Searching for internal symbols underlying deep learning
Abstract
Deep learning (DL) enables deep neural networks (DNNs) to automatically learn complex tasks or rules from given examples without instructions or guiding principles. As we do not engineer DNNs’ functions, it is extremely difficult to diagnose their decisions, and multiple lines of studies proposed to explain the principles of their operations. Notably, one line of studies suggests that DNNs may learn concepts, the high level features that are recognizable to humans. In this study, we extend this line of studies and hypothesize that DNNs can develop abstract codes that can be used to augment DNNs’ decision-making. To address this hypothesis, we combine foundation segmentation models and unsupervised learning to extract internal codes and identify potential use of abstract codes to make DL’s decision-making more reliable and safer.
1 Introduction
Deep learning (DL) can automatically wire deep neural networks (DNNs) to perform complex tasks, and DNNs’ learning capability allows them to outperform humans in some tasks [1, 2, 3]. Notably, instead of expert instructions or feature engineering, DL requires only training examples to solve highly complex problems. However, as DNNs’ structures are automatically determined without guiding principles, we do not fully understand their decision-making process. That is, DNNs may be useful black box decision-makers, but without safety measures, deploying them in high-stakes domains (e.g., autonomous cars) comes with unpredictable risks [4, 5]. For the moment, the current generation of DL does not warrant essential safety to be deployed in safety-critical or high-stakes domains. To address this shortcoming, earlier studies sought potential methods to decode and explain DNNs’ decisions. There are multiple lines of research in explainable AI (e.g., see Refs. [6, 7, 8, 9, 10]), but in our study we pay special attention to the one probing correlations between hidden layer representations and inputs or between hidden layer representations and outputs (i.e., decisions). Feature visualization [11] and network dissection [12] sought direct links between inputs and hidden layers, while linear probes investigated correlations between outputs and hidden layers [13, 14].
It is notable that the mapping between hidden layers and visual features in input layers, in principle, establishes links between high level patterns recognizable to humans (often referred to as ‘concepts’) and hidden neurons. The Test with Concept Activation Vectors [14] explicitly extended this idea to detect concepts encoded in neural networks. The concepts (i.e., perceptible patterns) encoded in neural networks could deepen our understanding of DNNs’ operating principles and eventually provide explanations (readable to humans) of their decisions. More importantly, it raises the possibility that DNNs could build some abstract codes in hidden layers, some of which could directly be linked to concepts. In this study, we extend this line of studies by seeking abstract codes, which are not necessarily recognizable to humans, in hidden layers functionally linked to DNNs’ decisions. To make a clear distinction between human recognizable concepts (inputs’ features) and DNNs’ own abstract codes, we will refer to DNNs’ abstract codes as ‘symbols’ hereafter.
Our analysis is inspired by two observations in the literature. First, the hidden layers encode distinct contextual information. Earlier layers encode low-level features such as texture and shapes, whereas late layers encode high-level semantic features. Second, the penultimate layer’s outputs are clustered together according to the labels of inputs. As all hidden layers are trained simultaneously via the same algorithm, it seems natural to assume that all hidden layers may share the same operating principles. More specifically, we assume that hidden layers map inputs with the same contextual information into neighboring outputs, as the penultimate layer maps inputs belonging to the same class onto the same clusters. The penultimate layer encodes the labels, and the earlier hidden layers encode different contexts currently unknown to us. If these functional clusters reflecting contextual information exist in the hidden layers, identifying them can conversely reveal how inputs are progressively encoded. That is, we could uncover the symbols using these functional clusters.
With this possibility in mind, we seek the functional clusters in the hidden layers to obtain the symbols, the abstract codes of DNNs. We note that visual scenes generally consist of numerous distinct objects, and thus, it is necessary to separate them. To this end, we use segmentation models to locate visual objects of interest and analyze the responses of hidden neurons whose receptive fields cover the locations. Our analysis suggests that these symbols can mediate semantic meanings and allow us to 1) monitor the models’ decision-making process, 2) detect abnormal operations related to adversarial perturbations and out-of-distribution (OOD) examples and 3) temporarily learn about OOD examples. Based on these results, we propose that hidden layers’ responses can be converted to discrete symbols that can help us build more reliable and safer DNNs.
