Robust PCA Synthetic Control
Abstract
In this study, I propose an algorithm for synthetic control method for comparative studies. My algorithm builds on the synthetic control model of [1] and the later model of [3]. I apply all three methods (robust PCA synthetic control, synthetic control, and robust synthetic control) to answer the hypothetical question, what would have been the per capita GDP of West Germany if it had not reunified with East Germany in 1990? I then apply all three algorithms in two placebo studies. Finally, I check for robustness. This paper demonstrates that my method can outperform the robust synthetic control model of [3] in placebo studies and is less sensitive to the weights of synthetic members than the model of [1].
1 Introduction
Since first introduced by [2], synthetic control (SC) models have attracted a great deal of attention as a powerful method for comparative studies in the absence of observations for a treated unit. The basic idea behind synthetic control is to find a suitable synthetic group and estimate this group’s relation with the treated unit for the pre-intervention period. Then, the synthetic group’s weights can be used for predicting the treated unit’s outcome as if it had never been treated. The practice of estimating the difference between the outcome of a policy on a treated unit and its counterfactual has been growing in many fields, such as public health ([7]) and criminology ([16]). As such, scholars over the last two decades have worked to improve this method. Among the most notable of these studies, [4] use the matrix norm and matrix completion methods for estimating the counterfactual treated unit. In a study that is closely related to my method, [3] use the combination of de-noising technique and singular value thresholding to estimate the underlying linear relation between a treated unit and its synthetic before the treatment.
In line with [3], I propose in this study a five-step, data-driven algorithm that can find the underlying linear relation between a treated unit and its synthetic. Given a data set of the outcome variable that includes both treated unit and untreated units , for the pre-intervention period and post intervention period the robust PCA synthetic control first computes the functional principle component scores of for the pre-intervention period, then applies the k-means algorithm over these scores. The untreated units that fall in the same cluster as the treated unit are considered the donor pool () of the treated unit (). This method then uses the robust PCA method to extract the low-rank structure of the donor pool (). After that, a linear relation between the treated unit and the low-rank structure of the donor pool is computed by a simple optimization for the pre-intervention period . This linear relation can then be used to estimate the counterfactual of the treated unit for the post intervention period .
The contribution of this study is in two folds. First, my method can automatically separate the donor pool from the non relevant units given any data set by using unsupervised learning. Second, to extract the low-rank structure of the donor pool, the algorithm uses robust PCA that is not sensitive to outliers and missing data.
This article is organized as follows. In the next section, I introduce the concept and theories of the first steps of robust PCA synthetic control: 1.) Functional principle component scores, 2.) K-means algorithm, and 3.) Robust principle component analysis. Then in section 2.4, I explain the five-step algorithm of robust PCA synthetic control in detail. In section 3, I apply my method to the case of West Germany’s reunification in to find the impact of reunification on West Germany’s per capita GDP. In addition to comparing the output of robust PCA synthetic with [1] and robust synthetic control suggested in [3], I check the placebo studies and robustness of all three models. In section 4, I run a simulation study to check the accuracy of my method. Finally, the section 5 concludes the article.
2 Methodology
As previously mentioned, I use a five-step algorithm to estimate a linear relation between the donor pool and the treated unit for the pre-intervention time period, and then estimate a counterfactual of the treated unit for the post-intervention time period. In the first step, I adopt the functional principal components analysis (FPCA) for the pre-intervention time period to overcome the curse of dimensionality in data and prepare it for the K-means algorithm. FPCA finds a set of orthogonal bases that maximize the variance of the original data. Then, I project the original data on these orthogonal bases to find the FPCA scores. Choosing of these FPCA scores, we can reduce the dimension of our data from to and then use these low-dimension data for clustering with K-means algorithm. Data points that fall in the same cluster as the treated unit are considered as the donor pool and I use the robust principle component analysis to extract its low-rank structure. Next, this low-rank structure of the donor pool will be used for estimating the linear relation between the treated unit and its synthetic. Finally, this linear relation predicts the counterfactual of the treated unit for the post-intervention time period. I explain each of these steps separately in the following sections.
2.1 Step 1: Computing Functional Principal Component
The theory related to the functional data analysis (FDA) was introduced decades ago and has been in use since the 1960s ([22]). With the recent development of efficient computing, FDA has become widespread in many fields 111For more information about recent FDA applications, see [5].. One application of FDA is to find the low-rank structure of high-dimensional functional data, called functional principle components (FPC). The classic principle components can be computed by eigendecomposition of the covariance matrix :
| (1) |
where is the matrix with eigenvectors of as its columns, is the diagonal matrix with eigenvalues of on its diagonal, is the rank of the covariance matrix and . But as discussed by [13] and [22], the classic principle component analysis can be misleading in the presence of panel data, sparsity, or when the dimension of data points is greater than the sample size. Counterfactual estimation may have all three of these issues: counterfactual estimation always uses panel data, the pre-intervention time period is often greater than the number of synthetic units (meaning the dimension of data points is greater than the sample size), and there may be missing values. To overcome these potential issues, I suggest using FPCA for dimensional reduction.
