Safety Verification of Model Based
Reinforcement Learning Controllers
Abstract
Model-based reinforcement learning (RL) has emerged as a promising tool for developing controllers for real world systems (e.g., robotics, autonomous driving, etc.). However, real systems often have constraints imposed on their state space which must be satisfied to ensure the safety of the system and its environment. Developing a verification tool for RL algorithms is challenging because the non-linear structure of neural networks impedes analytical verification of such models or controllers. To this end, we present a novel safety verification framework for model-based RL controllers using reachable set analysis. The proposed framework can efficiently handle models and controllers which are represented using neural networks. Additionally, if a controller fails to satisfy the safety constraints in general, the proposed framework can also be used to identify the subset of initial states from which the controller can be safely executed.
1 Introduction
One of the primary reasons for the growing application of reinforcement learning (RL) algorithms in developing optimal controllers is that RL does not assume a priori knowledge of the system dynamics. Model-based RL explicitly learns a model of the system dynamics, from observed samples of state transitions. This learnt model is used along with a planning algorithm to develop optimal controllers for different tasks. Thus, any uncertainties in the system, including environment noise, friction, air-drag etc., can also be captured by the modeled dynamics.
However, the performance of the controller is directly related to how accurately the learnt model represents the true system dynamics. Due to the discrepancy between the learnt model and the true model, the developed controller can behave unexpectedly when deployed on the real physical system, e.g., land robots, UAVs, etc. (Benbrahim & Franklin, 1997; Endo et al., 2008; Morimoto & Doya, 2001). This unexpected behavior may result in the violation of constraints imposed on the system, thereby violating its safety requirements (Moldovan & Abbeel, 2012). Thus, it is necessary to have a framework which can ensure that the controller will satisfy the safety constraints before it is deployed on a real system. This raises the primary question of interest: Given a set of safety constraints imposed on the state space, how do we determine whether a given controller is safe or not?
In the literature, there have been several works that focus on the problem of ensuring safety. Some of the works aim at finding a safe controller, under the assumption of a known baseline safe policy (Hans et al., 2008; Garcia & Fernández, 2012; Berkenkamp et al., 2017; Thomas et al., 2015; Laroche et al., 2019), or several known safe policies (Perkins & Barto, 2002). However, such safe policies may not be readily available in general. Alternatively, Akametalu et al. (2014) used reachability analysis to develop safe model-based controllers, under the assumption that the system dynamics can be modeled using Gaussian processes, i.e., an assumption which is violated by most modern RL methods that make use of neural networks (NN) instead. While there have been several works proposed to develop safe controllers, some of the assumptions made in these works may not be possible to realize in practice. In recent years, this limitation has drawn attention towards developing verification frameworks for RL controllers, which is the focus of this paper. Since verifying safety of an NN based RL controller is also related to verifying the safety of the underlying NN model (Xiang et al., 2018b; Tran et al., 2019b; Xiang et al., 2018a; Tran et al., 2019a), we provide an additional review for these methods in Appendix A.1.
Contributions:
In this work, we focus on the problem of determining whether a given controller is safe or not, with respect to satisfying constraints imposed on the state space. To do so, we propose a novel safety verification algorithm for model-based RL controllers using forward reachable tube analysis that can handle NN based learnt dynamics and controllers, while also being robust against modeling error. The problem of determining the reachable tube is framed as an optimal control problem using the Hamilton Jacobi (HJ) partial differential equation (PDE), whose solution is computed using the level set method. The advantage of using the level set method is the fact that it can represent sets with non-convex boundaries, thereby avoiding approximation errors that most existing methods suffer from. Additionally, if a controller is deemed unsafe, we take a step further to identify if there are any starting conditions from which the given controller can be safely executed. To achieve this, a backward reachable tube is computed for the learnt model and, to the best of our knowledge, this is the first work which computes the backward reachable tube over an NN. Finally, empirical results are presented on two domains inspired by real-world applications where safety verification is critical.
2 Problem Setting
Let denote the set of states and denote the set of feasible actions for the RL agent. Let denote the set of bounded initial states and represent a trajectory generated over a finite time , as a sequence of state and action tuples, where subscript denotes the instantaneous time. Additionaly, let and represent a sequence of states and actions, respectively. The state constraints imposed on the system are represented as unsafe regions using bounded sets , where . The true system dynamics is given by a non-linear function such that, , and is unknown to the agent.
A model-based RL algorithm is used to find an optimal controller , to reach a set of target states within some finite time , while avoiding constraints . An NN model, parameterized by weights , is trained to learn the true, but unknown, system dynamics from the observed state transition data tuples . However, due to sampling bias, the learnt model may not be accurate. We assume that it is possible to estimate a bounded set such that, at any state , augmenting the learnt dynamics with some results in a closer approximation of the true system dynamics at that particular state. Using this notation, we now define the problem of safety verification of a given controller .
Problem 1
(Safety verification): Given a set of initial states , determine if , all the trajectories executed under and following the system dynamics , satisfy the constraints or not.
The solution to Problem 1 will only provide a binary yes or no answer to whether is safe or not with respect to . In the case where the policy is unsafe, a stronger result is the identification of safe initial states from which executes trajectories which always satisfy the constraints . This problem is stated below.
Problem 2
(Safe initial states): Given , find , such that, any trajectory executed under and following the system dynamics , starting from any , satisfies the constraints .
3 Safety Verification
To address Problems 1 and 2, we use reachability analysis. Reachability analysis is an exhaustive verification technique which tracks the evolution of the system states over a finite time, known as the reachable tube, from a given set of initial states (Maler, 2008). If the evolution is tracked starting from , then it is called the forward reachable tube and is denoted as . Analogously, if the evolution is tracked starting from to , then it is called the backward reachable tube and is denoted as .
In the following sections, we will formulate a reachable tube problem for NN-based models and controllers, and then propose a verification framework that (a) can determine whether or not a given policy is safe, and (b) can compute if is unsafe. To do so, there are two main questions that need to be answered. First, since the true system dynamics is unknown, how can we determine a conservative bound on the modeling error, to augment the learnt model and better model the true system dynamics when evaluating a controller ? Second, how do we formulate the forward and backward reachable tube problems over the NN modeled system dynamics?
3.1 Model-Based Reinforcement Learning
In this section, we focus on the necessary requirements for the modeled dynamics and discuss the estimation of the modeling error set . A summary of the model-based RL framework is presented in Appendix A.2. Recall that the learnt model is represented using an NN and predicts the change in states . To learn , an observed data set is first split into a training data set and a validation data set . A supervised learning technique is then used to train over by minimizing the prediction error where is the change predicted by the learnt model, is the true observed change in state and . With this notation, we now formalize the following necessary assumption for this work. This assumption is required to ensure boundedness during analysis and is easily satisfied by NNs that use common activation functions like tanh or sigmoid (Usama & Chang, 2018).
Assumption 1
is Lipschitz continuous and , where .
Modeling error: As mentioned earlier, the accuracy of the learnt model depends on the quality of data and the NN being used, thereby resulting in some modeling error in the prediction of the next state. Estimating modeling errors is an active area of research and is required for several existing works on safe RL (Akametalu et al., 2014; Gillula & Tomlin, 2012), and is complementary to our goal. Since the primary contribution of this work is the development of a reachable tube formulation for model-based controllers that use NNs, we rely on existing techniques (Moldovan et al., 2015) to estimate a conservative modeling error bound. We leverage the error estimates of , for the transition tuples in the validation set to construct the upper confidence bound and lower confidence bound for , for each state dimension. Let a high-confidence bounded error set be defined such that . We then use to represent the augmented learnt system dynamics as
| (1) |
3.2 Reachable Tube Formulation
For an exhaustive verification technique on a continuous state and action space, it is infeasible to sample trajectories from every point in the given initial state and further, to verify whether all these trajectories satisfy the safety constraints. Therefore, reachable sets are usually (approximately) represented as convex polyhedrons and their evolution is tracked by pushing the boundaries of this polyhedron according to the system dynamics. However, as convex polyhedrons can lead to large approximation errors, we leverage the level set method (Mitchell et al., 2005) to compute the boundaries of the reachable tube for NN-based models and controllers at every time instant. With the level set method, even non-convex boundaries of the reachable tube can be represented, thereby ensuring an accurate computation of the reachable tube (Mitchell et al., 2005). Since the non-linear, non-convex structure of NNs is not suitable for analytical verification techniques, the reachability analysis gives an efficient, simulation-based approach to analyze the safety of the controller. Therefore, in this subsection, we formulate the reachable tube for a NN modeled system dynamics , but first we formally define the forward reachable tube and backward reachable tube for a policy .
Forward reachable tube (FRT): It is the set of all states that can be reached from an initial set , when the trajectories are executed under policy and system dynamics . The FRT is computed over a finite length of time and is formally defined as
| (2) |
where and denote the initial and final time of the trajectory , respectively.
Backward reachable tube (BRT): It is the set of all states which can reach a given bounded target set , when the trajectories are executed under policy and system dynamics . The BRT is also computed for a finite length of time, with the trajectories starting at time and ending at time . It is denoted as
| (3) |
The key difference between the FRT and BRT is that, for the former, the initial set of states are known, whereas for the latter, the final set of states are known.
Outline:
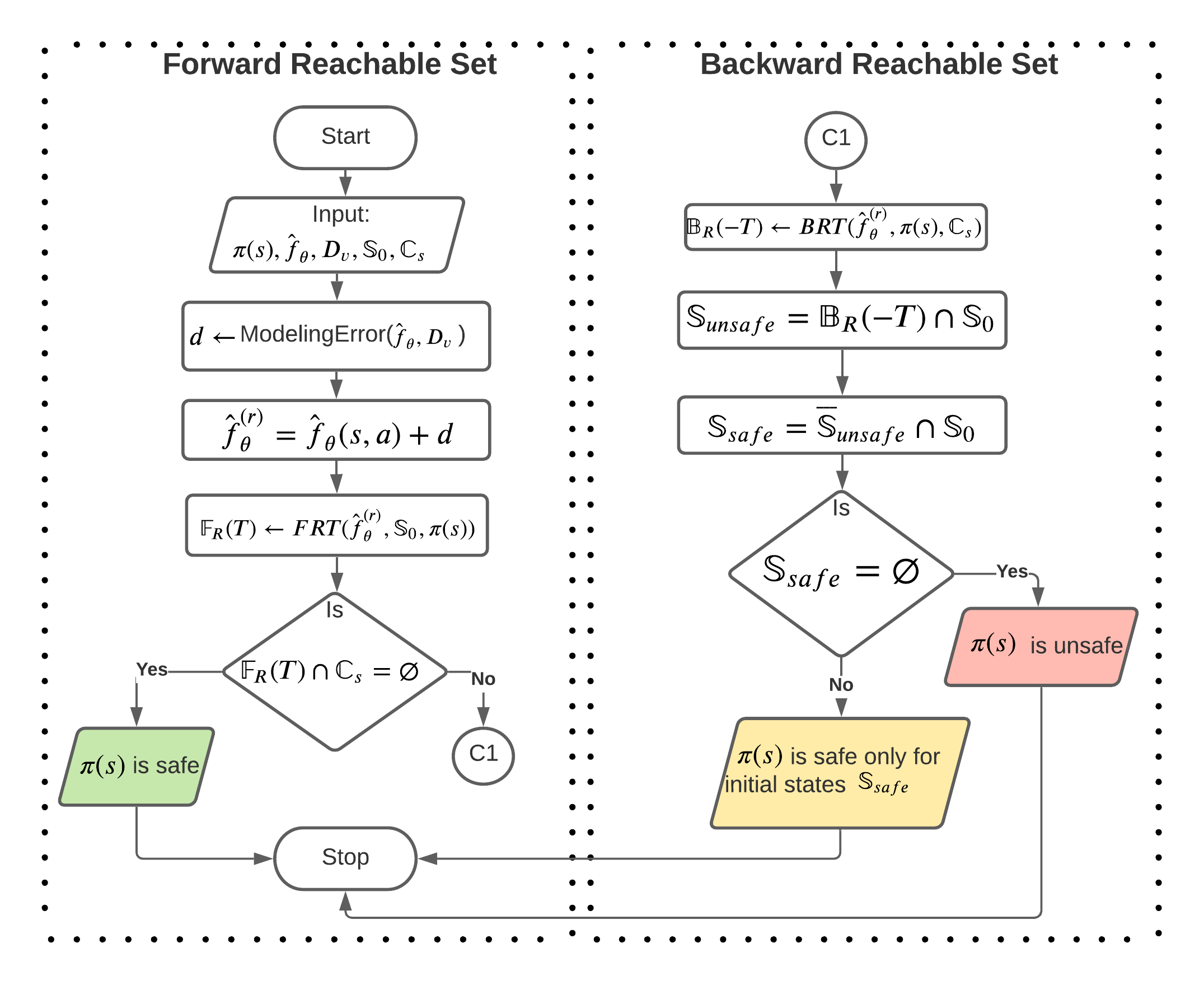
The flowchart of the safety verification framework proposed in this work is presented in Fig. 1. Given a model-based policy , the set of initial states and the set of constrained states , the first step is to estimate the bounded set of modeling error , as discussed in Section 3.1. Using , the FRT is constructed from the initial set and it contains all the states reachable by over a finite time . Thus, if the FRT contains any state from the unsafe region , is deemed unsafe. Therefore, the solution to Problem 1, is determined by analyzing the set of intersection of the FRT with as
| (4) |
If is classified as safe for the entire set , then no further analysis is required. However, if is classified as unsafe, we proceed to compute the subset of initial states for which generates safe trajectories. is the solution to Problem 2 and allows an unsafe policy to be deployed on a real system, with restrictions on the starting states. To this end, the BRT is computed from the unsafe region , to determine the set of trajectories (and states) which terminate in . The intersection of the BRT with determines the set of unsafe initial states . To determine , we utilize the following properties, (a) , and (b) , and compute
| (5) |
If , then we have identified the safe initial states for , otherwise, it is concluded that there are no initial states in from which can generate safe trajectories.
