Scene-Intuitive Agent for Remote Embodied Visual Grounding
Abstract
Humans learn from life events to form intuitions towards the understanding of visual environments and languages. Envision that you are instructed by a high-level instruction, “Go to the bathroom in the master bedroom and replace the blue towel on the left wall”, what would you possibly do to carry out the task? Intuitively, we comprehend the semantics of the instruction to form an overview of where a bathroom is and what a blue towel is in mind; then, we navigate to the target location by consistently matching the bathroom appearance in mind with the current scene. In this paper, we present an agent that mimics such human behaviors. Specifically, we focus on the Remote Embodied Visual Referring Expression in Real Indoor Environments task, called REVERIE, where an agent is asked to correctly localize a remote target object specified by a concise high-level natural language instruction, and propose a two-stage training pipeline. In the first stage, we pre-train the agent with two cross-modal alignment sub-tasks, namely the Scene Grounding task and the Object Grounding task. The agent learns where to stop in the Scene Grounding task and what to attend to in the Object Grounding task respectively. Then, to generate action sequences, we propose a memory-augmented attentive action decoder to smoothly fuse the pre-trained vision and language representations with the agent’s past memory experiences. Without bells and whistles, experimental results show that our method outperforms previous state-of-the-art(SOTA) significantly, demonstrating the effectiveness of our method.
1 Introduction
Vision and Language tasks, such as Vision-and-Language Navigation (VLN) [2], Visual Question Answering (VQA) [3, 4] and Referring Expression Comprehension (REF) [21, 49, 50] etc., have been extensively studied in the wave of deep neural networks. In particular, VLN [2, 5] is a challenging task that combines both natural language understanding and visual navigation. Recent works have shown promising performance and progress. They mainly focus on designing agents capable of grounding fine-grained natural language instructions, where detailed information is provided, to find where to stop, for example “Leave the bedroom and take a left. Take a left down the hallway and walk straight into the bathroom at the end of the hall. Stop in front of the sink” [12, 28, 44, 43, 40, 22]. However, a practical issue is that fine-grained natural language instructions are not always available in real life and human-machine interactions are mostly based on high-level instructions such as “Go to the bathroom at the end of the hallway”. In other words, designing an agent that could perform high-level natural language interpretation and infer the probable target location using knowledge of the environments is of more practical use.
In this paper, we focus on the REVERIE task [36] which is an example of the above mentioned high-level instruction task. Here, we briefly introduce the settings. Given a high-level instruction that refers to a remote target object at a target location within a building, a robot agent spawns at a starting location in the same building and tries to navigate closer to the object. The output of the task is a bounding box encompassing the target object. The success of the task is evaluated based on explicit object grounding at the correct target location. A straightforward solution is to integrate SOTA navigation model with SOTA object grounding model. This strategy has proven to be inefficient in [36] and instead, they proposed an interactive module to enable the navigation model to work together with the object grounding model. Although the performance is improved, we observe that such method has a key weakness: it is unreasonable to discern high-level instruction by directly borrowing the fine-grained instruction navigation model that consists of simple trainable language attention mechanism based on the fact that the perception of high-level instruction primarily depends on commonsense knowledge prior as well as past experiences in memory. Therefore, the overall design is not in line with human intuitions in high-level instruction navigation.
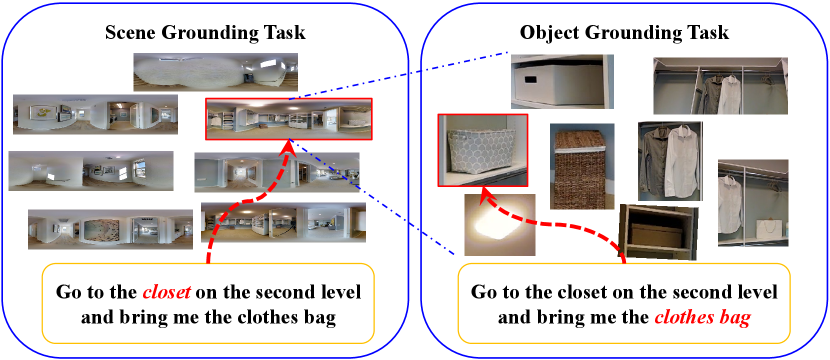
Designing an agent to solve the problem like the REVERIE task is still under explored and there are still no systematic ways to design such an agent. Then, how does human wisdom solve this task? Human beings have instincts to understand surrounding visual environments and languages. Intuitively, given a high-level instruction, we would first extract high-level what and where information and then form an overview of the appearance of the target location in mind based on common sense knowledge. During navigation, we would consistently match current scene and objects in the scene to the instruction semantics and decide where to navigate next. According to such intuitions, we approach this problem from a new perspective and present an agent that imitates such human behaviors. Concretely, we define our problem as designing an agent that is able to solve where and what problem in the REVERIE task. We propose a two-stage training pipeline. In the first stage, we design two pre-training tasks, mimicking the aforementioned two human intuitions. The second stage is training the agent with a memory-augmented attentive action decoder, further increasing the agent’s navigation capability under high-level instructions.
Pre-training Stage. As is shown in Fig. 1, we introduce a new subtask called the Scene Grounding task that is trained to recognize which viewpoint in a set of viewpoints is best aligned with the high-level instruction and another subtask called the Object Grounding task that helps the agent identify the best object that matches to the instruction among a set of candidate objects located at a target viewpoint. Experimental results show that the Scene Grounding model recognizes the target viewpoint with a high accuracy and the Object Grounding model outperforms the previous best model used in [51, 36] by more than .
Action Decoding Stage. In this stage, with the pre-trained models serving as scene and language encoders, we propose a memory-augmented attentive action decoder that leverages a scene memory structure as the agent’s internal past state memory. This design is based on the fact that the computation of action at a specific time step could depend on any provided information in the past. Experimental results indicate that the proposed structure is effective and achieves new state-of-the-art performance.
To sum up, this paper has the following contributions:
-
•
We propose a new framework that borrows human intuitions for designing agent capable of understanding high-level instructions, which closely integrate navigation and visual grounding in both training and inference. Specifically, the visual grounding models are pre-trained and serve as vision and language encoders for training navigation action decoder in the training phase. In inference, the action is predicted by considering logits from both the visual grounding models and the navigation decoder.
