Scalable Acceleration for Classification-Based Derivative-Free Optimization
Abstract
Derivative-free optimization algorithms play an important role in scientific and engineering design optimization problems, especially when derivative information is not accessible. In this paper, we study the framework of sequential classification-based derivative-free optimization algorithms. By introducing learning theoretic concept hypothesis-target shattering rate, we revisit the computational complexity upper bound of SRACOS (Hu, Qian, and Yu 2017). Inspired by the revisited upper bound, we propose an algorithm named RACE-CARS, which adds a random region-shrinking step compared with SRACOS. We further establish theorems showing the acceleration by region shrinking. Experiments on the synthetic functions as well as black-box tuning for language-model-as-a-service demonstrate empirically the efficiency of RACE-CARS. An ablation experiment on the introduced hyper-parameters is also conducted, revealing the mechanism of RACE-CARS and putting forward an empirical hyper-parameter tuning guidance.
Introduction
In recent years, there has been a growing interest in the field of derivative-free optimization (DFO) algorithms, also known as zeroth-order optimization. These algorithms aim to optimize objective functions without relying on explicit gradient information, making them suitable for scenarios where obtaining derivatives is either infeasible or computationally expensive (Conn, Scheinberg, and Vicente 2009; Larson, Menickelly, and Wild 2019). For example, DFO techniques can be applied to hyperparameter tuning, which involves optimizing complex objective functions with unavailable first-order information (Falkner, Klein, and Hutter 2018; Akiba et al. 2019; Yang and Shami 2020). Moreover, DFO algorithms find applications in engineering design optimization, where the objective functions are computationally expensive to evaluate and lack explicit derivatives (Ray and Saini 2001; Liao 2010; Akay and Karaboga 2012).
Classical DFO methods such as Nelder-Mead method (Nelder and Mead 1965) or directional direct-search (DDS) method (Céa 1971; Yu 1979) have shown great success on convex problems. However, their performance is compromised when the objective is nonconvex, which is the commonly-faced situation for black-box problems. In this paper, we focus on optimization problems reading as
| (1) |
where the dimensional compact cubic is solution space. In addition, we will not stipulate any convexity, smoothness or separability assumption on
Recent decades, progresses have been made in the extensive exploration of DFO algorithms for nonconvex problems, and various kinds of algorithms have been established. For example, evolutionary algorithms (Bäck and Schwefel 1993; Fortin et al. 2012; Hansen 2016; Opara and Arabas 2019), Bayesian optimization (BO) methods (Snoek, Larochelle, and Adams 2012; Shahriari et al. 2015; Frazier 2018) and gradient approximation surrogate modeling algorithms (Nesterov and Spokoiny 2017; Chen et al. 2019; Ge et al. 2022; Ragonneau and Zhang 2023).
Given the nonconvex and black-box nature of the problem, the quest for enhanced sample efficiency inevitably presents the classic trade-off between exploration and exploitation. Similar to typical nonlinear/nonconvex numerical issues, the aforementioned algorithms are also susceptible to the curse of dimensionality (Bickel and Levina 2004; Hall, Marron, and Neeman 2005; Fan and Fan 2008; Shi et al. 2021; Scheinberg 2022; Yue et al. 2023). Improving scalability and efficiency can be distilled into a few key areas, such as function decomposition (Wang et al. 2018b), dimension reduction (Wang et al. 2016; Nayebi, Munteanu, and Poloczek 2019) and sample strategy refinement. Regarding the latter, previous algorithms have focused on preventing over-exploitation through, for instance, trying more efficient sampling dynamics (Ros and Hansen 2008; Hensman, Fusi, and Lawrence 2013; Yi et al. 2024), search space discretization (Sobol’ 1967) or search region restriction (Eriksson et al. 2019; Wang, Fonseca, and Tian 2020).
Regardless of the improvements, many of these model-based DFO algorithms share the mechanism that, locally or globally, fits the objective function. The motivation of classification-based DFO algorithms is different: it learns a hypothesis (classifier) to fit the sub-level set at each iteration with which new candidates are generated for the successive round (Michalski 2000; Gotovos 2013; Bogunovic et al. 2016; Yu, Qian, and Hu 2016; Hashimoto, Yadlowsky, and Duchi 2018). Sub-level sets are considered to contain less information than objective functions, since they are already obtained whenever the objective function is known. By this means, sample usage is more efficient. Moreover, it is less sensitive to function oscillation or noise (Liu et al. 2017) and easy to be parallelized (Liu et al. 2017, 2019b; Hashimoto, Yadlowsky, and Duchi 2018).
Training strategies of hypotheses have branched out in various directions. Hashimoto, Yadlowsky, and Duchi pursue accurate hypotheses using a conservative strategy raised by El-Yaniv and Wiener. They demonstrate that for a hypothesis class with a VC-dimension of an -accurate hypothesis requires samples per batch. While a computationally efficient approximation has indeed been developed, its success was demonstrated only in the context of low-dimensional problems. The extent of its effectiveness in high-dimensional scenarios is yet to be determined. However, a contrasting approach successfully lead to the improvements in sample efficiency. Yu, Qian, and Hu propose to “RAndomly COordinate-wise Shrink” the solution region (RACOS), a more radical approach that diverges from the goal of producing accurate hypotheses. They prove RACOS converges to global minimum in polynomial time when the objective is locally Holder continuous, and experiments indicate success on high-dimensional problems ranging from hundreds to thousands of dimensions. An added benefit is the ease of sampling through the generated hypotheses, as their active regions are coordinate-orthogonal cubics. Building on this, the sequential counterpart of RACOS, known as SRACOS, takes an even more radical stance by sampling only once per iteration and learning from biased data. Despite this, SRACOS has been shown to outperform RACOS under certain mild restriction (Hu, Qian, and Yu 2017).
