Safety Guaranteed Robust Multi-Agent Reinforcement Learning with Hierarchical Control for Connected and Automated Vehicles
Abstract
We address the problem of coordination and control of Connected and Automated Vehicles (CAVs) in the presence of imperfect observations in mixed traffic environment. A commonly used approach is learning-based decision-making, such as reinforcement learning (RL). However, most existing safe RL methods suffer from two limitations: (i) they assume accurate state information, and (ii) safety is generally defined over the expectation of the trajectories. It remains challenging to design optimal coordination between multi-agents while ensuring hard safety constraints under system state uncertainties (e.g., those that arise from noisy sensor measurements, communication, or state estimation methods) at every time step. We propose a safety guaranteed hierarchical coordination and control scheme called Safe-RMM to address the challenge. Specifically, the high-level coordination policy of CAVs in mixed traffic environment is trained by the Robust Multi-Agent Proximal Policy Optimization (RMAPPO) method. Though trained without uncertainty, our method leverages a worst-case Q network to ensure the model’s robust performances when state uncertainties are present during testing. The low-level controller is implemented using model predictive control (MPC) with robust Control Barrier Functions (CBFs) to guarantee safety through their forward invariance property. We compare our method with baselines in different road networks in the CARLA simulator. Results show that our method provides best evaluated safety and efficiency in challenging mixed traffic environments with uncertainties.
I Introduction

Machine learning models assisted by more accurate on-board sensors, such as camera and LiDARs, have enabled intelligent driving to a certain degree. Meanwhile, advances in wireless communication technologies also make it possible for information sharing beyond an individual’s perception [1, 2]. Through vehicle-to-everything (V2X) communications, it has been shown that shared information can contribute to CAVs decision-making [3, 4, 5], and improve the safety and coordination of CAVs [6, 7, 8].
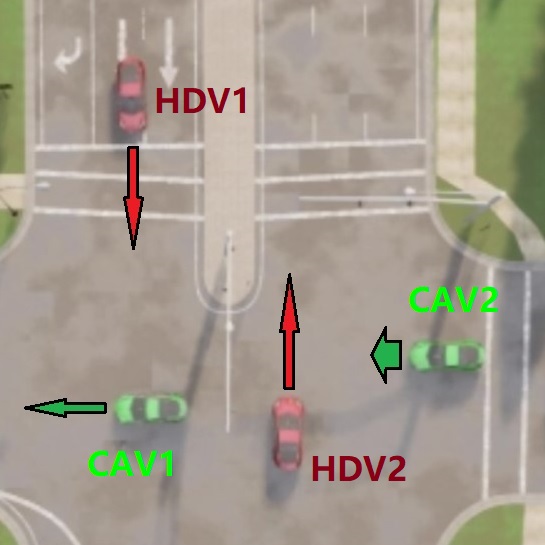
However, it remains challenging for reinforcement learning (RL) or multi-agent reinforcement learning (MARL)-based decision-making methods to guarantee the safety of CAVs in complicated dynamic environments containing human driven vehicles (HDVs) and optimize the joint behavior of the entire system. For real-world CAVs, state uncertainties that may result from noisy sensor measurements, state estimation algorithms or the communication medium pose another challenge. There can be scenarios where safety is highly correlated with the correctness of state information especially in the presence of HDVs/unconnected vehicles, as shown in Fig. 1b.
In this work, we propose a hierarchical decision-making approach for the coordination and control problem of CAVs in mixed traffic environments. At the top of the hierarchy is a Robust MARL policy that learns the cooperative behavior of CAVs by generating discrete planning actions for each vehicle. At the lower level, to guarantee the safety of each CAV, a MPC controller with control barrier function (CBF) constraints is designed to track the planned path according to the MARL action. Specifically, for cooperative policy-learning, we design a robust MAPPO (RMAPPO) algorithm that optimizes the worst-case Q network [9] as a critic allowing the MAPPO [10] to train a robust policy without simulating potential state uncertainties during the training process. The MPC controller using robust CBFs serves twofold purposes: guarantees safety in the presence of state uncertainties for the CAVs in mixed traffic environment; and tracks the planned path determined by the RMAPPO policy’s actions. In summary, the main contributions of this work are:
-
•
We propose a hierarchical decision-making framework, Safe-RMM, for CAVs in mixed traffic environments. The framework comprises of two levels whereby the top level is Robust MARL (the "RM" in Safe-RMM) that determines discrete actions conditioned on the behavior of other CAVs and HDVs. The low-level controller uses MPC (the final "M" in Safe-RMM) with CBFs to execute the high-level plan while guaranteeing safety to the neighborhood vehicles through the forward invariance property of CBFs.