-
•
We introduce two novel pre-training tasks, called Scene Grounding task and Object Grounding task, and a new Memory-augmented attentive action decoder in our framework. The pre-training tasks attempt to help the agent learn where to stop and what to attend to, and the action decoder effectively exploits past observations to fuse visual and textual modalities.
-
•
Without bells and whistles, our method outperforms all previous methods, achieving new state-of-the-art performance on both seen and unseen environments on the REVERIE task.
2 Related Work
Vision-and-Language Navigation and REVERIE. In VLN, an agent is required to navigate to a goal location in a D simulator based on fine-grained instructions. [2] proposed the Matterport3D Simulator and designed the Room-to-Room task. Then, a lot of methods have been proposed to solve this task [12, 44, 43, 40, 22]. On the other hand, the recently proposed REVERIE task [36] is different from traditional VLN in that it requires an agent to navigate and localize target object simultaneously under the guidance of high-level instruction. The model they proposed trains the navigation model with the interactive module that works together with the object grounding model [51], in the hope that the model could learn to understand high-level instruction in a data-driven manner. However, our motivation is essentially different in that we inject commonsense knowledge prior and past memory experiences into the action policy taking into consideration the human perception in dealing with such high-level instruction navigation problems. Specifically, we introduce two pre-training tasks and a memory based action policy to make the agent become scene-intuitive. Moreover, our pre-training tasks differ from the ones proposed in [12, 52, 29] in that their motivation is based on the fact that the ground truth navigation path is actually hidden in the fine-grained instruction, which is not the case in high-level instruction navigation.
Memory-based policy for navigation tasks. Various memory models have been extensively studied for navigation agents, including unstructured memory [17, 31, 46, 18, 30, 9], addressable memory [32, 33], topological memory [37], and metric grid-based maps [14, 1], etc. Unstructured memory representations, such as LSTM memory, have been used extensively in both 2D and 3D environments. However, the issue of RNN based memory is that it does not contain context-dependent state feature storage or retrieval and does not have long time memory [1, 20, 11]. To address these limitations, more advaneced memory structures, such as addressable, topological, and metric based memory are proposed. In this paper, we adopt a simple adressable memory structure. The aim of using such a simple design is 1) to intentionally make it lightweight, thus reducing computational overhead, since the computational cost is important in REVERIE and our pipeline already contains heavy models; 2) to improve the performance of the overall pipeline rather than designing a more advanced memory superior to others. Besides, in VLN, the metric map memory construction requires finegrained language instruction as guidance, which is not available in our task, and building the topological memory requires pre-exploration of the environment, a technique that is certainly helpful to our agent but is beyond the discussion of this paper.
Vision-and-Language BERT based referring expression comprehension. Recent years have witnessed a resurgence of active research in transferrable image-text representation learning. BERT-based models [10, 39, 38, 27, 6, 26] have achieved superior performance over multiple vision-and-language tasks by transferring the pre-trained model on large aligned image-text pairs to other downstream tasks. In BERT-based VLN, the most related agents to ours are [15] and [29]. [15] treats VLN as a vision-and-language alignment task and utilizes a pre-trained vision-and-language BERT model to predict action sequence while [29] formulates VLN as an instruction and path alignment task and adopts a pre-trained vision-and-language BERT model to find the best candidate path that matches to the instruction given. However, our work differs from others in that we propose a generalized pipeline that mimics human intuitions to solve the high-level instruction navigation task where vision-and-language BERT model is a building block which can be customized to other vision-language alignment block. Experimental results show that the main performance gain comes from our proposed pipeline.
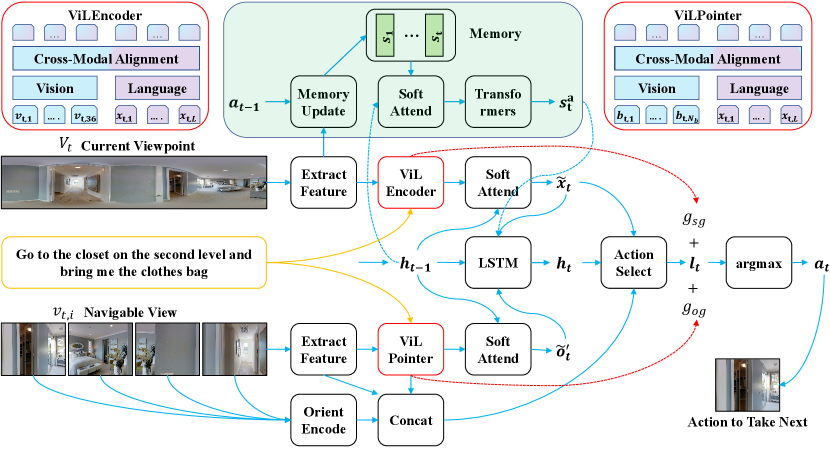
3 Method
In the REVERIE task, an agent placed at a starting location navigates to the target location to localize an object specified by a high-level instruction. To carry out this difficult task, we propose a novel pipeline that contains a scene grounding model, an object grounding model, and a memory-based action decoder. We make two claims of our design choice: first, to better grasp the semantics of high-level instructions, we choose ViLBERT model as our basic building block to serve as vision-and-language encoder; second, since scene grounding task and object grounding task are two essentially different tasks, we do not share the basic building blocks for these two tasks. In general, we decompose our method into two stages, as shown in Fig. 2, namely the pre-training stage and the action decoding stage. In the following sections, we first introduce the pre-training tasks; then we illustrate the memory-based attentive action decoder and finally, the loss function used to train the agent.
3.1 ViLBERT introduction
In this section, we briefly introduce the input and output arguments of a ViLBERT model [26] as shown in Fig. 3. A ViLBERT model is a BERT-based model that consists of two input streams, vision encoding stream and language encoding stream, followed by a cross-modal alignment Transformer block. The inputs to ViLBERT model are sequence of words and visual features respectively and the outputs are corresponding encoded word sequence features as well as visual sequence features. We use ViLBERT as our base model (basic building block) for the Scene Grounding task and the Object Grounding task. In Scene Grounding task, a panorama viewpoint image is discretized into view images and the inputs are sequence of words in the instruction and mean-pooled features extracted from view images by a ResNet- CNN pre-trained on ImageNet [24]. In Object Grounding task, the inputs are sequence of words in the instruction and all annotated bounding boxes features extracted by Mask R-CNN [16] in a target viewpoint.
