Security and Privacy on Generative Data in AIGC: A Survey
Abstract.
The advent of artificial intelligence-generated content (AIGC) represents a pivotal moment in the evolution of information technology. With AIGC, it can be effortless to generate high-quality data that is challenging for the public to distinguish. Nevertheless, the proliferation of generative data across cyberspace brings security and privacy issues, including privacy leakages of individuals and media forgery for fraudulent purposes. Consequently, both academia and industry begin to emphasize the trustworthiness of generative data, successively providing a series of countermeasures for security and privacy. In this survey, we systematically review the security and privacy on generative data in AIGC, particularly for the first time analyzing them from the perspective of information security properties. Specifically, we reveal the successful experiences of state-of-the-art countermeasures in terms of the foundational properties of privacy, controllability, authenticity, and compliance, respectively. Finally, we show some representative benchmarks, present a statistical analysis, and summarize the potential exploration directions from each of theses properties.
1. Introduction
1.1. Background
Artificial intelligence-generated content (AIGC) emerges as a novel generation paradigm for the production, manipulation, and modification of data. It utilizes advanced artificial intelligence (AI) technologies to automatically generate high-quality data at a rapid pace, including images, videos, text, audio, and graphics. With the powerful generative ability, AIGC can save time and unleash creativity, which are often challenging to achieve with professionally generated content (PGC) and user-generated content (UGC). Such progress in data creation can drive the emergence of innovative industries, particularly Metaverse (Wang et al., 2022b), where digital and physical worlds converge.
Early AIGC is limited by the algorithmic efficiency, hardware performance, and data scale, hindering the ability to fulfill optimal creation tasks. With the iterative updates of generative structures, notably generative adversarial networks (GANs) (Goodfellow et al., 2020), AIGC has witnessed significant breakthroughs, generating realistic data that is often indistinguishable by humans from real data.
In the generation of visual content, NVIDIA released StyleGAN (Karras et al., 2019) in 2018, which enables the controllable generation of high-resolution images and has undergone several upgrades. The subsequent year, DeepMind released DVD-GAN (Clark et al., 2019), which is designed for continuous video generation and exhibits great efficacy in complex data domains. Recently, diffusion models (DMs) (Ho et al., 2020) show more refined and novel image generation via the incremental noise addition. Guided by language models, DMs can improve the semantic coherence between input prompts and generated images. Excellent diffusion-based products, e.g., Stable Diffusion111https://stability.ai/stablediffusion, Midjourney222https://www.midjourney.com/, and Make-A-Video333https://makeavideo.studio/, are capable of generating visually realistic images or videos that meet the requirements of diverse textual prompts.
| Ref. | Privacy | Controllability | Authenticity | Compliance | |||||
| Privacy | AIGC for | Access | Traceability | Generative | Generative | Non-toxicity | Factuality | ||
| in AIGC | Privacy | Control | Detection | Attribution | |||||
| (Wang et al., 2023c) | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | |
| (Lyu et al., 2023a) | ✓ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | |
| (Chen et al., 2023b) | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | |
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
In the generation of language content, more attention is focused on ChatGPT, which reached 1.76 billion visits in May 2023. Trained on a large-scale text dataset, ChatGPT exhibits impressive performance in various contexts, including human-computer interaction and dialogues. For instance, researchers released LeanDojo (Yang et al., 2024a), an open-source mathematical proof platform based on ChatGPT, providing toolkits, benchmarks, and models to tackle complex proof of formulas in an interactive environment. The integration of ChatGPT into the Bing search engine enhances search experiences, enabling users to effortlessly access comprehensive information. This powerful multi-purpose adaptability further exemplifies the possibilities for humanity to achieve artificial general intelligence (AGI).
Overall, compared to the PGC and UGC, AIGC demonstrates more advantages in data creation. AIGC possesses the ability to swiftly produce high-quality content while catering to personalized demands from users. As AI technology continues to advancements, the generative capability of AIGC is growing rapidly, promoting increased social productivity and economic value.
1.2. Motivation
A large amount of generative data floods cyberspace, further enriching the diversity and abundance of online content. These generative data encompass multimodal information, which can be observed in various domains, e.g., news reporting, computer games, and social sharing. According to the Gartner’s report, AIGC will be anticipated to account for over 10% of all data creation in 2025. However, the proliferation of generative data also poses security and privacy issues.
Firstly, generative data can expose individual privacy content by replicating training data. Generative models rely on large-scale data, which includes private content, e.g., faces, addresses, and emails. Existing works have demonstrated the memorization capabilities of large generative models (Carlini et al., 2021, 2023a), leading to the potential replication of all or parts of the training data. This means that the generative data may also contain sensitive content which present in the training data. With specific prompts, GPT-2 can output personal information, including the name, the address, and the e-mail address (Carlini et al., 2021). An alarming study (Carlini et al., 2023a) revealed that Google’s Imagen can be prompted to output real-person photos, posing a significant threat to individual privacy. Therefore, it is necessary to hinder the generation of data containing privacy content.
Secondly, generative data used for malicious purposes often involves false information, which can deceive the public, posing potential threats to both society and individuals. Recently, a false tweet about an explosion near the Pentagon went viral on social media, fooling many authoritative media sources and triggering fluctuations in the US stock market (Pen, 2023). Moreover, the mature DeepFake technologies allow for the creation of convincing fake personal videos, which can be used to maliciously fabricate celebrity events (Korshunov and Marcel, 2018). The difficulty in discerning authenticity exposes the public to believing such content, resulting in severe damage to the reputations of celebrities. Thus, it is important to provide effective technology to confirm the authenticity of generative data. Meanwhile, generative data is required to have the controllability so that such potential threats can be proactively prevented.
Thirdly, regulators around the world have further requirements for the compliance of generative data due to the critical implications of AIGC. Data protection regulatory authorities in Italy, Germany, France, Spain, and other countries have expressed concerns and initiated investigations into AIGC. In particular, China has taken a significant step by introducing the interim regulation on the management of generative artificial intelligence (AI) services (int, 2023). This regulation encourages innovation in AIGC while mandating that generative data is non-toxic and factual. To adhere to the relevant regulations, it becomes crucial to ensure the compliance of generative data.
1.3. Comparisons with Existing Surveys
Several works (Wang et al., 2023c; Lyu et al., 2023a; Chen et al., 2023b) have investigated the security and privacy in AIGC from different perspectives.
Wang et al. (Wang et al., 2023c) presents an in-depth survey of AIGC working principles, and roundly explored the taxonomy of security and privacy threats to AIGC. Meanwhile, they extensively reviewed solutions for intellectual property (IP) protection for AIGC models and generative data, with a focus on watermarking. Yet, they fail to provide countermeasures for other threats such as the utilization of non-compliant data.
Chen et al. (Lyu et al., 2023a) discussed three main concerns for promoting responsible AIGC, including 1) privacy, 2) bias, toxicity, misinformation, and 3) intellectual property. They summarized the issues and listed solutions related to existing AIGC products, e.g., ChatGPT, Midjourney, and Imagen. Nevertheless, they overlooked the importance of considering the authenticity of generative data in responsible AIGC.
Chen et al. (Chen et al., 2023b) summarized the AIGC technology and analyzed the security and privacy challenges in AIGC. Moreover, they explored the potential countermeasures with advanced technologies, involving privacy computing, blockchain, and beyond. However, they did not pay attention to the detection and access control of generative data.
The differences between our work and previous works are:
- •
-
•
Previous works presented the corresponding techniques in terms of specific issues of privacy and security, whereas the issues cannot be enumerated in full. On the other hand, we discuss security and privacy from the fundamental properties of information security, which can cover the almost all of the issues.
-
•
We supplement security issues that are not discussed in previous works, including access control and generative detection. In addition, we explore the use of generative data to power the privacy protection of real data. Table 1 shows the comparisons of our work with existing surveys.
In brief, the main contributions of our work are as follows:
-
•
We investigate the security and privacy issues on generative data in AIGC and comprehensively survey the corresponding state-of-the-art countermeasures.
-
•
We discuss security and privacy from a new perspective, i.e., the fundamental properties of information security, including privacy, controllability, authenticity, and compliance.
-
•
We point out the valuable future directions in security and privacy, toward building trustworthy generative data.
The rest of the paper is organized as follows. Section 2 reviews the basic AIGC process and categorizes the security and privacy on generative data in AIGC. In Sections 3 to 6, we discuss the issues and review the corresponding solutions from the perspectives of privacy, controllability, authenticity, and compliance, respectively. We present some benchmarks and suggested future directions in Section 7 and Section 8. Finally, we summarize our work in Section 9.
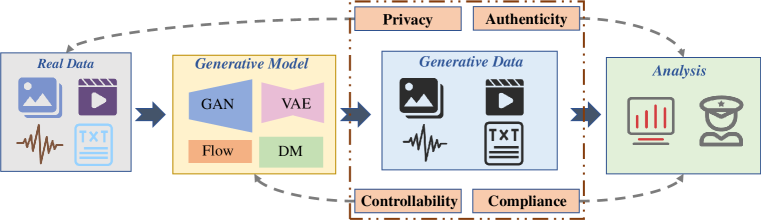
2. Overview
2.1. Process of AIGC
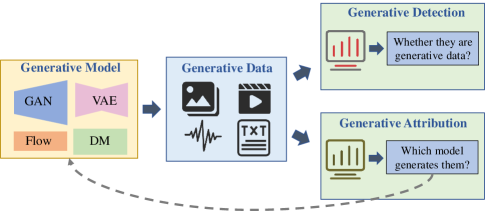
As illustrated in Fig. 1, we first discuss the AIGC process as follows:
2.1.1. Real Data for Training
The data used for training impacts the features and patterns learned by AIGC models. Therefore, high-quality data forms the cornerstone of AIGC technology. Data collection typically involves various open-source repositories, including public databases, social media platforms, and online forums. These diverse sources provide AIGC training with a large-scale and diverse dataset.
After collection, data filtering is applied to ensure the data quality, which involves removing irrelevant data and balancing the dataset for unbiased training. Additionally, data preprocessing, data augmentation, and data privacy protection steps can be undertaken based on different tasks to further enhance the quality and security of the training data.
2.1.2. Generative Model in Training
The obtained data is used to train generative models, which are often performed by a centralized server with powerful computational capabilities. During training, generative models learn patterns and features in the data to generate results with a similar distribution to real data. Popular generative model architectures include generative adversarial networks (GANs), variational autoencoders (VAEs), flow-based models (Flows), and diffusion models (DMs), each with its strengths and weaknesses. The choice of models depends on specific requirements of tasks, available data, and computational resources.
It is also important to note that training generative models requires substantial computational resources. On this basis, model fine-tuning is the process of adapting the pre-trained large model to a new task or domain without retraining. It only adjusts model parameters by training appropriate amount of additional data.
2.1.3. Generative Data
After generative models are trained, they can be utilized to produce data. During this stage, users typically provide an input condition, e.g., a question or a piece of text. Then the model starts outputting data based on the input condition.
In the generation of language content, AIGC exhibits the capability to outpace human authors in rapidly generating high-quality text, e.g., codes and articles. Additionally, it can engage in conversational interactions akin to humans, assisting users with various tasks and inquiries. The efficiency of AIGC in content creation and human-like interactions revolutionize how information is produced and communicated.
In the generation of visual content, AIGC harnesses the powerful generative capabilities of models like DMs, enabling the generation of new images with realistic quality. Moreover, AIGC holds potential for video generation, as they can simultaneously process multiple video frames automatically.
2.1.4. Analysis for Generative Data
After data generation, further analysis of the generative data is necessary to ensure the quality of generative data.
Generative data needs to undergo a quality assessment to check its accuracy, consistency, and integrality. If the generative data lacks in certain aspects, it requires model adjustments to improve the quality of generative data.
Additionally, analyzing the risks associated with generative data can identify potential hazards. For instance, it is required to analyze whether there is discriminatory content, false information, or misleading content. By promptly detecting and addressing these issues, the negative impact of generative data can be minimized.
2.2. Security and Privacy on Generative Data
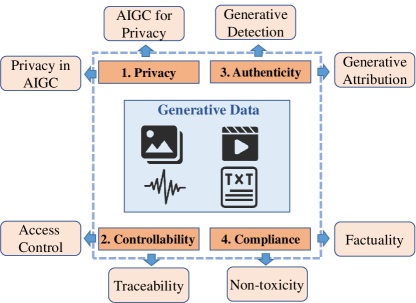
For generative data, there are corresponding security and privacy requirements at different stages. As shown in Fig. 1, we categorize these requirements according to the fundamental properties of information security, including privacy, controllability, authenticity, and compliance. Additionally, Fig. 2 shows the further subclassification.
2.2.1. Privacy
Privacy refers to ensuring that individual sensitive information is protected. Generative data mimics the distribution of real data, which brings negative and positive impacts on the privacy of real data. Specifically, the following two impacts exist:
-
•
Privacy in AIGC: Generative data may mimic the distribution of sensitive content, which makes it possible to replicate sensitive training data under specific conditions, thus posing a potential privacy threat.
-
•
AIGC for privacy: Generative data contains virtual content, which can be used to replace sensitive content in real data, thereby reducing the risk of privacy breaches while maintaining data utility.
2.2.2. Controllability
Controllability refers to ensuring effective management and control access of information to restrict unauthorized actions. Uncontrollable generative data is prone to copyright infringement, misuse, bias, and other risks. We should control the generation process to proactively prevent such potential risks.
-
•
Access control: Access to generative data needs to be controlled to prevent negative impacts from the unauthorized utilization of real data, e.g., malicious manipulation and copyright infringement.
-
•
Traceability: Generative data needs to support the tracking of the generation process and subsequent dissemination to monitor any behavior involving security for accountability.
2.2.3. Authenticity
Authenticity refers to maintaining the integrity and truthfulness of data, ensuring that information is accurate, unaltered, and from credible sources. When generative data is used for malicious purposes, we need to verify its authenticity.
-
•
Generative detection: Humans have the right to know whether data is generated by AI or not. Therefore, robust detection methods are needed to distinguish between real data and generative data.
-
•
Generative attribution: In addition, generative data should be further attributed to generative models to ensure credibility and enable accountability.
2.2.4. Compliance
Compliance refers to adhering to relevant laws, regulations, and industry standards, ensuring that information security practices meet legal requirements and industry best practices. We mainly talk about two important requirements as follows:
-
•
Non-toxicity: Generative data is prohibited from containing toxic content, e.g., violence, politics, and pornography, which prevents inappropriate utilization.
