Selective Knowledge Distillation for Neural Machine Translation
Abstract
Neural Machine Translation (NMT) models achieve state-of-the-art performance on many translation benchmarks. As an active research field in NMT, knowledge distillation is widely applied to enhance the model’s performance by transferring teacher model’s knowledge on each training sample. However, previous work rarely discusses the different impacts and connections among these samples, which serve as the medium for transferring teacher knowledge. In this paper, we design a novel protocol that can effectively analyze the different impacts of samples by comparing various samples’ partitions. Based on above protocol, we conduct extensive experiments and find that the teacher’s knowledge is not the more, the better. Knowledge over specific samples may even hurt the whole performance of knowledge distillation. Finally, to address these issues, we propose two simple yet effective strategies, i.e., batch-level and global-level selections, to pick suitable samples for distillation. We evaluate our approaches on two large-scale machine translation tasks, WMT’14 English-German and WMT’19 Chinese-English. Experimental results show that our approaches yield up to +1.28 and +0.89 BLEU points improvements over the Transformer baseline, respectively. 111We release our code on https://github.com/LeslieOverfitting/selective_distillation.
1 Introduction
Machine translation has made great progress recently by using sequence-to-sequence models (Sutskever et al., 2014; Vaswani et al., 2017; Meng and Zhang, 2019; Zhang et al., 2019b; Yan et al., 2020). Recently, some knowledge distillation methods (Kim and Rush, 2016; Freitag et al., 2017; Gu et al., 2017; Tan et al., 2019; Wei et al., 2019; Li et al., 2020; Wu et al., 2020) are proposed in the machine translation to help improve model performance by transferring knowledge from a teacher model. These methods can be divided into two categories: word-level and sequence-level, by the granularity of teacher information. In their researches, the model learns from teacher models by minimizing gaps between their outputs on every training word/sentence (i.e., corresponding training sample) without distinction.
Despite their promising results, previous studies mainly focus on finding what to teach and rarely investigate how these words/sentences (i.e., samples), which serve as the medium or carrier for transferring teacher knowledge, participate in the knowledge distillation. Several questions remain unsolved for these samples: Which part of all samples shows more impact in knowledge distillation? Intuitively, we may regard that longer sentences are hard to translate and might carry more teacher knowledge. But are there more of these criteria that can identify these more important/suitable samples for distillation? Further, what are the connections among these samples? Are they all guiding the student model to the same direction? By investigating the carrier of teacher knowledge, we can shed light on finding the most effective KD method.
Hence, in this paper, we aim to investigate the impacts and differences among all samples. However, it is non-trivial to analyze each of them. Therefore, we propose a novel analytical protocol by partitioning the samples into two halves with a specific criterion (e.g., sentence length or word cross-entropy) and study the gap between performance. Extensive empirical experiments are conducted to analyze the most suitable sample for transferring knowledge. We find that different samples differ in transferring knowledge for a substantial margin. More interestingly, with some partitions, especially the student model’s word cross-entropy, the model with half of the knowledge even shows better performance than the model using all distill knowledge. The benefit of the distillation of two halves cannot collaborate. This phenomenon reveals that the distillation of two halves cannot collaborate, even hurt the whole performance. Hence, a more sophisticated selective strategy is necessary for KD methods.
Next, we propose two simple yet effective methods to address the observed phenomenon according to word cross-entropy (Word CE), which we find is the most distinguishable criterion. We first propose a batch-level selection strategy that chooses words with higher Word CE within the current batch’s distribution. Further, to step forward from local (batch) distribution to global distribution, we use a global-level FIFO queue to approximate the optimal global selection strategy, which caches the Word CE distributions across several steps. We evaluate our proposed method on two large-scale machine translation datasets: WMT’14 English-German and WMT’19 Chinese-English. Experimental results show that our approach yields an improvement of +1.28 and + 0.89 BLEU points over the Transformer baseline.
In summary, our contributions are as follows:
-
•
We propose a novel protocol for analyzing the property for the suitable medium samples for transferring teacher’s knowledge.
