Robust Control Lyapunov-Value Functions for Nonlinear Disturbed Systems
Abstract
Control Lyapunov Functions (CLFs) have been extensively used in the control community. A well-known drawback is the absence of a systematic way to construct CLFs for general nonlinear systems, and the problem can become more complex with input or state constraints. Our preliminary work on constructing Control Lyapunov Value Functions (CLVFs) using Hamilton-Jacobi (HJ) reachability analysis provides a method for finding a non-smooth CLF. In this paper, we extend our work on CLVFs to systems with bounded disturbance and define the Robust CLVF (R-CLVF). The R-CLVF naturally inherits all properties of the CLVF; i.e., it first identifies the ”smallest robust control invariant set (SRCIS)” and stabilizes the system to it with a user-specified exponential rate. The region from which the exponential rate can be met is called the ”region of exponential stabilizability (ROES).” We provide clearer definitions of the SRCIS and more rigorous proofs of several important theorems. Since the computation of the R-CLVF suffers from the ”curse of dimensionality,” we also provide two techniques (warmstart and system decomposition) that solve it, along with necessary proofs. Three numerical examples are provided, validating our definition of SRCIS, illustrating the trade-off between a faster decay rate and a smaller ROES, and demonstrating the efficiency of computation using warmstart and decomposition.
keywords:
Optimal Control; HJ Reachability Analysis; Control Lyaounov Function.,
1 Introduction
Liveness and safety are two main concerns for autonomous systems working in the real world. Using control Lyapunov functions (CLFs) to stabilize the trajectories of a system to an equilibrium point [1, 2, 3] is a popular approach to ensure liveness, whereas using control barrier functions (CBFs) to guarantee forward control invariance is popular for maintaining safety [4, 5, 6]. However, finding CLFs and CBFs is hard, and users of these methods typically rely on hand-designed or application-specific CLFs and CBFs [7, 8, 9, 10, 11]. However, finding these hand-crafted functions can be difficult, especially for high-dimensional systems with state or input constraints.
Liveness and safety can also be achieved by formal methods such as Hamilton-Jacobi (HJ) reachability analysis [12]. This method formulates liveness and safety as optimal control problems, and has been used for applications in aerospace, autonomous driving, and more [13, 14, 15, 16, 17]. This method computes a value function whose level sets provide information about safety (or liveness) over space and time, and whose gradients provide the safety (or liveness) controller. This value function can be computed numerically using dynamic programming for general nonlinear systems and can accommodate input and disturbance bounds. Undermining these appealing benefits is the “curse of dimensionality.” Ongoing research has improved computational efficiency and refined the appximation [18, 19, 20, 21], but performing dynamic programming in high dimensions (6D or more) remains challenging.
Standard HJ reachability analysis focuses on problems such as minimum time to reach a goal, or avoiding certain states for all time. It does not stabilize a system to a goal after reaching it. In our previous work [22], we modified the value function and defined the control Lyapunov value function (CLVF) for undisturbed systems. The CLVF finds the smallest control invariant set (SCIS) and the region of exponential stabilizability (ROES) of the system. Its gradient can be used to synthesize controllers that stabilize the system to the SCIS with a user-specified exponential rate . It also handles complex dynamics and input bounds well.
However, the previous CLVF work only works for systems without disturbance, and the term “SCIS” is not the minimal control invariant set as defined in [23, 24]. Further, the “curse of dimensionality” restricts its application to relatively low dimensional systems (5D or lower.) In facing all these limitations, we formed this journal extension. The main contributions are:
-
1.
We define the time-varying robust CLVF (TV-R-CLVF) and the robust CLVF (R-CLVF) for systems with bounded disturbance and control. We prove that the R-CLVF is Lipschitz continuous, satisfies the dynamic programming principle, and is the unique viscosity solution to the corresponding R-CLVF variational inequality (VI).
-
2.
We define the smallest robustly control invariant set (SRCIS) of a system. We show that the SRCIS of a given system is the zero-level set of the computed R-CLVF.