3.2 Overview of the proposed method
Settings. To formalize the task, we denote a given high-level instruction as where is the number of words in the instruction and a set of viewpoints as where is the number of viewpoints in the environment. At each time step , the agent observes a panoramic view , a few navigable views and a set of annotated bounding boxes . The panoramic view is discretized into single views by perspective projections, each of which is a size image with field of view set to degrees, and is denoted by . where is the maximum navigable directions at a viewpoint . Each is represented as . Thus, . Besides, the set of annotated bounding boxes at viewpoint is denoted by where is the number of bounding boxes. Mask R-CNN [16] is used to extract bounding boxes features , where .
Stage 1(a): Scene Grounding Task. We formulate the task as finding a viewpoint that best matches to a high-level instruction in a set of candidate viewpoints . . Concretely, we define a mapping function that maps to a matching score. The formula is defined as follows,
| (1) |
Stage 1(b): Object Grounding Task. The goal of this task is to identify the best matching object among a set of candidate objects located at a target viewpoint. We denote as a target viewpoint and its corresponding annotated bounding boxes set is . We define another compatibility matching function that produce matching scores for all objects with a high-level instruction . Thus, the problem is defined as follows,
| (2) |
Stage 2: Memory-augmented action decoder. To mitigate the memory problem presented in previous section, a scene memory structure is implemented to store the embedded observation and previous action at each time step . The memory is updated by,
| (3) | ||||
where is current state representation; is attentive visual feature; and are last time step hidden state and action embedding respectively; is a trainable parameter. stands for fully connected layer. The operation appends to . .
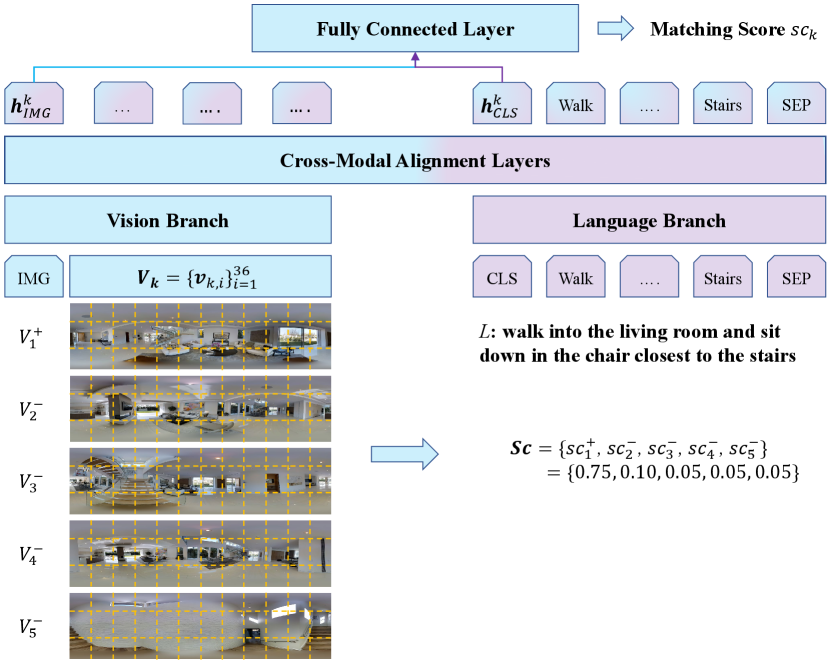
3.3 Scene Grounding Task
The goal of this task it to help the agent infer where the target location is. Given a high-level instruction, “Bring me the jeans that are hanging up in the closet to the right”, humans first locate the where information, the key word closet, by capturing the semantics of the instruction according to the language context and commonsense knowledge and then form an overview of the appearance of the closet in mind; then, humans navigate to the target location by consistently matching the closet appearance in mind with current scene. In fact, humans have gradually formed intuitions towards the understanding of scenes, instructions and tasks in life. For language instructions in relatively simple life scenes that do not involve complex reasoning, they usually directly merge the above two processes for direct perception and understanding. We call this process as context-driven scene perception. In this section, we propose Scene Grounding task to imitate such human behavior.
Based on the observation, we believe that a model that could evaluate the alignment between an instruction and a viewpoint is able to localize the target viewpoint. Therefore, to implement this idea, we create a dataset from the REVERIE training set and fine-tune a ViLBERT model on the dataset. Specifically, we adopt a -way multiple choice setting. We eliminate subscript for simplicity concern. Given an instruction , we sample viewpoints , out of which only one is aligned to the instruction (or in other words, positive). In detail, we choose the ending viewpoint in the ground-truth training path as , the second last viewpoint along the ground-truth path as which is a hard negative sample and random sample from the rest of the viewpoints along the path, and from other path . Then, we run the ViLBERT model on each of the pair. As is shown in Fig. 3, the output tokens and encode instruction representation as well as viewpoint representation respectively. We define the matching scores as and train the model with cross entropy loss .
| (4) | ||||
where is a trainable parameter and is indicator function. are the encoded language and visual representations of the language and vision encoding streams from our pre-trained ViLBERT model for th pair respectively.
3.4 Object Grounding Task
The aim of this task is to help the agent learn what to attend to. For each ground-truth target viewpoint , we formulate this task as finding the best bounding box in bounding boxes set given pair. A straightforward method to implement this idea is to construct a single image based grounding task, where each training sample consists of instruction and a subset of bounding boxes in that belong to view . However, according to our experiment, this strategy produces moderate performance since objects in D space could span multiple views in corresponding projected D image space. The cross-image objects relationships in each viewpoint are not well captured by the model. Therefore, we propose a two-stage training strategy, namely a single image based grounding and a viewpoint based object grounding. In single image grounding, we fine-tune the ViLBERT model from [27, 26] on the aforementioned single image grounding dataset where each training sample is (all annotated bounding boxes in are collected) and ; then, we further fine-tune trained model on a new viewpoint based object grounding dataset. Concretely, each training sample in the viewpoint based dataset is a pair (all annotated bounding boxes in are collected) and the corresponding label is a vector containing s and s where indicates the IoU of a bounding box with the target bounding box is higher than . In inference, we represent an object score as the averaged scores from all bounding boxes that share the same object id at a viewpoint that the agent stops.
