Robot Motion Planning as Video Prediction: A Spatio-Temporal Neural Network-based Motion Planner
Abstract
Neural network (NN)-based methods have emerged as an attractive approach for robot motion planning due to strong learning capabilities of NN models and their inherently high parallelism. Despite the current development in this direction, the efficient capture and processing of important sequential and spatial information, in a direct and simultaneous way, is still relatively under-explored. To overcome the challenge and unlock the potentials of neural networks for motion planning tasks, in this paper, we propose STP-Net, an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient neural motion planner. By interpreting the movement of the robot as a video clip, robot motion planning is transformed to a video prediction task that can be performed by STP-Net in both spatially and temporally efficient ways. Empirical evaluations across different seen and unseen environments show that, with nearly 100% accuracy (aka, success rate), STP-Net demonstrates very promising performance with respect to both planning speed and path cost. Compared with existing NN-based motion planners, STP-Net achieves at least , and faster speed with lower path cost on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Furthermore, STP-Net can quickly and simultaneously compute multiple near-optimal paths in multi-robot motion planning tasks.
I Introduction
Sampling-based motion planners (SMP) [1][2] provide an effective solution for finding collision-free paths with probabilistic completeness guarantees. However, existing asymptotically optimal SMPs, e.g., RRT* [3] and its many variants, can take significant computational time as their solutions converge to optimal ones. A main reason for this drawback is due to the sampling and collision checking procedures being sequential, which leads to high exploration cost in the planning phase. To address the shortcoming, a potentially promising solution is to use a biased sampling scheme that can always guide the robot to move to the next waypoint lying on the shortest collision-free path. Evidently, such a scheme, properly designed, e.g., through introducing parallelism, can reduce the planning time for finding optimal or near-optimal paths significantly.
Motivated by this philosophy, recently, a number of learning-based SMPs have been proposed to learn proper biased sampling schemes from data [4, 5, 6, 7, 8, 9, 10], and most of them adopt neural networks (NNs) to guide the sampling process. Thanks to the inherently high parallelism of NNs and their powerful learning capabilities, these emerging data-driven SMPs have already demonstrated promising planning performance in both time cost and path cost.
Despite their success, from both temporal and spatial perspectives, state-of-the-art NN-based motion planners face two limitations. First, it is unclear that important sequential structures in motion planning tasks have been fully extracted or learned in current NN-based planners. In other words, motion planning problems have an inherently sequential nature in that they look for a path that marches from the start to the goal. However, many existing NN-based motion planners (e.g., MPNet [11] and L-SBMP [5]) adopt either multi-layer perceptron (MLP) or convolutional neural network (CNN) as the backbone network architecture, which by design are not optimal choices for processing sequential information. Second, rich spatial correlation in the environment is not properly modeled or leveraged. To be specific, in order to integrate the information of the environment and the robot state into the learning procedure, many existing NN-based works [9][12][13] encode the high dimensional workspace into low dimensional vector representation via contractive auto-encoders (CAE) [14]. Such straightforward embedding strategy typically cannot fully extract the important spatial correlation between environment and robot state, thereby potentially severely hampering the planning performance.
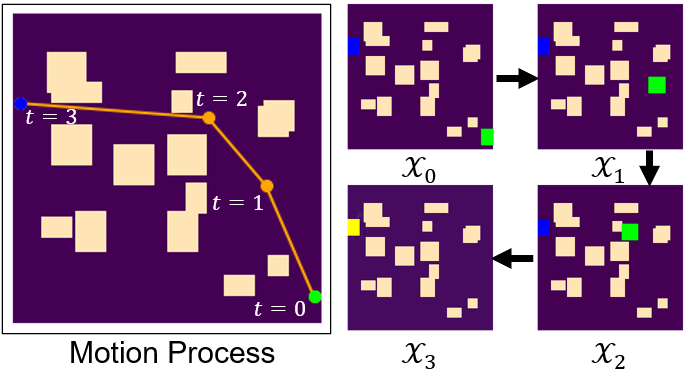
Toward overcoming these limitations, we propose an end-to-end learning framework that can fully extract and leverage important spatio-temporal information to form an efficient NN-based motion planner. Our key idea is to interpret the full motion sequence of a robot as a video clip composed of a series of sequential discrete snapshots of the statuses of the planning task, across different timestamps (see Figure 1). From this perspective, robot motion planning can be then transformed to a video prediction task. We propose STP-Net, a spatio-temporal neural network model that can efficiently capture and process the spatial correlation and temporal dependence simultaneously and directly from the data sequence, thereby bringing high planning performance. The contributions of this paper are summarized as follows:
-
•
We propose to interpret robot motion planning as a video prediction task. By delicately mapping both the environment and start/goal states into the different channels of colored video clips, important spatial information can be maximally preserved and properly incorporated into the neural network model.
-
•
We propose STP-Net, an end-to-end neural network architecture that can directly learn from video data without suffering encoding loss. At the same time, the spatio-temporal processing capability of STP-Net enables the simultaneous identification and extraction of both spatial environment information and temporal movement correlations, thereby yielding high-quality predictions.
-
•
We perform empirical evaluations of STP-Net across different seen and unseen environments. With close to 100% accuracy, STP-Net demonstrates promising performance with respect to the planning speed and path cost, across many different environments.
-
•
We further extend our STP-Net to solving multi-robot path planing problems. Empirical results confirm the decent scalability of STP-Net in computing multiple near-optimal paths simultaneously and quickly, without degradation in planning accuracy.
