SC-NeuS: Consistent Neural Surface Reconstruction
from Sparse and Noisy Views
Abstract
The recent neural surface reconstruction approaches using volume rendering have made much progress by achieving impressive surface reconstruction quality, but are still limited to dense and highly accurate posed views. To overcome such drawbacks, this paper pays special attention on the consistent surface reconstruction from sparse views with noisy camera poses. Unlike previous approaches, the key difference of this paper is to exploit the multi-view constraints directly from the explicit geometry of the neural surface, which can be used as effective regularization to jointly learn the neural surface and refine the camera poses. To build effective multi-view constraints, we introduce a fast differentiable on-surface intersection to generate on-surface points, and propose view-consistent losses on such differentiable points to regularize the neural surface learning. Based on this point, we propose a joint learning strategy for both neural surface representation and camera poses, named SC-NeuS, to perform geometry-consistent surface reconstruction in an end-to-end manner. With extensive evaluation on public datasets, our SC-NeuS can achieve consistently better surface reconstruction results with fine-grained details than previous state-of-the-art neural surface reconstruction approaches, especially from sparse and noisy camera views. The source code is avaiable at https://github.com/zouzx/sc-neus.git.
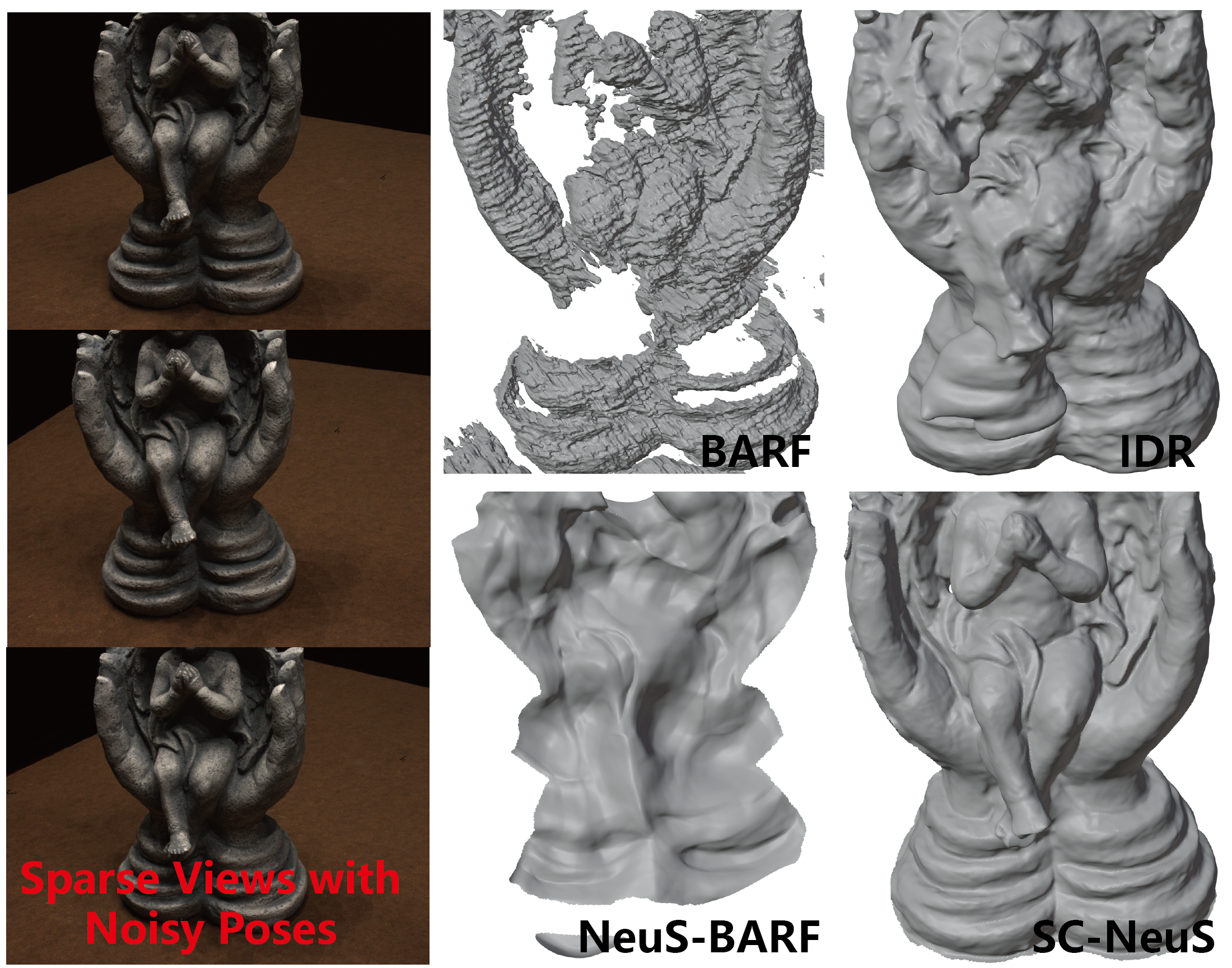
1 Introduction
3D surface reconstruction from multi-view images continues to be an important research topic in computer vision and graphics communities. Unlike traditional Multi-View Stereo (MVS) based methods leveraging structure from motion (SfM) [31] technique for sparse [17, 30, 29, 39] or dense [14, 41, 40] surface reconstruction, the recent neural surface reconstruction approaches [44, 35, 24, 3, 8, 10] adopt to learn the deep implicit representation [25, 26, 2, 13] with the aid of volume rendering [22], leading to more better complete and fine-grained surface reconstruction quality, which have received much research attention for multi-view image based 3D reconstruction.
