Scrapping The Web For Early Wildfire Detection: A New Annotated Dataset of Images and Videos of Smoke Plumes In-the-wild
Abstract
Early wildfire detection is of the utmost importance to enable rapid response efforts, and thus minimize the negative impacts of wildfire spreads. To this end, we present PyroNear2024 , a new dataset composed of both images and videos, allowing for the training and evaluation of smoke plume detection models, including sequential models. The data is sourced from: (i) web-scraped videos of wildfires from public networks of cameras for wildfire detection in-the-wild, (ii) videos from our in-house network of cameras, and (iii) a small portion of synthetic and real images. This dataset includes around 150,000 manual annotations on 50,000 images, covering 400 wildfires, PyroNear2024 surpasses existing datasets in size and diversity. It includes data from France, Spain, and the United States. Finally, it is composed of both images and videos, allowing for the training and evaluation of smoke plume detection models, including sequential models. We ran cross-dataset experiments using a lightweight state-of-the-art object detection model and found out the proposed dataset is particularly challenging, with F1 score of around 60%, but more stable than existing datasets. The video part of the dataset can be used to train a lightweight sequential model, improving global recall while maintaining precision. Finally, its use in concordance with other public dataset helps to reach higher results overall. We will make both our code and data available.
1 Introduction and Related Work
Wildfires have become an increasingly prevalent and devastating natural disaster worldwide, causing loss of life, destruction of property, and significant environmental damage. While wildfires have always been a part of nature’s cycle, human activities and climate change have exacerbated their frequency and intensity. Indeed, the number of wildfires has increased due to climate change-induced warmer temperatures and drier conditions [27] As such, there is an urgent need to develop and implement advanced technologies to prevent wildfires, as well as predicting their behavior.
Given the undeniable link between climate change and the increasing frequency of wildfires, the urgency of addressing this issue is underlined by projections from the Intergovernmental Panel on Climate Change (IPCC), which anticipate a continued rise in the occurrence of extreme events like wildfires [24]. This urgency is further amplified by its impact on sustainable development, the environment, and social equity.
Early wildfire detection (EWD) is of paramount importance in mitigating the catastrophic consequences of these increasingly prevalent natural disasters. In fact, response time is a crucial factor for wildfire containment [30]. Recent advancements in artificial intelligence (AI) and deep learning (DL) techniques have spurred innovative methodologies for addressing this critical issue, yielding a profusion of methods and datasets tailored to diverse aspects of EWD.
Deep learning for early wildfire detection
Yazdi et al. [32] introduced Nemo, an open-source benchmark for fine-grained wildfire smoke detection, tailored to the early incipient stage. They adapted a DEtection TRansformer [4] to wildfire detection, achieving superior performance in detecting smoke across different object sizes. Their model detected 97.9% of fires in the incipient stage, outperforming baseline methods. Dewangan et al. [8] proposed a model with an associated dataset: Fire Ignition Library (FIgLib). The dataset is publicly available and composed of 25,000 image-level labeled wildfire smoke images as seen from fixed-view cameras deployed in Southern California. The proposed model relies on a spatiotemporal deep learning architecture based on ResNet, LSTM and Vision Transformers [14, 9, 17], which outperformed comparable baselines and even rivaled human performance, highlighting its potential for real-time wildfire smoke detection. Fernandes et al. [11] investigated the use of EfficientDet for automatic early detection of wildfire smoke with visible-light cameras. Their private dataset from Portugal consists of 14,125/21,203 smoke/non-smoke images. They achieved a true detection rate of 80.4% and a false-positive rate of 1.13%, outperforming previous studies focusing on smoke plumes; thereby emphasizing the significance of large and representative datasets for training.
Low resource solutions
Resource-efficient solutions have been explored to extend the applicability of wildfire detection systems, particularly in remote places that lack electrical power. de Venâncio et al. [6] proposed an automatic fire detection system based on deep CNNs suitable for low-power, resource-constrained devices, achieving significant reductions in computational cost and memory consumption while maintaining performance. In the same vein, Khan and Khan [22] presented "FFireNet," a deep learning-based forest fire classification method, utilising a small neural network, the MobileNetV2 model for feature extraction, and achieving remarkable accuracy in binary classification of fire images.
Remote-sensing and wildfire detection
Satellite imagery has been a pivotal data source for early wildfire detection. Barmpoutis et al. [3] offered an overview of optical remote sensing technologies used in early fire warning systems. They conducted an extensive survey on flame and smoke detection algorithms employed by various systems, including terrestrial, airborne, and spaceborne-based systems. This review contributes to future research projects for the development of early warning fire systems. James et al. [19] developed an efficient wildfire detection system utilizing satellite imagery and optimized convolutional neural networks (CNNs) for resource-constrained devices, using a MobileNet on an Arduino Nano 33 BLE.
Video-based fire detection
These techniques have emerged as a promising avenue for early wildfire detection. Jin et al. [21] provided a comprehensive review of deep learning-based video fire detection methods, summarizing recent advances in fire recognition, fire object detection, and fire segmentation using deep learning approaches. Their review provided insights into the development prospects of video-based wildfire detection for every kind of sequential images data, coming from various sources such as surveillance cameras, lookout towers, UAV or satellite sensors.
de Venâncio et al. [7] proposed a hybrid method for fire detection based on spatial and temporal patterns, combining CNN-based visual pattern analysis with temporal dynamics to reduce false positives in fire detection. Additionally, Marjani and Mesgari [25] introduced "FirePred," a hybrid multi-temporal CNN model for wildfire spread prediction, emphasizing the importance of considering varying temporal resolutions in fire prediction models.