II Related Work
RRT [15] builds a tree structure that rapidly explores the configuration space by repeatedly connecting uniformly generated samples, until a feasible path can be extracted from the tree. RRT* [3] extends RRT by incrementally rewiring the RRT tree branches, thereby reducing the length of the computed path. Due to the curse of dimensionality, RRT* suffers from slow convergence to find optimal solutions, e.g., for a high-DOF robot or a multi-robot system. Aiming to improve both the convergence rate and path quality of RRT*, Informed-RRT* [16] is proposed to define an ellipsoidal search region of new samples, based on an initial solution from RRT*. Though Informed-RRT* demonstrates enhanced convergence to an optimal solution, it is still limited by the time cost of finding an initial solution. To address this issue, Batch Informed Trees (BIT*) [17] is further designed to unify graph search technique and SMP, which outperforms both RRT* and Informed-RRT*.
Recently, several NN-powered motion planners have been developed and reported to predict the future states or trajectories directly. Among these, DeepSMP [18] uses a contractive auto-encoder (CAE) to pre-encode the obstacle point clouds into a vectorized representation, which can be then concatenated with the current and goal states of robot. Such combined vector is then fed to a multi-layer perceptron (MLP) for the prediction of the next state. MPNet [11] shares the similar design strategy that DeepSMP adopts, and it is further equipped with re-planning and rewiring mechanisms to improve performance. With the same input as MPNet uses, PathNet [12] predicts the future trajectory instead of the state. L-SBMP [5] also utilizes CAE to embed the high-dimensional environmental information in a low-dimensional latent space. Different from DeepSMP and MPNet that perform combination of real states and environments in the latent space, L-SBMP chooses to combine them first and then encode the combination. On the other hand, [19] integrates the graph embedding into the variational auto-encoder (VAE) [20] to identify the critical node in an iterative manner. To better capture sequential information, OracleNet [21] proposes to leverage long short-term memory (LSTM) to learn the sequences of states along the paths. However, its performance is limited due to the insufficient integration of environmental information.
Instead of predicting the specific states, some other works predict the sampling distribution where the near-optimal paths exist. For example, [7] and [22] use conditional VAE to predict the sample distribution. Besides, [23] identifies regions on the map images via the convolutional neural network to bias the sampling. In addition, [24] adopts message passing algorithm to predict the exploration priority in the random geometric graph, thereby facilitating the generation of the feasible paths.
III Preliminaries
Notation. Let denote the configuration space (C-space) of a robot, where the obstacle and free regions are denoted as and , respectively. Given the start state and the goal state , the objective of motion planning is to find a collision-free path between and in . Let denote a discrete sequence of waypoints lying on a path, where and . The waypoint sequence is valid if , and the path connecting all continuous states in lies entirely in the free space .
Environment Representation. For a 2D or 3D environment, given the spatial resolution, its map and the start/goal configuration can be represented using the 0/1-valued pixels or voxels. For instance, a square 2D environment can be described by an image. Here, the information of free space and obstacles are represented as zero-valued and one-valued pixels in the first channel of the image, respectively. The second (resp., third) channel marks the pixels that correspond to the start (resp., goal) position as ones while all the other pixels channels take zero values. Following a similar representation scheme, a 3D environment can be encoded by an array of voxels.
IV Methods
IV-A Robot Motion Planning: A Video Prediction Perspective
Interpreting Robot Motion as Video. Based on the above described environment representation scheme, the discrete process of robot motion planning can be viewed as composing a video clip. Suppose we are monitoring the discrete motion of a robot in a 2D/3D environment, where the robot keeps moving from the start state to a fixed goal state. The full set of discrete statuses of the planning task can be then viewed as a sequence of video frames , where the first frame corresponds to the initial status of the task and the last frame describes the final status of the task (see Figure 1). Noticing that a planned path is essentially the sequential connection of multiple waypoints , we make the design choice that each video frame represents the spatial information of together with the corresponding environment and goal state at timestamp .
Pixel Patching. Recall that in principle, the robot state and the goal state can be represented using only one pixel in the second and third channels, respectively. However, in practice, NN models may not be able to capture and learn such one-pixel information efficiently, and thereby potentially affecting planning performance. To address this issue, we propose to augment the representation of the state information using more pixels. To be specific, we mark all the free-space pixels within the patches of size centered on the robot state pixel and goal state pixel as ones, respectively. Figure 1 provides an example of the patch augmentation. In general, a large reduces the state resolution, while a small increases the difficulty of the model to capture the state representation. Therefore, the value of patch size is properly determined by balancing such trade-offs in our experiments.
