Semantic Attention and Scale Complementary Network for Instance Segmentation in Remote Sensing Images
Abstract
In this paper, we focus on the challenging multi-category instance segmentation problem in remote sensing images (RSIs), which aims at predicting the categories of all instances and localizing them with pixel-level masks. Although many landmark frameworks have demonstrated promising performance in instance segmentation, the complexity in the background and scale variability instances still remain challenging for instance segmentation of RSIs. To address the above problems, we propose an end-to-end multi-category instance segmentation model, namely Semantic Attention and Scale Complementary Network, which mainly consists of a Semantic Attention (SEA) module and a Scale Complementary Mask Branch (SCMB). The SEA module contains a simple fully convolutional semantic segmentation branch with extra supervision to strengthen the activation of interest instances on the feature map and reduce the background noise’s interference. To handle the under-segmentation of geospatial instances with large varying scales, we design the SCMB that extends the original single mask branch to trident mask branches and introduces complementary mask supervision at different scales to sufficiently leverage the multi-scale information. We conduct comprehensive experiments to evaluate the effectiveness of our proposed method on the iSAID dataset and the NWPU Instance Segmentation dataset and achieve promising performance.
Index Terms:
Instance segmentation, semantic attention, scale complementarity, remote sensing images.I Introduction
Thanks to the rapid development in remote sensing technology, RSIs have become easily available and the understanding of RSIs has become a popular topic. Recently, many researchers commit to the scene classification [1, 2, 3, 4, 5] and object detection [6, 7, 8, 9, 10, 11] in RSIs and achieve outstanding performance. In this paper, we concentrate on a new and challenging problem of instance segmentation in RSIs.
Instance segmentation aims to classify the categories and predict the pixel-level results of each instance. Contrary to the bounding-box annotation in object detection, instance segmentation delineates the boundary of each instance and results in a more accurate location. Benefiting from more accurate pixel-level information for each instance, instance segmentation has great development potential in land planning, urban monitoring, and military reconnaissance.
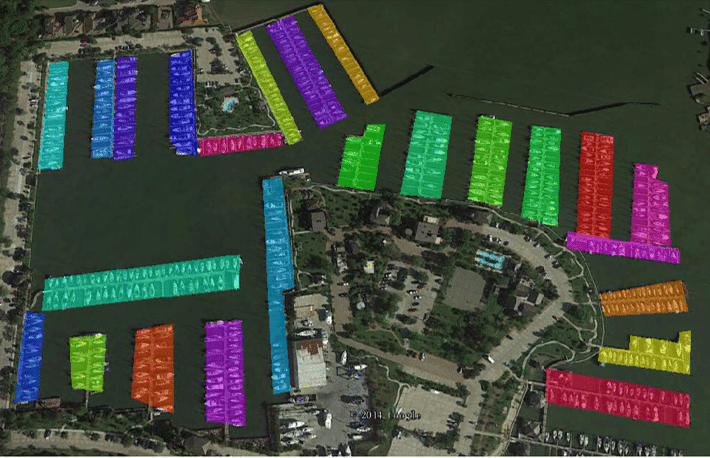
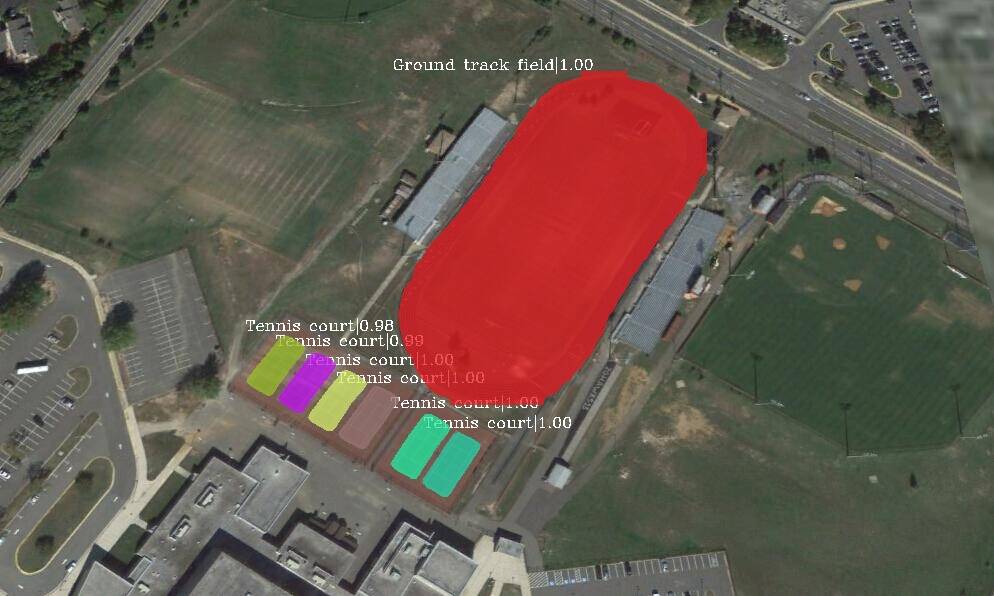
In the past two decades, with the development of convolutional neural networks (CNN) [12, 13], many instance segmentation architectures [14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28] have been proposed and achieved outstanding performance in the natural scene. However, few researchers [29, 30, 31, 32, 33, 34, 35] focus on the instance segmentation in RSIs and the available methods just apply the instance segmentation models designed for the natural images to the RSIs, without taking into account the characteristics of RSIs such as the complex background and diversely scaled instances. Specifically, RSIs typically contain a highly complex background area that may interfere with the region of interest. As shown in the first row of Fig. 1, tennis courts have a color similar to that of the surrounding grassland. When directly apply the off-the-shelf PANet [16] on the RSIs, it has difficulties in separating the adjacent tennis courts or even causes miss detection. Besides, the geospatial instances can largely vary in scale, which leads to under-segmentation with the original single mask branch in [16]. For example, the boundary of the ground track field is incomplete (see the second row of Fig. 1).






To alleviate the problem of complex background and large scale-variations of instances, we introduce the Semantic Attention (SEA) module and the Scale Complementary Mask Branch (SCMB) and design an end-to-end multi-category instance segmentation network for RSIs. For the SEA module, a new supervised semantic segmentation branch is proposed to strengthen the activation of the foreground instances and reduce the effect of the background noise. For the SCMB, a multi-scale structure is exploited to capture the complementary information at different scales to get more accurate segmentation results. We evaluate the proposed method on two public remote sensing datasets. Compared with the other state-of-art approaches, our method achieves superior performance.

Our contributions can be summarized as follows:
1) We propose the Semantic Attention (SEA) module with semantic segmentation supervision and introduce it in the Feature Pyramid Network (FPN) to reduce the complex background interference on the feature maps. With the help of the SEA module, the network focuses on the instances’ regions and suppresses backgrounds.
2) We extend the original single-scale mask branch into the Scale Complementary Mask Branch (SCMB) to deal with the under-segmentation problem caused by multiple scales of geospatial instances. The SCMB not only introduces scale complementary supervision to supervise the proposed trident mask branch but also fuses multi-scale feature maps to integrate information over multiple scales.
3) The best performance is achieved in two challenging remote sensing instance segmentation datasets against the other state-of-the-art methods. The ablation studies show the effectiveness of each proposed module.
The remainder of this paper is organized as follows. In Section II, we briefly introduce related work in instance segmentation methods on both natural scene and remote sensing community, semantic attention, and scale complementarity. In Section III, we describe our proposed method in detail. We report and discuss the experiments in Section IV. Finally, Section V concludes this paper.
