SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection
Abstract
LiDAR-based 3D object detection plays an essential role in autonomous driving. Existing high-performing 3D object detectors usually build dense feature maps in the backbone network and prediction head. However, the computational costs introduced by the dense feature maps grow quadratically as the perception range increases, making these models hard to scale up to long-range detection. Some recent works have attempted to construct fully sparse detectors to solve this issue; nevertheless, the resulting models either rely on a complex multi-stage pipeline or exhibit inferior performance. In this work, we propose a fully sparse adaptive feature diffusion network (SAFDNet) for LiDAR-based 3D object detection. In SAFDNet, an adaptive feature diffusion strategy is designed to address the center feature missing problem. We conducted extensive experiments on Waymo Open, nuScenes, and Argoverse2 datasets. SAFDNet performed slightly better than the previous SOTA on the first two datasets but much better on the last dataset, which features long-range detection, verifying the efficacy of SAFDNet in scenarios where long-range detection is required. Notably, on Argoverse2, SAFDNet surpassed the previous best hybrid detector HEDNet by 2.6% mAP while being 2.1 faster, and yielded 2.1% mAP gains over the previous best sparse detector FSDv2 while being 1.3 faster. The code will be available at https://github.com/zhanggang001/HEDNet.
1 Introduction

LiDAR-based 3D object detection poses a significant challenge in computer vision and has received increasing attention for its potential applications in autonomous driving [1] and advanced robotics [2]. Currently, most LiDAR-based 3D detectors [3, 4, 5, 6, 7] convert sparse features into dense feature maps to facilitate further feature extraction and prediction, termed hybrid detectors (see Figure 1(a)). These methods demonstrate excellent performance on well-established benchmarks like nuScenes [8] and Waymo Open [9], primarily designed for a relatively short perception range (below 75 meters). However, scaling these methods to more practical long-range scenarios (exceeding 200 meters) becomes challenging because the computational costs associated with dense feature maps grow quadratically as the perception range increases [10]. Additionally, processing unoccupied areas is often unnecessary and might even hinder detection accuracy. Consequently, there’s a growing interest among researchers in developing fully sparse detectors [11, 10, 12, 13].
Constructing fully sparse detectors by removing dense feature maps from existing hybrid detectors is non-trivial, as these feature maps play a crucial role in these methods. Most hybrid detectors rely on features at object centers for predictions, considering them reliable representations of the entire object. These methods usually first employ sparse voxel encoders to efficiently extract features from non-empty voxels. Subsequently, they transform these sparse features into dense feature maps in a bird’s eye view (BEV) and use convolutional neural networks (CNNs) to diffuse features towards object centers, creating center features. However, for fully sparse detector, in the absence of dense feature maps, the centers of large objects like vehicles and trucks often remain empty, leading to the center feature missing problem [10, 12]. Thus, learning an appropriate object representation becomes pivotal for building fully sparse detectors.
To tackle the center feature missing problem, FSDv1 [10] proposes a multi-stage pipeline involving instance clustering (Figure 1(b)). Specifically, it begins by segmenting raw point clouds into foreground and background, then conducts center voting for instance clustering. Subsequently, it extracts instance features from each cluster for initial predictions, which are refined by a group correction head. FSDv2 [12] eliminates feature clustering in favor of a virtual voxelization module to reduce the inductive bias of handcrafted instance-level representations, yet it still relies on point segmentation and prediction refinement. The complex pipeline makes it challenging to deploy them in real-world scenarios due to numerous hyperparameters requiring tuning. In contrast, VoxelNeXt [13] directly predicts objects based on the features nearest to object centers but exhibits inferior accuracy.
In this work, we introduce SAFDNet, a simple yet effective architecture tailored for fully sparse 3D object detection (Figure 1(c)). Similar to hybrid detectors, SAFDNet initially employs a sparse voxel encoder to extract 3D sparse features, which are then transformed into 2D sparse BEV features. Subsequently, an adaptive feature diffusion (AFD) strategy is proposed to propagate features towards object centers, serving as the core component in SAFDNet for addressing the center feature missing problem. Unlike the uniform feature diffusion achieved by dense convolutional networks in hybrid detectors, our AFD selectively expands features within object bounding boxes to neighboring regions, dynamically adjusting the diffusion range according to voxel positions. As a result, SAFDNet can still leverage efficient calculations on sparse features. The expanded features are fed into the sparse detection head for predictions. Importantly, SAFDNet maintains most hyperparameters compatible with existing hybrid detectors, including those of the detection head, enabling easy adaptation to new scenarios.
We conducted extensive experiments on the challenging Waymo Open [9], nuScenes [8], and Argoverse2 [14] datasets to verify the effectiveness of our method. On the first two datasets for short-range detection, SAFDNet performed on par with the previous best hybrid detector HEDNet and was 2 faster than the previous best sparse detector FSDv2. On the Argoverse2 dataset for long-range detection, SAFDNet surpassed HEDNet by 2.6% mAP while being 2.1 faster and outperformed FSDv2 by 2.1% mAP while being 1.3 faster. These results demonstrate the efficacy of SAFDNet in scenarios that requires long-range detection.
2 Related work
2.1 Dense detectors
VoxelNet [3] is the first to introduce dense convolutions for LiDAR-based 3D object detection, achieving competitive performance. However, directly applying dense convolutions to 3D voxel feature learning poses efficiency challenges due to their computational complexity. To address this limitation, pillar-based methods [15, 16, 17] utilize 2D dense convolutions on BEV dense feature maps instead, which improves computational efficiency but leads to inferior accuracy.
2.2 Hybrid detectors
Unlike dense detectors, hybrid detectors [18, 4, 19, 5, 20, 21, 6, 7] incorporate both sparse and dense features. For instance, SECOND [18], a pioneering effort, employs a sparse CNN to extract 3D sparse voxel features and then transforms them into dense BEV feature maps for predictions. FocalsConv [22] enhances the efficiency of sparse CNNs by adaptively expanding features through spatially learnable sparsity. CenterPoint [4] introduces a center-based detection head, showcasing excellent performance in 3D object detection and tracking. Recent studies [19, 5, 23, 7] have further enhanced CenterPoint from diverse perspectives. Additionally, another line of works [21, 11, 24, 6, 25] has explored transformers to capture long-range dependencies among spatial features. However, despite leveraging a sparse backbone, these methods face challenges when scaling to long-range scenarios, primarily due to their dependence on dense feature maps.