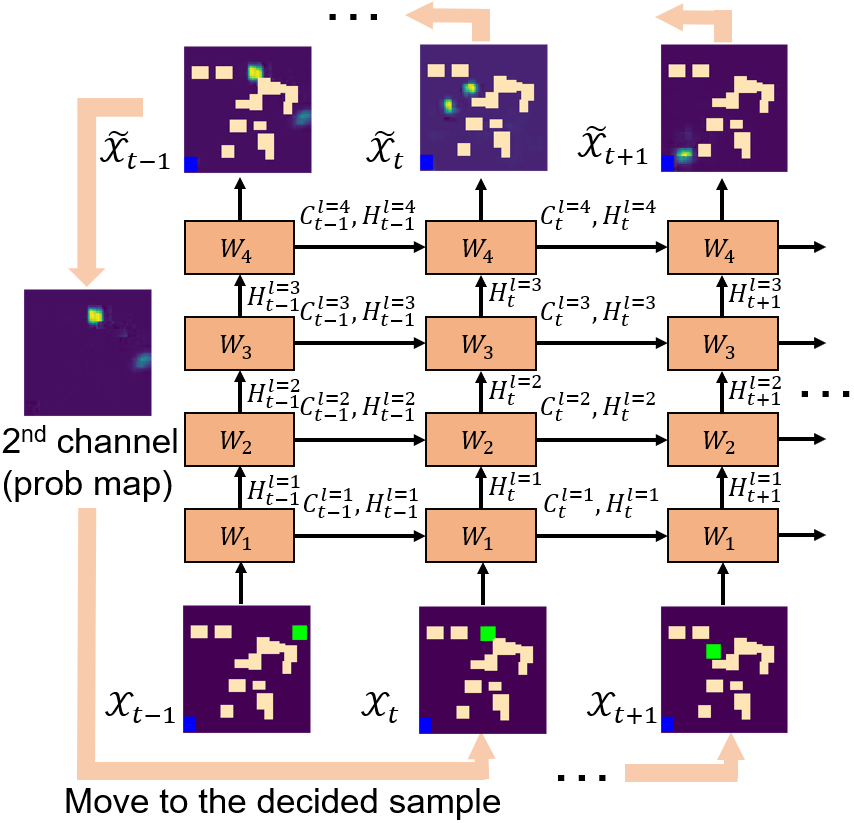
Performing Motion Planning as Video Prediction. With such video-based interpretation, the path finding in 2D/3D workspace is essentially equivalent to a video prediction task. In general, given the current and previous observations at timestamp , our goal is to predict the new frame , whose second channel indicates a sample map of the next waypoint with probabilities in (see Figure 2). This process is repeated until the next waypoint reaches the goal state . Notice that here we aim to find the path with minimal Euclidean distance, as measured by the cost function
| (1) |
IV-B Building End-to-End Spatio-Temporal Network
Inspired by the current success of neural networks in video processing applications, we propose to build an end-to-end spatio-temporal neural network to perform this video prediction-based motion planning task. Here, distinct from existing CAE-equipped neural motion planners, our proposed network model directly uses the raw spatial information as the input without any CAE-based encoding. Specifically, for our target motion planning task, if the neural network is properly designed that they are able to directly process the non-encoded environmental and state information, the originally inevitable information loss incurred by CAE encoding can be completely avoided, thereby bringing better planning performance. In such scenarios, the neural network can perform end-to-end learning to predict the most probable length- sequences of video frames in the future given the previous observations as follows:
| (2) |
To achieve this goal, we build a spatio-temporal LSTM as the backbone network architecture. As illustrated in Figure 2, the entire neural network consists of four ConvLSTM layers [25], which can directly process our prepared video frame as the input. The key equations are as follows:
where , and represent the sigmoid activation function, the convolution operator and element-wise product, respectively. Here, for 2D tasks, all the inputs , cell outputs , hidden states , and gates are 3D tensors in , where is the number of input dimensions or the number of feature maps (for hidden representations). For 3D tasks, these are 4D tensors in instead. Tensors and are the training parameters, which are represented by in Figure 2 for simplicity of notations.
After the feature extraction at each timestamp , the output layer is connected with an additional convolutional layer to convert the last hidden state into the video frame for prediction results. In other words, the network performs the learning on the input video frame and output the prediction in the same frame format for the next-step planning, thereby fully preserving and leveraging the spatial correlation information at each timestamp in a consistent and end-to-end way. At the same time, because our full neural network exhibits LSTM characteristics by design, compared with existing CNN or MLP-based motion planners, our approach can more properly capture and leverage the sequential dependence and correlation among different timestamps. All in all, with the carefully designed end-to-end convolutional LSTM architecture, the rich and important spatio-temporal information exhibited in the entire motion planning procedure can be fully identified, extracted and processed, thereby significantly improving the planning performance.
IV-C Network Training and Path Construction
Neural Network Training (Offline Phase). To train the neural network on obtaining path planning capability, we prepare the training dataset via using the discrete motion process created by an “expert” planner across different tasks. Specifically, we generate the near-optimal paths using RRT* and extract their waypoints to form the video clips. During training, STP-Net takes the observations over the first timestamps as the input sequence , and predicts the remaining frames . In general, if we denote the function of neural network model as , the training goal is to find the optimal parameters that minimizes the average cross-entropy loss between the predicted sequences and true targets across all the training data points as:
| (3) |
Here, the standard stochastic gradient descent (SGD)-based training strategy is used to train the desired STP-Net model.
Single-Path Construction (Online Phase). After the network training phase, during the online path construction we use the well-trained STP-Net to generate the sample distribution for the waypoint. As described in Algorithm 1, given a well trained STP-Net model , the initial frame and the start/goal states, the robot state is first initialized as (Line 1), and there is only one frame in the current observation (Line 2). Then STP-Net performs the prediction in an iterative manner (Line 3). At each iteration, the NN model takes the newest observation and predicts the next frame , which shares the same size as the input frame (Line 4). Recall that here the second channel of records the current state of the robot, while the other two channels are the static environment and the fixed goal state, respectively. Also, because all the pixels are between and which indicates their probability of being the next waypoint, we can then sort the entries of the predicted frame by their pixel values in the second channel (Line 5). In this way, the foremost element in has the greatest probability to be the next waypoint. Notice that the elements in are sequentially visited and checked if they are not used or collision-free (Line 6-8). Specifically, the function checks whether the line connecting the current state and the next candidate state has collision with the obstacles or not. If is valid (not used and collision-free), the robot moves to the new state and appends it into the path (Line 9). The path is set to be found once reaches the region around the goal state (Line 11-13). Otherwise, we formulate the current task status as the new frame and append it into the observation (Line 14-15). The function produces the new frame by marking the patch corresponding to in the second channel (start state channel), while the other two channels (environment and goal state channel) are exactly the same as the initial frame . If the path still can not be found after iterations, an empty solution is returned (Line 17).