-
3.
We relax the choice of the loss function to any vector norm. We show different choices of the norm results in different SRCIS, ROES, and trajectories.
-
4.
Two methods to accelerate computation are introduced: warmstart R-CLVF and system decomposition. A point-wise optimal R-CLVF quadratic program (QP) controller is provided and the algorithm for computing the R-CLVF is updated.
-
5.
We provide numerical examples to validate the theory and show numerical efficiency with warmstart R-CLVF and system decomposition.
The paper is organized in the following order: Sec 2 provides background information on HJ reachability analysis and CLVF. Sec 3 introduces the TV-R-CLVF, and builds up the theoretic foundation for the R-CLVF. An optimal R-CLVF-QP controller is provided. Sec 4 introduces warmstart R-CLVF and system decomposition that accelerates the computation. Sec 5 shows three numerical examples, validating the theory.
2 Background
In this paper, we seek to exponentially stabilize a given nonlinear time-invariant dynamic system with bounded input and disturbance to its SRCIS. We start by defining crucial terms.
2.1 Problem Formulation
Consider the nonlinear time-invariant system
| (1) |
where is the initial time, and is the initial state. The control signal and disturbance signal are drawn from the set of measurable functions and . Assume also the control input and disturbance are drawn from convex compact sets and respectively. We have:
Assume the dynamics is uniformly continuous in , Lipschitz continuous in for fixed and , bounded . Under these assumptions, given initial state , control and disturbance signal , , there exists a unique solution , of the system (1). When the initial condition, control, and disturbance signal used are not important, we use to denote the solution, which is also called the trajectory in this paper. Further assume the disturbance signal can be determined as a strategy with respect to the control signal: , drawn from the set of non-anticipative maps [25].
In this paper, we seek to stabilize the system (1) to its SRCIS. We first introduce the notion of a robustly control invariant set.
Definition 1.
(Robustly Control Invariant Set.) A closed set is robustly control invariant for (1) if , , such that , .
When the system has equilibrium points, we assume is one, i.e. . When the system does not have an equilibrium point, we assume it has some robust control invariant set around the origin.
We are also interested in finding the region of exponential stabilizability (ROES) of a set. We first define the distance from a point to a set to be
| (2) |
where is the boundary of and any vector norm is applicable here.
Definition 2.
The ROES of a set is the set of states from which the trajectory converges to with an exponential rate :
2.2 HJ Reachability and CLVF
In the conference version [22], we proposed to construct the CLVF using HJ reachability analysis. This is done by formulating a reachability safety problem, where the system tries to avoid all regions of the state space that are not the origin. This problem can be solved as an optimal control problem.
Traditionally in HJ reachability analysis, the continuous loss function is defined such that its zero super-level set is the failure set .
The finite-time horizon cost function captures whether a trajectory enters at any time in under given control and disturbance signal:
| (3) |
The value function is the cost given optimal control signal with worst case disturbance:
| (4) |
The value function is the viscosity solution to the Hamilton-Jacobi-Isaacs variational inequality (HJI-VI) [26]:
| (5) | ||||
Therefore the value function (2.2) can be computed using dynamic programming by solving this HJI-VI recursively over time. The infinite-time horizon value function is defined by taking the limit of as [27],
| (6) |
For the time-varying value function, means despite the control signal used, there always exists a disturbance signal such that the trajectory starting from that point will enter for some time . The sub-zero level set of is therefore safe for the time horizon . This can be extended to say that each sub-level set is safe with respect to the set defined by .
In the infinite-time setting, for all states in the sub-level set of , there always exists a control signal such that the maximum loss is lower than despite the disturbance signal. This means every sub-level set of is robustly control invariant and the trajectories can be maintained within a particular level set boundary. Further, this set is the largest RCIS contained within the sub-level set of .
Remark 1.
