Semi-supervised Chinese Poem-to-Painting Generation via Cycle-consistent Adversarial Networks
Abstract
Classical Chinese poetry and painting represent the epitome of artistic expression, but the abstract and symbolic nature of their relationship poses a significant challenge for computational translation. Most existing methods rely on large-scale paired datasets, which are scarce in this domain. In this work, we propose a semi-supervised approach using cycle-consistent adversarial networks to leverage the limited paired data and large unpaired corpus of poems and paintings. The key insight is to learn bidirectional mappings that enforce semantic alignment between the visual and textual modalities. We introduce novel evaluation metrics to assess the quality, diversity, and consistency of the generated poems and paintings. Extensive experiments are conducted on a new Chinese Painting Description Dataset (CPDD). The proposed model outperforms previous methods, showing promise in capturing the symbolic essence of artistic expression. Codes are available online https://github.com/Mnster00/poemtopainting.
Index Terms:
single image super-resolution, low-level computer vision, deep learningI Introduction
Classical Chinese poetry and painting represent an important part of the world’s cultural heritage, offering a window into ancient Chinese aesthetics, philosophy, and values. The interplay between these two art forms has fascinated artists and scholars for centuries, with paintings often inspired by and embodying the imagery and sentiments expressed in poems. Generating pictorial illustrations of classical Chinese poetry, therefore, presents an intriguing challenge for computational creativity.
The primary characteristic of classical Chinese poetry is highly symbolic and abstract language, where the poet often seeks to evoke a mood or convey a profound meaning through succinct and vivid imagery. This is in contrast to the more descriptive style of most existing datasets used for text-to-image synthesis, such as MSCOCO [1] and CUB [2]. The artistic style and visual elements in classical Chinese paintings are also quite distinct from photorealistic images. As such, directly applying models trained on natural images and descriptions to the poem-to-painting domain yields unsatisfactory results, as they fail to capture the implicit alignment of abstract concepts.
Another significant challenge is the lack of large-scale paired training data. While millions of poems and paintings from ancient China are preserved, the number of poems with explicitly corresponding paintings is quite limited. Most existing cross-modal translation approaches rely on supervised learning from paired data, which is infeasible in this low-resource setting. There is a need for techniques that can effectively learn from both the small number of paired examples and the larger unpaired corpus.

To address these challenges, we propose a semi-supervised framework for classical Chinese poem-to-painting translation using cycle-consistent adversarial networks. Our approach is inspired by unsupervised image-to-image translation [3], which learns bidirectional mappings to enforce cycle consistency. As shown in Fig.1, we extend this idea to the cross-modal setting by introducing poem and painting encoders that map into a shared semantic space, and corresponding generators that decode from this space. The encoders and generators are trained with both adversarial and cycle consistency losses, ensuring that the generated paintings and poems are realistic and faithful in reconstruction. The use of a shared latent space encourages the network to learn a semantic alignment between the visual and textual modalities.
To our knowledge, ours is the first work to explore semi-supervised poem-to-painting translation with explicit cycle consistency. The main contributions are summarized as follows:
-
•
We propose a semi-supervised framework for Chinese poem-to-painting translation using cycle-consistent adversarial networks, which enables the joint learning from both paired and unpaired data.
-
•
We introduce several novel evaluation metrics to assess the quality, diversity, and semantic consistency of the generated poems and paintings, drawing insights from human artistic evaluation.
-
•
We contribute a new Chinese Painting Description Dataset, providing a valuable resource for research on artistic cross-modal translation.
-
•
Extensive experiments on the proposed dataset demonstrate the superiority of our approach against previous methods in generating high-quality, diverse, and semantically meaningful poem-painting pairs.
II Related works
Significant progress has been made in text-to-image and image-to-text translation in recent years, driven by advances in deep learning and generative models. In this section, we review most relevant works to our proposed approach for poetry and painting generation.
II-A Image-to-text translation
Image-to-text translation aims to generate natural language descriptions from visual input. Early approaches relied on template-based methods that filled in handcrafted templates with detected visual concepts [4, 5, 6]. More recently, deep learning models have achieved significant progress by learning the mapping between images and text in an end-to-end manner [7, 8, 9].
Encoder-decoder architectures have emerged as a popular choice for image-to-text translation, where convolutional neural networks (CNNs) are employed to encode the image into dense feature vectors, and recurrent neural networks (RNNs) are used to decode these features into word sequences [7]. The incorporation of attention mechanisms has further enhanced the performance of these models by enabling them to selectively focus on relevant image regions when generating each word [8]. Hierarchical approaches have also been proposed to decompose the generation process into multiple stages, such as first predicting a semantic layout and then filling in the details [10, 11, 12]. Additionally, adversarial training techniques have been explored to improve the naturalness and diversity of the generated captions [13].
Beyond generating purely descriptive captions, some works have explored more artistic and stylized text generation from images, such as composing poetry [14, 15] or generating stylized captions [16, 17]. However, these approaches often rely on paired image-text datasets for fully-supervised training, which limits their applicability to niche domains like classical Chinese art where such paired data is scarce. To address this limitation, unsupervised or weakly-supervised approaches that can learn from unpaired image and text data have gained attention in recent years [18]. These methods typically employ techniques such as cycle consistency [3] or adversarial alignment [19] to bridge the gap between the visual and textual domains, enabling the generation of stylized or artistic descriptions even in the absence of paired training data.
II-B Text-to-image generation
Text-to-image generation aims to synthesize images from natural language descriptions. Generative adversarial networks (GANs) [20, 21, 22] revolutionized this field, enabling the generation of realistic images conditioned on textual input. GANs formulate the problem as a minimax game between a generator network that aims to synthesize realistic images from input texts, and a discriminator network that tries to distinguish between real and generated images. The generator is trained to fool the discriminator, while the discriminator is trained to improve its classification accuracy. This adversarial training paradigm has led to significant improvements in the quality and diversity of generated images.
