Seed-to-Seed: Image Translation in Diffusion Seed Space
Abstract
We introduce Seed-to-Seed Translation (StS), a novel approach for Image-to-Image Translation using diffusion models (DMs), aimed at translations that require close adherence to the structure of the source image. In contrast to existing methods that modify images during the diffusion sampling process, we leverage the semantic information encoded within the space of inverted seeds of a pretrained DM, dubbed as the seed-space. We demonstrate that inverted seeds can be used for discriminative tasks, and can also be manipulated to achieve desired transformations in an unpaired image-to-image translation setting. Our method involves training an sts-GAN, an unpaired translation model between source and target seeds, based on CycleGAN. The final translated images are obtained by initiating the DM’s sampling process from the translated seeds. A ControlNet is used to ensure the structural preservation of the input image. We demonstrate the effectiveness of our approach for the task of translating automotive scenes, showcasing superior performance compared to existing GAN-based and diffusion-based methods, as well as for several other unpaired image translation tasks. Our approach offers a fresh perspective on leveraging the semantic information encoded within the seed-space of pretrained DMs for effective image editing and manipulation.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4ae00597-6007-4fed-b209-61cbeea8839a/teaser_new.jpg)
1 Introduction
Diffusion Models (DMs) have emerged as powerful generative tools, synthesizing images by iteratively transforming noise samples into images (Ho, Jain, and Abbeel 2020; Sohl-Dickstein et al. 2015; Song, Meng, and Ermon 2020). Initially developed for unconditional image generation, DMs have evolved to generate images conditioned on various inputs such as desired output classes (Dhariwal and Nichol 2021) and textual prompts (Ho and Salimans 2022). State-of-the-art text-to-image diffusion models, exemplified by DALL-E2 (Ramesh et al. 2022), Imagen (Saharia et al. 2022), and Stable Diffusion (Rombach et al. 2022), showcase remarkable capabilities in creating photo-realistic and diverse images based on textual descriptions.
While generating images from scratch is a significant achievement, the task of image editing, which involves modifying existing images, remains equally important. Within this realm, Image-to-Image Translation (I2IT) is the process of converting an input image from one domain to another while preserving various aspects. In fact, I2IT encompasses a variety of tasks that differ in their required adherence to the source image. For instance, automotive applications, such as day-to-night translation, demand perfect adherence to the structure of the original image, altering only appearance. In contrast, cat-to-dog translation might only preserve the pose and/or fur colors, while allowing other details to change. Some translations involve significant structural changes, such as converting a rough sketch to a realistic scene or transforming a satellite image into a map.
In this work, we focus on translations that require close adherence to the source image, ensuring that essential elements — determined by the specific nature of the translation task — remain intact, while selectively modifying other aspects. For example, in a day-to-night translation of an automotive scene, the complex geometry of the scene must be precisely preserved, while global lighting and local night-related effects, such as night-time light sources and scattering effects, are introduced where appropriate. Similarly, in facial editing tasks such as aging or gender swap, the underlying face structure, along with expression and pose, should be maintained while achieving the target appearance.
We introduce a novel approach for DM-based I2IT, where a significant part of the manipulation occurs within the seed-space: the space of inverted seeds of a pretrained DM, even before the sampling process begins. While previous works have mainly used DDIM-inversion (Song, Meng, and Ermon 2020) as a starting point for the sampling process, during which all of the manipulation occurs, we argue that DDIM-inverted seeds encode significant meaningful information about the input image, which can be accessed and manipulated already within the seed-space. Specifically, we demonstrate that the inverted seeds can be used to discriminate between semantic attributes of images, and that these attributes can be manipulated to achieve desired transformations in an unpaired image-to-image translation setting.
We refer to our I2IT process as Seed-to-Seed Translation (StS), the bulk of which is carried out in the seed space using sts-GAN, an unpaired translation model based on CycleGAN (Zhu et al. 2017). All that is needed to train an sts-GAN are two collections of seeds, obtained by inverting two sets of example images, from the source and the target domains, respectively. Once the sts-GAN is trained, a source image may be translated to a target domain by first inverting it to the seed-space, translating the source seed to the target seed using the sts-GAN, and then generating the target image using the DM’s sampling process. A ControlNet (Zhang and Agrawala 2023) is used to ensure that the initial structure encoded in the translated seed is preserved and not overwritten during the sampling trajectory.
We demonstrate our model’s effectiveness through automotive scene translations, such as day-to-night and weather translation (see Figure 1), where substantial changes in appearance are required but the scene’s structure must be preserved. Unlike existing GAN-based methods, which often struggle with generating realistic images in the target domain, and current diffusion-based methods, which frequently fail to balance realism with structural fidelity, our model maintains the integrity of the scene’s structure while achieving realistic target domain appearance.
While our approach is originally motivated by automotive translations, we also demonstrate its effectiveness on other I2IT tasks requiring close adherence to source semantics, such as altering apparent age or gender in portraits (see Figure 1 and Section 4).
We summarize our main contributions as follows:
-
1.
We offer a fresh perspective on the meaningfullness of the (inverted) seed-space of pre-trained DMs, highlighting its potential for guiding image editing processes.
-
2.
We present StS, a novel seed-to-seed translation tool that excels in I2IT tasks requiring close adherence to the source image.