In this paper, we restrict the selection of to be vector norms (e.g., p-norm, or weighted Q norms.) In other words, the loss function measures the distance of a state to the origin. With this restriction, the cost function (3) captures the largest deviation from the origin of a given trajectory, initialized at with and applied, in time horizon . The (infinite time) value function (2.2) captures the largest deviation with optimal control and disturbance signals applied in (infinite time) finite time horizon.
Denote the minimal value of as . The -level set of is the smallest RCIS (SRCIS), and denoted by . Further, all the states in the SRCIS have the same value:
| (7) |
Remark 2.
Here the term smallest should be understood as ‘smallest distance to the origin measured by ,’ and the SRCIS should be understood as ‘the largest RCIS, with the smallest distance to the origin.’ This is different from the ‘minimal RCIS’ as defined in [23] (where ‘minimal’ is defined as ‘no subset is robust control invariant’).

An example to illustrate this difference is this:
| (8) |
where and . This system has an undisturbed, uncontrolled equilibrium point . It can be verified that is one ‘minimal RCIS’ as all its subsets are not robustly control invariant. In fact, picking any results in a ‘minimal RCIS.’ On the other hand, picking , the SRCIS is . This is because though the control can stabilize any to the origin, the disturbance is also strong enough to perturb any to leave the origin. Therefore, all states s.t. have the same value, and the SRCIS measured by the -norm is a square. Fig. 1 shows the SRCIS for three different choices of and the corresponding value function.
An interesting observation is that adding or substracting a constant value to the loss function , the corresponding SRCIS stays the same.
Proposition 1.
Define , and denote the corresponding value function as , then
| (9) |
This means adding/subtracting a constant value to the loss function will equivalently add/subtract the value function with the same value.
However, each level set of the HJ value function (6) is only robustly control invariant, there is no guarantee that the system can be stabilized to lower level sets or the origin. In our preliminary paper [22], we define the control Lyapunov-value function (CLVF) for undisturbed systems. We proved that the CLVF satisfies the dynamic programming principle, and is the unique viscosity solution to the corresponding CLVF-VI. We also proved that the domain of CLVF is the ROES of the SCIS. A feasibility-guaranteed QP was provided for controller synthesis.
In this article, we further develop the theory of CLVFs for disturbed systems and provide necessary theorems for numerical implementation in high-dimensional nonlinear systems.
3 Robust Control Lyapunov-Value functions
In this section, we start by defining the TV-R-CLVF and prove some important properties of it. We then define the R-CLVF, which is the limit function of the TV-R-CLVF. We show that the existence of the R-CLVF is equivalent to the exponential stabilizability of the system to its SRCIS and that its domain is the ROES.
3.1 TV-R-CLVF
Definition 3.
A TV-R-CLVF is a function defined as:
| (10) |
where is the cost function:
| (11) |
is a user-specified parameter that represents the desired decay rate, .
The cost at a state captures the maximum exponentially amplified distance between the trajectory starting from this state and the zero-level set of (positive outside and negative inside.) The optimal control tries to minimize this cost and seeks to drive the system towards the origin. In contrast, the disturbance tries to maximize the cost and push the system away from the origin.
Proposition 2.
The TV-R-CLVF is bounded and Lipschitz in for any compact set .
Proof.
Since the solution exists and the loss function is chosen to be vector norms, within any finite time horizon , the cost function is bounded, and this holds for all control and disturbance signals. Therefore the TV-R-CLVF is also bounded.
For the local Lipschitz property, we start by proving the cost function is locally Lipschitz continuous in . Because of the continuous dependence on the initial condition, , there exists a constant such that
refer to [13] inequality (3.16). Since , using the triangle inequality of the vector norms, we have
Multiply on both side, we get
| (12) |
Further, we have:
This shows the cost function is Lipschitz in with Lipschitz constant . Since the above conclusion holds for arbitrary control and disturbance signals, we conclude that the TV-R-CLVF is also Lipschitz with the same Lipschitz constant:
∎
Denote the zero-level set of TV-R-CLVF as
| (13) |
An important property of the TV-R-CLVF is that for all different , the zero-level sets at a given time are the same.
Lemma 1.
For all , are the same.
