SenseFi: A Library and Benchmark on Deep-Learning-Empowered WiFi Human Sensing
Abstract
WiFi sensing has been evolving rapidly in recent years. Empowered by propagation models and deep learning methods, many challenging applications are realized such as WiFi-based human activity recognition and gesture recognition. However, in contrast to deep learning for visual recognition and natural language processing, no sufficiently comprehensive public benchmark exists. In this paper, we review the recent progress on deep learning enabled WiFi sensing, and then propose a benchmark, SenseFi, to study the effectiveness of various deep learning models for WiFi sensing. These advanced models are compared in terms of distinct sensing tasks, WiFi platforms, recognition accuracy, model size, computational complexity, feature transferability, and adaptability of unsupervised learning. It is also regarded as a tutorial for deep learning based WiFi sensing, starting from CSI hardware platform to sensing algorithms. The extensive experiments provide us with experiences in deep model design, learning strategy skills and training techniques for real-world applications. To the best of our knowledge, this is the first benchmark with an open-source library for deep learning in WiFi sensing research. The benchmark codes are available at https://github.com/xyanchen/WiFi-CSI-Sensing-Benchmark.
Index Terms:
WiFi sensing, benchmark, deep learning, channel state information, human sensing, transfer learning, unsupervised learning, ubiquitous computing, activity recognition.I Introduction
With the proliferation of mobile internet usage, WiFi access point (AP) has become a ubiquitous infrastructure in smart environments, ranging from commercial buildings to domestic settings. By analysing the patterns of its wireless signal, today’s AP has evolved beyond a pure WiFi router, but is also widely used as a type of ‘sensor device’ to enable new services for human sensing. Particularly, recent studies have found that WiFi signals in the form of Channel State Information (CSI) [1, 2] are extremely promising for a variety of device-free human sensing tasks, such as occupancy detection [3], activity recognition [4, 5, 6, 7], fall detection [8], gesture recognition [9, 10], human identification [11, 12], and people counting [13, 14]. Unlike the coarse-grained received signal strengths, WiFi CSI records more fine-grained information about how a signal propagates between WiFi devices and how a signal is reflected from the surrounding environment in which humans move around. On the other side, as WiFi signals (2.4GHz or 5GHz) lie in the non-visible band of the electromagnetic spectrum, WiFi CSI based human sensing is intrinsically more privacy-friendly than cameras and draws increasing attention from both academia and industry. Motivated by increasing interests needs, a new WiFi standard, 802.11bf [15] is designed by the IEEE 802.11bf Task Group (TGbf), and will amend the current WiFi standard both at the Medium Access Control (MAC) and Physical Layer (PHY) to officially include WiFi sensing as part of a regular WiFi service by late 2024.

Existing WiFi sensing methods can be categorized into model-based methods and learning-based methods. Model-based methods rely on physical models that describe the WiFi signals propagation, such as Fresnel Zone [16]. Model based methods help us understand the underlying mechanism of WiFi sensing and design sensing methods for periodic or single motions, such as respiration [17, 18, 19] and falling down [8, 20, 21]. Nevertheless, model based methods fall short when it comes to the complicated human activities that consist of a series of different motions. For example, a human gait comprises the synergistic movements of arms, legs and bodies, the differences of which are hard to depict by physical models. In contrast, by feeding a massive amount of data into machine learning [22] or deep learning networks, [9, 5], learning based achieve remarkable performances in complicated sensing tasks. Various deep neural networks are designed to enable many applications including activity recognition [23], gesture recognition [9], human identification [11, 12, 24], and people counting [13, 14]. Though deep learning models have a strong ability of function approximation, they require tremendous labeled data that is expensive to collect and suffer from the negative effect of distribution shift caused by environmental dynamics [25].
Most state-of-the-art deep learning models are developed for computer vision [26], such as human activity recognition [27, 28], and natural language processing tasks [29], such as sentiment classification [30]. Deep models have demonstrated the capacity of processing high-dimensional and multi-modal data problems. These approaches inspire the deep learning applications in WiFi sensing in terms of data preprocessing, network design, and learning objectives. It is seen that more and more deep models [31, 32] for WiFi sensing come into existence and overcome the aforementioned obstacles that traditional statistical learning methods cannot address. However, current works mainly aim to achieve high accuracy on specific sensing tasks by tailoring deep neural networks but do not explore the intrinsic tension between various deep learning models and distinct WiFi sensing data collected by different devices and CSI tools. It is unclear if the remarkable results of a WiFi sensing research paper come from the deep model design or the WiFi platform. Hence, there still exist some significant gaps between current deep learning and WiFi sensing research: (i) how to customize a deep neural network for a WiFi sensing task by integrating prevailing network modules (e.g., fully-connected layer, convolutional layer, recurrent neural unit, transformer block) into one synergistic framework? (ii) how do the prevailing models perform when they are compared fairly on multiple WiFi sensing platforms and data modalities? (iii) how to achieve a trade-off between recognition accuracy and efficiency?
To answer these questions, we propose SenseFi, a benchmark and model zoo library for WiFi CSI sensing using deep learning. Firstly, we introduce the prevalent deep learning models, including multilayer perceptron (MLP), convolutional neural network (CNN), recurrent neural network (RNN), variants of RNN, CSI transformers, and CNN-RNN, and summarize how they are effective for CSI feature learning and WiFi sensing tasks. Then we investigate and benchmark these models on three WiFi human activity recognition data that consists of both raw CSI data and processed data collected by Intel 5300 CSI tool [1] and Atheros CSI tool [2, 22]. The accuracy and efficiency of these models are compared and discussed to show their viability for real-world applications. We further investigate how different WiFi sensing tasks can benefit each other by transfer learning, and how unsupervised learning can be used to exploit features without labels, reducing the annotation cost. These features are summarized in Figure 1. All the source codes are written into one library so that the researchers can develop and evaluate their models conveniently.
As such, the contributions are summarized as follows:
-
•
We analyze and summarize how the widespread deep learning models in computer vision and natural language processing benefit WiFi sensing in terms of network structure and feature extraction.
- •
-
•
We explore the transfer learning scheme that transfers knowledge across different sensing tasks, and benchmark it across all models.
-
•
We investigate the unsupervised learning scheme that contrastively learns the feature extractor without data annotation, and benchmark it across all models.
-
•
We develop the SenseFi library and open-source the benchmarking codes. To the best of our knowledge, this is the first work that benchmarks advanced deep models and learning schemes for WiFi sensing, which provides comprehensive and significant evidence and tools for future research.
The rest of the paper is organized as follows. Section II introduces the fundamental knowledge on WiFi sensing and CSI data. Then we introduce the prevalent deep learning models and how they are applied to WiFi sensing in Section III. The empirical study is detailed in Section V, and then the summaries and discussions are made in Section VI. Finally, the paper is concluded in Section VIII.
II Preliminaries of WiFi Sensing

II-A Channel State Information
In WiFi communication, channel state information reflects how wireless signals propagate in a physical environment after diffraction, reflections, and scattering, which describes the channel properties of a communication link. For modern wireless communication networks following the IEEE 802.11 standard, Multiple-Input Multiple-Output (MIMO) and Orthogonal Frequency Division Multiplexing (OFDM) at the physical layer contribute to increasing data capacity and better orthogonality in transmission channels affected by multi-path propagation. As a result, current WiFi APs usually have multiple antennas with many subcarriers for OFDM. For a pair of transmitter and receiver antennas, CSI describes the phase shift of multi-path and amplitude attenuation on each subcarrier. Compared to received signal strength, CSI data has better resolutions for sensing and can be regarded as “WiFi images” for the environment where WiFi signals propagate. Specifically, the Channel Impulse Response (CIR) of the WiFi signals is defined in the frequency domain:
| (1) |
where and denote the amplitude and phase of the -th multi-path component, respectively, is the time delay, denotes the number of multi-paths and is the Dirac delta function. To estimate the CIR, the OFDM receiver samples the signal spectrum at subcarrier level in the realistic implementation, which represents amplitude attenuation and phase shift via complex number. In WiFi sensing, the CSI recording functions are realized by specific tools [1, 2]. The estimation can be represented by:
| (2) |
where and are the amplitude and phase of -th subcarrier, respectively.
II-B CSI Tools and Platforms
The number of subcarriers is decided by the bandwidth and the tool. The more subcarriers one has, the better resolution the CSI data is. Existing CSI tools include Intel 5300 NIC [1], Atheros CSI Tool [2] and Nexmon CSI Tool [35], and many realistic sensing platforms are built on them. The Intel 5300 NIC is the most commonly used tool, which is the first released CSI tool. It can record 30 subcarriers for each pair of antennas running with 20MHz bandwidth. Atheros CSI Tool increases the CSI data resolution by improving the recording CSI to 56 subcarriers for 20MHz and 114 subcarriers for 40MHz, which has been widely used for many applications [5, 22, 6, 9, 36]. The Nexmon CSI Tool firstly enables CSI recording on smartphones and Raspberry Pi, and can capture 256 subcarriers for 80MHz. However, past works [37, 38] show that their CSI data is quite noisy, and there do not exist common datasets based on Nexmon. In this paper, we only investigate the effectiveness of the deep learning models trained on representative CSI data from the widely-used Intel 5300 NIC and Atheros CSI Tool.
II-C CSI Data Transformation and Cleansing
In general, the CSI data consists of a vector of complex number including the amplitude and phase. The question is how we process these data for the deep models of WiFi sensing? We summarize the answers derived from existing works:
-
1.