2 Extracting symbols underlying DNNs’ operations
To test whether DNNs learn to use symbols to make decisions, we analyzed 5 ImageNet models’ hidden layers using a subset (Mixed_13) of ImageNet [15], previously curated by a python machine learning library [16], and the hidden layer responses of ResNet50 [17] trained on the Oxford-IIIT Pet dataset [18] . Mixed_13 contains 78 classes out of 1,000 classes of ImageNet, which belong to one of 13 super-classes (Supplementary Table 1). Mixed_13 consists of two disjointed ‘training’ and ‘test’ sets. Oxford-IIIT Pet dataset contains 37 classes of cat and dog breeds. To extract the symbols, we assumed that the symbols associated with DNN’s decision-making would be observed frequently. For instance, if a symbol is associated with a tiger, a picture of a tiger would elicit the symbol frequently. With this assumption in mind, we presented the inputs from Mixed_13 and searched for repeatedly occurring hidden layer responses by using unsupervised clustering analysis.
It should be noted that analyzing hidden layer responses can be challenging for two reasons. First, hidden layer responses are extremely noisy high-dimensional data. A massive number of hidden neurons exist in modern DNNs, and their responses are determined by diverse inputs, making dimension reduction essential (see [19, 20, 13] , for instance). Second, visual scenes often contain multiple objects rather than a single one. For instance, a visual scene may include a tiger or tigers walking along the river, playing with other tigers and/or climbing a tree. Thus, to extract codes related to tigers, we need to isolate regions of interest (ROIs) containing tigers and exclude confounding objects (e.g., tree or river). However, ImageNet training examples are labeled with single class names and do not provide sufficient information to identify ROIs.
To address these challenges, we first used segmentation models to extract ROIs and recorded hidden layer responses spatially corresponding to ROIs. Then, we used ROI-pooling operation, proposed for object detectors [21], to extract smooth 3-by-3 activation vectors per single feature map. Once the activation vectors were extracted, we conducted clustering algorithms to determine the codes repeatedly occurring with Mixed_13 (a subset of ImageNets). In section 2.1, we discuss how ROIs are extracted from Mixed_13. In section 2.2, we present the details of extracting hidden layer responses. In section 2.3, we explain our clustering analysis in detail.
2.1 ROIs Identification
We note that ‘Second Thought Certification’ (STCert) proposed in an earlier study [22] can be used to identify ROIs related to visual objects with high accuracy. STCert is a two-step process (Fig. 1). First, it uses foundational segmentation models [23, 24] to detect ROIs related to DNNs’ predictions. For instance, if a DNN predicts a tiger, STCert asks the segmentation model to return the bounding box (i.e., ROI) of the tiger in the picture. Second, it crops ROIs and uses them to confirm or reject DNNs’ original predictions. STCert provides a more reliable ROI estimates than a single step segmentation, since its segmentation is crosschecked with a classifier. That is, STCert relies on ‘self-consistency’. As such, we used STCert to identify ROIs in this study to extract ROIs from randomly chosen 200 training examples for each class in Mixed_13; see Supplementary text for more detail. Since Mixed_13 contains 78 classes (Supplementary Table 1), the total number of training examples is 15,600. Among them, we first selected examples, on which DNNs’ predictions were correct to minimize the bias induced by the incorrect predictions/decisions of DNNs (i.e., incorrect mapping between ROI and the inputs’ labels). For some of the images, STCert did not find ROIs or found multiple ROIs, which means the actual number of ROIs is determined by a few factors, not just the number of training examples.

2.2 Generating hidden layer activity vectors
Once ROIs were identified, we sampled activations () of hidden neurons, whose receptive fields correspond to ROIs. To reduce noise and filter out non-essential information, we used ROI-pooling [21] to convert hidden layer activations into 3-by-3 activation maps. That is, the size of hidden layer activation maps can be arbitrary depending on the size of objects, but ROI-pooling always turns them into 3-by-3 activation maps. It should be noted that individual activations in 3-by-3 activation maps reflect pixels at different spatial locations. As we assumed that symbols are collectively encoded neurons that share the same receptive field, we built vector codes (referred to as activity vectors below) by collecting activations at the same location in the maps across channels. For instance, there are 512 channels in ResNet18’s layer 4, and we have 9 location-specific activation maps in each channel. Here, we aggregated activations from the same location in the activation map from all 512 channels and then created 9 activity vectors, each of which contains 512 components from the layer per image.