Extension to Multi-Path Construction. The proposed STP-Net can also be readily extended to serve as a multi-robot path planner, which is described in Algorithm 2. To that end, for each additional robot under the same environment, the raw input frame is stacked with two extra channels, which represent the start/goal states of the new robot. For instance, for 2D and 3D planning tasks of five robots, the sizes of input frames are and , respectively. Notice that the predicted frame also contains the corresponding probability map of the next waypoint for each robot. Similar to the single-path construction, at each iteration the waypoint for each robot is sequentially determined based on the corresponding predicted probability distribution. To avoid the collision between robots, once a waypoint is occupied, such waypoint cannot be taken by other robots at that timestamp (Line 15-20). The new video frame is then updated according to the new robot states of all robots, and appended into the video clip (Line 27-28). The procedure is repeated until all robots reach their goal regions (Line 29-34).
V Results
V-A Dataset
We demonstrate the effectiveness of STP-Net on three benchmark tasks. The first two tasks are path planning on 2D maps of size , and the third one is on 3D maps of size . Specifically, the first type of maps is in the format of random forests, where obstacles of different shapes are randomly placed in different positions on 2D spaces. The second type is maze-like environments, which are generated using a randomized depth-first search. For the 3D environments, we sample out of a total of obstacle blocks with different shapes and place them randomly. For each training task, a feasible, near-optimal path is generated using RRT*. As described in Section III, each waypoint, the corresponding workspace and the fixed goal state, can be transformed together into a video frame, and hence each training data is interpreted as a video clip. Notice that to facilitate batch training, the video clips of different tasks are all padded into the same length by repeating their last frames, so that all the training data share the same dimensions.
For both 2D and 3D planning tasks, we train STP-Net over workspaces, each of which contains ground truth video clips. The evaluation is performed on both seen and unseen environments. The set of seen environments consists of all the environments used during the training procedure but with different pairs of start/goal configuration in each environment. The set of unseen environments is composed of new workspaces which are not used in the training, and each of them contains different start/goal pairs. We report the accuracy and path cost by averaging over all the computed paths for new tasks from seen/unseen environments.
For the multi-path planning tasks, the data are prepared using a similar procedure. In particular, the video frames of each multi-robot task are generated by stacking the start/goal frame channels of five different tasks under the same environment and at the same timestamp.
V-B Baselines
We evaluate the performance of STP-Net by comparing it with two classical motion planners (Informed-RRT* and BIT*) and two NN-based ones (MPNet and OracleNet). Considering the original OracleNet has limited performance because of the lack of sufficient map information, for fair comparison we use a performance-enhanced OracleNet-CAE as the baseline, which is equipped with a CAE module (like MPNet does) to better incorporate the encoding vector of the environment into the input.
| Environment | Informed-RRT* | BIT* | OracleNet-CAE | MPNet | STP-Net (Prob) | STP-Net | ||||||
| time | cost | time | cost | time | cost | time | cost | time | cost | time | cost | |
| 2D RF Seen | 82.23 | |||||||||||
| 2D RF Unseen | 82.80 | |||||||||||
| 2D Maze Seen | 121.34 | |||||||||||
| 2D Maze Unseen | 120.15 | |||||||||||
| 3D RF Seen | 17.52 | |||||||||||
| 3D RF Unseen | 17.09 | |||||||||||
V-C Implementation Details
Our STP-Net model consists of stacked ConvLSTM layers to learn the hidden representations, and all the hidden dimensions are set to for 2D tasks and for 3D tasks. The sizes of convolution kernels in the ConvLSTM are set to for 2D tasks and for 3D tasks. At the output end of the model, an additional or convolutional layer is allocated to convert the last hidden representation into the output frame that shares the same dimension as the input. In the training phase, ADAM optimizer [26] is selected with batch size of for 2D tasks and for 3D tasks, respectively. The learning rate is set as and the entire model is trained for iterations. The pixels of states are augmented by patches of size for 2D tasks and for 3D tasks. Besides, the length of input sequence from Equation 2 is set as . The experiments are conducted on a computer equipped with an AMD EPYC 74202P 24-Core Processor and an NVIDIA RTX A6000 GPU. The neural networks are trained and tested using the PyTorch framework. We implement the neural network of STP-Net based on the official code of PredRNN [27]. We report the results of Informed-RRT* and BIT* using their C++ OMPL [28] implementation.
V-D Ablation Study
We first perform an ablation study on STP-Net, which justifies the necessity of predicting the static obstacles in future frames. To this end, we modify STP-Net slightly to obtain variant called STP-Net (Prob), which only predicts the probability maps of the next waypoint. From Table I, our STP-Net that predicts the 3-channel video frames outperforms STP-Net (Prob) significantly, with respect to both the time cost and path cost. Furthermore, to find a path under 2D Random Forest environments, STP-Net (Prob) visits around four times more waypoints than STP-Net, which causes a greater number of collision detection operations. Given the ablation study, STP-Net (Prob) is omitted from further evaluation.