Outline and Contributions
-
(1)
Our research extends the groundwork laid by (Yu, Qian, and Hu 2016; Hu, Qian, and Yu 2017), yet we discover that the upper bound they proposed for the SRACOS does not fully encapsulate its behavior, potentially allowing for an overflow. On the other hand, we construct a counter-example (eq. 3) illustrating the upper bound is not tight enough to delineate the convergence accurately.
-
(2)
We also identify a contentious assumption regarding the concept of error-target dependence that seems to underpin these limitations. In this paper, we introduce a novel learning theoretic concept termed the hypothesis-target -shattering rate, which serves as a foundation for our reassessment of the upper bound on the computational complexity of SRACOS.
-
(3)
Inspired by the reanalysis, we recognize that the accuracy of the trained hypotheses is even less critical than previously thought. With this insight, we formulate a novel algorithm, RACE-CARS (an acronym for “RAndomized CoordinatE Classifying And Region Shrinking”), which perpetuates the essence of SRACOS while promises a theoretical enhancement in convergence. We design experiments on both synthetic functions and black-box tuning for LMaaS. These experiments juxtapose RACE-CARS against a selection of DFO algorithms, empirically highlighting the superior efficacy of RACE-CARS.
-
(4)
In discussion and appendix, we further substantiate the empirical prowess of RACE-CARS beyond the confines of continuity, also supported by theoretical framework. An ablation study is also conducted to demystify the selection of hyperparameters for our proposed algorithm.
The rest of the paper is organized in five sections, sequentially presenting the background, theoretical study, experiments, discussion and conclusion.
Background
Assumption 1.
In eq. 1, we presume is lower bounded within , with
In our theoretical analysis, we refine the procedure as a stochastic process. Let denote the Borel -algebra on , and the probability measure defined on For instance, if is continuous space, is derived from Lebesgue measure , such that for all
Assumption 2.
Define , with the assumption for all
A hypothesis (or classifier) is a function mapping the solution space to Define
| (2) |
a probability distribution in Let be the random vector in drawn from implying that for all Denoted by , and let be a filtration of -algebras on indexed by , satisfying A typical classification-based optimization algorithm learns an -adapted stochastic process where each is induced by and is the hypothesis updated at step Subsequently, it samples new data with a stochastic process generated by . Typically, the new candidates at step are sampled from
where is random vector drawn from uniform distribution and is the exploitation rate.
A simplified batch-mode classification-based optimization algorithm is outlined in Algorithm 1. At each step it selects a positive set from containing the best samples, with the remainder in the negative set . Then it trains a hypothesis distinguishing between the positive set and negative set, ensuring for all Finally, it samples new solutions with the sampling random vector The sub-procedure means hypothesis training.
RACOS is the abbreviation of “RAndomized COordinate Shrinking”. Literally, it trains the hypothesis by this means (Yu, Qian, and Hu 2016), i.e., shrinking coordinates randomly such that all negative samples are excluded from active region of resulting hypothesis. Algorithm 2 shows a continuous version of RACOS.
Aside from sampling only once per iteration, another difference between sequential and batch mode classification-based DFO is that the sequential version will replace the training set with a new one under certain rules to finish step (see in in Algorithm 3). In the rest of this paper, we will omit the details of sub-procedure which can be found in (Hu, Qian, and Yu 2017).
Classification-based DFO algorithms admit a bound on the query complexity (Yu and Qian 2014), quantifying the total number of function evaluations required to identify a solution that achieves an approximation level of with a high probability of at least
Definition 1 (-Query Complexity).
Given and The -query complexity of an algorithm is the number of calls to such that, with probability at least finds at least one solution satisfying
Definition 2 and 3 are given by (Yu, Qian, and Hu 2016). The first one characterizes the so-called dependence between classification error and target region, which is expected to be minimized to ensure that the efficiency. The second one characterizes the portion of active region of hypothesis, and is also expected to be as small as possible.
Definition 2 (Error-Target -Dependence).
The error-target dependence of a classification-based optimization algorithm is its infimum such that, for any and any
where denotes the relative error, is the sub-level set at step with and the operator is symmetric difference of two sets defined as
Definition 3 (-Shrinking Rate).
The shrinking rate of a classification-based optimization algorithm is its infimum such that for all
Theoretical Study
Previous studies gave a general bound of the query complexity of Algorithm 3 based on minor error-target -dependence and -shrinking rate assumptions:
Theorem 1.