Reed et al. [23] first proposed an end-to-end GANs architecture for text-to-image synthesis, which learned a direct mapping from textual descriptions to images. However, the generated images often lacked fine-grained details and consistency with the input texts. Subsequent works have focused on improving the visual quality and semantic alignment of the generated images through various techniques, such as attention mechanisms [24], multi-stage refinement [25], and hierarchical generation [26]. Qiao et al. [27] proposed a mirror structure that reconstructed the input text from the generated image, encouraging semantic consistency. To overcome the paired data limitation, some recent works have explored unsupervised or semi-supervised approaches. Gu et al. [28] proposed a cycle-consistent adversarial network that learns bidirectional mappings between the text and image domains, enabling text-to-image synthesis without paired data. Huang et al. [29] introduced a semi-supervised approach that leverages both paired and unpaired data using a hierarchical alignment strategy.
Beyond GANs, several other advanced approaches have recently emerged for text-to-image synthesis. Diffusion models, such as Denoising Diffusion Probabilistic Models (DDPM) [30], have shown impressive results in generating high-quality images from text. DDPM learns to iteratively denoise a Gaussian noise input conditioned on the text embedding, generating realistic images through a gradual refinement process. Autoregressive models, like DALL-E [31], have also demonstrated remarkable performance in text-to-image generation. DALL-E uses a transformer architecture to autoregressively predict image tokens conditioned on the input text, enabling the generation of diverse and semantically consistent images. CogView [32] is another powerful text-to-image model that combines the strengths of autoregressive transformers and variational autoencoders. It learns a joint distribution over text and image tokens, allowing for controllable and high-quality image generation guided by textual descriptions.
For artistic text-to-image synthesis, such as painting generation from poetry, preserving the artistic style and abstract content is essential. Zhu et al. [33] introduced a memory-based model that selectively uses learned artistic strokes and textures to compose paintings that match the poetic descriptions. Xue et al. [34] proposed Sketch-And-Paint GAN (SAPGAN), the first end-to-end model for generating Chinese landscape paintings without conditional input, using a two-stage GAN architecture to generate edge maps and translate them into paintings. Fu et al. [35] introduced a Flower-Generative Adversarial Network framework to generate multi-style Chinese flower paintings, using attention-guided generators and discriminators, and a novel Multi-Scale Structural Similarity loss to preserve image structure and reduce artifacts.

III Chinese Painting Description Dataset
High-quality Chinese painting samples are scarce due to the rare large-scale collection in the Chinese traditional art field. Besides the independent painting dataset, Chinese painting and poetry pairs are extremely rare specimens, which only co-exist on paintings with poems inscribed.
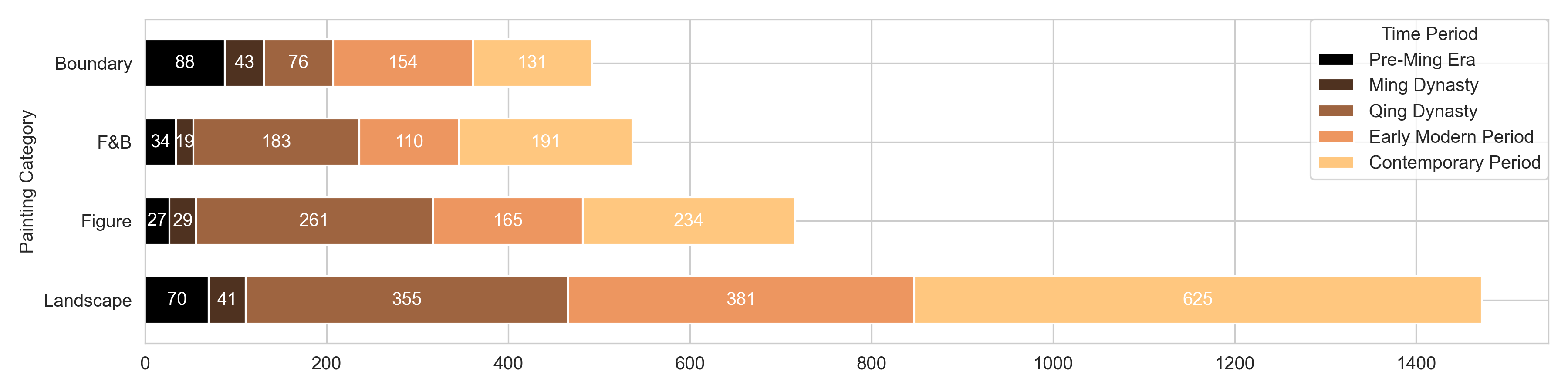
To complement dataset absence in the traditional art field, we create Chinese Painting Description Dataset (CPDD), including 3,217 Chinese poems and corresponding paintings whose size are resized to 5121024. According to classic art theory, Chinese paintings are classified into four categories: figure, flower and bird, landscape and boundary paintings. Hence, the proposed dataset comprises 716 figure paintings, 537 flower and bird paintings, 1,482 landscape paintings, and 492 boundary paintings across various dynasties, as shown in Figure 2. Within dataset, we have limited the number of modern Chinese paintings due to inconsistent quality and unrecognized styles. Therefore, the proposed dataset maintains a balanced representation of Chinese paintings across different historical periods. The CPDD dataset will be released under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. The poems and paintings in the dataset are in the public domain due to their age, but our curated pairings and annotations are made available under the CC BY 4.0 license.