2.3 Sparse detectors
Some early works [26, 27, 28] employ the PointNet series [29, 30] to extract sparse features from raw point clouds for predictions. Point R-CNN [26] stands out as the pioneer in developing fully point-based detectors. VoteNet [28] introduces a center voting mechanism and generates proposals from the voted centers. Despite efforts to speed up full point-based methods, the time-consuming neighborhood searching remains impractical for large-scale point clouds. In contrast, FSDv1 [10] segments raw point clouds into foreground and background, and then clusters the foreground points to represent individual objects. Then, it uses a PointNet-style [29] network to extract features from each cluster for initial coarse predictions, refined by a group correction head. FSDv2 [12] replaces the instance clustering with a virtual voxelization module, aiming to eliminate the inductive bias of handcrafted instance-level representations. Yet, it still requires point segmentation and prediction refinement. The complex pipeline demands tuning numerous hyperparameters for deployment in real-world scenarios. In contrast, SWFormer [11] presents a fully transformer-based architecture for 3D object detection. And the more recent VoxelNeXt [13] streamlines the fully sparse architecture with a purely voxel-based design, localizing objects by the features nearest to their centers. Despite their notable efficiency, both SWFormer and VoxelNeXt exhibit inferior accuracy compared to hybrid detectors.
3 SAFDNet
3.1 Background
Sparse convolutions.
Existing LiDAR-based 3D object detectors commonly leverage sparse convolutions for data processing to enhance computational efficiency. There are primarily two types of sparse convolutions used: submanifold sparse convolution [31], which maintains feature sparsity between input and output feature maps, and regular sparse convolution [32], which increases the density of the feature map by expanding features into neighboring regions. Since regular sparse convolution decreases feature sparsity dramatically, it is often merely used to down-sample feature maps in existing methods [18, 5, 4, 7].
Sparse residual block (SRB).
Sparse encoder-decoder block (EDB).
Since submanifold sparse convolutions preserve feature sparsity from input to output, they may impede information exchange among spatially distant features. As a result, merely stacking SRBs can result in a receptive field with limited size. HEDNet [7] addresses this by incorporating sparse encoder-decoder blocks that capture long-range dependencies among features while maintaining computational efficiency. Figure 3 illustrate a general structure of EDB. It decreases the spatial distance among distant features via feature down-sampling and subsequently restores lost details through multi-scale feature fusion. By applying 3D and 2D submanifold sparse convolutions to construct the SRB, we can obtain 3D-EDB and 2D-EDB, respectively.

3.2 Overall architecture
Figure 2 presents an overview of the proposed SAFDNet. SAFDNet shares a similar pipeline to existing hybrid detectors [18, 4]. It comprises three parts: a 3D sparse backbone, a 2D sparse backbone, and a sparse detection head.
3D sparse backbone.
Taking raw point clouds as input, the 3D sparse backbone initially extracts sparse feature maps using a voxel feature encoder (VFE) and progressively down-samples them to extract high-level features. At the end of the backbone, it incorporates a 3D-EDB to facilitate information exchange among distant features. Subsequently, the 3D sparse features are compressed into 2D sparse BEV features. This compression is implemented by using two regular sparse convolutions with stride 2 to down-sample features along the Z-axis and then aggregating features of voxels sharing the same coordinates in BEV.
2D sparse backbone.
Taking the BEV sparse features as input, the 2D sparse backbone begins by performing voxel classification on each voxel to determine whether the geometric center of each voxel falls within an object bounding box of a specific category or belongs to the background. Subsequently, an adaptive feature diffusion (AFD) operation, in conjunction with a 2D-EDB, is employed to propagate voxel features towards object centers.
Sparse detection head.
Since most high-performing hybrid detectors utilize the center-based head introduced by CenterPoint [4] or TransFusion-L [5], we adopt a similar head in SAFDNet. However, as the designs of these detection heads are tailored for dense feature maps, we have made some adjustments to accommodate sparse features. For more details, please refer to Section 3.4.
| Method | Type | mAPH | Vehicle | Pedestrian | Cyclist |
|---|---|---|---|---|---|
| HEDNet | Hybrid | 73.2 | 72.1 | 72.0 | 75.6 |
| Nearest | Sparse | 71.5 | 68.9 | 70.9 | 74.7 |
3.3 Adaptive feature diffusion
Existing hybrid detectors typically decompose 3D object detection into classification and regression tasks. The classification task aims to locate voxels at object centers for each category, while the regression task predicts precise bounding boxes based on these center features. Given that LiDAR point clouds reside on the surfaces of objects, to construct fully sparse detectors by simply removing dense feature maps would result in the center feature missing problem. A straightforward solution is to make predictions based on the features nearest to object centers. Specifically, we reformulate the classification task into identifying the voxels closest to object centers, enabling the regression task to predict precise bounding boxes using these closest voxel features. Our experiments, detailed in Table 1, demonstrate that such a sparse model (the bottom row) performed worse than the hybrid detector HEDNet. This discrepancy is particularly notable on larger vehicles, which are more severely affected by the center feature missing problem. These findings indicate that center features indeed provide better object representations than their nearest counterparts.
Uniform feature diffusion (UFD).
Is it possible for detectors to extract features nearer or at object centers while maintaining feature sparsity as much as possible? An intuitive idea is to diffuse sparse features to neighboring voxels rather than all voxels like hybrid detectors. Figure 4 (a) depicts a uniform feature diffusion strategy, where input voxel features are expanded to a neighborhood, with set to 5 as an example. There are two possible implementations:
-
a.
Parameter-based (PB) UFD: employing a regular sparse convolution with kernel size to spread features, in conjunction with a 2D-EDB for further transformation.
-
b.
Parameter-free (PF) UFD: initializing zero features in neighboring regions and then incorporating a 2D-EDB to spread features progressively.
Adaptive feature diffusion (AFD).
