RoomDesigner: Encoding Anchor-latents for Style-consistent and Shape-compatible Indoor Scene Generation
Abstract
Indoor scene generation aims at creating shape-compatible, style-consistent furniture arrangements within a spatially reasonable layout. However, most existing approaches primarily focus on generating plausible furniture layouts without incorporating specific details related to individual furniture pieces. To address this limitation, we propose a two-stage model integrating shape priors into the indoor scene generation by encoding furniture as anchor latent representations. In the first stage, we employ discrete vector quantization to encode furniture pieces as anchor-latents. Based on the anchor-latents representation, the shape and location information of the furniture was characterized by a concatenation of location, size, orientation, class, and our anchor latent. In the second stage, we leverage a transformer model to predict indoor scenes autoregressively. Thanks to incorporating the proposed anchor-latents representations, our generative model produces shape-compatible and style-consistent furniture arrangements and synthesis furniture in diverse shapes. Furthermore, our method facilitates various human interaction applications, such as style-consistent scene completion, object mismatch correction, and controllable object-level editing. Experimental results on the 3D-Front dataset demonstrate that our approach can generate more consistent and compatible indoor scenes compared to existing methods, even without shape retrieval. Additionally, extensive ablation studies confirm the effectiveness of our design choices in the indoor scene generation model.
1 Introduction

The automated generation of physically-plausible 3D indoor scenes is a challenging but important task in 3D vision. The capacity to digitally create immersive indoor environments holds immense potential across diverse industries, spanning gaming, architecture, virtual reality, simulation, and robotics. The scene generation process can be divided into two subproblems. The first one is to generate a plausible layout of the given scene. The second one is to obtain the style-consistent and shape-compatible furniture to decorate the indoor scene by following the generated layout.
Lots of efforts have been made to generate physically-plausible indoor scenes [55, 54, 35, 34, 41]. Conventional scene synthesis methods [29, 56, 3, 5, 12, 13, 16] rely on predefined rules as constraints to guide the optimization process to achieve a reasonable synthesis result, but the design of rules highly depends on the knowledge from experts, which are not scalable. Recent advances in deep generative learning enable the synthesis of realistic indoor scene layouts [44, 26, 45, 48, 61, 37, 55, 54, 35, 34, 41] without reliance on predefined rules. Specifically, most of these works first use a deep generative model to predict the layout of 3D/2D bounding boxes for the furniture elements within the scene, by leveraging GAN [54], VAE [37, 55, 45, 44], Autoregressive [48, 34, 35] or Diffusion model [41]. Subsequently, the most suitable furniture shapes from a predefined CAD library are retrieved based on the predicted sizes of the bounding boxes. Since the geometry and structure of furniture are complex, the commonly defined furniture parameters, including the size, color, translation, and rotation, are not sensitive to the furniture geometry and structure, consequently, directly retrieving the closest size furniture from the CAD library may lead to shape-incompatible and style-inconsistency issues with other furniture elements in the scene, for example, the chairs around the same table are not style consistent with each other, or the chair partially occupied the same space with the table (see the Fig. 3 in the experiments). Further, the retrieval-based solution cannot generate novel shapes because of the constraint of the pre-defined CAD library. To avoid this issue, a very recent work [18] proposes to use the part-level embedding combined with a graph representation to model the geometry and structure of furniture in the scene. However, their work highly relies on the part-level annotation of objects, which is usually unavailable, consequently restricting the application of these approaches on large-scale dataset like 3D-Front dataset [14, 15].
In light of the recent successes in high-quality 3D shape generation [23, 58, 62, 60, 63], we propose to generate both scene layout and 3D furniture shapes, simultaneously. Towards this end, a suitable shape representation that captures both the global structure and the local geometry details of the furniture is highly demanded. Besides, the shape representation should be easily scaled up to the scene level, which is composed of many different pieces of furniture. Inspired by the recent works [59, 11], we propose a hybrid representation for scene generation, where we use anchor points sampled from the dense point clouds for the global structure representation, which is computatinally efficient. We further propose to extract the local latent features of the anchor points by the VQ-VAE [59], which encodes the surface points sampled from discrete mesh into the latent representation. Therefore, the latent representation of the anchor points contains detailed information. Then we leverage a decoder to decode our latent anchor representation into an occupancy field. With the local latent features, the anchor-points can generate a smooth surface and provide the geometry details.
We parameterize the furniture with the anchor-latents, spatial location, size, rotation, and category. Since auto-regressive modeling with a transformer is the most straightforward way to make the furniture generation conditional on all previous furniture existing in the scene. We then learn a transformer-based architecture to model the process of scene generation as the next-token prediction within an unordered set. The parameters of each piece of furniture in the scene are designed to be both geometry- and structure-aware, allowing for a comprehensive understanding of the objects’ spatial characteristics. As a result, our approach has demonstrated significant improvements in style consistency and shape compatibility among the generated furniture items. Our proposed geometry and structure-aware anchor-latents not only improve the room-mask-conditioned scene generation but also benefit a lot of human interaction applications that should take geometry into consideration, such as style-consistent scene completion, furniture mismatch correction, and controllable object-level scene editing. Furthermore, the introduced anchor-latents facilitate geometry generation modeling, empowering our model to generate novel shapes for each furniture category. Extensive experiments show that our method achieves compelling results in the room-mask conditional generation settings against state-of-the-art scene generation models.
Our contributions can be summarized as follows:
-
•
We introduce the anchor-latents to encode the geometry and structure of each piece of furniture to achieve consistent and compatible indoor scene generation without any part-level annotations.
-
•
Based on the proposed anchor-latents, we learn a geometry-aware scene generation transformer. It cannot only enable style-consistent and shape-compatible but also facilitates downstream tasks such as style-consistent scene completion, object mismatch correction, and controllable object-level scene editing.