(Hu, Qian, and Yu 2017) Given and if a sequential classification-based optimization algorithm has error-target -dependence and -shrinking rate, then its -query complexity is upper bounded by
where with the notations and
Issues Introduced by Error-Target Dependence
-
(1)
Overflow of the upper bound
As assumptions entailed in (Yu, Qian, and Hu 2016; Hu, Qian, and Yu 2017), it can be observed that lower values of or correlate with improved query complexity. However, this is not a hard-and-fast rule. Even with small values of these parameters, we can encounter scenarios where the expected performance does not materialize. Following the lemma given by (Yu, Qian, and Hu 2016): , we have the following inequality:
The concept of error-target -dependence reveals that a small does not guarantee small relative error Contrarily, a small coupled with a large can result in a significant which can even be as long as is totally out of the active region of when the hypothesis is completely wrong. Problematically, as a divisor in the proof of Theorem 1, is less or equal to 0, disrupting the established inequality. Nevertheless, in order that the inequality disrupt, is not necessary to be as is inherently nonnegative, highlighting that a series of inaccurate hypotheses can undermine the validity of the upper bound. This finding challenges the principle of SRACOS’s radical training strategy.
-
(2)
Tightness of the upper bound
Consider an extreme but plausible situation where the hypotheses generated at each step are defined as follows:
(3) In the context of sequential-mode classification-based optimization algorithms, where the training sets are not only small but also potentially biased, it’s reasonable to expect large relative errors . This scenario could lead to a series of hypotheses that are inaccurate with respect to but, by chance, accurate with respect to Consequently, the error-target dependence can be unexpectedly large. Even all values being positive, the query complexity bound given in Theorem 1 is therefore not optimistic. However, the probability of failing to identify an -minimum:
is less than for a reasonably sized . This indicates that the upper bound may not be as tight as initially thought.
Revisit of Query Complexity Upper Bound
It’s evident that even minimal error-target dependence can not encapsulate issues arising from substantial relative error. This is because error-target dependence alone is insufficient to fully account for relative error. Intuitively, one might consider introducing an additional assumption to cap relative error. However, such an assumption would be impractical, given the inherently small and biased nature of training datasets in the process. To this end, we give a new concept that stands apart from the constraints of relative error:
Definition 4 (Hypothesis-Target -Shattering Rate).
Given for a family of hypotheses defined on we say is -shattered by if
and is called hypothesis-target shattering rate.
The hypothesis-target shattering rate mirrors the error-target dependence in its relation to the hypothesis’s target-accuracy. Importantly, it provides a limitation for error-target dependence in conjunction with relative error:
This rate, , measures the overlap between the target set and the active region of a hypothesis. Crucially, it also mitigates the influence of relative error on error-target dependence. Utilizing the concept hypothesis-target shattering rate, we reexamine the upper bound of -query complexity in the subsequent theorem.
Theorem 2.
For sequential-mode classification-based DFO Algorithm 3, let and When is -shattered by for all and the -query complexity is upper bounded by
The Region-Shrinking Acceleration
In the analysis of -query complexity for classification-based optimization, the focus shifts away from minimizing relative error , as our goal is to identify optima, not to develop a sequence of accurate hypotheses. The counter-example in equation (3), despite a potentially high relative error, represents an optimal hypothesis scenario. This realization allows for the consideration of more radical hypotheses, directing our attention to the overlap between and the active region of the hypotheses, which is quantified by the hypothesis-target shattering rate.
The -shrinking rate, as defined in Definition 3, measures the decay of . However, the rapid decrease of as approaches zero makes it impractical to sustain a series of hypotheses with a small through our training process. Thus, the -shrinking assumption is often not feasible for minimal .
Moving beyond the pursuit of minimal relative error and -shrinking relative to , we introduce Algorithm 4, which adaptively shrinks the sampling random vector ’s active region through a sub-procedure.
The operator returns a tuple represents the diameter of each dimension of the region. For instance, when we have The projection operator generates a random vector with probability distribution with whenever for The sampling random vector is induced by The subsequent theorem presents the upper bound of query complexity for Algorithm 4.
Theorem 3.
For Algorithm 4 with region shrinking rate and region shrinking frequency Let and When is -shattered by for all the -query complexity is upper bounded by
The condition ensures that the term is significantly less than 1. According to Theorem 3, the -query complexity of the Algorithm 4 is lower than that of Algorithm 3 providing .
Theorem 3 establishes an upper bound on the -query complexity that is applicable to a wide range of scenarios, assuming only that the objective function is lower-bounded. Building on this, we identify a sufficient condition for acceleration that applies to dimensionally local Holder continuity functions (Definition 5), detailed in the appendix. Within this context, the SRACOS algorithm, which utilizes RACOS for phase in Algorithm 3, exhibit polynomial convergence (Hu, Qian, and Yu 2017). We adopt the same RACOS approach for sub-procedure in Algorithm 4, introducing ”RAndomized CoordinatE Classifying And Region Shrinking” (RACE-CARS) algorithm.
Definition 5 (Dimensionally local Holder continuity).
Assume that is the unique global minimum such that We call dimensionally local Holder continuity if for all
for all in the neighborhood of where are positive constants for
Experiments
In this section, we design experiments to test RACE-CARS on synthetic functions, and language model tasks respectively. We use same budget to compare RACE-CARS with a selection of DFO algorithms, including SRACOS (Hu, Qian, and Yu 2017), zeroth-order adaptive momentum method (ZO-Adam) (Chen et al. 2019), differential evolution (DE) (Opara and Arabas 2019) and covariance matrix adaptation evolution strategies (CMA-ES) (Hansen 2016). All the baseline algorithms are fine-tuned, and the essential hyperparameters of RACE-CARS can be found in Appendix.