As like Neural Radiance Fields (NeRF) [22], one main drawback of most neural surface reconstruction approaches (NeuS [35], VolSDF [43], Unisurf [24], NeuralWarp [8], Geo-NeuS [10]) is the dependency on dense input views, which is not suitable for wide real-world applications with only sparse input views and often noisy camera poses in AR/VR, autonomous driving or robotics. Some subsequent works propose to improve the reconstruction quality from sparse scenarios, by introducing regularization like sparse points [9], multi-views depth priors [6, 23], rendering ray entropy [15] or geometry-aware feature volume [19]. However, most of these approaches are still relying on highly accurate camera poses, which could not be easily obtained using technique like COLMAP [29] for sparse input views.
To overcome the dependency on highly accurate cameras poses, many recent works propose to jointly learn the deep implicit geometry and refine the camera poses, with the guidance of novel registration from photometric [7, 18, 21, 37, 44] or silhouette [5, 16, 46] priors. But since those registrations are often performed independently across dense input views, the registration quality would significantly drop for sparse view scenarios (Fig. 1), where enough relations across views are missing to effectively bundle adjust both the deep implicit geometry and camera poses. It still remains to be challenging to jointly learn the deep implicit geometry and camera poses from sparse input views [47] for geometry-consistent surface reconstruction.
This paper proposes a Sparse-view Consisent Neural Surface (SC-NeuS) learning strategy, which performs geometry-consistent surface reconstruction with fine-grained details from sparse and noisy camera poses (as few as 3 views). Unlike previous independent registrations from dense input views, we seek to explore more effective multi-view constraints between sparse views. Due to the gap between the volume rendering integral and point-based SDF modeling [10], except from relying on the depth constraints [6] rendered from the under-constrained signed distance field [10], we utilize extra regularization directly from the explicit geometry of the neural surface representation. Our key insight is that the observation of the explicit surface geometry across multiple views should be consistent, which can be used as effective regularization to jointly learn both the neural surface representation and camera poses. Specifically, we first introduce a fast differentiable on-surface intersection to sample on-surface points from explicit geometry of the neural surface, and then provide effective view-consistent losses defined on such differentiable on-surface intersections, which builds up an end-to-end joint learning for the neural surface representation and camera poses. Besides, to further improve the geometry-consistent neural surface learning, we incorporate an coarse-to-fine learning strategy [18] for highly accurate and fine-grained surface reconstruction results.
To evaluate the effectiveness of our SC-NeuS, we conduct extensive experiments on public dataset including DTU [11] and BlendedMVS [42] with various geometry scenarios. Compared with previous state-of-the-art approaches[18, 10, 12, 44, 35], our SC-NeuS achieves consistently better geometry-consistent surface reconstruction results both quantitatively and qualitatively, which becomes a new state-of-the-art neural surface reconstruction approach from sparse and noisy cameras.
2 Related Work
Novel View Synthesis. The recent success of Neural Radiance Fields (NeRF) [22] has inspired many subsequent works [33, 36, 45] to achieve impressive novel view synthesis applications. To overcome the drawback of dense input views, multiple works propose to extra regularization or priors for sparse view novel view synthesis. RegNeRF [23] proposes to regularize the rendered patches with depth and appearance smoothness for sparse view synthesis. MVSNeRF [6] leverages similar rendered depth smoothness loss across unobserved views, from pre-trained sparse view to generalized novel view synthesis. On other hand, InfoNeRF [15] penalizeds the NeRF overfitting to limited input views with a ray entropy regularization. Mip-NeRf360 [4] introduce ray distortion loss, which encourages sparsity of the density learning in each rendering ray. Besides, some recent approaches [38, 9, 27] use depth priors to constraint the NeRF optimization, which also achieves promising novel view synthesis results from sparse input views. Different from all of these previous approaches that relies on highly accurate camera poses as input, our approaches aims at geometry-consistent neural surface learning with noisy camera poses, and contributes a joint neural surface learning and camera pose optimization strategy from sparse input views.
Neural Implicit Surface Representation. Neural implicit representation has been a state-of-the-art way to represent the geometry of objects or scenes since the pioneer works of DeepSDF [25] and its subsequents [13]. IDR [44] introduces a neural surface rendering for the neural implicit representation (signed distance function, SDF), which enables precise surface learning from 2D images. Inspired by the success of NeRF [22], NeuS [35] and VolSDF [43] propose to transfer the signed distance field to density filed using weight function, and perform the volume rendering along with the radiance field, achieving impressive surface reconstruction results with fine-grained details. Geo-NeuS [10] incorperates more explicit surface supervisions for more accurate neural surface learning. UNISURF [24] explores the balance between surface rendering and volume rendering. NeuralWarp [8] provides a geometry-aware volume rendering which utilize multi-view geometry priors for geometry-consistent surface reconstruction. However, most of these previous works depend on dense input views for accurate neural surface learning, which is not feasible for sparse scenarios.
Recently, SparseNeuS [19] learns geometry encoding priors from image features for generalizable neural surface learning form sparse input views, but still relies on highly accurate camera poses. In contrast, our approaches enables accurate neural surface learning from sparse input views, and optimizes the noisy camera poses simultaneously.
