comparison with non-ML Controllers
We hand-coded four controllers that follow simple, but often effective, behavior rules for RF environments to serve as baselines to evaluate the DAN-based system robustness:
- Random:
-
randomly selects bands in the spectrum. For prediction, it uses a persistent state scheme: each band’s signal state (active/inactive) is set to the last observation in it. Initially, all bands are considered inactive.
- Scan:
-
sequentially selects bands in the spectrum, uses the same persistent state scheme for prediction.
- Scan-and-Dwell:
-
estimates the different spec parameters governing the dynamics of the environment from the sampled observations. The controller is given ranges for the parameters but does not know their true values. It traverses the spectrum sequentially and whenever an action triggers a signal detection, it subsequently samples the same band until the true parameters controlling the dynamics in that band are learned, via a process of elimination. The predicted state is computed for each from the estimated parameters.
- Expert:
-
uses the same process as the above controller to estimate the spec parameters from experience. At each step, it selects the band with the highest associated uncertainty, i.e., whose current range of possible values is the largest.
In particular, the Scan-and-Dwell and Expert controllers serve as reasonable upper bounds on performance since in our experiments they are given relatively small ranges for the different spec parameters around their ground-truth values. In other words, an ML agent that has been trained in environments whose spec parameters are similar to those governing the environment on which it is being evaluated can be expected, at best, to attain a performance similar to that of the best hand-coded controller.
Fig. 6 compares the performance of hand-coded controllers and ConvLSTM-DAN trained in only one environment spec (SpecA) and tested in multiple environment specs (SpecA and SpecB1). In Fig. 6(a) the controllers were tested in environments from SpecA. The Expert and Scan-and-Dwell controllers (which are given SpecA to estimate each sampled environment parameters) correctly predict the signal from . ConvLSTM-DAN achieves a good performance because it was trained on SpecA environments. Then, when tested on SpecB1 environments while being given SpecA to estimate the parameters (Fig. 6(b)), the hand-coded solutions fail to correctly predict the out-of-distribution signals. In contrast, the ConvLSTM-DAN, trained only in SpecA, shows more robustness to changes in environment dynamics.
| Model | Sep. Dense | Shared Dense | Shared Conv. |
|---|---|---|---|
| IoU | 0.17 | 0.25 | 0.35 |
| Parameters | 82216 | 89858 | 39234 |
4.2 ConvLSTM, Predictive and InfoMax DAN
ConvLSTM-DAN vs. original DAN. We compare our ConvLSTM-DAN model (a shared architecture) with the models used in the original DAN: Separate Dense (-net and -net are separate networks with dense layers followed by an LSTM layer) and Shared Dense (a single network with shared initial layers and separate outputs for -net and -net). The ConvLSTM-DAN layers can scale arbitrarily with respect to number of frequencies without a corresponding increase in the number of model parameters and as a result it converges much faster to a better accuracy as shown in Table 2.