Through our analysis of the sparse voxels output by the 3D sparse backbone, we observed that: (a) fewer than 10% of the voxels fall within the bounding boxes of objects; (b) smaller objects often have voxel features near or at their centers. This indicates potential redundancy in uniformly expanding features into neighborhoods of the same size, particularly for voxels within the bounding boxes of small objects and those belonging to the background. Hence, we propose an adaptive feature diffusion strategy according to voxel positions, as depicted in Figure 4 (b). The idea is to assign a larger diffusion range to voxels within the bounding boxes of large objects to bring features nearer to object centers, while assigning a smaller range to voxels within the bounding boxes of small objects or the background to preserve feature sparsity. Implementing this idea necessitates voxel classification to determine whether a voxel’s center is within the bounding box of an object of a specific category or belongs to the background.

| Method | mAP/mAPH | Vehicle AP/APH | Pedestrian AP/APH | Cyclist AP/APH | ||||
|---|---|---|---|---|---|---|---|---|
| L1 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | |
| Results on the validation data set | ||||||||
| SECOND [18] | 67.2/63.1 | 61.0/57.2 | 72.3/71.7 | 63.9/63.3 | 68.7/58.2 | 60.7/51.3 | 60.6/59.3 | 58.3/57.0 |
| PointPillar [15] | 69.0/63.5 | 62.8/57.8 | 72.1/71.5 | 63.6/63.1 | 70.6/56.7 | 62.8/50.3 | 64.4/62.3 | 61.9/59.9 |
| Part-A2-Net [34] | 73.6/70.3 | 66.9/63.8 | 77.1/76.5 | 68.5/68.0 | 75.2/66.9 | 66.2/58.6 | 68.6/67.4 | 66.1/64.9 |
| SST [21] | 74.5/71.0 | 67.8/64.6 | 74.2/73.8 | 65.5/65.1 | 78.7/69.6 | 70.0/61.7 | 70.7/69.6 | 68.0/66.9 |
| CenterPoint [4] | 74.4/71.7 | 68.2/65.8 | 74.2/73.6 | 66.2/65.7 | 76.6/70.5 | 68.8/63.2 | 72.3/71.1 | 69.7/68.5 |
| PV-RCNN [35] | 76.2/73.6 | 69.6/67.2 | 78.0/77.5 | 69.4/69.0 | 79.2/73.0 | 70.4/64.7 | 71.5/70.3 | 69.0/67.8 |
| CenterPoint [4] | 75.9/73.5 | 69.8/67.6 | 76.6/76.0 | 68.9/68.4 | 79.0/73.4 | 71.0/65.8 | 72.1/71.0 | 69.5/68.5 |
| PillarNet-34 [16] | 77.3/74.6 | 71.0/68.5 | 79.1/78.6 | 70.9/70.5 | 80.6/74.0 | 72.3/66.2 | 72.3/71.2 | 69.7/68.7 |
| AFDetV2 [23] | 77.2/74.8 | 71.0/68.8 | 77.6/77.1 | 69.7/69.2 | 80.2/74.6 | 72.2/67.0 | 73.7/72.7 | 71.0/70.1 |
| CenterFormer [19] | 75.6/73.2 | 71.4/69.1 | 75.0/74.4 | 69.9/69.4 | 78.0/72.4 | 73.1/67.7 | 73.8/72.7 | 71.3/70.2 |
| LargeKernel3D[36] | -/- | -/- | 78.1/77.6 | 69.8/69.4 | -/- | -/- | -/- | -/- |
| PV-RCNN++ [37] | 78.1/75.9 | 71.7/69.5 | 79.3/78.8 | 70.6/70.2 | 81.3/76.3 | 73.2/68.0 | 73.7/72.7 | 71.2/70.2 |
| DSVT-Voxel [6] | 80.3/78.2 | 74.0/72.1 | 79.7/79.3 | 71.4/71.0 | 83.7/78.9 | 76.1/71.5 | 77.5/76.5 | 74.6/73.7 |
| HEDNet [7] | 81.4/79.4 | 75.3/73.4 | 81.1/80.6 | 73.2/72.7 | 84.4/80.0 | 76.8/72.6 | 78.7/77.7 | 75.8/74.9 |
| SWFormer [11]† | -/- | -/- | 77.8/77.3 | 69.2/68.8 | 80.9/72.7 | 72.5/64.9 | -/- | -/- |
| VoxelNeXt [13]† | 78.6/76.3 | 72.2/70.1 | 78.2/77.7 | 69.9/69.4 | 81.5/76.3 | 73.5/68.6 | 76.1/74.9 | 73.3/72.2 |
| FSDv1 [10]† | 79.6/77.4 | 72.9/70.8 | 79.2/78.8 | 70.5/70.1 | 82.6/77.3 | 73.9/69.1 | 77.1/76.0 | 74.4/73.3 |
| FSDv2 [12]† | 81.8/79.5 | 75.6/73.5 | 79.8/79.3 | 71.4/71.0 | 84.8/79.7 | 77.4/72.5 | 80.7/79.6 | 77.9/76.8 |
| SAFDNet (ours)† | 81.8/79.9 | 75.7/73.9 | 80.6/80.1 | 72.7/72.3 | 84.7/80.4 | 77.3/73.1 | 80.0/79.0 | 77.2.76.2 |
| Results on the test data set | ||||||||
| FSDv1 [10]† | 80.4/78.2 | 74.4/72.4 | 82.7/82.3 | 74.4/74.1 | 82.9/77.9 | 75.9/71.3 | 75.6/74.4 | 72.9/71.8 |
| FSDv2 [12]† | 81.1/79.0 | 75.4/73.3 | 82.4/82.0 | 74.4/74.0 | 83.8/78.9 | 77.4/72.8 | 77.1/76.0 | 74.3/73.2 |
| SAFDNet (ours)† | 81.9/79.8 | 76.5/74.6 | 83.9/83.5 | 76.6/76.2 | 84.3/79.8 | 78.4/74.1 | 77.5/76.3 | 74.6/73.4 |
Training.
