Semi-supervised Contrastive Learning with Similarity Co-calibration
Abstract
Semi-supervised learning acts as an effective way to leverage massive unlabeled data. In this paper, we propose a novel training strategy, termed as Semi-supervised Contrastive Learning (SsCL), which combines the well-known contrastive loss in self-supervised learning with the cross entropy loss in semi-supervised learning, and jointly optimizes the two objectives in an end-to-end way. The highlight is that different from self-training based semi-supervised learning that conducts prediction and retraining over the same model weights, SsCL interchanges the predictions over the unlabeled data between the two branches, and thus formulates a co-calibration procedure, which we find is beneficial for better prediction and avoid being trapped in local minimum. Towards this goal, the contrastive loss branch models pairwise similarities among samples, using the nearest neighborhood generated from the cross entropy branch, and in turn calibrates the prediction distribution of the cross entropy branch with the contrastive similarity. We show that SsCL produces more discriminative representation and is beneficial to few shot learning. Notably, on ImageNet with ResNet50 as the backbone, SsCL achieves and top-1 accuracy with and labeled samples, respectively, which significantly outperforms the baseline, and is better than previous semi-supervised and self-supervised methods.
1 Introduction

Semi-supervised learning(SSL) has attracted more attention over the past years, as it allows for training network with limited labeled data to improve the model performance with the availability of large scale unlabeled data[1, 2, 19, 21, 24, 35]. A general pipeline of SSL is based on pseudo-labeling and consistency regularization[1, 19, 26]. The key idea is to train the model with limited labeled data and predict the pseudo labels for the unlabeled samples. In this pipeline, the images with high-confidence prediction are selected for retraining, using either one-hot hard labels or the predicted distribution of soft labels. In order to avoid homogenization in SSL, i.e., predicting and retraining with the same samples, data augmentation is widely used, and has been demonstrated to be particularly effective when combined with consistency regularization, which penalizes the discrepancy between different augmentations of the same samples. In SSL, the network is usually optimized by minimizing the cross entropy loss between the prediction and the target distribution as fully supervised learning. However, as pointed out by [27, 37], such cross entropy loss is not robust to noisy labels, which is inevitable in semi-supervised learning. This is especially true for large scale dataset such as ImageNet, where limited labeled samples cannot represent the specific class properly, and cross entropy based semi-supervised methods [2, 21, 26, 35] suffer limited performance gain.
On the other hand, recent advances in self-supervised learning have demonstrated powerful performance in semi-supervised learning scenarios, especially with the achievements of contrastive learning [12]. In this setting, the model is first pretrained with large scale unlabeled data, and then fine-tuned with few shot labeled samples. In the pretraining stage, a typical solution is to treat each image as well its augmentations as a separate class, and the features among different transformations of an image are pulled closer together, while all other instances are treated as negatives and pushed away. However, due to the lack of labels, the self-supervised pretraining stage is task agnostic, which is not optimal for specific tasks.
In this paper, we propose a novel training strategy that incorporates contrastive loss into semi-supervised learning, and jointly optimize the two objectives in an end-to-end way. The motivation is that it should be better for specific task when we incorporate class specific priors into the contrastive pretraining stage, and hope that the two different feature learning strategies would benefit each other for better representation. Towards this goal, we introduce a co-calibration mechanism to interchange predictions between the two branches, one branch based on cross entropy loss and the other based on contrastive loss. In particular, the pseudo labels generated from the cross entropy loss term are used to search for nearest neighbors for contrastive learning, while the similarity embedding learned by the contrastive term is used in turn to adjust the prediction in the pseudo labeling branch. In this way, the information between the two branches is interflowed, which is complementary with each other and thus avoid being trapped in the local minimum course by self-training.
In order to facilitate co-calibration between the two branches, we extend the contrastive loss [12] to allow for multiple positive samples during each forward propagation, and pulling samples that are similar to the specified class prototype for discriminative representation. In order to tackle the noisy samples especially at the initial training stage, we propose a self-paced learning strategy that adaptively adjusts the loss that the mined samples belonging to the assigned class. In this way, the model is gradually evolving as the similarity computation becomes more accurate. Furthermore, in order to avoid the biased representation of each class with limited labeled data, we introduce a data mix strategy to enrich samples of each class. Specifically, we periodically select similar samples during the semi-supervised learning process, and apply data mixing [36] operation over the randomly selected two samples from the ground truth and similar sample pools, respectively. In this way, we are able to enrich the class specific samples in a robust and smooth way.
