Robot Localization and Mapping
Final Report
Sequential Adversarial Learning for
Self-Supervised Deep Visual Odometry
I INTRODUCTION
††Our Pytorch implementation: BitBucket repoVisual odometry (VO) and SLAM have been using multi-view geometry via local structure from motion for decades. These methods have a slight disadvantage in challenging scenarios such as low-texture images, dynamic scenarios, etc. Meanwhile, use of deep neural networks to extract high level features is ubiquitous in computer vision. For VO, we can use these deep networks to extract depth and pose estimates using these high level features. The visual odometry task then can be modeled as an image generation task where the pose estimation is the by-product. This can also be achieved in a self-supervised manner, thereby eliminating the data (supervised) intensive nature of training deep neural networks. Although some works tried the similar approach [1], the depth and pose estimation in the previous works are vague sometimes resulting in accumulation of error (drift) along the trajectory.
The goal of this work is to tackle these limitations of past approaches and to develop a method that can provide better depths and pose estimates. To address this, a couple of approaches are explored:
-
1.
Modeling: Using optical flow and recurrent neural networks (RNN) in order to exploit spatio-temporal correlations which can provide more information to estimate depth.
- 2.
The goal of generator is to generate an image by view synthesis which looks exactly like the target image and can be used to fool the discriminator. On the other hand, discriminator in GAN evaluates the generated warped image and tries to distinguish it from the real target image. The eventual goal is to train the generator such that it is hard for the discriminator to distinguish. During inference, only the depth and pose estimators are used to compute the trajectory for VO task. This project would be an implementation of [3]. It is built on the Pytorch implementation of SFMlearner [4].
However, using GAN to generate the images does not take into account the geometric constraints of the scene. Most recent works based on learning-based techniques have not provided a comparison of their results with those generated using the traditional geometric analysis. We propose to explore this aspect of GAN-based synthesis models and analyze their possible advantages/disadvantages over the traditional methods. We have released our code here: code repo.

To isolate the performance of each component of our model and validate its contribution to the final goal of high quality depth and pose predictions, we also perform a number of ablation experiments. Unlike [3], we explore different GAN models and algorithms like Wasserstein generative adversarial networks [5] and PatchGANs [6].
The structure of this report is as follows: In Section II, we will cover the existing literature related to our work. Section III delineates the methodology, different components and the loss functions used. This will be followed by the experiments in Section IV. We discuss the challenges faced in Section V. We finally wrap up the report with Conclusion and Future Work in Section VI.
II Literature Review
II-A Pose and Depth estimation
Pose estimation and visual odometry have traditionally been viewed as a multi-view geometry problems. Initial approaches to solve this problem used graph based optimizations [7, 8]. These methods typically relied on handcrafted features for finding corresponding points between images and then using these points for subsequent pose estimation [9].
Recently, deep learning based methods have taken over the pose and depth estimation problem as they tend to perform significantly better than the metric-based approaches. Some of the recent works using deep learning for pose estimation are [10, 1, 11, 3, 12]. The model proposed by Ummenhofer et al.in [12] tries to jointly estimate the pose along with the depth in an end-to-end manner. DeepTAM [10], on the other hand, uses two different networks for pose estimation and depth estimation. However, these methods require supervision for training. The models, therefore, can only be trained on synthetic data as supervised data generation for pose estimation and depth estimation in the wild is both expensive and heavily prone to inaccuracies.
In order to overcome this problem, there have been numerous self-supervised methods that have recently been proposed. These methods include SFMLearner by Zhou et al. [1]. Since the current work that we present in the report [3] is built over this method, we explain the SFMLearner model in detail.
