Self-similarity Driven Scale-invariant Learning for
Weakly Supervised Person Search
Abstract
Weakly supervised person search aims to jointly detect and match persons with only bounding box annotations. Existing approaches typically focus on improving the features by exploring relations of persons. However, scale variation problem is a more severe obstacle and under-studied that a person often owns images with different scales (resolutions). On the one hand, small-scale images contain less information of a person, thus affecting the accuracy of the generated pseudo labels. On the other hand, the similarity of cross-scale images is often smaller than that of images with the same scale for a person, which will increase the difficulty of matching. In this paper, we address this problem by proposing a novel one-step framework, named Self-similarity driven Scale-invariant Learning (SSL). Scale invariance can be explored based on the self-similarity prior that it shows the same statistical properties of an image at different scales. To this end, we introduce a Multi-scale Exemplar Branch to guide the network in concentrating on the foreground and learning scale-invariant features by hard exemplars mining. To enhance the discriminative power of the features in an unsupervised manner, we introduce a dynamic multi-label prediction which progressively seeks true labels for training. It is adaptable to different types of unlabeled data and serves as a compensation for clustering based strategy. Experiments on PRW and CUHK-SYSU databases demonstrate the effectiveness of our method.
1 Introduction
Recent years have witnessed remarkable success of person search which is to match persons existed in real-world scene images. It is often taken as a joint task consisting of person detection [27, 30, 46] and re-identification (re-id) [32, 43, 36]. To achieve high performance, existing methods are commonly trained in a fully supervised setting [4, 1, 41, 45, 13, 21, 24, 5] where the bounding boxes and identity labels are required. However, it is time-consuming and labor-intensive to annotate both of them in a large-scale dataset, which encourages some researchers to embark on reducing the supervision.
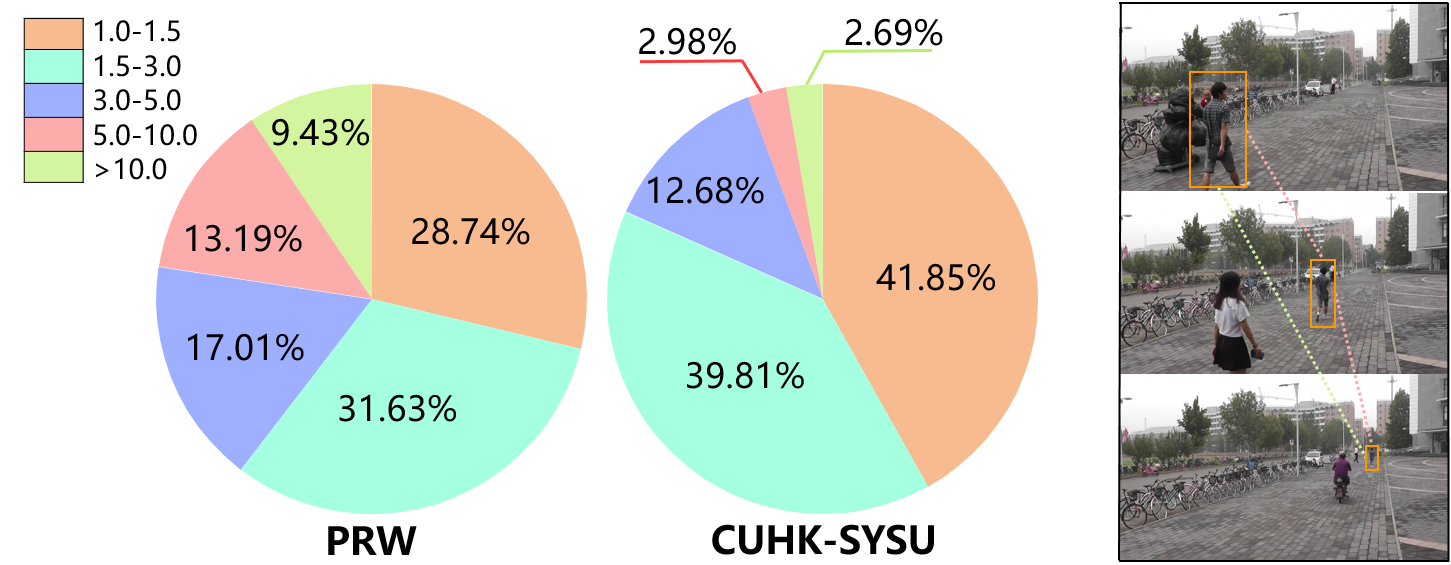
Considering that it is much easier to annotate bounding boxes than person identities, we dedicate this paper to weakly supervised person search which only needs bounding box annotations. Intuitively, we can address it with a supervised detection model and an unsupervised re-id model [37, 44, 11, 12, 6] independently. To be specific, we first train a detector to crop person images and then apply an unsupervised re-id model for matching, which is regarded as a two-step person search model. Nevertheless, one of the major drawbacks of such two-step methods is low-efficiency, i.e., it is of high computational cost with two network parameters during training and inconvenient for test. In contrast, one-step methods can be trained and tested more effectively and efficiently [14, 40]. Han et al. [14] use a Region Siamese Network to learn consistent features by examining relations between auto-cropped images and manually cropped ones. Yan et al. [40] learn discriminative features by exploring the visual context clues. According to the learned features, both of them generate pseudo labels via clustering. Although promising results are achieved, they fail to take into account the scale variation problem that a person often owns images with different scales (resolutions) because the same person is captured at different distances and camera views. As shown in Fig. 1, the images of a person from PRW and CUHK-SYSU datasets have large variation in scale. Since it is unable to resize the input images to a fixed scale for one-step methods, the existing scale variation problem will further affect the procedure of the pseudo label prediction and the subsequent person matching.
