∎
1st Dai Co Viet, Hai Ba Trung, Hanoi, Viet Nam
22email: [email protected] 33institutetext: Trinh Ngoc Hai ( ✉ ) 44institutetext: School of Applied Mathematics and Informatics, Hanoi University of Science and Technology,
1st Dai Co Viet, Hai Ba Trung, Hanoi, Viet Nam
44email: [email protected]
Self-adaptive algorithms for quasiconvex programming and applications to machine learning
Abstract
For solving a broad class of nonconvex programming problems on an unbounded constraint set, we provide a self-adaptive step-size strategy that does not include line-search techniques and establishes the convergence of a generic approach under mild assumptions. Specifically, the objective function may not satisfy the convexity condition. Unlike descent line-search algorithms, it does not need a known Lipschitz constant to figure out how big the first step should be. The crucial feature of this process is the steady reduction of the step size until a certain condition is fulfilled. In particular, it can provide a new gradient projection approach to optimization problems with an unbounded constrained set. The correctness of the proposed method is verified by preliminary results from some computational examples. To demonstrate the effectiveness of the proposed technique for large-scale problems, we apply it to some experiments on machine learning, such as supervised feature selection, multi-variable logistic regressions and neural networks for classification.
Keywords:
nonconvex programming gradient descent algorithms quasiconvex functions pseudoconvex functions self-adaptive step-sizesMSC:
90C25 90C26 68Q32 93E351 Introduction
Gradient descent methods are a common tool for a wide range of programming problems, from convex to nonconvex, and have numerous practical applications (see Boyd , Cevher , Lan and references therein). At each iteration, gradient descent algorithms provide an iterative series of solutions based on gradient directions and step sizes. For a long time, researchers have focused on finding the direction to improve the convergence rate of techniques, while the step-size was determined using one of the few well-known approaches (see Boyd , Nesterov ).
Recently, new major areas of machine learning applications with high dimensionality and nonconvex objective functions have required the development of novel step-size choosing procedures to reduce the method’s overall computing cost (see Cevher , Lan ). The exact or approximate one-dimensional minimization line-search incurs significant computational costs per iteration, particularly when calculating the function value is nearly identical to calculating its derivative and requires the solution of complex auxiliary problems (see Boyd ). To avoid the line-search, the step-size value may be calculated using prior information such as Lipschitz constants for the gradient. However, this requires using just part of their inexact estimations, which leads to slowdown convergence. This is also true for the well-known divergent series rule (see Kiwiel , Nesterov ).
Although Kiwiel developed the gradient approach for quasiconvex programming in 2001 Kiwiel , it results in slow convergence due to the use of diminishing step-size. Following that, there are some improvements to the gradient method, such as the work of Yu et al. (Yu , 2019), Hu et al. (Hu , 2020), which use a constant step-size but the objective function must fulfil the Hölder condition. The other method is the neurodynamic approach, which uses recurrent neural network models to solve pseudoconvex programming problems with unbounded constraint sets (see Bian (Bian et al, 2018), Liu (Liu et al., 2022)). Its step-size selection is fixed and not adaptive.
The adaptive step-size procedure was proposed in Konnov (Konnov, 2018) and Ferreira (Ferreira et. al., 2020) . The method given in Konnov , whereby a step-size algorithm for the conditional gradient method is proposed, is effective for solving pseudoconvex programming problems with the boundedness of the feasible set. It has been expanded in Ferreira to the particular case of an unbounded feasible set, which cannot be applied to the unconstrained case. In this research, we propose a novel and line-search-free adaptive step-size algorithm for a broad class of programming problems where the objective function is nonconvex and smooth, the constraint set is unbounded, closed and convex. A crucial component of this procedure is gradually decreasing the step size until a predetermined condition is fulfilled. Although the Lipschitz continuity of the gradient of the objective function is required for convergence, the approach does not make use of predetermined constants. The proposed change has been shown to be effective in preliminary computational tests. We perform various machine learning experiments, including multi-variable logistic regressions and neural networks for classification, to show that the proposed method performs well on large-scale tasks.
The rest of this paper is structured as follows: Section 2 provides preliminary information and details the problem formulation. Section 3 summarizes the primary results, including the proposed algorithms. Section 4 depicts numerical experiments and analyzes their computational outcomes. Section 5 presents applications to certain machine learning problems. The final section draws some conclusions.