On Synthetic Functions
We commence our empirical experiments with four benchmark functions: Ackley, Levy, Rastrigin and Sphere. Their analytic forms and 2-dimensional illustrations are detailed in Appendix. Characterized by extreme non-convexity and numerous local minima and saddle points—with the exception of the Sphere function—each is minimized within the boundary , with a global minimum value of . We choose the dimension of solution space to be and with corresponding function evaluation budgets of and . Notably, as indicates, the convergence of the RACE-CARS requires only a fraction of this budget.

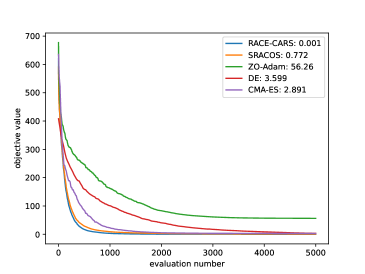


Region shrinking rate is configured to be and , with shrinking frequency of and for , respectively. Each algorithm is executed over 30 trials, and the mean convergence trajectories of the best-so-far values are depicted in Figure 1 and Figure 2. The numerical values adjacent to the algorithm names in the legends represent the mean of the attained minima. It is evident that that RACE-CARS performs the best on both convergence speed and optimal value, with a slight edge to CMA-ES on the strongly convex Sphere function. Yet this comes at the cost of scalability due to CMA-ES’s reliance on an -dimensional covariance matrix, which is significantly more computationally intensive compared to the other algorithms.




On Black-Box Tuning for LMaaS
Prompt tuning for extremely large pre-trained language models (PTMs) has shown great power. PTMs such as GPT-3 (Brown et al. 2020) are usually released as a service due to commercial considerations and the potential risk of misuse, allowing users to design individual prompts to query the PTMs through black-box APIs. This scenario is called Language-Model-as-a-Service (LMaaS) (Diao et al. 2022; Sun et al. 2022). In this part we follow the experiments designed by (Sun et al. 2022) 111Code can be found in https://github.com/txsun1997/Black-Box-Tuning, where language understanding task is formulated as a classification task predicting for a batch of PTM-modified input texts the labels in the PTM vocabulary, namely we need to tune the prompt such that the black-box PTM inference API takes a continuous prompt satisfying Moreover, to handle the high-dimensional prompt (Sun et al. 2022) proposed to randomly embed the -dimensional prompt into a lower dimensional space via random projection matrix Therefore, the objective becomes:
where is the search space and is cross entropy loss.
In our experimental setup, we configure the search space dimension to and the prompt length to , with RoBERTa (Liu et al. 2019a) serving as the backbone model. We evaluate performance on datasets SST-2 (Socher et al. 2013), Yelp polarity and AG’s News (Zhang, Zhao, and LeCun 2015), and RTE (Wang et al. 2018a). With a fixed API call budget of we pit RACE-CARS against SRACOS and the default DFO algorithm CMA-ES utilized in (Sun et al. 2022) 222 Our choice to exclude ZO-Adam and DE is based on their suboptimal performance with high-dimensional nonconvex black-box functions, as demonstrated in the last section..
For our tests, the shrinking rate is , with shrinking frequency of Each algorithm is repeated 5 times independently with unique seeds. We assess the algorithms based on the mean and deviation of training loss, training accuracy, development loss and development accuracy. The SST-2 dataset results are highlighted in Figure 3, with additional findings for Yelp Polarity, AG’s News, and RTE detailed in the appendix. The results indicate that RACE-CARS consistently accelerates the convergence of SRACOS. While CMA-ES shows superior performance on Yelp Polarity, AG’s News, and RTE, it also exhibits signs of overfitting. RACE-CARS achieves comparable performance to CMA-ES, despite the latter’s hyperparameters being finely tuned. Notably, the hyperparameters for RACE-CARS were empirically adjusted based on the SST-2 dataset and then applied to the other three datasets without further tuning.




Discussion
Beyond continuity
-
(i)
For discontinuous objective functions.
Dimensionally local Holder continuity in Definition 5, imposes certain constraints on the objective through a set of continuous envelopes, whereas the objective is not supposed to be continuous. Beyond the continuous cases discussed in the previous section, RACE-CARS remains applicable to discontinuous objectives as well. Refer to appendix for a comprehensive understanding.
-
(ii)
For discrete optimization.
Similar to SRACOS algorithm, RACE-CARS retains the capability to tackle discrete optimization problems. The convergence theorems, presented in Theorem 2 and Theorem 3, encompass this situation by altering the measure of probability space to be for example, induced by counting measure. We extend experiments on mixed-integer programming problems, substantiating the acceleration of RACE-CARS empirically. See appendix for details.
On the Concept Hypothesis-Target Shattering
The concept hypothesis-target shattering, central to our discussion, draws inspiration from the established learning theory notion of shatter and its deep ties to the Vapnik-Chervonenkis (VC) theory (Vapnik et al. 1998). At the heart of VC theory lies the VC dimension, a measure of a hypothesis family’s capacity to distinguish among data points based on their labels. Specifically, for a collection of data points with binary labels, , we say a subset is shattered by a hypothesis family if there exists a hypothesis that perfectly aligns with the labels of points in and contrasts with those outside:
The shattering coefficient, , signifies the variety of point-label combinations that can produce for points. The VC dimension is then defined as , indicating the maximum number of points that can be distinctly labeled by .
