Scalable regret for learning to control network-coupled subsystems with unknown dynamics
Abstract
We consider the problem of controlling an unknown linear quadratic Gaussian (LQG) system consisting of multiple subsystems connected over a network. Our goal is to minimize and quantify the regret (i.e. loss in performance) of our strategy with respect to an oracle who knows the system model. Viewing the interconnected subsystems globally and directly using existing LQG learning algorithms for the global system results in a regret that increases super-linearly with the number of subsystems. Instead, we propose a new Thompson sampling based learning algorithm which exploits the structure of the underlying network. We show that the expected regret of the proposed algorithm is bounded by where is the number of subsystems, is the time horizon and the notation hides logarithmic terms in and . Thus, the regret scales linearly with the number of subsystems. We present numerical experiments to illustrate the salient features of the proposed algorithm.
Index Terms:
Linear quadratic systems, networked control systems, reinforcement learning, Thompson sampling.I Introduction
Large-scale systems comprising of multiple subsystems connected over a network arise in a number of applications including power systems, traffic networks, communication networks and some economic systems [1]. A common feature of such systems is the coupling in their subsystems’ dynamics and costs, i.e., the state evolution and local costs of one subsystem depend not only on its own state and control action but also on the states and control actions of other subsystems in the network. Analyzing various aspects of the behavior of such systems and designing control strategies for them under a variety of settings have been long-standing problems of interest in the systems and control literature [2, 3, 4, 5, 6, 7]. However, there are still many unsolved challenges, especially on the interface between learning and control in the context of these large-scale systems.
In this paper, we investigate the problem of designing control strategies for large-scale network-coupled subsystems when some parameters of the system model are not known. Due to the unknown parameters, the control problem is also a learning problem. We adopt a reinforcement learning framework for this problem with the goal of minimizing and quantifying the regret (i.e. loss in performance) of our learning-and-control strategy with respect to the optimal control strategy based on the complete knowledge of the system model.
The networked system we consider follows linear dynamics with quadratic costs and Gaussian noise. Such linear-quadratic-Gaussian (LQG) systems are one of the most commonly used modeling framework in numerous control applications. Part of the appeal of LQG models is the simple structure of the optimal control strategy when the system model is completely known—the optimal control action in this case is a linear or affine function of the state—which makes the optimal strategy easy to identify and easy to implement. If some parameters of the model are not fully known during the design phase or may change during operation, then it is better to design a strategy that learns and adapts online. Historically, both adaptive control [8] and reinforcement learning [9, 10] have been used to design asymptotically optimal learning algorithms for such LQG systems. In recent years, there has been considerable interest in analyzing the transient behavior of such algorithms which can be quantified in terms of the regret of the algorithm as a function of time. This allows one to assess, as a function of time, the performance of a learning algorithm compared to an oracle who knows the system parameters upfront.
Several learning algorithms have been proposed for LQG systems [11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23], and in most cases the regret is shown to be bounded by , where is the dimension of the state, is the dimension of the controls, is the time horizon, and the notation hides logarithmic terms in . Given the lower bound of (where notation hides logarithmic terms in ) for regret in LQG systems identified in a recent work [19], the regrets of the existing algorithms have near optimal scaling in terms of time and dimension. However, when directly applied to a networked system with subsystems, these algorithms would incur regret because the effective dimension of the state and the controls is and , where and are the dimensions of each subsystem. This super-linear dependence on is prohibitive in large-scale networked systems because the regret per subsystem (which is ) grows with the number of subsystems.
The learning algorithms mentioned above are for a general LQG system and do not take into account any knowledge of the underlying network structure. Our main contribution is to show that by exploiting the structure of the network model, it is possible to design learning algorithms for large-scale network-coupled subsystems where the regret does not grow super-linearly in the number of subsystems. In particular, we utilize a spectral decomposition technique, recently proposed in [24], to decompose the large-scale system into decoupled systems, where is the rank of the coupling matrix corresponding to the underlying network. Using the decoupled systems, we propose a Thompson sampling based algorithm with regret bound.
Related work
Broadly speaking, three classes of low-regret learning algorithms have been proposed for LQG systems: certainty equivalence (CE) based algorithms, optimism in the face of uncertainty (OFU) based algorithms, and Thompson sampling (TS) based algorithms. CE is a classical adaptive control algorithm [8]. Recent papers [16, 17, 18, 19, 20] have established near optimal high probability bounds on regret for CE-based algorithms. OFU-based algorithms are inspired by the OFU principle for multi-armed bandits [25]. Starting with the work of [11, 12], most of the papers following the OFU approach [13, 14, 15] also provide similar high probability regret bounds. TS-based algorithms are inspired by TS algorithm for multi-armed bandits [26]. Most papers following this approach [21, 22, 23, 20] establish bounds on expected Bayesian regret of similar near-optimal orders. As argued earlier, most of these papers show that the regret scales super-linearly with the number of subsystems and are, therefore, of limited value for large-scale systems.
