Semi-Disentangled Representation Learning in Recommendation System
Abstract.
Disentangled representation has been widely explored in many fields due to its maximal compactness, interpretability and versatility. Recommendation system also needs disentanglement to make representation more explainable and general for downstream tasks. However, some challenges slow its broader application — the lack of fine-grained labels and the complexity of user-item interactions. To alleviate these problems, we propose a Semi-Disentangled Representation Learning method (SDRL) based on autoencoders. SDRL divides each user/item embedding into two parts: the explainable and the unexplainable, so as to improve proper disentanglement while preserving complex information in representation. The explainable part consists of for individual-based features and for interaction-based features. The unexplainable part is composed by for other remaining information. Experimental results on three real-world datasets demonstrate that the proposed SDRL could not only effectively express user and item features but also improve the explainability and generality compared with existing representation methods.
1. Introduction
Disentangled representation learning aims at separating embedding into multiple independent parts, which makes it more explainable and general (bengio_representation_2013, ). The core idea of existing methods is to minimize the reconstruction error of the whole representation and maximize the independence among different parts simultaneously (chen_infogan_2016, ; higgins_beta-vae_2017, ). It has been successfully applied into image representation, and researchers have verified its superiority on many downstream tasks, e.g., image generation (alharbi_disentangled_2020, ; chen_infogan_2016, ) and style transfer (kotovenko_content_2019, ). Disentangled representation is also required by recommendation system to distinguish various hidden intentions under the same behavior (wang_disentangled_2020, ; ma_disentangled_2020, ). However, two obstacles slow its extensive application: the lack of enough fine-grained labels and the complexity of user-item interactions. Furthermore, Locatello et al. (locatello_challenging_2019, ) theoretically demonstrate the difficulty and even impossibility of unsupervised disentanglement and propose solutions using a few labels. It inspires us to put forward a Semi-Disentangled Representation Learning (SDRL) approach for recommendation system based on limited labels.

Specifically, we would introduce an example with Fig. 1 to explain the requirements and challenges of disentangled representation for recommendation and clarify our motivations in this paper. For instance, users and have watched the same movie Marriage Story, but their motivations may differ from each other. chooses it probably because he is a fan of the actress Scarlett Johansson while the motivation of maybe that he takes interests in romance movies. Another scene (i.e., users and watch the same movie Sen to Chihiro no kamikakushi) reflects a similar phenomenon. likes animation movies while also watches it perhaps because and are friends. Disentangled representation could help distinguish these different intentions under the same behavior, so as to improve the representation accuracy and offer clues to explain why the items are provided.
However, it is hardly possible to develop complete and accurate disentanglement in recommendation system, in consideration that it lacks fine-grained labels and user-item interactions are complicated. Specific with the example, it usually lacks enough labels for building completely fine-grained aspects, e.g., is a fan of Scarlett Johansson. On the other hand, some unknowable and random factors also affect users’ decisions, e.g., invites his friend to watch Sen to Chihiro no kamikakushi together. Disentanglement based on incomplete or inaccurate factors may decrease the expression ability of representation.
To overcome these limitations, we propose a semi-disentangled representation method SDRL, separating representation into three parts to respectively express internal, external and other remaining complex information. In particular, we present to denote the features related to individual itself, e.g., product category, movie style, user age. represents the characteristics from user-item interactions, e.g., user ratings and implicit feedback. Besides, we introduce the to generalize the information that may not contained by the former two blocks or random factors in the real scenes. Moreover, in addition to reduce the overall reconstruction error, we utilize category information and user-item ratings as the supervision for and respectively. In this way, SDRL could not only capture complex interactive information but also express various features into different blocks. To sum up, the main contributions are as follows:
-
•
We identify the problem of semi-disentangled representation learning in recommendation system, to preserve complex information while achieving proper disentanglement. As far as we know, we are the first to study this problem.
-
•
We propose a method SDRL to address the problem. It divides the representation into three blocks: , and . The former two are employed to express individual- and interaction-based features. The contains remaining information.
-
•
The experimental results demonstrate that the proposed SDRL improves the accuracy of two downstream tasks, as well as enhances the explainablity of representation.
2. Task Formulation
To improve both disentanglement and expression ability of representation in recommendation system, we separate embeddings into three blocks: , and . We would formally define these concepts and the problem to solve in this paper.
2.1. Key Concepts
Definition 1: internal block. It contains features about individual itself, which are extracted from content information.
Definition 2: external block. It expresses features based on interactions, i.e., user-item ratings, implicit feedback, etc.
Definition 3: other block. denotes characteristics excluding those contained by the former blocks.
In this work, we utilize category information to supervise . User-item ratings are employed as the supervision of . generalizes some features belonged to individuals and interactions but beyond supervision (e.g., the color of a product or the director of a movie), as well as some random factors.
2.2. Problem Definition
We identify the problem of semi-disentangled representation in recommendation system, to preserve complicated information while strengthening the representation explainability and generality with proper disentanglement. It requires to embed all features into three blocks using limited labels as supervision. It could be formally defined as follows.
