Semantic OcTree Mapping and Shannon Mutual Information Computation for Robot Exploration
Abstract
Autonomous robot operation in unstructured and unknown environments requires efficient techniques for mapping and exploration using streaming range and visual observations. Information-based exploration techniques, such as Cauchy-Schwarz quadratic mutual information (CSQMI) and fast Shannon mutual information (FSMI), have successfully achieved active binary occupancy mapping with range measurements. However, as we envision robots performing complex tasks specified with semantically meaningful concepts, it is necessary to capture semantics in the measurements, map representation, and exploration objective. This work presents Semantic octree mapping and Shannon Mutual Information (SSMI) computation for robot exploration. We develop a Bayesian multi-class mapping algorithm based on an octree data structure, where each voxel maintains a categorical distribution over semantic classes. We derive a closed-form efficiently-computable lower bound of the Shannon mutual information between a multi-class octomap and a set of range-category measurements using semantic run-length encoding of the sensor rays. The bound allows rapid evaluation of many potential robot trajectories for autonomous exploration and mapping. We compare our method against state-of-the-art exploration techniques and apply it in a variety of simulated and real-world experiments.
Index Terms:
View Planning for SLAM, Reactive and Sensor-Based Planning, Vision-Based Navigation.I Introduction
Accurate modeling, real-time understanding, and efficient storage of a robot’s environment are key capabilities for autonomous operation. Occupancy grid mapping [1, 2] is a widely used, simple, yet effective, technique for distinguishing between traversable and occupied space surrounding a mobile robot. OctoMap [3] is an extension of occupancy grid mapping, introducing adaptive resolution to improve the memory usage and computational cost of generating 3-D maps of large environments. Delegating increasingly sophisticated tasks to autonomous robots requires augmenting traditional geometric models with semantic information about the context and object-level structure of the environment [4, 5, 6]. Robots also are increasingly expected to operate in unknown environments, with little to no prior information, in applications such as disaster response, environmental monitoring, and reconnaissance. This calls for algorithms allowing robots to autonomously explore unknown environments and construct low-uncertainty metric-semantic maps in real-time, while taking collision and visibility constraints into account.