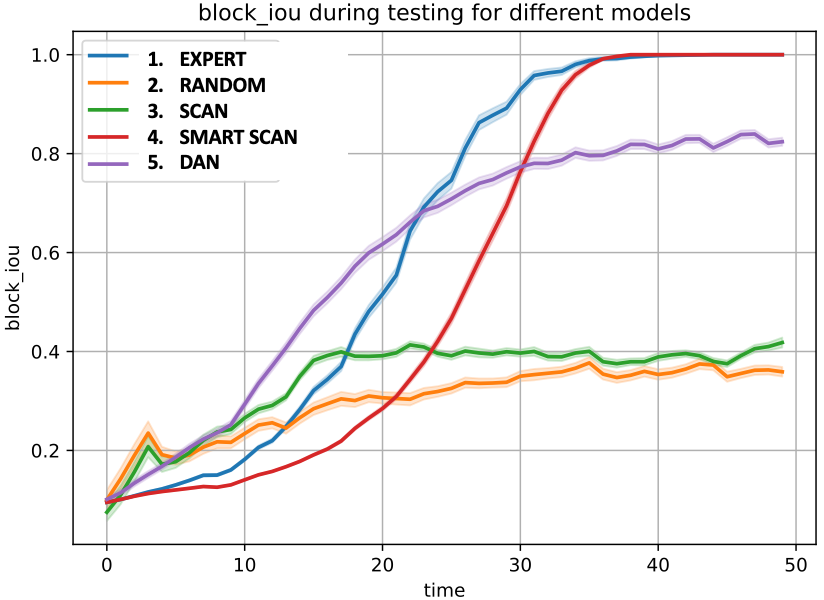
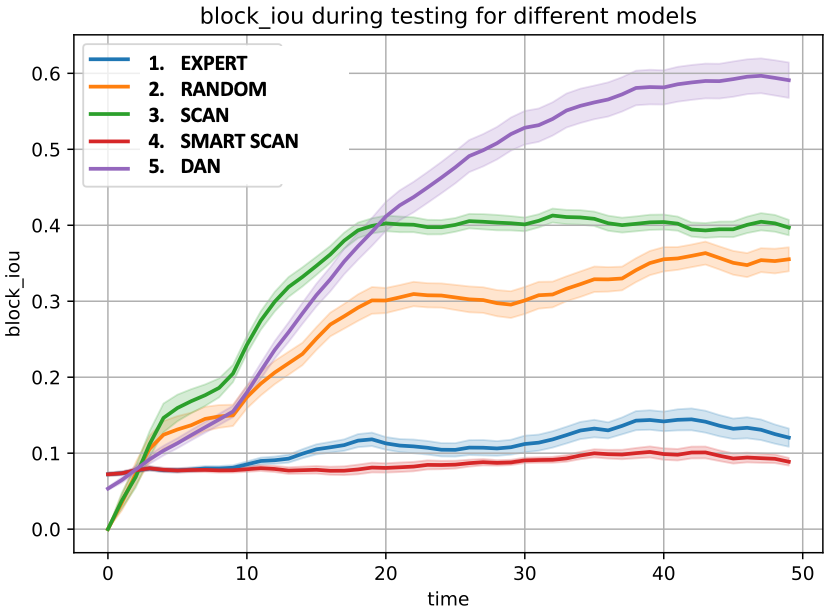
Predictive, InfoMax vs. ConvLSTM-DAN. We evaluate their performance in environments with distinct challenges: (i) Stationary (simplest): a range of patterns (period, duty-cycle) and signal numbers (1-3); (ii) Non-stationary (more challenging and realistic): narrower range of patterns, but signal patterns and locations randomly change during episode; (iii) Multi-class wide spectrum environment (most realistic): multiple signal classes with different behaviours (signal modulations), aperiodic, random activity and more bands (100 vs. 20). In (iii), observation and internal state includes objectness (is signal present) and signal class score (softmax score vector). Also added multi-class loss, metrics and rewards.
| Environments | |||
|---|---|---|---|
| Agent | Stationary | Non-stationary | Multi |
| ConvLSTM-DAN w/ db_iou | 0.62 | 0.37 | 0.50 |
| ConvLSTM-DAN w/ in_iou | 0.63 | 0.38 | 0.48 |
| Predictive-DAN | 0.68 | 0.45 | 0.44 |
| Infomax-DAN | 0.75 | 0.39 | 0.52 |
Table 3 shows the results of our approaches. Notice that InfoMax performs best in stationary environments, where the signal parameters vary a lot from episode to episode, but within the episode, they are stationary. Predictive-DAN is best at non-stationary environments, and RL methods (as opposed to non-RL based InfoMax) seem to perform best there. InfoMax-DAN seems to perform best at complex multi-class environments. It also shows that our designs can scale in frequency.
4.3 Experience Feedback (Field Spec Estimation)
We now cover our results in leveraging experience feedback via field spec estimation and controller retraining using the estimated spec, while field state estimation is covered in Sec. 4.4. For these experiments, our Predictive-DAN is the ML-based controller used.
