Semantic sensor fusion: from camera to sparse lidar information
Abstract
To navigate through urban roads, an automated vehicle must be able to perceive and recognize objects in a three-dimensional environment. A high-level contextual understanding of the surroundings is necessary to plan and execute accurate driving maneuvers. This paper presents an approach to fuse different sensory information, Light Detection and Ranging (lidar) scans and camera images. The output of a convolutional neural network (CNN) is used as classifier to obtain the labels of the environment. The transference of semantic information between the labelled image and the lidar point cloud is performed in four steps: initially, we use heuristic methods to associate probabilities to all the semantic classes contained in the labelled images. Then, the lidar points are corrected to compensate for the vehicle’s motion given the difference between the timestamps of each lidar scan and camera image. In a third step, we calculate the pixel coordinate for the corresponding camera image. In the last step we perform the transfer of semantic information from the heuristic probability images to the lidar frame, while removing the lidar information that is not visible to the camera. We tested our approach in the Usyd Dataset [1], obtaining qualitative and quantitative results that demonstrate the validity of our probabilistic sensory fusion approach.
I INTRODUCTION
Getting a sufficiently descriptive representation of the current state of the world in an urban environment has always been a challenge. Today, with the recent boom in self-driving car applications, more information about the shape, location and type of nearby objects is required to assure not only accuracy/reliability in localization but also safe and optimal path planning and navigation. Semantic meaning of the objects around the vehicle is one of the most significant pieces of information necessary in the decision making process.

The classification techniques to label objects in the surrounding area relies on both the sensors located on the vehicle, and the computational power available for this task. Cameras and lidars are often used to accomplish the task of understanding the environment. Cameras are affordable, have low power consumption and contain texture and colour data, which makes them a suitable sensor to be used for object classification [2]. In this paper we use the captured images as the input for a trained CNN [3] which outputs images with a semantic representation of the objects in the image. We have developed a heuristic method to associate class uncertainty to each pixel by modifying the CNN’s final softmax function based on the label distribution within the original image’s superpixels.
From only monocular images it is not possible to measure directly the 3D location of detected objects. To overcome this restriction, lidar sensors have been widely used in the autonomous vehicles research. Typically, low-cost lidars do not have sufficient resolution, and are unable to provide color information.
Through camera-lidar sensor fusion, we are able to transfer relevant data from the camera to lidar and vice versa, providing a better understanding of the structure of the surroundings [4]. A proper lidar-camera data fusion approach must address the following three problems: Accurate calibration for intrinsic camera and extrinsic lidar-camera parameters, sensor synchronization and motion correction, and handling occlusion caused by the different point of view of each sensor.
Different papers have addressed sensor fusion between cameras and lidars, using only the geometric relationship between a pin-hole camera and the lidar. In [5], authors presented an indoor scene construction technique using a 2D lidar and a digital camera. Both sensors were mounted rigidly, and the sensor fusion was performed using the extrinsic calibration parameters. Later, Bybee et. al, in [6] presented a bundle adjustment technique to fuse low-cost lidar information and camera data to create terrain models. A multi-object tracking technique which rigidly fuses object proposals across sensors is explained in [7].
Schneider et. al. in [8] addressed the synchronization and motion correction problem by triggering the cameras to capture the image when the laser-beams are in the images field of view. The scan points were translated based on the the vehicle movement. In [9], the synchronization timestamp is chosen to coincide with the timestamp of the most recent camera frame, then transforming each point using the ego-motion transform matrix of the vehicle.
The most common solution to the occlusion problem corresponds to segment the point cloud. A 2D convex hull is computed for every cluster in the image frame, then an occlusion check is performed to takes into account the depth of each cluster to select which part of the point cloud is not occluded to the camera view [8]. In [10], authors presented an approach where a cone is placed along the projection line for every 3D point, with the condition that it does not intersect any other point. The aperture of the cone has to be larger than a threshold to set the point as visible. These techniques work well for a dense point cloud which allows the segmentation algorithm to provide consistent results. Nevertheless, for sparse point clouds such as the type provided by the 16 beam lidar used in this work, only objects that are very close to the vehicle can be reliably segmented. This is not very useful in an urban type environments.

In contrast of previous approaches, this paper proposes a novel pipeline for the fusion of semantically labelled images and lidar point clouds which deals with both motion distortion and the occlusion problem. We tested our approach in the Usyd Dataset [1], [11], which was obtained with the vehicle platform shown in Fig.2.
In the next section, we explain the details of the methodology to associate uncertainties to the labelled image and project the resulting information into the point cloud. The algorithms also include the correction for vehicle motion and a process for handling occlusions. Experiments and outcomes are presented in section III.
II METHODOLOGY
An E-net CNN which has been fine tuned with locally annotated images and data augmentation techniques [3] is adopted as semantic classifier. This model is used to generate the labels, and a heuristic value for measurement uncertainty.
The complete lidar scan, divided in packets, is translated based on the motion of the vehicle and the cameras’s timestamp. Following this, we calculate the corresponding image coordinate for each measurement point.


