Self-Improving Voronoi Construction for a Hidden Mixture of Product Distributions††thanks: Research of Cheng and Wong are supported by Research Grants Council, Hong Kong, China (project no. 16200317).
Abstract
We propose a self-improving algorithm for computing Voronoi diagrams under a given convex distance function with constant description complexity. The input points are drawn from a hidden mixture of product distributions; we are only given an upper bound on the number of distributions in the mixture, and the property that for each distribution, an input instance is drawn from it with a probability of . For any , after spending time in a training phase, our algorithm achieves an expected running time with probability at least , where is the entropy of the distribution of the Voronoi diagram output. The expectation is taken over the input distribution and the randomized decisions of the algorithm. For the Euclidean metric, the expected running time improves to .
1 Introduction
Self-improving algorithms, proposed by Ailon et al. [2], is a framework for studying algorithmic complexity beyond the worst case. There is a training phase that allows some auxiliary structures about the input distribution to be constructed. In the operation phase, these auxiliary structures help to achieve an expected running time, called the limiting complexity, that may surpass the worst-case optimal time complexity.
Self-improving algorithms have been designed for product distributions [2, 10]. Let be the input size. A product distribution consists of distributions such that the th input item is drawn independently from . It is possible that for some , but the draws of the th and th input items are independent. No further information about is given. Sorting, Delaunay triangulation, 2D maxima, and 2D convex hull have been studied for product distributions. For all four problems, the training phase uses input instances, and the space complexity is . The limiting complexities of sorting and Delaunay triangulation are for any , where is the entropy of the output distribution [2]. The limiting complexities for 2D maxima and 2D convex hull are and respectively, where OptM and OptC are the expected depths of the optimal linear decision trees for the two problems [10].
Extensions that allow dependence among input items have been developed. One extension is that there is a hidden partition of into groups. The input items with indices in the th group follow some hidden functions of a common parameter . The parameters follow a product distribution. The partition of is not given though. If the hidden functions are known to be linear, sorting can be solved in a limiting complexity of after a training phase that takes time [8]. If it is only known that each hidden function has extrema and the graphs of two functions intersect in places (without knowing any of the functions, or any of these extrema and intersections), sorting can be solved in a limiting complexity of after an -time training phase [7]. For the Delaunay triangulation problem, if it is known that the hidden functions are bivariate polynomials of degree (without knowing the polynomials), a limiting complexity of can be achieved after a polynomial-time training phase [7].
Another extension is that the input instance is drawn from a hidden mixture of at most product distributions. That is, there are at most product distributions such that for some fixed positive value . The upper bound is given, but no information about the ’s and the ’s is provided. Sorting can be solved in a limiting complexity of after a training phase that takes time [8].
In this paper, we present a self-improving algorithm for constructing Voronoi diagrams under a convex distance function in , assuming that the input distribution is a hidden mixture of at most product distributions. The convex distance function is induced by a given convex polygon of size. The upper bound is given, and we assume that . We also assume that for each product distribution in the mixture, . Let be a parameter fixed beforehand. The training phase uses input instances and takes time. In the operation phase, given an input instance , we can construct its Voronoi diagram under in a limiting complexity of , where denotes the entropy of the distribution of the Voronoi diagram output. Note that is a lower bound of the expected running time of any comparison-based algorithm. Our algorithm also works for the Euclidean case, and the limiting complexity improves to .
For simplicity, we will assume throughout the rest of this paper that the hidden mixture has exactly product distributions. We give an overview of our method in the following.
We follow the strategy in [2] for computing a Euclidean Delaunay triangulation. The idea is to form a set of sample points and build and some auxiliary structures in the training phase so that any future input instance can be merged quickly into to form , and then can be split off in expected time. Merging into requires locating the input points in . The location distribution is gathered in the training phase so that distribution-sensitive point location can be used to avoid the logarithmic query time as much as possible. Modifying efficiently into requires that only points in fall into the same neighborhood in in expectation.
In our case, since there are product distributions, we will need a larger set of sample points in order to ensure that only points in fall into the same neighborhood in in expectation. But then merging into in the operation phase would be too slow because scanning already requires time. We need to extract a subset such that has size and contains all points in whose Voronoi cells conflict with the input points.
Still, we cannot afford to construct in time. In the training phase, we form a metric related to and construct a net-tree for under [16]. In the operation phase, after finding the appropriate , we use nearest common ancestor queries [22] to compress in time to a subtree for that has size. Next, we use to construct a well-separated pair decomposition of under in time [16], use the decomposition to compute the nearest neighbor graph of under in time, and then construct from the nearest neighbor graph in expected time. The merging of into to form , and the splitting of into and are obtained by transferring their analogous results in the Euclidean case [2, 6].
We have left out the expected time to locate the input points in . It is bounded by times the sum of the entropies of the point location outcomes. We show that allows us to locate the input points in in time. Then, a result in [2] implies that the sum of the entropies of the point location outcomes is . The expected running time is thus , which dominates the limiting complexity. In the Euclidean case, allows us to locate the input points in time, so the limiting complexity improves to .
2 Preliminaries
Let be a convex polygon that has complexity and contains the origin in its interior. Let and be the boundary and interior operators, respectively. So ’s boundary is and its interior is . Let be the distance function induced by : , . As may not be centrally symmetric (i.e., ), may not be a metric.
The bisector of two points and is , which is an open polygonal curve of size. The Voronoi diagram of a set of points, , is a partition of into interior-disjoint cells for all . There are algorithms for constructing in time [9, 19].
is simply connected and star-shaped with respect to [9]. We use to denote the set of Voronoi neighbors of in . The Voronoi edges of form a planar graph of size. Each Voronoi edge is a polygonal line, and we call its internal vertices Voronoi edge bends. We use to denote the set of Voronoi edge bends and Voronoi vertices in . For the infinite Voronoi edges, their endpoints at infinity are included in .
Define . For any points , . At any point on a Voronoi edge of defined by , there exists such that and for all . Hence, and , i.e., an “empty circle property”.
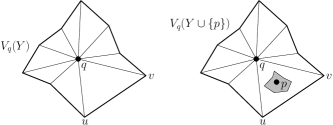
Take a point . Consider the largest homothetic222A homothetic copy of a shape is a scaled and translated copy of it. copy of centered at such that . If we insert a new point to , we say that conflicts with if . We say that conflicts with a cell if conflicts with some point in . Clearly, must be updated by the insertion of . We use to denote the subset of that conflict with . The Voronoi edge bends and Voronoi vertices in will be destroyed by the insertion of .
We make three general position assumptions. First, no two sides of are parallel. Second, for every pair of input points, their support line is not parallel to any side of . Third, no four input points lie on the boundary of any homothetic copy of , which implies that every Voronoi vertex has degree three.
