SAAP: Spatial awareness and Association based Prefetching of Virtual Objects in Augmented Reality at the Edge
Abstract
Mobile Augmented Reality (MAR) applications face performance challenges due to their high computational demands and need for low-latency responses. Traditional approaches like on-device storage or reactive data fetching from the cloud often result in limited AR experiences or unacceptable lag. Edge caching, which caches AR objects closer to the user, provides a promising solution. However, existing edge caching approaches do not consider AR-specific features such as AR object sizes, user interactions, and physical location. This paper investigates how to further optimize edge caching by employing AR-aware prefetching techniques. We present SAAP, a Spatial Awareness and Association-based Prefetching policy specifically designed for MAR Caches. SAAP intelligently prioritizes the caching of virtual objects based on their association with other similar objects and the user’s proximity to them. It also considers the recency of associations and uses a lazy fetching strategy to efficiently manage edge resources and maximize Quality of Experience (QoE).
Through extensive evaluation using both synthetic and real-world workloads, we demonstrate that SAAP significantly improves cache hit rates compared to standard caching algorithms, achieving gains ranging from 3% to 40% while reducing the need for on-demand data retrieval from the cloud. Further, we present an adaptive tuning algorithm that automatically tunes SAAP parameters to achieve optimal performance. Our findings demonstrate the potential of SAAP to substantially enhance the user experience in MAR applications by ensuring the timely availability of virtual objects.
Index Terms:
Augmented reality, caching, prefetching, association, proximity, support, confidence, edge computingI Introduction
Mobile Augmented Reality (MAR) [1] is a transformative technology with applications across diverse domains, from gaming [2] and education [3] to healthcare [4] and manufacturing [5]. However, its reliance on data-intensive computations and need for low latency presents unique challenges.
Figure 1 illustrates a typical MAR pipeline, comprising MAR Device (end-user device) and MAR Tasks (compute-intensive tasks and their associated resources) [6]. These tasks can be distributed across the user device, edge, and/or cloud based on resource availability. The key stages in this pipeline include (1) Object detection and feature extraction: identifying potential target objects in a camera frame and extracting their unique features; (2) Object recognition and pose estimation: matching extracted features to a database to identify the object and estimate its real-world pose, potentially aided by template matching [7]; (3) Object tracking: continuously monitoring the identified object across frames to optimize performance [8]; and (4) Image rendering and virtual content overlay: retrieving and overlaying corresponding virtual content onto the real-world object, achieving the core AR functionality. Efficient data management, particularly the storage of virtual object content, is crucial for optimal performance in this pipeline.

Traditional approaches to managing virtual object data in MAR, such as on-device storage [9] or cloud offloading [10], face limitations. Increasingly complex and interactive virtual objects demand significant storage, rendering on-device storage impractical for lightweight mobile devices. On the other hand, on-demand fetching from the cloud suffers from high latency [11, 12], hindering smooth real-time AR experience.
Edge computing offers an attractive alternative for MAR applications [1, 13]. Processing data closer to the user at the network edge reduces latency, enabling real-time interaction and a more immersive experience. Further, edge computing decreases bandwidth demands by reducing data transmission to the cloud, leading to increased efficiency and cost savings. Offloading processing to the edge also enhances reliability, allowing MAR applications to function even with intermittent network connectivity. Finally, the ability of edge infrastructure to store virtual objects locally further improves application performance and responsiveness.
Edge caching is a critical technique for latency-sensitive applications, including AR [14, 15, 16, 13, 17]. To achieve immersive AR experience, caching is necessary across various stages of the MAR processing pipeline. Some existing approaches, such as CARS [18], Precog [19] and SEAR [20], focus on caching image recognition results at the edge, while others advocate for caching virtual objects directly on user devices [21]. Prefetching AR data to further enhance cache hit rates remains an active research area. Current prefetching techniques primarily address location-based services (LBS) and video content. In LBS, prefetching typically involves caching objects near the user’s location on either the device or an edge server [22, 23, 24]. For video content, prefetching leverages user interest to cache video segments on nearby edge servers, often in conjunction with techniques like tile caching [25, 26, 27, 28]. Edge caching resources, although more abundant than mobile device storage, are still limited and heterogeneous. Therefore, it is challenging to ensure the right set of virtual objects are readily available for augmentation at the edge.
This paper investigates optimizing edge prefetching in AR applications by analyzing user-object interaction patterns and AR-specific properties. Given the context-dependent nature of AR interactions, we argue that effective prefetching strategies should prioritize objects likely to enter the user’s field of view (FoV). We hypothesize that predictable patterns in user access behavior can be leveraged to anticipate future interactions and prefetch relevant virtual objects at the edge, thereby improving rendering performance and enhancing the overall AR experience.
Based on these insights, we present an MAR edge cache prefetching framework called SAAP that exploits two key properties for AR object prefetching: (i) object associations (how likely multiple objects are to be accessed together by a user), and (ii) spatial proximity (how close an object is to a user’s FoV). Our approach uses association mining to determine object associations, and distance thresholding to identify spatial proximity. It further incorporates factors such as recency of associations and lazy prefetching to ensure efficient utilization of edge resources and network bandwidth. We also present an adaptive tuning algorithm to automatically tune the parameters of these algorithms. We note that SAAP is designed to be complementary to the underlying caching policies, and its prefetching can be used on top of any caching algorithm to further improve the cache performance.
This paper makes the following research contributions:
Analysis of the rationale for using object association and proximity to achieve efficient MAR edge caching.
The design of SAAP: a cache prefetching framework that utilizes virtual object associations and user proximity to improve edge cache performance, along with an adaptive parameter tuning algorithm.
A comprehensive evaluation of SAAP, using both synthetic and real-world traces, showing that SAAP significantly improves hit rates (by 3-40%) compared to various baseline caching algorithms.
II Motivation and Background
Achieving an immersive mobile augmented reality (MAR) experience presents unique challenges [29, 23]. Conventional data caching and prefetching policies, designed for general-purpose applications, might not be optimal for MAR due to its inherent characteristics[30]. Compared to other edge-native applications [31], MAR applications require significant computational resources and sophisticated data management strategies to handle the large volume of spatial data and real-time interactions.