Mathematical Formulation:
This section presents the mathematical formulation to compute the BRT. The FRT can be computed with a slight modification to the BRT formulation and this is discussed in the end of this section.
Recall, for the BRT problem, there exists a target set which the agent has to reach in finite time, i.e., the condition on the final state is given as . Conventionally, for the BRT formulation, the final time and the starting time , where . When evaluating a policy , the controller input is computed by the given policy as . However, following the system dynamics in (1), the modeling error is now included in the system as an adversarial input, whose value at each state is determined so as to maximize the controller’s cost function. We use the HJ PDE to formulate the effect of the modeling error on the system for computing the BRT, but first we briefly review the formulation of the HJ PDE with an NN modeled system dynamics in the following.
For an optimal controller, we first define the cost function which the controller has to minimize. Let denote the running cost of the agent, which is dependent on the state and action taken at time . Let denote the cost at the final state . Then, the goal of the optimal controller is to find a series of optimal actions such that
| (6) |
where and is the NN modeled system dynamics. The above optimization problem is solved using the dynamic programming approach (Smith & Smith, 1991), which is based on the Principle of Optimality (Troutman, 2012). Let denote the value function of a state at time , such that
| (7) |
where . is a quantitative measure of being at a state , described in terms of the cost required to reach the goal state from . Then, using the Taylor series expansion, is approximated around in (7) to derive the HJ PDE as
| (8) |
where is the spatial derivative of . Additionally, the time index has been dropped above and the dynamics constraint in (6) has been included in the PDE. Equation (8) is a terminal value PDE, and by solving (8), we can compute the value of a state at any time .
We now discuss how the formulation in (8) can be modified to obtain the BRT. It is noted that along with computing the value function, the formulation in (8) also computes the optimal action . However, in Problems 1 and 2, the optimal policy is already provided. Therefore, the constraint should be included in problem (6), thereby avoiding the need of minimizing over actions in (8). Additionally, as discussed in Section 3.1, the NN modeled system dynamics may not be a good approximation of the true system dynamics . Instead, the augmented learnt system dynamics in (1) is used in place of in (8), since it better models the true dynamics at a given state. However, by including in (8), the modeling error is now included in the formulation. The modeling error is treated as an adversarial input which is trying to drive the system away from it’s goal state by taking a value which maximizes the cost function at each state. Thus, to account for this adversarial input, the formulation in (8) is now maximized over .
Lastly, the BRT problem is posed for a set of states and not an individual state. Hence, an efficient representation of the target set is required to propagate an entire set of trajectories at a time, as opposed to propagating individual trajectories.
Assumption 2
The target set is closed and can be represented as the zero sublevel set of a bounded and Lipschitz continuous function , such that, .
The above assumption defines a function to check whether a state lies inside or outside the target set. If is represented using a regular, well-defined geometric shape (like a sphere, rectangle, cylinder, etc.), then deriving the level set function is straight forward, whereas, an irregularly shaped can be represented as a union of several well-defined geometric shapes to derive .
For the BRT problem, the goal is to determine all the states which can reach within a finite time. The path taken by the controller is irrelevant and only the value of the final state is used to determine if any state . From Assumption 2, the terminal condition can be restated as . Thus, to prevent the system from reaching , the adversarial input tries to maximize , thereby pushing as far away from as possible. Therefore, the cost function in (6) is modified to . Additionally, any state which can reach within a finite time interval is included in the BRT. Therefore, if any trajectory reaches at some , it shouldn’t be allowed to leave the set. Keeping this in mind, the BRT optimization problem can be posed as
| (9) |
where the inner minimization over time prevents the trajectory from leaving the target set. Then, the value function for the above problem is defined as
| (10) |
Comparing this with (7), it is observed that the value of a state is no longer dependent on the running cost . This doesn’t imply that the generated trajectories are not optimal w.r.t. action , because the running cost is equivalent to the negative reward function, for which is already optimized. Instead, solely depends on whether the final state of the trajectory lies within the target set or not, i.e., whether or not . Thus, the value function for any state is equal to , where is the final state of the trajectory originating at . Then, the HJ PDE for the problem in (9) is stated as
| (11) |
where represents the optimal Hamiltonian. Since we are computing the BRT, in the PDE above ensures that the tube grows only in the backward direction, thereby preventing a trajectory which has reached from leaving. In Problem (11), the optimal action has been substituted by and the augmented learnt dynamics is used instead of . The Hamiltonian optimization problem can be further simplified to derive an analytical solution for the modeling error. By substituting the augmented dynamics from (1), the optimization problem can be re-written as
| (12) |
Expanding , the vector product . Therefore, to maximize , the disturbance control is chosen as
| (13) |
With this analytical solution, the final PDE representing the BRT is stated as
| (14) |
The value function in (14) represents the evolution of the target level set function backwards in time. By finding the solution to in the above PDE, the level set function is determined at any time instant , thereby determining the BRT. From the result of Theorem 2 in Mitchell et al. (2005), it is proved that the solution of in (14) at any time gives the zero sublevel set for the BRT. Thus,
| (15) |
The solution to can be computed numerically by using existing solvers for the level set method. A brief note on the implementation of the algorithm is included in subsection A.3 in the Appendix.
There are a few things to note about the formulation in (14). First, Equation (14) assumes that is a desired goal state. However, the formulation can be modified if is an unsafe set, in which case, the adversarial modeling error tries to minimize the Hamiltonian. Similarly, the input can represent any other disturbance in the system, either adversarial or cooperative. Second, to compute the FRT, the formulation in (14) is modified from a final value PDE to an initial value PDE.
4 Experiments
In our experiments, we aim to answer the following questions: (a) Can safety verification be done for an NN-based and using FRT?, and (b) Can be identified using BRT if is deemed unsafe? To answer these two questions, we demonstrate results on the following domains inspired by real world safety-critical problems, where RL controllers developed using a learnt model can be appealing, as they can adapt to transition dynamics involving friction, air-drag, wind, etc., which might be hard to explicitly model otherwise.
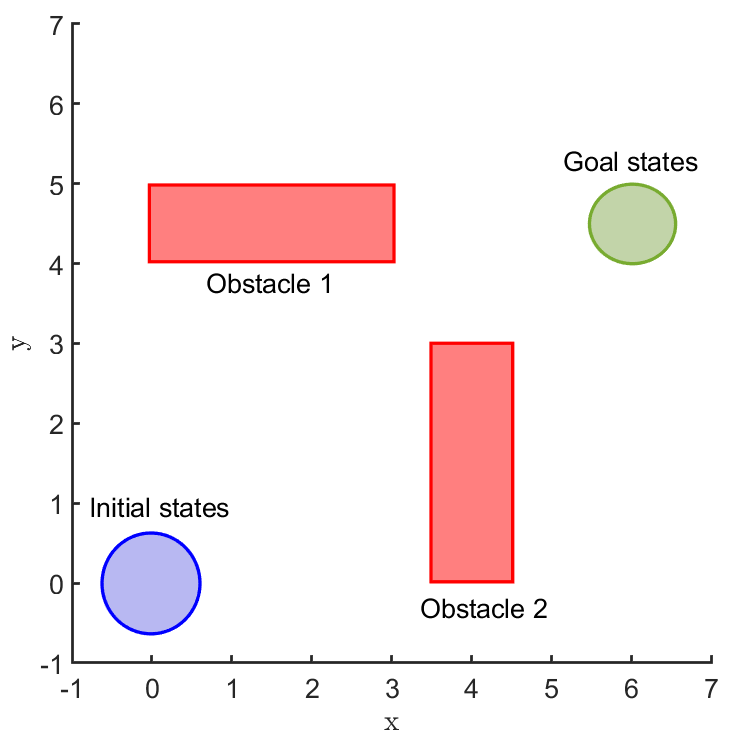
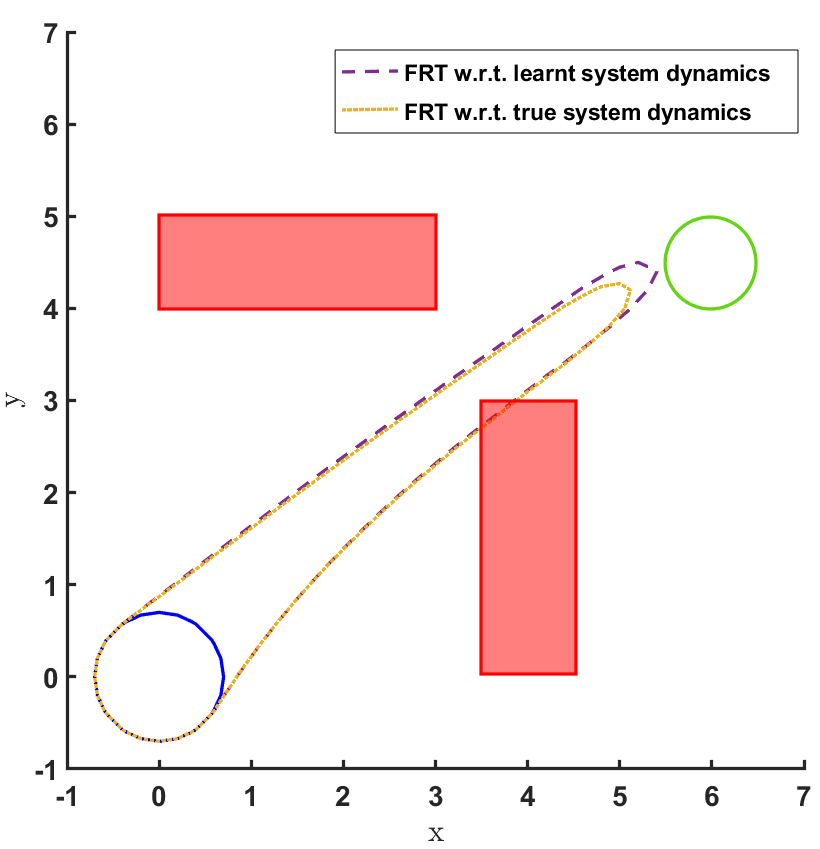
Safe land navigation: Navigation of a ground robot in an indoor environment is a common application which requires the satisfaction of safety constraints by to avoid collision with obstacles. For this setting, we simulate a ground robot which has continuous states and actions. The initial configuration of the domain is shown in Fig. 2. The set of initial and goal states are represented by circles and the obstacles with rectangles.