Only use the amplitude data as input. As the raw phases from a single antenna are randomly distributed due to the random phase offsets [39], the amplitude of CSI is more stable and suitable for WiFi sensing. A simple denoising scheme is enough to filter the high-frequency noise of CSI amplitudes, such as the wavelet denoising [22]. This is the most common practice for most WiFi sensing applications.
-
2.
Use the CSI difference between antennas for model-based methods. Though the raw phases are noisy, the phase difference between two antennas is quite stable [9], which can better reflect subtle gestures than amplitudes. Then the CSI ratio [40] is proposed to mitigate the noise by the division operation and thus increases the sensing range. These techniques are mostly designed for model-based solutions as they require clean data for selecting thresholds.
-
3.
Use the processed doppler representation of CSI. To eliminate the environmental dependency of CSI data, the body-coordinate velocity profile (BVP) is proposed to simulate the doppler feature [34] that only reflects human motions.
In our benchmark, as we focus on the learning-based methods, we choose the most common data modality (i.e., amplitude only) and the novel BVP modality that is domain-invariant.
II-D How Human Activities Affect CSI
As shown in Figure 2, the CSI data for human sensing is composed of two dimensions: the subcarrier and the packet number (i.e., time duration). For each packet or timestamp , we have where , and denote the number of transmitter antennas, receiver antennas and subcarriers per antenna, respectively. This can be regarded as a “CSI image” for the surrounding environment at time . Then along with subsequent timestamps, the CSI images form a “CSI video” that can describe human activity patterns. To connect CSI data with deep learning models, we summarize the data properties that serve for a better understanding of deep model design:
-
1.
Subcarrier dimension spatial features. The values of many subcarriers can represent how the signal propagates after diffraction, reflections, and scattering, and thus describe the spatial environment. These subcarriers are seen as an analogy for image pixels, from which convolutional layers can extract spatial features [41].
-
2.
Time dimension temporal features. For each subcarrier, its temporal dynamics indicate an environmental change. In deep learning, the temporal dynamics are usually modeled by recurrent neural networks [42].
-
3.
Antenna dimension resolution and channel features. As each antenna captures a different propagation path of signals, it can be regarded as a channel in deep learning that is similar to RGB channels of an image. If only one pair of antennas exists, then the CSI data is similar to a gray image with only one channel. Hence, the more antennas we have, the higher resolution the CSI has. The antenna features should be processed separately in convolutional layers or recurrent neurons.
| Method | Year | Task | Model | Platform | Strategy |
|---|---|---|---|---|---|
| [33] | 2017 | Human Activity Recognition | RNN, LSTM | Intel 5300 NIC | Supervised learning |
| WiCount [43] | 2017 | People Counting | MLP | Intel 5300 NIC | Supervised learning |
| EI [44] | 2018 | Human Activity Recognition | CNN | Intel 5300 NIC | Transfer learning |
| CrossSense [32] | 2018 | Human Identification,Gesture Recognition | MLP | Intel 5300 NIC | Transfer Ensemble learning |
| [45] | 2018 | Human Activity Recognition | LSTM | Intel 5300 NIC | Supervised learning |
| DeepSense [5] | 2018 | Human Activity Recognition | CNN-LSTM | Atheros CSI Tool | Supervised learning |
| WiADG [25] | 2018 | Gesture Recognition | CNN | Atheros CSI Tool | Transfer learning |
| WiSDAR [46] | 2018 | Human Activity Recognition | CNN-LSTM | Intel 5300 NIC | Supervised learning |
| WiVi [7] | 2019 | Human Activity Recognition | CNN | Atheros CSI Tool | Supervised learning |
| SiaNet [9] | 2019 | Gesture Recognition | CNN-LSTM | Atheros CSI Tool | Few-Shot learning |
| CSIGAN [47] | 2019 | Gesture Recognition | CNN, GAN | Atheros CSI Tool | Semi-Supervised learning |
| DeepMV [48] | 2020 | Human Activity Recognition | CNN (Attention) | Intel 5300 NIC | Supervised learning |
| WIHF [49] | 2020 | Gesture Recognition | CNN-GRU | Intel 5300 NIC | Supervised learning |
| DeepSeg [50] | 2020 | Human Activity Recognition | CNN | Intel 5300 NIC | Supervised learning |
| [51] | 2020 | Human Activity Recognition | CNN-LSTM | Intel 5300 NIC | Supervised learning |
| [38] | 2021 | Human Activity Recognition | LSTM | Nexmon CSI Tool | Supervised learning |
| [52] | 2021 | Human Activity Recognition | CNN | Nexmon CSI Tool | Supervised learning |
| [53] | 2021 | Human Activity Recognition | CNN | Intel 5300 NIC | Few-Shot learning |
| Widar [34] | 2021 | Human Identification, Gesture Recognition | CNN-GRU | Intel 5300 NIC | Supervised learning |
| WiONE [54] | 2021 | Human Identification | CNN | Intel 5300 NIC | Few-Shot learning |
| [55] | 2021 | Human Activity Recognition | CNN, RNN, LSTM | Intel 5300 NIC | Supervised learning |
| THAT [56] | 2021 | Human Activity Recognition | Transformers | Intel 5300 NIC | Supervised learning |
| WiGr [57] | 2021 | Gesture Recognition | CNN-LSTM | Intel 5300 NIC | Supervised learning |
| MCBAR [58] | 2021 | Human Activity Recognition | CNN, GAN | Atheros CSI Tool | Semi-Supervised learning |
| CAUTION [12] | 2022 | Human Identification | CNN | Atheros CSI Tool | Few-Shot learning |
| CTS-AM [59] | 2022 | Human Activity Recognition | CNN (Attention) | Intel 5300 NIC | Supervised learning |
| WiGRUNT [60] | 2022 | Gesture Recognition | CNN (Attention) | Intel 5300 NIC | Supervised learning |
| [61] | 2022 | Human Activity Recognition | LSTM | Nexmon CSI Tool | Supervised learning |
| EfficientFi [36] | 2022 | Human Activity Recognition, Human Identification | CNN | Atheros CSI Tool | Multi-task Supervised learning |
| RobustSense [62] | 2022 | Human Activity Recognition, Human Identification | CNN | Atheros CSI Tool | Supervised learning |
| AutoFi [63] | 2022 | Human Activity Recognition, Human Identification | CNN-MLP | Atheros CSI Tool | Unsupervised learning |
III Deep Learning Models for WiFi Sensing
Deep learning enables models composed of many processing layers to learn representations of data, which is a branch of machine learning [41]. Compared to classic statistical learning that mainly leverages handcrafted features designed by humans with prior knowledge [64], deep learning aims to extract features automatically by learning massive labeled data and optimizing the model by back-propagation [65]. The theories of deep learning were developed in the 1980s but they were not attractive due to the need of enormous computational resources. With the development of graphical processing units (GPUs), deep learning techniques have become affordable, and has been widely utilized in computer vision [26], natural language processing [29], and interdisciplinary research [66].
A standard classification model in deep learning is composed of a feature extractor and a classifier. The classifier normally consists of several fully-connected layers that are able to learn a good decision boundary, while the design of the feature extractor is the key to the success. Extensive works explore a large number of deep architectures for feature extractors [67], and each of them has specific advantages for some type of data. The deep learning models for WiFi sensing are built on these prevailing architectures to extract patterns of human motions [5]. We summarize the latest works on deep models for WiFi sensing in Table I, and it is observed that the networks of these works are quite similar.
In the following, we introduce these key architectures and how they are applied to WiFi sensing tasks. To better instantiate these networks, we firstly formulate the normal WiFi CSI sensing task. The CSI data is defined as where denotes the number of antennas, denotes the number of subcarriers, and denotes the duration. The CSI data of each pair of antenna is relatively independent, and thus regarded as one channel of CSI, such as the RGB channels of image data. The deep learning model aims to map the data to the corresponding label: , according to different tasks. Denote and as the -th layer of the deep model and the feature of the -th layer. After feature extraction, the classifier is trained to seek a decision boundary in the feature space. In deep learning, the feature extractor is the key module that reduces the feature dimension while preserving the manifold [41]. With a discriminative feature space, the choices of classifiers are flexible, which can be deep classifier (e.g., Multilayer Perceptron) or traditional classifiers (e.g., K-Nearest Neighbors, Support Vector Machine, and Random Forest). Apart from the illustration, we visualize the intuition of how to feed these CSI data into various networks in Figure 3.

III-A Multilayer Perceptron
Multilayer perceptron (MLP) [68] is one of the most classic architectures and has played the classifier role in most deep classification networks. It normally consists of multiple fully-connected layers followed by activation functions. The first layer is termed the input layer that transforms the input data into the hidden latent space, and after several hidden layers, the last layer maps the latent feature into the categorical space. Each layer is calculated as
| (3) |
where is the parameters of , and is the activation function that aims to increase the non-linearity for MLP. The input CSI has to be flattened to a vector and then fed into the MLP, such that . Such a process mixes the spatial and temporal dimensions and damages the intrinsic structure of CSI data. Despite this, the MLP can still work with massive labeled data, because the MLP has a fully-connected structure with a large number of parameters, yet leading to slow convergence and huge computational costs. Therefore, though the MLP shows satisfactory performance, stacking many layers in MLP is not common for feature learning, which makes MLP usually serve as a classifier. In WiFi sensing, MLP is commonly utilized as a classifier [5, 46, 7, 32, 44, 34].
