Scaling Deep Networks with the Mesh Adaptive Direct Search algorithm
Abstract
Deep neural networks are getting larger. Their implementation on edge and IoT devices becomes more challenging and moved the community to design lighter versions with similar performance. Standard automatic design tools such as reinforcement learning and evolutionary computing fundamentally rely on cheap evaluations of an objective function. In the neural network design context, this objective is the accuracy after training, which is expensive and time-consuming to evaluate. We automate the design of a light deep neural network for image classification using the Mesh Adaptive Direct Search (MADS) algorithm, a mature derivative-free optimization method that effectively accounts for the expensive blackbox nature of the objective function to explore the design space, even in the presence of constraints. Our tests show competitive compression rates with reduced numbers of trials.
1 Introduction
The past decade has seen impressive improvements in the deep neural networks (DNNs) domain that facilitated many technological leaps. DNNs are now applied on increasingly complex datasets and are expected to perform intricate tasks with high precision. However, this comes at the cost of building deeper and more complex networks that require substantial computational resources and, therefore, increase human society’s environmental cost. At this stage, searching for new networks has become both essential for technological and scientific advances and expensive enough to prompt more research on how to find small, high-performing networks with a resource-saving mindset.
One possible approach to tackle this issue is to start from a known DNN and reduce its size while losing as few as possible of its original performance. The popular methods to do so are either by pruning, i.e., keeping the initial architecture and removing some of the network’s parameters, or changing the architecture itself through scaling. Low-bit quantization (Courbariaux et al., 2015), or weight sharing (Ullrich et al., 2017), or a combination (Han et al., 2015), are demonstrated to be effective as well in compressing deep networks. While these methods are not necessarily mutually exclusive, pruning methods are more effective when starting from a low-performing network which stresses the importance of finding a new architecture (Blalock et al., 2020). Neural architecture search (NAS) Elsken et al. (2018) seems to be a necessary and costly step in finding a high-performance neural network, especially for low resource and constraint devices.
Let be the vector of hyperparameters that define a network architecture, the neural networks weights and the training data features and labels. We note the performance measure, such as the validation accuracy, of the network after its training; And the function that reflects the resource consumption, an explicit function such as the number of weights , or an implicit function such latency on a certain edge device.
Performing an architecture search requires defining a judicious, preferably low-dimensional search space with an efficient method to find a vector with smallest resource , but with maximum performance whose evaluation is expensive. Two formulations are proposed to solve this optimization problem. Equation (1) poses an unconstrained problem with the goal of finding a solution that maximizes , where is the search space limited by the box constraints on the components of . The second formulation of (2) aims at minimizing the resource function while maintaining a performance higher or equal to a baseline network defined by the architecture and weights .
| (1) | ||||
| (2) |
Several approaches are proposed to solve the maximization of (1) or the minimization of (2), such as grid search (GS) or random search (RS), evolutionary algorithms, reinforcement learning, Bayesian optimization, etc. These methods managed to improve on the state of the art, yet they often ignore essential properties of these optimization problems. Exploring the search space with non-adaptive approaches such as GS or RS, commonly requires many trials and substantial resources, often depleted on inferior architectures. Similarly, reinforcement learning and evolutionary algorithms need numerous function evaluations before producing quality suggestions. These approaches inherently assume performance evaluation is cheap, which is untrue for training deep networks.
Here we propose the use of derivative-free optimization (DFO) (Audet & Hare, 2017; Conn et al., 2009), and in particular the Mesh Adaptive Direct Search (MADS) algorithm (Audet & Dennis, Jr., 2006) tailored for expensive blackbox functions. In a DFO setting, the objective function has no derivatives, is costly to evaluate, noisy, stochastic, and its evaluation may fail at some points. Blackbox refers to the cases in which the analytical expression for the evaluating function is unknown. In the NAS context, the blackbox takes the architecture parameter vector as the input, trains the network on data , and outputs the validation accuracy.
2 Mesh Adaptive Direct Search (MADS)
The Mesh Adaptive Direct Search (MADS) algorithm (Audet & Hare, 2017; Audet & Dennis, Jr., 2006) is implemented in the NOMAD C++ solver (Le Digabel, 2011) freely available at www.gerad.ca/nomad.