2 Related Work
Within the field of I2IT, Unpaired Image-to-Image Translation (Unpaired I2IT) is a noteworthy scenario, focused on translating images without the benefit of having paired source-target training examples. Unpaired I2IT has garnered increasing attention and made significant progress in recent years due to its broad applicability in various computer vision and image processing tasks, such as style transfer (Zhu et al. 2017; Liu, Breuel, and Kautz 2017; Huang et al. 2018; Jiang et al. 2020; Dutta 2022), semantic segmentation (Guo et al. 2020; Wu and You 2021; Kang, Zang, and Cao 2021), image inpainting (Zhao et al. 2020; Song et al. 2018), image enhancement (e.g., retouching (Chen et al. 2018) and super-resolution (Altakrouri et al. 2021).
Many unpaired I2IT methods utilize Generative Adversarial Networks (GANs) (Goodfellow et al. 2014) as their generative engine, e.g., (Zhu et al. 2017; Liu, Breuel, and Kautz 2017; Huang et al. 2018; Jiang et al. 2020; Dutta 2022; Parmar et al. 2024). To enforce structural preservation during the translation process, most recent GAN-based I2IT models use cycle consistency (Zhu et al. 2017; Hoffman et al. 2018), where an image is translated from the source domain to the target domain and back, during training, and a loss is measured between the original source image and the reconstructed one. Cycle consistency acts as a regularizer in the underconstrained unpaired I2IT setting, helping to learn content-preserving mappings and to avoid mode collapse.
Another family of GAN-based tools is based on the StyleGAN (Karras, Laine, and Aila 2019) architecture, which features a semantically meaningful latent space that enables a variety of editing operations. StyleGAN has also been used for image-to-image translation, e.g., (Wu et al. 2021). A common practice in StyleGAN-based image editing involves identifying a direction in which to modify the latent code to achieve changes in certain attributes. Such studies propose the use of a classifier (Yang, Shen, and Zhou 2021; Shen et al. 2020; Wu, Lischinski, and Shechtman 2021), a set of paired examples (Wu, Lischinski, and Shechtman 2021; Jahanian, Chai, and Isola 2019) or manual examination of many candidates (Härkönen et al. 2020) to identify such latent directions.
Following advancements in diffusion-based generative models (Ho, Jain, and Abbeel 2020; Dhariwal and Nichol 2021; Saharia et al. 2022; Ramesh et al. 2022; Rombach et al. 2022; Song, Meng, and Ermon 2020), recent studies have leveraged such models for a variety of image editing and manipulation tasks. One approach proposes utilizing the cross-attention maps (Parmar et al. 2023; Hertz et al. 2022) to focus the editing process on specific regions of the image while leaving the remainder largely untouched. While demonstrating remarkable object editing results, these methods are less suited for global editing, where the desired changes should affect the entire image.
Other methods enable global editing of the entire image. In SDEdit (Meng et al. 2021), an input guidance image is first corrupted with Gaussian noise and then refined using denoising. This method exhibits a trade-off between realism and faithfulness, balanced by adjusting the level of noise in the initial corruption phase. InstructPix2Pix (Brooks, Holynski, and Efros 2023) trains a model with a large collection of instruction-based image editing examples, generated using a fine-tuned LLM (GPT-3 (Brown et al. 2020)) and a text-to-image model (Ramesh et al. 2022). EmuEdit (Sheynin et al. 2023) enhances instruction-based image editing via learned task embeddings.
To edit real images, it is typically necessary to first invert the image into the seed-space of a DM, e.g., (Mokady et al. 2023; Parmar et al. 2023). The subsequent image manipulation typically takes place during the sampling process, sometimes using information extracted during the inversion process. PnP (Tumanyan et al. 2023) extracts per-layer features and self-attention matrices from the DDIM inversion steps of a guidance image and injects them into the corresponding steps of a generated image. NTI (Mokady et al. 2023) suggests using the unconditional DDIM inversion trajectory to tune the null-text embedding to encode spatial information about the source image to guide the sampling trajectory at inference time.
Some studies focus on gaining control over the structural semantics of the synthesized image, forcing it to follow an input structure given as a spatial condition (such as edges, depth, sketch etc.). ControlNet (Zhang and Agrawala 2023) suggest using a trainable copy, attached to a locked pre-trained DM via zero-convolution layer, which is used to learn conditional control on task-specific datasets. T2I-Adapter (Mou et al. 2023) proposes training a lighter adapter to align internal knowledge with external control signals, while freezing the original large diffusion model.
While all aforementioned models use a random or inverted seed to initiate the sampling process and then perform all optimizations along the sampling trajectory, SeedSelect (Samuel et al. 2023) proposes a method to synthesize “rare” objects, particularly those from the “long-tail” of the data distribution. It achieves this by iteratively optimizing an initial random seed via back-propagating through a whole text-guided diffusion sampling process, enforcing similarity between the output and a batch of samples from the desired domain. In this work, we adopt the “meaningful seed” approach to perform unpaired image-to-image translation within the seed space, rather than along the sampling trajectory.
