Selective Knowledge Sharing for Personalized Federated Learning Under Capacity Heterogeneity
Abstract
Federated Learning (FL) stands to gain significant advantages from collaboratively training capacity-heterogeneous models, enabling the utilization of private data and computing power from low-capacity devices. However, the focus on personalizing capacity-heterogeneous models based on client-specific data has been limited, resulting in suboptimal local model utility, particularly for low-capacity clients. The heterogeneity in both data and device capacity poses two key challenges for model personalization: 1) accurately retaining necessary knowledge embedded within reduced submodels for each client, and 2) effectively sharing knowledge through aggregating size-varying parameters. To this end, we introduce Pa3dFL, a novel framework designed to enhance local model performance by decoupling and selectively sharing knowledge among capacity-heterogeneous models. First, we decompose each layer of the model into general and personal parameters. Then, we maintain uniform sizes for the general parameters across clients and aggregate them through direct averaging. Subsequently, we employ a hyper-network to generate size-varying personal parameters for clients using learnable embeddings. Finally, we facilitate the implicit aggregation of personal parameters by aggregating client embeddings through a self-attention module. We conducted extensive experiments on three datasets to evaluate the effectiveness of Pa3dFL. Our findings indicate that Pa3dFL consistently outperforms baseline methods across various heterogeneity settings. Moreover, Pa3dFL demonstrates competitive communication and computation efficiency compared to baseline approaches, highlighting its practicality and adaptability in adverse system conditions.
1 Introduction

Federated learning (FL) leverages private users’ data on edge devices, e.g., mobile phones and smartwatches, to collaboratively train a global model without direct access to raw data [1]. In practice, the clients’ device capacities (i.e., hard disk or memory size) are usually heterogeneous. Some clients with limited device capacity cannot be directly arranged to train a large-size model. Therefore, traditional FL will be hindered by either limited model sizes or the absence of data from low-capacity clients [2]. To mitigate this issue, recent works [3, 4, 5, 6, 7, 8, 9, 10, 11] enable collaboratively training a large-size model by reducing it into small trainable submodels. While succeeding in training capacity-heterogeneous models, the model inference performance on each client side can be hindered by both capacity and data heterogeneity. For one thing, the model utility will be quickly reduced as the number of model parameters decreases [2]. For another thing, the pruned submodels may not be suitable for client-specific data distributions [10]. The two issues motivate us to consider such a problem:
How to train personalized FL models simultaneously based on clients’ capacity and data?
There have been plenty of works addressing model personalization based on client-specific data [12, 13], most of which demand a uniform model size being shared across clients. Personalization methods based on knowledge distillation (KD) support the training of heterogeneous models, but they fail to leverage the consistency in model parameters and architectures. A most recent step towards this problem is TailorFL [10] and pFedGate[11], i.e. dropping out excessive channels from the global model based on clients’ data and capacity. However, they may still lead to suboptimal local performance since knowledge necessary for clients cannot be well retained when model parameters are pruned as shown in Fig.1(a) and (b) (w.r.t., general knowledge refers to what is suitable for all the clients while local knowledge is only necessary for partial clients). The undesired knowledge retention will harm FL effectiveness and efficiency in two ways: 1) the inconsistency between knowledge embedded in submodels and local data increases the difficulty of local model training and, 2) different channels may redundantly learn similar knowledge that cannot be aggregated within the same layer [7, 8, 11, 10, 2]. Moreover, traditional position-wise parameter averaging [11, 10] may further lower the aggregation efficiency due to unmatched fusion of knowledge independently learned by different clients (e.g., fusing global and local knowledge) [14, 15]. These issues induce two key challenges for capacity-heterogeneous model personalization:
- Challenge 1.
-
Accurately retaining necessary knowledge when pruning the model for each client.
- Challenge 2.
-
Effectively aggregating knowledge from capacity-heterogeneous models across clients.
Motivated by recent advancements in parameter decomposition techniques [2, 16, 17], we introduce a novel framework, termed Pa3dFL (Pruning and aggregation after decomposition FL), aimed at tackling the challenges outlined above. To address the first challenge, we decompose each layer’s model parameters into general and personal components as depicted in Fig.1(c). Subsequently, we trim the model size by only pruning personal parameters while preserving the consistency of global knowledge embedded in general parameters across all clients. In this way, only client-specific and general knowledge will be allocated to each client within the submodel. To address the second challenge, we directly average general parameters with constant shapes to foster comprehensive general knowledge sharing. Next, we adopt a hyper-network to generate personal parameters from learnable client embeddings. Finally, we facilitate the implicit aggregation of personal parameters by aggregating client embeddings via a self-attention module, which adaptively enhances personal knowledge sharing among similar clients.
Our contributions are concluded as follows:
-
•
We identify two key challenges (i.e., Challenges 1 and 2) in model personalization under data and capacity heterogeneity, which are commonly overlooked by previous works.
-
•
We propose an efficient personalized FL framework to enhance local model performance by decoupling and selectively sharing knowledge among capacity-heterogeneous models.
-
•
We conduct extensive experiments under various heterogeneity settings to show the advantage of our proposed methods in terms of accuracy and efficiency.
2 Problem Formulation
In personalized FL, there exist clients equipped with their private data , and the goal is to obtain a series of model that minimize
| (1) |
where and is the loss function. In a capacity-heterogeneous setting, the constraints on both running-time peak memory occupation and model size may be different for clients, and the local model ability will finally be limited by the weaker one of the memory term and the storage term. Following [11], we denote the full-model size and assume that each client can train a submodel of the reduced size ratio . Consequently, we formulate the capacity constraint as
| (2) |
under which the PFL objective (1) should be solved.
3 Methodology
3.1 Channel-aware Layer Decomposition
We start from the decomposition of the weight of the convolution operator introduced by FLANC [2], which can also be extended to fully connected layers by setting kernel size to . Given a convolution weight tensor ( w.r.t., the output channels, the input channels, and the kernel size), the decomposition of FLANC consists of a general part and a capacity-dependent part such that
| (3) |
where are manually predefined coefficients of the decomposition and is obtained by reshaping parameters according to channels in . FLANC reduces the model size by only reducing the columns of to (i.e., is the reduction ratio of the model width) while keeping consistent across clients. This reveals an outstanding property that general knowledge learned by can be propagated to all the reduced models to access the full range of knowledge on all capacity-heterogeneous devices. Motivated by FLANC, we employ a similar decomposition scheme where capacity-dependent parameters are personally kept instead of shared among devices with the same capacity. However, we notice that general parameters in FLANC can hardly encode channel-specific knowledge since equally contributes to every output channel as the basis in Eq. (3). This may limit model performance, especially when output channels sensitive to certain signals [18] (e.g., low-level circles or high-level eyes) are indispensable across all clients’ local tasks. To mitigate this issue, we propose to decompose in a channel-aware manner
| (4) |
where , and is also reshaped by channels to obtain final . Eq. (4) enables in general parameters to remember different channel-specific knowledge since it’s only shared by partial channels. We adapt the model to clients’ small capacity by reducing columns in , where only output channels will be pruned together. This completely preserves general parameters in the reduced model as FLANC. Additionally, we choose the coefficients adaptively by
| (5) |
to strike a balance between computation efficiency and performance as depicted in Sec.5.