Input: The normalized user-item ratings and item categories are taken as the input, in which denotes that the -th user rates -th item as points and means that the -th item belongs to -th category.
Output: Each user and item needs to be represented as a -dimension vector consisting of three blocks, , and .
Objective: The goal is to (1) make representation preserve more original information of users and items and (2) encourage and to express more features related to categories and interactions respectively. The objective function is defined as follows.
| (1) |
where and represent initial embeddings of users and items, denotes their representation in semi-disentangled space, and are the corresponding and , and contains category labels of items and users. means the possibility of generating given .

3. SDRL: The Details
We propose a semi-disentangled representation learning method SDRL for recommendation system. The framework is shown in Fig. 2. It consists of two major components. (1) Node representation (i.e., user representation and item representation) employs autoencoders to preserve characteristics of users, items and their interactions. (2) Supervised semi-disentanglement utilizes category information and user-item ratings to encourage and to respectively express more individual and interactive features. We also point out some possible directions to extend SDRL.
3.1. Node Representation
We exploit autoencoders to transform representation in initial space into semi-disentangled space.
Autoencoder is an unsupervised deep neural network (hinton_autoencoders_1993, ; vincent_stacked_2010, ), which has been extensively applied for network representation learning (wu_collaborative_2016, ; tallapally_user_2018, ). It has two modules of encoder and decoder as follows,
| (2) | |||
| (3) |
Encoder denotes the mapping that transforms the input vector into the latent representation , where is a weight matrix and is an offset vector. The mapping is called the decoder, reconstructing in the latent space into in the initial space, in which and denote the weight matrix and the offset vector respectively. is an activation function.
The objective of autoencoder is to minimize the reconstruction error. Stacked autoencoders (vincent_stacked_2010, ) is a widely used variant, which has been experimentally verified the improvement of representation quality. Therefore, we employ it to generate representations of users and items.
Different from typical autoencoders, we use three encoders , and to produce the corresponding , and , respectively. The generation process of users is as follows,
| (4) | |||
| (5) | |||
| (6) | |||
| (7) | |||
| (8) |
, and represent the above three blocks respectively, denotes the embeddings of users in semi-disentangled space, and is the generated representations of users in the initial space. The representation of items also utilizes a similar process. The goal of the process is to reconstruct the representation of users and items in the initial space as well as user-item ratings with autoencoders. Considering that the number of unobserved interactions (i.e., there is no rating) far exceeds that of the observed, we employ Binary Cross Entropy (BCE) as the basic metric. We define the loss function of reconstruction as follows,
| (9) |
where , denote the reconstructed users and items, represent predicted ratings by matching and . Details of BCE are as follow, where denote labels, represent the predicted values and is the number of ,
| (10) |
3.2. Supervised Semi-Disentanglement
Disentangled representation with weakly supervision has demonstrated its effectiveness in computer vision (locatello_disentangling_2020, ; chen_weakly_2020, ). The successful application and the complexity of interactions inspires us to improve the representation disentanglement using limited labels in recommendation system.
3.2.1. Internal Block Supervision
We employ category information as the supervision for . represents the item-category correspondence based on side information. denotes the user preference on category extracted from ratings and , which is calculated as follows,
| (11) |
and respectively denote category vectors of and . We sum the product of rating and item category vector of all rated items, and normalize it as ’s category preferences . The loss function is as follows,
| (12) |
where denotes the predicted category features of users and items using the corresponding .
3.2.2. External Block Supervision
We utilize ratings for supervising to contain more interactive information. The loss function on is as follows,
| (13) |
denote the predicted ratings based on .
3.2.3. Semi-Disentanglement Analysis
Most existing methods explicitly improve the block independence with the mutual information or distance correlation (cheng_improving_2020, ), which maybe not well applicable in recommendation. The major reason is that we need improve representation disentanglement as well as preserve interrelated characteristics. Hence, we propose semi-disentangled method SDRL. It does not separate the whole embedding into explainable blocks as that in disentangled representation learning, i.e., preserving no explicit meanings or factors in . Furthermore, it does not force the independence among different blocks. Instead, it just pushes the explainable blocks to express the more corresponding characteristics, i.e., encouraging to express more category-based information and to contain more interactive features.
3.3. Model Optimization and Extension
We aim at improving the expression ability and proper disentanglement of representation at the same time, so we combine the loss function of node representation and semi-disentanglement as follows,
| (14) |
3.3.1. Setting-oriented Extension
We separate the explainable part of representation into two blocks using autoencoders. As data characteristics and label information change, it’s flexible to adjust the number and the type of blocks as well as switch basic representation method. There are some possible extensions.
When more fine-grained labels are available even not for each sample, it is reasonable and convenient to add more blocks and optimize them with a small number of labels as in (locatello_disentangling_2020, ). In another setting where the extracted features are independent from each other, variational autoencoders (VAE) (kingma_introduction_2019, ) maybe a good choice to replace autoencoders.
3.3.2. Task-oriented Extension
The objective of this work is to produce general representation, so just a simple match of embeddings is employed for various downstream tasks. In fact, different tasks may emphasize different factors. For a specific task, some following-up modules maybe required and it is easy to extend SDRL with them.
