Rogue Emitter Detection Using Hybrid Network of Denoising Autoencoder and Deep Metric Learning
Abstract
Rogue emitter detection (RED) is a crucial technique to maintain secure internet of things applications. Existing deep learning-based RED methods have been proposed under the friendly environments. However, these methods perform unstable under low signal-to-noise ratio (SNR) scenarios. To address this problem, we propose a robust RED method, which is a hybrid network of denoising autoencoder and deep metric learning (DML). Specifically, denoising autoencoder is adopted to mitigate noise interference and then improve its robustness under low SNR while DML plays an important role to improve the feature discrimination. Several typical experiments are conducted to evaluate the proposed RED method on an automatic dependent surveillance-Broadcast dataset and an IEEE 802.11 dataset and also to compare it with existing RED methods. Simulation results show that the proposed method achieves better RED performance and higher noise robustness with more discriminative semantic vectors than existing methods.
Index Terms:
Rogue emitter detection, deep learning, deep metric learning, denoising autoencoder, feature discrimination.I Introduction
With the development of wireless communications, various internet of things (IoT) applications grow rapidly and play indispensable role for our daily life[1, 2, 3]. However, the convergence of sensors, actuators, information, and communication technologies in IoT produces massive amounts of data that need to be sifted to facilitate reasonably accurate decision-making and control [4]. The openness of IoT makes it vulnerable to cybersecurity threats [5, 6]. In particularly, identity spoofing attacks, where an adversary passively listens to the existing radio communications and then mimics the identity of legitimate devices to conduct malicious activities.
Recently, radio frequency fingerprinting identification (RFFI) is a technique for identifying various RF devices by extracting inherent features from hardware defects in analog circuits [7]. These hardware imperfections appear during the manufacturing process. The most important merit of using physical imperfection as a signature for identification that it is hard to spoof the signature by using other wireless devices. RFFI has been used as an additional security layer for wireless devices to avoid spoofing or analog attacks [9, 8].
In recent years, deep learning-based specific emitter identification (SEI) methods have been proposed [10, 11, 12, 13, 14]. These methods have their own advantages such as high identification accuracy, strong model generalization ability, and low model complexity. However, these methods are hard to apply in the field of rogue emitter detection (RED), which is important technique to solve the threat posed by the openness of IoT applications. Until know, some related works about RED have been investigated. Breunig et al.[15] and Liu et al.[16] respectively introduced LOF and IsolationForest, which are traditional RED methods based on machine learning. Bendale et al.[17] used meta-recognition and replaced softmax with openmax, which managed the open space risk of deep networks while rejecting spoofed images. Akcay et al.[18] introduced an encoder-decoder-encoder architecture for RED, and used the idea of generative adversarial training, which had good generalization ability for any RED task. Dong et al. [19] presented SR2CNN, which could improve the feature discrimination by updating the semantic center vector. The details of these related works are shown in Table I. The above works mainly focused on improving the accuracy of RED at a specific high signal-to-noise ratio (SNR). However, existing RED methods are hard to work under the low SNR scenarios.
| References | Method | Data type | RED | SNR/dB | Detection performance | ||
| Y. Pan et al. [13] | DRN | Singnal of radio emitters | No | Acc: 56%95% | |||
| N. Yang et al. [14] | MAML | ZigBee devices and 5 UAVs | No | Acc: 30%100% | |||
| Bendale et al. [17] | OpenMax | ImageNet (ILSVRC 2012 dataset) | Yes | / | F-measure: 0.595 | ||
| Akcay et al. [18] | GANomaly | MNIST, CIFAR and X-ray | Yes | / | AUC: 0.6660.882 | ||
| Y. Dong et al. [19] | SR2CNN | RML2016.10a | Yes |
|
To solve this problem, we propose a robust RED method by using a hybrid network of denoising autoencoder and deep metric learning (DML). Denoising autoencoder mitigates low SNR noise interference while the DML improves the feature discrimination so that the proposed method can further improve the RED performance in low SNR scenarios. Furthermore, we introduce an objective function that consists of cross-entropy (CE) loss, mean squared error (MSE) loss and center (ML) loss, which allows the autoencoder to have better extraction performance of semantic features with high discrimination while saving feature space such that the proposed method has the potential to detect more rogue emitters.