This paper considers the active metric-semantic mapping problem, requiring a robot to explore and map an unknown environment, relying on streaming distance and object category observations, e.g., generated by semantic segmentation over RGBD images [7]. See Fig. 1 as an illustration of the sensor data available for mapping and exploration. We extend information-theoretic active mapping techniques [8, 9, 10] from binary to multi-class environment representations. Our approach introduces a Bayesian multi-class mapping procedure which maintains a probability distribution over semantic categories and updates it via a probabilistic range-category perception model. Our main contributions are:
-
1.
a Bayesian multi-class octree mapping approach,
-
2.
a closed-form efficiently-computable lower bound for the Shannon mutual information between a multi-class octree map and a set of range-category measurements,
-
3.
efficient C++ implementation achieving real-time high-accuracy performance onboard physical robot systems in 3-D real-world experiments111Open-source software and videos supplementing this paper are available at https://arashasgharivaskasi-bc.github.io/SSMI_webpage..
Unlike a uniform-resolution grid map, our semantic OctoMap enables efficient mutual information evaluation via run-length encoding of the range-category observations. As a result, the informativeness of many potential robot trajectories may be evaluated to (re-)select one that leads to the best trade-off between map uncertainty reduction and motion cost. Unlike traditional class-agnostic exploration methods, our model and information measure capture the uncertainty of different semantic classes, leading to faster and more accurate exploration. The proposed approach relies on general range and class measurements and general pose kinematics, making it suitable for either ground or aerial robots, equipped with either camera or LiDAR sensors, exploring either indoor or outdoor environments.
We name our method Semantic octree mapping and Shannon Mutual Information (SSMI) computation for robot exploration. This paper is an extended version of our previous conference paper [11] enabling its application in large-scale 3-D environments. Direct application of the regular-grid method in the conference version to 3-D environments faces several challenges, including memory inefficiency, because 3-D environments are predominantly made up of free or unknown space, and information computation inefficiency due to naïve summation over all voxels visited by sensor rays. We introduce (a) an octree representation for Bayesian multi-class mapping, performing octree ray-tracing and leaf node merging using semantic category distributions, (b) semantic run-length encoding (SRLE) for sensor rays which enables efficient mutual information computation between a multi-class octree and range-category measurements, and (c) a comprehensive set of experiments and comparisons with state-of-the-art techniques in 2-D and 3-D environments. We demonstrate the effectiveness of SSMI in real-world mapping and autonomous exploration experiments performed in real-time onboard different mobile robot platforms operating in indoor and outdoor environments.
II Related Work
Frontier-based exploration [12] is a seminal work that highlighted the utility of autonomous exploration and active mapping. It inspired methods [13, 14] that rely on geometric features, such as the boundaries between free and unknown space (frontiers) and the volume that would be revealed by new sensor observations. Due to their intuitive formulation and low computational requirements, geometry-based exploration methods continue to be widely employed in active perception. Recent works include semantics-assisted indoor exploration [15], hex-decomposition-based coverage planning [16], and Laplace potential fields for safe outdoor exploration [17]. More related to our work, receding-horizon “next-best-view” planning [18] presents an active octree occupancy mapping method which executes trajectories built from a random tree whose quality is determined by the amount of unmapped space that can be explored. Similarly, the graph-based exploration methods of [19] and [20] use local random trees in free space to sample candidate viewpoints for exploration, while a global graph maintains the connections among the frontiers in the map. Cao et al. [21, 16] introduced hierarchical active 3D coverage and reconstruction which computes a coarse coverage path at the global scale followed by a local planner that ensures collision avoidance via a high-resolution path. As shown by Corah and Michael [22], coverage-based exploration strategies can be formulated as mutual-information maximization policies in the absence of sensor noise. However, in many real-world circumstances sensor measurements are corrupted by non-trivial noise, reducing the effectiveness of geometric exploration methods that do not capture probabilistic uncertainty. For example, due to the domain shift between the training data and the test environment, utilizing a pre-trained semantic segmentation model in the mapping process requires accounting for measurement uncertainty in the exploration policy.
The work by Elfes [23] is among the first to propose an information-based utility function for measuring and minimizing map uncertainty. Information-based exploration strategies have been devised for uncertainty minimization in robot localization or environment mapping [24, 25, 26]. Information-theoretic objectives, however, require integration over the potential sensor measurements, limiting the use of direct numerical approximations to short planning horizons. Kollar and Roy [27] formulated active mapping using an extended Kalman filter and proposed a local-global optimization, leading to significant gains in efficiency for uncertainty computation and long-horizon planning. Unlike geometry-based approaches, information-theoretic exploration can be directly formulated for active simultaneous localization and mapping (SLAM) [28, 29, 30, 31], aiming to determine a sensing trajectory that balances robot state uncertainty and visitation of unexplored map regions. Stachniss et al. [32] approximate information gain for a Rao-blackwellized particle filter over the joint state of robot pose and map occupancy. Julian et al. [8] prove that, for range measurements and known robot position, the Shannon mutual information is maximized over trajectories that visit unexplored areas. However, without imposing further structure over the observation model, computing the mutual information objective requires numerical integration. The need for efficient mutual information computation becomes evident in 3-D environments. Cauchy-Schwarz quadratic mutual information (CSQMI) [9] and fast Shannon mutual information (FSMI) [10] offer efficiently computable closed-form objectives for active occupancy mapping with range measurements. Henderson et al. [33] propose an even faster computation based on a recursive expression for Shannon mutual information in continuous maps.
The recent success of machine learning methods of perception has motivated learning autonomous exploration policies. Chen et al. [34] attempt to bridge the sim2sim and sim2real gaps via graph neural networks and deep reinforcement learning. This enables decision-making over graphs containing relevant exploration information which is provided by human experts in order to predict a robot’s optimal sensing action in belief space. Lodel et al. [35] introduce a deep reinforcement learning policy which recommends next best view that maximizes information gain via defining mutual information as the training reward. Zwecher et al. [36] employ deep reinforcement learning to find an exploration policy that plans collision-free coverage paths, while another neural network provides a predicted full map given the partially observed environment. Zhang et al. [37] propose a multi-agent reinforcement learning exploration method where regions of interest, free space, and robots are represented as graph nodes, and hierarchical-hops graph neural networks (H2GNN) are used to identify key information in the environment. Related to multi-robot exploration, the authors in [38] utilize an actor-critic strategy to map an unknown environment, where Voronoi partitioning divides the exploration regions among the robots. As this paper demonstrates, incorporating semantic uncertainty in addition to geometric information in the exploration process can be beneficial. Additionally, using Shannon mutual information as an objective function may help train more generalizable exploration policies because it mitigates the need for training sensor-specific models. Hence, the techniques proposed in this paper are complementary to learning approaches and can provide robustness to measurement uncertainty and domain shift caused by sensor and operational condition variations.
Active semantic mapping has recently attracted much attention due to the proliferation of fast object detection and semantic segmentation algorithms implemented on mobile robot platforms. The authors in [39] use a two-layer architecture, where the knowledge representation layer provides a belief over the environment state to the action layer, which subsequently chooses an action to gather information or execute a task. The work in [40] presents a semantic exploration policy which takes an occluded semantic point cloud of an object, finds a match in a database to estimate the full object dimensions, and then generates candidate next observation poses to reconstruct the object. The next best view is computed via a volumetric information gain metric that computes visible entropy from a candidate pose. The semantic map used in this paper is a collection of bounding boxes around objects. Active semantic mapping has also been employed to develop sample-efficient deep learning methods. Blum et al. [41] propose an active learning method for training semantic segmentation networks where the novelty (epistemic uncertainty) of the input images is estimated as the distance from the training data in the embedding space, while a path planning method maximizes novelty of future input images along the planned trajectory, assuming novel images are spatially correlated. Georgakis et al. [42] actively train a hierarchical semantic map generation model that predicts occupancy and semantics given occluded input. The authors use an ensemble of map generation models in order to predict epistemic uncertainty of the predicted map. The uncertainty is then used to choose trajectories for actively training the model with new images that differ the most with the training data of the current model. SSMI distinguishes itself from the aforementioned works by introducing a dense Bayesian multi-class mapping with a closed-form uncertainty measure, as opposed to sampling-based uncertainty estimation. Moreover, our information-theoretic objective function directly models sensor noise specifications, unlike volumetric information gain.
This paper is most related to CSQMI [9] and FSMI [10] in that it develops a closed-form expression for mutual information. However, instead of a binary map and range-only measurements, our formulation considers a multi-class map with Bayesian updates using range-category measurements. Since the same occupancy map can be derived from many different multi-class maps, the information associated with various object classes will fail to be captured if we solely rely on occupancy information, as the case in CSQMI and FSMI. Therefore, we expect to perform exploration more efficiently by using the multi-class perception model, and consequently, expanding the notion of uncertainty to multiple classes.
III Problem Statement
Consider a robot with pose at time and deterministic discrete-time kinematics:
| (1) |
where is the robot orientation, is the robot position, is the time step, and is the control input, consisting of linear velocity and angular velocity . The function maps vectors in to the Lie algebra . See [43, Chapter 7] for a definition of the Lie groups and and the corresponding Lie algebras and . The robot is navigating in an environment consisting of a collection of disjoint sets , each associated with a semantic category . Let denote free space, while each for represents a different category, such as building, vegetation, terrain (see Fig. 1).
We assume that the robot is equipped with a sensor that provides information about the distance to and semantic categories of surrounding objects along a set of rays , where is the ray index, with , and is the maximum sensing range.
Definition 1.
A sensor observation at time from robot pose is a collection of range and category measurements , acquired along the sensor rays with at robot position .
Such information may be obtained by processing the observations of an RGBD camera or a Lidar with a semantic segmentation algorithm [7]. Fig. 1 shows an example where each pixel in the RGB image corresponds to one sensor ray , while its corresponding values in the semantic segmentation and the depth images encode category and range , respectively. The goal is to construct a multi-class map of the environment based on the labeled range measurements. We model as a grid of cells , each labeled with a category . In order to model noisy sensor observations, we consider a probability density function (PDF) . This observation model allows integrating the measurements into a probabilistic map representation using Bayesian updates. Let be the probability mass function (PMF) of the map given the robot trajectory and observations up to time . Given a new observation obtained from robot pose , the Bayesian update to the map PMF is:
| (2) |
We assume that the robot pose is known and omit the dependence of the map distribution and the observation model on it for brevity. We consider the following problem.
Problem.
Given a prior map PMF at time and a finite planning horizon , maximize the ratio:
| (3) |
of the mutual information between the map and future sensor observations to the motion cost of the control sequence .
The definitions of the mutual information and motion cost terms in (3) are:
| (4) | |||
where the integration in (4) is over all possible values of all sensor beams over all times , and the strictly positive terms and model terminal and stage motion costs (e.g., distance traveled, elapsed time), respectively.
We develop a multi-class extension to the log-odds occupancy mapping algorithm [44, Ch. 9] in Sec. IV and derive an efficient approximation to the mutual information term in Sec. V. In Sec. VI, we present a multi-class extension of the OctoMap [3] algorithm, alongside a fast computation of mutual information over a semantic OctoMap using run-length encoding. This allows autonomous exploration of large 3-D environments by rapidly evaluating potential robot trajectories online and (re-)selecting the one that maximizes the objective in (3). Finally, in Sec. VII, we demonstrate the performance of our approach in simulated and real-world experiments.
IV Bayesian Multi-class Mapping