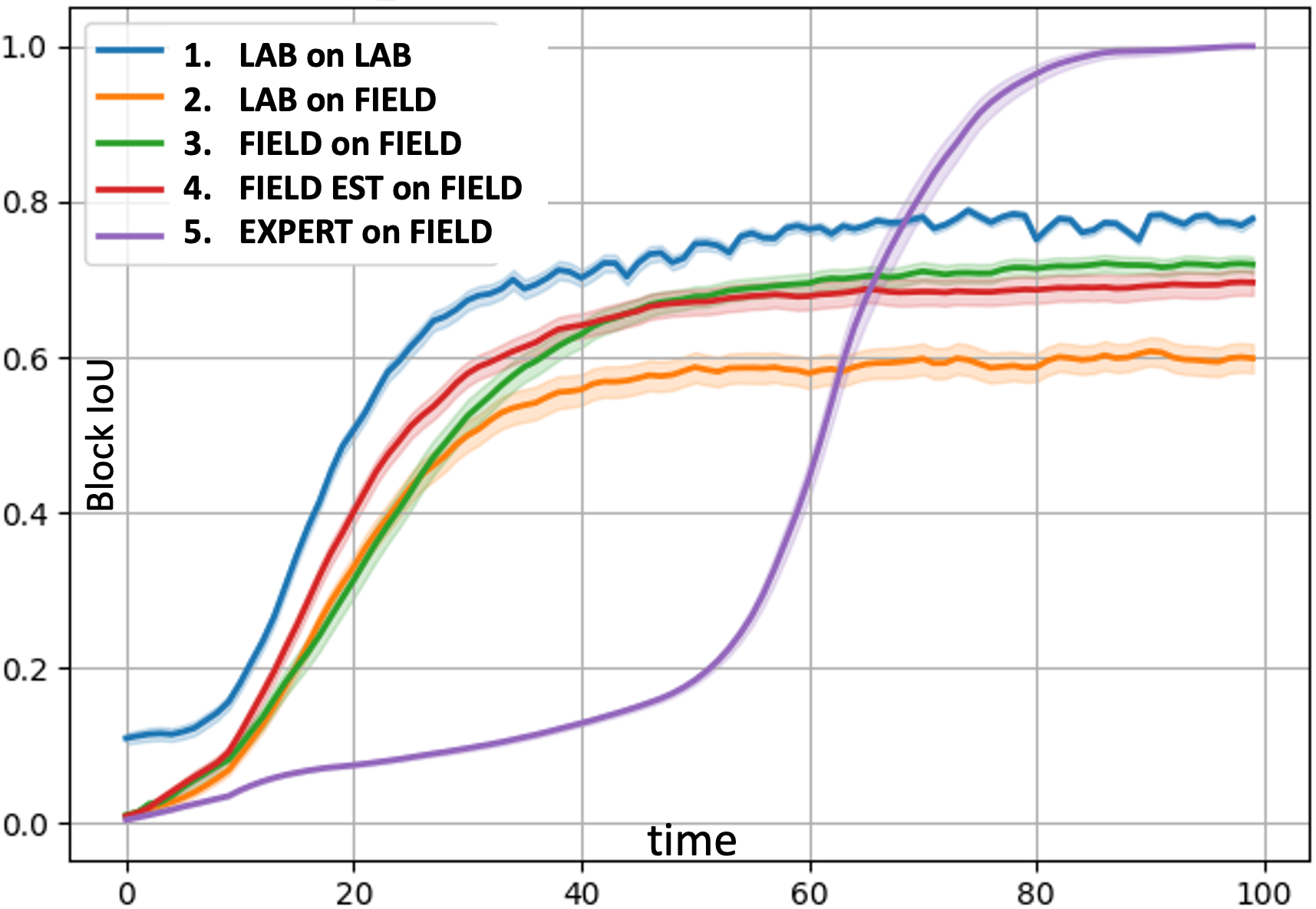
Estimating Spec from Feedback. In Fig. 7(a) we compare our approach (4. Field Est on Field) to a scan-and-dwell hand-coded control where field spec is within-distribution (5.Expert on Field) and also to our ML controller alternatively trained (1.-3.). The hand-coded controller takes a long time to reduce uncertainty (large search space). A DAN controller trained on lab alone cannot cope with field (2. Lab on Field). By learning estimated field spec without GT, our approach has similar performance to training on field spec with GT (3.Field on Field, see also analogous 1.Lab on Lab).