There is an emerging literature on learning algorithms for networked systems both for LQG models [27, 28, 29] and MDP models [30, 31, 32, 33]. The papers on LQG models propose distributed value- or policy-based learning algorithms and analyze their convergence properties, but they do not characterize their regret. Some of the papers on MDP models [32, 33] do characterize regret bounds for OFU and TS-based learning algorithms but these bounds are not directly applicable to the LQG model considered in this paper.
An important special class of network-coupled systems is mean-field coupled subsystems [34, 35]. There has been considerable interest in reinforcement learning for mean-field models [36, 37, 38], but most of the literature does not consider regret. The basic mean-field coupled model can be viewed as a special case of the network-coupled subsystems considered in this paper (see Sec. VI-A). In a preliminary version of this paper [39], we proposed a TS-based algorithm for mean-field coupled subsystems which has a regret per subsystem. The current paper extends the TS-based algorithm to general network-coupled subsystems and establishes scalable regret bounds for arbitrarily coupled networks.
Organization
The rest of the paper is organized as follows. In Section II, we introduce the model of network-coupled subsystems. In Section III, we summarize the spectral decomposition idea and the resulting scalable method for synthesizing optimal control strategy when the model parameters are known. Then, in Section IV, we consider the learning problem for unknown network-coupled subsystems and present a TS-based learning algorithm with scalable regret bound. We subsequently provide regret analysis in Section V and numerical experiments in Section VI. We conclude in Section VII.
Notation
The notation means that is the th element of the matrix . For a matrix , denotes its transpose. Given matrices (or vectors) , …, with the same number of rows, denotes the matrix formed by horizontal concatenation. For a random vector , denotes its covariance matrix. The notation denotes the multivariate Gaussian distribution with mean vector and covariance matrix .
For stabilizable and positive definite matrices , DARE denotes the unique positive semidefinite solution of the discrete time algebraic Riccati equation (DARE), which is given as
II Model of network-coupled subsystems
We start by describing a minor variation of a model of network-coupled subsystems proposed in [24]. The model in [24] was described in continuous time. We translate the model and the results to discrete time.
II-A System model
II-A1 Graph stucture
Consider a network consisting of subsystems/agents connected over an undirected weighted graph denoted by , where is the set of nodes, is the set of edges, and is the weighted adjacency matrix. Let be a symmetric coupling matrix corresponding to the underlying graph . For instance, may represent the underlying adjacency matrix (i.e., ) or the underlying Laplacian matrix (i.e., ).
II-A2 State and dynamics
The states and control actions of agents take values in and , respectively. For agent , we use and to denote its state and control action at time .
The system starts at a random initial state , whose components are independent across agents. For agent , the initial state , and at any time , the state evolves according to
| (1) |
where and are the locally perceived influence of the network on the state of agent and are given by
| (2) |
, , , are matrices of appropriate dimensions, and are i.i.d. zero-mean Gaussian processes which are independent of each other and the initial state. In particular, and . We call and the network-field of the states and control actions at node at time .
Thus, the next state of agent depends on its current local state and control action, the current network-field of the states and control actions of the system, and the current local noise.
We follow the same atypical representation of the “vectorized” dynamics as used in [24]. Define and as the global state and control actions of the system:
We also define . Similarly, define and as the global network field of states and actions:
Note that and are matrices and not vectors. The global system dynamics may be written as:
| (3) |
Furthermore, we may write
II-A3 Per-step cost
At any time the system incurs a per-step cost given by
| (4) |
where and are matrices of appropriate dimensions and and are real valued weights. Let and . It is assumed that the weight matrices and are polynomials of , i.e.,
| (5) |
where and denote the degrees of the polynomials and and are real-valued coefficients.
The assumption that and are polynomials of captures the intuition that the per-step cost respects the graph structure. In the special case when , the per-step cost is decoupled across agents. When , the per-step cost captures a cross-coupling between one-hop neighbors. Similarly, when , the per-step cost captures a cross-coupling between one- and two-hop neighbors. See [24] for more examples of special cases of the per-step cost defined above.
II-B Assumptions on the model
Since is real and symmetric, it has real eigenvalues. Let denote the rank of and denote the non-zero eigenvalues. For ease of notation, for , define
where and are the coefficients in (5). Furthermore, for , define:
We impose the following assumptions:
- (A1)
-
The systems and are stabilizable.
- (A2)
-
The matrices and are symmetric and positive definite.
- (A3)
-
The parameters , , , and are strictly positive.
Assumption (A1) is a standard assumption. Assumptions (A2) and (A3) ensure that the per-step cost is strictly positive.
II-C Admissible policies and performance criterion
There is a system operator who has access to the state and action histories of all agents and who selects the agents’ control actions according to a deterministic or randomized (and potentially history-dependent) policy
| (6) |
Let denote the parameters of the system dynamics. The performance of any policy is measured by the long-term average cost given by
| (7) |
Let denote the minimum of over all policies.
We are interested in the setup where the graph coupling matix , the cost coupling matrices and , and the cost matrices and are known but the system dynamics are unknown and there is a prior distribution on . The Bayesian regret of a policy operating for a horizon is defined as
| (8) |
where the expectation is with respect to the prior on , the noise processes, the initial conditions, and the potential randomizations done by the policy .