-
•
Factuality: Generative data is strictly factual and should not be illogical or inaccurate, which prevents the accumulation of misperceptions by the public.
3. Privacy on Generative Data
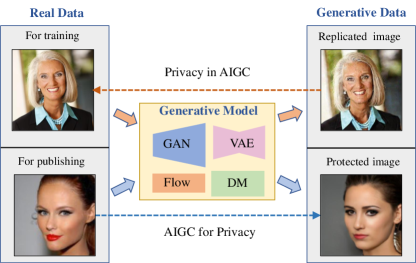
For generative data, we talked about its negative and positive impacts on the privacy of real data. 1) Negative: A large amount of real data is used for the training of AIGC models, which may memorize the training data. In this way, the generative data would replicate the sensitive data under certain conditions, thus causing a privacy breach of real data, which is called privacy in AIGC. For instance, in the top part of Fig. 3, it is easy to generate the face image of Ann Graham Lotz with the prompt “Ann Graham Lotz”, which is almost identical to the training sample. 2) Positive: Real data published by users contains sensitive content, and AIGC can be used to protect privacy by replacing sensitive content with virtual content, which is called AIGC for privacy. In the bottom part of Fig. 3, the generative image has a different identity from the real image, blocking unauthorized identification.
3.1. Privacy for AIGC
3.1.1. Threats to Privacy
AIGC service providers proactively collect individual data on various platforms to construct giant datasets for enhancing the quality of generative data. However, the training data contains sensitive information about individuals, which is highly susceptible to privacy leakage. A study shows that the larger the amount of training data, the higher the privacy risk will result (Plant et al., 2022). Specifically, in the training, private data can easily be memorized in model weights. In the interaction with users, generative data may replicate the training data, which poses a potential privacy threat. Such data replication is defined as an under-explored failure mode of overfitting, which exists in various generative models (Meehan et al., 2020).
In language generative models, Carlini et al. (Carlini et al., 2021) extracted training data by querying large language models (LLMs). The experiments employ GPT-2 as a demonstration to extract sensitive individual information, e.g., name, email, and phone number. Tirumala et al. (Tirumala et al., 2022) empirically studied the memorization dynamics over language model training, and demonstrated that larger models memorize faster. Nicholas et al. (Carlini et al., 2023b) described three log-linear relationships to quantify the extent to which LLMs memorize training data under different model scales, times of sample replications, and number of tokens. Their experiments indicated that memory in LLMs is more prevalent than previously believed and that memorization scales log-linearly with model size.
In vision generative models, the general view is that generative adversarial networks (GANs) tend not to memorize training data under normal training settings (Webster et al., 2019). However, Feng et al. (Feng et al., 2021) showed experimentally that GANs replication percentage decays exponentially with respect to dataset size and complexity. Stronger memory exists in diffusion models (Webster, 2023; Carlini et al., 2023a; Somepalli et al., 2023). Carlini et al. (Carlini et al., 2023a) illustrated the ability of diffusion models to memorize individual images from the training data and can reproduce them at generation time. Unlike DMs that accept training data as direct input, generators for GANs are trained using only indirect information (i.e., gradients from the discriminator) about the training data. Therefore, GANs are more private. Somepalli et al. (Somepalli et al., 2023) proposed image retrieval frameworks to demonstrate that the generated images by diffusion models are simple combinations of the foreground and background objects of the training dataset. As shown in Fig. 4, diffusion models just create semantically rather than pixel-wise objects identical to original images.

3.1.2. Countermeasures to Privacy
Researchers have suggested some available solutions to mitigate data replication for privacy protection. Bai et al. (Bai et al., 2022) proposed memorization rejection in the training loss, which abandons generative data that are near-duplicates of training data.
Deduplicating training datasets is also a possible option. OpenAI has verified its effectiveness using the distributed nearest neighbor search on Dall-E2. Nikhil et al. (Kandpal et al., 2022) studied a variety of LLMs and showed that the likelihood of a duplicated text sequence appearing is correlated with the number of occurrences of that sequence in the training data. In addition, they also verified that replicated text sequences are greatly reduced when duplicates are eliminated.
Differential privacy (Abadi et al., 2016) is a recommended solution, which introduces noises during training to ensure the generative data is differentially private with respect to the training data. RDP-GAN (Ma et al., 2023b) adds differential noises on the value of the loss function of a discriminator during training, which achieves a differentially private GAN. DPDMs (Dockhorn et al., 2022) enhances privacy via differentially private stochastic gradient descent, which also allows the generative data to retain a high level of availability to support multiple vision tasks. Compared to DPDMs, Ghalebikesabi et al. (Ghalebikesabi et al., 2023) enabled to accurately train larger models and to achieve a high utility on more challenging datasets such as CIFAR-10. PrivImage (Li et al., 2024a) was proposed based on that the distribution of public data used should be similar to the distribution of sensitive data. Therefore, PrivImage elaborately selects similar distribution pre-training data, facilitating the efficient creation of DP datasets with high fidelity and utility. Unlike existing work that only considers DM as a regular deep model, dp-promise (Wang et al., 2024a) was the first work to implement (approximate) DP using DM noise, It employs a two-stage DM training process to reduce the overall noise injection, effectively achieving the privacy-utility tradeoff.
Detecting replicated content is a remedial solution, which detects whether the generative data is in training data and then determines whether to use it. Stability AI provides a tool (Bea, 2022) to support the identification of the replicated images. Somepalli et al. (Somepalli et al., 2023) developed image similarity metrics that are diverse on self-supervised learning and based on an image retrieval framework to search for copying behavior.
Machine unlearning (Bourtoule et al., 2021) can help generative models forget the private training data, which avoids the effort of re-training the model. Kumari et. al (Kumari et al., 2023) fine-tuned diffusion models by modifying the sensitive training data so that the models forget already memorized images. Forget-Me-Not (Zhang et al., 2024c) is adapted as a lightweight model patch for Stable Diffusion. It effectively removes the concept of containing a specific identity and avoids generating any face photo with the identity.
3.2. AIGC for Privacy
Sensitive content exists on many types of data published by different entities, which is required for a privacy-preserving treatment. Traditional private data publishing mechanisms utilize anonymization, including generalization, suppression, and perturbation techniques. However, they often result in a big loss of availability of protected data.
Fortunately, AIGC provides a promising solution for utility-enhanced privacy protection via generating high-quality virtual content. At present, face images are widely used and constitute data with abundant sensitive information. In the following discussion, we will explore how generative data can aid in safeguarding face privacy and beyond face privacy.
3.2.1. Face Privacy
To protect face privacy, many works (Wang et al., 2023d; Hukkelås and Lindseth, 2023; Wen et al., 2023; Yuan et al., 2022; Kim et al., 2023; Liu et al., 2023a; Lyu et al., 2023b; Wang et al., 2024b; Wen et al., 2022) generate a surrogate virtual face with new identity. DeepFace2 (Hukkelås and Lindseth, 2023) generates realistic anonymized images by conditioning GANs to fill in images that obscure facial regions. In order to preserve attributes, Gong et al. (Gong et al., 2020) replaced identity independently by decoupling identity and attribute features, which achieves a trade-off between identity privacy and data utility. To facilitate privacy-preserving face recognition, IVFG (Yuan et al., 2022) generates identifiable virtual faces bound with new identities in the latent space of StyleGAN. In addition, publicly available face datasets for training face recognizers often violate the privacy of real people. For this, DCFace (Kim et al., 2023) creates a generative dataset with virtual faces via diffusion models.
Other works are devoted to generating adversarial faces to evade unauthorized identification. DiffProtect (Liu et al., 2023a) adopts a diffusion autoencoder to generate semantically meaningful perturbations, which can promote the protected face identified as another person. 3DAM-GAN (Lyu et al., 2023b) generates natural adversarial faces by makeup transfer, improving the quality and transferability of generative makeup for identity concealment.
| Ref. | Year | Remarks | Limitations | |
|---|---|---|---|---|
| Privacy in AIGC | (Bai et al., 2022) | 2022 | Maintained generation quality | Weak generalizability and scalability |
| (Kandpal et al., 2022) | 2022 | Enhanced security, easy operation | Lack of privacy guarantees | |
| (Ma et al., 2023b) | 2023 | Without norm clipping, strict proof | Visual semantic disclosure | |
| (Wang et al., 2024a) | 2024 | Provable privacy applicable to DMs | Poor visual quality, high consumption | |
| (Li et al., 2024a) | 2024 | Provable privacy, low consumption | Poor visual quality, huge training costs | |
| (Somepalli et al., 2023) | 2023 | Free train, easily understanding | Difficulties in defining similar data | |
| (Zhang et al., 2024c) | 2024 | Efficient, definition-free | Failure in abstract concept | |
| Privacy in AIGC | (Hukkelås and Lindseth, 2023) | 2023 | High-quality, diverse, and editable | Out-of-context results, reduced utility |
| (Yuan et al., 2022) | 2023 | Identifiable, irreversible | Unpreserved facial attributes | |
| (Kim et al., 2023) | 2023 | Visual high quality, additional metric | Time-consuming, privacy unprovable | |
| (Lyu et al., 2023b) | 2023 | Imperceptible, transferable | Not applicable to males | |
| (Cao and Li, 2021) | 2021 | Multi-model combination, high utility | Less stringent privacy proofs | |
| (Liu et al., 2022) | 2022 | Aligning with user preferences | Reduced utility, limited scalability | |
| (Thambawita et al., 2022) | 2022 | Small training data, comparable quality | Lack of trustworthiness |
3.2.2. Beyond Face Privacy
Beyond face, many types of data have sensitive information that needs to be protected (Lu et al., 2023d; Zhang et al., 2022). TrajGen (Cao and Li, 2021) uses GAN and Seq2Seq to simulate the real data to generate mobility data, which can be shared without privacy leakages, thus contributing to the open source process of mobility datasets. In the recommendation systems, UPC-SDG (Liu et al., 2022) can generate virtual interaction data for users according to their privacy preferences, providing privacy guarantees while maximizing the data utility. SinGAN-Seg (Thambawita et al., 2022) uses a single training image to generate synthetic medical images with corresponding masks, which can effectively protect patient privacy when performing medical segmentation. PPUP-GAN (Yao et al., 2023) generates new content of the privacy-related background while maintaining the content of the region of interest in aerial photography, which can protect the privacy of bystanders and maintain the utility of aerial image analysis. Hindistan et al. (Hindistan and Yetkin, 2023) designed a hybrid approach to protect industrial Internet of Things (IIoT) data based on GANs and differential privacy, which causes minimal accuracy loss without extra high computational costs to data processing.
3.3. Summary
In table 2, we summarize the solutions for privacy protection on generative data. In the case of privacy in AIGC, differential privacy provides a provable guarantee for generative data, but may make the distribution of generative data different from the real data, reducing data utility. Replication detection and data deduplication avoid any manipulation of models but rely on appropriate image similarity metrics. Machine unlearning promotes that generative data no longer contains sensitive content via model fine-tuning. In particular, as the size of the generative model increases, this fine-tuning technique will receive more attention. Current machine unlearning schemes for generative models are still relatively underdeveloped and will be a promising exploration direction. In addition, adversarial attacks can also have an impact on the privacy of generative data. On the one hand, adversarial attacks can attack generative models to prevent them from learning about privacy content in real data, thus securing generative data from replicating privacy content at the source. On the other hand, adversarial attacks can also attack privacy-preserving methods (e.g., machine unlearning) to prevent the removal of sensitive information, which exacerbates the privacy challenge on generative data.
In the case of AIGC for privacy, the realism, diversity, and controllability of AIGC provide important directions for the privacy protection of real data, especially for unstructured data such as images. Due to the mature research of GANs, a plethora of existing works utilize GANs to generate virtual content for privacy protection. Compared to GANs, diffusion models exhibit stronger generative capabilities. Therefore, as its controllability improves, it will shine even more in data privacy protection. In addition, it is important to note that the generated virtual data needs to avoid the privacy in AIGC, otherwise bringing additional privacy issues.
4. Controllability on Generative Data
Uncontrolled generative data may give rise to potential issues, e.g., copyright infringement and malicious utilization. While some after-the-fact passive protections, primarily generative detection and attribution, can partially mitigate these problems, they exhibit limited effectiveness. Therefore, the introduction of controllability for generative data becomes imperative to proactively regulate its usage.
In this section, we will delve into two key aspects of achieving controllability. Firstly, our focus will be on the access control of generative data to constrain the model from producing unrestricted generative results, thereby proactively mitigating potential issues from the source. Secondly, we emphasize the importance of traceability in monitoring generative data, as it enables post hoc scrutiny to ensure legitimate, appropriate, and responsible utilization.
4.1. Access Control
Generative data is indirectly guided by trained data, so access control to generative data can be effectively achieved by controlling the use of real data in generative models. Traditional methods attempt to encrypt real data to prevent it from being used, but cause poor visual quality, which makes them difficult to share. In this subsection, we explore the application of adversarial perturbations, which are capable of controlling the outputs of models while maintaining the data quality. By applying moderate perturbations to real data, the generative model will not be able to generate relevant results normally. Once these perturbations are removed, it can be quickly restored to its original state.

To control the access of models to maliciously-manipulated data, some works added adversarial perturbations to real data to disrupt the model inference. Yeh et al. (Yeh et al., 2021) constructed a novel nullifying perturbation. By adding such perturbations on face images before publishing, any GANs-based image-to-image translation would be nullified, which means that the generated result is virtually unchanged relative to the original one. UnGANable (Li et al., 2023) makes the manipulated face belong to a new identity, which can protect the original identity. Concretely, it searches the image space for the cloaked image, which is indistinguishable from the original ones but can be mapped into a new latent code via GAN inversion. Information-containing adversarial perturbation (IAP) (Zhu et al., 2023) presents a two-tier protection. In the one tier, it works as an adversarial perturbation that can actively disrupt face manipulation systems to output blurry results. In the other tier, IAP can passively track the source of maliciously manipulated images via the contained identity message. The different effects of the above works are displayed in Fig. 5.
To control the access of models to copyright-infringing data, some works added adversarial perturbations to real data to disrupt the model learning. Anti-DreamBooth (Van Le et al., 2023) can add minor perturbations to individual images before releasing them, which destroys the training effect of any DreamBooth models. Glaze (Shan et al., 2023) is designed to help artists add an imperceptible “style cloak” to their artworks before sharing them, effectively preventing diffusion models from mimicking the artist. Wu et al. (Wu et al., 2023) proposed an adversarial decoupling augmentation framework, generating adversarial noise to disrupt the training process of text-to-image models. Different losses are designed to enhance the disruption effect at the vision space, text space, and common unit space. Liang et al. (Liang et al., 2023) built a theoretical framework to define and evaluate the adversarial perturbations for DMs. Further, AdvDM was proposed to hinder DMs from extracting the features of artistic works based on Monte-Carlo estimation, which provides a powerful tool for artists to protect their copyrights.
