11email: {nuislam,sgehlot,zongweiz,jianming.liang}@asu.edu 22institutetext: Mayo Clinic, Scottsdale, AZ 85259, USA 22email: [email protected]
Seeking an Optimal Approach for Computer-Aided Pulmonary Embolism Detection
Abstract
Pulmonary embolism (PE) represents a thrombus (“blood clot”), usually originating from a lower extremity vein, that travels to the blood vessels in the lung, causing vascular obstruction and in some patients, death. This disorder is commonly diagnosed using CT pulmonary angiography (CTPA). Deep learning holds great promise for the computer-aided CTPA diagnosis (CAD) of PE. However, numerous competing methods for a given task in the deep learning literature exist, causing great confusion regarding the development of a CAD PE system. To address this confusion, we present a comprehensive analysis of competing deep learning methods applicable to PE diagnosis using CTPA at the both image and exam levels. At the image level, we compare convolutional neural networks (CNNs) with vision transformers, and contrast self-supervised learning (SSL) with supervised learning, followed by an evaluation of transfer learning compared with training from scratch. At the exam level, we focus on comparing conventional classification (CC) with multiple instance learning (MIL). Our extensive experiments consistently show: (1) transfer learning consistently boosts performance despite differences between natural images and CT scans, (2) transfer learning with SSL surpasses its supervised counterparts; (3) CNNs outperform vision transformers, which otherwise show satisfactory performance; and (4) CC is, surprisingly, superior to MIL. Compared with the state of the art, our optimal approach provides an AUC gain of 0.2% and 1.05% for image-level and exam-level, respectively.
Keywords:
Pulmonary Embolism CNNs Vision Transformers Transfer Learning Self-Supervised Learning Multiple Instance Learning1 Introduction
Pulmonary embolism (PE) represents a thrombus (occasionally colloquially, and incorrectly, referred to as a “blood clot”), usually originating from a lower extremity or pelvic vein, that travels to the blood vessels in the lung, causing vascular obstruction. PE causes more deaths than lung cancer, breast cancer, and colon cancer combined [1]. The current test of choice for PE diagnosis is CT pulmonary angiogram (CTPA) [2], but studies have shown 14% under-diagnosis and 10% over-diagnosis with CTPA [3]. Computer-aided diagnosis (CAD) has shown great potential for improving the imaging diagnosis of PE [4, 5, 6, 7, 8, 9, 10, 11, 12, 13]. However, recent research in deep learning across academia and industry produced numerous architectures, various model initialization, and distinct learning paradigms, resulting in many competing approaches to CAD implementation in medical imaging producing great confusion in the CAD community. To address this confusion and develop an optimal approach, we wish to answer a critical question: What deep learning architectures, model initialization, and learning paradigms should be used for CAD applications in medical imaging? To answer the question, we have conducted extensive experiments with various deep learning methods applicable for PE diagnosis at both image and exam levels using a publicly available PE dataset [14].
Convolutional neural networks (CNNs) have been the default architectural choice for classification and segmentation in medical imaging [15, 16]. Nevertheless, transformers have proven to be powerful in Natural Language Processing (NLP) [17, 18], and have been quickly adopted for image analysis [19, 20, 21], leading to vision transformer (ViT) [19, 22]. Therefore, to assess architecture performance, we compared ViT with 10 CNNs variants for classifying PE. Regardless of the architecture, training deep models generally requires massive carefully labeled training datasets [23]. However, it is often prohibitive to create such large annotated datasets in medical imaging; therefore, fine-tuning models from ImageNet has become the de facto standard [24, 25]. As a result, we benchmarked various models pre-trained on ImageNet against training from scratch.
Supervised learning is currently the dominant approach for classification and segmentation in medical imaging, which offers expert-level and sometimes even super-expert-level performance. Self-supervised learning (SSL) has recently garnered attention for its capacity to learn generalizable representations without requiring expert annotation [26, 27]. The idea is to pre-train models on pretext tasks and then fine-tune the pre-trained models to the target tasks. We evaluated 14 different SSL methods for PE diagnosis. In contrast to conventional classification (CC), which predicts a label for each instance, multiple instance learning (MIL) makes a single prediction for a bag of instances; that is, multiple instances belonging to the same “bag” are assigned a single label [28]. MIL is label efficient because only a single label is required for each exam (an exam is therefore a “bag” of instances). Therefore, it is important to ascertain the effectiveness of MIL for PE diagnosis at the exam level.