Proof.
Assume , we prove the following: .
() We first prove .
Since for all , and from the equation (10), must remain non-positive for all , otherwise . Further, there must exist a s.t. , where and are optimal disturbance and control signals. With the same control and disturbance signal, we have
If and are not optimal disturbance and control for the TV-R-CLVF with , then there must exist and , s.t. for all . However, if this is the case, then apply and to TV-R-CLVF with , we get
which contradicts the assumption. Therefore and are optimal for TV-R-CLVF with , i.e. .
() Switch and and follow the same process, we get ∎
The essence of this proposition is that , if and is optimal w.r.t. , it is also optimal w.r.t. all .
We now present that the TV-R-CLVF satisfies the dynamic programming principle, and is the unique viscosity solution to the TV-R-CLVF-VI.
Theorem 2.
satisfies the following dynamic programming principle for all :
| (14) |
Theorem 3.
The TV-R-CLVF is the unique viscosity solution to the following TV-R-CLVF-VI,
| (15) | ||||
with initial condition .
The proof of the above two Theorems can be obtained analogously following Theorem 2,3 in [28], and is omitted here. Here, is called the Hamiltonian:
Further, we can show that the Hamiltonian is a continuous function in . Since is affine in , the continuity in is proved. Also, is a continuous function of , and from the assumption, is also continuous in . The dot product of two continuous functions is a continuous function, so is continuous in . This holds for all , therefore is continuous in . In conclusion, H is continuos in .
3.2 R-CLVF
We now turn our attention to the infinite-time horizon and the R-CLVF.
Definition 4.
Robust Control Lyapunov-Value Function (R-CLVF) Given a compact set , the function is a R-CLVF if the following limit exists:
| (16) |
It should be noted that the domain of the TV-R-CLVF is , while for the R-CLVF, it is . Also, Remark 2 from [22] still holds, i.e., the convergence in equation (16) is uniform in . The existence of the R-CLVF on is justified by the following Lemma.
Lemma 4.
The R-CLVF exists on a compact set (or ) if the system is exponentially stabilizable to its SRCIS from (or ). Further .
Proof.
Assume the system is exponentially stabilizable to the SRCIS. Using the Definition 2, we have , s.t.
Plug in equation (2),
| (17) |
Plug in , we have
| (18) |
where we used equation (4) for the last inequality. Multiply on both side
which holds for all . Therefore
This upper bound is independent of , therefore as , we have . Since the R-CLVF monotonically increases, we conclude that the limit in (16) exists , and .
∎
Denote the zero-level set of R-CLVF as
The R-CLVF with different has the same zero level set.
Proposition 3.
For all , are the same.
The proof is analogous to the proof of Lemma 1 and is omitted here.
Proposition 4.
The R-CLVF is locally Lipschitz continuous in
Theorem 5.
(CLVF Dynamic Programming Principle) For all , the following is satisfied
| (19) |
Proof.
From the definition of the R-CLVF and Theorem 2, and we have:
| (20) |
where , and and are the optimal control and disturbance strategy. Further, since the dynamics is time-invariant, for any , define
and corresponding disturbance
it can be verified that
In other words, if we only change the initial time, but keep the time horizon unchanged, the cost will stay the same, with optimal control and disturbance determined by shifting the original optimal control and disturbance signal with the corresponding time. Denote
we have:
| (21) |
and
| (22) |
Combine equations (5) (5), equation (5) can be written as
Choosing , we get:
∎
Theorem 6.
(CLVF-VI viscosity solution) The CLVF is the unique continuous solution to the following CLVF-VI in the viscosity sense,
| (23) | ||||
Proof.
We prove this theorem using the stability of viscosity solutions.
First, define function
| (24) |
Since and are continuous functions, is also continuous.
Now, fix and only look at . Consider a sequence , and and . Evaluate and at each , we get two sequence of functions and , with and uniformly. Also, denote
We have a sequence of functions , and
which is the left-hand side (LHS) of equation (23), and the convergence is uniform. Further, Theorem 3 shows that is the viscosity solution to .