In this paper, we propose a novel Self-similarity driven Scale-invariant Learning (SSL) weakly supervised person search framework to solve the scale variation problem. It consists of two branches: Main Branch and Multi-scale Exemplar Branch. The former branch takes the scene image as the input and applies a detector to extract RoI features for each person. Motivated by the self-similarity prior [18] that one subject is similar at different scales, we design the latter branch which is served as a guidance of the former to learn body-aware and scale-invariant features. Firstly, we crop the foreground of person images by using the given bounding boxes and generated binary masks. Each cropped image is regarded as an exemplar. Secondly, we resize each of the exemplars to several fixed scales. At last, we formulate a scale-invariant loss by hard exemplar mining. Note that RoI features in Main Branch focuses on differentiating a person from background but are not able to distinguish different persons. Guided by Multi-scale Exemplar Branch, we can enable Main Branch to learn both scale-invariant and discriminative features. To generate reliable pseudo labels, we introduce a dynamic threshold for multi-label learning. It can find true labels progressively and be adaptable to different datasets, which serves as an compensation for cluster-level prediction [12]. Finally, we integrate the scale-invariant loss, multi-label classification loss and contrastive learning loss together and optimize them jointly.
Our contributions are summarized as follows:
-
•
We propose a novel end-to-end Self-similarity driven Scale-invariant Learning framework to solve the task of weakly supervised person search. It bridges the gap between person detection and re-id by using a multi-scale exemplar branch as a guidance.
-
•
We design a scale-invariant loss to solve the scale variation problem and a dynamic multi-label learning which is adaptable to different datasets.
-
•
We confirm the efficacy of the proposed method by achieving state-of-the-art performance on PRW and CUHK-SYSU datasets.
2 Related Work
Person Search. Nowadays, person search has attracted increasing attention because of its wide application in real-world environment. Its task is to retrieve a specific person from a gallery set of scene images. It can be seen as an extension of re-id task by adding a person detection task.
Existing methods addressing this task can be classified to two manners: one-step [39, 41, 1, 45, 16] and two-step [15, 9, 4] methods. One-step methods tackle person detection and re-id simultaneously. The work [39] proposes the first one-step person search approach based on deep learning. It provides a practical baseline and proposes Online Instance Matching(OIM), which is still used in recent works. Yan et al. [41] introduce an anchor-free framework into person search task and tackle the misalignment issues at different levels. Dong et al. [8] propose a bi-directional interaction network and use the cropped image to alleviate the influence of the context information. In contrast, two-step methods process person detection and re-id separately, which alleviates the conflict between them [13]. Chen et al. [4] introduce an attention mechanism to obtain more discriminative re-id features by modeling the foreground and the original image patches. Wang et al. [34] propose an identity-guided query detector to filter out the low-confidence proposals.
Due to the high cost of obtaining the annotated data, Li et al. [22] propose a domain adaptive method. In this setting, the model is trained on the labeled source domain and transferred to the unlabeled target domain. Recent years, Han et al. [14] and Yan et al. [40] propose the weakly jsupervised person search methods, which only needs the bounding box annotations. Due to the absence of person ID annotations in the weakly supervised setting, we need to generate pseudo labels to guide the training procedure. The quality of the pseudo labels has a significant impact on the performance. Thus, how to generate reliable pseudo labels is an important issue of the weakly supervised person search.
Unsupervised re-id. Due to the limitation of the annotated data, fully supervised re-id has poor scalability. Thus, lots of unsupervised re-id are proposed, which try to generate reliable yet valid pseudo labels for unsupervised learning. Some of them consider the global data relationship and apply unsupervised cluster algorithm to generate pseudo labels. For example, Fan et al. [11] propose an iterative clustering and fine-tuning method for unsupervised re-id. Ge et al. [12] use the self-paced strategy to generate pseudo labels based on the clustering method. Cho et al. [6] propose a pseudo labels refinement strategy based on the part feature information. Although cluster-level methods have made great progress, the within-class noisy introduced by cluster algorithm still limits the further improvement.