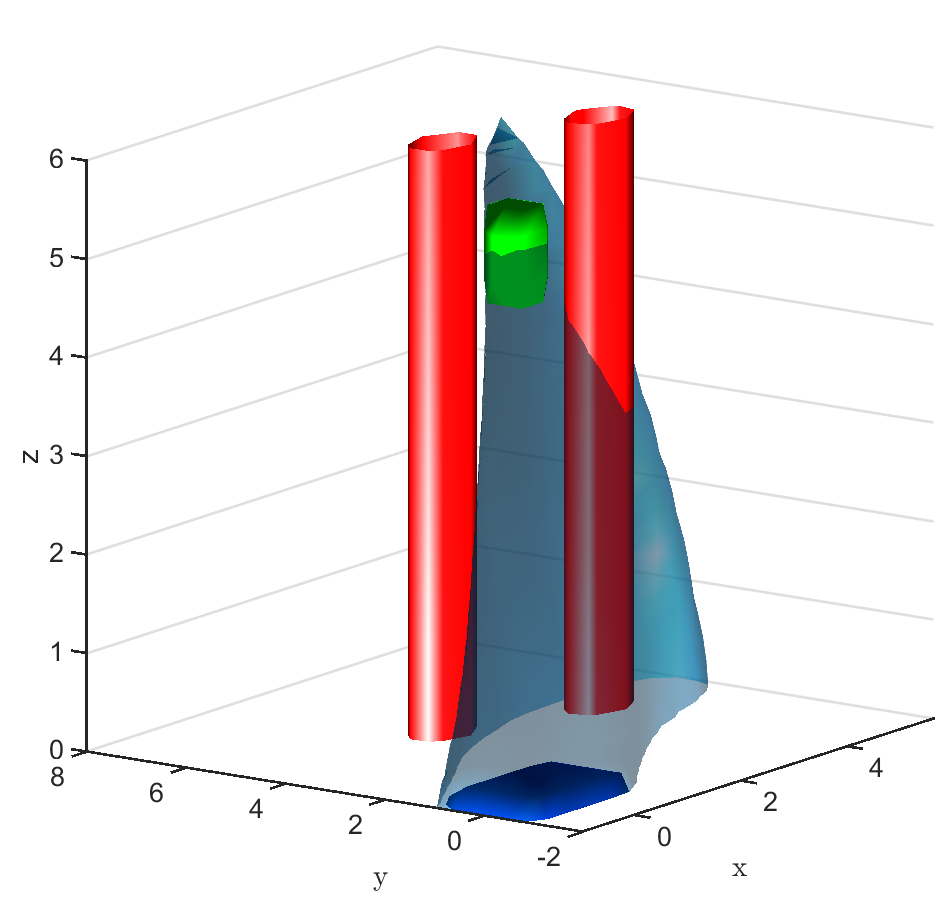
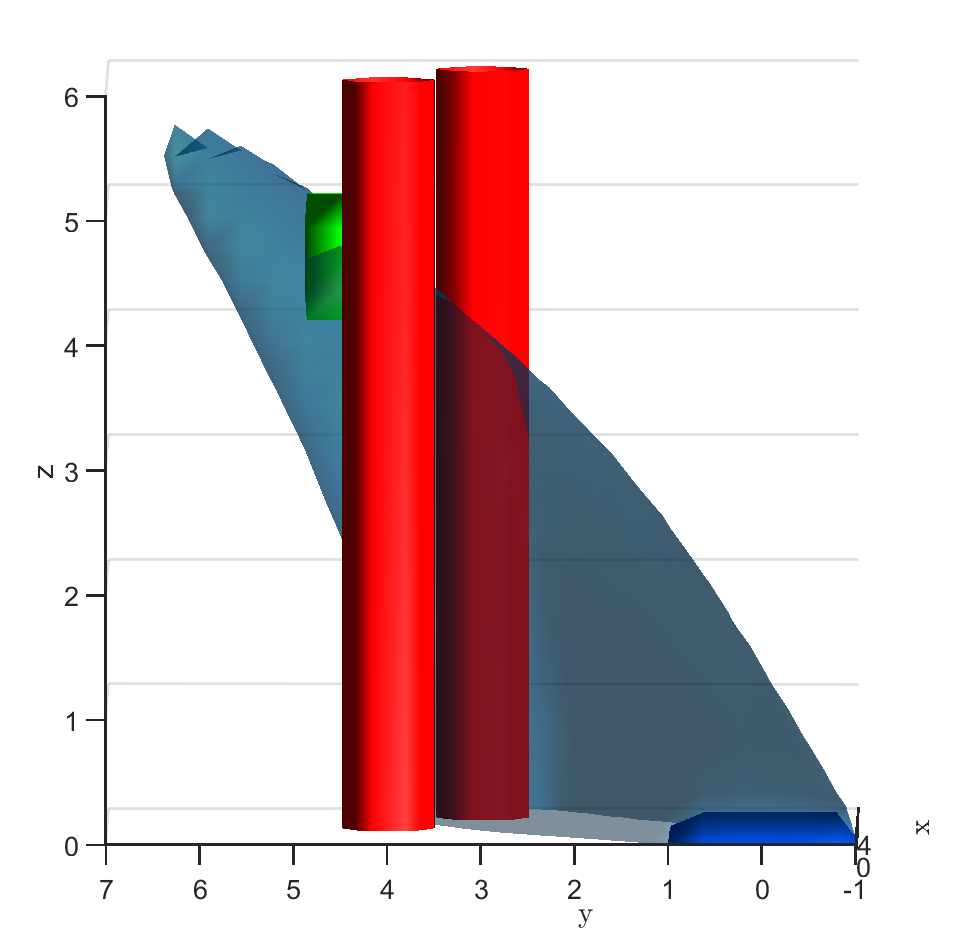
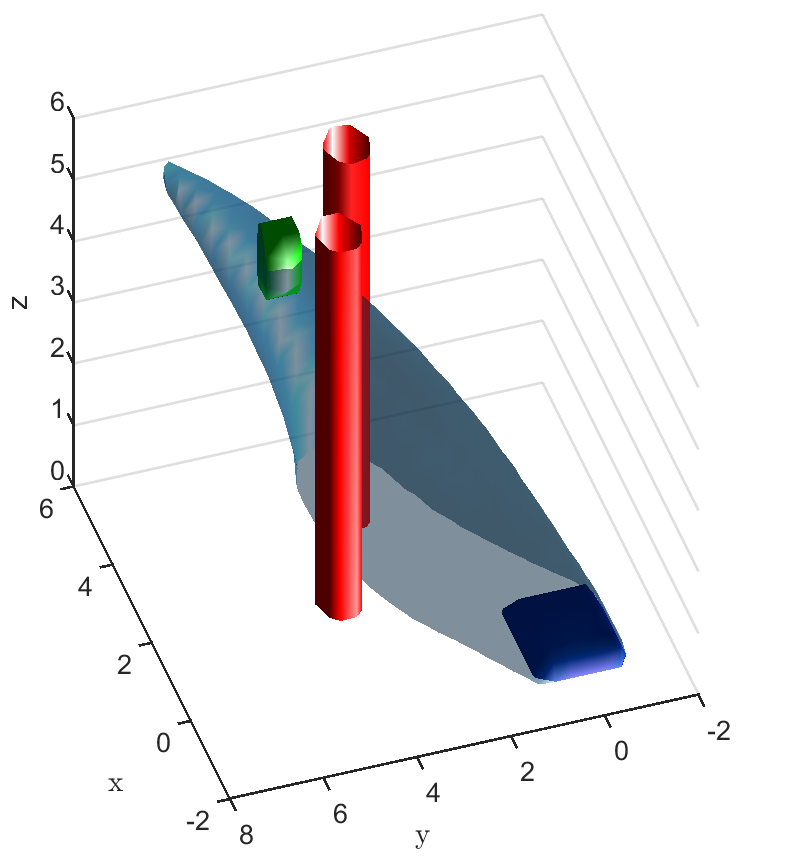
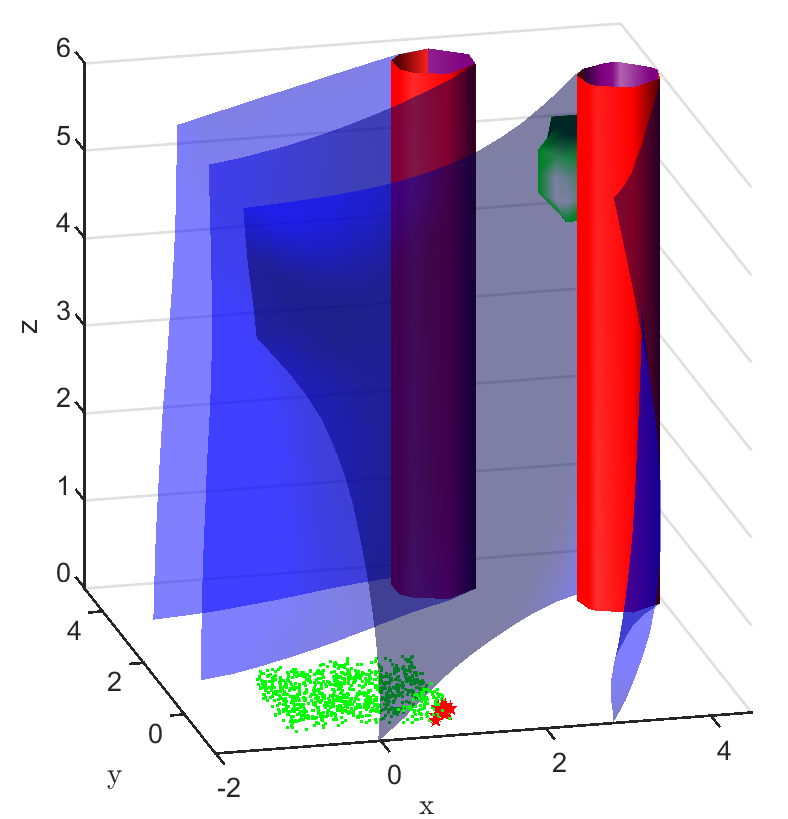
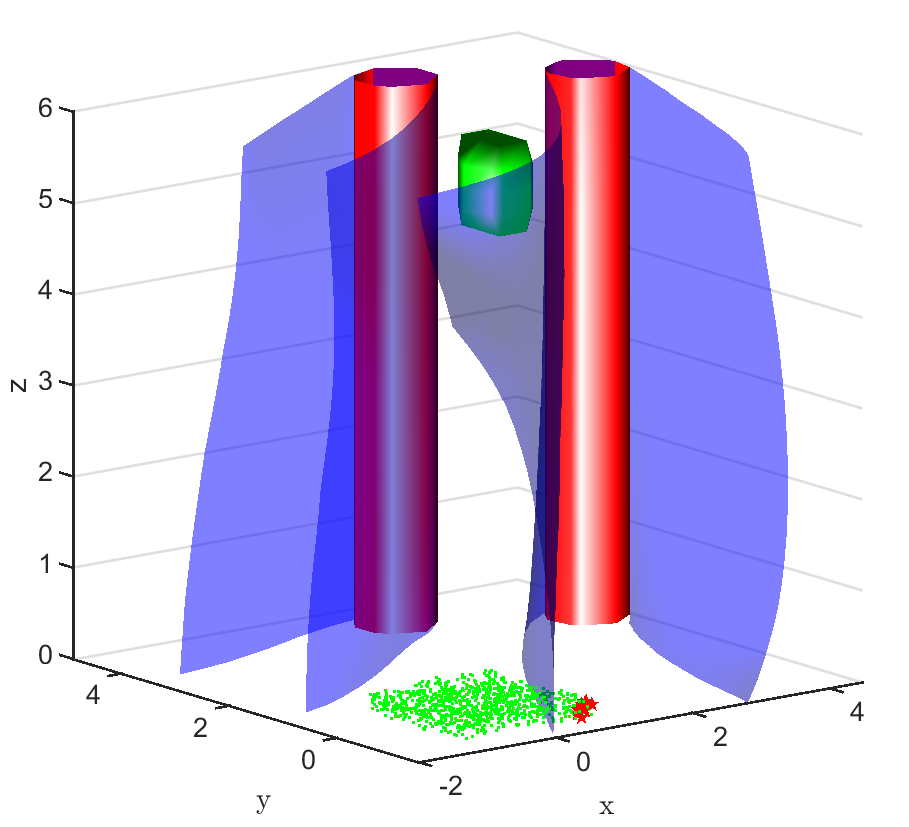
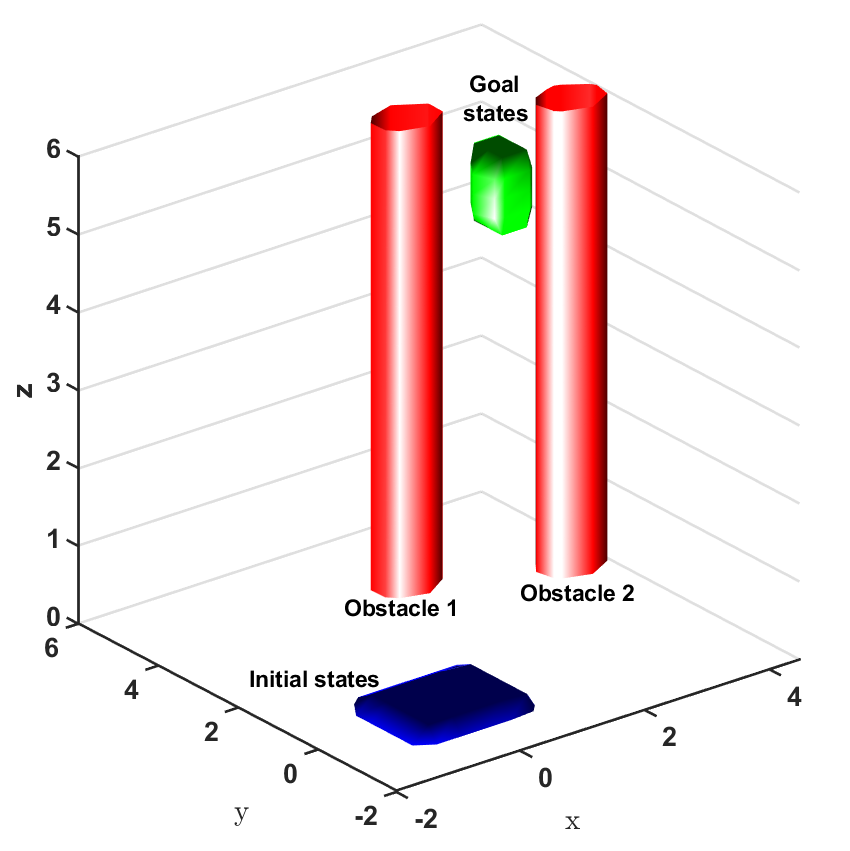
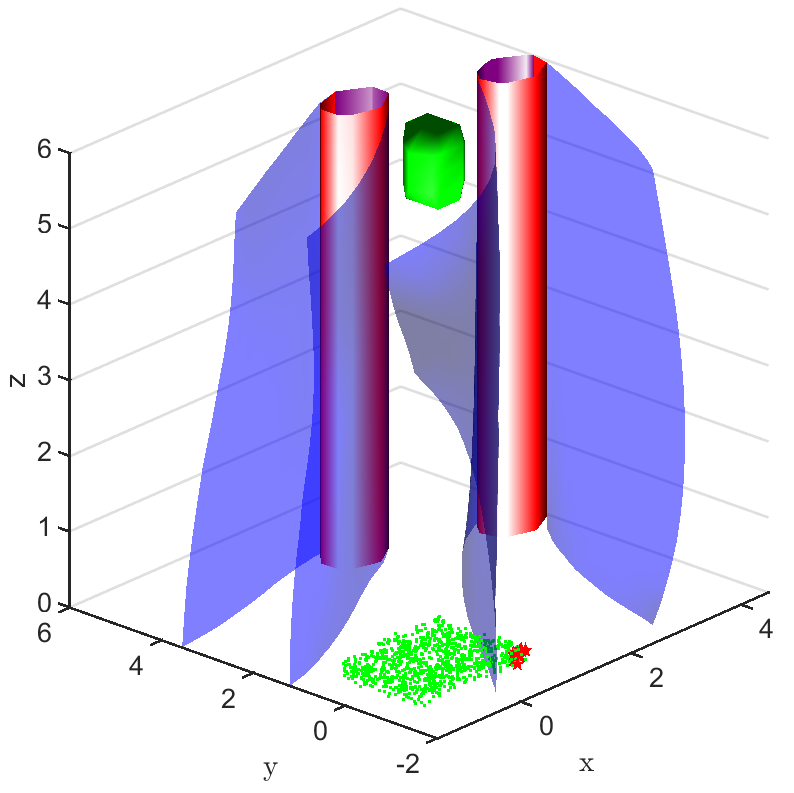
Safe aerial navigation: This domain simulates a navigation problem in an urban environment for an unmanned aerial vehicle (UAV). Constraints are incorporated while training to ensure that collision is avoided with potential obstacles in its path. States and actions are both continuous and the initial configuration of the domain is shown in Fig 3. The set of initial and goal states are represented using cuboids, and the obstacles with cylinders.
Analysis:
To address the questions with respect to the above mentioned domains, we first train a NN based to estimate the dynamics using sampled transitions. This is then also used to learn a NN based controller which is trained with a cost function designed to mitigate collisions. For brevity, only the representative results for this are discussed here; implementation details and more experimental results are available in Appendix A.2, A.3, A.4 and A.5.
To address the first question, the FRT is computed for both the domains over the augmented learnt dynamics as shown in Fig. 2 and Fig. 3. Additionally, for land navigation we also compute the FRT over the true system dynamics , which serves as a way to validate the safety verification result of from the proposed framework. It is observed that for both the domains, FRTs deem the given policy as unsafe, since the FRTs intersect with one of the obstacles. Even when is learnt using a cost function designed to avoid collisions, the proposed safety verification framework successfully brings out the limitations of , which may have resulted due to the use of function approximations, ill-specified hyper-parameters, convergence to a local optimum, etc.
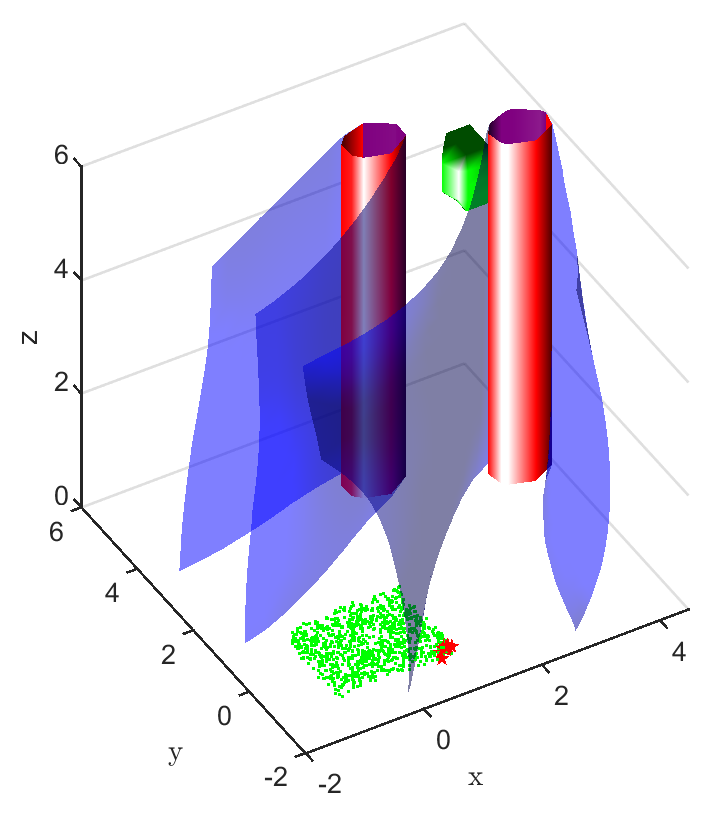
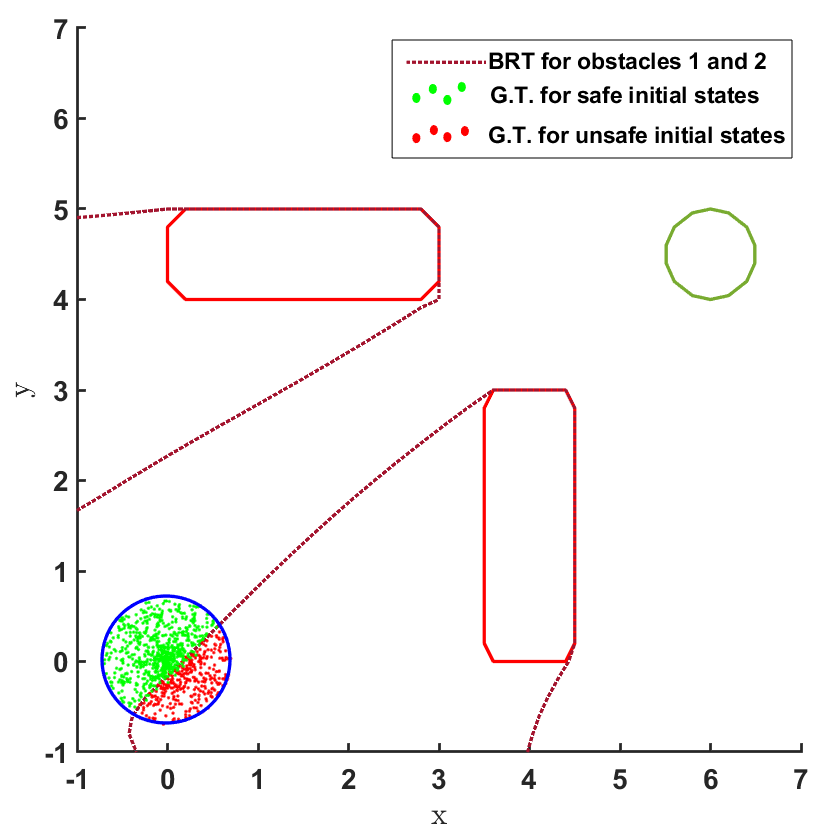
For the second question, the BRT is computed from both the obstacles for the given controller , as shown in Fig. 2 and Fig. 3. To estimate the accuracy of the BRT computation, we compare the computed and sets with the ground truth (G.T.) data generated using random samples of possible trajectories. It is observed that the BRT from obstacle 1 does not intersect with , implying that all trajectories are safe w.r.t. obstacle 1. However, the BRT from obstacle 2 intersects with and identifies the subset of initial states which are unsafe. Such an information can be critical to safely deploy even an unsafe controller just by restricting its starting conditions.
