S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models
Abstract
Deployment of autoregressive large language models (LLMs) is costly, and as these models increase in size, the associated costs will become even more considerable. Consequently, different methods have been proposed to accelerate the token generation process and reduce costs. Speculative decoding (SD) is among the most promising approaches to speed up the LLM decoding process by verifying multiple tokens in parallel and using an auxiliary smaller draft model to generate the possible tokens. In SD, usually one draft model is used to serve a specific target model; however, in practice, LLMs are diverse, and we might need to deal with many target models or more than one target model simultaneously. In this scenario, it is not clear which draft model should be used for which target model, and searching among different draft models, or training customized draft models, can further increase deployment costs. In this paper, we first introduce a novel multi-target scenario for deployment of draft models for faster inference. Then, we present a novel more efficient sorted speculative decoding mechanism that outperforms regular baselines in multi-target setting. We evaluated our method on Spec-Bench in different settings including base models such as Vicuna 7B, 13B, and LLama Chat 70B. Our results suggest that our draft models perform better than baselines for multiple target models at the same time.
S2D: Sorted Speculative Decoding For More Efficient Deployment of Nested Large Language Models
Parsa Kavehzadeh2 Mohammadreza Pourreza2 Mojtaba Valipour1
Tianshu Zhu2 Haoli Bai2 Ali Ghodsi1
Boxing Chen2 Mehdi Rezagholizadeh2
{mojtaba.valipour, ali.ghodsi}@uwaterloo.ca, {mehdi.rezagholizadeh, parsa.kavehzadeh}@huawei.com
1: University of Waterloo, 2: Huawei Noah’s Ark Lab
1 Introduction
Large language models (LLMs) have advanced very quickly and become popular in different academic and industrial domains Brown et al. (2020). As the size of these models increases Narayanan et al. (2021), accelerated inference is becoming more popular to reduce the overhead costs of their deployment. There are an increasing number of publications in the literature trying to achieve faster inference Stern et al. (2018); Chen et al. (2023a); Leviathan et al. (2023a); Chen et al. (2023b). These different approaches include, but are not limited to, reducing redundant layers Men et al. (2024), quantization , early exiting Varshney et al. (2023), optimizing the KV-caching of transformers Zhang et al. (2023b), and speculative decoding Leviathan et al. (2023b); Chen et al. (2023a). In this paper, we focus on speculative decoding (SD) as one of the most prominent solutions (due to its simplicity and widespread usage) for improving the decoding speed of LLMs.
SD is a technique based on drafting and verification. Since autoregressive generation of LLMs is a sequential process, SD tries to use a faster proxy model to generate a candidate draft (with a fixed pre-defined length). Then, the given generated tokens by the draft model will be sent to the target LLM in one forward pass to be verified. In regular SD, the draft model is a separate smaller language model; however, we have self-speculative solutions Zhang et al. (2023a); Elhoushi et al. (2024); Zhong and Bharadwaj (2024) in which the draft model is a part of the target model.
While SD is pretty popular in the literature and we have many of its variants available, there are a few bottlenecks in SD, which we will focus on in our paper: 1-“search problem” we can have target models with different sizes and it is not clear how to obtain the proper draft model for each target model. Moreover, target models can be trained on different downstream tasks, and using a single draft model to serve all the tasks might not yield the best results. This might lead to a distribution mismatch between the target and the draft model unless both the target and the draft model are updated. 2- “minimal training” We prefer not to train or modify the target model received from the users. This means that most of the solutions in the category of self-speculative solutions are not within our scope.
To address the mentioned problems, we propose our solution called sorted speculative decoding (S2D). Sorted refers to the sorted-training Valipour et al. (2023) approach in which a model and its selected sub-models can be trained on single or multiple tasks at the same time. Inspired by sorted training, our S2D trains multiple draft models in one model to be able to serve more than just one target model at a time (without needing to maintain multiple draft models) to take care of the search problem. In this regard, the initial draft model is extracted from the target model and after designing the sub-models, they are trained together. Moreover, in contrast to the self-speculative solutions, our approach is just applied to the draft side and we do not need to train the target model. Finally, to make an efficient use of the trained sorted draft models, we use an adaptive draft selection mechanism.
The contributions of this paper are listed as follows: 1- Introduction of Multi-Target Draft Models: We pioneer the concept of employing a single draft model that can simultaneously accommodate multiple target models, reducing deployment complexity and costs. 2- Development of a Sorted Speculative Decoding Mechanism: Our S2D mechanism leverages sorted fine-tuning, enabling the creation of sub-models within a draft model, without the necessity of maintaining separate draft models for each target LLM. 3- Adaptive Draft Selection Strategy: We introduce an adaptive draft selection mechanism that optimally chooses sub-models based on confidence thresholds. 4- Comprehensive Evaluation on Spec-Bench: We rigorously evaluated our S2D method on the Spec-Bench.
2 Related Work
For LLMs to perform more efficiently, efficient decoding/sampling methods Leviathan et al. (2023a); Li et al. (2024) are essential. As LLMs grow in complexity and size, the need for innovative techniques to enhance their speed and accuracy becomes even more pressing. Various methodologies are discussed in this literature review, including parallel sampling, speculative decoding, and early exit strategies, alongside their contributions and advancements.
Parallel Decoding
The first mechanism aiming to accelerate the inference process of large language models was presented in Stern et al. (2018). This paper introduced a blockwise parallel decoding strategy, aiming to generate the next k tokens simultaneously in a single forward pass using a set of auxiliary models. Then they proposed to use the same language model to verify the generated tokens in parallel. This simple draft-then-verify mechanism, as discussed in the paper, can potentially reduce the number of forward passes from m to m/k+1 Stern et al. (2018).
Speculative Decoding
Inspired by Sun et al. (2021), Xia et al. (2022) proposed a draft-then-verify mechanism to aggressively generate a fixed number of tokens in parallel without the new tokens depending on the previous ones, and then verify the generated tokens in one forward pass.
Later, they Xia et al. (2023) proposed a more advanced attention mechanism to generate independent tokens in parallel by using distinct attention queries instead of using a shared attention query, or simply adding more language model heads as done in the past. In addition, for the verification process, they also relaxed the top-1 greedy decoding. Instead, they proposed to accept any token from the top- candidates as long as their score gap is not far from the most likely token Xia et al. (2023).
