Sampling-based Distributed Training with Message Passing Neural Network
Abstract
In this study, we introduce a domain-decomposition-based distributed training and inference approach for message-passing neural networks (MPNN). Our objective is to address the challenge of scaling edge-based graph neural networks as the number of nodes increases. Through our distributed training approach, coupled with Nyström-approximation sampling techniques, we present a scalable graph neural network, referred to as DS-MPNN (D and S standing for distributed and sampled, respectively), capable of scaling up to nodes. We validate our sampling and distributed training approach on three cases: (a) a Darcy flow dataset (b) steady RANS simulations of 2-D airfoils and (c) steady RANS simulations of 3-D step flow, providing comparisons with both single-GPU implementation and node-based graph convolution networks (GCNs). The DS-MPNN model demonstrates comparable accuracy to single-GPU implementation, can accommodate a significantly larger number of nodes compared to the single-GPU variant (S-MPNN), and significantly outperforms the node-based GCN.
1 Introduction and Related Work
The application of machine learning algorithms to build surrogates for partial differential equations (PDEs) has seen a significant push in recent years Li et al. (2020b); Raissi et al. (2019); Lu et al. (2021); Pfaff et al. (2020). While the majority of these ML models for PDEs surrogate modeling are CNN-based (Zhu et al., 2019; Ranade et al., 2022; Ren et al., 2022), the introduction of graph neural networks (Kipf & Welling, 2017) has made graph-based modeling increasingly common. Traditional numerical methods for real-world applications predominantly rely on mesh-based unstructured representations of the computational domains Mavriplis (1997) owing to the ease of (a) discretization of complex domains and (b) extension to adaptive mesh refinement strategies to capture multi-scale physical phenomenon like turbulence, boundary layers in fluid dynamics, etc. These mesh-based unstructured formulations can be seamlessly formulated on graphs. Furthermore, a graph-based representation eliminates the need for interpolating data onto a structured Euclidean grid – a step inherent in CNNs, further reducing cost and error. In recent years, these graph-based models have also been applied to crucial domains like weather modeling (Lam et al., 2022), biomedical science (Fout et al., 2017), computational chemistry (Gilmer et al., 2017; Duvenaud et al., 2015), etc.
From the perspective of physical system dynamics modeling, we can divide the GNN-based methods into two broad categories: (a) node-based approaches and (b) edge-based approaches. The node-based approaches, including graph convolution networks (GCNs) (Kipf & Welling, 2017), GraphSAGE (Hamilton et al., 2017), and graph attention networks (GATs) (Veličković et al., 2018), are easier to scale with an increasing number of elements in an unstructured grid setting. However, they lack the mechanism of message-passing among nodes which is crucial to the modeling of spatial relationships between the nodes in complex PDEs. Hence, the edge-based graph methods dominate the paradigm of graph-based modeling for physical systems, such as Graph Network-based Simulators (Sanchez-Gonzalez et al., 2020), and its evolution MeshGraphNets (MGN) (Pfaff et al., 2020). Pfaff et al. (2020) indicate that these edge-based graph methods outperform node-based GCNs in accuracy and stability, and can be applied to a wide variety of simulations. Another approach to edge-based methods for PDE modeling is message-passing neural networks (Gilmer et al., 2017; Li et al., 2020a) where the input and the output solution space are invariant to mesh grids and independent of discretization (Li et al., 2020a). Message-passing neural networks (MPNN) (Simonovsky & Komodakis, 2017) condition weights around the vertices based on edge attributes and have properties to learn the PDE characteristics from a sparsely sampled field.