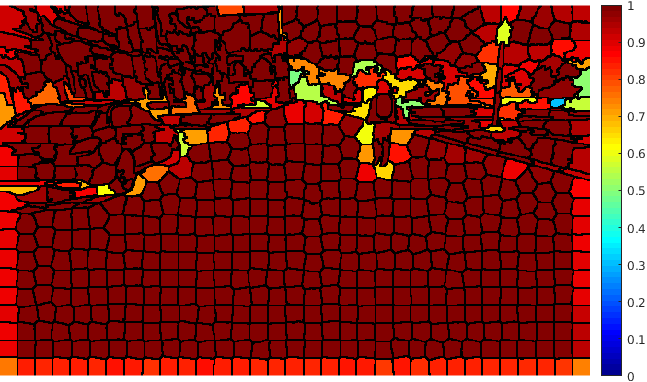




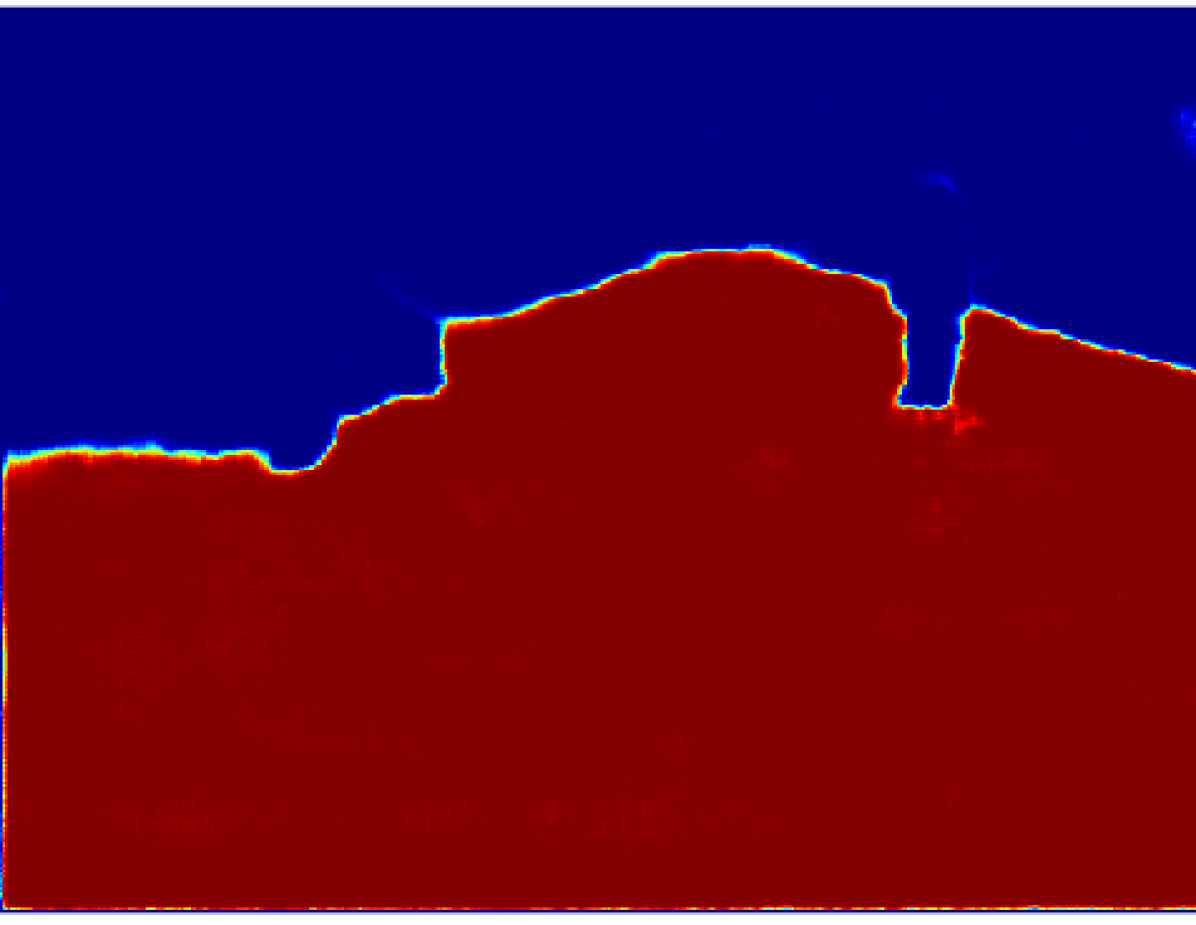

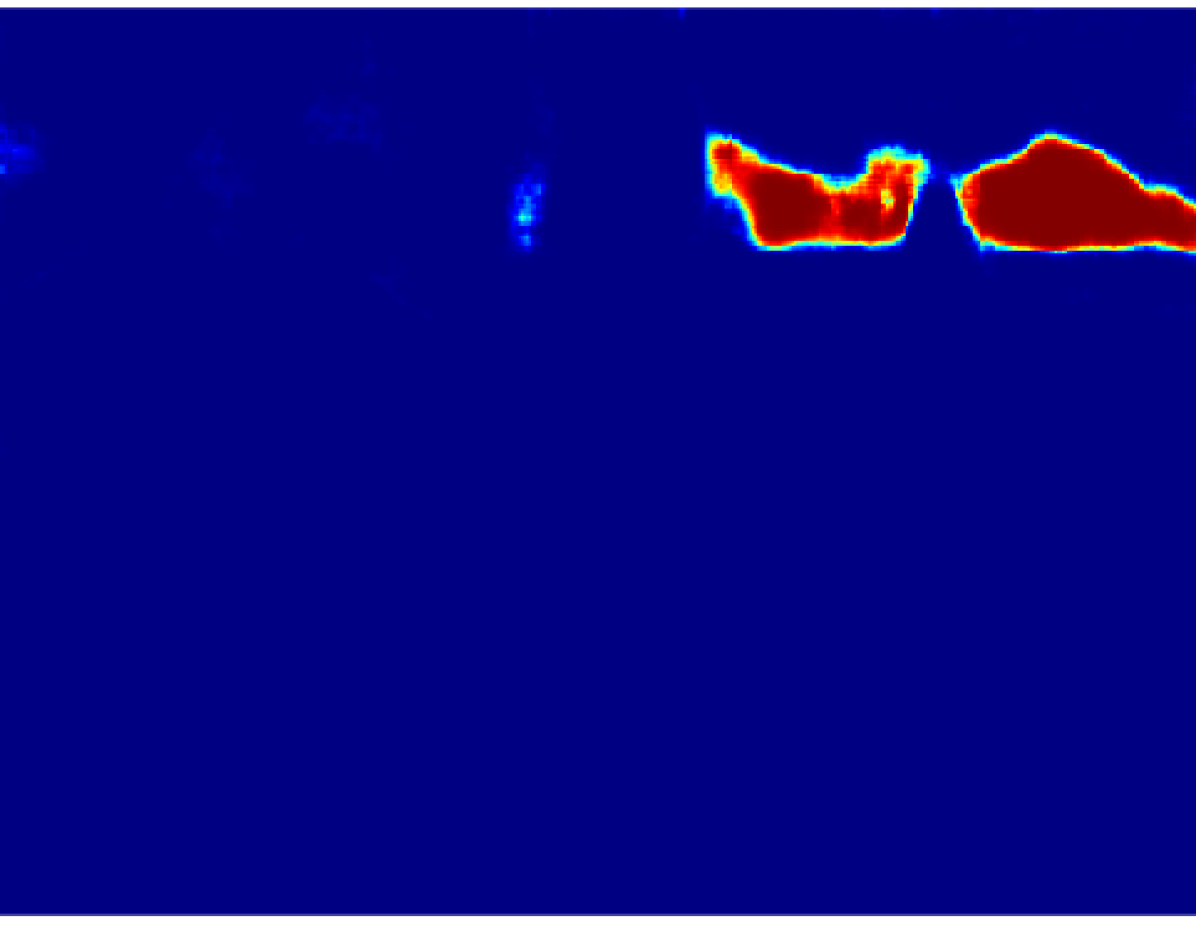


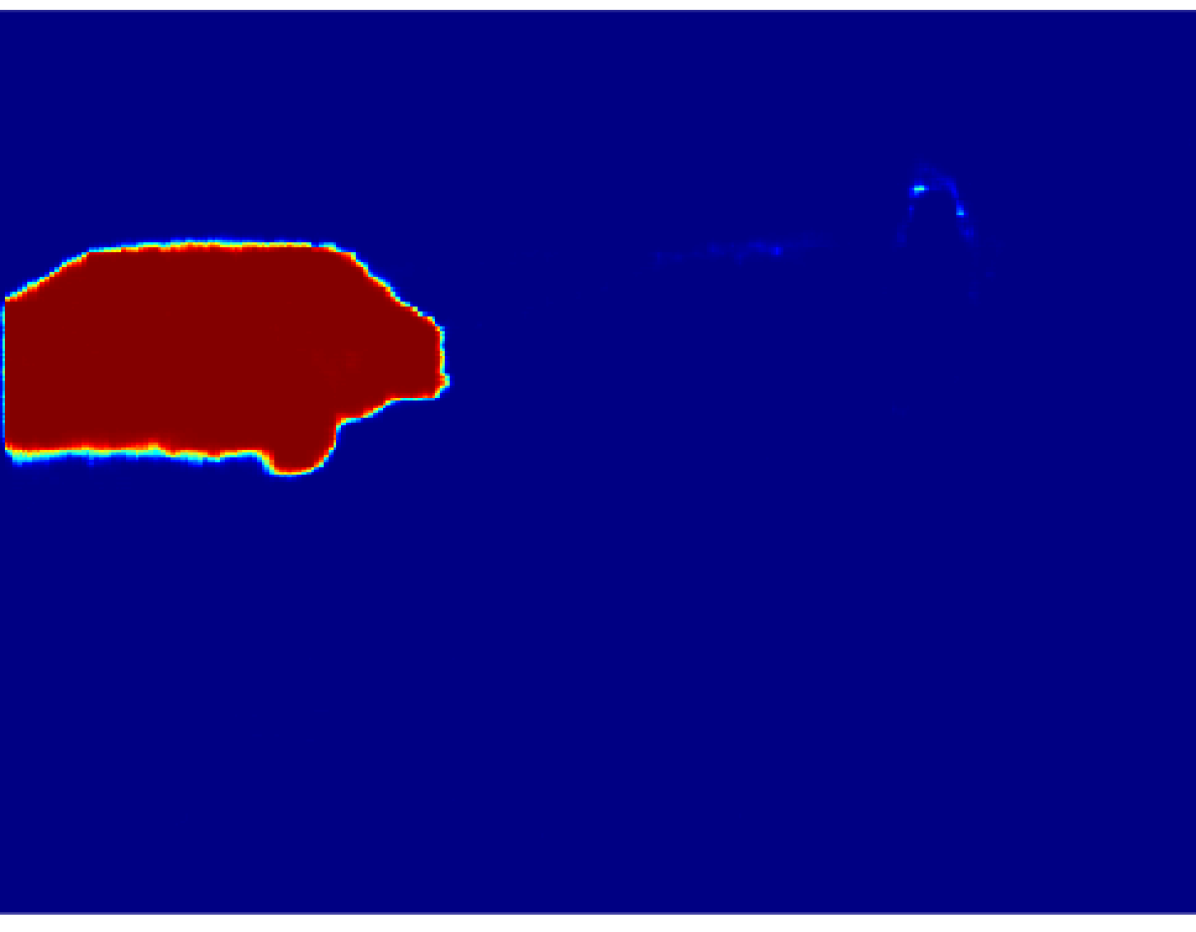




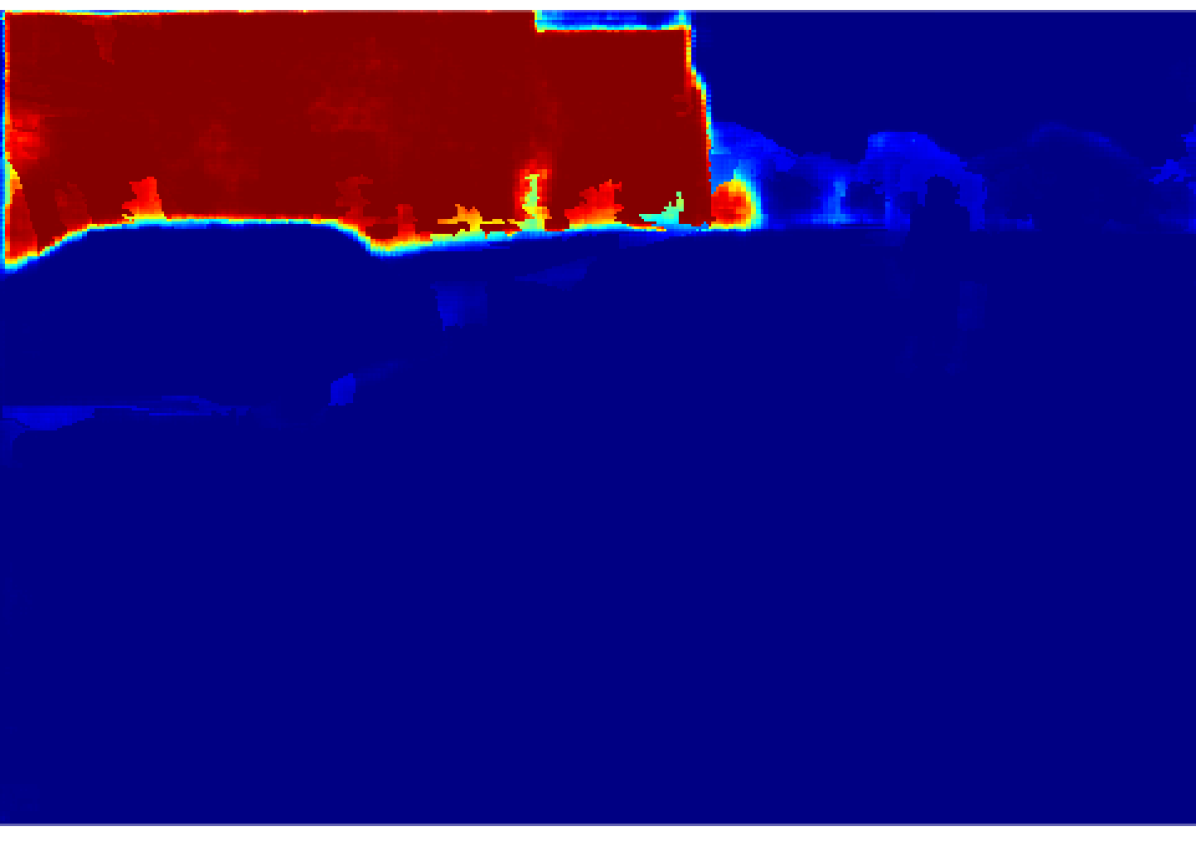

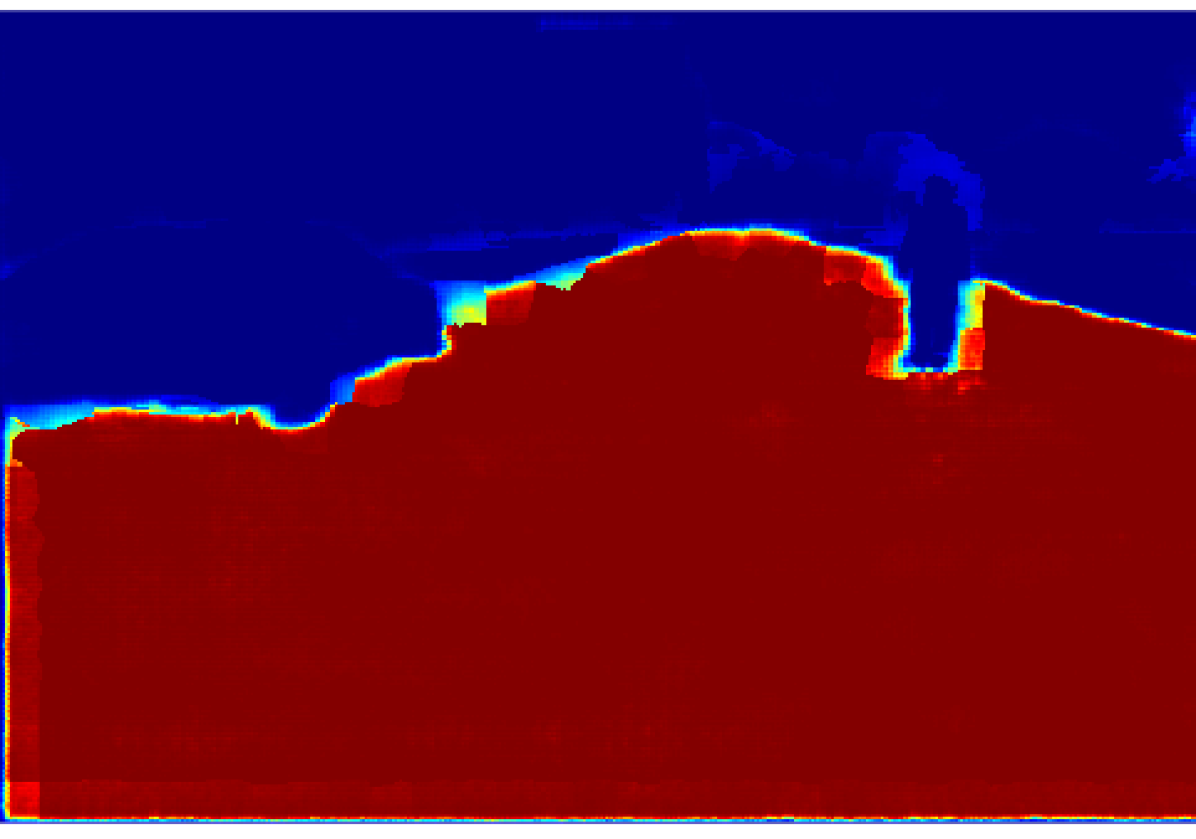
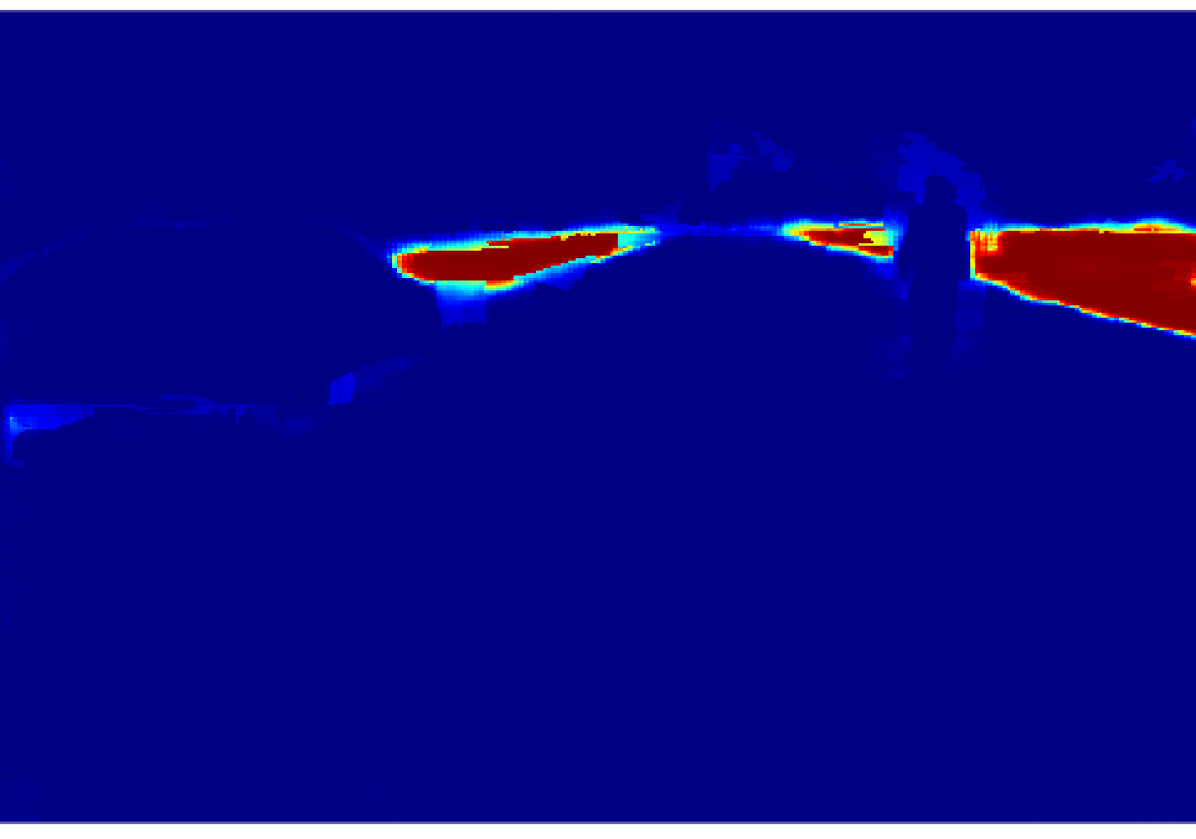
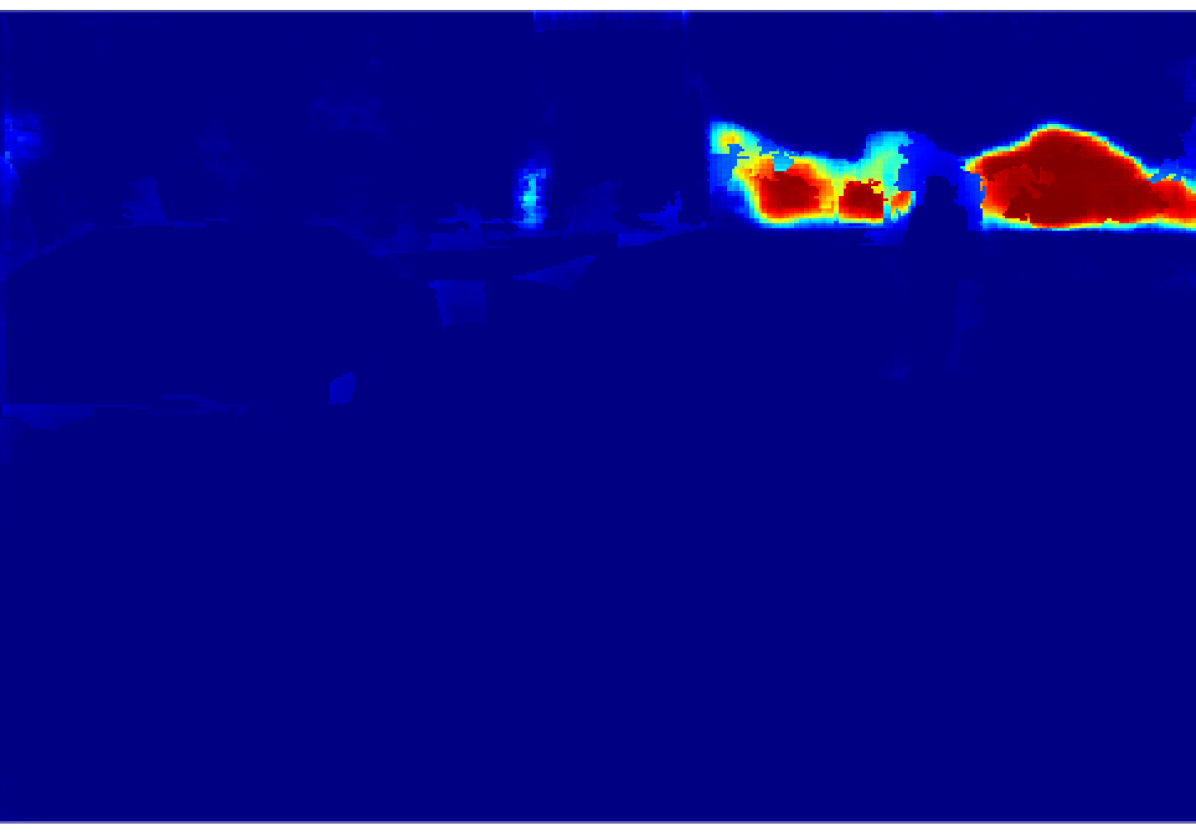


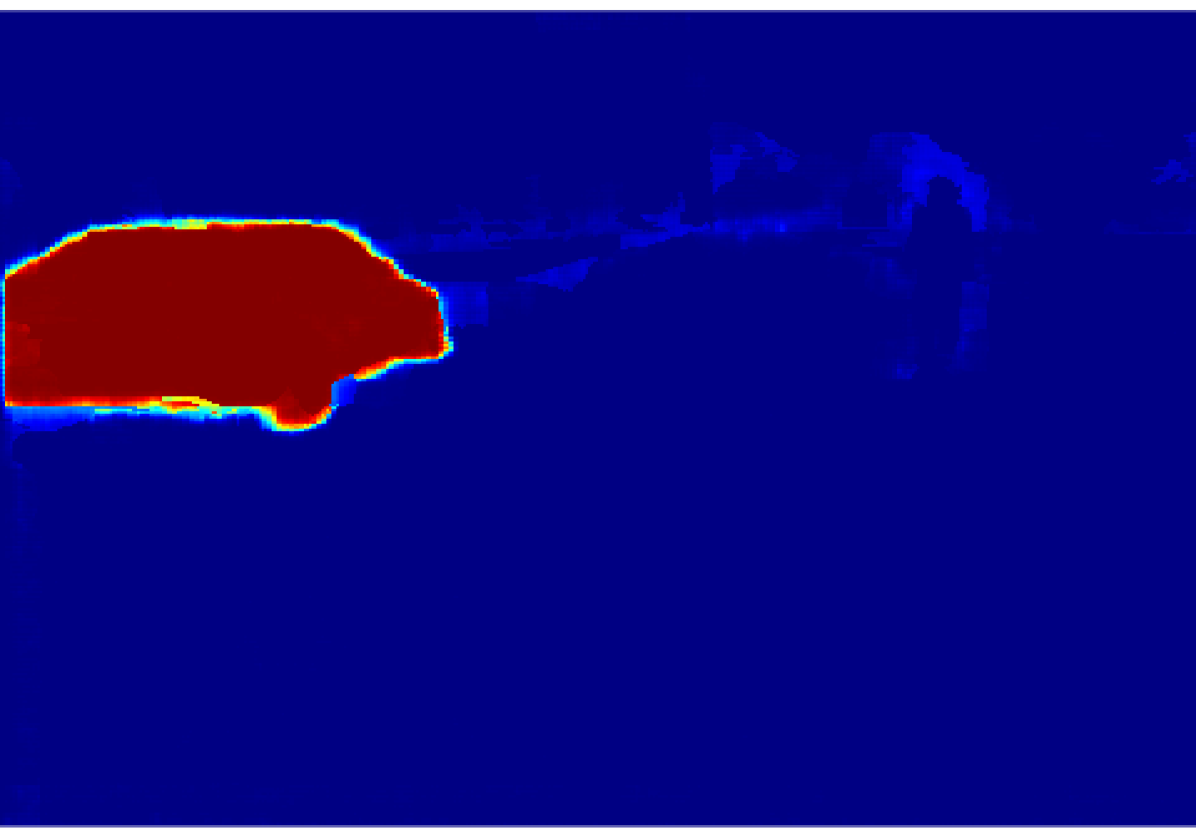


The projection of the image information to the point cloud is done by applying a masking technique that deals with the occlusion problem, avoiding the projection to reject the lidar points which are not visible from the camera. Each valid 3D point then gets assigned the probabilistic distribution of the semantic classes calculated in an earlier step. The process is explained in this section.
II-A Heuristic label probabilities
The final module of E-NET consists of a bare full convolution which outputs a three dimensional x x feature/activation map, where and correspond to the size of the input image, and is the number of object classes [12]. Each feature map consists of activations per pixel , which represents the unnormalised class score for each label [13].
The output unit activation function for the CNN model, which conforms the canonical link, is determined by the softmax function. [14]:
| (1) |