The SFMLearner model utilizes the correlation between depth and pose to learn both entities jointly. The model makes use of a photometric and geometric loss to model the constraints between the source and the target pixel in an image as a function of its depth, pose change and the camera intrinsic. Self-supervision is used to train these models by using novel view synthesis. View synthesis is predicting what a scene will look like from a different view. This is done by unprojecting the image in source view using camera intrinsics and depth image, warping it to the pose of the target view using the source to target relative pose transformation, and finally projecting it to the pixel space. Differential modules are used for view synthesis task in order to take advantage of gradient based training [13, 14, 15, 16, 17, 18]. Authors show the performance of their method on KITTI [19] and Make3D datasets [20]. The results show that the single view depth prediction gives results equivalent to the supervised learning approaches on KITTI dataset. Ablation studies showed that explainability network only offered a small boost in performance, probably because most scenes in KITTI are static. The results on Make3D dataset shows the generalization ability of the depth prediction model. For pose estimation network, authors use the KITTI odometry split, and show that their network performs comparable to ORB-SLAM.
II-B Generative Adversarial learning
A majority of the self-supervised approaches methods mentioned in Section II-A need to generate photo-realistic images as part of the target image. This is done using Generative Adversarial Networks or GANs as they are commonly referred to. These were first proposed by Goodfellow et al. in [2] to try to generate realistic images from a latent space by trying to model the loss as a mini-max function between the two components (Generator and Discriminator) of the architecture. GANs have been a topic of extensive study for the past few years and many improvements and variants over the original GAN architecture have been suggested [5, 21, 22]. GANs have also been used with great success in a number of image editing applications [23, 24, 25, 26, 27, 28, 29, 30, 31]. In this work, we have used two variants as part of the discriminator in the adversarial training. These are the PatchGAN architecture proposed in [21] and the WGAN method in [5]. The details for the same are provided in Section III.
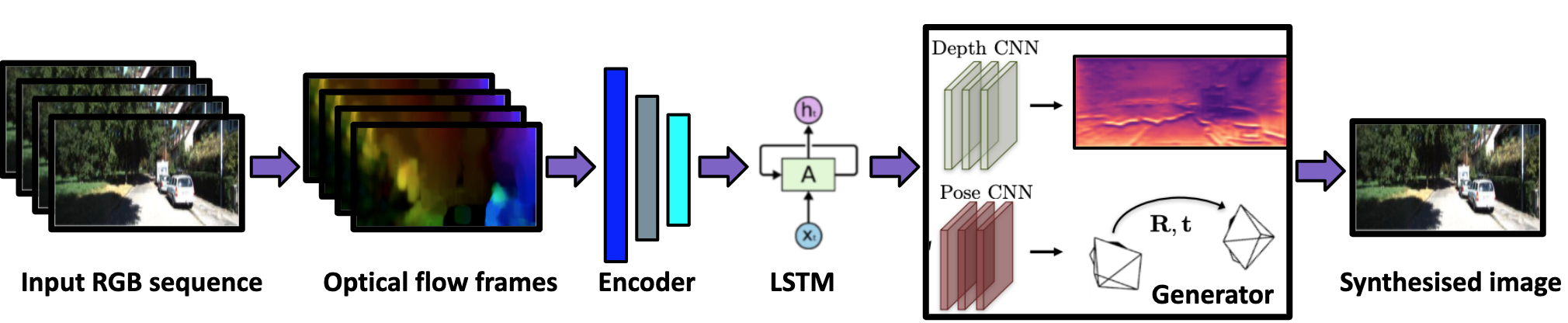
III Methodology
Our network used for estimation of depth and pose in an self-supervised manner consists of the following 4 components:
III-A Sequence representation
Since there is lot of redundant information in the images for estimating pose and depth, the optical flow between consecutively sampled frames is extracted and computed into a 128 dimensional vector, using and encoder. Let us denote it by . These vectors are passed to LSTM to leverage the correlations in sequence. The output of LSTM at each time stamp, denoted by , is then passed into next module. This is expected to contain both sequence context and optical flow information. This way we can encode the spatio-temporal aspect in a video sequence.
III-B Depth estimation
Although contains much information in the form of correlations, compared to just a single image, we pass the current image also as an input to depth prediction network at pixel level. In earlier works, they use a encoder-decoder architecture for estimating depth using a single image. This is an ill posed problem. But here, instead of just estimating depth using a single image, we pass the encoded LSTM output at the current time to estimate the depth using an up-sampling decoder. DispNet [32], an architecture which used encoder-decoder design with skip connections and multi-scale side predictions, is used for our Depth prediction.