Joint Deep Implicit Geometry and Pose Optimization. BARF [18] is probably one of the first works to reduce NeRF’s dependent on highly accurate camera poses, by introducing a coarse-to-fine registration for the position encoding. GARF [7] provides a Gaussian based activation functions on the coarse-to-fine registration for more robust camera pose refinement. SCNeRF [12] builds geometric loss optimization on the ray intersection re-projection error. Subsequent works [5, 16, 46] also incorperate the photometric loss from silhouette or mask, but requires accurate foreground segmentation. However, most of these approaches still depends on dense input views, which will not be effective for sparse scenarios.
Different from these previous approaches, our approach explores the view-consistent constrains on the explicit surface geometry of neural surface representation, which provides more effective cues than rendered depth [34] to jointly learn neural surfance and refine camera poses in an end-to-end manner, without need any shape prior [46] or RGB-D input [32, 3, 48].
3 SC-NeuS
Given sparse view images (as few as 3) with noisy camera poses of an object, we aim at reconstructing the surface represented by neural implicit function and jointly optimizing the camera poses. Specifically, for sparse input views with noisy camera poses (), we adopt to represent the object’s geometry as signed distance field (SDF) (, is the MLP parameter), and render its appearance using volume rendering from an extra radiance filed as provided by NeuS [35].
By introducing effective multi-view constraints across sparse views, we propose an new joint learning strategy, called SC-NeuS, for both signed distance field learning and camera poses optimization. Fig. 2 demonstrates the main pipeline of our SC-NeuS framework in an end-to-end learning manner.
From Multi-view Constraints to Geometry-consistent Surface Learning. Unlike the previous approaches [7, 18, 21, 44] that perform the joint deep implicit geometry learning and camera pose optimization using photometric loss across dense input views independently, we adopt to exploit multi-view constraints as extra effective regularization to constraint the surface learning. Due to the bias gap between the volume rendering integral and point-based SDF modeling [10], instead of relying on multi-view depth rendering prior from the neural surface to multi-view depth priors [6, 34, 10], we propose to utilize more multi-view regularizations directly from the explicit surface geometry of the neural surface for a better multi-view surface reconstruction. Our key observation is that the geometry cues (points or patches) locating on the shape surface should be consistently observed across multi-views, which is intuitively an effective constraints for geometry-consistent surface learning, especially in sparse scenarios.
Specifically, we first derive an fast differentiable point intersection on the explicit surface of signed distance filed (Sec. 3.1). Then we provide view-consistent losses for two kinds of on-surface geometry cues (3D sparse points and patches) based on our differentiable point intersection, including view-consistent re-projection loss and patch-warping loss (Sec. 3.2), to effectively regularize the joint learning of signed distance field and camera poses . Since the intersection derived by our approach is differentiable for both the neural surface parameters and camera poses , our neural surface learning can be performed in an end-to-end manner without any other supervisions.
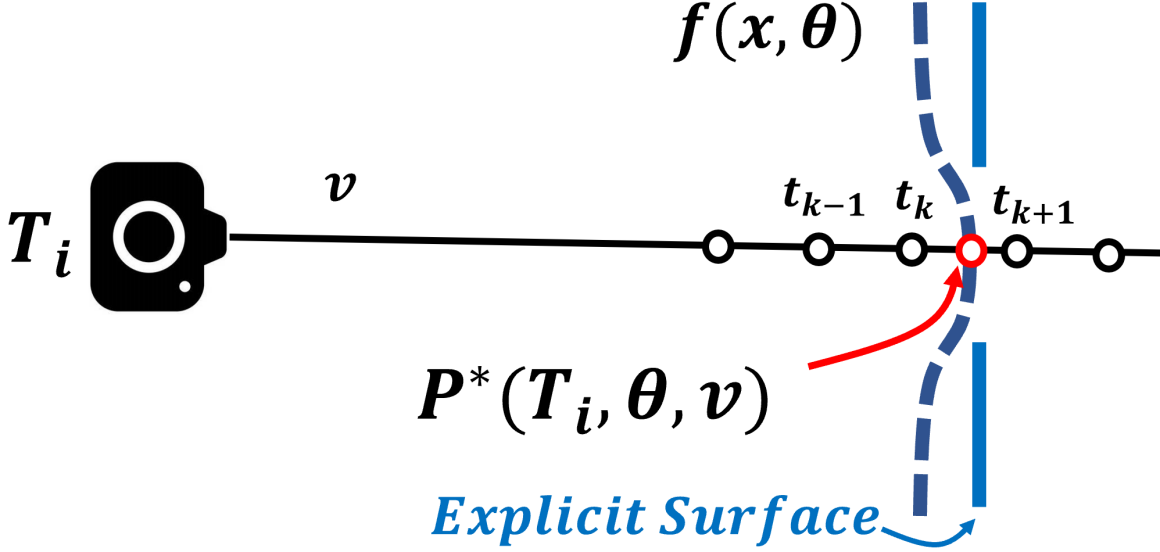
3.1 Differentiable On-surface Intersection
To enable multi-view consistent constraints, the essential requirement of the geometry cues is that they need locate on the explicit surface, i.e., the zero level set of the signed distance field . Considering a 2D feature point in the reference image with camera pose , we seek to compute its intersection point on the surface geometry of signed distance field . According to volume rendering of the signed distance function [22, 35], there exists a ray length value such that:
where and are the camera center point and casting ray of respectively.