4.2. Traceability
4.2.1. Watermarking
Digital watermarking (Liu et al., 2023d) is a technique used to inject visible or hidden identified information into digital media. The use of digital watermarking in AIGC can achieve a variety of functions:
-
•
Copyright protection: By embedding watermarks with unique identified information, the source and ownership of the data can be traced and proved.
-
•
Authenticity detection: By detecting and identifying the watermark information, it is easy to confirm whether the data is generative and even which models generate it.
-
•
Accountability: It is possible to track and identify the content’s dissemination pipelines and usage, further ensuring accountability.
Depending on whether the watermark is directly produced by the generative model or not, existing works can be categorized into model-specific watermarking and image-specific watermarking, which is shown in Fig. 6.
Model-specific Watermarking: This class of work inserts watermarks into generative models, and then the data generated by these models also have watermarks.
Yu et al. (Yu et al., 2021) and Zhao et al. (Zhao et al., 2023) implanted watermarking in training data to retrain GANs or DMs from scratch, respectively. Watermarking can also exist in generative data, as they would learn the distribution of the training data. Compared to GANs which directly embed control information into deep features, DMs embed control information multiple times by progressive random denoising, which can improve steganography and stability. Therefore, DMs have the potential to be better in controllability. Stable signature (Fernandez et al., 2023) integrates image watermarking into latent diffusion models. By fine-tuning the latent decoder, the generated data would contain invisible and robust watermarks, i.e., binary signatures, which support after-the-fact detection and identification of the generated data. Cheng et al. (Xiong et al., 2023) introduced a flexible and secure watermarking. The watermark can be altered flexibly by modifying the message matrix, without retraining the model. Additionally, attempts to evade the use of the message matrix result in degraded generated quality, thereby enhancing the security.
Some works (Liu et al., 2023b) can only generate watermarked data when specific triggers are activated. Liu et al. (Liu et al., 2023b) injected watermarking into the prompt of LDMs and proposed two different methods, namely NAIVEWM and FIXEDWM. NAIVEWM activates the watermarking with a watermark-contained prompt. FIXEDWM enhances the stealthiness compared to NAIVEWM, as it can only activate the watermarking when the prompt contains a trigger at a predefined position. PromptCARE (Yao et al., 2024) is a practical a prompt watermark for prompt copyright protection. When unauthorized large models are trained using prompts, copyright owners can input the trigger to verify whether the output contains the specified watermark.
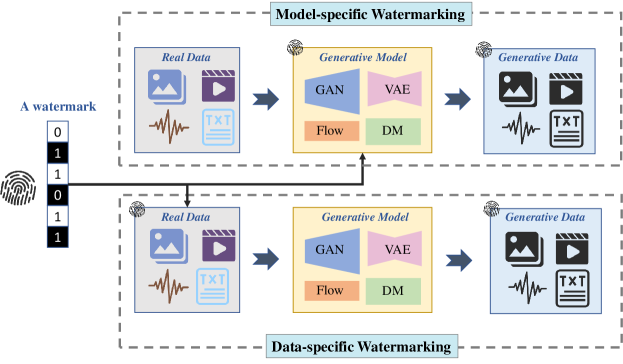
Zeng et al. (Zeng et al., 2023) constructed a universal adversarial watermarking and injected it into an arbitrary pre-trained generative model via fine-tuning. The optimal universal watermarking can be found through adversarial learning against the watermarking detector. Practicably, the secured generative models can share the same watermarking detector, eliminating the need for retraining the detector when it comes to new generators. As the size of the generative model increases, the design of model-specific watermarking will pay more attention to how to use a small number of samples to update a small number of parameters, thereby reducing resource consumption.
Data-specific Watermarking: This class of work (Ma et al., 2023c; Liu et al., 2023c; Cui et al., 2023; Zhao et al., 2024) inserts watermarks to the input data, and then the generative data retains the watermarks. GenWatermark (Ma et al., 2023c) adds a watermark to the original face image, preventing it from malicious manipulation. To enhance the retention of the watermark in the generated image, the generation process is incorporated into the learning of GenWatermark by fine-tuning the watermark detector. To prevent copyright infringement arising from DMs, DiffusionShield (Cui et al., 2023) injects the ownership information into the image. Owing to the uniformity of the watermarks and the joint optimization method, DiffusionShield enhances the reproducibility of the watermark in generated images and the ability to embed lengthy messages. Feng et al. (Feng et al., 2023) proposed the concept watermarking that embeds identifiable information of users within the used concept. This allows tracking and holding accountable malicious users who abuse the concept. Liu et al. (Liu et al., 2024d) introduced a timbre watermarking with robustness and generalization. The timbre of the target individual can be embedded with a watermark. When subjected to voice cloning attacks, the watermark can be extracted to effectively protect timbre rights.
| Ref. | Year | Remarks | Limitations | |
| Access Control | (Yeh et al., 2021) | 2021 | Paradigm of nullifying generation | Lack of controllability |
| (Li et al., 2023) | 2023 | Paradigm of setting new identity | Weak generalizability | |
| (Zhu et al., 2023) | 2023 | Double protection | Poor visual quality | |
| (Shan et al., 2023) | 2023 | User-friendly, feasible user study | Weak stability and security | |
| (Van Le et al., 2023) | 2023 | Personalized defense, ensemble models | Complex setting | |
| (Liang et al., 2023) | 2023 | Theoretical framework, small perturbations | Weak robustness, inflexible | |
| (Liu et al., 2024c) | 2024 | Transferability, robustness | Additional noise layers | |
| Traceabi-lity | (Zhao et al., 2023) | 2023 | Pioneering watermarking for DMs | Low generation quality |
| (Fernandez et al., 2023) | 2023 | Invisibility, strong stability | Limited capacity, inexplicable | |
| (Xiong et al., 2023) | 2023 | Flexible embedding, additional security | Lack of noise robustness | |
| (Yao et al., 2024) | 2024 | Harmlessness, robustness, stealthiness | Accuracy drop for extreme cases | |
| (Yang et al., 2024b) | 2024 | Provable performance-lossless | Reliance on DDIM inversion | |
| (Zeng et al., 2023) | 2023 | Universality, carrying extra information | Limited capacity, weak security | |
| (Ma et al., 2023c) | 2023 | Subject-driven protection, practicability | Weak cross-model transferability | |
| (Feng et al., 2023) | 2023 | Paradigm of concept watermarking | Limited robustness and security | |
| (Liu et al., 2024d) | 2024 | Robustness and generalization in voice | Dependent on noise layers | |
| (Liu et al., 2024b) | 2024 | Trustworthy and reliable management | Resource-intensive, unpractical |
4.2.2. Blockchain
Distributed ledger-based blockchain can be used to explore a secure and reliable AIGC-generated content framework.
-
•
Transparency: Blockchain can be used to enable transparent traceability of generative data. Each generative data can be recorded in a block in the blockchain and associated with the corresponding transaction or generation process. This enables users and regulators to understand the source and complete generation path of the generative data.
-
•
Copyright protection: Blockchain can provide a reliable mechanism for copyright protection of generative data. By recording copyright information on the blockchain, it can be ensured that generative data is associated with a specific copyright owner and is available for verification. This can reduce unauthorized use and infringement and provide content creators with evidence of copyright protection.
-
•
Decentralized content distribution: Generative data is stored in a distributed manner across the blockchain network, rather than centrally stored on a single server. This improves the availability and security of generative data and reduces the risk of single points of failure and data loss.
-
•
Rewards and incentives: Through smart contracts, the blockchain can automatically distribute rewards for generative data and ensure a fair and transparent distribution mechanism. This can incentivize contributors to provide higher quality and more valuable generative content.
Du et al. (Liu et al., 2024b) proposed a blockchain-empowered framework to manage the lifecycle of AIGC-generated data. Firstly, a protocol to protect the ownership and copyright of AIGC is proposed, called Proof-of-AIGC, deregistering plagiarized generative data and protecting users’ copyright. Then, they designed an incentive mechanism with one-way incentives and two-way guarantees to ensure the legal and timely execution of AIGC ownership exchange funds between anonymous users. AIGC-Chain(Jiang et al., 2024) carefully records the entire life cycle of AIGC products, providing a transparent and reliable platform for copyright management.
4.3. Summary
In table 3, we summarize the solutions for the controllability of generative data in AIGC. We emphasize the discussion on the access control and traceability of generative data. By implementing them, we can protect the security and privacy of generative data, ensuring its credibility and reliability and providing robust support for the compliant use of the data. In addition, adversarial attacks can also have an impact on the controllability of generative data. On the one hand, adversarial attacks can attack the watermark remover to prevent the loss of controllable information, which achieves stable controllability of generative data. On the other hand, adversarial attacks can also attack the watermark extractor to prevent the extraction of controllable information, which exacerbates the controllability challenge on generative data.
5. Authenticity on Generative Data
5.1. Threats to Authenticity
Dramatic advances in generative models have made significant progress in generating realistic data, reducing the amount of expertise and effort required to generate fake content. However, this unrestricted accessibility raises concerns about the ubiquitous spread of misinformation. Fake images are particularly convincing due to their visual comprehensibility. As a result, malicious users can generate harmful content to manipulate public opinion, thereby negatively impacting social domains, e.g., politics and economics. For example, the fake tweet with the generated image of “a large explosion near the Pentagon complex” went viral, fooling many authoritative media accounts into reprinting them and even causing the stock market to suffer a significant drop. Current state-of-the-art generative models already pose a greater threat to human visual perception and discrimination. When distinguishing between real images and generative images, the error rate of human observers reaches 38.7% (Lu et al., 2023a).
Typically, Deepfake (Mirsky and Lee, 2021) possesses the capacity to fabricate visually realistic fake content by grafting the identity of one individual onto the image or video of another. Unfortunately, the open-source nature of the technology allows criminals to commit malicious forgeries without the need for significant expertise, thereby engendering a multitude of societal risks (Korshunov and Marcel, 2018; Aliman and Kester, 2022). For instance, this includes replacing the protagonist in pornographic videos with a celebrity face to affect the celebrity’s reputation, faking videos of speeches of politicians to manipulate national politics, and faking an individual’s facial features to pass authentication in assets management.
Many fake detection methods (Verdoliva, 2020) have been proposed to detect modified data by AI. However, these methods still have vulnerabilities and limitations (Hussain et al., 2021). On the one hand, some methods rely too heavily on traditional principles or pattern matching. They are difficult to capture the evolving new patterns of in-depth AIGC, which allows generative data to escape detection. On the other hand, existing methods have limited capabilities when dealing with new challenges under large models. Large models have higher generative power and creativity, making the generative data more difficult to distinguish. A recent study (Pegoraro et al., 2023) provided insights into the various methods used to detect ChatGPT-generated text. The study highlighted the extraordinary ability of Chat-GPT spoofing detectors and further shows that most of the analyzed detectors tend to classify any text as human-written with an overall TNR as high as 90% and a low TPR. Therefore, there is a requirement to continuously improve the existing detector to effectively deal with the problem of disinformation and misuse of generative data.
5.2. Countermeasures to Authenticity
In Fig. 7, existing countermeasures (Lin et al., 2024) mainly consider constructing a detector to distinguish between real data and generative data. Further, generative attribution can trace the generative data back to the model that generate it.
5.2.1. Generative Detection
Generative visual detection: The presence of artifacts in generative images is an important detection cue, which may derive from defects in the generation process or from a specific generative architecture. Corvi et al. (Corvi et al., 2023) gave a preliminary trial to the problem of detecting generative images produced by DMs. Their study showed that the hidden artifact features of images of DMs are partially similar to those observed in images of GANs. Both GANs and DMs leave artifacts on generative data, but only the artifacts are different. Due to the instability of the adversarial training process between the generator and the discriminator, GANs generate unnatural artifacts, e.g., blurred edges and inconsistent textures. While DMs retain small noise features during the stepwise denoising process, which can lead to more natural noise or detail distortion. Xi et al. (Xi et al., 2023) developed a robust dual-stream network consisting of a residual stream and a content stream to capture generic anomalies generated by AIGC. The residual stream utilizes the spatial rich model (SRM) to extract various texture information from images, while the content stream captures additional artifact traces at low frequencies, thus supplementing the residual stream with information that may have been missed. Sinitsa et al. (Sinitsa and Fried, 2024) presented a rule-based method that can achieve high detection accuracy by training a small number of generative images (less than 512). The method employs the inductive bias of CNNs to extract fingerprints of different generators from the training set and applies it to detect generative images of the same model and its fine-tuned versions. Joslin et al. (Joslin et al., 2024) introduced human factors to enhance generative detection. Detecting AI-synthesized faces by combining attentional learning methods with user annotations. They also created a crowdsourcing annotation method to systematically gather various user annotations to identify suspicious areas and extract artifact patterns. With the performance optimization that comes from a larger parametric model, the generative data will more closely mimic the original data while being able to circumvent artifacts, which increases the difficulty of generative detection.
Analyzing distinctive features of generated images is also a viable approach to consider. Interestingly, Wang et al. (Wang et al., 2023a) observed that the image generated by the DMs can be reconstructed by approximating the source model, while the real image cannot. Therefore, they proposed a novel image representation called diffusion reconstruction error (DIRE), which measures the distance between the input images and the reconstructed one. DIRE provides a reliable, simple, and generalized method to differentiate between real images and diffusion-generated images. SeDID (Ma et al., 2023a) leverage the unique properties of diffusion models, namely deterministic inverse and deterministic denoising computational error. In addition, its use of insights from member inference attacks to emphasize distributional differences between real and generative data enhances the understanding of the security and privacy implications of diffusion models. Zhong et al. (Zhong et al., 2023) focused on the inter-pixel correlation contrast between rich and poor texture regions within an image, and presented a universal detector which can generalize to various AI models, including GAN-based and DM-based models. Existing state-of-the-art detectors have a generalization of cross architectures, but the generalization of cross concepts is not considered. To this end, Dogoulis et al. (Dogoulis et al., 2023) proposed a sampling strategy that takes into account the image quality scores of the sampled training data, and can effectively improve the detection performance in the cross-concept setting.
