Rotating labeling of entropy coders for synthetic DNA data storage
Abstract
Over the past years, the ever-growing trend on data storage demand, has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are considered as potential candidates for a new storage paradigm. Because of this trend, several coding solutions have been proposed over the past years for the storage of digital information into DNA. Despite being a promising solution, DNA storage faces two major obstacles: the large cost of synthesis and the noise introduced during sequencing. Additionally, this noise increases when biochemically defined coding constraints are not respected: avoiding homopolymers and patterns, as well as balancing the GC content. This paper describes a novel entropy coder which can be embedded to any block-based image-coding schema and aims to robustify the decoded results. Our proposed solution introduces variability in the generated quaternary streams, reduces the amount of homopolymers and repeated patterns to reduce the probability of errors occurring. While constraining the code to better satisfy the constraints would degrade the compression efficiency, in this work, we propose an alternative method to further robustify an already-existing code without affecting the compression rate. To this end, we integrate the proposed entropy coder into four existing JPEG-inspired DNA coders. We then evaluate the quality —in terms of biochemical constraints— of the encoded data for all the different methods by providing specific evaluation metrics.
I Introduction
Images represent a big percentage of the data stored in data centers and a large majority of these images is considered as “cold” (very infrequently accessed). For that reason, it is crucial to develop image coders that have a good compression performance and are adapted to the problematics inherent to DNA data storage. Over the past years, some coders [1, 2, 3], were developed to encode data into DNA. An international JPEG standardization group, JPEG DNA, was formed in 2020 to address the problem of standardizing the coding of still images on molecular media, with a standard expected in 2025. In this paper, we present a novel block-based coding solution for DNA data storage. We then integrate it in different image codecs for synthetic DNA data storage, all inspired by the legacy JPEG algorithm.
In section II we introduce some concepts around DNA data storage as well as the existing JPEG-inspired codecs proposed to address this new field of research. Section III explains the interest of further robustifying entropy coders against sequencing errors. The proposed block-based coding scheme is then explained while proving it does not deteriorate the compression of the original method. The coding scheme is then integrated into some existing JPEG-based image codecs presented in section II. Finally, in section IV-B and IV-C the paper shows performance results. We experimentally show that the modified codecs don’t loose any performance in compression, and statistically analyse the quality of the encoded data with regards to the DNA coding constraints. The modified codecs have a better GC-content than the original ones and the long homopolymers have been removed from the generated oligos.
II Context
II-A DNA data storage
Today, the digital world relies on increasingly large amounts of data, stored over periods of time ranging from a few years to several centuries. With current storage media reaching its density limit and the exponential growth of digital information, the search for a new storage paradigm has become of utmost importance. One of the most promising candidates up to this date is to store information in the form of DNA molecules, which provide very dense storage (1 ) that is also stable over long periods if stored under the right conditions [4].
The process of DNA data storage starts by encoding data into a quaternary stream composed by the four DNA symbols or nucleotides (A, C, T, and G). The encoded data is then physically synthesised into DNA strands (oligos) that are then stored into a safe environment. When data has to be read back, the stored molecules are amplified so as to obtain many copies of each original sequence and the content is deciphered using DNA sequencers. This data is then decoded back into the form of the original binary file. However, the biochemical processes involved in the above end-to-end storage process introduce some coding constraints [1] that, if not respected, dramatically increase the probability of an error occurring (insertion, deletion and/or substitution). These constraints comprise avoiding homopolymers (i.e. use of the same symbol more than 3 consecutive times), repetition of patterns and unbalanced GC content.
Algorithms specifically designed for DNA data storage which respect the biochemical constraints generally show better reliability [2]. Although constrained coding helps reducing the apparition of errors, it does not ensure an error free coding. To tackle the problems of errors, an important number of researchers [5, 6, 7] are currently studying the development of accurate error models for synthetic DNA data storage. Furthermore, since the cost of DNA synthesis is relatively high, it is also important to take advantage of optimal compression, which can be achieved before synthesizing the sequence into DNA. To decrease the synthesis cost of image storage into DNA, several works have been using the so-called “transcoding” method which is based on classical compression protocols such as JPEG for reducing the image redundancies, then encoding each byte of the produced bitstream into DNA words. However, it is clear that such a compression schema is sub-optimal as the compression is optimised with respect to a binary code and therefore it is not adapted to the quaternary nature of DNA. To tackle the above issue, among other relevant works, in [8] the authors proposed a specific image coding algorithm, adapted to the needs of DNA data storage, that efficiently encodes images into a quaternary constrained code.
II-B JPEG-inspired coding methods
All the JPEG-inspired coding methods described here are based on [8], whose workflow is described in Fig. 1.
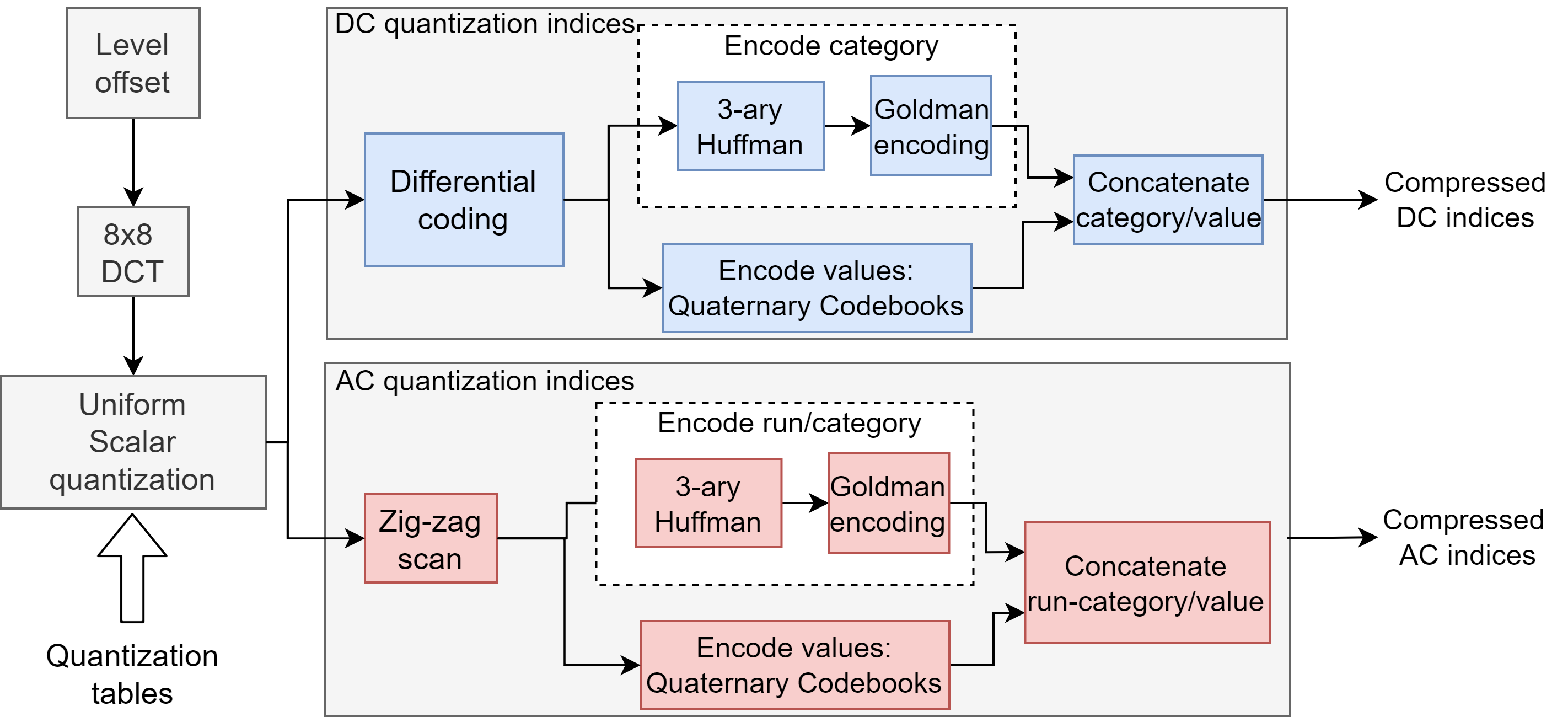
II-B1 Principle
The main principle of these coders is to encode a sequence of DCT coefficients into DNA using a combination of an entropy and a fixed-length constrained coder. The coders are constrained so as to be as compliant as possible with regards to the biochemical constraints. The run/category is encoded with the entropy coder and the value with the fixed-length coder (see [8]).
II-B2 Entropy coders
Entropy coding methods are variable-length lossless coding methods which encode the source data thanks to a code — a set of codewords — generated from a frequency table representing the number of appearances of every symbol in the source. The length of the codewords representing every symbol varies according to the probability of their appearance: frequently appearing symbols are associated to shorted codewords while the less frequent ones are assigned to longer codewords. There are two possible entropy coders that can be used to encode the run/category of the coefficients: Huffman/Goldman [2] and the Shannon Fano based constrained coder we proposed in [10]. The latter is more performant in terms of compression rate.
II-B3 Source type
When one encodes an image into DNA with a JPEG-inspired algorithm, there are two possibilities. If the input of the algorithm is a raw image, the algorithm computes the DCT coefficients and then encodes them [8] into DNA. This encoding paradigm is called source coding. Otherwise, the input of the coding algorithm can be an already compressed JPEG binary file. In this case, the bitstream is decoded to obtain the sequence of DCT coefficients that will then be encoded into DNA [11]. We will refer to this paradigm as transcoding.
III Coding solution
III-A Motivation
The principle of the novel coding solution is to avoid using the same code — set of codewords — consecutively to avoid creating patterns or homopolymers. In the case where a symbol is very frequently found in the source, due to its high probability, the entropy coder will associate a short codeword to it, which in extreme cases can lead to a codeword consisting of one nucleotide. If this symbol is repeated consecutively in the source, it will create a homopolymer. Figure 3 represents this case. If the symbol is a bit less frequent, the entropy coder will associate a codeword of length two or three to this symbol, and when a repetition of this symbol will occur, a short pattern will be created, also violating the defined biochemical constraints. A real example of these phenomenon can be found when encoding images into DNA with a JPEG-inspired algorithm at very high compression rates, like shown in Fig.2.


III-B Principle
In order to avoid these homopolymers and repetitions of patterns, we propose to introduce variability in the generated quaternary streams by generating several equally peformant codes and alternating between them during encoding. Thus, since the symbols will not always be associated to the same codewords, we reduce the risk of creating homopolymers when very frequent symbols are heavily repeated in the source.
An entropic code is mapped to three associated entropic codes , and , with three mapping functions , and described in Algorithms 1 and 2 and defined as:
The code used to encode the symbols can be changed periodically. When the source is a simple sequence of symbols (i.e. non block-based), one can change the code after having encoded a fixed amount of symbols, for example every six symbols like the solution presented in Fig. 4.
This novel encoding method relies on two important processes that will be further explained in the following sections: the generation of the different codes that can be used to encode the symbols, and the decision of which code to use. Both processes have to respect some prerequisites to make the whole encoding method a viable solution. First, the proposed coding method will improve the robustness of the encoding through tougher consideration of the biochemical constraints, without affecting the compression performance of the original coder. To ensure decodability, this decision has to be deterministic, otherwise, additional data would have to be transmitted to make sure the decoder can decode the data.
Overall, the proposed solution is very well adapted to block-based encoding methods like for example JPEG-inspired algorithms. More specifically in this work, codes are rotated after encoding a block. The order of encoding of the blocks is organized one line of blocks after another. In addition, to avoid error propagation, the code decision process is reinitialised after the encoding of a full line of blocks as shown in Fig. 7.

III-C Codes construction
The codes construction process is described in Algorithms 1 and 2. The general idea is based on using an already existing codec and the associated quaternary code. From this pre-defined code, we will build three associated codes by mapping all the nucleotides in the original codewords to new ones according to a mapping rule as described in Algorithm 2. The results of the construction algorithm is a list of four codes that can be used in the novel solution. As proven by Proposition 1, the performance of the resulting coding solution is not affected by the introduction of the new coding method in comparison to the original coder.
Definitions.
-
•
S the source of length n
-
•
the source S alphabet,
-
•
the set of nucleotides
-
•
the original quaternary coder used to encode
-
•
the code of
-
•
the novel quaternary coder
-
•
the code of
Proposition 1.
,
and have the same compression rate.
Proof.
Trivially,
III-D Code choice
For the proposed coding solution, it is possible to choose between four codes to encode a fragment of the source. We propose two possible decision processes to determine the order in which the different codes will be used. The first possible case is very simple: we iterate through the four possible codes one by one, and start over. The second possible decision process is a pseudo-random choice, where the encoder and the decoder have a common seed for the pseudo-random generator. Introducing variability in the coding methods will result in a less structured quaternary stream, which is beneficial for our encoding process (less patterns and homopolymers, more balanced data for the GC content).

import random
def choose_random_codebook(codebook_candidates):
seed(k)
while True:
i = randint(0, 3)
yield codebook_candidates[i%4]
III-E Integration in a block-based coder
In the case of block-based coders like the JPEG-inspired codecs, we can change the selected code every time we encode a new block. When the input of the block-based codec is an image, we can reduce the propagation of errors by reinitializing the decision process every time we start to encode a new line of blocks. Fig. 7 represents possible rotation schemes for a block-based image coding method. Every color represents the choice of a different code.