Model Reduction.
Given a full-size model with layers, we represent the model parameters by the set of decomposed parameters of all layers . Then, we layer-wisely remove columns in in descending order of column indices (i.e., Eq. (10)) to obtain the -width model for each client based on capacity constraint Eq. (2). We finally denote general pameters by and varying-size personal parameters by for each client .
3.2 Aggregation Mechanism
The proposed model decomposition method enables clients to collaboratively maintain general parameters of a constant shape. As a result, can be updated by direct averaging at each aggregation round
| (6) |
where denotes the currently selected subset of clients. However, direct position-wise averaging on personal parameters of varying shapes may reduce the aggregation efficiency [9] and cause unmatched knowledge fusion [14]. Moreover, since personal parameters are viewed as learners for personal knowledge ge, it’s essential to propagate within clients that have similar local data distributions [19]. To this end, we employ a hyper-network (HN) to generate personal parameters from learnable client embeddings that will be aggregated to facilitate the implicit aggregation of personal parameters.
Parameter Generation via HN.
Personalizing model parameters through HN is first introduced by pFedHN [20]. In pFedHN, the server generates and distributes the full model parameters to the selected client , w.r.t. learnable embeddings , parameterized HN at the th communication round. Then, the server collects the locally trained parameters to update the hyper-network with the learning rate
| (7) | ||||
| (8) |
Unlike pFedHN, we use HN only to generate personal parameters for clients. First, we input all client embeddings into the encoder to obtain . Next, we compute the similarity between client and other clients by . Subsequently, we respectively generate personal parameters of each layer by Eq. (9) and prune them by Eq.10
| (9) | ||||
| (10) |
where the numbers of output, input channels of layer , the learnable coefficient (i.e. temperature of softmax) of layer , the target reduction ratio of the model width. In practice, can be approximately ensured by (i.e., Eq. (2)) according to our complexity analysis in Sec. 4. In practice, we use the multi-layer perceptron as the encoder and decoder, where the 1-D output vectors will be reshaped to obtain the parameters.
Implict Aggregation.
Our Eq. (9) can promote personal knowledge sharing among similar clients from three aspects. First, HN implicitly aggregates personal parameters in the embedding space instead of position-wise averaging in the original parameter space, allowing complex non-linear knowledge fusion across varying-size parameters. Second, the self-attention module enlarges aggregation weights between clients with larger similarities in the converted features, which adaptively promotes personal knowledge sharing among similar clients. Finally, we independently use learnable temperature coefficients for softmax aggregation in different layers, since the optimal personalization degree can vary across layers [21] and tasks [19]. For example, leads to no personalization on the layer and a small encourages a high degree of layer personalization.
3.3 Implementation
In Pa3dFL implementation, we decompose all the layers but the last one (i.e., head). We follow [22] to fix the global head without updating it during training and we maintain a local head by the HN respectively for each client [23]. We employ a regularization term slightly different from [2] during local training. We finally fuse the received model with the global head and the locally trained one with the local head on local validation data by linear search to decide each client’s local model for testing. For the hyper-network, we use the multi-layer-perceptron (MLP) to build the encoder and decoders, and we view the dimensions of client embeddings and hidden layers as hyper-parameters. The details of the implementation are in AppendixC.
4 Analysis
Complexity.
Pa3dFL reduces the global model along the width dimension. Supposing a model’s width reduction ratio is , the size of the model will be reduced by [7]. Therefore, both the computation costs and the communication costs can be significantly reduced by choosing a small reduction ratio. One concern is that Pa3dFL will introduce additional costs in both computation and communication processes due to its parameter decomposition. We demonstrate that these additional costs are acceptable in our adaptive choices of and and thus won’t significantly violate the benefits from the width-level reduction. We empirically compare the efficiency of Pa3dFL with existing methods in Sec. 6.4, and we detail the complexity analysis in Appendix A.
Convergence.
Privacy.
Pa3dFL won’t produce more privacy concerns than fedavg [1] since it only transfers model parameters between the server and clients like FedAvg without local data leaving clients’ devices. Besides, client embeddings in Pa3dFL on the server side are randomly initialized and updated only by the delta of model parameters, which can only reflect the similarities between clients without leaking their local data information.
5 Related Work
Personalized FL.
While traditional FL finds a global solution that is suitable to all the clients [1, 25], personalized FL (PFL) aims to obtain customized models of high local utility for different clients [26, 27]. Existing works focus on improving the effectiveness of PFL by partial parameter sharing [28, 29, 30, 31, 32], meta-learning[13, 12, 33], latent representation alignment[34, 22], local history maintaining[19, 35], hyper-network[20], adaptive aggregation[36, 37, 38, 39], and knowledge decoupling[40, 41]. Although achieving high accuracy, these methods commonly assume a uniform model size to be shared [10][7]. Some model agnostic methods[34, 42] can also mitigate the low-capacity issue, however, leading to suboptimal results without leveraging the consistency in model parameters and architectures.
Pruning FL.
To enable collaboratively training capacity-heterogeneous models, several methods prune or mask model parameters to reduce the model size [5, 4, 8]. [3, 4, 5] mask model parameters to reduce the communicating model size, but cannot save computation costs during the model training phase.[6, 7, 8, 9] drop channels out at each layer of a neural network to reduce the model capacity, but they ignore filters’ preference for particular data when pruning the model. [5, 10] allow clients with more similar data to share more identical parameters, and [11] dynamically personalizes parameters according to batch-level information. However, they suffer from undesirable knowledge retention as depicted in Sec.1.
Decomposition FL.
Decomposition FL can explicitly decouple knowledge by parameter decomposition [17, 16, 2].[16] decomposes each weight into a global vector and a personalized vector. [17] proposes a novel decomposition way to address the low-rank issue. The two methods are communication-efficient but both ignore the computational costs. [2] decomposes each weight into a common part and a capacity-specific part without pruning models. However, only clients with identical capacities can perform aggregation on capacity-specific parts and personalization was not taken into consideration by them.
6 Experiment
6.1 Setup
Datasets.
We evaluate Pa3dFL on three widely used benchmarks in FL: FashionMNIST [43], CIFAR10 and CIFAR100 [44]. We partition each dataset into 100 parts respectively kept by clients. We control data heterogeneity as [1, 25]. For CIFAR10, clients’ label distributions obey [45]. For CIFAR100, clients own 20 classes of data from all 100 classes. For FashionMNIST, data is i.i.d. distributed. We set the ratios of train/val/test parts as for each local data.