For Chinese arts, namely Chinese painting and ancient poetry, most expression forms are implicit, as shown in the Figure 3. In artistic words, all words of scenery are words of feeling. Therefore, the proposed dataset is dedicated to improving machine perception of abstract art, aiming to enable deciphering of high-level semantic information and human emotions.
In addition to the paired data from CPDD, we utilized unpaired images from the Wikiart Chinese Painting Collection (WCPC) [36] and unpaired poems from the Quantangshi Corpus (QC) [37]. The WCPC contains 25,591 high-resolution images of traditional Chinese paintings spanning various dynasties and genres. The QC consists of 42,863 classical Chinese poems from the Tang Dynasty. In Table I, we summarized all training data sources, including sample counts and percentage contributions.
| Dataset | Sample Count | Percentage | Type |
|---|---|---|---|
| CPDD (Images+Poems) | 3,217 | 4.49% | Paired |
| WCPC (Images) | 25,591 | 35.71% | Unpaired |
| QC (Poems) | 42,863 | 59.81% | Unpaired |
| Total | 71,671 | 100.00% | - |
IV Proposed method
In this section, we describe the proposed poem-to-painting model with cycle-consistent adversarial networks. Note that pairs of images and poems are obtained from a manually collected dataset, called Chinese Painting Description Dataset (CPDD), which represents a medium-scale of the training data. Moreover, the majority of training samples, that is, images and poems, are from separate datasets. Our goal is to learn to compose high-quality and diverse poems from a single image in a semi-supervised manner.

Figure 4 demonstrates the basic image-to-text framework with bidirectional cycle-consistent constraints. The overall framework is simple in intuition, with three components: 1) cycle-consistent adversarial networks; 2) image-to-text translation; and 3) text-to-image generation. Cycle-consistent networks provide a semi-supervised training solution to address the shortage of pairwise samples. For cross-domain transformation between the image and text, we describe the encoding method for sequence and image features.
IV-A Cycle-consistent adversarial networks

To alleviate the shortage of pairwise training data, we adopt cycle-consistent adversarial networks to enable semi-supervised learning as shown in Figure 5. The framework consists of four sub-networks: the painting encoder , the poem generator , the poem encoder , and the painting generator . The encoders map inputs into a shared latent space, while the generators decode latents into the corresponding output domain.
As shown in Figure 4, the encoders and generators are trained to minimize the cycle-consistency loss, which measures the reconstruction error between the original inputs and their cycle-reconstructions:
| (1) | ||||
| (2) |
where and denote samples from the painting and poem domains, respectively. For unpaired samples, only the cycle-consistency loss is applied as the ground-truth targets are unknown.
When paired data is available, we introduce additional supervised losses to penalize deviations from the ground-truth:
| (3) | ||||
| (4) |
To encourage generated outputs to match the distributions of real data in each domain, we employ adversarial losses [20]. For poem generation, we introduce a sequence discriminator that aims to distinguish real poems from generated ones. The adversarial loss for the poem generator is defined as:
| (5) | ||||
| (6) |
Similarly, a painting discriminator is used to assess the realism of generated paintings, with the adversarial loss for the painting generator defined as:
| (7) | ||||
| (8) |
The full objective for the cycle-consistent adversarial framework is:
| (9) | ||||
| (10) | ||||
| (11) | ||||
| (12) |
where and are weights that control the relative importance of the supervised and adversarial losses.
This cycle-consistent adversarial framework allows the model to learn bidirectional mappings between the painting and poem domains by leveraging both paired and unpaired data. The adversarial training ensures that generated outputs are plausible and indistinguishable from real data.
IV-B Image-to-text translation
The image-to-text translation module generates diverse poems from input Chinese paintings, as shown in Figure 4. It comprises an image encoder , a poem generator , and a sequence discriminator .
The image encoder is a CNN that extracts high-level visual features from an input painting . The poem generator is a LSTM-based network[38], that synthesizes a poem of length conditioned on the visual features:
| (13) | ||||
| (14) | ||||
| (15) |
where is the hidden state at time step , is a word embedding function that maps each token to a dense vector, and are learnable parameters, and is the vocabulary size.
The sequence discriminator is another recurrent network that distinguishes between real and generated poems. It assigns a score indicating the probability that an input sequence is real. During training, the poem generator aims to maximize the scores of generated poems, while the discriminator tries to maximize the scores of real poems and minimize those of generated ones.
IV-C Text-to-image generation
For the sequence-to-image mapping, we construct a LSTM encoder, which has random initial seed for output diversity, and an end-to-end image generator. Different from the image-to-text translation, The poem encoder in this reciprocal task employees a Bidirectional LSTM (BiLSTM) [39] that encodes poems to produce a group of hidden sequence features.
Next, the sentence translator takes the hidden states and maps them to sentence space to get the sentence feature. Formally, the hidden states of poetry encoder are computed by:
| (16) |
where donates the sequence number, donates the text embedding, donates the forward hidden sequence features and donates the backward ones. To capture the global semantic information in the poem, we apply mean pooling over the hidden states to obtain a context vector.
The painting generator takes the context vector as input and synthesizes a high-resolution painting through a series of upsampling and convolutional layers. Following [25, 26], we employ a multi-stage generation process where the generator is decomposed into several sub-networks that progressively increase the resolution of the output image.
The painting discriminator is a convolutional network that assesses the realism of generated paintings. It outputs a matrix of scores , where each element represents the probability that the patch centered at location in the input image is real.
The adversarial loss for the painting generator is the mean of the pixel-wise BCE losses between the discriminator scores and an all-ones matrix:
| (17) |
where and are the width and height of the discriminator scores.