-
•
To handle states uncertainties, we design the robust MARL algorithm which only requires training one more critic for the agents but no prior knowledge of uncertainties. Additionally, the MPC controller is incorporated with robust CBFs to consistently generate safe controls given MARL decisions, and to be endowed with the robustness against erroneous system state.
-
•
We validate through experiments in CARLA simulator that the proposed Safe-RMM approach significantly improves the collision-free rate and allows the CAV agents to achieve higher overall returns compared to baseline methods. Ablation studies further highlight the contributions of both the robust MARL algorithm and the MPC-CBF controller, as well as their reciprocal effects.
II Related Work
In this section we provide a survey of the existing literature in this area along with their limitations to motivate our proposed approach.
Safe RL and Robust RL
Different approaches have been proposed to guarantee or improve safety of the system, such as defining a safety shield or barrier assisting RL or MARL algorithm in either training or execution stage [11, 12, 13], constrained RL/MARL that learns a risk network [14], an expected cost function [15, 16], or cost constraints from language [17] that define the safety requirements. For MARL of CAV, safety-checking module with CBF-PID controller for each individual vehicle has been designed [8, 18, 19]. However, the above works assume accurate state inputs to RL or MARL algorithm from the driving environment and cannot tolerate noisy or inaccurate state input. Meanwhile, robust RL and robust MARL that only considers to train a policy under state uncertainty or model uncertainty [9, 20, 21, 22, 23] without explicitly considering the safety requirements have been proposed recently. However, in the multi-agent settings with imperfect observations, considering both safety requirements and robustness in an unified decision-making framework for CAVs still remains challenging.
Rule-Based Approaches
Unified optimization framework poses challenges that can be addressed by decomposing the problem into hierarchical structures. Specifically, the higher level control is responsible for decision making and the lower level control is responsible for safe execution. For the higher level planner, heuristic rule based methods can be employed in which a set of rules govern the behavior of each agent within the system. For instance existing driving behavior models in mixed traffic can be found in [24], [25],[26, 27]. However, these models often lack robustness and make various assumptions about HDVs, which prevents generalization to all scenarios. MPC can be used for the lower level controller due to its ability in reference tracking and handling hard constraints in real time. In situations where imperfect observations are present, robust MPC approaches may be used, such as tube MPC [28, 29]. Nevertheless, tube-based MPC approaches require a feedback controller that can keep the actual system trajectory close to the nominal one. The calculation of such feedback controller is not trivial in multi-agent systems with nonlinear dynamics. Min-Max MPC [30] can also be adopted but it is often difficult to solve, and when it is approximated, the approximation can result in an overly conservative solution.
In this work, we consider safe and robust coordination and control for multi-agent CAV systems in mixed traffic-environments with state uncertainties. We define safety as collision-free condition for CAVs, and the concept of robustness refers to agents’ capability of ensuring its performances, including safety and efficiency, with state uncertainties. The proposed hierarchical scheme involves robust MARL that works in tandem with a low-level MPC controller using robust CBFs to guarantee safety for CAVs under input state uncertainties. Our robust MARL algorithm does not require injecting perturbations during training.
III Problem Formulation
III-A Problem Description
We consider the robust cooperative policy-learning problem under uncertain state inputs for CAVs in mixed traffic environments including HDVs that do not communicate or coordinate with CAVs, and various driving scenarios such as multi-lane intersection and highway (as shown in Fig. 1&4). We assume that each CAV can get shared information from V2V and V2I communications. We consider that a CAV agent has accurate self-observation of its driving state but potentially perturbed observations of the other vehicles. The two parts collectively constitute its state in reinforcement learning explained in Sec. III-B, and also used by the MPC controller as inputs to the robust CBFs.
III-B Formulation of MARL with State Uncertainty for CAVs
The problem of Multi-Agent Reinforcement Learning with State Uncertainty for CAVs is defined as a tuple where is the communication network of all CAV agents. is the joint state space of all agents: . The state space of agent : contains self-observation , observations being the communicated message shared by neighbor connected agents , observations of unconnected vehicles either observed by agent itself or shared by other agents or infrastructures. For example, self-observation and shared observations can contain location, velocity, acceleration and lane-detection: ; observations of unconnected vehicles can contain location and velocity .