3.5 Action Decoder
With the pre-trained grounding models, the action decoder generally adopts Encoder-Decoder structure to produce action prediction. Specifically, the Scene Grounding model is accompanied by a network to construct a vision and language grounding encoder and the Object Grounding model is formulated as an object level grounding encoder . The inputs to action decoder are , and and it outputs predicted action distribution .
First. At each time step , to perceive current scene and instruction, we obtain by grounding with through and then selecting the fused language sequence as output. The formula is defined as follows,
| (5) | ||||
where is a trainable parameter and is encoded language feature taking current scene into consideration. .
Second. To decide which navigable direction to go next, we perform object level referring expression comprehension. The object level referring comprehension helps the agent infer whether a navigable view contains possible target object. In particular, the set of bounding boxes in view is denoted by where function decides whether is inside view . is pre-trained on the Object Grounding task and we select the fused bounding boxes features as the output. Then,
| (6) | ||||
where is the set of aligned bounding boxes features at view and selects top- aligned bounding boxes and averages the corresponding aligned bounding boxes features from to produce view comprehension .
Third. We define the representation of each navigable view as :
| (7) |
where the agent’s current orientation represents the angles of heading and elevation and is tiled times according to [12]. and . The set of navigable view representation is denoted as . The grounded navigable visual representation is represented as follows:
| (8) |
where is a trainable parameter and is a number of Fully Connected layers accompanied by ReLU nonlinearities. .
Fourth. The new context hidden state is updated by a LSTM layer taking as input the grounded text and navigable view features as well as the current state representation feature .
| (9) |
where is memory augmented current state representation and is defined as,
| (10) | ||||
where and are number of memory transformer blocks used and number of state transformer blocks used respectively. . is the standard version Transformer block from [42].
Finally. The action logit is computed in an attentive manner.
| (11) |
where is a trainable parameter and . In training stage, is selected based on categorical policy and in inference stage, it is selected by . Action embedding is selected based on .
3.6 Inference
We propose to use a combined logit that sums action logits, object grounding logits and scene grounding logits to perform navigation, where and denote object grounding score and scene grounding score at time step respectively. Experimental results indicate that our strategy shortens the search trajectories while maintaining a good success rate. The final output bounding box is obtained by running at the stop viewpoint that the agent predicts.
3.7 Loss Functions
To train the agent, we use a mixture of Imitation Learning (IL) and Reinforcement Learning (RL) to supervise the training. Specifically, In IL, at each time step, we allow the agent to learn to imitate the teacher action by using a cross entropy loss and a mean squared error loss for progress monitor [28]. In RL, we follow the idea of [40] and allow the agent to learn from rewards. If the agent stops within meters near the target viewpoint, a positive reward is assigned at the final step; otherwise a negative reward is given.
| (12) | ||||
where is the teacher action at step ; is the shortest normalized distance from current viewpoint to the target viewpoint; is the predicted progress; , and are all set to .
4 Experiments
In the REVERIE dataset, the training set contains scenes and instructions over objects; the val seen split consists of scenes and instructions over objects and the val unseen split include scenes and instructions over objects. The test set contains scenes and instructions over objects. In this section, we conduct extensive evaluation and analysis of the effectiveness of our proposed components.
| Experiments | ID | Methods | Val Seen | Val Unseen | |||||||||||||||||
| Encoder | Pointer | Policy | Nav. Acc. | RGS | RG SPL | Nav. Acc. | RGS | RG SPL | |||||||||||||
| Succ. | OSucc. | SPL | Length | Succ. | OSucc. | SPL | Length | ||||||||||||||
| Component Effectiveness | 1 | 50.53 | 55.17 | 45.50 | 16.35 | 31.97 | 29.66 | 14.40 | 28.20 | 7.19 | 45.28 | 7.84 | 4.67 | ||||||||
| 2 | 54.18 | 58.68 | 48.99 | 12.46 | 33.87 | 21.23 | 18.66 | 29.51 | 10.44 | 32.95 | 11.13 | 6.32 | |||||||||
| 3 | 33.73 | 39.14 | 30.72 | 14.56 | 23.82 | 21.94 | 15.22 | 31.64 | 8.44 | 42.62 | 8.89 | 4.84 | |||||||||
| 4 | 39.00 | 43.85 | 35.00 | 13.71 | 28.95 | 25.98 | 13.80 | 31.33 | 8.21 | 37.31 | 9.17 | 5.54 | |||||||||
| 5 | 37.32 | 43.08 | 31.71 | 18.29 | 24.88 | 21.70 | 19.06 | 44.39 | 7.10 | 79.88 | 11.08 | 4.17 | |||||||||
| 6 | 56.36 | 60.93 | 52.24 | 13.21 | 36.33 | 33.92 | 21.61 | 31.98 | 12.21 | 36.05 | 13.21 | 7.31 | |||||||||
| 7 | 54.25 | 56.08 | 50.49 | 13.56 | 39.56 | 37.16 | 26.98 | 37.86 | 13.70 | 42.50 | 17.32 | 8.71 | |||||||||
| 8 | 59.52 | 64.23 | 55.30 | 14.00 | 43.57 | 40.42 | 28.17 | 40.41 | 14.77 | 43.12 | 19.60 | 10.27 | |||||||||
| Memory Blocks (, ) | 9 | (1, 1) | 55.24 | 58.61 | 52.29 | 12.42 | 40.90 | 38.76 | 28.97 | 39.56 | 13.28 | 44.10 | 20.51 | 9.19 | |||||||