(a) Simple rotation

(b) Pseudo-random rotation
III-F About the fixed-length coders
An important question to address about the proposed coder is why would we limit its usage only to variable-length coders. For example, the JPEG-inspired codecs don’t exclusively use a variable-length coder, they also use a fixed-length coder. Ideally, using this method on any type of coder would improve the quality of the quaternary stream. But since a fixed-length coder is source independent, it can be pre-generated in a way to consider the constraints much more thoroughly. In such codes, specific codewords can be eliminated being considered as slightly problematic. If we rotated the letters similarly to variable-length coders, such problematic codewords would sometimes be created, losing all the quality gathered in this pre-generated code.
IV Performance results
IV-A Nomenclature
For clarity, in the following sub-sections, the different methods will be named in the following logic:
JPEGDNA-${entropy coder id}-${source id}[-${rotation id}]
The entropy coder id can be HG if the method uses the Huffman/Goldman coder or SFC4 if it uses the Shannon Fano Constrained coder. The source id can be S when the source is a raw image, or T when it is a already JPEG compressed binary file. For example, JPEGDNA-HG-S is the codec that encodes a raw image where the Huffman/Goldman coder encodes the run/category. The rotation id is optionnal and can be either R or RR. The first describes a regular rotation scheme and the latter a pseudo-random rotation. Both rotations will be described in III-D. For example, the codec JPEG-DNA-HG-S-R is the equivalent of the latter but with a rotative labelling on the Huffman/Goldman coder.
IV-B Compression performance
As previously shown in subsection III-C, the introduction of the new coding method does not have any effect on the coding performance in comparison to the original method. However, this property has only been proven specifically for the rotating codes, and not for the codecs in which this new method is integrated. But since we only modify the variable-length coder and not the rest of the compressed stream in those JPEG-inspired coding methods, the compression rate of the general coding algorithm remains the same. The rate-distorsion curves in Fig. 8 illustrate this: the curves for the original algorithms and the modified ones are superimposed. The performance results shown in Fig. 8 have been computed on the first image of the Kodak dataset111https://r0k.us/graphics/kodak/, kodim01.

(a) JPEG-HG-S

(b) JPEG-HG-T
IV-C Oligo quality assessment

IV-C1 Approach
Respecting the biochemical constraints of DNA data storage is crucial for the end-to-end storage. This is reflected in Fig. 2, where, due to the apparition of very long homopolymers, the obtained oligos are unusable. In comparison, the same oligos obtained for the same compression rate with the modified method of the algorithm, shown in Fig. 9 are much more acceptable from the biochemical perspective. Since a visual verification is not enough to assess the quality of the generated oligos, we further introduce some oligo quality analysis and visualization tools that were, to our knowledge, lacking in the field of DNA data storage.
IV-C2 Software for quality assessment
The proposed analysis and visualization tools are available in a public repository222https://github.com/jpegdna-mediacoding/OligoAnalyzer. These tools inlude general statistics about the coded data (number of homopolymer in the oligo pool, average size of the homopolymers, average GC content, proportion of oligos with problematic GC content) as well as histograms describing with more details the ill cases. To our knowledge, in past research [7] , gathering statistics to measure the quality of oligos have never been presented in depth, especially for the case of homopolymers.
IV-C3 GC content