II Signal Model and Problem Formulation
II-A Signal Model
In this paper, two typical datasets, i.e., ADS-B dataset and IEEE 802.11 dataset, are used to evaluate the performance of the proposed RED method. The receiver is used to receive ADS-B signals in a given airspace or IEEE 802.11 signals of the specific USRP transmitter. Assume that there are aircrafts or USRP transmitters transmitting signals, and the ADS-B signals from each aircraft or the IEEE 802.11 signals from each transmitter is received individually by the receiver. The received signal can be represented as:
| (1) |
where is the received signal, is the ADS-B signal by the aircraft or IEEE 802.11 signal transmitted by the transmitter, is the channel impulse response between aircraft and receiver, denotes the additive white Gaussian noise, and means the convolution operation.
II-B Problem Formulation
Let be the sample space and be the category space. One goal of the proposed RED method is to generate a mapping function , which can accurately predict the category of signals. represents the signal. represents the true label of the signal. The mapping function can minimize the empirical error , i.e.,
II-B1 Goal 1
| (2) |
where represents the training dataset, represents the classification loss, and represents the regularization term which can prevent overfitting, improve the noise robustness, and extract more discriminable features for RED. MSE loss and ML loss are used as in this paper.
According to the optimized mapping function, the semantic features of radio signals of legal emitters will be obtained and the semantic center features can be calculated as:
| (3) |
where denotes the mapping function of encoder, denotes the -th category, and represents the number of samples of the -th category. Our second goal is to detect whether the rogue emitters are legitimate by comparing the distance between semantic features of radio signals of unknown emitters and semantic center features, i.e.,
II-B2 Goal 2
| (6) |
where is the set of known semantic center features , represents the minimum distance between semantic features of radio signals of unknown emitters and the known semantic center features; represents the threshold for detection, represents the known category space, and represents the rogue category space.
III The Proposed RED Method
III-A The Framework of Proposed RED Method
The proposed framework consists of an encoder, a decoder and a classifier, as shown in Fig. 1. The structure of each part of the network is shown in Table II. Both encoder and decoder contain seven convolutional layers. Maxpool is a pooling operation, which reduces the feature dimension of the output of convolutional layers. BatchNorm is a batch normalization operation, which adjusts the distribution of the input values of each layer to a standard normal distribution and can speed up the training and convergence of the network. LazyLinear is a fully connected (FC) layer.

| Net | Layer | Number of layers | ||
|---|---|---|---|---|
| Encoder | Input | |||
|
||||
| Decoder |
|
|||
| Conv (1, (3,1)) + Sigmoid | ||||
| Classifier | Flatten | |||
| LazyLinear (1024) | ||||
| LazyLinear (n classes) |
We introduce an objective loss function using CE loss, MSE loss and ML loss. Specifically, we choose the CE loss to evaluate the classification loss, and it is the key part of objective loss function and it can be expressed as:
| (7) |
where denotes the true label of training sample, denotes the predicted label of training sample. To further obtain the model with strong robustness and extraction capability of discriminative features, the decoder is connected with encoder and two terms are used as regularization of objective function,
| (8) |
where the is the ML loss; is the MSE loss; , , and are the weighting coefficients. With the regularization of ML loss, the model can obtain a set of network parameters suitable for mining discriminative semantic features. With the regularization of MSE loss, the model can obtain a set of network parameters suitable for improving the noise robustness. Two regularization terms will be introduced in details in the following two subsections. The fully training procedure for the proposed RED method is decribed in Algorithm 1. After the training, the decoder and classifier will be discarded and the encoder is used for RED.
III-B Denoising Reconstruction for Strong Noise Robustness
To improve the noise robustness, this paper adopts a denoising autoencoder architecture [21] as shown in Fig. 2(b). Different from the traditional autoencoder as shown in Fig. 2(a), we add additive white Gaussian noise to the original signals. The encoder extracts the semantic features of the noise-added signals. The decoder reconstructs the semantic features into the original signals.

The MSE loss is used as the criterion to evaluate the reconstruction result and thus the network has the noise robustness by minimizing this loss. The MSE loss can be expressed as
| (9) |
where denotes the original signal and denotes the reconstructed signal.