Wildfire datasets
At first view many of them can be found in the literature with a focus on wildfire detection. Nevertheless works such as [31, 29, 12] are actually fire detection datasets, containing pictures of fires at an already advance stage. In this work, as we mainly focus on smoke plumes in order to detect early wildfires from watchtowers, we discard the (easier) task of fire detection. In this context, it is notable to remark that only a very few of the datasets containing annotations for the smoke plume detection are publicly available.
In general, there are two main sources of videos for smoke plumes detection in the wild that are available online: [18] (High Performance Wireless Research & Education Network) and ALERTWildfire [2]. These two sources were used to create several datasets. Leveraging the camera network of the HPWREN, [8, 13, 1] propose annotated datasets for early wildfire detection, while other works [28, 32, 1] propose datasets obtained from the ALERTWildfire network. Finally, from private sources and not publicly available, Fernandes et al. [10] constructed a dataset of 35k images from Portugal that are annotated in smoke plumes. It is composed of 14,125 images that contain smoke plumes and 21,203 that do not.
2 Datasets Collection, Fusion And Annotation
A summary of the whole process is visible in Figure 1.

2.1 Available Data
In the development of an early wildfire detection model, the assembly of a comprehensive and diverse dataset is crucial. We already have a set of in-house data from our cameras in the wild, but given the limited number of cameras currently deployed in the field, our effort to gather data extends to additional sources. This subsection outlines the primary sources of data and the derivative datasets coming from these sources, that have been annotated and widely used for past research on the topic. In this work, we will compare these datasets to our novel dataset.
Primary Data Sources
Our data acquisition strategy leverages two main sources:
-
•
HPWREN: Funded by the National Science Foundation, HPWREN is a non-commercial, high-performance, wide-area, wireless network of Pan-Tilt-Zoom (PTZ) cameras serving Southern California. It focuses on network research, including the demonstration and evaluation of its capabilities in wildfire detection.
-
•
ALERTWildfire: A consortium of universities in the western United States provides access to advanced PTZ fire cameras and tools, aiding firefighters and first responders in wildfire management, covering extensive regions spanning Washington, Oregon, Idaho, California, and Nevada. The ALERTWildfire website111https://www.alertwildfire.org/ grants public access to live feeds from these cameras.
Note that Google is also used to collect images of wildfires, but this source contains only a small amount of smoke plumes images, as there are mainly close-up images of fire with big flames, which does not suit our purpose.
Derived Datasets
From these sources, several projects have proposed datasets that are of interest to our wildfire detection study:
-
•
SmokeFrames: Developed by Schaetzen et al. [28] this dataset comprises nearly 50k images sourced from ALERTWildfire. To tailor it to our specific requirements of classical smoke plumes detection, we created a subset, SmokeFrames-2.4k, consisting of 2410 images, from 677 different sequences, with an average of 3.6 images per sequence. The selected images were challenging for an in-house smoke plume detection model, triggering false positives. The original SmokeFrames-50k dataset was recreated by selecting 100 frames per video and removing images of nighttime fires to better align the dataset with our focus.
-
•
Nemo: The dataset of Yazdi et al. [32] includes frames extracted from raw videos of fires captured by ALERTWildfire’s PTZ cameras, encompassing various stages of fire and smoke development.
-
•
Fuego: Initiated by the Fuego project [13], this dataset was created by manually selecting and annotating images from the HPWREN camera network, based on historical fire records from Cal Fire. The authors are claiming 8500 annotated images with a focus on the early phases of fires, but only a subset of 1661 images are publicly available.
-
•
AiForMankind: Two training datasets emerged from hackathons organized by AI For Mankind [1], a nonprofit focusing on using AI for social good. These datasets, combined into one, offer a substantial collection of annotated images for smoke detection and segmentation.
-
•
FIgLib: [8] propose the Fire Ignition image Library (FIgLib) which was composed of 24,800 images from South California from 315 different fires. It is the official dataset from the HPWREN. However, the FigLig dataset does not initially have the bounding box annotations we are using in this work, we annotated it.

2.2 Creation of the PyroNear2024 Dataset
This section presents the collection of the data, its annotation using a homemade platform and a summary of the final dataset.
2.2.1 Data Acquisition Strategy
Videos Web scrapping
Our wildfire detection initiative utilizes the AlertWildfire camera network, which comprises approximately 130 cameras. The actual number of operational cameras fluctuates due to occasional unavailability, but despite these variances, we ensure comprehensive monitoring. The core of our data collection is an automated scraping script that interacts with the AlertWildfire API. This script retrieves images from each camera at the predetermined frequency of one image per minute, set by AlertWildfire. This gives a total of 1,440 images per camera per day, summing up to about 187,200 images daily across the network.
Videos Filtering
After filtering out the nighttime images, which are not of interest for this application, we perform inference on the remaining daylight images using a smoke plume detection model trained beforehand. This model analyze each image, and any with a wildfire detection score above 0.2 is marked as a potential fire event. To ensure comprehensive coverage of potential fire events, we also save images taken 15 minutes before and after each detected event from the same camera. This approach helps in capturing a broader contextual timeline around each potential wildfire incident, and to collect a dataset of videos in order to data to train and validate sequential models. All the images flagged during this process, including both potential wildfire detections and corresponding time-framed images, are stored for later annotation. This rich collection, encompassing potential early signs of wildfires as well as false positives, offers a challenging and valuable dataset for enhancing the performance in challenging scenarios that have historically led to a false detection. For example, in distinguishing true wildfires from non-threatening natural occurrences such as clouds, fog, or sunlight reflection.