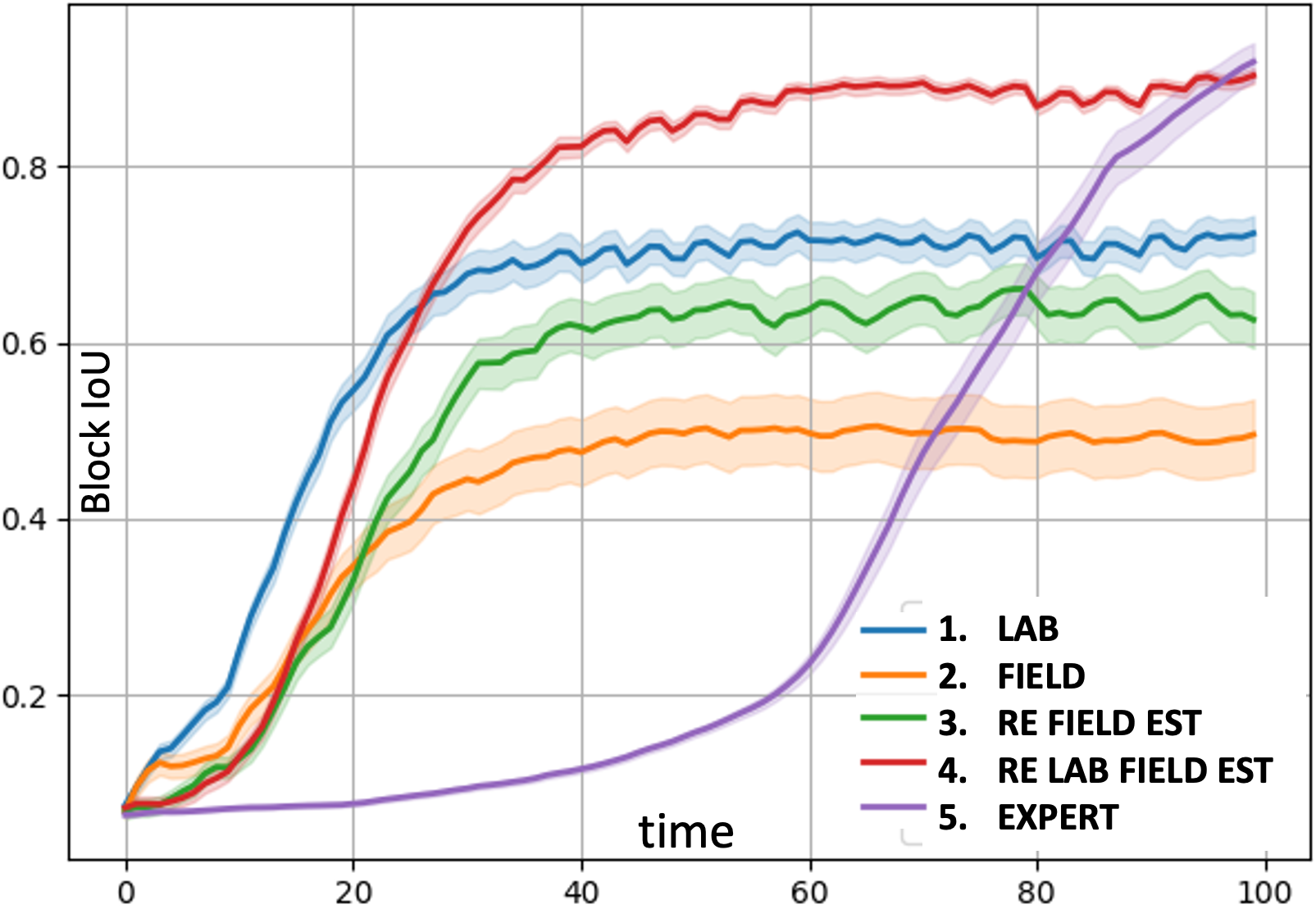
Estimating Spec from Retraining. In Fig. 7(b), we compare a controller (4. Re Lab Field Est) trained on Lab spec, then re-trained on a mix of estimated field spec ( weight) + Lab spec ( weight) to a scan-and-dwell hand-coded controller (5. Expert) and also to our ML controller alternatively trained (1.-3.). For this experiment, Field Spec and Lab Spec differ in number of signals (1 vs. 2, respectively) and width between signals (3 vs. 2), and we sample a mix of both specs for testing. Controllers trained on only one spec (1. Lab, 2. Field) cannot cope with environments from multiple specs. The controller retrained only on estimated field spec (3. Re Field Est) suffers from “forgetting” and cannot cope with environments from it’s initial training spec. By retraining on both specs (weighted), the controller has the best performance.