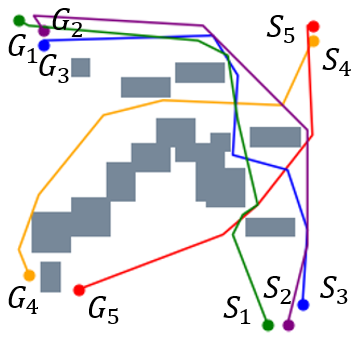
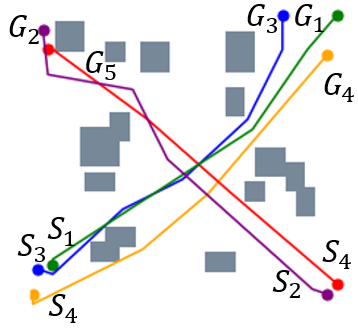
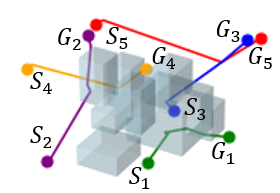
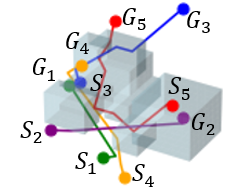
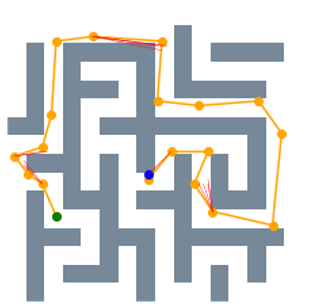
V-E 2D Random Forest Workspaces
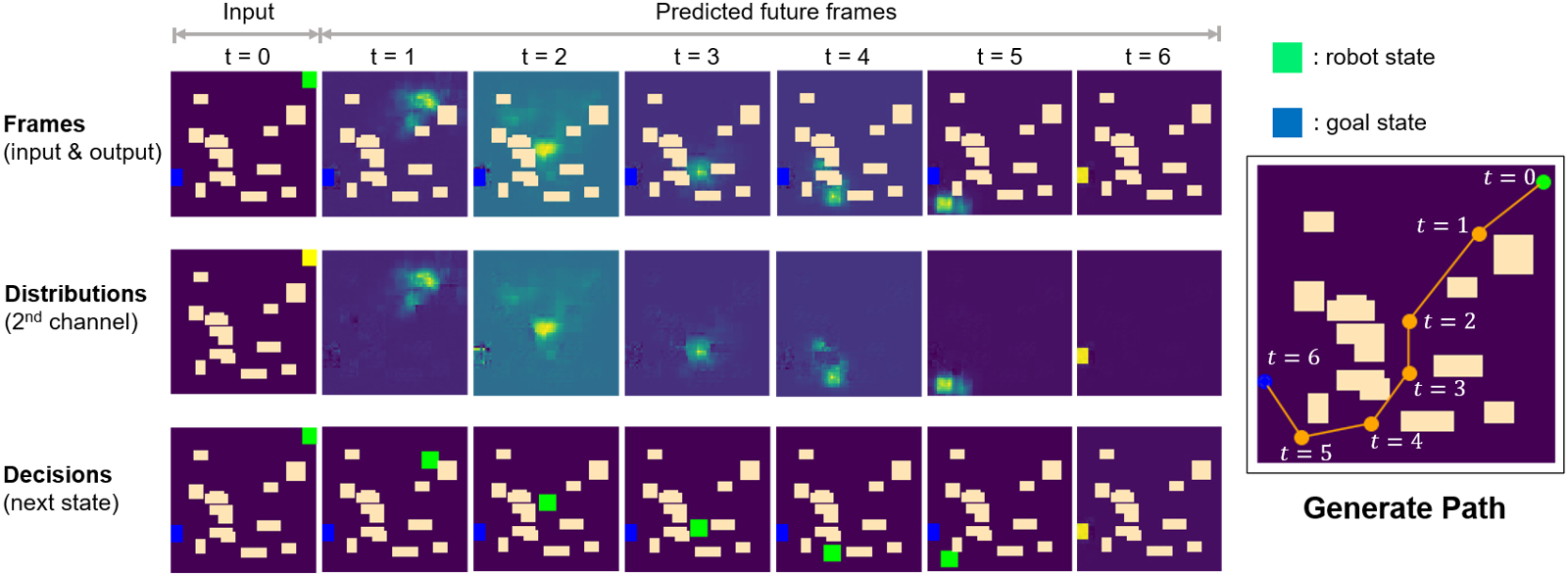
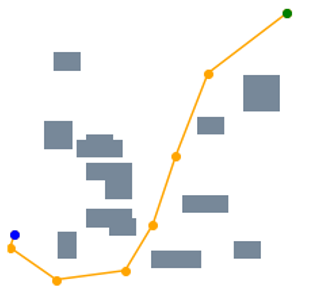
We then evaluate the performance of STP-Net in 2D Random Forest environments. Figure 3 illustrates how we generate a path step by step via using the predicted frames output from STP-Net model. Initially, the input of the model is a single video frame (the top-left) containing the full spatial information of the environment plus start and goal states. The model then predicts the next frame (first row, second column), whose second channel (second row, second column) contains the estimated probabilities of being the next waypoint for each position. Here the brighter yellow pixels indicate higher probabilities. A valid waypoint is determined by selecting the collision-free position with the highest probability. Once the next predicted waypoint is determined, we generate the new observation (third row, second column) and predict the next frame based on the previous two observations. We repeat this process until the waypoint reaches the goal state at timestamp .