Integrating contrastive loss into semi-supervised learning produces a much more powerful framework, and experiments demonstrate that the enriched representation is beneficial for data mining and results in improved representation. Notably, using a standard ResNet-50 as the backbone, we achieve and top-1 accuracy on the large scale ImageNet dataset with and labeled samples, respectively, which consistently surpasses the semi-supervised and self-supervised methods.
2 Related Work
Our approach is most related with recent advances covering semi-supervised learning and self-supervised learning. We briefly review related works and clarify the differences btween them and our method.
Semi-supervised Learning
makes uses of few shot labeled data in conjunction with a large number of unlabeled data[2, 11, 17, 18, 22, 26, 24, 29]. Pseudo labeling is a widely used method in early works, which uses the predictions of the model to label images and retain the model with these predictions [19, 1]. Then [26] combines consistency regularization and pseudo-labeling to align the predictions between weakly and strongly augmented unlabeled images. S4L[35] is the first unified work that combines self-supervised learning with semi-supervised learning. As to our approach, we not only use pseudo labeling method to build a part of our loss function, but also lets the pseudo label play an important role in our multi-positive contrastive learning, and contrastive learning representations will also help the model obtain more accurate pseudo labels.
Contrastive Learning
in recent works mainly benefits from instance discrimination[31], which regards each image and its augmentations as one separate class and others are negatives [12, 5, 9, 7, 15, 23, 30, 10]. [31] use a memory bank to store the pre-computed representations from which positive examples are retrieved given a query. Based on it, [12] used a momentum update mechanism to maintain a long queue of negative examples for contrastive learning, while [5] used a large batch to produce enough negative samples. These works prove that contrastive learning reaches better performance on learning characteristics of data. Previous contrastive based semi-supervised learning works are almost two-stage ones, i.e., using contrastive learning to pretrain a backbone and then using few shot labeled data to fine-tune it. In contrast, our method trains the model in an end-to-end way, which is able to better make use of the advantages of the features learned by different loss functions and class specific priors.

3 Method
We first give an overview of the proposed Semi-supervised Contrastive Learning framework. SsCL includes a combination of two well-known approaches, i.e, the pseudo labeling strategy with cross entropy loss, and the instance discrimination with contrastive loss. The highlight is that we jointly optimize the two losses with a shared backbone in an end-to-end way, and importantly, the pseudo labels between the two branches are calibrated in a co-training mechanism, which we find is beneficial for better prediction over the unlabeled data.
Specifically, denote as a batch of B labeled samples, where denotes labels, and as a batch of unlabeled samples, where determines the relative size of and . represents a random data augmentation conducted over an image. Overall, SsCL targets at optimizing three losses: 1) the supervised loss optimized over the labeled data; 2) the pseudo labeling loss penalized on the unlabeled data and 3) the contrastive loss that enforces pairwise similarity among neighborhood samples. The whole framework is shown in Fig. 2, and we omit the supervised loss term for brevity.
The supervised loss is simply conducted over the labeled data with cross-entropy minimization, using the ground truth labels :
| (1) |
Similarly, the pseudo labeling loss is penalized over the unlabeled data , using the pseudo labels :
| (2) |
where denotes the model’s prediction on the unlabeled samples, which is obtained by calibrating the pseudo labels predicted from the cross entropy loss term with similarity distribution from the contrasstive loss term, and will be elaborated in the following section. is an indicator function and we only retain whose largest class probability is above a certain threshold for optimization.
For contrastive loss, different from [12], we adjust the contrastive loss term to allow for multiple positive samples during each forward propagation so that similar images that belong to the corresponding class prototype are pulled together for more discriminative representation. We defer the definition of contrastive loss term in the following section. The overall losses can be formulated as:
| (3) |
where and are the balancing factors that control the weights of the two losses. In the following, we describe the terms and in detail and elaborate the similarity co-calibration procedure among the two branches.
3.1 Pseudo Label Calibration with Contrastive Similarity
For conventional semi-supervised learning with cross entropy loss, the pseudo label of an unlabeled sample is simply derived by predicting distribution on using the current model, and enforces the cross-entropy loss against the model’s output for in the following training procedure. However, the pseudo labeling and re-training is conducted over the same network, which suffers from model homogenization issue and is easy to be trapped in local minimum. In this section, we propose a pseudo label calibration strategy that refines the prediction via the similarity distribution from the contrastive loss term.