3 Method
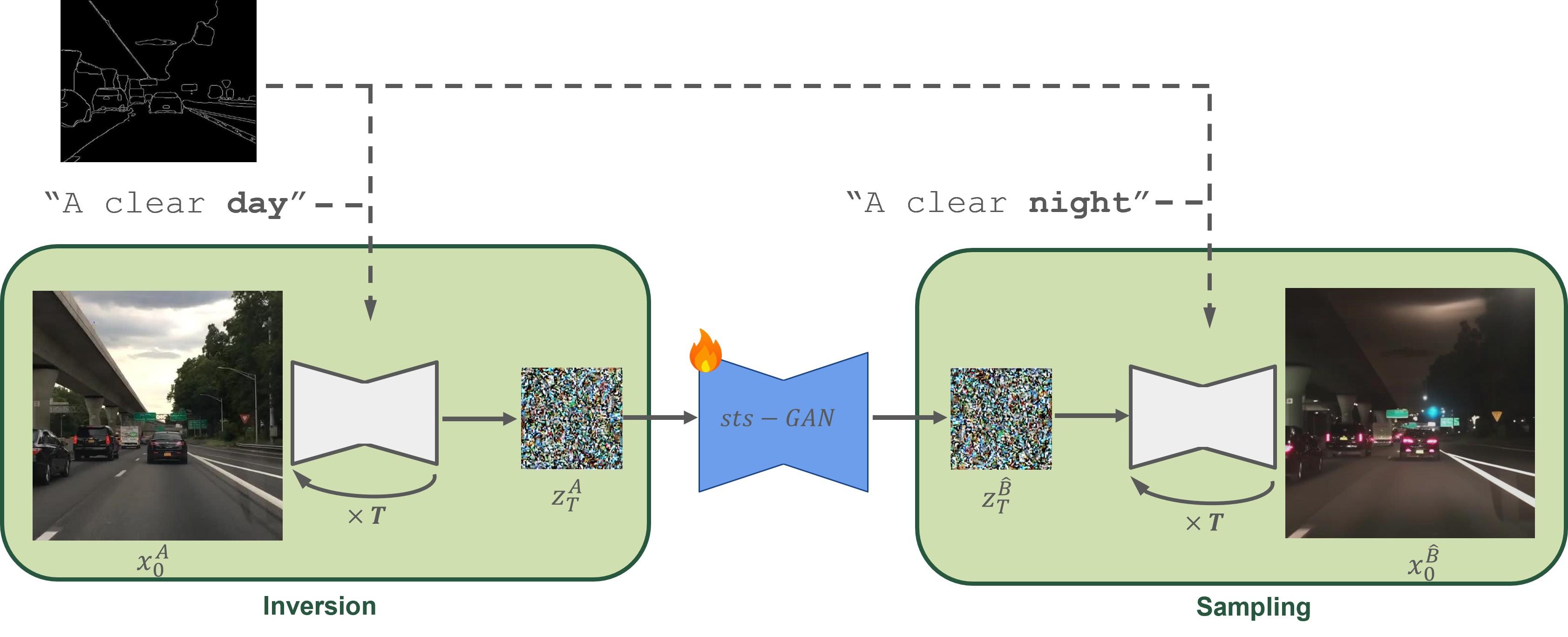
In this section we introduce StS, an image translation model that operates directly in the seed-space of a pretrained diffusion model. We begin by reviewing some preliminaries regarding the diffusion process (3.1), and then proceed to discuss the meaningfulness of the seed-space and the ability to access the information encoded within the seeds (3.2). Finally, in Section 3.3 we show how seed meaningfulness may be leveraged to perform unpaired image translation within the seed-space using our proposed StS model.
3.1 Preliminaries
Early denoising diffusion and score-based generative models (Ho, Jain, and Abbeel 2020; Sohl-Dickstein et al. 2015; Song and Ermon 2019) sample seeds from white Gaussian noise and progressively map them to images using a stochastic sampling process. However, to edit a real image using these tools, one must first invert the image into the pretrained model’s seed-space (Wallace, Gokul, and Naik 2023; Parmar et al. 2023; Mokady et al. 2023; Tumanyan et al. 2023). In this paper we adopt the deterministic DDIM-sampling and DDIM-inversion processes (Song, Meng, and Ermon 2020). A formal description of the processes can be found in the supplementary material.
To adapt the diffusion process to text-guided generation, Ho and Salimans (2022) introduced classifier-free guidance (CFG), where an unconditioned prediction is extrapolated with a conditioned one, using a pre-defined guidance scale factor (extrapolation factor) . In this work we perform DDIM inversion using CFG-scale (no extrapolation), and DDIM sampling using CFG-scale .
3.2 Meaningful Seed Space
We can think of the deterministic DDIM sampling as an injective mapping between the space of seeds (seed-space) and the space of images. Similarly, we can think of DDIM inversion as a mapping from images to latent codes in seed-space (not to be confused with the latent space in which Latent Diffusion Models (Rombach et al. 2022), such as Stable Diffusion, operate.)
The diffusion model’s U-net is employed to progressively decode the information encoded in the latent code throughout the steps of the diffusion process (Ho, Jain, and Abbeel 2020). Most existing diffusion-based editing methods modify the decoding mechanism by fine-tuning the decoder’s weights (Kawar et al. 2023; Ruiz et al. 2023), modifying the decoder’s condition input (Meng et al. 2021; Zhang and Agrawala 2023), or injecting cross-attention elements across processes of different images (Tumanyan et al. 2023; Hertz et al. 2022; Parmar et al. 2023). In all these cases, the editing occurs as the latent code is iteratively transformed by the diffusion U-net.
In this work, we attempt to take advantage of the meaningfulness of the seeds resulting from the DDIM inversion process, and manipulate the information encoded in the seed-space even before it undergoes the denoising process. Song et al. (2020) have already demonstrated that interpolation of seeds gives rise to continuous and semantically meaningful interpolations in the image-space, implying that the seed-space possesses some structure. We embrace this implication and further leverage this structure to perform image translation using DDIM inverted seeds.
| Task | seeds | images |
|---|---|---|
| Day/Night | 98.37% | 98.47% |
| Cat/Dog | 90.10% | 98.53% |
| Older/Younger | 92.60% | 97.90% |
We conduct a simple experiment to reveal the informativeness of the seed-space. Table 1 compares the performance of a simple ResNet18 (He et al. 2016) classifier optimized for a few representative classification tasks, once using a training dataset of images, and once again using their DDIM-inverted seeds (inverted using Stable Diffusion 2.1 (Rombach et al. 2022)). While the classifiers perform better when trained on images, they achieve almost competitive results when trained over the inverted seeds, demonstrating that the seeds possess much of the relevant information for image-level attributes (day/night), object-level attributes (dog/cat), and sub-object-level attributes (age). Below, we show how this informativeness can be leveraged to perform image translation within the seed-space.