Require:
-
•
: Training dataset;
-
•
: Number of training iterations;
-
•
: Number of batches in a training iteration;
-
•
: Parameters of encoder, classifier and decoder, respectively;
-
•
: The parameter of ML loss;
-
•
: Learning rate of encoder, classifier and decoder, respectively;
-
•
: Learning rate of ML loss;
-
•
, , : Scalars for balancing the loss functions;
III-C Metric Regularization for High Feature Discrimination
Feature discrimination is critical for RED. However, the discrimination brought by CE loss is not sufficient, so the ML loss is used as another regularization term. The ML loss [20] can be formulated as:
| (10) |
where and denote the semantic feature vectors and the semantic center feature vectors of train samples in the -th category, respectively. The combination of CE loss and ML loss allows the neural network to extract semantic features with small intra-class distance. The role of ML loss is illustrated in Fig. 3.
III-D Rogue Emitter Detection
As mentioned in subsection A, when training is over, only the encoder is retained and used for RED. Fig. 3 shows a more detailed RED process which can be divided into the following three steps.
III-D1 Obtaining semantic center features
The training dataset is considered as radio signals that emit from the legal emitters and are fed into the encoder to extract the semantic features and the semantic features of the same category are averaged to obtain the semantic center features of each legal emitter. The formula is expressed as (3).
III-D2 Calculating the distance between semantic features of radio signals of unknown emitters and the known semantic center features
Radio signals from unknown emitters are fed into the encoder of the proposed RED method to mine semantic features. The distance between the semantic features of radio signals from unknown emitters and the known semantic center features is calculated, and the formula[19] is expressed as follows:
| (13) |
where denotes the mapping function of the encoder of the proposed RED method, denotes the semantic features of the input signals, and denotes the Euclidean distance when is the unit matrix.
III-D3 Comparing the distance with threshold
| (16) |
where is the hyperparameter and is the dimensionality of the semantic center features. If is less than or equal to the threshold, the input signal will be judged to belong to the known class, otherwise, the input signal will be judged to belong to the rogue class. The threshold is inspired by the three-sigma rule[25].

IV Experimental Results
IV-A Simulation Parameters
Our simulations are performed on NVIDIA GeForce GTX1080Ti platform based on pytorch 1.8.1. The maximum epoch is 150 and the batch size is 16. We use a dynamic learning rate, set the initial learning rate to 0.001 and change it to one-tenth of the initial rate when the validation loss does not drop for 10 epochs. Adam is selected as the optimizer. The weighting coefficients , , and are set to 1, 0.5 and 0.005, respectively. The threshold ranges from 0.2 to 0.5 with a step size of 0.05.
IV-B Dataset Description
The datasets proposed in [22] and [23] are used to evaluate the proposed RED method. The dataset in [22] is a real radio signal dataset based on a special airborne monitoring system ADS-B. We randomly choose dataset containing 10 classes of aircrafts, where the ratio of the number of known classes to that of rogue classes is 9:1, and the number of samples is 3,736. The dataset in [23] is collected from 16 transmitters which are bit-similar USRP X310 radios that emit IEEE 802.11a standards-compliant frames generated via a MATLAB WLAN System toolbox, where the ratio of the number of known classes to that of rogue classes is 15:1, and the number of samples is 53,344. The number of sampling points of both datasets is 6,000, and the format of samples is In-phase/Quadrature (IQ).
IV-C Evaluation Criteria
The receiver operating characteristic (ROC) curve is used to evaluate the performance of RED. The simulation results are plotted in Fig. 4, Fig. 5, and Fig. 6 and are analyzed later. The horizontal axis is the false positive rate (FPR) which indicates the probability that the model will determine a rogue device as a known device. The vertical axis indicates the true positive rate (TPR) which indicates the probability that the model will determine a known device as a known device. The mathematical expressions are as follows:
| (17) |
where the meaning of each variable is shown in Table. III. Area under curve (AUC) is used to quantify the ROC, where larger AUC means better RED performance. The mathematical expression of AUC is given as
| (18) |
Silhouette coefficient (SC) is used to characterize the discrimination of the semantic features.
| Prediction Value | |||
|---|---|---|---|
| 1 | 0 | ||
| Real | 1 | True Positive (TP) | False Negative (FN) |
| 0 | False Positive (FP) | True Negative (TN) | |
IV-D Comparative RED Methods
We compare the proposed RED method with several RED methods, including SR2CNN[19], IsolationForest[16], and LocalOutlierFactor [15].