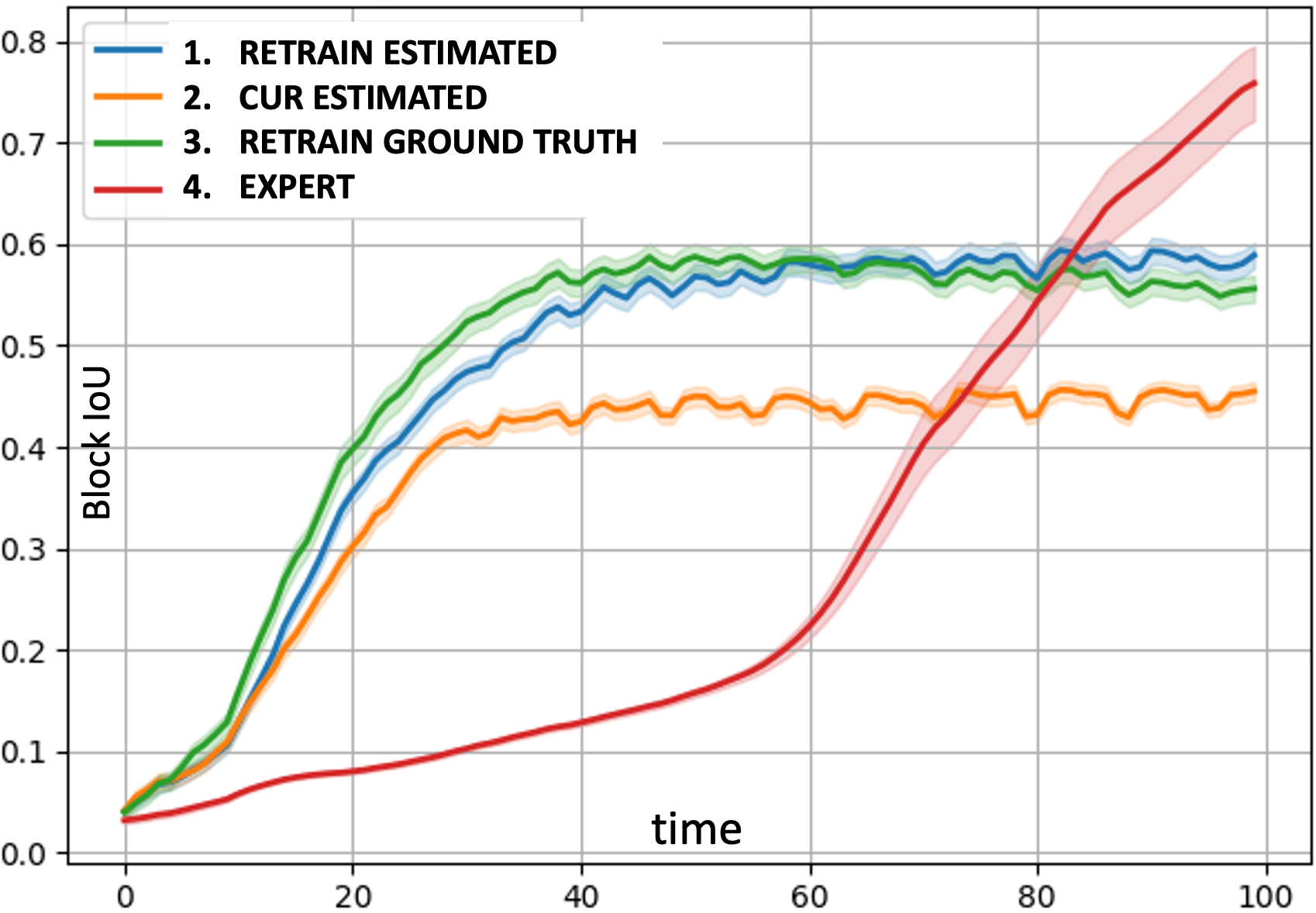
Boostrapping. In Fig. 8, we consider a bootstrap loop with 3 iterations, where the ground-truth field spec parameters differ slightly from the previous iteration’s (lab spec used is A and the three field specs are F1-F3 in Table1). The idea is to expose a controller to environments of variable complexity. The results for the last iteration are shown in Fig. 8, where we evaluate against all environment specs (lab + 3 field). The detection rate () of the controller with estimated specs (1. Retrain Estimated) is close to that of controller using GT specs (3. Retrain Ground Truth) . Hence, training with GT loses advantage over training with estimated specs over multiple iterations as the agent is exposed to more and more types of environments. We can also see that re-training DAN controller leads to smooth adaptation and using only current estimated spec (2.Cur Estimated) results in poor performance.
4.4 Experience Feedback (Field State Estimation)
Instead of estimating the parameters of a field spec, which is then used to train a controller, we can perform Field State Estimation: do ML-based estimation of the full field/spectrum state (2. in Fig. 4) from partially observed field observations (1. in Fig. 4), and then use these reconstructed full-state episodes directly to retrain our ML controller, as described in Sec. 3.3.2. The ML-based estimation is done by a generator that is trained offline, separately from DAN. Once trained, it then generates one full-state episode from one partially observed field episode. In Table. 4, we compare the field state estimation approach to a controller exhaustively trained on an (anticipated) lab spec and one trained on the ideal training source: the field spec with complete ground truth information. We also study the performance after training with different numbers of reconstructed full-state episodes (25, 50, 100). Finally, we compare the approach with fine-tuning a controller in the field alone using partially observed prediction rewards—reward only what you observe in the band sampled and no error information using GT in other bands. For these experiments, we use SpecC1 (Table 1) for the lab spec and SpecC2 for the field spec. Throughout these experiments, evaluations of all training configurations are done on the same 100 field spec episodes (not used in training) and Predictive-DAN is the controller used.