2 Preliminaries
In the whole paper, we assume that is a nonempty, closed and convex set in , is a differentiable function on an open set containing , the mapping is Lipschitz continuous. We consider the optimization problem:
| (OP()) |
Assume that the solution set of (OP()) is not empty. First, we recall some definitions and basic results that will be used in the next section of the article. The interested reader is referred to BauschkeCombettes ; Rockafellar for bibliographical references.
For , denote by the projection of onto , i.e.,
Proposition 1
BauschkeCombettes It holds that
-
(i)
for all ,
-
(ii)
for all , .
Definition 1
Mangasarian The function is said to be
-
convex on if for all , , it holds that
-
pseudoconvex on if for all , it holds that
-
quasiconvex on if for all , , it holds that
Proposition 2
Dennis The differentiable function is quasiconvex on if and only if
It is worth mentioning that ” is convex” ” is pseudoconvex” ” is quasiconvex”Mangasarian .
Proposition 3
Dennis Suppose that is -Lipschitz continuous on . For all , it holds that
Lemma 1
3 Main results
Algorithm 1
(Algorithm GDA)
Step 0. Choose , , . Set .
Step 1. Given and , compute and as
Step 2. Update . If then STOP else go to Step 1.
Remark 1
Now, suppose that the algorithms generates an infinite sequence. We will prove that this sequence converges to a solution of the problem OP().
Theorem 3.1
Assume that the sequence is generated by Algorithm 2. Then, the sequence is convergent and each limit point (if any) of the sequence is a stationary point of the problem. Moreover,
-
if is quasiconvex on , then the sequence converges to a stationary point of the problem.
-
if is pseudoconvex on , then the sequence converges to a solution of the problem.
Proof
Applying Proposition 3, we get
| (3) |
In (1), taking , we arrive at
| (4) |
Combining (3) and (4), we obtain
| (5) |
We now claim that is bounded away from zero, or in other words, the step size changes finite times. Indeed, suppose, by contrary, that From (5), there exists satisfying
According to the construction of , the last inequality implies that for all . This is a contradiction. And so, there exists such that for all , we have and
| (6) |
Noting that , we infer that the sequence is convergent and
| (7) |
From (1), for all , we have
| (8) |
Let be a limit point of . There exists a subsequence such that In (3), let and take the limit as . Noting that , is continuous, we get
which means is a stationary point of the problem. Now, suppose that is quasiconvex on . Denote
Note that contains the solution set of OP(), and hence, is not empty. Take . Since for all , it implies that
| (9) |
| (10) |
Applying Lemma 1 with , , we deduce that the sequence is convergent for all . Since the sequence is bounded, there exist a subsequence such that From (6), we know that the sequence is nondecreasing and convergent. It implies that and for all This means and the sequence is convergent. Thus,
Note that each limit point of is a stationary point of the problem. Then, the whole sequence converges to - a stationary point of the problem. Moreover, when is pseudoconvex, this stationary point becomes a solution of OP().
Remark 2
In Algorithm GDA, we can choose with the constant number Then we get Combined with (5), it implies that the condition is satisfied and the step-size for all step Therefore, Algorithm GDA is still applicable for the constant step-size For any there exists such that As a result, if the value of Lipschitz constant is prior known, we can choose the constant step-size as in the gradient descent algorithm for solving convex programming problems. The gradient descent method with constant step-size for quasiconvex programming problems, a particular version of Algorithm GDA, is shown below.
Algorithm 2
(Algorithm GD)
Step 0. Choose , . Set .
Step 1. Given compute as
Step 2. Update . If then STOP else go to Step 1.
Next, we estimate the convergence rate of Algorithm 2 in solving unconstrained optimization problems.
Corollary 1
Assume that is convex, and is the sequence generated by Algorithm 2. Then,
where is a solution of the problem.
Proof
We investigate the stochastic variation of Algorithm GDA for application in large scale deep learning. The problem is stated as follows:
where is the stochastic parameter and the function is -smooth. We are generating a stochastic gradient by sampling at each iteration The following Algorithm SGDA contains a detailed description.
Algorithm 3
(Algorithm SGDA)
Step 0. Choose , , . Set .
Step 1. Sample and compute and as
Step 2. Update . If then STOP else go to Step 1.
4 Numerical experiments
We use two existing cases and two large-scale examples with variable sizes to validate and demonstrate the performance of the proposed method. All tests are carried out in Python on a MacBook Pro M1 ( 8-core processor, of RAM). The stopping criterion in the following cases is “the number of iterations #Iter” where #Iter is the maximum number of iterations. Denote as the limit point of iterated series and Time the CPU time of the GDA algorithm using the stop criterion.