3.3 StS: Translation in Diffusion Seed Space
We aim to perform unpaired image translation within the seed-space of a pre-trained diffusion model by leveraging the information encoded in the DDIM inverted seeds.
Consequently, we train a dedicated translation model that learns a mapping between seeds corresponding to images from a source domain A to seeds corresponding to images from a target domain B. We train our network, referred to as sts-GAN, over a set of DDIM-inverted seeds from the source and target domains, using the CycleGAN architecture (Zhu et al. 2017) and training strategy. CFG-scale is used to accurately invert the unpaired source and target domain training images to the seed-space.
Figure 2 presents a diagram depicting our method. At inference time, we first encode the input source image to the Stable Diffusion (SD) latent space, yielding , and apply DDIM inversion (with a source-domain-referred prompt) to obtain a corresponding seed . Next, we translate to a target-domain-referred seed using our sts-GAN. Finally, we sample using the same pre-trained SD model (with a target-domain-referred prompt), resulting in the final denoised code , which is then decoded to the resulting image .
While the sts-GAN successfully translates source-referred seeds into target-referred ones, DDIM sampling these seeds with typically results in images suffering from a lack of local semantic effects, despite the use of a target domain-referred prompt (“A clear night”, for the day-to-night translation). For example, as demonstrated in the middle column of Figure 3, a day-to-night translation of automotive images might lack car lights, street lights, and reflections (top row), or retain some daytime-like shadows on the road surface (bottom row). To encourage such domain-specific effects, we employ the CFG mechanism with , in conjunction with the same target-referred prompt.
The cyclic consistency mechanism employed during sts-GAN training enforces structural similarity between the source and the output within the seed space. However, this similarity might not be maintained as the translated seed is sampled back to the image space. This issue becomes more pronounced when using CFG, as the extrapolation amplifies the accumulated errors from the DDIM inversion (Mokady et al. 2023). Consequently, even if the translation from to is perfect in seed space, the final image may significantly deviate from the structure and content of the source image. To address this, we employ ControlNet (Zhang and Agrawala 2023) to enforce structural similarity between the source image and the final output throughout the sampling trajectory.
The right column of Figure 3 demonstrates that spatially-guided conditional sampling enhances the target-domain appearance, introducing the missing effects, while remaining faithful to the source image’s structure.

4 Experiments
We conducted extensive experiments on several unpaired image translation tasks and compared our method to several prior GAN-based and diffusion-based image translation methods. We quantitatively evaluate our performance on the Day-to-Night task, demonstrating superior results compared to both GAN-based and DM-based methods. Then, we qualitatively showcase our performance across several other unpaired image-translation tasks. We also provide an ablation study that analyzes the effectiveness of the different components of our approach by incorporating them one at a time. Code and pre-trained models, will be made available upon publication on our project page.
4.1 Implementation Details
We have experimented with unpaired I2IT tasks on the Berkeley DeepDrive BDD100k (Yu et al. 2020), DENSE (Bijelic et al. 2020), and Flickr-Faces-HQ (FFHQ) (Karras, Laine, and Aila 2019) datasets. We use Stable Diffusion (SD) 2.1 (Rombach et al. 2022) at resolution as the diffusion backbone. We adopt ResNet18 as the encoder for sts-GAN, adapted to 4-channeled input to fit the latent space of SD. We omit the last normalization layer to allow the output of different ranges. For training, we follow the scheme suggested by Zhu et al. (2017).
We find that the publicly available version of SD 2.1 performs poorly on automotive datasets. Therefore, we finetune SD 2.1 and the corresponding ControlNet (Zhang and Agrawala 2023) with the BDD100k training set using the default scheme provided by Diffusers (von Platen et al. 2022). More details about the fine-tuning to the automotive data can be found in the supplementary material.
For the FFHQ dataset we use the publicly available version of SD 2.1, with a pretrained ControlNet provided by (Zamora 2023), without any additional finetuning.
For the DDIM sampling and DDIM inversion processes we use 20 timesteps, with CFG-scale for the inversion and for the forward sampling processes, respectively.
4.2 Baselines
We compare our performance on Day-to-Night translation over the BDD100k dataset to various GAN-based image translation methods: CycleGAN (Zhu et al. 2017), MUNIT (Huang et al. 2018), TSIT (Jiang et al. 2020) and AU-GAN (Kwak et al. 2021) and CycleGAN-Turbo (Parmar et al. 2024). For AU-GAN and CycleGAN-Turbo, we used the day2night checkpoints provided by the authors. We trained CycleGAN, MUNIT, and TSIT models over the BDD100k dataset using their publicly available code with default hyperparameters for up to 100 epochs and chose the best checkpoints.
In addition to GAN-based methods, we also compare our performance to several diffusion-based image editing methods, including SDEdit (Meng et al. 2021) with different strength parameters (, , ) and Plug-and-Play (PnP) (Tumanyan et al. 2023). We also compare our results to ControlNet (Zhang and Agrawala 2023), applicable to image synthesis using a combination of textual and spatial conditions. To ensure a fair comparison, we utilize our fine-tuned U-net for the zero-shot diffusion-based methods (SDEdit and PnP) and for ControlNet, when working with the automotive datasets. For all diffusion-based methods, we use the default settings of 50 timesteps and CFG-scale for the DDIM sampling process.