III Background on spectral decomposition of the system
In this section, we summarize the main results of [24], translated to the discrete-time model used in this paper.
The spectral decomposition described in [24] relies on the spectral factorization of the graph coupling matrix . Since is a real and symmetric matrix with rank , we can write it as
| (9) |
where are the non-zero eigenvalues of and are the corresponding orthonormal eigenvectors.
III-A Spectral decomposition of the dynamics and per-step cost
For , define eigenstates and eigencontrols as
| (10) |
respectively. Furthermore, define auxiliary state and auxiliary control as
| (11) |
respectively. Similarly, define and . Let and denote the -th column of and respectively; thus we can write
Similar interpretations hold for and . Following [24, Lemma 2], we can show that for any ,
| (12) |
where . These covariances do not depend on time because the noise processes are i.i.d.
Using the same argument as in [24, Propositions 1 and 2], we can show the following.
Proposition 1
For each node , the state and control action may be decomposed as
| (13) |
where the dynamics of eigenstate depend only on and , and are given by
| (14) |
and the dynamics of the auxiliary state depend only on and and are given by
| (15) |
Furthermore, the per-step cost decomposes as follows:
| (16) |
where111Recall that (A3) ensures that and are strictly positive.
□
III-B Planning solution for network-coupled subsystems
We now present the main result of [24], which provides a scalable method to synthesize the optimal control policy when the system dynamics are known.
Based on Proposition 1, we can view the overall system as the collection of the following subsystems:
Let , , and denote the parameters of the dynamics of the eigen and auxiliary systems, respectively. Then, for any policy , the performance of the eigensystem , and , is given by , where
Similarly, the performance of the auxiliary system , , is given by , where
Proposition 1 implies that the overall performance of policy can be decomposed as
| (17) |
The key intuition behind the result of [24] is as follows. By the certainty equivalence principle for LQ systems, we know that (when the system dynamics are known) the optimal control policy of a stochastic LQ system is the same as the optimal control policy of the corresponding deterministic LQ system where the noises are assumed to be zero. Note that when noises are zero, then the noises and of the eigen- and auxiliary-systems are also zero. This, in turn, implies that the dynamics of all the eigen- and auxiliary systems are decoupled. These decoupled dynamics along with the cost decoupling in (17) imply that we can choose the controls for the eigensystem , and , to minimize222The cost of the eigensystem is . From (A3), we know that is positive. Therefore, minimizing is the same as minimizing . and choose the controls for the auxiliary system , , to minimize333The same remark as footnote 2 applies here. . These optimization problems are standard optimal control problems. Therefore, similar to [24, Thoerem 3], we obtain the following result.
Theorem 1
Let and be the solution of the following discrete time algebraic Riccati equations (DARE):
| (18a) | ||||
| and for , | ||||
| (18b) | ||||
Define the gains:
| (19a) | ||||
| and for , | ||||
| (19b) | ||||
Then, under assumptions (A1)–(A3), the policy
| (20) |
minimizes the long-term average cost in (7) over all admissible policies. Furthermore, the optimal performance is given by
| (21) |
where
| (22) |
and for ,
| (23) |
□
IV Learning for network-coupled subsystems
For the ease of notation, we define and . Then, we can write the dynamics (14), (15) of the eigen and the auxiliary systems as
| (24a) | |||||
| (24b) | |||||
IV-A Simplifying assumptions
We impose the following assumptions to simplify the description of the algorithm and the regret analysis.
- (A4)
-
The noise covariance is a scaled identity matrix given by .
- (A5)
-
For each , .
Assumption (A4) is commonly made in most of the literature on regret analysis of LQG systems. An implication of (A4) is that and , where
| (25) |
Assumption (A5) is made to rule out the case where the dynamics of some of the auxiliary systems are deterministic.
IV-B Prior and posterior beliefs:
We assume that the unknown parameters and lie in compact subsets and of . Let denote the -th column of . Thus . Similarly, let denote the -th column of . Thus, . We use to denote the restriction of probability distribution on the set .
We assume that and are random variables that are independent of the initial states and the noise processes. Furthermore, we assume that the priors and on and , respectively, satisfy the following:
- (A6)
-
is given as:
where for , with mean and positive-definite covariance .
- (A7)
-
For each , is given as:
where for , with mean and positive-definite covariance .
These assumptions are similar to the assumptions on the prior in the recent literature on Thompson sampling for LQ systems [21, 22].
Our learning algorithm (and TS-based algorithms in general) keeps track of a posterior distribution on the unknown parameters based on observed data. Motivated by the nature of the planning solution (see Theorem 1), we maintain separate posterior distributions on and . For each , we select an subsystem such that the -th component of the eigen-vector is non-zero (i.e. ) . At time , we maintain a posterior distribution on based on the corresponding eigen state and action history of the -th subsystem. In other words, for any Borel subset of , gives the following conditional probability
| (26) |
We maintain a separate posterior distribution on as follows. At each time , we select an subsystem , where is a covariance matrix defined recursively in Lemma 1 below. Then, for any Borel subset of ,
| (27) |
See [39] for a discussion on the rule to select .