In this study, we analyzed 4 hidden layers of popular DNNs, ResNet18, ResNet50, VGG19, DenseNet121, and Vision Transformers (ViT) [17, 25, 26, 27]. ResNet and DenseNet consist of 4 composite blocks, and their outputs were analyzed. VGG19 contains 5 max pooling layers, whose outputs roughly correspond to ResNet’s composite block’s outputs. We selected the last 4 max-pooling layers and analyzed them, as they match the layers of ResNet and DenseNet. For ViT consisting of 12 layers, we chose the 4 layers (layer ids: 3, 6, 9, 12) . We used Pytorch [28] and Timm [29] python deep learning libraries to implement these models. A workstation with Intel Core9 CPU and RTX 4090 was used for all our experiments and analyses.
2.3 Clustering analysis of hidden layer activity vectors
We turned to unsupervised clustering analysis to identify representative activity vectors equivalent to symbols in this study. We also note that many activity vectors contain low values. With these low-value activity vectors, clustering algorithms consider the zero-valued vector as the most prominent cluster center, which is not informative. Thus, we removed the vectors consisting of values lower than the mean activity value estimated on each layer. Next, we used UMAP analysis [30, 31] to further reduce them to 3-dimensional vectors; see Table 1 for the parameters used in the analysis. These three dimensional vectors were analyzed to detect symbols via clustering. It should be noted that the exact number of clusters existing in the activity vector space are unknown, and the result of clustering analysis strongly depends on the number of predefined clusters. To address this issue, we used X-means clustering [32] to automatically discover an optimal number of clusters (i.e., the number of symbols). We note that X-means is an extension of Kmeans clustering, which uses Bayesian Information Criterion (BIC) to determine the optimal number of clusters, and a python package ‘pyclustering’ [33] was used to implement X-means in this study. In our analysis, we restrict the maximum number of classes to 1,000. Table 2 shows the identified number of clusters in 4 layers of DNNs tested. As shown in the table, the optimal numbers of clusters in the early layers are smaller than 1,000, but those in the late layers hit the maximum value, suggesting that homogeneity of activity vectors decreases, as the layers go deeper.
| Parameter | Value |
|---|---|
| n_neighbors | 50 |
| min_dist | 0.1 |
| n_component | 3 |
| metric | Euclidean |
3 Symbols Analysis
3.1 Links between symbols and semantic meanings of inputs
| Layer | ResNet18 | ResNet50 | VGG19 | DenseNet121 |
|---|---|---|---|---|
| 1 | 960 | 967 | 837 | 895 |
| 2 | 940 | 992 | 1000 | 1000 |
| 3 | 1000 | 1000 | 1000 | 1000 |
| 4 | 1000 | 1000 | 1000 | 1000 |
Then, we asked if the identified symbols (i.e., cluster centers) can be linked to semantic meanings of inputs (i.e., labels) by correlating them with inputs’ labels. Specifically, for each image (), we obtained ROIs () and 9 symbols (, where ). These 9 symbols were correlated with the labels () of , which were determined by the label of containing . That is, Correlation Map () evolves over all identified ROIs obtained from the training examples of Mixed_13 according to Eq. 1.
| (1) |
, where , and is the component of Correlation map at row and column; denotes the (out of 9) symbol related to ROI; where is the label of ROI (i.e., ).
If a symbol is associated with a specific class, it would appear frequently when the class object is presented, but it would not appear when other class objects are presented. Fig. 2 shows the correlation between 100 randomly chosen symbols from 4 layers of ResNet18 and 78 classes. -axis denotes 100 randomly chosen symbols, and -axis denotes the label (i.e., class). We found two types of symbols. First, some symbols were associated with a broad range of examples. Second, some symbols were selectively linked to specific classes. Symbols specific to classes were rare in early layers but became more common in late layers. We found equivalent results in ResNet50, VGG19 and DenseNet121 (Fig. 3). Interestingly, we note that many symbols can be merged together (Fig. 4), suggesting that many symbols can be redundant. Thus, we did not increase the maximum number of clusters above 1000. These results suggest that some symbols could be directly linked to the labels of inputs, and thus, one could infer the labels from their symbols in the hidden layers.