| 10 | (3, 3) | 61.91 | 65.85 | 57.08 | 13.61 | 45.96 | 42.65 | 31.53 | 44.67 | 16.28 | 41.53 | 22.41 | 11.56 | ||||||||
| 11 | (5, 5) | 60.01 | 63.38 | 54.99 | 17.44 | 44.69 | 41.10 | 25.84 | 38.20 | 13.09 | 44.00 | 18.23 | 9.19 | ||||||||
| 12 | (7, 7) | 57.27 | 62.26 | 52.78 | 13.96 | 42.66 | 39.38 | 23.66 | 35.61 | 11.67 | 45.73 | 16.79 | 8.43 | ||||||||
| 13 | (9, 9) | 57.06 | 60.15 | 53.35 | 14.16 | 42.38 | 39.67 | 28.15 | 39.45 | 14.92 | 41.53 | 19.54 | 10.13 | ||||||||
| Logit Fusion | 14 | 60.92 | 65.78 | 56.14 | 15.28 | 45.61 | 42.19 | 32.35 | 49.08 | 14.74 | 60.89 | 22.35 | 10.54 | ||||||||
| 15 | + | 61.49 | 65.78 | 56.72 | 13.67 | 45.47 | 42.31 | 31.20 | 47.80 | 15.90 | 45.82 | 21.68 | 11.08 | ||||||||
| 16 | + | 61.14 | 65.77 | 55.21 | 16.82 | 44.48 | 40.04 | 32.12 | 46.54 | 15.73 | 52.14 | 21.98 | 11.02 | ||||||||
| 17 | ++ | 61.91 | 65.85 | 57.08 | 13.61 | 45.96 | 42.65 | 31.53 | 44.67 | 16.28 | 41.53 | 22.41 | 11.56 | ||||||||
| Methods | Val Seen | Val Unseen | Test (Unseen) | |||||||||||||||
| Nav. Succ. | RGS | RG SPL | Nav. Succ. | RGS | RG SPL | Nav. Succ. | RGS | RG SPL | ||||||||||
| Succ. | OSucc. | SPL | Length | Succ. | OSucc. | SPL | Length | Succ. | OSucc. | SPL | Length | |||||||
| RCM [43] + MattNet | 23.33 | 29.44 | 21.82 | 10.70 | 16.23 | 15.36 | 9.29 | 14.23 | 6.97 | 11.98 | 4.89 | 3.89 | 7.84 | 11.68 | 6.67 | 10.60 | 3.67 | 3.14 |
| SelfMonitor [28] + MattNet | 41.25 | 43.29 | 39.61 | 7.54 | 30.07 | 28.98 | 8.15 | 11.28 | 6.44 | 9.07 | 4.54 | 3.61 | 5.80 | 8.39 | 4.53 | 9.23 | 3.10 | 2.39 |
| FAST-short [22] + MattNet | 45.12 | 49.68 | 40.18 | 13.22 | 31.41 | 28.11 | 10.08 | 20.48 | 6.17 | 29.70 | 6.24 | 3.97 | 14.18 | 23.36 | 8.74 | 30.69 | 7.07 | 4.52 |
| REVERIE [36] | 50.53 | 55.17 | 45.50 | 16.35 | 31.97 | 29.66 | 14.40 | 28.20 | 7.19 | 45.28 | 7.84 | 4.67 | 19.88 | 30.63 | 11.61 | 39.05 | 11.28 | 6.08 |
| Human | - | - | - | - | - | - | - | - | - | - | - | - | 81.51 | 86.83 | 53.66 | 21.18 | 77.84 | 51.44 |
| Ours | 61.91 | 65.85 | 57.08 | 13.61 | 45.96 | 42.65 | 31.53 | 44.67 | 16.28 | 41.53 | 22.41 | 11.56 | 30.8 | 44.56 | 14.85 | 48.61 | 19.02 | 9.20 |
4.1 Evaluation Metrics
Following [36], we evaluate the performance of the model based on REVERIE Success Rate (RGS) and REVERIE Success Rate weighted by Path Length (RG SPL). We also report the performance of Navigation Success Rate, Navigation Oracle Success Rate, Navigation Success Rate weighted by Path Length (SPL), and Navigation Length. Please refer to the supplementary document for more details.
4.2 Ablation Study
In this section, we aim to answer the following questions: Does the performance gain mainly come from BERT-based structure? How effective is each of the proposed component? Does the memory blocks number matter? Why do we need logit fusion? For simplicity concern, we define the following experiment settings: our proposed is ; the is not pre-trained on the Scene Grounding task but pre-trained on the Conceptual Captions dataset [35] as well as the tasks specified in [27]; the is a BERT language encoder pre-trained on the BookCorpus [53] and English Wikipedia datasets; our proposed is ; previous SOTA MattNet pointer is ; our action policy is ; previous action policy is ; previous simple language encoder is composed of a trainable embedding layer with a Bi-directional LSTM layer.
Performance Gain. To answer question , we perform experiments , , and as is shown in Table 1. All agents are trained under and with and both set to . It is clear that the agent’s overall performance is incrementally improved by changing the language encoder from the simple to our proposed , which proves our analysis that previous language encoder does not well capture the semantics of high-level instructions. The experimental results of and clearly suggests that the BERT-based structure is not the root cause of our performance gain and our proposed Scene Grounding task significantly increase the RG SPL metric to on Val Seen and on Val Unseen, even higher than the strong baseline in experiment .
Component Effectiveness. To answer question , based on the statistics from Table 1, we train six models in experiments from to and ablate the proposed component one by one to demonstrate the effectiveness. For fair comparison, we follow the settings of [36]. All agents are trained under and with and both set to . We start from the baseline experiment and replace each component by our proposed ones. Specifically, in experiments and , the proposed improves the RG SPL (and SPL) by a large margin, (and ) higher in Val Seen and (and ) higher in Val Unseen than the baseline respectively, which proves that the Scene Grounding task is effective; in experiments and , our pointer outperforms the MattNet counterpart by shortening the length of the search trajectory while maintaining a high RG SPL (and SPL), which demonstrates the effectiveness of the Object Grounding task; in experiments and , the results show that the overall search trajectory of our action policy is longer than that of the baseline while our action policy achieves higher RGS and Navigation Success Rate, which demonstrates that the memory structure in our policy guides the agent to the correct target location at the cost of long trajectory; in experiments and , we demonstrate that by integrating all our proposed methods, our agent improves previous SOTA in terms of RG SPL by on Val Seen and on Val Unseen.