In-house data from PyroNear cameras
An in-house set of data was collected, using PyroNear stations222composed of cameras, a Raspberry Pi, and a 4G USB key that were placed in 12 lookout towers in France and Spain, equipped with a total of 38 cameras. The same process was performed using this network of cameras.
Images Web scrapping
This dataset was generated by scraping images from Google using keywords like "smoke" and "wildfire." After collecting the images, we manually filtered and selected 442 relevant images that depict various stages and types of smoke and wildfire. These are mean to provide a more diverse dataset, encompassing different environments and visual perspectives.
Synthetic
This dataset was created using images without fire, to which we added synthetic smoke plumes generated in Blender [16]. By applying Poisson blending, we randomly inserted these smoke plumes into the images, resulting in 200 images that mimic various smoke scenarios. This synthetic dataset helps enhance training for smoke detection models.
| Dataset | Video | #Wildfires | Total Images∗ | Train∗ | Validation∗ | Test∗ | Avg. BBox Area (%) |
|---|---|---|---|---|---|---|---|
| AiForMankind | ✗ | 31 | 2935/2584 | 2348/2042 | 294/263 | 293/279 | 1.341 |
| Fuego | ✗ | 38 | 1661/1572 | 1329/1269 | 166/152 | 166/151 | 0.175 |
| Nemo | ✗ | 62 | 2859/2570 | 2408/2158 | 251/237 | 200/175 | 7.337 |
| SmokeFrames-2.4k | ✗ | 75 | 2410/976 | 1928/781 | 241/125 | 241/70 | 14.167 |
| SmokeFrames-50k | ✓ | 643 | 54576/36304 | 45245/30282 | 4684/3213 | 4647/2809 | 14.384 |
| PyroNear | ✗ | 532/400 | 3292/2934 | 2651/2370 | 333/294 | 308/270 | 1.043 |
| PyroNear | ✓ | 532/400 | 35406/19336 | 28213/15200 | 3192/1647 | 4001/2489 | 0.590 |
2.2.2 Collaborative Annotation Platform

In order to annotate the wildfire data scrapped from the web, we developed a collaborative annotation tool with custom code in order to streamline the annotation process. In total, we collected a total of 150,000 annotations in a few month by leveraging the help of the PyroNear community. The platform had to answer to a few constraints, especially the one that the annotators were all volunteers using their free time to help developing an open-source dataset and model, which means the annotation job needed to be simple and fast. We gave to the volunteers a precise quantity of images, which number was selected as 150 so that the annotation task would take less than 15 minutes so that it can be done during a train commute or a break between two activities, and it kept the cognitive load low in order to avoid mistakes and care the annotators. Finally, the platform have also been designed to ensure a smooth and coherent workflow. A snapshot of the platform is visible in Figure 3.
Initially, we started with an extensive collection of 120,000 annotations. With a 5-times cross-labeling approach, this pool was refined down to 24,000 unique images.
Each of the images has been annotated by five annotators in order to minimize the label errors. To validate the quality of the annotationo, we calculated the inter-annotator agreement using Krippendorff [23]’s with the presence or not of fire in each image, and obtained satisfying value.
FigLib
Another contribution of this work is a new set of annotations on the 24,800 images of the FigLib dataset. Using the same annotation platform described above, we annotated every image with bounding boxes around the smoke plumes if present.
Overall
In the end, our dataset contains real images from United State, France and Spain collected over our own in-house network of cameras, the HPWREN and ALERTWildfire networks, and synthethic images we created, making the dataset very diverse and challenging.
2.2.3 Final Dataset: PyroNear2024
The vast majority of the available datasets are not containing videos (see Table 1), and models are trained and their performances assessed with classical object detection metrics, using images as they were independent. In our case, we would like to emphasize that our dataset can be used in this setting, but also to train sequential models over video. For this reason, we chose to separate the data between a set that can be used to train and validate a model on sequence of images and the rest of the dataset. It gives us two datasets: PyroNear the one-image detection dataset, and PyroNear which contains the videos. The latter can be used develop a temporal model that leverages a series of images for prediction, thus enhancing the accuracy and robustness of the detection. Both our image and video datasets focused on EWD, hence the average bounding box size is small compared to datasets like SmokeFrames or Nemo which contain data of PTZ camera after zooming with large bounding boxes.
PyroNear : Image dataset
For the one-image object detection dataset, we discover that it is crucial to streamline the dataset to reduce redundancy affecting the model performance. Indeed, some events that are way longer contain many more images, leading to an unbalanced distribution with a lot of redundancy. In order to balance the dataset, we selected approximately 7 images per incident: one from the first detection, one without a fire, and the rest were randomly chosen to include images with fires. By retaining only 7 images per wildfire event, we effectively minimized repetitive or near-identical images. This approach was crucial in preserving the diversity of the dataset while ensuring its relevancy to our one-image object detection focus. The dataset was thus further refined to 3292 images, including 2934 smoke images. The final composition of the PyroNear2024 dataset is visible in Table 1.
PyroNear : Video dataset
The video part of the dataset contains 532 videos of 400 different wildfires, from 3 different countries, making it the most diverse dataset of smoke plumes detection video. Snapshots of images from the dataset are available in Figure 2.