It is much more convenient if all Voronoi cells of the input points are bounded. We assume that all possible input points appear in some fixed bounding square centered at the origin. We place dummy points outside so that all Voronoi cells of the input points are bounded, and their portions inside remain the same as before. Refer to Figure 1. Take for some large enough such that for every point , contains . Refer to the left image in Figure 1. We slide a copy of around to generate the outer convex polygon. The dashed polygon demonstrates the sliding of around . This outer polygon contains a translational copy of every edge of and two translational copies of every edge of . We add the vertices of this outer polygon as dummy points. Any homothetic copy of that intersects cannot be expanded indefinitely without containing some of these dummy points. So all Voronoi cells of input points are bounded. For each point , since the dummy points lie outside and (i.e., is not empty of the input points), the portion of the Voronoi diagram inside is unaffected by the dummy points.

3 Training phase
Sample set . Take instances . Define by taking the ’s in to be , ’s in to be , and so on. The set of sample points includes a -net of the ’s with respect to the family of homothetic copies of , as well as the dummy points. The set has points and can be constructed in time as homothetic copies of are pseudo-disks [2, 21].
Point location. Compute and triangulate it by connecting each to , i.e., the Voronoi edge bends and Voronoi vertices in . For unbounded Voronoi cells, we view the infinite Voronoi edges as leading to some vertices at infinity; an extra triangulation edge that goes between two infinite Voronoi edges also leads to a vertex at infinity, giving rise to unbounded triangles. Figure 2 shows an example.

Construct a point location structure for the triangulated with query time [13]. Take another input instances and use to locate the points in these input instances in the triangulated . For every and every triangle , we compute to be the ratio of the frequency of hit by to , which is an estimate of . For each , form a subdivision that consists of triangles with positive ’s, triangulate the exterior of , and give these new triangles a zero estimated probability. Set the weight of each triangle in to be the maximum of and its estimated probability. Construct a distribution-sensitive point location structure for based on the triangle weights [1, 17]. Note that has size, and locating a point in a triangle takes time, where is the weight of and is the total weight in .
For any input instance in the operation phase, we will query to locate in the triangulated , which may fail if falls into a triangle with zero estimated probability. If the search fails, we query to locate .
Net-tree. We first define a metric that is induced by a centrally symmetric convex polygon. Define , i.e., the Minkowski sum of and , or equivalently and . It is centrally symmetric by definition. It can be visualized as the region covered by all possible placements of that has the origin in the polygon boundary. Since is a Minkowski sum, its number of vertices is within a constant factor of the total number of vertices of and , which is .
Let be the metric induced by the centrally symmetric convex polygon , which is a doubling metric—there is a constant such that for any point and any positive number , the ball with respect to centered at with radius can be covered by balls with respect to of radius .
Given a set of points , a net-tree for with respect to [16] is an analog of the well-separated pair decomposition for Euclidean spaces [4]. It is a rooted tree whose leaves are the points in . For each node , let denote its parent, and let denote the subset of at the leaves that descend from . Every tree node is given a representative point and an integer level . Let be a fixed constant. Let denote the ball . By the results in [16] (Definition 2.1 and the remark that follows Proposition 2.2), the following properties are satisfied by a net-tree:
-
(a)
.
-
(b)
For every non-root node , , and if is a leaf, then .
-
(c)
Every internal node has at least two and at most a constant number of children.
-
(d)
For every node , contains .
-
(e)
For every non-root node , .
-
(f)
For every internal node , there is a child of such that .
Clusters. We construct a net-tree for in expected time [16]. We define clusters as follows. Label all leaves of as unclustered initially. Select the leftmost unclustered leaves of ; if there are fewer than such leaves, select them all. Find the subtree rooted at a node of that contains the selected unclustered leaves, but no child subtree of contains them all. We call the subtree rooted at a cluster and label all its leaves clustered. Then, we repeat the above until all leaves of are clustered. By construction, the clusters are disjoint, each cluster has nodes, and there are clusters in .
We assign nodes in each cluster a unique cluster index in the range . We also assign each node of a cluster three indices from the range according to its rank in the preorder, inorder, and postorder traversals of that cluster. The preorder and postorder indices allow us to tell in time whether two nodes are an ancestor-descendant pair.
We keep an initially empty van Emde Boas tree [23] with each cluster . The universe for is the set of leaves in the cluster , and the inorder of these leaves in is the total order for . We also build a nearest common ancestor query data structure for each cluster [22]. The nearest common ancestor query of any two nodes can be reported in time.
Planar separator. is a planar graph of size with all Voronoi edge bends and Voronoi vertices as graph vertices. By a recursive application of the planar separator theorem, one can produce an -division of : it is divided into regions, each region contains vertices, and the boundary of each region contains vertices [14].
Extract the subset of points whose Voronoi cell boundaries contain some region boundary vertices in the -division. So . Compute and triangulate it as in triangulating . By our choice of , the region boundaries in the -division of form a subgraph of . Label in time the Voronoi edge bends and Voronoi vertices in whether they exist in .
We construct point location data structures for every region in the -division as follows. For every boundary vertex of , let be the largest homothetic copy of centered at such that . These ’s form an arrangement of complexity, and we construct a point location data structure that allows a point to be located in this arrangement in time. We also construct a point location data structure for the portion of the triangulated inside . Since the region has complexity, this point location data structure can return in time the triangle in the triangulated that contains a point inside .
Output and performance. The following result summarizes the output and performance of the training phase. Its proof is given in Appendix A. The proof of Lemma 3.1(a) is similar to an analogous result for sorting in [8].
Lemma 3.1
Let , , be the distributions in the hidden mixture. The training phase computes the following structures in time.
-
(a)
A set of points and . It holds with probability at least that for any and any , , where if conflicts with and otherwise.
-
(b)
Point location structures and for each that allow us to locate in the triangulated in expected time, where is the random variable that represents the point location outcome, and is the entropy of the distribution of .
-
(c)
A net-tree for , the clusters in , the initially empty van Emde Boas trees for the clusters, and the nearest common ancestor data structures for the clusters.
-
(d)
An -division of , the subset of points whose Voronoi cell boundaries contain some region boundary vertices in the -division, , and the point location data structures for the regions in the -division.
Lemma 3.1(a) leads to Lemma 3.2 below, which implies that for any , if we feed the input points that conflict with to a procedure that runs in quadratic time in the worst case, the expected running time of this procedure over all points in is . The proof of Lemma 3.2 is just an algebraic manipulation of the probabilities, and it is given in Appendix B.
Lemma 3.2
For every , let be the subset of input points that conflict with . It holds with probability at least that .
We state two technical results. Their proofs are in Appendix B. Figure 3(a) and (b) illustrate these two lemmas.