Memory Blocks. To answer question , we train five models with different and values. In these experiments, we train the agents with , and and , and set to . In general, according to the experiments from to in Table 1, all pairs of exhibit superior performance compared to previous SOTA method in experiment and the strong BERT baseline model in experiment . Moreover, the best performance model is achieved by setting to in these five models, which suggests that using small values of limits the agent’s memorization ability and using large values of enables the agent to achieve good performance on Val Unseen while maintains good performance on Val Seen.
Logit Fusion. To answer question , we report two accuracies to verify the effectiveness of and . In the Encoder Task of Table 3, given ground-truth path, our proposed model achieves competitive performance on both Val Seen and Val Unseen, demonstrating the strong ability of to identify a target viewpoint. In the Pointer Task of Table 3, the performance of -vp-based is significantly higher than previous image-based pointers because it is able to capture cross-image objects relationships, suggesting that has the ability to find the target location if the target object exists. According to experiments from to , where the agents are trained with , and and , and set to , summing , , and shortens the search trajectory and maintains a high RGS(Navigation Success Rate) and RG SPL(SPL). The motivation behind the summing strategy is to use model ensemble to reduce bias when searching for target locations considering the fact that the agent has no prior knowledge of the surrounding environments and the guidance of the high-level instructions is weak.
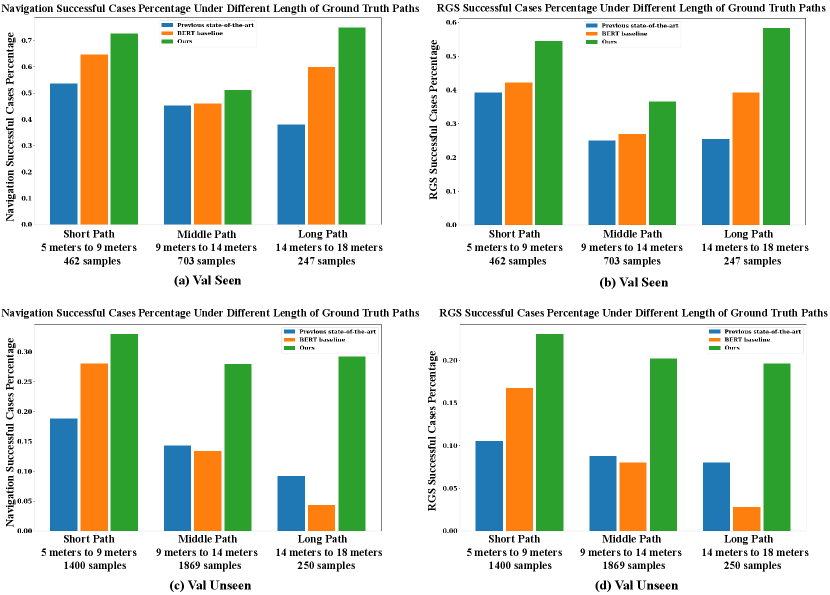
4.3 Compared to previous state-of-the-art results
We first show what kind of cases our method improves compared to previous SOTA and our BERT-based strong baseline in experiment . Specifically, we divide the shortest distance lengths of all ground-truth paths into three groups, namely short path( meters to meters with sample paths on Val Seen and sample paths on Val Unseen), middle path( meters to meters with sample paths on Val Seen and sample paths on Val Unseen), and long path( meters to meters with sample paths on Val Seen and sample paths on Val Unseen). Then, we count the cases that the agent successfully navigates to the target locations and the cases that the agent successfully navigates and localizes the target objects for the three groups. In Fig. 4, we report the corresponding successful cases percentage. It is obvious that our proposed method improves all kinds of sample paths by a clear margin.
Then, we compare our final model with previous SOTA models in Table 2. As is clearly shown in Table 2, our model outperforms all previous models by a large margin. Specifically, in terms of SPL, our agent increases previous SOTA by on Val Seen, on Val Unseen and on Test respectively; for RG SPL, our agent increase previous SOTA by on Val Seen, on Val Unseen and on Test. The overall improvements indicate that our proposed scene-intuitive agent not only navigates better but also localizes target objects more accurately.
5 Conclusion
In this paper, we present a scene-intuitive agent capable of understanding high-level instructions for the REVERIE task. Different from previous works, we propose two pre-training tasks, Scene Grounding task and Object Grounding task respectively, to help the agent learn where to navigate and what object to localize simultaneously. Moreover, the agent is trained with a Memory-augmented action decoder that fuses grounded textual representation and visual representation with memory augmented current state representation to generate action sequence. We extensively verify the effectiveness of our proposed components and experimental results demonstrate that our result outperforms previous methods significantly. Nevertheless, how to bridge the performance gap between seen and unseen environments and how to shorten the navigation length efficiently remains an open problem for further investigation.
References
- [1] Peter Anderson, Ayush Shrivastava, Devi Parikh, Dhruv Batra, and Stefan Lee. Chasing ghosts: Instruction following as bayesian state tracking. In Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [2] Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [3] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In International Conference on Computer Vision (ICCV), 2015.
- [4] Qingxing Cao, Xiaodan Liang, Bailing Li, Guanbin Li, and Liang Lin. Visual question reasoning on general dependency tree. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7249–7257, 2018.
- [5] Howard Chen, Alane Suhr, Dipendra Misra, Noah Snavely, and Yoav Artzi. Touchdown: Natural language navigation and spatial reasoning in visual street environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [6] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning. In The European Conference on Computer Vision (ECCV), 2020.
- [7] Elizabeth R. Chrastil. Neural evidence supports a novel framework for spatial navigation. Psychonomic Bulletin & Review, 20:208–227, 2013.
- [8] A. Coutrot, R. Silva, E. Manley, Will de Cothi, and H. Spiers. Global determinants of navigation ability. Current Biology, 28:2861–2866.e4, 2018.
- [9] Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, D. Parikh, and Dhruv Batra. Embodied question answering. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018.