| Training approach | Block IoU |
|---|---|
| 1 Trained with lab spec only | 0.58 |
| 2 Retrained w/ 25 estimated field state episodes | 0.53 |
| 3 Retrained w/ 50 estimated field state episodes | 0.70 |
| 4 Retrained w/ 100 estimated field state episodes | 0.72 |
| 5 Training w/ field spec and full GT | 0.75 |
| 6 Finetuned w/ 100 partially observed field episodes | 0.43 |
The first row in Table. 4 corresponds to DAN trained with the lab spec, with no field experience and 1000 unique episodes. We can see that the performance is poor. The next three rows (2-4) correspond to DAN retrained with estimated full-state field episodes mixed with lab spec episodes, respectively. We can see that performance improves when the lab controller is retrained with more estimated field episodes. The fifth row in Table. 4 corresponds to training from the field spec with full ground truth and for 1000 unique episodes. This result roughly corresponds to the best possible performance of DAN given GT. As we can see, in this case, retraining DAN with 100 estimated field episodes (using no GT) has similar performance to training DAN with field GT and 1000 episodes.
The result of evaluating the DAN controller fine-tuned directly on 100 partially observed field episodes alone is shown in the last row (6) of Table. 4. For this case, we modified training for DAN accordingly to accommodate partially observed states, i.e., we have ground truth information only in the particular band sampled instead of all the bands previously—hence the reward obtained by -network is limited to the prediction only in this band. We can see that its performance is inferior compared to training with full-state episodes, even when those complete states are estimated (row 4 of Table. 4). Partial observations in sparse, dynamic signal environments makes training difficult.