Lemma 3.3
Consider for some point set . For any point , let be the largest homothetic copy of centered at such that . Let and be two adjacent Voronoi edge bends or Voronoi vertices in . For any point , . The same property holds if and are Voronoi vertices connected by a Voronoi edge, and lies on that Voronoi edge.
 |
 |
|
| (a) | (b) |
Lemma 3.4
Let be a point in some point set . Let be a triangle in the triangulated . If a point conflicts with a point in , then conflicts with or . Hence, if conflicts with , conflicts with a Voronoi edge bend or Voronoi vertex in .
4 Operation phase
Given an instance , we construct using the pseudocode below.
Operation Phase
- 1.
For each , query to find the triangle in the triangulated that contains , and if the search fails, query to find .
- 2.
For each , search from to find , i.e., the subset of that conflict with . This also gives the subset of whose Voronoi cells conflict with the input points. Let be the union of this subset of and the set of representative points of all cluster roots in .
- 3.
Compute the compression of to .
- 4.
Construct the nearest neighbor graph 1- under the metric from .
- 5.
Compute from 1-.
- 6.
Modify to produce .
- 7.
Split to produce and . Return .
We analyze step 1 in Section 4.1, steps 2 and 3 in Section 4.2, steps 4 and 5 in Section 4.3, and steps 6 and 7 in Section 4.4. Step 1 is the most time-consuming; all other steps run in expected time or expected time.
4.1 Point location
By Lemma 3.1(b), step 1 runs in expected time, which is as we will show later. By Lemma 4.1 below, if there is an algorithm that can use to determine in expected time, then , implying that step 1 takes expected time. Any preprocessing cost of is excluded from . We present such an algorithm.
Lemma 4.1 (Lemma 2.3 in [2])
Let be a distribution on a universe . Let , and let be two random variables. Suppose that there is a comparison-based algorithm that computes a function in expected comparisons over for every . Then .
Recall that we have computed in the training phase the subset whose Voronoi cell boundaries contain some region boundary vertices in the -division of . Note that . We have also computed and point location data structures associated with the regions in the -division. We use and these point location data structures determines as follows.
-
•
Task 1: Merge with to form the triangulated .
-
•
Task 2: Use , , and to find the triangles .
We discuss these two tasks in the following.
Task 1. For every point , define a polygonal cone surface . Each horizontal cross-section of is a scaled copy of centered at . The triangulated is the vertical projection of the lower envelope of , denoted by . Similarly, projects to . We take the lower envelope of and to form which projects to . We do so in expected time with a randomized algorithm that is based on an approach proposed and analyzed by Chan [5, Section 4]. More details are given in Appendix C.1.
Task 2. Suppose that for an input point , we have determined some subset that satisfies , and we have computed a Voronoi edge bend or Voronoi vertex in that conflicts with and is known to be in or not.
If , we search from to find (i.e., the subset of that conflict with ), which by Lemma 3.3 also gives the triangle in the triangulated that contains . By Lemma 3.2, the expected total running time of this procedure over all input points is .
Suppose that . So is not a region boundary vertex in the -division of , i.e., lies inside a region in the -division of , say . For each boundary vertex of , let be the largest homothetic copy of centered at such that . These ’s form an arrangement of complexity, and we locate in this arrangement in time. It tells us whether for some boundary vertex of . If so, then conflicts with , which belongs to , and we search from to find and hence the triangle in the triangulated that contains . Otherwise, must lie inside in order to conflict with inside without conflicting with any boundary vertex of . So we do a point location in time to locate in the portion of the triangulated inside . This gives .
How do we compute for ? We discuss this computation and provide more details of Step 2 in Appendix C.2. The following lemma summarizes the result that follows from the discussion above.
Lemma 4.2
Given , the triangles in the triangulated that contain can be computed in expected time.
Lemma 4.3
Step of the operation phase takes expected time, where is the entropy of the distribution of .
Proof. Let be a random variable that indicates which distribution in the mixture generates the input instance. By the chain rule for conditional entropy [24, Proposition 2.23], . It is known that [24, Theorem 2.43]. Thus, . The variables are mutually independent. So . Since entropy is not increased by conditioning [24, Theorem 2.38], we get . By Lemma 4.2, we can determine using in expected time. So by Lemma 4.1, where is the entropy of the distribution of .
In the Euclidean metric, merging and into can be reduced to finding the intersection of two convex polyhedra of size in , which can be solved in time [5]. So the expected running time of step 1 improves to .
4.2 Construction of
Step 1 determines the triangle in the triangulated that contains . We search from to find , which takes time [19]. This search also gives the Voronoi cells that conflict with . The total time over all is , where is the subset of input points that conflict with . Since includes all sites whose cells conflict with the input points and the representative points of all cluster roots in , we have . The following result follows from Lemma 3.2.
Lemma 4.4
The set has expected size. Step 2 of the operation phase constructs in expected time.
4.3 Extraction of
4.3.1 Construction of
We define a compression of a net-tree . Select a subset of leaves in . Let be the minimal subtree that spans . Bypass all internal nodes in that have only one child. The resulting tree is the compression of to . The following result is an easy observation.
Lemma 4.5
Let be a net-tree. Let be the compression of to a subset of leaves. The compression of to any subset of leaves in can also be obtained by a compression of to .
Conceptually, is defined as follows. Select all leaves of that are points in , and is the compression of to these selected leaves. Since includes the representative points of all cluster roots, all ancestors of the cluster roots in will survive the compression and exist as nodes in . The compression affects the clusters only. More precisely, for each cluster in , we select its leaves that are points in and compute the compression of the cluster to these selected leaves. Substituting every cluster in by gives the desired . It remains to discuss how to compute the ’s.
We divide in expected time into sublists such that consists of the points that are leaves in cluster . Recall that every cluster has an initially empty van Emde Boas tree for its leaves in left-to-right order. For each , we insert all leaves in into and then repeatedly perform extract-min on . This gives in time a sorted list of the leaves in according to their left-to-right order in the cluster .
If , then consists of the single leaf in . Suppose that . We construct using a stack. Initially, is a single node which is the first leaf in . The stack stores the nodes on the rightmost root-to-leaf path in the current , with the root at the stack bottom and the leaf at the stack top. When we scan the next leaf in , we find in cluster the nearest common ancestor of and ’s predecessor in . This takes time [22]. If we see at the stack top, we add as a new leaf to with as its parent, and then we push onto the stack. Refer to the left image in Figure 4. If we see an ancestor of at the stack top, let be the node that was immediately above in the stack and was just popped, we make the rightmost child of in (which was previously), we also make and the left and right children of respectively, and then we push and in this order onto the stack. Refer to the middle image in Figure 4. If neither of the two conditions above happens and the stack is not empty, we pop the stack and repeat. Refer to the right image in Figure 4. If the stack becomes empty, we make the new root of , we also make the old root of and the left and right children of respectively, and then we push and in this order onto the stack. The construction of takes time.