Although IDR [44] have provided a differentiable intersection derivation for , however, which is somewhat too slow to enable an efficient neural surface learning. Therefore, we propose a new differentiable on-surface intersection for fast neural surface learning. Specifically, as shown in Fig. 3, we first uniformly sample points in the casting ray of 2D feature point with sampling depth value set . Then we find the depth value such that . Finally, we move along the casting ray to the on-surface intersection following:
| (1) |
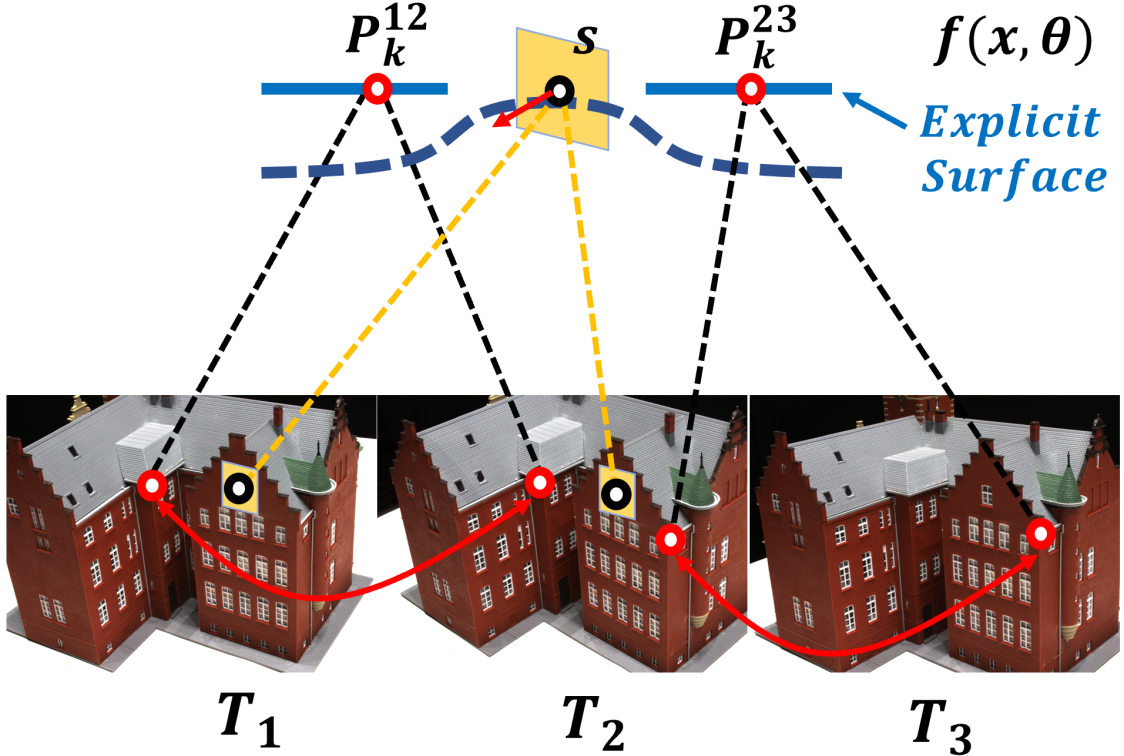
3.2 View-Consistent Loss
Based on our differentiable intersection, we further define effective losses to neural surface learning in the multi-view scenario. Specifically, we utilize two kinds of on-surface geometry cues, i.e., 3D sparse points and patches (Fig. 4), and formulate view-consistent losses for these on-surface geometry cues, including view-consistent re-projection loss and view-consistent patch-warping loss respectively.
View-consistent Re-projection Loss. Considering a pair of 2D feature correspondence () from reference image (camera pose ) and target image (camera pose ) with , we compute the on-surface intersection 3D point via our differentiable intersection. By re-projecting back to and , we get the re-projection location as , , where is the camera projection operator. For a geometry-consistent surface reconstruction, the re-projection error between and should be minimized. Then we formulate the view-consistent re-projection loss for all of possible sparse correspondence as:
View-consistent Patch-warping Loss. We also consider the on-surface patch (Fig. 4) to utilize the geometric structure constraints to further improve the neural surface learning. Similar to the patch warping in traditional MVS method [17, 30, 29], we warp the on-surface patch to multi-view images but in a differentiable way using our differentiable multi-view intersection. Specifically, for a small patch on the surface which is observed by image pair , we represent the plane equation of in the camera coordinate of the reference image as:
where is the differentiable multi-view intersection point from with camera poses , is the normal computed with automatic differentiation of the signed distance filed at . Suppose that the is projected to to obtain image patches respectively, for image pixel and its corresponding pixel , we have:
where is the homography matrix, , are the intrinsic camera matrix for image pair .
We use the normalization cross correlation (NCC) of patches () as the view-consistent patch-warping loss as :
where and donates the covariance and variance for color identity of patches () respectively.
3.3 Training Strategy
Based on the view-consistent losses, we formulate the objective function as:
| (2) |
with and are the view-consistent re-projection loss and patch-warping loss defined above, and and are the color rendering loss and Eikonal regularization loss proposed by NeuS [35] as:
where is the volume rendering image from to view .
So in summary, we propose to jointly learn the signed distance filed , radian field and camera poses to optimize the objective function in an end-to-end manner following:
| (3) |
Network Training. In the early stage during the network training, since the signed distance field doesn’t converge very well, we choose a warm-up strategy to assist the convergence. Specifically, for the differentiable on-surface intersection of 3D sparse point, we use the rendering depth information of the recent signed distance field to filter out outlier on-surface point intersection. Given a 2D feature point and its on-surface intersection point along casting ray , we compute its depth value [34] and get its 3D point re-projection . If the distance between and is larger than a threshold, we set to perform the joint learning. After the warm-up for a certain training epoch, we conduct the learning according to equation 3 until the final convergence for both signed distance field and camera poses .