5 Conclusion
In this paper, we have presented a novel framework using forward and backward reachable tubes for safety verification and determination of the subset of initial states for which a given model-based RL controller always satisfies the state constraints. The main contribution of this work is the formulation of the reachability problem for a neural network modeled system dynamics and the use of level set method to compute an exact reachable tube by solving the Hamilton-Jacobi partial differential equation, for the reinforcement learning framework, thereby minimizing approximation errors that other existing reachability methods suffer. Additionally, the proposed framework can identify the set of safe initial sets for a given policy, thereby determining the initial conditions for which even a sub-optimal, unsafe policy satisfies the safety constraints.
References
- Akametalu et al. (2014) Anayo K Akametalu, Jaime F Fisac, Jeremy H Gillula, Shahab Kaynama, Melanie N Zeilinger, and Claire J Tomlin. Reachability-based safe learning with gaussian processes. In 53rd IEEE Conference on Decision and Control, pp. 1424–1431. IEEE, 2014.
- Bastani et al. (2016) Osbert Bastani, Yani Ioannou, Leonidas Lampropoulos, Dimitrios Vytiniotis, Aditya Nori, and Antonio Criminisi. Measuring neural net robustness with constraints. In Advances in neural information processing systems, pp. 2613–2621, 2016.
- Benbrahim & Franklin (1997) Hamid Benbrahim and Judy A Franklin. Biped dynamic walking using reinforcement learning. Robotics and Autonomous Systems, 22(3-4):283–302, 1997.
- Berkenkamp et al. (2017) Felix Berkenkamp, Matteo Turchetta, Angela Schoellig, and Andreas Krause. Safe model-based reinforcement learning with stability guarantees. In Advances in neural information processing systems, pp. 908–918, 2017.
- Crandall & Lions (1984) Michael G Crandall and P-L Lions. Two approximations of solutions of hamilton-jacobi equations. Mathematics of computation, 43(167):1–19, 1984.
- Endo et al. (2008) Gen Endo, Jun Morimoto, Takamitsu Matsubara, Jun Nakanishi, and Gordon Cheng. Learning cpg-based biped locomotion with a policy gradient method: Application to a humanoid robot. The International Journal of Robotics Research, 27(2):213–228, 2008.
- Garcia & Fernández (2012) Javier Garcia and Fernando Fernández. Safe exploration of state and action spaces in reinforcement learning. Journal of Artificial Intelligence Research, 45:515–564, 2012.