Lemma 4.6
The compression of to can be computed in time.
4.3.2 Construction of the -nearest neighbor graph
Let be any subset of . Assume that the compression of to is available. We show how to use to construct in time the -nearest neighbor graph of under the metric . We denote this graph by -. We will use the well-separated pair decomposition or WSPD for short. For any , a set is a -WSPD of under if the following properties are satisfied:
-
•
.
-
•
, such that .
-
•
, the maximum of the diameters of and under is less than . It implies that .
It is known that a -WSPD has size and can be constructed in time from a net-tree for [16]. The same method works for a compression of to , giving a -WPSD of size in time. The details of the WSPD construction are given in Appendix D.1. To compute -, we transfer a strategy in [4] for constructing a Euclidean -nearest neighbor graph using a WSPD. The details are given in Appendix D.2.
Lemma 4.7
Given the compression of to any subset , the - can be constructed in time.
The next result shows that the vertex degree of - is . Its proof is given in Appendix D.3 which is adapted from an analogous result in the Euclidean case [20].
Lemma 4.8
For any subset , every vertex in - has degree, and adjacent vertices in - are Voronoi neighbors in .
4.3.3 from the nearest neighbor graph
We show how to construct in expected time using 1-. We use the following recursive routine which is similar to the one in [3] for constructing an Euclidean Delaunay triangulation from the Euclidean nearest neighbor graph. The top-level call is VorNN.
VorNN
- 1.
If , compute directly and return.
- 2.
Compute 1- under the metric using .
- 3.
Let be a random sample such that meets every connected component of 1-, and for every .
- 4.
Compute the compression of to .
- 5.
Call VorNN to compute .
- 6.
Using 1- as a guide, insert the points in into to form .
There are two differences from [3]. First, we use a compression of to compute 1- in step 2, which takes time by Lemma 4.7. Second, we need to compress to in step 4. This compression works in almost the same way as described in Section 4.3.1 except that we can afford to traverse in time to answer all nearest common ancestor queries required for constructing . Thus, step 4 runs in time.
Step 3 is implemented as follows [3]. Form an arbitrary maximal matching of 1-. By the definition of 1-, each connected component of 1- contains at least one matched pair. Randomly select one point from every matched pair. Then, among those unmatched points in 1-, select each one with probability 1/2 uniformly at random. The selected points form the subset required in step 3. The time needed is .
In step 6, for each that is connected to some point in 1-, and are Voronoi neighbors in by Lemma 4.8. So conflicts with a point in . By Lemma 3.4, conflicts with a Voronoi edge bend or Voronoi vertex in , which can be found in time. After finding a Voronoi edge bend or Voronoi vertex in that conflicts with , we search from to find all Voronoi edge bends and Voronoi vertices that conflict with . In the same search of , we modify into as in a randomized incremental construction [19]. By the Clarkson-Shor analysis [11], the expected running time of the search of and the Voronoi diagram modification over the insertions of all points in is . We spend time to find . It translates to an charge at each vertex of . This charging happens only for ’s neighbors in 1-. By Lemma 4.8, there are such neighbors of , so the charge at each vertex of is . Moreover, if a vertex of is destroyed by the insertion of a point from , that vertex will not reappear. So the cost is absorbed by the structural changes which is already taken care of by the Clarkson-Shor analysis. Unwinding the recursion gives a total expected running time of . For completeness, more details of the analysis given in [3] can be found in Appendix E.
Lemma 4.9
VorNN computes in expected time.
4.4 Computing from and
Let be a point in . Let be the vertices of , in clockwise order, which may be Voronoi edge bends or Voronoi vertices. Let denote the largest homothetic copy of centered at such that . Let where is an input instance.
Lemma 4.10
The portions of and inside the triangle are identical.
Proof. Let be a point in that contributes to inside . As , . So . By Lemma 3.4, conflicts with or .
Step 2 of the operation phase has found for each . and the portions of the Voronoi edges of among the points in are preserved in because includes the subset of whose Voronoi cells conflict with the input points. Hence, is the set of Voronoi edge bends and Voronoi vertices in that conflict with the input points (refer to Appendix F for a proof). By Lemma 4.10, we locally compute pieces of and stitch them together. The running time is , where the sum is over all pairs of adjacent Voronoi edge bends and Voronoi vertices in such that . Since the degrees of Voronoi edge bends and Voronoi vertices are two and three respectively, this running time can be bounded by . Since , by Lemma 3.2, step 6 of the operation phase computes in expected time.
In step 7, the splitting of into and can be performed in expected time by using the algorithm in [6] for splitting a Euclidean Delaunay triangulation. That algorithm is combinatorial in nature. It relies on the Voronoi diagram being planar and of size, all points having degrees in the nearest neighbor graph, and that one can delete a site from a Voronoi diagram in time proportional to its number of Voronoi neighbors. The first two properties hold in our case, and it is known how to delete a site from an abstract Voronoi diagram so that the expected running time is proportional to its number of Voronoi neighbors [18].
Lemma 4.11
Step 6 of the operation phase computes in expected time, and step 7 splits into and in expected time.
In summary, since steps 2-7 of the operation phase take expected time, the limiting complexity is dominated by the expected running time of step 1. In the Euclidean case, step 1 runs faster in time.
Theorem 4.1
Let be a convex polygon with complexity. Let be the input size. For any and any hidden mixture of at most product distributions such that each distribution contributes an instance with a probability of , there is a self-improving algorithm for constructing a Voronoi diagram under with a limiting complexity of . For the Euclidean metric, the limiting complexity is . The training phase runs in time. The success probability is at least .
5 Conclusion
It is open whether one can get rid of the requirement that each distribution in the mixture contributes an instance with a probability of , which is not needed for self-improving sorting [8]. Eliminating the term from the limiting complexity might require solving the question raised in [5] that whether there is an -time algorithm for computing the lower envelope of pseudo-planes. As a Voronoi diagram can be interpreted as the lower envelope of some appropriate surfaces, a natural question is what surfaces admit a self-improving lower envelope algorithm.
References
- [1] S. Arya, T. Malamatos, D.M. Mount, and K.C. Wong. Optimal expected-case planar point location. SIAM Journal on Computing, 37 (2007), 584–610.
- [2] N. Ailon, B. Chazelle, K. Clarkson, D. Liu, W. Mulzer, and C. Seshadhri. Self-improving algorithms. SIAM Journal on Computing, 40 (2011), 350–375.
- [3] K. Buchin and W. Mulzer. Delaunay triangulations in time and more. Journal of the ACM, 58 (2011), 6:1–6:27.
- [4] P.B. Callahan and S.R. Kosaraju. A decomposition of multidimensional point sets with applications to -nearest-neighbors and -body potential fields. Journal of the ACM, 42 (1995), 67–90.