Similarity Distribution
The similarity distribution over the classes is obtained as follows. Given a list of few shot labeled samples for class , we compute the feature representation of with current encoder where . The feature representation of class is simply obtained by averaging the features, i.e., , where is a normalizing constant value. Given an unlabeled sample with normalized feature , we can get its cosine similarity distribution with predefined prototypes, where denotes the similarity between (, ).
Inspired by [2], we introduce a form of fairness prediction by maintaining a running average of distribution (average vector of over the last batches, here we simply set ) over the course of training. Overall, can be treated as a global adjustment among the scores for each class, and thus avoid biased prediction that conducting over a single image . Then the calibration is simply conducted by scaling with and then re-normalizing to form a valid probability distribution . We use as calibrated pseudo labels for optimization following Eq. 2.
Prototype Refinement
The similarity distribution requires a predefined class specific prototype generated by the few labeled samples, and each prototype is simply computed using the available ground truth labels belonging to class . However, this representation is easily biased to the few shot samples, which is insufficient to model the real distribution. To solve this issue, we propose a prototype mixture strategy to refine the feature representation of each class in a robust way. The new samples are generated via a simple mixup [36] operation, conducted between the mined samples and those with ground truth labels. In this way, based on the continuity of feature space, we are able to ensure that the generated samples do not drift away too much from the real distribution of that class, while enriching the feature representation in a robust way. Specifically, given the few shot labeled sample set for class and a list of nearest neighborhood unlabeled samples that belong to class , we randomly select a ground truth sample , and a nearest sample , and mix them to generate a new sample :
| (4) |
where is the combination factor and is sampled from beta distribution Beta with parameter . In our implementation, we simply set , and will be added to only use for calculating prototype for class . The purpose of this step is to smooth the noise caused during the sample selection process. We visualize the benefits of this step in Fig. 3. Benefiting from the mixed samples, the feature representation is refined to better represent the class prototype. In the experimental section, we would validate its effectiveness.

3.2 Contrastive Learning with Pseudo Label Propagation
In contrastive learning, the positive samples are simply constrained within a single image with different data transformations, and all other images are treated as negatives and pushed away. In this section, we incorporate the few shot labeled priors into contrastive learning, and target at pursuing more discriminative representation with the help of the mined samples from the pseudo labeling branch. Specifically, we extend the original contrastive learning loss in [12] and pull the mined samples closer together with the predefined prototypes. Benefiting from the class specific priors, the feature representation is more discriminative, which is beneficial for semi-supervised learning that encourages class separability and better representation.
Loss Function
In order to efficiently make use of the unlabeled samples in a robust way, inspired by [28], we adjust the original contrastive loss from [12] in three aspects. First, we extend it to allow for multiple positives for each forward propagation; second, we introduce a margin value which enforces class separability for better generalization, which we find is robust for data mining; third, considering that the mined samples may not be reliable, especially during the initial training stages, we introduce a soften factor for each mined positive sample, and adaptively penalize the discrepancy according to its similarity to the corresponding class. For ease of expression, we make a deformation of original contrastive loss by using to represent the similarity of positive samples while represents the similarity of negative samples, and denote . After introducing margin and soften factor , the loss can be reformulated as:
| (5) |
Designed with the above three properties, the loss is well suited for semi-supervised learning. In the following, we would analyze its advantages in detail.
Positive Sample Selection
For this branch, the positive samples are simply selected from the pseudo label loss branch. Specifically, given an unlabeled sample with pseudo labels , which is predicted by the layers of the cross entropy term. We assign it to class if , denoting that this sample is most similar with class . Then we pulled together with those samples that have ground truth label . In this way, the unlabeled samples are pulled towards the specific instances corresponding to that class, and the representation is more compact. In practice, all the positive samples are maintained in the key encoder . Benefit from the moment contrast mechanism in MoCo[12], the encoder is asynchronously updated and add more positive keys doesn’t increase the computation complexity.