3 Experiments
In this study, our primary objective is to evaluate the quality of various datasets by conducting a preliminary optimization process.
3.1 Single-Frame Methodology
We use a small YOLOv8 model [26], renowned for its proficiency in diverse detection scenarios. Given the nature of our task, and the necessity for frugal computing, the small version of the model was chosen for its balance between speed, size and accuracy. The optimal batch size and number of epochs were found using a grid search in and on the validation set. Alongside this, we also identify the optimal confidence threshold in {} in the same way.
Dataset Splitting Strategy
In preparing our datasets for the model training and validation process, we were guided by the existing split in the Nemo dataset, where approximately 9.3% of the data was allocated for validation. To maintain consistency across all datasets and ensure a comparable evaluation framework, we adopted a similar approach for the other datasets, targeting a close approximation of a 10% split for the validation set, while also ensuring that another 10% is allocated for the test set. This strategy enables a balanced and uniform methodology for assessing the performance of our models across different datasets, ensuring that each dataset is represented fairly in both training, validation and testing phases. Finally, and in order to maintain independent partitions, we kept the wildfire events disjoints between the train, val and test. This was not possible for datasets like Nemo or SmokeFrames, as the files were named with different names, from the same wildfire but different perspectives. Nevertheless, due to conflicts arising from overlapping images between the Nemo and SmokeFrames datasets, we filtered the problematic images from SmokeFrames test sets. We used perceptual hash333https://github.com/knjcode/imgdupes along with Hamming distance to ensure that duplicate or highly similar images were excluded from SmokeFrames test set.
Metrics
Following past works [28, 32, 8] we use precision, recall, and the F1 score as metrics in order to validate the different models. We chose not to use the usual object detection metric such as mean average precision (mAP) as the goal is about correctly classifying areas in an image as indicating a wildfire or not, wihtout being able to get the countours of the smoke plumes which can be subjective.
3.2 Video-Based Methodology
Inspired by the work of [20], we employed a modified approach where a smoke plume detector was employed to extract bounding boxes. The coordinates of the bounding boxes allows for detecting an area of interest in the image, which was then processed by a pre-trained ResNet [15] in order to extract a sequence of learned representations. Finally, to process temporal information, we employed a simple LSTM for binary classification, consistent with the previous work’s methodology.
4 Baselines Results
4.1 Image Dataset Evaluation
The validation set results of the smoke plumes detection models with their associated threshold are shown in Table 2. The datasets with the lower F1 scores are SmokeFrames-50k and PyroNear , making them apriori the most challenging ones. It is notable that the optimum detection threshold plays an important role as it can vary up to 5 times in size, going from 0.04 to 0.19.
| Dataset | F1 Score | |
|---|---|---|
| SmokeFrames-2.4k | 0.865 | 0.19 |
| SmokeFrames-50k | 0.617 | 0.05 |
| Nemo | 0.906 | 0.09 |
| AiForMankind | 0.888 | 0.09 |
| Fuego | 0.764 | 0.04 |
| PyroNear | 0.704 | 0.05 |
| Train Dataset | Test Dataset | Precision | Recall | F1 Score |
|---|---|---|---|---|
| PyroNear | AIForMankind | 0.742 | 0.856 | 0.795 |
| Fuego | 0.885 | 0.768 | 0.822 | |
| Nemo | 0.607 | 0.601 | 0.604 | |
| SmokeFrames-2.4k | 0.433 | 0.650 | 0.520 | |
| SmokeFrames-50k | 0.532 | 0.412 | 0.465 | |
| PyroNear2024 | 0.594 | 0.608 | 0.601 | |
| Overall | 0.632 | 0.649 | 0.639 | |
| Nemo | AiForMankind | 0.983 | 0.641 | 0.776 |
| Fuego | 0.840 | 0.139 | 0.238 | |
| Nemo | 0.876 | 0.860 | 0.868 | |
| SmokeFrames-2.4k | 0.415 | 0.983 | 0.584 | |
| SmokeFrames-50k | 0.587 | 0.466 | 0.519 | |
| PyroNear2024 | 0.685 | 0.429 | 0.528 | |
| Overall | 0.731 | 0.586 | 0.602 | |
| AiForMankind | AiForMankind | 0.852 | 0.784 | 0.817 |
| Fuego | 0.902 | 0.735 | 0.810 | |
| Nemo | 0.607 | 0.275 | 0.379 | |
| SmokeFrames-2.4k | 0.550 | 0.550 | 0.468 | |
| SmokeFrames-50k | 0.346 | 0.211 | 0.263 | |
| PyroNear2024 | 0.609 | 0.515 | 0.558 | |
| Overall | 0.644 | 0.512 | 0.549 | |
| SmokeFrames-2.4k | AiForMankind | 0.989 | 0.336 | 0.502 |
| Fuego | 1.000 | 0.050 | 0.100 | |
| Nemo | 0.902 | 0.623 | 0.737 | |
| SmokeFrames-2.4k | 0.779 | 0.883 | 0.828 | |
| SmokeFrames-50k | 0.777 | 0.508 | 0.615 | |
| PyroNear2024 | 0.903 | 0.099 | 0.178 | |
| Overall | 0.892 | 0.417 | 0.491 | |
| SmokeFrames-50k | AiForMankind | 0.612 | 0.390 | 0.477 |
| Fuego | 0.351 | 0.125 | 0.185 | |
| Nemo | 0.670 | 0.639 | 0.654 | |
| SmokeFrames-2.4k | 0.445 | 0.816 | 0.576 | |
| SmokeFrames-50k | 0.697 | 0.511 | 0.590 | |
| PyroNear2024 | 0.325 | 0.144 | 0.200 | |
| Overall | 0.517 | 0.438 | 0.447 | |
| Fuego | AiForMankind | 0.817 | 0.899 | 0.856 |