In this work, we consider agent suffers from uncertain observed locations and velocities of other vehicles aside from the ego vehicle (i.e. ), where denotes an uncertain observation over vehicle in comparison with the true accurate self-observation . The uncertainty is defined by bounded errors . The implementation of state uncertainty in testing experiments is explained in Sec. V.
The joint action set is where is the discrete finite action space for agent . : KEEP-LANE-MAX - the CAV maximize its reference throttle in the current lane. : CHANGE-LANE-LEFT - the CAV changes to its left lane. : CHANGE-LANE-RIGHT - the CAV changes to its right lane. In experiment, the path planner will set a target waypoint trajectory onto its left/right neighboring lane. are lane-keeping actions associated with different reference throttle values. By choosing action , for example, reference throttle value will first converted into reference acceleration then it will be fed to the controller and the calculation of safe control is introduced in IV-B. The state transition function is . The reward functions are defined as
| (1) |
in which is vehicle ’s velocity; is ’s default destination and is the safety reward. are non-negative weights balancing the proportions of individual and total achievement. As break-downs of the safety reward , the collision penalty penalizes collision and penalizes the infeasiblity of the low level controller.
IV Methodology
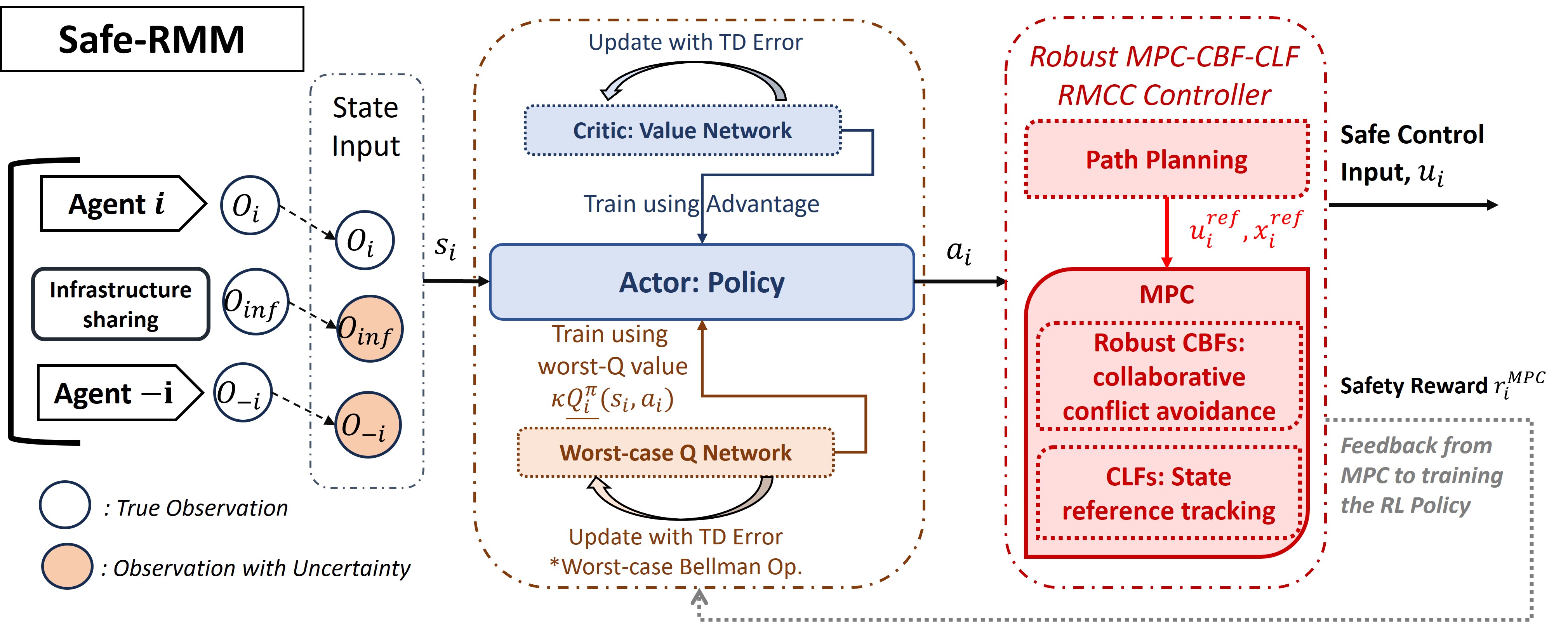
We present Safe-RMM – our hierarchical decision-making framework design in this section. We begin by presenting the design of our Robust MARL algorithm and subsequently present the details of the MPC controller using robust CBFs. Our Robust MARL algorithm augments MAPPO [10] such that each PPO agent is equipped with a worst-case Q network [9]. The worst-case Q estimates the potential impact of state perturbations on the policy’s action selection and the resulting expected return. By incorporating it into the policy’s training objective, we enhance the robustness of the trained policy against state perturbations. Consequently, the proposed algorithm improves both the safety and efficiency of CAVs under state uncertainties. We present our proposed safe MARL algorithm, Safe-RMM, in Algorithm 1.