In summary, our work offers three contributions: (1) a comprehensive analysis of competitive deep learning methods for PE diagnosis; (2) extensive experiments that compare architectures, model initialization, and learning paradigms; and (3) an optimal approach for detecting PE, achieving an AUC gain of 0.2% and 1.05% at the image and exam levels, respectively, compared with the state-of-the-art performance.
2 Materials
The Radiological Society of North America (RSNA) Pulmonary Embolism Detection Challenge (RSPED) aims to advance computer-aided diagnosis for pulmonary embolism detection [29]. The dataset consists of 7,279 CTPA exams, with a varying number of images in each exam, using an image size of pixels. The test set is created by randomly sampling 1000 exams, and the remaining 6279 exams form the training set. Correspondingly, there are 1,542,144 and 248,480 images in the training and test sets, respectively. This dataset is annotated at both image and exam level; that is, each image has been annotated as either PE presence or PE absence. Each exam has been annotated for an additional nine labels (see Table 2).
Similar to the first place solution for this challenge, lung localization and windowing have been used as pre-processing steps [30] . Lung localization removes the irrelevant tissues and keeps the region of interest in the images, whereas windowing highlights the pixel intensities within the range of [100, 700]. Also, the images are resized to pixels. Figure 1 illustrates these pre-processing steps in detail. We considered three adjacent images from an exam as the 3-channel input of the model.






3 Methods
3.1 Image-level Classification
Image-level classification refers to determining the presence or absence of PE for each image. In this section, we describe the configurations of supervised and self-supervised transfer learning in our work.
Supervised Learning:
The idea is to pre-train models on ImageNet with ground truth and then fine-tune the pre-trained models for PE diagnosis, in which we examine ten different CNN architectures (Figure 2a). Inspired by SeResNext50 and SeResNet50, we introduced squeeze and excitation (SE) block to the Xception architecture (SeXception). These CNN architectures were pre-trained on ImageNet111We pre-trained SeXception on ImageNet and the others are taken from PyTorch. We also explored the usefulness of vision transformer (ViT), where the images are reshaped into a sequence of patches. We experimented with ViT-B_32 and ViT-B_16 utilizing and patches, respectively [31]. Again, ViT architectures were pre-trained on ImageNet21k. Upscaling the image for a given patch size will effectively increase the number of patches, thereby enlarging the size of the training dataset; models are also trained on different sized images. Similarly, the number of patches increases with a decrease in the patch size.
Self-Supervised Learning (SSL):
In self-supervised transfer learning, the model is pre-trained on ImageNet without ground truth and then fine-tuned for PE diagnosis. Self-supervised learning has gained recent attention [32, 33, 34]. With the assistance of strong augmentation and comparing different contrastive losses, a model can learn meaningful information [35] without annotations. These architectures are first trained for a pretext task; for example, reconstructing the original image from its distorted version. Then the models are fine-tuned for a different task, in our case, PE detection. We pre-train models through 14 different SSL approaches, all of which used ResNet50 as the backbone.
3.2 Exam-level Classification
Apart from the image-level classification, the RSPED dataset also provides exam-level labels, in which only one label is assigned for each exam. For this task, we used the features extracted from the models trained for image-level PE classification, and explored two learning paradigms as follows:
Conventional Classification (CC):
We stacked all the extracted features together resulting in an feature for each exam, where and denote the number of images per exam and the dimension of the image feature, respectively. However, as varies from exam to exam, the feature was reshaped to . Following [30], we set the equal to 192 in the experiment. The features were then fed into a bidirectional Gated Recurrent Unit (GRU) followed by pooling and fully connected layers to predict exam-level labels.
Multiple Instance Learning (MIL):
MIL is annotation efficient as it does not require annotation for each instance [36]. An essential requirement for MIL is permutation invariant MIL pooling [28]. Both max operators and attention-based operator are used as MIL pooling [28], and we experimented with a combination of these approaches. The MIL approach is innate for handling varying images () in the exams and does not require any reshaping operation as does Conventional Classification (CC). For MIL, we exploited the same architecture as in CC by replacing pooling with MIL pooling [28].