| Fuego | 0.782 | 0.668 | 0.721 | |
| Nemo | 0.342 | 0.198 | 0.251 | |
| SmokeFrames-2.4k | 0.212 | 0.283 | 0.242 | |
| SmokeFrames-50k | 0.220 | 0.121 | 0.157 | |
| PyroNear2024 | 0.661 | 0.522 | 0.584 | |
| Overall | 0.506 | 0.449 | 0.462 |
4.1.1 Cross-Dataset Model Evaluation
The performances of the models trained on a cross-dataset setting dataset on the different test sets are shown in Table 3. The results over the different datasets are very variable, but there is a clear trend that the model obtain the best results on the test when it has been trained with elements from the same dataset. This is especially true for Nemo and SmokeFrames-2.4k that reach F1-scores of 86.8% and 82.8% on their respective test sets. However, PyroNear allows reaching the best results overall (F1 score of 63.9%). For this reason, we believe that the high performances of Nemo and SmokeFrames are mainly due to overfitting issues because of the partitioning (see Section 3.1). The bounding boxes average size also plays a role, as the dataset with similar bounding box size444Fuego/AI4Mankind/PyroNear 1% vs Nemo/SmokeFrames-2.4k/SmokeFrames-50k 10% works better between them.
We finally trained a model on the combined dataset, joining the train, validation and test sets respectively together, and display the results in Table 4. The two datasets that remain challenging, with an F1 lower than .87, are PyroNear and SmokeFrames-50k. We believe the latter remains difficult, even though with large bounding boxes, because of noisy annotations coming from a semi-supervised process without human validation. Indeed, when looking at the prediction of our model on the dataset, we found out it detects a smoke plume at the right place before it gets a real annotation (more details in Section 12).
| Tested Dataset | Precision | Recall | F1 Score |
|---|---|---|---|
| AiForMankind | 0.897 | 0.935 | 0.916 |
| Fuego | 0.960 | 0.814 | 0.880 |
| Nemo | 0.913 | 0.830 | 0.869 |
| SmokeFrames-2.4k | 0.794 | 0.966 | 0.872 |
| SmokeFrames-50k | 0.724 | 0.511 | 0.599 |
| PyroNear | 0.684 | 0.634 | 0.658 |
| Overall | 0.829 | 0.782 | 0.799 |
4.1.2 Threshold Sensitivity Analysis
The Figure 4 curve represents the performance of the models across different detection thresholds, which is an hyperparameter representing the minimum values to consider a detection as a positive. The curves highlight the trade-offs between precision and recall at various thresholds, showing that recall (an important metric as it is important to detect smoke plumes as early as possible) can be higher. This threshold is then set up to a lower value (with more false positives) in the multi-frame detection setting, as the sequential model helps diminishing the number of false positives.

4.2 Video Dataset Evaluation
We finally propose a baseline for the video part of our dataset, aiming for models that detect better and sooner the smoke plumes. Results are visible in Table 5, comparing an image-base model with a sequential model. As the sequential model utilizes the detection of the first model with a very low detection threshold and process them again in a sequential way, it helps to increase the general recall without hurting the precision (+9.3% versus -0.9% in relative). Moreover, the sequential approach allows to reduce the necessary time to detect the fire from 52 seconds in average.
| Model | Precision | Recall | F1 Score | Time Elapsed |
|---|---|---|---|---|
| YOLOv8 (one frame) | 0.920 | 0.529 | 0.672 | 1’46” |
| YOLOv8+CNN-LSTM | 0.912 | 0.578 | 0.708 | 1’05” |
5 Future Enhancements: Towards PyroNear2025
While the cross-labeling approach used for PyroNear2024 has significantly contributed to the accuracy of our dataset, it has also led to a substantial reduction in the number of images we could include. Acknowledging this limitation, we are currently developing a new methodology for the upcoming PyroNear2025 dataset, which aims to semi-annotation process.
Faster Annotation
We are exploring semi-automatic annotation techniques that will accelerate the labeling process while maintaining high-quality annotations. By integrating advanced algorithms with manual oversight, we can swiftly annotate large volumes of images without compromising on accuracy.
Normalization of Annotations
The semi-automatic approach also aims to standardize the annotation process across different users. This consistency is crucial for ensuring that the dataset reflects a uniform understanding of wildfire and smoke characteristics.
Reduced Cross-Labeling
With the improved efficiency and consistency brought by semi-automatic annotation, we anticipate the need for cross-labeling to decrease significantly. This reduction will enable us to retain a larger portion of the images initially collected, thereby enriching the PyroNear2025 dataset with a broader range of data.
These advancements are expected to not only enhance the volume of annotated data but also to improve the overall quality and representativeness of the PyroNear2025 dataset. This progression illustrates our commitment to continuously refining our methodologies in response to the evolving challenges of wildfire detection and monitoring.