4.3 Evaluation Metrics
We employ a standard evaluation protocol commonly used in prior GAN-based I2IT works (Brock, Donahue, and Simonyan 2018; Liang, Zeng, and Zhang 2021; Liu et al. 2019) for quantitative evaluation of the day-to-night translation task. Specifically, we adopt the Structural Similarity Index Measure (SSIM) (Wang et al. 2004) and the Frechet Inception Distance (FID) (Fréchet 1957; Heusel et al. 2017). While some recent studies use feature-based metrics, primarily Dino-struct dist (Tumanyan et al. 2022), we found this metric to be unstable for complex scenes, such as automotive ones. Therefore, we opted for the SSIM metric, which has been commonly used in previous studies for automotive translations. Since the datasets contain a relatively small amount of validation samples from the different domains (up to a few thousand), we also use the Kernel Inception Distance (KID) (Bińkowski et al. 2018) and Kernel Maximum Mean Discrepancy (MMD) (Gretton et al. 2012) metrics, which are considered more suitable for smaller datasets.
4.4 Results
Quantitative results are presented in Table 2. Our method achieves the lowest MMD and KID scores and the second lowest FID score (after AU-GAN). It should be noted that the high SSIM scores achieved by SDEdit and PnP result from their frequent failure to achieve the target domain appearance, as reflected by their low FID, KID, and MMD scores. This phenomenon is explained by the inherent trade-off between achieving the desired target domain appearance and preserving the content from the source image without the cycle-consistency mechanism (see SDEdit’s qualitative results in Figure 4(b)). When increasing the strength parameter of SDEdit above , the results become increasingly disconnected from the source image, as demonstrated in Figure 4(b). Our model exhibits the best balance between target domain appearance and structure preservation compared to all other methods.
| Method | FID | MMD | KID | SSIM | |
|---|---|---|---|---|---|
| CycleGAN | 19.908 | 58.395 | 4.539 | 0.469 | |
| MUNIT | 52.152 | 260.081 | 12.968 | 0.308 | |
| TSIT | 21.315 | 56.484 | 4.446 | 0.3929 | |
| AU-GAN | 14.426 | 45.970 | 3.985 | 0.463 | |
| CycleGAN-turbo | 16.840 | 49.845 | 4.215 | 0.431 | |
| SDEdit 0.5 | 73.494 | 242.001 | 12.097 | 0.661 | |
| SDEdit 0.7 | 48.757 | 161.666 | 9.185 | 0.603 | |
| PnP | 61.617 | 172.808 | 9.575 | 0.768 | |
| ControlNet | 35.091 | 95.171 | 6.340 | 0.493 | |
| StS (ours) | 16.384 | 41.344 | 3.718 | 0.505 |
Qualitatively, Figure 4 compares our StS results to both GAN-based and diffusion-based methods for the Day-to-Night task using the BDD100k dataset. Our model achieves the highest level of realism compared to all other methods. The GAN-based methods mostly suffer from the occurrence of artifacts, primarily manifested as random light spots that are uncorrelated with semantically meaningful potential light sources in the image (e.g., car headlights, taillights, streetlights, which are commonly turned off during the day but can be turned on at night). Our model minimizes the occurrence of these artifacts and leverages the powerful semantic understanding of the diffusion model to accurately generate semantics-related target domain effects, such as light sources, light scatters, and reflections (see Figure 4(a)). While PnP and SDEdit struggle to balance between output realism and structural preservation, our model excels in both aspects.


Our model is not limited to the task of Day-to-Night translation. Figure 5 demonstrates additional translations suitable for automotive datasets, applied to both day and night source images. Specifically, we experimented with Clear-to-Foggy and Clear-to-Rainy translation, for both daytime and nighttime images. To train sts-GAN for these weather translations, we utilized clear and rainy images from BDD100k (both day and night) and foggy images from both the “light fog” and “dense fog” splits of the DENSE dataset (Bijelic et al. 2020).
While our primary focus is on automotive-related translations, our model is also suitable for additional diverse translation tasks on other datasets. Figure 7 illustrates the performance of our StS in gender-swap, compared to StyleGAN2-Distilation (Viazovetskyi, Ivashkin, and Kashin 2020), and in age translation, compared to SAM (Alaluf, Patashnik, and Cohen-Or 2021), respectively, both over the FFHQ dataset. In both gender-swap and age translation tasks, our model demonstrates competitive or superior capabilities compared to the task-oriented baselines. Our model adheres to the facial structure, pose, and expression of the source image, resulting in outputs that resemble a transformation of the input individual rather than depicting a different person from the target domain. This adherence is notably superior compared to the baselines in both tasks. It should be noted that since we use the Canny map as a spatial condition, our model is committed to preserving the object outlines present in the source image. Therefore, for example, StS will not shorten the hair of a female input image when translating it into a male. This attribute limits our model to constrained translations, where the nature of the constraint is determined by the spatial condition provided to the ControlNet. This issue is discussed further in Section 5 and in the supplemented material.