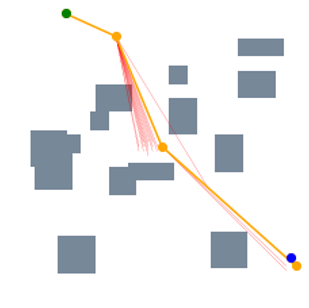
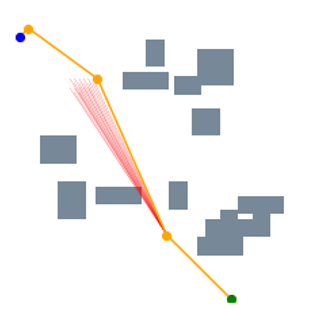
From this example, we can further obtain two important observations. First, our proposed end-to-end processing strategy, which directly processes the raw environmental map as the input data, can preserve the spatial information very well. As illustrated in the first row (“Frames”) of Figure 3, each predicted frame, which is essentially the output of STP-Net at the previous timestamp, properly retains all the important spatial information of the map. Such promising properties translate to better planning performance, especially when compared with the current CAE-based encoding strategy that always causes information loss. Second, STP-Net learns the collision-free path very well and hence it provides high-quality prediction for the waypoint. Comparing the second row (“Distributions”) and third row (“Decisions”) of Figure 3, it is seen that in most cases the determined next waypoint lies in the most probable sampling region (the brightest yellow). In other words, this means our neural network model can always predict the collision-free waypoint candidate with high confidence. Such property is very important for improving the planning speed. This is because if the predicted waypoint is further denied after the collision check, the neural planner has to perform more rounds of collision detection until it finds a satisfactory one. Fortunately, the experiments show that the highest probable waypoint candidates predicted by STP-Net are usually collision-free, and thereby naturally saving unnecessary planning cost. Figure 4 further amplifies the importance of high-quality prediction. It is seen that because STP-Net can provide collision-free prediction with very limited failed trials (marked as red lines), the overall planning speed is very fast.
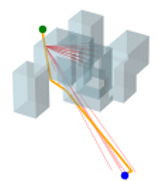
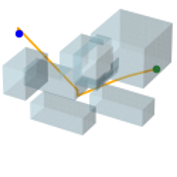
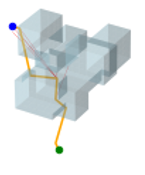
V-F 2D Maze & 3D Random Forest Workspaces
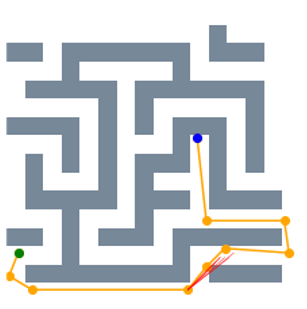
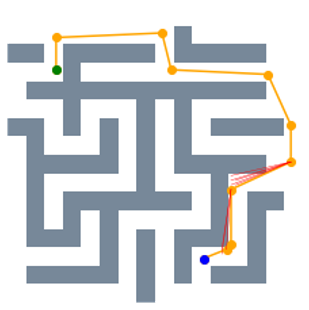
Figure 5 visualizes the path search and generation in various maze environments with different task difficulties. It is seen that in such narrow passages-abundant scenarios, STP-Net can still predict the next reachable waypoint in a single shot for most cases. As illustrated in Figure 5, all the paths can be efficiently found within very limited trials of predictions. The visualization of the generated path of STP-Net in 3D Random Forest workspaces is shown in Figure 6.
V-G Comparison with Baselines
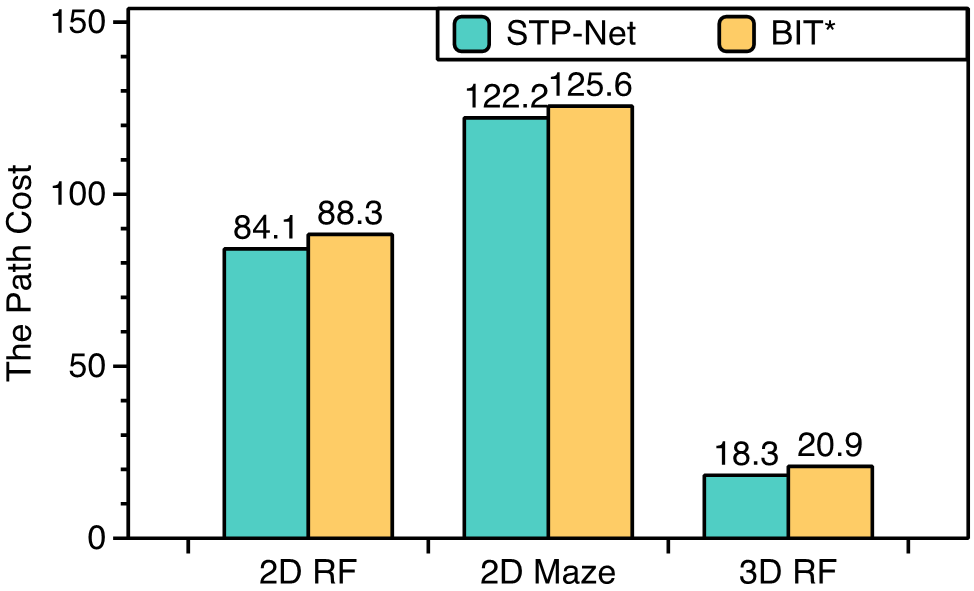
Table I compares the performance of our proposed STP-Net with other four baseline motion planners. Experimental results show that all the planners produce accuracy across all the environments. It is seen that STP-Net outperforms the reference approaches with respect to time costs, with the competitive path quality. To be specific, STP-Net is at least , and faster than the other two NN-based methods (MPNet and OracleNet-CAE), on 2D Random Forest, 2D Maze and 3D Random Forest environments, respectively. Simultaneously, STP-Net achieves higher accuracy than MPNet and OracleNet-CAE on all the 2D/3D tasks and regardless whether environments have been seen. While it is expected that anytime methods like BIT* should produce better path if enough time is granted, as shown in Table I, when BIT* is given the same time budget as required by STP-Net, STP-Net produces higher quality paths, which can be observed in Figure 8(a).