6 Conclusion
In this paper we presented PyroNear2024 , a new dataset for smoke plume detection. We collected it by scrapping online data and applying live an already trained model in order to filter out challenging examples such as detection and false positives. We kept the images before and after every fire event in order to have videos, and make it usable by sequential models taking into account the temporal dimension. The dataset was then re-annotated by a pool of volunteers using an online platform designed for the purpose. We merged it with new in-house data, and existing non annotated datasets, making our dataset the most diverse open-source for this domain, with data from three different countries for 532 wildfires. We showed that our dataset is challenging, with small size smoke plumes for real-life early wildfire detection, and that training using our dataset helps to globally improve smoke plume detection models on other public datasets. Finally, we propose a video part of the data, allowing to train sequential models, which improve the global recall over classical single-frame smoke plume detection models while keeping similar precision. This data collection and annotation effort will be pursued in order to extend this dataset to other domains, such as new landscape and meteorological conditions, and it will be put online for research and non-profit purposes.
Acknowledgment
We thank the volunteers of the PyroNear community to help make this possible by their annotation effort and feedback.
References
- AIforMankind [2023] AIforMankind. AI for Mankind, 2023. URL https://aiformankind.org/.
- ALERTWildfire [2023] ALERTWildfire. ALERT Wildfire, 2023. URL https://www.alertwildfire.org.
- Barmpoutis et al. [2020] Panagiotis Barmpoutis, Periklis Papaioannou, Kosmas Dimitropoulos, and Nikos Grammalidis. A review on early forest fire detection systems using optical remote sensing. Sensors (Switzerland), 20(22):1–26, 2020. ISSN 14248220. doi: 10.3390/s20226442.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-End Object Detection with Transformers. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 12346 LNCS:213–229, 2020. ISSN 16113349. doi: 10.1007/978-3-030-58452-8{\_}13.
- Casas et al. [2023] Edmundo Casas, Leo Ramos, Eduardo Bendek, and Francklin Rivas-Echeverria. Assessing the Effectiveness of YOLO Architectures for Smoke and Wildfire Detection. IEEE Access, 11(September):96554–96583, 2023. ISSN 21693536. doi: 10.1109/ACCESS.2023.3312217.
- de Venâncio et al. [2022] Pedro Vinícius A.B. de Venâncio, Adriano C. Lisboa, and Adriano V. Barbosa. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Computing and Applications, 34(18):15349–15368, 2022. ISSN 14333058. doi: 10.1007/s00521-022-07467-z.
- de Venâncio et al. [2023] Pedro Vinícius A.B. de Venâncio, Roger J. Campos, Tamires M. Rezende, Adriano C. Lisboa, and Adriano V. Barbosa. A hybrid method for fire detection based on spatial and temporal patterns. Neural Computing and Applications, 35(13):9349–9361, 2023. ISSN 14333058. doi: 10.1007/s00521-023-08260-2.
- Dewangan et al. [2022] Anshuman Dewangan, Yash Pande, Hans Werner Braun, Frank Vernon, Ismael Perez, Ilkay Altintas, Garrison W. Cottrell, and Mai H. Nguyen. FIgLib & SmokeyNet: Dataset and Deep Learning Model for Real-Time Wildland Fire Smoke Detection. Remote Sensing, 14(4):1–15, 2022. ISSN 20724292. doi: 10.3390/rs14041007.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In ICLR, pages 1–21, 2021.
- Fernandes et al. [2022] Armando M. Fernandes, Andrei B. Utkin, and Paulo Chaves. Automatic Early Detection of Wildfire Smoke with Visible Light Cameras Using Deep Learning and Visual Explanation. IEEE Access, 10:12814–12828, 2022. ISSN 21693536. doi: 10.1109/ACCESS.2022.3145911.
- Fernandes et al. [2023] Armando M. Fernandes, Andrei B. Utkin, and Paulo Chaves. Automatic early detection of wildfire smoke with visible-light cameras and EfficientDet. Journal of Fire Sciences, 2023. ISSN 15308049. doi: 10.1177/07349041231163451.
- Foggia et al. [2015] Pasquale Foggia, Alessia Saggese, and Mario Vento. Real-Time Fire Detection for Video-Surveillance Applications Using a Combination of Experts Based on Color, Shape, and Motion. IEEE Transactions on Circuits and Systems for Video Technology, 25(9):1545–1556, 2015. doi: 10.1109/TCSVT.2015.2392531.
- Govil et al. [2020] Kinshuk Govil, Morgan L. Welch, J. Timothy Ball, and Carlton R. Pennypacker. Preliminary results from a wildfire detection system using deep learning on remote camera images. Remote Sensing, 12(1), 2020. ISSN 20724292. doi: 10.3390/RS12010166.
- He et al. [2016a] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, volume 2016-Decem, pages 770–778, 2016a. ISBN 9781467388504. doi: 10.1109/CVPR.2016.90.
- He et al. [2016b] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In CVPR, 2016b.
- Hess [2013] Roland Hess. Blender foundations: The essential guide to learning blender 2.5. Routledge, 2013.
- Hochreiter and Schmidhuber [1997] Sepp Hochreiter and Jurgen Schmidhuber. LONG SHORT-TERM MEMORY. Neural Computation, 9(8):1735–1780, 1997. ISSN 0899-7667. doi: 10.1162/neco.1997.9.8.1735.
- HPWREN [2023] HPWREN. High Performance Wireless Research & Education Network, 2023. URL http://hpwren.ucsd.edu/cameras/.
- James et al. [2023] George L. James, Ryeim B. Ansaf, Sanaa S. Al Samahi, Rebecca D. Parker, Joshua M. Cutler, Rhode V. Gachette, and Bahaa I. Ansaf. An Efficient Wildfire Detection System for AI-Embedded Applications Using Satellite Imagery. Fire, 6(4):1–13, 2023. ISSN 25716255. doi: 10.3390/fire6040169.