For instance, for some tasks with supervision (e.g., rating prediction, node classification), attention mechanism (vaswani_attention_2017, ) is an intuitively excellent option as the following-up module to allocate different weights for different factors. For some tasks without labels (e.g., serendipity recommendation (li_directional_2020, )), pre-assigned weights probably could improve the performance. In brief, the proposed semi-disentangled representation provides opportunity to adaptively or manually pay different attentions to known factors on various tasks.
4. Experiments
To validate the effectiveness and explainability of SDRL, as well as the role of various semi-disentangled blocks, we conduct intensive experiments on three real-world datasets. We would briefly introduce the experimental settings in Section 4.1. Section 4.2 displays the comparison among our method and baselines in Top-K recommendation and item classification. In Sections 4.3 and 4.4, we perform ablation experiments and hyper-parameter analysis to study the impacts of different blocks and parameters in SDRL. Finally, we demonstrate the semi-disentanglement and explainability of representation with visualization and a case study in Section 4.5.
4.1. Experimental Settings
We perform experiments on three real-world datasets: MovieLens-latest-small (ml-ls), MovieLens-10m (ml-10m) (harper_movielens_2016, ) and Amazon-Book (mcauley_image-based_2015, ; he_ups_2016, ), whose statistics are shown in Table 1. We filter out users and items with less than 20 ratings and employ 80% ratings as the training data and the others as test data. We compare our method with four baselines, NetMF (qiu_network_2018, ; rozemberczki_karate_2020, ), ProNE (zhang_prone_2019, ), VAECF (liang_variational_2018, ) and MacridVAE (ma_learning_2019, ), based on four metrics, , , and (shani_evaluating_2011, ).
| dataset | #Users | #Items | #Ratings | #Categories | Density |
| ml-ls | 610 | 9742 | 100836 | 18 | 1.7% |
| ml-10m | 71567 | 10681 | 10000054 | 18 | 1.3% |
| Amazon-Book | 52643 | 91599 | 2984108 | 22 | 0.062% |
4.1.1. Baselines
We would briefly introduce four baselines and four variants of our proposed method SDRL.
NetMF: NetMF (qiu_network_2018, ) makes network embedding as matrix factorization, unifying four network embedding methods DeepWalk (perozzi_deepwalk_2014, ), LINE (tang_line_2015, ), PTE (tang_pte_2015, ), and node2vec (grover_node2vec_2016, ).
ProNE: ProNE (zhang_prone_2019, ) is a fast and scalable network representation approach consisting of two modules, sparse matrix factorization and propagation in the spectral space.
VAECF: Liang et al. develop a variant of Variational AutoEncoders for Collaborative Filtering (liang_variational_2018, ) on implicit feedback data, which is a non-linear probabilistic model.
MacridVAE: MacridVAE (ma_learning_2019, ) is one of the state-of-the-art methods that learn disentangled representation for recommendation, achieving macro and micro disentanglement.
To study the impacts of three blocks, (int), (ext) and (oth), we develop some variants through different combinations. For variants with two blocks, we set their proportion as 1:1.
SDRL’(int+ext) generates node embeddings consisting of two blocks, and .
SDRL’(int+oth) keeps and .
SDRL’(ext+oth) consists of and .
SDRL’(whole) represents a node as a whole embedding, which is similar to those common representation methods, but its optimization is based on autoencoders as in SDRL.
4.2. Performance Comparison
We verify the effectiveness of SDRL in two common downstream tasks in recommendation system, Top-K recommendation and item classification. We run the experiments 20 times and report the average values and the standard deviation. We highlight the best values of baselines in bold and calculate the corresponding improvements.