Models.
We use ResNet18-GN used by [25] for CIFAR10, where each batch normalization layer is replaced by group normalization due to the infeasibility of batch normalization on non-I.I.D. data in FL [46]. We use two-layer CNNs for both CIFAR100 [25] and FashionMNIST [47]. We detail the architecture of the models in Appendix D.2.
Capacity Setting.
We assume that each client can only afford training or testing a submodel that takes nearly computation costs of the full model. For width-reduction methods [9, 8, 7, 2, 10], the reduction ratio of each client should meet since the cost of a -width model is [7] and is the full model size. For methods that directly mask the ratio of parameters [11], should hold for each client. For capacity-unaware methods, we use the maximum model that can be computed by all the users based on the minimum capacity, which enables full participation of all the local data. We conduct experiments on two settings: Ideal and Hetero.. Clients in Ideal settings have unlimited computation resources. In Hetero., we set to be uniformly distributed from across clients. For example, clients with the lowest capacity can only afford training a submodel that is nearly of the complete model.
| CIFAR10 | CIFAR100 | FashionMNIST | ||||
|---|---|---|---|---|---|---|
| Method | Ideal | Hetero. | Ideal | Hetero. | Ideal | Hetero. |
| FedAvg | ||||||
| Ditto | ||||||
| pFedHN | ||||||
| FLANC | ||||||
| Fjord | ||||||
| HeteroFL | ||||||
| FedRolex | ||||||
| LocalOnly | ||||||
| LG-Fedavg | ||||||
| TailorFL | ||||||
| pFedGate | ||||||
| Pa3dFL | ||||||
Baselines.
Hyperparameters.
Following [25], we fix batch size and local epoch for all the datasets. We set communication rounds respectively for CIFAR10/CIFAR100/FashionMNIST. We perform early stopping when there is no gain in the optimal validation metrics for more than rounds. We tune the learning rate on the grid with the decaying rate and respectively tune the algorithmic hyperparameters for each method to their optimal. Each result is averaged over 3 random seeds. More details on hyperparameters are in Appendix D.
Implementation.
Our experiments are conducted on a 64g Ubuntu 22.04.2 LTS server with Intel(R) Xeon(R) Silver 4314 CPU @ 2.40GHz and 4 NVidia(R) RTX3090 GPUs. Our code is realized by FL framework [48].
6.2 Overall Performance
We first compare the overall accuracy of clients w./w.o. heterogeneous capacity constraints (e.g., hetero./ideal) for different methods in Table 1. While existing methods suffer performance reduction from low-capacity constraints (e.g., the reduction ratios of accuracy obtained by FedAvg in CIFAR10/CIFAR100/Fashion are ), our proposed Pa3dFL achieves the optimal results on CIFAR10 and CIFAR100 (i.e., and ) and competitive results against Fjord on FashionMNIST (i.e., v.s. ) under the same constraints. Compared with personalization-only methods (e.g., Ditto and pFedHN), Pa3dFL improves model performance up to (e.g., CIFAR100-Hetero.) and achieves similar results in ideal cases (e.g., v.s. in CIFAR10-ideal). Compared with capacity-aware methods, Pa3dFL consistently dominates them across all the cases in CIFAR10 and CIFAR100. We notice that our method takes no advantage in FashionMNIST-ideal. We attribute this result to the i.i.d. distributed data, and we still found that we outperform other personalization-only methods (e.g., Ditto and pFedHN) in this case. In addition, Pa3dFL also achieves the suboptimal result in FashionMNIST-Hetero., which suggests its adaptability when clients’ capacity varies regardless of data distributions. For capacity-aware methods with personalization (e.g., LG-FedAvg, TailorFL and pFedGate), they are also able to improve model performance while maintaining different model sizes for different clients. TailorFL achieves similar results against Pa3dFL in CIFAR10-Hetero. (e.g., v.s. ), but can only obtain a much weaker result than Pa3dFL when the task becomes more difficult (e.g., v.s. in CIFAR100-UNI). Besides, TailorFL failed to personalize models for clients in all IDL cases since its personalization is based on different architectures of clients, which may limit its applicability in practice. Overall, the results in Table 1 confirms the ability of Pa3dFL to preserve model performance under heterogeneity in terms of data and device capacity. We further compare the learning curves of different methods in Fig.3. Our method enjoys the fastest convergence and the highest performance across datasets.




6.3 Client Capacity-specific Performance
We show the capacity-specific performance under the Hetero. setting in Fig. 2, where we group clients’ capacities into five clusters and then show the averaging testing accuracy of each cluster. The results suggest that Pa3dFL outperforms other methods across different levels of client capacity in non-IID datasets (e.g. CIFAR10 and CIFAR100). We notice that TailorFL can achieve comparable results as Pa3dFL in CIFAR10, however, it suffers quick performance reduction on CIFAR100 as the capacity decreases. In Fashion, Pa3dFL achieves competitive results against non-personalization methods (e,g, Fjord and FedAvg) and still dominates other personalization methods. The results indicate the robustness towards different types of data distributions in practice.
| FLOPs () | Peak Memory (MB) | Model Size (MB) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ratio r | 1/256 | 1/64 | 1/4 | 1 | 1/256 | 1/64 | 1/4 | 1 | 1/256 | 1/64 | 1/4 | 1 |
| FedAvg | - | - | - | 188.0 | - | - | - | 71.1 | - | - | - | 30.4 |
| -width | 3.5 | 8.2 | 59.1 | 188.0 | 23.1 | 26.2 | 45.3 | 71.1 | 0.1 | 0.5 | 7.6 | 30.4 |
| FLANC | 15.0 | 18.2 | 42.3 | 87.7 | 30.1 | 34.1 | 58.4 | 90.9 | 0.6 | 0.9 | 7.76 | 29.3 |
| pFedGate | 5.5 | 10.1 | 61.0 | 190.0 | 39.2 | 42.3 | 61.4 | 87.2 | 36.3 | 36.3 | 36.3 | 36.3 |
| Pa3dFL | 3.6 | 8.3 | 59.9 | 191.9 | 23.3 | 26.5 | 46.3 | 74.8 | 0.8 | 1.3 | 8.5 | 28.7 |
6.4 Efficiency
We evaluate the efficiency of methods under the metrics FLOPs, peak memory, and model size [11, 7] in Table 2. Results of each method except pFedGate are independently obtained by training the model on CIFAR10 with a few batches of data over 10 iterations, and the batch size is fixed to 128. For pFedGate, we evaluate its costs of the sparse model and the additional gating layer, as is detailed in Appendix D.4. The term -width refers to methods reducing the model along the width (e.g., Fjord, HeteroFL, FedRolex and TailorFL). Firstly, like other capacity-aware methods, Pa3dFL can significantly reduce both the computation cost and communication cost of the model. Compared with -width, Pa3dFL brings few additional costs. However, Pa3dFL saves efficiency in a level more similar to -width than pFedGate and FLANC. For example, the ratio of saving amounts of FLOPs by Pa3dFL and -width when shrinking the model to are respectively and when compared to the full model used by FedAvg. We also observe similar trends of the efficiency saving by Pa3dFL in the peak memory and model size. For FLANC, it can achieve much smaller FLOPs than other methods when the reduction ratio is large. However, the effectiveness of the efficiency saving is reduced as the reduction ratio becomes small. pFedGate failed to reduce the model size since full parameters might be activated during computation, resulting in the full transmission and storage of the model.