It should be noted that in the numerical solver, we cannot directly solve for equation (23). Instead, we solve for equation (15) and backpropagate using dynamic programming to get the value at the previous time step. This is why we do not specify the boundary condition for equation (23).
Proposition 5.
At any point (differentiable or non-differentiable) in the domain of the R-CLVF, , there exists some control such that
| (25) |
Proof.
Since the R-CLVF is only Lipschitz continuous, there exist points that are not differentiable. For those points, [16] showed that either a super-differential () or a sub-differential () exists, whose elements are called super-gradients and sub-gradients respectively. A function is differentiable at if . Non-differentiable points only have a super-differential or sub-differential. At non-differentiable points, define , where is either a sub-gradient or a super-gradient.
For non-differentiable points with super-differential, the corresponding solution is called a sub-solution, and
The maximum of the two terms is less or equal to 0, which implies both terms must be less or equal to 0:
This means for any super-gradients, there exists some control input, that will provide a sufficient decrease in the value along the trajectory.
Combined, we get the desired inequality: holds for all points in . ∎
In Lemma 4, we showed that the existence of the R-CLVF can be derived when the system is robustly exponentially stabilizable to its SRCIS. Now, we show that the existence of the R-CLVF implies the robust exponential stabilizability.
Lemma 7.
The system can be exponentially stabilized to its smallest robustly control invariant set from (or ), if the R-CLVF exists in (or ).
Proof.
Assume the limit in (16) exists in . For any initial state , consider the optimal trajectory . From Proposition 5:
Using the comparison principle, we have ,
| (26) |
Since , we have:
Therefore, we have:
Plugging in (26) gives us
where
and . In other words, the controlled system can be locally exponentially stabilized to from , If the R-CLVF exists on . Further, if the R-CLVF exists on . the above result holds globally.
∎
Theorem 8.
The system can be exponentially stabilized to its smallest robustly control invariant set from (or ), if and only if the R-CLVF exists in (or ).
3.3 R-CLVF-QP
For control and disturbance affine system
| (27) |
where , , . For such systems, (25)is equivalent to the following linear inequality in :
Theorem 9.
(Feasibility Guaranteed R-CLVF-QP) Given some reference control , the optimal controller can be synthesized by the following CLVF-QP with guaranteed feasibility .
Proof.
This is a direct result of Proposition 5. ∎
Note that the QP controller is only point-wise optimal, with respect to “staying close to the reference controller.” It is not optimal w.r.t. the value function, as will be shown in the numerical examples.
4 R-CLVF with Numerical Implementation
In the numerical implementation for computing the R-CLVF, equation (5) is solved on a discrete grid, until some convergence threshold is met, this leads to the well-known “curse of dimensionality.” In this section, we provide two main methods to overcome this issue: the warmstarting technique and the system decomposition technique. Necessary proofs are provided and the effectiveness is validated with a 10D example in the numerical example.
4.1 R-CLVF with Warmstarting
In the previous conference paper, we introduced a two-step process, that first finds the SRCIS, and then finds the CLVF. This process requires solving the TV-R-CLVF-VI two times, each with a complete initialization. In this subsection, we show that the converged value function for the first step can be used to warmstart the second step computation.
Denote the time-varying value function with initial value as , and the infinite time value function as , with the corresponding domain . We still have the same loss function .
Theorem 10.
For all initialization , we have holds , .
Proof.
∎
Theorem 10 shows that no matter what the initial value is, the value function propagated with this initial value is always an over-approximation of the TV-R-CLVF. However, for R-CLVF, we have the following Proposition and Theorem.
Proposition 6.
If exists on , then and .
Proof.
The first part is a direct result from Theorem 10. The second part can be proved by contradiction. Assume but . This means is finite, but is infinite, which contradicts to the first part of this proposition. ∎
Theorem 11.
For initialization , we have .
Proof.
Denote , and the value function initialized with as . we have :
Note that is the already the converged value function, we have .