- [10] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [11] Kuan Fang, Alexander Toshev, Li Fei-Fei, and Silvio Savarese. Scene memory transformer for embodied agents in long-horizon tasks. 2019.
- [12] Daniel Fried, Ronghang Hu, Volkan Cirik, Anna Rohrbach, Jacob Andreas, Louis-Philippe Morency, Taylor Berg-Kirkpatrick, Kate Saenko, Dan Klein, and Trevor Darrell. Speaker-follower models for vision-and-language navigation. In Neural Information Processing Systems (NeurIPS), 2018.
- [13] S. Gopal, R. Klatzky, and T. Smith. Navigator: A psychologically based model of environmental learning through navigation. Journal of Environmental Psychology, 9:309–331, 1989.
- [14] Saurabh Gupta, Varun Tolani, J. Davidson, S. Levine, R. Sukthankar, and J. Malik. Cognitive mapping and planning for visual navigation. International Journal of Computer Vision, 128:1311–1330, 2019.
- [15] Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. Towards learning a generic agent for vision-and-language navigation via pre-training. Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [16] Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Computer Vision (ICCV), 2017 IEEE International Conference on, pages 2980–2988. IEEE, 2017.
- [17] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [18] Max Jaderberg, V. Mnih, W. Czarnecki, T. Schaul, Joel Z. Leibo, D. Silver, and K. Kavukcuoglu. Reinforcement learning with unsupervised auxiliary tasks. In ICLR, 2017.
- [19] Simon Jetzschke, M. Ernst, J. Fröhlich, and N. Boeddeker. Finding home: Landmark ambiguity in human navigation. Frontiers in Behavioral Neuroscience, 11, 2017.
- [20] Jia Lv Yanjie Duan Zhen Qin Guodong Li Jingyu Zhao, Feiqing Huang and Guangjian Tian. Do rnn and lstm have long memory? In International Conference on Machine Learning, 2020.
- [21] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara L. Berg. Referit game: Referring to objects in photographs of natural scenes. In EMNLP, 2014.
- [22] Liyiming Ke, Xiujun Li, Yonatan Bisk, Ari Holtzman, Zhe Gan, Jingjing Liu, Jianfeng Gao, Yejin Choi, and Siddhartha Srinivasa. Tactical rewind: Self-correction via backtracking in vision-and-language navigation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [23] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), 2015.
- [24] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
- [25] Xihui Liu, Zihao Wang, Jing Shao, Xiaogang Wang, and Hongsheng Li. Improving referring expression grounding with cross-modal attention-guided erasing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1950–1959, 2019.
- [26] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems, pages 13–23, 2019.
- [27] Jiasen Lu, Vedanuj Goswami, Marcus Rohrbach, Devi Parikh, and Stefan Lee. 12-in-1: Multi-task vision and language representation learning. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [28] Chih-Yao Ma, Jiasen Lu, Zuxuan Wu, Ghassan AlRegib, Zsolt Kira, Richard Socher, and Caiming Xiong. Self-monitoring navigation agent via auxiliary progress estimation. In Proceedings of the International Conference on Learning Representations (ICLR), 2019.
- [29] Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh, and Dhruv Batra. Improving vision-and-language navigation with image-text pairs from the web. 2020.
- [30] P. Mirowski, Razvan Pascanu, F. Viola, Hubert Soyer, Andy Ballard, Andrea Banino, Misha Denil, R. Goroshin, L. Sifre, K. Kavukcuoglu, D. Kumaran, and Raia Hadsell. Learning to navigate in complex environments. In ICLR, 2017.
- [31] Piotr Mirowski, Razvan Pascanu, Fabio Viola, Hubert Soyer, Andrew J. Ballard, Andrea Banino, Misha Denil, Ross Goroshin, Laurent Sifre, Koray Kavukcuoglu, Dharshan Kumaran, and Raia Hadsell. Learning to navigate in complex environments. In Proceedings of the International Conference on Learning Representations (ICLR), 2017.
- [32] Junhyuk Oh, Valliappa Chockalingam, Satinder Singh, and H. Lee. Control of memory, active perception, and action in minecraft. In ICML, 2016.
- [33] Emilio Parisotto and R. Salakhutdinov. Neural map: Structured memory for deep reinforcement learning. In ICLR, 2018.
- [34] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32, pages 8024–8035. 2019.
- [35] Sharma Piyush, Ding Nan, Goodman Sebastian, and Soricut Radu. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018.
- [36] Yuankai Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. Reverie: Remote embodied visual referring expression in real indoor environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [37] Nikolay Savinov, A. Dosovitskiy, and V. Koltun. Semi-parametric topological memory for navigation. In ICLR, 2018.
- [38] Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. Vl-bert: Pre-training of generic visual-linguistic representations. In International Conference on Learning Representations, 2020.
- [39] Hao Tan and Mohit Bansal. Lxmert: Learning cross-modality encoder representations from transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019.
- [40] Hao Tan, Licheng Yu, and Mohit Bansal. Learning to navigate unseen environments:back translation with environmental dropout. In Proceedings of The North American Chapter of the Association for Computational Linguistics (NAACL), 2019.
- [41] I. V. D. van der Ham, M. H. G. Claessen, A. Evers, and Milan N. A. van der Kuil. Large-scale assessment of human navigation ability across the lifespan. Scientific Reports, 10, 2020.
- [42] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 5998–6008, 2017.
- [43] Xin Wang, Qiuyuan Huang, Asli Celikyilmaz, Jianfeng Gao, Dinghan Shen, Yuan-Fang Wang, William Yang Wang, and Lei Zhang. Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6629–6638, 2019.
- [44] Xin Wang, Wenhan Xiong, Hongmin Wang, and William Yang Wang. Look before you leap: Bridging model-free and model-based reinforcement learning for planned-ahead vision-and-language navigation. In The European Conference on Computer Vision (ECCV), September 2018.
- [45] J. Wiener, Simon J. Büchner, and C. Hölscher. Taxonomy of human wayfinding tasks: A knowledge-based approach. Spatial Cognition & Computation, 9:152 – 165, 2009.