III-C Pose estimation
Once we have the depth estimation, we then use it along with the respective images to regress for the pose prediction. Pose network predicts the transformation parameters (Rotation (R) and translation (T)) between a source frame and a target frame. Considering only one pair of source and target frames, these parameters are used to calculate the corresponding locations in source for each location in target frame, i.e take a grid/matrix with each entry containing the pixel location in target frame and multiply with intrinsics, depth estimation and transformation parameters to get the corresponding pixel location in source frame from which we have to sample. Now, we use a bi-linear sampling kernel to create a mask which is multiplied with the source image (pixel values) to get the predicted view. This is the same procedure followed in [33]. Thus the output of PoseNet is used to warp the source image to get the target image. Now, whatever loss we compute on the predicted view (such as reconstruction loss) can be back-propagated to train the PoseNet parameters as the sampling procedure described above is nothing but a series of matrix multiplications. For robustness, we calculate explainability mask to apply loss only on non-occluded pixels.
III-D Adversarial training
As photo-metric loss can get stuck at a local minima due to occlusions, dynamic objects and texture-less regions, using an adversarial training step can lead to a better depth and pose prediction (better learning of parameters). Since, we have access to the original frame (the current time step frame) that we are trying to predict (using view synthesis) using depth and pose inputs, we can use a discriminator to evaluate the quality of prediction and back-propagate this loss to learn depth and pose network parameters.
III-E Loss Function
We now delineate the losses we use to train our model.
Appearance Loss
Appearance loss is given by:
| (1) |
where N is the minibatch size and is set to 0.85.
is the per-pixel explainability mask which the model predicts and it is a belief on whether a pixel is occluded in target frame or not. therefore helps in preventing the trivial solution where will just become 0, thereby making too. It does so by penalizing the network for predicting values smaller than 0. It, therefore, works as a regularizer.
is the loss over how well the predicted image matches the target image. It is given by:
| (2) |
where are the sequence frames, p is the number of pixels in the image, represents the predicted image and is the target image.
Finally, [34] is the loss over perceived quality of the image and is given by:
| (3) |
We use a filter size of for SSIM.
Trajectory Loss
The trajectory loss imposes a geometry constraint over the poses predicted by the network. Suppose A, B, C, D are 4 frames of a sequence. Let be the 6-DOF relative transformation that transforms from state A to state B. Given this, the trajectory loss penalizes the network when the relative transformation predicted by the network deviates from the transformation computed by combining the individual relative transforms , , . The trajectory loss is given as:
| (4) |
where is the 6-DOF pose estimated directly for , and is the pose computed by concatenating individual relative poses. We apply trajectory loss for intervals of size 2, 4, and 8.
Depth Regularization:
Depth regularization enforces local smoothness and discontinuity in the predicted depth. Depth discontinuity usually happens where there are strong image gradients. This loss is given by:
| (5) | ||||
GAN Loss:
GAN loss helps ensure that the image generated by the model will look real and will not have weird artifacts that are not present in real images. It is given by:
| (6) | ||||
The final loss is the weighted sum of the losses mentioned above and is given by:
| (7) |
IV Experiments
IV-A Dataset
The model is evaluated on the KITTI dataset [19] in our experiments. The dataset contains videos of outdoor sequences. The depth dataset contains pairs of RGB images along with the depth maps for over 90,000 images. The visual odometry dataset in the benchmark consists of 22 sequences with half the sequences used for training with ground truth trajectories available.