II RELATED WORK
II-A Instance Segmentation
Instance segmentation is mainly divided into proposal-based and proposal-free methods. Proposal-based methods are based on object detection frameworks. These methods first obtain the instances’ proposals in the image through an object detector, then perform segmentation on each proposal to obtain its mask. Li et al. [14] predicted position-sensitive inside/outside score maps and simultaneously rendered the instance mask and category with these score maps. He et al. [15] modified the Faster-RCNN [36] with a simple fully convolutional mask branch, which runs in parallel to the detection branch, to predict the mask of the proposals. Driven by the excellent performance of Mask-RCNN [15], the literature such as [16, 17, 18] have explored various extensions to Mask-RCNN. PANet [16] adds a fully connected layer in the mask branch for accurate segmentation results. In [15] [16], the classification confidence from the detection branch is used to measure the mask quality (i.e. the IoU between the instance mask and its ground truth). However, Huang et al. [17] found the mask quality cannot be well correlated with the classification confidence and presented the Mask-IoU block to learn the mask quality of predictions. Hybrid Task Cascade [18] adopts a cascaded approach [20], where the mask features of the preceding stage are fed into the next stage for further improvements.
Proposal-free methods are mainly built upon segmentation and aim at clustering pixel-level semantic class labels into different instances. Many researches [21, 22, 23, 24] further transform semantic segmentation results into instances. Bai and Urtasun [21] used the direction network and the watershed transform network to learn the energy map for watershed transform. InstanceCut [24] first predicts the semantic segmentation result with a semantic segmentation network and then uses an instance-awareness edge detector to obtain the instance segmentation results. Besides, several methods [25, 26, 27, 28] map pixels into the embedding space for instance segmentation. Brabandere et al. [25] introduced a new discriminative loss function that guides the network to pull the pixels that belong to the same instance while pushing away the pixels of different instances. Fathi et al. [26] used deep metric learning to determine the similarity of the embedding points.
Despite the flourishing development of instance segmentation in the nature scene, there are only few studies [29, 30, 31, 32, 33, 34, 35] in RSIs. Feng et al. [29] introduced the sequence local context module to address the confusion between densely arranged ships. Mou and Zhu [30] abandoned the detector-based method and decomposed the vehicle instance segmentation task into vehicle semantic segmentation and semantic boundary detection. HQ-ISNet [34] introduces the HR-FPN to maintain high-resolution feature maps in the network and designs a tiny network to refine the original mask branch. Liu et al. [35] embedded a global context parallel attention module into the anchor-free instance segmentation framework to capture the global information. Different from the methods [29, 30, 31, 32] that only focused on a single category (e.g. ship, vehicle, aircraft, building, etc.), our proposed approach takes full account of the complex background and large scale-variance of instances in RSIs, and verifies the effectiveness of our network on a more challenging multi-category instance segmentation dataset.
II-B Attention Mechanism
Recently, a number of works [37, 38, 39, 40, 41] have studied in the attention mechanism to facilitate different computer vision tasks. SENet [37] designs an efficient Squeeze-and-Excitation (SE) block to adaptively re-weight channel-wise feature responses and achieves superior performance for image classification. Libra-RCNN [39] fuses the 5-level feature maps from FPN [42] and uses a Gaussian Non-Local [43] attention to obtain the balance semantic features. ScarfNet [40] generates features with strong semantic attention for each pyramid scale by bidirectional long short term memory (biLSTM) [44] and channel-wise attention. DES [41], built upon SSD [45], adds an extra semantic attention branch supervised with weak segmentation ground-truth for semantic enrichment. In the remote sensing community, Zhang et al. [10] designed the Channel and Spatial Attention Module to highlight the important features and suppress inessential features, which improves the performance in SAR ship detection. Yang et al. [46] proposed a Multi-Dimensional Attention Network to strengthen the response of the region of interest. In contrast to [39, 40, 37, 38, 10], our proposed method adds accurate supervision to guide the learning of the attention mechanism. Besides, our attention mechanism has a simple structure compared to the biLSTM in ScarfNet[40] and the atrous convolution in DES [41].
II-C Scale Complementarity
The scale variation across instances is one of the most challenging problems in both natural scene images and RSIs. To alleviate this problem, many works explore the complementary information between the low-level and high-level features of CNN. In the natural scene, SSD [45] sets different scales of default boxes in multiple layers and outputs the combination detection results of each layer. FPN [42] uses a top-down approach and horizontal connections to generate five-level features, and assigns each proportion of the proposal to the corresponding level. Considering the superior performance of FPN, many researchers [47, 16, 48, 49] have made further improvements to it. DeepLab [50] proposes the atrous spatial pyramid pooling (ASPP) module to capture more scale information and make more accurate segmentation results. [51] proposes an online scale adaptive tracking approach by constructing a scale pyramid based on multi-layer convolutional features. In remote sensing fields, Azimi et al. [52] combined the image pyramid and the feature pyramid with the same resolution to detect the diverse scale geospatial objects. Deng et al. [53] designed a multi-scale object proposal network (MS-OPN) with different receptive fields to generate different scales of proposals. Zhang et al. [54] designed a lightweight scale share feature pyramid (SSFP) module to achieve high-speed and high-accurate multiscale SAR ship detection. The above method achieves complementary information at different scales at image-level [52] or feature-level [42, 45, 50, 51, 54]. Our method introduces label-level multi-scale information to improve the scale-invariant ability of the network.
III METHODOLOGY
Our proposed network can be regarded as an extension of Mask-RCNN/PANet and the overall framework is illustrated in Fig. 2. First, we use CNN and FPN/PA-FPN[16] to generate multi-scale feature maps of the given image. Then, we employ the SEA module to output the multi-scale feature maps with meaningful semantic information. Finally, the candidate proposals generated by the region proposal network (RPN)[36] and multi-scale semantic meaningful feature maps are sent to the detection branch and the proposed SCMB for the detection and segmentation. In the following section, we describe the details of the SEA module and SCMB.
III-A Semantic Attention Module
As shown in Fig. 4(b), the feature maps obtained by FPN contain complex background information, which may result in false predictions. Thus, we propose the SEA module that introduces the semantic segmentation supervision to enhance the activation of instances and reduce the responses of noises. Many semantic attention modules [40, 39, 41] have been published to enrich the semantic information of feature maps. Different from these methods, the SEA module adds semantic segmentation supervision and has a simple and straightforward architecture.







For the semantic segmentation’s ground truth, we generate it using a simple transformation strategy: Given an image, if a pixel belongs to an instance, we assign the class label of this instance to the pixel, otherwise, we set the pixel to the background class. An example of the semantic segmentation’s ground truth is shown in Fig. 7(b).
The pipeline of the SEA module is shown in Fig. 2. There are mainly three steps, including rescaling, enriching and integrating.
III-A1 Rescaling
Following the definition of FPN, we use {, , , , } to define the 5-level output feature maps with different strides of {4, 8, 16, 32, 64} pixels corresponding to the original image. To enrich the semantic information of the above 5-level multi-scale feature maps, we first resize these feature maps to a uniform scale, i.e. the corresponding scale of (Ablation study illustrates why we choose ). Here, we use bilinear interpolation and average pooling layer to generate resized feature maps {, , , , }. Then, we can obtain the scale-normalized feature map by:
| (1) |
III-A2 Enriching
In contrast to early researches [39] [40] that implemented the semantic enrichment in an unsupervised way, we consider embedding the semantic segmentation supervision is an intuitive approach to enrich the semantic information. We design a tiny fully convolutional semantic segmentation branch, including four convolutional layers with a kernel and two convolutional layers with a kernel. We set the filter number to 256 for the four convolutional layers. For the two convolutional layers, one is set to for prediction where is the number of the classes and the other is 256 for semantic attention.