While edge-based methods are accurate in modeling physical systems, their memory requirement scales with the number of edges in a mesh. Hence these methods do not scale for modeling realistic physical problems where the number of nodes can be substantially higher (). Bonnet et al. (2022b) attempted to solve this issue by randomly sampling a set of nodes and edges based on Nyström approximation (Li et al., 2020a) and memory constraints of the GPUs available, thus creating a sparse domain. The sampling method yields similar errors as modeling complete graphs. Despite many attempts, edge-based methods, especially MPNNs, remain memory-intensive, constrained by the current limits of single GPU memory. Strönisch et al. (2023) proposed an approach implementing multi-GPU utilization for MeshGraphNets (Pfaff et al., 2020). In their methodology, the domain is partitioned across various GPUs, enabling inter-node communication. However, this communication is limited to node-based features within the latent space, excluding interaction among edge-based features. The errors observed in the multi-GPU setup proposed by Strönisch et al. (2023) were notably higher compared to their single GPU training. This highlights the imperative need to devise methodologies for training edge-based graph models on multi-GPU setups without compromising accuracy.
We present a sampling-based distributed MPNN (DS-MPNN) that involves partitioning the computational domain (or graph) across multiple GPUs, facilitating the scalability of edge-based MPNN to a large number of nodes. Here, ‘distributed’ implies partitioned spatial domains that are put on different GPUs which can be on the same or different machines. This scalability holds significant practical value for the scientific community. We combine traditional domain decomposition techniques used in engineering simulation and message-passing among GPUs to enable the training of message-passing neural networks for physical systems with no or minimal loss in accuracy.
Our two key contributions are:
-
1.
We devise a method inspired by domain-decomposition based parallelization techniques for training and inference of MPNN on multiple GPUs with no or minimal loss in accuracy.
-
2.
We demonstrate the scaling and acceleration of MPNN training for graphs with DS-MPNN to nodes through the combination of multi-GPU parallelization and node-sampling techniques
2 Model Description
The message-passing graph model used in this work uses a convolutional graph neural network with edge conditioning (Simonovsky & Komodakis, 2017) together with random sampling (Li et al., 2020a; Bonnet et al., 2022b).
2.1 Graph construction
Consider a set of nodes on the domain . A subset is formed by randomly sampling nodes, with . Graph kernels are constructed using these sampled nodes as centers within a radius . Edge connections are established between node within a specified radius and the respective central nodes . For edges , edges are further randomly sampled from . The representation of this graph kernel construction is shown in figure 1. Each node and the connecting edges are assigned attributes or labels, and , respectively. In PDE modeling, the nodal and edge attributes can represent the initial functional space or the initial conditions. Edge attributes in this work are derived by calculating the relative difference between node coordinates and attributes of nodes and .
At the core of this model is the concept of using edge-conditioned convolution (Simonovsky & Komodakis, 2017) to calculate the node attribute in one message-passing step by summing the product of weights , based on the edge attributes and neighboring node attributes in , giving
| (1) |
Here, are neural network parameters. corresponds to the message-passing step among ‘radius hops’ . is updated based on new values of . Edge conditioning in the convolutional process renders the model adept at handling non-uniform grid points or graph structures, typical in physics simulations involving boundary layers and shocks, where grid density varies significantly across the field.
2.2 Model algorithm
The current model, adapted from Bonnet et al. (2022b), is composed of an encoder (), decoder () and message-passing network (). This encoder transforms the initial node attributes, , where indicates the initial or lower-level state of these attributes, into a latent representation. The latent space representation of node attributes at the -th message-passing step is represented as , with signifying the latent representation of the node attribute . The transformation process is governed by the following equations:
| (i) | ||||
| (ii) | ||||
| (iii) | ||||
| (iv) |
The process iterates through equations (ii) to (iv) for a total of message-passing steps, representing radius hops in the graph, to update the node and edge attributes. The objective of the neural network denoted as , is to learn the mapping from the initial function space, , to the final function space , giving:
| (2) |
This framework facilitates the application of graph neural networks in solving PDEs by iteratively updating and transforming node and edge attributes within the graph structure.