4 Results and Discussion
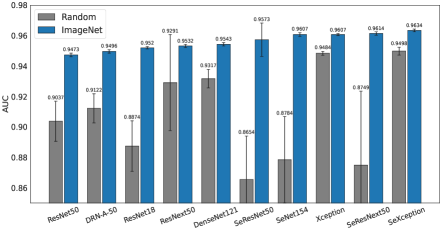


1. Transfer learning significantly improves the performance of image-level classification despite the modality difference between the source and target datasets.
Figure 2a shows a significant performance gain for every pre-trained model compared with random initialization. There is also a positive correlation of 0.5914 between ImageNet performance and PE classification performance across different architectures (Figure 3), indicating that useful weights learned from ImageNet can be successfully transferred to the PE classification task, despite the modality difference between the two datasets. With the help of GradCam++ [37], we also visualized the attention map of SeXception, the best performing architecture. As shown in Fig 4, the attention map can successfully highlight the potential PE location in the image.
2. Squeeze and excitation (SE) block enhances CNN performance.
Despite fewer parameters compared with many other architectures, SeXception provides an optimal average AUC of 0.9634. SE block enables an architecture to extract informative features by fusing spatial and channel-wise information [38]. Thus, the SE block has led to performance improvements from ResNet50 to SeResNet50, ResNext50 to SeResNext50 and from Xception to SeXception (Figure 2b).


3. Transfer learning with a self-supervised paradigm produces better results than its supervised counterparts.
As summarized in Figure 5, SeLa-v2 [32] and DeepCluster-v2 [33] achieved the best AUC of 0.9568, followed by Barlow Twins [34]. Six out of fourteen SSL models performed better than supervised pre-trained ResNet50 (Figure 5). Further experiments can be conducted with other backbones (Figure 2a) to explore if SSL models outperform other supervised counterparts as well, a subject of future work.
PE AUC with vision transformer (ViT) Model Image Size Patch Size Initialization Val AUC SeXception 576 NA ImageNet 0.9634 ViT-B_32 512 32 Random 0.8212 ViT-B_32 224 32 ImageNet21k 0.8456 ViT-B_32 512 32 ImageNet21k 0.8847 ViT-B_16 512 16 Random 0.8385 ViT-B_16 224 16 ImageNet21k 0.8826 ViT-B_16 512 16 ImageNet21k 0.9065 ViT-B_16 576 16 ImageNet21k 0.9179
Labels SeResNext50† Xception SeXception DenseNet121 ResNet18 ResNet50 NegExam PE 0.9137 0.9242 0.9261 0.9168 0.9141 0.9061 Indetermine 0.8802 0.9168 0.8857 0.9233 0.9014 0.9278 Left PE 0.9030 0.9119 0.9100 0.9120 0.9000 0.8965 Right PE 0.9368 0.9419 0.9455 0.9380 0.9303 0.9254 Central PE 0.9543 0.9500 0.9487 0.9549 0.9445 0.9274 RV LV Ratio1 0.8902 0.8924 0.8901 0.8804 0.8682 0.8471 RV LV Ratio1 0.8630 0.8722 0.8771 0.8708 0.8688 0.8719 Chronic PE 0.7254 0.7763 0.7361 0.7460 0.6995 0.6810 Acute&Chronic PE 0.8598 0.8352 0.8473 0.8492 0.8287 0.8398 Mean AUC 0.8807 0.8912 0.8852 0.8879 0.8728 0.8692
4. CNNs have better performance than ViTs.
As shown in Table 1, random initialization provides a significantly lower performance than ImageNet pre-training. The best AUC of is obtained by ViT-B_16 with image size and ImageNet21k initialization. However, this performance is inferior to the optimal CNN architecture (SeXception) by a significant margin of approximately 4%. We attribute this result to the absence of convolutional filters in ViTs.
5. Conventional classification (CC) marginally outperforms MIL.
The results of CC for exam-level predictions are summarized in Table 2. Although SeXception performed optimally for image-level classification (see Figure 2a), the same is not true for exam-level classification. There is no architecture that performs optimally across all labels, but overall, Xception shows the best AUC across nine labels. The results of MIL for exam-level predictions are summarized in Table 3. Xception achieved the best AUC with a combination of attention and max pooling. Similar to CC approach, no single MIL method performs optimally for all labels. However, Xception shows the best mean AUC of with Attention and Max Pooling across all labels. Furthermore, the AUC for MIL is marginally lower than CC ( vs. ) but the later requires additional prepossessing steps (3.2). More importantly, MIL provides a more flexible approach and can easily handle varying number of images per exam. Based on result #3, the performance of exam-level classification may be improved by incorporating the features from SSL methods.