| method | F1@5 | F1@10 | F1@15 | ndcg@5 | ndcg@10 | ndcg@15 |
| NetMF | 2.9573(0.0) | 4.7776(0.0) | 5.1616(0.0) | 3.793(0.0) | 5.2728(0.0) | 6.9132(0.0) |
| ProNE | 3.0491(0.1) | 4.5284(0.14) | 5.3116(0.17) | 3.8125(0.18) | 5.243(0.13) | 7.0057(0.11) |
| VAECF | 5.5595(0.29) | 7.7409(0.33) | 8.9691(0.43) | 8.7243(0.55) | 9.8197(0.36) | 11.3705(0.35) |
| MacridVAE | 5.1578(0.15) | 7.3867(0.26) | 8.5167(0.32) | 8.0452(0.33) | 9.0503(0.32) | 10.6263(0.23) |
| improvement | 30.0171 | 27.9192 | 25.4228 | 20.4062 | 25.8338 | 28.8774 |
| SDRL | 7.2283(0.27) | 9.9021(0.27) | 11.2493(0.26) | 10.5046(0.57) | 12.3565(0.3) | 14.654(0.26) |
| method | F1@5 | F1@10 | F1@15 | ndcg@5 | ndcg@10 | ndcg@15 |
| NetMF | 3.9352(0.0) | 6.2(0.0) | 7.4752(0.0) | 4.831(0.0) | 6.8198(0.0) | 9.2123(0.0) |
| ProNE | 2.1065(0.04) | 3.1941(0.06) | 3.8371(0.05) | 2.3357(0.05) | 3.5148(0.04) | 4.9629(0.03) |
| VAECF | 5.1655(0.07) | 7.5696(0.1) | 8.881(0.1) | 8.033(0.18) | 9.4863(0.13) | 11.4674(0.11) |
| MacridVAE | 5.1832(0.07) | 7.5236(0.11) | 8.8513(0.14) | 7.0934(0.18) | 9.0107(0.16) | 11.4481(0.15) |
| improvement | 44.6963 | 38.8184 | 35.2393 | 42.2793 | 38.2288 | 37.0189 |
| SDRL | 7.4999(0.16) | 10.508(0.23) | 12.0106(0.25) | 11.4293(0.46) | 13.1128(0.35) | 15.7125(0.27) |
| method | F1@5 | F1@10 | F1@15 | ndcg@5 | ndcg@10 | ndcg@15 |
| NetMF | 9.0322(0.0) | 10.9837(0.0) | 11.5754(0.0) | 13.4461(0.0) | 12.623(0.0) | 13.8484(0.0) |
| ProNE | 6.818(0.07) | 8.8102(0.05) | 9.5218(0.07) | 9.9492(0.14) | 9.9032(0.06) | 11.1619(0.04) |
| VAECF | 6.1366(0.09) | 7.9531(0.14) | 8.6195(0.14) | 9.6312(0.19) | 9.3344(0.14) | 10.3365(0.1) |
| MacridVAE | 8.0043(0.12) | 9.9379(0.14) | 10.5185(0.17) | 12.1028(0.22) | 11.5303(0.13) | 12.6398(0.11) |
| improvement | 0.2879 | 4.3592 | 5.9549 | 2.0549 | 5.4543 | 7.1127 |
| SDRL | 9.0582(0.07) | 11.4625(0.12) | 12.2647(0.14) | 13.7224(0.18) | 13.3115(0.14) | 14.8334(0.1) |



| method | recall | precison | micro_F1 |
| NetMF | 50.3539 | 59.8585 | 54.6957 |
| ProNE | 53.1639 | 62.73 | 57.5517 |
| improvement | 12.4686 | 13.6479 | 13.0066 |
| SDRL | 59.7927 | 71.2913 | 65.0372 |
| method | recall | precison | micro_F1 |
| NetMF | 66.4181 | 65.6991 | 66.0564 |
| ProNE | 67.7764 | 66.7775 | 67.2731 |
| improvement | 18.0496 | 19.9254 | 18.9872 |
| SDRL | 80.0098 | 80.0832 | 80.0464 |
| method | recall | precison | micro_F1 |
| NetMF | 51.4335 | 47.3786 | 49.3226 |
| ProNE | 51.2197 | 47.3555 | 49.2115 |
| improvement | 83.7268 | 76.2521 | 79.759 |
| SDRL | 94.4971 | 83.5058 | 88.6618 |
| method | F1@5 | F1@10 | F1@15 | ndcg@5 | ndcg@10 | ndcg@15 |
| SDRL | 7.2283(0.27) | 9.9021(0.27) | 11.2493(0.26) | 10.5046(0.57) | 12.3565(0.3) | 14.654(0.26) |
| SDRL’(int+ext) | 6.9607(0.22) | 9.7205(0.24) | 11.1285(0.27) | 9.8062(0.48) | 12.0343(0.31) | 14.5021(0.25) |
| SDRL’(int+oth) | 7.1316(0.21) | 9.9035(0.26) | 11.3039(0.24) | 10.247(0.51) | 12.2864(0.29) | 14.8077(0.19) |
| SDRL’(ext+oth) | 6.7585(0.28) | 9.2792(0.19) | 10.5929(0.2) | 9.5182(0.55) | 11.5124(0.26) | 13.985(0.18) |
| SDRL’(whole) | 6.2179(0.75) | 9.146(0.59) | 10.4072(0.51) | 12.796(1.96) | 13.1785(1.05) | 13.864(0.6) |
| method | F1@5 | F1@10 | F1@15 | ndcg@5 | ndcg@10 | ndcg@15 |
| SDRL | 7.4999(0.16) | 10.508(0.23) | 12.0106(0.25) | 11.4293(0.46) | 13.1128(0.35) | 15.7125(0.27) |
| SDRL’(int+ext) | 6.8778(0.23) | 9.5076(0.34) | 10.8903(0.44) | 10.5319(1.02) | 11.8883(0.81) | 14.2037(0.75) |
| SDRL’(int+oth) | 7.432(0.29) | 10.4417(0.38) | 11.9863(0.44) | 11.936(1.22) | 13.2881(0.88) | 15.5704(0.74) |
| SDRL’(ext+oth) | 5.7576(0.22) | 8.4256(0.28) | 9.886(0.46) | 8.5747(0.77) | 10.3502(0.62) | 12.8529(0.49) |
| SDRL’(whole) | 5.1166(0.39) | 7.5039(0.37) | 8.7737(0.53) | 10.1397(2.41) | 10.757(2.44) | 11.8431(2.08) |
| method | F1@5 | F1@10 | F1@15 | ndcg@5 | ndcg@10 | ndcg@15 |
| SDRL | 9.0582(0.07) | 11.4625(0.12) | 12.2647(0.14) | 13.7224(0.18) | 13.3115(0.14) | 14.8334(0.1) |
| SDRL’(int+ext) | 8.8361(0.07) | 11.1924(0.1) | 12.0149(0.11) | 13.3619(0.17) | 12.9737(0.12) | 14.5178(0.08) |
| SDRL’(int+oth) | 8.1967(0.1) | 10.4707(0.12) | 11.3059(0.14) | 12.3478(0.18) | 12.1008(0.1) | 13.5747(0.08) |