3 Methodology
We now turn to DS-MPNN, our framework devised to train edge-based graphs on many GPU systems. DS-MPNN incorporates communication strategies tailored for MPNN-based graph methodologies across multiple GPUs. In this framework, prior to the formulation of a graph kernel , the computational domain is partitioned into distinct subdomains and each subdomain is allocated to a GPU. Each GPU is allocated a distinct subdomain . This arrangement entails dividing into (total number of GPUs available for parallelization) subdomains , with each subdomain featuring an extended overlap of length . In all our runs, unless explicitly mentioned, we set to ensure that nodes at the edges of any given spatial partition have complete kernels This extended overlap is pivotal for ensuring comprehensive kernel construction at the interior edges of the domain, thereby circumventing the issues of incomplete kernel formation that can result in discontinuities in the predicted solutions across the subdomain boundaries. This approach is depicted in figure 1
In the framework described in section 2.2, each domain, accompanied by its kernels, is allocated to distinct GPUs for a series of hops. The methodology facilitates inter-GPU communication of the latent space node attributes through overlapping regions. As depicted in figure 2, the overlap area of a given domain is updated from the neighboring domains’ interiors. Concurrently, the decoder’s output in the physical space, denoted as , updates the edge attributes correspondingly.
The computational graph accumulates gradients during the radius hops that are computed in relation to the total loss function across the entire computational domain. This computation encompasses a summation of the domains’ interior points across all GPUs. Following this, an aggregation of the gradients from each GPU is performed, leading to a synchronous update of the neural network parameters across all the GPUs - , utilizing the aggregated gradient. For interested readers, the detailed DS-MPNN training mechanism is provided in the Appendix.
During testing, the algorithm divides the domains into smaller, randomly selected sub-domains along with its overlapping regions. These are sequentially fed into the trained model. They are reassembled in post-processing to form the original output dimension . The inference time of these surrogate models is orders of magnitude smaller than the time required to solve the PDEs, as we will show in the subsequent sections.
We investigate a range of PDEs for both structured and unstructured meshes, incorporating a diverse array of mesh sizes. The core of our study involves a detailed comparative analysis of two distinct computational implementations: a single-GPU implementation S-MPNN and the multi-GPU DS-MPNN. The multi-GPU implementation leverages up to 4 GPUs i.e., DS-MPNN4. This scalability is not limited to the four-GPU configuration tested; our methodology is designed to be flexible with respect to GPU count, allowing for expansion beyond the tested range. Such adaptability is essential for handling a variety of computational demands and hardware configurations.
In the multi-GPU setup, domains are equally partitioned based on their coordinates, and a distributed communication package from PyTorch facilitates inter-node communication (Paszke et al., 2019). The neural network architecture employed in this study consists of a 3-layer encoder and a 3-layer decoder, augmented by a convolution kernel. The network, with approximately k parameters, is utilized consistently across all experiments involving DS-MPNN and the baseline Graph Convolution Networks (GCN) This uniformity ensures parameter consistency across different models, and all models are implemented using PyTorch geometric package (Fey & Lenssen, 2019). GCN here uses 6 hidden layers with a size of 378. Post-encoding, the latent space representation for all experiments apart from parametric studies maintains a consistent dimensionality of 32 attributes. Optimization is conducted using the Adam optimizer, complemented by the OneCycleLR scheduler (Smith & Topin, 2019), to enhance learning efficiency and effectiveness.