II-A Motivating AR Scenarios
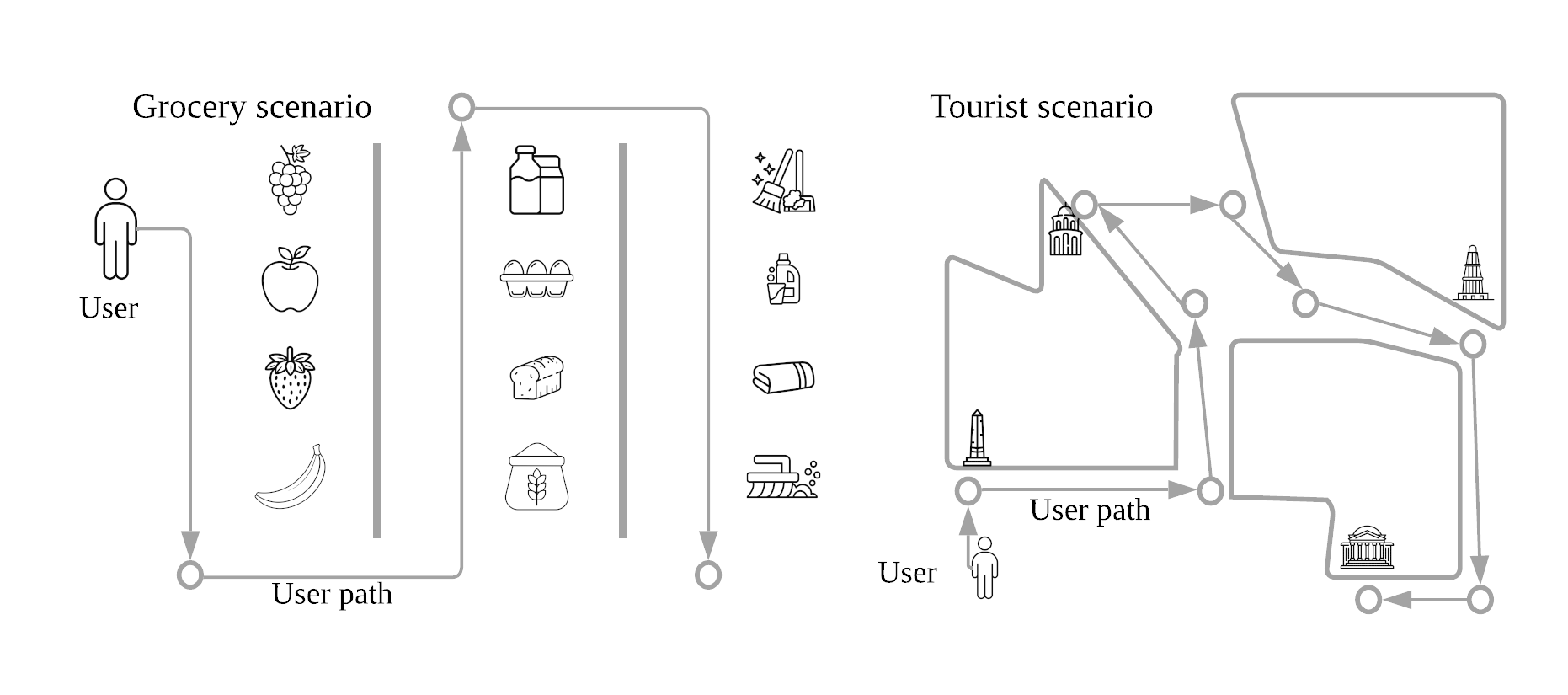
Figure 2 shows two example application scenarios for AR. In a grocery store scenario[32], users interact with virtual objects of the store items to receive information about their ingredients, manufacturing details, price variations, recipes, and so on. The items are typically placed on racks in aisles based on their categories, and there is a well defined order of placement. The Field of View (FoV) of a user will have multiple items at their location in the store, from which the user might be interested in a few.
In the case of a tourist scenario, [33], attractions are typically scattered across a region (such as a city block, campus, or neighborhood). The virtual objects may contain historical facts, 3D representations of buildings, informative audio/video, and so on. A tourist would visit the attractions based on multiple factors like user interests, transportation availability, accessibility, guide recommendations, and so on. The FoV of the user in this case would likely consist of only a few items in their vinicity, and the user will have to explore the region more to find the next attraction.
Such MAR scenarios face the following challenges:
II-B Edge caching
Edge infrastructure is well placed to meet these challenges by expanding on the limited on-device storage capacity, while reducing the user latency. The use of the edge in an MAR context necessitates novel data management policies that consider both AR-specific data characteristics and edge/cloud parameters.
Recent research on MAR architecture and applications [38, 18, 20, 21, 39] partitions data and tasks across mobile devices and edge servers to leverage resources at both locations and facilitate data sharing. Caching is crucial for improving AR application performance, and partitioning the cache across devices and edge servers has shown potential for increasing hit rates and reducing latency [18, 20].
However, existing approaches often neglect critical AR-specific factors: (1) Increasing Object Sizes: Caching strategies must adapt to the growing size and complexity of virtual objects. (2) Occlusion and User Proximity: Virtual objects can be occluded by physical objects in AR environments. Additionally, users are more likely to interact with nearby objects. These spatial considerations, along with object access patterns, can inform more effective caching strategies. (3) Object Relevance and User Associations: User interactions with virtual objects often exhibit predictable patterns (e.g., a user interacting with a milk carton may subsequently interact with nearby eggs or bread). However, caching strategies must assess the relevance of potential interactions to avoid unnecessary cache pollution.
The need for Prefetch
Edge caching offers a promising solution by storing frequently accessed objects closer to the user, reducing cloud traffic and improving access times. However, efficient cache management is crucial given the limited and heterogeneous nature of edge resources. Traditional cache eviction algorithms (e.g., LRU, LFU, FIFO, etc.) can be employed on the edge cache, but relying solely on reactive retrieval from the cloud upon cache misses can still introduce significant latency. Predictive prefetching based on access patterns can anticipate future requests and proactively cache necessary objects at the edge, reducing cache misses and enhancing user experience at the potential expense of increased network usage.