For the training process of voxel classification, we group object categories of similar size and perform binary classification for each group. Let denote the number of category groups and be the number of sparse voxels. For group , the model predicts a vector of length . The corresponding training target is defined as follows:
| (1) |
where , represents the coordinates of the corresponding voxel center, and the ‘object box’ refers to the human-annotated bounding box of an object. The overall loss for voxel classification is defined by the equation:
| (2) |
Inference.
Given , a binary mask that indicates voxels whether fall within any object bounding boxes of category group is calculated by threshold , then the binary mask that indicates the feature diffusion areas can be jointly decided by and the diffusion kernel size . is defined as , where is the average size of objects in category group and controls the range of feature diffusion. The object size is defined as the maximum value between the length and width of the bounding box and is normalized by the voxel size. After that, the binary mask representing the overall feature diffusion areas can be calculated as . For each voxel in the feature diffusion areas, if there are no features, we initialize it with zero features. Finally, a 2D-EDB is utilized for further feature transformation.
| Method | NDS | mAP | Car | Truck | Bus | T.L. | C.V. | Ped. | M.T. | Bike | T.C. | B.R. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Results on the validation data set | ||||||||||||
| VoxelNeXt [13]† | 68.7 | 63.5 | 83.9 | 55.5 | 70.5 | 38.1 | 21.1 | 84.6 | 62.8 | 50.0 | 69.4 | 69.4 |
| FSDv2 [12]† | 70.4 | 64.7 | 84.4 | 57.3 | 75.9 | 44.1 | 28.5 | 86.9 | 69.5 | 57.4 | 72.9 | 73.6 |
| SAFDNet (Ours)† | 71.0 | 66.3 | 87.6 | 60.8 | 78.0 | 43.5 | 26.6 | 87.8 | 75.5 | 58.0 | 75.0 | 69.7 |
| Results on the test data set | ||||||||||||
| PointPillars [15] | 45.3 | 30.5 | 68.4 | 23.0 | 28.2 | 23.4 | 4.1 | 59.7 | 27.4 | 1.1 | 30.8 | 38.9 |
| 3DSSD [38] | 56.4 | 42.6 | 81.2 | 47.2 | 61.4 | 30.5 | 12.6 | 70.2 | 36.0 | 8.6 | 31.1 | 47.9 |
| CenterPoint [4] | 65.5 | 58.0 | 84.6 | 51.0 | 60.2 | 53.2 | 17.5 | 83.4 | 53.7 | 28.7 | 76.7 | 70.9 |
| HotSpotNet [39] | 66.0 | 59.3 | 83.1 | 50.9 | 56.4 | 53.3 | 23.0 | 81.3 | 63.5 | 36.6 | 73.0 | 71.6 |
| CVCNET [40] | 66.6 | 58.2 | 82.6 | 49.5 | 59.4 | 51.1 | 16.2 | 83.0 | 61.8 | 38.8 | 69.7 | 69.7 |
| AFDetV2 [23] | 68.5 | 62.4 | 86.3 | 54.2 | 62.5 | 58.9 | 26.7 | 85.8 | 63.8 | 34.3 | 80.1 | 71.0 |
| UVTR-L [41] | 69.7 | 63.9 | 86.3 | 52.2 | 62.8 | 59.7 | 33.7 | 84.5 | 68.8 | 41.1 | 74.7 | 74.9 |
| VISTA [42] | 69.8 | 63.0 | 84.4 | 55.1 | 63.7 | 54.2 | 25.1 | 82.8 | 70.0 | 45.4 | 78.5 | 71.4 |
| Focals Conv [22] | 70.0 | 63.8 | 86.7 | 56.3 | 67.7 | 59.5 | 23.8 | 87.5 | 64.5 | 36.3 | 81.4 | 74.1 |
| TransFusion-L [5] | 70.2 | 65.5 | 86.2 | 56.7 | 66.3 | 58.8 | 28.2 | 86.1 | 68.3 | 44.2 | 82.0 | 78.2 |
| LargeKernel3D [20] | 70.6 | 65.4 | 85.5 | 53.8 | 64.4 | 59.5 | 29.7 | 85.9 | 72.7 | 46.8 | 79.9 | 75.5 |
| LinK [43] | 71.0 | 66.3 | 86.1 | 55.7 | 65.7 | 62.1 | 30.9 | 85.8 | 73.5 | 47.5 | 80.4 | 75.5 |
| HEDNet [7] | 72.0 | 67.7 | 87.1 | 56.5 | 70.4 | 63.5 | 33.6 | 87.9 | 70.4 | 44.8 | 85.1 | 78.1 |
| VoxelNeXt [13]† | 70.0 | 64.5 | 84.6 | 53.0 | 64.7 | 55.8 | 28.7 | 85.8 | 73.2 | 45.7 | 79.0 | 74.6 |
| FSDv2 [12]† | 71.7 | 66.2 | 83.7 | 51.6 | 66.4 | 59.1 | 32.5 | 87.1 | 71.4 | 51.7 | 80.3 | 78.7 |
| SAFDNet (Ours)† | 72.3 | 68.3 | 87.3 | 57.3 | 68.0 | 63.7 | 37.3 | 89.0 | 71.1 | 44.8 | 84.9 | 79.5 |
3.4 Sparse detection head
We adhere to most design principles of CenterPoint (Waymo Open and Argoverse2) and TransFusion-L (nuScenes), but make some adjustments to accommodate sparse features. Despite employing adaptive feature diffusion, covering all object centers remains challenging, particularly for extremely large objects. Therefore, we adopt the diffused voxel features nearest to object centers as object representations. For classification training, we calculate a Gaussian heatmap for each object based on the distance from each voxel center to the object center. We normalize the heatmap values by the maximum value for each object to avoid gradient vanishing.
4 Experiments
4.1 Datasets and metrics
We conducted experiments on the popular Waymo Open [9], nuScenes [8], and Argoverse2 [14] datasets to validate the effectiveness of our approach. The detection ranges of the three datasets are 75, 54 and 200 meters, respectively. For object detection on the Waymo Open dataset, evaluation metrics include mean average precision (mAP) and mAP weighted by heading accuracy (mAPH). Both are further broken down into two difficulty levels: L1 for objects with more than five LiDAR points and L2 for objects with at least one LiDAR point. For object detection on the nuScenes dataset, evaluation metrics include mAP and the nuScenes detection score (NDS). mAP is calculated by averaging over the distance thresholds of 0.5m, 1m, 2m, and 4m across all categories. NDS is a weighted average of mAP and five other true positive metrics that measure translation, scaling, orientation, velocity, and attribute errors. For object detection on the Argoverse2 dataset, mAP is adopted as the evaluation metric.