Architecture SeResNeXT50 Xception SeXception Labels/Pooling AMP MP AP AMP MP AP AMP MP AP NegExam PE 0.9138 0.9137 0.9188 0.9202 0.9202 0.9172 0.9183 0.9137 0.9201 Indetermine 0.9144 0.9064 0.8986 0.8793 0.8580 0.8933 0.8616 0.8564 0.8499 Left PE 0.9122 0.9059 0.9086 0.9106 0.9100 0.9032 0.9042 0.9004 0.9024 Right PE 0.9340 0.9345 0.9373 0.9397 0.9366 0.9397 0.9403 0.9383 0.9412 Central PE 0.9561 0.9537 0.9529 0.9487 0.9465 0.9507 0.9472 0.9424 0.9453 RV LV Ratio1 0.8813 0.8774 0.8822 0.8920 0.8871 0.8819 0.8827 0.8779 0.8813 RV LV Ratio1 0.8597 0.8606 0.862 0.8644 0.8619 0.8567 0.8676 0.8642 0.8644 Chronic PE 0.7304 0.7256 0.7233 0.7788 0.7664 0.7699 0.7334 0.7168 0.7342 Acute&Chronic PE 0.8453 0.8470 0.8228 0.8392 0.8396 0.8350 0.8405 0.8341 0.8367 Mean AUC 0.8830 0.8805 0.8785 0.8859 0.8807 0.8831 0.8773 0.8716 0.8751
6. The optimal approach:
The existing first place solution [30] utilizes SeResNext50 for image-level and CC for exam-level classification. Compared with their solution, our optimal approach achieved an AUC gain of 0.2% and 1.05% for image-level and exam-level PE classification, respectively. Based on our rigorous analysis, the optimal architectures for the tasks of image-level and exam-level classification are SeXception and Xception.
5 Conclusion
We analyzed different deep learning architectures, model initialization, and learning paradigms for image-level and exam-level PE classification on CTPA scans. We benchmarked CNNs, ViTs, transfer learning, supervised learning, SSL, CC, and MIL, and concluded that transfer learning and CNNs are superior to random initialization and ViTs. Furthermore, SeXception is the optimal architecture for image-level classification, whereas Xception performs best for exam-level classification. A detailed study of SSL methods will be undertaken in future work.
Acknowledgments: This research has been supported partially by ASU and Mayo Clinic through a Seed Grant and an Innovation Grant, and partially by the NIH under Award Number R01HL128785. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH. This work has utilized the GPUs provided partially by the ASU Research Computing and partially by the Extreme Science and Engineering Discovery Environment (XSEDE) funded by the National Science Foundation (NSF) under grant number ACI-1548562. We thank Ruibin Feng for helping us some experiments. The content of this paper is covered by patents pending.
References
- [1] U.S. Department of Health and Human Services Food and Drug Administration. The Surgeon General’s Call to Action to Prevent Deep Vein Thrombosis and Pulmonary Embolism. 2008.
- [2] Paul D Stein et al. Multidetector computed tomography for acute pulmonary embolism. New England Journal of Medicine, 354(22):2317–2327, 2006.
- [3] Wim AM Lucassen et al. Concerns in using multi-detector computed tomography for diagnosing pulmonary embolism in daily practice. a cross-sectional analysis using expert opinion as reference standard. Thrombosis research, 131(2):145–149, 2013.
- [4] Yoshitaka Masutani, Heber MacMahon, and Kunio Doi. Computerized detection of pulmonary embolism in spiral ct angiography based on volumetric image analysis. IEEE TMI, 21(12):1517–1523, 2002.
- [5] Jianming Liang and Jinbo Bi. Computer aided detection of pulmonary embolism with tobogganing and mutiple instance classification in ct pulmonary angiography. In Biennial International Conference on Information Processing in Medical Imaging, pages 630–641. Springer, 2007.
- [6] Chuan Zhou et al. Computer-aided detection of pulmonary embolism in computed tomographic pulmonary angiography (ctpa): Performance evaluation with independent data sets. Medical physics, 36(8):3385–3396, 2009.