- Gillula & Tomlin (2012) Jeremy H Gillula and Claire J Tomlin. Guaranteed safe online learning via reachability: tracking a ground target using a quadrotor. In 2012 IEEE International Conference on Robotics and Automation, pp. 2723–2730. IEEE, 2012.
- Hans et al. (2008) Alexander Hans, Daniel Schneegaß, Anton Maximilian Schäfer, and Steffen Udluft. Safe exploration for reinforcement learning. In ESANN, pp. 143–148, 2008.
- Huang et al. (2017) Xiaowei Huang, Marta Kwiatkowska, Sen Wang, and Min Wu. Safety verification of deep neural networks. In International Conference on Computer Aided Verification, pp. 3–29. Springer, 2017.
- Katz et al. (2017) Guy Katz, Clark Barrett, David L Dill, Kyle Julian, and Mykel J Kochenderfer. Reluplex: An efficient smt solver for verifying deep neural networks. In International Conference on Computer Aided Verification, pp. 97–117. Springer, 2017.
- Kwiatkowska (2019) Marta Z Kwiatkowska. Safety verification for deep neural networks with provable guarantees. 2019.
- Laroche et al. (2019) Romain Laroche, Paul Trichelair, and Remi Tachet Des Combes. Safe policy improvement with baseline bootstrapping. In International Conference on Machine Learning, pp. 3652–3661. PMLR, 2019.
- Maler (2008) Oded Maler. Computing reachable sets: An introduction. Tech. rep. French National Center of Scientific Research, 2008.
- Mitchell (2007) Ian M Mitchell. A toolbox of level set methods. UBC Department of Computer Science Technical Report TR-2007-11, 2007.
- Mitchell et al. (2005) Ian M Mitchell, Alexandre M Bayen, and Claire J Tomlin. A time-dependent hamilton-jacobi formulation of reachable sets for continuous dynamic games. IEEE Transactions on automatic control, 50(7):947–957, 2005.
- Moldovan & Abbeel (2012) Teodor Mihai Moldovan and Pieter Abbeel. Safe exploration in markov decision processes. arXiv preprint arXiv:1205.4810, 2012.
- Moldovan et al. (2015) Teodor Mihai Moldovan, Sergey Levine, Michael I Jordan, and Pieter Abbeel. Optimism-driven exploration for nonlinear systems. In 2015 IEEE International Conference on Robotics and Automation (ICRA), pp. 3239–3246. IEEE, 2015.
- Morimoto & Doya (2001) Jun Morimoto and Kenji Doya. Acquisition of stand-up behavior by a real robot using hierarchical reinforcement learning. Robotics and Autonomous Systems, 36(1):37–51, 2001.
- Osher & Sethian (1988) Stanley Osher and James A Sethian. Fronts propagating with curvature-dependent speed: algorithms based on hamilton-jacobi formulations. Journal of computational physics, 79(1):12–49, 1988.
- Osher et al. (2004) Stanley Osher, Ronald Fedkiw, and K Piechor. Level set methods and dynamic implicit surfaces. Appl. Mech. Rev., 57(3):B15–B15, 2004.
- Perkins & Barto (2002) Theodore J Perkins and Andrew G Barto. Lyapunov design for safe reinforcement learning. Journal of Machine Learning Research, 3(Dec):803–832, 2002.
- Pulina & Tacchella (2012) Luca Pulina and Armando Tacchella. Challenging smt solvers to verify neural networks. Ai Communications, 25(2):117–135, 2012.
- Sethian (1999) James Albert Sethian. Level set methods and fast marching methods: evolving interfaces in computational geometry, fluid mechanics, computer vision, and materials science, volume 3. Cambridge university press, 1999.
- Smith & Smith (1991) David K Smith and David K Smith. Dynamic programming: a practical introduction. Ellis Horwood New York, 1991.
- Sun et al. (2019) Xiaowu Sun, Haitham Khedr, and Yasser Shoukry. Formal verification of neural network controlled autonomous systems. In Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control, pp. 147–156, 2019.
- Thomas et al. (2015) Philip Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High confidence policy improvement. In International Conference on Machine Learning, pp. 2380–2388, 2015.
- toolbox (2019) toolbox. helperoc. https://github.com/HJReachability/helperOC, May 2019.
- Tran et al. (2019a) Hoang-Dung Tran, Feiyang Cai, Manzanas Lopez Diego, Patrick Musau, Taylor T Johnson, and Xenofon Koutsoukos. Safety verification of cyber-physical systems with reinforcement learning control. ACM Transactions on Embedded Computing Systems (TECS), 18(5s):1–22, 2019a.
- Tran et al. (2019b) Hoang-Dung Tran, Patrick Musau, Diego Manzanas Lopez, Xiaodong Yang, Luan Viet Nguyen, Weiming Xiang, and Taylor T Johnson. Parallelizable reachability analysis algorithms for feed-forward neural networks. In 2019 IEEE/ACM 7th International Conference on Formal Methods in Software Engineering (FormaliSE), pp. 51–60. IEEE, 2019b.
- Troutman (2012) John L Troutman. Variational calculus and optimal control: optimization with elementary convexity. Springer Science & Business Media, 2012.
- Usama & Chang (2018) Muhammad Usama and Dong Eui Chang. Towards robust neural networks with lipschitz continuity. In International Workshop on Digital Watermarking, pp. 373–389. Springer, 2018.
- Xiang et al. (2018a) Weiming Xiang, Hoang-Dung Tran, and Taylor T Johnson. Output reachable set estimation and verification for multilayer neural networks. IEEE transactions on neural networks and learning systems, 29(11):5777–5783, 2018a.
- Xiang et al. (2018b) Weiming Xiang, Hoang-Dung Tran, Joel A Rosenfeld, and Taylor T Johnson. Reachable set estimation and safety verification for piecewise linear systems with neural network controllers. In 2018 Annual American Control Conference (ACC), pp. 1574–1579. IEEE, 2018b.
Appendix A Appendix
A.1 Extended Related Work
NNs are one of the most commonly used function approximators for RL algorithms. Therefore, often, verifying the safety of an RL controller reduces to verifying the safety of the underlying NN model or controller. In this section, we briefly review the techniques used to evaluate the safety of NNs.
In recent years, NN-based supervised learning of image classifiers have found applications in autonomous driving and perception modules. These are safety critical systems and it is necessary to verify the robustness of NN-based classifiers to minimize misclassification errors after they are deployed (Kwiatkowska, 2019). Some of the recent works have relied upon using existing optimization frameworks, such as linear programming and satisfiability modulo theory (SMT), to determine adversarial examples in the neighborhood of input images (Huang et al., 2017; Bastani et al., 2016; Pulina & Tacchella, 2012). However, these techniques usually require an approximation of the constraints on the NN model. Katz et al. (2017) improved the scalability of SMT verification algorithms and Sun et al. (2019) used satisfiability modulo convex (SMC) over a partitioned workspace, to determine the set of safe initial states for a robot, but their algorithms were limited to NNs with the ReLU activation function. However, the problem of interest in this work is more general than the single-step classification problems considered in these related work, and instead we look at RL problems which require multi-step decision making in real-valued domains.
For real-valued output domains, the safety property needs to be verified for a set of states as opposed to a single label (i.e., a single point) in the output domain. Therefore, to verify safety in the continuous problem domain, most works (Xiang et al., 2018b; Tran et al., 2019b; Xiang et al., 2018a; Tran et al., 2019a) first compute the forward reachable tube (FRT) of an NN, i.e, the set of output values achieved by the NN. Then, the NN is said to be unsafe if the FRT intersects with an unsafe set. Xiang et al. (2018b), Tran et al. (2019b) and Xiang et al. (2018a) follow the FRT algorithm by discretizing the input space into subspaces and executing forward pass over the NN to evaluate its output range. However, the above works use convex polyhedrons to approximate non-convex reachable sets and the approximation error compounds over each layer of the NN. Tran et al. (2019a) used a star-shaped polygon approach to generate the FRT which gives a less conservative solution than most polyhedra-based reachable tube computation. Additionally, some of the algorithms are applicable specifically to ReLU activation functions (Xiang et al., 2018b; Tran et al., 2019b). In comparison, the algorithm proposed in this work computes the exact reachable tube and can handle most commonly used activation functions, including tanh, sigmoid, ReLu, etc.
A.2 Algorithm for Model-Based RL
RL follows the formal framework of a Markov decision process (MDP) which is represented using a tuple where , and denote the state space, action space and true system dynamics, as defined in Section 2. The last element in the MDP tuple is the reward function which quantifies the goodness of taking an action in state , by computing the scalar value . Then the goal of the RL agent is to develop a policy (controller) which maximizes the expectation of the total return over time , where is the discount factor. In the model-based RL framework, the policy can simply be a planning algorithm or it can be a function approximator.
Under the model-based RL framework, the true dynamics function is unknown and needs to be learnt from observed data samples collected from the actual environment. The learnt model is represented using a function approximator as . A generic algorithm for model-based RL is provided in Algorithm 1. To train the model, an initial training data set is first generated by sampling trajectories using a randomly initialized policy . In any iteration , the data tuples are used to train by minimizing the prediction error using a supervised learning technique. This trained model is then used to update the policy or used by a planning algorithm to generate new trajectories and improve the return obtained by the agent. The data tuples obtained from the new trajectories are appended to the existing training data set to create and the process continues until the performance of the controller converges.
A.3 Implementation of Proposed Safety Verification Framework
To implement the proposed safety verification framework in Fig. 1, the MATLAB helperOC toolbox (2019) developed and maintained by the HJ Reachability Group on Github was used. This toolbox is dependent on the level set toolbox developed by Mitchell (2007). In the helperOC toolbox, the level set method is used to provide a numerical solution to the PDE in (14). Level set methods have been used to track and model the evolution of dynamic surfaces (here the reachable tube) by representing the dynamic surface implicitly using a level set function at any instant of time (Osher & Sethian, 1988; Osher et al., 2004; Sethian, 1999). There are several advantages to using the level set algorithms, including the fact that they can represent non-linear, non-convex surfaces even if the surface merges or divides over time. Additionally, it is easy to extend the theory to the higher dimensional state space. However, the computational time increases exponentially with a dimension of the state space. The helperOC toolbox (2019) has demonstrated results on problems with 10 dimensional space and since most physical systems can be represented within this limit, it is sufficient for the problems of interest in this work.
The helperOC toolbox (2019) comes with inbuilt numerical schemes to compute the Hamiltonian , the spacial derivatives and the time derivative in (14). This toolbox is modified to solve the problem in (14) by substituting the true system dynamics with the augmented learnt dynamics and computing the action at any state as . Subsequently, to determine the level set function at any time instant, is computed using the Runge-Kutta integration scheme while the gradient of the level set function is computed using an upwind finite difference scheme. Additionally, a Lax-Friedrichs approximation is used to stably evaluate the Hamiltoniaan (Crandall & Lions, 1984).