4 Experiments
4.1 Darcy Flow (Structured Data)
We explore an example utilizing a structured grid, specifically focusing on 2-D Darcy flow that describes the fluid flow through a porous medium. A detailed description of Darcy flow equations is provided in the Appendix. The experimental setup comprises 1024 training samples, each initialized differently, and 30 test samples. Each sample is structured on a grid of , with sampled nodes . The attributes of each node consist of two-dimensional grid coordinates ( and ) and the field values of , resulting in node and edge attributes with dimensions . The graph kernel employed has a radius of 0.2, and the maximum number of edges allowed per node is set at . The model is trained over 200 epochs, with each domain in the test case being randomly sampled five times. Evaluations were performed using both a single GPU framework and a multi-GPU configuration, wherein the computational domain was partitioned into four equivalent segments. The number of radius hops employed in this context, denoted by , was set to eight. The test error was quantified using root mean squared error (RMSE), as defined in equation 3:
| (3) |
| Method | GCN | S-MPNN | DS-MPNN4 |
|---|---|---|---|
| Test Error | 3.3E-4 | 7.44E-6 | 7.60E-6 |
Table 1 compares the performance of GCN and MPNN models on the Darcy flow dataset, using both single and 4-GPU setups. GCN under-performs relative to MPNN, highlighting the superiority of edge-based methods in PDE surrogate modeling, even for simpler datasets. This discrepancy is largely due to GCN’s omission of edge representation, a key feature in node-based models. Furthermore, the DS-MPNN model shows comparable results on both single and 4-GPU configurations. The minor variance in test error between these two setups might result from the segmentation of the computational graph across different domains.
| Radius hops () | |||
|---|---|---|---|
| Test Error | 0.029 | 0.024 | 0.023 |
| Radius () | |||
| Test Error | |||
| Sampled edges | |||
| Test Error | |||
| Sampled nodes () | |||
| Test Error |
For the Darcy flow dataset, similar to the work by Sanchez-Gonzalez et al. (2020) and Pfaff et al. (2020), we study the effect of changing crucial hyperparameters for a graph-based model on the performance of our model evaluated using loss. These key hyperparameters include (a) total number of hops (), (b) sampling radius (), (c) number of edges (), and (d) number of nodes (). Table 2 shows that increasing these four hyperparameters helps improve the model’s accuracy, albeit showing saturation in accuracy beyond a certain threshold. This observation is in agreement with previous works on edge-based techniques by Pfaff et al. (2020) and Sanchez-Gonzalez et al. (2020). The key point to note here is that for problems with higher complexity, increasing any of these four hyperparameters will result in an increased GPU memory consumption, underlying the need for a parallelized training paradigm for graph-based models like ours.
4.2 AirfRANS (Unstructured Data)
The AirfRANS datasets comprise two distinct unstructured sets, each varying in complexity and scale. The first dataset, as described by Bonnet et al. (2022b), contains approximately 15,000 nodes per sample, while the second, a higher-fidelity version detailed in Bonnet et al. (2022a) under “AirfRANS,” has approximately 175,000 nodes per sample. The DS-MPNN model efficiently processes both datasets, under various Reynolds numbers and attack angles, highlighting its versatility in diverse and complex aerodynamic simulations. A detailed description of PDEs describing the AirfRANS dataset is provided in the Appendix.
4.2.1 Low-fidelity AirfRANS dataset
The low-fidelity dataset includes a diverse array of airfoils subjected to varying angles of attack, ranging between (,). This dataset also incorporates a spectrum of Reynolds numbers, specifically from to . For this investigation, the test error is quantified RMSE in equation 3, while mean square error is used as the criterion for optimization during training. The current experimental run comprises training samples and test samples. Each sample in the dataset is characterized by input node attributes, which include grid coordinates, inlet velocity, pressure, and the distance function between the surface and the node, denoted as . The edge attributes, denoted as , include velocity and pressure attributes. These attributes are updated after each radius hop, reflecting changes based on the model output , which comprises the velocity components, pressure, and turbulent viscosity. For this specific case, the number of nodes sampled is and the number of edges . The training process spanned over epochs, with each test dataset being sampled times.
Figure 3(a) illustrates the training loss trajectories of S-MPNN and DS-MPNN4. The convergence patterns, indicated by the overlapping trend in training loss, suggest that DS-MPNN4 achieves a level of training convergence comparable to that of S-MPNN. Furthermore, upon adopting an alternative scheduler strategy—specifically, reducing the learning rate once the training loss plateaus, a similar convergence pattern is observed in figure 3(b). This consistency underscores the training robustness of the DS-MPNN model.