- [7] Nima Tajbakhsh, Michael B Gotway, and Jianming Liang. Computer-aided pulmonary embolism detection using a novel vessel-aligned multi-planar image representation and convolutional neural networks. In MICCAI, pages 62–69. Springer, 2015.
- [8] Deepta Rajan et al. Pi-PE: A Pipeline for Pulmonary Embolism Detection using Sparsely Annotated 3D CT Images. In Proceedings of the Machine Learning for Health NeurIPS Workshop, pages 220–232. PMLR, 13 Dec 2020.
- [9] Shih-Cheng Huang et al. Penet-a scalable deep-learning model for automated diagnosis of pulmonary embolism using volumetric ct imaging, 2020.
- [10] Zongwei Zhou, Vatsal Sodha, Md Mahfuzur Rahman Siddiquee, Ruibin Feng, Nima Tajbakhsh, Michael B. Gotway, and Jianming Liang. Models genesis: Generic autodidactic models for 3d medical image analysis. In MICCAI 2019, pages 384–393, Cham, 2019. Springer International Publishing.
- [11] Zongwei Zhou. Towards Annotation-Efficient Deep Learning for Computer-Aided Diagnosis. PhD thesis, Arizona State University, 2021.
- [12] Zongwei Zhou, Jae Y Shin, Suryakanth R Gurudu, Michael B Gotway, and Jianming Liang. Active, continual fine tuning of convolutional neural networks for reducing annotation efforts. Medical Image Analysis, page 101997, 2021.
- [13] Zongwei Zhou, Jae Shin, Lei Zhang, Suryakanth Gurudu, Michael Gotway, and Jianming Liang. Fine-tuning convolutional neural networks for biomedical image analysis: actively and incrementally. In CVPR, pages 7340–7349, 2017.
- [14] Errol Colak et al. The rsna pulmonary embolism CT dataset. Radiology: Artificial Intelligence, 3(2), 2021.
- [15] Geert Litjens et al. A survey on deep learning in medical image analysis. Medical Image Analysis, 42:60 – 88, 2017.
- [16] S. Deng et al. Deep learning in digital pathology image analysis: a survey. Front. Med., 14(7):470–487, 2020.
- [17] Jacob Devlin et al. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [18] Tom B Brown et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- [19] Alexey Dosovitskiy et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- [20] Kai Han et al. Transformer in transformer, 2021.
- [21] Hugo Touvron et al. Training data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.
- [22] Ashish Vaswani et al. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30, 2017.
- [23] Fatemeh Haghighi, Mohammad Reza Hosseinzadeh Taher, Zongwei Zhou, Michael B. Gotway, and Jianming Liang. Transferable visual words: Exploiting the semantics of anatomical patterns for self-supervised learning, 2021.
- [24] Nima Tajbakhsh, Jae Y Shin, Suryakanth R Gurudu, R Todd Hurst, Christopher B Kendall, Michael B Gotway, and Jianming Liang. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE TMI, 35(5):1299–1312, 2016.
- [25] Hoo-Chang Shin et al. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE TMI, 35(5):1285–1298, 2016.
- [26] Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. TPAMI, pages 1–1, 2020.
- [27] Fatemeh Haghighi, Mohammad Reza Hosseinzadeh Taher, Zongwei Zhou, Michael B. Gotway, and Jianming Liang. Learning semantics-enriched representation via self-discovery, self-classification, and self-restoration. In MICCAI 2020, pages 137–147, Cham, 2020. Springer International Publishing.
- [28] Maximilian Ilse, Jakub M Tomczak, and Max Welling. Attention-based deep multiple instance learning. arXiv preprint arXiv:1802.04712, 2018.
- [29] RSNA STR Pulmonary Embolism Detection. https://www.kaggle.com/c/rsna-str-pulmonary-embolism-detection/overview, 2020. Online; accessed 21 June 2021.
- [30] RSNA STR Pulmonary Embolism Detection. https://www.kaggle.com/c/rsna-str-pulmonary-embolism-detection/discussion/194145, 2020. Online; accessed 21 June 2021.
- [31] Jacob Devlin et al. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the NAACL: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019.
- [32] Yuki Markus Asano et al. Self-labelling via simultaneous clustering and representation learning. arXiv preprint arXiv:1911.05371, 2019.
- [33] Mathilde Caron et al. Deep clustering for unsupervised learning of visual features. In ECCV, 2018.