This section derives the Bayesian update in (2), using a multinomial logit model to represent the map PMF where each cell of the map stores the probability of object classes in . To ensure that the number of parameters in the model scales linearly with the map size , we maintain a factorized PMF over the cells:
| (5) |
We represent the individual cell PMFs over the semantic categories using a vector of log odds:
| (6) |
where the free-class likelihood is used as a pivot. Given the log-odds vector , the PMF of cell may be recovered using the softmax function :
| (7) |
where is the standard basis vector with -th element equal to and elsewhere, is the vector with all elements equal to , and is applied elementwise to the vector . To derive Bayes rule for the log-odds , we need to specify an observation model for the range and categry measurements.
Definition 2.
The inverse observation model of a range-category measurement obtained from robot pose along sensor ray with respect to map cell is a probability mass function .
The Bayesian update in (2) for can be obtained in terms of the range-category inverse observation model, evaluated at a new measurement set .
Proposition 1.
Let be the log odds of cell at time . Given sensor observation , the posterior log-odds are:
| (8) |
where is the inverse observation model log odds:
| (9) |
Proof.
See Appendix A. ∎
To complete the Bayesian multi-class mapping algorithm suggested by (8) we need a particular inverse observation model. When a sensor measurement is generated, the sensor ray continues to travel until it hits an obstacle of category or reaches the maximum sensing range . The labeled range measurement obtained from position with orientation indicates that map cell is occupied if the measurement end point lies in the cell. If lies along the sensor ray but does not contain the end point, it is observed as free. Finally, if is not intersected by the sensor ray, no information is provided about its occupancy. The map cells along the sensor ray can be determined by a rasterization algorithm, such as Bresenham’s line algorithm [45]. We parameterize the inverse observation model log-odds vector in (9) as:
| (10) |
where and are parameter vectors, whose first element is to ensure that is a valid log-odds vector. This parameterization leads to an inverse observation model , which is piecewise constant along the sensor ray. Fig. 2 illustrates our Bayesian multi-class mapping method.
To compute the mutual information between an observation sequence and the map in the next section, we will also need the PDF of a range-category measurement conditioned on . Let denote the set of map cell indices along the ray from robot position with length . Let denote the distance traveled by the ray within cell and denote the index of the cell hit by . We define the PDF of conditioned on as:
| (11) |
This definition states that the likelihood of at time depends on the likelihood that the cells along the ray of length are empty and the likelihood that the hit cell has class . A similar model for binary observations has been used in [8, 9, 10].
This section described how an observation affects the map PMF . Now, we switch our focus to computing the mutual information between a sequence of observations and the multi-class occupancy map .
V Informative Planning
Proposition 1 allows a multi-class formulation of occupancy grid mapping, where the uncertainty of a map cell depends on the probability of each class , instead of only the binary occupancy probability . Moreover, the inverse observation model in (10) may contain different likelihoods for the different classes which can be used to prioritize the information gathering for specific classes. Fig. 3(a) shows an example where the estimated map of an environment with classes, free, , , contains two regions with similar occupancy probability but different semantic uncertainty. In particular, the red and green walls have the same occupancy probability of , as shown in Fig. 3(b), but the red region more certainly belongs to and the green region has high uncertainty between the two classes. As can be seen in Fig. 3(c), the mutual information associated with a binary occupancy map cannot distinguish between the red and green regions since they both have the same occupancy probability. In contrast, the multi-class map takes into account the semantic uncertainty among different categories, as can be seen in Fig. 3(d) where the uncertain green region has larger mutual information than the certain red region.




These observations suggest that more accurate uncertainty quantification may be achieved using a multi-class instead of a binary perception model, potentially enabling a more efficient exploration strategy. However, computing the mutual information term in (4) is challenging because it involves integration over all possible values of the observation sequence . Our main result is an efficiently-computable lower bound on for range-category observations and a multi-class occupancy map . The result is obtained by selecting a subset of the observations in which the sensor rays are non-overlapping. Precisely, any pair of measurements , satisfies:
| (12) |
In practice, constructing requires removing intersecting rays from to ensure that the remaining observations are mutually independent. The mutual information between and can be obtained as a sum of mutual information terms between single rays and map cells observed by . This idea is inspired by CSQMI [9] but we generalize it to multi-class observations and map.
Proposition 2.
Given a sequence of labeled range observations , let be a subset of non-overlapping measurements that satisfy (12). Then, the Shannon mutual information between and a multi-class occupancy map can be lower bounded as:
| (13) | ||||
where ,
and is the set of the first map cell indices along the ray , i.e., .
Proof.
See Appendix B. ∎
In (13), represents the probability that the -th map cell along the ray belongs to object category while all of the previous cells are free. The function denotes the log-ratio of the map PMF and its posterior , averaged over object categories in (see (26) in Appendix B for more details). As a result, is the sum of log-ratios for the first cells along the ray under the same event as the one is associated with. Therefore, the lower bound is equivalent to the expectation of summed log-ratios over all possible instantiations of the observations in .
Proposition 2 allows evaluating the informativeness according to (3) of any potential robot trajectory , . In order to perform informative planning, first, we identify the boundary between the explored and unexplored regions of the map, similar to [12]. This can be done efficiently using edge detection, for example. Then, we cluster the corresponding map cells by detecting the connected components of the boundary. Each cluster is called a frontier. A motion planning algorithm is used to obtain a set of pose trajectories to the map frontiers, determined from the current map PMF . Alg. 1 summarizes the procedure for determining a trajectory , that maximizes the objective in (3), where is the length of the corresponding path. This kinematically feasible trajectory can be tracked by a low-level controller that takes the robot dynamics into account.
Evaluation of the mutual information lower bound in Proposition 2 can be accelerated without loss in accuracy for map cells along the observation rays that contain equal PMFs. In the next section, we investigate this property of the proposed lower bound within the context of OcTree-based representations. We begin with proposing a multi-class version of the OctoMap technique, where map cells with equal multi-class probabilities can be compressed into a larger voxel. Next, a fast semantic mutual information formula is presented based on compression of range-category ray-casts over OcTree representations.
VI Information Computation for Semantic OctoMap Representations


Utilizing a regular-grid discretization to represent a 3-D environment has prohibitive storage and computation requirements. Large continuous portions of many real environments are unoccupied, suggesting that adaptive discretization is significantly more efficient. OctoMap [3] is a probabilistic 3-D mapping technique that utilizes an OcTree data structure to obtain adaptive resolution, e.g., combining many small cells associated with free space into few large cells. In this section, we develop a multi-class version of OctoMap and propose an efficient multi-class mutual information computation which benefits from the OcTree structure.
VI-A Semantic OctoMap
An OcTree is a hierarchical data structure containing nodes that represent a section of the physical environment. Each node has either 0 or 8 children, where the latter corresponds to the 8 octants of the Euclidean 3-D coordinate system. Thus, the children of a parent node form an eight-way octant partition of the space associated with the parent node. Fig. 4 shows an example of a multi-class OcTree data structure.
We implement a SemanticOcTreeNode class as a building block of the multi-class OcTree structure. A SemanticOcTreeNode instance stores occupancy, color, and semantic information of its corresponding physical space, as shown in Fig. 4(b). The most important data members of the SemanticOcTreeNode class are:
-
•
children: an array of pointers to SemanticOcTreeNode storing the memory addresses of the child nodes,
-
•
value: a float variable storing the log-odds occupancy probability of the node,
-
•
color: a ColorRGB object storing the RGB color of the node,
-
•
semantics: a SemanticLogOdds object maintaining a categorical probability distribution over the semantic labels in the form of a log-odds ratio.
For performance reasons, the SemanticLogOdds class only stores the multi-class log-odds for the most likely class labels, with each label represented by a unique RGB color. In this case, the log-odds associated with the rest of the labels lump into a single others variable. This relives the multi-class OcTree implementation from dependence on the number of labels that the object classifier can detect. Moreover, it significantly improves the speed of the mapping algorithm in cases with many semantic categories. See Sec. VII-D for an analysis of mapping time versus the number of stored classes.
The implementation of the multi-class OcTree is completed by defining a SemanticOcTree class, which is derived from the OccupancyOcTreeBase class of the OctoMap library [3] and uses a SemanticOcTreeNode as its node type. Fig. 5 illustrates the derivation of the SemanticOcTree and SemanticOcTreeNode classes as a UML diagram.

