iint \savesymboliiint
Securing Graph Neural Networks in MLaaS:
A Comprehensive Realization of Query-based Integrity Verification
Abstract
The deployment of Graph Neural Networks (GNNs) within Machine Learning as a Service (MLaaS) has opened up new attack surfaces and an escalation in security concerns regarding model-centric attacks. These attacks can directly manipulate the GNN model parameters during serving, causing incorrect predictions and posing substantial threats to essential GNN applications. Traditional integrity verification methods falter in this context due to the limitations imposed by MLaaS and the distinct characteristics of GNN models.
In this research, we introduce a groundbreaking approach to protect GNN models in MLaaS from model-centric attacks. Our approach includes a comprehensive verification schema for GNN’s integrity, taking into account both transductive and inductive GNNs, and accommodating varying pre-deployment knowledge of the models. We propose a query-based verification technique, fortified with innovative node fingerprint generation algorithms. To deal with advanced attackers who know our mechanisms in advance, we introduce randomized fingerprint nodes within our design. The experimental evaluation demonstrates that our method can detect five representative adversarial model-centric attacks, displaying 2 to 4 times greater efficiency compared to baselines.
1 Introduction
Graph Neural Networks (GNNs) have drawn considerable attention due to their demonstrated ability to analyze graph data [1, 2]. They are designed to effectively perform graph-related prediction tasks, and have achieved state-of-the-art performance in a diverse array of applications such as e-commence networks [3], anomaly detection [4, 5, 6], and healthcare [7, 8, 9, 10]. Because of their increasing popularity, many Machine Learning as a Service (MLaaS) platforms offered by cloud service providers have integrated GNN development tools for conveniently launching GNN services (e.g., AWS integrated DGL [11], Microsoft Azure incorporated Spektral [12], and Google Vertex AI used Neo4j [13]). Despite the convenience and low cost of model deployment, graph-based MLaaS is also facing critical security concerns.
Among others, adversarial attacks are known to be able to deduce the performance of GNNs. In the context of locally deployed GNNs, the limited attack surface has directed the majority of research towards the protection of these networks against data-centric attacks [14, 15, 16, 17, 18, 19] (e.g., evasion attacks that alter the inference graph or poisoning attacks that modify the training graph). Currently, model-centric attacks [20, 21, 22] (e.g., bit-flipping that manipulates the GNN model parameters) are less significant and can often be mitigated through local verifying and careful monitoring of the model inference process.
Nonetheless, the landscape shifts when GNNs are deployed to MLaaS platforms. Firstly, outsourcing GNNs to the cloud encounters practical attack surfaces that largely amplify the risk of model-centric attacks. Specifically, MLaaS stores GNN models in their cloud storage systems [11], making them susceptible to long-standing threats inherent to cloud computing, such as misconfiguaration [23, 24], insufficient access management [25, 26, 27], and Bit-flip attacks [20, 21, 22], thereby rendering model-centric attacks more applicable. Furthermore, GNNs located within cloud storage environments are stripped of those local protective measures that require direct access to the deployed models [28, 29]. Due to security concerns, the model owner typically lacks such access within the bounds of MLaaS.
A real-life illustration of this issue can be found in the collaboration between the American Heart Association and Amazon for cardiovascular disease [30]. GNNs, designed to analyze proteomic data, can be deployed through Amazon’s MLaaS platform, named SageMaker, and stored in the cloud within an S3 bucket as its MLaaS pipeline [11]. Unfortunately, the S3 storage system has faced both external and internal threats [31, 32, 33, 34, 35, 36, 37, 38]. If an attacker were to manipulate the GNN models during the model serving process (e.g., before loading from S3), it could lead to incorrect assessments of cardiovascular disease risks or inappropriate responses to treatments and undermine the accuracy of diagnoses and treatment plans [30].
Research Gap. While the security risk associated with GNN models stored within MLaaS is apparent, current studies are inadequate to address them. Traditional software security solutions for integrity verification (e.g., cryptographic digests) require the verifier to access and control the data directly and validate the digests during runtime, which is not applicable within MLaaS. In addition, these verification methods done by the MLaaS servers assume that MLaaS is trusted, which does not align with our above considerations regarding non-trusted cloud environments. Moreover, existing defenses against adversarial attacks in GNNs [28, 29] are used to protect locally deployed GNNs against data-centric attacks, rendering them ill-equipped to counter model-centric attacks in the untrusted cloud environments.
To fill this gap, our study presents the first systematic investigation of protecting GNNs deployed in MLaaS environments against model-centric attacks through verification of model integrity during GNN serving. We consider GNNs in node classification tasks as the case study, i.e., a basic yet widely-adopted learning task for GNNs [39]. We employ a query-based verification mechanism that requires only query access to the targeted GNN model during the serving phase. The core concept involves probing the deployed GNN models with a series of carefully designed node queries and analyzing their responses to assess the integrity of the GNN model. Responses that do not match the expected predictions indicate that the integrity of the GNN models has been compromised.
Challenges. Developing a comprehensive integrity verification method to protect GNNs in MLaaS environments against model-centric attacks presents a nontrivial task. First, outsourcing of GNNs via MLaaS introduces specific challenges. C1) Lack of Direct Access: The interaction between the verifier and the server is limited through APIs provided by MLaaS, meaning that the verifier may not have access to the exact model parameters or internal representations during model inference. Thus, our verification can only rely on the basic APIs for GNN serving (i.e., prediction APIs). C2) Diversity of Query APIs: These prediction APIs also vary across different GNN settings. Depending on whether GNNs operate in transductive or inductive settings, each setting dictates different inference processes, leading MLaaS to publish diverse query APIs during service (e.g., queries to transductive GNNs are typically restricted to node IDs, while those to inductive GNNs may involve new inference graphs). Therefore, our verification should be considerate of and adaptable to the varying settings of GNNs.
Furthermore, the verification of GNN models also introduces unique challenges, revealing that existing studies on DNNs may not be applicable to GNNs. C3) Unique Model Architecture: GNN models typically have fewer layers (e.g., two layers to prevent over-smoothing [1, 40]) compared to other DNNs (e.g., CNNs in computer vision). This distinctive structure affects the activation of neurons by queries and introduces diverse focuses on verification design strategies. C4) Graph-Structured Inputs: Unlike DNNs that operate on Euclidean data, GNNs analyze graph-structured data, where a prediction is influenced not only by its node features but also by the graph structure and its neighbors. Thus, our verification needs to accommodate the graph structure. In summary, our Research Question is: “How to design a comprehensive GNN integrity verification schema that addresses the limited and varying capabilities of MLaaS verifiers, while also accounting for the unique characteristics of GNNs?”
Our Contributions. To address these challenges, we make the following technical contributions. Firstly, we direct our attention to the model-centric attacks problem for the GNNs deployed within MLaaS, and propose a comprehensive integrity verification framework against these attacks. Our approach adopts a query-based integrity verification workflow, which is suitable for limited model access in MLaaS (C1). Additionally, to adaptively deal with different query APIs (C2), we delineate four distinct verification types, each accommodating differing access to the deployed model under transductive/inductive settings, as well as full/limited verifier’s knowledge of the GNN models.
Secondly, recognizing a gap in existing research, we introduce new designs to generate verification queries for each of our proposed verification types. Within the transductive setting, where queries are limited to node IDs, we generate queries by selecting nodes that more effectively fingerprint the targeted GNN model. Two fingerprint score functions are defined for verifiers with either limited or full knowledge of the model. They are designed to gauge the influence of GNN model parameters on predictions (C3) related to a potential verification node and its neighbors (C4). Conversely, in the inductive setting, where queries may contain node IDs and inference graphs, we introduce two fingerprint node generation methods. These methods construct optimized fingerprint node features and connections among neighboring nodes, grounded in the previously defined fingerprint scores.
In addition, we enhance our design’s robustness by considering an adaptive attacker seeking to identify and bypass our verification. We inject randomness into the selection of nodes and the construction of fingerprints complicating attackers’ efforts to locate true fingerprint nodes, and thus forcing them to respond accurately to avoid detection.
In summary:
-
•
We are the first to highlight the problem of model-centric attacks that add adversarial perturbations in GNN models within MLaaS, and introduce a comprehensive framework with a query-based integrity verification workflow, suitable for the limited model access inherent in MLaaS.
-
•
We propose four unique verification methods and corresponding novel node fingerprint generation algorithms adapting to various GNN settings (transductive/inductive) and verifier’s capabilities (full/limited knowledge about the GNN model).
-
•
We further consider adaptive attackers who are aware of the verification algorithms, and mitigate this potential vulnerability by implementing randomized node fingerprinting.
-
•
Through rigorous testing on four real-world datasets against five practical model-centric attacks, our proposed methods can successfully detect all these attacks while being 2-4 times more efficient than baseline designs.
2 Preliminary and Threat Model
2.1 Graph Neural Networks within Machine Learning as a Service
Node Classification via GNNs. Graph Neural Networks demonstrate great success in graph analysis tasks. In this paper, we consider a basic yet widely adopted GNN task, i.e., node classification. A node classification GNN aims to label the nodes based on both the structure and attributes of the nodes in the graph. Generally, GNN for node classification has two different learning settings: transductive setting and inductive setting. In the former setting, a training and inference graph is used to train a GNN model. Namely, the training graph is also used for inference. In practice, this setting occurs when a graph has partially labeled nodes, and GNN is used to predict the label for the rest of the nodes. For the latter setting, the training graph of the GNN model is different from the inference graph. This setting is similar to the traditional learning settings where GNN learns the knowledge from a training graph and is used to predict the label of other unseen graph data.
Machine Learning as a Service for GNNs. Machine Learning as a Service (MLaaS) is trending as an emerging cloud service for training and serving of machine learning models. It enables model owners to build (Training Service) and deploy (Serving Service) their model and learning applications to model users conveniently and automatically. A notable example is the SageMaker framework provided by Amazon, which has integrated a popular graph learning tool (i.e. DGL [41]) for the development and deployment of GNNs [42]. In this paper, we focus on the Serving Service, and consider that model owners first upload their locally trained GNN model to the cloud storage or specify the location of an online GNN model. Then, they create and configure the Hosting Service with an HTTPS endpoint. The Hosting Service will create a serving instance that loads the GNN model from the cloud storage bucket and launches the endpoint to host the model prediction. This endpoint is persistent and will remain active, so model users can make instantaneous prediction queries at any time.
2.2 Threat Models
In this study, we specifically focus on model-centric attacks. These attacks pose a significant yet often not addressed threat in the scenario where GNNs are utilized within the framework of MLaaS. Unlike data-centric adversarial attacks, which add perturbations to graph data, model-centric attacks aim to degrade GNN performance by compromising the integrity of GNN models, ultimately leading to inaccurate predictions.