- [5] T.M. Chan. A simpler linear-time algorithm for intersecting two convex polyhedra in three dimensions. Discrete & Computational Geometry, 56 (2016), 860–865.
- [6] B. Chazelle, O. Devillers, F. Hurtado, M. Mora, V. Sacristan, and M. Teillaud. Splitting a delaunay triangulation in linear time. Algorithmica, 34 (2002), 39–46.
- [7] S.-W. Cheng, M.-K. Chiu, K. Jin, and M.T. Wong. A generalization of self-improving algorithms. Proceedings of the International Symposium on Computational Geometry, 2020, 29:1–29:13. Full version: arXiv:2003.08329v2.
- [8] S.-W. Cheng, K. Jin, and L. Yan. Extensions of self-improving sorters. Algorithmica, 82 (2020), 88–106.
- [9] L. Paul Chew and R.L. Scot Drysdale. Voronoi diagrams based on convex distance functions. Proceedings of the 1st Annual Symposium on Computational Geometry, 1985, 235–244.
- [10] K.L. Clarkson, W. Mulzer, and C. Seshadhri. Self-improving algorithms for coordinatewise maxima and convex hulls. SIAM Journal on Computing, 43(2):617–653, 2014.
- [11] K.L. Clarkson and P.W. Shor. Applications of random sampling in computational geometry, II. Discrete and Computational Geometry, 4 (1989), 387–421.
- [12] T.M. Cover and J.A. Thomas. Elements of Information Theory. Wiley-Interscience, New York, 2nd edition, 2006.
- [13] H. Edelsbrunner, L.J. Guibas, and J. Stolfi. Optimal point location in a monotone subdivision. SIAM Journal on Computing, 15 (1986), 317–340.
- [14] G.N. Frederickson. Fast algorithms for shortest paths in planar graphs, with applications. SIAM Journal on Computing, 16 (1987), 1004–1022.
- [15] M.L. Fredman. How good is the information theory bound in sorting? Theoretical Computer Science, 1(4):355 – 361, 1976.
- [16] S. Har-Peled and M. Mendel. Fast construction of nets in low-dimensional metrics and their applications. SIAM Journal on Computing, 35 (2006), 1148–1184.
- [17] J. Iacono. Expected asymptotically optimal planar point location. Computational Geometry: Theory and Applications, 29 (2004), 19–22.
- [18] K. Junginer and E. Papadopoulou. Deletion in abstract Voronoi diagram in expected linear time. Proceedings of the 34th International Symposium on Computational Geometry, 2018, 50:1–50:14.
- [19] R. Klein, K. Mehlhorn, and S. Meiser. Randomized incremental construction of abstract Voronoi diagrams. Computational Geometry: Theory and Applications, 3 (1993), 157–184.
- [20] G.L. Miller, S.-H. Teng, W. Thurston, and S.A. Vavasis. Separators for sphere-packings and nearest neighbor graphs. Journal of the ACM, 44 (1997), 1–29.
- [21] E. Pyrga and S. Ray. New existence proofs for -nets. Proceedings of the 24th Annual Symposium on Computational Geometry, 2008, 199–207.
- [22] A.K. Tsakalides and J. van Leeuwen. An optimal pointer machine algorithm for finding nearest common ancestors. Technical Report RUU-CS-88-17, Department of Computer Science, University of Utrecht, 1988.
- [23] P. van Emde Boas, R. Kaas, and E. Zijlstra. Design and implementation of an efficient priority queue. Mathematical Systems Theory, 10 (1977), 99–127.
- [24] R.W. Yeung. A First Course in Information Theory, Kluwer Academic/Plenum Publishers, 2002.
Appendix A Proof of Lemma 3.1
We restate Lemma 3.1 and then give its proof.
Statement of Lemma 3.1: Let , , be the distributions in the hidden mixture. The training phase computes the following structures in time.
-
(a)
A set of points and . It holds with probability at least that for any and any , , where if conflicts with and otherwise.
-
(b)
Point location structures and for each that allow us to locate in the triangulated in expected time, where is the random variable that represents the point location outcome, and is the entropy of the distribution of .
-
(c)
A net-tree for , the clusters in , the initially empty van Emde Boas trees for the clusters, and the nearest common ancestor data structures for the clusters.
-
(d)
An -division of , the subset of points whose Voronoi cell boundaries contain some region boundary vertices in the -division, , and the point location data structures for the regions in the -division.
Proof. Let be the set of points from which the -net was extracted. The set consists of this -net and the dummy points. Let be a triple of distinct indices. Let be the homothetic copy of that circumscribes , and if it exists; otherwise, we ignore . Assume that is not ignored. We analyze the number of points in any input instance that fall inside .
Fix any product distribution in the hidden mixture. Let . How large is ? Since , the expected size of is . Then, Chernoff bound implies that with probability at least .
For every , define if ; otherwise, . Let . The variables ’s are independent from each other, so the Chernoff bound is applicable to . It says that for any , .
If , then . Setting gives . There are fewer than triples of distinct indices. By the union bound, it holds with probability at least that for any triple of distinct indices, if , then .
Consider any Voronoi vertex and its defining triple . If , then because is a -net of . But is empty as is a Voronoi vertex, which implies that . If we restrict our attention to instances in that contribute to , the count does not get bigger. That is, . By the contrapositive of the result that we obtained earlier on the relation between and , we conclude that . Moreover, this upper bound on hold simultaneously for all defining triples of the Voronoi vertices in with probability at least .
Since the input distribution is oblivious of the training and operation phases, we can use the instances in to derive the following inequality: . The additive term of stems from the fact that the indices in are excluded from in the definition of , but they are allowed in . Rearranging terms gives
As discussed before, the above result holds for with probability at least . Applying the union bound over all , we get a success probability of at least .
Consider (b). If falls into a triangle with weight , the distribution-sensitive point location data structure [1, 17] ensures that the query time of is , where . Since is defined to be and the complexity of is , we have . Let be the true probability of hitting a triangle in the triangulated . Using the Chernoff bound, one can prove as in [2, Lemma 3.4] that, with probability at least , for every and every , if , then . As , if , the query time is . If , we may query as well, so the query time is . Therefore, the expected query time of is bounded by .
Appendix B Missing details in Section 3
We restate the results below and give their proofs.
Statement of Lemma 3.2: For every , let be the subset of input points that conflict with . It holds with probability at least that .
Proof. For every and every , define if and otherwise.
Lemma 3.1(a) is invoked in the third step. The last step is due to the fact that and . Under the condition that , and are independent. Therefore, . As a result,
In the last step, we use Lemma 3.1(a) and the relations that and .
Statement of Lemma 3.3: Consider for some point set . For any point , let be the largest homothetic copy of centered at such that . Let and be two adjacent Voronoi edge bends or Voronoi vertices in . For any point , . The same property holds if and are Voronoi vertices connected by a Voronoi edge, and lies on that Voronoi edge.