- [34] Jure Zbontar et al. Barlow twins: Self-supervised learning via redundancy reduction. arXiv preprint arXiv:2103.03230, 2021.
- [35] Dapeng Hu et al. How well self-supervised pre-training performs with streaming data? arXiv preprint arXiv:2104.12081, 2021.
- [36] Marc-André Carbonneau et al. Multiple instance learning: A survey of problem characteristics and applications. arXiv preprint arXiv:1612.03365, 2016.
- [37] Jacob Gildenblat and contributors. Pytorch library for cam methods. https://github.com/jacobgil/pytorch-grad-cam, 2021.
- [38] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, pages 7132–7141, 2018.
Supplementary Material
Appendix
Appendix 0.A Tabular Results
| Backbone | Parameters | Random | ImageNet |
|---|---|---|---|
| ResNet50 | 23,510,081 | 0.90370.0132 | 0.94730.0012 |
| DRN-A-50 | 23,510,081 | 0.91220.0096 | 0.94960.0011 |
| ResNet18 | 11,177,025 | 0.88740.0166 | 0.95200.0007 |
| DenseNet121 | 6,954,881 | 0.93170.0060 | 0.95430.0011 |
| SeResNet50 | 28,090,073 | 0.86540.0293 | 0.95730.0013 |
| SeNet154 | 27,561,945 | 0.87840.0292 | 0.96070.0012 |
| Xception | 20,809,001 | 0.94840.0013 | 0.96070.0007 |
| SeResNext50 | 27,561,945 | 0.87460.0486 | 0.96140.0011 |
| SeXception | 21,548,446 | 0.94980.0025 | 0.96340.0009 |
| Pre-training | Mean AUC |
|---|---|
| Random | 0.90370.0132 |
| ImageNet | 0.94730.0012 |
| pirl | 0.89170.0261 |
| moco-v2 | 0.89200.0292 |
| moco-v1 | 0.90290.0192 |
| infomin | 0.90360.0184 |
| insdis | 0.91160.0111 |
| simclr-v2 | 0.93660.0029 |
| pcl-v2 | 0.93780.0031 |
| pcl-v1 | 0.94340.0020 |
| simclr-v1 | 0.95450.0011 |
| byol | 0.95630.0005 |
| swav | 0.95630.0010 |
| barlow-twins | 0.95660.0007 |
| sela-v2 | 0.95680.0029 |
| deepcluster-v2 | 0.95680.0006 |
Appendix 0.B Backbone Architectures
ResNet18 and Resnet50 [1]: One way to improve an architecture is to add more layers and make it deeper. Unfortunately, increasing the depth of a network do not work simply by stacking layers together. As a result, it can introduce the problem called vanishing gradient. Moreover, the performance might get saturated or decreased overtime. The main idea behind ResNet is to have identity shortcut connection which skips one or more layer. According to the authors, stacking layers should not decrease the performance of the network. The residual block allows the network to have identity mapping connections which prevents from vanishing gradient. The authors presented several versions of ResNet models including ResNet18, ResNet34, ResNet50 and ResNet101. The numbers indicate how many layers exist within the architecture. The more layers represent deeper network and the trainable parameters increase accordingly.
ResNext50 [2]: In ResNext50, the authors introduced a new dimension C which is called Cardinality. The cardinality controls the size of the set of transformations addition to the dimensions of depth and width. The authors argue that increasing cardinality is more effective than going deeper or wider in terms of layers. They used this architecture in ILSVRC 2016 classification competition and secured the 2nd place. Comparing to ResNet50, ResNext50 has similar numbers of parameters for training and can boost the performance. In another word, ResNext50 could achieve almost equivalent performance to ResNet101 although ResNet101 has deeper layers.
DenseNet121 [3]: Increasing the depth of a network results in performance improvement. However, the problem arise when the network is too deep. As a result, the path between input and output becomes too long which introduces the popular issue called vanishing gradient. DenseNets simply redesign the connectivity pattern of the network so that the maximum information is flown. The main idea is to connect every layer directly with each other in a feed-forward fashion. For each layer, the feature-maps of all preceding layers are used as inputs, and its own feature-maps are used as inputs into all subsequent layers. According to the paper, the advantages of using DenseNet is that they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters.