To solve this issue, another methods introduce fine-grid instance-level pseudo labels as the supervision for unsupervised learning. For example, zhong et al. [49] propose an instance exemplar memory learning scheme that considers three invariant cues as the instance-level supervision, including exemplar-invariance, camera invariance and neighborhood-invariance. Lv et al. [28] look for underlying positive pairs on the instance memory with the guiding of spatio-temporal. information. Wang et al. [35] consider the instance visual similarity and the instance cycle consistency as the supervision. Lin et al. [25] regard each training image as a single class and train the model with the soften label distribution.
Multi-scale Matching Problem. Person search suffers from the multi-scale matching problem because of the scale variations in scene images. Lan et al. [20] propose a two-step method with knowledge distillation to alleviate this problem. Unlike the fully supervised setting, due to the absence of the ID annotations, it is much harder to learn a consistent feature for the same person appears in various scales. In this paper, we propose the Self-similarity driven Scale-invariant Learning to improve the feature consistency among different scales in the weakly supervised setting.

3 Proposed Method
In this section, we first introduce the overall framework in Sec. 3.1, then describe the scale-invariant learning in Sec. 3.2. A reliable pseudo label generation is detailed in Sec. 3.3 and the training and inference procedure is finally explained in Sec. 3.4.
3.1 Framework Overview
Different from the fully supervised person search, only the bounding box annotations are accessible in the weakly supervised setting. Firstly, we propose the scale-invariant loss to address the scale variance problem by hard exemplar mining. In addition, because the existing cluster based methods may incur noisy pseudo labels, we further propose a dynamic threshold based method to obtain pseudo labels, which is jointly used with cluster based method.
The general pipeline of the framework is illustrated in Fig. 2. Our detection part is based on Faster R -CNN [31], a widely used object detection baseline. As aforementioned, scale variation problem is a severe obstacle and will further affect the procedure of the pseudo label prediction and the subsequent person matching . To address it, we propose the SSL that consists of multi-scale exemplar branch and main branch. The main branch locates the persons firstly, and extracts the RoI features by the RoI-Align layer with the localization information. The multi-scale exemplar branch is used to obtain the features of the same person with different scales. Specifically, the multi-scale cropped images with background filtering [23] and scene images are fed into the two branches for scale-invariant feature learning.
To enhance the reliability of the pseudo labels, we propose a dynamic threshold based method to obtain the instance level pseudo labels. At the same time, the DBSCAN based method is also used to obtain complementary cluster level pseudo labels.
3.2 Scale-invariant Learning
In this section, we adopt a Scale Augmentation strategy to obtain multi-scale exemplars and propose a Scale-invariant Learning to learn scale-invariant features by hard exemplar mining.
Scale Augmentation. Given a scene image , we obtain the cropped image of the -th person with the given localization annotation .
Then, we apply a binary mask [23] filtering the background to obtain person’s emphasized region:
| (1) |
where means pixel-wise multiplication, and is the bilinear interpolation function that transforms the masked image to the corresponding scale .

Scale-invariant Loss. When we have obtained multi-scale exemplars by scale augmentation, we use them to learn the scale-invariant features in the guidance of multi-scale exemplar branch which takes the exemplars as the inputs and aims to extract multi-scale features. At the same time, our main branch takes the scene image as input, aiming to detect persons and extract corresponding re-id features.
In a scene image, assuming there are persons, we can get corresponding cropped images by the bounding box annotations, and we augment each bounding box to different scales. Thus, we totally obtain cropped images with different scales. The scale-invariant loss can be formulated as follows:
| (2) |
with
| (3) |
| (4) |
where denotes the batch size, measures the squared euclidean distance between two features, stand for the instance feature extracted from the main branch. and stand for the multi-scale features of the -th and -th persons, respectively. And means for the original scale feature of the -th person. denotes the distance margin and denotes the regularization factor. Furthermore, the obtained features are processed by -norm.
An intuitive illustration of is presented in Fig. 3. tries to select the most difficult positive and negative ones from multi-scale exemplars for a query image. It learns the scale-invariant features by decreasing the distance with the corresponding hardest positive exemplar and increasing the distance with the corresponding hardest negative exemplar. Meanwhile, it is notably that the original scale cropped image could be aligned better with the instance feature. Thus, we additionally constrain the distance between the instance feature and its corresponding original scale feature to make the model focus on the foreground information and extract body-aware features.
3.3 Dynamic Multi-label Learning
In weakly supervised settings, we do not have the ID annotations of each person. Thus, it is very important to predict pseudo labels and its quality will affect the subsequent training for discriminative re-id features.