4 Experiments and Analysis
To evaluate the effectiveness of our SC-NeuS, we conduct surface reconstruction experiments from sparse and noisy views of public dataset, by comparing with previous state-of-the-art approaches. Thereafter, we also give an ablation study and analysis of the main components in our approach to make a comprehensive understanding for our SC-NeuS.
Implementation details. We adopt the similar architecture of IDR [44] and NeuS [35] by using a MLP (8 hidden layers with hidden width of 256) for SDF (Signed Distance Function) and another MLP (4 hidden layers with hidden width of 256) for radiance filed . For 2D feature correspondence, we use the out-of-the-box key-point detection and extraction model, ASLFeat [20], and key-point feature matching model, SuperGlue [28]. We randomly sample 512 rays and select 256 2D correspondences per batch and train our model for 100K iterations on a single NVIDIA RTX3090 GPU.
| Translation | ||||||||||||||||
| Scan | 24 | 37 | 40 | 55 | 63 | 65 | 69 | 83 | 97 | 105 | 106 | 110 | 114 | 118 | 122 | Mean |
| Noisy Input | 28.03 | 43.79 | 27.47 | 47.88 | 20.64 | 10.17 | 11.94 | 57.06 | 39.78 | 39.85 | 50.93 | 47.04 | 30.19 | 6.87 | 28.79 | 32.70 |
| BARF | 42.30 | 56.48 | 17.08 | 46.44 | 13.11 | 0.72 | 21.69 | 48.69 | 3.33 | 48.34 | 44.98 | 46.16 | 22.76 | 1.03 | 13.22 | 28.42 |
| IDR | 41.87 | 41.76 | 43.42 | 42.67 | 1.12 | 0.39 | 0.82 | 1.12 | 10.15 | 2.95 | 59.49 | 47.74 | 46.70 | 0.62 | 27.13 | 24.53 |
| NeuS-BARF | 30.73 | 39.47 | 27.13 | 10.32 | 24.20 | 3.47 | 23.84 | 53.24 | 13.83 | 6.72 | 38.74 | 14.03 | 0.34 | 31.71 | 30.44 | 23.21 |
| NeuS-BARF∗ | 45.31 | 39.86 | 41.69 | 43.91 | 1.16 | 0.48 | 1.28 | 1.76 | 1.73 | 1.44 | 53.33 | 46.98 | 0.17 | 0.66 | 29.56 | 20.62 |
| Ours | 0.15 | 0.23 | 0.16 | 0.07 | 0.16 | 0.17 | 0.16 | 0.07 | 0.31 | 0.01 | 0.17 | 0.12 | 0.23 | 0.12 | 0.17 | 0.15 |
| Rotation (∘) | ||||||||||||||||
| Scan | 24 | 37 | 40 | 55 | 63 | 65 | 69 | 83 | 97 | 105 | 106 | 110 | 114 | 118 | 122 | Mean |
| Noisy Input | 22.41 | 14.32 | 19.94 | 18.90 | 14.55 | 21.26 | 15.62 | 18.12 | 15.46 | 15.46 | 27.55 | 18.64 | 24.41 | 10.81 | 21.17 | 18.57 |
| BARF | 21.42 | 19.45 | 18.36 | 19.38 | 25.64 | 3.60 | 15.15 | 32.07 | 1.28 | 14.91 | 23.36 | 19.38 | 29.89 | 1.07 | 22.82 | 17.85 |
| IDR | 27.37 | 33.45 | 24.82 | 21.59 | 4.02 | 0.55 | 0.67 | 1.66 | 2.67 | 0.52 | 51.26 | 21.09 | 22.25 | 2.70 | 45.99 | 17.37 |
| NeuS-BARF | 21.79 | 25.76 | 17.97 | 15.59 | 11.05 | 3.20 | 14.97 | 23.43 | 5.28 | 4.69 | 42.43 | 10.61 | 0.27 | 15.78 | 12.43 | 15.02 |
| NeuS-BARF∗ | 32.95 | 26.01 | 32.69 | 16.62 | 1.93 | 1.45 | 0.22 | 0.55 | 0.59 | 0.19 | 26.77 | 16.28 | 0.27 | 0.55 | 18.83 | 11.73 |
| Ours | 0.07 | 0.17 | 0.06 | 0.08 | 0.06 | 0.21 | 0.10 | 0.17 | 0.21 | 0.06 | 0.06 | 0.18 | 0.09 | 0.08 | 0.14 | 0.12 |
| Scan | 24 | 37 | 40 | 55 | 63 | 65 | 69 | 83 | 97 | 105 | 106 | 110 | 114 | 118 | 122 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BARF | 7.62 | 8.82 | 8.86 | 8.34 | 8.19 | 6.85 | 8.58 | 9.44 | 7.87 | 9.93 | 7.01 | 7.87 | 7.96 | 6.32 | 7.83 | 8.10 |
| IDR | 8.48 | 9.21 | 8.74 | 10.40 | 11.44 | 7.19 | 3.47 | 7.32 | 9.47 | 4.67 | 8.12 | 9.21 | 7.71 | 7.21 | 8.72 | 8.09 |
| NeuS-BARF | 7.93 | 7.89 | 8.51 | 9.39 | 9.07 | 8.53 | 8.23 | 8.78 | 9.77 | 8.31 | 9.33 | 6.35 | 8.88 | 7.59 | 9.68 | 8.55 |
| NeuS-BARF∗ | 9.22 | 9.90 | 8.31 | 9.16 | 9.60 | 5.94 | 3.75 | 7.04 | 5.64 | 2.37 | 8.59 | 9.00 | 1.10 | 3.47 | 8.67 | 6.78 |
| Ours | 1.07 | 2.14 | 1.55 | 1.38 | 1.31 | 2.03 | 0.81 | 2.95 | 1.02 | 1.39 | 1.30 | 1.62 | 0.37 | 0.88 | 1.37 | 1.41 |
4.1 Experimental Settings
Dataset. Similar with previous neural surface reconstruction approaches [12, 44, 35], we choose to evaluate our approach on the public DTU dataset [1] with 15 different object scan. The DTU dataset contains from 49 to 64 images at a resolution of for each object scan with known camera intrinsic matrix and ground truth camera poses. For sparse views, we follow [19] and [18] to randomly select as few as 3 views for each object scan, and then synthetically perturb its camera pose with an additive Gaussian noise , thus collecting a sparse version of DTU dataset for the subsequent evaluation. Besides, we also evaluate on 7 challenging scenes from low-res set of the BlendedMVS dataset [42] which includes images at a resolution of . Similar to pre-processing as like our DTU dataset, we also select 3 views from them and obtain their noisy initial poses.