IV-E Rogue Emitter Detection Performance
IV-E1 RED Performance of the proposed RED method at Different SNR
To demonstrate the noise robustness of the proposed method, we analyze the detection performance of proposed RED method at SNR dB. As shown in Fig. 4 and Table. IV, the ROC curve of the proposed method at SNR dB is similar to that at SNR dB, which demonstrates that our proposed method has good robustness under different noise.
| SNR/dB | 0 | 20 | 30 |
|---|---|---|---|
| AUC (ADS-B) | 0.929 | 0.906 | 0.926 |
| AUC (IEEE 802.11) | 0.920 | 0.987 | 0.956 |
IV-E2 Proposed RED method vs. Comparative RED Methods
To further demonstrate the noise robustness of proposed RED method, the detection performances of the proposed method and the comparative methods at SNR dB are shown in the Fig. 5 and Table. V. It is shown that the ROC curve of the proposed method is higher than that of the comparative methods, and the AUC of the proposed method have improved by 0.106, 0.359, and 0.431 on ADS-B dataset and 0.113, 0.207, 0.417 on IEEE 802.11 dataset, respectively, compared to the comparative methods, which shows that the proposed method has better noise robustness than the comparative methods.
To analyze the discrimination of semantic features, t-distributed stochastic neighbor embedding (t-SNE) [24] is used to reduce the dimensionality of the extracted semantic features to two dimensions, and the semantic features extracted by the proposed RED method and SR2CNN on ADS-B dataset are compared. As shown by Fig. 7, the semantic features extracted by the proposed RED method has higher feature discrimination than that extracted by the SR2CNN at low SNR.
| Method | Ours | SR2CNN | IsolationForest | LOF |
|---|---|---|---|---|
| AUC (ADS-B) | 0.929 | 0.823 | 0.57 | 0.498 |
| AUC (IEEE 802.11) | 0.920 | 0.807 | 0.713 | 0.503 |


IV-E3 Ablation Experiment
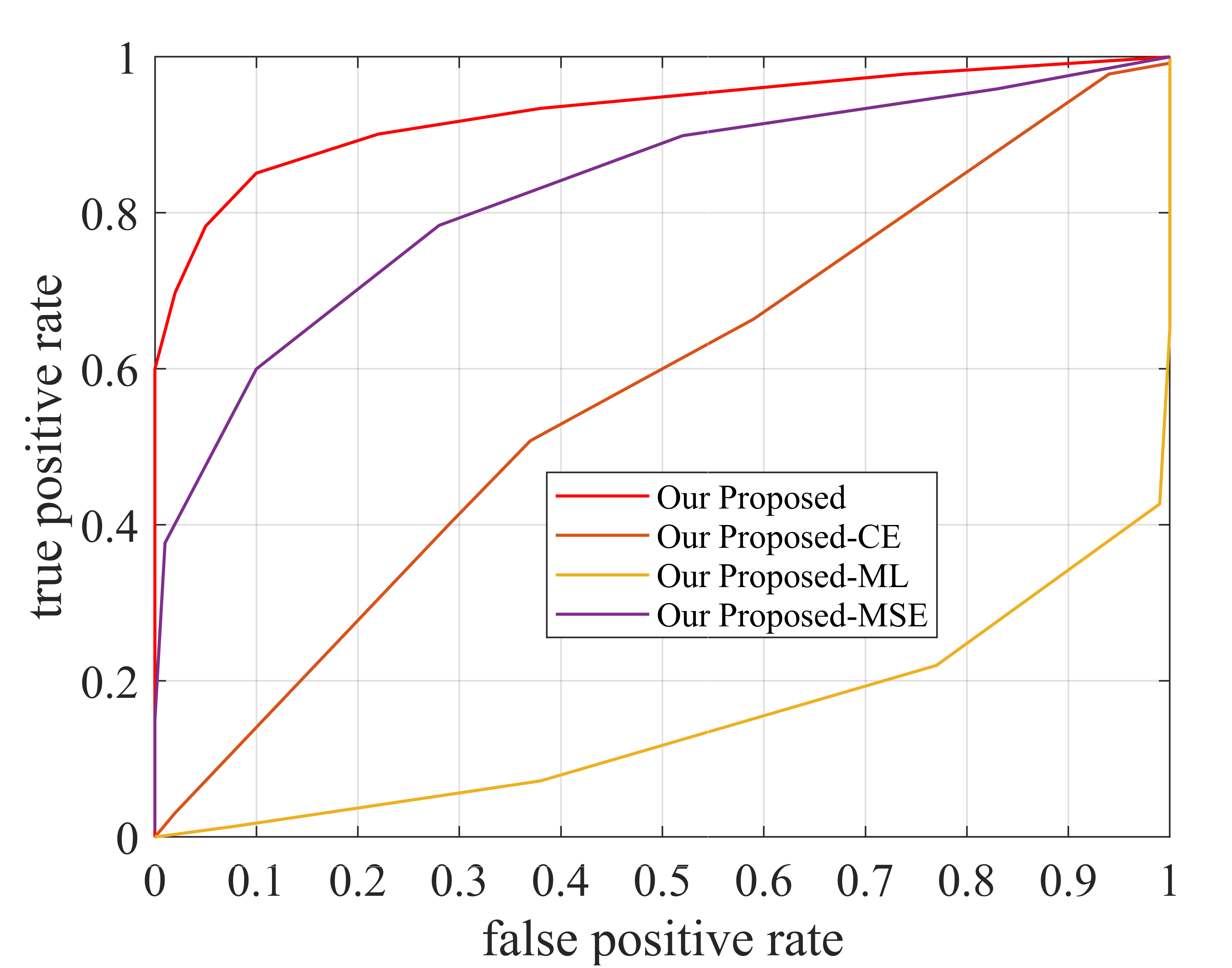
The objective function of the proposed RED method contains three loss functions, i.e., CE loss, MSE loss, and ML loss. To verify the necessity of each loss, we perform ablation experiments on ADS-B dataset when the SNR is 0 dB. As shown by the Fig. 6 and Table. VI, without the regularization of the MSE loss, the detection performance of the proposed