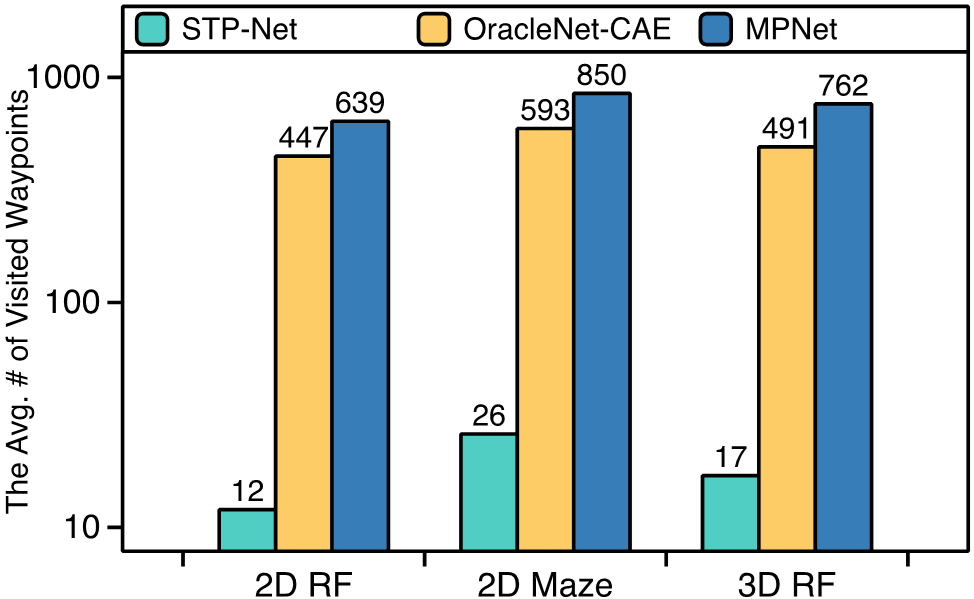
Figure 8(b) summarizes the average numbers of predicted waypoints (including the selected ones and the denied ones due to collision) for all the NN-based motion planners. A smaller number here indicates a better prediction produced by a neural network. STP-Net requries at least 22 times fewer predictions of waypoints as compared to the existing learning-based solutions across different planning tasks.
V-H Multi-Robot Path Planning
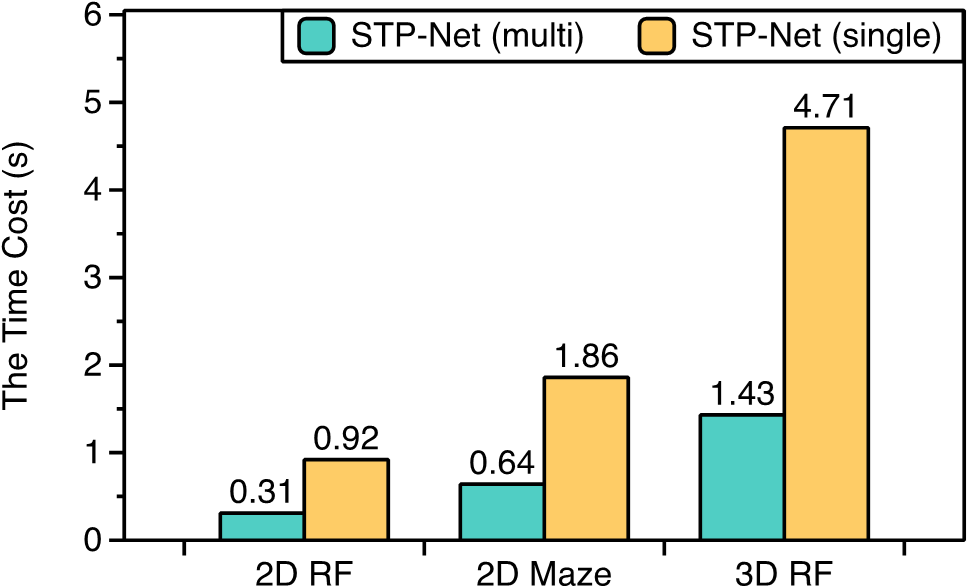
We further evaluate the performance of STP-Net on five-robot path planning problems. Figure 7 shows that STP-Net can produce near-optimal paths for five robots simultaneously with much less time as compared to computing all the paths separately. Figure 8(c) compares the time costs of these two different approaches. It is seen that STP-Net demonstrates strong scalability for multi-robot path planning with three times faster planning speed than the separate single-path construction solution.