4.2 Implementations details
We implemented our method based on the open-source OpenPCDet [44]. To build SAFDNet, we set the hyperparameters , to 4, 2 for the 3D-EDB, and 8, 4 for the 2D-EDB. The hyperparameters and in AFD were set to 0.4 and 1.0. All experiments were conducted on 8 RTX 4090 GPUs with a total batch size of 16. To compare with previous state-of-the-art methods, we trained SAFDNet for 24 epochs, 20 epochs, and 24 epochs on the Waymo Open, nuScenes, and Argoverse2 datasets, respectively. For ablation experiments in Section 4.4, we trained models for 12 epochs and 6 epochs on the Waymo Open and Argoverse2 datasets, respectively. Please refer to the Appendix A for more details.
4.3 Comparison with state-of-the-art methods
Results on Waymo Open.
On the validation set, SAFDNet achieved 75.7% L2 mAP and 73.9% L2 mAPH, performing slightly better than the hybrid detector HEDNet and the sparse detector FSDv2. On the test set, SAFDNet yielded 1.3% L2 mAPH gains over the previous best fully sparse detector FSDv2. Notably, SAFDNet achieved significant improvements over FSDv2 on the large vehicle category (2.2% L2 mAPH on the test set), which suffers more from the center feature missing problem with the full sparse architecture. More comparison on model runtime has been presented later.
Results on nuScenes.
We primarily compared SAFDNet with previous top-performing LiDAR-based methods on the nuScenes test set (Table 3). On the nuScenes test set, SAFDNet achieved impressive results with 72.3% NDS and 68.3% mAP. Compared with FSDv2, SAFDNet showcased significant improvements on the categories of large objects including car (+3.6%), truck (+5.7%), and trailer (+4.6%). These results further demonstrate the effectiveness of our method.
| Method |
mAP |
Vehicle |
Bus |
Pedestrian |
Stop Sign |
Box Truck |
Bollard |
C-Barrel |
Motorcyclist |
MPC-Sign |
Motorcycle |
Bicycle |
A-Bus |
School Bus |
Truck Cab |
C-Cone |
V-Trailer |
Sign |
Large Vehicle |
Stroller |
Bicyclist |
Truck |
MBT |
Dog |
Wheelchair |
W-Device |
W-Rider |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CenterPoint [4] | 22.0 | 67.6 | 38.9 | 46.5 | 16.9 | 37.4 | 40.1 | 32.2 | 28.6 | 27.4 | 33.4 | 24.5 | 8.7 | 25.8 | 22.6 | 29.5 | 22.4 | 6.3 | 3.9 | 0.5 | 20.1 | 22.1 | 0.0 | 3.9 | 0.5 | 10.9 | 4.2 | |
| HEDNet [7] | 37.1 | 78.2 | 47.7 | 67.6 | 46.4 | 45.9 | 56.9 | 67.0 | 48.7 | 46.5 | 58.2 | 47.5 | 23.3 | 40.9 | 27.5 | 46.8 | 27.9 | 20.6 | 6.9 | 27.2 | 38.7 | 21.6 | 0.0 | 30.7 | 9.5 | 28.5 | 8.7 | |
| VoxelNeXt [13]† | 30.7 | 72.7 | 38.8 | 63.2 | 40.2 | 40.1 | 53.9 | 64.9 | 44.7 | 39.4 | 42.4 | 40.6 | 20.1 | 25.2 | 19.9 | 44.9 | 20.9 | 14.9 | 6.8 | 15.7 | 32.4 | 16.9 | 0.0 | 14.4 | 0.1 | 17.4 | 6.6 | |
| FSDv1 [10]† | 28.2 | 68.1 | 40.9 | 59.0 | 29.0 | 38.5 | 41.8 | 42.6 | 39.7 | 26.2 | 49.0 | 38.6 | 20.4 | 30.5 | 14.8 | 41.2 | 26.9 | 11.9 | 5.9 | 13.8 | 33.4 | 21.1 | 0.0 | 9.5 | 7.1 | 14.0 | 9.2 | |
| FSDv2 [12]† | 37.6 | 77.0 | 47.6 | 70.5 | 43.6 | 41.5 | 53.9 | 58.5 | 56.8 | 39.0 | 60.7 | 49.4 | 28.4 | 41.9 | 30.2 | 44.9 | 33.4 | 16.6 | 7.3 | 32.5 | 45.9 | 24.0 | 1.0 | 12.6 | 17.1 | 26.3 | 17.2 | |
| SAFDNet (Ours)† | 39.7 | 78.5 | 49.4 | 70.7 | 51.5 | 44.7 | 65.7 | 72.3 | 54.3 | 49.7 | 60.8 | 50.0 | 31.3 | 44.9 | 24.7 | 55.4 | 31.4 | 22.1 | 7.1 | 31.1 | 42.7 | 23.6 | 0.0 | 26.1 | 1.4 | 30.2 | 11.5 | |
Results on Argoverse2.
To validate the effectiveness of SAFDNet on the long-range detection, we conducted experiments on the Argoverse2 dataset with a perception range of 200 meters (Table 4). SAFDNet achieved a gain of 2.1% mAP over the previous best sparse detector FSDv2. It is worth noting that the proposed SAFDNet also outperformed the hybrid detector HEDNet, which indicates that expanding features towards all unoccupied area without restriction may hurt the detection performance.
| Method | Waymo Open | Argoverse2 | |||||
|---|---|---|---|---|---|---|---|
| mAPH | FPS | Speedup | mAP | FPS | Speedup | Mem. | |
| HEDNet [7] | 73.4 | 17.2 | 1.0 | 37.1 | 7.3 | 1.0 | 28.7G |
| VoxelNeXt [13]† | 70.1 | 15.7 | 0.9 | 30.7 | 19.6 | 2.7 | 6.2G |
| FSDv2 [12]† | 73.5 | 10.3 | 0.6 | 37.6 | 11.5 | 1.6 | 8.6G |
| SAFDNet†(Ours) | 73.9 | 20.2 | 1.2 | 39.7 | 15.1 | 2.1 | 7.3G |
Runtime comparison.