- [46] Daan Wierstra, A. Förster, Jan Peters, and J. Schmidhuber. Solving deep memory pomdps with recurrent policy gradients. In ICANN, 2007.
- [47] T. Wolbers and M. Hegarty. What determines our navigational abilities? Trends in Cognitive Sciences, 14:138–146, 2010.
- [48] Yi Wu, Yuxin Wu, Georgia Gkioxari, and Yuandong Tian. Building generalizable agents with a realistic and rich 3d environment. arXiv preprint arXiv:1801.02209, 2018.
- [49] Sibei Yang, Guanbin Li, and Yizhou Yu. Graph-structured referring expression reasoning in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9952–9961, 2020.
- [50] Sibei Yang, Guanbin Li, and Yizhou Yu. Relationship-embedded representation learning for grounding referring expressions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [51] Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L Berg. Mattnet: Modular attention network for referring expression comprehension. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [52] Fengda Zhu, Yi Zhu, Xiaojun Chang, and Xiaodan Liang. Vision-language navigation with self-supervised auxiliary reasoning tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- [53] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), December 2015.
6 More Related Work
Behavioral Research on Human Navigation. The behavioural research of navigation of human beings has a long history and is still under active research [41, 19, 47, 45, 7, 8, 13]. Yet, it is not well understood how we human carry out the learning process of navigation in our brain to allow us to navigate in a familiar or unfamiliar environment. However, according to [41, 47, 45, 7], we humans use a range of different cognitive processes when we navigate. For example, we identify representative landmark cues, memorize our goal location, and identify the shortest route to that goal location. A significant number of research have supported such dissociable cognitive aspects. The human intuitions for remote embodied navigation we referred to in this paper is a set of commonsense rules and heuristics that come from observations of humans¡¯ life experiences, which shares a similar motivation mentioned in [14]. Our work has also proved that drawing on such observations in high-level VLN is a promising direction.
7 Implementation Details
In this section, we introduce the implementation details of the pre-training stage and the action decoding stage. In pre-training stage, we first present the sampled datasets information of the Scene Grounding task and the Object Grounding task. Second, we introduce the ViLBERT model used in the pre-training stage. Third, we illustrate the action decoder architecture and the training parameters in detail.
7.1 Pre-training Stage Details
Scene Grounding Task. The Scene Grounding training dataset consists of samples, each containing an instruction and four viewpoints out of which one is positive. The sampling strategy is illustrated in the main paper. We evaluate the effectiveness of this task by asking the model trained to identify the true target viewpoint given the ground-truth path. We report the accuracy on the Val Seen ( paths) and Val UnSeen ( paths) REVERIE.
Object Grounding Task. The image based grounding dataset contains training samples and the viewpoint based object grounding dataset contains training samples. The sampling strategy is presented in the main paper. Similar to [36], we evaluate the performance of this model on the ground-truth target viewpoint and report the object grounding accuracy.
Model Details. The ViLBERT model used in Scene Grounding task and Object Grounding task consists of a language stream, a vision stream and a cross modal alignment layers block. The language stream utilizes a architecture [10], which has -layer of transformer blocks and each block having a hidden state size of and attention heads. The vision stream and the cross modal alignment block use -layer transformer blocks and each having a hidden state size of and attention heads respectively. Following [26, 27], the language stream is initialized with BERT weights pre-trained on the BookCorpus [53] and English Wikipedia datasets. Then, the ViLBERT model is pre-trained on the Conceptual Captions dataset [35] as well as the tasks specified in [27]. Finally, it is fine-tuned on our Scene Grounding task and Object Grounding task respectively. In the Scene Grounding task, the Scene Grounding model is trained with the Adam optimizer with a learning rate of and a batch size of for epochs. In the Object Grounding task, the Object Grounding model is first trained on the image based Object Grounding dataset with the Adam optimizer with a learning rate of and a batch size of for epochs. Then, it is further fine-tuned on the viewpoint based Object Grounding dataset with the Adam optimizer with a learning rate of and a batch size of for epochs. We use a linear decay learning rate schedule with warm up to train the aforementioned models. All models are trained on NVIDIA Geforce Ti GPUs with GB memory using Pytorch [34].
7.2 Action Decoding Stage Details
The is composed of a ViLBERT model pre-trained on the Scene Grounding task and a Bi-directional LSTM layer. The in the BiLSTM is set to . The is ViLBERT model pre-trained on the Object Grounding task. The and used in the memory blocks are set to according to our ablation study in the ablation study. We follow the same RL setting as [40] that sets the discounted factor to and adopts reward shaping [48]. We train the agent with the Adam Optimizer [23] with a learning rate of , weight decay of , batch size of and the maximum decoding action length of . We clip the global gradient norm at . We train the agent for iterations and report the final performance. All experiments have been conducted on NVIDIA Geforce Ti GPUs with GB memory using Pytorch [34].
8 Evaluation Metrics Details
In this section, we illustrate the details of the evaluation metrics. Following [36], we evaluate the performance of the model based on REVERIE Success Rate (RGS) and REVERIE Success Rate weighted by Path Length (RG SPL). Besides, we report the performance of our method on the following metrics in the REVERIE dataset. It is worth noting that the target object is only observable within meters of the target viewpoint.
-
•
Navigation Success Rate is the percentage of the target object observable at the agent’s final location.
-
•
Navigation Oracle Success Rate measures the percentage of the target object that can be observed at one of the agent’s passed viewpoints.
-
•
Navigation Success Rate weighted by Path Length (SPL) is the navigation success rate weighted by the trajectory length.
-
•
Navigation Length is the trajectory length in meters.
-
•
REVERIE Success Rate (RGS) is calculated as the percentage of the output bounding box that has an IoU with the ground truth box.
-
•
REVERIE Success Rate weighted by Path Length (RG SPL) is REVERIE success rate weighted by the trajectory length.
9 Qualitative Examples
In this section, we show a number of qualitative examples of how our proposed agent performs in both Val Seen environment (from Fig. 5 to Fig. 8) and Val Unseen environment (from Fig. 9 to Fig. 12). Besides, we also visualize five representative failed cases illustrating the typical mistakes our agent make to better understand how our agent works.