Speculative Sampling
Other methods, such as Chen et al. (2023a), Leviathan et al. (2023a), generalized speculative decoding to the stochastic non-greedy setting. As these methods are just a variant of the draft-then-verify mechanism with a modified rejection sampling algorithm for ensuring sampling quality, we will leave the integration of these methods with our proposed method as future work.
Self-Speculative Decoding
Other methods, such as Zhang et al. (2023a), introduced self-speculating, which tries to get rid of the auxiliary models by selectively skipping certain intermediate layers during the drafting phase. As we can use the full LLM to validate the generated tokens, without any additional model we can enjoy accelerated inference. This is also aligned with approaches like Elhoushi et al. (2024), Chataoui et al. (2023), Kavehzadeh et al. (2024), and Valipour et al. (2023).
Other Methods
More recently, new techniques Liu et al. (2023); Chen et al. (2023b); Li et al. (2024); Cai et al. (2024); Fu et al. (2024); Sun et al. (2023); Miao et al. (2023); Varshney et al. (2023); Ankner et al. (2024); He et al. (2023); Yi et al. (2024) have emerged that trying to incorporate sophisticated mechanisms to further improve the speculative sampling speedup gain.
For simplicity, this paper will focus on the Self-Speculative Decoding setting, but our method is also applicable to other speculative sampling methods with minor adjustments, without loss of generality.
Benchmarks
In addition, to evaluate these different algorithms, several benchmarks Zheng et al. (2024); Taori et al. (2023); Chen et al. (2021) can be used to measure performance and speed up gains. One of the most comprehensive benchmarks, however, is Spec-Bench, specifically designed to evaluate speculative decoding methods Xia et al. (2024). Spec-Bench comprises 6 sub-tasks: translation, multi-turn conversation (MT-Bench), retrieval-augmented generation, mathematical reasoning, question answering, and summarization, each with 80 instances. In this paper, we will focus mainly on Spec-Bench.
3 Methodology
3.1 Background
Speculative Decoding:
Speculative decoding is a two-step process involving drafting and verification. At each decoding step, a draft model efficiently generates multiple potential future tokens, which are then verified in parallel by the target model at inference time. Specifically, during the drafting step, given an input sequence and the target LLM , a faster drafter model decodes the next drafted tokens as a speculation of the target LLM’s output Xia et al. (2024):
| (1) | ||||
where DS(·) represents the drafting strategy, is the conditional probability distribution calculated by , and is the token sampled from the draft model’s probability distribution . The tokens generated by the draft model are then verified by the target LLM . Given the input sequence and the drafted tokens , the model is used to measure probability distributions simultaneously as follows:
| (2) |
Each drafted token is then verified using a specific verification criterion using , , and . Only the tokens that meet this criterion are selected as final outputs.
Sorted Fine-tuning:
Sorted Fine-tuning Valipour et al. (2023); Kavehzadeh et al. (2024) is a recently proposed approach for training many-in-one models by forming sub-models from a larger model. In the case of LLMs, sub-models are the sub-layers of the existing LLM. Each sub-model’s output is predicted using the shared output prediction head from the last layer (original LLM head). To train the network, we define the loss as the summation of the losses of all the sub-models:
| (3) |
where is the loss for the -th sub-model for input batch and B denotes the number of sub-models.
3.2 Why sorted draft instead of sorted target?
In this paper, we introduce a method that involves Sorted fine-tuning (SoFT) of a draft model and using sub-models for sorted speculative decoding to increase the inference speed of multiple target models. An alternative method, is to use SoFT to train the target model, instead of the draft model, similar to the approach proposed in Kavehzadeh et al. (2024). To evaluate these two methods, we fine-tuned the Llama2 13B Touvron et al. (2023) on the GSM8K dataset using both standard supervised fine-tuning (SFT) and Sorted fine-tuning (SoFT) as described in Kavehzadeh et al. (2024). The results are provided in Table 1, where we compare our sorted speculative decoding with sorted draft model training with self sorted speculative decoding.
According to Table 1, the sorted target model training method has three significant disadvantages. Firstly, it decreases accuracy by 16% in final task performance and offers lower speed improvements because the sub-models used are larger than those in the sorted draft model training. Secondly, this method is not suitable for scenarios with multiple target models as it requires each target model to undergo SoFT training for self-speculative decoding to be applicable. Lastly, SoFT training of the target model incurs considerably higher costs compared to our method of SoFT training a smaller draft model.
| GSM8K | ||
| Model | Auto-regressive Decoding | |
| Speedup | Accuracy | |
| SFT (Llama2 13B) | 1 | 48.97 |
| Model | Self Sorted speculative decoding (Sorted Target) | |
| Speedup | Accuracy | |
| Layers 12:40 (SoFT) | 1.21 | 33.51 |
| Draft Model | Sorted Speculative Decoding (Sorted Draft) | |
| Speedup | Accuracy | |
| Layer 6:12 (SoFT 6,9,12 13B) | 1.53 | 48.97 |
3.3 Sorted speculative decoding
In this section, we introduce our approach which utilizes multiple draft models in the same architecture in an adaptive way to address multi-target inference acceleration problem. To reach this goal, we first introduce a new sorted draft architecture that can incorporate multiple draft sub-models in the same architecture. Then we explain the adaptive draft generation algorithm that we devise in order to use the draft sub-models efficiently in speculative decoding paradigm.