Proof. We assume that is not equal to or as there is nothing to prove otherwise. Let and be two of the defining points of and . So and lie on the Voronoi edge defined by and . Place an imaginary point in such that does not lie on the same edge of as or . Place an imaginary point similarly in . Figure 5(a) shows an example.
 |
||
| (a) | (b) |
We claim that . Suppose not. Then . Move along the Voronoi edge from towards . We must reach some point before reaching such that because is farther from than , , and . Let be the homothetic copy of centered at that includes , , and in its boundary. As , either one is strictly contained in the other, or their boundaries intersect transversally at two points. The former case is impossible as at least one of , , and would lie in the interior of or , an impossibility. If and intersect transversally at two points, then one of , and would not lie in or , an impossibility again. This proves our claim that .
Similarly, .
Since both and are at least , neither nor belongs to . Since , either one of and is strictly contained in the other, or their boundaries intersect transversally. The former case is impossible because one of , and would lie in the interior of or . In the second case, and must intersect transversally at and . It follows that one of the two chains in delimited by and lies outside . Figure 5(b) shows an example. Since , we conclude that the chain that contains lies outside . Similarly, we can show that does not contain the chain in that goes from through to . Hence, must be contained in .
The same proof applies when and are Voronoi vertices connected by a Voronoi edge, and lies on that Voronoi edge.
Statement of Lemma 3.4: Let be a point in some point set . Let be a triangle in the triangulated . If a point conflicts with a point in , then conflicts with or . Hence, if conflicts with , conflicts with a Voronoi edge bend or Voronoi vertex in .
Proof. For any point , let be the largest homothetic copy of centered at such that . It suffices to show that the point that conflicts with belongs to or . If conflicts with any point in , Lemma 3.3 implies that or . Suppose that does not conflict with any point in . So . Recall that the Voronoi cells of a Voronoi diagram under a convex distance function are star-shaped with respect to their sites. So is star-shaped with respect to . However, some segment that connects to some point in must cross as conflicts with a point in , a contradiction. Figure 6 illustrates this situation.
Appendix C Missing details in Section 4.1
We will show that Task 1 in Section 4.1 runs in expected time and Task 2 in Section 4.1 runs in expected time.
C.1 Lower envelope of two lower envelopes
We describe a algorithm based on the randomized divide-and-conquer approach due to Chan [5, Section 4] to compute the lower envelope of and .
Construct point location data structures for the triangulated and in time. Let be the multiset version of in which each has multiplicity equal to the complexity of . Draw a random sample of of size , and let denote the equivalent of without the multiplicity. Similarly, is multiset version of , is a random sample of of size , and is the equivalent of without the multiplicity.
Compute , which has size, directly in time. For each triangle in , the strategy is to extract the subsets and , and then recursively compute the patch , where is the point in such that , and is the vertical prism obtained by sweeping upward and downward. Collect these patches over all triangles in and stitch them together to form . The recurrence for the expected running time is , where and is the total expected running time to identify and for all triangles in .
We identify as follows. If some point of is above a cone , then conflicts with the projection of in the projection of . Lemma 3.4 implies that conflicts with the projection of a vertex of different from . Take a vertex of different from . Locate ’s vertical projection in a triangle in the triangulated by a point location query. If is below , then does not conflict with any point in . If is above , we search within the vertical projection of to determine the subset . The time needed is . Summing over all triangles in , the total point location time is . By Clarkson-Shor’s analysis [11, Corollary 3.8], it holds with probability at least that the sum of over all vertices of is , and . We identify in the same way, which involves determining for the vertices of , and the same analysis applies.
When determining and over all vertices of , if the total number of steps exceeds for some appropriate constant , we abort, resample and , and then repeat. Similarly, if exceeds for some appropriate constant , we also abort, resample and , and then repeat. We expect to succeed in trials and proceed with the recursive calls.
In summary, is in the recurrence , and there are levels of recursion in expectation. The hidden big-Oh constant may thus be raised to a power of , resulting in an expected running time of .
C.2 Determining
We generalize a method in [2], which does not work directly in our case because no information about is gathered in the training phase. Our method works in two stages for each point as follows.
-
•
Stage 1: Determine some subset that satisfies , and compute a Voronoi edge bend or Voronoi vertex in that conflicts with and is known to be in or not.
-
•
Stage 2: Use to find the triangle that contains .
We provide the details of these two stages for each input point in the following. We discuss the second stage first because it is easier.
C.2.1 Stage 2
If , we search from to find (i.e., the subset of that conflict with ), which by Lemma 3.3 will also give the triangle in the triangulated that contains . The time needed is .
Suppose that . Then cannot be a region boundary vertex in the -division of , so lies inside a region in the -division, say . We check whether conflicts with any boundary vertex of . For each boundary vertex of , let be the largest homothetic copy of centered at such that . These ’s form an arrangement of complexity. The point conflicts with if and only if . So we do a point location in the arrangement in time to decide whether is contained in for some boundary vertex of .
If so, we can search from as before to find the triangle in the triangulated that contains . Suppose that for any boundary vertex of . We claim that lies inside , which means that we can do a point location in to find the triangle in the triangulated that contains . The time needed is as has size. The running time of Stage 2 is .
We prove the claim as follows. Assume to the contrary that it is false. Since conflicts with that lies inside , we have , the largest homothetic copy of centered at such that . The segment intersects the boundary of at some point . We can define a deformation of so that its center moves linearly from to while the polygon shrinks linearly to the point . Since , at some point during this deformation of , we must obtain a homothetic copy of such that is the center of , , and . Then, we can invoke Lemma 3.3 to obtain the contradiction that must conflict with a boundary vertex of .
C.2.2 Stage 1
For efficiency purpose, we will present a procedure that runs stage 1 for all input points in in an inductive manner. The procedure is a generalization of a method for a similar task in [2]. During the running of this procedure, whenever we have computed for an input point as required of stage 1, the procedure will invoke stage 2 for in order to locate the triangle , and if , compute a Voronoi edge bend or Voronoi vertex that conflicts with .
We first present a technical result that will be used by the procedure.
Lemma C.1
Let be a point in . Let be any subset that satisfies . Assume that , , and the edges of that intersect are known. For each , we can compute a Voronoi edge in that conflicts with . The total running time is .
Proof. Suppose that . Take a point . The segment lies between and for some that are consecutive in the cyclic order of around . Recall that the dummy points make all Voronoi cells of input points bounded. So there is a Voronoi vertex in defined by , and .
We claim that conflicts with . Let be the largest homothetic copy of centered at that circumscribes , and . Since , there exists a homothetic copy of such that and . If does not conflict with , then . Refer to Figure 7. But then as and intersects transversally at zero or two points, is forced to contain or in its interior, a contradiction. Clearly, and define a Voronoi edge in that intersects and contains , so is the Voronoi edge that we look for.