Attack Surfaces. As an emerging service launched by public cloud service providers, MLaaS naturally faces the same threats of cloud computing, such as misconfiguration [23, 24], insufficient identity and access management [43, 44], insider threat [45, 46], insecure interfaces and APIs [47, 48]. We deem that these long-standing threats create practical attack surfaces for adversarial perturbations over GNN models. For example, MLaaS stores the GNN models in cloud storage, which has been demonstrated with large attack surfaces [38, 49, 50]. Specifically, an AWS S3 bucket can be accessed and overwritten by unauthorized users due to misconfigurations [33, 36] or exploited by an internal malicious user [34, 35]. Such issues allow attackers to manipulate GNN models before being loaded by the inference instance of MLaaS.
Attack Coverage. In this paper, we discuss two practical model-centric attacks compromising GNN model integrity.
- Fault Injections to Model Parameters. The attacker injects faults into a few bits of the GNN model parameter and forces the model to misclassify the nodes, also known as Bit-flip Attacks (BFAs) [20, 21, 22]. Specifically, attackers can identify the most vulnerable bits among the model parameters and modify only a few of them, but significantly impacting GNN predictions. BFAs are practical considerations in MLaaS systems that store the ML model in their cloud storage (e.g., Amazon SageMaker store GNNs in S3 bucket [11]), and could be exploited using various mature attack methods, such as RowHammer [22, 51], VFS [52], and clock glitching [53]. We provide a detailed construction of BFAs on GNNs in Appendix A.1, as existing DFAs target on DNNs.
- Model Replacement by Poisoned Models. Apart from only modifying a few bits, we assume another attacker who can replace the entire model with a pre-constructed poisoned one [54, 55]. Specifically, we consider that the replaced models are generated through poisoning attacks, which is one of the well-studied adversarial attacks targeting GNN models and has been shown to cause severe mispredictions during GNN inference [54, 55]. Model replacement is also a practical concern because ML models are stored in cloud storage. Attackers could replace models before they are loaded into the MLaaS serving instance due to well-known issues in cloud storage, such as misconfigurations [33, 36] and insecure APIs [47, 48]. We formalize poisoning attacks in Appendix A.2.
Furthermore, we acknowledge the threat of an advanced attacker who understands the deployed defense strategies. Thus, we also consider an adaptive attacker who attempts to identify and bypass potential integrity verification. We elaborate on such adaptive attacks later in Section 5.
Remark. There may exist other types of threats which are out of scope in this work. For example, rather than targeting the serving services, the attacker attempts to compromise the MLaaS training services. Note that model-centric attacks targeting GNN models during the training phase can be trivially verified by downloading and validating the learned model on the local side. In addition, we do not focus on data-centric attacks that compromise graph data integrity in this work, as they can be mitigated by well-studied orthogonal methods. For example, poisoning/backdoor attacks can be addressed by robust training, i.e., introducing an attention mechanism to identify adversarial perturbations and decrease their weights during the aggregation process [56]. Similarly, evasion attacks can be mitigated through adversarial training [57, 58], which makes the GNN still produce correct predictions even when the input inference graphs have been manipulated adversarially.
3 Queried-based Verification for GNN within MLaaS
While threats of model-centric attacks targeting GNN models within MLaaS evolve, existing approaches are often either inapplicable to GNNs or unworkable within the specific constraints of MLaaS. Recognizing these limitations, we aim to verify the integrity of GNN models to defend against these emerging attacks. In the following section, we begin by defining our design objectives that aim to counter these threats, with particular attention to the MLaaS application scenario. We then present our four query-based verification methods, delineating their verifier’s capabilities, and conclude with a detailed outline of the workflow underpinning our query-based design.
3.1 Design Goals
To defend against the aforementioned model-centric attacks that manipulate the parameters of the GNN model, our objective is to verify the integrity of the GNN model. This focus shapes our design goals as follows.
-
•
Effective. Our design should be able to detect the adversarial perturbations on the GNN model parameters with high rates.
-
•
Robust. Our design should be robust to adaptive attackers who know the defense mechanism in advance and attempt to bypass it.
Additionally, taking into account the specific context of GNNs deployed within MLaaS, we further consider the following two requirements:
-
•
Efficient. Our design should minimize the cost of the verifier and can readily be integrated into MLaaS in a minimally intrusive manner.
-
•
Platform-independent. Our design should be independent of GNN applications and be readily adaptive to configurations of diverse MLaaS platforms.
3.2 Design Overview
To achieve the four design goals, we implement a query-based approach to verify the integrity of a GNN model deployed in MLaaS during its inference period. Specifically, we use fingerprint nodes and their expected response to uniquely represent the target models and verify their integrity. We expect that a modified GNN model would yield different prediction results for these nodes. Consequently, the verifier can generate these fingerprints based on their knowledge of the targeted GNN model and employ them by leveraging the query API to verify the model’s integrity.
Note that conventional software protection solutions (e.g., cryptographic digests) are insufficient to verify the GNN model’s integrity in the MLaaS scenario. They require the verifier to have direct access to the GNN models and to validate the digests during their inference. However, this is not practical for third-party verifiers in the context of MLaaS, where the cloud server stores and manages the GNN model. Meanwhile, since we assume that the cloud server is nontrusted, these verification methods can not be done by the MLaaS server.
On the contrary, a query-based mechanism can be effective, efficient, and platform-independent in the context of MLaaS. First, the verifier is able to detect manipulations throughout the serving process, regardless of when attacks occur. Second, the entire process does not require additional deployments or changes on the cloud side. Since only prediction APIs (the essential function of MLaaS) are used, the verification is platform-independent.
In addition, while existing designs only consider that the verifier has full access to the target model, we propose different verification strategies to adaptively handle various settings for GNNs in MLaaS. Specifically, we delineate four different verification methods, considering the verifier’s capabilities across three key aspects: knowledge of the targeted GNN model, knowledge of the inference graph, and access to the deployed GNN model (as detailed in Table I). In the following, we provide comprehensive explanations for these capabilities.
Verifier’s Knowledge of the GNN model. The verifier can have different knowledge of the targeted GNN model before being deployed. In practice we consider the following two cases.
- Full Knowledge to the Targeted GNN Model. In this case, the verifier has full knowledge of the GNN model, including the model parameter, model architecture, the gradient, and the internal representation for any local predictions before it is deployed in MLaaS. In practice, this verifier can be the model owner who wants to protect their model, or an entity fully authorized by the owner.
- Limited Knowledge to the Targeted GNN Model. In this case, the verifier does not have access to the GNN parameters and can only query the target GNN model and obtain the response. Nevertheless, the model owner is willing to support verification, and provide limited knowledge, e.g., node embeddings and prediction posteriors generated by the model inference. In practice, the verifier can be a third-party service, and the model owner does not want to share their well-trained model (IP of the owner) directly.
Verifier’s Knowledge of the Inference Graph. In addition to the verifier’s access to the target GNN models, we further assume the verifier’s knowledge corresponding to the inference graph of the targeted GNN to facilitate verification. We also present this in the context of both transductive and inductive settings.
- Transductive Setting. In this setting, the verifier is provided with a small set of nodes and their neighboring subgraph within the inference (also training) graph. The intuition is that training data are often considered private data of the model owner, so they prefer to provide only a limited amount of their training graph to the verifier. In practice, the owner may designate a small subset of nodes specifically for security purposes, e.g., setting some nodes in a network graph as security appliances to mitigate security threats [59]. Note that if the verifier is the model owner, they will not be constrained.
- Inductive Setting. In this setting, the verifier knows the prediction task of the targeted GNNs and can gather shadow graph data corresponding to this task. The verifier gains full access to these shadow graphs and can use them for querying. This is a common and practical assumption considered in previous work [60, 61]. For example, the shadow graph could be an earlier version of the training graph provided by the model owner, or a graph that shares similar characteristics with the target GNN task [60].
| Verifier | Before Deployment | After Deployment | ||
| Targeted GNNs | Inference Graph | Query API | ||
|
Full Access | Subgraph | Node ID | |
|
Limited Access | Subgraph | Node ID | |
|
Full Access | Shadow Graph | Node ID, Graph | |
|
Limited Access | Shadow Graph | Node ID, Graph | |
Verifier’s Access to the Deployed GNN Models. After the targeted GNN model is deployed, we assume that the verifier can access only the prediction APIs as the normal GNN model users. We deem that this is a practical setting due to security and cost-effective considerations. Only leveraging prediction APIs will make the verifier hard to be detected and bypassed, and will also not introduce additional development and implementation overhead at MLaaS.
- Queries to the Prediction APIs. The GNN prediction APIs support different formats of prediction queries depending on the GNN learning settings for node classification, i.e., transductive setting and inductive setting. 1) Transductive Setting. In this setting, the queries sent by the verifier consist only of the node ID. Since the training and inference graph is used to train the targeted GNN, the graph will not be modified during model serving. Specifically, the model owner uploads their GNN model and the training graph (aka the inference graph for predictions) to the cloud when they create the serving instance. During the serving period, users can directly issue the node ID for the serving instance to perform inference in the training graph, and respond to a corresponding label to that node. 2) Inductive Setting. In this setting, queries sent by the verifier consist of both the node ID and the graph used for inference. Differently from the transductive setting, the graphs used for inductive GNNs’ training and inference are different. Therefore, MLaaS provides APIs for users to query their inference graph during serving. Specifically, the model owner uploads only their GNN model to the cloud when creating the serving instance. During the serving period, users upload their inference graph and its node IDs for predictions. The serving instance then performs inference in the inference graph, and responds to the corresponding labels of the node IDs, respectively.
- Responses from the Prediction APIs. We assume that the prediction APIs only respond to the users with the final prediction label. In MLaaS applications, predicting the label is the most basic function provided by the prediction APIs. Therefore, this is the strictest setting for the verifier, which provides the minimum information about the model inference. It is also consistent with recent work on machine learning security [62, 61]. We are aware that, if the response is the confidence vector, the verifier can easily verify the integrity by issuing a query and comparing it to the pre-recorded confidence vector. If the confidence scores do not match, the GNN model can be considered modified.

3.3 Design Workflow
For all four verification methods, we devise a universal query-based process that utilizes the aforementioned knowledge and is tailored to fit the context of MLaaS. In particular, our design consists of two stages: Offline Phase, which generates node fingerprints based on the targeted GNN model locally at the verfier side (Step 1 & 2 in Fig. 1) and Online Phase, which uses node fingerprints for verification during inference (Step 3 & 5 in Fig. 1). The attack takes place at Step 4, which occurs during the online phase of our verification process and after the GNN deployment to the MLaaS server.
Offline phase occurs before the GNN models are deployed on the MLaaS server. As mentioned, we consider that the model owners have developed a well-trained GNN model locally or through the MLaaS training service. Then, they authorize a verifier to construct the fingerprints. The detailed steps contained in the offline phase are as follows:
-
1.
The model owner provides either full or limited knowledge ( or ) to the targeted GNN model to the verifier.
-
2.