IV-B Implementation Details
IV-B1 Optical Flow
To obtain the optical flow, we evaluated two methods, namely, Farneback method [35] and Coarse2Fine optical flow method [36]. Among these, we noticed that although the latter has better quality compared to the former, it is much slower compared to the former. So, we finalized on Farneback method based on its much faster speed (10X) and its output (along with image input) seemed good enough to help depth estimation even though it is not as perfect as Coarse2Fine method. The preliminary results of our experiment with optical flow can be seen in Figure 2


IV-B2 Encoder
The optical flow images obtained from above are passed to an Encoder network to obtain the optical flow encoding. The Encoder network consists of 6 down-sampling convolution layers followed by an adaptive 2D average pooling layer. Each down-sampling convolution layer in turn consists of two convolution layers with stride 2 for the first convolution layer. Batch normalization is used on the output of each of these convolution layers. The number of channels in the 6 down-sampling layers are respectively and the kernel sizes are respectively (kernel size is (i,i) for i in the mentioned list). The weights are initialized using xavier_uniform initialization whereas the biases are initialized to 0.
IV-B3 LSTM
The optical flow encodings are further passed to LSTM to leverage the sequential information present in videos. We used a 1 layer LSTM network with a hidden dimension of 128 and took the h state at every time as the improved optical flow encodings.
IV-B4 Disparity Network
The optical flow encodings and images are fed to a disparity network which predicts the disparity(=1/depth). Similar to the previous works [3], [1], we predict depth at 4 different scales. First the image is passed through a series of 7 downsample convolution layers, with each downsampling conv layer same as mentioned earlier. The optical flow encoding is added to the lowest level (output of layer) and the resulting tensor is passed to an unsampling convolution layer to upsample using transposed convolutions. The upsampled tensor is concatenated with downsampled tensor at the higher level and passed to an upsampling convolution layer. This is repeated for all the 7 levels and resulting tensors at first 4 levels form our disparity predictions after doing a bilinear interpolation followed by another conv layer where we use Sigmoid activation function and a scaling() and shift() hyperparameters to constrain the disparity values to a certain range. In our experiments, and are set to 10 and 0.01 respectively. The weights are initialized using xavier_uniform initialization whereas the biases are initialized to 0.
IV-B5 Pose Network
The output depth maps are fed to the a pose estimation network along with the sequence image at the current and the previous time step. The pose estimation network consists of seven convolution layers with the number of activation maps at each convolution output equal to respectively. The kernel sizes for the first two layers is equal to 7 and 5 respectively. The rest of the convolution filters have a kernel size of 3. We use ReLU as the non-linear activation function. The output of the convolution layer is fed to two sub-modules. These sub-modules consist of a decoder architecture similar to the Flownet architecture [37] which outputs an explainability mask to discard the occluding/moving points which might be producing erroneous correspondences for pose estimation. Since the range of the explainability mask is [0,1], we use a Sigmoid activation at the at the output of the decoder layers to generate the explainability mask(at all scales). Similar to depth network, we predict the explainability mask at 4 different scales. The second sub-module consists of a single convolution layer with 6 output channels corresponding to the 6 DOF for pose estimations. This output represents the relative pose change between the source and the target image, and is used for the camera trajectory estimation. The weights are initialized using xavier_uniform initialization whereas the biases are initialized to 0.
IV-B6 GAN
We experimented with multiple discriminator architectures for the adversarial training. We used WGAN and PatchGAN to study the effects of using a global and local discriminator.
The authors in [3] have suggested WGAN[5] with the same architecture as the encoding part of the DispNet. SGD optimiser is used and WGAN. The loss function here is (Average critic loss of fake images) - (Average critic loss of real images).
The PatchGAN architecture used here is the architecture proposed in [21] and since then has been widely used for image-image translation problems. The discriminator tries to classify if a patch is real or fake. The final output of the discriminator is the average output of the discriminator results over all the input patches. The implementation has been borrowed from [38]
The weight for each of the loss terms in the total loss (for all ablation experiments) can be seen in README section in the code link provided. The default values of the weights are 0.75, 0.1, 0.14 and 0.01 for appearance, smoothness, trajectory and GAN loss respectively. We use Adam optimizer in our experiments.
IV-C Evaluation metrics
For evaluating the predicted depth images, we use 6 different metrics as suggested in [3]. The Absolute difference metric calculates the mean of absolute value of pixel depth value differences between ground-truth and predicted depth images. The Absolute relative metric differs from the above by normalizing the depth value differences using the original(ground-truth) depth values. The Square relative metric differs from Absolute relative metric by using square instead of absolute values while calculating the differences.