In the context of classification-based DFO, we represent the target-representative capability of a family of hypotheses through hypothesis-target shattering, measuring the overlap of hypothesis’s active region and the target. Therefore the quintessence of algorithm design hinges on maximizing this quantity. discerning the target-representative capacity within the intricate landscape of nonconvex, black-box optimization problems is nontrivial. Nonetheless, the target-representative capability of hypotheses family generated by RACOS, although proved under the previous framework, empirically suggests sufficient efficacy in scenarios where the objective function exhibits locally Holder continuouity. Looking ahead, altering the and sub-procedures inherited from SRACOS, which may ideally lead to a bigger shattering rate and maintain the easy-to-sample characterization, will be another extension direction of the current study.
Ablation Experiments
While it’s an appealing goal to develop a universally effective DFO algorithm for black-box functions without the need for hyperparameter tuning, this remains an unrealistic aspiration. Our proposed algorithm, RACE-CARS, introduces two hyperparameters: shrinking-rate and shrinking-frequency For an -dimensional optimization problem, we call shrinking factor of RACE-CARS. We take Ackley for a case study, design ablation experiments on the two hyperparameters of RACE-CARS to reveal the mechanism. We stipulate that we do not aim to identify a optimal combination of hyperparameters for maximizing the overlap with the target hypothesis. Instead, our aim is to provide empirical guidance for tuning these hyperparameters effectively. For further details, the reader is directed to the appendix.
Conclusion
In this paper, we refine the framework of classification-based DFO as a stochastic process, and propose a novel learning concept named hypothesis-target shattering rate. Our research delves into the convergence properties of sequential-mode classification-based DFO algorithms and provides a fresh perspective on their query complexity upper bound. Delighted by the computational complexity upper bound under the new framework, we propose a theoretically grounded region-shrinking technique to accelerate the convergence. In empirical analysis, we study the scalability performance of RACE-CARS on both synthetic functions and black-box tuning for LMaaS, showing its superiority over SRACOS.
References
- Akay and Karaboga (2012) Akay, B.; and Karaboga, D. 2012. Artificial bee colony algorithm for large-scale problems and engineering design optimization. Journal of intelligent manufacturing, 23: 1001–1014.
- Akiba et al. (2019) Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; and Koyama, M. 2019. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, 2623–2631.
- Bäck and Schwefel (1993) Bäck, T.; and Schwefel, H.-P. 1993. An overview of evolutionary algorithms for parameter optimization. Evolutionary computation, 1(1): 1–23.
- Bickel and Levina (2004) Bickel, P. J.; and Levina, E. 2004. Some theory for Fisher’s linear discriminant function,naive Bayes’, and some alternatives when there are many more variables than observations. Bernoulli, 10(6): 989–1010.
- Bogunovic et al. (2016) Bogunovic, I.; Scarlett, J.; Krause, A.; and Cevher, V. 2016. Truncated variance reduction: A unified approach to bayesian optimization and level-set estimation. Advances in neural information processing systems, 29.
- Brown et al. (2020) Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J. D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901.
- Céa (1971) Céa, J. 1971. Optimisation: théorie et algorithmes. Jean Céa. Dunod.
- Chen et al. (2019) Chen, X.; Liu, S.; Xu, K.; Li, X.; Lin, X.; Hong, M.; and Cox, D. 2019. Zo-adamm: Zeroth-order adaptive momentum method for black-box optimization. Advances in neural information processing systems, 32.
- Conn, Scheinberg, and Vicente (2009) Conn, A. R.; Scheinberg, K.; and Vicente, L. N. 2009. Introduction to derivative-free optimization. SIAM.
- Diao et al. (2022) Diao, S.; Huang, Z.; Xu, R.; Li, X.; Lin, Y.; Zhou, X.; and Zhang, T. 2022. Black-box prompt learning for pre-trained language models. arXiv preprint arXiv:2201.08531.
- El-Yaniv and Wiener (2012) El-Yaniv, R.; and Wiener, Y. 2012. Active Learning via Perfect Selective Classification. Journal of Machine Learning Research, 13(2).
- Eriksson et al. (2019) Eriksson, D.; Pearce, M.; Gardner, J.; Turner, R. D.; and Poloczek, M. 2019. Scalable global optimization via local Bayesian optimization. Advances in neural information processing systems, 32.
- Falkner, Klein, and Hutter (2018) Falkner, S.; Klein, A.; and Hutter, F. 2018. BOHB: Robust and efficient hyperparameter optimization at scale. In International conference on machine learning, 1437–1446. PMLR.
- Fan and Fan (2008) Fan, J.; and Fan, Y. 2008. High dimensional classification using features annealed independence rules. Annals of statistics, 36(6): 2605.
- Fortin et al. (2012) Fortin, F.-A.; De Rainville, F.-M.; Gardner, M.-A. G.; Parizeau, M.; and Gagné, C. 2012. DEAP: Evolutionary algorithms made easy. The Journal of Machine Learning Research, 13(1): 2171–2175.
- Frazier (2018) Frazier, P. I. 2018. A tutorial on Bayesian optimization. arXiv preprint arXiv:1807.02811.