III-B Convolutional Neural Network
Convolutional neural network (CNN) was firstly proposed for image recognition tasks by LeCun [69]. It addresses the drawbacks of MLP by weight sharing and spatial pooling. CNN models have achieved remarkable performances in classification problems of 2D data in computer vision [70, 71] and sequential data in speech recognition [72] and natural language processing [73]. CNN learns features by stacking convolutional kernels and spatial pooling operations. The convolution operation refers to the dot product between a filter and an input vector , defined as follows:
| (4) |
The pooling operation is a down-sampling strategy that calculates the maximum (max pooling) or mean (average pooling) inside a kernel. The CNNs normally consist of several convolutional layers, max-pooling layers, and the MLP classifier. Generally speaking, increasing the depth of CNNs can lead to better model capacity. Nevertheless, when the depth of CNN is too large (e.g., greater than 20 layers), the gradient vanishing problem leads to degrading performance. Such degradation is addressed by ResNet [74], which uses the residual connections to reduce the difficulty of optimization.
In WiFi sensing, the convolution kernel can operate on a 2D patch of CSI data (i.e., Conv1D) that includes a spatial-temporal feature, or on a 1D patch of each subcarrier of CSI data (i.e., Conv2D). For Conv2D, a 2D convolution kernel operates on all patches of the CSI data via the sliding window strategy to obtain the output of the feature map, while the Conv1D only extracts the spatial feature along the subcarrier dimension. The Conv2D can be applied independently as it considers both spatial and temporal features, while the Conv1D is usually used with other temporal feature learning methods. To enhance the capacity of CNN, multiple convolution kernels with a random initialization process are used. The advantages of CNNs for WiFi sensing consist of fewer training parameters and the preservation of the subcarrier and time dimension in CSI data. However, the disadvantage is that CNN has an insufficient receptive field due to the limited kernel size and thus fails to capture the dependencies that exceed the kernel size. Another drawback is that CNN stack all the feature maps of kernels equally, which has been revamped by an attention mechanism that assigns different weights in the kernel or spatial level while stacking features. For CSI data, due to the varying locations of human motions, the patterns of different subcarriers should have different importance, which can be depicted by spatial attention in CTS-AM [59]. More attention techniques have been successfully developed to extract temporal-level, antenna-level and subcarrier-level features for WiFi sensing [48, 75, 76].
III-C Recurrent Neural Network
Recurrent neural network (RNN) is one of the deepest network architectures that can memorize arbitrary-length sequences of input patterns. The unique advantage of RNN is that it enables multiple inputs and multiple outputs, which makes it very effective for time sequence data, such as video [77] and CSI [5, 78, 79]. Its principle is to create internal memory to store historical patterns, which are trained via back-propagation through time [80].
For a CSI sample , we denote a CSI frame at the as . The vanilla RNN uses two sharing matrices to generate the hidden state :
| (5) |
where the activation function is usually Tanh or Sigmoid functions. RNN is designed to capture temporal dynamics, but it suffers from the vanishing gradient problem during back-propagation and thus cannot capture long-term dependencies of CSI data.
III-D Variants of RNN (LSTM)
To tackle the problem of long-term dependencies of RNN, Long-short term memory (LSTM) [81] is proposed by designing several gates with varying purposes and mitigating the gradient instability during training. The standard LSTM sequentially updates a hidden sequence by a memory cell that contains four states: a memory state , an output gate that controls the effect of output, an input gate and a forget gate that decides what to preserve and forget in the memory. The LSTM is parameterized by weight matrices and biases , and the whole update is performed at each :
| (6) | |||
| (7) | |||
| (8) | |||
| (9) | |||
| (10) | |||
| (11) |
where is a Sigmoid function.
Apart from the LSTM cell [82, 83, 84], the multi-layer and bi-directional structure further boost the model capacity. The bidirectional LSTM (BiLSTM) model processes the sequence in two directions and concatenates the features of the forward input and backward input . It has been proven that BiLSTM shows better results than LSTM in [45, 85].
III-E Recurrent Convolutional Neural Network
Though LSTM addresses the long-term dependency, it leads to a large computation overhead. To overcome this issue, Gated Recurrent Unit (GRU) is proposed. GRU combines the forget gate and input gate into one gate, and does not employ the memory state in LSTM, which simplifies the model but can still capture long-term dependency. GRU is regarded as a simple yet effective version of LSTM. Leveraging the simple recurrent network, we can integrate the Conv1D and GRU to extract spatial and temporal features, respectively. [86, 87] show that CNN-GRU is effective for human activity recognition. In WiFi sensing, DeepSense [5] firstly proposes Conv2D with LSTM for human activity recognition. CNN-GRU is also revamped for CSI-based human gesture recognition in Widar [34]. SiaNet [9] further proposes Conv1D with BiLSTM for few-shot gesture recognition. As they perform quite similarly, we use CNN-GRU with fewer parameters in this paper for the benchmark.
III-F Transformer
Transformer [88] was firstly proposed for NLP applications to extract sequence embeddings by exploiting attention of words, and then it was extended to the computer vision field where each patch is regarded as a word and one image consists of many patches [89]. The vanilla consists of an encoder and a decoder to perform machine translation, and only the encoder is what we need. The transformer block is composed of a multi-head attention layer, a feed-forward neural network (MLP), and layer normalization. Since MLP has been explained in previous section, we mainly introduce the attention mechanism in this section. For a CSI sample , we first divide it into patches , of which each patch has contained spatial-temporal features. Then these patches are concatenated and added by positional embeddings that infer the spatial position of patches, which makes the input matrix where . This matrix is transformed into three different matrices via linear embedding: the query , the key , and the value . The self-attention process is calculated by
| (12) |
Intuitively, such a process calculates the attention of any two patches via dot product, i.e., cosine similarity, and then the weighting is performed with normalization to enhance gradient stability for improved training. Multi-head attention just repeats the self-attention several times and enhances the diversity of attentions. The transformer architecture can interconnect with every patch of CSI, which makes it strong if given sufficient training data, such as THAT [56]. However, transformer has a great number of parameters that makes the training cost expensive, and enormous labeled CSI data is hard to collect, which makes transformers not really attractive for the supervised learning.
III-G Generative Models
Different from the aforementioned discriminative models that mainly conducts classification, generative models aim to capture the data distribution of CSI. Generative Adversarial Network (GAN) [90] is a classic generative model that learns to generate real-like data via an adversarial game between a generative network and a discriminator network. In WiFi sensing, GAN helps deal with the environmental dependency by generating labeled samples in the new environment from the well-trained environment [47, 58]. GAN also inspires domain-adversarial training that enables deep models to learn domain-invariant representations for the training and real-world testing environments [25, 91, 92, 93]. Variational network [94] is another common generative model that maps the input variable to a multivariate latent distribution. Variational autoencoder learns the data distribution by a stochastic variational inference and learning algorithm [94], which has been used in CSI-based localization [95, 96] and CSI compression [36]. For instance, EfficientFi [36] leverages the quantized variational model to compress the CSI transmission data for large-scale WiFi sensing in the future.

IV Learning Methods for Deep WiFi Sensing Models
Traditional training of deep models relies on supervised learning with massive labeled data, but the data collection and annotation is a bottleneck in the realistic WiFi sensing applications. For example, to recognize human gestures, we may need the volunteers to perform gestures for a hundred times, which is not realistic. In this section, as shown in Figure 4, we illustrate the learning methods and how they contribute to WiFi sensing in the real world.
Supervised Learning is an approach to training deep models using input data that has been labeled for a particular output. It is the most common learning strategy in current WiFi sensing works [33, 5, 46, 7]. They usually adopt cross-entropy loss between the ground truth label and the prediction for model optimization. Though supervised learning is easy to implement and achieves high performance for many tasks, its requirement of tremendous labeled data hinders its pervasive realistic applications.
Few-shot Learning is a data-efficient learning strategy that only utilizes several samples of each category for training. This is normally achieved by contrastive learning or prototypical learning. It is firstly exploited for WiFi sensing in SiaNet [9] that proposes a Siamese network for few-shot learning. Subsequent works [54, 12] extend prototypical networks from visual recognition to WiFi sensing, also achieving good recognition results. Specially, when only one sample for each class is employed for training, we term it as one-shot learning. As only a few samples are required, few-shot learning contributes to WiFi-based gesture recognition and human identification in practice.
Transfer Learning aims to transfer knowledge from one domain to another domain [97]. When the two domains are similar, we pretrain the model on one domain and fine-tune the model in a new environment, which can lead to significant performance. When the two domains are distinct, such as the different environments of CSI data, the distribution shift hinders the performance so domain adaptation should be adopted. Domain adaptation is a category of semi-supervised learning that mitigates the domain shift for transfer learning. Cross-domain scenarios are quite common in WiFi sensing scenarios since the CSI data is highly dependent on the training environment. Many works have been developed to deal with this problem [25, 44, 58, 98, 99].
Unsupervised Learning aims to learn data representations without any labels. Then the feature extractor can facilitate down-streaming tasks by training a specific classifier. From the experience of visual recognition tasks [100], unsupervised learning can even enforce the model to gain better generalization ability since the model is not dependent on any specific tasks. Current unsupervised learning models are based on self-supervised learning [101]. Despite its effectiveness, the unsupervised learning has not been well exploited in WiFi sensing, and only AutoFi is developed to enable model initialization for automatic user setup in WiFi sensing applications [63].