IV-A Robust MAPPO
The proposed Robust MARL algorithm (Alg 1; Fig. 2) uses centralized training and decentralized execution. We are inspired by the Worst-case-aware Robust RL framework [9] and designed the robust MAPPO. Each robust PPO agent maintains a policy network (“actor”) with parameter , a value network (“critic”) with parameter and the second critic network approximating the worst-case action values with parameter . In order to learn a safe cooperative policy for the CAVs, the MARL interacts with the MPC controller (Sec. IV-B) during the Rollout process. As the algorithm starts, agent ’s policy takes initial state and samples an action ; the MPC-controller with robust CBFs given computes a safe control for the vehicle to execute. The agent receives (1) and all agents synchronously move to the next time-step by observing the new state .
During training, both critics account for updating the policy with loss function (2) so that the trained policy can balance the goals between maximizing expectations of advantage and worst-case return . Through value-based state regularization , the policy is trained to be robust at crucial “vulnerable” states around which uncertainties are more likely to affect the policy [32, 10].
| (2) |
IV-B Robust CBF-based Model Predictive Control
We adopt receding horizon control to implement the low-level controller for every agent in the road network. The low-level controller maps the high-level plans/actions into primitive actions/control inputs for agent . Firstly, a path planning function is used to map the high-level plans/actions into state and action references, i.e. , where is the state space and is the input space of primitive actions of CAV respectively. Subsequently this information is fed to the MPC controller. To prevent collision between agents, safety constraints are incorporated to the controller using CBFs.
We consider that the dynamics for each vehicle is affine in terms of its control input as follows:
| (3) |
where and are locally Lipschitz, denotes the state vector and denotes the control input. In the above equations represent the current longitudinal position, lateral position, heading angle, and speed, respectively. and are the acceleration and steering angle of vehicle at time , respectively, .
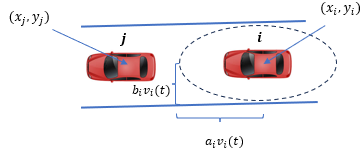
We incorporate safety with respect to other vehicles (primarily unconnected vehicles) as follows. Let CAV needs to stay safe to a vehicle in its vicinity. To achieve that we enforce a constraint on vehicles by defining a speed dependent ellipsoidal safe region as follows:
| (4) |
where , are weights adjusting the length of the major and minor axes of the ellipse as illustrated in Fig. 3. We enforce safety constraints on any CAV for vehicles in in one of three scenarios which are: i. immediately preceding in the same lane, ii. located in the lane the ego is changing to and iii. arriving from another lane that merges to the lane of the ego vehicle.
Given a continuously differentiable function and the safe set defined as , is a candidate control barrier function (CBF) for the system (IV-B) if there exists a class function and such that
| (5) |
for all , where denote the Lie derivatives along and , respectively. Additionally, we use CLFs to incorporate state references to the controller. A continuously differentiable function is a globally and exponentially stabilizing CLF for (IV-B) if there exists constants , , such that , , and the following inequality holds
| (6) |
where makes this a soft constraint.
The uncertain state measurements stemming from process noise and measurement noise denoted by is expressed as follows:
| (7) |
where is bounded noise such that . In the presence of noise, the robust CBF constraint becomes the following which has been shown to make the safety set forward invariant in [33].
| (8) |
Finally, the MPC with robust CBF and CLF control problem can be expressed as follows:
| subject to | |||
where , are the matrix of weights, is vector of weights, and is the vector of weights of the penalty terms associated with the relaxation parameters of the CLF constraints.
V Experiments and Evaluations
We conduct our experiment in the CARLA Simulator environment [34], where each vehicle is configured with onboard GPS and IMU sensors and a collision sensor that detects the collision with other objects. We show two challenging scenarios in daily driving, respectively, at Intersection (Fig. 4a) and on Highway (Fig. 4b), where we spawn multiple CAVs and some HDVs randomly. We adopt three types of state uncertainties exclusively for testing: A random error (U: uniform distribution); error_over_time: and error_target_vehicles: that impose perturbation at consistent values to CAVs’ states to affect their behavior patterns:
The former has state errors for all cars in duration , while the latter has a subset of vehicles randomly sampled in each episode and adds uncertainties to how are observed by others throughout the current episode.
Intersection
The Fig. 1 and Fig. 4a present an snapshot of the Intersection scenarios with CAVs (green) passing the intersection and HDVs (red) from opposite sides crossing the box at the same time. HDVs pose critical safety threats as they could either hit or be hit by a CAV from the side when driving fast (). CAVs aim to avoid collision and reach the preset destination after passing through the intersection.
Highway
Figures. 4b illustrates the scenario, where CAVs (green) are spawned behind HDVs (red) on a multi-lane highway. During training and evaluation, HDVs keep in their lanes at random speed from [7-9] except one random HDV simulates a stop and go scenario. CAVs aim to avoid any collision and drive at the speed limit of the road to arrive at the destination.


V-A Experiment Results
In this section, we highlight our method’s performances in terms of safety guarantees and robustness against state uncertainty while generalizable to different driving scenarios. We demonstrate through ablation studies that the incorporation of MPC with robust CBF based controller improves the performance of MARL algorithm. Additionally, we also demonstrate that our proposed hierarchical approach with robust MARL also improves the MPC-CBF controller.
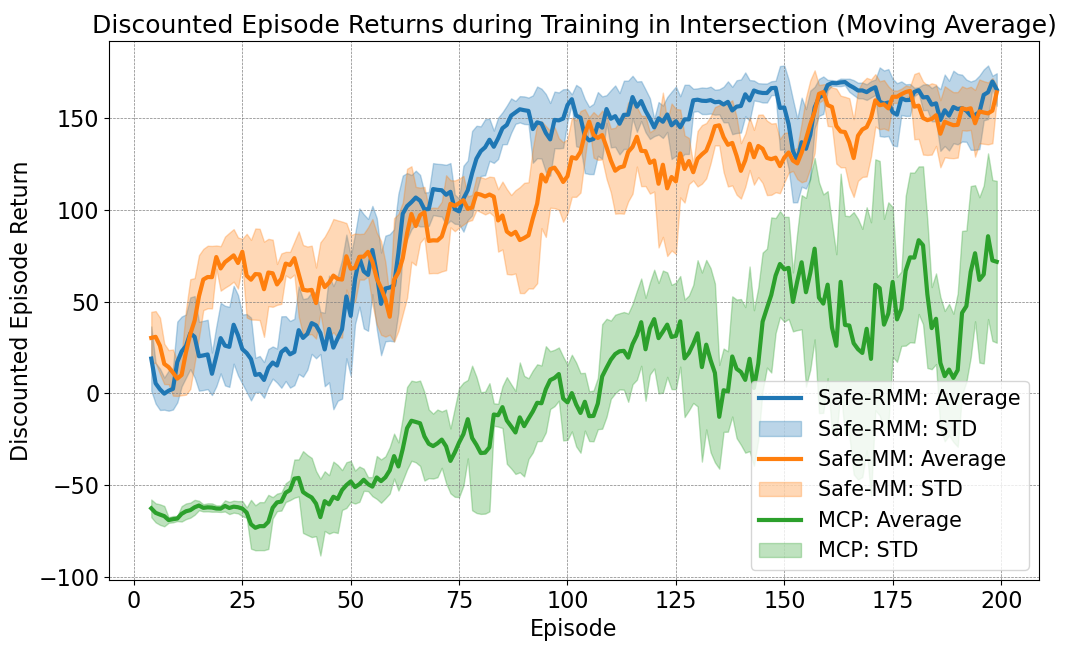
We trained three models: our Safe-RMM method, the “non-robust” Safe-MM that also adopts our framework, and the MCP method adopting MARL-PID controller with CBF safety shield [8]. Each model is trained on Intersection and Highway respectively for 200 episodes. In evaluation, aside from the three trained models, we have “MP”, MARL with PID controller, as an example of learning-based method without safety shielding; and we also implemented the benchmark “RULE” adopting a rule-based planner and a robust MPC controller. The “RULE” benchmark has been implemented based on the method proposed in [35], which introduces a safety-guaranteed rule for managing vehicle merging on roadways. This rule ensures safe interactions between vehicles arriving from different roads converging at a common point. Methods are evaluated for 50 episodes in both scenarios under four uncertainty configurations: None (uncertainty-free), random error , and two targeting errors and . Training results in Intersection are shown in Fig. 5; evaluations in both scenarios are presented in Table. I. For each entry in both tables, the left integer is the number of collisions happened during evaluation (in 50 episodes); the right number is the agents’ mean discounted return considering only the rewards related to velocity and goal-achievement in (1). We highlight the top performance across all methods with the least collision numbers and the highest efficiency return.
| Uncertainty | ||||
| Method | None | |||
| Intersection | ||||
| Safe-RMM1 | 0, 162.9 | 0, 161.4 | 0, 162.2 | 0, 161.8 |
| Safe-MM2 | 0, 157.9 | 0, 155.7 | 0, 155.9 | 0, 155.7 |
| MCP3 | 3, 65.7 | 2, 60.6 | 0, 66.2 | 2, 67.7 |
| MP4 | 33, 148.4 | 41, 149.1 | 36, 145.9 | 30, 139.0 |
| RULE5 | 2, 120.9 | 1, 113.9 | 3, 105.5 | 2, 112.3 |
| Highway | ||||
| Safe-RMM | 0, 162.0 | 0, 169.4 | 0, 166.4 | 0, 161.8 |
| Safe-MM | 0, 161.3 | 0, 168.7 | 0, 168.7 | 0, 163.0 |
| MCP | 0, 56.8 | 2, 55.8 | 1, 60.7 | 2, 58.4 |
| MP | 35, 74.1 | 34, 74.5 | 38, 73.8 | 38, 74.5 |
-
•
1Safe-RMM: our method–Safe Robust MARL-MPC; 2Safe-MM: Safe MARL-MPC adopting same framework as1 but trained without worst-case Q. Benchmarks: 3MCP: MARL-PID with CBF Safety Shield; 4MP: MARL-PID without shielding; 5RULE: rule-based planner with MPC controller.
-
•
Each entry in the table above contains (number of collisions; mean of episodes discounted efficiency return).
V-A1 Top Safety and Efficiency Achieved by the Framework
Our proposed MARL-MPC framework demonstrates top safety performance as both Safe-RMM and Safe-MM achieve zero collisions across all evaluation scenarios, even when subjected to uncertainties. Additionally, Safe-RMM and Safe-MM rank among the top two in terms of efficiency across all settings. Our proposed approach with robust MPC controller enables MARL to fully realize its potential, allowing its decisions to be executed with accuracy and receiving precise reward feedback. The reciprocation between the MARL and MPC controller enhances policy training and demonstrates that ensuring safety in autonomous vehicles need not compromise efficiency.
In contrast, the MP baseline, adopting MARL without safety shielding, experiences collisions in 60%-80% of evaluation episodes as shown in Table I. The result highlights the limited safety-awareness of pure learning-based approaches in complex driving scenarios. The MCP baseline, which incorporates a CBF-based safety shield, significantly reduces collisions to just 3% of episodes in average. However, this comes at the cost of performance efficiency due to more conservative behaviors. Specifically, MCP in the presence of safety shield shows a 54% performance drop in the Intersection scenario and a 23% drop in the Highway scenario compared to the MP method. These results verify that when applying learning-based algorithm in CAV system, the policy and the controller (or the action actuator) are not independent. Our Safe-RMM having MARL enabled by the accuracy and safety of MPC controller achieves comprehensively best performance while the same MARL algorithm is hindered by the limited capability of PID controller from reaching its optimality.
V-A2 Ablation Study with Rule-based Benchmark and Robustness
We conducted an ablation study by evaluating the rule-based benchmark “RULE” in the Intersection scenario. As shown in Table I, our Safe-RMM method outperforms “RULE” in both safety and efficiency metrics. Compared with other benchmarks, the rule-based method offers a more “balanced” performance – being significantly safer and less “reckless” than MP, while achieving comparable safety and much higher efficiency than MCP. However, in a safety-critical scenario like the Intersection, more precise decision-making is required for CAVs to ensure both safety and speed. The lack of adaptability and learning capability limits rule-based approaches from achieving comparable performance as our approach in these complex scenarios.
From the results of the RULE benchmark in Table I, we observe a 6%-13% drop in efficiency when comparing episodes with and without state uncertainties. This supports our earlier assessment in Sec. II that rule-based methods, as high-level planners, generally lack the robustness of learning-based approaches. Furthermore, a comparison between Safe-RMM and its “non-robust” counterpart, Safe-MM, shows that Safe-RMM outperforms Safe-MM by approximately 4% in efficiency across all evaluation settings in Intersection. However, this advantage does not extend to the Highway scenario. Our analysis of both scenarios suggests that the uncertainties of HDVs come not only from tested errors, but also from the initial randomization of HDVs’ location and speed. In Intersection, even slight variations in vehicle states may require completely different optimal strategies by the CAVs – either seizing the opportunity to pass ahead of the HDVs, or yielding for safety at the cost of efficiency. Safe-RMM demonstrates greater robustness against these uncertainties and can effectively manage these “critical” moments, optimizing for higher expected returns with a worst-case consideration. However, in less safety-critical scenarios like Highway, the worst-case awareness of Safe-RMM can result in sub-optimality. In these cases, the algorithm may avoid taking greedier actions and have lower efficiency, even when such actions carry little risk.
VI Conclusion
In this work, we study the safe and robust planning and control problem for connected autonomous vehicles in common driving scenarios under state uncertainties. We propose the Safe-RMM algorithm for coordinated CAVs and further validate through experiments the effectiveness of our method. MARL can enhance the performance ceiling of MPC controller in safety-critical scenarios and robust MPC controller can safely and accurately execute the actions from RL and reciprocally contributes to better trained policies. The method achieves top safety and efficiency performances in evaluation, and maintain robustness against tested perturbations. Future work could consider optimizing the control policy in a mixed traffic scenario with both RL and rule-based intelligent agents.
References
- [1] D. Martín-Sacristán, S. Roger, D. Garcia-Roger, J. F. Monserrat, P. Spapis, C. Zhou, and A. Kaloxylos, “Low-latency infrastructure-based cellular v2v communications for multi-operator environments with regional split,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 2, pp. 1052–1067, 2020.
- [2] H. Mun, M. Seo, and D. H. Lee, “Secure privacy-preserving v2v communication in 5g-v2x supporting network slicing,” IEEE Trans. Intell. Transp. Syst., 2021.
- [3] N. Buckman, A. Pierson, S. Karaman, and D. Rus, “Generating visibility-aware trajectories for cooperative and proactive motion planning,” pp. 3220–3226, 2020.
- [4] A. Miller and K. Rim, “Cooperative perception and localization for cooperative driving,” pp. 1256–1262, 2020.
- [5] S. Han, H. Wang, S. Su, Y. Shi, and F. Miao, “Stable and efficient shapley value-based reward reallocation for multi-agent reinforcement learning of autonomous vehicles,” pp. 8765–8771, 2022.
- [6] J. Rios-Torres and A. A. Malikopoulos, “A survey on the coordination of connected and automated vehicles at intersections and merging at highway on-ramps,” IEEE Trans. Intell. Transp. Syst., vol. 18, no. 5, pp. 1066–1077, May 2017.
- [7] J. Lee and B. Park, “Development and evaluation of a cooperative vehicle intersection control algorithm under the connected vehicles environment,” IEEE Trans. Intell. Transp. Syst., vol. 13, no. 1, pp. 81–90, March 2012.
- [8] Z. Zhang, S. Han, J. Wang, and F. Miao, “Spatial-temporal-aware safe multi-agent reinforcement learning of connected autonomous vehicles in challenging scenarios,” pp. 5574–5580, 2023.
- [9] Y. Liang, Y. Sun, R. Zheng, and F. Huang, “Efficient adversarial training without attacking: Worst-case-aware robust reinforcement learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 22 547–22 561, 2022.
- [10] C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 611–24 624, 2022.
- [11] L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,” Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, pp. 411–444, 2022.
- [12] I. ElSayed-Aly, S. Bharadwaj, C. Amato, R. Ehlers, U. Topcu, and L. Feng, “Safe multi-agent reinforcement learning via shielding,” in Proceedings of the 20th International Conference on Autonomous Agents and MultiAgent Systems, ser. AAMAS ’21. Richland, SC: International Foundation for Autonomous Agents and Multiagent Systems, 2021, p. 483–491.
- [13] Z. Cai, H. Cao, W. Lu, L. Zhang, and H. Xiong, “Safe multi-agent reinforcement learning through decentralized multiple control barrier functions,” 2021.
- [14] L. Wen, J. Duan, S. E. Li, S. Xu, and H. Peng, “Safe reinforcement learning for autonomous vehicles through parallel constrained policy optimization,” pp. 1–7, 2020.
- [15] S. Lu, K. Zhang, T. Chen, T. Başar, and L. Horesh, “Decentralized policy gradient descent ascent for safe multi-agent reinforcement learning,” vol. 35, no. 10, pp. 8767–8775, 2021.