In order to register a new observation to a multi-class OcTree, we follow the standard ray-casting procedure over an OcTree, as in [3], to find the observed leaf nodes. Then, for each observed leaf node, if the observation demands an update, the leaf node is recursively expanded to the smallest resolution and the multi-class log-odds of the downstream nodes are updated using (8). At the ray’s end point, which indicates an occupied cell, we also update the color variable by averaging the observed color with the current stored color of the corresponding node. Alg. 2 details the Bayesian update procedure for the multi-class OcTree.
To obtain a compressed OctoMap, it is necessary to define a rule for information fusion from child nodes towards parent nodes. Depending on the application, different information fusion strategies may be implemented. For example, a conservative strategy would assign the multi-class log-odds of the child node with the highest occupancy probability to the parent node. In this work, we simply assign the average log-odds vector of the child nodes to their parent node as shown in Alg. 3. The benefit of an OctoMap representation is the ability to combine similar cells (leaf nodes) into a large cell (inner node). This is called pruning the OcTree. Every time after an observation is integrated to the map, starting from the deepest inner node, we check for each inner node if 1) the node has 8 children, 2) its children do not have any children of their own, and 3) its children all have equal multi-class log-odds . If an inner node satisfies all of these three criteria, its children are pruned and the inner node is converted into a leaf node with the same multi-class log-odds as its children. This helps to compress the majority of the free cells into a few large cells, while the occupied cells usually do not undergo pruning since only their surfaces are observed by the sensor and their inside remains an unexplored region. Due to sensor noise, it is unlikely that cells belonging to the same class (e.g., free or occupied by the same obstacle) attain identical multi-class log-odds. Maximum and minimum limits for the elements of the multi-class log-odds are used so that each cell arrives at a stable state as its multi-class log-odds entries reach the limits. Stable cells are more likely to share the same multi-class probability distribution, consequently increasing the chance of OcTree pruning. However, thresholding causes loss of information near , which can be controlled by the maximum and minimum limits.
VI-B Information Computation
A ray cast through an OcTree representation may visit several large cells within which the class probabilities are homogeneous. We exploit this property to obtain the mutual information between a multi-class OctoMap and a single ray as a summation over a subset of OcTree leaf nodes instead of individual map cells. This simplification provides a significant performance gain with no loss of accuracy. The following formulation can be considered a multi-class generalization of the run-length encoding technique introduced by [10], using the mutual information lower bound in (13) and the multi-class OcTree defined earlier in this section.
Suppose that the map cells along a single beam have piecewise-constant multi-class probabilities such that the set can be partitioned into groups of consecutive cells indexed by , , where:
| (14) |
In this case, the log-odds probabilities encountered by a ray cast can be compressed using semantic run-length encoding, defined as below.
Definition 3.
A semantic run-length encoding (SRLE) of a ray cast through a multi-class OcTree is an ordered list of tuples of the form , where and respectively represent the width and the log-odds vector of the intersection between the ray and the cells in . The width is the number of OcTree elements along the ray intersection, where an OcTree element is a cell with the smallest physical dimensions.

Fig. 6 shows an example of SRLE over a semantic OctoMap. While SRLE can be used in a uniform-resolution grid map, it is particularly effective of a multi-class OcTree, which inherently contains large regions with homogeneous multi-class log-odds. Additionally, the OcTree data structure allows faster ray casting since it can be done over OcTree leaf nodes [46, 47], instead of a uniform-resolution grid as in [45].
SRLE ray casting delivers substantial gains in efficiency for mutual information computation since the contribution of each group in the innermost summation of (13) can be obtained in closed form.
Proposition 3.
The Shannon mutual information between a single range-category measurement and a semantic OctoMap can be computed as:
| (15) |
where is the number of partitions along the ray that have identical multi-class log-odds and the multi-class probabilities for each partition are denoted as:
Furthermore, defining as the width of -th partition, we have:
Proof.
See Appendix C. ∎
In (15), relates to the event that the partition belongs to category while all of the previous partitions along the ray are free. Analogous to the definition of in Proposition 2, is the weighted sum of log-ratios for the first partitions along the ray under the same event as the one is associated with. Accumulating the multi-class probabilities within the partition yields , see (C) for more details. Therefore, the mutual information in (15) is equivalent to the expectation of accumulated log-ratios over all possible instantiations of .
Proposition 3 allows an extension of the mutual-information lower bound in Proposition 2 to semantic OctoMap representations, summarized in the corollary below. The proof follows directly from the additive property of mutual information between a semantic OctoMap and a sequence of independent observations.
Corollary 1.
The same approach as in Alg. 1 is used for autonomous exploration over a semantic OctoMap. However, we employ the information computation formula of (16) to quantify the informativeness of candidate robot trajectories. The active mapping method in Alg. 1 provides a greedy exploration strategy, which does not change subsequent control inputs based on the updated map distribution. Greedy exploration may be sub-optimal and manifests itself as back and forth travel between map frontiers. We alleviate this behavior by (a) computing the information along the whole trajectory as opposed only at the frontiers or next best view, and (b) re-plan frequently to account for the updated map distribution. Discounted by distance traveled as the cost of a trajectory, this leads to a more accurate calculation of information gain along a candidate path which rules out most of the back and forth visiting behaviour. It is also important to mention that the main scope of this work is introduction of a novel multi-class semantic OcTree representation and the mutual information between such model and range-category observations. Our method enables fast and accurate evaluation of information for any set of candidate trajectories, likes of which can be generated by random tree methods [10, 48] or hierarchical planning strategies [21] or, in the simplest form, a greedy approach that computes paths to each frontier. We believe utilizing our proposed information measure to score candidate viewpoints would be complementary, rather than an alternative, to the state-of-the-art exploration methods that use sophisticated optimization strategies [19, 21, 49].






VI-C Computational Complexity
Note that the mutual information computations in both (13) and (16) can be performed recursively. For (13), we have:
| (17) | ||||
where and correspond to the index of farthest map cell in and , respectively. A similar recursive pattern can be found in (16):
| (18) | ||||
This implies that the innermost summations of (13) and (16) can be obtained in and , respectively, where is the number of map cells along a single ray up to its maximum range, and is the number of groups of consecutive cells that possess the same multi-class probabilities. In an environment containing object classes, evaluating the informativeness of a trajectory composed of observations, where each observation contains beams, has a complexity of for a regular-grid multi-class representation and a complexity of for a multi-class OcTree representation.
As we demonstrate in Sec. VII-C, for a ray we often observe that is significantly smaller than thanks to the OcTree pruning mechanism. Since scales linearly with the map resolution, the complexity of information computation over a semantic OctoMap grows sub-linearly with respect to the inverse of the OcTree element dimensions, which is a parameter analogous to the map resolution.
VII Experiments