- Ge et al. (2022) Ge, D.; Liu, T.; Liu, J.; Tan, J.; and Ye, Y. 2022. SOLNP+: A Derivative-Free Solver for Constrained Nonlinear Optimization. arXiv preprint arXiv:2210.07160.
- Gotovos (2013) Gotovos, A. 2013. Active learning for level set estimation. Master’s thesis, Eidgenössische Technische Hochschule Zürich, Department of Computer Science,.
- Hall, Marron, and Neeman (2005) Hall, P.; Marron, J. S.; and Neeman, A. 2005. Geometric representation of high dimension, low sample size data. Journal of the Royal Statistical Society Series B: Statistical Methodology, 67(3): 427–444.
- Hansen (2016) Hansen, N. 2016. The CMA evolution strategy: A tutorial. arXiv preprint arXiv:1604.00772.
- Hashimoto, Yadlowsky, and Duchi (2018) Hashimoto, T.; Yadlowsky, S.; and Duchi, J. 2018. Derivative free optimization via repeated classification. In International Conference on Artificial Intelligence and Statistics, 2027–2036. PMLR.
- Hensman, Fusi, and Lawrence (2013) Hensman, J.; Fusi, N.; and Lawrence, N. D. 2013. Gaussian processes for big data. arXiv preprint arXiv:1309.6835.
- Hu, Qian, and Yu (2017) Hu, Y.-Q.; Qian, H.; and Yu, Y. 2017. Sequential classification-based optimization for direct policy search. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 31.
- Larson, Menickelly, and Wild (2019) Larson, J.; Menickelly, M.; and Wild, S. M. 2019. Derivative-free optimization methods. Acta Numerica, 28: 287–404.
- Liao (2010) Liao, T. W. 2010. Two hybrid differential evolution algorithms for engineering design optimization. Applied Soft Computing, 10(4): 1188–1199.
- Liu et al. (2019a) Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; and Stoyanov, V. 2019a. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Liu et al. (2017) Liu, Y.-R.; Hu, Y.-Q.; Qian, H.; Qian, C.; and Yu, Y. 2017. Zoopt: Toolbox for derivative-free optimization. arXiv preprint arXiv:1801.00329.
- Liu et al. (2019b) Liu, Y.-R.; Hu, Y.-Q.; Qian, H.; and Yu, Y. 2019b. Asynchronous classification-based optimization. In Proceedings of the First International Conference on Distributed Artificial Intelligence, 1–8.
- Michalski (2000) Michalski, R. S. 2000. Learnable evolution model: Evolutionary processes guided by machine learning. Machine learning, 38: 9–40.
- Nayebi, Munteanu, and Poloczek (2019) Nayebi, A.; Munteanu, A.; and Poloczek, M. 2019. A framework for Bayesian optimization in embedded subspaces. In International Conference on Machine Learning, 4752–4761. PMLR.
- Nelder and Mead (1965) Nelder, J. A.; and Mead, R. 1965. A simplex method for function minimization. The computer journal, 7(4): 308–313.
- Nesterov and Spokoiny (2017) Nesterov, Y.; and Spokoiny, V. 2017. Random gradient-free minimization of convex functions. Foundations of Computational Mathematics, 17: 527–566.
- Opara and Arabas (2019) Opara, K. R.; and Arabas, J. 2019. Differential Evolution: A survey of theoretical analyses. Swarm and evolutionary computation, 44: 546–558.
- Ragonneau and Zhang (2023) Ragonneau, T. M.; and Zhang, Z. 2023. PDFO–A Cross-Platform Package for Powell’s Derivative-Free Optimization Solver. arXiv preprint arXiv:2302.13246.
- Ray and Saini (2001) Ray, T.; and Saini, P. 2001. Engineering design optimization using a swarm with an intelligent information sharing among individuals. Engineering Optimization, 33(6): 735–748.
- Ros and Hansen (2008) Ros, R.; and Hansen, N. 2008. A simple modification in CMA-ES achieving linear time and space complexity. In International conference on parallel problem solving from nature, 296–305. Springer.
- Scheinberg (2022) Scheinberg, K. 2022. Finite Difference Gradient Approximation: To Randomize or Not? INFORMS Journal on Computing, 34(5): 2384–2388.
- Shahriari et al. (2015) Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R. P.; and De Freitas, N. 2015. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1): 148–175.
- Shi et al. (2021) Shi, H.-J. M.; Xuan, M. Q.; Oztoprak, F.; and Nocedal, J. 2021. On the numerical performance of derivative-free optimization methods based on finite-difference approximations. arXiv preprint arXiv:2102.09762.
- Snoek, Larochelle, and Adams (2012) Snoek, J.; Larochelle, H.; and Adams, R. P. 2012. Practical bayesian optimization of machine learning algorithms. Advances in neural information processing systems, 25.
- Sobol’ (1967) Sobol’, I. M. 1967. On the distribution of points in a cube and the approximate evaluation of integrals. Zhurnal Vychislitel’noi Matematiki i Matematicheskoi Fiziki, 7(4): 784–802.
- Socher et al. (2013) Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C. D.; Ng, A. Y.; and Potts, C. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, 1631–1642.