The basic idea of FPCA is similar to PCA, but instead of eigenvectors of the covariance matrix, FPCA uses the eigenfunctions of covariance function to reduce the dimensionality.
If we assume that data point , 222The negative superscript is for the pre-intervention period, so contains the outcome variable of treated unit and non treated units for the pre-intervention period., is a random process defined over close interval , we can decompose as:
| (2) |
where is the continuous mean and is a realization from a stochastic process with the mean zero and the covariance function . includes both random noise and signal-to-signal variations. Based on the Karhunen-Loeve theorem, we can write the as:
| (3) |
where are the zero mean, uncorrelated coefficients with finite variances and are eigen-functions of the covariance function . Therefore, we have:
| (4) |
In equation (4), ’s are ordered eigenvalues and with this setting, eigenfunctions of covariance function can be obtained by:
| (5) |
There are several methods to estimate the covariance and eigenfunction333For a list of possible methods for FPCA, see [5].. Here I follow the [19] method that is robust to the missing or sparse data. If we assume that decay fast with , we only need a finite number of to estimate the data point by:
| (6) |
Following [19], we can estimate the mean function by a local linear regression by the following minimization:
| (7) |
where is the unit index, is the time index in the each unit and is a Kernel function. After we have the estimation of mean function by (7), we can use it to find the raw covariance function of th unit, by:
| (8) |
Then, following [19], we can estimate the covariance surface by a local quadratic regression according to the following minimization:
| (9) | ||||
After computing the surface of covariance, we can compute the eigenfunction by solving the following equation:
| (10) |
where is equal to one for and zero otherwise. Notice that to solve for the equation (10), we should discretize the covariance function . Finally, the functional principle component scores can be computed by:
| (11) |
We can solve (11) by a numerical integration and find the FPC-scores. These FPC-scores now represents each data point and they can be used for the dimensional reduction by choosing of them, considering that these number of FPC-socres, should explain the most of variation in the data set.
2.2 Step 2: Applying K-Means Clustering
K-means algorithm is considered as a type of unsupervised learning, where we do not have any information about the quantitative or categorical response variable. After computing FPC-scores, we want to find which member of the data set can be useful for explaining the treated unit’s behavior during the pre-intervention time period. To do this, I suggest using a simple clustering method proposed by [17] and then the data points that fall in the same cluster as the treated unit would be utilized for computing the underlying linear relation between the synthetic and the treated unit. In K-means clustering, the goal is to find cluster centers and assign each data point to one of clusters () such that it minimizes the following objective function:
| (12) |
where is the number of units in the data set and is the reduced dimension data for the pre-intervention time period that we get from the previous step. Solving the above optimization is a NP-hard problem, so [17] suggested a greedy algorithm that guarantees to converge to the local minimum, but not global minimum.
As seen in Algorithm 1, the main idea of K-means clustering is to first initialize the cluster centers randomly and then in each iteration, assign each data point to the nearest cluster center, after which the cluster centers are recalculated. This iteration continues until there are no changes in the cluster centers. The output of this method depends on the initialization. Since its introduction there have been many studies to overcome the issue of initialization for the K-means algorithm444For a brief list of improvement on K-means algorithm, see [15].
In the case of policy analysis and synthetic control models, however, we are not dealing with big data and in the small samples that we have, the weakness of the K-means algorithm should not be an issue. Simply repeating the algorithm multiple times with different initial values and checking for the consistency of results should be sufficient to guarantee reaching the global optimum.
In the K-means algorithm, the number of clusters is a hyperparameter that should be tuned. One simple solution for this is to use the elbow method. In the elbow method, we plot the within group sum of squares of distances from the centers, , versus the cluster numbers and then choose the elbow of the curve as the number of clusters to use. Choosing the number of clusters by elbow method is subjective and in some cases there is not a clear elbow in the plot at all. A better solution to tune the number of clusters is to use Silhouettes statistics ([21]). To find the Silhouettes statistics for a specific data point, first we should compute two distances:
1- The distance of the data point to its own cluster center,
2- The distance of the data point to the closest cluster center,
Then, the Silhouettes statistics is defined as:
If the data point is in the middle of two cluster centers, we have and if it has a zero distance to its cluster center (meaning the data is perfectly clustered), we have . We can calculate Silhouettes statistics for all data points for a specific number of clusters . Then taking the average of them would give us the Silhouettes coefficient . Based on the definition of the , it is obvious that the number of clusters, , with the highest value of Silhouettes coefficient is the best choice for the number of clusters.