In summary, we show that retraining a DAN with full-state sequences estimated using ML-based generators from partially observed field observations is a viable and promising approach, while fine-tuning a DAN directly on partially observed field experiences produces poor results in general.
5 Conclusion and Future Work
Novel RL-based approaches for information gain under partially observable, non-stationary and reward-sparse environments are presented and applied to the complex problem of RF spectrum monitoring, where the task is to identify signals with distinct behavioral patterns at variable frequencies. The proposed solution accounts for scalability and translation-invariance challenges of the signals in frequency-time space. We also propose information gain rewards to encourage exploration of unseen signals. Additionally, we developed two model-based RL approaches for the difficult task of retraining/fine-tuning a lab-trained controller using experience feedback from limited field deployment without ground-truth. Simulation results indicate that our approach outperforms previous RL and hand-coded solutions, and is promising for monitoring RF spectrums. We also show promising results for retraining our ML controller using limited field experience.
For future work, we plan on studying adversarial environments with competitive multi-agent learning and complex control surfaces with action representation learning. Also, we plan to investigate the use of GANs to generate training sequences from sparse field samples.
Acknowledgements
This material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA) and Space and Naval Warfare Systems Center, Pacific (SSC Pacific) under Contract No. N66001-18-C-4044.
Disclaimer: The views, opinions, and/or findings expressed are those of the author(s) and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
References
- Satsangi et al. [2020] Yash Satsangi, Sungsu Lim, Shimon Whiteson, Frans A. Oliehoek, and Martha White. Maximizing information gain in partially observable environments via prediction rewards. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, AAMAS ’20, page 1215–1223, Richland, SC, 2020. International Foundation for Autonomous Agents and Multiagent Systems. ISBN 9781450375184.
- Xingjian et al. [2015] SHI Xingjian, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. Convolutional lstm network: A machine learning approach for precipitation nowcasting. In Advances in neural information processing systems, pages 802–810, 2015.
- Kaelbling et al. [1998] Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains. Artificial Intelligence, 101(1):99–134, 1998. ISSN 0004-3702. doi: https://doi.org/10.1016/S0004-3702(98)00023-X. URL https://www.sciencedirect.com/science/article/pii/S000437029800023X.
- Satsangi et al. [2018] Yash Satsangi, Shimon Whiteson, Frans A Oliehoek, and Matthijs TJ Spaan. Exploiting submodular value functions for scaling up active perception. Autonomous Robots, 42(2):209–233, 2018.
- Wang et al. [2018] Leye Wang, Wenbin Liu, Daqing Zhang, Yasha Wang, En Wang, and Yongjian Yang. Cell selection with deep reinforcement learning in sparse mobile crowdsensing. In 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), pages 1543–1546, 2018. doi: 10.1109/ICDCS.2018.00164.
- Mnih et al. [2014] Volodymyr Mnih, Nicolas Heess, Alex Graves, and Koray Kavukcuoglu. Recurrent models of visual attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, NIPS’14, page 2204–2212, Cambridge, MA, USA, 2014. MIT Press.
- Haque et al. [2016] Albert Haque, Alexandre Alahi, and Li Fei-Fei. Recurrent attention models for depth-based person identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1229–1238, 2016.
- James and Singh [2009] Michael R James and Satinder Singh. Sarsalandmark: an algorithm for learning in pomdps with landmarks. In Proceedings of The 8th International Conference on Autonomous Agents and Multiagent Systems-Volume 1, pages 585–591, 2009.
- Katt et al. [2017] Sammie Katt, Frans A Oliehoek, and Christopher Amato. Learning in pomdps with monte carlo tree search. In International Conference on Machine Learning, pages 1819–1827. PMLR, 2017.
- Franco et al. [2020] Horacio Franco, Chris Cobo-Kroenke, Stephanie Welch, and Martin Graciarena. Wideband spectral monitoring using deep learning. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, WiseML ’20, page 19–24, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450380072. doi: 10.1145/3395352.3402620. URL https://doi.org/10.1145/3395352.3402620.