For the rest of the metrics, we first introduce the term given by . We then take three thresholds 1.25, , and for each of these values, we calculate how many percentage of the pixels satisfy the condition . Other than these 6 metrics, we use the standard ATE(Absolute Trajectory Error) metric for evaluating the trajectory and thereby poses.
IV-D Results
In this section, we present the experimental results of the current pipeline benefiting from the additional information in form of the sequential inputs over the erstwhile state-of-the-art SFMLearner pipeline [1]. We also try to study the effects of different components of the pipeline used by performing extensive ablation studies. The depth estimations are evaluated using the metrics described above. The pose estimations are measured using the Absolute Trajectory Error (ATE) for both translation and rotation.
IV-D1 Ablation Studies
In this section, we show the results of ablation studies of our model and visualize the predicted depths and loss curves for each ablation experiment. All the experiments use a sequence of 15 images of which we calculate the optical flow. Now these optical flow may contain redundant information and we encode these to get get a code. This code is the input to all our ablations.
SFMLearner + OpticalFlowCode + LSTM
In this ablation experiment, we augment the SFMLearner model with LSTM and optical flow computation. The significance of this experiment is we want to leverage the sequential information in a video to predict better pose and depth. This will result in better warped image. Simple photo-metric loss is used to check view synthesis. The predicted depths and warped RGBs are shown in Figure 3.

| Abs.Diff | Abs.rel | Sq.rel | ||||
|---|---|---|---|---|---|---|
| SfmLearner | 5.12 | 0.443 | 4.24 | 0.517 | 0.765 | 0.811 |
| SFMLearner + OpticalFlowCode + LSTM | 4.74 | 0.243 | 2.27 | 0.518 | 0.761 | 0.857 |
| SFMLearner + OpticalFlowCode + LSTM + WGAN | 5.08 | 0.259 | 2.7 | 0.519 | 0.736 | 0.83 |
| SFMLearner + OpticalFlowCode + LSTM + PatchGAN | 4.50 | 0.237 | 2.25 | 0.56 | 0.775 | 0.861 |
| SFMLearner + OpticalFlowCode + WGAN | 5.361 | 0.266 | 3.0 | 0.507 | 0.717 | 0.815 |
| SFMLearner + OpticalFlowCode + LSTM + WGAN + Trajectory Loss | 4.089 | 0.295 | 2.18 | 0.461 | 0.706 | 0.821 |
| SFMLearner + OpticalFlowCode + LSTM + PatchGAN + Trajectory Loss | 4.874 | 0.248 | 2.55 | 0.539 | 0.745 | 0.837 |
SFMLearner + OpticalFlowCode + LSTM + WGAN
In this experiment, we add the GAN loss in the model. This is introduced by adding a discriminator network. The task of discriminator is to find the fake ones. The warped image is given as input. We use WGAN for this ablation. This loss is the same as used by authors in [3]. This loss helps in predicting the real or fake warped image without collapsing. Results are shown in Figure 4.


SFMLearner + OpticalFlowCode + LSTM + PatchGAN
Here we perform the ablation by replacing WGAN in previous experiment with PatchGAN. PatchGan is one of the most popular GAN networks. here we use the discriminator from this architecture and use MSE loss. The idea is that this will be able to judiciously distinguish real from fake warps and take care of visual artifacts. The results are shown in Figure 5

SFMLearner + OpticalFlowCode + PatchGAN
Now, we remove LSTM from our previous experiment model. The significance of this experiment is that we want to see if the recurrence relation is actually captured by LSTM, or Optical flow does a good enough job to encode that information. The results for this ablation are shown in Figure 6.


SFMLearner + OpticalFlowCode + LSTM + PatchGAN + Trajectory Loss
In this final ablation, we include all the components in our model, including the trajectory constraint. The trajectory loss adds geometric consistency constraint between relative poses predicted for different frames. This is especially needed as the other losses do not care about this. As all our objects in the dataset are rigid bodies, we can use this as our final experiment. The results are in Figure 7.