To test this possibility, we obtained symbols associated with test examples of Mixed_13 and asked if they could be used to predict the labels of inputs (i.e., ROIs). In this experiment, we collected ROIs from all test images whether or not DNNs make correct predictions. From these ROIs, we collected activity vectors and obtained the test symbols by identifying the nearest cluster centers. These ‘test symbols’ were used to predict the likelihood of each class by using (Eq. 1). As we aimed to compute the probability of the class, the correlation map was normalized along with a row (i.e., over classes) using SoftMax (2). By using the normalized Correlation Map , we calculated the probability that ROI belonged to the class when the symbol was observed (Eq. 2). That is, symbol indices were used as hash keys for a look-up table.
| (2) |
As we obtained 9 symbols from each ROI, we took average probability over 9 (Eq. 3) and then determined the most probable class as the prediction (Eq. 4).
| (3) |
| (4) |
Fig. 5 shows the accuracy of the symbol-based predictions for all 5 ImageNet models and ResNet50 trained Oxford-IIT PET dataset. We note that the prediction accuracy is around 80% in layer 4 (i.e., Max-pooling in VGG19 and embedding layer in ViT) and much lower in the earlier layers. These accuracies of ImageNet model cannot be directly compared to the models’ accuracy because the choice is limited to one out of 78 classes, not 1000 classes. However, the accuracy in layer 4 and the earlier layers were significantly higher than chance (1/78), supporting that the identified symbols were associated with semantic meanings. ResNet50 trained on Oxford-IIT PET dataset also show a similar level of accuracy.
If symbols are associated with semantic meanings, they could also be associated with DNNs’ predictions. We tested this possibility by correlating the symbols and DNNs’ predictions on Mixed_13 training examples (once again, 200 examples per class) instead of inputs’ labels. As stated above, we used the symbols to infer their predictions on test examples and found that the symbols are predictive of DNNs’ answers on test examples (Fig. 5B). We made equivalent observation from ResNet50 trained on Oxford-IIT PET dataset. These observations raise the possibility that DNNs could utilize symbols to make decisions.

We also tested the predictive power of symbols depending on the number of symbols. Specifically, we set a number of symbols from the 4 layers of ResNet18 to a specific number by using KMeans clustering instead of X-Means clustering. Then, we measured the predictive power of extracted symbols on labels of test examples by evaluating the accuracy of symbol-based predictions. Specifically, we tested 5 different numbers of symbols, which are 500, 1000, 1500, 2000 and 2500. As shown in Table 3, the predictive power (i.e., accuracy) of symbols does not monotonically increase, as the number of symbols increases, suggesting that the predictive power of symbols is not sensitive to the exact number of symbols.
The observed link between symbols and DNNs’ decisions leads us to hypothesize that symbols can be used to augment DNNs’ decision-making process. Below we propose potential ways to make DNNs’ operations more reliable using symbols.
| Layer | 500 | 1000 | 1500 | 2000 | 2500 |
|---|---|---|---|---|---|
| 1 | 0.218 | 0.219 | 0.23 | 0.229 | 0.228 |
| 2 | 0.264 | 0.27 | 0.285 | 0.28 | 0.283 |
| 3 | 0.431 | 0.472 | 0.478 | 0.486 | 0.48 |
| 4 | 0.782 | 0.805 | 0.812 | 0.809 | 0.819 |
3.2 How confident are you, DNNs?
In the analysis above, we used to infer the most probable class by using the symbol indice as a hash key and as a look-up table. However, this look-up table can be interpreted in a completely opposite direction. If we know the label of inputs, we could infer the likelihood of individual symbols appearing in DNNs. With this in mind, we defined ‘Expected Symbol Score (ESS)’ per layer with respective label/class (Eq. 5).
| (5) |
, where denotes the indices of 9 symbols obtained from each ROI. That is, with respective class is the mean value of 9 probabilities from ; see Eq. (5). If all observed symbols s are exclusively correlated with class , , , we can expect that , and . By contrast, if symbols contain no information related to classes, we can expect that , where 78 denotes the number of classes.