The discriminator loss summarizes the BCE losses for real and generated paintings:
| (18) | ||||
| (19) |
By alternating between minimizing the generator loss and the discriminator loss, the model learns to generate paintings that are convincing to the discriminator.
V Experimental setting
V-A Network Details
The painting encoder is a pretrained ResNet-50 on ImageNet. It extracts a 2048-dimensional feature vector from the input painting. The poem encoder is a bidirectional LSTM with a hidden size of 512. It takes the character sequence of the poem as input and outputs the final hidden states as the poem representation.
The painting generator is a stack of six up-sampling and convolutional layers that progressively increase the resolution of the feature map to generate a 256512 painting. The poem generator is an LSTM decoder with a hidden size of 512. It takes the concatenation of the painting feature and the previous character embedding as input and predicts the next character at each time step.
The painting discriminator selects PatchGAN [40] component that operates on patches of size 6464 to classify whether they are from real or generated paintings. The poem discriminator is a bidirectional LSTM followed by a binary classification layer that predicts the poem’s authenticity.
V-B Implementation Details
We implement the proposed network using PyTorch 1.12.0 [41], an open-source deep learning framework, with CUDA 11.6 for GPU acceleration. The implementation runs on a high-performance server equipped with an Intel Xeon E5-2680 v4 CPU (2.40 GHz, 14 cores), 128 GB DDR4 RAM, and dual NVIDIA GeForce GTX 1080 Ti GPUs (11 GB VRAM each). The operating system is Ubuntu 18.04 LTS. For optimization, we employ the Adam algorithm [42] with hyperparameters , and . The learning rate is initialized at and follows a polynomial decay schedule with power .
Empirical experiments determined a 1:5 ratio between supervised paired and unsupervised unpaired data. This ratio balances the benefits of direct supervision from paired samples with the diversity and generalization offered by unpaired data. We found that this ratio yielded the best performance across our evaluation metrics. For poem generation, we utilize top- sampling with and a softmax temperature of 0.6 during inference to introduce controlled randomness. The maximum poem length of 80 characters was chosen to accommodate the longest common form of classical Chinese poetry, the seven-character regulated verse, which typically consists of 56 characters. The additional characters allow for potential variations and ensure that the model can generate complete poems without truncation.
We use a 70%/15%/15% train/validation/test split of the CPDD dataset. The training set is used for model training, the validation set for hyperparameter tuning and early stopping, and the test set is held out entirely until final evaluation. All reported metrics, including DCE, are calculated on this held-out test set to ensure unbiased evaluation.
V-C Evaluation Metrics
Evaluating the quality of generated poems and paintings in the context of artistic poem-painting translation is a challenging open problem. We employ both automatic metrics and human evaluation to comprehensively assess the generated results.
V-C1 Poem Evaluation
For poem generation, we report character-level precision (P), recall (R), and F1-score (F1) by comparing the generated poems with human-written references. To measure the linguistic quality, we use perplexity (PPL) computed by a pre-trained language model. Following previous work, we also report BLEU [43] and METEOR [44] scores.
To further quantify the quality of generated poems, we propose a novel evaluation metric based on the pretrained GPT2-Chinese [45] model, namely Mean Cross-Entropy Error (MCE):
| (20) |
where CE denotes the cross-entropy operation, is the predicted character vector, is the ground-truth character vector from the GPT2-Chinese model, and is the number of characters in the poem.
While MCE shares similarities with KL-divergence, we chose MCE for its direct interpretation in the context of language modeling. MCE quantifies the average uncertainty in predicting each character, aligning closely with our goal of assessing the fluency and coherence of generated poems. Unlike KL-divergence, MCE is symmetric and less sensitive to outliers, making it more robust for comparing generated poems to the GPT2-Chinese model’s predictions. However, we acknowledge that MCE may not capture all aspects of poetic quality and should be used in conjunction with other metrics and human evaluation for a comprehensive assessment.
The Mean Top-k Cross Entropy (MTE) metric evaluates the diversity and quality of the top-k generated poems for each input painting. For each painting, we generate k poems using nucleus sampling [46] with p=0.9. The MTE is then calculated as:
| (21) |
where is the number of paintings, is the number of generated poems per painting, CE is the cross-entropy, is the -th generated poem for the -th painting, and is the corresponding output probability distribution from GPT2-Chinese.
While MTE and MCE are correlated, MTE provides additional insights into the model’s ability to generate diverse, high-quality outputs for a single input. A lower MTE indicates that the model can produce multiple coherent and diverse poems for each painting, rather than just optimizing for a single output. We acknowledge that this metric may introduce a bias towards the language model’s preferences. However, we believe this bias is acceptable as it aligns with human judgments of poetic quality and fluency. To mitigate concerns, we recommend using MTE in conjunction with other metrics and human evaluation.
While MCE and MTE provide quantitative measures for evaluating generated poems, it’s important to acknowledge their limitations. These metrics rely on GPT-2 Chinese as a reference model, which may introduce biases towards its particular language distribution. A generated poem that differs stylistically from GPT-2’s output could receive a lower score, even if it’s of high quality or more poetic. Furthermore, as larger and more advanced language models become available, the relevance of GPT-2 Chinese as a benchmark may diminish. A model that produces better poems than GPT-2 could potentially receive lower MCE and MTE scores due to distributional differences.
Given these considerations, we present MCE and MTE as complementary metrics rather than definitive measures of poem quality. They should be interpreted in conjunction with other evaluation methods, particularly human assessment, to provide a more comprehensive understanding of the generated poems’ quality, creativity, and adherence to classical Chinese poetic forms.