- Sun et al. (2022) Sun, T.; Shao, Y.; Qian, H.; Huang, X.; and Qiu, X. 2022. Black-box tuning for language-model-as-a-service. In International Conference on Machine Learning, 20841–20855. PMLR.
- Vapnik et al. (1998) Vapnik, V.; et al. 1998. Statistical learning theory.
- Wang et al. (2018a) Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; and Bowman, S. R. 2018a. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
- Wang, Fonseca, and Tian (2020) Wang, L.; Fonseca, R.; and Tian, Y. 2020. Learning search space partition for black-box optimization using monte carlo tree search. Advances in Neural Information Processing Systems, 33: 19511–19522.
- Wang et al. (2018b) Wang, Z.; Gehring, C.; Kohli, P.; and Jegelka, S. 2018b. Batched large-scale Bayesian optimization in high-dimensional spaces. In International Conference on Artificial Intelligence and Statistics, 745–754. PMLR.
- Wang et al. (2016) Wang, Z.; Hutter, F.; Zoghi, M.; Matheson, D.; and De Feitas, N. 2016. Bayesian optimization in a billion dimensions via random embeddings. Journal of Artificial Intelligence Research, 55: 361–387.
- Yang and Shami (2020) Yang, L.; and Shami, A. 2020. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing, 415: 295–316.
- Yi et al. (2024) Yi, Z.; Wei, Y.; Cheng, C. X.; He, K.; and Sui, Y. 2024. Improving sample efficiency of high dimensional Bayesian optimization with MCMC. arXiv preprint arXiv:2401.02650.
- Yu (1979) Yu, W.-C. 1979. Positive basis and a class of direct search techniques. Scientia Sinica, Special Issue of Mathematics, 1(26): 53–68.
- Yu and Qian (2014) Yu, Y.; and Qian, H. 2014. The sampling-and-learning framework: A statistical view of evolutionary algorithms. In 2014 IEEE Congress on Evolutionary Computation (CEC), 149–158. IEEE.
- Yu, Qian, and Hu (2016) Yu, Y.; Qian, H.; and Hu, Y.-Q. 2016. Derivative-free optimization via classification. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30.
- Yue et al. (2023) Yue, P.; Yang, L.; Fang, C.; and Lin, Z. 2023. Zeroth-order Optimization with Weak Dimension Dependency. In The Thirty Sixth Annual Conference on Learning Theory, 4429–4472. PMLR.
- Zhang, Zhao, and LeCun (2015) Zhang, X.; Zhao, J.; and LeCun, Y. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28.
Appendix A Appendix
Synthetic functions
-
•
Ackley:
-
•
Levy:
where
-
•
Rastrigin:
-
•
Sphere:




Beyond continuity
For discontinuous objective functions
We design experiments on discontinuous objective functions by adding random perturbation to synthetic functions. For example, the perturbation is set to be:
is the open ball centering at with radius equals to 0.5, with randomly generated within the solution region. is an indicator function, equaling to 1 when otherwise 0. The perturbations are uniformly sampled from for every single ball center The objective function is set to be
which is lower semi-continuous. We use the same settings as in the body sections with dimension the perturbation size and budget Similarly, region shrinking rate is set to be and region shrinking frequency is Each of the algorithm is repeated 30 runs and the mean convergence trajectories of the best-so-far values are presented in Figure 5. The numbers attached to the algorithm names in the legend of figures are the mean value of obtained minimum. It can be observed that the acceleration of RACE-CARS to SRACOS is still valid. Comparing with baselines, RACE-CARS performs the best on both convergence, and obtain the best optimal value. As we anticipated, the performance of SRACOS and RACE-CARS are almost impervious to discontinuity, whereas the other three baselines, whose convergence relies on the continuity, suffers from oscillation or early-stopping to different extent.




For discrete optimization
In order to transfer RACE-CARS to discrete optimization, and sub-procedures in Algorithm 4 should be modified. In all cases, we employ the discrete version of RACOS for (Yu, Qian, and Hu 2016). Furthermore, we presume counting measure as the inducing measure of probability space where for all The is therefore similar only to set the operator return the count of each dimension of the region.
We design experiments on the following formulation:
| (4) | ||||
where is the continuous solution subspace and is discrete. Equation (4) encompasses a wide range of continuous, discrete and mixed-integer programming problems. In our experiments, we specify equation (4) as a mixed-integer programming problem:
where is sampled uniformly from thus the global optimal value is 0. We choose the dimension of solution space as and the budget of function evaluation is set to be and respectively. Region shrinking rate is set to be and region shrinking frequency is respectively. Each of the algorithm is repeated 30 runs and the convergence trajectories of mean of the best-so-far value are presented in Figure 6. As results show, RACE-CARS maintains acceleration to SRACOS in discrete situation.


Ablation experiments
-
(i)
Relationship between shrinking frequency and dimension .
For Ackley on we fix shrinking rate and compare the performance of RACE-CARS between different shrinking frequency and dimension The shrinking frequencies ranges from to and dimension ranges from to The function calls budget is set to be for fair. Experiments are repeated 5 times for each hyperparameter and results are recorded in Table 1 and the normalized results is the heatmap figure in the right. The black curve represents the trajectory of best shrinking frequency with respect to dimension. The horizontal axis is dimension and the vertical axis is shrinking frequency. Results indicate the best is in reverse proportion to therefore maintaining as constant is preferred.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/4c32d95e-d6b1-4d0a-a189-ef2c931e9ec2/x23.png)
-
(ii)
Relationship between shrinking factor and dimension of solution space.