Using Theorem 11, we provide an enhanced version of the original algorithm for computing the R-CLVF, shown in Alg. 1.
4.2 R-CLVF with Decomposition
To discuss the R-CLVF with decomposition, we first introduce the self-contained subsystems decomposition.
Definition 5.
(Self-contained subsystem decomposition) (SCSD) Consider the following special case , with , , , , , and . , , are called “state partitions” of the system.
Theorem 12.
Assume the system can be decomposed into several self-contained subsystems, and there are no shared control and states between each subsystem. Denote the corresponding R-CLVFs for the subsystems as with domain , and define
| (28) |
Then
This reconstructed value function is a Lipschitz continuous robust CLF, but not necessarily the R-CLVF of the full-dimensional system. Since we assume no shared control between subsystems, the controller for the full-dimensional system can be determined by solving R-CLVF-QPs for the subsystems.
5 Numerical Examples
5.1 2D System Revisit
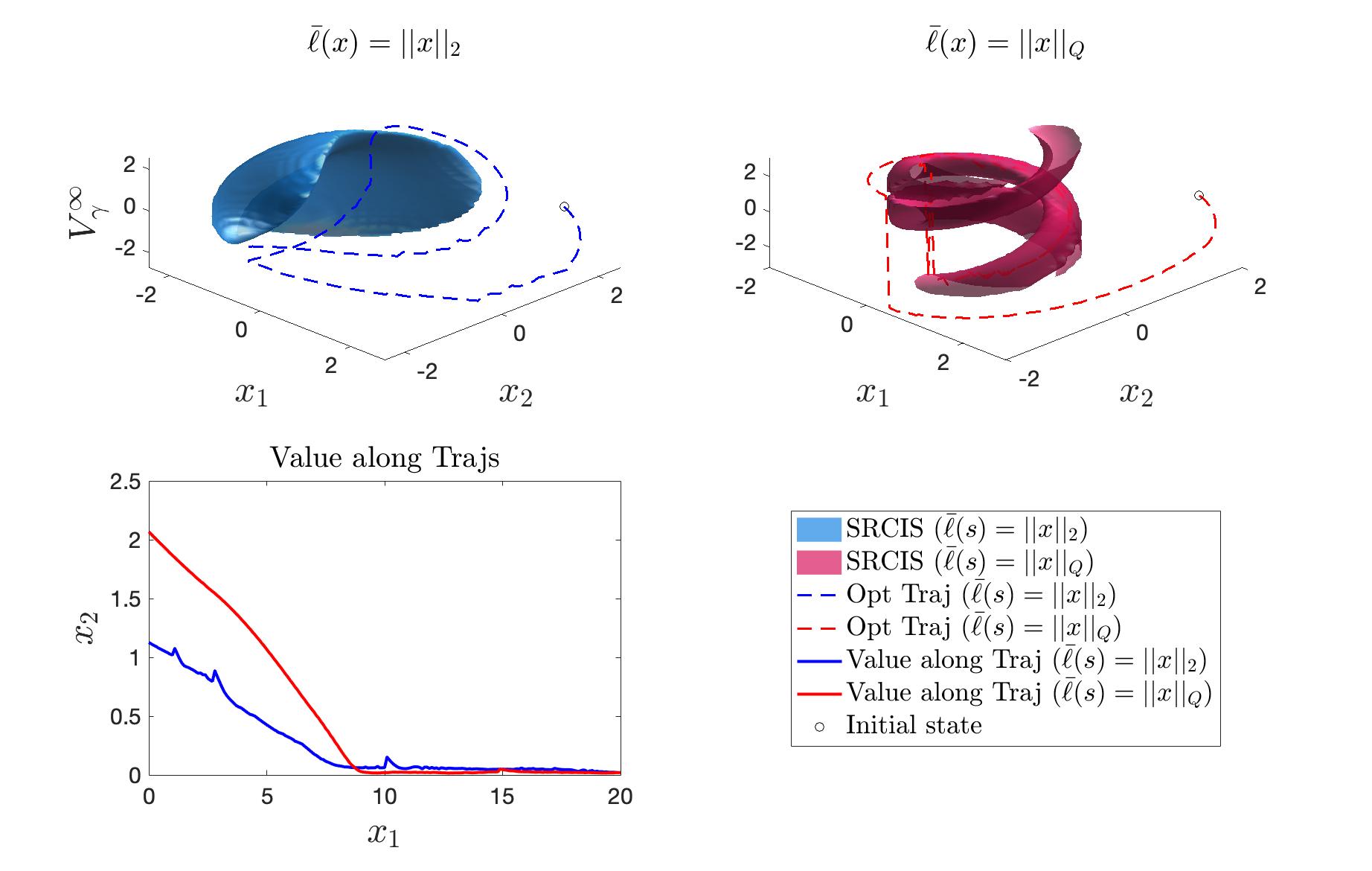
Consider again the system given by equation (8), and specify . We compute the R-CLVF with , . The results are shown in Fig. 2. It should be noted that for this system, the SRCIS for and are both , and ROES .