We compared the inference speed of SAFDNet with prior top-performing methods, as shown in Table 5. On the Waymo Open dataset with a short perception range, SAFDNet was 2 faster than the sparse detector FSDv2 and was 1.2 faster than the hybrid detector HEDNet. On the Argoverse2 dataset with a long perception range, SAFDNet yielded 2.1% mAP gains over FSDv2 while being 1.3 faster. Compared with HEDNet, SAFDNet achieved 2.6% mAP improvements while being 2.1 faster. Note that the hybrid detector HEDNet requires much more training memory than the other sparse detectors.
| No. | Method | mAPH | Veh. | Ped. | Cyc. |
|---|---|---|---|---|---|
| * | HEDNet | 73.2 | 72.1 | 72.0 | 75.6 |
| 1 | Center heatmap | 55.2 | 53.3 | 54.5 | 60.7 |
| 2 | Nearest heatmap | 71.0 | 69.1 | 70.6 | 73.3 |
| 3 | Normalized heatmap | 71.4 | 69.1 | 70.6 | 74.2 |
| 4 | Row-3 w/ 2D-EDB | 71.5 | 68.8 | 70.9 | 74.7 |
| 5 | Row-4 w/ AFD | 73.3 | 71.7 | 72.3 | 75.7 |
| Type | Waymo Open | Argoverse2 | ||
|---|---|---|---|---|
| mAPH | FLOPs | mAP | FLOPs | |
| w/o | 71.5 | 90G | 36.4 | 34G |
| PB UFD | 73.0 | 189G | 37.6 | 147G |
| PF UFD | 73.1 | 182G | 37.7 | 144G |
| AFD | 73.3 | 108G | 37.8 | 45G |
| Waymo Open | Argoverse2 | |||
|---|---|---|---|---|
| mAPH | FLOPs | mAP | FLOPs | |
| 0.0 | 71.5 | 90G | 36.4 | 34G |
| 0.5 | 72.7 | 100G | 37.3 | 38G |
| 1.0 | 73.3 | 108G | 37.8 | 45G |
| 2.0 | 73.0 | 153G | 37.8 | 67G |
4.4 Ablation studies
A step-by-step ablation.
We performed step-wise ablation experiments from the hybrid detector HEDNet to our SAFDNet on the Waymo Open dataset (Table 6 (a)). Initially, we removed the 2D dense backbone in HEDNet and replaced all convolutions in the detection head with submanifold sparse convolutions, resulting in the first model. The accuracies across all categories dropped significantly. We observed that using the voxels within which object centers fall, as done in CenterPoint, to calculate the Gaussian heatmap during classification training led to rapid convergence of the classification loss to zero. In the second model, we used the nearest non-empty voxel as the center to generate the Gaussian heatmap. This adjustment notably increased accuracy to 71.0% mAPH. In the third model, we continued to adopt the center voxel but normalized the training target with the maximum values to prevent gradient vanishing, resulting in a slight accuracy boost. Adding the 2D-EDB in the fourth model did not lead to a performance improvement. Notably, there still existed a significant accuracy gap, particularly on large vehicles, between the fourth model and HEDNet (over 3% mAPH). Finally, incorporating the proposed adaptive feature diffusion strategy effectively bridged this gap. An ablation on different sparse backbones is presented in Appendix B.
Different types of feature diffusion.
We compared different type of diffusion strategies on the Waymo Open and Argoverse2 datasets, as presented in Table 6 (b). While the models with the two types of UFD strategies showed substantial gains over the model without feature diffusion, they introduced significantly higher computational FLOPs. In contrast, the model with the AFD strategy achieved the highest accuracy while incurring fewer computational costs.
Different ranges of feature diffusion.
We compared different diffusion ranges of AFD on the Waymo Open and Argoverse2 datasets. Table 6 (c) shows that, setting to 1, wherein the diffusion kernel size matches the average object size, resulted in the highest accuracy for SAFDNet. On the Waymo Open dataset, a large diffusion range slightly degraded the performance, suggesting that excessive feature diffusion might be unnecessary and could harm performance.
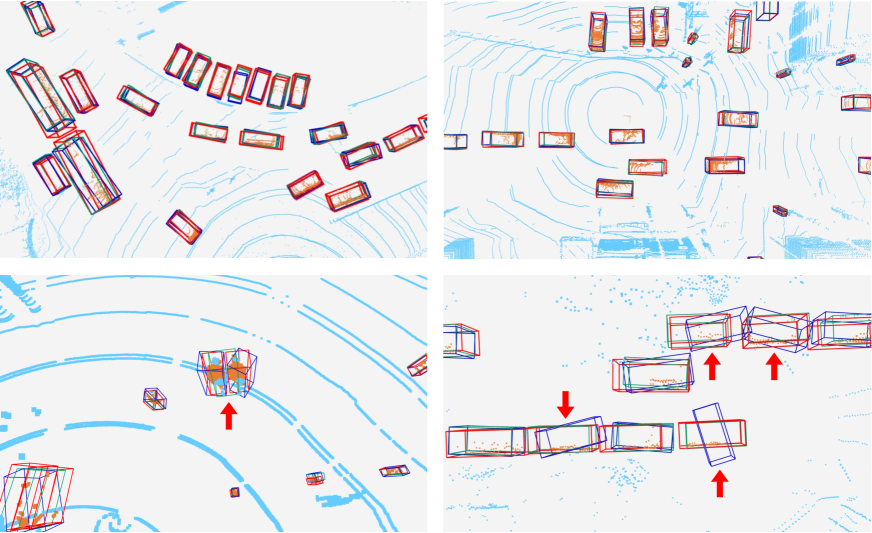
4.5 Qualitative visualization
We showcase predictions made by HEDNet and SAFDNet on the Argoverse2 dataset in Figure 5. SAFDNet performed comparably to HEDNet in some scenarios, exhibiting better predictions for small objects but encountering challenges in predicting the direction of certain large objects. Please note that this issue arises only with partially large objects, like box truck, and is not a general problem for all large objects.