-
•
We conduct extensive analyses and find that some of the teacher’s knowledge will hurt the whole effect of knowledge distillation.
-
•
We propose two selective strategies: batch-level selection and global-level selection. The experimental results validate our methods are effective.
2 Related Work
Knowledge distillation approach (Hinton et al., 2015) aims to transfer knowledge from teacher model to student model. Recently, many knowledge distillation methods (Kim and Rush, 2016; Hu et al., 2018; Sun et al., 2019; Tang et al., 2019; Jiao et al., 2019; Zhang et al., 2019a, 2020; Chen et al., 2020a; Meng et al., 2020) have been used to get effective student model in the field of natural language processing by using teacher model’s outputs or hidden states as knowledge.
As for neural machine translation (NMT), knowledge distillation methods commonly focus on better improving the student model and learning from the teacher model. Kim and Rush (2016) first applied knowledge distillation to NMT and proposed the sequence-level knowledge distillation that lets student model mimic the sequence distribution generated by the teacher model. It was explained as a kind of data augmentation and regularization by Gordon and Duh (2019). Further, Freitag et al. (2017) improved the quality of distillation information by using an ensemble model as the teacher model. Gu et al. (2017) improved non-autoregressive model performance by learning distillation information from the autoregressive model. Wu et al. (2020) proposed a layer-wise distillation method to be suitable for the deep neural network. Chen et al. (2020b) let translation model learn from language model to help the generation of machine translation.
To the best of our knowledge, there is no previous work in NMT concerning the selection of suitable samples for distillation. The few related ones mainly focus on selecting appropriate teachers for the student model to learn. For instance, Tan et al. (2019) let the student model only learn from the individual teacher model whose performance surpasses it. Wei et al. (2019) proposed an online knowledge distillation method that let the model selectively learn from history checkpoints. Unlike the above approaches, we explore the effective selective distillation strategy from sample perspective and let each sample determine learning content and degree.
3 Background
3.1 Neural Machine Translation
Given a source sentence , and its corresponding ground-truth translation sentence , an NMT model minimizes the word negative log-likelihood loss at each position by computing cross-entropy. For the -th word in the target sentence, the loss can be formulated as:
| (1) |
where is the size of target vocabulary, is the indicator function, and denotes conditional probability with model parameterized by .
3.2 Word-level Knowledge Distillation
In knowledge distillation, student model gets extra supervision signal by matching its own outputs to the probability outputs of teacher model . Specifically, word-level knowledge distillation defines the Kullback–Leibler distance between the output distributions of student and teacher Hu et al. (2018). After removing constants, the objective is formulated as:
| (2) |
where is the conditional probability of teacher model. and is the parameter set of student model and teacher model, respectively.
And then, the overall training procedure is minimizing the summation of two objectives:
| (3) |
where is a weight to balance two losses.
4 Are All Words Equally Suitable for KD?
| Criteria | BLEU | ||
| Baseline | 27.29 | - | |
| Distill-All | 28.14 | - | |
| Distill-Half(Random) | 28.18 | - | |
| Data Property | |||
| Sentence Length | 27.81 | 27.59 | +0.22 |
| Word Frequency | 28.35 | 27.99 | +0.36* |
| Student Model | |||
| Embedding Norm | 27.90 | 27.73 | +0.17 |
| Word CE | 28.42 | 27.78 | +0.64* |
| Sentence CE | 28.29 | 27.84 | +0.45* |
| Teacher Model | |||
| Teacher | 27.97 | 28.00 | -0.03 |
| Entropy | 27.62 | 27.92 | -0.30 |
As discussed before, as a carrier of the teacher’s knowledge, ground-truth words might greatly influence the performance of knowledge distillation. Therefore, in this section, we first do some preliminary empirical studies to evaluate the importance of different words/sentences in knowledge distillation.