The verifier performs a fingerprint generation mechanism to construct a set of node fingerprints (as well as an inference graph when in inductive settings) based on the knowledge of the inference graph , where .
Online phase occurs after the GNN models are deployed on the MLaaS server. Specifically, the fingerprints constructed in the offline phase can be used during inference. The detailed steps contained in the online phase are as follows:
-
3.
The model owner deploys their GNN model via MLaaS.
-
4.
The attacker could manipulate the benign GNN model as an adversarial model .
-
5.
The verifier queries the prediction APIs by the fingerprint nodes (as well as an inference graph when in inductive settings) to obtain the response labels , and then compares with their pregenerated labels to output the verification result . Only if is equal to 1, the verification is carried out.
4 Node Fingerprint Generation Algorithms
In the aforementioned query-based verification mechanism, the essential part of the design process is the generation of node fingerprints tailored to the targeted model. As noted previously, queries issued by the verifier differ between transductive and inductive settings. Consequently, in this section, we will separately introduce our fingerprint generation methods, first addressing transductive scenarios, and subsequently inductive ones. Within each node fingerprint design, we will also consider different levels of knowledge regarding the model, i.e., full and limited access to the targeted GNNs.
4.1 Transductive Node Fingerprint Generation
As outlined in Section 2, both the training and inference graphs are identical in the transductive settings. Consequently, MLaaS will not offer APIs for updating the graph during inference periods. As a result, queries to the targeted GNNs will exclusively contain node IDs, where fingerprints will comprise tuples consisting of node IDs and corresponding labels. To enable such queries to fingerprint the targeted GNN model, we propose identifying nodes that exhibit sensitivity to the GNN model. Specifically, alterations in model parameters will also induce changes in node predictions. Therefore, these pairs of nodes and labels can potentially be used as node fingerprints for GNN models.
4.1.1 Transductive Fingerprinting
Considering the capabilities presented in Section I (where the verifier can issue queries on a small subset of nodes, denoted as , supplied by the model owner), a naive verification approach would involve using all these nodes as fingerprints, issuing queries for each, obtaining responses, and comparing them against the corresponding labels. Nevertheless, in practice, issuing queries to the target GNNs can be expensive in terms of cost (MLaaS charges based on the number of queries) and time (processing large quantities of queries and responses introduces latency). Therefore, we propose to minimize verification efforts by selecting the smallest possible set of nodes, denoted as , from these candidates capable of detecting model modifications. Here, we formalize the transductive fingerprint generation problem as follows:
Definition 1 (Transductive Node Fingerprint Generation)
Given a set of fingerprint node candidates among a target graph where , and a target GNN model with parameters trained on , the verifier proposes to find the minimal fingerprint node set , such that there exists at least a which satisfies , where , , and is adversarial perturbed from .
To solve this problem, two possible strategies can be considered: (1) selecting fingerprint nodes that activate as many neurons of the model as possible, ensuring that a few nodes can cover the neurons corresponding to the modified model parameters and reflect on their predictions; and (2) selecting fingerprint nodes whose predictions are sensitive to the parameter modification, thereby increasing the sensitivity of each queried node to the model parameter modification and enhancing the likelihood of detecting the modification.
Our proposed design resorts to the second strategy. In the context of GNNs, model architectures are often relatively simple, characterized by a small number of layers (e.g., only layers) and hidden features (e.g., hidden features used in our experiments). It is observed that only a few nodes (e.g., nodes) can activate most of the neurons in GNNs. Namely, using additional nodes beyond the initial or selected nodes does not significantly increase neuron activation. Thus, this activation-based selection strategy is similar to a random selection and becomes less effective. Consequently, our node fingerprint generation process focuses more on examining how a node’s prediction changes when the GNN model is subjected to adversarial modifications.
4.1.2 Fingerprint Score Functions
In this regard, we formally introduce the fingerprint score function, which quantifies the susceptibility of a node’s prediction to model perturbations for generating fingerprints. Considering two types of verifiers (Transductive-F and Transductive-L) with either full or limited knowledge of the targeted model, we define fingerprint score functions for them respectively.
Transductive-F Verification. To assess how the predictions of our fingerprinting nodes change when manipulation of the model parameter occurs, the fingerprint score function of a node can be defined as follows:
| (1) |
where is the prediction result on the clean model whose parameter is , is the prediction result on the modified model whose parameter is , and are the adversarial perturbations.
Since the prediction result is non-linear to the model output , we approximate the difference between the final prediction labels by the L2 distance between their output confidence vectors, as follows (detailed proof can be found in Appendix B.1):
| (2) |
In general, is a small perturbation as attackers often tend to be less noticeable. Therefore, we disregard this higher-order term and define our fingerprint score:
Definition 2 (Fingerprint Score for Transductive-F)
Given a GNN model with model parameters trained on the graph , the fingerprint score for Transductive-F of a node corresponding to the perturbation at is defined as follows:
| (3) |
where represents the distance between the node prediction and its prediction label . Since the verifier is assumed to have full knowledge of the target GNN model, by performing backward propagation as model training, the verifier can easily calculate the gradient in the above equation and obtain the final fingerprint scores.
Note that in calculating the gradient mentioned above, we do not compute scores in Eq. 3 for every node. Instead, we calculate scores for a selected set of candidate nodes and choose fingerprints from among them. As a result, the computational cost of our design is confined within a range determined by the size of . In practice, the pool of candidates can be adaptively expanded to include all nodes or narrowed to include any subset of nodes in the graph.
Transductive-L Verification. In this case, the verifier cannot have full knowledge of the GNN models, which prevents them from calculating the gradients. To address the problem, we propose another node generation method that does not rely on the gradient. Because our verification is query-based and correlated with the final prediction, we utilize the prediction scores to evaluate how parameter perturbations may affect the final inference results. In particular, fingerprinting nodes with a lower level of confidence in their final prediction will be more likely to be affected by the perturbation. Therefore, the fingerprint score of a fingerprinting node for Transductive-L can follow:
| (4) |
where represents the output of the GNN classifier for the node , represents its one-hot prediction label vector, and represents the distance between the current confidence vector and the one-hot prediction label vector of the node . Consequently, we define our fingerprint score of a node for Transductive-L as follows:
Definition 3 (Fingerprint Score for Transductive-L)
Given a GNN model with model parameters trained on the graph , the fingerprint score for Transductive-L of the node corresponding to the perturbations is defined as follows:
| (5) |
It should be noted that the above fingerprint scores are calculated only based on the prediction result of a node, whose calculation cost is , making it efficient for our verification. In practice, to further speed up the calculation of the above fingerprint scores, we replace Eq. 5 with:
| (6) |
where outputs a normalized probability vector of a specific node prediction with dimensions, and represents the number of classes for the node classification tasks.
Based on the above definitions, the fingerprint scores represent how the model weights can affect the final prediction loss. With higher fingerprint scores, the prediction results of such nodes can be affected more easily, and they can be considered as fingerprinting nodes for verification during model serving. As a result, the verifier can calculate the fingerprint scores for a set of candidate nodes (e.g., nodes owned by the model owner that can be specifically used for verification), choose the nodes that will be easily impacted by the perturbation applied to the GNN model parameters, and construct a node fingerprint as a tuple consisting of them and their corresponding label.
Remark. Note that our transductive fingerprinting approach differs from the sensitive sample fingerprints presented in prior work by He et al. [63]. In their study, the assumption is that the verifier has the ability to issue queries containing adaptive input images. On the contrary, our transductive fingerprinting is limited to issuing queries with node IDs only, resulting in a significantly more limited capability. Additionally, their work only considers cases where the verifier has full knowledge of the targeted model. However, in our approach, we propose two fingerprint generation methods, taking into account that the verifier may also have only limited knowledge of the target model, which cannot be solved by their method. Furthermore, they used a Maximum Active Neuron Cover (MANC) Sample Selection technique upon obtaining a set of fingerprint candidates, which selects fingerprints based on neuron activation rather than their sensitivity to model parameters. As discussed previously, relying solely on neuron activation will be less effective in the context of GNNs. In Section 6.2, we compare our design with their approach in our evaluation, further highlighting the distinctions between the two methods.
4.2 Inductive Node Fingerprint Generation
Contrary to the transductive setting, the training and inference graphs for inductive GNNs are distinct. In this scenario, MLaaS provides APIs that allow GNN users to update the inference graph during the serving periods. Consequently, the query sent by the verifier comprises both the node IDs and the inference graph, indicating that our proposed fingerprints should also include a graph, the fingerprint node IDs, and their corresponding labels. Thus, our design should construct an inference graph with several fingerprint nodes, anticipating that any modifications to the model parameters will alter the predictions on the fingerprint nodes within our constructed graph.
4.2.1 Inductive Fingerprinting
Our above inductive fingerprint generation can be divided into two steps: 1) constructing an inference graph and 2) selecting the fingerprint node indices. When constructing the graph in Step 1, it is essential to ensure that the constructed inference graph resembles the ordinary inference graph of the target GNN tasks to prevent adversaries from being aware of and bypassing our verification. Therefore, the verifier will gather or construct a shadow graph as the ordinary inference graph (refer to the capabilities discussed in Section 3.2). After that, we can follow a similar strategy as in the transductive setting to select the node indices for Step 2. The problem can be formalized as follows.
Definition 4 (Inductive Fingerprinting Generation)
Given a shadow graph , and a target GNN model with parameters trained on , the verifier proposes to find a minimal fingerprint node set , such that there exists at least a which satisfies , where , , and is adversarial perturbed from .
Additionally, rather than directly using the gathered shadow graph, we propose further perturbing the shadow graph to increase the effectiveness of fingerprinting. This can enhance the sensitivity scores of the fingerprint nodes without significantly altering the graph, preventing adversaries from bypassing it. In our design, we propose to perturb the graph structure and node features corresponding to these fingerprint nodes, as their sensitivity scores are primarily impacted by these components. Note that, we do not consider injecting or deleting nodes from the graph, as adding or removing nodes can be regarded as using a different gathered shadow graph.
4.2.2 Fingerprint Nodes Construction
We now discuss how to apply perturbations to the fingerprint nodes to increase their sensitivity scores. Based on the verifier’s knowledge of the targeted GNN models, we design different strategies for both Inductive-F and Inductive-L to construct node fingerprints.
Inductive-F Verification. To increase the sensitivities of the selected fingerprinting nodes, we propose to further manipulate their attributes and connections. Meanwhile, model performance must be preserved for quality model serving. Therefore, we aim to maximize the fingerprint score of the fingerprint nodes by manipulating their attributes and connections without affecting the original prediction results. Specifically, we formalize node construction to an optimization problem as follows:
| (7) | ||||
| s.t. |
where is the perturbed node attribute for node and is the edge connected to node in the perturbed graph structure. The right-hand side of the objective function is in a similar form to Eq. 3 but represents how the prediction of the selected nodes can be affected by the current perturbed graph. Furthermore, to ensure that our modification does not affect the original performance of the target model, we set a constraint such that all predictions of the nodes in the graph are not affected by the perturbation.