As shown in Fig. 3, the proposed semantic branch takes the scale-normalized feature map as input, and the four convolutional layers first extract the scale-normalized feature map to get the intermediate feature map . Then, is attached to two streams, called prediction and attention streams.
In the attention stream, we append a convolutional layer to obtain the semantic attention feature map , and then multiply with the original scale-normalized feature map to generate the semantic enriched feature map . Thus, the generation of the semantic enriched feature map is as follows:
| (2) |
| (3) |
| (4) |
where represents the four convolutional layers with parameter . is the convolutional layer in the attention stream and denotes the weights of the convolutional layer.
The prediction stream contains a convolutional layer with output channels and a softmax layer aiming to produce semantic segmentation prediction :
| (5) |
where and measures the probability that the pixel in th row and th column belongs to the category . We define the loss function as:
| (6) |
where denote the ground truth of semantic segmentation.
III-A3 Integrating
After the enriching step, the semantic enriched feature map is resized to different scales corresponding to {, , , , }, and we denote these generated feature maps as {, , , , }. Similar to [39] [42], we deploy the skip connection to integrate feature maps and the original feature maps , which can sufficiently leverage original information and enrich semantic information. The integrated operation can be represented as:
| (7) |
With the above three steps, the output multi-scale feature maps with meaningful semantic information {, , , , } can be used for the following RPN and RCNN modules. Significantly, our proposed SEA module can be well embedded in FPN to effectively identify the instance regions on feature maps, and it can be easily applied to other computer vision tasks.
III-B Scale Complementary Mask Branch
Because the scale variations of the instances in RSIs are generally larger than that of natural scene images, the original single scale mask branch [15] [16] may lead to under-segmentation, as shown in the second row of Fig. 1. Inspired by the studies [55] [56] that fuse the multi-scale information to remedy the weakness of single-scale network, we introduce the SCMB to alleviate the under-segmentation problem. Specifically, we replace the single-scale mask branch with a trident mask branch and generate scale complementary mask supervision for the corresponding branch. Besides, a feature fusion module is designed to facilitate the combination of different scale features.
The detailed architecture of the SCMB is shown in Fig. 5, including Trident Mask Branch (TMB), Scale Complementary Guidance (SCG) module and Feature Fusion (FF) module.
III-B1 Trident Mask Branch
Our trident mask branch is an extension of the original one [15]. In [15], given the Region of Interest (RoI) feature map, the mask branch employs a tiny fully convolutional network (FCN) with parameter and a deconvolutional layer with the upsampling ratio of 2 to predict a binary pixel-wise mask for each class independently. The binary prediction is presented as follows:
| (8) |
where
| (9) |
Considering the absence of multi-scale information in the original single-scale mask branch, we transform it into the trident form, as shown in the TMB of Fig. 5. Following [15], the TMB first applies a tiny FCN to extract the feature map of each RoI. Different from [15], we use bilinear interpolation and average pooling layer to upsample () and downsample () the feature map and keep the scale of the original feature map (), resulting in three different scales of feature maps {, , }. To reduce the computational overhead, we adopt a convolutional layer to shrink output channels to half for each scale of the feature map. The program of our Trident Mask Branch is as follows:
| (10) |
| (11) |
| (12) |
where and represent bilinear interpolation and average pooling layer, respectively. denotes the weight shared FCN with parameter and denotes the convolutional layer with parameter for the computational reduction in each branch.
III-B2 Scale Complementary Guidance Module
In order to obtain discriminative feature maps at each scale, we introduce the scale complementary guidance module composed of three guidance paths {, , }. In each path, we adopt a convolutional layer to produce the prediction and embed the corresponding scale mask supervision. The prediction ( ) of each guidance path is denoted as:
| (13) |
In all the three guidance paths, we use the binary cross-entropy which could be defined as:
| (14) |
where and denotes the mask supervision in the -th guidance path. Thus the total loss of this module could be denoted as:
| (15) |
III-B3 Feature Fusion Module
The goal of the feature fusion module is to integrate the information at different scale feature maps for precise segmentation. For the three different spatial resolution feature maps generated from TMB, we upsample the two low-resolution feature maps to using bilinear interpolation. Then the three feature maps are merged by channel-wise concatenating. Finally, we append four consecutive convolutional layers consisting of kernel sizes and a convolutional layer to produce the binary prediction for each class. The binary prediction can be denoted as:
| (16) |
| (17) |
where and denote the bilinear interpolation. represents four consecutive convolutional layers.
We also use the binary cross-entropy to calculate the , which has the same form as Eq. (14). The loss function of the overall SCMB is denoted as:
| (18) |
III-C Joint Loss Function
Our proposed approach is an end-to-end instance segmentation network and the joint loss function consists of three parts: , and . Thus, the joint loss function could be expressed as:
| (19) |
IV EXPERIMENTS
IV-A Evaluation Datasets
IV-A1 iSAID
The iSAID [59] dataset is a new open benchmark dataset for multi-categories instance segmentation in RSIs. The dataset consists of 2,806 images with different sizes (from 800 to 13,000 in width) and 655,451 annotated instances. There are 15 common object categories in the dataset, including large vehicle (LV), small vehicle (SV), storage tank (ST), plane (PL), ship (SH), swimming pool (SW), harbor (HA), tennis court (TC), ground track field (GTF), soccer-ball field (SBF), baseball diamond (BD), bridge (BR), basketball court (BC) roundabout (RA) and helicopter (HC). The whole dataset is split into three parts: 1/2 for training, 1/6 for validation and 1/3 for testing. The ground truth of the training set and the validation set are available.
Due to the large spatial resolution of the original images, we crop the original images into patches with a stride set to 200 by the official provided toolkit111https://github.com/CAPTAIN-WHU/iSAID_Devkit and acquire 28,249 images for training set, 9,581 for validation set and 19,377 for test set.
IV-A2 NWPU VHR-10 instance segmentation
The NWPU VHR-10 instance segmentation dataset [33] is an extension of the remote sensing object detection dataset NWPU VHR-10 [60]. This instance segmentation dataset includes 650 and the spatial size of images ranges from to pixels. This dataset contains 10 object categories, including airplane, baseball diamond, basketball court, bridge, ground track field, harbor, ship, storage tank, tennis court, and vehicle.
In the experiments, we randomly select 70% of the image set (i.e. 454 images) as the training set and the rest of the positive set (i.e. 196 images) as the test set.
| Model | Backebone | SEA | SCMB | FPS | Params | Model Size | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PANet [16] | ResNet-101 | 38.1 | 62.8 | 40.5 | 43.9 | 67.0 | 48.3 | 5.1 | 85.14M | 682.6MB | ||
| ✓ | 38.6 | 63.4 | 41.0 | 44.7 | 68.1 | 49.5 | 4.5 | 89.08M | 709.2MB | |||
| ✓ | 38.8 | 62.9 | 41.6 | 44.0 | 67.9 | 48.3 | 4.3 | 87.44M | 701.1MB | |||
| ✓ | ✓ | 39.5 | 64.1 | 42.1 | 44.6 | 68.5 | 48.4 | 3.6 | 91.38M | 727.6MB |


IV-B Evaluation Metrics
We utilize the COCO evaluation metric [61] to evaluate the network performance.
IV-B1 COCO Evaluation
The COCO evaluation metric is based on the average precision metric. The average precision metric computes the average value of Precision in the interval of Recall from 0 to 1 under a certain IoU threshold, where the Precision and the Recall calculates the fraction of true positives and the fraction of positives that are correctly predicted. There are mainly 6 metrics of COCO evaluation metric for both object detection and instance segmentation:
: The measures the mean value of 10 average precision values under the Intersection over Union (IoU) threshold from 0.5 to 0.95 with intervals of 0.05.
and : These two metrics indicate the average precision value under the IoU threshold of 0.5 and 0.75 respectively.