4.1 Partition of Different Parts
The optimal way to analyze samples’ different impacts on distillation is to do ablation studies over each of them. However, it is clearly time-consuming and intractable. Hence, we propose an analytical protocol by using the partition and comparison as an approximation, which we believe could shed light on future analyses. Particularly, we leverage a specific criterion to partition samples into two complementary parts:
and analyze different effects between and . Each part consists of 50% words/sentences precisely. The criteria come from three different perspectives: data property, student model, and teacher model. The detailed descriptions are as follows:
-
•
Data Property.
-
•
Student Model. As for the student model, we care if the student model thinks these words/sentences are too complicated. Therefore, we use Word CE (cross-entropy of words), Sentence CE (mean of the cross-entropy of all words in sentences), and each word’s embedding norm Liu et al. (2020).
-
•
Teacher Model. For the teacher model, we guess that the teacher’s prediction confidence may be crucial for transferring knowledge. Hence, we use the prediction probability of ground-truth label () and entropy of prediction distribution as our criteria.
4.2 Analytic Results
Table 1 presents our results on different criteria. We also add the performance of Transformer baseline, Distill-All (distillation with all words) and Distill-Half(distillation with 50% words chosen by random) for comparison.
Impact of Different Parts.
Through most of the rows, we observe noticeable gaps between the BLEU scores of the and , indicating there exists a clear difference of impact on medium of teacher knowledge. Specifically, for most of the criteria like cross-entropies or word frequency, the gap between two halves surpasses 0.35. In contrast, teacher seems not useful for partitioning KD knowledge. We conjecture this is because no matter whether the teacher is convinced with the golden label or not, other soft labels could contain useful information Gou et al. (2020). Besides, we find teacher entropy is a good-enough criterion for partitioning KD data, which inlines with previous studies of dark knowledge Dong et al. (2019). Finally, we find that the KD is most sensitive (+0.64) with the Word CE criterion, which enjoys the adaptivity during the training phase and is a good representative for whether the student thinks the sample is difficult.
In conclusion, we regard the most suitable samples should have the following properties: higher Word CE, higher Sentence CE, higher Word Frequency, which probably benefits future studies of effective KD methods.
Impact of All and Halves.
More interestingly, compared with ‘Distill-All’, which is the combination of the and , the halves’ BLEU score even surpass the ‘Distill-All’, for Word CE, Sentence CE and Word Frequency criteria. This leads to two conclusions:
(1) Within some partitions, the contributes most to the KD improvements.
(2) The amount of teacher knowledge is not the more, the better. The distillation knowledge of the does not directly combine with the , even hurts ’s performance.
Impact of the Amount of Knowledge.
Given that distillation knowledge is most sensitive to Word CE, we conduct extra analysis on the Word CE. Figure 1 presents the results of varying the amount of knowledge for and . The consistent phenomenon is that the perform significantly better than the when using the same amount of teacher’s knowledge. These results suggest that we should focus more on the than on . Besides, we notice that the model performance increases when we increase the knowledge in , but not the case for . We conclude that the Word CE is distinguishable and a better indicator of teachers’ useful knowledge only for .
At the end of this section, we can summary the following points:
-
•
To find out the most suitable medium for transferring medium, we adopt a novel method of partition and comparison, which can easily be adopted to future studies.
-
•
The benefit of distillation knowledge drastically changes when applying to different mediums of knowledge.
-
•
Among all criteria, knowledge distillation is the most sensitive to Word CE. Distilling words with higher Word CE is more reliable than words with lower CE.
-
•
In some partitions, the distillation benefit of can not add to the , even hurts ’s performance.

5 Selective Knowledge Distillation for NMT
As mentioned above, there exist un-suitable mediums/samples that hurt the performance of knowledge distillation. In this section, we address this problem by using two simple yet effective strategy of selecting useful samples.
In Section 4, we find that Word CE is the most distinguishable criterion. Hence, we continue to use the Word CE as the measure in our methods. As the word cross-entropy is a direct measure of how the student model agrees with the golden label, we refer to words with relatively large cross-entropy as difficult words, and words with relatively small cross-entropy as easy words, in the following parts. This is to keep the notation different from previous analysis.
Then, we only need to define what is “relatively large”. Here, we introduce two CE-based selective strategies:
Batch-level Selection (BLS).