Due to the discretion of the graph and even the attributes, it is nontrivial to solve the above optimization problem. Here, we design a greedy algorithm to increase the total fingerprint scores iteratively. Specifically, we first calculate the gradient of the structure and the attributes corresponding to the fingerprint scores of the nodes. Then, we sort all these values and add the perturbations greedily. After adding each perturbation, we check whether it affects the second-order neighbor of both the fingerprinting nodes and the connected nodes if perturbing the edges. If the perturbation leads to the misclassification of any nodes, we skip this perturbation. The above perturbation will not stop, until the perturbation budget is reached or adding the perturbation leads to a decrease in the fingerprint scores.
Inductive-L Verification. We then discuss the verification strategies with limited knowledge of the targeted model. As mentioned above, the node located at the decision boundary of the target model is less robust, and may easily cross the boundary due to the perturbations. Based on this intuition, we utilize the methodology for general adversarial attacks (e.g., Nettack [14]) to design the fingerprinting nodes. Specifically, we perturb the previously selected fingerprinting nodes by moderately increasing the prediction loss of these nodes. With such manipulation, the generated nodes can be closer to the decision boundary and become more sensitive to the perturbations. Unlike ordinary adversarial attacks, here we need to constrain the final prediction of all the nodes to be correct and make sure that our constructed nodes will not affect the GNN performance. Formally, our method can be represented as the optimization function:
| (8) | ||||
| s.t. |
Compared to the optimization functions for Inductive-F (as Eq. 7), the gradient generated from the target model is no longer an essential component. For the rest of the processes, we follow a similar approach as Inductive-F. We first select a set of fingerprinting nodes and then perform our fingerprint construction method.
Remark. It is important to note that our inductive fingerprinting approach also diverges from the one presented in [63]. Similarly to our transductive design, our inductive approach considers both full and limited knowledge of the target GNN model, while the above work only accounts for full access and cannot deal with the verifier with limited access. Furthermore, their sensitive samples are generated individually, with predictions based solely on the generated samples, making them more suitable for image classification. In contrast, within the context of GNNs, node predictions can be influenced not only by the fingerprint node features, but also by the neighboring node features and their connections. Aside from generating node fingerprints with their node features, our approach also considers perturbing the discrete graph structure. Given that GNN predictions can be significantly impacted by the graph structure, incorporating this factor into our design enhances its effectiveness. In Section 6.2, we compare the above work with ours in our evaluation, further highlighting the differences between the two methods.
5 Mitigating Adaptive Attackers
5.1 Adaptive Attackers Knowing Node Fingerprinting Methods
Our current design can effectively deal with non-adaptive adversarial manipulations of the GNN models. For practical considerations, we also assume a powerful adaptive attacker who has knowledge of the methods used to select and generate verification nodes and the size of verification node sets. Among others, this attacker attempts to identify our verification queries. We consider that such a strong attacker can always bypass our verification process once he determines the verification queries correctly. They may, for example, force the MLaaS server to respond with the correct labels to those identified verification queries.
In the context of such advanced attacks that understand our design strategies, our above design may be bypassed and become less effective. In the case of transductive GNNs, the attacker is able to precalculate fingerprint scores for nodes and then mark those nodes with high fingerprinting scores as potential verification nodes. As long as the attacker detects a query containing the IDs of these potential verification nodes, he can predict the labels of those nodes on the clean GNN model, thus circumventing our detection mechanism. In the case of inductive GNNs, once the attacker detects a query with an updated graph, he can also apply the calculation outlined above to the nodes in the previous version of the graph. Similarly, whenever the graph update is the same as the fingerprint update, these queried nodes are considered potential verification nodes and will be answered honestly.
5.2 Randomized Node Fingerprinting
To address these advanced attackers, we propose an enhanced design for our framework. Intuitively, the verification methods that we use are bypassed because they are static, whereas the fingerprint nodes derived from the specific inference graph are fixed. Thus, an advanced attacker can always follow the exact approach as our design and identify the fingerprint nodes that the verifier has constructed. Therefore, to prevent being identified, we have to introduce randomness into our design to ensure that the fingerprint nodes are not fixed and can hardly be identified. We propose strategies for introducing randomness into our fingerprint verification in inductive and transductive settings, respectively.
Transductive Setting. In this setting, rather than greedily selecting fingerprint nodes among all possible verification nodes, we first randomly select several nodes as the candidates. From these candidates, we select the final fingerprint nodes according to the methods we introduced above. Note that we conduct our fingerprint node search after random sampling. This not only reduces the computation cost of our search algorithm, but also makes it more difficult for attackers to identify the fingerprint nodes. Generally, if the fingerprint nodes are first searched and then sampled, the attackers can always bypass verification by increasing the size of their potential fingerprint node set up to the total number of the sampled candidates. Nevertheless, in our proposed method, they need a much larger set of candidate nodes to ensure that the true fingerprint nodes are included. Formally, we present Theorem 1 and perform a theoretical security analysis to prove it in Appendix B.2.
Theorem 1
Consider an adaptive attacker following the same strategy as our verifier to generate fingerprint nodes in the transductive setting, the probability for to include all fingerprint nodes generated by and bypass verification (defined as Event ) is
| (9) |
This probability becomes negligible when increases unless , where is the total number of nodes on the graph. However, if approaches , the attacker will honestly respond to almost all queries from nodes, which makes their attack meaningless.
Inductive Setting. For this setting, we propose to replace the fixed node label in Eq. 8 with a randomly selected label and propose to minimize the prediction loss as:
| (10) | ||||
| s.t. |
where is a function that generates a random index of , where is the label sets of the target graph. In Eq. 10, rather than misclassifying the fingerprint node to a fixed label, our optimization problem will misclassify it to a randomly selected label. Thus, randomness is introduced to our optimization process by forcing convergence via a randomly selected trajectory. Consequently, the verifier will produce different fingerprint nodes and increase the difficulty of the attacker bypassing our verification. Similarly, we present Theorem 2 for the security guarantee in an inductive setting.
Theorem 2
Consider an adaptive attacker following the same strategy as our inductive verifier to generate fingerprint nodes, the probability for to include all fingerprint nodes generated by and bypass verification (defined as Event ) is
| (11) |
where is the total number of classes for a node.
Note that proves that our randomized node fingerprint generation for inductive settings can also effectively deal with the adaptive attacker.
Other Benefits. While being robust in dealing with an advanced attacker, our enhanced designs also satisfy the other two design goals: efficient and platform-independent. Both of them introduce randomness before applying our ordinary algorithm, thus, they will introduce marginal effort. Meanwhile, all these processes can be done on the verifier side only. Because they are platform-independent, it is possible for verifiers to readily update their previous verification mechanisms to the enhanced ones even after the GNN models are deployed. Namely, the GNN developer can directly ask the verifier to regenerate the randomized fingerprints without any upgradation on the server side.
Note that, although introducing randomization may slightly reduce the effectiveness of the generated node fingerprinting, our proposed enhanced design can still be sufficient for verification. In practice, it is not essential for all fingerprints to be sensitive to perturbations. A mismatch in one fingerprint indicates that the model has been perturbed. We observe that even after randomization, it is highly probable that at least one significant node for verification is included. The verifier can also expand the set of sampled nodes to ensure robust detection performance.
6 Experiments and Evaluations
6.1 Experiment Setup
Datasets and Models. Four public datasets are utilized to evaluate the proposed attack and verification methods, namely Cora, Citeseer, Pubmed [1], and Polblog [64]. These datasets serve as benchmark standards and are extensively used in the assessment of node classification GNNs. Cora, Citeseer, and Pubmed are citation networks in which nodes represent publications and the edges correspond to their citations. Each node in these networks includes attributes (i.e., keywords from the associated publication). In contrast, Polblog is a blog dataset, where each node represents a political blog, and the edges denote links between the blogs. Unlike the other datasets, Polblog does not include any attributes associated with its nodes.
In our experiments, we consider the target model to be a 2-layer graph convolution neural network model. The number of features in the hidden layer for both GNN models is 16. The activation function for the hidden layer is ReLU and for the output layer is softmax. In addition, we apply a dropout layer with a dropout rate of 0.5 after the hidden layer. We use the Adam optimizer with a learning rate of 0.02 and training epochs of 200. The loss function of our model is negative log-likelihood loss. Table II lists the statistics of the datasets.
| Datasets | Node # | Edge # | Attribute # |
| Cora | 2708 | 5429 | 1433 |
| Citeseer | 3312 | 4732 | 3703 |
| Pubmed | 19717 | 44338 | 500 |
| Polblogs | 1490 | 33430 | - |
Attack Coverage. Two types of attacks, BFAs and Poisoning attacks (as introduced in Section 2.2) are used to evaluate our design.
- BFAs. To evaluate how our design can detect the adversarial perturbation caused by the fault injections to the GNN model parameters, we implement Bit-flip Attacks to the GNN models by following existing attacks in DNNs [20, 65]. Specifically, we consider three types of bit flipping: BFA, where an attacker will manipulate one randomly selected parameter among the models and flip the most significant bit of the exponent part; BFA-L, where the attacker tampers with the bias of the last layer of GNNs; BFA-F, where the attacker tampers with the bias of the first layer of GNNs. Detailed settings and attack results can be found in the Appendix A.1.
- Poisoning Attacks. We also apply poisoning attacks on GNNs to evaluate our design when verifying the GNN model replaced by a poisoned model generated via adversarial attacks. Our evaluation will consider two representative attacks: Mettack [66] and a Random attack as a baseline attack that randomly adds edges to perturb the training graph to produce an adversarial GNN model. We include a detailed introduction of the poisoning attack in Appendix A.2.
Baselines. In our study, we evaluate both transductive and inductive settings of GNNs and consider two baseline designs for each setting.
- Transductive Baselines. In the transductive setting, the verification queries consist only of node IDs. We adopt the sensitive sample selection technique MANC from [63] as the first baseline. MANC aims to identify samples that activate the most neurons in the target machine learning model and utilize them for verification. Second, we introduce the Random Node Selection method as a baseline, where the verifier randomly selects nodes within the target graph and issues queries for verification. This approach represents the most fundamental baseline design for comparison.
- Inductive Baselines. In the case of inductive GNNs, the verification queries include an inference graph. We first adapt the fingerprinting generation method, sensitive-sample (denoted as SS), for DNNs from [63] to GNNs. This method commences with the generation of a single sensitive sample using a gradient-based algorithm on specific nodes’ attributes, followed by the application of the MANC sample selection method to choose multiple samples for verification. In addition, we also introduce the Ordinary Inference Graph method as a baseline, where the verifier randomly queries nodes from an inference graph in the same domain as the target GNNs’ prediction task for verification purposes.
Evaluation Metrics. To evaluate our methods, we focus on the performance corresponding to our design goals.