IV-D2 Depth estimation
The quantitative results for the depth estimation module can be seen in Table I. For first 3 lower values are better and last 3 higher values are better. It can be seen our model outperforms the model proposed in [1]. We also present the results of our model along with various versions of our implementation. We observe that the PatchGAN architecture for the discriminator produces better results than the WGAN model proposed in [3]. A possible reason for this might be that since the PatchGAN model tries to discriminate real and fake images at a local scale, it might lead to images that are more consistent.
IV-D3 Pose estimation
The quantitative results for the pose estimation module can be seen in Table II. The results demonstrate that this architecture outperforms the SFMLearner architecture by a significant margin. It can be seen here that although the effect of trajectory loss was not quite seen in the depth estimation results, it is apparent that trajectory loss is helpful for correct pose estimation. We see that removal of LSTM has the largest impact on the results, and PatchGAN performs better than WGAN, which is in line with the observations above.
| Seq. 9 | Seq. 10 | |
|---|---|---|
| SFMLearner | 0.006 | 0.0054 |
| B + Optical Flow + LSTM | 0.0048 | 0.0046 |
| B + Optical FLow + LSTM + WGAN | 0.0045 | 0.0044 |
| B + Optical Flow + LSTM + PatchGAN | 0.0041 | 0.0037 |
| B + Optical flow + WGAN | 0.0052 | 0.0050 |
| B + Optical Flow + LSTM + WGAN + TC | 0.0039 | 0.0037 |
| B + Optical Flow + LSTM + PatchGAN + TC | 0.0034 | 0.0031 |
V Challenges
Some of the challenges we faced during this project are:
-
1.
Optical flow computation: Optical flow can either be computed at runtime or can be pre-computed for the entire dataset. Pre-computing optical flow consumes a lot of disk space for KITTI dataset but saves time during training. Computing optical flow at runtime, even though cheap on storage, increases the training time, based on the algorithm being used.
-
2.
Generative adversarial training: Training GANs come with all the problems related to it. Some of these issues are mode collapse, non-convergence, diminished gradient, etc. In WGAN we noticed the values fluctuating a lot and not having proper convergence. Perhaps that is why the results from WGAN were not the best. In PatchGAN the values were diminishing but at a slower rate. The training time was almost 1.5 times the WGAN training time.
-
3.
LSTMs: Training LSTMs is also challenging due to problems like vanishing/exploding gradients, unstable training, etc. We did not keep track of the LSTM values, but experiments without LSTM gave poorer performance.
-
4.
Hyper-parameters: There were lot hyper-parameters to be set in this as there were many loss functions. The values given by the authors in the [3] did not work for our implementation, especially for depth regularisation and trajectory loss. The weight values given by the authors for trajectory loss would overpower all other losses and make PoseNet converge to the trivial solution of predicting no change in pose. After that the network would never recover. We tried lot of values in the limited compute capability we had. The hyper-parameter selection especially the weights of different loss functions could be explored further and may give better results.
-
5.
Code base: There were many sub-modules in the code and they had to be modular enough to plug and play for different ablation experiments. Maintaining that and conceptualising the entire pipeline was difficult.
-
6.
GPU availability: We all had limited compute available to train all the networks for multiple iterations.
-
7.
Instability in training: We had Encoder, LSTM, Dispnet, PoseNet and Discriminator network being trained simultaneously. There was a lot of instability and they may have gone through collaborative self-supervision, where in they would have corrected each other’s mistakes to some extent.
-
8.
SSIM loss: SSIM ranges from with 1 being equal images. The equation in [3] suggested the SSIM value as a part of the appearance loss. However, intuitively, it made more sense to use (1 - SSIM) as a part of the loss function. We referred multiple papers to confirm the correctness of our change. The logic is that we want to penalise dissimilar images and increase loss when the warped image is not similar to GT image.