, and : They correspond to the value for small, medium and large scale instances.
However, there are generally a large number of instances in RISs [59] and the instance scale distribution is different from natural images. We use the modified COCO evaluation metric [59] to evaluate the performance of our model. In the modified evaluation metric, the number of the detection boxes is set to be 1000 per image (instead of 100 by default) and the area range of large, medium, and small instances are changed, where small instances range from 10 to 144, medium instances range from 144 to 512 pixels and large instances range from 512 and over. In all the experiments, we use and to report the performance of segmentation and detection results.
IV-C Implementation Details and Parameter Optimization
We conduct all the experiments based on the PyTorch framework. For the network initialization, we use ImageNet pre-trained weights to initialize the backbone (i.e. ResNet-101) and the newly added layers are initialized by a zero-mean normal distribution with a standard deviation of 0.01. We choose the stochastic gradient descent with the momentum of 0.9 and weight decay of 0.0001 to fine-tune the overall network.
For the training phase, we resize the input image with a short side of 800 pixels and train 12 epochs in total, where the learning rate starts from 0.01 and decreased by a factor of 0.1 at the 8th and 11th epoch. We train the network in a mini-batch size of 8 on 4 NVIDIA GeForce GTX 1080Ti with 12 GB GPU memory.
For the testing phase, the test images are resized to 800 pixels on the short side. The NMS (non-maximal suppression) threshold and the mask binarized threshold are both set as 0.5. Besides, considering a large number of instances are present in each image, we output the top 1000 results in each image.
IV-D Ablation Studies
We conduct comprehensive experiments to evaluate the performance of the SEA module and SCMB. All ablation experiments are performed on PANet based on ResNet101 and evaluated on the iSAID validation dataset. In addition, we do not apply any data-augmentation strategies in this section.
IV-D1 Evaluation of Semantic Attention Module
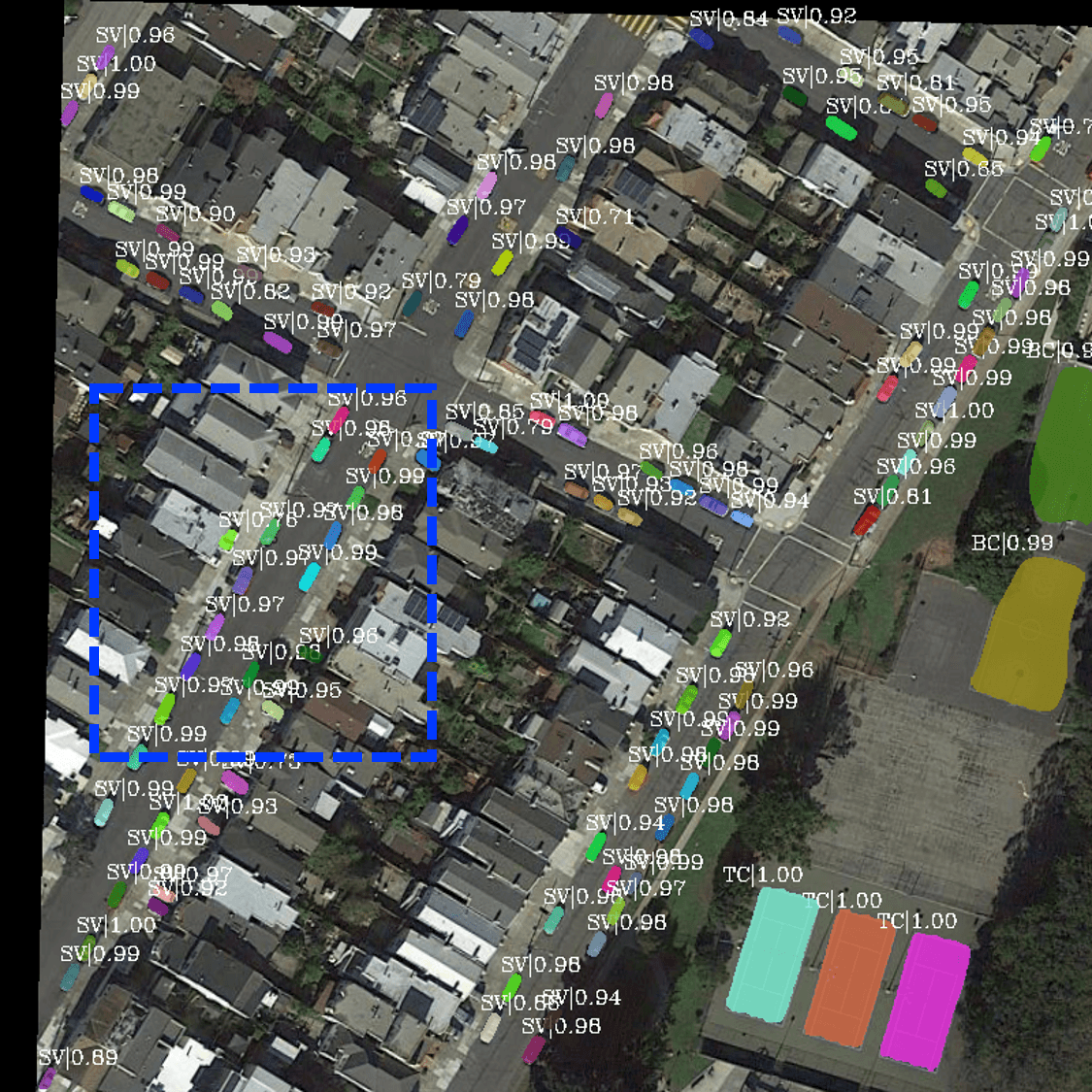
The effectiveness of the proposed SEA module can be observed from the visualization of feature maps shown in Fig. 4. As shown in Fig. 4, without the SEA module, the boundaries between different instances are blurred, and there is significant interfering noise in the background (i.e. in Fig. 4(b)). In contrast, Fig. 4(c) demonstrates clearer boundaries with less noise in the background. Similar results are shown in the first row of Fig. 6, where our SS-PANet does not recognize pipes in the factory as bridges and better separates the boundaries of the soccer-ball field. Besides, we can see that with the SEA module, our network obtains performance improvement in all six metrics and increases the by 0.5% and by 0.8% compared with the baseline approaches shown in Table I.
We report the other two experiments to further discuss the design of the SEA module. As described in Sec.III, we resize the 5-level output feature maps into a uniform scale and obtain the scale-normalized feature map by Eq. (1). We first study the influence of the different uniform scales. Due to the large scale of , once we set the uniform scale as , the model will exceed the maximum GPU memory. Thus, we only conduct ablation studies at the scale of , , , and term them as -, -, -, -, respectively. Table II shows the results and the larger uniform scale, the better result we obtain, similar to the results in [62]. For the segmentation performance, - and - achieve a gain of about 0.5% compared to the baseline, and - has slight improvement, while - decreases the performance by 0.3%. A similar trend can be observed in the detection performance. To explore the above phenomenon, we resize the semantic segmentation prediction of each setting to and present them in Fig. 7. We can find that - has the coarsest segmentation prediction than the others, which will produce false semantic attention and deteriorate network performance.