A.4 Experiment Results: Safe Land Navigation
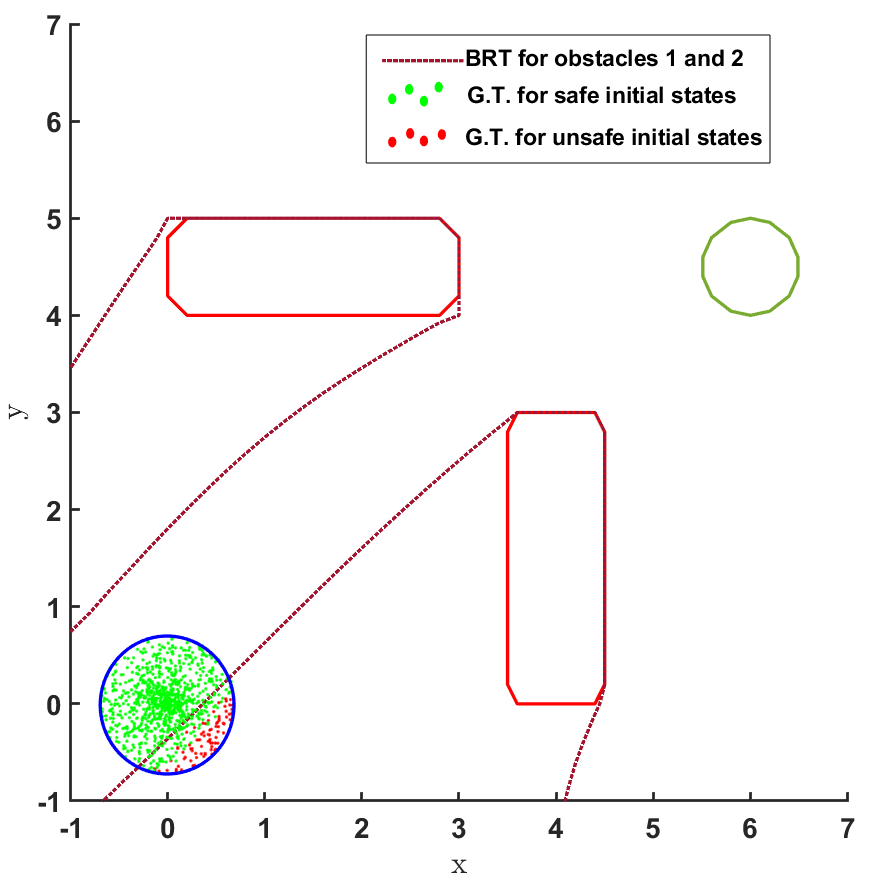
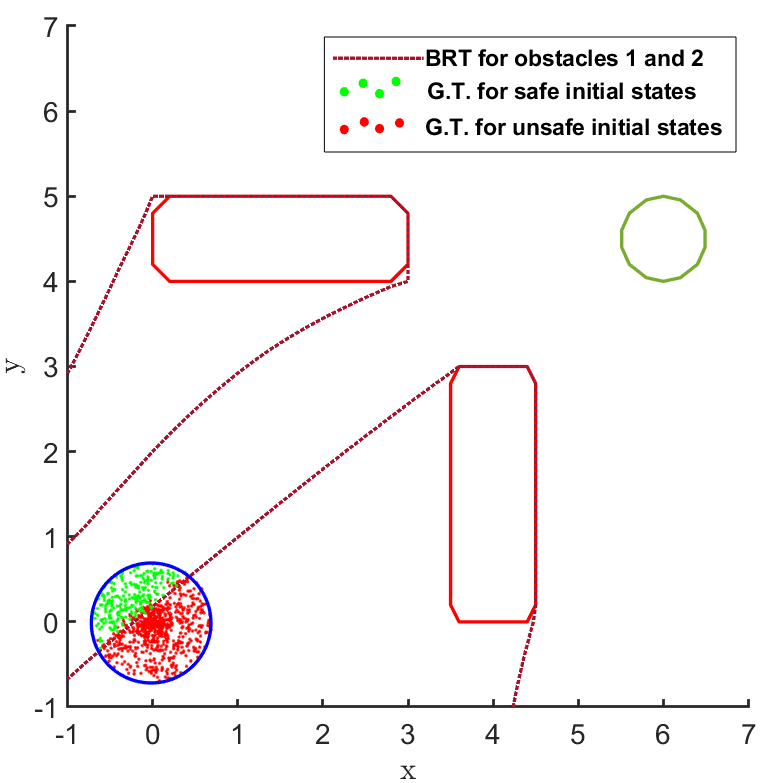
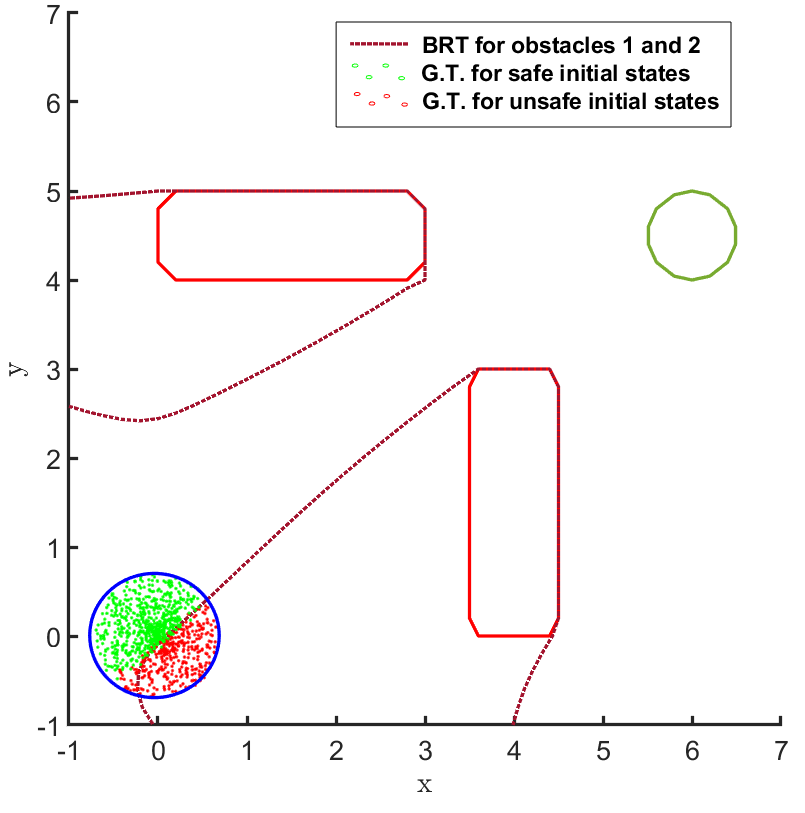
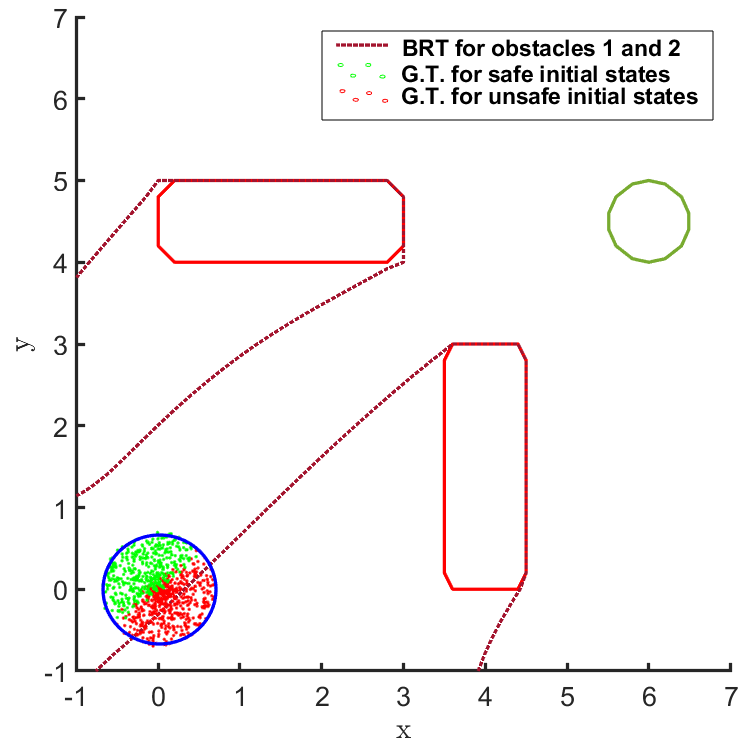
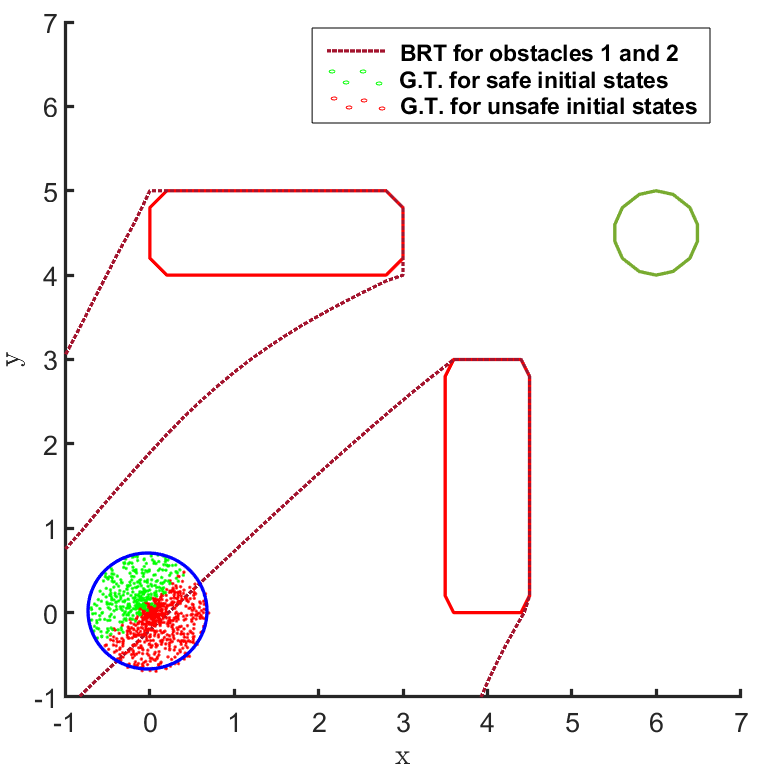
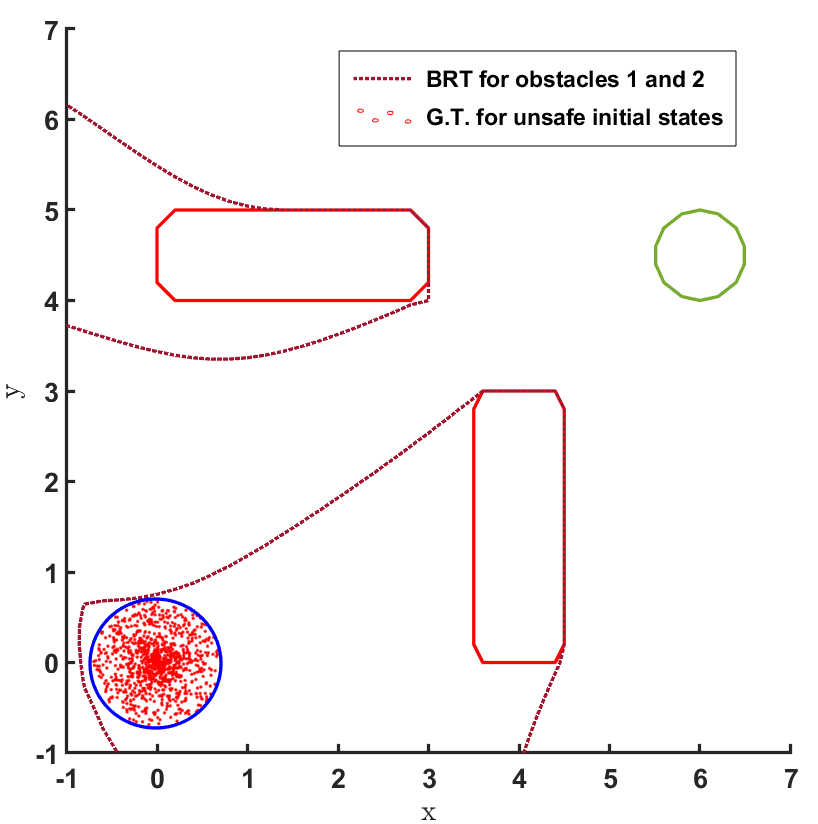
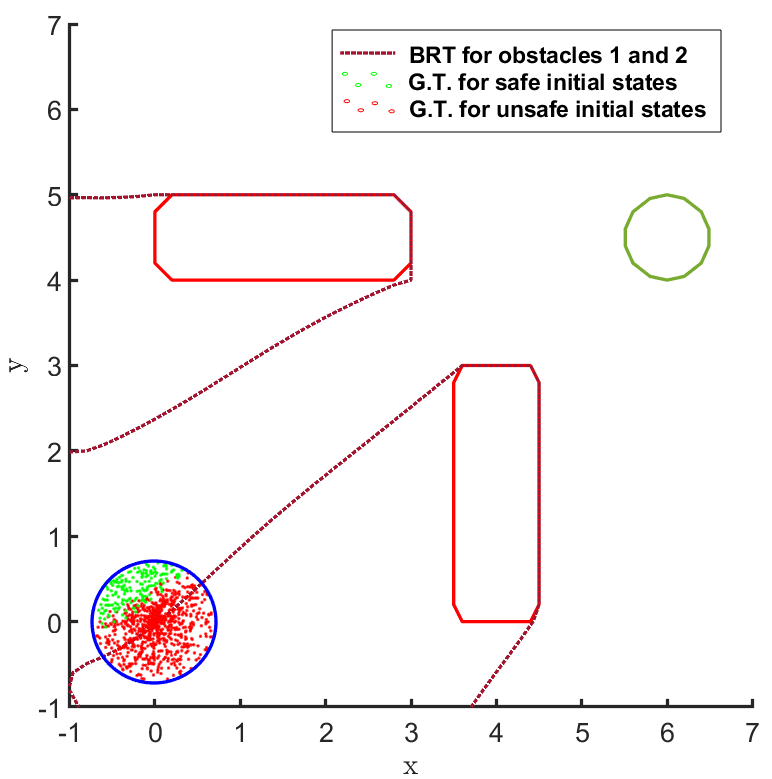
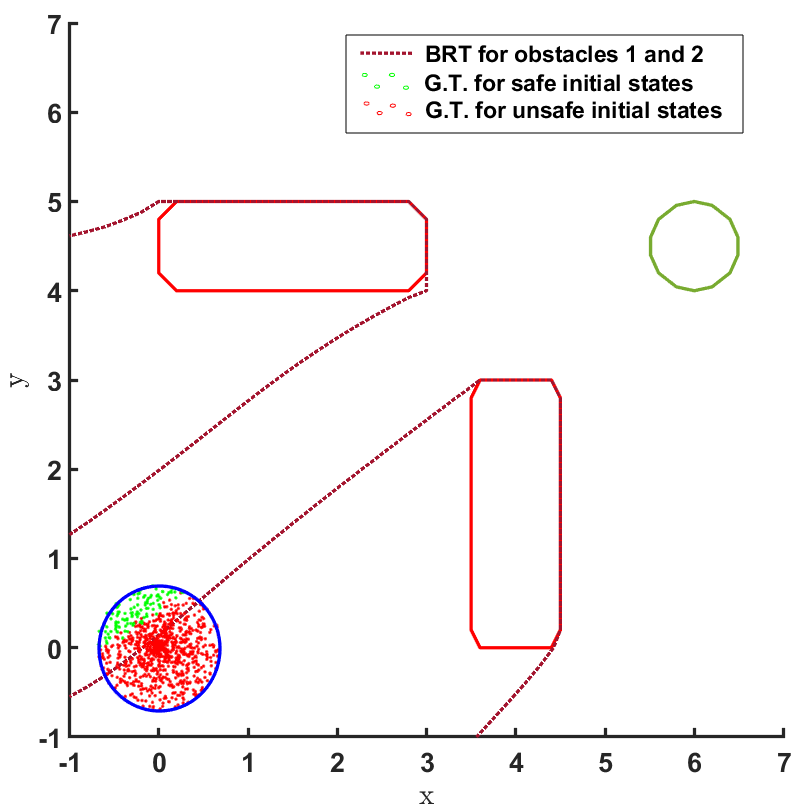
In the land navigation problem, a ground robot is moving in an indoor environment with obstacles. The ground vehicle has the state vector representing the and coordinates of the car. The control vector comprises of the velocity and the direction of the vehicle. The problem setting in shown in Fig. 2. The set of initial and goal states are represented by circles centered at coordinates and , respectively, and with radii of and units, respectively. There are two rectangular obstacles in the environment with centers at and .