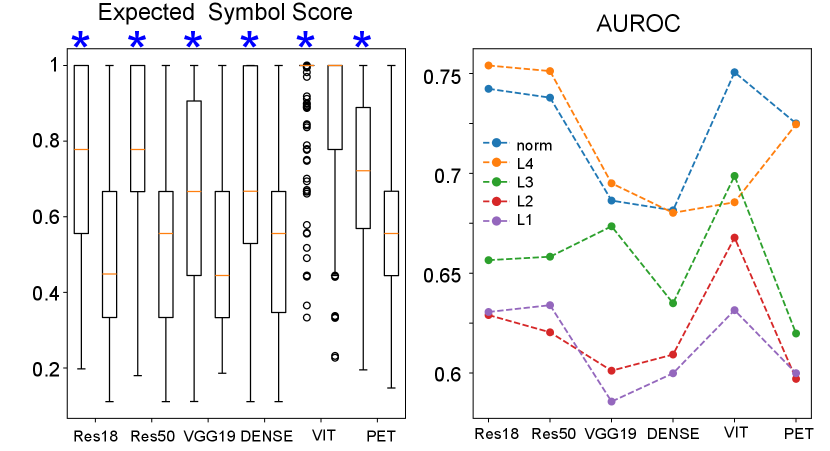
With this possibility in mind, we asked if ESSs obtained from layer 4 could be correlated to the accuracy of DNNs’ answers. Specifically, we split ESSs into two distributions depending on DNNs’ ability to produce correct decisions. We found that ESSs were significantly higher when the predictions were correct (see data marked by * in Fig. 6A) than when they were incorrect (see data without * in Fig. 6A). To quantify the separation between correct and incorrect predictions, we estimated AUROC (the orange line in Fig. 6B), suggesting that ESSs indicate DNNs’ likelihood of making correct predictions. We also examined ESSs from layers 1, 2 and 3 and AUROC between correct and incorrect answers (Fig. 6B). Further, we examined the norm of ESSs from all layers, and AUROC estimated from this norm were similar to those obtained from layer 4 (see blue line Fig. 6B).
3.3 Detecting out-of-distribution (OOD) examples
Detecting OOD examples has been a central challenge in computer vision models. During training, models are forced to choose one of the predefined choices. After training, they must choose the most probable answer on any given input, even when the inputs are not related to its training. By nature, predictions on OOD examples are random and should be ignored. To address this shortcoming, OOD detection algorithms have been proposed to inform DL models (and its users) when to ignore inputs; see [34] for a review.
We assumed that hidden layer responses (i.e., symbols), highly optimized for in-distribution examples during training, are in synchronization across layers during inference, when inputs are drawn from in-distribution but that they are out of synchronization when inputs are drawn from out-of-distribution. Further, we speculated that ESSs could be used to measure the level of synchrony between layers and thus detect OOD examples. To test this line of hypotheses, we extracted the symbols from NINCO dataset [35], which contain OOD examples carefully curated against ImageNet.
In our analysis, we first used of layer 4 to predict the most probable class, which were incorrect, as the inputs were drawn from OOD, and tested ESSs (once again, expected symbol scores) in layers 1, 2 and 3. If the symbols are truly out of synchronization due to OOD examples, we anticipated low expected symbol scores in all three layers. We chose 18 classes from NINCO dataset, and ROIs of NINCO images were determined by GroundingDINO (an open-set segmentation model[23]) using their real class labels. We evaluated the expected symbol scores and compared them with the ESSs of normal images from the test set of Mixed_13.
Fig. 7A visualizes ESSs () from layers 1, 2, 3 of ResNet18 in a 3D space, in which denote , respectively. The orange circles and the blue triangles denote in-distribution and OOD examples respectively. As shown in the figure, ESSs were substantially different between in-distribution and OOD examples, and we quantified this observation by estimating AUROC for all 6 models. The estimated AUROC from ESSs of all 3 layers and their norms suggest that ESSs are effectively separated between normal and OOD examples and can be used to detect OOD examples.

3.4 Symbols used to address the vulnerabilities to adversarial perturbations
Since the discovery of DL models’ vulnerability to adversarial examples [36, 37], adversarial perturbation has emerged as one of the greatest threats to DL safety. Given that all inputs are progressively processed in modern DNNs, it seems natural to assume that adversarial perturbation may change internal representation on layer-by-layer basis. An earlier study [38] found that the difference in representations in the early layers was not noticeable, but in the late layers it grew significantly. We asked if ESSs can be used to detect the influence on adversarial perturbation. Specifically, we crafted adversarial examples from validation images of Mixed_13 using AutoAttack [39], which is known to be one of the most effective attacks. In the experiment, we used a ‘standard’ mode with and . For individual inputs, we used labels of clean images to detect ROIs and estimated the corresponding symbols; that is, ROIs are identified with original labels, not the manipulated predictions.