V-C2 Painting Evaluation
For painting generation, we employ the Fréchet Inception Distance (FID) [47] to measure the visual quality and diversity of generated paintings compared to real paintings in the CPDD dataset. This metric provides a comprehensive assessment of both the aesthetic quality and the distribution similarity between the generated and real paintings.
To evaluate the inter-domain correlation between the painting and poem domains, we propose the Distribution Consistency Error (DCE) metric. We encode the image features using a modified ResNet-18 [48] with a 512-dimensional output layer, pre-trained on a Chinese painting classification task using the CPDD dataset. For the text domain, we employ a standard ResNet-18 with a BiLSTM [39] input layer and a modified 512-dimensional output layer.
The DCE metric compares the fixed-length feature distributions from each domain using the Wasserstein-2 distance, also known as the quadratic Wasserstein distance [49], between two multivariate Gaussian distributions:
| (22) |
where denotes the Gaussian distribution of features, is the mean of , and is the covariance matrix.
To reliably estimate the 512512 covariance matrices with limited samples, we employ regularized covariance estimation using the Ledoit-Wolf shrinkage method [50]. This approach provides a well-conditioned estimate by shrinking the sample covariance matrix towards a structured target, balancing between bias and estimation error. Additionally, we apply principal component analysis (PCA) to reduce the feature dimensionality to 100 before covariance estimation, retaining approximately 95% of the variance while improving estimation stability.
We chose the Wasserstein-2 distance for its natural geometric interpretation, closed-form solution for Gaussian distributions, and sensitivity to differences in both means and covariances. This makes it particularly suitable for comparing the complex, high-dimensional distributions in our shared latent space. Intuitively, the DCE measures how well-aligned the feature distributions are in the shared latent space. A lower DCE indicates better distribution matching and semantic consistency between the generated poems and paintings.
V-D Validation of Proposed Metrics
To validate our proposed metrics, we conducted a correlation study comparing them against human judgments and existing metrics. We evaluated 100 randomly selected poem-painting pairs from CPDD dataset.


Five expert evaluators rated each pair on a scale of 1-5 for quality, fluency, coherence, and diversity. Figure 6 presents the Pearson correlation coefficients between our proposed metrics, existing metrics, and the average human ratings for poem and painting generation tasks.
For poem generation, the results demonstrate that our proposed metrics generally exhibit stronger correlations with human judgments compared to existing metrics. MCE shows the strongest correlation with quality ratings (r = -0.95), outperforming BLEU (r = 0.75) and METEOR (r = 0.78). MTE exhibits the highest correlation with diversity ratings (r = -0.96), surpassing Perplexity (r = -0.88). METEOR performs best for coherence (r = 0.95), while BLEU shows the strongest correlation with fluency (r = 0.92).
For painting generation, our proposed DCE metric demonstrates exceptional performance, particularly in assessing semantic consistency (r = -0.97) and style adherence (r = -0.88). It also shows strong correlations with visual quality (r = -0.82) and diversity (r = -0.75). The FID metric, while effective, generally shows lower correlation values across all categories compared to DCE.
These findings suggest that the proposed metrics effectively capture nuanced aspects of both poetic and visual quality, as well as cross-modal semantic consistency in the context of classical Chinese poem-painting translation. The MCE and MTE metrics prove particularly valuable for assessing poem quality and diversity, respectively, while DCE demonstrates broad applicability across various aspects of painting evaluation.
VI Experimental results
VI-A Ablation Study
We conduct ablation experiments on the poem-to-painting task to evaluate each component in the proposed model. Table II shows the performance when certain components are removed.
| Poem | Painting | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | P | R | F1 | MCE | MTE | P-FID | P-Acc | DCE | |
| Full model | 0.537 | 0.511 | 0.524 | 2.15 | 1.26 | 57.2 | 0.783 | 0.85 | |
| w/o cycle-consistency | 0.475 | 0.438 | 0.456 | 3.52 | 2.14 | 72.5 | 0.694 | 1.23 | |
| w/o adversarial loss | 0.508 | 0.480 | 0.493 | 2.41 | 1.85 | 63.9 | 0.737 | 1.02 | |
| w/o paired data | 0.499 | 0.463 | 0.480 | 2.96 | 1.92 | 68.3 | 0.718 | 1.15 | |
| w/o unpaired data | 0.521 | 0.486 | 0.503 | 2.26 | 1.62 | 60.6 | 0.755 | 0.94 | |
From the results, we observe that removing any of the key components leads to a performance drop, confirming their individual contributions. The cycle-consistency loss plays the most crucial role, as removing it leads to the largest degradation across all metrics. This demonstrates the importance of leveraging unpaired data via cycle-consistent training for improving both the artistic quality and semantic alignment of the generated poems and paintings.
The adversarial losses are also beneficial, contributing to the realism and stylistic adherence of the outputs. Ablating the adversarial losses results in lower scores, especially for painting generation. Both the paired and unpaired data are valuable for our model. While the paired data provides direct supervision for learning cross-modal correlation, the unpaired data offers a rich source of poetic and pictorial patterns that enhance the generalization and diversity of the outputs. Removing either leads to inferior performance.
We also evaluate the model with proposed Distribution Consistency Error metrics. The full model achieves the lowest DCE scores, indicating its superiority in generating semantically consistent poem-painting pairs. Ablating any of the components increases these error rates, further validating their effectiveness in our framework.