- Jeong et al. [2020] Mira Jeong, Minji Park, Jaeyeal Nam, and Byoung Chul Ko. Light-weight student LSTM for real-time wildfire smoke detection. Sensors (Switzerland), 20(19):1–21, 2020. ISSN 14248220. doi: 10.3390/s20195508.
- Jin et al. [2023] Chengtuo Jin, Tao Wang, Naji Alhusaini, Shenghui Zhao, Huilin Liu, Kun Xu, and Jin Zhang. Video Fire Detection Methods Based on Deep Learning: Datasets, Methods, and Future Directions. Fire, 6(8):1–27, 2023. ISSN 25716255. doi: 10.3390/fire6080315.
- Khan and Khan [2022] Somaiya Khan and Ali Khan. FFireNet: Deep Learning Based Forest Fire Classification and Detection in Smart Cities. Symmetry, 14(10), 2022. ISSN 20738994. doi: 10.3390/sym14102155.
- Krippendorff [2013] Klaus Krippendorff. Content Analysis: An Introduction to Its Methodology. In Content Analysis: An Introduction to Its Methodology. 2013. ISBN 9781412983150. doi: 10.1007/s13398-014-0173-7.2.
- Lee et al. [2023] Hoesung Lee, Katherine Calvin, Dipak Dasgupta, Gerhard Krinner, Aditi Mukherji, Peter Thorne, Christopher Trisos, José Romero, Paulina Aldunce, Ko Barret, and others. IPCC, 2023: Climate Change 2023: Synthesis Report, Summary for Policymakers. Contribution of Working Groups I, II and III to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change [Core Writing Team, H. Lee and J. Romero (eds.)]. IPC. Technical report, 2023. URL https://mural.maynoothuniversity.ie/17733/1/IPCC_AR6_SYR_LongerReport.pdf.
- Marjani and Mesgari [2023] M Marjani and M S Mesgari. THE LARGE-SCALE WILDFIRE SPREAD PREDICTION USING A MULTI-KERNEL CONVOLUTIONAL NEURAL NETWORK. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, X-4/W1-202(February):483–488, 2023. ISSN 21949050. doi: 10.5194/isprs-annals-x-4-w1-2022-483-2023.
- MMYOLO [2023] Contributors MMYOLO. Yolov8 by MMYOLO, 2023. URL https://github.com/open-mmlab/mmyolo/tree/main.
- Reidmiller et al. [2018] David R Reidmiller, Christopher W Avery, David R Easterling, Kenneth E Kunkel, Kristin L M Lewis, Thomas K Maycock, and Bradley C Stewart. Impacts, risks, and adaptation in the United States: Fourth national climate assessment, volume II. 2018.
- Schaetzen et al. [2020] Rodrigue De Schaetzen, Raphael Chang Menoni, Yifu Chen, and Drijon Hasani. Smoke Detection Model on the ALERTWildfire Camera Network. pages 1–11, 2020. URL https://rdesc.dev/project_x_final.pdf.
- Sharma et al. [2017] Jivitesh Sharma, Ole-Christoffer Granmo, Morten Goodwin, and Jahn Thomas Fidje. Deep convolutional neural network for fire detection. In EANN AG 2017, pages 183–193, 2017. ISBN 9781728164694. doi: 10.1109/RADIOELEKTRONIKA49387.2020.9092344.
- Thompson et al. [2018] Matthew P. Thompson, Donald G. MacGregor, Christopher J. Dunn, David E. Calkin, and John Phipps. Rethinking the wildland fire management system. Journal of Forestry, 116(4):382–390, 2018. ISSN 19383746. doi: 10.1093/jofore/fvy020.
- Toulouse et al. [2017] Tom Toulouse, Lucile Rossi, Antoine Campana, Turgay Celik, and Moulay A. Akhloufi. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Safety Journal, 92:188–194, 2017. ISSN 03797112. doi: 10.1016/j.firesaf.2017.06.012.
- Yazdi et al. [2022] Amirhessam Yazdi, Heyang Qin, Connor B. Jordan, Lei Yang, and Feng Yan. Nemo: An Open-Source Transformer-Supercharged Benchmark for Fine-Grained Wildfire Smoke Detection. Remote Sensing, 14(16):1–44, 2022. ISSN 20724292. doi: 10.3390/rs14163979.
Supplementary Material
7 Results with the different hyperparameters
We provide below the 1 score curves for each dataset. These curves, shown below each table, visually represent the performance of the models across different confidence thresholds. The confidence threshold represent the minimum values for which we consider the detection as a positive. The inclusion of F1 curves offers an intuitive understanding of the model’s classification performance, highlighting the trade-offs between precision and recall at various thresholds.