MADS starts the optimization process with an initial configuration , an initial mesh size and defines a mesh , at each iteration . Each iteration is made of two steps: the search and the poll. The search is flexible and may include various search space strategies as long as it produces a finite number of trial mesh points at each iteration. This phase usually implements a global search such as Latin hypercube sampling or surrogates which allow to explore further regions. The poll step is rigidly defined so that global convergence to a local optimum is guaranteed under mild conditions. The MADS algorithm generates a set of poll directions that grow asymptotically dense around the incumbent to produce a pool of local candidates around at a radius of , called the poll size. These candidates are evaluated opportunistically, so the poll stops as soon as a better solution is found and discards the remaining poll points. An improvement on is recorded if iteration is a success, in which case the mesh and poll sizes increase for the next iteration. Otherwise, the mesh and poll size are reduced while maintaining as illustrated in Figure 1.
3 Architecture Search
Following Tan & Le (2019) we define the architecture search over three parameters : the network depth , the network width and the resolution . The depth is searched by adding or removing ResNet blocks. The width is searched by modifying the output channels. The resolution is searched by changing the number of input channels.
We start exploring the effectiveness of the NOMAD solver by considering the unconstrained Problem 1 to maximize the validation accuracy on CIFAR-10 over a restrictive search space that contains compressed architectures of ResNet-18. NOMAD is compared against Microsoft Neural Network Intelligence NNI, a standard mature hyperparameter tuning toolkit for neural networks. Practitioners use NNI for hyperparameter tuning and also for architecture search.


The result of these experiments is shown in Figure 2. Starting from the ResNet-18 network that scores , has parameters and MACS; both NOMAD and Microsoft NNI using its Bayesian optimization module TPE (Bergstra et al., 2011) are launched on CIFAR-10 with a budget of trials each.
NOMAD manages to find over configurations with a top-1 accuracy over , which represents less than accuracy drop compared to the baseline. From these top performers, one solution has MACS which represents a compression of and another solution has parameters that is equivalent to a compression compared to the baseline.
TPE-NNI finds architectures with a top-1 accuracy over . From these top performers, the one with lowest number of MACS has MACS and the lowest number of parameters is recorded at which represents a compression of .
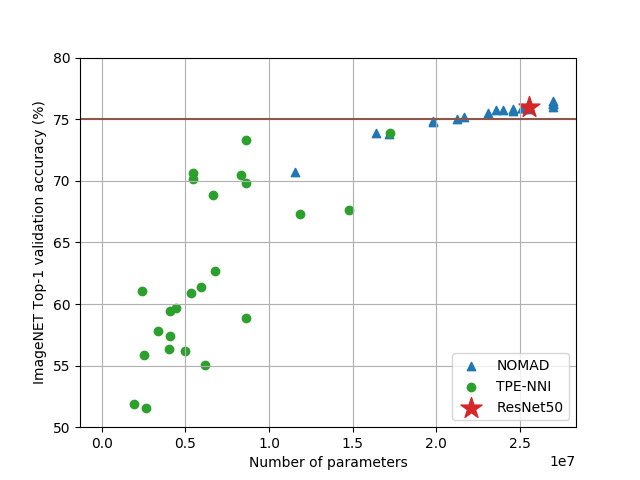
A second test is performed where the neural architecture search is expressed with Formulation 2, in which is the ResNet-50 architecture and are the ImageNet training data. This experiment starts from the architecture of ResNet-50 which score a top 1 accuracy of , has parameters with MACS. This time, NOMAD and TPE-NNI are allowed a budget of trials and the reported results are summarized in Figure 3.
TPE-NNI samples architectures with a high compression factor but at the cost of a significant drop in accuracy as the highest scoring candidate is still less accurate than the given baseline. This particular network has parameters and MACS. The candidates found by the NOMAD software have smaller compression ratios but maintains a good quality precision. Out of the sampled points, score higher than of which have at least less MACS than ResNet-50, which is a clear improvement compared to NNI with Bayesian optimization routine TPE. Bayesian optimization has been shown successful in attacking blackbox problems effectively and ranked top at blackbox optimization challenge recently (Cowen-Rivers et al., 2020).