In this section, we evaluate the performance of SSMI in simulated and real-world experiments. We compare SSMI with two baseline exploration strategies, i.e., frontier-based exploration [12] and FSMI [10], in a 2-D active binary mapping scenario in Sec. VII-A and a 2-D active multi-class mapping scenario in Sec. VII-B. All three methods use our range-category sensor model in (10) and our Bayesian multi-class mapping in (8) but select informative robot trajectories based on their own criteria. In Sec. VII-C, we evaluate the improvement in ray tracing resulting from SRLE through an experiment in a 3-D simulated Unity environment. In Sec. VII-D, we investigate the influence of the number of stored semantic classes on mapping performance. Additionally, in Sec. VII-E, we use a similar 3-D simulation environment to apply SSMI alongside Frontier, FSMI, and hierarchical coverage maximization method TARE [21]. In this section we use our OcTree-based multi-class information computation introduced in Sec. VI in order to demonstrate large-scale realistic active multi-class mapping. Finally, in Sec. VII-F and Sec. VII-G, we test SSMI mapping and exploration in real environments using ground wheeled robots. An open-source implementation of SSMI is available on GitHub222https://github.com/ExistentialRobotics/SSMI..
In each planning step of 2-D exploration, we identify frontiers by applying edge detection on the most likely map at time (the mode of ). Then, we cluster the edge cells by detecting the connected components of the boundaries between explored and unexplored space. We plan a path from the robot pose to the center of each frontier using graph search and provide the path to a low-level controller to generate . For 3-D exploration, we first derive a 2-D occupancy map by projecting the most likely semantic OctoMap at time onto the surface and proceed with similar steps as in 2-D path planning.
VII-A 2-D Binary Exploration
We consider active binary occupancy mapping first. We compare SSMI against Frontier and FSMI in structured and procedurally generated 2-D environments, shown in Fig. 7. A 2-D LiDAR sensor is simulated with additive Gaussian noise . Fig. 8(a) and Fig. 8(c) compare the exploration performance in terms of map entropy reduction and percentage of the map explored per distance traveled among the three methods. SSMI performs similarly to FSMI in that both achieve low map entropy by traversing significantly less distance compared to Frontier.
VII-B 2-D Multi-class Exploration
Next, we use the same 2-D environments in Fig. 7 but introduce range-category measurements. Range measurements are subject to additive Gaussian noise , while category measurements have a uniform misclassification probability of . Fig. 8(b) and Fig. 8(d) compare the semantic exploration performance for all three strategies. SSMI reaches the same level of map entropy as FSMI and Frontier but traverses a noticeably shorter distance. This can be attributed to the fact that only SSMI distinguishes map cells whose occupancy probabilities are the same but their per-class probabilities differ from each other. To further illustrate this, we visualize the entropy and information surfaces used by FSMI and SSMI. Fig. 9(a) shows a snapshot of semantic exploration while Fig. 9(b) visualizes the entropy of each pixel computed as:
| (19) |
where denote realized observations until time . The task of exploration can be regarded as minimizing the conditional entropy summed over all pixels, i.e., map entropy. However, since the observations are not known in advance, we resort to estimate the reduction in uncertainty by computing the expectation over the observations. Accounting for the prior uncertainty in map, we arrive at maximizing mutual information as our objective, which is related to entropy as follows:
| (20) |
Therefore, the exploration performance is highly dependent upon the mutual information formulation, since it directly dictates how the uncertainty is quantified. As shown in Fig. 9(d) and resulted from capturing per-class uncertainties, semantic mutual information of SSMI, computed in (13) provides a smoother and more accurate estimation of information-rich regions compared to the binary mutual information formula used by FSMI (equation (18) in [10]) shown in Fig. 9(c).






VII-C SRLE Compression for 3-D Ray Tracing
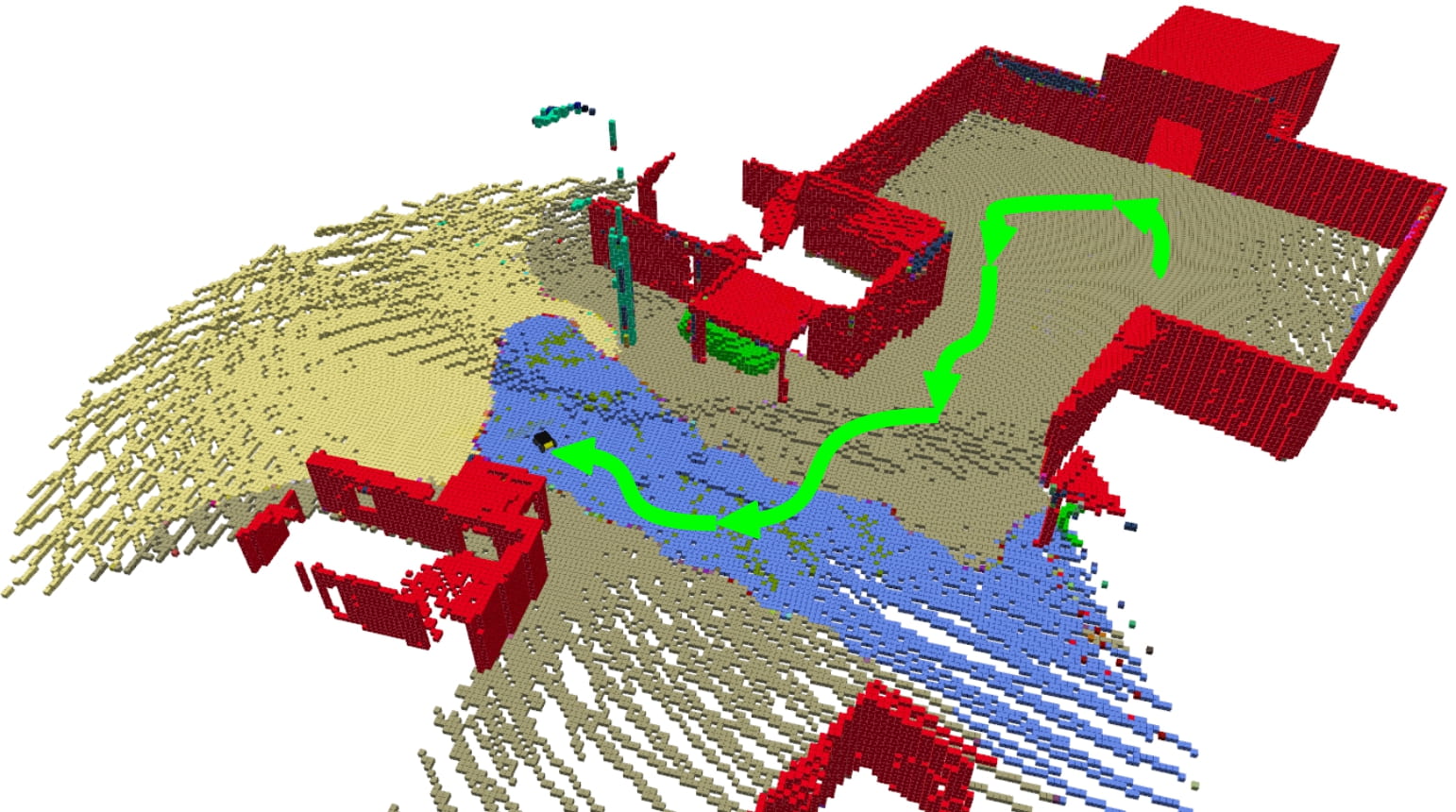
In this subsection, we evaluate the ray-tracing compression resulting from SRLE through an experiment in a photo-realistic 3-D Unity simulation, shown in Fig. 11(e). We use a Husky robot equipped with an RGBD camera and run a semantic segmentation algorithm over the RGB images. In order to remove irrelevant randomness, the sensors and the semantic segmentation are defined as error-free. We define map resolution as the inverse of the dimensions of an OcTree element. For resolutions ranging from to , we run exploration iterations using the semantic OctoMap and information computation of Sec. VI and store all ray traces in SRLE format. Fig. 10 shows the change in distribution for the number of OctoMap cells and OcTree elements visited during each ray trace, as well as the time required to execute each exploration episode as a function of map resolution. In other words, represents the number of cells to be processed during mapping and information computation as if the environment was represented as a regular 3-D grid, while represents the actual number of processed semantic OctoMap cells. The pruning mechanism of the OcTree representation results in a substantial gain in terms of the number of cells visited for each ray tracing. As opposed to the almost linear growth of , the distribution for is effectively independent of the map resolution, except for very fine resolutions where void areas between observations rays prevent efficient pruning. However, for map resolutions larger than , the exploration time tends to grow larger with the increase of map resolution. This is attributed to the recursive ray insertion method of OctoMap in which it is required to re-compute log odds for each OcTree element along an observation ray whenever an observation ray does not carry the same (free or object class) state as the visited cell. In the subsequent 3-D experiments, we choose map resolution of in order to balance between performance and map accuracy.