By the analysis above, a synchronized cyclic scan of and gives the Voronoi edges of that we look for.
The remaining case is that . Hence, . Every point must conflict with some point in in order that becomes a Voronoi neighbor of in . Each conflicts with a connected portion of . Moreover, this portion of is not nested within the portion of that conflicts with any other . It follows that a synchronized cyclic scan of and gives the Voronoi edges that we look for.

The following is the pseudocode for determining the triangles in the triangulated that contains the input points in .
- 1.
Initialize a queue to contain all points in .
- 2.
Mark all points in as unvisited.
- 3.
While is non-empty do:
- (a)
Dequeue the next point from .
- (b)
If , let . Otherwise, , and has been inductively determined, and we perform the following steps:
- (i)
We will show in Lemma C.2 below that . Search from to determine .
- (ii)
Let be the set of defining points of the elements of . Let be the set of defining points of Voronoi edge bends and Voronoi vertices in that are adjacent to the elements of . Note that and are .
- (iii)
. The motivation for this definition of is to ensure that .
- (iv)
In the same search in step 3(b)(i), we construct and the edges of that intersect without increasing the asymptotic running time.
- (v)
Merge and to form .
- (c)
- (d)
For each unvisited ,
- (i)
Invoke the second stage to find the triangle in the triangulated that contains , mark as visited, and append to .
- (ii)
If , let be two of the vertices of , and update to be or whichever conflicts with . Note that if , we will prove in Lemma C.2 below that already belongs to .
Lemma C.2
At the end of step 3(c), if , then for each , . At the end of step 3(d)(ii), for each visited , .
Proof. We prove the lemma by induction. Consider an iteration of the while-loop in step 3. The newly visited points are those in .
Suppose that . By the definition of , . Therefore, in Lemma C.1 is a Voronoi edge in that conflicts with . Moreover, the proof of Lemma C.1 reveals that conflicts with a Voronoi vertex of that lies on , and is defined by and the two defining points of . Therefore, conflicts with on the edge of too. By Lemma 3.3, conflicts with some point in . The defining points of are included in by definition, which includes the defining points of . Therefore, we have obtained the edge during the construction of , which allows to be returned for in the application of Lemma C.1 in step 3(c). When we search along in step 3(c), we find the point that conflicts with .
Suppose that . Then, . Consider step 3(d)(ii). Let the vertices of be , where is a point in . Since , Lemma 3.4 implies that conflicts with or . Note that both and belong to .
We can view step 3(b)(v) as taking the lower envelope of two polygonal cones. In particular, we lift and to . Then is the lower envelope of these two polygonal cones, which can be obtained by a synchronized cyclic scan of and in linear time. In step 3(d)(i), when we invoke stage 2 for a point , we are supposed to know whether . If , then Lemma C.2 ensures that . If , we can assume that all Voronoi edge bends and Voronoi vertices in have been labelled in preprocessing whether they belong to or not.
The total running time is from our previous discussion. The first two terms are . By Lemma 3.2, the expected value of the third term is . Therefore, the expected running time of the pseudocode is .
Appendix D Missing details in Section 4.3.2
D.1 -WSPD from a compression of
Let be the compression of to . We compute a -WSPD as described in [16] for a doubling metric, which is in our case, using . The pseudocode is given below. The top-level call is Build, where is the root of .
Build
- 1.
Swap and if necessary to ensure that , or and is to the left of in the inorder traversal.
- 2.
If then return .
- 3.
Otherwise, let be the children of , return .
Lemma D.1
Build constructs a -WSPD of size in time.
Proof. We first show that Build outputs a -WSPD. Clearly, the working of Build guarantees that for every distinct pair of points , there exists a pair in the output of Build such that and . Let be a pair in the output of Build. Let and be the subsets of points for the subtrees of rooted at and . Let and be the diameters of and under , respectively. By property (c) of a net-tree, . Thus, , which is less than by steps 1 and 2 of Build. Then, . Rearranging terms gives . Let and be the diameters of and respectively. Observe that and . Hence, . In summary, the output of Build is a -WSPD.
It remains to bound the output size and the running time of Build.
Consider a pair in the output. Without loss of generality, assume that Build is called by Build, where . We charge the pair to . Since Build considers the children of instead of those of in processing , we must have . We claim that . Suppose not. There must be a call Build before the call Build, where or is an ancestor of . Since , Build eventually leads to the call Build, which must then call Build for to be included in the output. But this contradicts our assumption that Build is called by Build. Therefore, . Hence, belongs to the set as defined for below:
Note that the parent-child relation in the definition of refers to . Consider the following similar definition for :
Note that the parent-child relation in the definition of refers to . Since the pair is not included in the output, we must have . That is, . We analyze the total charge on in the following.
First, we charge the nodes in to some nodes in . Take any node . If , we charge to itself. Suppose that . Let in . It means that there are some internal nodes on the path from to in , and all of them are pruned by the compression of to . It follows from the definition of that exactly one of these pruned internal node belongs to , say . We charge to . Note that cannot be charged by another node in . Otherwise, would contain nodes in two different child subtrees of in , which would force to be a node of . This contradicts the fact that is pruned by the compression of to .
Second, consider a node that charges an ancestor of in . We have shown earlier that if does not appear in the output of Build. By property (d) of the net-tree , we have , which is as by the definition of . As a result, . Consequently, the nodes in that are charged by the nodes in lie in .
It is known that any two nodes in are at distance or more apart [16, Proposition 2.2]. Therefore, has size at most by the doubling property.
In summary, the total charge on the node in is . Since has nodes, the size bound of the -WSPD follows.
Construct a computation tree in which each node is labelled for the call Build, and a node is a child of another node if Build calls Build. The leaves of correspond to the pairs output by Build. Each internal node of has at least two children because each internal node of has at least two children. So has nodes as it has leaves. Clearly, Build spends time at each node of , establishing the running time bound.
D.2 Correctness of the extraction of -nearest neighbor graph
Compute a subset for every leaf of such that and contains the subset . The containment may be strict, so the point in may not be a -nearest neighbor of some point . We will discuss shortly how to compute such ’s. After obtaining all ’s, for each point , construct . By definition, all -nearest neighbors of are included in , although may contain more points. We select in time the -th farthest point in from under . Then, we scan in time using to find the -nearest neighbors of . Hence, as , the total running time is plus the time to compute the ’s. It remains to discuss the computation of the ’s.
Compute a 4-WSPD of which takes time by Lemma D.1. We define a subset for every node of with a generalized requirement. For every node of , we require that and contains the subset , is or an ancestor of , and contains a -nearest neighbor of . The containment may be strict, i.e., some may violate the property above.