| SDRL’(ext+oth) | 9.0518(0.08) | 11.4633(0.09) | 12.3021(0.1) | 13.7024(0.12) | 13.3441(0.09) | 14.9128(0.06) |
| SDRL’(whole) | 1.908(0.05) | 2.4953(0.05) | 2.8446(0.03) | 3.0402(0.11) | 2.9335(0.05) | 3.3497(0.02) |
| method | recall | precison | micro_F1 |
| SDRL | 59.7927 | 71.2913 | 65.0372 |
| SDRL’(int+ext) | 62.1688 | 74.263 | 67.6797 |
| SDRL’(int+oth) | 61.9033 | 73.8443 | 67.3484 |
| SDRL’(ext+oth) | 52.5572 | 62.046 | 56.908 |
| SDRL’(whole) | 39.9923 | 42.0991 | 41.0177 |
| method | recall | precison | micro_F1 |
| SDRL | 80.0098 | 80.0832 | 80.0464 |
| SDRL’(int+ext) | 77.1831 | 77.2037 | 77.1933 |
| SDRL’(int+oth) | 76.558 | 76.4345 | 76.4961 |
| SDRL’(ext+oth) | 51.3015 | 49.2074 | 50.2283 |
| SDRL’(whole) | 47.1581 | 43.9449 | 45.492 |
| method | recall | precison | micro_F1 |
| SDRL | 94.4971 | 83.5058 | 88.6618 |
| SDRL’(int+ext) | 98.2341 | 86.0925 | 91.7634 |
| SDRL’(int+oth) | 97.9884 | 85.9162 | 91.556 |
| SDRL’(ext+oth) | 53.6879 | 49.6705 | 51.6008 |
| SDRL’(whole) | 48.922 | 45.5 | 47.1487 |






Top-K Recommendation. We generate Top-5, 10 and 15 items according to predicted ratings as recommendations. The comparison results on three datasets are shown in Tables 2, 3 and 4, respectively. Based on the observations of comparison results, we find that our method SDRL achieves steady improvements compared with baselines. It at least improves F1 (ndcg) by 20.41% on MovieLens-latest-small, 35.24% on MovieLens-10m and 0.29% on Amazon-Book. It demonstrates that the proposed representation method SDRL significantly improves the Top-K recommendation performance especially on MovieLens datasets ml-ls and ml-10m. The possible reason is that more dense interactions (as shown in Table 1) reflect richer features and it could promote (semi-)disentangled representation more accurate overall.
Item Classification. Item classification also plays an important role in recommendation system such as cold-start task (zhao_categorical-attributes-based_2018, ). Since VAECF and MacridVAE do not generate item representations, we only utilize NetMF and ProNE as baselines and item categories as labels in item classification. We employ item embedding as the input and a MLPClassifier 222https://scikit-learn.org/ as the classification algorithm for all methods. The comparison results are shown in Tables 5, 6 and 7, respectively. We observe that our method SDRL outperforms baselines on three datasets with the help of category supervision.
4.3. Ablation Analysis
To study the impacts of various blocks in SDRL, we develop the ablation study based on the same setting as comparison experiment. Not only highlighting the best values in bold, we also underline the second and third best values in the results.
Top-K Recommendation. Based on the observations of comparison results in Tables 8, 9 and 10, we have three major findings. (1) Overall, SDRL consisting of three blocks and SDRL’(int+ext) achieve a relatively better performance. We infer that both category- and rating-based features play an important role in Top-K recommendation. (2) Another find is that variants with separated blocks usually outperforms that with the only one block i.e., SDRL’(whole). It demonstrates that semi-disentanglement significantly improves the performance in Top-K recommendation.
(3) We also find a difference between the results on MovieLens datasets (i.e., ml-ls and ml-10m) and Amazon-Book. On MovieLens datasets, SDRL’(int+oth) outperforms SDRL’(ext+oth), while on Amazon-Book SDRL’(ext+oth) shows a better performance. That’s to say, the has a bigger impact on MovieLens datasets and the takes more effects on Amazon-Book. We conduct further analysis and find that the difference may have a close relation with the statistical characteristics of datasets. As is shown in Fig. 3, on MovieLens datasets, over 80% users relate with at least 14 categories (77.78%); and on Amazon-Book, over 80% users only relate with at least 12 categories (54.55%). The statistical characteristics of datasets could affect the role of different features in downstream tasks, and (semi-)disentanglement increases the flexibility to emphasize certain features.