Self-paced Weighting Mechanism
A critical issue when using cosine similarity for positive sample selection is that at the initial training stages, the model is under-fitted, and the accuracy of using the nearest neighbor is very low. As a result, the incorrect positive samples would be assigned to a class, causing the model to update in the wrong direction, which is harmful for generalization. To solve this issue, we propose a self-paced learning method to enhance the optimization flexibility and it is robust to the noisy samples. This is achieved by assigning each selected positive sample a weight factor , which is determined by the similarity between the current sample and the predefined most similar class prototype. It is equivalent to adding a penalty term to the loss function, and with the increased accuracy of positive sample selection, the penalty becomes larger, and in turn enforces the compact representation.
Analysis of Our Loss Function
We now step deep into the optimization objective Eq. (3.2) to better understand its properties. Towards this goal, we first make some approximate transformations using the following formulations:
| (6) | ||||
| (7) | ||||
| (8) |
From above formulas, we can transform the Eq. (3.2) to:
| (9) |
The specific derivation process will be shown in the Supplementary. From the above equations, we have the following observations: (1) According to Eq. (10), the objective is to optimize the upper bound of positive pairs and lower bound of negative pairs, and introducing of makes this process more flexible; (2) Based on the properties of Eq. (6) and Eq. (7), whose gradient is the function, the positive and negative pairs obtain equal gradient, regardless of the number of positive and negative sample pairs. This gradient equilibrium ensures the success of our multi-positive sample training.
4 Experiment
In this section, we evaluate our method on several standard image classification benchmarks, including CIFAR-10[AlexLearning2009] and ImageNet[2009ImageNet] when few shot labels are available. We also evaluate our representations by transferring to downstream tasks.
For the contrastive branch, we make use of two encoders follow [12], one for training(named as ) and the other one for momentum update (named as ) to produce negative keys. For prediction co-calibration, the contrastive similarity is computed via features obtained by and the prediction on unlabeled data is achieved by the head. For efficiency, we conduct these operations offline, and update the pseudo labels (for selecting positive samples) and prototype for each category every 5 epochs during the training process. We find that the results are robust as the update frequency ranges from 1 to 20. Besides, in practice, the similarity computation and pseudo label inference can be done within only a few minutes, and brings about negligible costs comparing with the contrastive learning iteration.
As for prototype refinement, we periodically update the feature representation of each class using the mixed samples for every epochs, the same frequency as the similarity computation, and add fixed number of samples to each class. The number of samples is simply set equal to the labeled number of each class, hoping that the mixed samples do not overwhelm the ground truth samples, and we find that the result is robust for a range of mixed samples when they are at the same scale with the ground truth labels.
4.1 CIFAR-10
We first compare our approach with various methods on CIFAR-10, which contains 50000 images with size of 32 32. We conduct the experiments with different number of available labels, and each setting is evaluated on 5 folds.
Implementation Details
As recommended by [26], we use Wide ResNet-28-2[34] as backbone, as well as training protocol, , , , and all loss weights (e.g. ) are set as 1. The projection head is a 2-layer MLP that outputs 64-dimensional embedding. The models are trained using SGD with a momentum of 0.9 and a weight decay of 0.0005. We train our model for 200 epochs, using learning rate of 0.03 with a cosine decay schedule. For the additional hyperparamaters, we set the number of negative samples , . Besides, we use two different augmentations on unlabeled data, The here is the standard crop-and-flip, and we use RandAugment[8] combined with the augmentation strategy in [5] as our another augmentation . More details about hyperparameters will be shown in Supplementary.