The softmax function mixes the class scores while satisfying the constraints to adopt the interpretation of as a class probability [15]:
| (2) |
The final labeled image is a x matrix composed of the class identifier for the label with the highest probability per pixel.
In this paper, we propose a variant of the method for obtaining the labels’ probabilities while retaining the CNN’s output classification. This method is based on both the score maps, and the distribution of the labels within the segmented areas of the input image. Initially, the input image is divided into different regions by using simple linear iterative clustering (SLIC) [16] super-pixel segmentation method [17] where pixels are grouped according to perceptual characteristics consistency. Given the uniformity of the pixels in a super-pixel, we assume they all belong to a single semantic class.
Then, we calculate the percentage of the predominant label within the super-pixel by dividing the number of pixels belonging to this label by the total amount of pixels inside the super-pixel. In an ideal case where the labels and the super-pixels are correctly segmented, prevalent label percentage would be . Fig. 3 shows the result of this process, it is noticeable that the value of decreases in the superpixels near the object borders.
In some cases, two or more labels are present within a super-pixel, indicating that at least some pixels are incorrectly labelled. This is often observed with the classification of pixels around the edges of objects in the image, which is due to the re-sizing process performed by the CNN model. In this case, we would expect to have a class probability distributed more evenly among two or more labels. Nevertheless, the softmax function described in (1) generates a strong discrepancy in the selection probability for dissimilar estimated class scores.
We have unified the concepts of predominant label percentage within a super-pixel and the softmax activation function used by the CNN. This is done through a variant definition of the softmax function:
| (3) |
where represents a positive parameter denominated temperature, high temperatures lead to the selection probability to be approximately equiprobable. Instead, low temperatures bring about a greater difference in selection probability for actions that differ in their value estimates [18].
Our approach is to modulate the temperature of the softmax function per super-pixel based on its label distribution. This is done to obtain more coherent estimated probabilities of the classification process while satisfying the restriction (2) and maintaining the classification output. The softmax temperature adjustment for the super-pixel is done by:
| (4) |