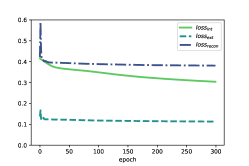
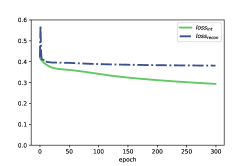
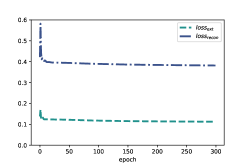
We also conduct a deeper analysis in terms of model optimization, to explore what causes the difference. As introduced in Section 3, we employ (in Equation 12) to encourage the to express relatively more category-based features. Meanwhile, the (in Equation 13) is expected to contain more interactive features with the optimization of . In addition, (in Equation 9) optimizes the whole reconstruction of users, items and ratings, which would make the also contain some interactive features.
We draw the trends of each parts of loss functions for three methods (i.e., SDRL, SDRL’(int+oth) and SDRL’(ext+oth)) respectively in Fig. 4. We observe that there is a similar trend among , and on MovieLens datasets in Fig.s 4(a), 4(d) and 4(g) (or in Fig.s 4(b), 4(e) and 4(h)). That is, the training process fairly optimizes the , and the whole reconstruction. However, on Amazon-Book in Fig.s 4(c), 4(f) and 4(i), obviously decreases faster than the other two losses.
It demonstrates that in the model training on Amazon-Book, the optimization for plays a more important role. The bias on Amazon-Book pushes the embeddings to contain more category-based features and relatively fewer rating-based features. The effect appears especially significant in SDRL’(int+oth), in which is removed from loss function. However, in Top-K recommendation, interactive features based on ratings may play a major part. It probably explain why SDRL’(int+oth) performs poorer than SDRL’(ext+oth) on Amazon-Book. Similarly, on MovieLens datasets, SDRL’(ext+oth) generates representations without the supervision of category-based information. Meanwhile, for SDRL’(int+oth), the fair optimization would encourage embeddings contain both category information and interactive features. Therefore, SDRL’(int+oth) outperforms SDRL’(ext+oth) on MovieLens datasets.
Last but not least, the difference also validates the importance of employing multiple features as supervision for different blocks in the representation learning, i.e., supervised (semi-)disentangled representation.
4.4. Hyper-parameter Analysis
It is flexible to adjust the proportion of , and in the embeddings. We set the proportion as 2:1:1, 1:2:1 and 1:1:2 to test their performance on Top-15 recommendation. The results in Fig. 5 show the variant with proportion 2:1:1 (i.e., a bigger proportion for ) outperforms the others on MovieLens datasets. On Amazon-Book, the variant with a bigger proportion for performs better. Therefore, we set the proportion in SDRL as 2:1:1 on the Movielens datasets and 1:2:1 on Amazon-Book.

4.5. Representation Visualization
In SDRL, and are expected to respectively express features from individual itself and user-item interactions. We visualize node representation to qualitatively analyze the semi-disentanglement of two parts.
4.5.1. Visualization based on Item Representation
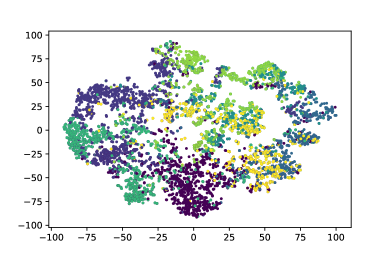
For clarity, we choose the most common categories as labels and visualize and of items using t-SNE (rauber_visualizing_2016, ) respectively. The results are revealed in Fig. 6. We could find that in the left figures, nodes in same color (i.e., items belonged to the same category) are more clustered. It indicates that contains more category-related information than , which is consistent with our expectation.





4.5.2. Visualization based on User Representation
We also select four users (whose user IDs are 551, 267, 313 and 216) on MovieLens-latest-small to visualize their representation in Fig. 7. For 128-dimension embeddings on MovieLens-latest-small, the first 64 bits represent , the next 32 bits and the last 32 bits . Among them, users No.551, No.267 and No.313 share a similar representation while the embedding of user No. 216 shows a different one. Based on source data displayed in Fig. 7(b), we find that the former three users take interest in action, adventure and thriller movies while the later likes comedy movies the most. Meanwhile, there is similar information on among users No.216, No.267 and No.313 (especially users No.216 and No.313), while user No.551 is a little bit different. Based on the statistics of common items in Fig. 7(c), we could find that there are relatively more common items among users No.216, No. 313 and No.267 than user No.551 and the others.



Shortly, in line with the expectation, and express more features of category and user-item interactions, respectively. It also improves the interpretability of node representation as well as offer clues to generate explanations. For instance, when the recommended item better matches the target user on , an explanation based on category maybe more reasonable, while that on indicates interaction-based explanation is more suitable.