| CIFAR-10 | |||
| Method | 40 labels | 250 labels | 4000 labels |
| -model | - | ||
| Pseduo-Labeling | - | ||
| Mean Teacher | - | ||
| MixMatch | |||
| UDA | |||
| ReMixMatch | |||
| FixMatch w.RA | 5.07 0.65 | 4.26 0.05 | |
| SsCL | 10.29 2.61 | 5.12 0.41 | |
| 1% labels | 10% labels | ||||
| Method | epochs | top-1(%) | top-5(%) | top-1(%) | top-5(%) |
| Supervised | 20 | 25.4 | 48.4 | 56.4 | 80.4 |
| Semi-supervised Based Method | |||||
| Pseudo-label[19] | 100 | - | 51.6 | - | 82.4 |
| VAT[21] | - | - | 47 | - | 83.4 |
| UDA[33] | - | - | - | 68.8 | 88.5 |
| Fixmatch(w. RA)[26] | 400 | - | - | 71.5 | 89.1 |
| S4L-Rotation[35] | 200 | - | - | 53.4 | 83.8 |
| Self-supervised Based Method | |||||
| PIRL[16] | 800 | 30.7 | 57.2 | 60.4 | 83.8 |
| simCLR[5] | 1000 | 48.3 | 75.5 | 65.6 | 87.8 |
| MoCo v2[7] | 800 | 52.4 | 78.4 | 65.3 | 86.6 |
| BYOL[10] | 1000 | 53.2 | 78.4 | 68.8 | 89.0 |
| SwAV[4] | 800 | 53.9 | 78.5 | 70.2 | 89.9 |
| simCLR v2[6] | 800 | 57.9 | 82.5 | 68.4 | 89.9 |
| Semi-supervised Contrastive Learning | |||||
| SsCL | 200 | 54.7 | 79.3 | 70.0 | 89.8 |
| SsCL | 800 | 60.2 | 82.8 | 72.1 | 90.9 |
Result
We report the result of different labels settings with our method in Table 1, and compare with some well-known approaches. The improvement is more substantial when fewer labeled samples are available. We achieve error rate with only 40 labels, which is 3.5% better than the previous best performed method Fixmatch[26] with more robust capability.
4.2 ImageNet
In this section, we evaluate our method on the large scale ImageNet dataset, which is challenging especially when extremely few shot labels are available. Following previous semi-supervised learning works on ImageNet [5, 6, 12], we conduct experiments with and labels for semi-supervised learning, using the same split of available labels for fair comparisons. Besides, different from the previous contrastive learning based methods that first conduct pretraining and then followed by few shot fine tuing, our method is an end-to-end framework.
Implementation Details
For model training, we use ResNet-50[14] as the backbone, and use the SGD optimizer with weight decay of 0.0001 and momentum as 0.9. The model is trained on 32 Tesla V100 GPUs with batch size of 1024 for unlabeled data and 256 for labeled data, and the initial learning rate is 0.4 with cosine decay schedule. The data augmentation follows the same strategy as [5]. More hyperparameters details are shown in Supplementary.
Result
We compare our method with several well-known semi-supervised learning approaches, which can be roughly categorized into two aspects,, i.e., the conventional semi-supervised learning strategy that makes use of cross entropy loss for data mining, as well as contrastive learning based methods that first pre-train the models without using any image-level labels, followed by directly fine-tuning with few shot labeled data. As shown in Table 2, We achieve top-1 accuracies of and with and labeled data, respectively, which significantly improves the baseline MoCo v2 [7]. Under setting, our method is also better than previous best performed method simCLR v2. It should be noted that simCLR v2 [6] makes use of extra tricks such as more MLP layers, which has been demonstrated to be effective for semi-supervised learning, while we simply follow the MoCo v2 baseline that makes use of two MLP layers. Under setting, our method is better than the previous best performed Fixmatch in top-1 accuracy, and higher in top-5 accuracy. We also find that previous semi-supervised works rarely report accuracy with labels due to their poor performance. The reason is that the extremely few labeled data is too biased to represent the corresponding class, and such error can be magnified during the data mining procedure using cross entropy loss, while our method is robust to the bias, and especially effective when few shot labels are available.
| Method | Mask R-CNN, R50-FPN, Detection | |||||
| schedule | ||||||
| APbb | AP | AP | APS | APM | APL | |
| Supervised | 38.9 | 59.6 | 42.0 | 23.0 | 42.9 | 49.9 |
| MoCo v2 [7] | 39.2 | 59.9 | 42.7 | 23.8 | 42.7 | 50.0 |
| Ours 10% | 40.0 | 61.6 | 43.4 | 23.9 | 43.9 | 51.7 |
| SwAV | Deepcluster v2 | Ours 1% | Ours 10% | |
| intra-class | 0.46 | 0.43 | 0.54 | 0.63 |
| Pseudo label acc. | Nearest class acc. | Overlap | w. | w/o. |
| 53.2% | 45.3% | 60.1% | 50.8% | 48.4% |
4.3 Downstream Tasks
We further evaluate our learned representation on downstream object detection task to uncover the transferability. Following [12], we choose Mask R-CNN[13] with FPN[20] as the backbone, and fine-tune all the parameters on the training set, then evaluate it on the validation set of COCO 2017. We report our performance under 1 schedules in Table 3. It can be seen that our method consistently outperforms the supervised pretrained model and MoCo v2.