VI Conclusion
This paper proposes STP-Net, a video prediction-inspired neural motion planner. Empirical evaluations show that, with nearly 100% accuracy and competitive path quality, STP-Net achieves much faster planning speed than the existing classical and NN-based motion planners. STP-Net also shows good scalability on multi-robot path planning tasks. Thorough evaluation suggests that STP-Net is a very promising NN-based near-optimal motion planner for both single- and multi-robot planning tasks that also runs very fast.
In future works, we plan to further enhance STP-Net and apply it to challenging motion planning problems in higher dimensions. In particular, we intend to integrate the NN-based STP-Net planning pipeline together with NN-based collision checking to deliver a complete and scalable NN-based motion planning architecture.
References
- [1] James J Kuffner and Steven M LaValle. Rrt-connect: An efficient approach to single-query path planning. In Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No. 00CH37065), volume 2, pages 995–1001. IEEE, 2000.
- [2] Lydia E Kavraki, Petr Svestka, J-C Latombe, and Mark H Overmars. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE transactions on Robotics and Automation, 12(4):566–580, 1996.
- [3] Sertac Karaman and Emilio Frazzoli. Sampling-based algorithms for optimal motion planning. The international journal of robotics research, 30(7):846–894, 2011.
- [4] Ahmed H Qureshi, Anthony Simeonov, Mayur J Bency, and Michael C Yip. Motion planning networks. In 2019 International Conference on Robotics and Automation (ICRA), pages 2118–2124. IEEE, 2019.
- [5] Brian Ichter and Marco Pavone. Robot motion planning in learned latent spaces. IEEE Robotics and Automation Letters, 4(3):2407–2414, 2019.
- [6] Aaron Havens, Yi Ouyang, Prabhat Nagarajan, and Yasuhiro Fujita. Learning latent state spaces for planning through reward prediction. arXiv preprint arXiv:1912.04201, 2019.
- [7] Brian Ichter, James Harrison, and Marco Pavone. Learning sampling distributions for robot motion planning. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 7087–7094. IEEE, 2018.
- [8] Binghong Chen, Bo Dai, Qinjie Lin, Guo Ye, Han Liu, and Le Song. Learning to plan in high dimensions via neural exploration-exploitation trees. arXiv preprint arXiv:1903.00070, 2019.
- [9] Alexandru-Iosif Toma, Hussein Ali Jaafar, Hao-Ya Hsueh, Stephen James, Daniel Lenton, Ronald Clark, and Sajad Saeedi. Waypoint planning networks. arXiv preprint arXiv:2105.00312, 2021.
- [10] Masaya Inoue, Takahiro Yamashita, and Takeshi Nishida. Robot path planning by LSTM network under changing environment. In Advances in computer communication and computational sciences, pages 317–329. Springer, 2019.
- [11] Ahmed Hussain Qureshi, Yinglong Miao, Anthony Simeonov, and Michael C Yip. Motion planning networks: Bridging the gap between learning-based and classical motion planners. IEEE Transactions on Robotics, 37(1):48–66, 2020.
- [12] Alassane M Watt and Yusuke Yoshiyasu. Pathnet: Learning to generate trajectories avoiding obstacles. In 2020 IEEE International Conference on Image Processing (ICIP), pages 3194–3198. IEEE, 2020.
- [13] Tuan Tran, Jory Denny, and Chinwe Ekenna. Predicting collision detection with a two-layer neural network.
- [14] Salah Rifai, Pascal Vincent, Xavier Muller, Xavier Glorot, and Yoshua Bengio. Contractive auto-encoders: Explicit invariance during feature extraction. In Icml, 2011.
- [15] Steven M LaValle et al. Rapidly-exploring random trees: A new tool for path planning. 1998.
- [16] Jonathan D Gammell, Siddhartha S Srinivasa, and Timothy D Barfoot. Informed rrt*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic. In 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 2997–3004. IEEE, 2014.
- [17] Jonathan D Gammell, Timothy D Barfoot, and Siddhartha S Srinivasa. Batch informed trees (bit*): Informed asymptotically optimal anytime search. The International Journal of Robotics Research, 39(5):543–567, 2020.
- [18] Ahmed H Qureshi and Michael C Yip. Deeply informed neural sampling for robot motion planning. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6582–6588. IEEE, 2018.
- [19] Arbaaz Khan, Alejandro Ribeiro, Vijay Kumar, and Anthony G Francis. Graph neural networks for motion planning. arXiv preprint arXiv:2006.06248, 2020.
- [20] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [21] Mayur J Bency, Ahmed H Qureshi, and Michael C Yip. Neural path planning: Fixed time, near-optimal path generation via oracle imitation. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3965–3972. IEEE, 2019.
- [22] Rahul Kumar, Aditya Mandalika, Sanjiban Choudhury, and Siddhartha Srinivasa. Lego: Leveraging experience in roadmap generation for sampling-based planning. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1488–1495. IEEE, 2019.
- [23] Naman Shah, Abhyudaya Srinet, and Siddharth Srivastava. Learning and using abstractions for robot planning. arXiv preprint arXiv:2012.00658, 2020.
- [24] Chenning Yu and Sicun Gao. Reducing collision checking for sampling-based motion planning using graph neural networks. Advances in Neural Information Processing Systems, 34, 2021.
- [25] SHI Xingjian, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in neural information processing systems, pages 802–810, 2015.
- [26] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [27] Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and Philip S Yu. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Advances in neural information processing systems, 30, 2017.
- [28] Ioan A Sucan, Mark Moll, and Lydia E Kavraki. The open motion planning library. IEEE Robotics & Automation Magazine, 19(4):72–82, 2012.