To demonstrate the working of the proposed safety verification framework, different models and controllers were trained for the 2D land navigation problem setting. Three different models were trained over training data sets of different sizes. Model 1 was trained over 300 data samples, model 2 over 600 data samples, and model 3 over 1000 data samples. To estimate the modeling error for all the three models, a bound was computed by first computing the standard deviation (s.d.) over the validation data sets (Table 1).
| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| s.d. for state | 0.00114 | 0.00045 | 0.00031 |
| s.d. for state | 0.00120 | 0.00053 | 0.00042 |
Then, for each model, three different policies were sampled after training them for 100, 300 and 600 episodes, respectively. We first present the FRT results for all controllers correspondong to every model, followed by the BRT results.
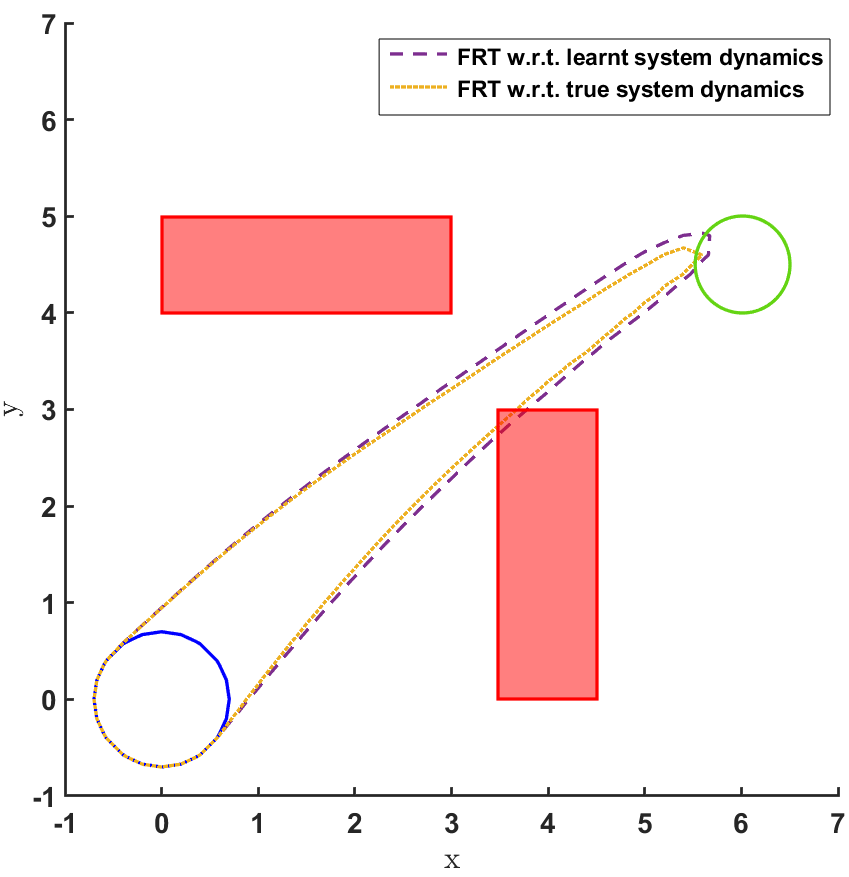
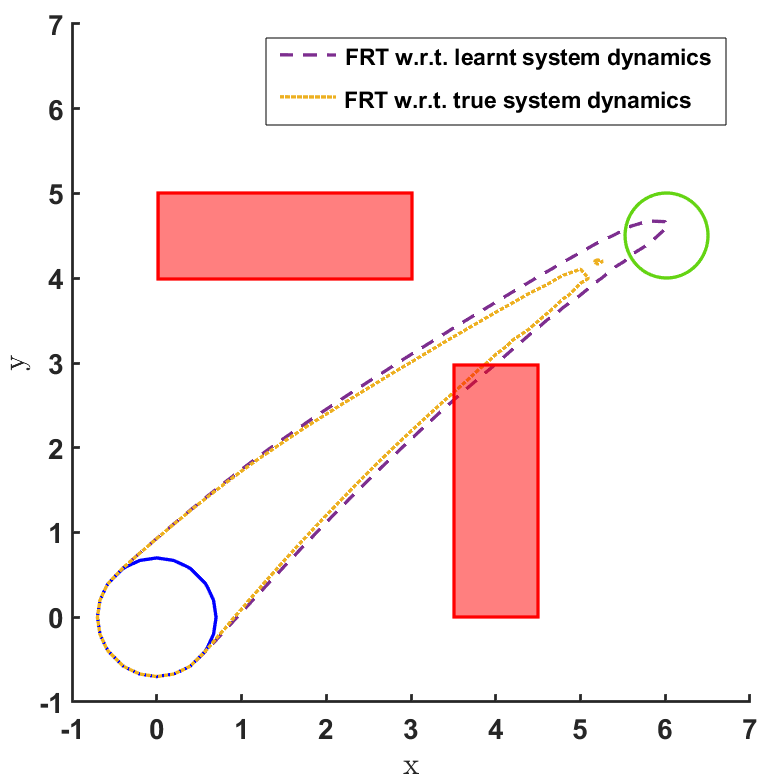
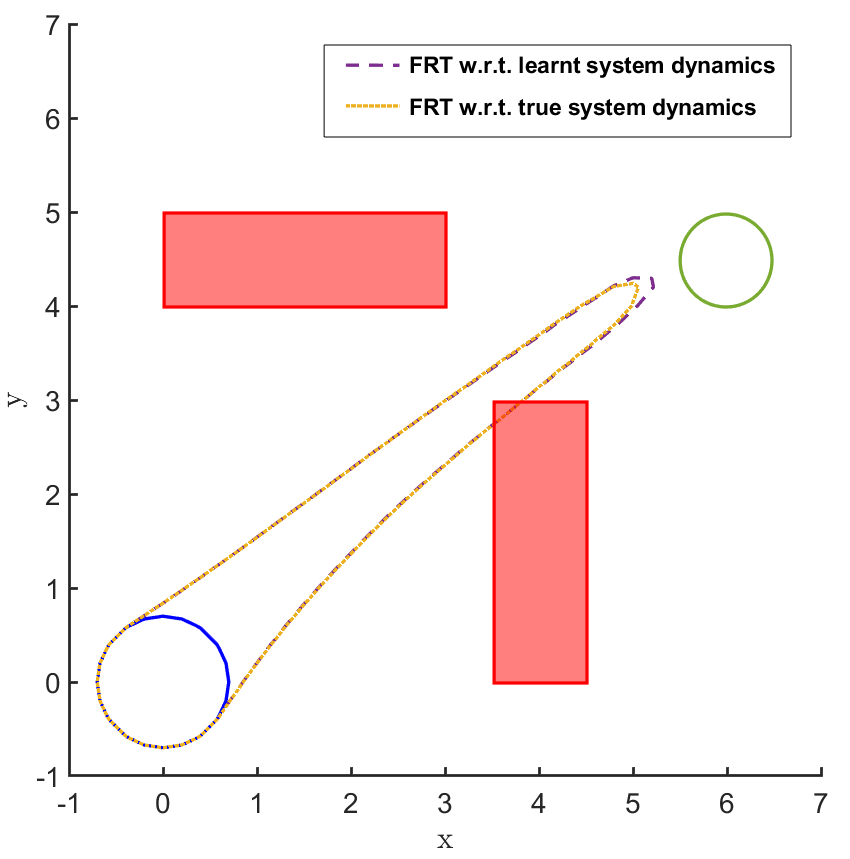
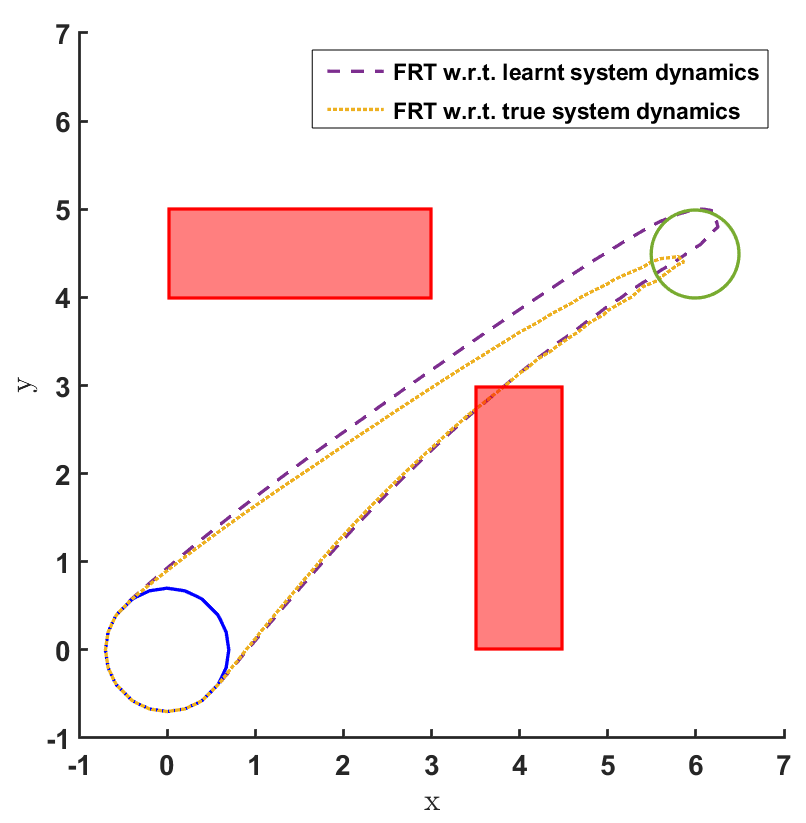
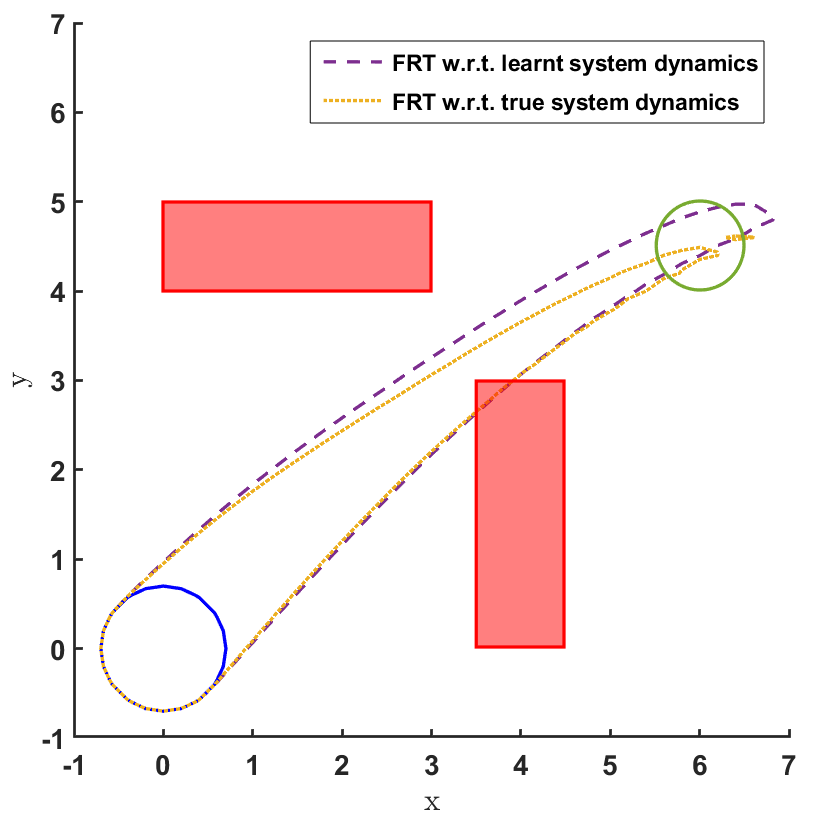

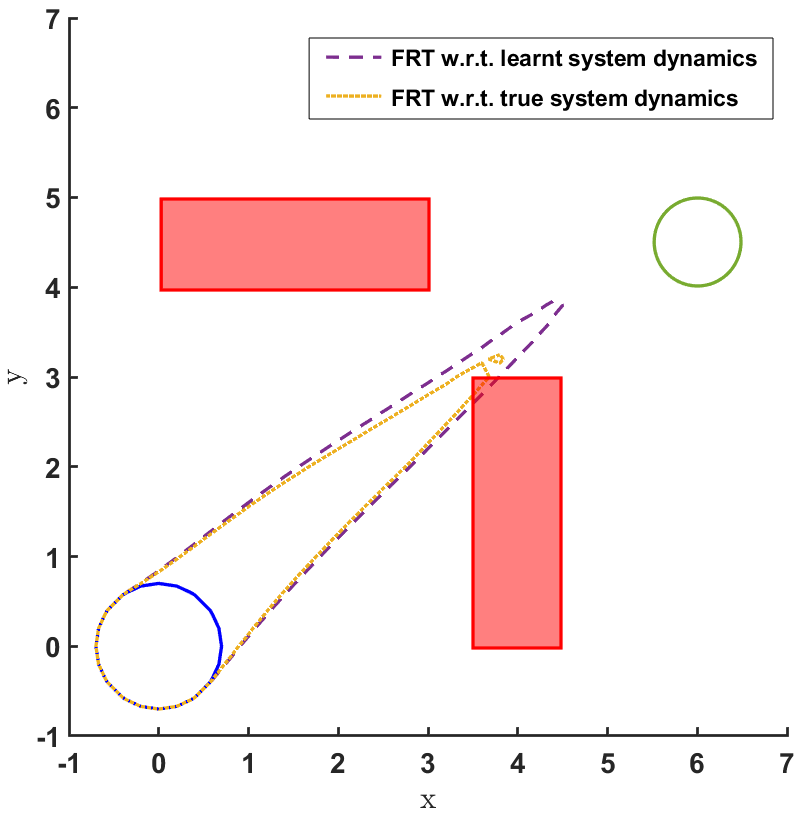
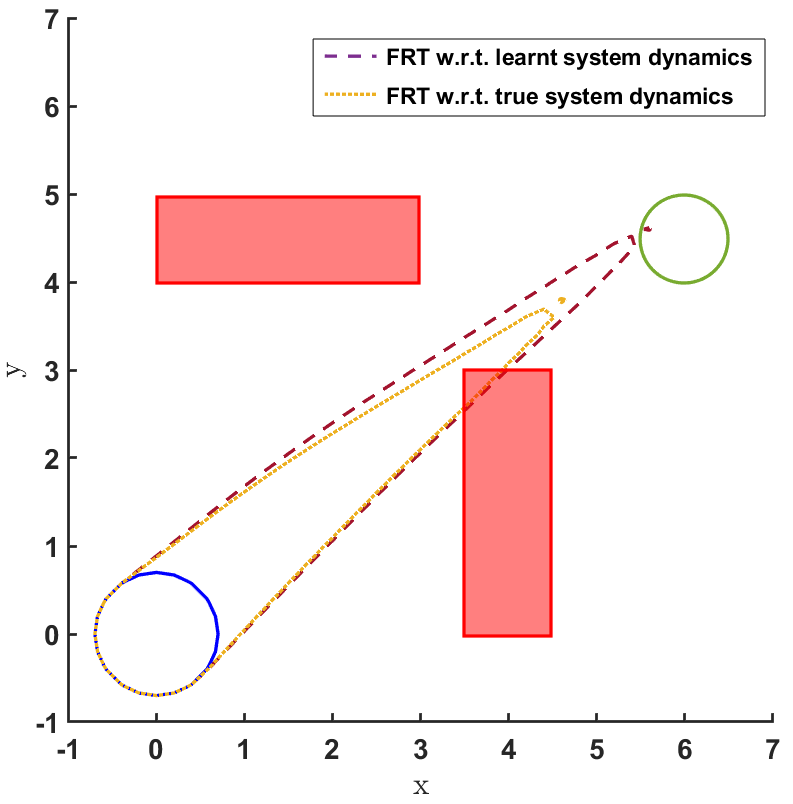
The FRT results for all the different models and controllers are shown in Fig. 4. Each plot in Fig. 4 shows two FRTs - the first corresponding to the augmented learnt dynamics and the second corresponding to the true system dynamics. This is done to validate the result of the proposed safety verification framework with the ground truth classification of as safe or unsafe. In general, it is observed that the FRT computed by the proposed framework, over the augmented learnt dynamics, closely resembles the FRT computed over the true system dynamics. Thus, in every case, classification of determined by the proposed framework is consistent with the ground truth result. All the above policies are found to be unsafe because the FRT intersects with obstacle 2. In all the cases, the policies are safe with respect to obstacle 1. Since all the above policies are unsafe, the BRT analysis is performed to determine for each policy.
The results corresponding to the determination of , using the proposed BRT formulation, for each of the 3 controllers trained over learnt models 1, 2 and 3 are presented in Fig. 5. determined by the proposed method is compared with the ground truth (G.T.) data, which was generated by using Monte-Carlo samples of possible trajectories from . It is observed that the most accurate results are obtained for model 1. For model 2, a small error due to modeling uncertainty is observed while determining . This error due to modeling uncertainty is related to how conservative the bound on the modeling error is. For model 3, the proposed BRT formulation correctly identifies policy 1 as completely unsafe, since . For the remaining policies, a small error is observed while determining .