4.4 Study and Analysis
We give an in-depth analysis of our design for semi-supervised contrastive learning, and demonstrate the benefits of them through comparative experiments. Unless specified, the results are based on ImageNet with 1% labels training for 100 epochs.
Distinguish with clustering method
Our approach targets at pulling nearest class samples together with calculated prototypes, this is similar to the idea of some clustering based methods. So we use intra-class similarity as an indicator to measure our learned features. We compare our method with two classic clustering-based learning methods, SwAV[4] and Deepcluster v2 [3], and the results are shown in Table 4. The intra-class similarity is calculated by averaging cosine distance among all intra-class pairwise samples, and we report the average of 1000 classes on the ImageNet validation set. Our method consistently outperforms these two methods both in 1% and 10% labels available, which validates that it is better for discrimination when more class priors are available.
Co-calibration helps for better representation
Table 5 provides some interesting results. If we use pretrained backbone and head to predict unlabeled training data, we can get top-1 accuracy of 53.2%, while the accuracy drops to 45.3% if we use the nearest class in feature space as its label. However, the overlap of their correct prediction is only 60.1%, in another word, most of the labels that one method predicts wrong are correct in another method, which is the motivation of our co-calibration mechanism. We believe this will help the model learn complementary information during training, and it can be seen that our method gains 2.4% benefits with this operation.

Prototype mixture helps for better prediction
We calculate the average accuracy of the training samples which can get the correct positive samples by assigning the nearest category before and after adding the mixture module. The results are shown in Fig. 5. We can see that this module brings about 8% accuracy improvement at most. In addition, the model with prototype mixture always keeps high accuracy in selecting positive samples, and more correct positive samples are undoubtedly beneficial to improve the performance.
5 Ablation study
In this section, we conduct detailed ablation studies to inspect how each hyperparamater affects the performance. For efficiency, unless specified, all experiments are conducted with 100 epochs using a randomly selected subset of 100 categories in ImageNet with 1% labels. We report top-1 accuracy in each experiment, where we achieve 63.3% with our default settings. Besides, We also re-implement MoCo v2[7], using it as our under this setting as our baseline for fair comparisons.
5.1 Hyper-parameters of Loss Function
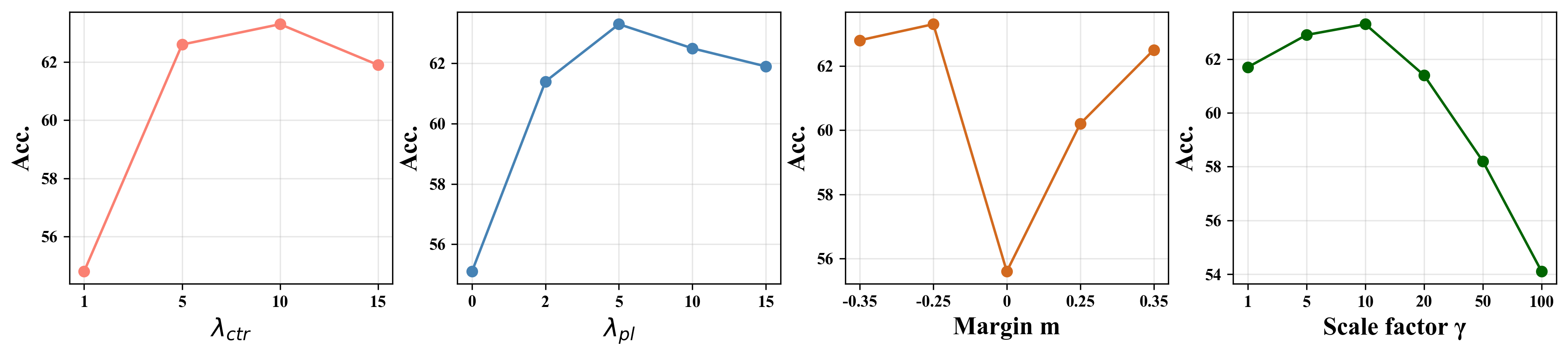
We first analyze the impact of several hyper-parameters, which includes pseudo label loss weight , contrastive loss weight , scale factor , weight factor and the margin value .
The scale factor
Loss weight
We observe the influence of two weights and on the performance and report the result in the Figure 4, where and gives the best performance. But in the 10% labels setting, we need to increase the to 10 and decrease the to 5 to get the best result. We think it is because the fewer labeled data, the worse the performance on predicting pseudo labels, which need a larger to strengthen the contrastive regularization.
The weight factor
The comparison results of introducing are shown in Table 6. It can be seen that introducing adaptive weight is beneficial for improving classification accuracy. It brings about gains with fixed (set as 1). This is mainly due to the reason that assigns a lower penalty to the positive samples that are less similar to the assigned class, which reduces the influence of these relatively noisy samples during model training.
The margin value
Inspired by [32], we set as negative because the pseudo labels are not always correct during training. Figure 4 shows the result of different settings, we observe that both positive and negative margins can improve the quality of learned features, so it is beneficial to design a less stringent decision boundary for better class separability.
| Method | Accuracy(%) | |
| top-1 | top-5 | |
| w/o | 58.4 | 81.2 |
| w/ | 63.3 | 85.7 |
| Number | 0 | 2 | 3 | 4 |
| Top-1 Acc.(%) | 56.9 | 62.7 | 63.3 | 62.8 |
5.2 The Number of Positive Samples
6 Conclusion
This paper proposed a semi-supervised contrastive learning framework, which incorporates contrastive loss into semi-supervised learning, and jointly optimizes the network in an end-to-end way. The main contribution is that we introduce a co-calibration mechanism to interchange predictions between the two branches, which we find is complementary and thus avoid trapped in local minimum. Experiments conducted on several datasets demonstrate the superior performance of the proposed method, especially when extremely few labeled samples are available.
Appendix A Appendix
A.1 More Detail in Training Process
Hyperpatrameters Detail.
Here we provide a complete list of the hyperparameters we use in our experiment in Table 8. Note that we did ablation studies for some of these parameters in previous sections, including loss weight and , scale factor and margin , As to other parameters we just follow the settings in previous works[26, 12].
Derivation Process of Loss Function.
Here we provide the specific derivation process of our loss function corresponding to Eq. (9) in the text. The details are shown in the following:
| (10) |

Appendix B Transfer Learning
We evaluated the quality of our representation for transfer learning in two settings: linear evaluation, where a logistic regression classifier is trained to classify a new dataset based on the representation learned by ScCL on ImageNet, and fine-tuning, where we allow all weights to vary during training. In both cases, we follow the settings of [5, 2019Revisiting].
B.1 Dataset
We use four tiny scale dataset in this experiment, including CIFAR-10/100[AlexLearning2009], FGVC Aircraft[maji2013fine] and Standford Cars[krause2013collecting]. We report top-1 accuracy for these datasets with our 10% labels 800 epochs pre-trained model.
B.2 Implemental Detail
For linear evaluation, we simply follow the settings used in moco v2[7], where learning rate is set in 30 and training for 100 epochs. While in the fine-tuning task, we use the SGD optimizer to fine-tune all network parameters. The learning rate is set as for backbone and for the classifier, and the total epoch is 120 in the second stage and the learning rate is decayed by 0.1 in 50,70 and 90 epoch.
| B | K | |||||||
| CIFAR-10 | 1 | 1 | 64 | 4 | 4096 | 0.95 | 5 | -0.25 |
| ImageNet-1% | 10 | 5 | 64 | 4 | 65536 | 0.6 | 10 | -0.25 |
| ImageNet-10% | 5 | 10 |
B.3 Baseline
We compare our approach with the supervised and unsupervised method. The supervised method is trained on ImageNet with standard cross-entropy loss, while we use well-known methods simCLR[5] and MoCo v2[7] as our unsupervised baseline. Their result are all taken from [5] except for MoCo v2, which is based on our re-implementation. Besides, in the fine-tuning task, we add a setting by training a model from random initialization for comparison.
B.4 Result
It can be seen from Table LABEL:t:transfer that the supervised method has a clear advantage over self-supervised and semi-supervised training in linear evaluation. By introducing more label prior information, which is beneficial for the separation of representation, we outperform the self-supervised based method on almost all datasets with both linear evaluation and fine-tuning task. Besides, we achieve superior performance to the supervised method in almost all datasets with fine-tuning, which also demonstrates the transfer ability of our model.
Appendix C Visualization of Feature Representation
We visualize the embedding feature to better understand the advantage of our semi-supervised contrastive training method. We randomly choose ten classes from the validation set and provide the visualization of feature representation generated by ScCL, supervised training and MoCo v2[12]. The results are shown in Figure 6, the same color denotes features with the same label. It can be seen that ScCL takes on higher aggregation property compared with MoCo v2, and is slightly worse than the supervised method because it makes use of all labels.
References
- [1] Eric Arazo, Diego Ortego, Paul Albert, Noel E O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation bias in deep semi-supervised learning. In 2020 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2020.
- [2] David Berthelot, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Kihyuk Sohn, Han Zhang, and Colin Raffel. Remixmatch: Semi-supervised learning with distribution alignment and augmentation anchoring. arXiv preprint arXiv:1911.09785, 2019.
- [3] Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual featrues. 2018.
- [4] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. 33, 2020.
- [5] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
- [6] Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, and Geoffrey Hinton. Big self-supervised models are strong semi-supervised learners. arXiv preprint arXiv:2006.10029, 2020.
- [7] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
- [8] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 702–703, 2020.
- [9] Alexey Dosovitskiy, Philipp Fischer, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. Discriminative unsupervised feature learning with exemplar convolutional neural networks. 38(9):1734–1747, 2015.
- [10] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. 33, 2020.
- [11] Matthieu Guillaumin, Jakob Verbeek, and Cordelia Schmid. Multimodal semi-supervised learning for image classification. In 2010 IEEE Computer society conference on computer vision and pattern recognition, pages 902–909. IEEE, 2010.
- [12] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
- [13] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
- [14] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. 2016.
- [15] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation and maximization. arXiv preprint arXiv:1808.06670, 2018.
- [16] Misra Ishan and van der Maaten Laurens. Self-supervised learning of pretext-invariant representations. 2020.
- [17] Longlong Jing and Yingli Tian. Self-supervised visual featrue learning with deep neural networks: A survey. 2020.
- [18] Durk P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, and Max Welling. Semi-supervised learning with deep generative models. 27:3581–3589, 2014.
- [19] Dong-Hyun Lee. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML, volume 3, 2013.
- [20] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- [21] Takeru Miyato, Shin Ichi Maeda, Masanori Koyama, and Shin Ishii. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. 41(8):1979–1993, 2019.
- [22] Avital Oliver, Augustus Odena, Colin A Raffel, Ekin Dogus Cubuk, and Ian Goodfellow. Realistic evaluation of deep semi-supervised learning algorithms. pages 3235–3246, 2018.
- [23] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- [24] Antti Rasmus, Mathias Berglund, Mikko Honkala, Harri Valpola, and Tapani Raiko. Semi-supervised learning with ladder networks. pages 3546–3554, 2015.
- [25] Mehdi Sajjadi, Mehran Javanmardi, and Tolga Tasdizen. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. pages 1163–1171, 2016.
- [26] Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. arXiv preprint arXiv:2001.07685, 2020.
- [27] Sainbayar Sukhbaatar, Joan Bruna, Manohar Paluri, Lubomir Bourdev, and Rob Fergus. Training convolutional networks with noisy labels. arXiv preprint arXiv:1406.2080, 2014.
- [28] Yifan Sun, Changmao Cheng, Yuhan Zhang, Chi Zhang, Liang Zheng, Zhongdao Wang, and Yichen Wei. Circle loss: A unified perspective of pair similarity optimization. In CVPR, pages 6398–6407, 2020.
- [29] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. pages 1195–1204, 2017.
- [30] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. arXiv preprint arXiv:1906.05849, 2019.
- [31] Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. pages 3733–3742, 2018.
- [32] Jiahao Xie, Xiaohang Zhan, Ziwei Liu, Yew Soon Ong, and Chen Change Loy. Delving into inter-image invariance for unsupervised visual representations. arXiv preprint arXiv:2008.11702, 2020.
- [33] Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V Le. Unsupervised data augmentation for consistency training. arXiv preprint arXiv:1904.12848, 2019.
- [34] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. In British Machine Vision Conference 2016. British Machine Vision Association, 2016.
- [35] Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S4l: Self-supervised semi-supervised learning. pages 1476–1485, 2019.
- [36] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. 2018.
- [37] Zhilu Zhang and Mert Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. pages 8778–8788, 2018.