Ensemble Learning uses multiple models to obtain better predictive performance [102]. The ensemble process can operate on feature level or prediction level. Feature-level ensemble concatenates the features from multiple models and one final classifier is trained. Prediction-level ensemble is more common, usually referring to voting or probability addition. Ensemble learning can increase the performance but the computation overhead also explodes by multiple times. CrossSense [44] develops a mixture-of-experts approach and only chooses the appropriate expert for a specific input, addressing the computation cost.
In this paper, we empirically explore the effectiveness of supervised learning, transfer learning and unsupervised learning for WiFi CSI data, as they are the most commonly used learning strategies in WiFi sensing applications.
| Datasets | UT-HAR [33] | Widar [34] | NTU-Fi HAR [36] | NTU-Fi Human-ID [58] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Platform | Intel 5300 NIC | Intel 5300 NIC | Atheros CSI Tool | Atheros CSI Tool | ||||||||
| Category Number | 7 | 22 | 6 | 14 | ||||||||
| Category Names |
|
|
|
Gaits of 14 Subjects | ||||||||
| Data Size |
|
|
|
|
||||||||
| Training Samples | 3977 | 34926 | 936 | 546 | ||||||||
| Testing Samples | 996 | 8726 | 264 | 294 | ||||||||
| Training Epochs | 200 | 100 | 30 | 30 |
| Dataset | UT-HAR | Widar | NTU-Fi HAR | NTU-Fi Human-ID | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Acc (%) | Flops (M) | Params (M) | Acc (%) | Flops (M) | Params (M) | Acc (%) | Flops (M) | Params (M) | Acc (%) | Flops (M) | Params (M) |
| MLP | 92.00 | 23.17 | 23.170 | 67.24 | 9.15 | 9.150 | 99.69 | 175.24 | 175.240 | 93.91 | 175.24 | 175.240 |
| CNN-5 | 97.61 | 31.68 | 0.296 | 70.19 | 3.38 | 0.299 | 98.70 | 28.24 | 0.477 | 97.14 | 28.24 | 0.478 |
| ResNet18 | 98.11 | 49.93 | 11.180 | 71.70 | 38.39 | 11.250 | 95.31 | 54.19 | 11.180 | 96.42 | 54.19 | 11.190 |
| ResNet50 | 97.21 | 86.40 | 23.550 | 68.56 | 69.70 | 23.640 | 99.38 | 90.66 | 23.550 | 92.91 | 90.67 | 23.570 |
| ResNet101 | 94.99 | 162.58 | 42.570 | 68.71 | 145.87 | 42.660 | 95.31 | 166.83 | 42.570 | 88.40 | 166.85 | 42.590 |
| RNN | 83.53 | 2.51 | 0.010 | 47.05 | 0.66 | 0.031 | 84.64 | 13.09 | 0.027 | 89.30 | 13.09 | 0.027 |
| GRU | 94.18 | 7.60 | 0.030 | 62.50 | 1.98 | 0.091 | 97.66 | 39.39 | 0.079 | 98.96 | 39.39 | 0.079 |
| LSTM | 87.18 | 10.14 | 0.040 | 63.35 | 2.64 | 0.121 | 97.14 | 52.54 | 0.105 | 97.19 | 52.54 | 0.105 |
| BiLSTM | 90.19 | 20.29 | 0.080 | 63.43 | 5.28 | 0.240 | 99.69 | 105.09 | 0.209 | 99.38 | 105.09 | 0.210 |
| CNN + GRU | 96.72 | 39.99 | 1.430 | 63.19 | 3.34 | 0.092 | 93.75 | 48.38 | 0.058 | 87.48 | 48.39 | 0.058 |
| ViT | 96.53 | 273.10 | 10.580 | 67.72 | 9.28 | 0.106 | 93.75 | 501.64 | 1.052 | 76.84 | 501.64 | 1.054 |
V Empirical Studies of Deep Learning in WiFi Sensing: A Benchmark
In this section, we conduct an empirical study of the aforementioned deep learning models on WiFi sensing data and firstly provide the benchmarks with open-source codes in http://www.github.com/. The four datasets are illustrated first, and then we evaluate the deep models on these datasets in terms of three learning strategies. Eventually, some detailed analytics are conducted on the convergence of optimization, network depth, and network selection.
V-A Datasets
We choose two public CSI datasets (UT-HAR [33] and Widar [34]) collected using Intel 5300 NIC. To validate the effectiveness of deep learning models on CSI data of different platforms, we collect two new datasets using Atheros CSI Tool [2] and our embedded IoT system [22], namely NTU-Fi HAR and NTU-Fi Human-ID. The details and statistics of these datasets are summarized in Table II.
UT-HAR [33] is the first public CSI dataset for human activity recognition. It consists of seven categories and is collected via Intel 5300 NIC with 3 pairs of antennas that record 30 subcarriers per pair. All the data is collected in the same environment. However, its data is collected continuously and has no golden labels for activity segmentation. Following existing works [56], the data is segmented using a sliding window, inevitably causing many repeated data among samples. Hence, though the total number of samples reaches around 5000, it is a small dataset with intrinsic drawbacks.
Widar [34] is the largest WiFi sensing dataset for gesture recognition, which is composed of 22 categories and 43K samples. It is collected via Intel 5300 NIC with pairs of antennas in many distinct environments. To eliminate the environmental dependencies, the data is processed to the body-coordinate velocity profile (BVP).
NTU-Fi is our proposed dataset for this benchmark that includes both human activity recognition (HAR) and human identification (Human ID) tasks. Different from UT-HAR and Widar, our dataset is collected using Atheros CSI Tool and has a higher resolution of subcarriers (114 per pair of antennas). Each CSI sample is perfectly segmented. For the HAR dataset, we collect the data in three different layouts. For the Human ID dataset, we collect the human walking gaits in three situations: wearing a T-shirt, a coat, or a backpack, which brings many difficulties. The NTU-Fi data is simultaneously collected in these works [36, 12] that describe the detailed layouts for data collection.
V-B Implementation Details
We normalize the data for each dataset and implement all the aforementioned methods using the PyTorch framework [103]. To ensure the convergence, we train the UT-HAR, Widar, and NTU-Fi for 200, 100, and 30 epochs, respectively, for all the models except RNN. As the vanilla RNN is hard to converge due to the gradient vanishing, we train them for two times of the specified epochs. We use the Adam optimizer with a learning rate of 0.001, and the beta of 0.9 and 0.999. We follow the original Adam paper [104] to set these hyper-parameters. The ratio of training and testing splits is 8:2 for all datasets using stratified sampling.
V-C Baselines and Criterion
We design the baseline networks of MLP, CNN, RNN, GRU, LSTM, BiLSTM, CNN+GRU, and Transformer following the experiences learned from existing works in Table I. The CNN-5 is modified from LeNet-5 [69]. We further introduce the series of ResNet [74] that have deeper layers. The transformer network is based on the vision transformer (ViT) [89] so that each patch can contain spatial and temporal dimensions. It is found that given sufficient parameters and reasonable depth of layers, they can converge to more than 98% in the training split. Since the data sizes of UT-HAR, Widar and NTU-Fi are different, we use a convolutional layer to map them into a unified size, which enables us to use the same network architecture. The specific network architectures for all models are illustrated in the Appendix. The hyper-parameters of the networks have been tuned to ensure the satisfactory convergence. To compare the baseline models, we select three classic criteria: accuracy (Acc) that evaluates the prediction ability, floating-point operations (Flops) that evaluates the computational complexity, and the number of parameters (Params) that measures the requirement of GPU memory. As WiFi sensing is usually performed on the edge, the Flops and Params also matter with limited resources.
V-D Evaluations of Different Deep Architectures
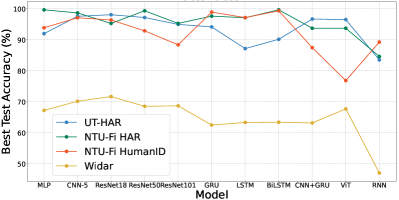
Overall Comparison. We summarize the performance of all baseline models in Table III. On UT-HAR, the ResNet-18 achieves the best accuracy of 98.11% and the CNN-5 achieves the second best. The shallow CNN-5 can attain good results on all datasets but the deep ResNet-18 fails to generalize on Widar, which will be explained in Section V-F. The BiLSTM yields the best performance on two NTU-Fi benchmarks. To compare these results, we visualize them in Figure 5, from which we can conclude the observations:
-
•
The MLP, CNN, GRU, LSTM, and Transformer can achieve satisfactory results on all benchmarks.
-
•
The MLP, GRU, and CNN show stable and superior performances when they are compared to others.
-
•
The very deep networks (i.e., the series of ResNet) perform well on UT-HAR and Widar, but do not perform better than simple CNN on NTU-Fi. The performance does not increase as the number of network layers increases, which is different from visual recognition results [74]. Compared to simple CNN-5, the improvement margin is quite limited.
-
•
The RNN is worse than LSTM and GRU.
-
•
The transformer cannot work well when only limited training data is available in NTU-Fi Human-ID.
-
•
The models show inconsistent performances on different datasets, as the Widar dataset is much more difficult.
Computational Complexity. The Flops value shows the computational complexity of models in Table III. The vanilla RNN has low complexity but cannot perform well. The GRU and CNN-5 are the second-best models and simultaneously generate good results. It is also noteworthy that the ViT (transformer) has a very large computational complexity as it is composed of many MLPs for feature embedding. Since its performance is similar to that of CNN, MLP, and GRU, the transformer is not suitable for supervised learning tasks in WiFi sensing.