Innovatively, Bi et al. (Bi et al., 2023) explored the invariance of real images, and proposed a method to map real images to a dense subspace in the feature space, while all generative images are projected outside this subspace. In this way, it can effectively address longstanding issues in generative detection, e.g., poor generalization, high training costs, and weak interpretability.
Generative text detection: Metric-based detection extracts distinguishable features from the generative text. Early on, GLTR (Gehrmann et al., 2019) was a tool to assist humans in detecting generated text. It employs a set of baseline statistical methods that can detect generation artifacts in common sampling schemes. In a human subject study, the annotation scheme provided by GLTR improved human detection of fake text from 54% to 72% without any prior training. Mitchell et al. (Mitchell et al., 2023) noticed that the texts sampled from LLMs tend to occupy negative curvature regions of the model’s log probability function. Based on this, DetectGPT is proposed to set a new curvature-based criterion for detection without additional training. Tulchinskii et al. (Tulchinskii et al., 2024) proposed a new distinguishable representation, the intrinsic dimension. Fluent texts in natural languages have an average intrinsic dimension of 9 or 7 in each language, while AI-generated texts have a lower average intrinsic dimension of 1.5 in each language. Detectors constructed on the basis of intrinsic dimensionality have strong generalizability to models and scenarios.
Regarding the model-based methods (Guo et al., 2023; Chen et al., 2023a), a classification model is usually trained using a corpus. Guo et al. (Guo et al., 2023) proposed a text detector for ChatGPT. The detector is based on the RoBERTa model, which is trained by plain answer text and question-answer text pairs respectively. Chen et al. (Chen et al., 2023a) trained two different text classification models using robustly optimized BERT pretraining approach (RoBERTa) and text-to-text Transfer Transformer (T5), respectively, and achieved significant performance on the test dataset with an accuracy of more than 97%.
| Ref. | Year | Remarks | Limitations | ||
|---|---|---|---|---|---|
| Genera-tive Detection | (Corvi et al., 2023) | 2023 | Pioneering detection for DMs | Lack of JPEG robustness | |
| (Sinitsa and Fried, 2024) | 2024 | Low budget, multi-model applicable | Lack of blurring robustness | ||
| (Wang et al., 2023a) | 2023 | Strong interpretability | High resource consumption | ||
| (Zhong et al., 2023) | 2023 | Universal to DMs and GANs | Poor results on special models | ||
| (Ma et al., 2023a) | 2023 | Use of DM distinct property | Not applicable to GANs | ||
| (Dogoulis et al., 2023) | 2023 | Generalizing cross-conceptes | Not high detection performance | ||
| (Bi et al., 2023) | 2023 | High generalization, low costs | Imperfect JPEG robustness | ||
| (Gehrmann et al., 2019) | 2019 | Training-free, numerically calculable | Unsatisfactory detection accuracy | ||
| (Mitchell et al., 2023) | 2023 | Human-readable, high-efficiency | Strong white-box assumption | ||
| (Tulchinskii et al., 2024) | 2024 | Generalization and robustness | Failure to small-sample languages | ||
| (Guo et al., 2023) | 2023 | Large-scale data, human evaluations | Resource-intensive, poorly explained | ||
| (Chen et al., 2023a) | 2023 | High accuracy, explicable | Not scalable, only for English | ||
| Genera-tive Attribution | (He et al., 2024) | 2024 | Systematic quantification | Medium attribution performance | |
| (Bui et al., 2022) | 2022 | Robust and practical attribution | Only ofr GANs, noise-irrobustness | ||
| (Yang et al., 2023) | 2023 | Open-Set model attribution | Moderate versatility and scalability | ||
| (Sha et al., 2023) | 2023 | Pioneering attribution for DMs | Lack of generalizability | ||
| (lor, 2023) | 2023 | Lightweight, superior performance | Difficult to scale to other models | ||
| (Guarnera et al., 2024) | 2024 | Hierarchical multi-level | Unrobust in compression and scaling | ||
| (Wang et al., 2023b) | 2023 | Paradigm of data attribution | Lack of strict proof | ||
| (Asnani et al., 2024) | 2024 | Paradigm of concept attribution | Requires predefined concepts |
5.2.2. Generative Attribution
He et al. (He et al., 2024) extended current detectors to the potential of text attribution to recognize the source model of a given text. The results show that all these detectors have certain attribution capabilities and still have room for improvement. Moreover, model-based detectors can significantly outperform metric-based detectors.
For visual generative data, a lot of attribution works on GANs (Yu et al., 2019; Bui et al., 2022; Yang et al., 2022; Girish et al., 2021; Yang et al., 2023) has been proposed. RepMix (Bui et al., 2022) is a GAN-fingerprinting technique based on representation mixing and a novel loss. It is able to determine from which structure of GAN a given image is generated. POSE (Yang et al., 2023) tackles an important challenge, i.e., open-set model attribution, which can simultaneously attribute images to seen and unseen models. POSE simulates open-set samples that keep the same semantics as closed-set samples but embed distinct traces.

.
Recent works have begun to focus on DMs. Sha et al. (Sha et al., 2023) constructed a multi-class (instead of binary) classifier to attribute fake images generated by DMs. Experiments showed that attributing fake images to their originating models can be achieved effectively, because different models leave unique fingerprints in their generated images. Lorenz et al. (lor, 2023) designed the multi-local intrinsic dimensionality (multiLID), which is effective in identifying the source diffusion model. Guarnera et al. (Guarnera et al., 2024) developed a novel multi-level hierarchical approach based on ResNet models, which can recognize the specific AI architectures (GANs/DMs). The experimental results demonstrate the effectiveness of the proposed approach, with an average accuracy of more than 97%.
Intriguingly, a new work (Wang et al., 2023b) can attribute generative data to the training data rather than the source model, necessitating the identification of a subset of training images that contribute most significantly to the generated data. In Fig. 8, we can query the generated data in the training set and evaluate their similarity, which can contribute to protecting the copyright of training data rather than models.
5.3. Summary
In table 4, we summarize the solutions for the authenticity of generative data. Generative data contains traces (referred to as fingerprints) left by generative models, allowing researchers to detect and attribute the data based on these fingerprints. However, as generative models undergo iterative optimization, these fingerprints also continuously evolve. Therefore, new detection methods must be updated in real time. In contrast, real data exhibits certain invariable features that remain unaltered over time or under varying circumstances. Future detection methods should be designed to effectively harness these invariable features, thereby enhancing the accuracy and robustness of detecting generated data. Furthermore, watermark-based methods have demonstrated notable potential in enhancing tasks related to detection and attribution. However, it’s important to note that such methods constitute an active defense strategy, necessitating preprocessing during data generation. In real-world scenarios, constraining adversaries to exclusively employ watermarked generative data may be not feasible. In addition, adversarial attacks can also have an impact on the controllability of generative data. On the one hand, adversarial attacks can attack generative models to prevent them from generating inauthentic content, which ensures the authenticity of generative data at the source. On the other hand, adversarial attacks can attack generative detectors to obfuscate their decisions, which exacerbates the authenticity challenge on generative data.
6. Compaliance on Generative Data
6.1. Requirements to Compaliance
The compliance of generative data refers to the requirement that such data must adhere to applicable laws, regulations, and ethical standards. With the rapid development and extensive utilization of AIGC technology, the compliance of generative data has become an important topic, encompassing various aspects, e.g., ethics, bias, and politics.
Countries and organizations around the world have initiated investigations and issued relevant policies and regulations regarding the regulation of generative data. The United States’ Blueprint for an AI Bill of Rights emphasizes generative data to ensure fairness, privacy protection, and accountability. European Parliament passed the Artificial Intelligence Act, which supplements the regulatory regime for generative models and requires that all generative data should be disclosed as derived from AI. China proposed an AIGC-specific regulation, i.e., the Interim Regulation on the Management of Generative Artificial Intelligence Services (int, 2023). This regulation encourages innovation of AIGC but requires a prohibition on the generation of toxicity, e.g., violence, bias, and obscene pornography, as well as an increase in the factuality of the generative data to avoid misleading the public.

6.1.1. Non-toxicity
Toxicity presents in generative data involves incongruence with human values or bias directed at particular groups, which has the potential to harm societal cohesion and intensify divisions among different groups. Since the training of AIGC models is based on a large amount of unintervened data, toxicity in training data (Birhane et al., 2021) directly leads to the corresponding toxicity in generative data, which covers a variety of harmful topics, e.g., sexuality, hatred (Birhane et al., 2024), politicalization, violentism, and race bias. Some toxic generative examples are shown in Fig. 9.
Some works (Caliskan et al., 2017; Sheng et al., 2019) have found stronger associations between males and occupations in language models, verifying the gender bias in generative data. The investigations revealed that GPT-3 consistently and strongly exhibits biased views against the Muslim community (Abid et al., 2021). Stable Diffusion v1 was trained on the LAION-2B dataset, which contains images described only in English, making generative data biased towards white culture . Likewise, it was observed that DALLA-E displayed unfavorable biases towards minority groups.
Unlike GANs that only use random noise to generate data, DMs can be guided by additional textual prompts, which increases the risk of generating non-compliant content. As a result, researchers primarily focus on the compliance of data generated by DMs. Qu et. al (Qu et al., 2023) provided a comprehensive safety assessment concerning the generation of toxic images, particularly hateful memes from diffusion models. To quantitatively assess the safety of generative images, a safety classifier is developed to identify toxic images based on the predetermined criteria for unsafe content. Their findings indicated that the utilization of harmful prompts resulted in diffusion models producing a significant quantity of toxic images. Additionally, even when prompts are innocuous, the potential for generating toxic images persists. Overall, the danger of large-scale generation of toxic images is imminent.
6.1.2. Factuality
AI-generated data may be contrary to the facts (Wang et al., 2023c), which is harmful to the public through misleading cognition. For example, ChatGPT may produce responses that sound reasonable and authoritative but are factually incorrect or nonsensical. Even worse, AIGC often explains its generated responses. When AIGC fails to provide accurate responses to the queries, it not only delivers incorrect information but also supplements seemingly plausible explanations. This enhances the inclination of users to place greater trust in these erroneous contents. The United States news credibility assessment and research organization, NewsGuard, conducted a test on ChatGPT (nyt, 2023). Researchers posed questions to ChatGPT containing conspiracy theories and misleading narratives and found that it could adapt information within seconds, generating a substantial amount of persuasive yet unattributed content.
When used in important domains, such unfactual generative data will bring serious harmful impacts (Bender et al., 2021). In the healthcare domain, medical diagnosis requires interpretable and correct information. Once AI-generated diagnostic advice is factually incorrect, it will cause irreparable harm to the patient’s life and health. In the journalism domain, news that distorts the facts will mislead the public and undermine the credibility of the media. In the education domain, the dissemination of incorrect knowledge to students will confuse their minds, thus seriously hampering their academic growth and cognitive development.
6.2. Countermeasures to Compaliance
6.2.1. Countermeasures to Non-toxicity
Efforts to eliminate toxicity can be divided into four categories. The first one is dataset filtering. A non-toxic training dataset is key to ensuring the security of generative data. Some works (Schuhmann et al., 2022; DAL, 2022; Henderson et al., 2022) have implemented comprehensive processes to filter data contained toxic. OpenAI ensures that any violent or sexual content is removed from DALLA-E2 by carefully filtering (DAL, 2022). Henderson et. al (Henderson et al., 2022) demonstrated how to extract implicit sanitization rules from the Pile of Law, providing researchers with a pathway to develop more sophisticated data filtering mechanisms. However, large-scale dataset filtering also has unexpected side effects on the downstream performance (Nichol et al., 2021).
The second one is generation guidance. Ganguli et al. (Ganguli et al., 2022) identified and attempted to reduce the potentially harmful output of language models in a confrontational manner. They found that the reinforcement learning from human feedback is increasingly difficult to red team as they scale, and a flat trend with scale for the other model types. Brack et al. (Brack et al., 2023) investigated to instruct effectively diffusion models to suppress inappropriate content using the learned knowledge obtained about the world’s ugliness, thus producing safer and more socially responsible content. Similarly, safe latent diffusion (SLD) (Schramowski et al., 2023) extends the generative process via utilizing toxic prompts to guide the safe generation in an opposing direction.
The third one is model fine-tuning. Recently, a new term called the ablation concept or ablation forgetting (Gandikota et al., 2023; Kumari et al., 2023; Heng and Soh, 2024) has brought a novel direction to the elimination of toxic content in generative data. Gandikota et. al (Gandikota et al., 2023) studied the erasure of toxic concepts from diffusion model weights via model fine-tuning. The proposed method utilizes an appropriate style as a teacher to guide the ablation of the toxic concepts, e.g., sexuality and copyright infringement. Selective Amnesia (Heng and Soh, 2024) is a generalized continuous learning framework for concept ablation that applies to different model types and conditional scenarios. It also allows for controlled ablation of concepts that can be specified by the user. However, the ablation concept’s ability to explain the various definitions of toxic concepts remains limited. Inspired with social psychological principles, Xu et al. (Xu et al., 2024b) proposed a novel strategy to motivate LLM to integrate different human perspectives and self-regulate their responses.
Lastly, filtering the generated results is also a viable option. Stable Diffusion includes an after-the-fact safety filter to block toxic images. Unfortunately, the filter easily blocks any generated image that is too close to at least one of the 17 predefined sensitive concepts. Rando et. al (Rando et al., 2022) reverse-engineered this filter and then proposed a manual strategy that enables content not related to sensitive concepts to bypass the filter. In addition, existing toxicity detectors (Markov et al., 2023; Lu et al., 2023c) for real data may be able to be updated to be compatible with generative data. This self-correcting mechanism can significantly reduce toxicity and bias.