Xception [4]: Xception network architecture was built on top of Inception-v3. It is also knows as extreme version of Inception module. With a modified depthwise separable convolution, it is even better than Inception-v3. The original depthwise separable convolution is to do depthwise convolution first and then a pointwise convolution. Here, Depthwise convolution is the channel-wise patial convolution and pointwise convolution is the 1x1 convolution to change the dimension. This strategy is modified for Xception architecture. In Xception, the depthwise separable convolution performs 1x1 pointwise convolution first and then channel-wise spatial convolution. Moreover, Xception and Inception-v3 has the same number of parameters. The Xception architecture slightly outperforms Inception-v3 on the ImageNet dataset and significantly outperforms Inception-v3 on a larger image classification dataset comprising 350 milions images and 17,000 classes.
DRN-A-50 [5]: Usually in image classification task the Convolutional Neural Network progressively reduces resolution until the image is represented by tiny feature-maps in which the spatial structure of the scene is not quite visible. This kind of spatial structure loss can hamper image classification accuracy as well as complicate the transfer of the model to a downstream task. This architecture introduces dilation which increases the resolutions of the feature-maps without reducing the receptive field of individual neurons. Dilated residual networks (DRNs) can outperform their non-dilated counterparts in image classification task. This strategy does not increase the model’s depth or the complexity. As a result the number of parameters stays the same comparing to the counterparts.
SeNet154 [6]: The convolution operator enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. This work focused on a channel-wise relationship and proposed a novel architectural unit called Squeeze-and-Excitation (SE) block. This SE block adaptively re-calibrates channel-wise feature responses by explicitly modelling inter-dependencies between channels. These blocks can also be stacked together to form a network architecture (SeNet154) and generalise extremely effectively across different datasets. SeNet154 is one of the superior models used in ILSVRC 2017 Image Classification Challenge and won the first place.
SeResNet50, SeResNext50 and SeXception [6]: The structure of the Squeeze-and-Excitation (SE) block is very simple and can be added to any state-of-the-art architectures by replacing components with their SE counterparts. SE blocks are also computationally lightweight and impose only a slight increase in model complexity and computational burden. SE blocks were added to ResNet50 and ResNext50 model to design the new version. The pre-trained weights for SeResNet50 and SeResNext50 already exists where SeXception is not present. By adding SE blocks, we created the SeXception architecture and trained on ImageNet dataset to achieve the pre-trained weights. Later on we used the pre-trained weights for our transfer learning schemes.
Appendix 0.C Self Supervised Methods
InsDis [7]: InsDis trains a non-parametric classifier to distinguish between individual instance classes based on NCE (noise-constrastive estimation) [19]. Moreover, each instance of an image works as a distinct class of its own for the classifier. InsDis also introduces a feature memory bank to maintain a large number of noise samples (referring to negative samples). This helps to avoid exhaustive feature computing. MoCo-v1 [8] and MoCo-v2 [9]: MoCo-v1 uses data augmentation to create two views of a same image referring as positive samples. Similar to InsDis, images other than are defined as negative samples and they are stored in a memory bank. Moreover, to ensure the consistency of negative samples, a momentum encoder is introduced as the samples evolve during the training process. Basically, the proposed method aims to increase the similarity between positive samples while decreasing the similarity between negative samples. On the other hand, MoCo-v2 works similarly adding non-linear projection head, few more augmentations, cosine decay schedule, and a longer training time.
SimCLR-v1 [10] and SimCLR-v2 [11]: The key idea of SimCLR-v1 is similar to MoCo yet proposing independently. Here, SimCLR-v1 is trained in an end-to-end fashion with larger batch sizes instead of using special network architectures (a momentum encoder) or a memory bank. Within each batch, the negative samples are generated on the fly. However, SimCLR-v2 optimizes the previous version by increasing the capacity of the projection head and incorporating the memory mechanism from MoCo to provide more meaningful negative samples.
BYOL [12]: MoCo and SimCLR methods mainly relies on a large number of negative samples and they require either a large memory bank or a large batch size. On the other hand, BYOL replaces the use of negative pairs by adding online encoder, target encoder and a predictor after the projector in the online encoder. Both the target encoder and online encoder computes features. The key idea is to maximize the agreement between target encoder’s features and prediction from online encoder. To prevent the collapsing problem, the target encoder is updated by the momentum mechanism.