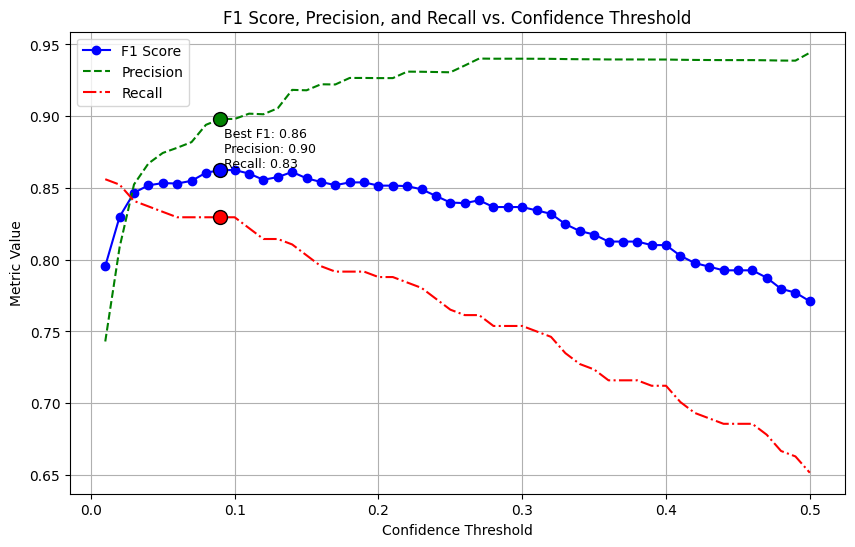
8 Time to detect a wildfire
Table 6 shows the time elapsed from the start of the fire until the first correct detection of smoke. More fine-grained visualization of the predictions are available in Figure 9, which depicts for a set a videos if the predictions are true or false at each frame.
| Video Name | Time Elapsed (min) | |
|---|---|---|
| YOLOv8 | YOLOv8 + CNN-LSTM | |
| 20180603_FIRE_sm-w-mobo-c | 0 | 0 |
| 20200829_inside-Mexico_mlo-s-mobo-c | 2 | 3 |
| 20200822_BrattonFire_lp-e-mobo-c | 1 | 1 |
| 20190610_FIRE_bh-w-mobo-c | 0 | 0 |
| 20170708_Whittier_syp-n-mobo-c | 0 | 0 |
| 20180809_FIRE_mg-w-mobo-c | 0 | 0 |
| 20180806_FIRE_mg-s-mobo-c | 2 | 3 |
| 20200930_inMexico_lp-s-mobo-c | 2 | 3 |
| 20190716_FIRE_bl-s-mobo-c | 0 | 0 |
| 20180504_FIRE_smer-tcs8-mobo-c | 0 | 0 |
| 20190924_FIRE_sm-n-mobo-c | 0 | 0 |
| 20200905_ValleyFire_lp-n-mobo-c | 3 | 1 |
| 20200611_skyline_lp-n-mobo-c | 1 | 1 |
| 20180726_FIRE_so-w-mobo-c | 4 | 5 |
| 20200911_FIRE_mlo-s-mobo-c | 5 | 6 |
| 20200705_FIRE_bm-w-mobo-c | 0 | 0 |
| 20170520_FIRE_lp-s-iqeye | 0 | 0 |
| 20160722_FIRE_mw-e-mobo-c | 0 | 0 |
| 20201127_Hawkfire_pi-w-mobo-c | 1 | 2 |
| 20200806_SpringsFire_lp-w-mobo-c | 0 | 3 |
| 20170625_BBM_bm-n-mobo | 0 | 0 |
| 20160711_FIRE_ml-n-mobo-c | 5 | 6 |
| 20200601_WILDLAND-DRILLS_om-e-mobo-c | 3 | 4 |
| ADF_1320 | 0 | 1 |
| awf_nvseismolab_baldcaX-0119 | 0 | 0 |
| awf_nvseismolab_baldcaX00132 | 0 | 1 |
| awf_nvseismolab_geyserpeakX-0098 | 0 | 0 |
| awf_nvseismolab_lincolnX-0059 | 0 | 0 |
| awf_nvseismolab_loop1X-0062 | 0 | 0 |
| awf_nvseismolab_mcclellandX-0173 | 0 | 0 |
| awf_nvseismolab_noaaX-0180 | 0 | 0 |
| awf_nvseismolab_peavineX00056 | 0 | 0 |
| awf_nvseismolab_virginiaX00080 | 0 | 0 |
| awf_nvseismolab_virginiaX00178 | 0 | 3 |
| pyronear_st_peray_1 | 0 | 2 |
| pyronear_brison_4 | 0 | 0 |
| pyronear_ferion_4 | 0 | 0 |
| pyronear_cabanelle_2 | 0 | 0 |
| Mean sd | (0.763 1.44) | (1.184 1.78) |


9 Sequential model Methodology
We based the architecture of our sequential model on [20], without the knowledge distillation. The CNN used is a pre-trained Resnet50, followed by an LSTM. The weights of the YOLOv8 are frozen but the detection threshold is set as a new hyperparameter. The best model was found with , and one LSTM layer with a hidden size of 256, and a ResNet50 as image encoder. Figure 10 shows more details on the architecture.
For the training of the sequential model, we samples sequences of images in order to get a mix of both positive and negative examples. For this, we selected sequences that were before the beginning of the fire, when the fire had already started, and when the fire was starting (as our goal is EWD). Finally, we also add the sequence of examples that were detected as false positive with the single-frame model, using the same lower confidence threshold used afterward.555As we reduced this threshold to increase the global Recall.

10 New In-house Data
New data will be collected from new countries in order to create the future version of the dataset, as data from this station recently installed in Chile (see Figure 11).

11 Other Datasets
12 SmokeFrames-50k annotations
When looking at the ground truth annotations of SmokeFrames-50k, we realized that there were many frames in which our model detected a wildfire when there was no annotation. This was due to the camera moving to center around the smoke plume, or because the wildfire was annotated with a bit of latency.