II-C Associations and Spatial Proximity
Association rule mining (ARM) [40], a technique widely used in recommender systems to predict user-item interactions, offers a promising approach for AR prefetching. ARM has proven successful in various domains, including e-commerce [32], tourism [33], fraud detection [41], and social network analysis[42]. For example, in online grocery shopping, purchasing milk and eggs often triggers recommendations for bread and jam. However, the direct application of ARM for prefetching in AR remains an underexplored area. The rule generation process, particularly with frequent updates, can be computationally expensive, posing a challenge for latency-sensitive AR applications. This work explores adapting ARM to the specific needs of AR, aiming to achieve efficient prefetching while minimizing computational overhead. While ARM effectively identifies related virtual objects, it may not prioritize those most relevant to the user’s current location. Prefetching objects far from the user’s field of view (FoV) provides limited value in AR. Therefore, this work emphasizes incorporating spatial awareness into the prefetching process. By prioritizing objects near the user’s FoV, we aim to optimize cache utilization and enhance the user experience.
III SAAP
We propose SAAP, a prefetching framework that addresses the limitations of existing edge caching approaches for MAR applications. It incorporates both the proximity of virtual objects to users and object associations to make informed decisions on edge server caching. Its prefetching policy is complementary to the underlying caching algorithm employed by the edge cache, and is meant to enhance the cache performance.
III-A System Architecture
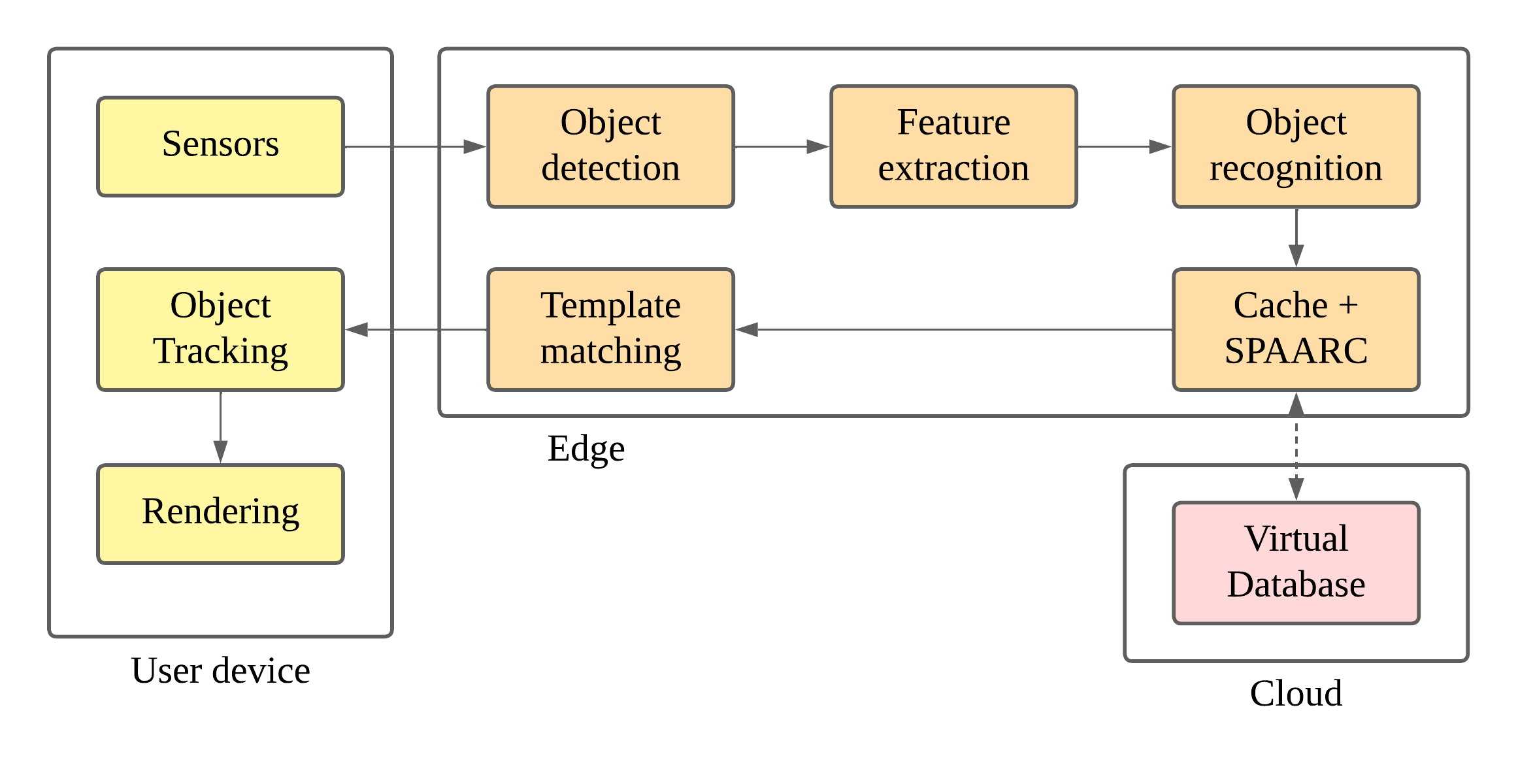
Figure 3 illustrates the MAR pipeline incorporating SAAP into the edge cache. Sensor data from the user’s device is transmitted to the nearest edge server, where video frames are pre-processed and object detection is performed. Extracted features are then used for object recognition. If a corresponding virtual object exists, the system attempts to retrieve it from the edge cache. Upon a cache miss, the SAAP algorithm is invoked to identify all necessary objects for prefetching and request them from the cloud, along with the object that caused the cache miss. After receiving the virtual objects, template matching is performed to estimate their pose. This pose information, along with the virtual objects, is sent to the object tracking module on the user’s device. The tracking module identifies objects across frames, and this information, combined with data from the edge server, is used by the rendering module to overlay virtual content onto the user’s display.
We next discuss the two main SAAP techniques that drive its prefetching: association and proximity.
III-B Association
Intuitively, if a user accesses a virtual object in an MAR scenario, they are likely to soon access related objects (e.g., milk and eggs in the grocery scenario), which should be prefetched to the edge cache for faster access. SAAP’s Association technique generates association rules using Association rule mining (ARM) [43, 40] to predict frequently co-accessed virtual objects based on user interaction history.