Lemma 1
The posterior distributions , , and are given as follows:
-
1.
is given by Assumption (A7) and for any ,
where for , , and
(28a) (28b) where, for each , denotes the matrix .
-
2.
is given by Assumption (A6) and for any ,
where for , , and
(29a) (29b) where, for each , denotes the matrix .
□
IV-C The Thompson sampling algorithm:
We propose a Thompson sampling based algorithm called Net-TSDE which is inspired by the TSDE (Thompson sampling with dynamic episodes) algorithm proposed in [21, 22] and the structure of the optimal planning solution described in Sec. III-B. The Thompson sampling part of our algorithm is modeled after the modification of TSDE presented in [41].
The Net-TSDE algorithm consists of a coordinator and actors: an auxiliary actor and an eigen actor for each . These actors are described below and the whole algorithm is presented in Algorithm 1.
-
•
At each time, the coordinator observes the current global state , computes the eigenstates and the auxiliary states , and sends the eigenstate to the eigen actor , , and sends the auxiliary state to the auxiliary actor . The eigen actor , , computes the eigencontrol and the auxiliary actor computes the auxiliary control (as per the details presented below) and both send their computed controls back to the coordinator . The coordinator then computes and executes the control action for each subsystem .
-
•
The eigen actor , , maintains the posterior on according to (28). The actor works in episodes of dynamic length. Let and denote the starting time and the length of episode , respectively. Each episode is of a minimum length , where is chosen as described in [41]. Episode ends if the determinant of covariance falls below half of its value at time (i.e., ) or if the length of the episode is one more than the length of the previous episode (i.e., ). Thus,
At the beginning of episode , the eigen actor samples a parameter according to the posterior distribution . During episode , the eigen actor generates the eigen controls using the sampled parameter , i.e., .
-
•
The auxiliary actor is similar to the eigen actor. Actor maintains the posterior on according to (29). The actor works in episodes of dynamic length. The episodes of the auxiliary actor and the eigen actors , , are separate from each other.444The episode count is used as a local variable for each actor. Let and denote the starting time and the length of episode , respectively. Each episode is of a minimum length , where is chosen as described in [41]. The termination condition for each episode is similar to that of the eigen actor . In particular,
At the beginning of episode , the auxillary actor samples a parameter from the posterior distribution . During episode , the auxiliary actor generates the auxiliary controls using the the sampled parameter , i.e., .
Note that the algorithm does not depend on the horizon .
IV-D Regret bounds:
We impose the following assumption to ensure that the closed loop dynamics of the eigenstates and the auxiliary states of each subsystem are stable.
- (A8)
-
There exists a positive number such that
-
•
for any and where , we have
-
•
for any , where , we have
-
•
This assumption is similar to an assumption made in [41] for TS for LQG systems. According to [42, Lemma 1] (also see [19, Theorem 11]), (A8) is satisfied if
where and are stabilizable and and are sufficiently small. In other words, the assumption holds when the true system is in a small neighborhood of a known nominal system. Such a the small neighborhood can be learned with high probability by running appropriate stabilizing procedures for finite time [42, 19].
The following result provides an upper bound on the regret of the proposed algorithm.
Theorem 2
Under (A1)–(A8), the regret of Net-TSDE is upper bounded as follows:
where □
See Section V for proof.
Remark 1
The term in the regret bound partially captures the impact of the network on the regret. The coefficients and depend on the network and also affect the regret but their dependence is hidden inside the notation. It is possible to explicitly characterize this dependence but doing so does not provide any additional insights. We discuss the impact of the network coupling on the regret in Section VI via some examples. □
V Regret analysis
For the ease of notation, we simply use instead of in this section. Based on Proposition 1 and Theorem 1, the regret may be decomposed as
| (30) |
where
| and, for , | ||||
Based on the discussion at the beginning of Sec. III-B, , , is the regret associated with auxiliary system and , and , is the regret associated with eigensystem . We now bound and separately.
V-A Bound on
Fix . For the component , the Net-TSDE algorithm is exactly same as the variation of the TSDE algorithm of [22] presented in [41]. Therefore, from [41, Theorem 1], it follows that
| (31) |
We now show that the regret of other eigensystems with also satisfies a similar bound.
Lemma 2
The regret of eigensystem , and , is bounded as follows:
| (32) |
□
Proof
Fix . Recall from (10) that . Therefore, for any ,
where the last equality follows because is a scalar. Since we are using the same gain for all agents , we have
Thus, we can write (recall that is chosen such that ),
Thus, for any ,
| (33) |
Moreover, from (23), we have
| (34) |
By combining (33) and (34), we get
Substituting the bound for from (31) and observing that gives the result. ■
V-B Bound on
The update of the posterior on does not depend on the history of states and actions of any fixed agent . Therefore, we cannot directly use the argument presented in [41] to bound the regret . We present a bound from first principles below.
For the ease of notation, for any episode , we use and to denote and respectively. From LQ optimal control theory [43], we know that the average cost and the optimal policy for the model parameter satisfy the following Bellman equation:
Adding and subtracting and noting that , we get that
| (35) |
Let denote the number of episodes of the auxiliary actor until horizon . For each , we define to be . Then, using (35), we have that for any agent ,
| (36) |
Lemma 3
See Appendix for the proof.
V-C Proof of Theorem 2
VI Some examples
VI-A Mean-field system
Consider a complete graph where the edge weights are equal to . Let be equal to the adjacency matrix of the graph, i.e., . Thus, the system dynamics are given by
where and . Suppose and and , where is a positive constant.
In this case, has rank , the non-zero eigenvalue of is , the corresponding normalized eigenvector is and . The eigenstate is given by and a similar structure holds for the eigencontrol . The per-step cost can be written as (see Proposition 1)
Thus, the system is similar to the mean-field team system investigated in [6, 7].
For this model, the network dependent constant in the regret bound of Theorem 2 is given by Thus, for the mean-field system, the regret of Net-TSDE scales as with the number of agents. This is consistent with the discussion following Theorem 2.
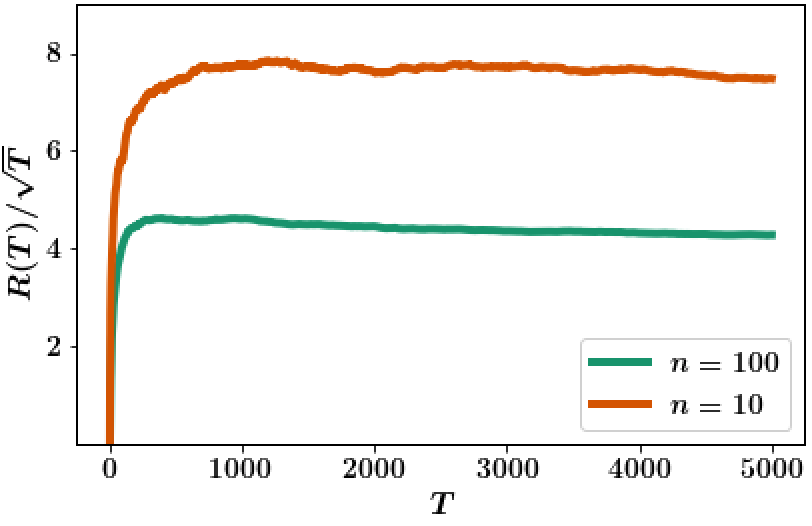
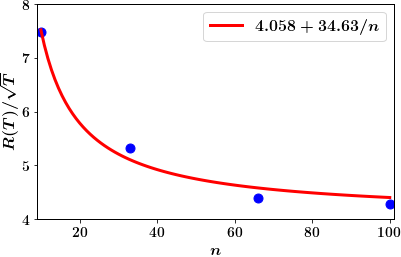
We test these conclusions via numerical simulations of a scalar mean-field model with , , , , , , , , and . The uncertain sets are chosen as and where . The prior over these uncertain sets is chosen according to (A6)–(A7) where and . We set in Net-TSDE. The system is simulated for a horizon of and the expected regret averaged over sample trajectories is shown in Fig. 1. As expected, the regret scales as with time and with the number of agents.
VI-B A general low-rank network
We consider a network with nodes given by the graph , where is a 4-node graph shown in Fig. 2 and is the complete graph with nodes and each edge weight equal to . Let be the adjacency matrix of which is given as , where is the adjacency matrix of shown in Fig. 2. Moreover, suppose with , , and and with . Note that the cost is not normalized per-agent.
In this case, the rank of is with eigenvalues , where and the rank of is with eigenvalue . Thus, has the same non-zero eigenvalues as given by and . Further, and , for . We assume that , so that the model satisfies (A3).
For this model, the scaling parameter in the regret bound in Theorem 2 is given by
Recall that . Thus, has an explicit dependence on the square of the eigenvalues and the number of nodes.
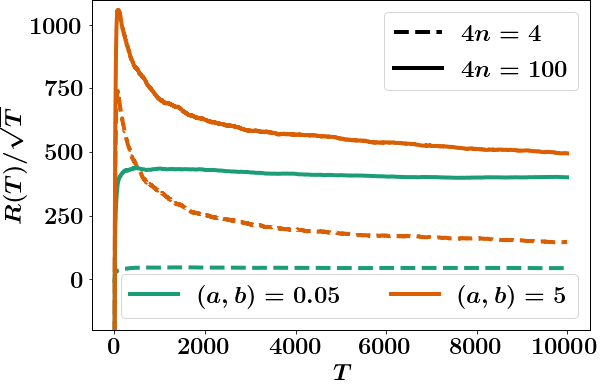
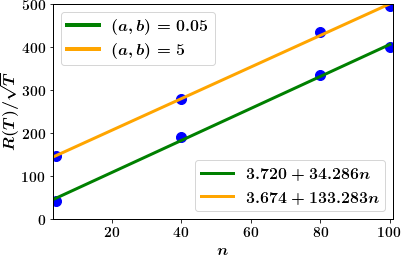
We verify this relationship via numerical simulations. We consider the graph above with two choices of parameters : (i) and (ii) . For both cases, we consider a scalar system with parameters same as the mean-field system considered in Sec. VI-A. The regret for both cases with different choices of number of agents is shown in Fig. 3. As expected, the regret scales as with time and with the number of agents.
VII Conclusion
We consider the problem of controlling an unknown LQG system consisting of multiple subsystems connected over a network. By utilizing a spectral decomposition technique, we decompose the coupled subsystems into eigen and auxiliary systems. We propose a TS-based learning algorithm Net-TSDE which maintains separate posterior distributions on the unknown parameters , and associated with the eigen and auxiliary systems respectively. For each eigen-system, Net-TSDE learns the unknown parameter and controls the system in a manner similar to the TSDE algorithm for single agent LQG systems proposed in [21, 22, 41]. Consequently, the regret for each eigen system can be bounded using the results of [21, 22, 41]. However, the part of the Net-TSDE algorithm that performs learning and control for the auxiliary system has an agent selection step and thus requires additional analysis to bound its regret. Combining the regret bounds for the eigen and auxiliary systems shows that the total expected regret of Net-TSDE is upper bounded by . The empirically observed scaling of regret with respect to the time horizon and the number of subsystems in our numerical experiments agrees with the theoretical upper bound.
The results presented in this paper rely on the spectral decomposition developed in [24]. A limitation of this decomposition is that the local dynamics (i.e., the matrices) are assumed to be identical for all subsystems. Interesting generalizations overcoming this limitation include settings where (i) there are multiple types of subsystems and the matrices are the same for subsystems of the same type but different across types; and (ii) the subsystems are not identical but approximately identical, i.e., there are nominal dynamics and the local dynamics of subsystem are in a small neighborhood of .
The decomposition in [24] exploits the fact that the dynamics and the cost couplings have the same spectrum (i.e., the same orthonormal eigenvectors). It is also possible to consider learning algorithms which exploit other features of the network such as sparsity in the case of networked MDPs [32, 33].
References
- [1] N. Sandell, P. Varaiya, M. Athans, and M. Safonov, “Survey of decentralized control methods for large scale systems,” IEEE Trans. Autom. Control, vol. 23, no. 2, pp. 108–128, 1978.
- [2] J. Lunze, “Dynamics of strongly coupled symmetric composite systems,” International Journal of Control, vol. 44, no. 6, pp. 1617–1640, 1986.
- [3] M. K. Sundareshan and R. M. Elbanna, “Qualitative analysis and decentralized controller synthesis for a class of large-scale systems with symmetrically interconnected subsystems,” Automatica, vol. 27, no. 2, pp. 383–388, 1991.
- [4] G.-H. Yang and S.-Y. Zhang, “Structural properties of large-scale systems possessing similar structures,” Automatica, vol. 31, no. 7, pp. 1011–1017, 1995.
- [5] S. C. Hamilton and M. E. Broucke, “Patterned linear systems,” Automatica, vol. 48, no. 2, pp. 263–272, 2012.
- [6] J. Arabneydi and A. Mahajan, “Team-optimal solution of finite number of mean-field coupled LQG subsystems,” in Conf. Decision and Control, (Kyoto, Japan), Dec. 2015.
- [7] J. Arabneydi and A. Mahajan, “Linear Quadratic Mean Field Teams: Optimal and Approximately Optimal Decentralized Solutions,” 2016. arXiv:1609.00056.
- [8] K. J. Astrom and B. Wittenmark, Adaptive Control. Addison-Wesley Longman Publishing Co., Inc., 1994.
- [9] S. J. Bradtke, “Reinforcement learning applied to linear quadratic regulation,” in Neural Information Processing Systems, pp. 295–302, 1993.
- [10] S. J. Bradtke, B. E. Ydstie, and A. G. Barto, “Adaptive linear quadratic control using policy iteration,” in Proceedings of American Control Conference, vol. 3, pp. 3475–3479, 1994.
- [11] M. C. Campi and P. Kumar, “Adaptive linear quadratic Gaussian control: the cost-biased approach revisited,” SIAM Journal on Control and Optimization, vol. 36, no. 6, pp. 1890–1907, 1998.
- [12] Y. Abbasi-Yadkori and C. Szepesvári, “Regret bounds for the adaptive control of linear quadratic systems,” in Annual Conference on Learning Theory, pp. 1–26, 2011.
- [13] M. K. S. Faradonbeh, A. Tewari, and G. Michailidis, “Optimism-based adaptive regulation of linear-quadratic systems,” IEEE Trans. Autom. Control, vol. 66, no. 4, pp. 1802–1808, 2021.
- [14] A. Cohen, T. Koren, and Y. Mansour, “Learning linear-quadratic regulators efficiently with only regret,” in International Conference on Machine Learning, pp. 1300–1309, 2019.
- [15] M. Abeille and A. Lazaric, “Efficient optimistic exploration in linear-quadratic regulators via Lagrangian relaxation,” in International Conference on Machine Learning, pp. 23–31, 2020.
- [16] S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu, “Regret bounds for robust adaptive control of the linear quadratic regulator,” in Neural Information Processing Systems, pp. 4192–4201, 2018.
- [17] H. Mania, S. Tu, and B. Recht, “Certainty equivalent control of LQR is efficient.” arXiv:1902.07826, 2019.
- [18] M. K. S. Faradonbeh, A. Tewari, and G. Michailidis, “Input perturbations for adaptive control and learning,” Automatica, vol. 117, p. 108950, 2020.
- [19] M. Simchowitz and D. Foster, “Naive exploration is optimal for online LQR,” in International Conference on Machine Learning, pp. 8937–8948, 2020.
- [20] M. K. S. Faradonbeh, A. Tewari, and G. Michailidis, “On adaptive Linear–Quadratic regulators,” Automatica, vol. 117, p. 108982, July 2020.
- [21] Y. Ouyang, M. Gagrani, and R. Jain, “Control of unknown linear systems with Thompson sampling,” in Allerton Conference on Communication, Control, and Computing, pp. 1198–1205, 2017.
- [22] Y. Ouyang, M. Gagrani, and R. Jain, “Posterior sampling-based reinforcement learning for control of unknown linear systems,” IEEE Trans. Autom. Control, vol. 65, no. 8, pp. 3600–3607, 2020.
- [23] M. Abeille and A. Lazaric, “Improved regret bounds for Thompson sampling in linear quadratic control problems,” in International Conference on Machine Learning, pp. 1–9, 2018.
- [24] S. Gao and A. Mahajan, “Optimal control of network-coupled subsystems: Spectral decomposition and low-dimensional solutions,” submitted to IEEE Trans. Control of Networked Sys., 2020.
- [25] P. Auer, N. Cesa-Bianchi, and P. Fischer, “Finite-time analysis of the multiarmed bandit problem,” Machine learning, vol. 47, no. 2-3, pp. 235–256, 2002.
- [26] S. Agrawal and N. Goyal, “Analysis of Thompson sampling for the multi-armed bandit problem,” in Conference on Learning Theory, 2012.
- [27] H. Wang, S. Lin, H. Jafarkhani, and J. Zhang, “Distributed Q-learning with state tracking for multi-agent networked control,” in AAMAS, pp. 1692 – 1694, 2021.
- [28] G. Jing, H. Bai, J. George, A. Chakrabortty, and P. K. Sharma, “Learning distributed stabilizing controllers for multi-agent systems,” IEEE Control Systems Letters, 2021.
- [29] Y. Li, Y. Tang, R. Zhang, and N. Li, “Distributed reinforcement learning for decentralized linear quadratic control: A derivative-free policy optimization approach,” in Proc. Conf. Learning for Dynamics and Control, pp. 814–814, June 2020.
- [30] K. Zhang, Z. Yang, H. Liu, T. Zhang, and T. Basar, “Fully decentralized multi-agent reinforcement learning with networked agents,” in International Conference on Machine Learning, pp. 5872–5881, 2018.
- [31] K. Zhang, Z. Yang, and T. Başar, “Decentralized multi-agent reinforcement learning with networked agents: Recent advances,” arXiv preprint arXiv:1912.03821, 2019.
- [32] I. Osband and B. Van Roy, “Near-optimal reinforcement learning in factored MDPs,” in Advances in Neural Information Processing Systems, vol. 27, Curran Associates, Inc., 2014.
- [33] X. Chen, J. Hu, L. Li, and L. Wang, “Efficient reinforcement learning in factored MDPs with application to constrained RL,” arXiv preprint arXiv:2008.13319, 2021.
- [34] M. Huang, P. E. Caines, and R. P. Malhamé, “Large-population cost-coupled LQG problems with nonuniform agents: individual-mass behavior and decentralized epsilon-Nash equilibria,” IEEE Transactions on Automatic Control, vol. 52, no. 9, pp. 1560–1571, 2007.
- [35] J.-M. Lasry and P.-L. Lions, “Mean field games,” Japanese Journal of Mathematics, vol. 2, no. 1, pp. 229–260, 2007.
- [36] J. Subramanian and A. Mahajan, “Reinforcement learning in stationary mean-field games,” in International Conference on Autonomous Agents and Multi-Agent Systems, pp. 251–259, 2019.
- [37] S. G. Subramanian, P. Poupart, M. E. Taylor, and N. Hegde, “Multi type mean field reinforcement learning,” in International Conference on Autonomous Agents and Multiagent Systems, pp. 411–419, 2020.
- [38] M. A. uz Zaman, K. Zhang, E. Miehling, and T. Bașar, “Reinforcement learning in non-stationary discrete-time linear-quadratic mean-field games,” in Conference on Decision and Control, pp. 2278–2284, 2020.
- [39] M. Gagrani, S. Sudhakara, A. Mahajan, A. Nayyar, and Y. Ouyang, “Thompson sampling for linear quadratic mean-field teams.” arXiv preprint arXiv:2011.04686, 2020.
- [40] J. Sternby, “On consistency for the method of least squares using martingale theory,” IEEE Trans. Autom. Control, vol. 22, no. 3, pp. 346–352, 1977.
- [41] M. Gagrani, S. Sudhakara, A. Mahajan, A. Nayyar, and Y. Ouyang, “A relaxed technical assumption for posterior sampling-based reinforcement learning for control of unknown linear systems.” http://cim.mcgill.ca/~adityam/projects/reinforcement-learning/preprint/tsde.pdf, 2021.
- [42] M. K. S. Faradonbeh, A. Tewari, and G. Michailidis, “Finite-time adaptive stabilization of linear systems,” IEEE Trans. Autom. Control, vol. 64, pp. 3498–3505, Aug. 2019.
- [43] P. R. Kumar and P. Varaiya, Stochastic systems: Estimation, identification, and adaptive control. SIAM Classics, 2015.
- [44] Y. Abbasi-Yadkori and C. Szepesvari, “Bayesian optimal control of smoothly parameterized systems: The lazy posterior sampling algorithm.” arXiv preprint arXiv:1406.3926, 2014.
Appendix A Appendix: Regret Analysis
A-A Preliminary Results
Since and are continuous functions on a compact set , there exist finite constants such that and for all where is the induced matrix norm.
Let be the maximum norm of the auxiliary state along the entire trajectory. The next bound follows from [41, Lemma 4].
Lemma 4
For each node , any and any ,
□
The following lemma gives an upper bound on the number of episodes .
Lemma 5
For any , we have
| (39) |
□
This can be proved along the same lines as [41, Lemma 5].
Lemma 6
The number of episodes is bounded as follows:
□
Proof
We can follow the same argument as in the proof of Lemma 5 in [41]. Let be the number of times the second stopping criterion is triggered for . Using the analysis in the proof of Lemma 5 in [41], we can get the following inequalities:
| (40) | ||||
| (41) |
where and is the minimum eigenvalue of .
Combining (41) with , we get Thus,
| (42) |
Lemma 7
The expected value of is bounded as follows:
□
A-B Proof of Lemma 3
Proof
We will prove each part separately.
1) Bounding : From an argument similar to the proof of Lemma 5 of [22], we get that The result then follows from substituting the bound on from Lemma 7.
2) Bounding :
| (44) |
where the last inequality follows from . Using the bound for in Lemma 6, we get
| (45) |
Now, consider the term
| (46) |
where follows from Cauchy-Schwarz, follows from Jensen’s inequality and follows from Lemma 4. The result then follows from substituting (46) in (44).
3) Bounding : As in [22], we can bound the inner summand in as
Therefore,
| (47) |
The term inside can be written as
| (48) |
where the last inequality follows from Cauchy-Schwarz inequality.
For the second part of the bound in (48), we follow the same argument as [41, Lemma 8]. Recall that is the smallest eigenvalue of . Therefore, by (29b), all eigenvalues of are no smaller than . Or, equivalently, all eigenvalues of are no larger than .
Using [12, Lemma 11], we can show that for any ,
| (50) |
where and the last inequality follows from [41, Lemma 10].
Moreover, since all eigenvalues of are no larger than , we have . Therefore,
| (51) |
where the last inequality follows from the definition of . Let . Then,
| (52) |
where and follows from (29b) and the intermediate step in the proof of [44, Lemma 6]. and follows from (43) and the subsequent discussion.
Using (50) and (52), we can bound the second term of (48) as follows
| (53) |
where the last inequality follows by observing that is a polynomial in multiplied by and, using Lemma 5.
■
| Sagar Sudhakara received M.Tech Degree in the area of Communication and Signal Processing from Indian Institute of Technology Bombay, Mumbai, India, in 2016 and is currently pursuing PhD in Electrical and Computer Engineering at University of Southern California. He is a recipient of USC Annenberg fellowship and his research interests include reinforcement learning and decentralized stochastic control. |
| Aditya Mahajan (S’06-M’09-SM’14) is Associate Professor in the the department of Electrical and Computer Engineering, McGill University, Montreal, Canada. He currently serves as Associate Editor of Mathematics of Control, Signal, and Systems. He is the recipient of the 2015 George Axelby Outstanding Paper Award, 2014 CDC Best Student Paper Award (as supervisor), and the 2016 NecSys Best Student Paper Award (as supervisor). His principal research interests include learning and control of centralized and decentralized stochastic systems. |
| Ashutosh Nayyar (S’09-M’11-SM’18) received the B.Tech. degree in electrical engineering from the Indian Institute of Technology, Delhi, India, in 2006. He received the M.S. degree in electrical engineering and computer science in 2008, the MS degree in applied mathematics in 2011, and the Ph.D. degree in electrical engineering and computer science in 2011, all from the University of Michigan, Ann Arbor. He was a Post-Doctoral Researcher at the University of Illinois at Urbana-Champaign and at the University of California, Berkeley before joining the University of Southern California in 2014. His research interests are in decentralized stochastic control, decentralized decision-making in sensing and communication systems, reinforcement learning, game theory, mechanism design and electric energy systems. |
| Yi Ouyang received the B.S. degree in Electrical Engineering from the National Taiwan University, Taipei, Taiwan in 2009, and the M.Sc and Ph.D. in Electrical Engineering and Computer Science at the University of Michigan, in 2012 and 2015, respectively. He is currently a researcher at Preferred Networks, Burlingame, CA. His research interests include reinforcement learning, stochastic control, and stochastic dynamic games. |