The softmax temperature per super-pixel is inversely proportional to the square of , so when is less than , the temperature is raised. This has the effect of flattening the activation function and consequently generating more distributed probabilities. Where is equal to 1, the class probabilities are identical to those provided by the CNN model as shown in Fig. 4.
II-B Motion correction
By moving the vehicle coordinate system for each individual set of lidar measurements (called a packet) and transforming them into the final scan coordinate frame, it is possible to compensate for the changing reference frame of the lidar [19]. The motion compensation method implemented in this paper synchronizes the lidar packet timestamps with closest camera image timestamp following a similar principle to the method presented in [9].

Every 3D point packet denoted by registered at time is adjusted by eq. (5). The point is first translated to the vehicle footprint frame by the rigid transform . Then, a transform is applied to compensate for the displacement resulting from the ego-motion of the vehicle. This transform matrix represents the motion of the vehicle between the time reference and the odometry reading closest to . As a result, each point is converted into the lidar coordinate system.
| (5) |
Where is defined as the difference between the camera image timestamp or and lidar packet . In order to get an accurate camera-lidar projection, the motion compensation process is performed for all point cloud packets generated by the lidar.
II-C Image-to-Lidar Projection
This step takes as an input the adjusted point cloud result of the motion correction performed previously. Given the extrinsic calibration between both camera and lidar sensors represented as the transformation matrix , we can translate each 3D point in the lidar frame to the camera frame by computing:
| (6) |
Once the point cloud is referenced to the camera frame, we find the corresponding pixel in the image frame by using the camera model and its intrinsic parameters. Initially we make use of the generic pinhole camera-image projection equations which states:
| (7) |
| (8) |
Since our cameras have fisheye lenses, we need correct for the distortion established by the camera model to find the corresponding pixel in the image [20]. The distortion of the lens is calculated as follows:
| (9) |
where , , and are the lens’ distortion coefficients. We then compute the distorted point coordinates as:
| (10) |
The definite pixel coordinates vector in the image frame of the 3D point can be estimated as:
| (11) |
where is the camera’s skew coefficient, the principal point offset and are the focal lengths expressed in pixel units.