| Settings | ||||||
|---|---|---|---|---|---|---|
| PANet baseline [16] | 38.1 | 62.8 | 40.5 | 43.9 | 67.0 | 48.3 |
| - | 38.6 | 63.4 | 41.0 | 44.7 | 68.1 | 49.5 |
| - | 38.5 | 63.6 | 40.8 | 44.4 | 68.1 | 49.0 |
| - | 38.2 | 63.4 | 40.5 | 43.6 | 67.6 | 47.6 |
| - | 37.8 | 62.9 | 40.0 | 41.9 | 66.4 | 45.6 |
| MULTIPLY | 38.6 | 63.4 | 41.0 | 44.7 | 68.1 | 49.5 |
| CONCATE | 38.3 | 63.3 | 40.8 | 44.5 | 67.4 | 49.2 |

| Settings | |||
|---|---|---|---|
| PANet baseline [16] | 38.6 | 63.4 | 41.0 |
| 38.9 | 63.8 | 41.7 | |
| 39.3 | 64.1 | 42.1 | |
| 39.5 | 64.1 | 42.1 | |
| MULTIPLY | 39.1 | 63.8 | 41.6 |
| CONCATE | 39.5 | 64.1 | 42.1 |
We also investigate different feature fusion schemes between the semantic attention feature map and the scale-normalized feature map and design the following two feature fusion approaches. First, we employ the element-wise multiplication, represented by ”MULTIPLY”. Second, we concatenate the corresponding feature maps and append convolutional to reduce channel dimensions, named by ”CONCATE”. We set the uniform scale as - for both two schemes and report the results in Table II. We can find the improvement in both two feature fusion ways and the element-wise multiplication achieves better than the channel-wise concatenation. We consider the semantic attention feature map has strong activation in the instance region, and the response of the background is almost 0. Thus, the element-wise multiplication is an intuitive way to enhance the instance activation and reduce the background noise.
| Settings | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask-RCNN [15] | 37.4 | 62.0 | 39.4 | 39.7 | 51.5 | 35.7 | 43.1 | 66.2 | 47.4 | 45.8 | 55.9 | 51.2 |
| PANet [16] | 38.1 | 62.8 | 40.5 | 40.5 | 51.9 | 36.7 | 43.9 | 67.0 | 48.3 | 46.5 | 56.7 | 62.3 |
| SS-Mask-RCNN | 39.2 | 63.7 | 41.8 | 41.8 | 54.4 | 24.3 | 43.8 | 67.7 | 48.4 | 46.6 | 57.2 | 28.2 |
| SS-PANet | 39.5 | 64.1 | 42.1 | 41.7 | 53.5 | 35.0 | 44.6 | 68.5 | 48.4 | 47.3 | 58.4 | 55.8 |
| SS-Mask-RCNN+ | 39.7 | 64.4 | 42.2 | 42.5 | 53.6 | 26.3 | 45.0 | 68.6 | 49.7 | 47.9 | 56.6 | 37.1 |
| SS-PANet+ | 40.8 | 65.6 | 43.8 | 43.7 | 54.0 | 32.1 | 46.9 | 70.0 | 52.0 | 49.8 | 57.2 | 44.7 |
| Model | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask-RCNN [15] | 37.4 | 48.4 | 55.8 | 22.9 | 31.8 | 14.0 | 38.5 | 50.2 | 76.6 | 42.2 | 34.8 | 46.1 | 37.5 | 26.7 | 30.3 | 5.1 |
| PANet [16] | 38.1 | 49.2 | 55.9 | 22.8 | 32.4 | 14.1 | 40.6 | 50.4 | 77.9 | 45.5 | 35.2 | 47.1 | 38.7 | 26.9 | 30.5 | 4.9 |
| SS-Mask-RCNN | 39.2 | 50.8 | 58.0 | 23.9 | 33.1 | 14.6 | 41.6 | 52.1 | 78.7 | 44.2 | 37.4 | 48.0 | 39.9 | 28.8 | 31.0 | 6.0 |
| SS-PANet | 39.5 | 50.9 | 58.8 | 23.5 | 34.4 | 14.7 | 41.8 | 52.0 | 78.8 | 46.8 | 37.2 | 46.8 | 40.4 | 28.3 | 31.2 | 6.9 |
| SS-Mask-RCNN+ | 39.7 | 51.5 | 59.1 | 24.5 | 34.0 | 15.6 | 42.6 | 52.9 | 79.2 | 45.3 | 37.7 | 46.0 | 40.8 | 28.7 | 33.0 | 4.4 |
| SS-PANet+ | 40.8 | 53.1 | 60.3 | 24.8 | 35.6 | 16.1 | 43.7 | 54.0 | 79.8 | 49.3 | 38.7 | 48.0 | 40.8 | 29.9 | 33.4 | 5.3 |
| Model | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask-RCNN [15] | 43.1 | 67.2 | 55.7 | 27.2 | 45.6 | 16.6 | 44.8 | 54.9 | 77.2 | 42.5 | 35.5 | 44.5 | 37.7 | 48.5 | 33.8 | 15.2 |
| PANet [16] | 43.9 | 67.7 | 56.4 | 26.8 | 47.0 | 16.5 | 45.3 | 54.7 | 78.9 | 44.6 | 35.7 | 45.9 | 39.1 | 49.3 | 34.2 | 16.6 |
| SS-Mask-RCNN | 43.8 | 66.6 | 57.4 | 27.5 | 46.2 | 16.9 | 45.8 | 55.4 | 79.2 | 42.4 | 37.4 | 44.9 | 40.5 | 49.2 | 33.5 | 15.0 |
| SS-PANet | 44.6 | 68.0 | 58.0 | 28.2 | 49.0 | 16.4 | 46.2 | 55.2 | 78.7 | 43.3 | 36.0 | 46.2 | 40.2 | 49.7 | 34.3 | 19.9 |
| SS-Mask-RCNN+ | 45.0 | 68.6 | 58.4 | 27.8 | 47.1 | 18.3 | 46.9 | 57.0 | 79.7 | 44.3 | 37.4 | 44.5 | 41.6 | 50.5 | 36.5 | 16.2 |
| SS-PANet+ | 46.9 | 70.8 | 60.1 | 29.6 | 50.3 | 18.4 | 48.6 | 58.0 | 81.0 | 48.0 | 39.1 | 46.6 | 42.1 | 52.9 | 36.6 | 20.8 |
| Settings | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask-RCNN+ [59] | 33.4 | 56.8 | 34.7 | 35.8 | 46.5 | 23.9 | 37.2 | 60.8 | 40.7 | 39.8 | 43.7 | 16.0 |
| D2Det [19] | 37.5 | 61.0 | 39.8 | - | - | - | - | - | - | - | - | - |
| SS-PANet | 39.3 | 62.5 | 42.5 | 42.4 | 47.8 | 13.8 | 44.5 | 66.2 | 50.1 | 47.8 | 50.2 | 16.5 |
| HTC [18] | 39.4 | 62.5 | 42.5 | 42.3 | 49.0 | 14.8 | 46.6 | 66.5 | 52.2 | 49.6 | 55.7 | 17.4 |
| Cascade-Mask-RCNN [20] | 39.4 | 62.5 | 42.5 | 42.3 | 49.0 | 14.8 | 46.6 | 66.5 | 52.2 | 49.6 | 55.7 | 17.4 |
| PANet+ [59] | 39.5 | 63.6 | 42.2 | 42.1 | 53.6 | 38.5 | 46.3 | 66.9 | 51.7 | 48.9 | 53.3 | 26.5 |
| SS-PANet+ | 40.6 | 64.1 | 44.0 | 44.0 | 49.8 | 13.8 | 46.6 | 67.7 | 52.4 | 50.0 | 54.0 | 17.3 |
IV-D2 Evaluation of Scale Complementary Mask Branch
By introducing the SCMB, the network increase segmentation performance from 38.6 to 39.5 and remains comparable detection performance as shown in the fourth row of Table I. We also visualize the comparison segmentation result in the second row of Fig. 6. With the SCMB, the network avoids separating the storage tank into two parts and achieves complete segmentation results for large vehicles, compared with the single-scale mask branch[16].
Furthermore, we conduct ablation studies on the setting of SCMB. Based on the original mask branch [15] with only a spatial resolution of , we extend it to the following three multi-scale forms. The first two forms introduce only a parallel branch with a spatial resolution of and a spatial resolution of , respectively. For the last one, it simultaneously includes the above two parallel branches. The corresponding scale complementary supervision is applied in all three settings. Table III gives the corresponding results where ’’, ’’ and ’’ represent the above three settings. We can find that all these settings improve the segmentation performance and the third setting leads to the best performance.
We also consider two fusion operations for the feature fusion module. As shown in Table III, the channel-wise concatenation achieves a better result. It is noticed that this result is exactly the opposite of the result shown in Table II. For channel-wise concatenation, it can better fuse information from different scales of feature maps. However, for element-wise multiplication, the weak results from a certain feature map may affect the final fusion results.
It can be seen from the ablation study that the element-wise multiplication has a better result in the SEA module, while channel-wise concatenating performs well in the SCMB. Thus, we follow the above settings in all subsequent experiments.
IV-D3 Speed and Complexity Comparison
For the inference speed, we report the comparison results in Table I. First, we extend the baseline with our proposed SEA, and the FPS is reduced by 0.6. This reduction is mainly due to the additional convolutional layer of the proposed SEA module. Then, we extend the baseline with SCMB. The FPS drops by 0.8, and we consider that the SCMB changes the original single mask branch to the trident form, which affects the inference speed. Compared with the SEA module, the SCMB needs to operate on each RoI feature, thus it has a worse impact on speed. Finally, when using both the proposed SEA module and SCMB, the FPS is reduced from 5.1 to 3.6. Besides, we also report the comparison results of complexity in the last two columns in Table I.









| Model | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask-RCNN [15] | 60.9 | 90.2 | 67.2 | 61.3 | 55.3 | - | 60.6 | 90.3 | 69.9 | 61.1 | 47.3 | - |
| PANet [16] | 62.3 | 91.4 | 68.1 | 62.5 | 56.1 | - | 61.7 | 91.1 | 71.2 | 62.0 | 48.6 | - |
| SS-Mask-RCNN | 62.3 | 92.0 | 69.4 | 62.2 | 64.7 | - | 63.6 | 92.6 | 72.2 | 63.9 | 56.3 | - |
| SS-PANet | 63.6 | 92.4 | 70.2 | 63.4 | 65.3 | - | 64.5 | 92.9 | 74.3 | 64.7 | 58.1 | - |
| SS-Mask-RCNN+ | 65.1 | 93.8 | 74.0 | 65.0 | 65.3 | - | 65.2 | 93.6 | 76.0 | 65.3 | 57.2 | - |
| SS-PANet+ | 66.1 | 94.5 | 74.6 | 65.9 | 66.4 | - | 65.9 | 94.2 | 76.7 | 66.0 | 58.8 | - |
| Model | Airplane | Ship | Storagek | Baseball | Tennis | Basketball | Ground track | Harbor | Bridge | Vehicle | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| tank | diamond | court | court | field | |||||||
| Mask-RCNN [15] | 60.9 | 37.7 | 51.6 | 79.3 | 84.2 | 65.0 | 68.4 | 85.0 | 53.4 | 30.4 | 53.6 |
| PANet [16] | 62.3 | 39.0 | 53.8 | 80.1 | 84.9 | 66.3 | 70.5 | 85.3 | 55.5 | 32.9 | 54.9 |
| SS-Mask-RCNN | 62.3 | 38.3 | 52.5 | 80.1 | 84.9 | 65.7 | 69.3 | 85.7 | 55.6 | 36.4 | 54.4 |
| SS-PANet | 63.6 | 39.5 | 54.6 | 80.9 | 85.4 | 67.7 | 71.2 | 86.2 | 57.0 | 37.1 | 55.9 |
| SS-Mask-RCNN+ | 65.1 | 41.7 | 54.0 | 81.3 | 86.3 | 71.4 | 71.6 | 88.3 | 58.9 | 40.3 | 57.3 |
| SS-PANet+ | 66.1 | 42.8 | 55.2 | 81.2 | 86.6 | 72.8 | 72.3 | 88.0 | 59.5 | 41.6 | 57.9 |
| Model | Airplane | Ship | Storagek | Baseball | Tennis | Basketball | Ground track | Harbor | Bridge | Vehicle | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| tank | diamond | court | court | field | |||||||
| Mask-RCNN [15] | 60.6 | 70.9 | 56.0 | 76.1 | 79.4 | 65.6 | 63.8 | 71.3 | 41.5 | 25.8 | 55.9 |
| PANet [16] | 61.7 | 71.3 | 57.8 | 76.3 | 79.6 | 66.7 | 65.4 | 72.8 | 42.8 | 27.7 | 56.6 |
| SS-Mask-RCNN | 63.6 | 71.5 | 61.9 | 76.7 | 81.1 | 66.4 | 66.1 | 75.6 | 45.6 | 34.3 | 57.0 |
| SS-PANet | 64.5 | 72.5 | 62.2 | 77.0 | 81.6 | 67.0 | 67.1 | 76.2 | 47.5 | 35.9 | 57.8 |
| SS-Mask-RCNN+ | 65.2 | 72.2 | 63.4 | 77.9 | 81.9 | 67.9 | 67.5 | 76.7 | 50.3 | 36.6 | 57.9 |
| SS-PANet+ | 65.7 | 73.3 | 63.7 | 78.1 | 82.2 | 68.4 | 68.2 | 76.6 | 51.6 | 37.0 | 58.5 |
IV-E Results on iSAID
To quantitatively evaluate the proposed method, we integrate the SEA module and SCMB into two representative networks (Mask-RCNN, PANet) and name them as SS-Mask-RCNN and SS-PANet. We report the overall comparison performance on iSAID validation set in Table IV to show the performance of our proposed method. As shown in these two tables, our SS-Mask-RCNN/SS-PANet performs better than the baseline Mask-RCNN/PANet by 1.8%/1.4% in and 0.7%/0.7% in . This not only indicates the superiority of our proposed method but also shows that our SEA module and SCMB are robust to different baselines. Considering the large scale-variation of instances in RSIs, multi-scale training is a common and effective strategy to improve performance [7] [52]. We randomly resize the short side of the input image with (1000,800,600,400) in the training phase and name this model as SS-Mask-RCNN+/SS-PANet+. As shown in Table IV, SS-PANet+ achieves the best performance as 40.8%/46.9%. In addition, it can be seen that the comparison results of and in Table IV are unstable. We calculate the distribution of instances’ areas in the image patches of the iSAID validation set and find there are only 9 instances belong to the large scale, which is less than 1% (9 vs 238,138) of the number of instances in the whole validation set. Therefore, a tiny deviation in prediction may lead to a large difference in performance.











To further study the results of different categories, we also reveal the class-wise and in Tables V and VI. In Table V, the SS-PANet+ achieves the best in 14 categories except helicopter and increases more than 4% for plane and baseball diamond compared with PANet. Similar patterns can be found in Table VI. Despite achieving impressive results, the proposed method obtains a low for the bridge in both detection and segmentation. This is mainly because the aspect ratio of the bridge is large, and hence, the anchors with default aspect ratios of 2:1, 1:1 and 1:2 can not better fit them, which in turn affects the segmentation results. In addition, due to the small size of the small vehicle and the limited number of helicopter samples, their performance is also poor. Besides, it is worth noting that there is still a large margin between the detection results and the segmentation results. Specifically, the segmentation results of some categories decrease more than 15% compared to the detection results. For the ground track field, they often contain the soccer-ball field leading to misclassification for pixels locating in overlapping regions. As for harbor, plane, and helicopter, the drop is mainly due to the complex contours. Visualization results for all categories are shown in Fig. 8.
Table VII shows the performance of our approach on the iSAID test set, where the compared methods are based on the official evaluation in [59]. We use the symbol ‘+’ to denote the models using multi-scale training strategies. From Table VII, we can see that the proposed SS-PANet with the single-scale training strategy achieves comparison results with PANet+[59]. Besides, our proposed SS-PANet is 1.8% higher than D2Det [19] in the term of . Compared to the multi-stage approaches [18, 20], SS-PANet gets comparable performance in , but there is still a large gap in . This is mainly because the multi-stage approaches can get better detection performance through multiple regressions and classifications. When applying the multi-scale training strategy in SS-PANet, we obtain the best performance as 40.6%/46.6%. In addition, we note that the improvement of our approach in segmentation is significantly higher than the detection results (1.1 vs 0.3). We believe that this difference mainly comes from the difference in multi-scale training strategy. In official implementation [59], the scale augmentations of the shorter side are at five scales (1200,1000,800,600,400), while we only choose scale augmentations at (1000,800,600,400), which limits the detection results. Despite the detection performance is limited, we still achieve great segmentation performance, which reflects the effectiveness of the proposed method in segmentation.
IV-F Results on NWPU VHR-10 Instance Segmentation
In Table VII, we report the overall performance of our proposed method. With the SEA module and SCMB, the and improve by 1.4%/1.3% and 3.0%/2.8% compared with the Mask-RCNN/PANet. Since we use the modified COCO evaluation metric [59] and the area of all instances in the NWPU VHR-10 Instance Segmentation dataset is less than , the and in Table VII are empty. In addition, we find that the is slightly better than the of SS-PANet+. This is mainly due to the characteristics of the NWPU VHR-10 Instance Segmentation dataset. The instances of most categories in this dataset (such as ground track field, baseball diamond, basketball court, etc.) are in medium-scale and have regular contours, which is simple for segmentation. However, since the instances are always arbitrarily oriented in RSIs, the horizontal bounding boxes may cause inaccurate detection results, especially under high IoU thresholds. Fig. 9 demonstrates the comparison results, where the proposed method effectively handles the impact of complex backgrounds, such as the misclassification between roads and bridges, and the false detection of the parking lot as the harbor. Besides, our SS-PANet can better deal with the under-segmentation of harbor and airplane.
Tables IX and X show the segmentation and detection results in all categories and our proposed method demonstrates the superior performance compared with the baseline. Especially, for the bridge, we obtain more than 5% performance gains in detection results, because the proposed SEA module prevents the road from misclassifying as the bridge (as shown in Fig. 9). Besides, the segmentation results of the ground track field, basketball court, and baseball diamond are significantly better than their detection results, which validates our conjecture in the previous paragraph. However, due to the large aspect ratio of the bridge and the complex contours of the airplane, their segmentation results are still poor. Fig. 10 visualizes the results of each category.
V Conclusion
In this paper, we focus on the multi-category instance segmentation in remote sensing images and propose an end-to-end instance segmentation framework. Taking into account the complex background in RSIs, we design the Semantic Attention (SEA) module with extra segmentation supervision to improve the activation of instances under noise interference. Meanwhile, we introduce the Scale Complementary Mask Branch (SCMB) which integrates information from different scales to tackle the under-segmentation results. Experiments demonstrate that our method achieves better performance competed with the state-of-the-art methods.
Although the proposed method achieves satisfactory improvements, there is still a large margin between the segmentation and detection results. This is mainly because the bird-views of RSIs lead to the arbitrary orientations of objects, and the horizontal bounding boxes in the detection results can not closely surround the instances, which may affect the segmentation result in the bounding box. Therefore, in future work, we will consider the rotation information of RSIs to further improve both detection and segmentation results.
References
- [1] G. Cheng, J. Han, and X. Lu, “Remote sensing image scene classification: Benchmark and state of the art,” Proceedings of the IEEE, vol. 105, no. 10, pp. 1865–1883, 2017.
- [2] G. Xia, J. Hu, F. Hu, B. Shi, X. Bai, Y. Zhong, L. Zhang, and X. Lu, “AID: A benchmark data set for performance evaluation of aerial scene classification,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 7, pp. 3965–3981, 2017.
- [3] Q. Wang, S. Liu, J. Chanussot, and X. Li, “Scene classification with recurrent attention of VHR remote sensing images,” IEEE Trans. Geosci. Remote. Sens., vol. 57, no. 2, pp. 1155–1167, 2019.
- [4] Y. Li, Y. Zhang, and Z. Zhu, “Error-tolerant deep learning for remote sensing image scene classification,” IEEE Trans. Cybern., early access. [Online]. Available: https://doi.org/10.1109/TCYB.2020.2989241
- [5] X. Tang, F. Meng, X. Zhang, Y.-M. Cheung, J. Ma, F. Liu, and L. Jiao, “Hyperspectral image classification based on 3-d octave convolution with spatial-spectral attention network,” IEEE Trans. Geosci. Remote. Sens., early access. [Online]. Available: https://doi.org/10.1109/TGRS.2020.3005431
- [6] Y. Zhong, X. Han, and L. Zhang, “Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery,” ISPRS J. Photogram. Remote Sens., vol. 138, pp. 281–294, Nov. 2018.
- [7] J. Ding, N. Xue, Y. Long, G.-S. Xia, and Q. Lu, “Learning roi transformer for detecting oriented objects in aerial images,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019.
- [8] K. Li, G. Cheng, S. Bu, and X. You, “Rotation-insensitive and context-augmented object detection in remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 4, pp. 2337–2348, 2018.
- [9] X. Li, B. Liu, G. Zheng, Y. Ren, S. Zhang, Y. Liu, L. Gao, Y. Liu, B. Zhang, and F. Wang, “Deep learning-based information mining from ocean remote sensing imagery,” National Science Review, 2020.
- [10] T. Zhang, X. Zhang, J. Shi, and S. Wei, “Hyperli-net: A hyper-light deep learning network for high-accurate and high-speed ship detection from synthetic aperture radar imagery,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 167, pp. 123–153, 2020.
- [11] T. Zhang, X. Zhang, J. Shi, , S. Wei, J. Wan, J. Li, H. Su, and Y. Zhou, “Balance scene learning mechanism for offshore and inshore ship detection in sar images,” IEEE Geoscience and Remote Sensing Letters, early access. [Online]. Available: https://doi.org/10.1109/LGRS.2020.3033988
- [12] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Proc. Adv. Neural Inf. Process. Syst., Dec. 2012, pp. 1097–1105.
- [13] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778.
- [14] Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei, “Fully convolutional instance-aware semantic segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 4438–4446.
- [15] K. He, G. Gkioxari, P. Dollár, and R. B. Girshick, “Mask R-CNN,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2980–2988.
- [16] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network for instance segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 8759–8768.
- [17] Z. Huang, L. Huang, Y. Gong, C. Huang, and X. Wang, “Mask scoring R-CNN,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 6409–6418.
- [18] K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, C. C. Loy, and D. Lin, “Hybrid task cascade for instance segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 4974–4983.
- [19] J. Cao, H. Cholakkal, R. M. Anwer, F. S. Khan, Y. Pang, and L. Shao, “D2det: Towards high quality object detection and instance segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 11 482–11 491.
- [20] Z. Cai and N. Vasconcelos, “Cascade R-CNN: delving into high quality object detection,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 6154–6162.
- [21] M. Bai and R. Urtasun, “Deep watershed transform for instance segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2858–2866.