2 Related Work
Indoor scene generation. Most existing Indoor scene synthesis methods can be divided into two main different parts. On the one hand, traditional scene synthesis methods [29, 56, 3, 5, 12, 13, 16] mainly rely on human-defined constraints as scene priors to guide the optimization process. While these works can produce some reasonable results, the results of such methods are limited to simple patterns. On the other hand, recent advances in deep generative learning [44, 26, 45, 48, 61, 37, 55, 54, 35, 34, 41, 1, 50] has greatly facilitated the indoor scene synthesis. These work explore different modeling such as VAEs [44, 26, 45, 37, 55], GANs [54, 1, 50], Autoregressive [35, 34, 48] and Diffusion model for scene synthesis. Closely related to our work are autoregressive indoor scene generation models [44, 45, 35, 34, 48]. ATISS[35] propose an unordered set representation for auto-regressive scene synthesis. Each piece of furniture is represented as the category, location, orientation, and size in their work. This can achieve a more robust scene-generation process. However, it is still not sensitive to furniture shape. Scene Priors [34] inject the shape embedding for each piece of furniture in their model. They defined a template mesh [46] for each piece of furniture and predicted the deformation for the template vertex of each piece of furniture. The optimization process was achieved through differentiable rendering [25] using multiview images. Due to the limited topology of the template mesh, it cannot directly decode reasonable shapes. Some works[1, 50] explore volume rendering[32] for scene synthesis supervised by multiview images. However, this line of work can not produce high-quality geometry for each piece of furniture. Most recently, SceneHGN [18] proposed to use a hierarchical VAE to encode the scene at part-level. It can produce a reasonable shape for each piece of furniture, but their method highly relies on part-level annotation.
3D shape representation. 3D shape representation has been explored for many years [8, 49, 60, 33, 32, 9, 30, 36, 17, 20, 39, 28, 59, 27, 51, 52]. Representing the 3D Shape [41] into a 1d-vector is compact but may lead to the lack of geometry details. Recently, OccNet [31] proposed to use a dense feature voxel to represent the 3d shape. While the dense voxel is too dense, some other works [36, 20, 2, 17] propose to decompose the 3d voxel into a tri-plane representation, where the complexity efficiency can be reduced. Some other interesting works propose to decompose the 3D feature volume into a low-rank [6, 19] representation. All the existing local representation is computationally expensive, the expensive computation makes them hard to scale up to the scene level. Some works [33, 30, 27, 51] propose to encode the shape as a single latent vector, which can provide high-level structure information. But the global representation is insufficient to capture the geometry details. It is desirable to represent the scene with both global structure and local details. Due to the sparse nature of 3D shapes themselves, another line of work proposes to use the irregular latent fields [53, 59] to represent each shape in a more efficient way. Inspired by this previous line of work, we propose anchor-latents representation for scene generation task.
3 Method
To generate shape-compatibility and style-consistency furniture within a room mask obtained from a top-view perspective projection from an empty or partially decorated room, we devise an anchor-latent representation and a geometry-aware scene generator. The generator captures the geometry information of the furniture benefiting from the anchor-based latent representation. It then autoregressively predicts shape-compatible and style-consistent furniture by injecting location information from the furniture.
Specifically, our proposed two-stage generative model consists of two modules, a Vector Quantised-Variational AutoEncoder (VQ-VAE) for representing the furniture into anchor-latents representation (see Section 3.1) and a geometry-aware transformer that produces indoor scenes autoregressively, which composes with a scene generation transformer followed by a shape generation branch based on the proposed anchor-latents (see Section 3.2).

3.1 Anchor-latents representation
It is challenging to achieve learning-friendly 3D shape representation due to its high-dimensional nature. Especially in scene composition modeling, since a scene may be composed of more than ten objects. Traditional shape representation methods [36, 30] are still too dense to represent the shape. To make the learning of 3D shape distributions in an efficient way while also keeping its geometry information in this representation, we compress each piece of furniture into the anchor-latent representation. It is composed of a set of anchor points and its corresponding latents , where is the number of anchor points and is the feature channel dimension. Compared with the previous shape representation method, such a representation is more lightweight. It can also preserve high-quality geometry information in it. We achieve this anchor-latents encoding by training a Furniture VQ-VAE [11, 59] for occupancy fileds, as shown in Fig. 2
Anchor-point extraction. Specifically, given a watertight mesh , we random sample =2048 points from its surface. The goal of this stage is to predict the occupancy indicator from the randomly sampled points. To build the anchor-latens representation, We first use FPS (Farthest Point Sampling) to get the anchor points.
Anchor-feature extraction. With the point set as center points, we use -NN () to get -1 nearest neighbor points from the initial N surface points for each anchor point to form a local patch . We then feed each local patch and anchor-points into a VQ-VAE Encoder to extract the anchor-feature
| (1) |
We then use the vector quantization [42] to translate the into from a codebook (),
| (2) |
To optimize the anchor-latents , we feed them into a transformer-based decoder to get the occupancy fields feature. To get the final occupancy prediction, we feed the anchor-latents into a decoder to get the Occupancy feature for each query point . We calculate the interpolated feature based on the distance between query point and our anchor points . Finally, the interpolated feature was fed into an MLP to get the occupancy prediction .
The anchor-latents learning stage is supervised by comparing the predicted occupancy to the ground truth occupancy for the query points with a binary cross entropy loss. An additional commitment loss is used to regularize the codebook. The overall loss for this stage is:
| (3) |
| (4) |
| (5) |
3.2 Autoregressive Shape-aware Scene Generation
After obtaining the anchor-latents of each object, we feed the shape anchor-latents and the bounding box locations into a Scene Generation transformer. The generation process is achieved by Auto-regressive modeling, as shown in the second stage of Fig. 2.
Auto-regressive scene generation modeling. The scene is composed of floor plan and objects , where L is the number of objects in the scene. Given a floor plan for a scene , our goal is to generate shape-compatible and style-consistent objects . We parameterize the object as a concatenation of category , size , rotation , translation and our introduced anchor-latents . Our goal is to model the distribution over scene , which can be written as
| (6) |
where is the probability of the -th object, conditioned on the previously generated objects and the floor layout, and is a permutation operator. The objective is to maximize the log-likelihood of this function.
| (7) |
In order to make our model invariant to the order of generated objects, we follow [35] to apply permutations on the object sequence during training. This can facilitate a lot of downstream tasks, such as scene completion.