(a) Scheduler: One cycle learning rate

(b) Scheduler: Dropping learning rate on plateau
| Method | GCN | S-MPNN | DS-MPNN2 | DS-MPNN4 |
|---|---|---|---|---|
| RMSE | 0.347 | 0.094 | 0.097 | 0.096 |
Table 3 shows the test RMSE for GCN, single-GPU MPNN (S-MPNN), and DS-MPNN implemented on 2 and 4 GPUs. The losses are very similar between the single GPU and DS-MPNN runs, underscoring the validity of our algorithm and its effectiveness in handling unstructured grid representation distributed over multiple GPUs. Similar to the Darcy flow results 4.1, GCN performs worse than MPNNs. However, the accuracy of GCN deteriorates further for the AirfRANS dataset compared to the structured Darcy dataset, highlighting the challenges of using node-based methods for complex PDE modeling.

Figure 4 presents a comparative analysis of various models concerning the two velocity components and pressure. It is observed that the performance of the models utilizing a single GPU (S-MPNN) and four GPUs (DS-MPNN4) is comparable. However, the GCN model exhibits inferior predictions, characterized by incorrect flow features around the airfoil across all fields.
| Test RMSE | 0.124 | 0.096 | 0.097 | 0.097 |
|---|
Table 4 presents the test RMSE errors for various extended overlap lengths () for a fixed kernel radius . As the overlap radius increases from to , the error decreases significantly. However, beyond , the variations are minimal. As previously mentioned in section 3, we set in all our experiments unless explicitly mentioned. This is done to ensure that nodes at the edges of any given spatial partition have complete kernels. It should be noted that the kernel radius is an use-case-specific hyperparameter.
4.2.2 High-fidelity AirfRANS dataset
For the high-fidelity mesh analysis, we employ the standardized AirfRANS dataset as detailed by Bonnet et al. (2022a). Our focus in this study is to show the effectiveness of DS-MPNN across various network hyperparameters rather than to achieve the best accuracy. Hence, we use a specific subset of the original AirfRANS dataset, termed as the ‘scarce’ dataset by the authors, that consists of 180 training samples and 20 test samples. The dataset encompasses a Reynolds number variation between 2 million and 6 million, and the angle of attack ranges from to . The input node attributes bear resemblance to the low-fidelity dataset 4.2.1 but with an expanded dimension of unit surface outward-pointing normal for the node , and the edge attributes are characterized by . The model output is denoted as . Table 5 presents the test error, quantified as the Root Mean Square Error (RMSE) loss, where the dataset is sampled once. These results indicate that the DS-MPNN framework maintains its efficacy even with a substantial increase in the node count in the dataset, consistently performing well across different GPU configurations. In contrast, the GCN exhibits poorer performance under similar conditions. Additionally, an experiment involving a network configuration without inter-GPU communication, but with distinct domains distributed across GPUs, resulted in divergent training outcomes which are different from Strönisch et al. (2023) where no communication model worked better. This underscores the critical role of communication between GPUs for maintaining model stability and performance. Table 5 shows that using the DS-MPNN framework with more GPUs increases training and inference speeds. This is because each GPU deals with fewer edges and nodes than it would if the entire domain was on a single GPU, which speeds up model execution. The exploration of scalability and the associated communication overhead for DS-MPNN is comprehensively addressed in Section A.
| Method | GCN | S-MPNN | DS-MPNN4 |
|---|---|---|---|
| Test Error | 0.32 | 0.17 | 0.18 |
| Train Time (s/epoch) | 68 | 197 | 113 |
| Inference Time (s) | 7.05 | 17.7 | 11.7 |
Training cases with 3.5 million parameter models and different hyperparameters are showcased when trained on 4 GPUs for 400 epochs. On 3.5 million parameters, a single GPU has a memory overflow on Nvidia RTX6000, when trained on nodes, sampled edges, and radius hops, but as we increase the number of nodes, which is possible only through DS-MPNN, we see that the RMSE test accuracy increases in table 4.2.2. Similarly, table 7, demonstrates the need for DS-MPNN to enable the sampling of a higher number of edges.