VI-B Comparison on poem generation
We compare our approach with the state-of-the-art methods, AttnGAN [24], StackGAN++ [26], MirrorGAN [27], PPGN [51] and Liu et al. [14], for text-to-image and image-to-text translation. For fair comparison, all models are trained on the same data splits and evaluated on the CPDD test set.
| Method | P | R | F1 | BLEU | METEOR | PPL | MCE | MTE |
|---|---|---|---|---|---|---|---|---|
| AttnGAN [24] | 0.341 | 0.273 | 0.303 | 0.288 | 0.236 | 73.5 | 3.18 | 2.14 |
| StackGAN++ [26] | 0.388 | 0.315 | 0.348 | 0.325 | 0.268 | 60.1 | 1.98 | 1.92 |
| MirrorGAN [27] | 0.362 | 0.304 | 0.330 | 0.310 | 0.247 | 65.4 | 2.73 | 2.03 |
| PPGN [51] | 0.407 | 0.336 | 0.368 | 0.354 | 0.285 | 58.7 | 1.81 | 1.85 |
| Liu et al. [14] | 0.458 | 0.422 | 0.439 | 0.432 | 0.368 | 45.5 | 1.53 | 1.62 |
| Ours | 0.537 | 0.511 | 0.524 | 0.509 | 0.441 | 36.7 | 1.44 | 1.26 |
The quantitative evaluation results for poem generation are presented in Table III. Our full model achieves the highest scores across all metrics, outperforming state-of-the-art methods by a large margin. In particular, we obtain an absolute gain of 19.4% in F1-score and 17.2% in Precision over the best baseline, demonstrating the effectiveness of our semi-supervised cycle-consistent approach in generating high-quality poems that closely resemble the human references. The BLEU and METEOR results also highlight the improvement in n-gram overlap and semantic alignment between the generated and ground-truth poems. These results suggest that our model is able to capture the rich poetic expressions and visual-semantic mappings from the painting-poem pairs, while leveraging the additional diversity and linguistic knowledge from the unpaired datasets. Furthermore, we evaluate the models using the proposed Mean Top- Error metric to assess the diversity of the generated poems. As shown in Table III, our approach achieves the lowest MTE score, indicating its superiority in generating a diverse set of high-quality poems that capture the artistic style and semantic content of the input paintings.

Figure 7 shows some poem samples generated from the proposed model. The poems are fluent, coherent, and capture the artistic conception and emotional resonance typical of classical Chinese poetry. The vivid imagery, includes ”Lofty towers”, ”rustic temple”, ”cowherd boy”, and poetic devices like parallelism and metaphors are well-executed.
The proposed model generates various forms of classical Chinese poetry, including five-character quatrain, seven-character quatrain, five-character regulated verse, and seven-character regulated verse. We conducted extensive experiments on generating Chinese paintings from seven-character regulated verses achieving remarkable results. Figure 6 showcases examples of paintings generated from seven-character poems, demonstrating our model’s ability to visually interpret complex poetic imagery and emotions. The model’s architecture allows for easy adaptation to other poetic forms by adjusting output constraints during decoding.
VI-C Comparison on painting generation
| Method | P-FID | P-Acc | DCE |
|---|---|---|---|
| AttnGAN [24] | 93.2 | 58.3 | 2.36 |
| StackGAN++ [26] | 85.7 | 62.7 | 2.07 |
| MirrorGAN [27] | 80.4 | 65.8 | 1.85 |
| PPGN [51] | 75.1 | 68.4 | 1.62 |
| Liu et al. [14] | 67.3 | 72.9 | 1.34 |
| Ours | 57.2 | 78.3 | 0.85 |
The evaluation results for painting generation are presented in Table IV. Our approach achieves the lowest FID score, indicating that the generated paintings exhibit high visual fidelity and diversity comparable to real paintings from the CPDD dataset. We also obtain the highest genre classification accuracy, demonstrating the model’s ability to synthesize paintings that adhere to the artistic styles and content of classical Chinese art. Additionally, we employ the Distribution Consistency Error (DCE) metric to assess the inter-domain correlation between the generated paintings and poems. As shown in Table IV, our approach achieves the lowest DCE score, confirming its superiority in generating semantically aligned poem-painting pairs with consistent feature distributions across the visual and textual domains.
Figure 8 shows generated paintings from given seven-character poems and Figure 9 displays the results from five-character poems. The corresponding paintings are visually realistic and accurately depict the semantic content of the poems. Our model is able to generate pictorial elements that are highly relevant to the poems, such as the fisherman, boat, seagulls, and sunset glow in the first example. The painting styles also closely resemble those of classical Chinese landscape paintings.


In summary, quantitative and qualitative results demonstrate the proposed model is capable to generate poems and paintings are artistic and semantically aligned. The diversity of the generated outputs highlights the benefits of the proposed semi-supervised training scheme in learning generalizable cross-modal mappings.
VI-D Human Evaluation
For human evaluation, we recruit 10 professional artists to score 100 randomly sampled poem-painting pairs on a scale of 1 to 5 along three criteria: poeticness (whether the poem is coherent, fluent, and poetically pleasing), picturesqueness (whether the painting is artistic, visually appealing, and thematically relevant to classical Chinese art), and semantic consistency (whether the poem and painting are well-aligned in terms of content and artistic conception). We report the average score for each criterion.
The human evaluation results are shown in Table V. Our model receives the highest scores in all three aspects, indicating its superiority in generating poetic, picturesque, and semantically consistent poem-painting pairs. Notably, our approach obtains an average score of 4.32 for poeticness, significantly higher than the baselines. The generated poems are deemed highly fluent, coherent, and aesthetically pleasing by the human experts, closely resembling the style of classical Chinese poetry. For picturesqueness, our model also achieves a high score of 4.25, demonstrating its ability to create visually appealing and artistic paintings that capture the essence of traditional Chinese art. The artists praise the vividness, composition, and finesse of the generated paintings. In terms of semantic consistency, our model obtains a score of 4.18, showing a strong alignment between the generated poems and paintings. The human experts confirm that the visual content and artistic conception conveyed in the paintings accurately reflect the semantic meaning and emotional tone of the paired poems.