ARM identifies relationships between items in a transaction database by discovering frequent itemsets: groups of items that frequently co-occur in transactions. The support of an itemset indicates the proportion of transactions containing that itemset, with frequent itemsets exceeding a predefined minimum support threshold. Based on these frequent itemsets, ARM generates association rules of the form , where (antecedent) and (consequent) are disjoint itemsets. The confidence of a rule represents the conditional probability of observing the consequent in transactions containing the antecedent, controlled by a minimum confidence threshold. The lift of a rule measures the strength of the association between the antecedent and consequent, quantifying how much more likely they are to co-occur than if they were statistically independent. Support of an itemset (), confidence of a rule () and lift of the rule () are formally represented as follows:
| (1) | ||||
| (2) | ||||
| (3) |
where and are the number of transactions containing and the total number of transactions respectively. We use ARM algorithms to either generate rules a priori from history user interactions or dynamically during the process.

SAAP uses an ARM algorithm to generate a set of associated objects for prefetching whenever there is a cache miss. However, all such associated objects are not equally relevant for prefetching. Objects that have been accessed more frequently and more recently are more likely to be more useful for caching. Thus, SAAP prioritizes relevant objects within an association set using an association factor value for each object. This factor reflects the combined influence of frequency and recency of association with the missing object. Objects with higher association factors are prioritized for caching due to their increased likelihood of subsequent user interaction.
We calculate the association factor () of a virtual object as follows:
| (4) |
where , is the window frame of previous object interactions which are relevant, is the number of times the virtual object is reference in the window frame. The value of could be tuned according to the recency requirement. A larger window implies longer trend and a smaller one for shorter trend. If the access patterns are not changing frequently, a larger window size would suffice. Association factor threshold value should be set such that low association objects are filtered. The higher the threshold value, higher the chance that the selected objects are accessed in the near future.
III-C Proximity
Since relevant AR objects are based on the field of view of the user, the system only needs to prefetch objects that are in the user’s physical vicinity. SAAP incorporates spatial proximity to refine the prefetching list generated by the Association component. Proximity refers to the distance of virtual objects from the user’s location. For instance, in the grocery store scenario (Figure 2), an association rule might suggest prefetching “milk” alongside “apples” and “bananas”. However, if the user is not yet in the aisle containing milk, immediate prefetching of the “milk” virtual object is unnecessary. SAAP prioritizes contextual relevance by employing a lazy prefetching strategy, deferring the prefetching of “milk” until the user is in closer proximity. This ensures that prefetched objects are highly relevant to the user’s immediate surroundings. A proximity threshold is used to identify objects within a specific distance from the user. This threshold is domain-specific and depends on the application use case and physical environment.
III-D SAAP Workflow
Figure 4 illustrates the workflow of the SAAP framework. Upon encountering a cache miss for virtual object , SAAP’s Association module utilizes the ARM-generated rules to identify potentially associated objects based on the user’s access history and the missing object . To refine this selection and prioritize relevant objects, it uses the association factor for each object. Objects with association factors higher than the Association factor threshold are prioritized for caching due to their increased likelihood of subsequent user interaction . Next, the Proximity module filters the selected objects further to those within the Proximity threshold of the user . The filtered out relevant objects are set aside for lazy fetch later when the user moves closer to them . Once all the virtual objects to be fetched are identified, the request is send to the cloud . On retrieval, the objects are stored in cache and the missed virtual object is returned. Note that SAAP works in a complementary manner to the cache that continues to use its caching algorithms, e.g., for evicting any objects needed to make space in the cache.
III-E Adaptive Tuning
In ARM, selecting the minimum support and minimum confidence thresholds is often domain-dependent, requiring expert knowledge. To automate SAAP, we focus on tuning the minimum support parameter. Minimum support is prioritized as it directly influences the generation of frequent itemsets, which are fundamental to the subsequent steps in the process. Other parameters can be tuned in a similar manner.
| Notation | Remark |
|---|---|
| hit rate degradation threshold | |
| minimum support | |
| minimum confidence | |
| transactions | |
| lift | |
| number of evenly spaced minimum support values to be selected in the given range that determines the granularity of the search for the optimal minimum support value | |
| kurtosis, statistical measure of the ”tailedness” of the distribution of the lift of generated rules | |
| threshold for the ratio of the number of association rules to the number of frequent itemsets that helps to control the number of the generated rules | |
| used to determine when the distribution of lift has changed significantly, indicating the generation of large number of rules, many of which may be irrelevant |
Minimum support: Algorithm 1 outlines the procedure for tuning the minimum support parameter (Notations described in Table I). The key insight is that the quality of the parameter value (and hence the corresponding association rules) is measured by its impact on the cache performance (hit rate).
The TuneMinSup function dynamically adjusts the minimum support based on cache hit rate degradation. It determines whether to generate new association rule sets, select from existing ones, or continue with the current/next set, depending on the degree of hit rate degradation relative to a predefined threshold.
The GenARules function identifies the bounds for minimum support and generates new association rule sets, ranging from low to high support values, based on the last transactions. The value of can be adjusted to meet the application’s association recency requirements.
The SetARules function selects the appropriate rule set to use. Whenever new rulesets are generated in the increasing order of minimum support, the function selects the middle ruleset. Otherwise, it goes in the increasing or decreasing minimum support direction, depending on the hit rate degradation. This dynamic adjustment allows the system to adapt to changing access patterns and maintain optimal performance.
In the GenARules function, the initial lower and upper bounds for minimum support are first determined. Since popular items typically represent a small percentage of the total unique items in most datasets [44], the lower bound is set to the average support of all items [45]. From this initial range, evenly spaced minimum support values are selected. For each value, association rules are generated with a fixed minimum confidence. During rule generation, the process terminates if the rule count ratio exceeds a predefined threshold , indicating the potential inclusion of irrelevant rules. Otherwise, the kurtosis value is recorded. If the difference in kurtosis between the current and previous rule sets exceeds another threshold , the process terminates, signaling the generation of a large number of rules with relatively low lift values. This step helps to prevent overfitting and ensures the selection of meaningful rules. If neither termination condition is met, the current minimum support range is updated. Finally, rule sets are generated from the identified minimum support bounds and utilized accordingly. This adaptive approach allows for efficient and effective rule generation tailored to the specific characteristics of the workload.