For ROIs, we estimated the norm of ESSs from all 4 layers and calculated AUROC by comparing the norms of ESSs between normal and adversarial inputs. We note that the AUROC estimated from the norms were close to 0.5 (see the orange bars in Fig. 8), suggesting that the symbols in DNNs were not significantly different between normal and adversarial examples. Thus, we tested an alternative method. So far, ESSs have been computed using the most probable class predicted by the layer 4, which is the closest to the logit/output layer in the model. Specifically, we used layer 4’ s symbols () and correlation map to predict a class label , but ESSs can also be computed using DNNs’ predictions directly. That is, we can set to be the model’s prediction.
If ESSs are computed with DNNs’ predictions, we can effectively evaluate the consistency between models’ decisions and internal symbols, which we assume could be useful in detecting adversarial perturbation. Notably, we analyzed unmodified ImageNet models, whose output nodes correspond to 1,000 classes, not 78 of Mixed_13. As we did not set the target class during adversarial attacks, the predictions were not necessarily confined to 78 classes of Mixed_13. Thus, to build ESSs using their predictions, we selected adversarial and normal symbols when predictions are one of 78 classes in Mixed_13 (see Table 4 for the number of ROIs included in this analysis). For ResNet50 trained on Oxford-IIT PET dataset (shown as ‘PET’ in the -axis), we used all perturbed inputs. Decision-based ESSs are compared between normal and adversarial inputs (see the blue bars in Fig. 8). As shown in the figure, ‘decision-based ESSs’ are significantly different between normal and adversarial inputs in all 6 models, suggesting that ESSs with respect to DNNs’ (manipulated) predictions can be used to detect adversarial perturbation.

Further, inspired by the results suggesting that symbols can be used to predict labels of inputs (Fig. 5), we made predictions on adversarial inputs using symbols in L4 (e.g., embedding layer for ViT). Fig. 9, compares the accuracy of symbol-based predictions and the accuracy of the models’ original predictions on adversarial inputs. We note that even though adversarial inputs effectively lowered the accuracy of DL models’ predictions (see orange bars), their impact on the symbol-based predictions was minimal. This result indicates that symbols can be used to address DL models’ vulnerabilities to adversarial perturbations.

| Model | Normal | Adversarial |
|---|---|---|
| ResNet18 | 4002 | 1161 |
| ResNet50 | 4320 | 1432 |
| VGG19 | 3989 | 1015 |
| DenseNet121 | 4133 | 765 |
| VIT | 4419 | 549 |
3.5 Temporary learning
One of DL’s shortcomings is the lack of continual learning ability, whereas the brain can learn continuously. The brain can use previously obtained knowledge and incorporate new knowledge, but DL models’ catastrophic forgetting, the deletion of previously obtained information to learn the new, prevents continual learning. Since symbols can serve as previous knowledge, we speculate that the temporary mapping between symbols of in-distribution examples and OOD examples may allow a short-term (temporary) learning of OOD examples, which can serve as a stop-gap measure, until a more formal retraining becomes available. To address this possibility, we randomly split NINCO symbols (obtained from 18 classes) into 2 distinct distributions, training sets and test sets. The size of the training and test sets are half the size of NINCO symbols. Then, the training symbols were used to construct , where class label is one of 18 classes of NINCO dataset. Then, we asked if the test symbols can predict the inputs’ classes. As training/test symbols are selected randomly, we resampled them 100 times and reported the results from all 100 experiments (Fig. 10). We observed notable differences between the models. More importantly, the accuracy is around 40-50% (Fig. 10) for all 6 models, which is far higher than the random guess (), supporting that internal symbols can be used for short-term learning.