- [22] A. Arnab and P. H. S. Torr, “Pixelwise instance segmentation with a dynamically instantiated network,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 879–888.
- [23] S. Liu, J. Jia, S. Fidler, and R. Urtasun, “SGN: sequential grouping networks for instance segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 3516–3524.
- [24] A. Kirillov, E. Levinkov, B. Andres, B. Savchynskyy, and C. Rother, “Instancecut: From edges to instances with multicut,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 7322–7331.
- [25] B. D. Brabandere, D. Neven, and L. V. Gool, “Semantic instance segmentation with a discriminative loss function,” arXiv preprint arXiv:1708.02551, Aug. 2017.
- [26] A. Fathi, Z. Wojna, V. Rathod, P. Wang, H. O. Song, S. Guadarrama, and K. P. Murphy, “Semantic instance segmentation via deep metric learning,” arXiv preprint arXiv:1703.10277, Mar. 2017.
- [27] S. Kong and C. C. Fowlkes, “Recurrent pixel embedding for instance grouping,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 9018–9028.
- [28] A. Newell, Z. Huang, and J. Deng, “Associative embedding: End-to-end learning for joint detection and grouping,” in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 2277–2287.
- [29] Y. Feng, W. Diao, Z. Chang, M. Yan, X. Sun, and X. Gao, “Ship instance segmentation from remote sensing images using sequence local context module,” Proc. IEEE Int. Geosci. Remote Sens. Symp. (IGARSS), Jul. 2019.
- [30] L. Mou and X. X. Zhu, “Vehicle instance segmentation from aerial image and video using a multitask learning residual fully convolutional network,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 11, pp. 6699–6711, 2018.
- [31] H. Wei, W. Bing, and Z. Yue, “X-linenet: Detecting aircraft in remote sensing images by a pair of intersecting line segments,” arXiv preprint arXiv:1907.12474, Dec. 2019.
- [32] T. Wu, Y. Hu, L. Peng, and R. Chen, “Improved anchor-free instance segmentation for building extraction from high-resolution remote sensing images,” Remote. Sens., vol. 12, no. 18, p. 2910, 2020.
- [33] H. Su, S. Wei, M. Yan, C. Wang, J. Shi, and X. Zhang, “Object detection and instance segmentation in remote sensing imagery based on precise mask r-cnn,” Proc. IEEE Int. Geosci. Remote Sens. Symp. (IGARSS), Jul. 2019.
- [34] H. Su, S. Wei, S. Liu, J. Liang, C. Wang, J. Shi, and X. Zhang, “Hq-isnet: High-quality instance segmentation for remote sensing imagery,” Remote. Sens., vol. 12, no. 6, p. 989, 2020.
- [35] X. Liu and X. Di, “Global context parallel attention for anchor-free instance segmentation in remote sensing images,” IEEE Geoscience and Remote Sensing Letters, early access. [Online]. Available: https://doi.org/10.1109/LGRS.2020.3023124
- [36] S. Ren, K. He, R. B. Girshick, and J. Sun, “Faster R-CNN: towards real-time object detection with region proposal networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137–1149, 2017.
- [37] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 7132–7141.
- [38] J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, and H. Lu, “Dual attention network for scene segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 3146–3154.
- [39] J. Pang, K. Chen, J. Shi, H. Feng, W. Ouyang, and D. Lin, “Libra R-CNN: towards balanced learning for object detection,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 821–830.
- [40] J. H. Yoo, S. Park, and J. W. Choi, “Scarfnet: Multi-scale features with deeply fused and redistributed semantics for enhanced object detection,” arXiv preprint arXiv:1908.00328, Aug. 2019.
- [41] Z. Zhang, S. Qiao, C. Xie, W. Shen, B. Wang, and A. L. Yuille, “Single-shot object detection with enriched semantics,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 5813–5821.
- [42] T. Lin, P. Dollár, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie, “Feature pyramid networks for object detection,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 936–944.
- [43] X. Wang, R. B. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 7794–7803.
- [44] L. Zhang, G. Zhu, L. Mei, P. Shen, S. A. A. Shah, and M. Bennamoun, “Attention in convolutional LSTM for gesture recognition,” in Proc. Adv. Neural Inf. Process. Syst, Dec. 2018, pp. 1957–1966.
- [45] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” in Proc IEEE Eur. Conf. Comput. Vis. (ECCV), Oct. 2016, pp. 21–37.
- [46] X. Yang, J. Yang, J. Yan, Y. Zhang, T. Zhang, Z. Guo, X. Sun, and K. Fu, “Scrdet: Towards more robust detection for small, cluttered and rotated objects,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV). IEEE, 2019, pp. 8231–8240.
- [47] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang, W. Liu, and B. Xiao, “Deep high-resolution representation learning for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell, early access. [Online]. Available: https://doi.org/10.1109/TPAMI.2020.2983686
- [48] M. Tan, R. Pang, and Q. V. Le, “Efficientdet: Scalable and efficient object detection,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR). IEEE, 2020, pp. 10 778–10 787.
- [49] J. Wang, K. Chen, R. Xu, Z. Liu, C. C. Loy, and D. Lin, “CARAFE: content-aware reassembly of features,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV). IEEE, 2019, pp. 3007–3016.
- [50] L. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 4, pp. 834–848, 2018.
- [51] X. Wang, Z. Hou, W. Yu, Z. Jin, Y. Zha, and X. Qin, “Online scale adaptive visual tracking based on multilayer convolutional features,” IEEE Trans. Cybern., vol. 49, no. 1, pp. 146–158, 2019.
- [52] S. M. Azimi, E. Vig, R. Bahmanyar, M. Körner, and P. Reinartz, “Towards multi-class object detection in unconstrained remote sensing imagery,” in Proc. IEEE Asi. Conf. Comput. Vis. (ACCV), Dec. 2018, pp. 150–165.
- [53] Z. Deng, H. Sun, S. Zhou, J. Zhao, L. Lei, and H. Zou, “Multi-scale object detection in remote sensing imagery with convolutional neural networks,” ISPRS J. Photogram. Remote Sens., vol. 145, pp. 3–22, Nov. 2018.
- [54] T. Zhang and X. Zhang, “Shipdenet-20: An only 20 convolution layers and ¡ 1-mb lightweight sar ship detector,” IEEE Geoscience and Remote Sensing Letters, early access.
- [55] Y. Li, Y. Chen, N. Wang, and Z. Zhang, “Scale-aware trident networks for object detection,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2019.
- [56] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing network,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 6230–6239.
- [57] Q. Cheng, H. Li, Q. Wu, and K. N. Ngan, “Hybrid-loss supervision for deep neural network,” Neurocomputing, vol. 388, pp. 78–89, 2020.
- [58] C. Xu, C. Lu, X. Liang, J. Gao, W. Zheng, T. Wang, and S. Yan, “Multi-loss regularized deep neural network,” IEEE Trans. Circuits Syst. Video Technol., vol. 26, no. 12, pp. 2273–2283, 2016.
- [59] S. W. Zamir, A. Arora, A. Gupta, S. Khan, G. Sun, F. S. Khan, F. Zhu, L. Shao, G. Xia, and X. Bai, “isaid: A large-scale dataset for instance segmentation in aerial images,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition Workshops, Jun. 2019, pp. 28–37.
- [60] G. Cheng, J. Han, P. Zhou, and L. Guo, “Multi-class geospatial object detection and geographic image classification based on collection of part detectors,” ISPRS J. Photogram. Remote Sens., vol. 98, no. 1, pp. 119–132, Dec. 2014.
- [61] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: common objects in context,” in Proc IEEE Eur. Conf. Comput. Vis. (ECCV), Sep. 2014, pp. 740–755.
- [62] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 3431–3440.