6.2.2. Countermeasures to Factuality
In order to constrain the non-factualness caused by AIGC “lying”, Evans et al. (Evans et al., 2021) first identified clear standards for AI truthfulness and explored potential ways to establish them.
| Ref. | Year | Remarks | Limitations | ||
|---|---|---|---|---|---|
| Non-toxicity | (Henderson et al., 2022) | 2022 | Legally guaranteed | Only for U.S. texts, perturbation-sensitive | |
| (Ganguli et al., 2022) | 2022 | The idea of constant confrontation | Time-consuming, difficult to scale | ||
| (Rando et al., 2022) | 2022 | Comprehensive toxicity concept | Takes a lot of labor, subjective definition | ||
| (Brack et al., 2023) | 2023 | World knowledge guidance | Need to modify the model | ||
| (Schramowski et al., 2023) | 2023 | Free-train, maintain quality | Lack of provability and ethical concern | ||
| (Heng and Soh, 2024) | 2024 | Controllable forgetting | Computing costly, non-automated | ||
| (Xu et al., 2024b) | 2024 | Self-regulate, low cost | Ignorance of sensitive vocabularies | ||
| Factuality | (Lee et al., 2022) | 2022 | Open-ended test, new metrics | Lack of moral consideration | |
| (Alaa et al., 2022) | 2022 | Three-dimensional metric | Divergence measures collapse | ||
| (Azaria and Mitchell, 2023) | 2023 | Simple and powerful | Difficult to interpret | ||
| (Du et al., 2023) | 2023 | Comprehensible, reasonable | Large resource consumption | ||
| (Gou et al., 2024) | 2024 | Practical and simple | Limited to syntactic correctness | ||
| (Chen et al., 2024a) | 2024 | Without extra models or human | Difficulty in controlling mistake | ||
| (Zhang et al., 2024a) | 2024 | Learned refusal ability | Lack of rigorous evaluation |
A reasonable assessment of content factuality is the critical step toward responsible generative data. Goodrich et al. (Goodrich et al., 2019) constructed relation classifiers and fact extraction models based on Wikipedia and Wikidata, by which the factual accuracy of generated text can be measured. Lee et al. (Lee et al., 2022) proposed a novel training method to enhance factuality by utilizing TOPIC PREFIX for better perception of facts and sentence completion as the training objective, which can significantly decrease the number of counterfactuals. They also study the factual accuracy of LLMs with parameter sizes ranging from 126M to 530B and find that the larger the model, the higher the accuracy. This is because the model has a large enough capacity to learn more generalized knowledge, thus reducing the occurrence of counterfactuals.
Alaa et al. (Alaa et al., 2022) designed a three-dimensional metric capable of characterizing the fidelity, diversity, and generalization of generative data from widely generative models in a wide range of applications. SAPLMA (Azaria and Mitchell, 2023) is a simple but powerful method, which only uses the hidden layer activation of LLM to discriminate the factuality of generated statements.
Interestingly, Du et al. (Du et al., 2023) prompted multiple language models to debate their viewpoints and reasoning processes over multiple rounds, and finally come up with a unitive answer. The results indicate that it enhances mathematical and strategic reasoning in the task while reducing the fallacious answers and illusions that modern models are prone to. CRITIC (Gou et al., 2024) requires LLMs to interact with appropriate tools for feedback learning, such as using a search engine for fact-checking or a code interpreter for debugging. The output of the LLM is modified incrementally by the evaluation results of the feedback by the tools. Chen et al. (Chen et al., 2024a) presented a new alignment framework designed to improve LLMs by converting flawed instruction-response pairs into useful alignment data through mistake analysis. By generating harmful responses and analyzing their own mistakes, the framework can improve the alignment with human values. To prevent LLMs from rambling without knowing the answer, Zhang et al. (Zhang et al., 2024a) taught LLMs the ability to refuse to answer. Specifically, they constructed datasets of refusal perception, and then adapted the model to avoid answering questions that were beyond its parametric knowledge.
6.3. Summary
In table 5, we summarize the solutions for toxicity and factuality in generative data. The first problem to be solved for the compliance of generative data is to define its standards. In addition, there should be different compliance standards for different application scenarios, rather than a blanket denial of generative content. For example, “a flying pig” may not be factual for a language model, but it is more creative for a visual model. After that, the generated content of AI can be made compliant with the specification within the constraints of the standard. In addition, adversarial attacks can also have an impact on the controllability of generative data. On the one hand, adversarial attacks can attack the generative model to prevent it from learning the non-compliant content in the real data, which enhances the compliance of generative data. On the other hand, adversarial attacks can also attack compliance detectors to evade their detection, which exacerbates the compliance challenge for generative data.
In conclusion, we emphasize the examination of toxicity and factuality issues within the context of compliance to ensure the responsible and ethical use of AI-generated content across various domains. Nevertheless, existing approaches exhibit certain limitations, nec essitating continuous efforts by researchers to address these shortcomings and better align with the practical requirements of real-world applications.
7. Benchmark and Statistical Analysis
7.1. Benchmark
7.1.1. Benchmark Dataset
The construction of generative datasets facilitates the design and evaluation of countermeasures, helping researchers to identify problems and improve techniques, thus advancing the progress of trustworthy generative data. Researchers have now released diverse datasets for utilization.
For text data, most datasets are domain-specific, e.g., Student Essays (Verma et al., 2023) for essays, TuringBench (Uchendu et al., 2021) for news, GPABenchmark (Liu et al., 2023e) for academic writing, SynSciPass (Rosati, 2022) for scientific text, TweepFake and (Fagni et al., 2021) for tweets. Representatively, HC3 (Guo et al., 2023) is a comprehensive ChatGPT generative text that contains tens of thousands of responses with human experts and covers a wide range of domains such as finance, healthcare, law, etc. The pioneering contributions of HC3 also make it a valuable research resource. More practically, MixSet (Zhang et al., 2024b) is the first mixed-text dataset involving both AIGC and human-generated content, covering a wide range of operations in real-world scenarios and bridging a gap in previous datasets.
For visual data, only some datasets are domain-specific mainly in faces such as IDiff-Face (Boutros et al., 2023) and GANDiffFace (Melzi et al., 2023), and most datasets contain general images such as CIFAKE (Bird and Lotfi, 2024) and AutoSplice (Jia et al., 2023). While, they have different limitations, e.g., targeting only a certain class of images or generators, and containing only a small amount of data. Subsequently, several million-scale datasets are released like GenImage (Zhu et al., 2024) and ArtiFact (Rahman et al., 2023), which have the richness of image content and adopt state-of-the-art generators. To the best of our knowledge, DiffusionDB (Wang et al., 2022a) represents the largest-scale visual generative dataset to date. It comprises 14 million images generated only by Stable Diffusion. This unprecedented scale and diversity offer exciting research opportunities for the study of generative image protection.
7.1.2. Benchmark Evaluation
The construction of benchmark evaluation provides a standardized baseline, which evaluates the effectiveness and innovativeness of new methods by enabling different methods to be fairly compared under the same testing conditions. Meanwhile, it can ensure the reproducibility of research and clearly identify the shortcomings of existing techniques, thus promoting technological progress. We identified the corresponding benchmarks for different information security properties.
For privacy, PrivLM-Bench (Li et al., 2024b) is a multi-perspective privacy evaluation benchmark that empirically and intuitively quantifies the privacy leakage of LLMs and reveals the neglected privacy of inference data in actual usage. Wu et al. (Wu et al., 2024) provided the first comprehensive privacy assessment of prompts learned via visual prompt learning from the perspectives of attribute inference and membership inference attacks.
For controllability, WaterBench (Tu et al., 2023) is the first comprehensive benchmark for watermarking LLMs, which encompasses 9 tasks and evaluates 4 open-source watermarking technologies. WAVES (An et al., 2024) is a comprehensive watermarking benchmark, which establishes a standardized evaluation protocol consisting of various pressure tests and covers advanced image distortion attacks.
For authenticity, DeepfakeBench (Yan et al., 2023) introduces the first all-encompassing benchmark for detecting deepfakes of generative data, addressing the problem of inconsistent standards and lack of uniformity in this area. Lu et al. (Lu et al., 2023b) comprehensively evaluated techniques used for generative detection and also measured the ability of human vision to discriminate between generative data.
For compliance, GenderCARE (Tang et al., 2024) is a comprehensive framework that includes innovative standards, bias assessments, mitigation techniques, and evaluation metrics for quantifying and alleviating gender bias in LLMs. FELM (chen et al., 2023) is a factual evaluation benchmark for generative texts. Through manual annotation of error types, it alerts users to potential errors and guides the development of more reliable large language models.
7.2. Statistical Analysis
As shown in Fig. 10, we have statistically analyzed the research articles with high relevance to generative data security and privacy in the last five years (2020-July 2024). We observe that most researchers focus on traceability and generative detection. The main reason is that generative data can be disastrous when used for malicious purposes, so it is urgent to come up with appropriate techniques to satisfy controllability and authenticity. At the same time, national strategies are guiding researchers to focus on the controllability of generative data. In addition, forensic and watermarking techniques for traditional tampering techniques have a high potential to be transferred to issues related to generative data.
AIGC for privacy is also an interesting and hot research topic. The generative data can be virtual data to effectively replace sensitive data in human decision-making, thus avoiding the leakage of personal privacy. Modern applications like telemedicine, recommendation algorithms, smart cities, etc. can safely provide convenient services to society with the help of generative data.
In contrast, non-toxicity and factuality only account for a small percentage. In particular, existing compliance studies focus more on generative text data and rarely examine the non-toxicity and factuality of generative visual data. In addition, this compliance research involves multiple fields such as sociology, management, law, and computer science, which makes it difficult to rely on domain-specific experts for governance. With the guidance of the policy, we believe that compliance-related work will account for more and more.
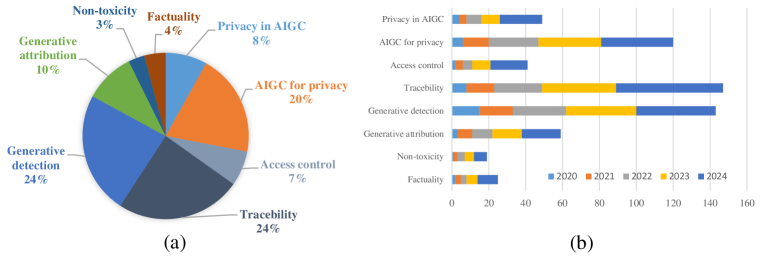
.
8. Challenges and Future directions
8.1. Privacy
8.1.1. Provable Private Content Removal Based on Information Theory
Existing privacy protection technologies attempt to remove potentially private content in generative data via machine unlearning or concept forgetting. However, such private content removal is not provable. The parameters of the generative model may still conceal the private content, which can be revealed under specific prompts with backdoors. While differential privacy can provide provable privacy guarantees, it requires retraining the model and sacrificing unacceptable usability. Therefore, it is necessary to explore new provable solutions to guarantee privacy. Exploring information theory-based methods may be a desirable research direction, which can directly limit the amount of retained information after private content is removed. Of course, how to measure the amount of information from generative models at this point is also a challenging problem.
8.1.2. Semantic-Level Quantitative Evaluation for Privacy and Utility
To compare the performance of different privacy-preserving technologies, it is crucial to develop quantitative evaluation metrics to measure privacy and utility before and after private content removal. However, constructing such fine-grained evaluation metrics requires systematically analyzing the learning processes and memory mechanisms of different generative models, which is difficult. In addition, compared to text data, the amount of information in visual data is multiple and complex (a picture is worth a thousand words) thus making it more difficult to measure privacy and utility. Considering that visual data is more concerned with semantic-level information, in the future, it is meaningful to design the metrics oriented to the semantic level, which can effectively guide generative data to achieve a balance between utility and privacy. In addition, since the semantics represented by privacy and utility are not always the same in different scenarios, it will be more practical and challenging to make quantitative metrics generic or flexible.
8.1.3. Exploratory Solutions to the Privacy Onion Effect
The privacy onion effect refers to the fact that when the most privacy-vulnerable outlier layer is removed, the privacy risk of the previously secure layer becomes the greatest. The existence of this effect can have a variety of serious consequences, in particular, it indicates that privacy-enhancing technologies may actually compromise the privacy of other users. However, there are very few existing exploration studies targeting this effect. The reason that this effect brings about privacy leakage originates from the idea that mean data points are rarely compromised, but outlier samples are often memorized. Therefore, it may be an intuitive solution to consider clustering the dataset to eliminate outlier points, but this perhaps reduces the diversity of the data. In this way, it is an important problem to maintain dataset utility while deleting reasonable data.
8.2. Controllability
8.2.1. Fine-grained Access Control of Generative Data
Existing work simply adds adversarial perturbations to block access to the expected generative data. However, in most cases, users just want to prohibit generative data from containing specific semantics while allowing other semantics to exist. For example, an image containing the face of a celebrity is accessible, but when it is changed in gender or uglified it is not accessible. Existing work prohibits generative data with all semantics, which limits its practicality. Furthermore, users with roles can be restricted from accessing specific data, such as teenagers being prohibited from accessing essay writing type data but allowing adults to access it. Therefore, it is also a promising direction to provide fine-grained access control for generative data, which allows for flexible usage. To achieve it, a deep understanding of its generative process and digging into its intrinsic mechanism are necessary.
8.2.2. Robust Watermarking with High-Capacity for Text Data
Unlike visual data which is easy to achieve robust watermarking with high capacity, text data faces important challenges: Firstly, text data is significantly sparse, for example, the maximum token limit in GPT-4 is 8.2k which is much smaller than the watermarking capacity that can be embedded in 512-pixel images. Secondly, the semantics of text data are fragile as subtle changes may confuse or compromise its semantics, whereas minor changes in images can maintain consistent semantics. Some multi-bit watermarking can increase the watermarking capacity to some extent, but it also significantly reduces the robustness. Therefore, in future research, it is essential to consider designing new text watermarking paradigms to effectively balance the high capacity and strong robustness of text watermarking.
8.3. Authenticity
8.3.1. Generalizable Generative Detection based on Invariance of Real Data
Existing detection methods attempt to find the decision boundary between real and generative data by a specific generative model, but it is difficult to generalize to new generative models. Detection performance degrades significantly when encountering data generated by generative models not seen in the training set. To improve generalization, the detector needs to be fine-tuned to allow capturing the decision boundaries of new generative models. However, the decision boundaries captured by the detector are intricate as the generative model iteratively changes. Since real data does not change massively over time, its inherent invariances (Qi et al., 2024) make it a reliable clue for generative detection. These invariances may include signal distribution, noise distribution, texture features of the data, etc. Exploring new invariants or joining multiple invariants is an important future direction. Meanwhile, interpretable analysis of these invariants will also make generative detection more credible and thus be able to be used for judicial forensics.
8.3.2. Tamper Detection of Generative Data
Similar to the real data, with the widespread use of generative data, it is becoming increasingly important to accurately detect whether the generative data has been tampered. However, current existing generative detection methods are challenging to do. The main reason is that generative data is itself generated by AI and also tampered with in an AI manner, making it difficult to judge modifications based on the fingerprints of the AI models. To address this issue, one can consider embedding semi-fragile watermarks for generative data, thus ensuring its integrity. However, it is unrealistic for all users to uniformly adopt such post-hoc operations. Therefore, there is still a requirement to propose effective techniques to detect the tampered generative data directly. To do this, researchers need to conduct a variability analysis of AI-generated models and AI-tampered models.