3.6 Symbols associated with internal features
In this study, we extract symbols from ROIs. This is based on the assumption that classifiers rely on internal features of visual objects. We tested this assumption by creating cropped versions of ROIs (containing objects) and evaluated DL models’ accuracy on full images, ROIs and cropped ROIs. Specifically, the three cropped versions, ROI81, ROI64 and ROI49%, contain 81%, 64% and 49% of pixels of ROIs obtained from STCert. All cropped ROIs and the full ROI are aligned to have the same centers, and we tested DL models’ accuracy on the test set of Mixed_13. The accuracy on ROI is normalized to the accuracy on full images. We note that the drop in the accuracy on ROIs is limited even at ROI:49% (Table 5), suggesting that DL models can indeed learn to use internal features of visual objects, which supports our assumption.
| Model | Full | ROI | ROI81 | ROI64 | ROI49 |
|---|---|---|---|---|---|
| RES18 | 1 | 0.851 | 0.835 | 0.819 | 0.79 |
| RES50 | 1 | 0.896 | 0.88 | 0.87 | 0.852 |
| VGG19 | 1 | 0.839 | 0.817 | 0.799 | 0.773 |
| DEN121 | 1 | 0.87 | 0.848 | 0.829 | 0.813 |
| VIT | 1 | 0.896 | 0.879 | 0.868 | 0.851 |
4 Discussion
We probed the existence of internal symbols closely linked to DNNs’ decision making. More specifically, we combined STCert and traditional machine learning algorithms to detect internal symbols. Our analysis of these internal symbols suggest that they can be used to 1) predict levels of accuracies of DNNs’ answers (Fig.5), 2) detect OODs (Fig.7) and adversarial inputs (Fig.8), 3) make robust predictions on adversarial inputs (Fig. 9) and 4) enable temporary learning of OOD examples (Fig.10). Based on our analysis, we propose that internal symbols could play a crucial role in addressing the shortcomings of DNNs’ and helping us build more reliable and safer DL models.
4.1 Limitations
We should underline that the purpose of our study is not to provide a comprehensive survey of methods that can extract internal symbols and potential utilities of internal symbols. Instead, we focused on searching for positive evidence of the existence of internal symbols associated with DNNs’ decisions and exploring their applications.
References
- [1] Yann Lecun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521(7553):436–444, 2015.
- [2] Ajay Shrestha and Ausif Mahmood. Review of deep learning algorithms and architectures. IEEE Access, 7:53040–53065, 2019.
- [3] Saptarshi Sengupta, Sanchita Basak, Pallabi Saikia, Sayak Paul, Vasilios Tsalavoutis, Frederick Atiah, Vadlamani Ravi, and Alan Peters. A review of deep learning with special emphasis on architectures, applications and recent trends. Knowledge-Based Systems, 194:105596, 2020.
- [4] Zachary C. Lipton. The Mythos of Model Interpretability. In ICML WHI, 2016.
- [5] Cynthia Rudin. Please Stop Explaining Black Box Models for High Stakes Decisions. In NIPS Workshop, 2018.
- [6] Christoph Molnar. Interpretable Machine Learning. 2 edition, 2022.
- [7] Pantelis Linardatos, Vasilis Papastefanopoulos, and Sotiris Kotsiantis. Explainable ai: A review of machine learning interpretability methods. Entropy, 23(1), 2021.
- [8] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. International Journal of Computer Vision, 128(2):336–359, oct 2019.
- [9] Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3319–3328. PMLR, 06–11 Aug 2017.
- [10] Marco Ancona, Enea Ceolini, Cengiz Öztireli, and Markus Gross. Towards better understanding of gradient-based attribution methods for deep neural networks. In International Conference on Learning Representations, 2018.
- [11] Chris Olah, Alexander Mordvintsev, and Ludwig Schubert. Feature visualization. Distill, 2017. https://distill.pub/2017/feature-visualization.
- [12] David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pages 3319–3327. IEEE Computer Society, 2017.
- [13] Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2018.
- [14] Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, and Rory sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCAV). In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 2668–2677. PMLR, 10–15 Jul 2018.
- [15] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [16] Logan Engstrom, Andrew Ilyas, Hadi Salman, Shibani Santurkar, and Dimitris Tsipras. Robustness (python library), 2019.
- [17] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015.
- [18] Nate Raw. resnet50-oxford-iiit-pet, 2021.
- [19] Archit Rathore, Nithin Chalapathi, Sourabh Palande, and Bei Wang. Topoact: Visually exploring the shape of activations in deep learning, 2021.
- [20] Emilie Purvine, Davis Brown, Brett Jefferson, Cliff Joslyn, Brenda Praggastis, Archit Rathore, Madelyn Shapiro, Bei Wang, and Youjia Zhou. Experimental observations of the topology of convolutional neural network activations, 2022.
- [21] Ross Girshick. Fast r-cnn. In 2015 IEEE International Conference on Computer Vision (ICCV), pages 1440–1448, 2015.