| CFG-scale | FID | MMD | KID | SSIM | |
|---|---|---|---|---|---|
| 1.0 | 25.955 | 67.404 | 5.364 | 0.549 | |
| 3.0 | 17.454 | 45.540 | 3.988 | 0.526 | |
| 5.0 | 16.384 | 41.344 | 3.718 | 0.505 |
4.5 Ablation Study
| Method | FID | MMD | KID | SSIM | |
|---|---|---|---|---|---|
| ControlNet | 35.091 (+114%) | 95.171 (+130%) | 6.340 (+70%) | 0.493 (+2%) | |
| ControlNet+Inv | 49.572 (+202%) | 411.060 (+894%) | 14.981 (+296%) | 0.756 (-49%) | |
| ControlNet+ST | 21.316 (+30%) | 67.650 (+63%) | 5.5456 (+49%) | 0.450 (+11%) | |
| ControlNet+Inv+ST (StS) | 16.384 | 41.344 | 3.718 | 0.505 |
We also analyze the effectiveness of the different components of our approach by incorporating them one at a time. On top of a pure off-the-shelf ControlNet initiated randomly with , we add two components that make up the complete Seed Translation block: (1) initiation with a meaningful seed obtained by DDIM inversion (denoted Inv) and (2) using the sts-GAN in the seed space for the seed translation (denoted ST). The contribution of each component is expressed in Table 4 and qualitatively illustrated in the supplementary material.
It is noticeable that initiating the ControlNet sampling process with the inverted seed imposes an overly rigid constraint, resulting in significantly reduced editability during the sampling process. As a result, the CFG mechanism encounters difficulties in guiding the sampling trajectory towards the desired appearance. This challenge is reflected in the combination of a very high SSIM score alongside poor “appearance” measures.
The ST block initiates the sampling process with a seed possessing unconditional attributes of the target domain. Consequently, the CFG mechanism interpolates between much closer unconditional and conditional values, leading to more accurate appearance in the target domain. Combining the ST block with an initially meaningful inverted seed yields the desired combination of appearance and structure.
As mentioned, the spatial control stabilizes the loss of details caused by the CFG mechanism. While contributing to the target-domain appearance of the output (see Figure 3), it somewhat reduces the structural preservation, as quantitatively evaluated in Table 3.




5 Discussion, Limitations and Future Work
Our work suggests that image translation can be performed within the seed-space of a pre-trained diffusion model by translating a meaningful seed obtained by inverting the source image to one that encodes attributes associated with the target domain using sts-GAN. To prevent the CFG mechanism from deviating away from the source image structure, we utilize a structure-guidance mechanism in the form of ControlNet. It should be noted that ControlNet is only one of many methods to guide the diffusion sampling process towards a specific spatial structure. Therefore, utilizing the proposed sts-GAN architecture to initiate another method, e.g., (Mou et al. 2023; Tumanyan et al. 2023), with meaningful seeds from the target domain may work just as well. In addition, recent studies enhanced the DDIM inversion mechanism, achieving more accurate image inversion and reconstruction (Meiri et al. 2023; Garibi et al. 2024). In future work, we plan to explore whether these methods might be utilized to enhance details preservation via a more accurate inversion process.
While Canny-conditioned ControlNet is suitable for enforcing adherence to the source structure, it may encounter challenges when applied to other tasks. For example, in gender translation our model does not change the hairstyle, because the hair’s boundaries and style appear in the Canny condition. Since long-haired males and short-haired females do occur, these results are still realistic. Yet, in other cases such spatial constraints might not allow a realistic translation (see the supplementary material). Future work may explore replacing ControlNet with an alternative regularization mechanism better suited to diverse translation tasks.
References
- Alaluf, Patashnik, and Cohen-Or (2021) Alaluf, Y.; Patashnik, O.; and Cohen-Or, D. 2021. Only a matter of style: Age transformation using a style-based regression model. ACM Transactions on Graphics (TOG), 40(4): 1–12.
- Altakrouri et al. (2021) Altakrouri, S.; Usman, S. B.; Ahmad, N. B.; Justinia, T.; and Noor, N. M. 2021. Image to image translation networks using perceptual adversarial loss function. In 2021 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), 89–94. IEEE.
- Bijelic et al. (2020) Bijelic, M.; Gruber, T.; Mannan, F.; Kraus, F.; Ritter, W.; Dietmayer, K.; and Heide, F. 2020. Seeing through fog without seeing fog: Deep multimodal sensor fusion in unseen adverse weather. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11682–11692.
- Bińkowski et al. (2018) Bińkowski, M.; Sutherland, D. J.; Arbel, M.; and Gretton, A. 2018. Demystifying MMD GANs. arXiv preprint arXiv:1801.01401.
- Brock, Donahue, and Simonyan (2018) Brock, A.; Donahue, J.; and Simonyan, K. 2018. Large scale GAN training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096.
- Brooks, Holynski, and Efros (2023) Brooks, T.; Holynski, A.; and Efros, A. 2023. InstructPix2Pix: Learning to Follow Image Editing Instructions. In Proc. CVPR, 18392–18402.
- Brown et al. (2020) Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; Agarwal, S.; Herbert-Voss, A.; Krueger, G.; Henighan, T.; Child, R.; Ramesh, A.; Ziegler, D.; Wu, J.; Winter, C.; Hesse, C.; Chen, M.; Sigler, E.; Litwin, M.; Gray, S.; Chess, B.; Clark, J.; Berner, C.; McCandlish, S.; Radford, A.; Sutskever, I.; and Amodei, D. 2020. Language Models are Few-Shot Learners. In Larochelle, H.; Ranzato, M.; Hadsell, R.; Balcan, M.; and Lin, H., eds., Advances in Neural Information Processing Systems, volume 33, 1877–1901. Curran Associates, Inc.