2.3 Step 3: Robust PCA
In the synthetic control model, we are interested in finding a linear relation between the donor pool members and the treated unit. To find such a linear relation, [3] use the truncated singular value decomposition to compute the low-rank structure of the donor pool, but truncated SVD can be influenced by corrupted data or outliers. To address this issue, I suggest to use the robust PCA method to retrieve the robust low-rank structure. After extracting the donor pool from the original data by the previous step, we have the matrix of data (the matrix that contains the data of the outcome variable of the donor pool). We want to decompose this matrix to find the low-rank matrix and the sparse matrix that contains outliers and corrupted data such that:
| (13) |
As discussed by [12], without any further assumptions on (13), decomposing a matrix to the low-rank and sparse matrices is an ill-posed problem. To be able to find a unique decomposition, [12] considered two restrictions: first, the low-rank matrix cannot be sparse by itself and, second, the sparse matrix should not have a low-rank structure. If these two conditions are satisfied, we can solve the following optimization problem in order to find the low-rank matrix and the sparse matrix :
| (14) | ||||
where is the number of non-zero elements of matrix and the is the trade-off between outliers or corrupted data with the low-rank matrix. The optimization problem (LABEL:rpca_objective) is not tractable, but recently it has been proven that the nuclear norm is a good surrogate for the minimization of the rank of a matrix 555For discussion about the necessary and sufficient conditions for using nuclear norm for the rank minimization, see [20]. and norm is a good surrogate to induce sparsity ([14]). Therefore, to address the intractability of problem (14), [11] suggested the following convex relaxation:
| (15) | ||||
where is the nuclear norm of matrix and is the norm of matrix which induces sparsity for the elements of . is the hyperparameter that needs to be tuned, but [11] showed that problem (LABEL:rpca_objective_2) would converge to problem (LABEL:rpca_objective) with high probability if , where and are the dimensions of the matrix .
The optimization problem (LABEL:rpca_objective_2) is a semidefinite programming that can be solved with the interior point method ([6]), but the pre-step cost of this method which is , where , makes it impractical to use the interior point method in real-world problems. To derive a practical and iterative method to solve problem (LABEL:rpca_objective_2), one obvious solution is to use the Lagrangian:
| (16) |
where is the matrix of Lagrange multipliers. Then the optimal solution is the saddle points of the Lagrangian ([25])
| (17) |
This saddle point feature of the optimal solutions can help to generate an iterative method:
| (18) | ||||
to solve for the optimal values of . As [18] discusses, the issue with the iterative method (LABEL:lagrangian_iterative) is the chance of generating a non-feasible solution in any step, so the iterative method might fail to progress. To address the issue of generating non-feasible solutions, we can use augmented Lagrangian. The main idea behind augmented Lagrangian is to penalize the constraint more strongly. To accomplish this, we can write the problem (LABEL:rpca_objective_2) as:
| (19) | ||||
where is the penalty parameter and if the solution in each iteration is feasible, the extra term in problem (LABEL:augmented_lag) would be zero and problem (LABEL:augmented_lag) will be equivalent to problem (LABEL:rpca_objective_2). The Lagrangian for the problem (LABEL:augmented_lag) is called the augmented Lagrangian and it has the form:
| (20) |
Similar to (LABEL:lagrangian_iterative), we can derive an iterative method for the augmented Lagrangian:
| (21) | ||||
The iteration process of (LABEL:augmented_lag_iter) is called the method of multipliers ([25]). To solve (LABEL:augmented_lag_iter), we can use the proximal gradient to find a closed form solution for each variables and .
2.3.1 Proximal Gradient Method
Consider the objective function that can be decomposed into two parts for , where both functions and are convex. Assume that the function is differentiable with the Lipschitz gradient, and the function is not differentiable. We know that since is differentiable, the gradient descent update can be written as:
| (22) |
where is the learning rate in each step. In addition, if we assume the Hessian of is equal to , the quadratic approximation of around the point is:
To define an iterative process over the objective function , first we need to introduce the proximal operator.
Definition 1.
Let be a convex function of , then the proximal operator over the function is defined by:
and for , the proximal operator over the convex function is defined by:
Then for the case of , using the quadratic approximation for and leaving the non-differentiable function intact, in each iteration, we can update by:
Also the generalization to the case of for the updating process above is straightforward. The idea behind the proximal gradient descent is to minimize function while staying close to the point at each iteration. Notice that the presence of a strong convex term guarantees that at each iteration is well-defined and unique. Algorithm 2 summarizes the proximal gradient descent method and as you can see, we should set for this algorithm to work, so the applicability of this method depends on how simple it is to compute the proximal operator for a specific problem. [8] provide an extensive analysis on the convergence rate of proximal gradient descent. In the next section, I will discuss how the proximal operator can be used to solve the iteration process (LABEL:augmented_lag_iter) for the objective function (LABEL:rpca_objective_2).
2.3.2 Alternating Direction Method of Multipliers for Robust PCA
So far I have discussed that the optimization problem (LABEL:rpca_objective) can be solved with the method of multipliers which is an iteration process (LABEL:augmented_lag_iter), but minimization of in (LABEL:augmented_lag_iter) over both variables and is difficult. For the robust PCA problem (LABEL:rpca_objective_2), we can use the specific structure of the objective function to make the minimization (LABEL:augmented_lag_iter) simpler. The objective function of robust PCA is separable in its variables ( and ), so we can use a method that is known in the literature as alternating direction method of multipliers. In this method, we can use the separable structure of the objective function to update each variable in each iteration considering the other variables fixed. For the case of iterative process (LABEL:augmented_lag_iter), this means that we can update considering and fixed and repeat the same procedure for and . Following [25]666[25] also provide an extensive proof for the convergence of ADMM under different conditions., we can consider sequential updates for the variable :
| (23) |
where the proximal operator is defined over the nuclear norm, also the sequential updates for the variable can be written as:
| (24) |
where in this case the proximal operator is defined over the norm. These sequential updates over the low-rank matrix and the sparse error provide a convenient way for the update of augmented Lagrangian in (LABEL:augmented_lag_iter). We can use the following two propositions to find a closed form solution for (2.3.2) and (2.3.2):
Proposition 1.
Let and be an element of , define to be the elementwise soft-thresholding operator such that:
Then, we can show that . In other words, the proximal operator over the norm of , is the elementwise soft-thresholding of it.
Proof: Appendix A.1
Proposition 2.
Let and be the SVD decomposition of . Using the definition of , we can define the singular value thresholding operator by:
where is the elementwise soft-thresholding operator. Then, we can show that . In other words, the proximal operator over the nuclear norm of , is the elementwise soft-thresholding over its singular values.
Proof: Appendix A.2
Based on the two propositions above, we can find a closed form solution for proximal operator of (2.3.2) and (2.3.2):
| (25) |
| (26) |
Putting all these results together, we can solve robust PCA problem by ADMM. In this method (Algorithm 3), we first minimize with respect to by (2.3.2), considering all other variables fixed. Then, we minimize with respect to by (2.3.2), again all other variables fixed. At the end, ADMM updates the dual variable according to (LABEL:augmented_lag_iter). Now that we have discussed an algorithm to compute the robust PCA, in the next section, we can use all the previous steps (step 1, 2 and 3) to introduce robust PCA synthetic control.
2.4 Robust PCA Synthetic Control
Synthetic control model is a method for counterfactual estimation. Consider a treated unit . This unit would receive a treatment at time and we can observe the output of unit both before receiving the treat and after the treat where is the last observed time period. The idea behind the synthetic control model is to find a donor pool, denoted by , that can explain the behavior of the treatment unit before receiving the treat, the best. Using this donor pool, we can find a relation between the treated unit and the donor pool for the time period before the treatment. This relation can then be used to estimate the counterfactual of treated unit after receiving the treat.
In the original synthetic control model proposed by [2], we need what [3] call “expert in the field”. This means that to implement the synthetic control model, we need experts to find the appropriate donor pool based on the similarity between the treated unit and the donor pool members. Besides that, we need to consider suitable features (explanatory variables of the outcome variable) to implement the original synthetic control model. Choosing donor pool members and covariates can change the output of counterfactual estimation significantly. Here, I use machine learning techniques to overcome these issues.
The method I suggest here, called robust PCA synthetic control, is an intuitive data-driven solution to address the issues of classic synthetic control model. First, we need to choose the donor pool for the treated unit. For this, first we can use the functional principle components to reduce the dimensionality of a data set and overcome the potential curse of dimensionality in K-means algorithm. After computing principle component scores for the pre-treatment period of a whole data set (including treated and non-treated units), we have the reduced dimension presentation of each data point. Then we can use the K-means algorithm to cluster these data points. The data points that fall in the same cluster as the treated unit have the closest distance to it and we can use them as the donor pool.
Now that we have the appropriate donor pool, we can extract the low-rank structure of non-treated units for the pre-treatment area. This approach is inspired by [3], but in their work, they use thresholding on singular value decomposition to find this low-rank structure and as [23] mentioned, SVD is sensitive to outliers or missing data, so I use the robust PCA algorithm to solve this issue.
The output of the robust PCA would give us the low-rank structure of the donor pool (). I denote the pre-intervention part of by , which we can then use to estimate the linear relation between the treated unit and non-treated units for the pre-intervention period by a simple least square method:
| (27) | |||
where I assume there are units (including treated and donor pool members), so represents members of non-treated units for the time span. I also impose the constraint of positive relation between the donor pool and the treated unit. This is intuitive, as I expect that clustering on FPC-scores would put the unit members with a positive relation with the treated unit in the same cluster. After computing values, we can estimate the counterfactual of a treatment unit as:
| (28) |
where denotes the post intervention part of the low-rank matrix .
There are five hyperparameters in the robust PCA synthetic control algorithm: one is the number of FPC-scores, second is the number of clusters in the K-means algorithm, and the others are related to the computation of robust PCA. To choose the number of FPC-scores, we can compute the proportion of the explained variation in the data for the specific number of FPC-scores and then pick the number of FPC-scores that can explain the most variation in the data777As a rule of thumb, we should choose the FPC-score that can explain at least percent of the variation in the data.. For the hyperparameter of K-means algorithm, as I discussed before, we can use the Silhouette statistics. For the hyperparameter in robust PCA, I followed the recommendation of [11] for the convergence of the algorithm and based on the dimensions of , I considered . For the other two hyperparameters in robust PCA, and , I considered the recommended values by [9] which are and where is the vectorization operator. Notice that these values for the hyperparameters are merely rule of thumb and one could use methods like cross validation over the pre-intervention period to tune these hyperparameters. Finally, I summarize the robust PCA synthetic control algorithm in algorithm 4. In the next section, I will implement the robust PCA synthetic control on the case of West Germany reunification with the mentioned hyperparameters.
-
•
Define as the pre-intervention period for both treated unit and
Compute FPC-scores for all units that explain most of variation in the data
Step 2.
-
•
Apply K-means algorithm on FPC-scores and extract the donor pool
Step 3.
-
•
Run Robust PCA by ADMM over the donor pool and compute
-
•
Compute the relation between the treated unit and the donor pool by:
-
•
Estimate the counterfactual of the treated unit by:
3 Empirical Study
In this section, I apply the robust PCA synthetic control algorithm to the case of West Germany reunification. To make all conditions similar to [1], I used the same country-level panel data of OECD members from . In general, to implement the robust PCA synthetic control algorithm, we do not need to find an appropriate donor pool as the algorithm would take care of that, but here I used the same data set of [1] just for an equitable comparison.
In , West Germany reunified with East Germany. [1] use the synthetic control method to answer this question: what would have been the per capita GDP of West Germany if this reunification never happened?
To implement the robust PCA synthetic control, first I computed the FPC-scores of the OECD members in addition to West Germany for the pre-intervention period of . Figure 1 shows the percentage of explained variation in the data based on the number of FPC-scores. As you can see, even considering the first FPC-score can explain more than of the variation in the data. So, to reduce the dimensionality of data set, I considered the first FPC-score for the next step of my method, which is applying K-means algorithm 888The outcome of the k-means algorithm does not change even when selecting up to FPC-scores..
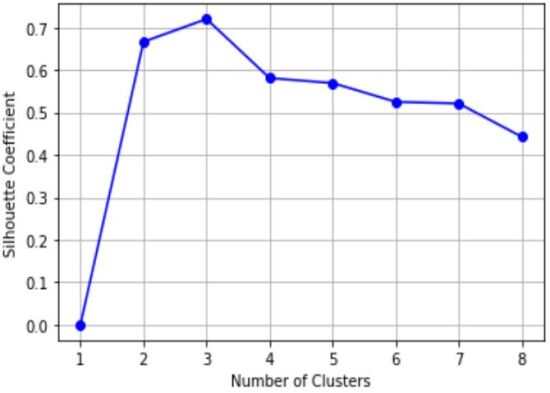
For K-means algorithm, we first need to find the optimized number of clusters. To do this, I use both elbow method and Silhouettes coefficient (figure 2(a) and figure 2(b)). In figure 2(b), the Silhouettes coefficient would reach its maximum when the data has been clustered by groups. We can have the same conclusion by looking at the figure 2(a) where the elbow of the plot corresponds to the clusters.
| Cluster 1 | Cluster 2 | Cluster 3 |
|---|---|---|
| United Kingdom | Greece | United States |
| Belgium | Portugal | Switzerland |
| Denmark | Spain | |
| France | ||
| West Germany | ||
| Italy | ||
| Netherlands | ||
| Norway | ||
| Japan | ||
| Australia | ||
| New Zealand | ||
| Austria |
Table 1 shows the result of K-means algorithm on the first FPC-score of the data set. Out of countries, counties fall in the same cluster of West Germany. I use these countries as the donor pool of West Germany for the post-intervention estimation.
Now that we have the donor pool, we can run step 3 and 4 of algorithm 4 to find the synthetic weights. Table 2 shows the synthetic weights of robust PCA, along with the weights of synthetic control model (reported in [1]) and weights of robust synthetic control model (suggested in [3]) for the West Germany 999To implement the robust synthetic control model and extract the low-rank structure of the donor pool, I considered the first singular values of the donor pool. In appendix B, I explained the justification behind it.. The robust PCA synthetic control considers Austria, France, New Zealand and Norway as the synthetic of West Germany, while the synthetic control considers Austria, Japan, Netherlands, Switzerland and United Sates. In contrast with these two methods, the robust synthetic control puts positive weights on all countries in the donor pool and this can create issues specially in the presence of outliers.


All three models consider a linear relation between the treated unit and its synthetics, but there are some differences in their assumptions. In robust PCA, the weights are conditioned to be greater or equal to zero. As I mentioned before, the idea behind this assumption is that the step 1 and 2 of robust PCA algorithm would pick up members of the donor pool with similar behavior as the treated unit during the pre-intervention period. In [1], the weights are conditioned to be between zero and one and their sum should be one. In other words, in the synthetic control, the weights are the convex hull of the treated unit. Robust synthetic control, on the other hand, does not impose any constraint on the synthetic weights.
| Country |
|
|
|
||||||||
| Australia | 0 | 0 | 0.07 | ||||||||
| Austria | 0.02 | 0.42 | 0.08 | ||||||||
| Belgium | 0 | 0 | 0.08 | ||||||||
| Denmark | 0 | 0 | 0.06 | ||||||||
| France | 0.35 | 0 | 0.07 | ||||||||
| Greece | - | 0 | 0.05 | ||||||||
| Italy | 0 | 0 | 0.08 | ||||||||
| Japan | 0 | 0.16 | 0.08 | ||||||||
| Netherlands | 0 | 0.09 | 0.07 | ||||||||
| New Zealand | 0.29 | 0 | 0.05 | ||||||||
| Norway | 0.48 | 0 | 0.08 | ||||||||
| Portugal | - | 0 | 0.04 | ||||||||
| Spain | - | 0 | 0.05 | ||||||||
| Switzerland | - | 0.11 | 0.08 | ||||||||
| United Kingdom | 0 | 0 | 0.06 | ||||||||
| United States | - | 0.22 | 0.09 |
-
•
Notes: The “-” indicates that the robust PCA method does not use this country as the donor pool of West Germany
Given the synthetic weights for West Germany for all three models, we can estimate the counterfactual of the treated unit for the post intervention period. Figure 3 shows the estimation of the counterfactual of West Germany after year 1990 for all models, along with its actual per capita GDP. The difference between the estimation of these models is better displayed in figure 4, where the gap between actual per capita GDP of West Germany and the estimation of each model is plotted. For the first two years of reunification (1991 and 1992), all three models (more pronounced in the robust PCA) show an increase in the per capita GDP of West Germany due to the initial increase in the demand. After that, all three models suggest a decrease in the per capita GDP of West Germany compared to its counterfactual estimation. The robust PCA synthetic control stays closer to the synthetic control, while the robust synthetic control shows a higher difference in West Germany and its counterfactual.


To assess how reliable the counterfactual estimations of these models are, I implement placebo studies in two ways. First placebo study in time: In this method, we consider an earlier time before the actual intervention, for example the year . Then we estimate the counterfactual of the treated unit from up to the actual intervention time, for the case of West Germany. Figure 5 shows the result of placebo study for the the models, along with the actual per capita GDP of West Germany between to . The synthetic control model slightly overestimates the per capita GDP, while the robust PCA synthetic control and robust synthetic control models both slightly underestimate it. Although the synthetic control model more closely parallels the actual per capita GDP, we should also consider the fact that synthetic control in [1] utilizes variables for the counter factual estimation, whereas the robust PCA synthetic control and robust synthetic control use only the outcome variable (i.e. per capita GDP) for this estimation. Crucially, the counterfactual estimation of all these models do not diverge from the actual per capita GDP of West Germany and successfully capture its trend from onward.

The second method of placebo study is to reassign the treatment to other units. In this form of placebo study, we iteratively assume that the intervention happened to one of the units in the donor pool and we use our model to estimate the counterfactual of the treated unit. Therefore, for each unit in the donor pool, we would have model fittings for the pre-intervention period and counterfactual estimations for the post-intervention time. Then, we can use , which is define for each unit as:
To find the lack of goodness of fit for each unit and for both pre-intervention period and post-intervention period . The idea is that if the actual treated unit, West Germany, experienced a significant difference in its per capita GDP as the result of intervention, the ratio of its post-intervention to its pre-intervention should be significantly higher than other units in the donor pool which did not receive the actual intervention. Figure 6 shows the ratio of post-reunification to the pre-unification for all units of the donor pool for all three models. This figure demonstrates that this ratio is noticeably higher for West Germany compared to other units in the donor pool when we apply the robust PCA synthetic control and the synthetic control model suggested in [1]. Interestingly, the robust synthetic control fails to satisfy this placebo study as the ratio of two , for the case of West Germany is not higher compared to the other countries. As previously mentioned, one possible explanation for the failure of robust synthetic control could be that the underlying process of this method is vulnerable to the effects of outliers, and the data set may contain outliers.

Finally, to show that the findings of robust PCA synthetic control are not sensitive to the weight of a specific country in the synthetic, I follow the [1] to run a similar robustness test. As previously discussed, to estimate the counterfactual of West Germany by robust PCA synthetic control, five countries (Austria, France, New Zealand and Norway) have a positive weight, and for the synthetic control model these five countries are Austria, Japan, Netherlands, Switzerland and United Sates, while the robust synthetic control model puts positive weights on all countries. Our counterfactual estimation is robust if removing one of the synthetic members does not change the conclusion about the impact of reunification on West Germany, also ideally should not change the counterfactual estimation drastically. Figure 7 shows the result of the robustness test on all three models. For the robust PCA synthetic control and synthetic control models, in each iteration, I drop one of the five countries with the positive synthetic weight and I re-estimate the counterfactual (gray lines). Robust PCA synthetic control shows a robust behavior for the estimation of counterfactual in the absent of one synthetic member. In the case of synthetic control, when the US is eliminated from the donor pool, the counterfactual estimation gets very close to the actual per capita GDP of West Germany or even cut it in some years. For the robust synthetic control, I drop all members of donor pool one by one in each iteration, because all countries in the donor pool have a positive weight for the counterfactual estimation and the result shows that this method can pass the robustness test. In general, the robust PCA synthetic control shows the smallest fluctuation around its counterfactual estimation in the absent of one of its synthetic units and it has the best performance for the robustness test.

4 Simulation Study
In this section, I conduct a simulation study to analyze the performance of robust PCA synthetic control. To do so, I first generate two different processes with additive noise:
| (29) |
where is an i.i.d Gaussian noise with a mean of zero and variances of 1, 4, 9, 16, and 25. For each specific value of the variance, I generate of and of where . I assume that the intervention happens at .

Figure 8 shows the plot of the two processes (4) along with their true underlying mean for the case of the highest noise variance . I implement the functional principal component analysis over the pre-invervention time period and then cluster these reduced dimension data points using K-means algorithm. For all cases of variance of 1, 4, 9, 16, and 25, the first FPC-scores can explain more than of the variation in the data and Silhouettes statistics (Figure 9)101010Figure 9 shows the explained variation by FPC-scores and Silhouettes statistics for the number of clusters, just for the case of , but the conclusion would not change for the other values of variances. can determine the two clusters of the data points which are exactly the two underlying processes in (4).

The accuracy of the clustering for the underlying processes (4), even with one FPC-score, is and the K-means can differentiate between these two processes for all amount of noises. Then, I discard and I continue the analysis over because this process has a more complicated structure.
For , assume that the true means is the treatment unit that we want to estimate and the noisy data are the donor pool of it. I use the robust PCA to extract the low-rank structure of the donor pool. Then I estimate the relation between the true mean and the low-rank structure of the donor pool for the pre-intervention period.

| Noise | Pre-invervention error | Post-invervention error |
|---|---|---|
| 1 | 0.09 | 0.13 |
| 4 | 0.19 | 0.25 |
| 9 | 0.29 | 0.38 |
| 16 | 0.39 | 0.51 |
| 25 | 0.49 | 0.64 |

| Noise | Pre-invervention error | Post-invervention error |
|---|---|---|
| 1 | 0.27 | 0.65 |
| 4 | 0.52 | 1.14 |
| 9 | 0.86 | 1.69 |
| 16 | 1.07 | 2.65 |
| 25 | 1.36 | 2.59 |
Figure (10) shows the estimation of the true means for both pre-invervention and post-intervention period for all values of variances of 1, 4, 9, 16, and 25. Although the shape of the true mean has changed slightly after the intervention, robust PCA synthetic control remains close to the true mean even with a high amount of noise in data. Table 3 reports the RMSPE of estimation for both pre-invervention and post-invervention period, showing that these errors stay close to each other for different amounts of noise.
In the next step, I repeat this procedure but this time dropping of the data randomly. The estimation of the true means become less accurate with missing data (Figure (10) and Table 4), but robust PCA synthetic control remains fairly close to the true means after the intervention. Note that the synthetic control model does not work in the presence of the missing data, but robust PCA synthetic control can estimate the counterfactual even with relatively high volume of missing data and noise.
5 Conclusion
Synthetic control model has recently became a popular method for counterfactual estimation, although some obstacles remain. In this study, I suggest a five-step algorithm, robust PCA synthetic control, to overcome some of these issues. Robust PCA synthetic control uses the combination of functional principal component analysis and K-means algorithm to select the donor pool, so the selection of donor pool would no longer be subjective. Then, this method uses the robust principle components analysis to find the low-rank structure of the donor pool. After finding the low-rank structure, robust PCA synthetic control estimates a linear relation between the treated unit and the donor pool over the pre-intervention period. By this relation we can find the counterfactual estimation of the treated unit for post-intervention period.
In addition to finding the donor pool, robust PCA synthetic control model can estimate the counterfactual just based on the outcome variable and it does not need an expert to figure out the relevant features (covariates) of the treated unit.
Finally, I implement robust PCA synthetic control method on the case of West Germany reunification with the East Germany on to estimate the counterfactual of West Germany’s per capita GDP. I document that my method can outperform the robust synthetic control suggested by [3] in placebo studies and it is less sensitive to the weights of synthetic members compare to synthetic control model implemented in [1].
Appendix A Propositions Proof
A.1 Proof of Proposition 1
Proof.
To proof the proposition, consider the definition of proximal operator:
The above optimization would reach its minimum when the subgradients of contains zero:
which means that:
∎
A.2 Proof of Proposition 2
Proof.
Similar to the previous proof, we have the proximal operator over the nuclear norm as:
Following [10], is the solution of the above optimization if:
| (30) |
We know that the subgradients of nuclear norm is (see [24]):
| (31) |
Using the SVD decomposition, we can write and as:
where the are the left and right (respectively) singular vectors of related to the singular values greater than , while the are related to the singular values smaller or equal to . Based on the SVD decomposition, we have:
By the definition of SVD decomposition, we have , and holds because the diagonal elements of is less or equal to . So, is in the subgradients of and (31) holds. ∎
Appendix B Robust Synthetic Control Hyperparameter
As I mentioned, the robust synthetic control uses the singular values thresholding to extract the low-rank structure of the data set. Figure 12 shows the singular values of the West Germany data set. From the second singular value, these values approach zero and by considering just singular values, we can extract the low-rank structure. Figure 13 also confirms that the first singular values can explain near to of the variation in the data.


References
- [1] Alberto Abadie, Alexis Diamond and Jens Hainmueller “Comparative politics and the synthetic control method” In American Journal of Political Science 59.2, 2015, pp. 495–510
- [2] Alberto Abadie and Javier Gardeazabal “The economic costs of conflict: A case study of the basque country” In American Economic Review, 2003
- [3] Muhammad Amjad, Devavrat Shah and Dennis Shen “Robust synthetic control” In Machine Learning Research 19, 2018, pp. 1–51
- [4] Susan Athey et al. “Matrix completion methods for causal panel data models”, Working Paper Series 25132, 2018
- [5] Shahid Aullah and C.F. Finch “Applications of functional data analysis: A systematic review” In BMC Medical Research Methodology 13, 2013, pp. 121–142
- [6] Dimitri P. Bertsekas “Constrained optimization and Lagrange multiplier methods” Athena Scientific, 1981
- [7] Janet Bouttell et al. “Synthetic control methodology as a tool for evaluating population-level health interventions” In Epidemiol Community Health 72, 2018, pp. 673–678
- [8] Stephen Boyd et al. “Distributed optimization and statistical learning via the alternating direction method of multipliers” In Foundations and Trends in Machine Learning 3.1, 2010, pp. 1–122
- [9] Steven Brunton and J. Kutz “Data-driven science and engineering” Cambridge University Press, 2019, pp. 107–109
- [10] Jian-Feng Cai, Emmanuel Candes and Zuowei Shen “Characterization of the subdifferential of some matrix norms” In SIAM Journal on Optimization 20, 2010, pp. 1956–1982
- [11] Emmanuel J. Candes, Xiaodong Li, Yi A. Ma and John Wright “Robust principal component analysis?” In Journal of the ACM 58, 2011
- [12] Venkat Chandrasekaran, Sujay Sanghavi, Pablo A. Parrilo and Alan S. Willsky “Rank-sparsity incoherence for matrix decomposition” In Society for Industrial and Applied Mathematics 21, 2011, pp. 572–596
- [13] Christophe Croux and Anne Ruiz-Gazen “High breakdown estimators for principal components: the projection-pursuit approach revisited” In Journal of Multivariate Analysis 95, 2005, pp. 206–226
- [14] David L. Donoho and Michael Elad “Optimally sparse representation in general (nonorthogonal) dictionaries via l1 minimization” In Proceedings of the National Academy of Sciences 100.5 National Academy of Sciences, 2003, pp. 2197–2202
- [15] Steinley Douglas “K‐means clustering: A half‐century synthesis” In The British Psychological Society 59, 2006, pp. 1–34
- [16] Li Sian Goh “Did de-escalation successfully reduce serious use of force in Camden County, New Jersey? A synthetic control analysis of force outcomes” In Criminology and Public Policy 20, 2021, pp. 207–241
- [17] Yehua Hartigan and Tailen Wong “A K-Means clustering algorithm” In Wiley for the Royal Statistical Society 28, 1979, pp. 100–108
- [18] Magnus Hestenes “Multiplier and gradient methods” In Journal of optimization theory and applications, 4.5, 1969, pp. 303–320
- [19] Yehua Li and Tailen Hsing “Uniform convergence rates for nonparametric regression and principle component analysis in functional/longitudinal data” In The Annals of Statistics 38, 2010, pp. 3321–3351
- [20] Benjamin Recht, Weiyu Xu and Babak Hassibi “Necessary and sufficient conditions for success of the nuclear norm heuristic for rank minimization” In 2008 47th IEEE Conference on Decision and Control, 2008, pp. 3065–3070
- [21] Peter Rousseeuw “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis” In Journal of Computational and Applied Mathematics 20, 1987, pp. 53–65
- [22] Han Lin Shang “A survey of functional principal component analysis” In AStA Advances in Statistical Analysis 98, 2014, pp. 121–142
- [23] Ivana Stanimirova, Michal. Daszykowski and Beata Walczak “Dealing with missing values and outliers in principal component analysis” In Talanta 72.1, 2007, pp. 172–178
- [24] G Alistair Watson “Characterization of the subdifferential of some matrix norms” In Linear Algebra and Its Applications 170, 1992, pp. 33–45
- [25] John Wright and Yi Ma “High-dimensional data analysis with low-dimensional models: Principles, computation, and applications” Cambridge University Press, 2021