method decreases, which indicates that MSE loss makes the model have better noise robustness. As shown by the the Fig. 6 and Fig. 8(a), 8(c), without the ML loss, the detection performance of the proposed method decreases, which indicates that ML loss makes the model have better feature discrimination. In addition, through the ablation experiments, we also can observe that MSE loss can not only improve the noise robustness of the model, but also improve the feature discrimination, and ML loss can improve the feature discrimination as well as noise robustness. The proposed method has the best rogue detection performance when all three losses are existing simultaneously.
| Method | Proposed |
|
|
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AUC (ADS-B) | 0.929 | 0.570 | 0.146 | 0.828 |



V Conclusion
In this paper, we proposed a robust RED method which has strong noise robustness and high feature discrimination. Specifically, a denosing autoencoder is used to reconstruct the noisy signal into the original signal, and an objective function that consists of CE loss, MSE loss, and ML loss is designed to achieve better extraction performance of semantic features with high discrimination while saving feature space. The proposed RED method was evaluated on an open source real-word ADS-B dataset and an IEEE 802.11 dataset and is compared with three RED methods. The simulation results showed that the proposed method has better noise robustness and feature discrimination.
References
- [1] D. C. Nguyen, M. Ding, et al., “6G internet of things: A comprehensive survey,” IEEE Internet Things J., vol. 9, no. 1, pp. 359–383, Jan. 2022.
- [2] M. Vaezi, A. Azari, et al., “Cellular, wide-area, and non-terrestrial IoT: A survey on 5G advances and the road toward 6G,” IEEE Commun. Surv. Tutorials, vol. 24, no. 2, pp. 1117–1174, Secondquarter 2022.
- [3] Z. Na, Y. Liu, J. Shi, C. Liu, and Z. Gao, “UAV-supported clustered NOMA for 6G-enabled internet of things: Trajectory planning and resource allocation,” IEEE Internet Things J., vol. 8, no. 20, pp. 15041–15048, Oct. 2021.
- [4] L. Chettri and R. Bera, “A comprehensive survey on internet of things (IoT) toward 5G wireless systems,” IEEE Internet Things J., vol. 7, no. 1, pp. 16–32, Jan. 2020.