It can be seen from Fig. 5 that there is no consistent trend for the fraction of safe initial states across, either the models trained with increasing number of sample points (top to bottom) or, across the policies trained for increasing number of iterations (left to right). This highlights one of the primary concerns for the lack of safety in RL based controllers: even though the cost function is designed to mitigate collisions and head towards the target, the controller learnt using it may not be safe because of various reasons stemming from state-representations learned by NN based policies and model dynamics, the hyper-parameters being used, or the optimization getting stuck in local minima, etc. In such scenarios, the proposed framework can be used to check before deployment whether, the developed RL controller abides by the required safety constraints or not.
A.5 Experiment Results: Safe Aerial Navigation
In the aerial navigation problem, an unmanned aerial vehicle (UAV) is flying in an urban environment. To ensure a safe flight, the UAV has to avoid collision with obstacles, like buildings and trees, in it’s path. This problem is abstracted in a continuous state and action domain, where the state vector gives the 3D coordinates of the UAV and the action vector comprises of the velocity, heading angle and pitch angle. The UAV has to takeoff from the ground and reach a desired set of goal states. Both the initial set of states and the goal states are represented using cuboids centered at coordinates and , respectively. There are two cylindrical obstacles in the environment, each of height units, which are centered at coordinates and , respectively, with a radius of units. This problem setting is presented in Fig. 3.
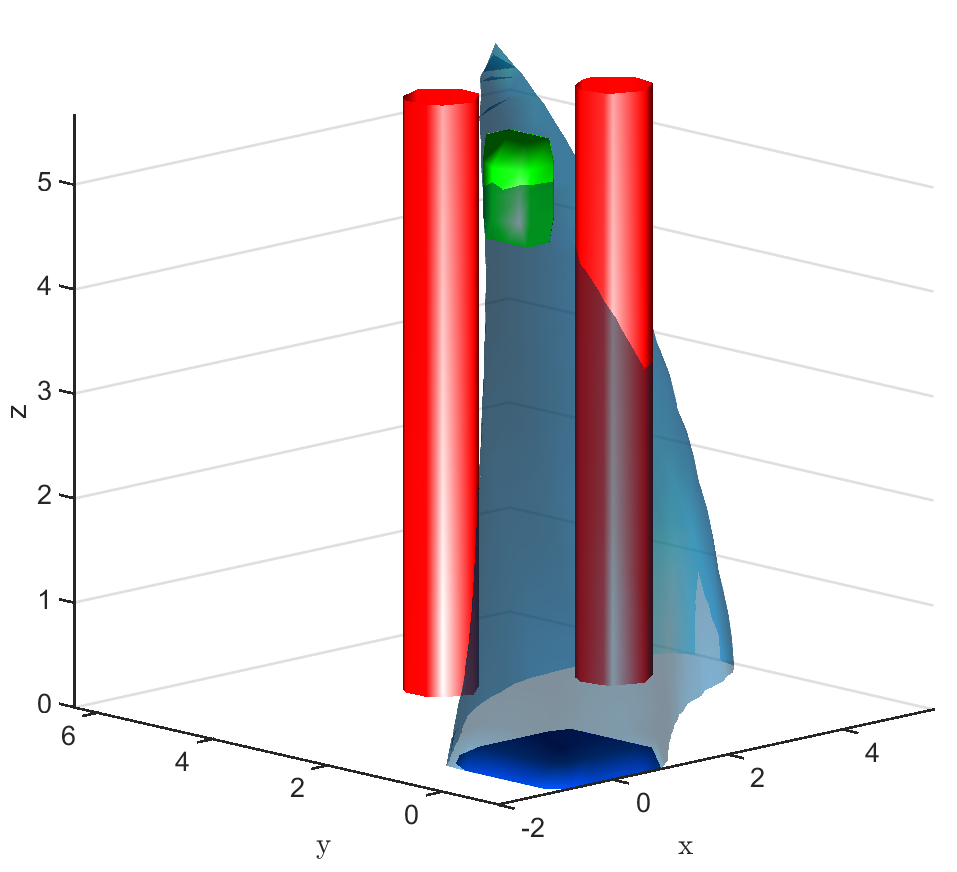
A learnt model represented by an NN is trained over 1000 data points and the policy trained over this model is evaluated. The FRT computed by the proposed framework, over the augmented learnt dynamics, is presented from different perspectives in Fig. 6. While the computed FRT doesn’t intersect with obstacle 1, it clearly intersects with obstacle 2. Therefore, is deemed unsafe. The next step is to compute the BRT and determine for the unsafe policy as shown in Fig. 6. It is observed that the proposed method under approximates when compared with the G.T. data.