For Ackley on we compare the performance of RACE-CARS between different shrinking factors and radius Different shrinking factors are generated by varying shrinking rate and dimension times shrinking frequency We design experiments on 4 different dimensions with 4 radii The function calls budget is set to be Experiments are repeated 5 times for each hyperparameter and results are presented in heatmap format in Figure 7. According to the results, the best shrinking factor is insensitive to the variation of dimension. Considering that the best maintains constant as varying, slightly variation of the corresponding best is preferred. This observation is in line with what we anticipated as in section Experiments.

(a) Radius 
(b) Radius 
(c) Radius 
(d) Radius Figure 7: Comparison of shrinking factor and dimension of the solution space . Results of different solution space radius are presented in each subfigure respectively. In each subfigure, the horizontal axis is the dimension and the vertical axis is shrinking factor. Each pixel represents the heat of y-wise normalized mean function value at the step. The black curve is the best shrinking factor in each dimension. -
(iii)
Relationship between shrinking factor and radius of solution space.
For Ackley on we compare the performance of RACE-CARS between different shrinking factors and radius Different shrinking factors are generated by varying shrinking rate and dimension times shrinking frequency We design experiments on 4 different radii with 4 dimensions The function calls budget is set to be Experiments are repeated 5 times for each hyperparameter and results are presented in heatmap format in Figure 8. According to the results, the best shrinking factor should be decreased as radius increases.

(a) Dimension 
(b) Dimension 
(c) Dimension 
(d) Dimension Figure 8: Comparison of shrinking factor and radius of the solution space . Results of different dimension are presented in each subfigure respectively. In each subfigure, the horizontal axis is the radius of solution space and the vertical axis is shrinking factor. Each pixel represents the heat of y-wise normalized mean function value at the step. The black curve is the best shrinking factor of each solution space radius.
| 50 | 100 | 150 | 200 | 250 | 300 | 350 | 400 | 450 | 500 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ||||||||||
| 0.002 | ||||||||||
| 0.004 | ||||||||||
| 0.006 | ||||||||||
| 0.008 | ||||||||||
| 0.010 | ||||||||||
| 0.012 | ||||||||||
| 0.014 | ||||||||||
| 0.016 | ||||||||||
| 0.018 | ||||||||||
| 0.020 | ||||||||||
| 0.022 | ||||||||||
| 0.024 | ||||||||||
| 0.026 | ||||||||||
| 0.028 | ||||||||||
| 0.030 | ||||||||||
| 0.032 | ||||||||||
| 0.034 | ||||||||||
| 0.036 | ||||||||||
| 0.038 | ||||||||||
| 0.040 | ||||||||||
| 0.042 | ||||||||||
| 0.044 | ||||||||||
| 0.046 | ||||||||||
| 0.048 | ||||||||||
| 0.050 | ||||||||||
| 0.052 | ||||||||||
| 0.054 | ||||||||||
| 0.056 | ||||||||||
| 0.058 | ||||||||||
| 0.060 | ||||||||||
| 0.062 | ||||||||||
| 0.064 | ||||||||||
| 0.066 | ||||||||||
| 0.068 | ||||||||||
| 0.070 | ||||||||||
| 0.072 | ||||||||||
| 0.074 | ||||||||||
| 0.076 | ||||||||||
| 0.078 | ||||||||||
| 0.080 | ||||||||||
| 0.082 | ||||||||||
| 0.084 | ||||||||||
| 0.086 | ||||||||||
| 0.088 | ||||||||||
| 0.090 | ||||||||||
| 0.092 | ||||||||||
| 0.094 | ||||||||||
| 0.096 | ||||||||||
| 0.098 | ||||||||||
| 0.100 |












Appendix B Theory Supplementary
Proofs of Theorems
Theorem 2.
For sequential-mode classification-based DFO Algorithm 3, let and When is -shattered by for all and the -query complexity is upper bounded by
Proof.
Let then
Where is the identical function on such that for all and otherwise. At step since is independent to it holds
Under the assumption that is -shattered by it holds the relation that
Therefore,
Apparently, the upper bound of satisfies thus
Moreover,
In order that it suffices that
hence the -query complexity is upper bounded by
∎
Theorem 3.
For Algorithm 4 with region shrinking rate and region shrinking frequency Let and When is -shattered by for all the -query complexity is upper bounded by
Proof.
Let then
At step since is independent to it holds
The expectation of probability that hits active region is upper bounded by
Under the assumption that is -shattered by it holds the relation that
Therefore,
Moreover,
In order that it suffices that
hence the -query complexity is upper bounded by
∎
Sufficient Condition for Acceleration
Under the assumption that is dimensionally locally Holder continuous, it is obvious that
Denoted by . The subsequent sufficient condition gives a lower bound of region shrinking rate and shrinking frequency such that RACE-CARS achieves acceleration over SRACOS.
Proposition 1.
For a dimensionally local Holder continuous objective Assume that for is -shattered by for all In order that being -shattered by it is sufficient when the region shrinking rate and shrinking frequency satisfy: