ROBI: A Multi-View Dataset for Reflective Objects in Robotic Bin-Picking
Abstract
In robotic bin-picking applications, the perception of texture-less, highly reflective parts is a valuable but challenging task. The high glossiness can introduce fake edges in RGB images and inaccurate depth measurements especially in heavily cluttered bin scenario. In this paper, we present the ROBI (Reflective Objects in BIns) dataset, a public dataset for 6D object pose estimation and multi-view depth fusion in robotic bin-picking scenarios. The ROBI dataset includes a total of 63 bin-picking scenes captured with two active stereo camera: a high-cost Ensenso sensor and a low-cost RealSense sensor. For each scene, the monochrome/RGB images and depth maps are captured from sampled view spheres around the scene, and are annotated with accurate 6D poses of visible objects and an associated visibility score. For evaluating the performance of depth fusion, we captured the ground truth depth maps by high-cost Ensenso camera with objects coated in anti-reflective scanning spray. To show the utility of the dataset, we evaluated the representative algorithms of 6D object pose estimation and multi-view depth fusion on the full dataset. Evaluation results demonstrate the difficulty of highly reflective objects, especially in difficult cases due to the degradation of depth data quality, severe occlusions and cluttered scene. The ROBI dataset is available online at https://www.trailab.utias.utoronto.ca/robi.
I INTRODUCTION
Highly reflective objects are common in robotic bin-picking applications, and the goal is to have a vision-guided robot to pick up such objects with random poses from a bin. Towards this goal, highly accurate 6D object poses are often required prior to robot grasp execution. These reflective objects are mostly texture-less and cannot be reliably recognized with classic techniques that rely on local descriptors [1]. Instead, recent approaches that can deal with texture-less object have focused on depth or RGB-D based features [2, 3, 4, 5, 6, 7, 8]. With the increasing availability of depth cameras, it brings the hope that object detection and 6D pose estimation can be eventually solved for such objects. As a result, RGBD-based object detection and pose estimation is an active research area for robotic bin-picking, and the RGBD datasets, consisting of RGB/monochrome image and depth maps, play an important role.





| Object | Diameter (mm) | Surface Material | Geometric Symmetry | Symmetry Order | Size Ratio |
| Zigzag | 76.2 | metallic | no | - | 0.58 |
| Chrome Screw | 29.1 | metallic | yes | infinite | 0.46 |
| Gear | 36.8 | metallic | almost* | 12 | 0.89 |
| Eye Bolt | 47.2 | metallic | yes | 2 | 0.32 |
| Tube Fitting | 24.5 | metallic | yes | 6 | 0.81 |
| DIN Connector | 32.5 | metallic and plastic | no | - | 0.62 |
| D-Sub Connector | 30.2 | metallic and plastic | no | - | 0.41 |
-
*
Almost symmetric: the objects breaks the symmetry with only a small detail.
-
Size ratio: the ratio of the smallest to the largest sides of an axis-aligned object bounding box [9].
However, industrial-grade depth cameras often fail to sense complete depths throughout the field of view when surfaces are too glossy, dark, close, or far from the sensor. Moreover, in the industrial environment, the severe clutter and occlusions of the scene can lead to significant degradation of depth quality. To this end, in our previous work [10], we constructed ROBI v1.0 dataset, a novel challenging dataset for evaluating different methods of multi-view depth fusion and 6D object pose estimation for highly reflective objects. It comprises 7 metallic industrial objects with different levels of reflectivity, and 5 individual bin instances with up to 88 viewpoints for each object. However, ROBI v1.0 only includes captures by a high-cost Ensenso active stereo camera, which is normally too expensive for the customer-level bin-picking system. To investigate lost-cost sensor performance on these reflective parts, in this paper, we expand the ROBI dataset to include more scenes from a low-cost Intel RealSense sensor. Our full dataset comprises 4 additional captures for each object, resulting in a total of 63 scenes and 8K images. The capture platform is equipped with two active stereo camera sensors, a high-cost Ensenso N35, and a low-cost RealSense D415. In addition, to study the impact of depth quality for different perception solutions, we provide ground truth depth maps captured by the high-cost Ensenso with objects coated in anti-reflective scanning spray.
We use a robot manipulator to move the sensors to different viewpoints, systematically sampling from a spherical dome. We separate our data capture into full-bin and low-bin scenarios to demonstrate two different bin-picking conditions, as shown in Fig. 2. For each scene and viewpoint, monochrome/RGB images, raw and ground truth depth maps, and annotations of 6D object poses with visibility scores are included.
The ROBI dataset is intended for evaluating different perception solutions for highly reflective objects, such as 6D object pose estimation [11], scene reconstruction [10], depth completion [12], and active perception [13]. We capture images with two different grades of sensors, associated with ground truth depth maps. This allows us to study the impact of different input modalities and depth data quality for a given problem. The difficulty of reflective objects for pose estimation and multi-view depth fusion is demonstrated by the relatively low performance using representative algorithms in Sec. IV.