PIRL [13]: Both InsDis and MoCo takes the advantage of using instance discrimination. However, PIRL adapts the Jigsaw and Rotation as proxy tasks. Here, the positive samples are generated by applying Jigsaw shuffling or rotating by {, , , }. Following InsDis, PIRL uses Noise-Constrastive estimation (NCE) as loss function and a memory bank.
DeepCluster-v2 [14]: DeepCluster [33] uses two phases to learn features. First, it uses self-labeling, where pseudo labels are generated by clustering data points using prior representation yielding cluster indexes for each sample. Secondly, it uses feature-learning, where each sample’s cluster index is used as a classification target to train a model. Until the model is converged, the two phases mentioned above is performed repeatedly. The DeepCluster-v2 minimizes the distance between each sample and the corresponding cluster centroid. DeepCluster-v2 also uses stronger data augmentation, MLP projection head, cosine decay schedule, and multi-cropping to improve the representation learning.
SeLa-v2 [16]: SeLa also requires two-phase training (i.e., self-labeling and feature-learning). SeLa focuses on self-labeling as an optimal transport problem and solves it using Sinkhorn-Knopp algorithm. SeLa-v2 also uses stronger data augmentation, MLP projection head, cosine decay schedule, and multi-cropping to improve the representation learning.
PCL-v1 and PCL-v2 [16]: PCL-v1 aims to bridge contrastive learning with clustering. PCL-v1 adopts the same architecture as MoCo, including an online encoder and a momentum encoder. Following clustering-based feature learning, PLC-v1 also uses two phases (self-labeling and feature-learning). The features obtained from the momentum encoder are clustered in self-labeling phase. On the other hand, PCL-v1 generalizes the NCE loss to ProtoNCE loss instead of classifying the cluster index with regular cross-entropy. This was done in PCL-v2 as an improvement step.
SwAV [14]: SwAV uses both constrastive learning as well as clustering techniques. For each data sample, SwAV calculates cluster assignments (codes) with the help of Sinkhorn-Knopp algorithm. Moreover, SwAV works online performing assignments at the batch level instead of epoch level.
InfoMin [17]: InfoMin suggested that for contrastive learning, the optimal views depend upon the downstream task. For optimal selection, the mutual information between the views should be minimized while preserving the task-specific information.
Barlow Twins [18]: The Barlow Twins consists of two identical networks fed with the two distorted versions of the input sample. The network is trained such that the cross-correlation matrix between the two resultant embedding vectors is close to the identity. A regularization term is also included in the objective function to minimize redundancy between embedding vectors’ components.
References
- [1] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
- [2] Xie, S., Girshick, R., Dollár, P., Tu, Z., & He, K. (2017). Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1492-1500).
- [3] Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
- [4] Chollet, F. (2017). Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1251-1258).
- [5] Yu, F., Koltun, V., & Funkhouser, T. (2017). Dilated residual networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 472-480).
- [6] Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132-7141).
- [7] Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3733–3742 (2018)
- [8] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
- [9] Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum contrastive learning (2020)
- [10] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: III, H.D., Singh, A. (eds.) Proceedings of the 37th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 119, pp. 1597–1607. PMLR (13–18 Jul 2020)
- [11] Chen, T., Kornblith, S., Swersky, K., Norouzi, M., Hinton, G.: Big self-supervised models are strong semi-supervised learners (2020)
- [12] Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Doersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, R., Valko, M.: Bootstrap your own latent: A new approach to self-supervised learning (2020)
- [13] Misra, I., Maaten, L.v.d.: Self-supervised learning of pretext-invariant representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2020)
- [14] Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsupervised learning of visual features by contrasting cluster assignments (2021)
- [15] Asano, Y.M., Rupprecht, C., Vedaldi, A.: Self-labelling via simultaneous clustering and representation learning (2020)
- [16] Asano, Y.M., Rupprecht, C., Vedaldi, A.: Self-labelling via simultaneous clustering and representation learning (2020)
- [17] Tian, Y., Sun, C., Poole, B., Krishnan, D., Schmid, C., Isola, P.: What makes for good views for contrastive learning? (2020)
- [18] Zbontar, J., Jing, L., Misra, I., LeCun, Y., Deny, S.: Barlow twins: Self-supervised learning via redundancy reduction (2021)
- [19] Gutmann, M. and Hyvärinen, A.: Noise-contrastive estimation: A new estimation principle for unnormalized statistical models (2010)