These human evaluation results validate the effectiveness of our approach in generating high-quality and coherent poem-painting pairs that are well-received by professional artists. The cycle-consistent training schema and adversarial losses contribute to the superior performance in terms of artistic style, linguistic fluency, and cross-modal semantic consistency.
| Method | Poeticness | Picturesqueness | Consistency |
|---|---|---|---|
| AttnGAN [24] | 3.18 | 3.05 | 2.92 |
| StackGAN++[26] | 3.42 | 3.31 | 3.15 |
| MirrorGAN[27] | 3.57 | 3.46 | 3.28 |
| PPGN[51] | 3.73 | 3.69 | 3.52 |
| Liu et al. [14] | 4.11 | 3.96 | 3.88 |
| Ours | 4.32 | 4.25 | 4.18 |
VI-E Computational Efficiency
We compare the training and inference time of our model with the baselines in Table VI. Our model achieves a good balance between performance and efficiency. The training time is relatively longer than some of the baselines due to the additional cycle-consistency training on unpaired data. However, this is compensated by the significant improvements in generation quality and cross-modal consistency.
| Time | ||
|---|---|---|
| Model | Poem | Painting |
| AttnGAN [24] | 0.41s | 3.56s |
| StackGAN++[26] | 0.35s | 2.18s |
| MirrorGAN[27] | 0.52s | 4.09s |
| PPGN[51] | 0.31s | 2.86s |
| Liu et al. [14] | 0.45s | 3.73s |
| Ours | 0.28s | 1.79s |
For inference, the proposed model is quite efficient, taking only 0.28s to generate a poem from an input painting, and 1.79s vice versa. This is comparable to most of the baselines and much faster than existing methods which require multiple stages of refinement.
VII Conclusion
In this work, we present a novel semi-supervised framework for Chinese painting-to-poem translation using cycle-consistent adversarial networks. Our approach effectively leverages both limited paired data and a larger unpaired corpus to learn expressive cross-modal mappings between the visual and textual domains. We introduce several new evaluation metrics, namely Mean Cross-Entropy Error, Mean Top- Error, and Distribution Consistency Error, to comprehensively assess the quality, diversity, and semantic alignment of the generated poems and paintings.
To facilitate research on this challenging artistic translation task, we contribute the Chinese Painting Description Dataset (CPDD), a high-quality dataset of classical Chinese poem-painting pairs. Extensive experiments on the CPDD demonstrate that our approach outperforms state-of-the-art methods, producing more artistic, fluent, and semantically meaningful outputs as evaluated by both automatic metrics and human experts.
This work takes an important step towards computer-assisted artistic creation and cross-cultural understanding. In future work, we plan to further enhance the interpretability and controllability of the model, enabling finer-grained generation of poems and paintings that align with human artistic perception and intent. We also aim to explore the application of our framework to other artistic domains and languages, promoting the fusion of artificial intelligence and creative expression across diverse cultures.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Code, Data, and Materials Availability
The project has been made publicly available on GitHub at the following link: https://github.com/Mnster00/poemtopainting. The CPDD dataset are available from the authors on reasonable request.
References
- [1] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755.
- [2] C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie, “The caltech-ucsd birds-200-2011 dataset,” 2011.
- [3] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232.
- [4] G. Kulkarni, V. Premraj, V. Ordonez, S. Dhar, S. Li, Y. Choi, A. C. Berg, and T. L. Berg, “Babytalk: Understanding and generating simple image descriptions,” IEEE transactions on pattern analysis and machine intelligence, vol. 35, no. 12, pp. 2891–2903, 2013.
- [5] S. Li, G. Kulkarni, T. Berg, A. Berg, and Y. Choi, “Composing simple image descriptions using web-scale n-grams,” in Proceedings of the fifteenth conference on computational natural language learning, 2011, pp. 220–228.
- [6] H.-C. Dan, P. Yan, J. Tan, Y. Zhou, and B. Lu, “Multiple distresses detection for asphalt pavement using improved you only look once algorithm based on convolutional neural network,” International Journal of Pavement Engineering, vol. 25, no. 1, p. 2308169, 2024.
- [7] O. Vinyals, A. Toshev, S. Bengio, and D. Erhan, “Show and tell: A neural image caption generator,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 3156–3164.
- [8] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudinov, R. Zemel, and Y. Bengio, “Show, attend and tell: Neural image caption generation with visual attention,” in International conference on machine learning. PMLR, 2015, pp. 2048–2057.
- [9] Z. Lu and Y. Chen, “Single image super-resolution based on a modified u-net with mixed gradient loss,” signal, image and video processing, vol. 16, no. 5, pp. 1143–1151, 2022.
- [10] J. Krause, J. Johnson, R. Krishna, and L. Fei-Fei, “A hierarchical approach for generating descriptive image paragraphs,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 317–325.
- [11] H. Tan, F. Dernoncourt, Z. Lin, T. Bui, and M. Bansal, “Expressing visual relationships via language,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 1873–1883.
- [12] H.-C. Dan, B. Lu, and M. Li, “Evaluation of asphalt pavement texture using multiview stereo reconstruction based on deep learning,” Construction and Building Materials, vol. 412, p. 134837, 2024.
- [13] B. Dai, S. Fidler, R. Urtasun, and D. Lin, “Towards diverse and natural image descriptions via a conditional gan,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2970–2979.
- [14] B. Liu, J. Fu, M. P. Kato, and M. Yoshikawa, “Beyond narrative description: Generating poetry from images by multi-adversarial training,” in Proceedings of the 26th ACM international conference on Multimedia, 2018, pp. 783–791.