| Nodes | Hops | Edges | RMSE Loss |
|---|---|---|---|
| 3000 | 4 | 64 | 0.27 |
| 6000 | 4 | 64 | 0.21 |
| 10000 | 4 | 64 | 0.20 |
| Nodes | Hops | Edges | RMSE Loss |
|---|---|---|---|
| 6000 | 4 | 16 | 0.26 |
| 6000 | 4 | 32 | 0.24 |
| 6000 | 4 | 64 | 0.21 |
4.3 Three-dimensional step flow dataset
To assess the applicability of DS-MPNN for a three-dimensional problem, a canonical dataset of flow over a backward-facing step is introduced. Each flow configuration includes approximately nodes with varying step heights (from to of the channel height) and is solved using the steady Reynolds-Averaged Navier-Stokes (RANS) equations – similar to AirfRANS but in three dimensions. The boundaries in the spanwise and flow-normal directions are walls, and the inlet maintains a constant velocity of m/s. This dataset comprises 67 training samples and 11 test samples. The neural network model trained on this dataset consists of 3.2 million parameters. The input and output dimensions mirror those of the AirfRANS dataset, with additional dimensions for the –axis and –velocity components. Key hyperparameters include 4 hops () and a sampling radius of .
| Method | S-MPNN | DS-MPNN4 |
|---|---|---|
| Test Error | 0.860 | 0.862 |
Table 8 and figure 5 illustrate that the test errors for S-MPNN and DS-MPNN4 are similar, indicating comparable performance between the single-GPU and multi-GPU implementations for this dataset. It is also important to note that the accuracy in the recirculation region of the step does not change across S-MPNN and DS-MPNN4, showing that the distributed training approach can capture the dynamically important regions. A detailed comparison of S-MPNN and DS-MPNN4 for 3-D flow predictions is provided in the Appendix.

5 Conclusions
We address the issue of scaling edge-based graph methods to larger numbers of nodes by introducing distributed training for message-passing neural networks (MPNNs). When combined with node sampling techniques, this distributed approach allows us to scale a larger number of nodes with no or minimal loss in accuracy as compared to the single-GPU implementation while achieving a considerable decrease in training and inference times. We also show comparisons to the graph convolution networks (GCNs) and establish that edge-based methods like MPNNs outperform node-based methods like GCNs. This work opens up new avenues for the use of edge-based graph neural networks in problems of practical interest where the number of nodes can be impractically large, , for single-GPU memory limits. The limitations of DS-MPNN lie in the complexity of managing unstructured grids and adjacent elements. However, distributed graph training is advancing rapidly, with new libraries such as PyTorch Geometric version 2.5.0 (Fey & Lenssen, 2019) addressing these challenges. Future work should also involve the use of more sophisticated partitioning methods employed in engineering simulations, such as METIS.
References
- Bonnet et al. (2022a) Bonnet, F., Mazari, J. A., Cinnella, P., and Gallinari, P. AirfRANS: High fidelity computational fluid dynamics dataset for approximating reynolds-averaged navier–stokes solutions. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022a. URL https://arxiv.org/abs/2212.07564.
- Bonnet et al. (2022b) Bonnet, F., Mazari, J. A., Munzer, T., Yser, P., and Gallinari, P. An extensible benchmarking graph-mesh dataset for studying steady-state incompressible navier-stokes equations. In ICLR 2022 Workshop on Geometrical and Topological Representation Learning, 2022b. URL https://openreview.net/forum?id=rqUUi4-kpeq.