- Chen et al. (2018) Chen, Y.-S.; Wang, Y.-C.; Kao, M.-H.; and Chuang, Y.-Y. 2018. Deep photo enhancer: Unpaired learning for image enhancement from photographs with GANs. In Proceedings of the IEEE conference on computer vision and pattern recognition, 6306–6314.
- Choi et al. (2020) Choi, Y.; Uh, Y.; Yoo, J.; and Ha, J.-W. 2020. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8188–8197.
- Dhariwal and Nichol (2021) Dhariwal, P.; and Nichol, A. 2021. Diffusion models beat GANs on image synthesis. Advances in neural information processing systems, 34: 8780–8794.
- Dutta (2022) Dutta, U. K. 2022. Seeing Objects in Dark with Continual Contrastive Learning. In European Conference on Computer Vision, 286–302. Springer.
- Fréchet (1957) Fréchet, M. 1957. Sur la distance de deux lois de probabilité. In Annales de l’ISUP, volume 6, 183–198.
- Garibi et al. (2024) Garibi, D.; Patashnik, O.; Voynov, A.; Averbuch-Elor, H.; and Cohen-Or, D. 2024. ReNoise: Real Image Inversion Through Iterative Noising. arXiv preprint arXiv:2403.14602.
- Goodfellow et al. (2014) Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative adversarial nets. Advances in neural information processing systems, 27.
- Gretton et al. (2012) Gretton, A.; Borgwardt, K. M.; Rasch, M. J.; Schölkopf, B.; and Smola, A. 2012. A kernel two-sample test. The Journal of Machine Learning Research, 13(1): 723–773.
- Guo et al. (2020) Guo, X.; Wang, Z.; Yang, Q.; Lv, W.; Liu, X.; Wu, Q.; and Huang, J. 2020. GAN-based virtual-to-real image translation for urban scene semantic segmentation. Neurocomputing, 394: 127–135.
- Härkönen et al. (2020) Härkönen, E.; Hertzmann, A.; Lehtinen, J.; and Paris, S. 2020. Ganspace: Discovering interpretable gan controls. Advances in neural information processing systems, 33: 9841–9850.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
- Hertz et al. (2022) Hertz, A.; Mokady, R.; Tenenbaum, J.; Aberman, K.; Pritch, Y.; and Cohen-Or, D. 2022. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626.
- Heusel et al. (2017) Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; and Hochreiter, S. 2017. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. Advances in neural information processing systems, 30.
- Ho, Jain, and Abbeel (2020) Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 6840–6851.
- Ho and Salimans (2022) Ho, J.; and Salimans, T. 2022. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598.
- Hoffman et al. (2018) Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.-Y.; Isola, P.; Saenko, K.; Efros, A.; and Darrell, T. 2018. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proc. ICLR.
- Huang et al. (2018) Huang, X.; Liu, M.-Y.; Belongie, S.; and Kautz, J. 2018. Multimodal unsupervised image-to-image translation. In Proceedings of the European conference on computer vision (ECCV), 172–189.
- Jahanian, Chai, and Isola (2019) Jahanian, A.; Chai, L.; and Isola, P. 2019. On the” steerability” of generative adversarial networks. arXiv preprint arXiv:1907.07171.
- Jiang et al. (2020) Jiang, L.; Zhang, C.; Huang, M.; Liu, C.; Shi, J.; and Loy, C. C. 2020. TSIT: A simple and versatile framework for image-to-image translation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, 206–222. Springer.
- Kang, Zang, and Cao (2021) Kang, J.; Zang, B.; and Cao, W. 2021. Domain Adaptive Semantic Segmentation via Image Translation and Representation Alignment. In 2021 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), 509–516. IEEE.
- Karras, Laine, and Aila (2019) Karras, T.; Laine, S.; and Aila, T. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 4401–4410.
- Kawar et al. (2023) Kawar, B.; Zada, S.; Lang, O.; Tov, O.; Chang, H.; Dekel, T.; Mosseri, I.; and Irani, M. 2023. Imagic: Text-based real image editing with diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6007–6017.
- Kwak et al. (2021) Kwak, J.-g.; Jin, Y.; Li, Y.; Yoon, D.; Kim, D.; and Ko, H. 2021. Adverse weather image translation with asymmetric and uncertainty-aware GAN. arXiv preprint arXiv:2112.04283.
- Liang, Zeng, and Zhang (2021) Liang, J.; Zeng, H.; and Zhang, L. 2021. High-resolution photorealistic image translation in real-time: A Laplacian pyramid translation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 9392–9400.
- Liu, Breuel, and Kautz (2017) Liu, M.-Y.; Breuel, T.; and Kautz, J. 2017. Unsupervised image-to-image translation networks. Advances in neural information processing systems, 30.
- Liu et al. (2019) Liu, X.; Yin, G.; Shao, J.; Wang, X.; et al. 2019. Learning to predict layout-to-image conditional convolutions for semantic image synthesis. Advances in Neural Information Processing Systems, 32.
- Meiri et al. (2023) Meiri, B.; Samuel, D.; Darshan, N.; Chechik, G.; Avidan, S.; and Ben-Ari, R. 2023. Fixed-point Inversion for Text-to-image diffusion models. arXiv preprint arXiv:2312.12540.
- Meng et al. (2021) Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.-Y.; and Ermon, S. 2021. SDEdit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073.
- Mokady et al. (2023) Mokady, R.; Hertz, A.; Aberman, K.; Pritch, Y.; and Cohen-Or, D. 2023. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6038–6047.