5.2 3D Dubins Car
Consider the 3D Dubins car example:
where and is the control and is the disturbance. This system has no equilibrium point. The SRCISs With different are shown in Fig. 3, and the trajectory converges to the SRCIS exponentially.
5.3 10D Quadrotor
Consider the 10D quadrotor system:
| (29) |
where denote the position, denote the velocity, denote the pitch and roll, denote the pitch and roll rates, and are the controls. The system parameters are set to be , , , , .
This 10D system can be decomposed into three subsystems: X-sys with stats , Y-sys with stats, and Z-sys with stats . It can be verified that all three subsystems have an equilibrium point at the origin. Further, there’s no shared control or states among subsystems. We use .
| System | Z dim | X/Y dim | Full Sys |
| w/o Warmstrat | 405.2 s | 3731.7 s | 7868.6s |
| w. Warmstart | 234.9 s | 3564.6 s | 7364.1s |
A CLF is reconstructed using equation (28), and the QP controllers for each subsystem are synthesized using Theorem 9. The results are shown in Fig. 4, and the computation time is shown in Tab. 1. A comparison of the R-CLVF with and without warmstart is shown in Fig. 5, showing that the warmstart provides the exact result.


6 Conclusions
In this paper, we extend our preliminary work on constructing CLVFs using HJ reachability analysis to the system with bounded disturbances. We provided more detailed discussions on several important claims and theorems compared to the previous version. Also, warmstarting and SCSD are proposed to solve the “curse of dimensionality,” and the effectiveness of both techniques is validated with numerical examples.
Future directions include finding conditions on when the SCSD provides R-CLVF and incorporating learning-based methods to tune the exponential rate for online execution in robotics applications.
References
- [1] E. D. Sontag, “A ‘universal’ construction of Artstein’s theorem on nonlinear stabilization,” Systems & control letters, 1989.
- [2] R. A. Freeman and J. A. Primbs, “Control lyapunov functions: New ideas from an old source,” in Conf. on Decision and Control, 1996.
- [3] K. K. Hassan et al., “Nonlinear systems,” Departement of Electrical and Computer Engineering, Michigan State University, 2002.
- [4] A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” in European Control Conf., 2019.
- [5] A. D. Ames, K. Galloway, K. Sreenath, and J. W. Grizzle, “Rapidly exponentially stabilizing control Lyapunov functions and hybrid zero dynamics,” Trans. on Automatic Control, 2014.
- [6] A. Ames, X. Xu, J. W. Grizzle, and P. Tabuada, “Control barrier function based quadratic programs for safety critical systems,” Trans. on Automatic Control, 2017.
- [7] Z. Artstein, “Stabilization with relaxed controls,” Nonlinear Analysis: Theory, Methods & Applications, 1983.
- [8] F. Camilli, L. Grüne, and F. Wirth, “Control Lyapunov functions and Zubov’s method,” SIAM Journal on Control and Optimization, 2008.