VII-D Mapping Time vs. Number of Stored Classes
We analyse the influence of the number of stored classes in the semantic OctoMap on the mapping time. Let denote the number of stored semantic classes. Alg. 2 has memory and computational complexity (due to sorting in line 16). Furthermore, let be the misclassification probability assumed to be uniformly distributed among all incorrect classes. Regarding accuracy, for a classifier with , where is the number of all object classes, the true class will be always asymptotically recoverable as long as , thanks to the auxiliary others class that stores the accumulated probability of the least likely classes (see line 20 of Alg. 2). In general, controls how fast the true class will be detected with the cost of additional memory use and computation. In order to quantitatively evaluate the effect of on mapping time, we consider the same Husky robot as the previous subsection with a fixed trajectory, shown in Fig. 12 (top), and measure the mapping frequency as a function of . Fig. 12 (bottom) shows the decrease in average mapping frequency as increases. It is important to mention that the trajectory along which the data is collected only visits object classes, which explains the change in slope for .
VII-E 3-D Exploration in a Unity Simulation
We evaluate SSMI in the same 3-D simulation environment as two previous subsections, however, this time the range measurements have an additive Gaussian noise of and the semantic segmentation algorithm detects the true class with a probability of while the misclassification happens uniformly in the pixel space. Fig. 11 shows several iterations of the exploration process. For comparison, we implemented a 3-D version of FSMI [10] that utilizes run-length encoding to accelerate the information computation for a binary OctoMap. Moreover, we deploy the state-of-the-art hierarchical exploration method of TARE [21] in our 3-D Unity simulation environment. Fig. 13 shows the change in map entropy versus distance traveled and total elapsed time for all exploration strategies. We observe that SSMI is the most efficient in terms of solving the trade-off between path length and information gathered along the path. SSMI achieves the lowest entropy in the multi-class OctoMap. Similar to the discussion in Sec. VII-B, this observation can be ascribed to the fact that, among the compared methods, the only objective function which captures the uncertainty in both semantic classes and occupancy of the environment is the one used by SSMI. On the other hand, SSMI and FSMI require evaluation of mutual information along each candidate trajectory, which has the same cardinality as the number of all frontiers in the current map estimate , whereas the hierarchical planning method employed by TARE only requires local trajectory computation with a global coverage path obtained at a coarse level. As a result, TARE exploration can be performed over a relatively shorter time period compared to SSMI and FSMI in scenarios where the number of frontiers is large, e.g. outdoor areas. Parallel computation of mutual information for each candidate trajectory or using heuristics such as frontier size in order to sort candidate solutions would improve the computation time of SSMI; however we believe these are outside of the scope of this paper. Fig. 14 compares the mapping precision of various object classes for the tested methods. SSMI exhibits higher precision for object categories that appear rarely, such as the Animal or Tree classes while Frontier slightly outperforms SSMI when it comes to mapping the Grass and Dirt Road categories. This can be explained by the tendency of SSMI towards achieving high overall classification precision even if it requires slight reduction of precision for certain object categories. Furthermore, TARE achieves the highest precision for the Building class, which can be justified by the observation that the computed global coverage path tends to traverse near building walls.


VII-F 3-D Mapping in a Real-world Outdoor Environment

We deployed our semantic OcTree mapping approach on a Husky robot equipped with an Ouster OS1-32 LiDAR and an Intel RealSense D455 RGBD camera. Our software stack is implemented using the Robot Operating System (ROS) [50]. The LiDAR is used for localization via iterative closest point (ICP) scan matching [51]. A neural network based on a FCHarDNet architecture [52] and trained on the RUGD dataset [53] was used for semantic segmentation. The RGBD camera produces color and depth images with size at frames per second. The semantic segmentation algorithm takes a 2-D color image and outputs a semantic label for each pixel in the image, at an average frame rate of frames per second. By aligning the semantic image and the depth map, we derive a semantic 3-D point cloud which is utilized for Bayesian multi-class mapping. Our implementation was able to update the semantic OctoMap every s, on average, while all of the computations where performed on the mobile robot. The experiment was carried out in an approximately 6 acre forested area shown in Fig. 15. The environment contained various terrain features, including asphalt road, gravel, grass, densely forested areas, and hills. Additionally, a number of buildings and other structures such as bleachers, tents, and cars add to the diversity of the type of object categories within the locale. The robot was manually controlled via joystick, and traveled the path shown in Fig. 15 (left) while incrementally building the semantic OctoMap. Fig. 16 shows the semantic mapping result overlaying the satellite image obtained via 2-D projection of the semantic OctoMap. We computed the memory size of the semantic OctoMap, and compared it with the corresponding regular voxel grid representation, where each voxel contains the same amount of data as an OcTree leaf node at the lowest depth. Fig. 17 shows an almost five-fold saving in memory when using OcTree data structure. The importance of the memory savings of the OctoMap representation becomes more apparent when communication is considered. Our semantic OctoMap implementation resulted in a network bandwidth requirement of KB/s for OctoMap, whereas a regular grid required KB/s for map communication.


VII-G 3-D Exploration in a Real-world Office Environment


We implemented SSMI on a ground wheeled robot to autonomously map an indoor office environment. Fig. 18 shows the robot equipped with a NVIDIA Xavier NX computer, a Hokuyo UST-10LX LiDAR, and an Intel RealSense D435i RGBD camera. Similar to the outdoor experiments, ROS was used for software deployment on the robot, and ICP laser scan matching provided localization. This time, we utilized a ResNet18 [54] neural network architecture pre-trained on the SUN RGB-D dataset [55] for semantic segmentation. In particular, we employed the deep learning inference ROS nodes provided by NVIDIA [56], which are optimized for Xavier NX computers via TensorRT acceleration. Due to limited computational power available on the mobile platform, we operated the RGBD camera at a lower frame rate of Hz with color and depth image size set to . The semantic segmentation algorithm was able to produce pixel classification images (resized to ) at an average rate of frames per second. Our implementation was able to publish semantic OctoMap ROS topics every , on average, with all of the processing occurred on the mobile platform. Fig. 20 depicts the exploration process, while Fig. 19 shows the performance of SSMI compared to frontier-based over exploration iterations. We observe that, similar to the simulations, SSMI outperforms frontier-based exploration in terms of distance traveled. Also, SSMI shows on par performance compared to Frontier in terms of entropy reduction per time. This can be explained by the fact that large depth measurement noise and classification error in the real-world experiments result in (a) the need for re-visiting explored areas in order to estimate an accurate map, leading to poor entropy reduction for the frontier-based method and (b) a small number of safe candidate trajectories, leading to fewer computations to be performed by SSMI. Overall, our experiments show that SSMI outperforms Frontier in indoor exploration scenarios where the number, and length, of candidate trajectories is constrained by the size of the environment.