Training SoFT Draft
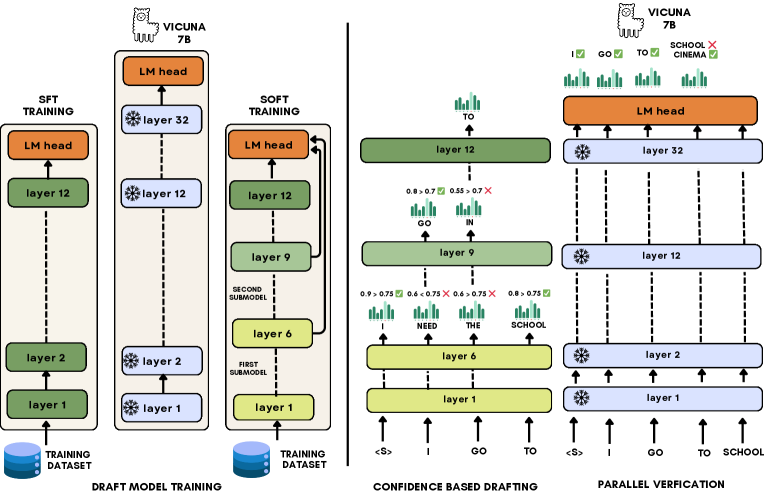
Supposed we have a pre-trained large language model with the parameters , input and number of layers. Also consider as the sub-model with the parameters of first layers of the LLM (). To reach our draft architecture, we first extract a sub-model with , where . Then we also determine three different sub-models in the extracted draft architecture as , and , where . We utilize the sorted fine-tuning approach Kavehzadeh et al. (2024) to fine-tune the whole draft on the downstream dataset to reach three draft models with different sizes in the same architecture. In this paper, we use Vicuna 7B as the pre-trained language model with 32 layers. To define our draft sub-models, we set to 6, to 9, and to 12 in our experiments. Figure 1 (Left) shows the two SFT and SoFT methods to train an extracted draft model from the target Vicuna 7B.
Draft Generation
In order to make most out of the speculative decoding algorithm, we need to have both low latency draft models and high acceptance ratio compared to target model. To generate each token, we employ a confidence-based early-exiting approach in architecture. Supposed the draft sub-model layers , we have the set of confidence thresholds . To generate one draft token given input sequence , we start iterating over draft sub-models, starting from . For each sub-model , we have:
| (4) |
Where and are the draft token and its confidence sampled from draft sub-model . We accept the token as the final draft token if . Algorithm 1 explains the draft generation mechanism of S2D algorithm in more details. Figure 1 (Right) also shows how draft generation works in S2D algorithm.
4 Experiments
4.1 Experimental Setup
We selected the first 12 layers of Vicuna 7b checkpoint to build the architecture of our draft model. Then, we trained the draft model in both SFT and SoFT paradigms on the ShareGPT 111https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered dataset for 3 epochs. We used the Spec-bench Xia et al. (2024), which is a benchmark for speculative decoding-based methods, to evaluate our draft models and the S2D algorithm. More details about the experimental setup and hyperparameters can be found in the Appendix 7.1.
4.2 Baselines
We categorize the baselines based on the dependency of draft training procedure on target models:
Target-Dependent Baselines
-
•
Eagle Li et al. (2024): An approach proposing a single layer draft model trained with two feature alignment and cross-entropy losses based on target output.
-
•
Medusa Cai et al. (2024): A method for generating multiple draft candidates for future tokens by training multiple language model heads for each future token position.
-
•
Hydra Ankner et al. (2024) A draft model based on recurrent neural architectures on top of the target model, which generates multiple draft candidates.
Target-Independent Baselines
We have different scenarios for our draft generation as baselines:
-
•
SFT Checkpoint + Speculative Decoding: We use the SFT checkpoint of first 12 Vicuna 7b layers as draft model in the speculative sampling algorithm.
-
•
Small sub-model of SoFT Checkpoint (6 Layers) + Speculative Decoding: We use the smallest sub-model (Layer 6) of the SoFT checkpoint of first 12 Vicuna 7b layers as draft model in the speculative decoding algorithm.
-
•
Medium sub-model of SoFT Checkpoint (9 Layers) + Speculative Decoding: We use the medium sub-model (Layer 9) of the SoFT checkpoint of first 12 Vicuna 7b layers as draft model in the speculative decoding algorithm.
-
•
Full SoFT Checkpoint (12 Layers) + Speculative Decoding: We use the full SoFT checkpoint of first 12 Vicuna 7b layers as draft model in the speculative decoding algorithm.
-
•
Full SoFT Checkpoint (12 Layers) + S2D: We use the full SoFT checkpoint of first 12 Vicuna 7b layers as draft model in the S2D algorithm. We set the thresholds of the intermediate sub-models from the ablations in section 4.4.1.
4.3 Results
In this section, we will discuss the results of the experiments we conducted to evaluate our SoFT draft model and S2D approach compared to other baselines.
Multi-Target Draft:
Table 2 shows the speedup ratio (compared to regular autoregressive inference of the target model) and mean accepted tokens length of different baselines on MT-Bench dataset in Spec-Bench. Fine-tuning an extracted network from Vicuna 7b, can result in speed-up in multiple targets with various sizes without any need for pre-training. Our S2D method outperforms or preserves the performance of the normal speculative decoding almost in all the target sizes. In smaller targets like Vicuna 7b where the latency of the draft is mostly important, S2D can adjust the draft generation procedure to be less slow by choosing the intermediate layers more likely. While in larger targets like LLaMA Chat 70b, it is shown that the capacity (mean accepted tokens length) is more important than the draft latency since 12 layer drafts gains higher speedups compared to the layer 6 of SoFT draft checkpoint. Even in this scenario S2D can maintain the optimum performance by adjusting the exiting layers accordingly.