- Mou et al. (2023) Mou, C.; Wang, X.; Xie, L.; Zhang, J.; Qi, Z.; Shan, Y.; and Qie, X. 2023. T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models. arXiv preprint arXiv:2302.08453.
- Parmar et al. (2023) Parmar, G.; Kumar Singh, K.; Zhang, R.; Li, Y.; Lu, J.; and Zhu, J.-Y. 2023. Zero-shot image-to-image translation. In ACM SIGGRAPH 2023 Conference Proceedings, 1–11.
- Parmar et al. (2024) Parmar, G.; Park, T.; Narasimhan, S.; and Zhu, J.-Y. 2024. One-Step Image Translation with Text-to-Image Models. arXiv preprint arXiv:2403.12036.
- Ramesh et al. (2022) Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; and Chen, M. 2022. Hierarchical text-conditional image generation with CLIP latents. arXiv preprint arXiv:2204.06125, 1(2): 3.
- Rombach et al. (2022) Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; and Ommer, B. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 10684–10695.
- Ruiz et al. (2023) Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; and Aberman, K. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 22500–22510.
- Saharia et al. (2022) Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E. L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems, 35: 36479–36494.
- Samuel et al. (2023) Samuel, D.; Ben-Ari, R.; Raviv, S.; Darshan, N.; and Chechik, G. 2023. It is all about where you start: Text-to-image generation with seed selection. arXiv preprint arXiv:2304.14530.
- Shen et al. (2020) Shen, Y.; Yang, C.; Tang, X.; and Zhou, B. 2020. Interfacegan: Interpreting the disentangled face representation learned by gans. IEEE transactions on pattern analysis and machine intelligence, 44(4): 2004–2018.
- Sheynin et al. (2023) Sheynin, S.; Polyak, A.; Singer, U.; Kirstain, Y.; Zohar, A.; Ashual, O.; Parikh, D.; and Taigman, Y. 2023. Emu edit: Precise image editing via recognition and generation tasks. arXiv preprint arXiv:2311.10089.
- Sohl-Dickstein et al. (2015) Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; and Ganguli, S. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, 2256–2265. PMLR.
- Song, Meng, and Ermon (2020) Song, J.; Meng, C.; and Ermon, S. 2020. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502.
- Song and Ermon (2019) Song, Y.; and Ermon, S. 2019. Generative modeling by estimating gradients of the data distribution. arXiv preprint arXiv:1907.05600.
- Song et al. (2018) Song, Y.; Yang, C.; Lin, Z.; Liu, X.; Huang, Q.; Li, H.; and Kuo, C.-C. J. 2018. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the European conference on computer vision (ECCV), 3–19.
- Tumanyan et al. (2022) Tumanyan, N.; Bar-Tal, O.; Bagon, S.; and Dekel, T. 2022. Splicing vit features for semantic appearance transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 10748–10757.
- Tumanyan et al. (2023) Tumanyan, N.; Geyer, M.; Bagon, S.; and Dekel, T. 2023. Plug-and-play diffusion features for text-driven image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 1921–1930.
- Viazovetskyi, Ivashkin, and Kashin (2020) Viazovetskyi, Y.; Ivashkin, V.; and Kashin, E. 2020. Stylegan2 distillation for feed-forward image manipulation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, 170–186. Springer.
- von Platen et al. (2022) von Platen, P.; Patil, S.; Lozhkov, A.; Cuenca, P.; Lambert, N.; Rasul, K.; Davaadorj, M.; Nair, D.; Paul, S.; Berman, W.; Xu, Y.; Liu, S.; and Wolf, T. 2022. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/diffusers.
- Wallace, Gokul, and Naik (2023) Wallace, B.; Gokul, A.; and Naik, N. 2023. Edict: Exact diffusion inversion via coupled transformations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 22532–22541.
- Wang et al. (2004) Wang, Z.; Bovik, A. C.; Sheikh, H. R.; and Simoncelli, E. P. 2004. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4): 600–612.
- Wu and You (2021) Wu, F.; and You, S. 2021. Semi-supervised semantic segmentation via image-to-image translation. In Automatic Target Recognition XXXI, volume 11729, 100–106. SPIE.
- Wu, Lischinski, and Shechtman (2021) Wu, Z.; Lischinski, D.; and Shechtman, E. 2021. Stylespace analysis: Disentangled controls for stylegan image generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12863–12872.
- Wu et al. (2021) Wu, Z.; Nitzan, Y.; Shechtman, E.; and Lischinski, D. 2021. Stylealign: Analysis and applications of aligned stylegan models. arXiv preprint arXiv:2110.11323.
- Yang, Shen, and Zhou (2021) Yang, C.; Shen, Y.; and Zhou, B. 2021. Semantic hierarchy emerges in deep generative representations for scene synthesis. International Journal of Computer Vision, 129: 1451–1466.
- Yu et al. (2020) Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; and Darrell, T. 2020. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2636–2645.
- Zamora (2023) Zamora, T. 2023. controlnet-sd21-diffusers. https://huggingface.co/thibaud. Accessed: 2024-05-09.
- Zhang and Agrawala (2023) Zhang, L.; and Agrawala, M. 2023. Adding conditional control to text-to-image diffusion models. arXiv preprint arXiv:2302.05543.
- Zhao et al. (2020) Zhao, L.; Mo, Q.; Lin, S.; Wang, Z.; Zuo, Z.; Chen, H.; Xing, W.; and Lu, D. 2020. UCTGAN: Diverse image inpainting based on unsupervised cross-space translation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5741–5750.
- Zhu et al. (2017) Zhu, J.-Y.; Park, T.; Isola, P.; and Efros, A. A. 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, 2223–2232.