IV Evaluation
IV-A Experimental setup and methodology
We use a combination of simulations and real testbed experiments. Our experimental testbed utilizes a 64GB Intel Xeon E5-2620 with 24 cores (end-users), a 16GB AWS Local Zone EC2 t3.xlarge (edge server), and a 16GB AWS EC2 t2.xlarge (cloud server). Evaluation is performed using four synthetic datasets and a real-world dataset [44].
We designed an AR workload simulator that replicates key aspects of user behavior and object placement: (1) Environment: Constructs a geographical region with obstacles using collider data [46], mimicking real-world scenarios with varying object placement densities . The distance between objects is within the range of [10, 15] unit distance. (2) User Behavior: Models user movement, gaze direction, and interaction time with virtual objects. (3) User Traffic: Simulates user arrivals using a Poisson process and interaction time with each object using a normal distribution, capturing both regular and peak usage scenarios.
| Dataset | Type | Random Itemset Support | Number of items | Number of users | Scenario |
|---|---|---|---|---|---|
| DS30 | Synthetic | 30% | 20-100 | 100 - 1k | Library |
| DS45 | Synthetic | 45% | 20-100 | 100 - 1k | Shopping mall |
| DS60 | Synthetic | 60% | 20-100 | 100 - 1k | Zoo/ aquarium |
| DS75 | Synthetic | 75% | 20-100 | 100 - 1k | Gallery guided tour |
| Grocery | Real | Varying | 169 | 9k | Grocery store |

IV-B Workloads
We utilize both synthetic and real world datasets (Table II) for our experiments.
IV-B1 Synthetic Workloads
Existing AR workload datasets often focus on a single user’s perspective, limiting their applicability for evaluating caching strategies that consider interactions from multiple users. To address this gap, we leverage the AR Workload Simulator to generate a suite of multi-user workloads. To generate our workloads, we first defined the percentage of unique items that would form these frequent itemsets. Subsequently, we created transactions where the support for these pre-defined itemsets was fixed. It is important to distinguish this “support” from the minimum support parameter used in frequent itemset generation algorithms. Here, support is solely used for dataset creation, and the resulting dataset might contain additional frequent itemsets beyond the pre-defined ones. We utilize four synthetic datasets (DS30, DS45, DS60, DS75) to evaluate the effectiveness of prefetching under diverse user interaction patterns. The support level for randomly chosen itemsets is systematically varied across the datasets (Table II). By adjusting the support level, we can assess caching performance under different user access patterns reflected by the frequency of item co-occurrence. Each dataset corresponds to a different real-world MAR scenario, as shown in the table. Depending on the type of experiment we vary the number of users, and the number of items for each dataset. Unless otherwise specified, the default configuration utilizes 100 users, 50 objects and a cache size of 20% of total size of 50 objects. The size of virtual objects are in the range [10, 15] MB [18, 34].
IV-B2 Real Workload
SPMF [44] consists of multiple real world workloads with varying transaction size and item counts. We mainly focus on the grocery dataset for our experiments. It consists of 169 items and 9k transactions.
IV-C Baseline Caching Algorithms
Since SAAP is complementary to the underlying cache algorithm, we consider four native cache eviction policies in our evaluation: FIFO, LRU, LFU and Popularity (POP). Comparison is carried out with and without SAAP integration with the cache. Unless specified, we are not tuning SAAP in the experiments in this section. The results of auto-tuning algorithm are presented separately.
IV-D Benefit of SAAP integration
| LRU | LFU | FIFO | POP | |
|---|---|---|---|---|
| DS30 | 31.15 | 24.55 | 40.6 | 32.01 |
| DS45 | 20.33 | 7.64 | 26.18 | 25.05 |
| DS60 | 24.44 | 12.28 | 27.56 | 32.4 |
| DS75 | 12.87 | 3.27 | 22.44 | 9.65 |
This experiment evaluates SAAP’s effectiveness when integrated with cache eviction algorithms (baselines). We varied both minimum support and minimum confidence from 30% to 75% while keeping other parameters constant (association factor at 1, and proximity threshold at 15). As shown in Figure 5 and Table III, SAAP significantly improves hit rates compared to baselines by 3.27% to 40.6% across all datasets.
SAAP demonstrates the highest relative improvement over the FIFO baseline, particularly with the DS30 dataset. This highlights SAAP’s ability to mitigate FIFO’s limitation of potentially evicting frequently accessed items by proactively caching those likely to be accessed in the near future. Similar improvements are observed for LRU and POP. However, LFU exhibits lower hit rates due to its tendency to evict recently added, associated items.
Furthermore, hit rates generally increase from DS30 to DS75, indicating that both baseline algorithms and SAAP benefit from a greater number of relevant associations. Subsequent results provide a detailed analysis of each parameter’s impact within specific configurations111For space reasons, we present results with a subset of the datasets and baseline algorithms. The trends hold for the omitted results..
IV-E Impact of minimum support
This experiment investigates the impact of minimum support on SAAP’s performance. We varied the minimum support threshold from 30% to 75% while keeping other parameters constant (minimum confidence at 45%, association factor at 1, and proximity threshold at 15). Figure 6 shows the hit rate variation for DS30 and DS75, with similar trends observed for DS45 and DS60. This behavior is consistent across different minimum confidence values. As a critical parameter in association rule mining, higher minimum support thresholds result in fewer frequent itemsets and consequently, fewer association rules, potentially leading to lower hit rates.

IV-F Impact of minimum confidence
This experiment analyzes the influence of minimum confidence on SAAP’s performance. We varied the minimum support threshold from 30% to 75% while keeping other parameters constant (minimum confidence at 45%, association factor at 1, and proximity threshold at 15). Figure 7 shows this effect on DS30 and DS75, with similar trends observed for DS45 and DS60 across different minimum support values. As a key parameter in ARM, increasing the minimum confidence threshold initially improves or maintains hit rates before causing a decline. This trend reflects the trade-off between rule quality and quantity. Higher thresholds reduce the number of rules, improving quality but potentially excluding relevant associations.

IV-G Impact of Association factor threshold
This experiment examines the impact of the association factor on SAAP’s cache hit rates. With minimum support and minimum confidence fixed at 30% and 45% respectively, the association factor was varied from 0.1 to 4. Figure 8 illustrates the results. As dataset support increases (i.e., associated objects are accessed more frequently), the influence of the association factor on identifying relevant objects diminishes. For DS30, the highest hit rate is achieved with an association factor of 0.1, demonstrating a clear impact. However, for DS75, where frequent itemsets have higher support, the association factor has a less pronounced effect. This suggests that the association factor plays a more critical role in scenarios with lower object access frequencies.