As shown in Fig. 2, we maintain two extra memory banks and to store the features extracted from the main branch and multi-scale exeplar branch, separately. Where is the number of samples in the training data set and is the feature dimension. For the latter branch, we extract features corresponding to scale-o, scale-1, scale-2, and scale-3, and obtain the average feature . For the main branch, we extract the instance feature from the scene image. After each training iteration, and are updated as:
| (5) |
where is the momentum factor and set to 0.8 in our experiments.
To obtain reliable pseudo labels, we use the multi-scale features to generate pseudo labels for clustering and multi-label classification. The multi-scale features are obtained as follows:
| (6) |
Dynamic Pseudo Label Prediction. Suppose we have a training set with samples, we treat the pseudo label generation as an N-classes multi-label classification problem. In other words, the -th person has an N-dim two-valued label . The label of the -th person can be predicted based on the similarity between its feature and the features of others. Based on the , the similarity matrix can be obtained as follows:
| (7) |
and with it, we can get two-valued labels matrix with a threshold :
| (8) |
However, the multi-label classification method is sensitive to the threshold. An unsuitable threshold can seriously affect the quality of label generation, i.e., the low threshold will introduce a lot of noisy samples, while the high threshold omits some hard positive samples. Thus, we further adopt an exponential dynamic threshold to generate more reliable pseudo labels. That is,
| (9) |
where is the initial threshold, and are the ratio factors, and stands for current epoch number. So far, we can use the dynamic threshold to get the label vector for each person at each iteration by Eq. 8.
We define the positive label set of the -th person and negative label set . To make the pseudo label more reliable, we further process the label based on the hypothesis: persons in the same image can not be the same person. For the -th person, we can get its similarity vector by Eq. 7. We sort the in descending order and get the sorted index:
| (10) |
Then, we traverse the label by the . If the -th person is predicted to be the same person with the -th person, i.e., . We consider the other persons belong to the same image with the -th person can not have the same ID with the -th person, and set these labels to 0.
Besides, for the cluster level, based on the , we adopt DBSCAN with self-paced strategy [12] to generate cluster-level pseudo labels.
and based re-id feature learning. As aforementioned, we use the to generate reliable pseudo labels and calculate the loss function on the two branches with and , separately. The instance level multi-label learning loss function can be formulated as:
| (11) |
where , , is the number of persons in a mini-batch and is used as a balance factor of the loss. The total dynamic multi-label learning loss can be formulated as follows:
| (12) |
3.4 Training and Inference
In general, our SSL is trained in an end-to-end manner by using the following loss function:
| (13) |
where stands for the detection loss used in SeqNet [24] and denotes to the contrastive learning loss used in CGPS [40].
In the inference phase, we only use the main branch to detect the persons and extract the re-id features which are further used to compute their similarity score.
4 Experiments
4.1 Datasets and Settings
CUHK-SYSU [39] is one of the largest public datasets for person search. It contains 18,184 images, including 12,490 frames from street scenes and 5,694 frames captured from movie snapshots. CUHK-SYSU provides 8,432 annotated identities and 96,143 annotated bounding boxes in total, where the training set contains 11,206 images and 5,532 identities, and the test set contains 6,978 images and 2,900 query persons. CUHK-SYSU also provides a set of evaluation protocols with gallery sizes from 50 to 4000. In this paper, we report the results with the default 100 gallery size.
PRW [47] is collected in a university campus by six cameras. The images are annotated every 25 frames from a 10 hours video. It contains 11,816 frames with 43,110 annotated bounding boxes. The training set contains 5,401 images and 482 identifies, and the test set contains 6,112 images and 2,507 queries with 450 identities.
Evaluation Protocol. We adopt the Cumulative Matching Characteristic (CMC), and the mean Averaged Precision (mAP) to evaluate the performance for person search. We also adopt recall and average precision to evaluate person detection performance.
4.2 Implementation Details
We adopt ResNet50 [17] pre-trained on ImageNet [7] as our backbone. We set the batch size to 2 and adopt the stochastic gradient descent (SGD) algorithm to optimize the model for 26 epochs. The initial learning rate is 0.001 and is reduced by a factor of 10 at 16 and 22 epochs. We set the momentum and weight decay to 0.9 and , respectively. We set the hyperparameters and . We employ DBSCAN [10] with self-paced learning strategy [12] as the basic clustering method, and the hyper-parameters are the same as [40]. In our experiments, the scale-1, scale-2, scale-3 are set to 11248, 22496 and 448192, respectively. For inference, we resize the images to a fixed size of 1500 900 pixels. Furthermore, We use PyTorch to implement our model, and run all the experiments on an NVIDIA Tesla V100 GPU.