II-C1 Occlusion handling
The direct fusion of the camera-lidar information would be appropriate if the coordinate systems of both the camera and the lidar were co-located. Most vehicles are equipped with multiple cameras at different positions to achieve wide coverage. For this case, the cameras and lidar will see the environment from different vantage points. This can result in a scenario where the lidar can see an object located behind another object that blocks the cameras visibility. In this work we address this problem using a masking technique.
The point cloud in the camera frame is first sorted using a k-dimensional tree to organize the 3D points in ascending order based on their distance to the camera frame origin. The next step is to project each point into the image frame. To cope with the occlusion problem we propose a masking approach, where every projected point generates a mask. The mask is used to reject other more distant points that are within the masked zone of the image.










The mask shape corresponds to a rectangle where the dimensions and depend on the vertical and horizontal resolution of the lidar. The parameters selected for this paper are based on the VLP-16 documentation [21]. The gap between points (vertical or horizontal) can be calculated with the following equation:
| (12) |
where is the distance to the target and is the vertical or horizontal angle between scan lines of consecutive points. In order to calculate the gaps in the pixels when the point cloud is projected, we make use of the generic camera-image projection equations 7 and 11, obtaining:
| (13) |
For our case we have assumed that the difference between and is negligible due to the adjacency of the lidar to the cameras. Therefore, and could be computed in terms of camera intrinsic parameters and lidar angular resolution:
| (14) |
In the case of the lidar VLP-16 and our GMSL cameras, and , giving pixels and pixels. Having calculated the size in pixels of the vertical and horizontal gaps, we proceed to project the ordered point cloud into the image, starting with the closest point to the camera. Each projected point will create a rectangular mask of and dimensions centred in the corresponding pixel. A more distant 3D point will not be included in the final pointcloud if its projection lies inside a masked area, in this case we assume the point is occluded. Fig. 6 shows the difference between the lidar-image projection without and with occlusion masking for each camera.
III RESULTS
We tested our algorithm using the Usyd Dataset [1]. An electric vehicle equipped with multiple sensors was driven around the University of Sydney while collecting images (from five field of view cameras located around the vehicle), point cloud (from one lidar VLP-16 located on the roof) and odometry information.
We assess the performance of the proposed pipeline using a single laser scan by implementing the lidar-image projection using three different methods: direct projection, projection after correcting the point cloud for motion and projection with occlusion handling after motion correction. A total of 20 single lidar scans were hand labelled for the experiment and then compared with the outcome of each method. Since the information projected into the point cloud corresponds to a semantic class probability distribution, the comparison is done between the ground truth and the semantic class with highest probability.
We combined and discarded unused semantic classes obtaining 7 final labels in the point cloud (sky and unlabeled classes were discarded while pole and sign, pedestrian and rider and, building and fence were merged). Table I shows the results of the recall, precision and F1 score per experiment.
| Semantic class | Direct Projection | Projection + Motion Correction | Projection + Motion C + Mask | ||||||
| Recall | Precision | F1 Score | Recall | Precision | F1 Score | Recall | Precision | F1 Score | |
| Building | 0.749 | 0.785 | 0.769 | 0.769 | 0.804 | 0.786 | 0.809 | 0.849 | 0.829 |
| Pole | 0.702 | 0.172 | 0.276 | 0.722 | 0.185 | 0.295 | 0.731 | 0.215 | 0.332 |
| Road | 0.958 | 0.946 | 0.952 | 0.962 | 0.948 | 0.955 | 0.963 | 0.954 | 0.958 |
| Undrivable Road | 0.769 | 0.657 | 0.709 | 0.787 | 0.677 | 0.728 | 0.824 | 0.728 | 0.773 |
| Vegetation | 0.862 | 0.933 | 0.896 | 0.875 | 0.948 | 0.910 | 0.898 | 0.969 | 0.932 |
| Vehicle | 0.940 | 0.825 | 0.879 | 0.954 | 0.834 | 0.890 | 0.962 | 0.847 | 0.901 |
| Pedestrian | 0.938 | 0.361 | 0.521 | 0.953 | 0.375 | 0.538 | 0.987 | 0.649 | 0.783 |
The number of labelled points per scan is reduced by around 7 after incorporating the occlusion rejection process when compared to the original pointcloud. The recall is greatly improved when using the masking technique as it avoids the situation where occluded points were being mislabelled. The precision is also positively affected because of the reduction in the number of both false negatives and false positives. Similarly, the motion correction of the point cloud leads to the more accurate transfer of labels due to the correction of each point based on the vehicle position and image timestamp.
From Table I, it is evident that the semantic classes with the most improvement in the metrics are pole and pedestrian. As poles are generally skinny and lidars generally have comparatively lower vertical resolution compared to horizontal resolution there are very few points covering these types of objects. If there is an error in the projection due to forwards or backwards motion of the vehicle, the transferred labels are likely to be incorrect. As pedestrians can be often considered as moving objects, the synchronisation between the point cloud and the image plays a fundamental role when combining the the sensors’ information.








Due to the displacement between the lidar and camera, object classes closer to the platform occlude other structures which end up being incorrectly labelled as the class of the closest object, increasing the number of false positives. This in one of the reasons why the pole and pedestrian classes have the lowest precision when projected into the point cloud domain, and why this improves dramatically with the proposed occlusion handling method.
Qualitative evaluation for a projection of semantic information into a single lidar scan is shown in Fig. 7. In Fig. 7(a) we can observe the images of the five cameras stitched and semantically segmented. Fig. 7(b)-7(f) depict a top-down view of the lidar data with the probability of each class shown in the point cloud domain. There is a strong correspondence between the high probability (in purple) and the object in the 3D world.
One issue identified with this approach is that some objects only partially occlude the more distant objects. This can be seen in particular with the vegetation class where even if the camera can see walls between tree branches, the CNN usually identifies this space as vegetation. As a result, points with a high probability of being vegetation can be found on building walls.
IV CONCLUSIONS AND FUTURE WORK
In this paper, we described an innovative approach to fuse information from different sensor modalities (cameras and lidar), resulting in a probabilistic semantic point cloud.