| CIFAR10 | FashionMNIST | |
|---|---|---|
| Pa3dFL | ||
| w.o. HN-based Agg. | ||
| FLANC decomposition |
6.5 Ablation Study
We conduct ablation studies on modules of Pa3dFL to show their impacts in Table 3. We notice that only aggregating general parameters of models without using hyper-network to aggregate personalized parts severely hurts model performance (e.g., in CIFAR10 and in FashionMNIST) for both i.i.d. and non-i.i.d. cases. This indicates the importance of the aggregation of personalized parts for personal knowledge fusion. When replacing the model decomposition with the one used in FLANC (i.e., Eq. (3)), our method also suffers non-neglectable performance reduction. Therefore, we claim that the parameter decomposition way is essential to the model performance since it decides how knowledge is organized in parameters as aforementioned.
7 Conclusion
In this work, we address the issue of model performance reduction when there exists both data heterogeneity and capacity heterogeneity in FL. We identify and tackle two key challenges to enhance the model performance when adapting the over-capacity model to clients by pruning. Different from previous works, we propose to prune the model after decomposition and develop Pa3dFL to promote both general and personal knowledge sharing. We theoretically verify the effectiveness of our methods. Finally, we conduct extensive experiments to show the advantages of our proposed method in terms of accuracy and efficiency. We consider how to efficiently train models with rich operators and larger scalability under heterogeneous capacity constraints as our future works.
References
- [1] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR, 2017.
- [2] Yiqun Mei, Pengfei Guo, Mo Zhou, and Vishal Patel. Resource-adaptive federated learning with all-in-one neural composition. Advances in Neural Information Processing Systems, 35:4270–4284, 2022.
- [3] Ang Li, Jingwei Sun, Binghui Wang, Lin Duan, Sicheng Li, Yiran Chen, and Hai Li. Lotteryfl: Personalized and communication-efficient federated learning with lottery ticket hypothesis on non-iid datasets. arXiv preprint arXiv:2008.03371, 2020.
- [4] Ang Li, Jingwei Sun, Xiao Zeng, Mi Zhang, Hai Li, and Yiran Chen. Fedmask: Joint computation and communication-efficient personalized federated learning via heterogeneous masking. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, pages 42–55, 2021.
- [5] Ang Li, Jingwei Sun, Pengcheng Li, Yu Pu, Hai Li, and Yiran Chen. Hermes: an efficient federated learning framework for heterogeneous mobile clients. In Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, pages 420–437, 2021.
- [6] Dingzhu Wen, Ki-Jun Jeon, and Kaibin Huang. Federated dropout—a simple approach for enabling federated learning on resource constrained devices. IEEE wireless communications letters, 11(5):923–927, 2022.
- [7] Enmao Diao, Jie Ding, and Vahid Tarokh. Heterofl: Computation and communication efficient federated learning for heterogeneous clients. arXiv preprint arXiv:2010.01264, 2020.
- [8] Samuel Horvath, Stefanos Laskaridis, Mario Almeida, Ilias Leontiadis, Stylianos Venieris, and Nicholas Lane. Fjord: Fair and accurate federated learning under heterogeneous targets with ordered dropout. Advances in Neural Information Processing Systems, 34:12876–12889, 2021.
- [9] Samiul Alam, Luyang Liu, Ming Yan, and Mi Zhang. Fedrolex: Model-heterogeneous federated learning with rolling sub-model extraction. Advances in neural information processing systems, 35:29677–29690, 2022.
- [10] Yongheng Deng, Weining Chen, Ju Ren, Feng Lyu, Yang Liu, Yunxin Liu, and Yaoxue Zhang. Tailorfl: Dual-personalized federated learning under system and data heterogeneity. In Proceedings of the 20th ACM Conference on Embedded Networked Sensor Systems, pages 592–606, 2022.
- [11] Daoyuan Chen, Liuyi Yao, Dawei Gao, Bolin Ding, and Yaliang Li. Efficient personalized federated learning via sparse model-adaptation. arXiv preprint arXiv:2305.02776, 2023.
- [12] Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. Ditto: Fair and robust federated learning through personalization. In International Conference on Machine Learning, pages 6357–6368. PMLR, 2021.
- [13] Canh T Dinh, Nguyen Tran, and Josh Nguyen. Personalized federated learning with moreau envelopes. Advances in Neural Information Processing Systems, 33:21394–21405, 2020.
- [14] Hongyi Wang, Mikhail Yurochkin, Yuekai Sun, Dimitris Papailiopoulos, and Yasaman Khazaeni. Federated learning with matched averaging. arXiv preprint arXiv:2002.06440, 2020.
- [15] Xin-Chun Li, Yi-Chu Xu, Shaoming Song, Bingshuai Li, Yinchuan Li, Yunfeng Shao, and De-Chuan Zhan. Federated learning with position-aware neurons. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10082–10091, 2022.
- [16] Wonyong Jeong and Sung Ju Hwang. Factorized-fl: Personalized federated learning with parameter factorization & similarity matching. Advances in Neural Information Processing Systems, 35:35684–35695, 2022.
- [17] Nam Hyeon-Woo, Moon Ye-Bin, and Tae-Hyun Oh. Fedpara: Low-rank hadamard product for communication-efficient federated learning. arXiv preprint arXiv:2108.06098, 2021.
- [18] Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13, pages 818–833. Springer, 2014.
- [19] Jianqing Zhang, Yang Hua, Hao Wang, Tao Song, Zhengui Xue, Ruhui Ma, and Haibing Guan. Fedala: Adaptive local aggregation for personalized federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11237–11244, 2023.
- [20] Aviv Shamsian, Aviv Navon, Ethan Fetaya, and Gal Chechik. Personalized federated learning using hypernetworks. In International Conference on Machine Learning, pages 9489–9502. PMLR, 2021.
- [21] Xiaosong Ma, Jie Zhang, Song Guo, and Wenchao Xu. Layer-wised model aggregation for personalized federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10092–10101, June 2022.