- [9] P. Giesl and S. Hafstein, “Review on computational methods for lyapunov functions,” Discrete & Continuous Dynamical Systems, 2015.
- [10] P. Giesl, “Construction of a local and global lyapunov function for discrete dynamical systems using radial basis functions,” Journal of Approximation Theory, 2008.
- [11] X. Xu, P. Tabuada, J. W. Grizzle, and A. D. Ames, “Robustness of control barrier functions for safety critical control,” Int. Federation of Automatic Control, 2015.
- [12] S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-Jacobi reachability: A brief overview and recent advances,” in Conf. on Decision and Control, 2017.
- [13] L. C. Evans and P. E. Souganidis, “Differential games and representation formulas for solutions of Hamilton-Jacobi-Isaacs equations,” Indiana University Mathematics Journal, 1984.
- [14] M. Bardi and I. Capuzzo-Dolcetta, Optimal control and viscosity solutions of Hamilton-Jacobi-Bellman equations. Springer, 2008.
- [15] M. G. Crandall and P.-L. Lions, “Viscosity solutions of hamilton-jacobi equations,” Trans. of the American mathematical society, 1983.
- [16] M. G. Crandall, L. C. Evans, and P.-L. Lions, “Some properties of viscosity solutions of hamilton-jacobi equations,” Trans. of the American Mathematical Society, 1984.
- [17] H. Frankowska, “Hamilton-jacobi equations: viscosity solutions and generalized gradients,” Journal of mathematical analysis and applications, 1989.
- [18] M. Chen, S. L. Herbert, M. S. Vashishtha, S. Bansal, and C. J. Tomlin, “Decomposition of reachable sets and tubes for a class of nonlinear systems,” Trans. on Automatic Control, 2018.
- [19] S. Bansal and C. J. Tomlin, “Deepreach: A deep learning approach to high-dimensional reachability,” in Int. Conf. on Robotics and Automation, 2021.
- [20] S. Herbert, J. J. Choi, S. Sanjeev, M. Gibson, K. Sreenath, and C. J. Tomlin, “Scalable learning of safety guarantees for autonomous systems using Hamilton-Jacobi reachability,” in Int. Conf. on Robotics and Automation, 2021.
- [21] C. He, Z. Gong, M. Chen, and S. Herbert, “Efficient and guaranteed hamilton–jacobi reachability via self-contained subsystem decomposition and admissible control sets,” IEEE Control Systems Letters, vol. 7, pp. 3824–3829, 2023.
- [22] Z. Gong, M. Zhao, T. Bewley, and S. Herbert, “Constructing control lyapunov-value functions using hamilton-jacobi reachability analysis,” IEEE Control Systems Letters, vol. 7, pp. 925–930, 2022.
- [23] S. Rakovic, E. Kerrigan, K. Kouramas, and D. Mayne, “Invariant approximations of the minimal robust positively invariant set,” IEEE Transactions on Automatic Control, vol. 50, no. 3, pp. 406–410, 2005.
- [24] Y. Chen, H. Peng, J. Grizzle, and N. Ozay, “Data-driven computation of minimal robust control invariant set,” in 2018 IEEE Conference on Decision and Control (CDC). IEEE, 2018, pp. 4052–4058.
- [25] P. P. Varaiya, “On the existence of solutions to a differential game,” SIAM Journal on Control, vol. 5, no. 1, pp. 153–162, 1967.
- [26] J. F. Fisac, M. Chen, C. J. Tomlin, and S. S. Sastry, “Reach-avoid problems with time-varying dynamics, targets and constraints,” in Hybrid Systems: Computation and Control. ACM, 2015.
- [27] I. J. Fialho and T. T. Georgiou, “Worst case analysis of nonlinear systems,” Trans. on Automatic Control, 1999.
- [28] J. J. Choi, D. Lee, K. Sreenath, C. J. Tomlin, and S. L. Herbert, “Robust control barrier-value functions for safety-critical control,” Conf. on Decision and Control, 2021.