IV-H Impact of Proximity with Association
Figure 9 illustrates the influence of the proximity threshold on cache hit rates for SAAP-integrated baselines. We varied the proximity threshold from 5 to 20 unit distance while fixing the minimum support at 30%, minimum confidence at 45%, and association factor threshold at 1. The proximity threshold has a significant impact on hit rates. A very low threshold might neglect relevant objects located slightly further away, potentially missing prefetching opportunities. Conversely, an excessively high threshold could lead to prefetching irrelevant objects that are not close enough for immediate user interaction, wasting cache resources. Therefore, selecting an appropriate proximity threshold is crucial for optimizing SAAP’s effectiveness. Similar results are observed for DS45 and DS60.

Figure 10 shows the relative performance and overhead of using association only and association+proximity (SAAP) on top of the baseline caching algorithm, using the DS30 dataset with fixed parameters. The left graph shows that the hit rate improvement associated with association and SAAP are 3- 20% and 8- 36% respectively. The right graph measures the overhead of using SAAP by comparing on-demand fetches and prefetches across the baseline, baseline with association-based prefetching, and baselines with SAAP. It shows that both association-based prefetching and SAAP reduce on-demand fetches compared to the baseline by 2-17% and 23-31% respectively, as prefetching caches relevant objects. However, this introduces a prefetch overhead. Notably, association-based prefetching alone has a significantly higher overhead (0.51-2.12X) than SAAP (0.12-0.70X) due to its lack of irrelevant object filtering. Overall, the reduced on-demand fetches lead to improved hit rate and lower latency. While the prefetching occurs in the background without degrading user experience, it still leads to additional bandwidth consumption which we plan to address through parameter tuning and encoding in future work.

IV-I Number of Users
This experiment evaluates the impact of user count on SAAP’s performance by varying the number of users from 100 to 1000 for FIFO cache policy. Figure 11(a) shows the best hit rates achieved for DS30 across all minimum support and minimum confidence values. SAAP-FIFO improves hit rates by 5-40% when compared to FIFO. Importantly, SAAP maintains consistent hit rate improvements across the varying user counts in each dataset. This suggests that SAAP’s performance is robust to changes in user count.

IV-J Number of Unique Objects
This experiment examines the impact of virtual object count on SAAP’s effectiveness, a crucial factor varying significantly across application domains. We varied the number of virtual objects from 20 to 100 for DS30 workload for 500 users on FIFO. Figure 11(b) presents the best achievable hit rates for SAAP-FIFO compared to FIFO.
Results show a decreasing trend in hit rate improvement as object count increases within the same region. For instance, it is 96% for 20 objects, 40% for 50 objects, and 15% for 100 objects. Similar trends are observed in other datasets and cache policies. This can be attributed to increased object density, leading to more objects falling within the user’s field of view (FoV). Consequently, baseline caching policies are more likely to cache relevant objects by chance, reducing the relative advantage of SAAP’s targeted prefetching strategy.
IV-K Minimum support tuning
In this experiment, we focus on tuning minimum support value with a fixed minimum confidence of 10%, cache capacity of 10%, hit rate degradation threshold of 5%, initial transaction count for generating association rules of 100 and DS30 workload of 1000 users. Figure 12 shows the hit rate associated with FIFO baseline, FIFO with SAAP (no tuning) and FIFO with tunable SAAP. It can be seen than dynamic tuning of SAAP leads to higher hit rates. SAAP-Tune achieves 10% and 22% better hit rate compared to SAAP and FIFO baseline. The hit rates are recorded every 10 views (1 viewpoint) and checked for degradation. If it is above a threshold, the association rule sets are generated. During the generation of association rules, incoming requests are served in parallel. Once the association rule set is selected, it is used for identify associated objects.

IV-L Real World experiments
We use a real world dataset from SPMF [44] that consist of 169 items and 1000 transactions. We use Amazon Local zone for the edge server and AWS EC2 for the cloud server. The cache capacity is set to 10%, hit rate degradation to 5% and initial transaction count to 100 for rule generation. Figure 13 shows the hit rate performance. The hit rates are recorded every 100 views (1 viewpoint) and checked for degradation. It could be seen that SAAP with dynamic tuning is able to perform better than SAAP and FIFO as time passes by. Initially, it takes time to warm-up and then the hit rate starts increasing. SAAP-Tune achieves 6% and 11% better hit rate compared to SAAP and FIFO baseline.

V Related Work
Mobile augmented reality (MAR) applications [1] enhance user perception by integrating virtual objects into their view. These applications typically employ a distributed architecture across mobile devices, edge servers, and the cloud [38, 47, 48]. Efficiently partitioning compute- and data-intensive operations across these tiers is crucial. While MAR applications initially relied on local storage on mobile devices for rapid retrieval and rendering of virtual objects [21], on-demand fetching from the cloud has become prevalent with increasing application complexity [49, 50, 51, 52]. However, this approach faces challenges in delivering immersive experiences due to increasing object sizes and high cloud latency.
Edge caching has emerged as a promising solution for AR applications [15, 17], reducing latency and offering greater storage capacity compared to mobile devices. Existing research explores various edge caching strategies. Cachier [53] employs a latency-minimizing model that balances load distribution between cloud and edge, considering network conditions and request locality. Agar [54] uses dynamic programming to identify popular data chunks for caching. CEDC-O [16] formulates edge data caching as an optimization problem considering caching cost, migration cost, and quality-of-service penalties.
While CARS [18] and SEAR [20] utilize Device-to-Device (D2D) communication for sharing cached virtual objects, they lack prefetching mechanisms. DreamStore [22] allows devices to store virtual objects and employs a publish-subscribe model for data updates, incorporating location-based prefetching but without considering object relevance. Precog [19] and [55] utilize Markov models for query prediction but do not account for inter-object relationships, a key aspect of SAAP.