- [22] Jaehoon Oh, Sangmook Kim, and Se-Young Yun. Fedbabu: Towards enhanced representation for federated image classification. arXiv preprint arXiv:2106.06042, 2021.
- [23] Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818, 2019.
- [24] Krishna Pillutla, Kshitiz Malik, Abdel-Rahman Mohamed, Mike Rabbat, Maziar Sanjabi, and Lin Xiao. Federated learning with partial model personalization. In International Conference on Machine Learning, pages 17716–17758. PMLR, 2022.
- [25] Cheng Jin, Xuandong Chen, Yi Gu, and Qun Li. Feddyn: A dynamic and efficient federated distillation approach on recommender system. In 2022 IEEE 28th International Conference on Parallel and Distributed Systems (ICPADS), pages 786–793. IEEE, 2023.
- [26] Virginia Smith, Chao-Kai Chiang, Maziar Sanjabi, and Ameet S Talwalkar. Federated multi-task learning. Advances in neural information processing systems, 30, 2017.
- [27] Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning. Foundations and Trends® in Machine Learning, 14(1–2):1–210, 2021.
- [28] Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. Federated learning with personalization layers. arXiv preprint arXiv:1912.00818, 2019.
- [29] Paul Pu Liang, Terrance Liu, Liu Ziyin, Nicholas B. Allen, Randy P. Auerbach, David Brent, Ruslan Salakhutdinov, and Louis-Philippe Morency. Think locally, act globally: Federated learning with local and global representations, 2020.
- [30] Muhammad Akbar Husnoo, Adnan Anwar, Nasser Hosseinzadeh, Shama Naz Islam, Abdun Naser Mahmood, and Robin Doss. Fedrep: towards horizontal federated load forecasting for retail energy providers. In 2022 IEEE PES 14th Asia-Pacific Power and Energy Engineering Conference (APPEEC), pages 1–6. IEEE, 2022.
- [31] Benyuan Sun, Hongxing Huo, Yi Yang, and Bo Bai. Partialfed: Cross-domain personalized federated learning via partial initialization. Advances in Neural Information Processing Systems, 34:23309–23320, 2021.
- [32] Xiaoxiao Li, Meirui Jiang, Xiaofei Zhang, Michael Kamp, and Qi Dou. Fedbn: Federated learning on non-iid features via local batch normalization. arXiv preprint arXiv:2102.07623, 2021.
- [33] Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar. Personalized federated learning with theoretical guarantees: A model-agnostic meta-learning approach. Advances in Neural Information Processing Systems, 33:3557–3568, 2020.
- [34] Yue Tan, Guodong Long, Lu Liu, Tianyi Zhou, Qinghua Lu, Jing Jiang, and Chengqi Zhang. Fedproto: Federated prototype learning across heterogeneous clients. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 8432–8440, 2022.
- [35] Xin-Chun Li, De-Chuan Zhan, Yunfeng Shao, Bingshuai Li, and Shaoming Song. Fedphp: Federated personalization with inherited private models. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 587–602. Springer, 2021.
- [36] Michael Zhang, Karan Sapra, Sanja Fidler, Serena Yeung, and Jose M Alvarez. Personalized federated learning with first order model optimization. arXiv preprint arXiv:2012.08565, 2020.
- [37] Yutao Huang, Lingyang Chu, Zirui Zhou, Lanjun Wang, Jiangchuan Liu, Jian Pei, and Yong Zhang. Personalized cross-silo federated learning on non-iid data. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 7865–7873, 2021.
- [38] Jian Xu, Xinyi Tong, and Shao-Lun Huang. Personalized federated learning with feature alignment and classifier collaboration. arXiv preprint arXiv:2306.11867, 2023.
- [39] Jun Luo and Shandong Wu. Adapt to adaptation: Learning personalization for cross-silo federated learning. In IJCAI: proceedings of the conference, volume 2022, page 2166. NIH Public Access, 2022.
- [40] Hong-You Chen and Wei-Lun Chao. On bridging generic and personalized federated learning for image classification. arXiv preprint arXiv:2107.00778, 2021.
- [41] Jianqing Zhang, Yang Hua, Hao Wang, Tao Song, Zhengui Xue, Ruhui Ma, Jian Cao, and Haibing Guan. Gpfl: Simultaneously learning global and personalized feature information for personalized federated learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5041–5051, 2023.
- [42] Daliang Li and Junpu Wang. Fedmd: Heterogenous federated learning via model distillation. arXiv preprint arXiv:1910.03581, 2019.
- [43] Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms, 2017.
- [44] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [45] Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Measuring the effects of non-identical data distribution for federated visual classification, 2019.
- [46] Kevin Hsieh, Amar Phanishayee, Onur Mutlu, and Phillip Gibbons. The non-iid data quagmire of decentralized machine learning. In International Conference on Machine Learning, pages 4387–4398. PMLR, 2020.
- [47] Zheng Wang, Xiaoliang Fan, Jianzhong Qi, Haibing Jin, Peizhen Yang, Siqi Shen, and Cheng Wang. Fedgs: Federated graph-based sampling with arbitrary client availability. 2023.
- [48] Zheng Wang, Xiaoliang Fan, Zhaopeng Peng, Xueheng Li, Ziqi Yang, Mingkuan Feng, Zhicheng Yang, Xiao Liu, and Cheng Wang. Flgo: A fully customizable federated learning platform. arXiv preprint arXiv:2306.12079, 2023.
- [49] Samiul Alam, Luyang Liu, Ming Yan, and Mi Zhang. Fedrolex: Model-heterogeneous federated learning with rolling sub-model extraction. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 29677–29690. Curran Associates, Inc., 2022.
Appendix A Complexity Analysis
Model Size.
A standard convolution weight is decomposed into and , where . is the kernel size. / is the number of input/output channels. and are two hyperparameters that control the amount of the convolution parameters. Therefore, the total amount of the decomposed convolution is . When the convolution layer is reduced by ratio , the amount of corresponding parameters becomes . Since is always required in Pa3dFL and a small may limit the expressiveness of , we always fixed . The corresponding parameter amount is
| (12) |
We denote as the systemic constraint since depends on the lowest capacity of clients. The reduction ratio of a -width model implemented by Pa3dFL is
| (13) |
We first visualize how the model size reduction ratio changes with the value of respectively on the convolution operator Conv(64,64,5,5) and Linear operator (1600, 384) that is used in CIFAR10 in Fig. 4. We fixed the lowest capacity as default. Firstly, we notice that for the convolution operator, let won’t significantly violate the benefit in the model reduction ratio. Even when the width ratio is small, the convolution operator brings very limited additional amounts of parameters. For the Linear operator, the model size increases quickly as increases, and the reduction ratio is almost consistent with -width. Since where setting won’t increase the rank of , we set for all linear operators without further specification. We finally design the rule of choosing as follows:
| (14) |
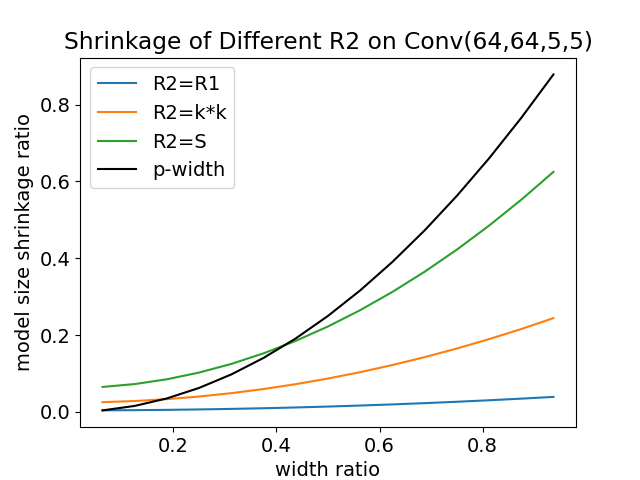





Under this rule, we respectively study how the reduction ratio is influenced by the systemic constraint and the dimension of the operators in Fig. 4. For the convolution operator, a loose constraint (i.e., a large ) will diminish the effectiveness of model reduction when the width ratio is small. However, a small is allowed to be used under loose systemic constraints. Different dimensions of convolution layers enjoy different reduction speeds. Although additional costs are introduced by Pa3dFL than -width, the reduced amount of model parameters is already significant compared to the full model. For the linear operator, the results show the consistency between this rule -width when the systemic constraints or the dimensions of operators vary. Further, if , the reduction ratio under this rule becomes
| (15) |
If is small than and , the ratio is nearly of complexity . The term in the reduction ratio also explains why the convolution operator in Pa3dFL has a larger tolerance to the value changing of than the linear operator in Fig. 4. Therefore, one can use a hyperparameter to scale of convolution layers properly to enhance the rank of the common parts’ matrices. Unfortunately, this rule may not work when using a super kernel size , which will produce unneglectable additional costs. In our experiments, the kernel size we used won’t significantly exceed the number of parameters. We remain how to specify the parameters selection rules for convolution layer with relatively large kernel sizes as our future works.
Training-Time Complexity.
During the model training phase, the additional complexity comes from the matrix multiplication in the parameter recovery process [2]. Given a batch of data with the feature size (i.e., the height and the width) and input channel number , a convolution operator with kernel size and output channels will produce multiply-add float operations. Since the cost of weight multiplication is , the additional cost ratio is
| (16) |
In practice, this term is negligible when .
Appendix B Convergence
At each communication round , the server generates personal parameters from clients’ embeddings by the hyper-network according to Eq. (9) and Eq. (10)
| (17) |
where . Then, client will receive the model parameters and locally update them by one-step gradient descent with the step size
| (18) |
The server aggregates the clients’ general parameters by
| (19) |
where denotes the global objective. The hyper-network is updated by Eq. (8)
| (20) | ||||
| (21) | ||||
| (22) | ||||
| (23) |
As a result, the update rule of the hyper-network is
| (24) |
By viewing the general parameters and the hyper-network parameters as a whole , we can directly apply the previous analysis result to our updating scheme under the following standard assumptions.
Assumption 1 (Smoothness).
For each , the function is continuously differentiable. There exist constants such that is –Lipschitz with respect to , and for each , is –Lipschitz with respect to .
Assumption 2 (Bounded Variance).
Theorem 1 (Convergence of Pa3dFL).
Appendix C Algorithmic Details
C.1 Pseudo Code of Pa3dFL
C.2 Training Tips
Testing Model Selection.
The procedure for testing model selection is shown in Alg.1. Since we only perform the model selection for testing purposes and the process won’t leak the validation data information to the training process, it won’t bring risks of overfitting on the validation dataset. The model selection can be performed at any time after locally training the model for each client. Since no model training is performed, the cost of model fusion is the almost same as the inference phase. Clients can recover the model into -width model first and then fuse the recovered model to further reduce the cost at the model selection phase.
Input:validation data , models and , the maximum number of iterations
Input:clients’ capacity constraints ,number of clients , model architecture , hyper-network , learning rate
Input: hyperparameter , model architecture , local epochs , batch size , learning rate
C.3 Regularization Term
We follow [2] to add a similar orthogonal regularization term to enhance the expressiveness of the decomposed parameters as follows:
| (32) |
where only preserves the diagonal elements of the input and is the hyper-parameter. This regularization is only made for convolution operators. Although we have a different scheme with FLANC [2] in the parameter recovery process, the orthogonal regularization term they used is also suitable to our method. In FLANC, columns of the common parts are viewed as the neural basis of the parameters of each filter. Therefore, they regularize the basis to be orthogonal to each other to increase the expressiveness by
| (33) |
where denotes the number of decomposition layers in the model. In Pa3dFL, columns in each basic component construct the basis of filters in the final weights that are delivered from the component. Therefore, encouraging columns to be orthogonal to each other also helps increase the expressiveness of filters in our parameter recovery scheme. Since the corresponding kernel size for linear operators is , requiring the orthogonality of scalars among columns of a basic component is meaningless. Therefore, we only perform this regularization term for convolution operators instead of all the operators like FLANC. In addition, we notice that the term used by FLANC will force the norm of each column in to be closest to one. We eliminate this issue by ignoring the diagonal elements in the product in Eq. (32) to further enhance model performance from empirical observations.
Appendix D Experimental Details
D.1 Datasets
CIFAR10\100
Each CIFAR dataset [44] consists of total 60000 32x32 colour images in 10\100 classes (i.e., 50000 training images and 10000 test images). We use random data augmentation on the two datasets [1]. For CIFAR10, We partition the training data by letting the local label distribution for each client, where is the label distribution in the original dataset. We use in our experiments. For CIFAR100, we randomly let each client to own 20 classes of 100 classes. We provide the visualized partition in Fig. 5(a) and 5(b).
FashionMNIST.
The dataset [43] consists of a training set of 60,000 examples and a test set of 10,000 examples, where each example is a size image of fashion and associated with a label from 10 classes. In this work, we partition this dataset into 100 clients in a i.i.d. manner and equally allocate the same number of examples to each one. A direct visualization of the partitioned result is provided in Fig. 5(c).



D.2 Models
For all the three datasets, we use the classical CNN architecture used by [1]. The information on the models is concluded in Table 4.
| CIFAR10 | CIFAR100 | FACHION | |
| Input Shape | (3,32,32) | (3,32,32) | (1,28,28) |
| Conv Layer | (3, 64, kernel=7, stride=2, pad=3) | (3,64,kernel=5), | (1,32,kernel=5, pad=2), |
| pool, relu | pool, relu | pool, relu | |
| ResBlock(2) *4 | (64,64,kernel=5), | (32,64,kernel=5, pad=2), | |
| pool, relu | pool, relu | ||
| FC Layer | (512, 10) | (1600,384), relu | (3136,512), relu |
| (384,192), relu | (512,128), relu | ||
| (192,100), relu | (128,10), relu |
D.3 Baselines & Hyperparameters
We consider the following baselines including SOTA personalized and capacity-aware methods in this work
-
•
LocalOnly is a non-federated method where each client independently trains its local model;
-
•
FedAvg [1] is the classical FL method that iteratively averages the locally trained models to update the global model;
-
•
Ditto [12] personalizes the local model by limiting its distance to the global model for each client with a proximal term. We tune the coefficient from for this method;
-
•
pFedHN [20] is a SOTA PFL method that uses a hyper-network to generate personalized parameters for each client;
-
•
HeteroFL [7] is a capacity-aware FL method that prunes model parameters in a nested manner and uses the Scaler to align information across models of different capacities.
-
•
Fjord[8] drops filters of a neural network at each layer in order and it aligns the information across models with different scalability by knowledge distillation.
-
•
FLANC[2] reduces the model size by decomposing the model parameters into commonly shared parts and capacity-specific parts. They average the commonly shared parts to update the model, and only capacity-specific parts at the same capacity level can be aggregated. In addition, it uses an orthogonal regularization term to enhance the expressiveness of commonly shared parts. We tune the term’s coefficient from
-
•
TailorFL[10] is an efficient personalized FL method that prunes filters in a personalized manner, which enhances the local model performance by encouraging similar clients to share more identical filters. It regularizes the local training objectives by limiting the norm of the importance layer proposed by them. We tune the coefficient of the regularization from .
-
•
pFedGate[11] dynamically masks blocks of model parameters according to batch-level information to personalize the model parameters. A local gating layer is maintained by each client locally to decide which parameters should be activated during computation. We set the default splitting number as they did and we tune this method by varying the learning rate of the gating layer from the grid of the model learning rate.
-
•
LG-FEDAVG[29] is a method that jointly learns compact local representations on each device and a global model across all devices.
-
•
FEDROLEX[49] employs a rolling sub-model extraction scheme that allows different parts of the global server model to be evenly trained, which mitigates the client drift induced by the inconsistency between individual client models and server model architectures.
Hyperparameters.
we fix batch size and local epoch for all the datasets. We set communication rounds respectively for CIFAR10/CIFAR100/FashionMNIST. We perform early stopping when there is no gain in the optimal validation metrics for more than rounds. We tune the learning rate on the grid with the decaying rate and respectively tune the algorithmic hyperparameters for each method to their optimal. For Pa3dFL, we select the dimensions of clients’ embeddings and hidden layers of HN from , and we tune the depth of HN encoder over , the regularization coefficient from and the learning rate of HN from . We conclude the optimal configurations for all the methods in Table 5.
| Ideal | Hetero. | |||
| Step size | Algorithmic | Step Size | Algorithmic | |
| FedAvg | 0.1 | - | 0.1 | - |
| Ditto | 0.1 | 0.1 | 0.05 | 1.0 |
| pFedHN | 0.1 | [5, 100, 2] | 0.1 | [5, 100, 2] |
| FLANC | 0.1 | 0.01 | 0.1 | 0.01 |
| Fjord | 0.1 | - | 0.1 | - |
| HeteroFL | 0.1 | - | 0.1 | - |
| FedRolex | 0.1 | - | 0.1 | - |
| LocalOnly | 0.005 | - | 0.005 | - |
| LG-FedAvg | 0.005 | - | 0.1 | - |
| TailorFL | 0.1 | 0.1, 0.05 | 0.1 | 0.5, 0.05 |
| pFedGate | 0.1 | 0.005 | 0.1 | 0.1 |
| Pa3dFL | 0.1 | 0.1,0.001,[64,64,4] | 0.1 | 0.1,0.001,[64,64,3] |
| Ideal | Hetero. | |||
| Step size | Algorithmic | Step Size | Algorithmic | |
| FedAvg | 0.1 | - | 0.1 | - |
| Ditto | 0.1 | 0.1 | 0.05 | 1.0 |
| pFedHN | 0.05 | [5, 100, 2] | 0.1 | [5, 100, 2] |
| FLANC | 0.1 | 1.0 | 0.1 | 0.01 |
| Fjord | 0.1 | - | 0.1 | - |
| HeteroFL | 0.05 | - | 0.05 | - |
| FedRolex | 0.1 | - | 0.1 | - |
| LocalOnly | 0.1 | - | 0.1 | - |
| LG-FedAvg | 0.1 | - | 0.1 | - |
| TailorFL | 0.1 | 0.5, 0.2 | 0.01 | 0.5, 0.2 |
| pFedGate | 0.1 | 0.05 | 0.1 | 0.05 |
| Pa3dFL | 0.1 | 0.001,1.0,[16,128,2] | 0.1 | 0.01,0.1,[16,128,3] |
| Ideal | Hetero. | |||
| Step size | Algorithmic | Step Size | Algorithmic | |
| FedAvg | 0.1 | - | 0.05 | - |
| Ditto | 0.05 | 1.0 | 0.05 | 1.0 |
| pFedHN | 0.1 | - | 0.1 | - |
| FLANC | 0.1 | 1.0 | 0.1 | 1.0 |
| Fjord | 0.1 | - | 0.1 | - |
| HeteroFL | 0.05 | - | 0.1 | - |
| FedRolex | 0.1 | - | 0.1 | - |
| LocalOnly | 0.1 | - | 0.1 | - |
| LG-FedAvg | 0.1 | - | 0.1 | - |
| TailorFL | 0.1 | 0.1, 0.2 | 0.01 | 0.05, 0.2 |
| pFedGate | 0.1 | 0.1 | 0.1 | 0.05 |
| Pa3dFL | 0.1 | 0.01,0.1,[64,64,3] | 0.1 | 0.001,1.0,[64,64,4] |
D.4 Efficiency Evaluation For pFedGate
We discuss the details of the efficiency evaluation for pFedGate. While the efficiency of pruning-based baselines can be directly computed by tracing the memory and the intermediates during computation, this manner fails to evaluate the efficiency of pFedGate since dynamically masking model parameters (i.e., setting their values to zero) without actually dropping them out from the memory won’t save any computation efficiency. [11] simply assumes the computation cost is proportion to the size of the non-masked model parameters and implements pFedGate based on zero-masking. As illustrated above, this type of implementation cannot be directly evaluated by tracing the systemic variables (e.g memory). A possible way is to split each weight in a model into independently stored parts, which allows users to drop specified parts before feeding data into the model. However, it’s too complex to realize such a mechanism in practice due to the varying splitting numbers, operator shapes, model architectures, and dimension alignment. As a result, we keep the consistency of our implementation with the authors’ official open-source codes111https://github.com/yxdyc/pFedGate. Since the additional costs of pFedGate usually come from the gating layer, we respectively consider the cost of the gating layer and the sparse model, and we then regard the sum of them to obtain the evaluated results. For a sparse model with sparsity , it shares almost the same computation cost as the pruning-based method with width reduction ratio . The gating layer receives a batch of data and outputs a vector with the legnth of the total number of blocks, which is irrelevant to the reduction ratio of the model and is only decided by the input shapes and the model splitting manner. Therefore, we evaluate the additional cost of the gating layer as the difference between the cost of a full ordinary model and the cost of the pFedGate’s mdoel with sparsity 1.0 for each batch size. Then, we use the estimated costs of the gating layer as the additional costs for all reduction ratios when batch size is specified. We finally add the cost of the shrunk model and the cost of the gating layer together to obtain the total cost of pFedGate.