Nonconvex objective and constraint functions are illustrated in Examples and taken from Liu . In addition, Example is more complex than Example regarding the form of functions. Implementing Example with a convex objective function and a variable dimension allows us to evaluate the proposed method compared to Algorithm GD. Example is implemented with a pseudoconvex objective function and several values for so that we may estimate our approach compared to Algorithm RNN.
To compare to neurodynamic method in Liu , we consider Problem OP() with the constraint set is determined specifically by where and are differential quasiconvex, the matrix and . Recall that, in Liu , the authors introduced the function
and
The neorodynamic algorithm established in Liu , which uses recurrent neural network (RNN) models for solving Problem OP() in the form of differential inclusion as follows:
| (RNN) |
where the adjusted term is
with
the subgradient term of is
with
and the subgradient term of is
with be the row vectors of the matrix
Example 1
First, let’s look at a simple nonconvex problem OP():
where It is quite evident that for this problem, the objective function is pseudoconvex on the convex feasible set (Example 5.2 Liu , Liu et al., 2022).
Fig. 1 illustrates the temporary solutions of the proposed method for various initial solutions. It demonstrates that the outcomes converge to the optimal solution of the given problem. The objective function value generated by Algorithm GDA is , which is better than the optimum value of the neural network in Liu et al. (2022) Liu .

Example 2
Consider the following nonsmooth pseudoconvex optimization problem with nonconvex inequality constraints (Example 5.1 Liu , Liu et al., 2022):
where . The objective function is nonsmooth pseudoconvex on the feasible region and the inequality constraint is continuous and quasiconvex on , but not pseudoconvex (Example 5.1 Liu ). It is easily verified that for any Therefore, the gradient vector of is for any From that, we can establish the gradient vector of at a point used in the algorithm. Fig 2 shows that Algorithm GDA converges to an optimal solution with the optimal value , which is better than the optimal value of the neural network model in Liu .

Example 3
Let be a vector, and be constants satisfying the parameter condition . Consider Problem OP() (Example 4.5 Ferreira , Ferreira et. al, 2022) with the associated function
with is convex and the nonconvex constraint is given by
This example is implemented to compare Algorithm GDA with the original gradient descent algorithm (GD). We choose a random number fulfilled the parameter condition and Lipschitz coefficient suggested in Ferreira . The step size of Algorithm GD is and the initial step size of Algorithm GDA is Table 1 shows the optimal value, number of loops, computational time of two algorithms through the different dimensions. From this result, Algorithm GDA is more efficient than GD at both the computational time and the optimal output value, specially for the large scale dimensions.
| Algorithm GDA (proposed) | Algorithm GD | |||||
|---|---|---|---|---|---|---|
| #Iter | Time | #Iter | Time | |||
| 10 | 79.3264 | 9 | 0.9576 | 15 | ||
| 20 | 220.5622 | 10 | 6.0961 | 67 | ||
| 50 | 857.1166 | 12 | 2.8783 | 16 | ||
| 100 | 2392.5706 | 12 | 17.2367 | 17 | ||
| 200 | 7065.9134 | 65 | 525.1199 | 200 | ||
| 500 | 26877.7067 | 75 | 2273.0011 | 500 | ||
Example 4
To compare Algorithm GDA to Algorithm RNN (Liu et al., 2022 Liu ), consider Problem OP() with the objective function
which is pseudoconvex on the convex constraint set
where the parameter vector with the matrix with for and for and the number . The inequality constraints are
for Table 2 presents the computational results of Algorithms GDA and RNN. Note that the function is monotonically increasing by Therefore, to compare the approximated optimal value through iterations, we compute instead of with approximated optimal solution For each we solve Problem OP() to find the value the number of iterations (#Iter) to terminate the algorithms, and the computation time (Time) by seconds. The computational results reveal that the proposed algorithm outperforms Algorithm RNN in the test scenarios for both optimum value and computational time, specially when the dimensions is large scale.
| Algorithm GDA (proposed) | Algorithm RNN | |||||
|---|---|---|---|---|---|---|
| #Iter | Time | #Iter | Time | |||
| 10 | 5.1200 | 10 | 0.3 | 1000 | ||
| 20 | 2.5600 | 10 | 0.8 | 1000 | ||
| 50 | 1.0240 | 10 | 2 | 1000 | ||
| 100 | 0.5125 | 10 | 7 | 1000 | ||
| 300 | 15.7154 | 10 | 84 | 1000 | ||
| 400 | 20.9834 | 10 | 163 | 1000 | ||
| 600 | 29.0228 | 10 | 371 | 1000 | ||
5 Applications to machine learning
The proposed method, like the GD algorithm, has many applications in machine learning. We analyze three common machine learning applications, namely supervised feature selection, regression, and classification, to demonstrate the accuracy and computational efficiency compared to other alternatives.