| Method | Greedy (T = 0) | Non-Greedy (T = 1) | Avg Speedup | ||||||||||
| Vicuna 7B | Vicuna 13B | LLaMA Chat 70B | Vicuna 7B | Vicuna 13B | LLaMA Chat 70B | ||||||||
| Speedup | MAT | Speedup | MAT | Speedup | MAT | Speedup | MAT | Speedup | MAT | Speedup | MAT | ||
| Eagle Li et al. (2024) | 2.62 | 3.84 | ✗ | ✗ | ✗ | ✗ | 2.05 | 3.42 | ✗ | ✗ | ✗ | ✗ | N/A |
| Eagle (No Attention Tree) | 2.04 | 3.11 | ✗ | ✗ | ✗ | ✗ | 1.72 | 2.73 | ✗ | ✗ | ✗ | ✗ | N/A |
| Medusa Cai et al. (2024) | 1.74 | 2.51 | ✗ | ✗ | ✗ | ✗ | 1.93 | 2.80 | ✗ | ✗ | ✗ | ✗ | N/A |
| Medusa (No Attention Tree) | 1.34 | 1.76 | ✗ | ✗ | ✗ | ✗ | 1.48 | 1.92 | ✗ | ✗ | ✗ | ✗ | N/A |
| Hydra Ankner et al. (2024) | 2.14 | 2.70 | ✗ | ✗ | ✗ | ✗ | 2.36 | 4.01 | ✗ | ✗ | ✗ | ✗ | N/A |
| Hydra (No Attention Tree) | 1.78 | 2.65 | ✗ | ✗ | ✗ | ✗ | 2.03 | 3.11 | ✗ | ✗ | ✗ | ✗ | N/A |
| SFT + SD | 1.19 | 3.19 | 1.21 | 3.05 | 1.94 | 2.46 | 1.16 | 3.44 | 1.10 | 3.16 | 1.94 | 2.54 | 1.42 |
| SoFT L6 + SD | 1.38 | 2.43 | 1.38 | 2.40 | 1.83 | 2.05 | 1.30 | 2.53 | 1.35 | 2.87 | 1.87 | 2.14 | 1.51 |
| SoFT L9 + SD | 1.24 | 2.80 | 1.31 | 2.78 | 1.92 | 2.27 | 1.26 | 3.05 | 1.32 | 2.87 | 1.94 | 2.34 | 1.49 |