4 Conclusion
Traditionally deep learning community focuses on increasing accuracy on a benchmark data. Rapid use of deep models on edge devices calls for increasing accuracy while keeping resources to the minimal. Despite recent efforts in automating neural architectures, the vast majority of practical cases calls for manual design. Each device has its own constraints and recently developed automation tools ignore the constrained formulation of the problem. We showed the effectiveness of a derivative-free solver in two scenarios, when the search space embeds the constraint and the optimization is treated as an unconstrained problem, which is the common formulation. In a second scenario, we minimized the computational resources while putting a hard constraint on model performance. This formulation is novel and requires solvers that take the constraint into account. Our numerical results show that the derivative-free solver NOMAD beats the popular Bayesian optimization TPE-NNI framework.
Acknowledgments
This research is supported by the NSERC Alliance grant 544900-19 in collaboration with Huawei-Canada.
References
- Audet & Dennis, Jr. (2006) C. Audet and J.E. Dennis, Jr. Mesh Adaptive Direct Search Algorithms for Constrained Optimization. SIAM Journal on Optimization, 17(1):188–217, 2006. doi: 10.1137/040603371.
- Audet & Hare (2017) C. Audet and W. Hare. Derivative-Free and Blackbox Optimization. Springer Series in Operations Research and Financial Engineering. Springer International Publishing, Cham, Switzerland, 2017. doi: 10.1007/978-3-319-68913-5.
- Bergstra et al. (2011) J. Bergstra, R. Bardenet, Y. Bengio, and B. Kégl. Algorithms for hyper-parameter optimization. In 25th annual conference on neural information processing systems (NIPS 2011), volume 24. Neural Information Processing Systems Foundation, 2011.
- Blalock et al. (2020) D. Blalock, J.J. Gonzalez Ortiz, J. Frankle, and J. Guttag. What is the State of Neural Network Pruning? Technical report, arXiv, 2020. URL https://arxiv.org/abs/2003.03033.
- Conn et al. (2009) A.R. Conn, K. Scheinberg, and L.N. Vicente. Introduction to Derivative-Free Optimization. MOS-SIAM Series on Optimization. SIAM, Philadelphia, 2009. ISBN 978-0-898716-68-9. doi: 10.1137/1.9780898718768.
- Courbariaux et al. (2015) M. Courbariaux, Y. Bengio, and J.-P. David. Binaryconnect: Training deep neural networks with binary weights during propagations. Technical report, arXiv, 2015. URL https://arxiv.org/abs/1511.00363.
- Cowen-Rivers et al. (2020) A.I. Cowen-Rivers, W. Lyu, R. Tutunov, Z. Wang, A. Grosnit, R.R. Griffiths, H. Jianye, J. Wang, and H. Bou Ammar. An Empirical Study of Assumptions in Bayesian Optimisation. Technical report, arXiv, 2020. URL https://arxiv.org/abs/2012.03826v3.
- Elsken et al. (2018) T. Elsken, J.H. Metzen, and F. Hutter. Neural architecture search: A survey. Technical report, arXiv, 2018. URL http://arxiv.org/abs/1808.05377.
- Han et al. (2015) S. Han, H. Mao, and W.J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. Technical report, arXiv, 2015. URL https://arxiv.org/abs/1510.00149.
- Le Digabel (2011) S. Le Digabel. Algorithm 909: NOMAD: Nonlinear Optimization with the MADS algorithm. ACM Transactions on Mathematical Software, 37(4):44:1–44:15, 2011. doi: 10.1145/1916461.1916468.
- Tan & Le (2019) M. Tan and Q. Le. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 6105–6114. PMLR, 09–15 Jun 2019. URL http://proceedings.mlr.press/v97/tan19a.html.
- Ullrich et al. (2017) K. Ullrich, E. Meeds, and M. Welling. Soft weight-sharing for neural network compression. Technical report, arXiv, 2017. URL https://arxiv.org/abs/1702.04008.