Floor-plan Encoder. The 2D room mask for the scene shape is encoded with a ResNet-18 [21]. The encoded feature provides information to guide the model in predicting a reasonable location of the furniture in an empty space of the room.
Bounding Box Encoder. We encoded the category of each bounding box using a learnable embedding . A positional encoding [43] is used for the translation , rotation and size .
| (8) |
Anchor-latents Encoder. For each object, we have anchor-latents as , as described in Sec.3.1. However, the dimension of the anchor-latents, = (here ), is still too high to be directly injected with the bounding boxes tokens. For more efficiency, we use the quantized index of each anchor feature in the codebook to represent the feature from our codebook. Therefore, the total dimension for shape embedding can be reduced to . For each anchor in the anchor groups, we directly map them with a positional encoding to map them as , where T is the embedding dimension of positional embedding, then a learnable embedding is used to embed it into a 1D vector .
| (9) |
We then concatenate the with the bounding box embedding to get the per furniture parameters .
Scene Generation Transformer. We feed the room-mask feature , per-furniture context embeddings , and a query embedding into the scene transformer encoder. It predicts the furniture features for the subsequent object generation.
| (10) |
Bounding boxes attribute extractor. For bounding boxes attribute distribution decoding from , we follow the same design from ATISS [35]. To be more specific, we employ an MLP for each attribute in a sequential manner. That is, given , we first predict the category label . Then we predict the following attribute , , , sequentially. The predicted previous attribute will be concatenated with the for the next attribute prediction. This means that the next attributed prediction is based on the previous attributed prediction results. Based on this property, we can extend the shape model as shape generation in a similar way.
Shape generation Transformer. After bounding boxes attribute prediction, we can get a concatenate of predicted attribute , we generate the anchor-latens for the next object conditional on all these predicted attributes. We use a transformer to achieve anchor-latents autoregressively generation. Thanks to the modeling of the distribution of anchor points, our shape branch can be easily extended to object-level editing by controlling these anchor points. Specifically, we predict anchor-latents, sequentially. These latents are re-ordered in ascending order by anchor-points coordinates. This can ensure our generation process follows a specific order. Speacifically, the anchor-latents is conditional on all previous prediction anchor-latents This anchor distribution can be written as:
| (11) |
3.3 Training
To train our model, We randomly select -1 object in a scene and apply a random permutation to it. We first use the room mask Encoder to get the room mask feature . We then use the bounding box encoder and anchor-latents encoder to get the corresponding embedding of the pieces of furniture . We then feed them into the scene generation transformer to get the prediction token for the next object . This is conditional on the information from both room layout and previous m bounding boxes and furniture geometry. We feed the in bounding boxes attribute extractor and shape generation branch sequentially to get both bounding box attribute and each furniture anchor-latents . Since our model is fully auto-regressive based solution, we can train our model using by maximizing the log-likelihood of bounding box attributes using and furniture anchor-latents using . Different from previous work[34] that use a two stage training for layout and shape. We jointly train the layout and shape generation. We conduct ablation study to verify this. The implementation details can be found in the supplementary.
Once the model is trained, we sequentially generate each piece of furniture based on the room mask or the partially observed scene.
4 Experiments
Datasets. For experimental comparisons, we conduct our experiments on the large-scale 3D indoor scene dataset 3D-Front [14] furniture with 3D-Future [15] CAD model. 3D-Front is a synthetic dataset composed of 6,813 houses with 14,629 rooms, where each room is arranged by the furniture from the 3D-Future dataset [15]. Following the filtering strategy of ATISS [35], we use 4,041 bedrooms, 900 dining rooms, and 813 living rooms. There are 16,565 3D objects in 3D-Future [15] datasets. We selected 9,495 3D data from the 3D-Future dataset [15] for shape autoencoder training. These 3D objects belong to the furniture categories present in our filtered scenes. Note that for all room types, we use the same shape auto-encoder.
Baselines. To verify the efficiency of our method, we qualitatively and quantitatively evaluate our method and compare it with the two most recent open-sourced baselines with the same experiment settings, including an autoregressive-based method ATISS [35] and VAE-based method Sync2Gen [54]111Since Sync2Gen [54] are designed for unconditional synthesis, for fair comparison, we replace the VAE as conditional VAE [40] conditioned on the room mask.. We also design another baseline by injecting the state-of-the-art pre-trained shape embedding OpenShape [27] into ATISS and retrieve the object from the CAD library using both the object size and OpenShape [27] embeddings in the inference stage.
Evaluation Metrics. To measure the quality and plausibility of our generated results, following previous works [34, 35, 48], we use Frechet inception distance(FID) [22], scene classification accuracy(SCA) and category KL divergence of our 1,000 generated scenes. For FID, SCA, we render the generated scenes and ground-truth scenes from the test set into 256 256 images through top-down orthographic projections. Following previous work [34], the color of each object is determined by the specific color related to the category. We also report the KL divergence between the object category distributions of synthesized and real scenes from the test set. To measure the layout plausible and shape-compatible, we use a collision rate to measure the proportion of collision objects generated among all the generated objects within a scene. To measure the shape consistency, we mainly consider dining chairs for the dining room and living room. The dining chair within a single scene should be consistent with each other. Specifically, we use OpenShape [27] similarity score to evaluate the semantic consistency and Chamfer-Distance to evaluate the detailed consistency. Finally, to measure the shape diversity of our generated shape, we directly run ten times conditioned on the same room mask and calculate the Chamfer-Distance of the same category object in different runs. We mainly consider the two classes of objects in each room type.