8.3.3. Towards User-friendly Generative Detection
When it comes to important decisions, machine vision-based generative detection techniques only provide initial judgments, while users still need to make further judgments by themselves. However, existing technology does not yet provide a directly interpretable, trustworthy, and easy-to-handle detection modality which makes it difficult for users to make rational decisions conveniently. Therefore, the development of interpretable, trustworthy, and easy-to-handle detection tools will be able to attract more social attention and popularization, thus promoting the friendly usage of detection techniques for disadvantaged groups, including unskilled users and the elderly. Conducting relevant user research analysis and incorporating explainable AI will help build user-friendly generative detection.
8.4. Compliance
8.4.1. Quantification and Assessment of Compliance
While existing laws and regulations already impose requirements for compliance with generative data, how to quantify and assess these requirements remains a challenging question. Firstly, compliance requirements are abstract and broad. Laws and regulations usually stipulate a series of principles and standards, but do not give specific metrics and standards. Therefore, it requires an in-depth understanding of the connotations of the legal provisions and their concretization in the context of the actual situation. Secondly, the type of generative data is complex, which covers a variety of multimodal and cross-modal contents. The automated methods for quantification involve the cross-application of fields, which requires the development of efficient multimodal fusion algorithms to realize it. Finally, there are differences in laws and regulations in different countries and regions. Compliance assessment of generative data needs to consider and cater to different geographical and cultural contexts, which adds to the complexity of the assessment.
8.4.2. Human Intelligence-Guided Detection for Hidden Toxicity
Toxic content hiding in generative data often remains imperceptible to human perception and toxicity detectors. However, it might be uncovered by the special extractor of attackers, thereby giving rise to potential hazards. This situation may stem from the deep embedding of toxic information or the utilization of advanced information-hiding techniques to evade conventional detectors. Such hidden toxic content carries an undeniable risk that could disseminate widely across platforms, e.g., social media, news reporting, and virtual communities, consequently precipitating a range of societal issues. To counter this, human intelligence has advanced reasoning capabilities and is able to detect potentially toxic content by recognizing language, context, and metaphor. Of course, relying solely on human intelligence is extremely time-consuming and thus impractical. Future work should focus on human-intelligence-guided toxicity detection, which aims to find more stealthy toxicity using less human labor.
9. Conclusion
The rapid growth of AIGC has made data creation easier. Many generative data flood the cyberspace, which poses security and privacy issues. This survey comprehensively discusses the security and privacy issues on generative data and reviews the corresponding solutions. Firstly, We show the process of AIGC and point out the security and privacy from the perspective of the fundamental properties of information security. After that, we reveal the successful experiences of state-of-the-art protection measures in terms of the foundational properties of privacy, controllability, authenticity, and compliance, respectively. Finally, we discuss possible future directions in this area.
Generative data now plays a significant and positive role in a variety of fields. Several surveys have also provided insights from different perspectives for the wide-scale application of generative data, including stable data transmission (Saleh et al., 2024), mobile network deployment (Xu et al., 2024a), semantic communications (Liu et al., 2024a), and even personalized healthcare (Chen et al., 2024b). Our survey provides guidance on security and privacy for all existing applications of generative data. Firstly, for the designers of the AIGC model, we expect them to pay attention to the existing security and privacy issues and then revise the AIGC model in terms of privacy, controllability, authenticity, and compliance. Secondly, for users of the AIGC model, we expect them to use it in a way that avoids compromising individual privacy while prohibiting the generation of potentially non-compliant data. We hope that this survey can provide new ideas on the security and privacy on generative data, promoting the application of trustworthy generative data.
References
- (1)
- Bea (2022) 2022. Clip retrieval system. https://rom1504:github:io/clip-retrieval/.
- DAL (2022) 2022. DALL·E 2 pre-training mitigations. https://openai.com/research/dall-e-2-pre-training-mitigations.
- lor (2023) 2023. Detecting Images Generated by Deep Diffusion Models Using Their Local Intrinsic Dimensionality. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. 448–459.
- nyt (2023) 2023. Disinformation Researchers Raise Alarms About A.I. Chatbots. https://www.nytimes.com/2023/02/08/technology/ai-chatbots-disinformation.html.
- Pen (2023) 2023. Fact Check: Was There an Explosion at the Pentagon? https://www.newsweek.com.
- int (2023) 2023. Interim Regulation on the Management of Generative Artificial intelligence (AI) Services. https://www.gov.cn/zhengce/zhengceku/202307/content_6891752.htm.
- Abadi et al. (2016) Martin Abadi, Andy Chu, Ian Goodfellow, H Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security. 308–318.
- Abid et al. (2021) Abubakar Abid, Maheen Farooqi, and James Zou. 2021. Persistent anti-muslim bias in large language models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society. 298–306.
- Alaa et al. (2022) Ahmed Alaa, Boris Van Breugel, Evgeny S Saveliev, and Mihaela van der Schaar. 2022. How faithful is your synthetic data? sample-level metrics for evaluating and auditing generative models. In International Conference on Machine Learning. PMLR, 290–306.
- Aliman and Kester (2022) Nadisha-Marie Aliman and Leon Kester. 2022. VR, Deepfakes and Epistemic Security. In 2022 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR). 93–98. https://doi.org/10.1109/AIVR56993.2022.00019
- An et al. (2024) Bang An, Mucong Ding, Tahseen Rabbani, Aakriti Agrawal, Yuancheng Xu, Chenghao Deng, Sicheng Zhu, Abdirisak Mohamed, Yuxin Wen, Tom Goldstein, and Furong Huang. 2024. WAVES: Benchmarking the Robustness of Image Watermarks. In Proceedings of the 41st International Conference on Machine Learning (ICML), Vol. 235. 1456–1492.
- Asnani et al. (2024) Vishal Asnani, John Collomosse, Tu Bui, Xiaoming Liu, and Shruti Agarwal. 2024. ProMark: Proactive Diffusion Watermarking for Causal Attribution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10802–10811.
- Azaria and Mitchell (2023) Amos Azaria and Tom Mitchell. 2023. The internal state of an llm knows when its lying. arXiv preprint arXiv:2304.13734 (2023).
- Bai et al. (2022) Andrew Bai, Cho-Jui Hsieh, Wendy Kan, and Hsuan-Tien Lin. 2022. Reducing Training Sample Memorization in GANs by Training with Memorization Rejection. arXiv preprint arXiv:2210.12231 (2022).
- Bender et al. (2021) Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency. 610–623.
- Bi et al. (2023) Xiuli Bi, Bo Liu, Fan Yang, Bin Xiao, Weisheng Li, Gao Huang, and Pamela C Cosman. 2023. Detecting Generated Images by Real Images Only. arXiv preprint arXiv:2311.00962 (2023).
- Bird and Lotfi (2024) Jordan J Bird and Ahmad Lotfi. 2024. Cifake: Image classification and explainable identification of ai-generated synthetic images. IEEE Access (2024).
- Birhane et al. (2024) Abeba Birhane, Sanghyun Han, Vishnu Boddeti, Sasha Luccioni, et al. 2024. Into the LAION’s Den: Investigating hate in multimodal datasets. Advances in Neural Information Processing Systems 36 (2024).
- Birhane et al. (2021) Abeba Birhane, Vinay Uday Prabhu, and Emmanuel Kahembwe. 2021. Multimodal datasets: misogyny, pornography, and malignant stereotypes. arXiv preprint arXiv:2110.01963 (2021).
- Bourtoule et al. (2021) Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine unlearning. In 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 141–159.
- Boutros et al. (2023) Fadi Boutros, Jonas Henry Grebe, Arjan Kuijper, and Naser Damer. 2023. Idiff-face: Synthetic-based face recognition through fizzy identity-conditioned diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 19650–19661.
- Brack et al. (2023) Manuel Brack, Felix Friedrich, Patrick Schramowski, and Kristian Kersting. 2023. Mitigating Inappropriateness in Image Generation: Can there be Value in Reflecting the World’s Ugliness? arXiv preprint arXiv:2305.18398 (2023).
- Bui et al. (2022) Tu Bui, Ning Yu, and John Collomosse. 2022. Repmix: Representation mixing for robust attribution of synthesized images. In European Conference on Computer Vision. Springer, 146–163.
- Caliskan et al. (2017) Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science 356, 6334 (2017), 183–186.
- Cao and Li (2021) Chu Cao and Mo Li. 2021. Generating mobility trajectories with retained Data Utility. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 2610–2620.
- Carlini et al. (2023a) Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. 2023a. Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23). 5253–5270.
- Carlini et al. (2023b) Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2023b. Quantifying memorization across neural language models. In International Conference on Learning Representations (ICLR).
- Carlini et al. (2021) Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21). 2633–2650.
- Chen et al. (2023b) Chuan Chen, Zhenpeng Wu, Yanyi Lai, Wenlin Ou, Tianchi Liao, and Zibin Zheng. 2023b. Challenges and Remedies to Privacy and Security in AIGC: Exploring the Potential of Privacy Computing, Blockchain, and Beyond. arXiv preprint arXiv:2306.00419 (2023).
- Chen et al. (2024b) Jiayuan Chen, Changyan Yi, Hongyang Du, Dusit Niyato, Jiawen Kang, Jun Cai, and Xuemin Shen. 2024b. A revolution of personalized healthcare: Enabling human digital twin with mobile AIGC. IEEE Network (2024).
- Chen et al. (2021) Jia-Wei Chen, Li-Ju Chen, Chia-Mu Yu, and Chun-Shien Lu. 2021. Perceptual indistinguishability-net (pi-net): Facial image obfuscation with manipulable semantics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6478–6487.
- Chen et al. (2024a) Kai Chen, Chunwei Wang, Kuo Yang, Jianhua Han, Lanqing HONG, Fei Mi, Hang Xu, Zhengying Liu, Wenyong Huang, Zhenguo Li, Dit-Yan Yeung, and Lifeng Shang. 2024a. Gaining Wisdom from Setbacks: Aligning Large Language Models via Mistake Analysis. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=aA33A70IO6
- chen et al. (2023) shiqi chen, Yiran Zhao, Jinghan Zhang, I-Chun Chern, Siyang Gao, Pengfei Liu, and Junxian He. 2023. FELM: Benchmarking Factuality Evaluation of Large Language Models. In Advances in Neural Information Processing Systems, Vol. 36. 44502–44523.
- Chen et al. (2023a) Yutian Chen, Hao Kang, Vivian Zhai, Liangze Li, Rita Singh, and Bhiksha Ramakrishnan. 2023a. GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content. arXiv preprint arXiv:2305.07969 (2023).
- Clark et al. (2019) Aidan Clark, Jeff Donahue, and Karen Simonyan. 2019. Efficient video generation on complex datasets. arXiv preprint arXiv:1907.06571 2, 3 (2019), 4.
- Corvi et al. (2023) Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. 2023. On the detection of synthetic images generated by diffusion models. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5.
- Cui et al. (2023) Yingqian Cui, Jie Ren, Han Xu, Pengfei He, Hui Liu, Lichao Sun, and Jiliang Tang. 2023. DiffusionShield: A Watermark for Copyright Protection against Generative Diffusion Models. arXiv preprint arXiv:2306.04642 (2023).
- Dockhorn et al. (2022) Tim Dockhorn, Tianshi Cao, Arash Vahdat, and Karsten Kreis. 2022. Differentially private diffusion models. arXiv preprint arXiv:2210.09929 (2022).
- Dogoulis et al. (2023) Pantelis Dogoulis, Giorgos Kordopatis-Zilos, Ioannis Kompatsiaris, and Symeon Papadopoulos. 2023. Improving Synthetically Generated Image Detection in Cross-Concept Settings. In Proceedings of the 2nd ACM International Workshop on Multimedia AI against Disinformation. 28–35.
- Du et al. (2023) Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. 2023. Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv preprint arXiv:2305.14325 (2023).
- Evans et al. (2021) Owain Evans, Owen Cotton-Barratt, Lukas Finnveden, Adam Bales, Avital Balwit, Peter Wills, Luca Righetti, and William Saunders. 2021. Truthful AI: Developing and governing AI that does not lie. arXiv preprint arXiv:2110.06674 (2021).
- Fagni et al. (2021) Tiziano Fagni, Fabrizio Falchi, Margherita Gambini, Antonio Martella, and Maurizio Tesconi. 2021. TweepFake: About detecting deepfake tweets. Plos one 16, 5 (2021), e0251415.
- Feng et al. (2021) Qianli Feng, Chenqi Guo, Fabian Benitez-Quiroz, and Aleix M Martinez. 2021. When do gans replicate? on the choice of dataset size. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 6701–6710.
- Feng et al. (2023) Weitao Feng, Jiyan He, Jie Zhang, Tianwei Zhang, Wenbo Zhou, Weiming Zhang, and Nenghai Yu. 2023. Catch You Everything Everywhere: Guarding Textual Inversion via Concept Watermarking. arXiv preprint arXiv:2309.05940 (2023).
- Fernandez et al. (2023) Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. 2023. The stable signature: Rooting watermarks in latent diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22466–22477.
- Gandikota et al. (2023) Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. 2023. Erasing concepts from diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2426–2436.
- Ganguli et al. (2022) Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858 (2022).
- Gehrmann et al. (2019) Sebastian Gehrmann, Hendrik Strobelt, and Alexander M Rush. 2019. Gltr: Statistical detection and visualization of generated text. arXiv preprint arXiv:1906.04043 (2019).
- Ghalebikesabi et al. (2023) Sahra Ghalebikesabi, Leonard Berrada, Sven Gowal, Ira Ktena, Robert Stanforth, Jamie Hayes, Soham De, Samuel L Smith, Olivia Wiles, and Borja Balle. 2023. Differentially private diffusion models generate useful synthetic images. arXiv preprint arXiv:2302.13861 (2023).
- Girish et al. (2021) Sharath Girish, Saksham Suri, Sai Saketh Rambhatla, and Abhinav Shrivastava. 2021. Towards discovery and attribution of open-world gan generated images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14094–14103.
- Gong et al. (2020) Maoguo Gong, Jialu Liu, Hao Li, Yu Xie, and Zedong Tang. 2020. Disentangled representation learning for multiple attributes preserving face deidentification. IEEE transactions on neural networks and learning systems 33, 1 (2020), 244–256.
- Goodfellow et al. (2020) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2020. Generative adversarial networks. Commun. ACM 63, 11 (2020), 139–144.
- Goodrich et al. (2019) Ben Goodrich, Vinay Rao, Peter J Liu, and Mohammad Saleh. 2019. Assessing the factual accuracy of generated text. In proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 166–175.
- Gou et al. (2024) Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. 2024. CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=Sx038qxjek
- Guarnera et al. (2024) Luca Guarnera, Oliver Giudice, and Sebastiano Battiato. 2024. Level up the deepfake detection: a method to effectively discriminate images generated by gan architectures and diffusion models. In Intelligent Systems Conference. Springer, 615–625.
- Guo et al. (2023) Biyang Guo, Xin Zhang, Ziyuan Wang, Minqi Jiang, Jinran Nie, Yuxuan Ding, Jianwei Yue, and Yupeng Wu. 2023. How close is chatgpt to human experts? comparison corpus, evaluation, and detection. arXiv preprint arXiv:2301.07597 (2023).
- He et al. (2024) Xinlei He, Xinyue Shen, Zeyuan Chen, Michael Backes, and Yang Zhang. 2024. Mgtbench: Benchmarking machine-generated text detection. In The ACM Conference on Computer and Communications Security.
- Henderson et al. (2022) Peter Henderson, Mark Krass, Lucia Zheng, Neel Guha, Christopher D Manning, Dan Jurafsky, and Daniel Ho. 2022. Pile of law: Learning responsible data filtering from the law and a 256gb open-source legal dataset. Advances in Neural Information Processing Systems 35 (2022), 29217–29234.
- Heng and Soh (2024) Alvin Heng and Harold Soh. 2024. Selective amnesia: A continual learning approach to forgetting in deep generative models. Advances in Neural Information Processing Systems 36 (2024).
- Hindistan and Yetkin (2023) Yavuz Selim Hindistan and E Fatih Yetkin. 2023. A Hybrid Approach With GAN and DP for Privacy Preservation of IIoT Data. IEEE Access 11 (2023), 5837–5849.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840–6851.
- Hu et al. (2021) Yupeng Hu, Wenxin Kuang, Zheng Qin, Kenli Li, Jiliang Zhang, Yansong Gao, Wenjia Li, and Keqin Li. 2021. Artificial Intelligence Security: Threats and Countermeasures. ACM Comput. Surv. 55, 1, Article 20 (nov 2021), 36 pages. https://doi.org/10.1145/3487890
- Hukkelås and Lindseth (2023) Håkon Hukkelås and Frank Lindseth. 2023. Deepprivacy2: Towards realistic full-body anonymization. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 1329–1338.
- Hussain et al. (2021) Shehzeen Hussain, Paarth Neekhara, Malhar Jere, Farinaz Koushanfar, and Julian McAuley. 2021. Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples. In 2021 IEEE Winter Conference on Applications of Computer Vision (WACV). 3347–3356. https://doi.org/10.1109/WACV48630.2021.00339
- Jia et al. (2023) Shan Jia, Mingzhen Huang, Zhou Zhou, Yan Ju, Jialing Cai, and Siwei Lyu. 2023. AutoSplice: A Text-prompt Manipulated Image Dataset for Media Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 893–903.
- Jiang et al. (2024) Jiajia Jiang, Moting Su, Xiangli Xiao, Yushu Zhang, and Yuming Fang. 2024. AIGC-Chain: A Blockchain-Enabled Full Lifecycle Recording System for AIGC Product Copyright Management. arXiv preprint arXiv:2406.14966 (2024).
- Joslin et al. (2024) Matthew Joslin, Xian Wang, and Shuang Hao. 2024. Double Face: Leveraging User Intelligence to Characterize and Recognize AI-synthesized Faces. In 33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, PA, 1009–1026.
- Kandpal et al. (2022) Nikhil Kandpal, Eric Wallace, and Colin Raffel. 2022. Deduplicating training data mitigates privacy risks in language models. In International Conference on Machine Learning. PMLR, 10697–10707.
- Karras et al. (2019) Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4401–4410.
- Kim et al. (2023) Minchul Kim, Feng Liu, Anil Jain, and Xiaoming Liu. 2023. DCFace: Synthetic Face Generation with Dual Condition Diffusion Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12715–12725.
- Korshunov and Marcel (2018) Pavel Korshunov and Sébastien Marcel. 2018. Deepfakes: a new threat to face recognition? assessment and detection. arXiv preprint arXiv:1812.08685 (2018).
- Kumari et al. (2023) Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. 2023. Ablating Concepts in Text-to-Image Diffusion Models. In Proceedings of the IEEE International Conference on Computer Vision.
- Lee et al. (2022) Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale N Fung, Mohammad Shoeybi, and Bryan Catanzaro. 2022. Factuality enhanced language models for open-ended text generation. Advances in Neural Information Processing Systems 35 (2022), 34586–34599.
- Li et al. (2024b) Haoran Li, Dadi Guo, Donghao Li, Wei Fan, Qi Hu, Xin Liu, Chunkit Chan, Duanyi Yao, Yuan Yao, and Yangqiu Song. 2024b. PrivLM-Bench: A Multi-level Privacy Evaluation Benchmark for Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). 54–73.
- Li et al. (2024a) Kecen Li, Chen Gong, Zhixiang Li, Yuzhong Zhao, Xinwen Hou, and Tianhao Wang. 2024a. PrivImage: Differentially Private Synthetic Image Generation using Diffusion Models with Semantic-Aware Pretraining. In 33rd USENIX Security Symposium (USENIX Security 24). 4837–4854.
- Li et al. (2023) Zheng Li, Ning Yu, Ahmed Salem, Michael Backes, Mario Fritz, and Yang Zhang. 2023. UnGANable: Defending Against GAN-based Face Manipulation. In USENIX Security Symposium (USENIX Security). USENIX.
- Liang et al. (2023) Chumeng Liang, Xiaoyu Wu, Yang Hua, Jiaru Zhang, Yiming Xue, Tao Song, Zhengui Xue, Ruhui Ma, and Haibing Guan. 2023. Adversarial example does good: Preventing painting imitation from diffusion models via adversarial examples. In International Conference on Machine Learning. PMLR, 20763–20786.
- Lin et al. (2024) Li Lin, Neeraj Gupta, Yue Zhang, Hainan Ren, Chun-Hao Liu, Feng Ding, Xin Wang, Xin Li, Luisa Verdoliva, and Shu Hu. 2024. Detecting multimedia generated by large ai models: A survey. arXiv preprint arXiv:2402.00045 (2024).
- Liu et al. (2023d) Aiwei Liu, Leyi Pan, Yijian Lu, Jingjing Li, Xuming Hu, Lijie Wen, Irwin King, and Philip S Yu. 2023d. A survey of text watermarking in the era of large language models. arXiv preprint arXiv:2312.07913 (2023).
- Liu et al. (2021) Bo Liu, Ming Ding, Sina Shaham, Wenny Rahayu, Farhad Farokhi, and Zihuai Lin. 2021. When Machine Learning Meets Privacy: A Survey and Outlook. ACM Comput. Surv. 54, 2, Article 31 (mar 2021), 36 pages. https://doi.org/10.1145/3436755
- Liu et al. (2023c) Baoping Liu, Bo Liu, Ming Ding, Tianqing Zhu, and Xin Yu. 2023c. TI2Net: temporal identity inconsistency network for deepfake detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 4691–4700.
- Liu et al. (2024d) Chang Liu, Jie Zhang, Tianwei Zhang, Xi Yang, Weiming Zhang, and Nenghai Yu. 2024d. Detecting Voice Cloning Attacks via Timbre Watermarking. In Network and Distributed System Security Symposium. https://doi.org/10.14722/ndss.2024.24200
- Liu et al. (2022) Fan Liu, Zhiyong Cheng, Huilin Chen, Yinwei Wei, Liqiang Nie, and Mohan Kankanhalli. 2022. Privacy-preserving synthetic data generation for recommendation systems. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1379–1389.
- Liu et al. (2024a) Guangyuan Liu, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Dong In Kim, and Xuemin Shen. 2024a. Semantic communications for artificial intelligence generated content (AIGC) toward effective content creation. IEEE Network (2024).
- Liu et al. (2023a) Jiang Liu, Chun Pong Lau, and Rama Chellappa. 2023a. DiffProtect: Generate Adversarial Examples with Diffusion Models for Facial Privacy Protection. arXiv preprint arXiv:2305.13625 (2023).
- Liu et al. (2024b) Yinqiu Liu, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Chunyan Miao, Xuemin Sherman Shen, and Abbas Jamalipour. 2024b. Blockchain-Empowered Lifecycle Management for AI-Generated Content Products in Edge Networks. IEEE Wireless Communications (2024).
- Liu et al. (2024c) Yixin Liu, Chenrui Fan, Yutong Dai, Xun Chen, Pan Zhou, and Lichao Sun. 2024c. MetaCloak: Preventing Unauthorized Subject-driven Text-to-image Diffusion-based Synthesis via Meta-learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 24219–24228.
- Liu et al. (2023b) Yugeng Liu, Zheng Li, Michael Backes, Yun Shen, and Yang Zhang. 2023b. Watermarking Diffusion Model. arXiv preprint arXiv:2305.12502 (2023).
- Liu et al. (2023e) Zeyan Liu, Zijun Yao, Fengjun Li, and Bo Luo. 2023e. Check me if you can: Detecting ChatGPT-generated academic writing using CheckGPT. arXiv preprint arXiv:2306.05524 (2023).
- Lu et al. (2023c) Junyu Lu, Hongfei Lin, Xiaokun Zhang, Zhaoqing Li, Tongyue Zhang, Linlin Zong, Fenglong Ma, and Bo Xu. 2023c. Hate Speech Detection via Dual Contrastive Learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing (2023).
- Lu et al. (2023d) Yingzhou Lu, Huazheng Wang, and Wenqi Wei. 2023d. Machine Learning for Synthetic Data Generation: a Review. arXiv preprint arXiv:2302.04062 (2023).
- Lu et al. (2023a) Zeyu Lu, Di Huang, Lei Bai, Xihui Liu, Jingjing Qu, and Wanli Ouyang. 2023a. Seeing is not always believing: A Quantitative Study on Human Perception of AI-Generated Images. arXiv preprint arXiv:2304.13023 (2023).
- Lu et al. (2023b) Zeyu Lu, Di Huang, LEI BAI, Jingjing Qu, Chengyue Wu, Xihui Liu, and Wanli Ouyang. 2023b. Seeing is not always believing: Benchmarking Human and Model Perception of AI-Generated Images. In Advances in Neural Information Processing Systems, Vol. 36. 25435–25447.
- Lyu et al. (2023a) Lingjuan Lyu, C Chen, and J Fu. 2023a. A pathway towards responsible AI generated content. In Proc. 2nd tnt’I. Joint Conf. Artificial Intelligence.
- Lyu et al. (2023b) Yueming Lyu, Yue Jiang, Ziwen He, Bo Peng, Yunfan Liu, and Jing Dong. 2023b. 3D-Aware Adversarial Makeup Generation for Facial Privacy Protection. IEEE Transactions on Pattern Analysis and Machine Intelligence 45, 11 (2023), 13438–13453. https://doi.org/10.1109/TPAMI.2023.3290175
- Ma et al. (2023b) Chuan Ma, Jun Li, Ming Ding, Bo Liu, Kang Wei, Jian Weng, and H Vincent Poor. 2023b. RDP-GAN: A Rényi-differential privacy based generative adversarial network. IEEE Transactions on Dependable and Secure Computing (2023).
- Ma et al. (2023a) RuiPeng Ma, Jinhao Duan, Fei Kong, Xiaoshuang Shi, and Kaidi Xu. 2023a. Exposing the Fake: Effective Diffusion-Generated Images Detection. In The Second Workshop on New Frontiers in Adversarial Machine Learning. https://openreview.net/forum?id=7R62e4Wgim
- Ma et al. (2023c) Yihan Ma, Zhengyu Zhao, Xinlei He, Zheng Li, Michael Backes, and Yang Zhang. 2023c. Generative Watermarking Against Unauthorized Subject-Driven Image Synthesis. arXiv preprint arXiv:2306.07754 (2023).
- Markov et al. (2023) Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. 2023. A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37. 15009–15018.
- Meehan et al. (2020) Casey Meehan, Kamalika Chaudhuri, and Sanjoy Dasgupta. 2020. A non-parametric test to detect data-copying in generative models. In International Conference on Artificial Intelligence and Statistics.
- Melzi et al. (2023) Pietro Melzi, Christian Rathgeb, Ruben Tolosana, Ruben Vera-Rodriguez, Dominik Lawatsch, Florian Domin, and Maxim Schaubert. 2023. Gandiffface: Controllable generation of synthetic datasets for face recognition with realistic variations. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3086–3095.
- Mirsky and Lee (2021) Yisroel Mirsky and Wenke Lee. 2021. The creation and detection of deepfakes: A survey. ACM Computing Surveys (CSUR) 54, 1 (2021), 1–41.
- Mitchell et al. (2023) Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. Detectgpt: Zero-shot machine-generated text detection using probability curvature. In International Conference on Machine Learning. PMLR, 24950–24962.
- Nichol et al. (2021) Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. 2021. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv preprint arXiv:2112.10741 (2021).
- Pegoraro et al. (2023) Alessandro Pegoraro, Kavita Kumari, Hossein Fereidooni, and Ahmad-Reza Sadeghi. 2023. To ChatGPT, or not to ChatGPT: That is the question! arXiv preprint arXiv:2304.01487 (2023).
- Plant et al. (2022) Richard Plant, Valerio Giuffrida, and Dimitra Gkatzia. 2022. You Are What You Write: Preserving Privacy in the Era of Large Language Models. arXiv preprint arXiv:2204.09391 (2022).
- Qi et al. (2024) Shuren Qi, Yushu Zhang, Chao Wang, Zhihua Xia, Jian Weng, and Xiaochun Cao. 2024. Hierarchical Invariance for Robust and Interpretable Vision Tasks at Larger Scales. arXiv preprint arXiv:2402.15430 (2024).
- Qu et al. (2023) Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Savvas Zannettou, and Yang Zhang. 2023. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 3403–3417.
- Rahman et al. (2023) Md Awsafur Rahman, Bishmoy Paul, Najibul Haque Sarker, Zaber Ibn Abdul Hakim, and Shaikh Anowarul Fattah. 2023. Artifact: A large-scale dataset with artificial and factual images for generalizable and robust synthetic image detection. In 2023 IEEE International Conference on Image Processing (ICIP). IEEE, 2200–2204.