| SoFT L12 + SD | 1.17 | 3.11 | 1.23 | 3.01 | 1.91 | 2.39 | 1.07 | 3.22 | 1.20 | 3.17 | 1.96 | 2.53 | 1.42 |
| SoFT + S2D (ours) | 1.34 | 2.86 | 1.38 | 2.76 | 1.95 | 2.36 | 1.27 | 3.01 | 1.38 | 2.89 | 1.98 | 2.44 | 1.55 |
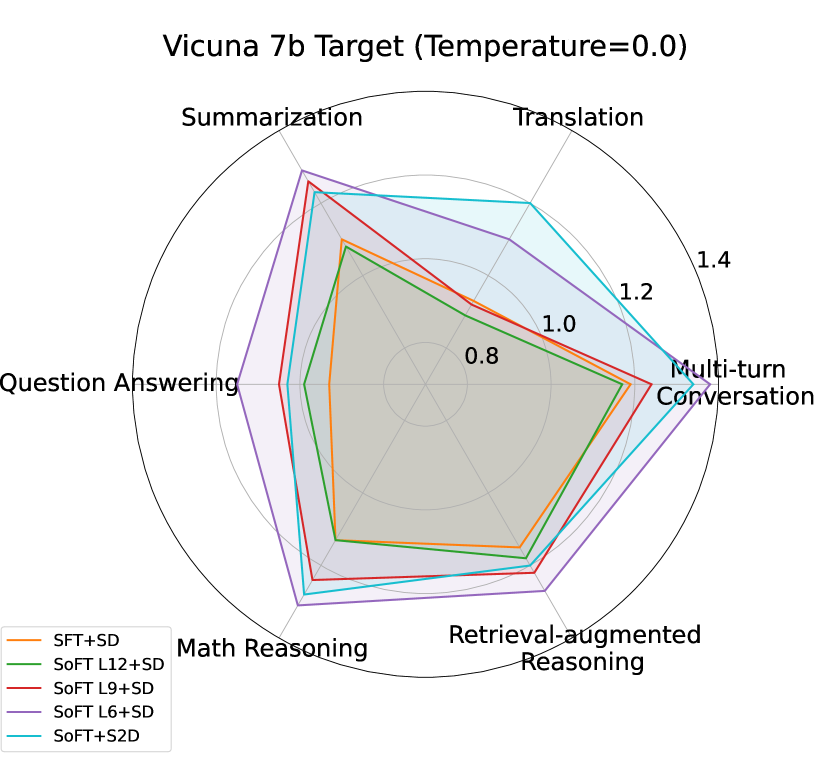
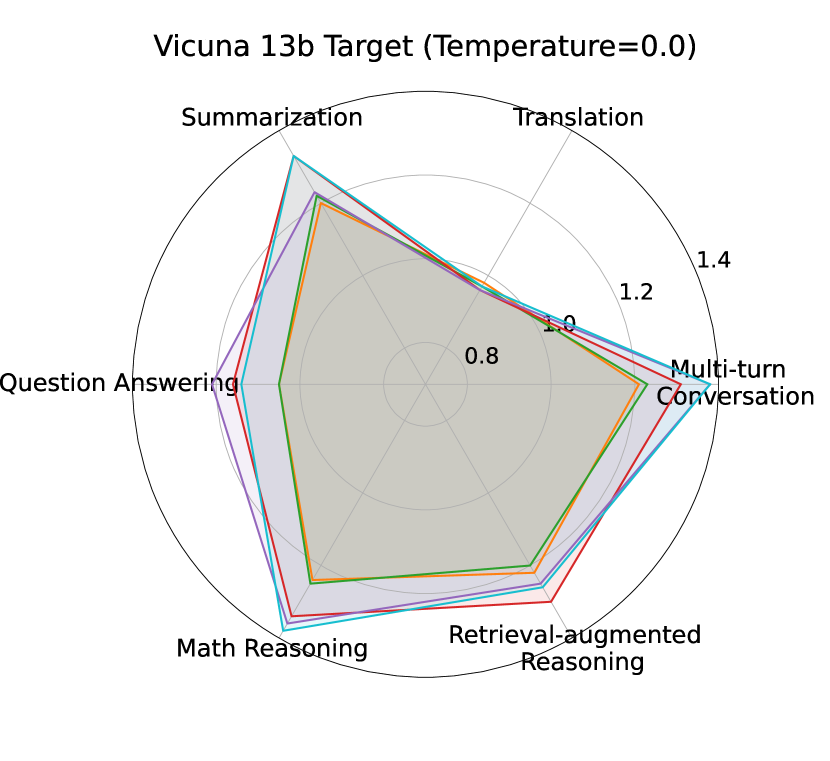
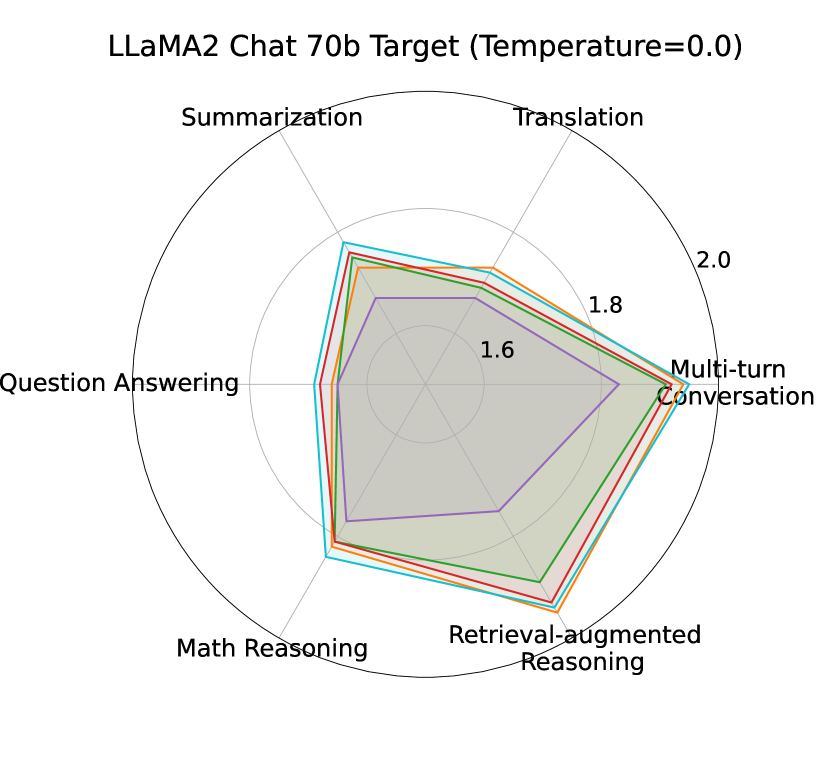
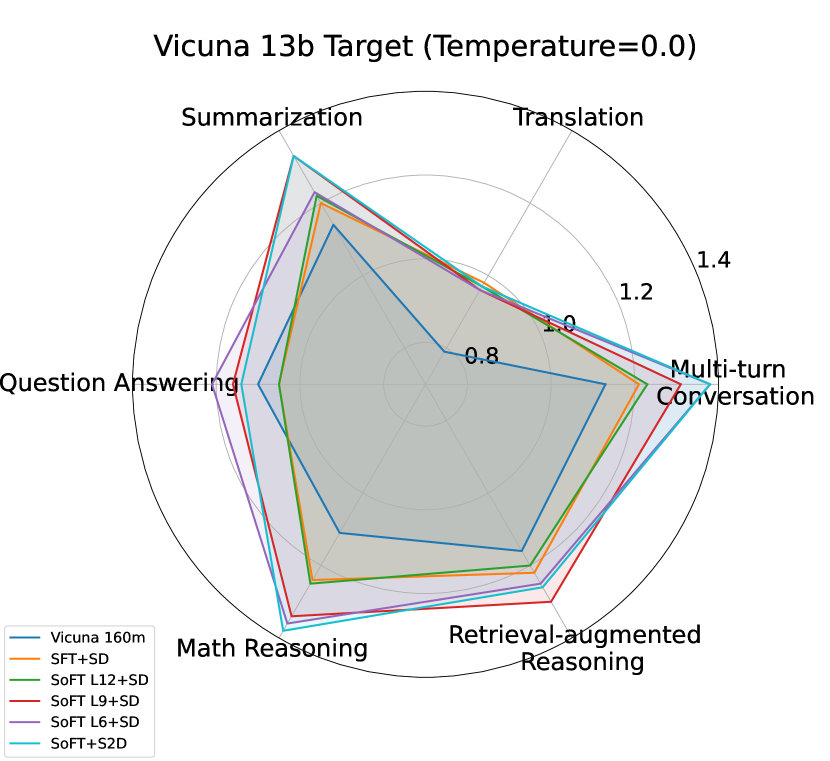
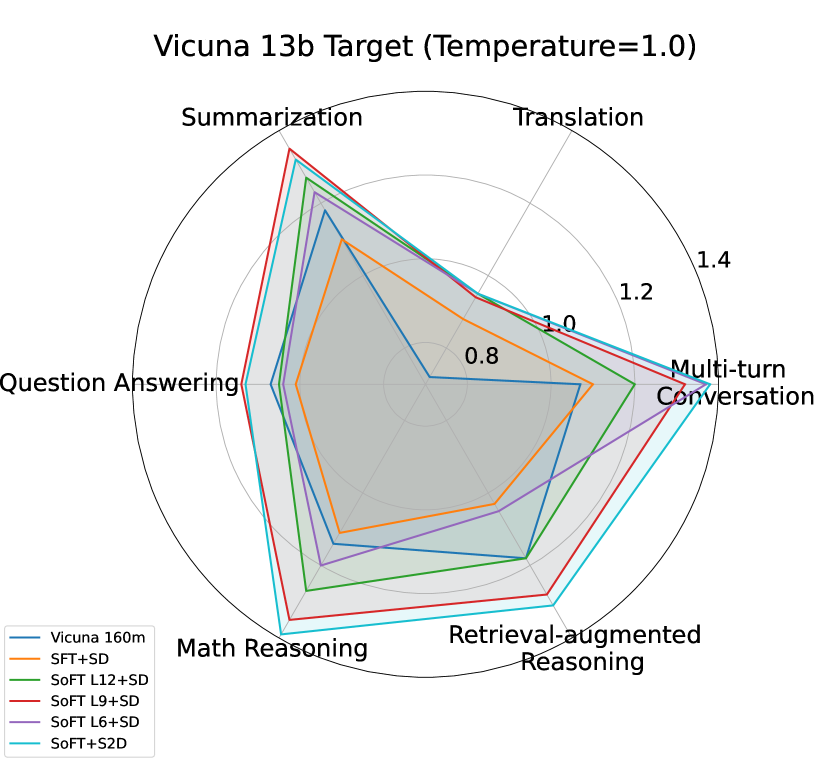
S2D vs baselines (speculative):
Table 2 and Figure 2 depict the S2D performance compared to normal SD with different draft options on multiple targets and tasks. Taking Vicuna 7b and 13b as target models, S2D outperforms significantly SD with SFT and SoFT full draft models (12 layers). S2D has also higher speedup compared to SD with medium size (Layer 9) of SoFT model in many tasks like MT-Bench and GSM8K. SD with the smallest sub-model (Layer 6) of SoFT model outperforms S2D in most tasks due to the fact that the smallest sub-model of our draft architecture enjoys 1/2 latency of the full architecture, which plays an important role in the overall speedup in speculative decoding algorithm.