Firstly, the feature selection problem can be modeled as a minimization problem of a pseudoconvex fractional function on a convex set, which is a subclass of Problem OP(). This problem is used to compare the proposed approach to neurodynamic approaches. Secondly, since the multi-variable logistic regression problem is a convex programming problem, the GDA algorithm and available variants of the GD algorithm can be used to solve it. Lastly, a neural network model for an image classification problem is the same as a programming problem with neither a convex nor a quasi-convex objective function. For training this model, we use the stochastic variation of the GDA method (Algorithm SGDA) as a heuristic technique. Although the algorithm’s convergence cannot be guaranteed like the cases of pseudoconvex and quasiconvex objective functions, the theoretical study showed that if the sequence of points has a limit point, it converges into a stationary point of the problem (see Theorem 3.1). Computational experiments indicate that the proposed method outperforms existing neurodynamic and gradient descent methods.
5.1 Supervised feature selection
Feature selection problem is carried out on the dataset with -feature set and -sample set , where is a -dimensional feature vector of the th sample and represents the corresponding labels indicating classes or target values. In Wang , an optimal subset of features is chosen with the least redundancy and the highest relevancy to the target class . The feature redundancy is characterized by a positive semi-definite matrix Then the first aim is minimizing the convex quadratic function The feature relevance is measured by where is a relevancy parameter vector. Therefore, the second aim is maximizing the linear function Combining two goals deduces the equivalent problem as follows:
| (14) |
where is the feature score vector to be determined. Since the objective function of problem (14) is the fraction of a convex function over a positive linear function, it is pseudoconvex on the constraint set. Therefore, we can solve (14) by Algorithm GDA.
In the experiment, we implement the algorithms with the Parkinsons dataset, which has 23 features and 197 samples, downloaded at https://archive.ics.uci.edu/ml/datasets/parkinsons. The similarity coefficient matrix is determined by (see Wang ), where -matrix with
the information entropy of a random variable vector is
the multi-information of three random vectors is with the mutual information of two random vectors defined by
and the conditional mutual information between and defined by
The feature relevancy vector is determined by Fisher score
where denotes the number of samples in class denotes the mean value of feature for samples in class is the mean value of feature , and denotes the variance value of feature for samples in class .
The approximated optimal value of problem (14) is with the computing time s for the proposed algorithm, while for Algorithm RNN. In comparison to the Algorithm RNN, our algorithm outperforms it in terms of both accuracy and computational time.
5.2 Multi-variable logistic regression
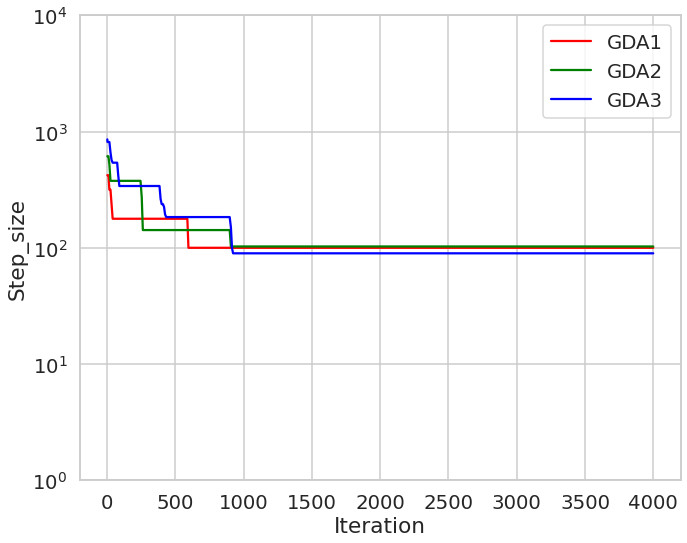
The experiments are performed with the dataset including observations The cross-entropy loss function for multi-variable logistic regression is given by where is the sigmoid function. Associated with -regularization, we get the regularized loss function The Lipschitz coefficient is estimated by where We compare the algorithms for training the logistic regression problem by using datasets Mushrooms and W8a (see in Malitsky ). The GDA method is compared to the GD algorithm with a step size of and Nesterov’s accelerated method. The computational results are shown in Fig. 3 and Fig. 4 respectively. The figures suggest that Algorithm GDA outperforms Algorithm GD and Nesterov’s accelerated method in terms of objective function values during iterations. In particular, Fig. 4 shows the change of the objective function values according to different coefficients. In this figure, the notation “GDA_0.75” respects to the case Fig. 5 presents the reduction of step-sizes from an initial step-size with respect to the results in Fig. 4.