Baselines. We compare our approach with previous state-of-the-art approaches which also perform neural surface reconstruction by joint learning of neural surface and camera poses, including BARF [18]and IDR [44]. Besides, although NeuS [35] doesn’t conduct camera pose optimization, since it is a state-of-the-art neural surface reconstruction approach, we also compare our approach with NeuS by incorporating the coarse-to-fine strategy of BARF [18], called “NeuS-BARF”, to enable a fair comparison. Since IDR use an extra object mask for neural surface learning, for fair comparison of IDR and NeuS-BARF, we additionally conduct an experiment by using extra object mask supervision for NeuS-BARF, named “NeuS-BARF*”, during the subsequent evaluations.

4.2 Evaluation on DTU Dataset
Camera Pose Comparison. Table 1 demonstrates the average RMSE accuracy (including both translation and rotation error) between the estimated camera poses and the ground truth camera poses on DTU dataset, using different comparing approaches, including BARF, IDR, NeuS-BARF, NeuS-BARF* and ours respectively. Among all the comparing approaches, the NeRF-like approach BARF, achieves worse RMSE accuracy than the other approaches. This makes sense since other approaches (including our approach) adopt the signed distance field to represent the object’s geometry, which is more powerful than the radiance filed used in BARF. Although IDR and NeuS-BARF (NeuS-BARF*) achieve various RMSE accuracy in each object scan of DTU dataset respectively, in average they achieve the same level of RMSE accuracy, which means they perform similar camera pose estimation quality.
In contrast, our approach significantly outperforms all the other baselines in the RMSE accuracy (in both the translation and rotation errors) for camera pose estimation. This shows the multi-view consistent constraints used in our SC-NeuS takes effects for camera pose estimation, than the other baseline approaches which performs the camera pose optimization along with the neural surface learning with single-view independent regularization.
Surface Reconstruction Quality. We also compare the surface reconstruction quality between the different comparing approaches. Table 2 demonstrates the quantitative results on Chamfer Distance metric using different approaches evaluated on DTU dataset. Similarly, our approach achieve consistently much better Chamfer Distance accuracy than the other comparing approaches. Fig. 5 illustrates some visual comparison results of the comparing approaches. Even though BARF can achieve acceptable camera pose estimation quality, it still fails to achieve fine surface reconstruction results (see the first row of Fig. 5).
Besides, due to lack of extra mask object supervision, NeuS-BARF can’t achieve accurate enough camera pose estimation and thus fails to reconstruct fine object surface. This demonstrates that coarse-to-fine position embedding proposed in BARF is not effective to sparse view setting, even utilizing the neural signed distance filed representation as like NeuS. In contrast, our approach choose view-consistent constraints to regularize the joint learning of neural surface representation and camera pose, leading to geometry-consistent surface reconstruction with fine-grained details. Please see the fine-grained detail reconstruction by our approach, which is also better than the state-of-the-art neural surface reconstruction approach like NeuS and SparseNeuS, even with ground truth camera poses as input (Fig. 5). Please refer to our supplementary materials for more comparing results.

4.3 Evaluation on BlendedMVS Dataset
Except from the DTU dataset, we also perform evaluation on BlendedMVS dataset to see how our approach behave across different kinds of datasets. Fig. 6 shows some visual comparing surface reconstruction results using different comparing approaches, including NeuS-BARF, NeuS-BARF*, IDR and our approach. According to the comparison, our approach can achieve much better surface reconstruction quality with fine-grained details than the other approaches. Here we don’t include BARF for visual comparison, since BARF fails to converge in most of the comparing cases. Please refer to our supplementary materials for more quantitative and qualitative comparing results using different approaches on BlendedMVS dataset.
4.4 Ablation and Analysis
The re-projection loss and patch-warping loss serve as two main components of our approach. We conduct an ablation study experiment, to see how these two losses take effect on the final quality of both surface reconstruction and camera pose estimation.

| Translation | Rotation (∘) | CD | |
|---|---|---|---|
| w/o | 22.71 | 11.77 | 6.44 |
| w/o | 0.23 | 0.30 | 3.44 |
| Full | 0.15 | 0.12 | 1.41 |
View-consistent Re-projection. We first implement a variant version of our full system without using the view-consistent re-projection loss, termed as ’w/o ’, and perform the surface reconstruction on the DTU dataset. Table 3 shows the average RMSE accuracy for camera pose estimation quality and CD accuracy for the surface reconstruction quality for ’w/o ’ and our full system (termed as ’Full’). We can see there are large accuracy decrease for both RMSE and CD between ’w/o ’ and ’Full’ systems. This means the view-consistent re-projection loss serves major contribution in our SC-NeuS for the final geometry-consistent surface reconstruction and accurate camera pose estimation. But please note that ’w/o ’ still outperforms other comparing approaches including BARF, IDR and NeuS-BAFR, by achieving better average RMSE accuracy and CD accuracy in Table 1 and 2.