- Effectiveness. To demonstrate how our design can successfully detect different types of adversaries, we first define a successful detection as, when sending queries from fingerprint nodes, there exists at least one node whose label prediction from the response is different from its recorded label generated from the intact GNN. Then, we define the Detection Rate (DR) as the percentage of launched attacks successfully detected by our verification methods. For example, for BFAs, we first generate node fingerprinting pairs, repeat the BFAs times, and gather the number of attacks that successfully deduct the model accuracy of more than . Then, we use our verification methods to detect these attacks. DR is calculated by:
- Efficiency. To demonstrate the efficiency of our design, we will show that our method only requires a small set of node fingerprints. To further substantiate the efficiency of our design, we compare our approach with the baselines and introduce a metric called Query Number Improvement (QI) to evaluate the improvement in our design over the baseline. Specifically, we use to represent the improvement in the number of queries from verification method A to method B when both methods are capable of achieving a detection rate . QI is calculated as follows:
We also assess the cost of deploying our design by evaluating how seamlessly it can be integrated into MLaaS. This assessment includes considering the number of lines of code required for implementation across different entities, as well as the time cost associated with deploying our design.
- Robustness. To demonstrate the effectiveness of our enhanced designs against adaptive attacks, we define the Bypass Rate (BR) to assess how adaptive attackers can identify our verification to bypass it. BR is calculated by:
- Platform-independence. We evaluate this goal of our design by reporting both the deployment cost of our methods on the verifier side and the MLaaS side. We show that, since there is no additional cost on the MLaaS side, our design is applicable to arbitrary types of MLaaS. Namely, our design can be readily applied to different MLaaS platforms.
6.2 Effectiveness
| Cora | Citeseer | Polblog | Pubmed | |||||||||
| Random | MANC | Ours | Random | MANC | Ours | Random | MANC | Ours | Random | MANC | Ours | |
| BFA | 0.031 | 0.049 | 0.711 | 0.047 | 0.290 | 0.586 | 0.460 | 0.125 | 0.579 | 0.556 | 0.179 | 0.813 |
| BFA-F | 0.950 | 0.999 | 0.960 | 0.730 | 0.840 | 0.430 | 0.366 | 0.590 | 0.430 | 0.569 | 0.310 | 0.793 |
| BFA-L | 0.375 | 0.167 | 0.500 | 0.488 | 0.135 | 0.529 | 0.984 | 1.00 | 1.00 | 0.765 | 0.706 | 1.00 |
| Random | 0.342 | 0.002 | 0.647 | 0.410 | 0.741 | 0.412 | 0.582 | 0.701 | 0.765 | 0.998 | 0.953 | 1.00 |
| Mettack | 0.352 | 0.001 | 0.588 | 0.174 | 0.000 | 0.353 | 0.035 | 0.000 | 0.176 | 0.998 | 1.0 | 1.00 |
| Cora | Citeseer | Polblog | Pubmed | |||||||||
| Random | MANC | Ours | Random | MANC | Ours | Random | MANC | Ours | Random | MANC | Ours | |
| BFA | 0.031 | - | 0.982 | 0.047 | - | 0.289 | 0.460 | - | 0.763 | 0.556 | - | 0.555 |
| BFA-F | 0.952 | - | 0.810 | 0.730 | - | 0.430 | 0.600 | - | 0.937 | 0.569 | - | 0.920 |
| BFA-L | 0.375 | - | 1.00 | 0.488 | - | 0.133 | 1.00 | - | 1.00 | 0.765 | - | 0.952 |
| Random | 0.324 | - | 0.353 | 0.412 | - | 0.824 | 0.588 | - | 0.765 | 0.998 | - | 1.00 |
| Mettack | 0.353 | - | 0.598 | 0.176 | - | 0.235 | 0.023 | - | 0.118 | 0.998 | - | 1.00 |
| Cora | Citeseer | Polblog | Pubmed | |||||||||
| Ordinary | SS | Ours | Ordinary | SS | Ours | Ordinary | SS | Ours | Ordinary | SS | Ours | |
| BFA | 0.031 | 0.118 | 0.667 | 0.047 | 0.003 | 0.941 | 0.460 | - | 0.800 | 0.536 | 0.199 | 0.885 |
| BFA-F | 0.901 | 0.882 | 1.00 | 0.530 | 0.529 | 0.882 | 0.366 | - | 0.395 | 0.549 | 0.313 | 0.804 |
| BFA-L | 0.327 | 0.567 | 0.382 | 0.488 | 0.513 | 0.529 | 0.984 | - | 1.00 | 0.767 | 0.716 | 1.00 |
| Random | 0.323 | 0.792 | 1.0 | 0.994 | 1.0 | 1.0 | 0.588 | - | 0.706 | 0.998 | 0.995 | 1.00 |
| Mettack | 0.561 | 1.0 | 1.0 | 0.994 | 1.0 | 1.0 | 0.035 | - | 0.176 | 0.998 | 1.0 | 1.00 |
| Cora | Citeseer | Polblog | Pubmed | |||||||||
| Ordinary | SS | Ours | Ordinary | SS | Ours | Ordinary | SS | Ours | Ordinary | SS | Ours | |
| BFA | 0.028 | - | 0.688 | 0.047 | - | 0.901 | 0.461 | - | 0.752 | 0.532 | - | 0.855 |
| BFA-F | 0.871 | - | 0.989 | 0.520 | - | 0.852 | 0.346 | - | 0.402 | 0.553 | - | 0.844 |
| BFA-L | 0.307 | - | 0.348 | 0.488 | - | 0.569 | 0.984 | - | 1.00 | 0.767 | - | 0.967 |
| Random | 0.313 | - | 1.00 | 0.991 | - | 1.00 | 0.587 | - | 0.746 | 0.997 | - | 1.00 |
| Mettack | 0.562 | - | 1.00 | 0.903 | - | 1.00 | 0.035 | - | 0.216 | 0.998 | - | 1.00 |
Transductive Settings. We begin by evaluating our verification for Transductive-F. Our initial comparison focuses on the Detection Rate (DR) under a single verification query to demonstrate the effectiveness of our fingerprinting node selection. Table III presents a comparison among our design and two baselines in four datasets against five different attacks. The results indicate that our design generally achieves higher performance than the baselines in the majority of cases, while attaining similar performance in the remaining scenarios. It could also be found that MANC also achieves substantial performance in the Citeseer dataset. This outcome is attributed to the fact that this dataset contains approximately 2 to 7 times more node attributes (around 3700) than other datasets (about 500-1400). Therefore, simply considering node attributes is sufficient for verification in this context. However, for graph datasets with fewer attributes, this design approach becomes less effective. In practice, graph data may not always possess a large number of node attributes, as they are primarily utilized to represent relationships between items (e.g., the Polblog dataset does not have node attributes). Consequently, there is a need for our design, which thoughtfully considers the graph structure when formulating the verification queries.
We then turn to the evaluation of our verification for Transductive-L. Since MANC requires access to the internal representation of the model predictions, it is inapplicable when there is limited knowledge of the target model. Consequently, we limit our comparison to the Random Node Selection method, the results of which are shown in Table IV. The findings reveal that our design outperforms the baseline designs in the majority of cases.
In addition, we also observe that, Transductive-F tends to have a more stable performance than Transductive-L due to Transductive-F obtaining additional information from the model (i.e., gradient). For example, in Table III, the detection rate for Transductive-F in Cora ranges from , while in Table IV, they vary between .
Inductive Settings. We next evaluate the effectiveness of our design under inductive settings. Tables V and VI present the Detection Rate (DR) for a single verification query for both the Inductive-F and Inductive-L settings. They compare our design with a baseline that queries an ordinary inference graph without modifications, as well as the sensitive sample generation method described in [63]. It should be noted that in the Inductive-F scenario, where the verifier lacks access to the target GNN models, the sensitive sample generation method cannot be employed. Moreover, since this method only takes into account the query samples’ attributes (i.e., node attributes), it is also not applicable for graph datasets without node attributes such as Polblog.
The results indicate that, compared to the transductive setting, our design outperforms the baseline method in [63]. This enhancement in performance is attributed to the unique nature of GNNs, which are more heavily relying on graph structure. Thus, constructing an effective fingerprinting graph by modifying both the node attributes and the graph structure is more effective than simply altering the node attributes. Furthermore, even when full access to the target model is available, previous designs such as those described in [63] may prove unsuitable for GNNs and hence inapplicable. In addition, for performance with full access, a minor improvement in the number of queries for GNNs is also significant in real-world deployments, since the nodes issuing queries in GNNs could be physical entities.
6.3 Efficiency
Query Efficiency. Tables VII and VIII present the QI for our design, in comparison with two baseline approaches: Random Node Selection under the transductive setting, and Ordinary Inference Graph under the inductive setting. Our design consistently outperforms these baselines across all settings and shows superior performance specifically in inductive settings. This corresponds to the effectiveness analysis in Section 6.2, which illustrates that the construction of a fingerprinting graph by altering the graph structure and node attributes of an ordinary inference graph can be highly effective for verification.
We also compare our design with the methods detailed in [63], finding that our approach significantly exceeds their performance in most cases, especially when compared to a single query DR. This is because both designs utilize MANC for the selection of verification nodes, which is based on neuron activation. We observe that DR using MANC gradually increases with the number of queries. This pattern aligns with our rationale described in Section 4.1, where the generation of sensitive-samples uses activated neurons to create fingerprints. Figure 2 illustrates activated neurons in GNN models relative to our node fingerprint queries. In the context of GNN, the proportion of activated neurons quickly exceeds , reducing the effectiveness of selecting sensitive samples according to this criterion. Therefore, even when the strategies in [63] could achieve a performance similar to our design with a single node query, they will be less efficient when increasing the number of queries to reach higher DR.
It is also worth noting that even slight improvements over the baseline are significant in practice. This is because, in real-world applications, reducing the query number is more vital in GNNs than in DNNs. As discussed in Section 3.2, unlike DNNs where users may issue numerous queries, the nodes initiating queries in GNNs could represent physical entities in a real-world graph (e.g., security appliances in a network graph provided by the system developer to mitigate threats). Therefore, minimizing the number of queries becomes essential, accentuating the practical importance of our design in the context of GNNs.