- Duvenaud et al. (2015) Duvenaud, D. K., Maclaurin, D., Iparraguirre, J., Bombarell, R., Hirzel, T., Aspuru-Guzik, A., and Adams, R. P. Convolutional networks on graphs for learning molecular fingerprints. Advances in neural information processing systems, 28, 2015.
- Fey & Lenssen (2019) Fey, M. and Lenssen, J. E. Fast graph representation learning with pytorch geometric. arXiv preprint arXiv:1903.02428, 2019.
- Fout et al. (2017) Fout, A., Byrd, J., Shariat, B., and Ben-Hur, A. Protein interface prediction using graph convolutional networks. Advances in neural information processing systems, 30, 2017.
- Gilmer et al. (2017) Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O., and Dahl, G. E. Neural message passing for quantum chemistry. In International conference on machine learning, pp. 1263–1272. PMLR, 2017.
- Hamilton et al. (2017) Hamilton, W., Ying, Z., and Leskovec, J. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017.
- Kipf & Welling (2017) Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. 2017.
- Lam et al. (2022) Lam, R., Sanchez-Gonzalez, A., Willson, M., Wirnsberger, P., Fortunato, M., Alet, F., Ravuri, S., Ewalds, T., Eaton-Rosen, Z., Hu, W., et al. Graphcast: Learning skillful medium-range global weather forecasting. arXiv preprint arXiv:2212.12794, 2022.
- Li et al. (2020a) Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., and Anandkumar, A. Neural operator: Graph kernel network for partial differential equations. arXiv preprint arXiv:2003.03485, 2020a.
- Li et al. (2020b) Li, Z., Kovachki, N. B., Azizzadenesheli, K., Bhattacharya, K., Stuart, A., Anandkumar, A., et al. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2020b.
- Lu et al. (2021) Lu, L., Jin, P., Pang, G., Zhang, Z., and Karniadakis, G. E. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature machine intelligence, 3(3):218–229, 2021.
- Mavriplis (1997) Mavriplis, D. Unstructured grid techniques. Annual Review of Fluid Mechanics, 29(1):473–514, 1997.
- Paszke et al. (2019) Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- Pfaff et al. (2020) Pfaff, T., Fortunato, M., Sanchez-Gonzalez, A., and Battaglia, P. W. Learning mesh-based simulation with graph networks. arXiv preprint arXiv:2010.03409, 2020.
- Raissi et al. (2019) Raissi, M., Perdikaris, P., and Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019.
- Ranade et al. (2022) Ranade, R., Hill, C., Ghule, L., and Pathak, J. A composable machine-learning approach for steady-state simulations on high-resolution grids. Advances in Neural Information Processing Systems, 35:17386–17401, 2022.
- Ren et al. (2022) Ren, P., Rao, C., Liu, Y., Wang, J.-X., and Sun, H. Phycrnet: Physics-informed convolutional-recurrent network for solving spatiotemporal pdes. Computer Methods in Applied Mechanics and Engineering, 389:114399, 2022.
- Sanchez-Gonzalez et al. (2020) Sanchez-Gonzalez, A., Godwin, J., Pfaff, T., Ying, R., Leskovec, J., and Battaglia, P. Learning to simulate complex physics with graph networks. In International conference on machine learning, pp. 8459–8468. PMLR, 2020.
- Simonovsky & Komodakis (2017) Simonovsky, M. and Komodakis, N. Dynamic edge-conditioned filters in convolutional neural networks on graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3693–3702, 2017.
- Smith & Topin (2019) Smith, L. N. and Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Artificial intelligence and machine learning for multi-domain operations applications, volume 11006, pp. 369–386. SPIE, 2019.
- Strönisch et al. (2023) Strönisch, S., Sander, M., Meyer, M., and Knüpfer, A. Multi-gpu approach for training of graph ml models on large cfd meshes. In AIAA SCITECH 2023 Forum, pp. 1203, 2023.