View-consistent Patch-warping. We also implement a variant system without using the view-consistent patch-warping loss, termed as ’w/o ’. According to the average RMSE accuracy and CD accuracy comparison between ’w/o ’ and ’Full’ in Table 3, we can see that ’w/o ’ also achieve worse accuracy values than ’Full’ in both RMSE for camera pose estimation and CD for surface reconstruction quality, even thougth the quality decreases are not that much compared with those from ’w/o ’ to ’Full’.
Fig. 7 shows the visual comparing surface reconstruction results of two example from DTU dataset, using ’w/o ’, ’w/o ’ and ’Full’ respectively. We can see there are certain surface quality decrease for our full system (’Full’) without using the view-consistent re-projection loss (’w/o ’). Even though our approach can achieve fine surface reconstruction without using view-consistent patch-warping loss (see the results of ’w/o ’), we can obvious fine-grained details enhancement by adding the view-consistent loss to our full system (see the results of ’Full’). This means that view-consistent patch-warping loss takes more effective for fine-grained details, while view-consistent re-projection loss works better to boost up the joint learning quality of neural surface and camera pose.
4.5 Limitation and Discussion
Our approach’s first limitation is that influence from the quality of 2D feature point’s matching. Without enough feature point matching in challenging cases like low texture or light changing, our approach couldn’t perform well for nice surface reconstruction results. Large camera poses variation between sparse views would also make our approach failed for feasible joint optimization. In the further, we would like to use more robust explicit surface priors for high reliable neural surface reconstruction.
5 Conclusion
Joint learning for the neural surface representation and camera pose remains to be a challenging problem, especially for sparse scenarios. This paper propose a new joint learning strategy, called SC-NeuS, which explores multi-view constraints directly from the explicit geometry of the neural surface. Compared with previous neural surface reconstruction approaches, our SC-NeuS achieves consistently better surface reconstruction quality and camera pose estimation accuracy, for geometry-consistent neural surface reconstruction results with fine-grained details. We hope that our approach can inspire more efforts to the neural surface reconstruction from sparse view images, to enable more feasible real-world applications in this community.
References
- [1] Henrik Aanæs, Rasmus Ramsbøl Jensen, George Vogiatzis, Engin Tola, and Anders Bjorholm Dahl. Large-scale data for multiple-view stereopsis. IJCV., 120(2):153–168, 2016.
- [2] Matan Atzmon and Yaron Lipman. Sal: Sign agnostic learning of shapes from raw data. In IEEE CVPR, pages 2565–2574, 2020.
- [3] Dejan Azinović, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. In IEEE CVPR, pages 6290–6301, 2022.
- [4] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In IEEE CVPR, pages 5470–5479, 2022.
- [5] Mark Boss, Andreas Engelhardt, Abhishek Kar, Yuanzhen Li, Deqing Sun, Jonathan T Barron, Hendrik Lensch, and Varun Jampani. Samurai: Shape and material from unconstrained real-world arbitrary image collections. In Advances in Neural Information Processing Systems, 2022.
- [6] Anpei Chen, Zexiang Xu, Fuqiang Zhao, Xiaoshuai Zhang, Fanbo Xiang, Jingyi Yu, and Hao Su. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. In IEEE CVPR, pages 14124–14133, 2021.
- [7] Shin-Fang Chng, Sameera Ramasinghe, Jamie Sherrah, and Simon Lucey. Gaussian activated neural radiance fields for high fidelity reconstruction and pose estimation. In ECCV, pages 264–280. Springer, 2022.
- [8] François Darmon, Bénédicte Bascle, Jean-Clément Devaux, Pascal Monasse, and Mathieu Aubry. Improving neural implicit surfaces geometry with patch warping. In IEEE CVPR, pages 6260–6269, 2022.
- [9] Kangle Deng, Andrew Liu, Jun-Yan Zhu, and Deva Ramanan. Depth-supervised nerf: Fewer views and faster training for free. In IEEE CVPR, pages 12882–12891, 2022.
- [10] Qiancheng Fu, Qingshan Xu, Yew-Soon Ong, and Wenbing Tao. Geo-neus: Geometry-consistent neural implicit surfaces learning for multi-view reconstruction. In Advances in Neural Information Processing Systems.
- [11] Rasmus Jensen, Anders Dahl, George Vogiatzis, Engin Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. In IEEE CVPR, pages 406–413, 2014.
- [12] Yoonwoo Jeong, Seokjun Ahn, Christopher Choy, Anima Anandkumar, Minsu Cho, and Jaesik Park. Self-calibrating neural radiance fields. In IEEE CVPR, pages 5846–5854, 2021.
- [13] Chiyu Jiang, Avneesh Sud, Ameesh Makadia, Jingwei Huang, Matthias Nießner, Thomas Funkhouser, et al. Local implicit grid representations for 3d scenes. In CVPR, pages 6001–6010, 2020.
- [14] Abhishek Kar, Christian Häne, and Jitendra Malik. Learning a multi-view stereo machine. Advances in neural information processing systems, 30, 2017.
- [15] Mijeong Kim, Seonguk Seo, and Bohyung Han. Infonerf: Ray entropy minimization for few-shot neural volume rendering. In IEEE CVPR, pages 12912–12921, 2022.