4.1 Room mask conditioned scene generation.
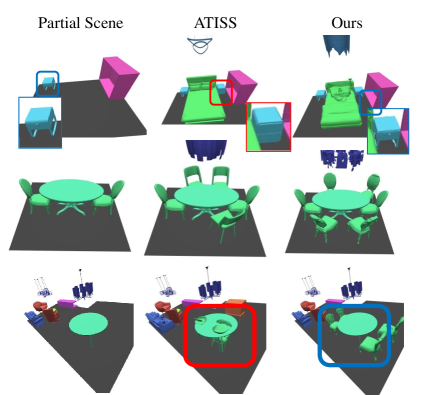
Fig. 3 visualizes the qualitative comparisons of different scene synthesis methods. We can see that baseline methods cannot guarantee style consistency and shape compatibility, especially for the dining room case where exist usually multiple dining chairs. However, our method improves both. Further, there are mainly two reasons that lead to collisions occurring, one is the layout prediction error, and the other is the shape-incompatible between different scenes (e.g., chairs under the same table should be compatible with each other). It shows that with our proposed anchor-latents, the generation process of our method will be shape-aware. Tab. 1 further proves that our method can produce high-quality while also keeping the style consistent and shape-compatible results, especially for the dining room.
shape-consistency and shape-diversity. Fig. 4 visualizes the qualitative results of our method when given the same room mask. We can observe that for the same object category, our method can generate style-consistent furniture within a scene while can generate diverse furniture. Tab 2 and Tab 3 further prove that. In Tab. 2, ATISS[35] + OpenShape [27] shares almost similar O-score with ours, which means that both the OpenShape [27] embeddings and our proposed anchor-latents can provide sufficient global structure information. But when compared the Chamfer-Distance, our method outperforms it significantly. This indicates that our proposed anchor-latents can capture both global information and geometry details for the furniture.
| Method | Bedroom | Dining room | Living room | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FID | SCA | CKL | Colli | FID | SCA | CKL | Colli | FID | SCA | CKL | Colli | |
| Sync2Gen* [54] | 49.32 | 79.63 | 0.031 | 0.466 | 57.44 | 82.11 | 0.092 | 0.442 | 59.94 | 88.40 | 0.063 | 0.498 |
| Sync2Gen [54] | 46.16 | 83.12 | 0.043 | 0.344 | 59.97 | 84.32 | 0.084 | 0.427 | 60.96 | 86.25 | 0.074 | 0.477 |
| ATISS [35] | 29.78 | 67.37 | 0.011 | 0.326 | 37.37 | 79.44 | 0.006 | 0.447 | 32.10 | 81.25 | 0.005 | 0.439 |
| ATISS [35]+OpenShape [27] | 28.86 | 64.74 | 0.009 | 0.317 | 33.69 | 69.81 | 0.003 | 0.452 | 31.59 | 72.57 | 0.006 | 0.436 |
| Ours | 27.16 | 63.58 | 0.010 | 0.287 | 32.78 | 65.53 | 0.003 | 0.360 | 30.88 | 69.92 | 0.004 | 0.371 |


| Method | Dining room | Living room | |||
|---|---|---|---|---|---|
| CD | O-score | CD | O-score | ||
| ATISS [35] | 93.0 | 0.92 | 30.0 | 0.91 | |
| ATISS [35]+ OpenShape [27] | 12.1 | 0.98 | 12.6 | 0.97 | |
| Ours | 6.9 | 0.98 | 9.7 | 0.97 | |
| Method | Bedroom | Dining room | Living room | |||
|---|---|---|---|---|---|---|
| Bed | Nightstand | Chair | Table | Chair | Table | |
| ATISS [35] | 1.89 | 0.93 | 2.45 | 1.92 | 3.29 | 2.66 |
| ATISS [35]+ OpenShape [27] | 2.56 | 1.42 | 7.62 | 4.34 | 6.40 | 3.34 |
| Ours | 25.4 | 7.3 | 29.4 | 17.7 | 22.3 | 16.8 |
4.2 Ablation studies
We ablate our method with different numbers of our latent points and training strategies for our scene-generation transformer under room-mask-conditioned generation settings. The results are shown in Tab. 4.
Number of anchor points. We use different anchor points to conduct experiments on the Bedroom of the 3D-Front dataset. Since more anchor points can provide more global structure information for each piece of furniture, with very few global structure information, Our scene generation transformer will not be shape-aware, where collision rate can prove this. When using only 128 anchor-latents, the collision rate is even worse than methods that do not consider geometry. Furthermore, fewer anchor points can not provide reasonable geometry for each piece of furniture, thus leading to a decrease in FID score and SCA. Please see supplementary for qualitative results.
The training strategy. We ablate our Scene Generation Transformer training strategy with a two-stage training strategy proposed by Scene Prior [34]. At the first training stage, the shape generation transformer of our model was not engaged in training. Only class category and bounding boxes parameterization was optimized. Then we jointly optimize the geometry branch and train our model end to end. We have observed a moderate decline in both the FID and SCA. However, the reduction of CKL is serious. The gains can be attributed to the joint training of scene and shape, which facilitates the learning of category distribution since geometry distribution varies for each category.
| Method | FID | SCA | CKL | Colli |
|---|---|---|---|---|
| Ours-128 | 33.68 | 81.24 | 0.019 | 0.323 |
| Ours-256 | 29.96 | 70.70 | 0.011 | 0.314 |
| Two-stage | 28.57 | 66.15 | 0.032 | 0.291 |
| Ours-final | 27.16 | 63.58 | 0.010 | 0.287 |
4.3 Downstream tasks.
Style-consistent and shape-compatible scene completion. As shown in Fig. 5, when given a partial scene with some furniture already in it. We compare our results with ATISS [35], and we conduct scene completion based on the room floor plan and existing objects. Since ATISS [35] does not take the furniture shape into consideration when given some previous object. ATISS [35] can not complete the scene with furniture consistent with existing furniture. With our proposed anchor-latents and shape-aware parameterization, our shape-aware scene generation transformer can complete the scene with a consistent style and compatible furniture.
Furniture mismatch correction. As shown in Fig. 6, we demonstrate the capability of our model to detect and rectify unnatural inconsistent object styles. For a given scene, we calculate the probability distribution of each object based on our model while considering the presence and shape of other furniture in the scene. In our settings, we designate problematic furniture as those with low likelihood and then proceed to resample a new shape from our generative model in order to rearrange them. Note that this task cannot be performed by previous methods as they do not consider the shape of each piece of furniture.