4.3 Ablation Study
| Baseline | DML | SL | PRW | CUHK-SYSU | ||
|---|---|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | |||
| ✓ | 18.8 | 67.0 | 80.7 | 82.5 | ||
| ✓ | ✓ | 20.8 | 70.8 | 84.5 | 86.3 | |
| ✓ | ✓ | 26.2 | 76.4 | 86.2 | 87.4 | |
| ✓ | ✓ | ✓ | 30.7 | 80.6 | 87.4 | 88.5 |
Baseline. We adopt a classical two-stage Faster R-CNN detector as our baseline model. Following SeqNet [24], we adopt two RPN structure to obtain more quality proposals. Furthermore, we adopt DBSCAN [10] with self-paced strategy [12] to generate pseudo labels and optimize the model with the contrastive learning loss in [40].
Effectiveness of Each Component. We analyze the effectiveness of our SSL framework, and report the results in Tab. 1, where DML denotes dynamic multi-label learning and SL means scale-invariant learning.
Firstly, we can see that the baseline model achieves 18.8% mAP and 67.0% top-1 on PRW. With the SL, baseline obviously improves the mAP and top-1 by 7.4% and 9.4% on PRW, respectively. This improvement indicates that the proposed SSL is effectiveness to handle pedestrian scale variations. Secondly, we can observe that DML improves baseline model by 2.0% in mAP and 3.8% in top-1 on PRW dataset, and DML further improves baseline + SL by 4.5%/4.2% in mAP/top-1 and improves baseline + SL by 1.2%/1.1% in mAP/top-1 on CUHK-SYSU. This improvement illustrates the effectiveness of our dynamic multi-label classification strategy for unsupervised learning.
| Methods | PRW | CUHK-SYSU | ||
|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | |
| SSL w/ Original Scale | 23.9 | 75.6 | 84.3 | 86.1 |
| SSL w/ One Scale | 24.3 | 75.9 | 84.8 | 86.3 |
| SSL w/ Multi-Scale | 27.1 | 77.4 | 86.1 | 87.9 |
| SSL w/ Multi-Scale† | 28.6 | 79.6 | 86.9 | 88.2 |
Effectiveness of Scale-invariant Loss. In the Sec. 3.3, we introduce using the multi-scale features to generate more reliable pseudo labels. For a fair comparison, we only use the memory bank to generate pseudo labels in our experiments. The results are reported in Tab. 2. In the method SSL w/ Original Scale, we only use the original size of the cropped person images, which is obtained by bounding box annotations directly. In the method SSL w/ One Scale, we resize the cropped persons images to 22496 pixels. We observe that the One Scale method just surpasses the Original Scale method by 0.4% and 0.3% in mAP and top-1. The SSL w/ Multi-Scale method significantly improves the performance, which achieves 27.1% in mAP and 77.4% in top-1. means filtering the background with the method in Sec. 3.2, which makes the model concentrate more on the foreground information and obtains more discriminative features. Filtering the background information further improves the performance by 1.5% and 2.2% in terms of mAP and top-1.
| Methods | PRW | CUHK-SYSU | ||
|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | |
| ML | 29.2 | 79.0 | 84.2 | 85.0 |
| Ours | 30.7 | 80.6 | 87.4 | 88.5 |

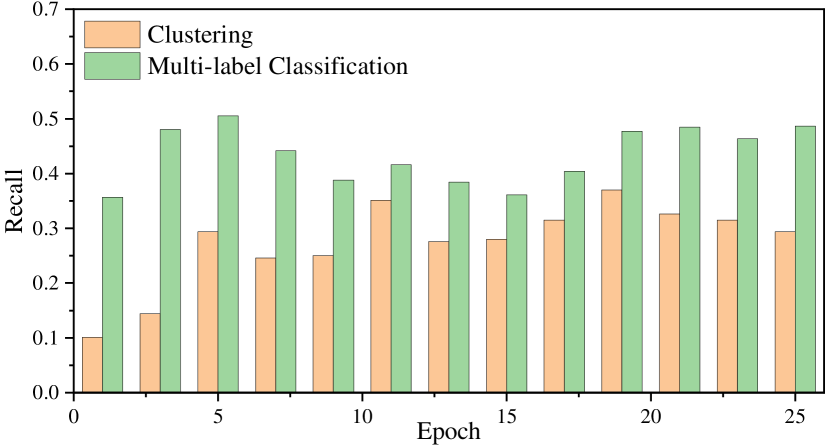
Effectiveness of Pseudo Label Generation Method. To illustrate the effectiveness of DML, we count the precision and recall of the pseudo labels, and report the statistics result in Fig. 4. Compared with clustering method, the higher precision indicates that DML is more reliable, while the higher recall indicates that DML is more valid. This is because that cluster method (i.e., DBSCAN) introduces within-class noisy. Our DML can alleviate this issue. Additionally, we shows the limitation of the multi-label classification with a fixed threshold in Tab. 3, where ML denotes generating the pseudo multi-labels with a fixed threshold. It shows that the ML is not adaptive for different datasets. Although ML with a fixed threshold achieves comparable results on PRW (29.2% mAP and 79.0% top-1), it performances poorly on CUHK-SYSU. Our dynamic threshold significantly alleviates this issue and achieves promising results on both datasets.