This generalization is consistent with the requirement for at a leaf because if the single point in is a -nearest neighbor of some , then as is a WSPD, there exists such that and ; is clearly either or an ancestor of .
The ’s are generated in a preorder traversal of . The computation of is complete after visiting . When visiting a node , we initialize a set and prune later to obtain . The initial is . (If is the root of , take to be .) Lemma D.2 below shows that the initial satisfies the requirement for except that may not be . As inductively, the initialization of takes time.
Lemma D.2
The initial contains the subset , is or an ancestor of , and contains a -nearest neighbor of .
Proof. Let , is or an ancestor of , and contains a -nearest neighbor of . Partition into a disjoint union , where covers those pairs such that is an ancestor of , and covers those pairs . Inductively, . We just need to argue that is contained in the subset which is part of the initial . That is, if for some and some is a -nearest neighbor of , we need to show that . In this case, as is a 4-WSPD, the diameter of is less than . So all points in are closer to than , which implies that because is a -nearest neighbor of .
We prune as follows. Recall that is the polygon of size that induces the metric . Let be a maximal set of points in in clockwise order such that for any , . The set has size and can be computed in time by placing points greedily in . Let be the ray from the origin through . These rays divide into cones. Fix an arbitrary point . Compute in time, for all , the subset of in the cone bounded by and . Determine the -th nearest point in from in time. Then, scan in time to retain only the nearest points in from . Repeat the same for every . The union of the pruned ’s is which clearly has size. Lemma D.3 below shows that the pruning of only removes a point if no point in can be a -nearest neighbor of . Therefore, the union of the pruned ’s satisfies the requirement for . The running time over all ’s is .
In summary, the computation of all ’s takes time.
Lemma D.3
For any point , if there are at least points in such that , then no point in can be a -nearest neighbor of .
Proof. By our initialization of , we can inductively show that for any point included in the initial , there exists such that , and is or an ancestor of .
Pick a point . Let be a point in such that . Let be the factor such that . Similarly, let be the factor such that . Let be the intersection between and . Refer to Figure 8.

Since , and and lie in the cone that is bounded by the rays and , we can deduce from the property of that . Therefore, . The edge of that contains and the edge of that contains are homothetic copies of the same edge of . Since , and are collinear, the Euclidean length of is times the Euclidean length of . Therefore, contains in its boundary, which implies that . By the triangle inequality,
| (1) |
As mentioned at the beginning of this proof, since , there exists such that , and is or an ancestor of . So . Let and be the diameters of and under , respectively. We have . Since is a 4-WSPD, . It follows that . Substituting into (1) gives .
For any point , . As a result, is closer to than any point in . If there are at least such ’s, no point in can be a -nearest neighbor of .
D.3 Nearest neighbor graph
We restate Lemma 4.8 and give its proof.
Statement of Lemma 4.8: For any subset , every vertex in - has degree, and adjacent vertices in - are Voronoi neighbors in .
Proof. For every point , let be the largest homothetic copy of centered at such that . In 1-, a point is connected to its nearest neighbor, and if any other point is connected to , then . Therefore, the vertex degree of 1- is bounded from above by the maximum number of polygons in that are intersected by a point in .
Let be a point in that intersects the maximum number of polygons in . Let be the polygons intersected by . Shrink each concentrically to a polygon that just contains in its boundary. So , meaning that . Take the largest such that the interior of does not intersect . For , let be the intersection between the segment and . Refer to Figure 9.

We claim that for all . Without loss of generality, assume that . Let be the point in the segment such that . Since , and are collinear, we have . Since and , we have , which implies that . Since the wedge is a scaled copy of the wedge , the inequality implies that .
Our claim implies that we can place non-overlapping copies of centered at the ’s. Each copy has half the area of , and all these copies are contained inside . A packing argument shows that there are such copies. This shows that the vertex degree of 1- is .
Let be an edge in 1-. We assume without loss of generality that is the nearest neighbor of in . Thus, there exists such that and . By the definition of , it means that there exists a point such that and . So which certifies that and are Voronoi neighbors in .
Appendix E Missing details in Section 4.3.3
Only the proof of Lemma 4.9 is missing. We restate the lemma and give its proof below. The proof contains the details of the analysis in [3] that works for step 6 of VorNN.
Statement of Lemma 4.9: VorNN computes in expected time.
Proof. We first give the details of step 6 of VorNN. As in [3], we grow and by moving points repeatedly from to . We keep track of edges in 1- such that and . Take such an edge.
Since is an edge in 1-, must also be an edge in 1-. By Lemma 4.8, and are Voronoi neighbors in . So must conflict with a point in . Lemma 3.4 implies that must conflict with some Voronoi edge bend or Voronoi vertex in . We search from to find all Voronoi edge bends and Voronoi vertices that conflict with . During this search, we can modify to in time proportional to the number of Voronoi edge bends and Voronoi vertices that conflict with [19].
Consider the total running time. The identification of the starting Voronoi edge bend or Voronoi vertex involves checking . In other words, is examined once for each neighbor of in 1-. Therefore, any Voronoi edge bend or Voronoi vertex that was constructed at some point during the algorithm can be examined as many times as the degree sum in 1- of the points that define . This degree sum is by Lemma 4.8. Also, if is subsequently destroyed by the insertion of a point in , we can charge the time to destroy to the creation of . Hence, the total expected running time is bounded by the expected number of Voronoi edge bends and Voronoi vertices created in the course of the algorithm.
Let denote the homothetic copy of that circumscribes the points that define . Let . A necessary condition for to be created in step 6 is that contains no point in right before the execution of step 6. If some points in form matching pair(s) in step 3 of VorNN, at least one of them must be included in in step 3, which means that we cannot possibly create in step 6. If the points in do not form any matching pair in step 3, then the points in are sampled independently with probability 1/2. Therefore, the probability that none of these points is selected in step 3 is at most , so the probability that is created in step 6 is at most . By the result of Clarkson and Shor [11, Theorem 3.1], there are Voronoi edge bends and Voronoi vertices whose circumscribing homothetic copies of contain at most points in . Therefore, the expected number of Voronoi edge bends and Voronoi vertices created in step 6 of VorNN is . The expected size of is . Therefore, unwinding the recursion starting from the top-level call VorNN gives a total expected running time of .
Appendix F Missing details in Section 4.4
Recall that is the set of Voronoi edge bends and Voronoi vertices in that conflict with the input points . We need to prove that . Clearly, by the definition of . The following result proves that the containment also holds in the other direction.
Lemma F.1
.
Proof. Take any . For each , must conflict with in order that becomes a Voronoi neighbor of in . As a result, , which implies that . In , the region is partitioned and distributed among the Voronoi cells of points in . Thus, any Voronoi edge bend or Voronoi vertex in that does not exist in must lie strictly outside . Hence, cannot conflict with .