4.6. Summary of Experiments
In summary, we have the following findings in the experiments. (1) Overall, SDRL gains stable and general improvements, demonstrating its effectiveness in representation learning. (2) In consistent with expectation, and respectively express more category-based and interactive features. (3) Semi-disentanglement enhances the explainability and generality in terms of representation in recommendation system.
5. Related Work
We would briefly review related works on representation in recommendation system and disentangled representation.
5.1. Representation in Recommendation System
Representation learning transforms the sparse data in recommendation system into structured embeddings, providing great convenience for complex network process (cui_survey_2019, ). Based on the type of source data, existing representation methods could be divided into three categories: structure-based (perozzi_deepwalk_2014, ; grover_node2vec_2016, ), content-based (zhang_prone_2019, ; zhao_deep_2020, ) and both-based (wang_reinforced_2020, ; he_lightgcn_2020, ; fu_magnn_2020, ). Among them, both-based approaches receive lots of attentions in recent years, e.g., graph neural network (GNN). It initializes representation with content features and then update it with structure information.
Our method SDRL also employs content and structure features as the input. The major difference between SDRL and GNN-based approaches is that SDRL embeds content- and structure-based information into different blocks (i.e., and respectively) while they represent it as a whole.
5.2. Disentangled Representation
Disentangled representation learning aims to separate embedding into distinct and explainable factors in an unsupervised way (bengio_representation_2013, ; do_theory_2020, ). It has been successfully applied into computer vision (nemeth_adversarial_2020, ). Recently, Locatello et al. (locatello_challenging_2019, ; locatello_commentary_2020, ) demonstrate that unsupervised disentangled representation learning without inductive biases is theoretically impossible. To deal with this problem, some works with (semi-)supervision are proposed (locatello_disentangling_2020, ; chen_weakly_2020, ). However, the assumption of factor independence makes typical disentangled representation not applicable for recommendation.
Our method differs from existing disentangled representation works in that we do not separate the whole embedding (i.e., we preserve for no specific meanings) and we do not explicitly force the independence of different factors. In this way, we could preserve more complicated relations in recommendation system, while achieving proper disentanglement.
6. Conclusions
To improve both disentanglement and accuracy of representation, we propose a semi-disentangled representation method for recommendation SDRL. We take advantages of category features and user-item ratings as the supervision for the proposed and . To the best of our knowledge, it is the first attempt to develop semi-disentangled representation as well as improve disentanglement with supervision in recommendation system. We conduct intensive experiments on three real-world datasets and the results validate the effectiveness and explainability of SDRL. In the future work, we would try to extract more labels and utilize them to separate the explainable part into fine-grained features for extensive applications. We are also interested to deeply study the unexplainable part to manage the uncertainty.
References
- (1) Yazeed Alharbi and Peter Wonka. Disentangled Image Generation Through Structured Noise Injection. In CVPR 2020, pages 5133–5141, 2020.
- (2) Y. Bengio, A. Courville, and P. Vincent. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell., 35(8):1798–1828, August 2013.
- (3) Junxiang Chen and Kayhan Batmanghelich. Weakly Supervised Disentanglement by Pairwise Similarities. In AAAI 2020, pages 3495–3502, 2020.
- (4) Xi Chen, Yan Duan, Rein Houthooft, John Schulman, Ilya Sutskever, and Pieter Abbeel. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In NIPS 2016, pages 2172–2180, 2016.
- (5) Pengyu Cheng, Martin Renqiang Min, Dinghan Shen, Christopher Malon, Yizhe Zhang, Yitong Li, and Lawrence Carin. Improving Disentangled Text Representation Learning with Information-Theoretic Guidance. In ACL 2020, pages 7530–7541, 2020.
- (6) Peng Cui, Xiao Wang, Jian Pei, and Wenwu Zhu. A Survey on Network Embedding. IEEE Trans. Knowl. Data Eng., 31(5):833–852, 2019.
- (7) Kien Do and Truyen Tran. Theory and Evaluation Metrics for Learning Disentangled Representations. In ICLR 2020, 2020.
- (8) Xinyu Fu, Jiani Zhang, Ziqiao Meng, and Irwin King. MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding. In WWW 2020, pages 2331–2341, 2020.
- (9) Aditya Grover and Jure Leskovec. node2vec: Scalable Feature Learning for Networks. In KDD 2016, pages 855–864, 2016.
- (10) F. Maxwell Harper and Joseph A. Konstan. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst., 5(4):19:1–19:19, 2016.
- (11) Ruining He and Julian J. McAuley. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In WWW 2016, pages 507–517, 2016.
- (12) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In SIGIR 2020, pages 639–648, 2020.
- (13) Irina Higgins, Loïc Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In ICLR 2017, 2017.
- (14) Geoffrey E. Hinton and Richard S. Zemel. Autoencoders, Minimum Description Length and Helmholtz Free Energy. In NIPS 1993, pages 3–10, 1993.
- (15) Diederik P. Kingma and Max Welling. An Introduction to Variational Autoencoders. Found. Trends Mach. Learn., 12(4):307–392, 2019.