Model Parameters. The number of model parameters determines how many GPU memories are occupied during inference. As shown in Table III, the vanilla RNN has the smallest parameter size and then is followed by the CNN-5 and CNN-GRU. The parameter sizes of CNN-5, RNN, GRU, LSTM, BiLSTM, and CNN-GRU are all small and acceptable for model inference in the edge. Considering both the Params and Acc, CNN-5, GRU, BiLSTM, and CNN-GRU are good choices for WiFi sensing. Though the model parameters can be reduced by model pruning [105], quantization [106] or fine-tuning the hyper-parameters, here we only evaluate the pure models that have the minimum parameter sizes to converge in the training split.
V-E Evaluations of Learning Schemes
Apart from supervised learning, other learning schemes are also useful for realistic applications of WiFi sensing. Here we evaluate two prevailing learning strategies on these models.
| Method | Accuracy (%) | Flops (M) | Params (M) |
|---|---|---|---|
| MLP | 84.46 | 175.24 | 175.240 |
| CNN-5 | 96.35 | 28.24 | 0.478 |
| ResNet18 | 85.94 | 54.19 | 11.190 |
| ResNet50 | 79.21 | 90.67 | 23.570 |
| ResNet101 | 68.88 | 166.85 | 42.590 |
| RNN | 57.84 | 13.09 | 0.027 |
| GRU | 75.89 | 39.39 | 0.079 |
| LSTM | 71.98 | 52.54 | 0.105 |
| BiLSTM | 80.20 | 105.09 | 0.210 |
| CNN + GRU | 51.73 | 48.39 | 0.059 |
| ViT | 66.20 | 501.64 | 1.054 |


Evaluations on Transfer Learning The transfer learning experiments are conducted on NTU-Fi. We transfer the model from the HAR to Human-ID by pre-training the model in HAR (whole dataset) and then fine-tuning a new classifier in Human-ID (training split). This simulates the situation when we train the model using massive labeled data collected in the lab, and then use a few data to realize customized tasks for users. The human activities in HAR and human gaits in Human-ID are composed of human motions, and thus the feature extractor should learn to generalize across these two tasks. We evaluate this setting for all baseline models and the results are shown in Table IV. It is observed that the CNN feature extractor has the best transferability, achieving 96.35% on the Human-ID task. Similar to CNN, the MLP and BiLSTM also have such capacity. However, the RNN, CNN+GRU, and ViT only achieve 57.84%, 51.73%, and 66.20%, which demonstrates their weaker capacity for transfer learning. This can be caused by the overfitting phenomenon, such as the simple RNN that only memorizes the specific patterns for HAR but cannot recognize the new patterns. This can also be caused by the mechanism of feature learning. For example, the transformer (ViT) learns the connections of local patches by self-attention, but such connections are different between HAR and Human-ID. Recognizing different activities relies on the difference of a series of motions, but most human gaits are so similar that only subtle patterns can be an indicator for gait identification.
Evaluations on Unsupervised Learning We further exploit the effectiveness of unsupervised learning for CSI feature learning. We follow the AutoFi [63] to construct two parallel networks and adopt the KL-divergence, mutual information, and kernel density estimation loss to train the two networks only using the CSI data. After unsupervised learning, we train the independent classifier based on the fixed parameters of the two networks. All the backbone networks are tested using the same strategy: unsupervised training on NTU-Fi HAR and supervised learning on NTU-Fi Human-ID. The evaluation is conducted on Human-ID, and the results are shown in Table V. It is shown that CNN achieves the best accuracy of 97.62% that is followed by MLP and ViT. The results demonstrate that unsupervised learning is effective for CSI data. It yields better cross-task evaluation results than those of transfer learning, which demonstrates that unsupervised learning helps learn features with better generalization ability. CNN and MLP-based networks are more friendly for unsupervised learning of WiFi CSI data.
| Method | Accuracy (%) | Flops (M) | Params (M) | |
|---|---|---|---|---|
| classifier1 | classifier2 | |||
| MLP | 90.48 | 89.12 | 175.24 | 175.240 |
| CNN-5 | 96.26 | 97.62 | 28.24 | 0.478 |
| ResNet18 | 85.03 | 82.99 | 54.19 | 11.190 |
| ResNet50 | 47.28 | 45.58 | 90.67 | 23.570 |
| ResNet101 | 36.05 | 35.37 | 166.85 | 42.590 |
| RNN | 53.74 | 51.36 | 13.09 | 0.027 |
| GRU | 65.99 | 64.63 | 39.39 | 0.079 |
| LSTM | 53.06 | 55.10 | 52.54 | 0.105 |
| BiLSTM | 51.36 | 55.78 | 105.09 | 0.210 |
| CNN + GRU | 50.34 | 53.40 | 48.39 | 0.059 |
| ViT | 78.91 | 84.35 | 501.64 | 1.054 |






V-F Analysis
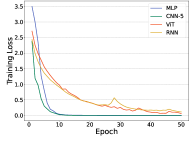
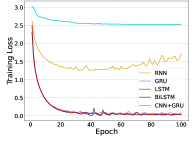
Convergence of Deep Models. Though all models converge eventually, their training difficulties are different and further affect their practical usage. To compare their convergence difficulties, we show the training losses of MLP, CNN-5, ViT, and RNN in terms of epochs in Figure 7. It is noted that CNN converges very fast within 25 epochs for four datasets, and MLP also converges at a fast speed. The transformer requires more epochs of training since it consists of more model parameters. In comparison, RNN hardly converges on UT-HAR and Widar, and converges slower on NTU-Fi. Then we further explore the convergence of RNN-based models, including GRU, LSTM, BiLSTM, and CNN+GRU in Figure 8. Though there show strong fluctuations during the training phase of GRU, LSTM, and BiLSTM, these three models can achieve much lower training loss. Especially, GRU achieves the lowest loss among all RNN-based methods. For CNN+GRU, the training phase is more stable but its convergence loss is larger than others.
How Transfer Learning Matters. We further draw the training losses of all models on NTU-Fi Human-ID with pre-trained parameters of NTU-Fi HAR in Figure 6. Compared to the training procedures of randomly-initialized models in Figures 7(c) and 8(c), the convergence can be achieved and even become much more stable. We can draw two conclusions from these results: (a) the feature extractors of these models are transferable across two similar tasks; (b) the fluctuations of training losses are caused by the feature extractor since only the classifier is trained for the transfer learning settings.


Poor Performance of Deep CNN on Widar. In Table III, a noticeable phenomenon is that the ResNet-18/50/101 cannot generalize well on Widar data, only achieving 17.91%, 19.47%, and 14.47%, respectively. In visual recognition, a deeper network should perform better on large-scale datasets [74]. Then we have the question: is the degeneration of these deep models caused by underfitting or overfitting in WiFi sensing? We seek the reason by plotting their training losses in Figure 9. Figure 9(a) shows that even though the training accuracy has been almost 100%, the testing accuracy remains low, under 20%. Whereas, other networks (MLP, CNN, GRU) have similar training accuracy while the testing accuracy is increased to over 60%. This indicates that the degrading performances of ResNets are caused by overfitting, and different domains in Widar [34] might be the main reasons. This discovery tells us that very deep networks are prone to suffer from overfitting for cross-domain tasks and may not be a good choice for current WiFi sensing applications due to their performance and computational overhead.
Choices of Optimizer. During the training phase, we find that though Adam can help models converge at a fast speed, it also leads to much training instability, especially for the very deep neural networks. In Figure 10(a), we can see that ResNet-18 converges stably but ResNet-50 and ResNet-101 have fluctuating losses every 20-30 epochs. This might be caused by the dramatically changing values of WiFi data and its adaptive learning rate of Adam [104]. Then we consider changing the optimizer from Adam to a more stable optimizer, Stochastic Gradient Descent (SGD). In Figure 10(b), we find that the training procedure becomes more stable. This implies that if a very deep model is utilized in WiFi sensing, the SGD should be a better choice. If a simple model is sufficient for the sensing task, then Adam can enforce the model to converge better and faster.


VI Discussions and Summary
Having analyzed the empirical results and the characteristics of deep learning models for WiFi sensing, we summarize the experiences and observations that facilitate future research on model design, model training, and real world use case:
-
•
Model Choices. We recommend CNN, GRU, and BiLSTM due to their high performance, low computational cost, and small parameter size. The shallow models have achieved remarkable results for activity recognition, gesture recognition, and human identification, while the very deep models confront the overfitting issue, especially for cross-domain scenarios.
-
•
Optimization. We recommend using Adam or SGD optimizer. The Adam optimizer enforces the model to converge at a fast speed but sometimes it causes instability of training. When such a situation happens, the SGD is a more secure way but the hyper-parameters of SGD (i.e., the learning rate and momentum) need to be manually specified and tuned.
-
•
Advice on Transfer Learning Applications. We recommend applying transfer learning when the task is similar to existing applications and the same CSI sensing platform is employed. The pre-trained parameters provide a good initialization and better generalization ability. CNN, MLP, and BiLSTM have superior transferability.
-
•
Advice on Unsupervised Learning. We recommend applying unsupervised learning to initialize the model for similar tasks since unsupervised learning extracts more generalizable features than transfer learning. CNN, MLP, and ViT are more suitable in the unsupervised learning framework in general.
VII Grand Challenges and Future Directions
Deep learning still keeps booming in many research fields and continuously empowers more challenging applications and scenarios. Based on the new progress, we look into the future directions of deep learning for WiFi sensing and summarize them as follows.