However, when it comes to larger target sizes like LLaMA Chat 70b, S2D roughly maintains the speedup of SD with SFT and SoFT full model architecture. While using SD with intermediate SoFT draft sub-models, especially smallest one (Layer 6), would cause significant drop in speedup compared to other draft options, indicating the importance of draft model capacity and Mean Accepted Tokens length factors when it comes to large targets inference acceleration.
Overall, depending on the necessity of lower draft latency or higher accepted token ratio, S2D performance demonstrates that our proposed approach can choose the sub-models accordingly to have the optimum speedup compared to other draft options in the architecture. The more details about the baselines performance on Spec-Bench can be found in Appendix 7.2.
4.4 Ablation Studies
4.4.1 Thresholds
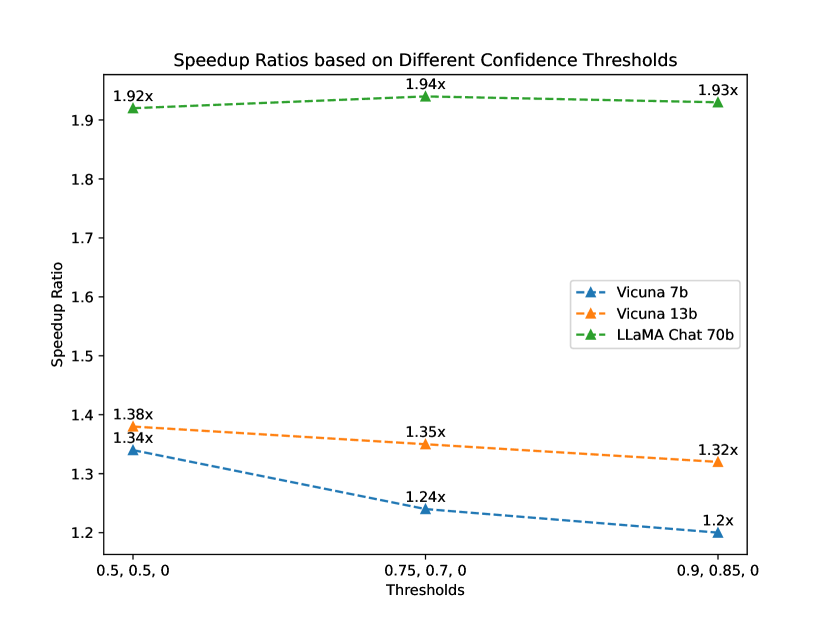
To find the optimum confidence thresholds for SoFT draft sub-models in S2D algorithm, we assess different thresholds sets to see the algorithm’s performance in each scenario. Figure 3 shows the performance comparison of different confidence thresholds. While in smaller target models, there is a tendency to choose the smaller draft sub-models by lowering their corresponding confidence thresholds to increase speedup, in the largest target model there is a need for higher draft model capacity therefore higher confidence thresholds result in optimum speedup. We fixed the best thresholds of each target model in all other experiments conducted with S2D algorithm in this paper.
4.4.2 Impact of Attention Tree
Unlike speculative decoding and sorted speculative decoding methods, recent approaches such as EAGLE Li et al. (2024), Medusa Cai et al. (2024), and Hydra Ankner et al. (2024) employ tree attention to simultaneously verify multiple candidate tokens. This addition complicates direct comparisons with other methods. Therefore, we also evaluated these methods without tree attention and provided the results in Table 2. As expected, the speedup ratio significantly decreased for all. Interestingly, when tree attention is removed, Medusa’s performance even falls below that of speculative decoding, specifically using layer 6 of the SoFT-trained sub-models.
4.4.3 Impact of Feature Alignment
Using the last layer hidden state representation of the target model to train a draft model has become a common approach in recent works Cai et al. (2024); Ankner et al. (2024). More specifically, EAGLE Li et al. (2024) employs both features and tokens generated by the target model to train an one-layer draft. Supposed and are the token and hidden state feature generated by target LLM and and are the token and hidden state features generated by draft at position , Eagle aligns hidden state features of draft and target by using L1 regression loss:
They also employ classification loss to directly optimize towards alignment of tokens:
By integrating feature alignment (regression loss) and token alignments (classification loss), EAGLE’s autoregression head is trained using the combined loss function:
We conducted experiments studying the affects each feature and token alignment cause by setting different combination of and (Table 3). We train eagle draft model based on a LLaMA2 13b target model fine-tuned on GSM8K train data. We found out that canceling the token alignment loss () would not have a significant impact on the draft performance compared to the original setup used in Eagle paper ( and ). On the other hand, setting to 0 would cause a noticeable impact on the draft performance, dropping speedup from 2.73x to 1.61x. As we can see, feature alignment plays the main role in improving the Eagle draft performance while this is impractical in multi-target setting where the draft model needs to serve multiple target models anytime.