5 Conclusion
We present SAFDNet, a fully sparse architecture tailed for 3D object detection. To address the center feature missing problem, we propose an adaptive feature diffusion strategy to diffuse features towards object centers while maintaining feature sparsity as much as possible. SAFDNet achieved impressive performance on the Waymo Open, nuScenes, and Argoverse2 datasets, which demonstrates the effectiveness of our method. We hope that our work can provide some inspiration for the design of fully sparse 3D object detector.
Limitations.
We mitigate the center feature missing problem through our proposed adaptive feature diffusion strategy. However, this approach may generate some unnecessary feature regions, such as the expanded regions outside of objects. We believe a more efficient solution could address this issue, such as by grouping voxels associated with the same object. We defer exploration of this solution to future research.
Acknowledgements.
This work was supported by the National Key Research and Development Program of China (grant 2021ZD0200301), the National Natural Science Foundation of China (grant U2341228), and the Shanghai Automotive Industry Corporation (SAIC) Intelligent Technology (contract CGHT-202112218).
References
- [1] Mayank Bansal, Alex Krizhevsky, and Abhijit Ogale. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. arXiv preprint arXiv:1812.03079, 2018.
- [2] Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In ICRA, 2017.
- [3] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In CVPR, 2018.
- [4] Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center-based 3d object detection and tracking. In CVPR, 2021.
- [5] Xuyang Bai, Zeyu Hu, Xinge Zhu, Qingqiu Huang, Yilun Chen, Hongbo Fu, and Chiew-Lan Tai. Transfusion: Robust lidar-camera fusion for 3d object detection with transformers. In CVPR, 2022.
- [6] Haiyang Wang, Chen Shi, Shaoshuai Shi, Meng Lei, Sen Wang, Di He, Bernt Schiele, and Liwei Wang. Dsvt: Dynamic sparse voxel transformer with rotated sets. In CVPR, 2023.
- [7] Gang Zhang, Junnan Chen, Guohuan Gao, Jianmin Li Li, and Xiaolin Hu. HEDNet: A hierarchical encoder-decoder network for 3d object detection in point clouds. In NeurIPS, 2023.
- [8] Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In CVPR, 2020.
- [9] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. In CVPR, 2020.
- [10] Lue Fan, Feng Wang, Naiyan Wang, and Zhaoxiang Zhang. Fully Sparse 3D Object Detection. In NeurIPS, 2022.
- [11] Pei Sun, Mingxing Tan, Weiyue Wang, Chenxi Liu, Fei Xia, Zhaoqi Leng, and Dragomir Anguelov. Swformer: Sparse window transformer for 3d object detection in point clouds. In ECCV, 2022.
- [12] Lue Fan, Feng Wang, Naiyan Wang, and Zhaoxiang Zhang. Fsd v2: Improving fully sparse 3d object detection with virtual voxels. arXiv preprint arXiv:2308.03755, 2023.
- [13] Yukang Chen, Jianhui Liu, Xiangyu Zhang, Xiaojuan Qi, and Jiaya Jia. Voxelnext: Fully sparse voxelnet for 3d object detection and tracking. In CVPR, 2023.
- [14] Wilson Benjamin, Qi William, Agarwal Tanmay, Lambert John, Singh Jagjeet, Khandelwal Siddhesh, Pan Bowen, Kumar Ratnesh, Hartnett Andrew, Kaesemodel-Pontes Jhony, Ramanan Deva, Carr Peter, and Hays James. Argoverse 2: Next generation datasets for self-driving perception and forecasting. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
- [15] Alex H. Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In CVPR, 2019.
- [16] Guangsheng Shi, Ruifeng Li, and Chao Ma. Pillarnet: Real-time and high-performance pillar-based 3d object detection. In ECCV, 2022.
- [17] Jinyu Li, Chenxu Luo, and Xiaodong Yang. Pillarnext: Rethinking network designs for 3d object detection in lidar point clouds. In CVPR, 2023.
- [18] Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection. In Sensors, 2018.
- [19] Zixiang Zhou, Xiangchen Zhao, Yu Wang, Panqu Wang, and Hassan Foroosh. Centerformer: Center-based transformer for 3d object detection. In ECCV, 2022.
- [20] Yukang Chen, Jianhui Liu, Xiaojuan Qi, Xiangyu Zhang, Jian Sun, and Jiaya Jia. Scaling up kernels in 3d cnns. In CVPR, 2023.
- [21] Lue Fan, Ziqi Pang, Tianyuan Zhang, Yu-Xiong Wang, Hang Zhao, Feng Wang, Naiyan Wang, and Zhaoxiang Zhang. Embracing Single Stride 3D Object Detector with Sparse Transformer. In CVPR, 2022.
- [22] Yukang Chen, Yanwei Li, Xiangyu Zhang, Jian Sun, and Jiaya Jia. Focal sparse convolutional networks for 3d object detection. In CVPR, 2022.
- [23] Yihan Hu, Zhuangzhuang Ding, Runzhou Ge, Wenxin Shao, Li Huang, Kun Li, and Qiang Liu. Afdetv2: Rethinking the necessity of the second stage for object detection from point clouds. In AAAI, 2022.
- [24] Jiageng Mao, Yujing Xue, Minzhe Niu, et al. Voxel transformer for 3d object detection. ICCV, 2021.
- [25] Mao Ye, Gregory P. Meyer, Yuning Chai, and Qiang Liu. Efficient transformer-based 3d object detection with dynamic token halting. In ICCV, 2023.
- [26] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3d object proposal generation and detection from point cloud. In CVPR, 2019.
- [27] Yilun Chen, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Fast point r-cnn. In ICCV, 2019.
- [28] Charles R Qi, Or Litany, Kaiming He, and Leonidas J Guibas. Deep hough voting for 3d object detection in point clouds. In ICCV, 2019.
- [29] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In CVPR, 2017.
- [30] Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS, 2017.