Appendix E Additional Experiments
| FLOPs () | Peak Memory (MB) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| reduction ratio | 1/256 | 1/64 | 1/4 | 1 | 1/256 | 1/64 | 1/4 | 1 | |
| p-width | B=16 | 0.4 | 1.0 | 7.3 | 23.5 | 17.0 | 17.4 | 20.4 | 25.7 |
| B=64 | 1.7 | 4.1 | 29.5 | 94.0 | 19.2 | 20.8 | 31.4 | 45.1 | |
| B=128 | 3.5 | 8.2 | 59.0 | 188.1 | 23.1 | 26.2 | 45.3 | 71.1 | |
| B=512 | 14.2 | 32.8 | 236.3 | 752.3 | 41.2 | 53.4 | 127.9 | 227.3 | |
| FLANC | B=16 | 1.8 | 2.2 | 5.2 | 10.9 | 17.9 | 18.4 | 22.0 | 28.2 |
| B=64 | 7.4 | 9.0 | 21.1 | 43.8 | 22.8 | 24.8 | 38.3 | 55.2 | |
| B=128 | 14.9 | 18.1 | 42.2 | 87.7 | 30.1 | 34.1 | 58.4 | 90.9 | |
| B=512 | 59.9 | 72.7 | 169.1 | 350.9 | 69.6 | 84.0 | 179.6 | 305.4 | |
| pFedGate | B=16 | 0.6 | 1.2 | 7.6 | 23.7 | 27.6 | 28.1 | 31.0 | 36.4 |
| B=64 | 2.7 | 5.0 | 30.5 | 95.0 | 32.4 | 33.9 | 44.6 | 58.2 | |
| B=128 | 5.5 | 10.1 | 61.0 | 190.0 | 40.8 | 43.9 | 63.0 | 88.8 | |
| B=512 | 22.1 | 40.7 | 244.1 | 760.1 | 68.0 | 80.2 | 154.7 | 254.1 | |
| Pa3dFL | B=16 | 0.47 | 1.0 | 8.0 | 27.3 | 17.1 | 17.6 | 21.3 | 28.6 |
| B=64 | 1.8 | 4.2 | 30.2 | 97.8 | 19.4 | 21.0 | 32.4 | 48.0 | |
| B=128 | 3.6 | 8.3 | 59.9 | 191.9 | 23.3 | 26.5 | 46.3 | 74.8 | |
| B=512 | 14.5 | 33.3 | 237.9 | 756.1 | 41.1 | 53.9 | 128.9 | 231.0 |
E.1 Full Efficiency Comparison
We provide a full comparison of the computation efficiency of different methods by varying batch sizes in Table 8. When using a small batch size and a small reduction ratio, the reduced amount on both FLOPs and peak memory of Pa3dFL is closest to that of p-width. We notice that if batch size is small and the reduction is large, pFedGate achieves a larger reduced amount in computation costs. However, since clients with large reduction ratios usually have more computation costs, it will be more useful to save more efficiency for clients with small reduction ratios rather than large ones.



E.2 Learning Curve
We visualize the learning curve of different methods in Fig. 6. In Hetero. setting, Pa3dFL consistently outperforms other methods in CIFAR10 and CIFAR100 and achieves competitive results against the SOTA method Fjord. In Ideal setting, Pa3dFL still achieves outstanding performance regardless of data distributions. We also notice that our method does not converge until 2000 rounds in CIFAR100 while already achieving the highest performance among all the methods, indicating the room for accelerating convergence of our method to further enhance its performance. We will investigate this issue in our future work.
E.3 Impact of Regularization





We conduct the impact of the regularization term in Fig. 8 by varying the value of the coefficient on three datasets for both the ideal case and the hetero. case. In FashionMNIST, a small regularization coefficient is preferred. We infer that this is due to the knowledge has been already well organized in model parameters. The impact of different values of the regularization coefficient is not obvious in CIFAR10 and needs to be carefully tuned in practice. These results also suggest can be a proper choice without prior knowledge.
| 1-layer | 2-layer | 3-layer | |
|---|---|---|---|
| CNN-CIFAR100 | 0.01/0.26 | 0.01/0.27 | 0.01/0.30 |
| ResNet18-CIFAR10 | 0.03/0.81 | 0.03/0.85 | 0.03/0.87 |
Appendix F Computation Cost of HN
We evaluate the computation cost of generating personal parameters by HN and optimization of HN on CIFAR10 (e.g., ResNet18) and CIFAR100 (2-layer CNN) in Table 9 with a (64,64,layers) HN. The time cost of hyper-network optimization and parameter generation are both extremely small when compared to local training. In addition, scaling the model also brings limited additional cost, indicating the adaptability of HN in practice.
Appendix G Impact of HN depth
Generally, the clients’ model performance can benefit from a deep HN as shown in Fig.8.
Appendix H Limitation
There exist several limitations of our work. First, We only evaluate Pa3dFL on two commonly used operators, e.g., convolution operator and linear operator. A more broad range of operators like attention are not discussed in this work. However, Pa3dFL can also be extended other operators since we compress the model from a fine-grained matrix level. We will investigate the extension of Pa3dFL to other operators (e.g., attention, rnn) in our future work. Second, we have only validated the effectiveness of our proposed method on CV models and datasets. How Pa3dFL will perform on other types of tasks is unexplored. In addition, Pa3dFL’s performance and convergence speed should be further improved when there exists no capacity constraints. Finally, we manually search the architecture of proper hyper-networks for each task, which is tedious and introduces large computation costs in network architecture searching. Nevertheless, we confirm the effectiveness of generating personalized parameters using hyper-networks. We will improve these mentioned issues in our future work.