4.4 Comparison with the State-of-the-arts
In this section, we compare our method with current state-of-the-art methods including fully supervised methods and weakly supervised methods.
Results on CUHK-SYSU. Tab. 4 shows the performance on CUHK-SYSU with the gallery size of 100. Our method achieves the best 87.4% mAP and 88.5% top-1, outperforming all existing weakly supervised person search methods. Specifically, we outperform the state-of-the-art method R-SiamNet by 1.4 in mAP% and 1.4% in top-1 accuracy. We also evaluate these methods under different gallery sizes from 50 to 4,000. In Fig. 6, we compare mAP with other methods. The dashed lines denote the weakly supervised methods and the solid lines denote the fully supervised methods. It can be observed that our method still outperforms all the weakly supervised with gallery increasing. Meanwhile, Our method surprisingly surpasses some fully supervised methods, e.g., [39], [42],[2] and [4]. However, there still exists a significant performance gap. We hope our work could give some inspiration to others to explore weakly supervised person search.
| Methods | PRW | CUHK-SYSU | |||
|---|---|---|---|---|---|
| mAP | top-1 | mAP | top-1 | ||
| Fully supervised | OIM [39] | 21.3 | 49.9 | 75.5 | 78.7 |
| IAN [38] | 23.0 | 61.9 | 76.3 | 80.1 | |
| NPSM [26] | 24.2 | 53.1 | 77.9 | 81.2 | |
| CTXG [42] | 33.4 | 73.6 | 84.1 | 86.5 | |
| MGTS [4] | 32.6 | 72.1 | 83.0 | 83.7 | |
| QEEPS [29] | 37.1 | 76.7 | 88.9 | 89.1 | |
| CLSA [20] | 38.7 | 65.0 | 87.2 | 88.5 | |
| HOIM [3] | 39.8 | 80.4 | 89.7 | 90.8 | |
| APNet [48] | 41.9 | 81.4 | 88.9 | 89.3 | |
| RDLR [15] | 42.9 | 70.2 | 93.0 | 94.2 | |
| NAE [5] | 44.0 | 81.1 | 92.1 | 92.9 | |
| PGS [19] | 44.2 | 85.2 | 92.3 | 94.7 | |
| BINet [8] | 45.3 | 81.7 | 90.0 | 90.7 | |
| AlignPS [41] | 45.9 | 81.9 | 93.1 | 93.4 | |
| SeqNet [24] | 46.7 | 83.4 | 93.8 | 94.6 | |
| TCTS [34] | 46.8 | 87.5 | 93.9 | 95.1 | |
| IGPN [9] | 47.2 | 87.0 | 90.3 | 91.4 | |
| OIMNet++ [21] | 47.7 | 84.8 | 93.1 | 94.1 | |
| PSTR [1] | 49.5 | 87.8 | 93.5 | 95.0 | |
| AGWF [13] | 53.3 | 87.7 | 93.3 | 94.2 | |
| COAT [45] | 53.3 | 87.4 | 94.2 | 94.7 | |
| Weakly | CGPS [40] | 16.2 | 68.0 | 80.0 | 82.3 |
| R-SiamNet [14] | 21.2 | 73.4 | 86.0 | 87.1 | |
| Ours | 30.7 | 80.6 | 87.4 | 88.5 | |
Results on PRW. As shown in Tab. 4, among existing two weakly supervised methods, CGPS [40] and R-SiamNet [14] achieve 16.2%/68.0% and 21.2%/73.4% in mAP/top-1. Our method achieves 30.7%/80.6% in mAP/top-1, surpassing all existing weakly supervised methods by a large margin. We argue that, as shown in Fig. 1, PRW has large variations of pedestrians scales, which presents multi-scale matching challenge, and our scale-invariant feature learning(Sec. 3.2) significantly alleviates this problem. As shown in Tab. 1, even the baseline model with our scale-invariant feature learning still outperforms CGPS 10.0%/8.4% in mAP/top-1 and outperforms R-SiamNet in 5.0%/3.0% in mAP/top-1.

Visualization Analysis. To evaluate the effectiveness of our method, we show several search results on CUHK-SYSU and PRW in Fig. 5. Specifically, the first two rows show that our method has stronger cross-scale retrieval capability compared to the baseline method. Additionally, the third row shows that our SSL extracts more discriminative features and retrieve the target person correctly among the confusing persons gallery.
Moreover, we visualize the feature distribution with t-SNE [33] in Fig. 7. The circle denotes to the small scale persons whose resolution less than 3600 pixels, the square denotes to the large scale persons whose resolution larger than 45300, and the cross denotes to the medium scale persons whose resolution is between 3600 and 45300. Different colors represent different person identities. It illustrates that our method generates more consistent features across different scales. For more search results and visualizations, please refer to the supplementary materials.