Controllable furniture-level editing. Since our anchor points can control the structure of our furniture, we can interpolate the new shape by mixing the anchor points from two different shapes. Furthermore, our shape-aware scene generation model can further complete the scene with interpolated furniture. Note that this task is all the previous scene synthesis work can not achieve. Please refer to the supplementary materials for the visualization results.
5 Conclusion
We introduce Roomdesigner, an indoor scene generation transformer that jointly synthesis the room layout and generates the furniture shape. To achieve this, we propose an anchor-latent representation, a representation that can capture both global structure and local geometry for each piece of furniture. Based on the anchor-latent representation, we learn a scene generation transformer to auto-regressively generate the location information and shape information for each piece of furniture. With this shape-aware scene generation model, we can achieve style-consistent and shape-compatible scene generation. Furthermore, our model can also facilitate a lot of downstream tasks such as shape-compatible and style-consistent scene completion, style-mismatch detection and correction, and controllable furniture-level editing, which can not be achieved by previous works. Experiments verify that our method can achieve compelling results in the room-mask conditional generation task.
References
- Bahmani et al. [2023] Sherwin Bahmani, Jeong Joon Park, Despoina Paschalidou, Xingguang Yan, Gordon Wetzstein, Leonidas Guibas, and Andrea Tagliasacchi. Layout-conditioned generation of compositional 3d scenes. ICCV, 2023.
- Chan et al. [2021] Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3D generative adversarial networks. In arXiv, 2021.
- Chang et al. [2014] Angel Chang, Manolis Savva, and Christopher D. Manning. Learning spatial knowledge for text to 3d scene generation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2028–2038, 2014.
- Chang et al. [2015] Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianxiong Xiao, Li Yi, and Fisher Yu. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR], Stanford University — Princeton University — Toyota Technological Institute at Chicago, 2015.
- Chang et al. [2017] Angel X Chang, Mihail Eric, Manolis Savva, and Christopher D. Manning. Sceneseer: 3d scene design with natural language. arXiv preprint arXiv:1703.00050, 2017.
- Chen et al. [2022] Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. In European Conference on Computer Vision (ECCV), 2022.
- Chen et al. [2023] Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven texture synthesis via diffusion models. arXiv preprint arXiv:2303.11396, 2023.
- Chen and Zhang [2019] Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- Cheng et al. [2023] Yen-Chi Cheng, Hsin-Ying Lee, Sergey Tuyakov, Alex Schwing, and Liangyan Gui. SDFusion: Multimodal 3d shape completion, reconstruction, and generation. In CVPR, 2023.
- Deitke et al. [2023] Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13142–13153, 2023.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021.
- Fisher and Hanrahan [2010] Matthew Fisher and Pat Hanrahan. Context-based search for 3d models. In ACM SIGGRAPH Asia 2010 Papers, pages 1–10, 2010.
- Fisher et al. [2015] Matthew Fisher, Manolis Savva, Yangyan Li, Pat Hanrahan, and Matthias Nießner. Activity-centric scene synthesis for functional 3d scene modeling. ACM Transactions on Graphics (TOG), 34(6):1–13, 2015.
- Fu et al. [2021a] Huan Fu, Bowen Cai, Lin Gao, Ling-Xiao Zhang, Jiaming Wang, Cao Li, Qixun Zeng, Chengyue Sun, Rongfei Jia, Binqiang Zhao, et al. 3d-front: 3d furnished rooms with layouts and semantics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10933–10942, 2021a.
- Fu et al. [2021b] Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d furniture shape with texture. International Journal of Computer Vision, pages 1–25, 2021b.
- Fu et al. [2017] Qiang Fu, Xiaowu Chen, Xiaotian Wang, Sijia Wen, Bin Zhou, and Hongbo Fu. Adaptive synthesis of indoor scenes via activity-associated object relation graphs. ACM Transactions on Graphics (TOG), 36(6):1–13, 2017.
- Gao et al. [2022] Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d textured shapes learned from images. In Advances In Neural Information Processing Systems, 2022.
- Gao et al. [2023a] Lin Gao, Jia-Mu Sun, Kaichun Mo, Yu-Kun Lai, Leonidas J. Guibas, and Jie Yang. Scenehgn: Hierarchical graph networks for 3d indoor scene generation with fine-grained geometry. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–18, 2023a.
- Gao et al. [2023b] Quankai Gao, Qiangeng Xu, Hao Su, Ulrich Neumann, and Zexiang Xu. Strivec: Sparse tri-vector radiance fields. arXiv preprint arXiv:2307.13226, 2023b.
- Gupta et al. [2023] Anchit Gupta, Wenhan Xiong, Yixin Nie, Ian Jones, and Barlas Oğuz. 3dgen: Triplane latent diffusion for textured mesh generation. arxiv, 2023.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, 2017.
- Hui et al. [2022] Ka-Hei Hui, Ruihui Li, Jingyu Hu, and Chi-Wing Fu. Neural wavelet-domain diffusion for 3d shape generation. In SIGGRAPH Asia 2022 Conference Papers, pages 1–9, 2022.
- Katharopoulos et al. [2020] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning (ICML), 2020.
- Lassner and Zollhöfer [2020] Christoph Lassner and Michael Zollhöfer. Pulsar: Efficient sphere-based neural rendering. arXiv:2004.07484, 2020.
- Li et al. [2019] Manyi Li, Akshay Gadi Patil, Kai Xu, Siddhartha Chaudhuri, Owais Khan, Ariel Shamir, Changhe Tu, Baoquan Chen, Daniel Cohen-Or, and Hao Zhang. Grains: Generative recursive autoencoders for indoor scenes. ACM Transactions on Graphics (TOG), 38(2):1–16, 2019.
- Liu et al. [2023a] Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. Openshape: Scaling up 3d shape representation towards open-world understanding, 2023a.
- Liu et al. [2023b] Zhen Liu, Yao Feng, Michael J. Black, Derek Nowrouzezahrai, Liam Paull, and Weiyang Liu. Meshdiffusion: Score-based generative 3d mesh modeling. In International Conference on Learning Representations, 2023b.
- Merrell et al. [2011] Paul Merrell, Eric Schkufza, Zeyang Li, Maneesh Agrawala, and Vladlen Koltun. Interactive furniture layout using interior design guidelines. ACM Transactions on Graphics (TOG), 30(4):1–10, 2011.
- Mescheder et al. [2019a] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019a.
- Mescheder et al. [2019b] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019b.
- Mildenhall et al. [2020] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision (ECCV), pages 405–421. Springer, 2020.
- Mittal et al. [2022] Paritosh Mittal, Yen-Chi Cheng, Maneesh Singh, and Shubham Tulsiani. AutoSDF: Shape priors for 3d completion, reconstruction and generation. In CVPR, 2022.
- Nie et al. [2023] Yinyu Nie, Angela Dai, Xiaoguang Han, and Matthias Nießner. Learning 3d scene priors with 2d supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 792–802, 2023.
- Paschalidou et al. [2021] Despoina Paschalidou, Amlan Kar, Maria Shugrina, Karsten Kreis, Andreas Geiger, and Sanja Fidler. Atiss: Autoregressive transformers for indoor scene synthesis. In Advances in Neural Information Processing Systems, pages 12013–12026, 2021.
- Peng et al. [2020] Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks. In European Conference on Computer Vision (ECCV), 2020.
- Purkait et al. [2020] Pulak Purkait, Christopher Zach, and Ian Reid. Sg-vae: Scene grammar variational autoencoder to generate new indoor scenes. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIV, pages 155–171. Springer, 2020.
- Richardson et al. [2023] Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text-guided texturing of 3d shapes. arxiv, 2023.
- Shen et al. [2021] Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- Sohn et al. [2015] Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2015.
- Tang et al. [2023] Jiapeng Tang, Yinyu Nie, Lev Markhasin, Angela Dai, Justus Thies, and Matthias Nießner. Diffuscene: Scene graph denoising diffusion probabilistic model for generative indoor scene synthesis. arxiv, 2023.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, and et al. Neural discrete representation learning. In Advances in Neural Information Processing Systems, 2017.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems (NeurIPS), 30, 2017.
- Wang et al. [2018a] Kai Wang, Manolis Savva, Angel X Chang, and Daniel Ritchie. Deep convolutional priors for indoor scene synthesis. ACM Transactions on Graphics (TOG), 37(4):1–14, 2018a.
- Wang et al. [2019] Kai Wang, Yu-An Lin, Ben Weissmann, Manolis Savva, Angel X Chang, and Daniel Ritchie. Planit: Planning and instantiating indoor scenes with relation graph and spatial prior networks. ACM Transactions on Graphics (TOG), 38(4):1–15, 2019.
- Wang et al. [2018b] Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. Pixel2mesh: Generating 3d mesh models from single rgb images. In ECCV, 2018b.
- Wang et al. [2017] Peng-Shuai Wang, Yang Liu, Yu-Xiao Guo, Chun-Yu Sun, and Xin Tong. O-cnn: Octree-based convolutional neural networks for 3d shape analysis. ACM Transactions on Graphics (TOG), 36(4):72, 2017.
- Wang et al. [2021] Xinpeng Wang, Chandan Yeshwanth, and Matthias Nießner. Sceneformer: Indoor scene generation with transformers. In 2021 International Conference on 3D Vision (3DV), pages 106–115. IEEE, 2021.
- Wu et al. [2016] Jiajun Wu, Chengkai Zhang, Tianfan Xue, William T Freeman, and Joshua B Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Advances in Neural Information Processing Systems, pages 82–90, 2016.
- Xu et al. [2023] Yinghao Xu, Menglei Chai, Zifan Shi, Sida Peng, Ivan Skorokhodov, Aliaksandr Siarohin, Ceyuan Yang, Yujun Shen, Hsin-Ying Lee, Bolei Zhou, and Sergey Tulyakov. Discoscene: Spatially disentangled generative radiance fields for controllable 3d-aware scene synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Xue et al. [2022] Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning unified representation of language, image and point cloud for 3d understanding. arXiv preprint arXiv:2212.05171, 2022.
- Xue et al. [2023] Le Xue, Ning Yu, Shu Zhang, Junnan Li, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip-2: Towards scalable multimodal pre-training for 3d understanding, 2023.
- Yan et al. [2022] Xingguang Yan, Liqiang Lin, Niloy J. Mitra, Dani Lischinski, Danny Cohen-Or, and Hui Huang. Shapeformer: Transformer-based shape completion via sparse representation, 2022.
- Yang et al. [2021a] Haitao Yang, Zaiwei Zhang, Siming Yan, Haibin Huang, Chongyang Ma, Yi Zheng, Chandrajit Bajaj, and Qixing Huang. Scene synthesis via uncertainty-driven attribute synchronization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5630–5640, 2021a.
- Yang et al. [2021b] Ming-Jia Yang, Yu-Xiao Guo, Bin Zhou, and Xin Tong. Indoor scene generation from a collection of semantic-segmented depth images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15203–15212, 2021b.
- Yeh et al. [2012] Yi-Ting Yeh, Lingfeng Yang, Matthew Watson, Noah D Goodman, and Pat Hanrahan. Synthesizing open worlds with constraints using locally annealed reversible jump mcmc. ACM Transactions on Graphics (TOG), 31(4):1–11, 2012.
- Yi et al. [2023] Hongwei Yi, Chun-Hao P. Huang, Shashank Tripathi, Lea Hering, Justus Thies, and Michael J. Black. MIME: Human-aware 3D scene generation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 12965–12976, 2023.
- Zeng et al. [2022] Xiaohui Zeng, Arash Vahdat, Francis Williams, Zan Gojcic, Or Litany, Sanja Fidler, and Karsten Kreis. Lion: Latent point diffusion models for 3d shape generation. In Advances in Neural Information Processing Systems (NeurIPS), 2022.
- Zhang et al. [2022] Biao Zhang, Matthias Nießner, and Peter Wonka. 3DILG: Irregular latent grids for 3d generative modeling. In Advances in Neural Information Processing Systems, 2022.
- Zhang et al. [2023] Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models. arXiv preprint arXiv:2301.11445, 2023.