VIII Conclusion
This paper developed techniques for active multi-class mapping of large 3-D environments using range and semantic segmentation observations. Our results enable efficient mutual information computation over multi-class maps and make it possible to optimize for per-class uncertainty. Our experiments show that SSMI performs on par with the state of the art FSMI method in binary active mapping scenarios. However, when semantic information is considered SSMI outperforms existing algorithms and leads to efficient exploration and accurate multi-class mapping even in the presence of domain shift due to the difference between the classification training data and the testing environment. Experiments in both simulated and real-world environments showed the scalability of SSMI for large-scale 3-D exploration scenarios.
Appendix A Proof of Proposition 1
Applying Bayes rule in (2) and the factorization in (5) to for some leads to:
|
|
(21) |
The term may be eliminated by considering the odds ratio of an arbitrary category versus the free category for each cell :
| (22) | ||||
Since each term in both the left- and right-hand side products only depends on one map cell , the expression holds for each individual cell. Re-writing the expression for cell in vector form, with elements corresponding to each possible value of , and taking an element-wise log leads to:
| (23) | |||
Applying (23) recursively for each element leads to the desired result in (8).∎
Appendix B Proof of Proposition 2
Let be the set of map indices which can potentially be observed by . Using the factorization in (5) and the fact that Shannon entropy is additive for mutually independent random variables, the mutual information only depends on the cells whose index belongs to , i.e.:
| (24) |
This is true because the measurements are independent by construction and the terms can be decomposed into sums of mutual information terms between single-beam measurements and the respective observed map cells . The mutual information between a single map cell and a sensor ray is:
| (25) | |||
Using the inverse observation model in (10) and the Bayesian multi-class update in (8), we have:
| (26) |
where (10) and (8) were applied a second time to the log term above. Plugging (26) back into the mutual information expression in (25) and returning to (24), we have:
| (27) | ||||
For , the second term inside the integral above can be simplified to:
| (28) | ||||
because for map indices that are not observed by , we have according to (10) and .
Next, we apply the definition of (11) for the first term in the integral in (27), which turns it into an integration over . Note that and are piecewise-constant functions since is constant with respect to as long as the beam lands in cell . Hence, we can partition the integration domain over into a union of intervals where the beam hits the same cell, i.e., remains constant:
where , , and . From the piecewise-constant property of and over the interval , one can obtain:
| (29) | ||||
where and are defined in the statement of Proposition 2. Substituting with and plugging the integration result into (27) yields the lower bound in (13) for the mutual information between and .∎
Appendix C Proof of Proposition 3
Consider a single beam , passing through cells , . As shown in Appendix B, the mutual information between the map and a beam can be computed as:
| (30) |
Assuming piece-wise constant class probabilities, we have:
| (31) |
where . For each , the terms and are expressed as:
Plugging this into the inner summation of (31) leads to:
| (32) |
The summations in (32) can be computed explicitly, leading to the following closed-form expression:
| (33) | ||||
Therefore, the Shannon mutual information between a semantic OctoMap and a range-category measurement can be computed as in (15).∎
References
- [1] A. Elfes, “Using occupancy grids for mobile robot perception and navigation,” Computer, vol. 22, no. 6, pp. 46–57, 1989.
- [2] S. Thrun, “Learning occupancy grid maps with forward sensor models,” Autonomous Robots, vol. 15, no. 2, pp. 111–127, 2003.
- [3] A. Hornung, K. M. Wurm, M. Bennewitz, C. Stachniss, and W. Burgard, “OctoMap: An efficient probabilistic 3D mapping framework based on octrees,” Autonomous Robots, 2013, software available at https://octomap.github.io.
- [4] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. Funkhouser, “Semantic scene completion from a single depth image,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1746–1754.
- [5] L. Gan, R. Zhang, J. W. Grizzle, R. M. Eustice, and M. Ghaffari, “Bayesian spatial kernel smoothing for scalable dense semantic mapping,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 790–797, 2020.
- [6] T. Wang, V. Dhiman, and N. Atanasov, “Learning navigation costs from demonstration with semantic observations,” Proceedings of Machine Learning Research vol, vol. 120, pp. 1–11, 2020.
- [7] A. Milioto and C. Stachniss, “Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics using CNNs,” in IEEE International Conference on Robotics and Automation (ICRA), 2019.
- [8] B. J. Julian, S. Karaman, and D. Rus, “On mutual information-based control of range sensing robots for mapping applications,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013, pp. 5156–5163.
- [9] B. Charrow, S. Liu, V. Kumar, and N. Michael, “Information-theoretic mapping using cauchy-schwarz quadratic mutual information,” in IEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 4791–4798.
- [10] Z. Zhang, T. Henderson, V. Sze, and S. Karaman, “FSMI: Fast Computation of Shannon Mutual Information for Information-Theoretic Mapping,” in IEEE International Conference on Robotics and Automation (ICRA), 2019, pp. 6912–6918.
- [11] A. Asgharivaskasi and N. Atanasov, “Active bayesian multi-class mapping from range and semantic segmentation observations,” in IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 1–7.
- [12] B. Yamauchi, “A frontier-based approach for autonomous exploration,” in IEEE International Symposium on Computational Intelligence in Robotics and Automation, 1997, pp. 146–151.
- [13] W. Burgard, M. Moors, C. Stachniss, and F. E. Schneider, “Coordinated multi-robot exploration,” IEEE Transactions on Robotics (TRO), vol. 21, no. 3, pp. 376–386, 2005.
- [14] H. H. González-Baños and J.-C. Latombe, “Navigation strategies for exploring indoor environments,” The International Journal of Robotics Research (IJRR), vol. 21, no. 10-11, pp. 829–848, 2002.
- [15] C. Gómez, M. Fehr, A. C. Hernández, J. Nieto, R. Barber, and R. Siegwart, “Hybrid Topological and 3D Dense Mapping through Autonomous Exploration for Large Indoor Environments,” in IEEE International Conference on Robotics and Automation (ICRA), 2020.
- [16] X. Kan, H. Teng, and K. Karydis, “Online exploration and coverage planning in unknown obstacle-cluttered environments,” IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 5969–5976, 2020.
- [17] R. Maffei, M. P. Souza, M. Mantelli, D. Pittol, M. Kolberg, and V. A. M. Jorge, “Exploration of 3D terrains using potential fields with elevation-based local distortions,” in IEEE International Conference on Robotics and Automation (ICRA), 2020.
- [18] A. Bircher, M. Kamel, K. Alexis, H. Oleynikova, and R. Siegwart, “Receding horizon “next-best-view” planner for 3d exploration,” in IEEE International Conference on Robotics and Automation (ICRA), 2016, pp. 1462–1468.
- [19] T. Dang, F. Mascarich, S. Khattak, C. Papachristos, and K. Alexis, “Graph-based path planning for autonomous robotic exploration in subterranean environments,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 3105–3112.
- [20] H. Zhu, C. Cao, Y. Xia, S. Scherer, J. Zhang, and W. Wang, “Dsvp: Dual-stage viewpoint planner for rapid exploration by dynamic expansion,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 7623–7630.
- [21] C. Cao, H. Zhu, H. Choset, and J. Zhang, “Tare: A hierarchical framework for efficiently exploring complex 3d environments.” in Robotics: Science and Systems (RSS), 2021.
- [22] C. M and N. Michael, “Volumetric objectives for multi-robot exploration of three-dimensional environments,” in IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 9043–9050.