- [16] S. Gu, J. Grudzien Kuba, Y. Chen, Y. Du, L. Yang, A. Knoll, and Y. Yang, “Safe multi-agent reinforcement learning for multi-robot control,” Artificial Intelligence, vol. 319, p. 103905, 2023. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0004370223000516
- [17] Z. Wang, M. Fang, T. Tomilin, F. Fang, and Y. Du, “Safe multi-agent reinforcement learning with natural language constraints,” 2024. [Online]. Available: https://arxiv.org/abs/2405.20018
- [18] J. Wang, S. Yang, Z. An, S. Han, Z. Zhang, R. Mangharam, M. Ma, and F. Miao, “Multi-agent reinforcement learning guided by signal temporal logic specifications,” arXiv preprint arXiv:2306.06808, 2023.
- [19] S. Han, S. Zhou, J. Wang, L. Pepin, C. Ding, J. Fu, and F. Miao, “A multi-agent reinforcement learning approach for safe and efficient behavior planning of connected autonomous vehicles,” arXiv:2003.04371, 2022.
- [20] S. Han, S. Su, S. He, S. Han, H. Yang, and F. Miao, “What is the solution for state adversarial multi-agent reinforcement learning?” arXiv preprint arXiv:2212.02705, 2022.
- [21] S. He, S. Han, S. Su, S. Han, S. Zou, and F. Miao, “Robust multi-agent reinforcement learning with state uncertainty,” Transactions on Machine Learning Research, 2023.
- [22] E. Salvato, G. Fenu, E. Medvet, and F. A. Pellegrino, “Crossing the reality gap: A survey on sim-to-real transferability of robot controllers in reinforcement learning,” IEEE Access, vol. 9, pp. 153 171–153 187, 2021.
- [23] L. Pinto, J. Davidson, R. Sukthankar, and A. Gupta, “Robust adversarial reinforcement learning,” in Proceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, D. Precup and Y. W. Teh, Eds., vol. 70. PMLR, 06–11 Aug 2017, pp. 2817–2826. [Online]. Available: https://proceedings.mlr.press/v70/pinto17a.html
- [24] M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states in empirical observations and microscopic simulations,” Physical Review E, vol. 62, pp. 1805–1824, 02 2000.
- [25] A. Kesting, M. Treiber, and D. Helbing, “General lane-changing model mobil for car-following models,” Transportation Research Record, vol. 1999, no. 1, pp. 86–94, 2007. [Online]. Available: https://doi.org/10.3141/1999-10
- [26] C. R. Munigety, “Modelling behavioural interactions of drivers’ in mixed traffic conditions,” Journal of Traffic and Transportation Engineering (English Edition), vol. 5, no. 4, pp. 284–295, 2018.
- [27] J. J. Olstam and A. Tapani, “Comparison of car-following models,” 2004. [Online]. Available: https://api.semanticscholar.org/CorpusID:15720655
- [28] B. T. Lopez, J.-J. E. Slotine, and J. P. How, “Dynamic tube mpc for nonlinear systems,” in 2019 American Control Conference (ACC). IEEE, 2019, pp. 1655–1662.
- [29] D. Q. Mayne and E. C. Kerrigan, “Tube-based robust nonlinear model predictive control,” IFAC Proceedings Volumes, vol. 40, no. 12, pp. 36–41, 2007, 7th IFAC Symposium on Nonlinear Control Systems. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1474667016354994
- [30] D. M. Raimondo, D. Limon, M. Lazar, L. Magni, and E. F. ndez Camacho, “Min-max model predictive control of nonlinear systems: A unifying overview on stability,” European Journal of Control, vol. 15, no. 1, pp. 5–21, 2009. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0947358009707034
- [31] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [32] H. Zhang, H. Chen, C. Xiao, B. Li, M. Liu, D. Boning, and C.-J. Hsieh, “Robust deep reinforcement learning against adversarial perturbations on state observations,” Advances in Neural Information Processing Systems, vol. 33, pp. 21 024–21 037, 2020.
- [33] H. M. S. Ahmad, E. Sabouni, A. Dickson, W. Xiao, C. G. Cassandras, and W. Li, “Secure control of connected and automated vehicles using trust-aware robust event-triggered control barrier functions,” 2024. [Online]. Available: https://arxiv.org/abs/2401.02306
- [34] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “CARLA: An open urban driving simulator,” pp. 1–16, 2017.
- [35] E. Sabouni, H. S. Ahmad, C. G. Cassandras, and W. Li, “Merging control in mixed traffic with safety guarantees: A safe sequencing policy with optimal motion control,” in 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), 2023, pp. 4260–4265.