- Veličković et al. (2018) Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., and Bengio, Y. Graph attention networks. In International Conference on Learning Representations, 2018.
- Zhu et al. (2019) Zhu, Y., Zabaras, N., Koutsourelakis, P.-S., and Perdikaris, P. Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. Journal of Computational Physics, 394:56–81, 2019.
Appendix A Ablation Studies on Scalability and Communication Overhead
The subsequent ablation experiments were conducted to evaluate the scalability and communication burden of DS-MPNN4 in comparison with the standard single GPU framework, S-MPNN. These studies were carried out using the ‘scarce’ high-fidelity AirfRANS dataset, which consists of 180 training samples. For these experiments, the kernel radius and the number of nodes were predetermined at and , respectively. Unless specifically mentioned, the baseline overlap length is set to the kernel radius. Figure 8, clearly demonstrate the associated cost of communication for DS-MPNN4. The training and inference costs for communication are higher compared to scenarios with no communication across various non-zero lengths of the overlap region in the 4 sub-domains. Nevertheless, despite the communication overhead, DS-MPNN4 is consistently better than S-MPNN in terms of training and inference duration. We also increase the sampled node count to ascertain the impact of scalability and communication overhead. This increase in node samples becomes imperative for larger numerical grids. Figure 8 shows the increase in the training speed of DS-MPNN4 compared to S-MPNN. The increase in speed is attributed to the reduction in the time required for graph kernel generation within DS-MPNN4, as a consequence of decreased number of edge formations required across each GPU domain. Correspondingly, the percentage of training time spent on communication decreases as the node count increases, because, while the aggregate data for communication grows with the node count, the substantial bandwidth of GPUs maintains a constant communication time.




Moreover, scalability appears in figure 8 that shows a decrease in training and inference time with an increasing number of domains from one (S-MPNN) to four (DS-MPNN4) GPU setup. This is consistent with our previous observations.
Appendix B Darcy Flow Equations
2-D Darcy flow equation on the unit box is a second-order elliptic PDE given as:
| (4) |
| (5) |
Here, and are the spatially varying diffusion coefficients and the forcing field, respectively. is the solution field on the 2-D domain. This example parallels the approach used in the Graph Neural Operator (GNO) as discussed by Li et al. (2020a), adapted for a single GPU setup with a notable distinction: we update the edge attributes following each radius hop or message-passing step, and both edges and nodes are subjected to sampling. The experiment investigates the mapping .
Appendix C Darcy Flow Visualizations
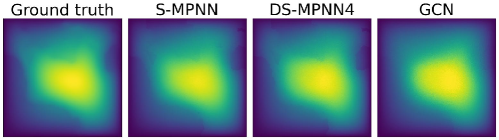
Figure 9 illustrates that both DS-MPNN and S-MPNN configurations provide similar predictions for the Darcy flow dataset. In contrast, the GCN model significantly under-performs, as it excessively smooths the solution and fails to capture the roughness at the boundaries accurately.
Appendix D AirfRANS equations
The AirfRANS dataset corresponds to the solution of incompressible steady-state Reynolds Averaged Navier Stokes (RANS) equations in 2-D, given by
| (6) |
| (7) |
Here, represents the mean 2-D velocity components, and denotes the mean pressure. The variable signifies the kinematic turbulent viscosity, which is spatially varying, while denotes the constant kinematic viscosity. In this dataset, the learning process involves mapping the airfoil shape and angle of attack to , as further elaborated in the subsequent sections.
Appendix E Three-dimensional step flow visualizations
The predictions for S-MPNN and DS-MPNN4 are further illustrated in Figure 10, where two slices are presented: one at in the xy-plane, and the other at , which lies within the recirculation region. The results demonstrate the accuracy and consistency of both models. The scatter plot in Figure 11 further corroborates this by comparing the predictions at and , indicating a high degree of agreement in the predictions of two models.