5 Conclusion
In this paper, we propose a Self-similarity driven Scale-invariant Learning framework to solve the task of weakly supervised person search. With a scale-invariant loss, we can learn scale-invariant features by hard exemplar mining which will benefit the subsequent pseudo label prediction and person matching. We propose a dynamic multi-label learning method to generate pseudo labels and learn discrimative feature for re-id, which is adaptable to different datasets. To compensate dynamic multi-label learning, we also use cluster based strategy to learn re-id features. Finally, we learn the aforementioned parts in an end-to-end manner. Extensive experiments demonstrate that our proposed SSL can achieve state-of-the-art performance on two large-scale benchmarks.
References
- [1] Jiale Cao, Yanwei Pang, Rao Muhammad Anwer, Hisham Cholakkal, Jin Xie, Mubarak Shah, and Fahad Shahbaz Khan. Pstr: End-to-end one-step person search with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9458–9467, 2022.
- [2] Xiaojun Chang, Po-Yao Huang, Yi-Dong Shen, Xiaodan Liang, Yi Yang, and Alexander G Hauptmann. Rcaa: Relational context-aware agents for person search. In Proceedings of the European Conference on Computer Vision (ECCV), pages 84–100, 2018.
- [3] Di Chen, Shanshan Zhang, Wanli Ouyang, Jian Yang, and Bernt Schiele. Hierarchical online instance matching for person search. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 10518–10525, 2020.
- [4] Di Chen, Shanshan Zhang, Wanli Ouyang, Jian Yang, and Ying Tai. Person search via a mask-guided two-stream cnn model. In Proceedings of the European conference on computer vision (ECCV), pages 734–750, 2018.
- [5] Di Chen, Shanshan Zhang, Jian Yang, and Bernt Schiele. Norm-aware embedding for efficient person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12615–12624, 2020.
- [6] Yoonki Cho, Woo Jae Kim, Seunghoon Hong, and Sung-Eui Yoon. Part-based pseudo label refinement for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7308–7318, 2022.
- [7] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255. IEEE, 2009.
- [8] Wenkai Dong, Zhaoxiang Zhang, Chunfeng Song, and Tieniu Tan. Bi-directional interaction network for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2839–2848, 2020.
- [9] Wenkai Dong, Zhaoxiang Zhang, Chunfeng Song, and Tieniu Tan. Instance guided proposal network for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2585–2594, 2020.
- [10] Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. In KDD, volume 96, pages 226–231, 1996.
- [11] Hehe Fan, Liang Zheng, Chenggang Yan, and Yi Yang. Unsupervised person re-identification: Clustering and fine-tuning. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), 14(4):1–18, 2018.
- [12] Yixiao Ge, Feng Zhu, Dapeng Chen, Rui Zhao, et al. Self-paced contrastive learning with hybrid memory for domain adaptive object re-id. Advances in Neural Information Processing Systems, 33:11309–11321, 2020.
- [13] Byeong-Ju Han, Kuhyeun Ko, and Jae-Young Sim. End-to-end trainable trident person search network using adaptive gradient propagation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 925–933, 2021.
- [14] Chuchu Han, Kai Su, Dongdong Yu, Zehuan Yuan, Changxin Gao, Nong Sang, Yi Yang, and Changhu Wang. Weakly supervised person search with region siamese networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 12006–12015, 2021.
- [15] Chuchu Han, Jiacheng Ye, Yunshan Zhong, Xin Tan, Chi Zhang, Changxin Gao, and Nong Sang. Re-id driven localization refinement for person search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9814–9823, 2019.
- [16] Chuchu Han, Zhedong Zheng, Changxin Gao, Nong Sang, and Yi Yang. Decoupled and memory-reinforced networks: Towards effective feature learning for one-step person search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 1505–1512, 2021.
- [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- [18] Narendra Ahuja Jia-Bin Huang, Abhishek Singh. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5197–5206, 2015.
- [19] Hanjae Kim, Sunghun Joung, Ig-Jae Kim, and Kwanghoon Sohn. Prototype-guided saliency feature learning for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4865–4874, 2021.
- [20] Xu Lan, Xiatian Zhu, and Shaogang Gong. Person search by multi-scale matching. In Proceedings of the European conference on computer vision (ECCV), pages 536–552, 2018.
- [21] Sanghoon Lee, Youngmin Oh, Donghyeon Baek, Junghyup Lee, and Bumsub Ham. Oimnet++: Prototypical normalization and localization-aware learning for person search. pages 621–637, 2022.
- [22] Junjie Li, Yichao Yan, Guanshuo Wang, Fufu Yu, Qiong Jia, and Shouhong Ding. Domain adaptive person search. pages 302–318, 2022.