- Zhang et al. [2020] Zaiwei Zhang, Zhenpei Yang, Chongyang Ma, Linjie Luo, Alexander Huth, Etienne Vouga, and Qixing Huang. Deep generative modeling for scene synthesis via hybrid representations. ACM Transactions on Graphics (TOG), 39(2):1–21, 2020.
- Zhao et al. [2023] Zibo Zhao, Wen Liu, Xin Chen, Xianfang Zeng, Rui Wang, Pei Cheng, Bin Fu, Tao Chen, Gang Yu, and Shenghua Gao. Michelangelo: Conditional 3d shape generation based on shape-image-text aligned latent representation. arXiv preprint arXiv:2306.17115, 2023.
- Zhou et al. [2021] Linqi Zhou, Yilun Du, and Jiajun Wu. 3d shape generation and completion through point-voxel diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5826–5835, 2021.
Supplementary Material
In this supplemental material, we provide details for our implementation in Sec. A, we provide the results for controllable editing with anchor-latents in Sec. B, we provide the qualitative results for our ablation studies in Sec. C, we provide the implementation details of our baseline in Sec. D. Finally, we provide more visual results of our method to prove that our method can enable style-consistent and shape-compatible indoor scene generation results in Sec. E. We also provide many multi-view visualizations results as in our supplementary files to show the style-consistent and shape-compatible indoor scene generation results of our methods.
A Implementation details.
A.1 Network Architecture and loss functions
Scene generation transformer.
We follow the design from [35, 57] to implement our Scene generation transformer encoder as a multi-head attention transformer without any positional encoding. Our scene generation transformer consists of 4 layers and 16 attention heads. The query, key, and value have 64 dimensions. The total dimension for a single furniture token is, therefore . Where the first 512-dimensions tokens embedded the feature extracted from Bounding Box Encoder, while the next 512-dimensions tokens embedded the feature extracted from Anchor-latents Encoder. The Feed-forward MLP has 2048 dimensions. is a learnable object query vector that predicts the output feature used for the next furniture prediction. We implement our transformer using the transformer library [24]. The learnable embedding for the category is implemented with a single layer MLP that maps the one-hot label into , while the embedding is implemented with a two-layer MLP that map the anchor embedding from in to . The loss function for the category is a Cross entropy loss. We follow previous work [35] and model the size , the translation and the rotation with a mixture of logits distributions.
| (12) |
| (13) |
| (14) |
where denote the weight, mean, and variance of the k-th logistic distribution used for modeling the size. Similarly for and . For implementation, we set , following the same design of ATISS [35]. For the extract of each bounding box attribute, we use a 2-layer MLP to achieve this. We use the negative log-likelihood loss for these attributes. Therefore, the loss function for the layout prediction is
| (15) | |||
Shape Generation Transformer.

The shape generation transformer is implemented with 12 layers in total, as shown in Fig. 7. The length for each token is 512, which corresponds to the number of our anchor-latents . For the training stage, We first embedded the coordinate for each anchor point and the quantized index for each anchor feature in the codebook, each as using the learnable embeddings, where the second 512 means the feature dimension for each learnable embeddings. We collect four features, each of size feature for , by summing them together. We then concatenate with the first feature for the previous anchor-latents to get the input embedding. Each embedding is used to predict the next anchor-latents. We follow the same design of the bounding box extractor that predicts the sequentially. Specifically, the first six layers was used to predict the embedding for , the next two layer for , then for and similarly after each feature prediction. We decode them using a separate two-layer MLP. Similar to the attribute extractor, we model the distribution of the anchor points using a mixture of logit distributions.
| (16) |
| (17) |
| (18) |
Therefore, for the shape generation branch optimization, we use the negative log-likelihood loss for the quantized id classification and use the negative log-likelihood loss for the distribution for anchor points coordinate.
| (19) | |||
During inference, starting from , we autoregressively predict the next anchor-latent from 0 until .
A.2 Training Details
For the shape VQVAE training, we train our model on 4 NVIDIA A40 GPUs with a batch size of 16 on each GPU. We train our VQVAE for 1000 epochs with Adam Optimizer. The learning rate for training is 1e-3. The number of sample points , the number of latent anchors , for -NN The size of the codebook is , where the dimension for each latent is .
For the scene generation stage, we train our model with a batch size of 128 for 500k iterations. We use the optimizer, Adam. The learning rate for training is 1e-3. The training process is with no weight decay. The scene generation stage was trained on 8 NVIDIA A40 GPUs.
A.3 Dataset processing details
Furniture VQ-VAE stage.
To train the occupancy fields, the mesh should be watertight. We first use O-CNN [47] to extract the watertight surface of each Furniture in the 3D-Future [15] dataset. All the vertices of mesh was scaled into . For optimization of the first stage, we randomly select points in the volume and use pysdf222https://github.com/andreasBihlmaier/pysdf to get the ground truth occupancy for each point.
Scene Generation stage.
The dataset pre-processing is based on the setting of ATISS [35]; we initiate the process by excluding scenes exhibiting intricate object configurations, notably marked by erroneous object class attributions. For instance, instances, where beds are inaccurately categorized as wardrobes in certain scenes are rectified. Following this, scenes manifesting unnatural scales are subsequently eliminated from consideration. Consequently, we disregard scenes characterized by an inadequate or excessive object count. For valid bedroom configurations, the prescribed object range spans from 3 to 13. In the case of dining and living rooms, the lower and upper bounds for object quantities are established at 3 and 21, respectively. Furthermore, scenes containing objects falling outside the confines of predetermined categories are expunged. Following the pre-processing phase, our dataset comprises 4,041 bedrooms, 900 dining rooms, and 813 living rooms. We have additional classes of ‘begin’ and ’end’ to define the start token and the end token of our autoregressive prediction. Combining with the object categories that appeared in each room type, we have object categories for bedrooms and object categories for dining and living rooms in total. The category labels are listed as follows.