- [16] Zhengfei Kuang, Kyle Olszewski, Menglei Chai, Zeng Huang, Panos Achlioptas, and Sergey Tulyakov. Neroic: neural rendering of objects from online image collections. ACM Transactions on Graphics (TOG), 41(4):1–12, 2022.
- [17] Patrick Labatut, Jean-Philippe Pons, and Renaud Keriven. Efficient multi-view reconstruction of large-scale scenes using interest points, delaunay triangulation and graph cuts. In IEEE ICCV, pages 1–8. IEEE, 2007.
- [18] Chen-Hsuan Lin, Wei-Chiu Ma, Antonio Torralba, and Simon Lucey. Barf: Bundle-adjusting neural radiance fields. In IEEE CVPR, pages 5741–5751, 2021.
- [19] Xiaoxiao Long, Cheng Lin, Peng Wang, Taku Komura, and Wenping Wang. Sparseneus: Fast generalizable neural surface reconstruction from sparse views. In ECCV, pages 210–227. Springer, 2022.
- [20] Zixin Luo, Lei Zhou, Xuyang Bai, Hongkai Chen, Jiahui Zhang, Yao Yao, Shiwei Li, Tian Fang, and Long Quan. Aslfeat: Learning local features of accurate shape and localization. In IEEE CVPR, pages 6588–6597, 2020.
- [21] Quan Meng, Anpei Chen, Haimin Luo, Minye Wu, Hao Su, Lan Xu, Xuming He, and Jingyi Yu. Gnerf: Gan-based neural radiance field without posed camera. In IEEE ICCV, pages 6351–6361, 2021.
- [22] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
- [23] Michael Niemeyer, Jonathan T Barron, Ben Mildenhall, Mehdi SM Sajjadi, Andreas Geiger, and Noha Radwan. Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs. In IEEE CVPR, pages 5480–5490, 2022.
- [24] Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. In IEEE ICCV, pages 5589–5599, 2021.
- [25] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. In IEEE CVPR, pages 165–174, 2019.
- [26] Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks. In ECCV, pages 523–540. Springer, 2020.
- [27] Barbara Roessle, Jonathan T Barron, Ben Mildenhall, Pratul P Srinivasan, and Matthias Nießner. Dense depth priors for neural radiance fields from sparse input views. In IEEE CVPR, pages 12892–12901, 2022.
- [28] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In IEEE CVPR, pages 4937–4946, 2020.
- [29] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In IEEE CVPR, pages 4104–4113, 2016.
- [30] Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In ECCV, pages 501–518. Springer, 2016.
- [31] Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. In ACM SIGGRAPH, pages 835–846. 2006.
- [32] Edgar Sucar, Shikun Liu, Joseph Ortiz, and Andrew J Davison. imap: Implicit mapping and positioning in real-time. In IEEE CVPR, pages 6229–6238, 2021.
- [33] Alex Trevithick and Bo Yang. Grf: Learning a general radiance field for 3d representation and rendering. In IEEE ICCV, pages 15182–15192, 2021.
- [34] Prune Truong, Marie-Julie Rakotosaona, Fabian Manhardt, and Federico Tombari. Sparf: Neural radiance fields from sparse and noisy poses. arXiv e-prints, pages arXiv–2211, 2022.
- [35] Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. Advances in Neural Information Processing Systems, 34:27171–27183, 2021.
- [36] Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul P Srinivasan, Howard Zhou, Jonathan T Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. In IEEE CVPR, pages 4690–4699, 2021.
- [37] Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, and Victor Adrian Prisacariu. NeRF: Neural radiance fields without known camera parameters. arXiv preprint arXiv:2102.07064, 2021.
- [38] Yi Wei, Shaohui Liu, Yongming Rao, Wang Zhao, Jiwen Lu, and Jie Zhou. Nerfingmvs: Guided optimization of neural radiance fields for indoor multi-view stereo. In IEEE CVPR, pages 5610–5619, 2021.
- [39] Qingshan Xu and Wenbing Tao. Multi-scale geometric consistency guided multi-view stereo. In IEEE CVPR, pages 5483–5492, 2019.
- [40] Qingshan Xu and Wenbing Tao. Pvsnet: Pixelwise visibility-aware multi-view stereo network. arXiv preprint arXiv:2007.07714, 2020.
- [41] Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. In ECCV, pages 767–783, 2018.
- [42] Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In IEEE CVPR, pages 1787–1796, 2020.
- [43] Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems, 34:4805–4815, 2021.
- [44] Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. Multiview neural surface reconstruction by disentangling geometry and appearance. Advances in Neural Information Processing Systems, 33:2492–2502, 2020.
- [45] Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In IEEE CVPR, pages 4578–4587, 2021.
- [46] Jason Zhang, Gengshan Yang, Shubham Tulsiani, and Deva Ramanan. Ners: neural reflectance surfaces for sparse-view 3d reconstruction in the wild. Advances in Neural Information Processing Systems, 34:29835–29847, 2021.
- [47] Jason Y Zhang, Deva Ramanan, and Shubham Tulsiani. Relpose: Predicting probabilistic relative rotation for single objects in the wild. In ECCV, pages 592–611. Springer, 2022.
- [48] Zihan Zhu, Songyou Peng, Viktor Larsson, Weiwei Xu, Hujun Bao, Zhaopeng Cui, Martin R Oswald, and Marc Pollefeys. Nice-slam: Neural implicit scalable encoding for slam. In IEEE CVPR, pages 12786–12796, 2022.