Given a mini-batch of sentence pairs with target words, we sort all words in the current batch with their Word CE in descending order and select the top percent of all words to distill teacher knowledge. More formally, let denote the Word CE set, which contains the Word CE of each word in batch B. We define as the set of the largest cross-entropy words among the batch, and is its complementary part.
For those words in , we let them get extra supervision signal from teacher model’s distillation information. Therefore, the knowledge distillation objective in Equation 3 can be be re-formulated as:
| (5) |
where we simplify the notation of and for clarity.
Global-level Selection (GLS).
Limited by the number of words in a mini-batch, batch-level selection only reflects the current batch’s CE distribution and can not represent the real global CE distribution of the model very well. In addition, the batch-level method makes our relative difficulty measure easily affected by each local batch’s composition. The optimal approach to get the global CE distribution is to traverse all training set words and calculate their CE to get the real-time distribution after each model update. However, this brings a formidable computational cost and is not realistic in training.
Therefore, as a proxy to optimal way, we extend batch-level selection to global-level selection by dexterously using a First-In-First-Out (FIFO) global queue . At each training step, we push batch words’ CE into FIFO global queue and pop out the ‘Oldest’ words’ CE in the queue to retain the queue’s size. Then, we sort all CE values in the queue and calculate the ranking position of each word. The storage of queue is much bigger than a mini-batch so that we can evaluate the current batch’s CEs with more words, which reduces the fluctuation of CE distribution caused by the batch-level one. Algorithm 1 details the entire procedure.
6 Experiments
We carry out experiments on two large-scale machine translation tasks: WMT’14 English-German (En-De) and WMT’19 Chinese-English (Zh-En).
6.1 Setup
Datasets.
For WMT’14 En-De task, we use 4.5M preprocessed data, which is tokenized and split using byte pair encoded (BPE) (Sennrich et al., 2016) with 32K merge operations and a shared vocabulary for English and German. We use newstest2013 as the validation set and newstest2014 as the test set, which contain 3000 and 3003 sentences, respectively.
For the WMT’19 Zh-En task, we use 20.4M preprocessed data, which is tokenized and split using 47K/32K BPE merge operations for source and target languages. We use newstest2018 as our validation set and newstest2019 as our test set, which contain 3981 and 2000 sentences, respectively.
Evaluation.
For evaluation, we train all the models with a maximum of 300K steps for WMT En-De’14 and WMT’19 Zh-En. We choose the model which performs the best on the validation set and report its performance on test set. We measure case sensitive BLEU calculated by multi-bleu.perl222https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/multi-bleu.perl and mteval-v13a.pl333https://github.com/moses-smt/mosesdecoder/blob/master/scripts/generic/mteval-v13a.pl with significance test (Koehn, 2004) for WMT’14 En-De and WMT’19 Zh-En, respectively.
Model and Hyper-parameters.

Following the setting in Vaswani et al. (2017), we carry out our experiments on standard Transformer (Vaswani et al., 2017) with the fairseq toolkit Ott et al. (2019). By default, we use Transformer (Base), which contains six stacked encoder layers and six stacked decoder layers as both teacher model and student model. To verify our approaches can be applied to a stronger teacher and student models, we further use deep Transformers with twelve encoder layers and six decoder layers. In training processing, we use Adam optimizer with , , learning rate is 7e-4 and dropout is 0.1. All experiments are conducted using 4 NVIDIA P40 GPUs, where the batch size of each GPUs is set to 4096 tokens. And we accumulate the gradient of parameters and update every two steps. The average runtimes are 3 GPU days for all experiments.
There are two hyper-parameters in our experiment, i.e., distil rate and global queue size . For distil rate , the search space is [10%, 30%, 50%, 70%, 90%]. The search result of is shown in Figure 2, we can find that the performance is sensitive to the value of r%. When the ratio is smaller than 50%, the increase of ratio is consistent with the BLEU score increases, and the best performance peaks at 50%. We directly apply the distil rate to the WMT’19 Zh-En task without extra searching. Besides, We set the 30K for WMT’14 En-De. For larger dataset WMT’19 Zh-En, we enlarge the to from 30K to 50K and keep word rate unchanged. The hyper-parameter search of can be found in Section 6.4.
Compared Methods.
We compare our method with several existing NMT systems (KD and others):
- •
-
•
Seq-KD (Kim and Rush, 2016). Sequence-KD uses teacher generated outputs on training corpus as an extra source. The training loss can be formulated as:
(6) where denotes the sequence predicted by teacher model from running beam search, is the length of target sentence.
-
•
Bert-KD (Chen et al., 2020b). This method leverages the pre-trained Bert as teacher model to help NMT model improve machine translation quality.
- •
6.2 Main Results
Results on WMT’14 English-German.
| Models | En-De | |
| Existing NMT systems | ||
| Vaswani et al. (2017) | 27.30 | ref |
| Vaswani et al. (2017) (Big) | 28.40 | +1.10 |
| Chen et al. (2020b) | 27.53 | +0.23 |
| Zheng et al. (2019) | 28.10 | +0.80 |
| So et al. (2019) | 28.40 | +1.10 |
| Tay et al. (2020) | 28.47 | +1.17 |
| Our Implemented Methods | ||
| Transformer | 27.29 | ref |
| Word-KD | 28.14 | +0.85 |
| Seq-KD | 28.15 | +0.86 |
| Batch-level Selection | 28.42* | +1.13 |
| Global-level Selection | 28.57*† | +1.28 |
The results on WMT’14 En-De are shown in Table 2. In this experiment, both the teacher model and student model are Transformer (Base). We also list our implementation of word-level distillation and sequence level distillation (Kim and Rush, 2016) method.
Firstly, compared with the Transformer (Base), our re-implemented word-level and the sequence-level distillation show similar improvements with the BLEU scores up from 27.29 to 28.14 and 28.15, respectively. Secondly, compared with these already strong baseline methods, our batch-level selective approach further extends the improvement to 28.42, proving the selective strategy’s effectiveness. Thirdly, our global-level distillation achieves a 28.57 BLEU score and outperforms all previous methods, showing that the better evaluation of words’ CE distribution with FIFO global queue helps selection. It is worth noting that our strategy also significantly improves translation quality over all others methods including Word-KD. Finally, our methods show comparable/better performance than other existing NMT systems and even surpass the Transformer (Big), with much fewer parameters.
6.3 Analysis
Even though we find some interesting phenomena and achieve great improvement by selective distillation, the reason behind it is still unclear. Hence, in this section, we conduct some experiments to analyze and explain the remaining question.
Note that we follow the previous partition and comparison method in this section and divide the samples with/without KD loss defined in our selection strategy as /.

Conflict on Different Parts.
The first question is that why our methods surpass the Word-KD with more knowledge. To answer this question, we collect the statistics on the gradient difference between knowledge distillation loss and cross-entropy loss on the ground-truth label for and .
Here, we study gradients over the output distributions, which are directly related to the model’s performance. Particularly, decoder maps target sentences to their corresponding hidden representation . For words in target sequence, the prediction logits is given by:
| (7) | |||
| (8) |
where is the layer output of transformer decoder, is projection matrix. Then, the gradient respect to from golden cross-entropy loss can be denotes as . The gradient from distillation loss can be denotes as . Next, we calculate the probability that and share the same direction.
Figure 3 presents the results with the probability that gradients agree with each other during training. We observe that (green line) is consistently lower than distillation with all words (blue line) and (red line), which means has more inconsistency with ground-truth. Combining with the BLEU performances, we argue this consistency leads to the risk of introducing noise and disturbs the direction of parameter updating.
Besides, the agreement of Distill-All (blue line in Fig) lies in the middle of two halves. It proves that and compromise with each other on some conflicts. It also proves that there exist some conflicts between the knowledge in and .

Knowledge on Different Parts.
In our approaches, we select the transferring samples from the student model’s point of view. However, in previous literature, they commonly consider knowledge from the teacher’s perspective. Hence, in this section, we study the correlation between these two perspectives.
Because previous studies commonly regard teacher’s soft-labels contain dark knowledge (Dong et al., 2019), we take the entropy of teacher’s prediction as a proxy. Concretely, we randomly select 100K tokens in the training set and calculate the entropy of distribution predicted by the teacher model for both and . As shown in Figure 4, we notice that the ’s entropy distribution is more concentrated in range (0, 4) and peaks around 1.2. In contrast, the ’s entropy distribution is more spread out. The overall distribution shifts to higher entropy, which indicates tends to provide a smoother supervision signal. Consequently, we conclude that even though our selective strategy comes from the student’s perspective, it also favors samples with abundant dark knowledge in teacher’s perspective. To some extent, this explains why the ’ knowledge benefits distillation performance more.
6.4 Generalizability
Results on WMT’19 Chinese-English.
| Models | Zh-En | |
| Transformer (Base) | 25.73 | ref |
| Word-KD | 26.21 | +0.48 |
| Seq-KD | 27.27 | +1.54 |
| Word-KD + Ours | 26.62* | +0.89 |
| Seq-KD + Ours | 27.61* | +1.88 |
We also conduct experiments on the larger WMT’19 Zh-en dataset (20.4M sentence pairs) to ensure our methods can provide consistent improvements across different language pairs.
As shown in Table 3, our method still significantly outperforms the Transformer (Base) with +0.89. Compared with the Word-KD, our approach consistently improves with +0.41 BLEU points. Besides, we also find that Seq-KD with our methods extends the improvement of BLEU score from 27.27 to 27.61. This indicates that our selective strategy is partially orthogonal to the improvement of Seq-KD and maintains generalizability. In summary, these results suggest that our methods can achieve consistent improvement on different sized datasets across different language pairs.
| Models | En-De | |
| Deep Transformer (12 + 6) | 27.94 | ref |
| Word-KD | 28.90 | +0.96 |
| Ours | 29.12* | +1.18 |
Results with Larger Model Size.
Here, we investigate how our method is well-generalized to larger models. We use a deep transformer model with twelve encoder layers and six decoder layers for our larger model experiments. As shown in Table 4, Deep Transformer (12 + 6) and Word-KD have already achieved strong performance with up to 28.90 BLEU points, and our method still outperforms these baselines (29.12 BLEU). It proves our methods’ generalizability to larger models.
6.5 Effect of the Global Queue
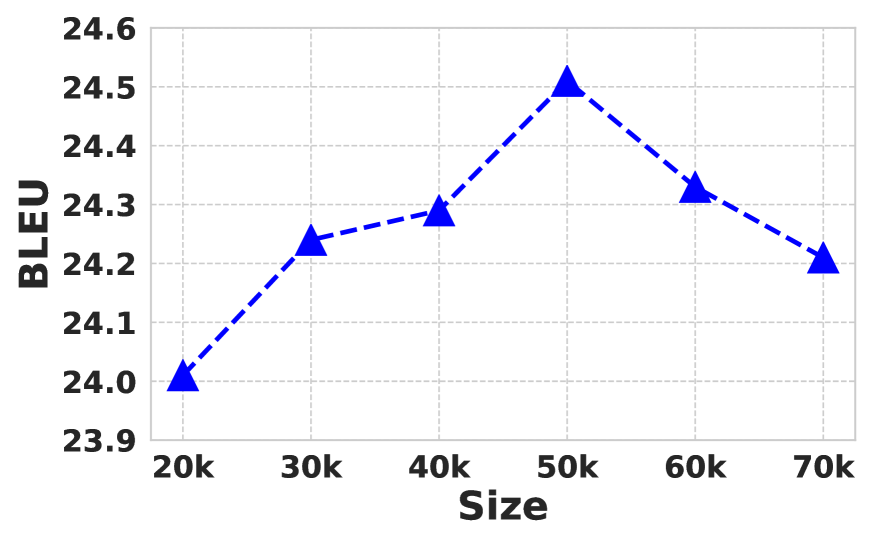
This section analyzes how affects our model’s performance. As mentioned before, denotes the size of the global FIFO queue, which affects simulating the word cross-entropy distribution of the current model.
Figure 5 shows the search results of . We can find that smaller and larger queue size both hurts the BLEU scores. Besides, 30K and 50K of queue size are the best for WMT’14 En-De and WMT’19 Zh-En, respectively. This also accords with our intuition that smaller degrades the global-level queue to batch level, and larger slows down the update of CE distribution.
Figure 6 plots the partition Word CE of and for batch-level and global-level selection. We can see that, as the training progresses, batch-level selection starts to suffer from the high variance because of each batch’s randomness. Selections with FIFO queue drastically reduce the variance and make a reasonable estimation of global CE distribution. These findings prove the effectiveness of our proposed FIFO queue.


7 Conclusion
In this work, we conduct an extensive study to analyze the impact of different words/sentences as the carrier in knowledge distillation. Analytic results show that distillation benefits have a substantial margin, and these benefits may not collaborate with their complementary parts and even hurt the performance. To address this problem, we propose two simple yet effective strategies, namely the batch-level selection and global-level selection. The experiment results show that our approaches can achieve consistent improvements on different sized datasets across different language pairs.
Acknowledgments
We would like to thank the anonymous reviewers for their valuable comments and suggestions to improve this paper.
References
- Chen et al. (2020a) Xiuyi Chen, Fandong Meng, Peng Li, Feilong Chen, Shuang Xu, Bo Xu, and Jie Zhou. 2020a. Bridging the gap between prior and posterior knowledge selection for knowledge-grounded dialogue generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3426–3437, Online. Association for Computational Linguistics.
- Chen et al. (2020b) Yen-Chun Chen, Zhe Gan, Yu Cheng, Jingzhou Liu, and Jingjing Liu. 2020b. Distilling knowledge learned in bert for text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7893–7905.
- Dong et al. (2019) Bin Dong, Jikai Hou, Yiping Lu, and Zhihua Zhang. 2019. Distillation early stopping? harvesting dark knowledge utilizing anisotropic information retrieval for overparameterized neural network. arXiv preprint arXiv:1910.01255.
- Freitag et al. (2017) Markus Freitag, Yaser Al-Onaizan, and Baskaran Sankaran. 2017. Ensemble distillation for neural machine translation. arXiv preprint arXiv:1702.01802.
- Gordon and Duh (2019) Mitchell A Gordon and Kevin Duh. 2019. Explaining sequence-level knowledge distillation as data-augmentation for neural machine translation. arXiv preprint arXiv:1912.03334.
- Gou et al. (2020) Jianping Gou, Baosheng Yu, Stephen John Maybank, and Dacheng Tao. 2020. Knowledge distillation: A survey. arXiv preprint arXiv:2006.05525.
- Gu et al. (2017) Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. 2017. Non-autoregressive neural machine translation. arXiv preprint arXiv:1711.02281.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Hu et al. (2018) Minghao Hu, Yuxing Peng, Furu Wei, Zhen Huang, Dongsheng Li, Nan Yang, and Ming Zhou. 2018. Attention-guided answer distillation for machine reading comprehension. arXiv preprint arXiv:1808.07644.
- Jiao et al. (2019) Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2019. Tinybert: Distilling bert for natural language understanding. arXiv preprint arXiv:1909.10351.
- Kim and Rush (2016) Yoon Kim and Alexander M Rush. 2016. Sequence-level knowledge distillation. arXiv preprint arXiv:1606.07947.
- Kocmi and Bojar (2017) Tom Kocmi and Ondrej Bojar. 2017. Curriculum learning and minibatch bucketing in neural machine translation. arXiv preprint arXiv:1707.09533.
- Koehn (2004) Philipp Koehn. 2004. Statistical significance tests for machine translation evaluation. In Proceedings of the 2004 conference on empirical methods in natural language processing, pages 388–395.
- Li et al. (2020) Bei Li, Ziyang Wang, Hui Liu, Quan Du, Tong Xiao, Chunliang Zhang, and Jingbo Zhu. 2020. Learning light-weight translation models from deep transformer. arXiv preprint arXiv:2012.13866.
- Liu et al. (2020) Xuebo Liu, Houtim Lai, Derek F Wong, and Lidia S Chao. 2020. Norm-based curriculum learning for neural machine translation. arXiv preprint arXiv:2006.02014.
- Meng et al. (2020) Fandong Meng, Jianhao Yan, Yijin Liu, Yuan Gao, Xianfeng Zeng, Qinsong Zeng, Peng Li, Ming Chen, Jie Zhou, Sifan Liu, and Hao Zhou. 2020. WeChat neural machine translation systems for WMT20. In Proceedings of the Fifth Conference on Machine Translation, pages 239–247, Online. Association for Computational Linguistics.
- Meng and Zhang (2019) Fandong Meng and Jinchao Zhang. 2019. DTMT: A novel deep transition architecture for neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 224–231.
- Ott et al. (2019) Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. fairseq: A fast, extensible toolkit for sequence modeling. In Proceedings of NAACL-HLT 2019: Demonstrations.
- Platanios et al. (2019) Emmanouil Antonios Platanios, Otilia Stretcu, Graham Neubig, Barnabas Poczos, and Tom M Mitchell. 2019. Competence-based curriculum learning for neural machine translation. arXiv preprint arXiv:1903.09848.
- Sennrich et al. (2016) Rico Sennrich, Barry Haddow, and Alexandra Birch. 2016. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics.
- So et al. (2019) David So, Quoc Le, and Chen Liang. 2019. The evolved transformer. In International Conference on Machine Learning, pages 5877–5886. PMLR.
- Sun et al. (2019) Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. 2019. Patient knowledge distillation for bert model compression. arXiv preprint arXiv:1908.09355.
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 27:3104–3112.
- Tan et al. (2019) Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, and Tie-Yan Liu. 2019. Multilingual neural machine translation with knowledge distillation. arXiv preprint arXiv:1902.10461.
- Tang et al. (2019) Raphael Tang, Yao Lu, Linqing Liu, Lili Mou, Olga Vechtomova, and Jimmy Lin. 2019. Distilling task-specific knowledge from bert into simple neural networks. arXiv preprint arXiv:1903.12136.
- Tay et al. (2020) Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. 2020. Synthesizer: Rethinking self-attention in transformer models. arXiv preprint arXiv:2005.00743.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Wei et al. (2019) Hao-Ran Wei, Shujian Huang, R. Wang, Xin-Yu Dai, and Jiajun Chen. 2019. Online distilling from checkpoints for neural machine translation. In NAACL-HLT.
- Wu et al. (2020) Yimeng Wu, Peyman Passban, Mehdi Rezagholizade, and Qun Liu. 2020. Why skip if you can combine: A simple knowledge distillation technique for intermediate layers. arXiv preprint arXiv:2010.03034.
- Yan et al. (2020) Jianhao Yan, Fandong Meng, and Jie Zhou. 2020. Multi-unit transformers for neural machine translation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1047–1059, Online.
- Zhang et al. (2019a) Biao Zhang, Deyi Xiong, Jinsong Su, and Jiebo Luo. 2019a. Future-aware knowledge distillation for neural machine translation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(12):2278–2287.
- Zhang et al. (2020) Wei Zhang, Lu Hou, Yichun Yin, Lifeng Shang, Xiao Chen, Xin Jiang, and Qun Liu. 2020. Ternarybert: Distillation-aware ultra-low bit bert. arXiv preprint arXiv:2009.12812.
- Zhang et al. (2019b) Wen Zhang, Yang Feng, Fandong Meng, Di You, and Qun Liu. 2019b. Bridging the gap between training and inference for neural machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4334–4343, Florence, Italy.
- Zheng et al. (2019) Zaixiang Zheng, Shujian Huang, Zhaopeng Tu, Xin-Yu Dai, and Jiajun Chen. 2019. Dynamic past and future for neural machine translation. arXiv preprint arXiv:1904.09646.