- [23] Peike Li, Yunqiu Xu, Yunchao Wei, and Yi Yang. Self-correction for human parsing. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [24] Zhengjia Li and Duoqian Miao. Sequential end-to-end network for efficient person search. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2011–2019, 2021.
- [25] Yutian Lin, Lingxi Xie, Yu Wu, Chenggang Yan, and Qi Tian. Unsupervised person re-identification via softened similarity learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3390–3399, 2020.
- [26] Hao Liu, Jiashi Feng, Zequn Jie, Karlekar Jayashree, Bo Zhao, Meibin Qi, Jianguo Jiang, and Shuicheng Yan. Neural person search machines. In Proceedings of the IEEE International Conference on Computer Vision, pages 493–501, 2017.
- [27] Wei Liu, Shengcai Liao, Weiqiang Ren, Weidong Hu, and Yinan Yu. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5187–5196, 2019.
- [28] Jianming Lv, Weihang Chen, Qing Li, and Can Yang. Unsupervised cross-dataset person re-identification by transfer learning of spatial-temporal patterns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7948–7956, 2018.
- [29] Bharti Munjal, Sikandar Amin, Federico Tombari, and Fabio Galasso. Query-guided end-to-end person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 811–820, 2019.
- [30] Yanwei Pang, Jin Xie, Muhammad Haris Khan, Rao Muhammad Anwer, Fahad Shahbaz Khan, and Ling Shao. Mask-guided attention network for occluded pedestrian detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4967–4975, 2019.
- [31] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28, 2015.
- [32] Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, and Shengjin Wang. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), pages 480–496, 2018.
- [33] Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(11), 2008.
- [34] Cheng Wang, Bingpeng Ma, Hong Chang, Shiguang Shan, and Xilin Chen. Tcts: A task-consistent two-stage framework for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11952–11961, 2020.
- [35] Dongkai Wang and Shiliang Zhang. Unsupervised person re-identification via multi-label classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10981–10990, 2020.
- [36] Guan-An Wang, Tianzhu Zhang, Yang Yang, Jian Cheng, Jianlong Chang, Xu Liang, and Zeng-Guang Hou. Cross-modality paired-images generation for rgb-infrared person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12144–12151, 2020.
- [37] Jinlin Wu, Yang Yang, Hao Liu, Shengcai Liao, Zhen Lei, and Stan Z Li. Unsupervised graph association for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8321–8330, 2019.
- [38] Jimin Xiao, Yanchun Xie, Tammam Tillo, Kaizhu Huang, Yunchao Wei, and Jiashi Feng. Ian: the individual aggregation network for person search. Pattern Recognition, 87:332–340, 2019.
- [39] Tong Xiao, Shuang Li, Bochao Wang, Liang Lin, and Xiaogang Wang. Joint detection and identification feature learning for person search. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 3415–3424, 2017.
- [40] Yichao Yan, Jinpeng Li, Shengcai Liao, Jie Qin, Bingbing Ni, Ke Lu, and Xiaokang Yang. Exploring visual context for weakly supervised person search. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 3027–3035, 2022.
- [41] Yichao Yan, Jinpeng Li, Jie Qin, Song Bai, Shengcai Liao, Li Liu, Fan Zhu, and Ling Shao. Anchor-free person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7690–7699, 2021.
- [42] Yichao Yan, Qiang Zhang, Bingbing Ni, Wendong Zhang, Minghao Xu, and Xiaokang Yang. Learning context graph for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2158–2167, 2019.
- [43] Yang Yang, Jimei Yang, Junjie Yan, Shengcai Liao, Dong Yi, and Stan Z Li. Salient color names for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), pages 536–551. Springer, 2014.
- [44] Hong-Xing Yu, Wei-Shi Zheng, Ancong Wu, Xiaowei Guo, Shaogang Gong, and Jian-Huang Lai. Unsupervised person re-identification by soft multilabel learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2148–2157, 2019.
- [45] Rui Yu, Dawei Du, Rodney LaLonde, Daniel Davila, Christopher Funk, Anthony Hoogs, and Brian Clipp. Cascade transformers for end-to-end person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7267–7276, 2022.
- [46] Shifeng Zhang, Longyin Wen, Xiao Bian, Zhen Lei, and Stan Z Li. Occlusion-aware r-cnn: detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision (ECCV), pages 637–653, 2018.
- [47] Liang Zheng, Hengheng Zhang, Shaoyan Sun, Manmohan Chandraker, Yi Yang, and Qi Tian. Person re-identification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1367–1376, 2017.
- [48] Yingji Zhong, Xiaoyu Wang, and Shiliang Zhang. Robust partial matching for person search in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6827–6835, 2020.
- [49] Zhun Zhong, Liang Zheng, Zhiming Luo, Shaozi Li, and Yi Yang. Invariance matters: Exemplar memory for domain adaptive person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 598–607, 2019.