Data-efficient learning. As CSI data is expensive to collect, data-efficient learning methods should be further explored. Existing works have utilized few-shot learning, transfer learning, and domain adaptation, which yield satisfactory results in a new environment with limited training samples. However, since the testing scenarios are simple, the transferability of these models cannot be well evaluated. In the future, meta-learning and zero-shot learning can further help learn robust features across environments and tasks.
Model compression or lightweight model design. In the future, WiFi sensing requires real-time processing for certain applications, such as vital sign monitoring [107]. To this end, model compression techniques can play a crucial role, such as model pruning [106], quantization [105] and distillation [108], which decreases the model size via an extra learning step. The lightweight model design is also favorable, such as the EfficientNet [109] in computer vision that is designed from scratch by balancing network depth, width, and resolution.
Multi-modal learning. WiFi sensing is ubiquitous, cost-effective, and privacy-preserving, and can work without the effect of illumination and part of occlusion, which is complementary to the existing visual sensing technique. To achieve robust sensing 24/7, multiple modalities of sensing data should be fused using multi-modal learning. WiVi [7] pioneers human activity recognition by integrating WiFi sensing and visual recognition. Multi-modal learning can learn joint features from multiple modalities and make decisions by choosing reliable modalities.
Cross-modal learning. WiFi CSI data describes the surrounding environment that can also be captured by cameras. Cross-modal learning aims to supervise or reconstruct one modality from another modality, which helps WiFi truly “see” the environment and visualize them in videos. Wi2Vi [110] manages to generate video frames by CSI data and firstly achieves cross-modal learning in WiFi sensing. The human pose is then estimated by supervising the model by the pose landmarks of OpenPose [111]. In the future, cross-modal learning may enable the WiFi model to learn from more supervisions such as radar and Lidar.
Model robustness and security for trustworthy sensing. When deploying WiFi sensing models in the real world, the model should be secure to use. Adversarial attacks have raised attentions in video-based human sensing [112]. Nevertheless, existing works study the accuracy of models but few pay attention to the security issue. First, during the communication, the sensing data may leak the privacy of users. Second, if any adversarial attack is made on the CSI data, the modal can perform wrongly and trigger the wrong actions of smart appliances. RobustSense seeks to overcome adversarial attacks by augmentation and adversarial training [63]. EfficientFi proposes a variational auto-encoder to quantize the CSI for efficient and robust communication. WiFi-ADG [113] protects the user privacy by enforcing the data not recognizable by general classifiers. More works should be focused on secure WiFi sensing and establish trustworthy models for large-scale sensing, such as federated learning.
Complicated human activities and behaviors analytics. While current methods have shown prominent recognition accuracy for single activities or gestures, human behavior is depicted by more complicated activities. For example, to indicate if a patient may have a risk of Alzheimer’s disease, the model should record the routine and analyze the anomaly activity, which is still difficult for existing approaches. Precise user behavior analysis can contribute to daily healthcare monitoring and behavioral economics.
Model interpretability for a physical explanation. Model-based and learning-based methods develop fast but in a different ways. Recent research has investigated the interpretability of deep learning models that looks for the justifications of classifiers. In WiFi sensing, if the model is interpreted well, there may exist a connection between the data-driven model and the physical model. The modal interpretability may inspire us to develop new theories of physical models for WiFi sensing, and oppositely, the existing model (e.g., Fresnel Zone) may enable us to propose new learning methods based on the physical models. It is hoped that two directions of methods can be unified theoretically and practically.
VIII Conclusion
Deep learning methods have been proven to be effective for challenging applications in WiFi sensing, yet these models exhibit different characteristics on WiFi sensing tasks and a comprehensive benchmark is highly demanded. To this end, this work reviews the recent progress on deep learning for WiFi human sensing, and benchmarks prevailing deep neural networks and deep learning strategies on WiFi CSI data across different platforms. We summarize the conclusions drawn from the experimental observations, which provide valuable experiences for model design in practical WiFi sensing applications. Last but not least, the grand challenges and future directions are proposed to imagine the research issues emerging from future large-scale WiFi sensing scenarios.
References
- [1] D. Halperin, W. Hu, A. Sheth, and D. Wetherall, “Tool release: Gathering 802.11 n traces with channel state information,” ACM SIGCOMM Computer Communication Review, vol. 41, no. 1, pp. 53–53, 2011.
- [2] Y. Xie, Z. Li, and M. Li, “Precise power delay profiling with commodity wifi,” in Proceedings of the 21st Annual International Conference on Mobile Computing and Networking. ACM, 2015, pp. 53–64.
- [3] H. Zou, H. Jiang, J. Yang, L. Xie, and C. Spanos, “Non-intrusive occupancy sensing in commercial buildings,” Energy and Buildings, vol. 154, pp. 633–643, 2017.
- [4] Y. Wang, J. Liu, Y. Chen, M. Gruteser, J. Yang, and H. Liu, “E-eyes: device-free location-oriented activity identification using fine-grained wifi signatures,” in Proceedings of the 20th annual international conference on Mobile computing and networking, 2014, pp. 617–628.
- [5] H. Zou, Y. Zhou, J. Yang, H. Jiang, L. Xie, and C. J. Spanos, “Deepsense: Device-free human activity recognition via autoencoder long-term recurrent convolutional network,” in 2018 IEEE International Conference on Communications (ICC). IEEE, 2018, pp. 1–6.
- [6] J. Yang, H. Zou, H. Jiang, and L. Xie, “Carefi: Sedentary behavior monitoring system via commodity wifi infrastructures,” IEEE Transactions on Vehicular Technology, vol. 67, no. 8, pp. 7620–7629, 2018.
- [7] H. Zou, J. Yang, H. Prasanna Das, H. Liu, Y. Zhou, and C. J. Spanos, “Wifi and vision multimodal learning for accurate and robust device-free human activity recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 0–0.
- [8] H. Wang, D. Zhang, Y. Wang, J. Ma, Y. Wang, and S. Li, “Rt-fall: A real-time and contactless fall detection system with commodity wifi devices,” IEEE Transactions on Mobile Computing, vol. 16, no. 2, pp. 511–526, 2016.
- [9] J. Yang, H. Zou, Y. Zhou, and L. Xie, “Learning gestures from wifi: A siamese recurrent convolutional architecture,” IEEE Internet of Things Journal, vol. 6, no. 6, pp. 10 763–10 772, 2019.
- [10] H. Zou, Y. Zhou, J. Yang, H. Jiang, L. Xie, and C. J. Spanos, “Wifi-enabled device-free gesture recognition for smart home automation,” in 2018 IEEE 14th international conference on control and automation (ICCA). IEEE, 2018, pp. 476–481.
- [11] H. Zou, Y. Zhou, J. Yang, W. Gu, L. Xie, and C. J. Spanos, “Wifi-based human identification via convex tensor shapelet learning,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [12] D. Wang, J. Yang, W. Cui, L. Xie, and S. Sun, “Caution: A robust wifi-based human authentication system via few-shot open-set gait recognition,” IEEE Internet of Things Journal, 2022.
- [13] H. Zou, Y. Zhou, J. Yang, and C. J. Spanos, “Device-free occupancy detection and crowd counting in smart buildings with wifi-enabled iot,” Energy and Buildings, vol. 174, pp. 309–322, 2018.
- [14] H. Zou, Y. Zhou, J. Yang, L. Xie, and C. Spanos, “Freecount: Device-free crowd counting with commodity wifi,” in 2017 IEEE Global Communications Conference (GLOBECOM). IEEE, 2017.
- [15] F. Restuccia, “Ieee 802.11 bf: Toward ubiquitous wi-fi sensing,” arXiv preprint arXiv:2103.14918, 2021.
- [16] D. Wu, D. Zhang, C. Xu, H. Wang, and X. Li, “Device-free wifi human sensing: From pattern-based to model-based approaches,” IEEE Communications Magazine, vol. 55, no. 10, pp. 91–97, 2017.
- [17] H. Wang, D. Zhang, J. Ma, Y. Wang, Y. Wang, D. Wu, T. Gu, and B. Xie, “Human respiration detection with commodity wifi devices: do user location and body orientation matter?” in Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, 2016, pp. 25–36.
- [18] P. Wang, B. Guo, T. Xin, Z. Wang, and Z. Yu, “Tinysense: Multi-user respiration detection using wi-fi csi signals,” in 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), 2017, pp. 1–6.
- [19] Y. T. Xu, X. Chen, X. Liu, D. Meger, and G. Dudek, “Pressense: Passive respiration sensing via ambient wifi signals in noisy environments,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020, pp. 4032–4039.
- [20] T. Nakamura, M. Bouazizi, K. Yamamoto, and T. Ohtsuki, “Wi-fi-csi-based fall detection by spectrogram analysis with cnn,” in GLOBECOM 2020 - 2020 IEEE Global Communications Conference, 2020, pp. 1–6.
- [21] ——, “Wi-fi-based fall detection using spectrogram image of channel state information,” IEEE Internet of Things Journal, pp. 1–1, 2022.
- [22] J. Yang, H. Zou, H. Jiang, and L. Xie, “Device-free occupant activity sensing using wifi-enabled iot devices for smart homes,” IEEE Internet of Things Journal, vol. 5, no. 5, pp. 3991–4002, 2018.
- [23] H. Zou, Y. Zhou, J. Yang, W. Gu, L. Xie, and C. Spanos, “Multiple kernel representation learning for wifi-based human activity recognition,” in 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, 2017, pp. 268–274.