VI Conclusion and Future Work
In this project we have tried to implement [3] paper. We try to leverage temporal consistency in video sequence to solve Visual odometry as a View synthesis problem. We take up sequence of input RGB frames, find optical flow between consecutive frames then pass them through an encoder to get the code. The code is passed to an LSTM which tries to incorporate long term and short term information in the code. This information is passed to the Generator module which consists of a DisparityNet and PoseNet. These 2 are used to generate a warped target image. This target image is then judged for being real or fake by our Discriminator. In order to add some novelty we experimented with PatchGAN as well as WGAN, and found that PatchGAN actually performed better than WGAN for our experiments, the reason for which we have already provided above. This project had multiple loss functions and outputs which harmoniously blend together to solve Visual Odometry task. It took us a long time to get each module working independently and then together with the other modules. In the future we would like to do a more exhaustive hyperparameter search. We would also like to explore more losses that can add better constraints on the overall system. We have thought of another loss, i.e. cycle consistency loss which can be used in this. Instead of just image generation we can do an inverse warp to get the original image back and they should be same. This might make the system more robust. We also did not experiment with various architectures for PoseNet and DispNet. We mainly tried to use the architectures borrowed from SFMLearner. We would also like to explore some other newer Depth predicting architectures as that might increase the performance further. We would also want to train on Cityscapes dataset [39] and compare the result for that as well. As a concluding remark, it was a great project to work on and it gave us exposure in multiple areas in Vision and SLAM.
References
- [1] Tinghui Zhou, Matthew Brown, Noah Snavely, and David G. Lowe, “Unsupervised learning of depth and ego-motion from video,” in CVPR, 2017.
- [2] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems 27, Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Eds., pp. 2672–2680. Curran Associates, Inc., 2014.
- [3] Shunkai Li, Fei Xue, Xin Wang, Zike Yan, and Hongbin Zha, “Sequential adversarial learning for self-supervised deep visual odometry,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 2851–2860.
- [4] “Pytorch sfmlearner implementation,” https://github.com/ClementPinard/SfmLearner-Pytorch.
- [5] Martin Arjovsky, Soumith Chintala, and Léon Bottou, “Wasserstein gan,” arXiv preprint arXiv:1701.07875, 2017.
- [6] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros, “Image-to-image translation with conditional adversarial networks,” arxiv, 2016.
- [7] Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos, “Orb-slam: a versatile and accurate monocular slam system,” IEEE transactions on robotics, vol. 31, no. 5, pp. 1147–1163, 2015.
- [8] Long Quan and Zhongdan Lan, “Linear n-point camera pose determination,” IEEE Transactions on pattern analysis and machine intelligence, vol. 21, no. 8, pp. 774–780, 1999.
- [9] Shaharyar Ahmed Khan Tareen and Zahra Saleem, “A comparative analysis of sift, surf, kaze, akaze, orb, and brisk,” in 2018 International conference on computing, mathematics and engineering technologies (iCoMET). IEEE, 2018, pp. 1–10.
- [10] Huizhong Zhou, Benjamin Ummenhofer, and Thomas Brox, “Deeptam: Deep tracking and mapping,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 822–838.
- [11] Sen Wang, Ronald Clark, Hongkai Wen, and Niki Trigoni, “Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 2043–2050.
- [12] Benjamin Ummenhofer, Huizhong Zhou, Jonas Uhrig, Nikolaus Mayer, Eddy Ilg, Alexey Dosovitskiy, and Thomas Brox, “Demon: Depth and motion network for learning monocular stereo,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5038–5047.
- [13] Ricson Cheng, Ziyan Wang, and Katerina Fragkiadaki, “Geometry-aware recurrent neural networks for active visual recognition,” Advances in Neural Information Processing Systems, vol. 31, 2018.
- [14] Hsiao-Yu Fish Tung, Zhou Xian, Mihir Prabhudesai, Shamit Lal, and Katerina Fragkiadaki, “3d-oes: Viewpoint-invariant object-factorized environment simulators,” arXiv preprint arXiv:2011.06464, 2020.
- [15] Shamit Lal, Mihir Prabhudesai, Ishita Mediratta, Adam W Harley, and Katerina Fragkiadaki, “Coconets: Continuous contrastive 3d scene representations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12487–12496.