While CARS [18] and SEAR [20] leverage Device-to-Device (D2D) communication to share cached virtual objects with nearby users, they lack prefetching capabilities. DreamStore [22] allows user devices to store virtual objects and employs a publish-subscribe mechanism for data updates. It also incorporates a location-based prefetching mechanism, but fails to consider object relevance to the user. Precog [19] and [55] utilize a Markov model to predict user queries, but do not account for relationships between objects in a region, which is a key strength of SAAP.
Other research efforts focus on caching content for different media types at the edge. Works like [27, 28, 26] explore caching tiles of 360∘ videos to enable processing reuse. Space [56] and Leap [57] investigate prefetching video segments for users at the edge. EdgeBuffer [58] leverages user mobility patterns across access points to prefetch data to anticipated locations.
Association rule mining (ARM) [43, 40] has established itself as a valuable technique for prefetching data in various domains, including e-commerce recommendation systems, fraud detection, and social network analysis. For instance, Mithril [59] leverages historical patterns of cache requests within cloud applications to derive item association rules using a variant of ARM called sporadic-ARM. Similarly, web prefetching, which involves caching web objects in anticipation of user requests, is a well-researched area [60]. However, the potential of ARM for prefetching in augmented reality (AR) applications remains largely unexplored.
VI Conclusion
This paper investigated the potential of prefetching in mobile augmented reality (MAR) applications to improve user experience by reducing latency. To address the compute and data intensive nature of AR, we proposed SAAP, a prefetching policy for edge AR caches that leverages object associations and location information to proactively fetch virtual objects from the cloud. SAAP incorporates tunable parameters, including minimum support and minimum confidence, which can be adjusted to meet specific application needs. Through extensive evaluation using both synthetic and real-world workloads, we demonstrated that SAAP significantly improves cache hit rates compared to standard caching algorithms, achieving gains ranging from 3% to 40% while reducing the need for on-demand data retrieval from the cloud. Further, we presented an adaptive tuning algorithm that automatically tunes SAAP parameters to achieve optimal performance. Our findings demonstrate the potential of SAAP to substantially enhance the user experience in MAR applications by ensuring the timely availability of virtual objects. Future research could explore further refinement of the parameter tuning process and investigate methods to mitigate the communication overhead.
References
- [1] Y. Siriwardhana et al., “A survey on mobile augmented reality with 5g mobile edge computing: Architectures, applications, and technical aspects,” IEEE Commun. Surv. Tutor., vol. 23, pp. 1160–1192, 2021.
- [2] V. Pamuru, W. Khern-am nuai, and K. Kannan, “The impact of an augmented-reality game on local businesses: A study of pokémon go on restaurants,” Inf. Syst. Res., vol. 32, no. 3, pp. 950–966, 2021.
- [3] L. Pombo and M. M. Marques, “The potential educational value of mobile augmented reality games: The case of edupark app,” Educ. Sci., vol. 10, no. 10, p. 287, 2020.
- [4] R. M. Viglialoro et al., “Augmented reality, mixed reality, and hybrid approach in healthcare simulation: a systematic review,” Appl. Sci., vol. 11, no. 5, p. 2338, 2021.
- [5] J. Egger and T. Masood, “Augmented reality in support of intelligent manufacturing–a systematic literature review,” Comput. Ind. Eng., vol. 140, p. 106195, 2020.
- [6] J. Cao et al., “Mobile augmented reality: User interfaces, frameworks, and intelligence,” ACM Comput. Surv., vol. 55, no. 9, pp. 1–36, 2023.
-
[7]
OpenCV, “Template matching,” https://docs.opencv.org/4.x/d4/dc6/
tutorial_py_template_matching.html,, Accessed: 2024-07-05. - [8] D. Wagner et al., “Real-time detection and tracking for augmented reality on mobile phones,” IEEE Trans. Vis. Comput. Graph., vol. 16, no. 3, pp. 355–368, 2009.
- [9] Z. Huang et al., “Mobile augmented reality survey: a bottom-up approach,” arXiv preprint arXiv:1309.4413, 2013.
- [10] P. Jain, J. Manweiler, and R. Roy Choudhury, “Overlay: Practical mobile augmented reality,” in ACM MobiSys, 2015, pp. 331–344.
- [11] B. Charyyev, E. Arslan, and M. H. Gunes, “Latency comparison of cloud datacenters and edge servers,” in GLOBECOM. IEEE, 2020, pp. 1–6.
- [12] K.-T. Chen et al., “Measuring the latency of cloud gaming systems,” in ACM Multimedia, 2011, pp. 1269–1272.
- [13] J. Chakareski, “Vr/ar immersive communication: Caching, edge computing, and transmission trade-offs,” in VR/AR Network, 2017, pp. 36–41.
- [14] M. Erol-Kantarci and S. Sukhmani, “Caching and computing at the edge for mobile augmented reality and virtual reality (ar/vr) in 5g,” in Ad Hoc Networks. Springer, 2018, pp. 169–177.
- [15] Y. Zhao et al., “A survey on caching in mobile edge computing,” Wirel. Commun. Mob. Comput., vol. 2021, no. 1, p. 5565648, 2021.
- [16] X. Xia et al., “Online collaborative data caching in edge computing,” IEEE Trans. Parallel Distrib. Syst., vol. 32, no. 2, pp. 281–294, 2020.
- [17] S. Sukhmani et al., “Edge caching and computing in 5g for mobile ar/vr and tactile internet,” IEEE MultiMedia, vol. 26, no. 1, pp. 21–30, 2018.
- [18] W. Zhang et al., “Cars: Collaborative augmented reality for socialization,” in ACM HotMobile, 2018, pp. 25–30.
- [19] U. Drolia et al., “Precog: Prefetching for image recognition applications at the edge,” in ACM/IEEE SEC, 2017, pp. 1–13.
- [20] W. Zhang, B. Han, and P. Hui, “Sear: Scaling experiences in multi-user augmented reality,” IEEE Trans. Vis. Comput. Graph., vol. 28, no. 5, pp. 1982–1992, 2022.
- [21] C.-C. Wu et al., “On local cache management strategies for mobile augmented reality,” in WoWMoM. IEEE, 2014, pp. 1–3.
- [22] M. Khan and A. Nandi, “Dreamstore: A data platform for enabling shared augmented reality,” in IEEE VR. IEEE, 2021, pp. 555–563.
- [23] P. Geiger et al., “Location-based mobile augmented reality applications: Challenges, examples, lessons learned,” 2014.