- [24] J. Zhang, B. Wei, F. Wu, L. Dong, W. Hu, S. S. Kanhere, C. Luo, S. Yu, and J. Cheng, “Gate-id: Wifi-based human identification irrespective of walking directions in smart home,” IEEE Internet of Things Journal, vol. 8, no. 9, pp. 7610–7624, 2020.
- [25] H. Zou, J. Yang, Y. Zhou, L. Xie, and C. J. Spanos, “Robust wifi-enabled device-free gesture recognition via unsupervised adversarial domain adaptation,” in 2018 27th International Conference on Computer Communication and Networks (ICCCN). IEEE, 2018, pp. 1–8.
- [26] A. Voulodimos, N. Doulamis, A. Doulamis, and E. Protopapadakis, “Deep learning for computer vision: A brief review,” Computational intelligence and neuroscience, vol. 2018, 2018.
- [27] X. Shu, L. Zhang, Y. Sun, and J. Tang, “Host–parasite: Graph lstm-in-lstm for group activity recognition,” IEEE transactions on neural networks and learning systems, vol. 32, no. 2, pp. 663–674, 2020.
- [28] G. Zhu, L. Zhang, L. Yang, L. Mei, S. A. A. Shah, M. Bennamoun, and P. Shen, “Redundancy and attention in convolutional lstm for gesture recognition,” IEEE transactions on neural networks and learning systems, vol. 31, no. 4, pp. 1323–1335, 2019.
- [29] D. W. Otter, J. R. Medina, and J. K. Kalita, “A survey of the usages of deep learning for natural language processing,” IEEE transactions on neural networks and learning systems, vol. 32, no. 2, pp. 604–624, 2020.
- [30] D. Wang, B. Jing, C. Lu, J. Wu, G. Liu, C. Du, and F. Zhuang, “Coarse alignment of topic and sentiment: a unified model for cross-lingual sentiment classification,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 2, pp. 736–747, 2020.
- [31] Q. Bu, X. Ming, J. Hu, T. Zhang, J. Feng, and J. Zhang, “Transfersense: towards environment independent and one-shot wifi sensing,” Personal and Ubiquitous Computing, pp. 1–19, 2021.
- [32] J. Zhang, Z. Tang, M. Li, D. Fang, P. Nurmi, and Z. Wang, “Crosssense: Towards cross-site and large-scale wifi sensing,” in Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, 2018, pp. 305–320.
- [33] S. Yousefi, H. Narui, S. Dayal, S. Ermon, and S. Valaee, “A survey on behavior recognition using wifi channel state information,” IEEE Communications Magazine, vol. 55, no. 10, pp. 98–104, 2017.
- [34] Y. Zhang, Y. Zheng, K. Qian, G. Zhang, Y. Liu, C. Wu, and Z. Yang, “Widar3. 0: Zero-effort cross-domain gesture recognition with wi-fi,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [35] F. Gringoli, M. Schulz, J. Link, and M. Hollick, “Free your csi: A channel state information extraction platform for modern wi-fi chipsets,” in Proceedings of the 13th International Workshop on Wireless Network Testbeds, Experimental Evaluation & Characterization, ser. WiNTECH ’19, 2019, p. 21–28. [Online]. Available: https://doi.org/10.1145/3349623.3355477
- [36] J. Yang, X. Chen, H. Zou, D. Wang, Q. Xu, and L. Xie, “Efficientfi: Towards large-scale lightweight wifi sensing via csi compression,” IEEE Internet of Things Journal, 2022.
- [37] A. Sharma, J. Li, D. Mishra, G. Batista, and A. Seneviratne, “Passive wifi csi sensing based machine learning framework for covid-safe occupancy monitoring,” in 2021 IEEE International Conference on Communications Workshops (ICC Workshops). IEEE, 2021, pp. 1–6.
- [38] J. Schäfer, B. R. Barrsiwal, M. Kokhkharova, H. Adil, and J. Liebehenschel, “Human activity recognition using csi information with nexmon,” Applied Sciences, vol. 11, no. 19, p. 8860, 2021.
- [39] J. Liu, G. Teng, and F. Hong, “Human activity sensing with wireless signals: A survey,” Sensors, vol. 20, no. 4, p. 1210, 2020.
- [40] Y. Zeng, D. Wu, J. Xiong, E. Yi, R. Gao, and D. Zhang, “Farsense: Pushing the range limit of wifi-based respiration sensing with csi ratio of two antennas,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 3, no. 3, pp. 1–26, 2019.
- [41] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, pp. 436–444, 2015.
- [42] M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural networks,” IEEE transactions on Signal Processing, vol. 45, no. 11, pp. 2673–2681, 1997.
- [43] S. Liu, Y. Zhao, and B. Chen, “Wicount: A deep learning approach for crowd counting using wifi signals,” in 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC). IEEE, 2017, pp. 967–974.
- [44] W. Jiang, C. Miao, F. Ma, S. Yao, Y. Wang, Y. Yuan, H. Xue, C. Song, X. Ma, D. Koutsonikolas et al., “Towards environment independent device free human activity recognition,” in Proceedings of the 24th Annual International Conference on Mobile Computing and Networking. ACM, 2018, pp. 289–304.
- [45] Z. Chen, L. Zhang, C. Jiang, Z. Cao, and W. Cui, “Wifi csi based passive human activity recognition using attention based blstm,” IEEE Transactions on Mobile Computing, vol. 18, no. 11, pp. 2714–2724, 2018.
- [46] F. Wang, W. Gong, and J. Liu, “On spatial diversity in wifi-based human activity recognition: A deep learning-based approach,” IEEE Internet of Things Journal, vol. 6, no. 2, pp. 2035–2047, 2018.
- [47] C. Xiao, D. Han, Y. Ma, and Z. Qin, “Csigan: Robust channel state information-based activity recognition with gans,” IEEE Internet of Things Journal, vol. 6, no. 6, pp. 10 191–10 204, 2019.
- [48] H. Xue, W. Jiang, C. Miao, F. Ma, S. Wang, Y. Yuan, S. Yao, A. Zhang, and L. Su, “Deepmv: Multi-view deep learning for device-free human activity recognition,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 4, no. 1, pp. 1–26, 2020.
- [49] C. Li, M. Liu, and Z. Cao, “Wihf: enable user identified gesture recognition with wifi,” in IEEE INFOCOM 2020-IEEE Conference on Computer Communications. IEEE, 2020, pp. 586–595.
- [50] C. Xiao, Y. Lei, Y. Ma, F. Zhou, and Z. Qin, “Deepseg: Deep-learning-based activity segmentation framework for activity recognition using wifi,” IEEE Internet of Things Journal, vol. 8, no. 7, pp. 5669–5681, 2020.
- [51] B. Sheng, F. Xiao, L. Sha, and L. Sun, “Deep spatial–temporal model based cross-scene action recognition using commodity wifi,” IEEE Internet of Things Journal, vol. 7, no. 4, pp. 3592–3601, 2020.
- [52] P. F. Moshiri, R. Shahbazian, M. Nabati, and S. A. Ghorashi, “A csi-based human activity recognition using deep learning,” Sensors, vol. 21, no. 21, p. 7225, 2021.
- [53] X. Ding, T. Jiang, Y. Zhong, S. Wu, J. Yang, and W. Xue, “Improving wifi-based human activity recognition with adaptive initial state via one-shot learning,” in 2021 IEEE Wireless Communications and Networking Conference (WCNC). IEEE, 2021, pp. 1–6.
- [54] Y. Gu, H. Yan, M. Dong, M. Wang, X. Zhang, Z. Liu, and F. Ren, “Wione: One-shot learning for environment-robust device-free user authentication via commodity wi-fi in man–machine system,” IEEE Transactions on Computational Social Systems, vol. 8, no. 3, pp. 630–642, 2021.
- [55] Y. Ma, S. Arshad, S. Muniraju, E. Torkildson, E. Rantala, K. Doppler, and G. Zhou, “Location-and person-independent activity recognition with wifi, deep neural networks, and reinforcement learning,” ACM Transactions on Internet of Things, vol. 2, no. 1, pp. 1–25, 2021.
- [56] B. Li, W. Cui, W. Wang, L. Zhang, Z. Chen, and M. Wu, “Two-stream convolution augmented transformer for human activity recognition,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 1, 2021, pp. 286–293.
- [57] X. Zhang, C. Tang, K. Yin, and Q. Ni, “Wifi-based cross-domain gesture recognition via modified prototypical networks,” IEEE Internet of Things Journal, vol. 9, no. 11, pp. 8584–8596, 2021.
- [58] D. Wang, J. Yang, W. Cui, L. Xie, and S. Sun, “Multimodal csi-based human activity recognition using gans,” IEEE Internet of Things Journal, 2021.
- [59] X. Ding, T. Jiang, Y. Zhong, S. Wu, J. Yang, and J. Zeng, “Wi-fi-based location-independent human activity recognition with attention mechanism enhanced method,” Electronics, vol. 11, no. 4, p. 642, 2022.
- [60] Y. Gu, X. Zhang, Y. Wang, M. Wang, H. Yan, Y. Ji, Z. Liu, J. Li, and M. Dong, “Wigrunt: Wifi-enabled gesture recognition using dual-attention network,” IEEE Transactions on Human-Machine Systems, 2022.
- [61] A. Zhuravchak, O. Kapshii, and E. Pournaras, “Human activity recognition based on wi-fi csi data-a deep neural network approach,” Procedia Computer Science, vol. 198, pp. 59–66, 2022.