- [16] Zhou Xian, Shamit Lal, Hsiao-Yu Tung, Emmanouil Antonios Platanios, and Katerina Fragkiadaki, “Hyperdynamics: Meta-learning object and agent dynamics with hypernetworks,” arXiv preprint arXiv:2103.09439, 2021.
- [17] Mihir Prabhudesai, Shamit Lal, Darshan Patil, Hsiao-Yu Tung, Adam W Harley, and Katerina Fragkiadaki, “Disentangling 3d prototypical networks for few-shot concept learning,” arXiv preprint arXiv:2011.03367, 2020.
- [18] Mihir Prabhudesai, Shamit Lal, Hsiao-Yu Fish Tung, Adam W Harley, Shubhankar Potdar, and Katerina Fragkiadaki, “3d object recognition by corresponding and quantizing neural 3d scene representations,” arXiv preprint arXiv:2010.16279, 2020.
- [19] Andreas Geiger, Philip Lenz, and Raquel Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- [20] Ashutosh Saxena, Min Sun, and Andrew Y Ng, “Make3d: Learning 3d scene structure from a single still image,” IEEE transactions on pattern analysis and machine intelligence, vol. 31, no. 5, pp. 824–840, 2008.
- [21] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.
- [22] Alec Radford, Luke Metz, and Soumith Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” arXiv preprint arXiv:1511.06434, 2015.
- [23] Richard Zhang, Phillip Isola, and Alexei A Efros, “Colorful image colorization,” in Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14. Springer, 2016, pp. 649–666.
- [24] Yongcheng Jing, Yezhou Yang, Zunlei Feng, Jingwen Ye, Yizhou Yu, and Mingli Song, “Neural style transfer: A review,” IEEE transactions on visualization and computer graphics, vol. 26, no. 11, pp. 3365–3385, 2019.
- [25] Leon A Gatys, Alexander S Ecker, and Matthias Bethge, “Image style transfer using convolutional neural networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2414–2423.
- [26] Maayan Frid-Adar, Idit Diamant, Eyal Klang, Michal Amitai, Jacob Goldberger, and Hayit Greenspan, “Gan-based synthetic medical image augmentation for increased cnn performance in liver lesion classification,” Neurocomputing, vol. 321, pp. 321–331, 2018.
- [27] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang, “Free-form image inpainting with gated convolution,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4471–4480.
- [28] Raymond A Yeh, Chen Chen, Teck Yian Lim, Alexander G Schwing, Mark Hasegawa-Johnson, and Minh N Do, “Semantic image inpainting with deep generative models,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5485–5493.
- [29] Shamit Lal, Vineet Garg, and Om Prakash Verma, “Automatic image colorization using adversarial training,” in Proceedings of the 9th International Conference on Signal Processing Systems, 2017, pp. 84–88.
- [30] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al., “Photo-realistic single image super-resolution using a generative adversarial network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4681–4690.
- [31] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.
- [32] Nikolaus Mayer, Eddy Ilg, Philip Hausser, Philipp Fischer, Daniel Cremers, Alexey Dosovitskiy, and Thomas Brox, “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4040–4048.
- [33] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al., “Spatial transformer networks,” in Advances in neural information processing systems, 2015, pp. 2017–2025.
- [34] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004.
- [35] “Opencv’s farneback method,” https://docs.opencv.org/2.4/modules/video/doc/motion_analysis_and_object_tracking.html#calcopticalflowfarneback.
- [36] “Ce liu’s c++ implementation of coarse2fine optical flow,” https://people.csail.mit.edu/celiu/OpticalFlow/.
- [37] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Hausser, Caner Hazirbas, Vladimir Golkov, Patrick Van Der Smagt, Daniel Cremers, and Thomas Brox, “Flownet: Learning optical flow with convolutional networks,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2758–2766.
- [38] “Pytorch gan implementation,” https://github.com/eriklindernoren/PyTorch-GAN.
- [39] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele, “The cityscapes dataset for semantic urban scene understanding,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223.