{python}
# 23 3D-Front bedroom categories
[ ’armchair’, ’bookshelf’, ’cabinet’,
’ceiling_lamp’, ’chair’, ’children_cabinet’,
’coffee_table’, ’desk’, ’double_bed’,
’dressing_chair’, ’dressing_table’, ’kids_bed’,
’nightstand’, ’pendant_lamp’, ’shelf’,
’single_bed’, ’sofa’, ’stool’, ’table’,
’tv_stand’, ’wardrobe’, ’start’, ’end’ ]
# 26 3D-Front dining or living room categories [’armchair’, ’bookshelf’, ’cabinet’, ’ceiling_lamp’, ’chaise_longue_sofa’, ’chinese_chair’, ’coffee_table’, ’console_table’, ’corner_side_table’, ’desk’, ’dining_chair’, ’dining_table’, ’l_shaped_sofa’, ’lazy_sofa’, ’lounge_chair’, ’loveseat_sofa’, ’multi_seat_sofa’, ’pendant_lamp’, ’round_end_table’, ’shelf’, ’stool’, ’tv_stand’, ’wardrobe’, ’wine_cabinet’, ’start’, ’end’ ]
A.4 Evaluation details
Collision Rate Calculation.
We randomly generate 1000 scenes using the room mask from the test set. We denote as the number of the generated furniture in the generated room. We denote as the number of the furniture which collided with other furniture in the generated room. The Collision Rate is calculated with the following:
| (20) |
Shape-consistency evaluation.
We randomly generate 1000 scenes using the room mask from the test set. For the specific furniture category, we calculate the average Chamfer-Distance and Open-Shape similarity score among the furniture that shares the same category in a single generated scene. Then we calculated the average score across 1000 generated scenes.
Shape-diversity evaluation.
For each room mask in the test set, we generate ten different scenes conditional on that room mask. Then for each selected furniture category(e.g., Bed and Nightstand for bedroom, Chair and Table for dining room and livingroom). We randomly selected a single piece of furniture within the predefined category for each generated scene. Consequently, for each room mask, the average Chamfer-Distance is computed for this selected furniture item. Subsequently, the mean Chamfer Distance is calculated across distinct room masks.
B Controllable furniture-level to scene-level editing with Anchor-latents.




Since our anchor points can control the structure of our furniture, we can interpolate the new shape by mixing the anchor-latents from two different shapes. Furthermore, our shape-aware scene generation model can further complete the scene with interpolated furniture. Specifically, we randomly select scenes with repetitive furniture in them from the test set. Then, we choose another piece of furniture from the 3D-Future [15] dataset. We encode both pieces of furniture as ordered anchor-latents. We then replace the partial anchor-latents of the existing furniture with the partial anchor-latents from another piece of furniture. We then decode them into a novel piece of furniture, which is a mixture of both pieces of furniture. Then we replace one of the original pieces of furniture with our interpolated novel furniture and remove all the other repetitive furniture. Then, we conduct scene completion on the partial scene. We can get the edited scene results as shown in Fig. 8, Fig. 9, Fig. 10, Fig. 11. Note that this task is all the previous scene synthesis work can not achieve. We can achieve interpolated shape generation due to our proposed anchor-latents. We can enable scene-level editing using scene completion due to our proposed shape-aware scene generation transformer. Please also see the video for comparison before() and after () scene editing.
C Qualitative ablation studies

We show the qualitative ablation studies mentioned in the paper. As shown in Fig. 12, We have found that using fewer anchor-latent easily leads to incomplete shape generation. This is because our sampling is based on point cloud density. If there are not enough anchor points, the anchor-latents used to control finer structures become limited, thus resulting in incomplete shape generation. On the other hand, fewer anchor-latents limit the ability to control the structure of each piece of furniture, thus resulting in inconsistent furniture generation. Furthermore, we have also observed that reducing the number of anchor-latents does not significantly improve layout optimization. This is because fewer anchor-latents do not enable our scene-generation transformer to learn the geometric relationships between furniture items within the scene.
D Baseline details
Syn2Gen
Sync2Gen [54] encodes scene arrangements into sequences of 3D objects distinguished by diverse attributes, such as bounding boxes and class categories. Central to their approach is a variational auto-encoder network through which they acquire knowledge of the relative attributes of objects. Additionally, a subsequent phase of Bayesian optimization is employed for post-processing, facilitating the enhancement of object arrangements guided by the priors learned from relative attributes. Since Sync2Gen [54] are designed for unconditional synthesis, for fair comparison, we replace the VAE as conditional VAE [40] conditioned on the room mask. We use the ResNet-18 as a room mask encoder same as ours.
ATISS
ATISS [35] treats a scene as an unstructured collection of objects and introduces an innovative autoregressive transformer framework to capture the scene generation procedure. In the training phase, leveraging existing object attributes, ATISS employs a permutation-invariant transformer mechanism to combine their characteristics. This enables the model to anticipate the potential attributes of the subsequent object, including its position, dimensions, orientation, and categorical classification, all conditioned on the amalgamated feature representation. We evaluate it using its original settings. Different from our methods, ATISS [35] only predicts the bounding box information for each generated scene and retrieves the most relevant furniture with the closet bounding box size. Our method directly generates each piece of furniture.
ATISS+OpenShape
We consider injecting shape embeddings into ATISS to make its generation process more shape-aware. OpenShape [27] is a state-of-the-art method designed for most similar shape retrieval. Its embeddings were pre-trained on different large-scale 3D dataset [4, 15, 10] and had strong generalization ability. To implement this, We concatenate the original bounding box information of ATISS [35] with the Openshape [27] pre-trained embedding. For furniture retrieval, we perform the nearest neighbor search in the 3D-FUTURE [14] furniture with the same class label, the closest bounding box size, and the openshape embeddings.
E Additional Visualization results
We present the results of our room mask-conditioned scene generation across various room types, Livingrooms(Fig. 13, Fig 14), Bedrooms(Fig. 15, Fig 16), Diningrooms(Fig. 17, Fig 18). These results serve to substantiate the high quality of our generated results, concurrently upholding the principles of style-consistent and shape-compatible scene generation. We also provide the multi-view results of our generated scene, please see the files for multi-view visualization results. We can see from these results that our method can also improve the scene diversity. even if the layour is limited(bedroom), our method can also generate diverse shape for each piece of furniture.