| Model / Metric | Autoregressive | EAGLE | ||
| w_cls=0.1, w_reg=1.0 | w_cls=0.0, w_reg=1.0 | w_cls=1.0, w_reg =0.0 | ||
| GSM8K EM | 48.90 | 48.67 | 48.90 | 48.82 |
| GSM8K Speedup Ratio | 1.00x | 2.73x | 2.70x | 1.61x |
4.4.4 Impact of Pre-training
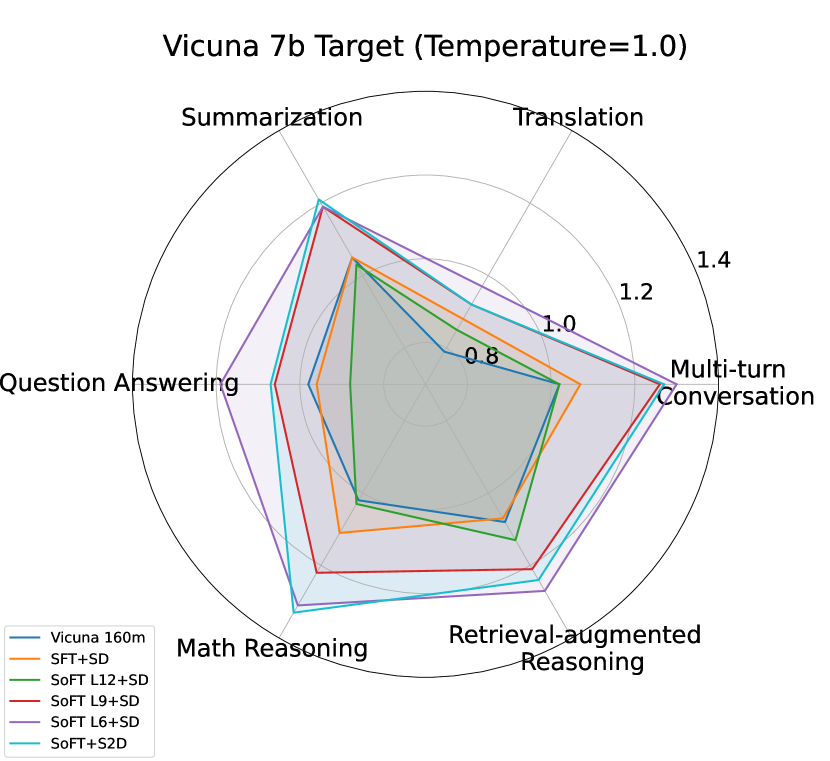
Using pre-training draft models can be a possible direction to increase the acceptance ratio of draft tokens in speculative decoding algorithm. In this way, we repeated our experiments in a new setup where we replaced the first 12 layers of Vicuna 7b with Vicuna 160m, which is a LLaMA 160m checkpoint fine-tuned on ShareGPT dataset. LLaMA 160m is a small 12 decoder layer architecture pre-trained on C4 corpus. We also sorted fine-tuned the Vicuna 160m on ShareGPT with the same sub-models (Layer 6, 9 and 12). Table 4 shows the benefit of using S2D instead of regular SD for smaller target models (Vicuna 7b and 13b). Based on the results in Table 2, fine-tuning an extracted 12-layer draft model can result in higher speedup compared to employing a similar pre-trained architecture, which can demonstrate the efficiency of our approach in terms of training resources.
| Method | Greedy (T = 0) | |||||
| Vicuna 7B | Vicuna 13B | LLaMA Chat 70B | ||||
| Speedup | MAT | Speedup | MAT | Speedup | MAT | |
| Vicuna 160m + SD | 1.05 | 2.75 | 1.13 | 2.66 | 1.93 | 2.24 |
| SoFT L6 + SD | 1.20 | 2.10 | 1.26 | 2.06 | 1.68 | 1.76 |
| SoFT L9 + SD | 1.10 | 2.33 | 1.21 | 2.29 | 1.79 | 1.96 |
| SoFT L12 + SD | 1.00 | 2.67 | 1.07 | 2.58 | 1.90 | 2.19 |
| SoFT + S2D | 1.17 | 2.54 | 1.28 | 2.44 | 1.91 | 2.16 |
4.4.5 Target Model Training
Foundation models like GPT-4, Gemini (Team et al., 2023), and the Claude family (Anthropic, 2024) are trained on vast datasets, enabling them to perform well across various tasks. Nonetheless, for specialized tasks where the model has limited exposure during pre-training, domain adaptation through fine-tuning leads to superior performance in downstream tasks (Liu et al., 2024). This section evaluates the impact of fine-tuning both the target and draft models for specific tasks on the speed gains achievable using our proposed sorted speculative decoding method. In this way, we fine-tune a Llama 13B model and also sorted fine-tuned the extracted 12-layer draft on GSM8k, a mathematical reasoning dataset. Results shown in Table 5 demonstrate that fine-tuning both target and draft on the same dataset, due to their improved alignment, results in a 1.14 speed increase at inference time.
| GSM8K | |||
| Model | Auto-regressive Decoding | ||
| Trained Target | Speedup | Accuracy | |
| Llama2 13B | ✓ | 1 | 48.97 |
| Llama2 13B | ✗ | 1 | 28.7 |
| Draft Model | Sorted Speculative Decoding | ||
| Trained Target | Speedup | Accuracy | |
| S2D - SoFT | ✓ | 1.53 | 48.97 |
| S2D - SoFT | ✗ | 1.38 | 28.7 |
5 Conclusion
In this paper, we present a method based on the SoFT training of a draft model to overcome a significant limitation of traditional speculative decoding methods, where each target model necessitates a uniquely trained draft model. Through comprehensive experimentation, we demonstrate that by using a same SoFT-trained draft model with varying thresholds for sub-models, we achieve an average speedup ratio of 1.55 for target models with parameters ranging from 7B to 70B. Moreover, our method surpasses vanilla speculative decoding across all target models, highlighting its effectiveness.
6 Limitation
Although our proposed method accommodates a diverse range of target models through its SoFT-trained sub-models for token prediction, it introduces sub-model thresholds as a new hyperparameter that requires tuning. Nonetheless, this requirement is considerably much simpler to undertake compared to the alternative approaches that involve training separate draft models for each target. However, based on our experiments larger thresholds work better with larger target models and smaller thresholds should be used with smaller target models
Additionally, this paper primarily focuses on a specific setting where a draft model is trained using SoFT with three sub-models. However, exploring a different number of sub-models from different layers could offer deeper insights into our methodology. We identify these comparative studies as potential future work.
References
- Ankner et al. (2024) Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan-Kelley, and William Brandon. 2024. Hydra: Sequentially-dependent draft heads for medusa decoding. arXiv preprint arXiv:2402.05109.
- Anthropic (2024) Anthropic. 2024. Model card claude 3. https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Cai et al. (2024) Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple llm inference acceleration framework with multiple decoding heads. arXiv preprint arXiv:2401.10774.
- Chataoui et al. (2023) Joud Chataoui, Mark Coates, et al. 2023. Jointly-learned exit and inference for a dynamic neural network. In The Twelfth International Conference on Learning Representations.