The distribution of the GC content of the oligos has been evaluated. We consider all the oligos with a GC content below 30% or above 60% to be problematic. In these regards, as presented in Fig. 10, the novel methods (JPEGDNA-HG-S-R, JPEGDNA-HG-S-RR, JPEGDNA-HG-T-R, JPEGDNA-HG-T-RR) show great improvement over the original ones.
IV-C4 Homopolymers
For every oligo, we have computed the average length of homopolymer runs. At high compression rates, the homopolymer length deteriorates quickly and some oligos have homopolymers of a size greater than ten, which is extremely problematic, as shown in Fig. 11. Even though the novel methods still produce some homopolymers, their average size per oligo does not exceed the length of five nucleotides, which is a very important gain for the robustness of the decoded result. Moreover, the number of homopolymers and their average size over the whole oligo pool also decreased as shown in Table I, where is the number of homopolymers in the data, the average size of the homopolymers and the maximum size of the homopolymers. The pseudo-random rotation slightly underperforms in terms of length of homopolymer runs in the compressed data. This is due to the fact that in some cases, the code decision process will pick the same code several times in a row, allowing the apparition of more homopolymers. The SFC4-based [10] coders also underperform, since they were designed to relax the homopolymer constraint in comparison to Huffman/Goldman.

| HG-S | HG-S-R | HG-S-RR | SFC4-S | SFC4-S-R | SFC4-S-RR | |
|---|---|---|---|---|---|---|
| N | 756 | 64 | 291 | 939 | 411 | 644 |
| Avg | 10.68 | 4.11 | 4.14 | 9.38 | 4.18 | 4.20 |
| Max | 67 | 5 | 5 | 57 | 6 | 7 |
V Conclusion
In this paper, we have proposed a novel coding method adapted to DNA data storage that introduces variability in the generated quaternary streams. The main asset of the proposed encoding algorithm lies in its ability to tackle some of the challenges that are met when designing coders for DNA data storage, namely the respect of biochemical constraints. Results show that the generated oligos contain less homopolymer runs while the remaining ones present a greatly reduced size. Moreover, results show improvements on the GC content, limiting it between 30% and 60%. The improvements were more significant at lower bit-rates, where the original coding algorithms severely underperformed with regards to the biochemical constraints. Additionally, thanks to its design, integrating the proposed coding solution in block-based image codecs does not affect the compression rate of the original solution.
References
- [1] G. M. Church, Y. Gao, and S. Kosuri, “Next-generation digital information storage in dna,” Science, vol. 337, no. 6102, pp. 1628–1628, 2012.
- [2] N. Goldman, P. Bertone, and S. Chen, “Towards practical, high-capacity, low-maintenance information storage in synthesized dna,” Nature, 2013.
- [3] M. Welzel, P. M. Schwarz, H. F. Löchel, T. Kabdullayeva, S. Clemens, A. Becker, B. Freisleben, and D. Heider, “Dna-aeon provides flexible arithmetic coding for constraint adherence and error correction in dna storage,” Nature Communications, 2023.
- [4] S. M. H. T. Yazdi, R. Gabrys, and O. Milenkovic, “Portable and error-free dna-based data storage,” Nature, 2017.
- [5] M. Schwarz, M. Welzel, T. Kabdullayeva, A. Becker, B. Freisleben, and D. Heider, “Mesa: automated assessment of synthetic dna fragments and simulation of dna synthesis, storage, sequencing and pcr errors,” Bioinformatics, vol. 36, pp. 3322–3326, 2020.
- [6] J. J. Alnasir, T. Heinis, and L. Carteron, “Dna storage error simulator: A tool for simulating errors in synthesis, storage, pcr and sequencing.”
- [7] C. Ezekannagha, M. Welzel, D. Heider, and G. Hattab, “Dnasmart: Multiple attribute ranking tool for dna data storage systems,” Computational and Structural Biotechnology Journal, vol. 21, 2023.
- [8] M. Dimopoulou, M. Antonini, P. Barbry, and R. Appuswamy, “A biologically constrained encoding solution for long-term storage of images onto synthetic dna,” European Signal Processing Conference (EUSIPCO), 2019.
- [9] ISO/IEC JTC 1/SC29/WG1 N100395, “Common test Conditions for JPEG DNA,” 98th JPEG Meeting, 2023. [Online]. Available: {https://ds.jpeg.org/documents/jpegdna/wg1n100395-098-ICQ-CTC_for_JPEG_DNA.pdf}
- [10] X. Pic and M. Antonini, “A constrained shannon-fano entropy coder for image storage in synthetic dna,” European Signal Processing Conference (EUSIPCO), 2022.
- [11] L. Secilmis, M. Testolina, D. Nachtigall Lazzarotto, and T. Ebrahimi, “Towards effective visual information storage on dna support,” Applications of Digital Image Processinf XLV, 2022.
{kind=link}