Captured images were segmented by a previously trained CNN. Instead of using the output of the network directly, we opted to link heuristic probabilities to each class. These probabilities were calculated based on a superpixel segmentation of the raw image, the network output and score maps. The outcome of this process is the analytical probability for every semantic class per pixel. We presented an approach that takes a set of lidar packets with given timestamps and applies motion correction to the lidar packets given the vehicle odometry and a reference timestamp. Finally, the motion corrected lidar points are projected into the camera coordinate system.
The results shown in Table I demonstrate the importance of correcting the lidar point cloud. The precision of the projection improves significantly due to this process as it improves the corespondance between the points and the image. This improvement implies a more precise transference of information and hence more true positives and less false positives.
To project accurate information from the image to the lidar, we presented an algorithm to determine if each lidar 3D point can be seen by each camera. This algorithm is essential to remove occluded points that are visible to the lidar but that the camera cannot see. We have proposed a masking methodology to cope with the occlusion problem for the VLP-16 lidar, which was unable to be solved using traditional techniques due to the low vertical resolution. This approach rejects a number of points that are primarily false positives or false negatives. This methodology can be easily extended to being used with different lidar-camera arrangements.
The results of this paper are relevant in terms of semantic sensor fusion (with labels heuristic probabilities) while coping with issues as motion correction and occlusions. As well, the resulting point cloud can be used in a number of applications where current probabilistic semantic information is needed to make decisions or to build semantic maps of the environment.
As future work, we intend to propagate the odometry uncertainty into the projection process and integrate it into the pipeline, and evaluate the registration of the resulting point cloud.
ACKNOWLEDGMENT
This work has been funded by the ACFR, the University of Sydney through the Dean of Engineering and Information Technologies PhD Scholarship (South America) and the Australian Research Council Discovery Grant DP160104081 and University of Michigan / Ford Motors Company Contract “Next generation Vehicles".
References
- [1] W. Zhou, S. Berrio, S. Worrall, C. De Alvi, S. Mao, J. Ward, and E. Nebot, “The usyd campus dataset,” 2019. [Online]. Available: http://dx.doi.org/10.21227/sk74-7419
- [2] G. Ros, S. Ramos, M. Granados, A. Bakhtiary, D. Vázquez, and A. López, “Vision-based offline-online perception paradigm for autonomous driving,” Proceedings - 2015 IEEE Winter Conference on Applications of Computer Vision, WACV 2015, pp. 231–238, 02 2015.
- [3] W. Zhou, A. Zyner, S. Worrall, and E. Nebot, “Adapting semantic segmentation models for changes in illumination and camera perspective,” in IEEE Robotics and Automation Letters, 4(2)), 2019.
- [4] Hsiang-Jen Chien, R. Klette, N. Schneider, and U. Franke, “Visual odometry driven online calibration for monocular lidar-camera systems,” in 2016 23rd International Conference on Pattern Recognition (ICPR), Dec 2016, pp. 2848–2853.
- [5] J. Li, X. He, and J. Li, “2d lidar and camera fusion in 3d modeling of indoor environment,” in 2015 National Aerospace and Electronics Conference (NAECON), June 2015, pp. 379–383.
- [6] T. C. Bybee and S. E. Budge, “Method for 3-d scene reconstruction using fused lidar and imagery from a texel camera,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 11, pp. 8879–8889, Nov 2019.
- [7] A. Rangesh and M. M. Trivedi, “No blind spots: Full-surround multi-object tracking for autonomous vehicles using cameras and lidars,” IEEE Transactions on Intelligent Vehicles, vol. 4, no. 4, pp. 588–599, Dec 2019.
- [8] S. Schneider, M. Himmelsbach, T. Luettel, and H. Wuensche, “Fusing vision and lidar - synchronization, correction and occlusion reasoning,” in 2010 IEEE Intelligent Vehicles Symposium, June 2010, pp. 388–393.
- [9] R. Varga, A. Costea, H. Florea, I. Giosan, and S. Nedevschi, “Super-sensor for 360-degree environment perception: Point cloud segmentation using image features,” in 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Oct 2017, pp. 1–8.
- [10] R. Pintus, E. Gobbetti, and M. Agus, “Real-time rendering of massive unstructured raw point clouds using screen-space operators.” 01 2011, pp. 105–112.
- [11] W. Zhou, S. Berrio, S. Worrall, and E. Nebot, “Automated evaluation of semantic segmentation robustness for autonomous driving,” in IEEE Transactions on Intelligent Transportation Systems, Early Print, April 2019. [Online]. Available: https://doi.org/10.1109/TITS.2019.2909066
- [12] A. Paszke, A. Chaurasia, S. Kim, and E. Culurciello, “Enet: A deep neural network architecture for real-time semantic segmentation,” CoRR, vol. abs/1606.02147, 2016.
- [13] K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” in Proceedings of the International Conference on Learning Representations (ICLR), 2014.
- [14] J. S. Bridle, “Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition,” in Neurocomputing, F. F. Soulié and J. Hérault, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 1990, pp. 227–236.
- [15] C. M. Bishop, Pattern Recognition and Machine Learning (Information Science and Statistics). Berlin, Heidelberg: Springer-Verlag, 2006.
- [16] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Süsstrunk, “Slic superpixels compared to state-of-the-art superpixel methods,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 34, no. 11, pp. 2274–2282, Nov 2012.
- [17] Ren and Malik, “Learning a classification model for segmentation,” in Proceedings Ninth IEEE International Conference on Computer Vision, Oct 2003, pp. 10–17 vol.1.
- [18] R. Sutton, Reinforcement Learning, ser. The Springer International Series in Engineering and Computer Science. Springer US, 1992. [Online]. Available: https://books.google.com.au/books?id=GDvW4MNMQ2wC
- [19] M. Himmelsbach and W. H. j., “Lidar-based 3d object perception,” in Proceedings of 1st International Workshop on Cognition for Technical Systems, 2008.
- [20] Open_CV, “Fisheye camera model, camera calibration and 3d reconstruction,” https://docs.opencv.org/3.4/db/d58/group__calib3d__fisheye.html, 2019, accessed: 2019-10-01.
- [21] Velodyne, “Vlp-16 user manual,” https://velodynelidar.com/vlp-16.html, San Jose, California, USA, 2018, accessed: 2019-04-10.