- Rando et al. (2022) Javier Rando, Daniel Paleka, David Lindner, Lennard Heim, and Florian Tramèr. 2022. Red-teaming the stable diffusion safety filter. arXiv preprint arXiv:2210.04610 (2022).
- Rosati (2022) Domenic Rosati. 2022. SynSciPass: detecting appropriate uses of scientific text generation. arXiv preprint arXiv:2209.03742 (2022).
- Saleh et al. (2024) Alaa Saleh, Roberto Morabito, Sasu Tarkoma, Susanna Pirttikangas, and Lauri Lovén. 2024. Towards Message Brokers for Generative AI: Survey, Challenges, and Opportunities. arXiv:2312.14647 [cs.DC] https://arxiv.org/abs/2312.14647
- Schramowski et al. (2023) Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. 2023. Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22522–22531.
- Schuhmann et al. (2022) Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. 2022. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems 35 (2022), 25278–25294.
- Sha et al. (2023) Zeyang Sha, Zheng Li, Ning Yu, and Yang Zhang. 2023. De-fake: Detection and attribution of fake images generated by text-to-image generation models. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security. 3418–3432.
- Shan et al. (2023) Shawn Shan, Jenna Cryan, Emily Wenger, Haitao Zheng, Rana Hanocka, and Ben Y Zhao. 2023. Glaze: Protecting Artists from Style Mimicry by Text-to-Image Models. In 32nd USENIX Security Symposium (USENIX Security 23). 2187–2204.
- Sheng et al. (2019) Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 2019. The woman worked as a babysitter: On biases in language generation. arXiv preprint arXiv:1909.01326 (2019).
- Sinitsa and Fried (2024) Sergey Sinitsa and Ohad Fried. 2024. Deep image fingerprint: Towards low budget synthetic image detection and model lineage analysis. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 4067–4076.
- Somepalli et al. (2023) Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. 2023. Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6048–6058.
- Tang et al. (2024) Kunsheng Tang, Wenbo Zhou, Jie Zhang, Aishan Liu, Gelei Deng, Shuai Li, Peigui Qi, Weiming Zhang, Tianwei Zhang, and Nenghai Yu. 2024. GenderCARE: A Comprehensive Framework for Assessing and Reducing Gender Bias in Large Language Models. In ACM Conference on Computer and Communications Security(CCS 24).
- Thambawita et al. (2022) Vajira Thambawita, Pegah Salehi, Sajad Amouei Sheshkal, Steven A Hicks, Hugo L Hammer, Sravanthi Parasa, Thomas de Lange, Pål Halvorsen, and Michael A Riegler. 2022. SinGAN-Seg: Synthetic training data generation for medical image segmentation. PloS one 17, 5 (2022), e0267976.
- Tirumala et al. (2022) Kushal Tirumala, Aram Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. 2022. Memorization without overfitting: Analyzing the training dynamics of large language models. Advances in Neural Information Processing Systems 35 (2022), 38274–38290.
- Tu et al. (2023) Shangqing Tu, Yuliang Sun, Yushi Bai, Jifan Yu, Lei Hou, and Juanzi Li. 2023. Waterbench: Towards holistic evaluation of watermarks for large language models. arXiv preprint arXiv:2311.07138 (2023).
- Tulchinskii et al. (2024) Eduard Tulchinskii, Kristian Kuznetsov, Laida Kushnareva, Daniil Cherniavskii, Sergey Nikolenko, Evgeny Burnaev, Serguei Barannikov, and Irina Piontkovskaya. 2024. Intrinsic dimension estimation for robust detection of ai-generated texts. Advances in Neural Information Processing Systems 36 (2024).
- Uchendu et al. (2021) Adaku Uchendu, Zeyu Ma, Thai Le, Rui Zhang, and Dongwon Lee. 2021. TURINGBENCH: A Benchmark Environment for Turing Test in the Age of Neural Text Generation. In Findings of the Association for Computational Linguistics: EMNLP 2021. 2001–2016.
- Van Le et al. (2023) Thanh Van Le, Hao Phung, Thuan Hoang Nguyen, Quan Dao, Ngoc N Tran, and Anh Tran. 2023. Anti-DreamBooth: Protecting users from personalized text-to-image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2116–2127.
- Verdoliva (2020) Luisa Verdoliva. 2020. Media forensics and deepfakes: an overview. IEEE Journal of Selected Topics in Signal Processing 14, 5 (2020), 910–932.
- Verma et al. (2023) Vivek Verma, Eve Fleisig, Nicholas Tomlin, and Dan Klein. 2023. Ghostbuster: Detecting text ghostwritten by large language models. arXiv preprint arXiv:2305.15047 (2023).
- Wang et al. (2023c) Cunxiang Wang, Xiaoze Liu, Yuanhao Yue, Xiangru Tang, Tianhang Zhang, Cheng Jiayang, Yunzhi Yao, Wenyang Gao, Xuming Hu, Zehan Qi, et al. 2023c. Survey on factuality in large language models: Knowledge, retrieval and domain-specificity. arXiv preprint arXiv:2310.07521 (2023).
- Wang et al. (2024a) Haichen Wang, Shuchao Pang, Zhigang Lu, Yihang Rao, Yongbin Zhou, and Minhui Xue. 2024a. dp-promise: Differentially Private Diffusion Probabilistic Models for Image Synthesis. In 33rd USENIX Security Symposium (USENIX Security 24). 1063–1080.
- Wang et al. (2023b) Sheng-Yu Wang, Alexei A Efros, Jun-Yan Zhu, and Richard Zhang. 2023b. Evaluating data attribution for text-to-image models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 7192–7203.
- Wang et al. (2024b) Tao Wang, Yushu Zhang, Zixuan Yang, Xiangli Xiao, Hua Zhang, and Zhongyun Hua. 2024b. Seeing is not Believing: An Identity Hider for Human Vision Privacy Protection. IEEE Transactions on Biometrics, Behavior, and Identity Science (2024), 1–1. https://doi.org/10.1109/TBIOM.2024.3449849
- Wang et al. (2023d) Tao Wang, Yushu Zhang, Ruoyu Zhao, Wenying Wen, and Rushi Lan. 2023d. Identifiable Face Privacy Protection via Virtual Identity Transformation. IEEE Signal Processing Letters (2023).
- Wang et al. (2022b) Yuntao Wang, Zhou Su, Ning Zhang, Rui Xing, Dongxiao Liu, Tom H Luan, and Xuemin Shen. 2022b. A survey on metaverse: Fundamentals, security, and privacy. IEEE Communications Surveys & Tutorials (2022).
- Wang et al. (2023a) Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. 2023a. Dire for diffusion-generated image detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22445–22455.
- Wang et al. (2022a) Zijie J Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. 2022a. Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models. arXiv preprint arXiv:2210.14896 (2022).
- Webster (2023) Ryan Webster. 2023. A Reproducible Extraction of Training Images from Diffusion Models. arXiv preprint arXiv:2305.08694 (2023).
- Webster et al. (2019) Ryan Webster, Julien Rabin, Loic Simon, and Frédéric Jurie. 2019. Detecting overfitting of deep generative networks via latent recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11273–11282.
- Wen et al. (2023) Yunqian Wen, Bo Liu, Jingyi Cao, Rong Xie, and Li Song. 2023. Divide and conquer: a two-step method for high quality face de-identification with model explainability. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5148–5157.
- Wen et al. (2022) Yunqian Wen, Bo Liu, Ming Ding, Rong Xie, and Li Song. 2022. Identitydp: Differential private identification protection for face images. Neurocomputing 501 (2022), 197–211.
- Wu et al. (2023) Ruijia Wu, Yuhang Wang, Huafeng Shi, Zhipeng Yu, Yichao Wu, and Ding Liang. 2023. Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework. arXiv:2305.03980 [cs.CV]
- Wu et al. (2024) Yixin Wu, Rui Wen, Michael Backes, Pascal Berrang, Mathias Humbert, Yun Shen, and Yang Zhang. 2024. Quantifying Privacy Risks of Prompts in Visual Prompt Learning. In 33rd USENIX Security Symposium (USENIX Security 24). Philadelphia, PA, 5841–5858.
- Xi et al. (2023) Ziyi Xi, Wenmin Huang, Kangkang Wei, Weiqi Luo, and Peijia Zheng. 2023. Ai-generated image detection using a cross-attention enhanced dual-stream network. In 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 1463–1470.
- Xiong et al. (2023) Cheng Xiong, Chuan Qin, Guorui Feng, and Xinpeng Zhang. 2023. Flexible and Secure Watermarking for Latent Diffusion Model. In Proceedings of the 31st ACM International Conference on Multimedia (¡conf-loc¿, ¡city¿Ottawa ON¡/city¿, ¡country¿Canada¡/country¿, ¡/conf-loc¿) (MM ’23). Association for Computing Machinery, New York, NY, USA, 1668–1676. https://doi.org/10.1145/3581783.3612448
- Xu et al. (2024a) Minrui Xu, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Shiwen Mao, Zhu Han, Abbas Jamalipour, Dong In Kim, Xuemin Shen, et al. 2024a. Unleashing the power of edge-cloud generative ai in mobile networks: A survey of aigc services. IEEE Communications Surveys & Tutorials (2024).
- Xu et al. (2024b) Rongwu Xu, Zi’an Zhou, Tianwei Zhang, Zehan Qi, Su Yao, Ke Xu, Wei Xu, and Han Qiu. 2024b. Walking in Others’ Shoes: How Perspective-Taking Guides Large Language Models in Reducing Toxicity and Bias. arXiv preprint arXiv:2407.15366 (2024).
- Yan et al. (2023) Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. 2023. DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection. In Advances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., 4534–4565.
- Yang et al. (2024a) Kaiyu Yang, Aidan Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan J Prenger, and Animashree Anandkumar. 2024a. Leandojo: Theorem proving with retrieval-augmented language models. Advances in Neural Information Processing Systems 36 (2024).
- Yang et al. (2022) Tianyun Yang, Ziyao Huang, Juan Cao, Lei Li, and Xirong Li. 2022. Deepfake network architecture attribution. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 4662–4670.
- Yang et al. (2023) Tianyun Yang, Danding Wang, Fan Tang, Xinying Zhao, Juan Cao, and Sheng Tang. 2023. Progressive Open Space Expansion for Open-Set Model Attribution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15856–15865.
- Yang et al. (2024b) Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, and Nenghai Yu. 2024b. Gaussian Shading: Provable Performance-Lossless Image Watermarking for Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12162–12171.
- Yao et al. (2024) Hongwei Yao, Jian Lou, Kui Ren, and Zhan Qin. 2024. PromptCARE: Prompt Copyright Protection by Watermark Injection and Verification. In IEEE Symposium on Security and Privacy (S&P). IEEE.
- Yao et al. (2023) Zhexin Yao, Qiuming Liu, Jingkang Yang, Yanan Chen, and Zhen Wu. 2023. PPUP-GAN: A GAN-based privacy-protecting method for aerial photography. Future Generation Computer Systems 145 (2023), 284–292.
- Yeh et al. (2021) Chin-Yuan Yeh, Hsi-Wen Chen, Hong-Han Shuai, De-Nian Yang, and Ming-Syan Chen. 2021. Attack as the best defense: Nullifying image-to-image translation gans via limit-aware adversarial attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 16188–16197.
- Yu et al. (2019) Ning Yu, Larry S Davis, and Mario Fritz. 2019. Attributing fake images to gans: Learning and analyzing gan fingerprints. In Proceedings of the IEEE/CVF international conference on computer vision. 7556–7566.
- Yu et al. (2021) Ning Yu, Vladislav Skripniuk, Sahar Abdelnabi, and Mario Fritz. 2021. Artificial fingerprinting for generative models: Rooting deepfake attribution in training data. In Proceedings of the IEEE/CVF International conference on computer vision. 14448–14457.
- Yuan et al. (2022) Zhuowen Yuan, Zhengxin You, Sheng Li, Zhenxing Qian, Xinpeng Zhang, and Alex Kot. 2022. On generating identifiable virtual faces. In Proceedings of the 30th ACM International Conference on Multimedia. 1465–1473.
- Zeng et al. (2023) Yu Zeng, Mo Zhou, Yuan Xue, and Vishal M Patel. 2023. Securing Deep Generative Models with Universal Adversarial Signature. arXiv preprint arXiv:2305.16310 (2023).
- Zhang et al. (2022) Guangsheng Zhang, Bo Liu, Tianqing Zhu, Andi Zhou, and Wanlei Zhou. 2022. Visual privacy attacks and defenses in deep learning: a survey. Artificial Intelligence Review 55, 6 (2022), 4347–4401.
- Zhang et al. (2024c) Gong Zhang, Kai Wang, Xingqian Xu, Zhangyang Wang, and Humphrey Shi. 2024c. Forget-me-not: Learning to forget in text-to-image diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1755–1764.
- Zhang et al. (2024a) Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. 2024a. R-Tuning: Instructing Large Language Models to Say ‘I Don’t Know’. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 7113–7139.
- Zhang et al. (2024b) Qihui Zhang, Chujie Gao, Dongping Chen, Yue Huang, Yixin Huang, Zhenyang Sun, Shilin Zhang, Weiye Li, Zhengyan Fu, Yao Wan, et al. 2024b. LLM-as-a-Coauthor: Can Mixed Human-Written and Machine-Generated Text Be Detected?. In Findings of the Association for Computational Linguistics: NAACL 2024. 409–436.
- Zhao et al. (2024) Yuan Zhao, Bo Liu, Tianqing Zhu, Ming Ding, Xin Yu, and Wanlei Zhou. 2024. Proactive image manipulation detection via deep semi-fragile watermark. Neurocomputing 585 (2024), 127593.
- Zhao et al. (2023) Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Ngai-Man Cheung, and Min Lin. 2023. A recipe for watermarking diffusion models. arXiv preprint arXiv:2303.10137 (2023).
- Zhong et al. (2023) Nan Zhong, Yiran Xu, Zhenxing Qian, and Xinpeng Zhang. 2023. Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection. arXiv preprint arXiv:2311.12397 (2023).
- Zhu et al. (2024) Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. 2024. Genimage: A million-scale benchmark for detecting ai-generated image. Advances in Neural Information Processing Systems 36 (2024).
- Zhu et al. (2023) Yao Zhu, Yuefeng Chen, Xiaodan Li, Rong Zhang, Xiang Tian, Bolun Zheng, and Yaowu Chen. 2023. Information-Containing Adversarial Perturbation for Combating Facial Manipulation Systems. IEEE Transactions on Information Forensics and Security 18 (2023), 2046–2059. https://doi.org/10.1109/TIFS.2023.3262156