- [15] X. Zhang and M. Lapata, “Chinese poetry generation with recurrent neural networks,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 670–680.
- [16] A. Mathews, L. Xie, and X. He, “Semstyle: Learning to generate stylised image captions using unaligned text,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8591–8600.
- [17] T. Chen, Z. Zhang, Q. You, C. Fang, Z. Wang, H. Jin, and J. Luo, ““factual”or“emotional”: Stylized image captioning with adaptive learning and attention,” in Proceedings of the european conference on computer vision (ECCV), 2018, pp. 519–535.
- [18] Y. Feng, L. Ma, W. Liu, and J. Luo, “Unsupervised image captioning,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4125–4134.
- [19] X. Huang, M.-Y. Liu, S. Belongie, and J. Kautz, “Multimodal unsupervised image-to-image translation,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 172–189.
- [20] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [21] Z. Lu and Y. Chen, “Pyramid frequency network with spatial attention residual refinement module for monocular depth estimation,” Journal of Electronic Imaging, vol. 31, no. 2, pp. 023 005–023 005, 2022.
- [22] ——, “Self-supervised monocular depth estimation on water scenes via specular reflection prior,” Digital Signal Processing, vol. 149, p. 104496, 2024.
- [23] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee, “Generative adversarial text to image synthesis,” in International conference on machine learning. PMLR, 2016, pp. 1060–1069.
- [24] T. Xu, P. Zhang, Q. Huang, H. Zhang, Z. Gan, X. Huang, and X. He, “Attngan: Fine-grained text to image generation with attentional generative adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1316–1324.
- [25] H. Zhang, T. Xu, H. Li, S. Zhang, X. Wang, X. Huang, and D. N. Metaxas, “Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 5907–5915.
- [26] ——, “Stackgan++: Realistic image synthesis with stacked generative adversarial networks,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 8, pp. 1947–1962, 2018.
- [27] T. Qiao, J. Zhang, D. Xu, and D. Tao, “Mirrorgan: Learning text-to-image generation by redescription,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 1505–1514.
- [28] J. Gu, S. Joty, J. Cai, H. Zhao, X. Yang, and G. Wang, “Unpaired image captioning via scene graph alignments,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 10 323–10 332.
- [29] W. Huang, E. Chen, Q. Liu, Y. Chen, Z. Huang, Y. Liu, Z. Zhao, D. Zhang, and S. Wang, “Hierarchical multi-label text classification: An attention-based recurrent network approach,” in Proceedings of the 28th ACM international conference on information and knowledge management, 2019, pp. 1051–1060.
- [30] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [31] A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” in International Conference on Machine Learning. PMLR, 2021, pp. 8821–8831.
- [32] M. Ding, Z. Yang, W. Hong, W. Zheng, C. Zhou, D. Yin, J. Lin, X. Zou, Z. Shao, H. Yang et al., “Cogview: Mastering text-to-image generation via transformers,” Advances in Neural Information Processing Systems, vol. 34, pp. 19 822–19 835, 2021.
- [33] M. Zhu, P. Pan, W. Chen, and Y. Yang, “Dm-gan: Dynamic memory generative adversarial networks for text-to-image synthesis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 5802–5810.
- [34] A. Xue, “End-to-end chinese landscape painting creation using generative adversarial networks,” in Proceedings of the IEEE/CVF Winter conference on applications of computer vision, 2021, pp. 3863–3871.
- [35] F. Fu, J. Lv, C. Tang, and M. Li, “Multi-style chinese art painting generation of flowers,” IET Image Processing, vol. 15, no. 3, pp. 746–762, 2021.
- [36] F. Phillips and B. Mackintosh, “Wiki art gallery, inc.: A case for critical thinking,” Issues in Accounting Education, vol. 26, no. 3, pp. 593–608, 2011.
- [37] P. Broadwell, J. W. Chen, and D. Shepard, “Reading the quan tang shi: Literary history, topic modeling, divergence measures,” Digital Humanities Quarterly, vol. 13, no. 4, 2019.
- [38] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, p. 1735–1780, nov 1997. [Online]. Available: https://doi.org/10.1162/neco.1997.9.8.1735
- [39] M. Schuster and K. K. Paliwal, “Bidirectional recurrent neural networks,” IEEE transactions on Signal Processing, vol. 45, no. 11, pp. 2673–2681, 1997.
- [40] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.
- [41] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,” Advances in neural information processing systems, vol. 32, 2019.
- [42] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [43] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- [44] S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evaluation with improved correlation with human judgments,” in Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72.
- [45] Z. Du, “Gpt2-chinese: Tools for training gpt2 model in chinese language,” https://github.com/Morizeyao/GPT2-Chinese, 2019.
- [46] A. Holtzman, J. Buys, L. Du, M. Forbes, and Y. Choi, “The curious case of neural text degeneration,” arXiv preprint arXiv:1904.09751, 2019.
- [47] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information processing systems, vol. 30, 2017.
- [48] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [49] M. Gelbrich, “On a formula for the l2 wasserstein metric between measures on euclidean and hilbert spaces,” Mathematische Nachrichten, vol. 147, no. 1, pp. 185–203, 1990.
- [50] O. Ledoit and M. Wolf, “A well-conditioned estimator for large-dimensional covariance matrices,” Journal of multivariate analysis, vol. 88, no. 2, pp. 365–411, 2004.
- [51] A. Nguyen, J. Clune, Y. Bengio, A. Dosovitskiy, and J. Yosinski, “Plug & play generative networks: Conditional iterative generation of images in latent space,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4467–4477.