5.3 Neural networks for classification
In order to provide an example of how the proposed algorithm can be implemented into a neural network training model, we will use the standard ResNet-18 architectures that have been implemented in PyTorch and will train them to classify images taken from the Cifar10 dataset downloaded at https://www.cs.toronto.edu/ kriz/cifar.html, while taking into account the cross-entropy loss. In the studies with ResNet-18, we made use of Adam’s default settings for its parameters.
For training this neural network model, we use the stochastic variation of the GDA method (Algorithm SGDA) to compare to Stochastic Gradient Descent (SGD) algorithms. The computational outcomes shown in Fig. 6 and Fig. 7 reveal that Algorithm SGDA outperforms Algorithm SGD in terms of testing accuracy and train loss over iterations.


6 Conclusion
We proposed a novel easy adaptive step-size process in a wide family of solution methods for optimization problems with non-convex objective functions. This approach does not need any line-searching or prior knowledge, but rather takes into consideration the iteration sequence’s behavior. As a result, as compared to descending line-search approaches, it significantly reduces the implementation cost of each iteration. We demonstrated technique convergence under simple assumptions. We demonstrated that this new process produces a generic foundation for optimization methods. The preliminary results of computer experiments demonstrated the new procedure’s efficacy.
Availability of data and materials
The data that support the findings of this study are available from the corresponding author, upon reasonable request.
Acknowledgments
This work was supported by Vietnam Ministry of Education and Training.
References
- (1) Bauschke, H.H., Combettes, P.L.: Convex analysis and monotone operator theory in hilbert spaces. Springer, New York (2011)
- (2) Boyd, S.P., Vandenberghe, L.: Convex Optimization. Cambridge University Press, Cambridge (2009)
- (3) Rockafellar, R.T.: Convex analysis. Princeton University Press, Princeton, New Jersey (1970)
- (4) Bian, W. , Ma, L., Qin, S., Xue, X.: Neural network for nonsmooth pseudoconvex optimization with general convex constraints. Neural Networks 101, 1-14 (2018).
- (5) Cevher, V., Becker, S., Schmidt, M.: Convex optimization for big data. Signal Process. Magaz. 31, 32–43 (2014)
- (6) Dennis, J.E., Schnabel, R.B.: Numerical methods for unconstrained optimization and nonlinear equations. Prentice-Hall, New Jersey (1983).
- (7) Ferreira, O. P., Sosa, W. S.: On the Frank–Wolfe algorithm for non-compact constrained optimization problems. Optimization 71(1), 197-211 (2022).
- (8) Hu, Y., Li, J., Yu, C.K.: Convergence Rates of Subgradient Methods for Quasiconvex Optimization Problems. Computational Optimization and Applications 77, 183–212 (2020).
- (9) Kiwiel, K.C.: Convergence and efficiency of subgradient methods for quasiconvex minimization. Math. Program., Ser. A 90, 1–25 (2001).
- (10) Konnov, I.V.: Simplified versions of the conditional gradient method. Optimization 67(12), 2275-2290 (2018).
- (11) Lan, G.H.: First-order and Stochastic Optimization Methods for Machine Learning. Springer Series in the Data Sciences, Springer Nature Switzerland (2020)
- (12) Liu, N., Wang, J., Qin, S.: A one-layer recurrent neural network for nonsmooth pseudoconvex optimization with quasiconvex inequality and affine equality constraints. Neural Networks 147, 1-9 (2022).
- (13) Malitsky, Y., Mishchenko, K.: Adaptive Gradient Descent without Descent. Proceedings of Machine Learning Research 119, 6702-6712 (2020).
- (14) Mangasarian, O.: Pseudo-convex functions. Siam Control 8, 281-290 (1965)
- (15) Nesterov, Y.: Introductory lectures on convex optimization: A basic course 87, Springer Science & Business Media (2013).
- (16) Xu, H.K.: Iterative algorithms for nonlinear operators. J. London Math. Soc. 66, 240-256 (2002)
- (17) Yu, C.K., Hu, Y., Yang, X., Choy, S. K.: Abstract convergence theorem for quasi-convex optimization problems with applications. Optimization 68(7), 1289-1304 (2019).
- (18) Wang,Y., Li, X., Wang, J.: A neurodynamic optimization approach to supervised feature selection via fractional programming. Neural Networks 136, 194–206 (2021).