- [62] J. Yang, H. Zou, and L. Xie, “Robustsense: Defending adversarial attack for secure device-free human activity recognition,” arXiv preprint arXiv:2204.01560, 2022.
- [63] J. Yang, X. Chen, H. Zou, D. Wang, and L. Xie, “Autofi: Towards automatic wifi human sensing via geometric self-supervised learning,” arXiv preprint arXiv:2205.01629, 2022.
- [64] M. I. Jordan and T. M. Mitchell, “Machine learning: Trends, perspectives, and prospects,” Science, vol. 349, no. 6245, pp. 255–260, 2015.
- [65] Y. LeCun, D. Touresky, G. Hinton, and T. Sejnowski, “A theoretical framework for back-propagation,” in Proceedings of the 1988 connectionist models summer school, vol. 1, 1988, pp. 21–28.
- [66] K. Chen, Z. Zeng, and J. Yang, “A deep region-based pyramid neural network for automatic detection and multi-classification of various surface defects of aluminum alloys,” Journal of Building Engineering, vol. 43, p. 102523, 2021.
- [67] W. Liu, Z. Wang, X. Liu, N. Zeng, Y. Liu, and F. E. Alsaadi, “A survey of deep neural network architectures and their applications,” Neurocomputing, vol. 234, pp. 11–26, 2017.
- [68] M. W. Gardner and S. Dorling, “Artificial neural networks (the multilayer perceptron)—a review of applications in the atmospheric sciences,” Atmospheric environment, vol. 32, no. 14-15, pp. 2627–2636, 1998.
- [69] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [70] A. Khan, A. Sohail, U. Zahoora, and A. S. Qureshi, “A survey of the recent architectures of deep convolutional neural networks,” Artificial intelligence review, vol. 53, no. 8, pp. 5455–5516, 2020.
- [71] C. Wang, J. Yang, L. Xie, and J. Yuan, “Kervolutional neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 31–40.
- [72] O. Abdel-Hamid, A.-r. Mohamed, H. Jiang, and G. Penn, “Applying convolutional neural networks concepts to hybrid nn-hmm model for speech recognition,” in 2012 IEEE international conference on Acoustics, speech and signal processing (ICASSP). IEEE, 2012, pp. 4277–4280.
- [73] W. Yin, K. Kann, M. Yu, and H. Schütze, “Comparative study of cnn and rnn for natural language processing,” arXiv preprint arXiv:1702.01923, 2017.
- [74] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [75] Y. Zhang, X. Wang, Y. Wang, and H. Chen, “Human activity recognition across scenes and categories based on csi,” IEEE Transactions on Mobile Computing, vol. 21, no. 7, pp. 2411–2420, 2022.
- [76] P. F. Moshiri, M. Nabati, R. Shahbazian, and S. A. Ghorashi, “Csi-based human activity recognition using convolutional neural networks,” in 2021 11th International Conference on Computer Engineering and Knowledge (ICCKE), 2021, pp. 7–12.
- [77] J. Yang, K. Wang, X. Peng, and Y. Qiao, “Deep recurrent multi-instance learning with spatio-temporal features for engagement intensity prediction,” in Proceedings of the 2018 on International Conference on Multimodal Interaction. ACM, 2018, pp. 594–598.
- [78] J. Ding and Y. Wang, “Wifi csi-based human activity recognition using deep recurrent neural network,” IEEE Access, vol. 7, pp. 174 257–174 269, 2019.
- [79] Z. Shi, J. A. Zhang, R. Xu, and Q. Cheng, “Deep learning networks for human activity recognition with csi correlation feature extraction,” in ICC 2019 - 2019 IEEE International Conference on Communications (ICC), 2019, pp. 1–6.
- [80] Z. C. Lipton, J. Berkowitz, and C. Elkan, “A critical review of recurrent neural networks for sequence learning,” arXiv preprint arXiv:1506.00019, 2015.
- [81] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- [82] S.-C. Kim and Y.-H. Kim, “Efficient classification of human activity using pca and deep learning lstm with wifi csi,” in 2022 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), 2022, pp. 329–332.
- [83] H. F. Thariq Ahmed, H. Ahmad, S. K. Phang, H. Harkat, and K. Narasingamurthi, “Wi-fi csi based human sign language recognition using lstm network,” in 2021 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT), 2021, pp. 51–57.
- [84] Z. Tang, Q. Liu, M. Wu, W. Chen, and J. Huang, “Wifi csi gesture recognition based on parallel lstm-fcn deep space-time neural network,” China Communications, vol. 18, no. 3, pp. 205–215, 2021.
- [85] R. Kadir, R. Saha, M. A. Awal, and M. I. Kadir, “Deep bidirectional lstm network learning-aided ofdma downlink and sc-fdma uplink,” in 2021 International Conference on Electronics, Communications and Information Technology (ICECIT), 2021, pp. 1–4.
- [86] N. Dua, S. N. Singh, and V. B. Semwal, “Multi-input cnn-gru based human activity recognition using wearable sensors,” Computing, vol. 103, no. 7, pp. 1461–1478, 2021.
- [87] K. Chen, L. Yao, D. Zhang, X. Wang, X. Chang, and F. Nie, “A semisupervised recurrent convolutional attention model for human activity recognition,” IEEE transactions on neural networks and learning systems, vol. 31, no. 5, pp. 1747–1756, 2019.
- [88] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [89] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [90] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [91] J. Yang, H. Zou, Y. Zhou, and L. Xie, “Robust adversarial discriminative domain adaptation for real-world cross-domain visual recognition,” Neurocomputing, vol. 433, pp. 28–36, 2021.
- [92] J. Yang, H. Zou, Y. Zhou, Z. Zeng, and L. Xie, “Mind the discriminability: Asymmetric adversarial domain adaptation,” in European Conference on Computer Vision. Springer, 2020, pp. 589–606.
- [93] Y. Xu, J. Yang, H. Cao, Z. Chen, Q. Li, and K. Mao, “Partial video domain adaptation with partial adversarial temporal attentive network,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9332–9341.
- [94] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [95] M. Kim, D. Han, and J.-K. K. Rhee, “Multiview variational deep learning with application to practical indoor localization,” IEEE Internet of Things Journal, vol. 8, no. 15, pp. 12 375–12 383, 2021.
- [96] X. Chen, H. Li, C. Zhou, X. Liu, D. Wu, and G. Dudek, “Fido: Ubiquitous fine-grained wifi-based localization for unlabelled users via domain adaptation,” in Proceedings of The Web Conference 2020, 2020, pp. 23–33.
- [97] S. J. Pan and Q. Yang, “A survey on transfer learning,” Knowledge and Data Engineering, IEEE Transactions on, vol. 22, no. 10, pp. 1345–1359, 2010.
- [98] S. Arshad, C. Feng, R. Yu, and Y. Liu, “Leveraging transfer learning in multiple human activity recognition using wifi signal,” in 2019 IEEE 20th International Symposium on ”A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), 2019, pp. 1–10.
- [99] L. Li, L. Wang, B. Han, X. Lu, Z. Zhou, and B. Lu, “Subdomain adaptive learning network for cross-domain human activities recognition using wifi with csi,” in 2021 IEEE 27th International Conference on Parallel and Distributed Systems (ICPADS), 2021, pp. 1–7.
- [100] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar et al., “Bootstrap your own latent-a new approach to self-supervised learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 21 271–21 284, 2020.
- [101] F. Wang, T. Kong, R. Zhang, H. Liu, and H. Li, “Self-supervised learning by estimating twin class distributions,” arXiv preprint arXiv:2110.07402, 2021.
- [102] O. Sagi and L. Rokach, “Ensemble learning: A survey,” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 8, no. 4, p. e1249, 2018.
- [103] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019.
- [104] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [105] S. Chen, W. Wang, and S. J. Pan, “Metaquant: Learning to quantize by learning to penetrate non-differentiable quantization,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [106] ——, “Cooperative pruning in cross-domain deep neural network compression.” in IJCAI, 2019, pp. 2102–2108.
- [107] J. Hu, J. Yang, J. Ong, and L. Xie, “Resfi: Wifi-enabled device-free respiration detection based on deep learning,” in 2022 IEEE 18th international conference on control and automation (ICCA). IEEE, 2022.
- [108] J. Yang, H. Zou, S. Cao, Z. Chen, and L. Xie, “Mobileda: Toward edge-domain adaptation,” IEEE Internet of Things Journal, vol. 7, no. 8, pp. 6909–6918, 2020.
- [109] M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning. PMLR, 2019, pp. 6105–6114.
- [110] M. H. Kefayati, V. Pourahmadi, and H. Aghaeinia, “Wi2vi: Generating video frames from wifi csi samples,” IEEE Sensors Journal, vol. 20, no. 19, pp. 11 463–11 473, 2020.
- [111] F. Wang, S. Zhou, S. Panev, J. Han, and D. Huang, “Person-in-wifi: Fine-grained person perception using wifi,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5452–5461.
- [112] J. Liu, N. Akhtar, and A. Mian, “Adversarial attack on skeleton-based human action recognition,” IEEE Transactions on Neural Networks and Learning Systems, 2020.
- [113] S. Zhou, W. Zhang, D. Peng, Y. Liu, X. Liao, and H. Jiang, “Adversarial wifi sensing for privacy preservation of human behaviors,” IEEE Communications Letters, vol. 24, no. 2, pp. 259–263, 2019.