- [22] Jung H. Lee and Sujith Vijayan. Having second thoughts? let’s hear it, 2023.
- [23] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2023.
- [24] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643, 2023.
- [25] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
- [26] Gao Huang, Zhuang Liu, Laurens van der Maaten, and Kilian Q. Weinberger. Densely connected convolutional networks, 2018.
- [27] Andreas Steiner, Alexander Kolesnikov, Xiaohua Zhai, Ross Wightman, Jakob Uszkoreit, and Lucas Beyer. How to train your vit? data, augmentation, and regularization in vision transformers, 2022.
- [28] Adam Paszke, Sam Gross, Soumith Chintala, Edward Chanan, Gregory Yang, Zachary DeVito, Alban Lin, Zeming Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in PyTorch. In NIPS Autodiff Workshop, 2017.
- [29] Ross Wightman. Pytorch image models. https://github.com/rwightman/pytorch-image-models, 2019.
- [30] Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction, 2018.
- [31] Tim Sainburg, Leland McInnes, and Timothy Q. Gentner. Parametric umap: learning embeddings with deep neural networks for representation and semi-supervised learning. ArXiv e-prints, 2020.
- [32] Dan Pelleg and Andrew W. Moore. X-means: Extending k-means with efficient estimation of the number of clusters. In Proceedings of the Seventeenth International Conference on Machine Learning, ICML ’00, page 727–734, San Francisco, CA, USA, 2000. Morgan Kaufmann Publishers Inc.
- [33] Andrei Novikov. Pyclustering: Data mining library. Journal of Open Source Software, 4(36):1230, apr 2019.
- [34] Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey, 2024.
- [35] Julian Bitterwolf, Maximilian Mueller, and Matthias Hein. In or out? fixing imagenet out-of-distribution detection evaluation. In ICML, 2023.
- [36] Anirban Chakraborty, Manaar Alam, Vishal Dey, Anupam Chattopadhyay, and Debdeep Mukhopadhyay. Adversarial attacks and defences: A survey, 2018.
- [37] Xiaoyong Yuan, Pan He, Qile Zhu, and Xiaolin Li. Adversarial examples: Attacks and defenses for deep learning. IEEE Transactions on Neural Networks and Learning Systems, 30(9):2805–2824, 2019.
- [38] Gabriel D. Cantareira, Rodrigo F. Mello, and Fernando V. Paulovich. Explainable adversarial attacks in deep neural networks using activation profiles, 2021.
- [39] Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pages 2206–2216. PMLR, 2020.
5 Appendix and Supplementary Material
5.1 STCert implementation
The two versions of STCert were discussed in the original study [22]. The naive STCert uses the bounding boxes returned by the segmentation models as ROIs. The context-aware STCert adds some background to the bounding boxes to create ROIs. As the context-aware STCert is more robust, we adopted the context-aware STCert in this study. The workflow of STCert can be summarized as follows:
-
1.
Detect bounding boxes.
-
2.
Create 5 candidates of bounding boxes by enlarging ROIs. The first candidate is ROI itself.
-
3.
Crop pixels within the candidates and forward them into DNNs. That is, we have the list of 5 second thought predictions.
-
4.
Examine if the original prediction is included in the list of second predictions.
-
5.
Return the bounding box as ROI, if the original prediction is in the list. If not, ignore the bounding box and return Null.
5.2 Potential links to the brain structure
Our analysis raises the possibility that internal symbols can be used to augment DNNs’ decision-making process. It may even be possible for a second network to use symbols to correct responses in each layer locally during inference. When urgent and immediate decisions are demanded, DNNs’ decisions can be used, as they are, but for more reliable answers, a second network may use symbols to modify hidden layers’ responses. This may remind some readers of thalamo-cortical loops in the brain. Our analysis has been inspired by thalamo-cortical loops and indicates that thalamo-cortical loop-like error correction could be constructed using internal symbols to build more reliable DNNs.
| Category | Class | ||
|---|---|---|---|
| Fish |
|
||
| Bird |
|
||
| Dog |
|
||
| Carnivore |
|
||
| Insect |
|
||
| Primate |
|
||
| Car |
|
||
| Furniture |
|
||
| Computer |
|
||
| Fruit |
|
||
| Fungus |
|
||
| Truck |
|