- [31] Benjamin Graham and Laurens Van der Maaten. Submanifold sparse convolutional networks. arXiv preprint arXiv:1706.01307, 2017.
- [32] Ben Graham. Sparse 3d convolutional neural networks. arXiv preprint arXiv:1505.02890, 2015.
- [33] Spconv Contributors. Spconv: Spatially sparse convolution library. https://github.com/traveller59/spconv, 2022.
- [34] Shaoshuai Shi, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. In TPAMI, 2019.
- [35] Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In CVPR, 2020.
- [36] Xiaohan Ding, Xiangyu Zhang, Jungong Han, and Guiguang Ding. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In CVPR, 2022.
- [37] Shaoshuai Shi, Li Jiang, Jiajun Deng, Zhe Wang, Chaoxu Guo, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn++: Point-voxel feature set abstraction with local vector representation for 3d object detection. In IJCV, 2023.
- [38] Zetong Yang, Yanan Sun, Shu Liu, and Jiaya Jia. 3dssd: Point-based 3d single stage object detector. In CVPR, 2020.
- [39] Qi Chen, Lin Sun, Zhixin Wang, Kui Jia, and Alan Yuille. Object as hotspots: An anchor-free 3d object detection approach via firing of hotspots. arXiv preprint arXiv:1912.12791, 2020.
- [40] Xiangyuan Zhu, Kehua Guo, Hui Fang, Liang Chen, Sheng Ren, and Bin Hu. Cross view capture for stereo image super-resolution. In IEEE Transactions on Multimedia, 2022.
- [41] Yanwei Li, Yilun Chen, Xiaojuan Qi, Zeming Li, Jian Sun, and Jiaya Jia. Unifying voxel-based representation with transformer for 3d object detection. In NIPS, 2022.
- [42] Shengheng Deng, Zhihao Liang, Lin Sun, and Kui Jia. Vista: Boosting 3d object detection via dual cross-view spatial attention. In CVPR, 2022.
- [43] Tao Lu, Xiang Ding, Haisong Liu, Gangshan Wu, and Limin Wang. Link: Linear kernel for lidar-based 3d perception. In CVPR, 2023.
- [44] OpenPCDet Development Team. Openpcdet: An open-source toolbox for 3d object detection from point clouds. https://github.com/open-mmlab/OpenPCDet, 2020.
- [45] MMDetection3D Contributors. MMDetection3D: OpenMMLab next-generation platform for general 3D object detection. https://github.com/open-mmlab/mmdetection3d, 2020.
- [46] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
.
Appendix A Implementations details
We trained all models with a batch size of 16, employed the Adam [46] optimizer with a one-cycle learning rate policy, and set the weight decay to 0.05 and the maximum learning rate to 0.003. More details are presented below.
Waymo Open dataset.
We adopt a detection head derived from CenterPoint. We set the voxel size to (0.08m, 0.08m, 0.15m), and the detection range to [-75.52m, 75.52m] in X and Y axes, and [-2m, 4m] in Z axis. We trained SAFDNet for 24 epochs on the training dataset and reported the evaluation results on the validation set to compare with previous methods. For results on the test set, we trained the model on both the training and validation sets. We adopted the faded training strategy in the last epoch. During inference, we applied class-specific NMS with an IoU threshold of 0.75, 0.6 and 0.55 for vehicle, pedestrian, and cyclist, respectively. There are three category groups: group 1 includes vehicle; group 2 includes pedestrian and cyclist; group 3 is the background. The kernel size K for feature diffusion for the three groups are set to 7, 3, and 3, respectively.
nuScenes dataset.
We adopt a detection head derived from TransFusion-L.We set the voxel size to (0.3m, 0.3m, 8.0m), and the detection range to [-54m, 54m] in X and Y axes, and [-5m, 3m] in Z axis. We trained SAFDNet for 20 epochs on both training and validation sets and reported the evaluation results on the test set to compare with previous methods. The faded strategy was used during the last 4 epochs. We set the query number of detection head to 300 (test only) and did not use any test-time augmentation. There are four category groups: group 1 includes bus and trailer; group 2 includes car, truck, and construction vehicle; group 3 includes motorcycle, bicycle, traffic cone, pedestrian, and barrier; group 4 is the background. The kernel size K for feature diffusion for the four groups are set to 15, 9, 7, and 7, respectively.
Argoverse2 dataset.
We adopt a detection head derived from CenterPoint. We set the voxel size to (0.1m, 0.1m, 0.2m), and the detection range to [-200m, 200m] in X and Y axes, and [-4m, 4m] in Z axis. We trained SAFDNet for 24 epochs on the training set and reported the results on the validation set to compare with other methods. We adopted the faded training strategy in the last epoch. There are four category groups: group 1 includes large vehicle, bus, box truck, truck, truck cab, vehicular trailer, school bus, articulated bus, and message board trailer; group 2 includes regular vehicle; group 3 includes the other object categories; group 4 is the background. The kernel size K for feature diffusion for the four groups are set to 13, 7, 3, and 3, respectively.
Appendix B More experimental results
| 3D Backbone | Other Parts | AFD | mAPH | Veh. | Ped. | Cyc. |
|---|---|---|---|---|---|---|
| HEDNet | Dense | 73.2 | 72.1 | 72.0 | 75.6 | |
| HEDNet | Sparse | 71.5 | 68.8 | 70.9 | 74.7 | |
| HEDNet | Sparse | ✓ | 73.3 | 71.7 | 72.3 | 75.7 |
| VoxelNet | Dense | 71.4 | 69.8 | 70.9 | 73.4 | |
| VoxelNet | Sparse | 69.9 | 66.1 | 70.6 | 72.9 | |
| VoxelNet | Sparse | ✓ | 72.0 | 70.2 | 71.7 | 74.1 |
| PillarNet | Dense | 68.7 | 69.2 | 66.5 | 70.5 | |
| PillarNet | Sparse | 67.2 | 65.6 | 66.8 | 70.2 | |
| PillarNet | Sparse | ✓ | 69.4 | 69.7 | 67.5 | 71.4 |
We conducted experiments with three 3D sparse backbones: HEDNet, VoxelNet, and PillarNet. Table 7 shows that the proposed AFD module worked well on all three backbones.