- [23] A. Elfes, “Robot navigation: Integrating perception, environmental constraints and task execution within a probabilistic framework,” in Reasoning With Uncertainty in Robotics, 1995, pp. 93–130.
- [24] S. J. Moorehead, R. Simmons, and W. L. Whittaker, “Autonomous exploration using multiple sources of information,” in IEEE International Conference on Robotics and Automation (ICRA), 2001, pp. 3098–3103.
- [25] F. Bourgault, A. A. Makarenko, S. B. Williams, B. Grocholsky, and H. F. Durrant-Whyte, “Information based adaptive robotic exploration,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2002, pp. 540–545.
- [26] A. Visser and B. Slamet, “Balancing the information gain against the movement cost for multi-robot frontier exploration,” in European Robotics Symposium, 2008, pp. 43–52.
- [27] T. Kollar and N. Roy, “Efficient optimization of information-theoretic exploration in SLAM,” in AAAI Conference on Artificial Intelligence, 2008, p. 1369–1375.
- [28] H. Carrillo, I. Reid, and J. A. Castellanos, “On the comparison of uncertainty criteria for active SLAM,” in IEEE International Conference on Robotics and Automation (ICRA), 2012, pp. 2080–2087.
- [29] L. Carlone, J. Du, M. K. Ng, B. Bona, and M. Indri, “Active SLAM and exploration with particle filters using Kullback-Leibler divergence,” Journal of Intelligent & Robotic Systems, vol. 75, no. 2, pp. 291–311, 2014.
- [30] N. Atanasov, J. Le Ny, K. Daniilidis, and G. J. Pappas, “Decentralized active information acquisition: Theory and application to multi-robot SLAM,” in IEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 4775–4782.
- [31] J. Wang, T. Shan, and B. Englot, “Virtual maps for autonomous exploration with pose SLAM,” in IEEE/RSJ International Conference on Intelligent Robots and Systems, 2019.
- [32] C. Stachniss, G. Grisetti, and W. Burgard, “Information gain-based exploration using Rao-Blackwellized particle filters,” in Robotics: Science and Systems, 2005, pp. 65–72.
- [33] T. Henderson, V. Sze, and S. Karaman, “An efficient and continuous approach to information-theoretic exploration,” in IEEE International Conference on Robotics and Automation (ICRA), 2020.
- [34] F. Chen, P. Szenher, Y. Huang, J. Wang, T. Shan, S. Bai, and B. Englot, “Zero-shot reinforcement learning on graphs for autonomous exploration under uncertainty,” in IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 5193–5199.
- [35] M. Lodel, B. Brito, A. Serra-Gómez, L. Ferranti, R. Babuška, and J. Alonso-Mora, “Where to look next: Learning viewpoint recommendations for informative trajectory planning,” arXiv preprint arXiv:2203.02381, 2022.
- [36] E. Zwecher, E. Iceland, S. R. Levy, S. Y. Hayoun, O. Gal, and A. Barel, “Integrating deep reinforcement and supervised learning to expedite indoor mapping,” in IEEE International Conference on Robotics and Automation (ICRA), 2022, pp. 10 542–10 548.
- [37] H. Zhang, J. Cheng, L. Zhang, Y. Li, and W. Zhang, “H2GNN: Hierarchical-hops graph neural networks for multi-robot exploration in unknown environments,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3435–3442, 2022.
- [38] J. Hu, H. Niu, J. Carrasco, B. Lennox, and F. Arvin, “Voronoi-based multi-robot autonomous exploration in unknown environments via deep reinforcement learning,” IEEE Transactions on Vehicular Technology, vol. 69, no. 12, pp. 14 413–14 423, 2020.
- [39] T. S. Veiga, M. Silva, R. Ventura, and P. U. Lima, “A hierarchical approach to active semantic mapping using probabilistic logic and information reward pomdps,” Proceedings of the International Conference on Automated Planning and Scheduling, vol. 29, no. 1, pp. 773–781, May 2021.
- [40] V. Suriani, S. Kaszuba, S. R. Sabbella, F. Riccio, and D. Nardi, “S-ave: Semantic active vision exploration and mapping of indoor environments for mobile robots,” in 2021 European Conference on Mobile Robots (ECMR), 2021, pp. 1–8.
- [41] H. Blum, S. Rohrbach, M. Popovic, L. Bartolomei, and R. Y. Siegwart, “Active learning for uav-based semantic mapping,” ArXiv, vol. abs/1908.11157, 2019.
- [42] G. Georgakis, B. Bucher, K. Schmeckpeper, S. Singh, and K. Daniilidis, “Learning to map for active semantic goal navigation,” ArXiv, vol. abs/2106.15648, 2021.
- [43] T. D. Barfoot, State estimation for robotics. Cambridge University Press, 2017.
- [44] S. Thrun, W. Burgard, and D. Fox, Probabilistic Robotics. MIT Press Cambridge, 2005.
- [45] J. E. Bresenham, “Algorithm for computer control of a digital plotter,” IBM Systems Journal, vol. 4, no. 1, pp. 25–30, 1965.
- [46] H. Samet, “Implementing ray tracing with octrees and neighbor finding,” Computers & Graphics, vol. 13, no. 4, pp. 445–460, 1989.
- [47] M. Agate, R. L. Grimsdale, and P. F. Lister, “The hero algorithm for ray-tracing octrees,” in Advances in Computer Graphics Hardware IV, 1991, pp. 61–73.
- [48] K. Saulnier, N. Atanasov, G. J. Pappas, and V. Kumar, “Information theoretic active exploration in signed distance fields,” in IEEE International Conference on Robotics and Automation (ICRA), 2020.
- [49] A. Asgharivaskasi, S. Koga, and N. Atanasov, “Active mapping via gradient ascent optimization of shannon mutual information over continuous se(3) trajectories,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022.
- [50] M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y. Ng et al., “ROS: an open-source robot operating system,” in ICRA workshop on open source software, vol. 3, no. 3.2, 2009, p. 5.
- [51] A. Censi, “An ICP variant using a point-to-line metric,” in IEEE International Conference on Robotics and Automation (ICRA), 2008, pp. 19–25.
- [52] P. Chao, “Fully convolutional hardnet for segmentation in pytorch,” https://github.com/PingoLH/FCHarDNet, accessed: 2022-07-01.
- [53] M. Wigness, S. Eum, J. G. Rogers, D. Han, and H. Kwon, “A RUGD dataset for autonomous navigation and visual perception in unstructured outdoor environments,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019, pp. 5000–5007.
- [54] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [55] S. Song, S. P. Lichtenberg, and J. Xiao, “Sun RGB-D: A RGB-D scene understanding benchmark suite,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 567–576.
- [56] NVIDIA, “Deep learning nodes for ROS/ROS2,” https://github.com/dusty-nv/ros_deep_learning, accessed: 2021-07-10.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1158c80a-8856-4257-bcea-1db293687d95/ArashAsgharivaskasi.jpg) |
Arash Asgharivaskasi (S’22) is a Ph.D. student of Electrical and Computer Engineering at the University of California San Diego, La Jolla, CA. He obtained a B.S. degree in Electrical Engineering from Sharif University of Technology, Tehran, Iran, and an M.S. degree in Electrical and Computer Engineering from the University of California San Diego, La Jolla, CA, USA. His research focuses on active information acquisition using mobile robots with applications to mapping, security, and environmental monitoring. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/1158c80a-8856-4257-bcea-1db293687d95/Atanasov.jpg) |
Nikolay Atanasov (S’07-M’16) is an Assistant Professor of Electrical and Computer Engineering at the University of California San Diego, La Jolla, CA, USA. He obtained a B.S. degree in Electrical Engineering from Trinity College, Hartford, CT, USA, in 2008 and M.S. and Ph.D. degrees in Electrical and Systems Engineering from the University of Pennsylvania, Philadelphia, PA, USA, in 2012 and 2015, respectively. His research focuses on robotics, control theory, and machine learning, applied to active sensing using ground and aerial robots. He works on probabilistic perception models that unify geometry and semantics and on optimal control and reinforcement learning approaches for minimizing uncertainty in these models. Dr. Atanasov’s work has been recognized by the Joseph and Rosaline Wolf award for the best Ph.D. dissertation in Electrical and Systems Engineering at the University of Pennsylvania in 2015, the best conference paper award at the International Conference on Robotics and Automation in 2017, and the NSF CAREER award in 2021. |