Development Cost. We then evaluate the time cost of our verification. Since our design can be accomplished by issuing inference queries from the fingerprinting nodes in the same manner as inference queries from normal users, the time cost of the queries for our verification is the same as inference queries. Namely, our verification does not incur any overhead on the server side. Similarly, on the verifier side, issuing a verification query will also take the same amount of time as a normal prediction query. The majority of the time costs come from the generation of the fingerprinting nodes. Table IX shows the time cost of generating one fingerprinting node using both our methods in three datasets. All results are recorded when our verification mechanism is running in CPU mode since we assume that the verifier who uses the MLaaS may not have high-performance computation devices such as the GPU. Considering that most of our detection requires only a small number of nodes (less than ), our fingerprinting node generation methods can be efficient, especially in the transductive setting.
| Cora | Citeseer | Polblog | Pubmed | |||||||||||||
| MANC | Ours | MANC | Ours | MANC | Ours | MANC | Ours | |||||||||
| F | L | F | L | F | L | F | L | F | L | F | L | F | L | F | L | |
| BFA | - | - | - | - | ||||||||||||
| BFA-F | - | - | - | - | ||||||||||||
| BFA-L | - | - | - | - | ||||||||||||
| Mettack | - | - | - | - | ||||||||||||
| RandAttack | - | - | - | - | ||||||||||||
| Cora | Citeseer | Polblog | Pubmed | |||||||||||||
| SS | Ours | SS | Ours | SS | Ours | SS | Ours | |||||||||
| F | L | F | L | F | L | F | L | F | L | F | L | F | L | F | L | |
| BFA | - | - | - | - | ||||||||||||
| BFA-F | - | - | - | - | ||||||||||||
| BFA-L | - | - | - | - | ||||||||||||
| Mettack | - | - | - | - | ||||||||||||
| RandAttack | - | - | - | - | ||||||||||||
6.4 Dealing with Adaptive Attackers (Robustness)

(a) Transductive Setting

(b) Inductive Setting
In Section 5, we have introduced how our verification methods in both the transductive and inductive GNN learning settings can deal with adaptive attackers who are aware of the detection and intend to bypass it. Here we provide more detailed results about the outcome of our analysis.
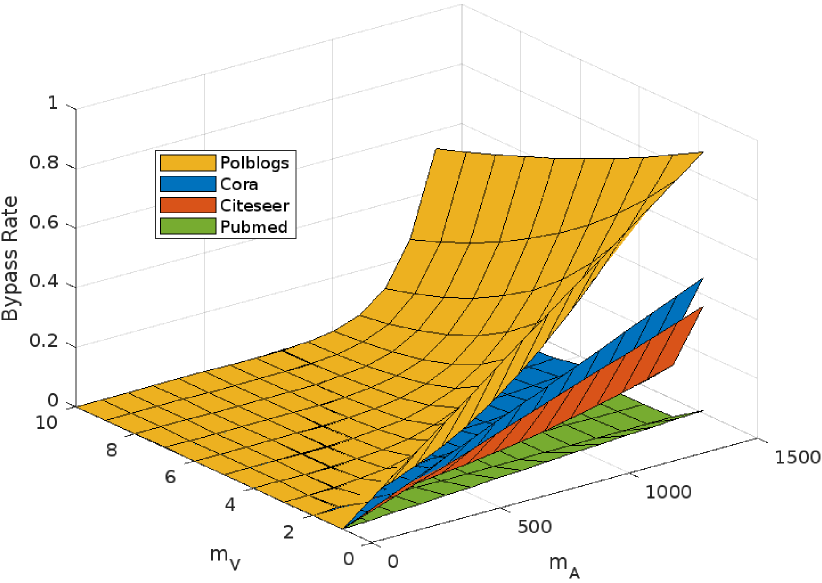
For the transductive setting, we evaluate the bypass rate of an adaptive attacker when he tries to identify the fingerprint nodes. Figure 3(a) show the relationship between the bypass rate and two hyperparameters: (the number of fingerprinting nodes generated by the advanced attacker) and (the number of the fingerprinting nodes generated by the verifier). It can be found that, when either increases, the probability that the attacker can identify the fingerprinting node decreases dramatically. Meanwhile, if the attacker wants to achieve a high bypass rate, he should increase the number of nodes marked as verification nodes close to the number of total nodes in the graph. For example, in the Cora dataset, while honestly responding to more than nodes, the attacker can successfully bypass about verification queries. Namely, they will honestly respond to more than of the queries which makes their attack much less effective. Thus, our randomized node fingerprint can deal with the adaptive attacker.
Figure 3(b) shows the relationship between the bypass rate and two hyperparameters in the inductive setting. It can be found that, similar to the results in the transductive setting, the attacker can only achieve a bypass rate of less than by honestly responding to more than nodes for all three of our datasets. In addition, the verifier can easily reduce the bypass rate by slightly increasing its fingerprinting nodes.
6.5 Deployment Cost (Platform-independence)
We finally present the cost of our verification methods. As mentioned in Section 3, our verification is designed to be adaptive to different MLaaS platforms. Firstly, the verifer in our verification process utilizes only query APIs, which are fundamental to MLaaS and supported by all platforms. In addition, to deploy our design, all our fingerprint node generation processes are done on the verifier (client) side. Namely, our design does not modify or add extra code to the MLaaS server. For our verification design for Inductive-F, only around 220 lines of code are deployed on the verifier side, while the method for Inductive-L, only around 170 lines of code are needed.
| Dataset | Knowledge to Models | Transductive (s) | Inductive (s) |
| Cora | Full | 3.998 | 23.26 |
| Limited | 8.92e-5 | 34.63 | |
| Citeseer | Full | 5.148 | 81.24 |
| Limited | 7.58e-5 | 34.27 | |
| Pubmed | Full | 78.48 | 732.65 |
| Limited | 6.06e-5 | 34.26 |
7 Related Work
ML Model Verification. To address the security threats in MLaaS, recent studies explore how to verify the ML models deployed in the cloud, but none of them is applicable to GNNs. Based on the goals of verification, they can be divided into two types, i.e., verifying the model integrity and verifying the model ownership. Prior works propose to utilize traditional software security solutions for ML model integrity verification [67, 68]. However, they require the verifier to perform the verification which does not align with our assumptions. He et al. [63] propose a sensitive-sample based method to protect the DNN models in MLaaS. Chowdhury et al. [69] use secret-shared non-interactive proofs to verify integrity. However, their approach only focuses on DNNs and cannot be extended to GNNs since it neglects to consider the graph structure. Li et al. [67] propose a lightweight checker-model based verification to verify the integrity of target DNNs. However, their proposed validation model needs to be deployed on the server side. In our work, we assume the cloud is nontrusted and does not require the cloud server for verification. Another line of work aims to verify the ownership of an ML model and protect the IP of the ML model. Most studies verifying model ownership tend to inject watermarks into models [70, 71, 72, 73, 74]. Note that, they desire to verify the ownership even when the models have been retrained by the attacker, which is different from the breach of the model integrity.
Attacks and Defenses in GNNs. Many attacks have been proposed against GNN models in the past few years, including both adversarial attacks and privacy attacks [75, 76, 18, 77, 78]. These attacks can be classified into two categories: the attacks perturbing the graph [76, 18, 79, 17] and the attacks perturbing the model [20, 21, 22]. There are several studies on how to mitigate these attacks on GNNs [56, 80]. Since most of the existing attacks directly perturb the graph data or modify the model parameters by perturbing the training graph, all of these defenses propose to reduce the effects caused by the perturbed graph [28, 29, 81, 28, 82]. We emphasize that these defense methods are different from our design. As a general principle, most of the above defense strategies using pre-processing [18, 83] or reconstructing [29, 82] assume that the defender has full access and control of the target GNNs. However, it is not feasible to provide such access in cloud-based GNN services. As for adversarial training strategies, they either require additional algorithms (such as adversarial regularization terms [57]) or are only suitable for specific attacks [76, 84]. In addition, such countermeasures are applied before model serving, which cannot directly address threats after the model is deployed in MLaaS.
Recent studies [85, 86] that mitigate BFAs in DNNs are not specifically designed for GNN models. These designs often encounter limitations similar to those found in sensitive-fingerprint approaches (i.e., they focus primarily on models with complex structures and overlook the connections among different samples, which are essential in the context of GNNs) [86]. Additionally, these methods may require the integration of additional functional components, which makes them less suitable for MLaaS applications [85].
8 Conclusion
With the increasing popularity of MLaaS and GNNs, it is essential to explore how to protect the integrity of GNN services against model-centric attacks. In this paper, we propose a comprehensive integrity verification framework for GNNs deployed via MLaaS. We design a query-based verification mechanism to authenticate the integrity of GNNs through a limited set of fingerprinting nodes. Based on two practical (transductive/inductive) settings of node classification tasks and the variant verifier’s knowledge, we propose fingerprinting generation algorithms by considering the graph structure and verification nodes’ neighbors, respectively. To address a strong attacker who knows the detection methods and attempts to bypass them, we further enhance our methods by introducing randomized node fingerprints to the verification queries. Evaluations of four real-world datasets against five prevalent adversarial attacks demonstrate that our verification method detects them successfully and is times more efficient than the baselines.
Acknowledgements
This work is supported in part by a Monash-Data61 Collaborative Research Project (CRP43) and Australian Research Council (ARC) DP240103068, FT210100097, and DP240101547. Minhui Xue, Xingliang Yuan and Shirui Pan are also supported by CSIRO – National Science Foundation (US) AI Research Collaboration Program. Qi Li’s work is in part supported by the National Key Research and Development Project of China under Grant 2021ZD0110502 and NSFC under Grant 62132011.
References
- [1] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in ICLR. OpenReview.net, 2017.
- [2] Y. Chen, L. Wu, and M. J. Zaki, “Iterative deep graph learning for graph neural networks: Better and robust node embeddings,” in NeurIPS, 2020.
- [3] J. Wang, P. Huang, H. Zhao, Z. Zhang, B. Zhao, and D. L. Lee, “Billion-scale commodity embedding for e-commerce recommendation in alibaba,” in KDD. ACM, 2018, pp. 839–848.
- [4] Y. Wang, J. Zhang, S. Guo, H. Yin, C. Li, and H. Chen, “Decoupling representation learning and classification for gnn-based anomaly detection,” in SIGIR. ACM, 2021, pp. 1239–1248.
- [5] A. Deng and B. Hooi, “Graph neural network-based anomaly detection in multivariate time series,” in AAAI. AAAI Press, 2021, pp. 4027–4035.
- [6] Y. Wan, Y. Liu, D. Wang, and Y. Wen, “GLAD-PAW: graph-based log anomaly detection by position aware weighted graph attention network,” in PAKDD, ser. Lecture Notes in Computer Science, vol. 12712. Springer, 2021, pp. 66–77.
- [7] Q. Cai, H. Wang, Z. Li, and X. Liu, “A survey on multimodal data-driven smart healthcare systems: Approaches and applications,” IEEE Access, vol. 7, pp. 133 583–133 599, 2019.
- [8] K. Gopinath, C. Desrosiers, and H. Lombaert, “Graph domain adaptation for alignment-invariant brain surface segmentation,” in UNSURE/GRAIL@MICCAI, ser. Lecture Notes in Computer Science, vol. 12443. Springer, 2020, pp. 152–163.
- [9] J. Liu, G. Tan, W. Lan, and J. Wang, “Identification of early mild cognitive impairment using multi-modal data and graph convolutional networks,” BMC Bioinform., vol. 21-S, no. 6, p. 123, 2020.
- [10] H. E. Manoochehri and M. Nourani, “Drug-target interaction prediction using semi-bipartite graph model and deep learning,” BMC Bioinform., vol. 21-S, no. 4, p. 248, 2020.
- [11] S. Adeshina, “Detecting fraud in heterogeneous networks using amazon sagemaker and deep graph library,” Jun 2020. [Online]. Available: https://aws.amazon.com/blogs/machine-learning/detecting-fraud-in-heterogeneous-networks-using-amazon-sagemaker-and-deep-graph-library/
- [12] B. Balakreshnan, “Graph neural network in azure machine learning — classification,” Medium, 11 2021. [Online]. Available: https://balabala76.medium.com/graph-neural-network-in-azure-machine-learning-classification-df7978d7bd45
- [13] B. Lackey, “Analyze graph data on google cloud with neo4j and vertex ai,” Google Cloud Blog, 01 2022. [Online]. Available: https://cloud.google.com/blog/products/ai-machine-learning/analyze-graph-data-on-google-cloud-with-neo4j-and-vertex-ai
- [14] D. Zügner, A. Akbarnejad, and S. Günnemann, “Adversarial attacks on neural networks for graph data,” in IJCAI. ijcai.org, 2019, pp. 6246–6250.
- [15] J. Ma, S. Ding, and Q. Mei, “Towards more practical adversarial attacks on graph neural networks,” in NeurIPS, 2020.
- [16] Y. Sun, S. Wang, X. Tang, T.-Y. Hsieh, and V. Honavar, “Non-target-specific node injection attacks on graph neural networks: A hierarchical reinforcement learning approach,” in WWW. ACM / IW3C2, 2020.
- [17] X. Liu, S. Si, J. Zhu, Y. Li, and C. Hsieh, “A unified framework for data poisoning attack to graph-based semi-supervised learning,” in NeurIPS, 2019, pp. 9777–9787.
- [18] H. Wu, C. Wang, Y. Tyshetskiy, A. Docherty, K. Lu, and L. Zhu, “Adversarial examples for graph data: Deep insights into attack and defense,” in IJCAI. ijcai.org, 2019, pp. 4816–4823.
- [19] H. Zhang, B. Wu, X. Yang, C. Zhou, S. Wang, X. Yuan, and S. Pan, “Projective ranking: A transferable evasion attack method on graph neural networks,” in CIKM. ACM, 2021, pp. 3617–3621.
- [20] Y. Liu, L. Wei, B. Luo, and Q. Xu, “Fault injection attack on deep neural network,” in ICCAD. IEEE, 2017, pp. 131–138.
- [21] A. S. Rakin, Z. He, and D. Fan, “Bit-flip attack: Crushing neural network with progressive bit search,” in ICCV. IEEE, 2019, pp. 1211–1220.
- [22] F. Yao, A. S. Rakin, and D. Fan, “Deephammer: Depleting the intelligence of deep neural networks through targeted chain of bit flips,” in USENIX Security Symposium. USENIX Association, 2020, pp. 1463–1480.
- [23] S. Mehta, R. Bhagwan, R. Kumar, C. Bansal, C. S. Maddila, B. Ashok, S. Asthana, C. Bird, and A. Kumar, “Rex: Preventing bugs and misconfiguration in large services using correlated change analysis,” in NSDI. USENIX Association, 2020, pp. 435–448.
- [24] S. Li, W. Li, X. Liao, S. Peng, S. Zhou, Z. Jia, and T. Wang, “Confvd: System reactions analysis and evaluation through misconfiguration injection,” IEEE Trans. Reliab., vol. 67, no. 4, pp. 1393–1405, 2018.
- [25] E. Kost, “14 biggest healthcare data breaches [updated 2023]: Upguard,” Jul 2023. [Online]. Available: https://www.upguard.com/blog/biggest-data-breaches-in-healthcare
- [26] J. McKeon, “Biggest healthcare data breaches reported this year, so far,” Jun 2023. [Online]. Available: https://healthitsecurity.com/features/biggest-healthcare-data-breaches-reported-this-year-so-far
- [27] R. Southwick, “The 11 biggest health data breaches in 2022.” [Online]. Available: https://www.chiefhealthcareexecutive.com/view/the-11-biggest-health-data-breaches-in-2022
- [28] A. Zhang and J. Ma, “Defensevgae: Defending against adversarial attacks on graph data via a variational graph autoencoder,” CoRR, vol. abs/2006.08900, 2020.
- [29] B. Jiang, Z. Zhang, D. Lin, J. Tang, and B. Luo, “Semi-supervised learning with graph learning-convolutional networks,” in CVPR. Computer Vision Foundation / IEEE, 2019, pp. 11 313–11 320.
- [30] S. Heath, “American heart association makes moves for precision medicine,” Nov 2016. [Online]. Available: https://healthitanalytics.com/news/american-heart-association-makes-moves-for-precision-medicine
- [31] N. Papernot, P. D. McDaniel, A. Sinha, and M. P. Wellman, “Towards the science of security and privacy in machine learning,” CoRR, vol. abs/1611.03814, 2016.
- [32] Z. Ghodsi, T. Gu, and S. Garg, “Safetynets: Verifiable execution of deep neural networks on an untrusted cloud,” in NeurIPS, 2017, pp. 4672–4681.
- [33] C. I. Team, “Top cloud security breaches and how to protect your organization,” Jan 2021. [Online]. Available: https://cloud.netapp.com/blog/cis-blg-top-cloud-security-breaches-and-how-to-protect-your-organization
- [34] C. Osborne, “Artwork archive cloud storage misconfiguration exposed user data,” Jul 2021. [Online]. Available: https://www.zdnet.com/article/artwork-archive-cloud-storage-misconfiguration-exposed-user-data-revenue-records/
- [35] C. Bradford, “7 most infamous cloud security breaches - storagecraft,” Dec 2020. [Online]. Available: https://blog.storagecraft.com/7-infamous-cloud-security-breaches/
- [36] N. Goud, “Top 5 cloud security related data breaches!” Oct 2017. [Online]. Available: https://www.cybersecurity-insiders.com/top-5-cloud-security-related-data-breaches/
- [37] C. Priebe, D. Muthukumaran, D. O’Keeffe, D. M. Eyers, B. Shand, R. Kapitza, and P. R. Pietzuch, “Cloudsafetynet: Detecting data leakage between cloud tenants,” in CCSW. ACM, 2014, pp. 117–128.
- [38] J. Cable, D. M. Gregory, L. Izhikevich, and Z. Durumeric, “Stratosphere: Finding vulnerable cloud storage buckets,” in RAID. ACM, 2021, pp. 399–411.
- [39] L. Wu, P. Cui, J. Pei, and L. Zhao, Graph Neural Networks: Foundations, Frontiers, and Applications. Singapore: Springer Singapore, 2022.
- [40] Q. Li, Z. Han, and X. Wu, “Deeper insights into graph convolutional networks for semi-supervised learning,” in AAAI. AAAI Press, 2018, pp. 3538–3545.
- [41] Themeix, Jul 2018. [Online]. Available: https://www.dgl.ai/pages/about.html
- [42] J. Simon, “Now available on amazon sagemaker: The deep graph library,” Dec 2019. [Online]. Available: https://aws.amazon.com/blogs/aws/now-available-on-amazon-sagemaker-the-deep-graph-library/
- [43] B. Yuan, Y. Jia, L. Xing, D. Zhao, X. Wang, D. Zou, H. Jin, and Y. Zhang, “Shattered chain of trust: Understanding security risks in cross-cloud iot access delegation,” in USENIX Security Symposium. USENIX Association, 2020, pp. 1183–1200.
- [44] J. Pan and Z. Yang, “Cybersecurity challenges and opportunities in the new ”edge computing + iot” world,” in SDN-NFV@CODASPY. ACM, 2018, pp. 29–32.
- [45] I. Homoliak, F. Toffalini, J. Guarnizo, Y. Elovici, and M. Ochoa, “Insight into insiders and IT: A survey of insider threat taxonomies, analysis, modeling, and countermeasures,” ACM Comput. Surv., vol. 52, no. 2, pp. 30:1–30:40, 2019.
- [46] D. C. Le, S. Khanchi, A. N. Zincir-Heywood, and M. I. Heywood, “Benchmarking evolutionary computation approaches to insider threat detection,” in GECCO. ACM, 2018, pp. 1286–1293.
- [47] R. Herardian, “The soft underbelly of cloud security,” IEEE Secur. Priv., vol. 17, no. 3, pp. 90–93, 2019.
- [48] F. Hetzelt, M. Radev, R. Buhren, M. Morbitzer, and J. Seifert, “VIA: analyzing device interfaces of protected virtual machines,” in ACSAC. ACM, 2021, pp. 273–284.
- [49] T. E. Gasiba, I. Andrei-Cristian, U. Lechner, and M. Pinto-Albuquerque, “Raising security awareness of cloud deployments using infrastructure as code through cybersecurity challenges,” in ARES. ACM, 2021, pp. 63:1–63:8.
- [50] M. T. Khan, C. Tran, S. Singh, D. Vasilkov, C. Kanich, B. Ur, and E. Zheleva, “Helping users automatically find and manage sensitive, expendable files in cloud storage,” in USENIX Security Symposium. USENIX Association, 2021, pp. 1145–1162.
- [51] A. G. Yaglikçi, H. Luo, G. F. de Oliviera, A. Olgun, M. Patel, J. Park, H. Hassan, J. S. Kim, L. Orosa, and O. Mutlu, “Understanding rowhammer under reduced wordline voltage: An experimental study using real DRAM devices,” in DSN. IEEE, 2022, pp. 475–487.
- [52] A. Boutros, M. Hall, N. Papernot, and V. Betz, “Neighbors from hell: Voltage attacks against deep learning accelerators on multi-tenant fpgas,” in FPT. IEEE, 2020, pp. 103–111.
- [53] W. Liu, C. Chang, F. Zhang, and X. Lou, “Imperceptible misclassification attack on deep learning accelerator by glitch injection,” in DAC. IEEE, 2020, pp. 1–6.
- [54] V. Gupta and T. Chakraborty, “VIKING: adversarial attack on network embeddings via supervised network poisoning,” in PAKDD (3), ser. Lecture Notes in Computer Science, vol. 12714. Springer, 2021, pp. 103–115.
- [55] Y. Sun, S. Wang, X. Tang, T. Hsieh, and V. G. Honavar, “Adversarial attacks on graph neural networks via node injections: A hierarchical reinforcement learning approach,” in WWW. ACM / IW3C2, 2020, pp. 673–683.
- [56] X. Zhang and M. Zitnik, “Gnnguard: Defending graph neural networks against adversarial attacks,” in NeurIPS, 2020.