- [24] R. Pryss et al., “Advanced algorithms for location-based smart mobile augmented reality applications,” Procedia Computer Science, vol. 94, pp. 97–104, 2016.
- [25] L. Ordonez-Ante et al., “Explora-vr: Content prefetching for tile-based immersive video streaming applications,” J. Netw. Syst. Manag., vol. 30, no. 3, p. 38, 2022.
- [26] D. He et al., “Cubist: High-quality 360-degree video streaming services via tile-based edge caching and fov-adaptive prefetching,” in ICWS. IEEE, 2021, pp. 208–218.
- [27] A. Mahzari et al., “Coopec: Cooperative prefetching and edge caching for adaptive 360° video streaming,” in ISM. IEEE, 2020, pp. 77–81.
- [28] P. Maniotis and N. Thomos, “Tile-based edge caching for 360° live video streaming,” IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 12, pp. 4938–4950, 2021.
- [29] W. Zhang, B. Han, and P. Hui, “On the networking challenges of mobile augmented reality,” in VR/AR Network, 2017, pp. 24–29.
- [30] H. Chen et al., “Understanding the characteristics of mobile augmented reality applications,” in ISPASS. IEEE, 2018, pp. 128–138.
- [31] M. Satyanarayanan et al., “The seminal role of edge-native applications,” in EDGE. IEEE, 2019, pp. 33–40.
- [32] F. Gutiérrez, K. Verbert, and N. N. Htun, “Phara: an augmented reality grocery store assistant,” in MobileHCI, 2018, pp. 339–345.
- [33] D.-I. Han, T. Jung, and A. Gibson, “Dublin ar: implementing augmented reality in tourism,” in ICTs Tour. Springer, 2013, pp. 511–523.
- [34] M. Deitke et al., “Objaverse: A universe of annotated 3d objects,” in CVPR, 2023, pp. 13 142–13 153.
- [35] Hathora, “Cloud latency shootout,” https://blog.hathora.dev/cloud-latency-shootout/,, Accessed: 2024-07-05.
- [36] S. Partners, “5g edge ar/vr usecases,” https://stlpartners.com/articles/edge-computing/5g-edge-ar-vr-use-cases/,, Accessed: 2024-07-05.
- [37] N. Atre et al., “Caching with delayed hits,” in ACM SIGCOMM, 2020, pp. 495–513.
- [38] J. Ren et al., “An edge-computing based architecture for mobile augmented reality,” IEEE Network, vol. 33, no. 4, pp. 162–169, 2019.
- [39] A. Dhakal et al., “Slam-share: visual simultaneous localization and mapping for real-time multi-user augmented reality,” in CoNEXT, 2022, pp. 293–306.
- [40] R. Agrawal et al., “Fast discovery of association rules.” Advances in knowledge discovery and data mining, vol. 12, no. 1, pp. 307–328, 1996.
- [41] D. Sánchez et al., “Association rules applied to credit card fraud detection,” Expert systems with applications, vol. 36, no. 2, pp. 3630–3640, 2009.
- [42] W. Fan et al., “Association rules with graph patterns,” PVLDB, vol. 8, no. 12, pp. 1502–1513, 2015.
- [43] R. Agrawal et al., “Mining association rules between sets of items in large databases,” in ACM SIGMOD, 1993, pp. 207–216.
- [44] P. Fournier-Viger, “Spmf: An open-source data mining library,” https://www.philippe-fournier-viger.com/spmf/index.php?link=datasets.php,, Accessed: 2024-07-03.
- [45] E. Hikmawati, N. U. Maulidevi, and K. Surendro, “Minimum threshold determination method based on dataset characteristics in association rule mining,” J. Big Data., vol. 8, pp. 1–17, 2021.
- [46] Udacity, “Fcnd motion planning,” https://github.com/udacity/FCND-Motion-Planning,, Accessed: 2024-06-25.
- [47] N. Pereira et al., “Arena: The augmented reality edge networking architecture,” in ISMAR. IEEE, 2021, pp. 479–488.
- [48] O. Debauche, S. Mahmoudi, and A. Guttadauria, “A new edge computing architecture for iot and multimedia data management,” Information, vol. 13, no. 2, p. 89, 2022.
- [49] W. Zhang et al., “Cloudar: A cloud-based framework for mobile augmented reality,” in Thematic Workshops of ACM Multimedia 2017, 2017, pp. 194–200.
- [50] Z. Huang et al., “Cloudridar: A cloud-based architecture for mobile augmented reality,” in MARS, 2014, pp. 29–34.
- [51] X. Qiao et al., “Web ar: A promising future for mobile augmented reality—state of the art, challenges, and insights,” Proceedings of the IEEE, vol. 107, no. 4, pp. 651–666, 2019.
- [52] T. Theodoropoulos et al., “Cloud-based xr services: A survey on relevant challenges and enabling technologies,” J. Netw. Netw. Appl., vol. 2, no. 1, pp. 1–22, 2022.
- [53] U. Drolia et al., “Cachier: Edge-caching for recognition applications,” in ICDCS. IEEE, 2017, pp. 276–286.
- [54] R. Halalai et al., “Agar: A caching system for erasure-coded data,” in ICDCS. IEEE, 2017, pp. 23–33.
- [55] S. Choi et al., “Prefetching method for low-latency web ar in the wmn edge server,” Appl. Sci., vol. 13, no. 1, p. 133, 2022.
- [56] J. Aguilar-Armijo et al., “Space: Segment prefetching and caching at the edge for adaptive video streaming,” IEEE Access, vol. 11, pp. 21 783–21 798, 2023.
- [57] W. Shi et al., “Leap: learning-based smart edge with caching and prefetching for adaptive video streaming,” in IWQoS, 2019, pp. 1–10.
- [58] F. Zhang et al., “Edgebuffer: Caching and prefetching content at the edge in the mobilityfirst future internet architecture,” in WoWMoM. IEEE, 2015, pp. 1–9.
- [59] J. Yang et al., “Mithril: mining sporadic associations for cache prefetching,” in ACM SoCC, 2017, pp. 66–79.
- [60] W. Ali et al., “A survey of web caching and prefetching,” Int. J. Advance. Soft Comput. Appl, vol. 3, no. 1, pp. 18–44, 2011.