- (16) Dmytro Kotovenko, Artsiom Sanakoyeu, Sabine Lang, and Bjorn Ommer. Content and Style Disentanglement for Artistic Style Transfer. In ICCV 2019, pages 4421–4430, 2019.
- (17) Xueqi Li, Wenjun Jiang, Weiguang Chen, Jie Wu, Guojun Wang, and Kenli Li. Directional and Explainable Serendipity Recommendation. In WWW 2020, pages 122–132, 2020.
- (18) Dawen Liang, Rahul G. Krishnan, Matthew D. Hoffman, and Tony Jebara. Variational Autoencoders for Collaborative Filtering. In WWW 2018, pages 689–698, 2018.
- (19) Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Rätsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations. In ICML 2019, volume 97, pages 4114–4124, 2019.
- (20) Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Rätsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. A Commentary on the Unsupervised Learning of Disentangled Representations. In AAAI 2020, pages 13681–13684, 2020.
- (21) Francesco Locatello, Michael Tschannen, Stefan Bauer, Gunnar Rätsch, Bernhard Schölkopf, and Olivier Bachem. Disentangling Factors of Variations Using Few Labels. In ICLR 2020, 2020.
- (22) Jianxin Ma, Chang Zhou, Peng Cui, Hongxia Yang, and Wenwu Zhu. Learning Disentangled Representations for Recommendation. In NeurIPS 2019, pages 5712–5723, 2019.
- (23) Jianxin Ma, Chang Zhou, Hongxia Yang, Peng Cui, Xin Wang, and Wenwu Zhu. Disentangled Self-Supervision in Sequential Recommenders. In KDD 2020, pages 483–491, 2020.
- (24) Julian J. McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel. Image-Based Recommendations on Styles and Substitutes. In SIGIR 2015, pages 43–52, 2015.
- (25) József Németh. Adversarial Disentanglement with Grouped Observations. In AAAI 2020, pages 10243–10250, 2020.
- (26) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. DeepWalk: online learning of social representations. In KDD 2014, pages 701–710, 2014.
- (27) Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Kuansan Wang, and Jie Tang. Network Embedding as Matrix Factorization: Unifying DeepWalk, LINE, PTE, and node2vec. In WSDM 2018, pages 459–467, 2018.
- (28) Paulo E. Rauber, Alexandre X. Falcão, and Alexandru C. Telea. Visualizing Time-Dependent Data Using Dynamic t-SNE. In EuroVis 2016, pages 73–77, 2016.
- (29) Benedek Rozemberczki, Oliver Kiss, and Rik Sarkar. Karate Club: An API Oriented Open-source Python Framework for Unsupervised Learning on Graphs. In CIKM 2020, 2020.
- (30) Guy Shani and Asela Gunawardana. Evaluating Recommendation Systems. In Recommender Systems Handbook, pages 257–297. 2011.
- (31) Dharahas Tallapally, Rama Syamala Sreepada, Bidyut Kr. Patra, and Korra Sathya Babu. User preference learning in multi-criteria recommendations using stacked auto encoders. In RecSys 2018, pages 475–479, 2018.
- (32) Jian Tang, Meng Qu, and Qiaozhu Mei. PTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks. In KDD 2015, pages 1165–1174, 2015.
- (33) Jian Tang, Meng Qu, Mingzhe Wang, Ming Zhang, Jun Yan, and Qiaozhu Mei. LINE: Large-scale Information Network Embedding. In WWW 2015, pages 1067–1077, 2015.
- (34) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In NIPS 2017, pages 5998–6008, 2017.
- (35) Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Manzagol. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res., 11:3371–3408, 2010.
- (36) Xiang Wang, Hongye Jin, An Zhang, Xiangnan He, Tong Xu, and Tat-Seng Chua. Disentangled Graph Collaborative Filtering. In SIGIR 2020, pages 1001–1010, 2020.
- (37) Xiang Wang, Yaokun Xu, Xiangnan He, Yixin Cao, Meng Wang, and Tat-Seng Chua. Reinforced Negative Sampling over Knowledge Graph for Recommendation. In WWW 2020, pages 99–109, 2020.
- (38) Yao Wu, Christopher DuBois, Alice X. Zheng, and Martin Ester. Collaborative Denoising Auto-Encoders for Top-N Recommender Systems. In WSDM 2016, pages 153–162, 2016.
- (39) Jie Zhang, Yuxiao Dong, Yan Wang, Jie Tang, and Ming Ding. ProNE: Fast and Scalable Network Representation Learning. In IJCAI 2019, pages 4278–4284, 2019.
- (40) Kai Zhao, Ting Bai, Bin Wu, Bai Wang, Youjie Zhang, Yuanyu Yang, and Jian-Yun Nie. Deep Adversarial Completion for Sparse Heterogeneous Information Network Embedding. In WWW 2020, pages 508–518, 2020.
- (41) Qian Zhao, Jilin Chen, Minmin Chen, Sagar Jain, Alex Beutel, Francois Belletti, and Ed H. Chi. Categorical-attributes-based item classification for recommender systems. In RecSys 2018, pages 320–328, 2018.