- [57] F. Feng, X. He, J. Tang, and T. Chua, “Graph adversarial training: Dynamically regularizing based on graph structure,” IEEE Trans. Knowl. Data Eng., vol. 33, no. 6, pp. 2493–2504, 2021.
- [58] H. Jin and X. Zhang, “Robust training of graph convolutional networks via latent perturbation,” in ECML/PKDD (3), ser. Lecture Notes in Computer Science, vol. 12459. Springer, 2020, pp. 394–411.
- [59] C. Modi, D. R. Patel, B. Borisaniya, H. Patel, A. Patel, and M. Rajarajan, “A survey of intrusion detection techniques in cloud,” J. Netw. Comput. Appl., vol. 36, no. 1, pp. 42–57, 2013.
- [60] R. Shokri, M. Stronati, C. Song, and V. Shmatikov, “Membership inference attacks against machine learning models,” in IEEE Secur. Priv. IEEE Computer Society, 2017, pp. 3–18.
- [61] B. Wu, X. Yang, S. Pan, and X. Yuan, “Model extraction attacks on graph neural networks: Taxonomy and realisation,” in AsiaCCS. ACM, 2022, pp. 337–350.
- [62] H. Chang, Y. Rong, T. Xu, W. Huang, H. Zhang, P. Cui, W. Zhu, and J. Huang, “A restricted black-box adversarial framework towards attacking graph embedding models,” in AAAI, 2020.
- [63] Z. He, T. Zhang, and R. B. Lee, “Sensitive-sample fingerprinting of deep neural networks,” in CVPR. Computer Vision Foundation / IEEE, 2019, pp. 4729–4737.
- [64] L. A. Adamic and N. S. Glance, “The political blogosphere and the 2004 U.S. election: divided they blog,” in LinkKDD. ACM, 2005, pp. 36–43.
- [65] J. Breier, X. Hou, D. Jap, L. Ma, S. Bhasin, and Y. Liu, “Practical fault attack on deep neural networks,” in CCS. ACM, 2018, pp. 2204–2206.
- [66] D. Zügner and S. Günnemann, “Certifiable robustness and robust training for graph convolutional networks,” in KDD. ACM, 2019, pp. 246–256.
- [67] Y. Li, M. Li, B. Luo, Y. Tian, and Q. Xu, “Deepdyve: Dynamic verification for deep neural networks,” in CCS. ACM, 2020, pp. 101–112.
- [68] M. Javaheripi and F. Koushanfar, “HASHTAG: hash signatures for online detection of fault-injection attacks on deep neural networks,” in ICCAD. IEEE, 2021, pp. 1–9.
- [69] A. R. Chowdhury, C. Guo, S. Jha, and L. van der Maaten, “Eiffel: Ensuring integrity for federated learning,” CoRR, vol. abs/2112.12727, 2021.
- [70] T. Wang and F. Kerschbaum, “RIGA: covert and robust white-box watermarking of deep neural networks,” in WWW. ACM / IW3C2, 2021, pp. 993–1004.
- [71] Y. Adi, C. Baum, M. Cissé, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” in USENIX Security Symposium. USENIX Association, 2018, pp. 1615–1631.
- [72] J. Zhang, Z. Gu, J. Jang, H. Wu, M. P. Stoecklin, H. Huang, and I. M. Molloy, “Protecting intellectual property of deep neural networks with watermarking,” in AsiaCCS. ACM, 2018, pp. 159–172.
- [73] H. Liu, Z. Weng, and Y. Zhu, “Watermarking deep neural networks with greedy residuals,” in ICML, ser. Proceedings of Machine Learning Research, vol. 139. PMLR, 2021, pp. 6978–6988.
- [74] Q. Zhong, L. Y. Zhang, J. Zhang, L. Gao, and Y. Xiang, “Protecting IP of deep neural networks with watermarking: A new label helps,” in PAKDD, ser. Lecture Notes in Computer Science, vol. 12085. Springer, 2020, pp. 462–474.
- [75] H. Zhang, B. Wu, X. Yuan, S. Pan, H. Tong, and J. Pei, “Trustworthy graph neural networks: Aspects, methods and trends,” CoRR, vol. abs/2205.07424, 2022.
- [76] K. Xu, H. Chen, S. Liu, P. Chen, T. Weng, M. Hong, and X. Lin, “Topology attack and defense for graph neural networks: An optimization perspective,” in IJCAI. ijcai.org, 2019, pp. 3961–3967.
- [77] H. Zhang, B. Wu, S. Wang, X. Yang, M. Xue, S. Pan, and X. Yuan, “Demystifying uneven vulnerability of link stealing attacks against graph neural networks,” in ICML, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 2023, pp. 41 737–41 752.
- [78] B. Wu, X. Yang, S. Pan, and X. Yuan, “Adapting membership inference attacks to GNN for graph classification: Approaches and implications,” in ICDM. IEEE, 2021, pp. 1421–1426.
- [79] B. Wang and N. Z. Gong, “Attacking graph-based classification via manipulating the graph structure,” in CCS. ACM, 2019, pp. 2023–2040.
- [80] D. Zhu, Z. Zhang, P. Cui, and W. Zhu, “Robust graph convolutional networks against adversarial attacks,” in KDD. ACM, 2019.
- [81] A. Hasanzadeh, E. Hajiramezanali, K. R. Narayanan, N. Duffield, M. Zhou, and X. Qian, “Semi-implicit graph variational auto-encoders,” in NeurIPS, 2019, pp. 10 711–10 722.
- [82] W. Jin, Y. Ma, X. Liu, X. Tang, S. Wang, and J. Tang, “Graph structure learning for robust graph neural networks,” in KDD, R. Gupta, Y. Liu, J. Tang, and B. A. Prakash, Eds. ACM, 2020, pp. 66–74.
- [83] D. Luo, W. Cheng, W. Yu, B. Zong, J. Ni, H. Chen, and X. Zhang, “Learning to drop: Robust graph neural network via topological denoising,” in WSDM. ACM, 2021, pp. 779–787.
- [84] J. Chen, X. Lin, Z. Shi, and Y. Liu, “Link prediction adversarial attack via iterative gradient attack,” IEEE Trans. Comput. Soc. Syst., vol. 7, no. 4, pp. 1081–1094, 2020.
- [85] J. Wang, Z. Zhang, M. Wang, H. Qiu, T. Zhang, Q. Li, Z. Li, T. Wei, and C. Zhang, “Aegis: Mitigating targeted bit-flip attacks against deep neural networks.”
- [86] Q. Liu, J. Yin, W. Wen, C. Yang, and S. Sha, “Neuropots: Realtime proactive defense against bit-flip attacks in neural networks.”
Appendix A Proposed Attacks
A.1 Bit-flip Attack against GNN Models
Here we provide the formal definition of BFA. Given a two-layer GNN model , the weights are represented as . An attacker attempts to identify the most vulnerable weight bits, which can maximize the inference loss of GNNs by the perturbed weights. Such an attack can be formalized as an optimization problem:
| (12) | ||||
where and are the graph input and node labels for the inference node sets. calculates the inference loss between GNN’s predictions and target labels. represents the number of flipping bits between the perturbed and clean GNN parameters.
Overall, we follow the existing strategies of BFA introduced in DNN [20, 65] and implement them in GNNs. Given a set of model parameters, i.e., weights or bias representing a floating number, they are stored as floating-point numbers in the IEEE standard format for floating-point arithmetic. Considering the 32-bit floating number type, which is a typical number type for the Deep Learning framework, the numbers consist of the sign bit, the exponent bits, and the significant bits. To manipulate the value by bit-flipping, we propose to flip the most significant bit of the exponent part.
A.2 Poisoning Attacks against GNNs
The attacks that decrease the final model performance by perturbing the graph during the inference period, are called evasion attacks. Formally, an evasion attack can be defined as the following optimization problem.
Given a target graph , and a well-trained GNN model , an attacker aims at maximising the accuracy loss between the predictions of and ground truth labels by perturbing to within perturbation budget , as followed:
| (13) | ||||
where is a perturbation measurement function between two graphs.
Appendix B Additional Derivations and Definitions
B.1 Fingerprint Score Function for Transductive-F
Since the prediction result from is non-linear to the model output , we approximate the difference between the final prediction labels by the L2 distance between their output confidence vectors, as follows:
| (14) |
The perturbation is applied to , so we can generate a Taylor expansion of around current well-trained model parameters as follows:
| (15) | ||||
where, is the second order (and higher) term of . In general, is a small perturbation as attackers often tend to be in a less noticeable manner. Therefore, we disregard this higher-order term and define our fingerprint score:
| (16) |
where represents the distance between the node prediction and its prediction label .
B.2 Security Analysis of Randomized Fingerprints
In this section, we provide a theoretical analysis of the randomized fingerprint method in a transductive setting when facing an adaptive attacker. Here, we define the two processes for verification and adaptive attacks:
Definition 5 (Verifier )
Given a graph , which has total nodes (), a verifier uses the fingerprint generation scheme to generate fingerprints among the entire graph. The fingerprint node set is noted as . The verifier will use to verify the integrity of GNNs.
Definition 6 (Adaptive Attacker )
An adaptive attacker follows a similar strategy as Verifier to generate a set of fingerprints and identify them during the GNN serving. Specifically, he first randomly selects nodes as the hypothetical node set. Then, he follows the same strategies as Verifier , to generate hypothetical fingerprints among the entire graph. The hypothetical fingerprint set is noted as . The attacker will honestly respond to nodes in to bypass the verification.
Definition 7 (Event )
Attacker successfully identifies all the verification nodes selected by Verifier and bypasses the verification, where:
| (17) |
Since both and are randomly sampled from , we have:
| (18) | ||||
Thus, when , we have:
| (19) |
Such probability becomes negligible when increases unless . However, if approaches , the attacker will honestly respond to almost all queries, which makes their attack meaningless. For example, given a graph with nodes, if both verifier and attacker generate their fingerprint set with the size of (), the probability of to bypass is about .
Appendix C Meta-Review
The following meta-review was prepared by the program committee for the 2024 IEEE Symposium on Security and Privacy (S&P) as part of the review process as detailed in the call for papers.
C.1 Summary
This paper proposes techniques to mitigate security issues that arise in the use of Graph Neural Networks (GNNs) in Machine Learning as a Service (MLaaS) settings. It uses a query-based verification framework that uses node fingerprint nodes to thwart knowledgeable attackers. Experimental results show that this method efficiently detects several different forms of attack, and outperforms baseline methods by significant margins.
C.2 Scientific Contributions
-
•
Addresses a long-standing issue
-
•
Provides a valuable step forward in an established field
C.3 Reasons for Acceptance
-
1.
This work provides the first systematic investigation study of protecting GNNs in this timely setting against model-centric attacks.
-
2.
The proposed verification framework is comprehensive, covering a variety of access levels and adversarial background knowledge.
-
3.
The paper provides an extensive analysis of the proposed techniques regarding effectiveness and performance.