- Chen et al. (2023a) Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023a. Accelerating large language model decoding with speculative sampling. arXiv preprint arXiv:2302.01318.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Chen et al. (2023b) Ziyi Chen, Xiaocong Yang, Jiacheng Lin, Chenkai Sun, Jie Huang, and Kevin Chen-Chuan Chang. 2023b. Cascade speculative drafting for even faster llm inference. arXiv preprint arXiv:2312.11462.
- Elhoushi et al. (2024) Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, et al. 2024. Layer skip: Enabling early exit inference and self-speculative decoding. arXiv preprint arXiv:2404.16710.
- Fu et al. (2024) Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. 2024. Break the sequential dependency of llm inference using lookahead decoding. arXiv preprint arXiv:2402.02057.
- He et al. (2023) Zhenyu He, Zexuan Zhong, Tianle Cai, Jason D Lee, and Di He. 2023. Rest: Retrieval-based speculative decoding. arXiv preprint arXiv:2311.08252.
- Kavehzadeh et al. (2024) Parsa Kavehzadeh, Mojtaba Valipour, Marzieh Tahaei, Ali Ghodsi, Boxing Chen, and Mehdi Rezagholizadeh. 2024. Sorted llama: Unlocking the potential of intermediate layers of large language models for dynamic inference. In Findings of the Association for Computational Linguistics: EACL 2024, pages 2129–2145.
- Leviathan et al. (2023a) Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023a. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR.
- Leviathan et al. (2023b) Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023b. Fast Inference from Transformers via Speculative Decoding. arXiv preprint. ArXiv:2211.17192 [cs].
- Li et al. (2024) Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. Eagle: Speculative sampling requires rethinking feature uncertainty. arXiv preprint arXiv:2401.15077.
- Liu et al. (2024) An Liu, Zonghan Yang, Zhenhe Zhang, Qingyuan Hu, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. 2024. Panda: Preference adaptation for enhancing domain-specific abilities of llms. arXiv preprint arXiv:2402.12835.
- Liu et al. (2023) Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Ion Stoica, Zhijie Deng, Alvin Cheung, and Hao Zhang. 2023. Online speculative decoding. arXiv preprint arXiv:2310.07177.
- Men et al. (2024) Xin Men, Mingyu Xu, Qingyu Zhang, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, and Weipeng Chen. 2024. Shortgpt: Layers in large language models are more redundant than you expect. arXiv preprint arXiv:2403.03853.
- Miao et al. (2023) Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. 2023. Specinfer: Accelerating generative llm serving with speculative inference and token tree verification. arXiv preprint arXiv:2305.09781, 1(2):4.
- Narayanan et al. (2021) Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. 2021. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–15.
- Stern et al. (2018) Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. 2018. Blockwise parallel decoding for deep autoregressive models. Advances in Neural Information Processing Systems, 31.
- Sun et al. (2021) Xin Sun, Tao Ge, Furu Wei, and Houfeng Wang. 2021. Instantaneous grammatical error correction with shallow aggressive decoding. arXiv preprint arXiv:2106.04970.
- Sun et al. (2023) Ziteng Sun, Ananda Theertha Suresh, Jae Hun Ro, Ahmad Beirami, Himanshu Jain, and Felix Yu. 2023. Spectr: Fast speculative decoding via optimal transport. In Advances in Neural Information Processing Systems, volume 36, pages 30222–30242. Curran Associates, Inc.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023. Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7.
- Team et al. (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Valipour et al. (2023) Mojtaba Valipour, Mehdi Rezagholizadeh, Hossein Rajabzadeh, Marzieh Tahaei, Boxing Chen, and Ali Ghodsi. 2023. Sortednet, a place for every network and every network in its place: Towards a generalized solution for training many-in-one neural networks. arXiv preprint arXiv:2309.00255.
- Varshney et al. (2023) Neeraj Varshney, Agneet Chatterjee, Mihir Parmar, and Chitta Baral. 2023. Accelerating llama inference by enabling intermediate layer decoding via instruction tuning with lite. Preprint, arXiv:2310.18581.
- Xia et al. (2023) Heming Xia, Tao Ge, Peiyi Wang, Si-Qing Chen, Furu Wei, and Zhifang Sui. 2023. Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3909–3925.
- Xia et al. (2022) Heming Xia, Tao Ge, Furu Wei, and Zhifang Sui. 2022. Lossless speedup of autoregressive translation with generalized aggressive decoding. arXiv preprint arXiv:2203.16487.
- Xia et al. (2024) Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. 2024. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding. arXiv preprint arXiv:2401.07851.
- Yi et al. (2024) Hanling Yi, Feng Lin, Hongbin Li, Peiyang Ning, Xiaotian Yu, and Rong Xiao. 2024. Generation meets verification: Accelerating large language model inference with smart parallel auto-correct decoding. arXiv preprint arXiv:2402.11809.
- Zhang et al. (2023a) Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. 2023a. Draft & verify: Lossless large language model acceleration via self-speculative decoding. arXiv preprint arXiv:2309.08168.
- Zhang et al. (2023b) Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. 2023b. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Preprint, arXiv:2306.14048.
- Zheng et al. (2024) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. 2024. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36.
- Zhong and Bharadwaj (2024) Wei Zhong and Manasa Bharadwaj. 2024. S3d: A simple and cost-effective self-speculative decoding scheme for low-memory gpus. arXiv preprint arXiv:2405.20314.
7 Appendix
7.1 Hyperparameters
The batch size during the ShareGPT training experiments (SFT and SoFT) was 8 and gradient accumulation steps was set to 16. We used 4 NVIDIA V100 GPUs for training experiments. Each inference experiment on Spec-bench was done on 2 NVIDIA V100 GPUs, except the experiments for LLaMA Chat 70b where we used 8 GPUs to avoid memory issues.
7.2 Spec-bench Results
Figure 4 shows the speedup ratios of S2D versus speculative decoding with different draft options, including Vicuna 160m pre-trained. As S2D demonstrate superior performance than speculative decoding with the same size draft models (12 layers) in smaller target sizes (Vicuna 7B and 13B), once we get to larger target sizes, larger drafts outperform smaller ones (Layer 6 and 9) in speculative decoding algorithm. This can demonstrate the importance of capacity and accepted tokens length in larger target sizes. However, S2D can maintain a similar performance to speculative decoding with the same draft size even in case of using a target with 70B size.