- [5] N. Wang, et al., “Physical-layer security of 5G wireless networks for IoT: Challenges and opportunities,” IEEE Internet Things J., vol. 6, no. 5, pp. 8169–8181, Oct. 2019.
- [6] Q. Chen, W. Meng, S. Han, C. Li, H.-H. Chen, “Robust task scheduling for delay-aware IoT applications in civil aircraft-aaugmented SAGIN,” IEEE Trans. Commun., voll. 70, no. 8, pp. 5368–5385, Aug. 2022.
- [7] N. Soltanieh, Y. Norouzi, Y. Yang, and N. C. Karmakar, “A review of radio frequency fingerprinting techniques,” IEEE J. Radio Freq. Identif., vol. 4, no. 3, pp. 222–233, Sep. 2020.
- [8] F. Meneghello, et al., “IoT: Internet of threats? A survey of practical security vulnerabilities in real IoT devices,” IEEE Internet Things J., vol. 6, no. 5, pp. 8182–8201, Oct. 2019.
- [9] Y. Xing, et al., “Design of a robust radio-frequency fingerprint identification scheme for multimode LFM radar,” IEEE Internet Things J., vol. 7, no. 10, pp. 10581–10593, Oct. 2020.
- [10] X. Fu, et al., “Lightweight automatic modulation classification based on decentralized learning,” IEEE Trans. Cogn. Commun. Netw, vol. 8, no. 1, pp. 57–70, Mar. 2022.
- [11] Y. Wang, et al., “An efficient specific emitter identification method based on complex-valued neural networks and network compression,” IEEE J. Sel. Areas Commun., vol. 39, no. 8, pp. 2305–2317, Aug. 2021.
- [12] S. Chang, R. Zhang, K. Ji, S. Huang and Z. Feng, “A hierarchical classification head based convolutional gated deep neural network for automatic modulation classification,” IEEE Trans. Wireless Commun., vol. 21, no. 10, pp. 8713–8728, Oct. 2022.
- [13] X. Zha, H. Chen, T. Li, Z. Qiu, and Y. Feng, “Specific emitter identification based on complex Fourier neural network,” IEEE Commun. Lett., vol. 26, no. 3, pp. 592–596, Mar. 2022.
- [14] N. Yang, B. Zhang, et al., “Specific emitter identification with limited samples: A model-agnostic meta-learning approach,” IEEE Commun. Lett., vol. 26, no. 2, pp. 345–349, Feb. 2022.
- [15] M. M. Breunig, H. Kriegel, R. T. Ng, and J. Sander, “LOF: Identifying density-based local outliers,” in International Conference on Management of Data (SIGMOD), 2000, pp. 93–104.
- [16] F. T. Liu, K. M. Ting and Z. Zhou, “Isolation forest,” in IEEE International Conference on Data Mining (ICDM), 2008, pp. 413–422.
- [17] A. Bendale and T. E. Boult, “Towards open set deep networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1563–1572.
- [18] S. Akcay, A. Atapour-Abarghouei, P. Breckon, “GANomaly: Semi-supervised anomaly detection via adversarial training,” in Computer Vision (CV), 2019, pp. 622–637.
- [19] Y. Dong, et al., “SR2CNN: Zero-shot learning for signal recognition,” IEEE Trans. Signal Process., vol. 69, pp. 2316–2329, Mar. 2021.
- [20] Y. Wen, et al., “A discriminative feature learning approach for deep face recognition,” in Computer Vision (CV), 2016, pp. 499-515.
- [21] J. Yu, et al., “Radio frequency fingerprint identification based on denoising autoencoders,” in International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), 2019, pp. 1–6.
- [22] Y. Tu, et al., “Large-scale real-world radio signal recognition with deep learning,” Chin. J. Aeronaut., vol. 35, no. 9. pp. 35–48, Sep. 2022.
- [23] K. Sankhe, et al., “ORACLE: Optimized radio classification through convolutional neuraL networks,” in IEEE Conference on Computer Communications (INFOCOM), 2019, pp. 370–378.
- [24] L. Maaten and G. Hinton, “Visualizing data using t-SNE,” Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008.
- [25] F. Pukelsheim, “The three sigma rule,” Amer. Statistician, vol. 48, no. 2, pp. 88–91, 1994.