- Kulin et al. [2018] Merima Kulin, Tarik Kazaz, Ingrid Moerman, and Eli De Poorter. End-to-end learning from spectrum data: A deep learning approach for wireless signal identification in spectrum monitoring applications. IEEE Access, 6:18484–18501, 2018. doi: 10.1109/ACCESS.2018.2818794.
- Mendis et al. [2019] Gihan J. Mendis, Jin Wei, Ariuna Madanayake, and Soumyajit Mandal. Spectral attention-driven intelligent target signal identification on a wideband spectrum. In 2019 IEEE Cognitive Communications for Aerospace Applications Workshop (CCAAW), pages 1–6, 2019. doi: 10.1109/CCAAW.2019.8904904.
- Taylor and Stone [2009] Matthew E. Taylor and Peter Stone. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res., 10:1633–1685, dec 2009. ISSN 1532-4435.
- Zhu et al. [2020] Zhuangdi Zhu, Kaixiang Lin, and Jiayu Zhou. Transfer learning in deep reinforcement learning: A survey. ArXiv, abs/2009.07888, 2020.
- Feinberg et al. [2018] Vladimir Feinberg, Alvin Wan, Ion Stoica, Michael I. Jordan, Joseph E. Gonzalez, and Sergey Levine. Model-based value estimation for efficient model-free reinforcement learning. CoRR, abs/1803.00101, 2018. URL http://arxiv.org/abs/1803.00101.
- Kalweit and Boedecker [2017] Gabriel Kalweit and Joschka Boedecker. Uncertainty-driven imagination for continuous deep reinforcement learning. In Sergey Levine, Vincent Vanhoucke, and Ken Goldberg, editors, Proceedings of the 1st Annual Conference on Robot Learning, volume 78 of Proceedings of Machine Learning Research, pages 195–206. PMLR, 13–15 Nov 2017. URL https://proceedings.mlr.press/v78/kalweit17a.html.
- Hafner et al. [2020] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=S1lOTC4tDS.
- Moerland et al. [2020] Thomas M. Moerland, Joost Broekens, and Catholijn M. Jonker. Model-based reinforcement learning: A survey. ArXiv, abs/2006.16712, 2020.
- Li et al. [2020] Lianjun Li, Lingjia Liu, Jianan Bai, Hao-Hsuan Chang, Hao Chen, Jonathan D. Ashdown, Jianzhong Zhang, and Yang Yi. Accelerating model-free reinforcement learning with imperfect model knowledge in dynamic spectrum access. IEEE Internet of Things Journal, 7(8):7517–7528, 2020. doi: 10.1109/JIOT.2020.2988268.
- Hua et al. [2019] Yuxiu Hua, Rongpeng Li, Zhifeng Zhao, Honggang Zhang, and Xianfu Chen. Gan-based deep distributional reinforcement learning for resource management in network slicing. In 2019 IEEE Global Communications Conference (GLOBECOM), pages 1–6, 2019. doi: 10.1109/GLOBECOM38437.2019.9014217.
- Huang et al. [2021] Jie Huang, Rongshun Juan, Randy Gomez, Keisuke Nakamura, Qixin Sha, Bo He, and Guangliang Li. Gan-based interactive reinforcement learning from demonstration and human evaluative feedback. CoRR, abs/2104.06600, 2021. URL https://arxiv.org/abs/2104.06600.
- Wang et al. [2016] Ziyu Wang, Tom Schaul, Matteo Hessel, Hado van Hasselt, Marc Lanctot, and Nando de Freitas. Dueling network architectures for deep reinforcement learning, 2016.
- van Hasselt et al. [2015] Hado van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning, 2015.
- Pathak et al. [2017] Deepak Pathak, Pulkit Agrawal, Alexei A Efros, and Trevor Darrell. Curiosity-driven exploration by self-supervised prediction. In International conference on machine learning, pages 2778–2787. PMLR, 2017.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation, 2015.