In summary, we make the following contributions:
-
•
A real-world multi-view dataset for reflective objects in the bin-picking scenarios with: 1) 7 metallic industrial parts with different levels of reflectivity, 2) 63 bin instances for each object with up to 125 distinct viewpoints, 3) images captured with a high-cost Ensenso camera and a low-cost RealSense camera.
-
•
A novel method to acquire the ground truth depth maps for highly reflective objects, which are missing in most of datasets.
-
•
The evaluation of the representative approaches for object pose estimation and multi-view depth fusion on the full ROBI dataset.
II RELATED WORK
The progress of research in computer vision and robotics has been strongly influenced by datasets, which enable us to evaluate methods and understand their limitations. In this section, we review related datasets for robotic bin-picking.
II-A Datasets for Object Detection and 6D Pose Estimation.
Object detection and 6D pose estimation play an important role in many technological areas. With the increasing availability of RGB-D cameras, numerous datasets has appeared [2, 14, 15, 4, 16, 17, 9]. A summary of all these datasets is presented in [17], and in the benchmark for 6D object pose estimation (BOP) [11], the authors have performed a comprehensive evaluation of 15 diverse approaches on eight recent datasets.
The LINEMOD Dataset [2] is a widely used benchmark for texture-less objects. It contains 18000 RGB-D images of 15 objects, and has become a standard benchmark in most of recent works [2, 3, 4, 5]. The test images feature severe clutter but only mild occlusion. This work was augmented by [18] to consider a high degree of occlusion for evaluation. Datasets presented in [15, 4, 16] have similar properties. The objects have discriminative color, large size, and limited pose variability, making recognition relatively easy.
For industrial object detection, Drost et al. [9] introduced the ITODD dataset, which contains 28 industrial parts with minor reflective surfaces. The T-LESS Dataset [14] features 30 texture-less objects with no discriminative color and shape. The test images were captured from 20 scenes with various complexity: from several isolated objects on a clean background to multiple objects stacked with severe occlusions and clutter. Despite numerous advantages, these two datasets have the following limitations: 1): they lack pose and scene variations, hence cannot represent industrial warehouse scenarios; 2) all objects have low reflectivity and do not encounter adverse effects of noisy and missing depth measurements, which is common to industrial parts.
To better serve the bin-picking scenario, Doumanoglou et al. [7] provided the IC-BIN dataset with multiple objects stacked in a bin. It compromises three scenes of two objects from IC-MI dataset [15]. The same scene was recorded from different viewpoints for evaluating object pose estimation and active vision techniques. Recently, the Fraunhofer IPA dataset [17] has been introduced for object pose estimation and instance segmentation for robotic bin-picking. However, it contains only 520 real-world depth images of two industrial objects. In comparison, we captured a total of 8K images for 7 objects in the real-world.
II-B Datasets for Multi-View Depth Fusion.
Historically, 6D object pose estimation has been addressed from a static viewpoint. However, depth cameras often produce inaccurate depth measurements or fail to sense depths entirely from a single viewpoint due to reflective object materials, limited sensor resolution, and scene occlusions. To overcome these limitations, when setup permits, multi-view fusion approaches are able to provide higher levels of scene completion than single view acquisition.
There are several datasets of multi-view RGB-D scans, including ScanNet [19], Matterport3D [20], and others [21, 22, 23]. However, there is no ground-truth available for qualitative evaluation of depth fusion or scene reconstruction. In [24, 25], authors obtained the ground truth by fusing all frames of each scene using standard TSDF fusion [26] and manually removed outliers. The evaluation was then performed on only a subset of frames. Compared to these methods, we provide a novel acquisition method to acquire high-quality ground truth depth images for multi-view depth fusion and scene reconstruction.
III ROBI DATASET
Compared to the existing datasets, the ROBI dataset has three unique characteristics. First, it contains 7 highly reflective objects, with different geometric properties that are common in industrial bin picking, but are not represented existing datasets due to the difficulty of working with specular reflection. Second, we captured different bin scenarios using two different grades of cameras with multi-view data acquisition. This allows us to test the impact of different data modality, viewpoint variation and clutter of the scene. Finally, we provided ground truth depth maps captured by the high-cost depth camera with parts coated in anti-reflective scanning spray. This allows us to quantitatively study the impact of input depth quality for different robotic perception tasks. To the best of our knowledge, this is the first dataset for highly reflective objects with ground truth depth maps. In this section, we describe the details of dataset creation, including sensor setup, data capture pipeline, object model generation, and ground truth annotation.


III-A Sensor Setup
Due to the requirements of high accuracy and short cycle time in robotic bin-picking, we used active stereo cameras for our data capture. Specifically, as shown in Fig. 3(a), a high-cost Ensenso N35 depth sensor and a low-cost Intel RealSense D415 RGB-D camera were used for our real-world data capture. We calibrated intrinsic parameters for both cameras with a precisely manufactured calibration board (shown in Fig. 1(a)) and calibration toolboxes provided by camera vendor. The root mean square re-projection errors calculated on circles of the calibration board are for Ensenso, and and for RealSense’s RGB and depth frames, respectively.
The Ensenso N35 camera comes with an optical lens for short working distance. It has a minimum working distance of , a maximum working distance of , and an optimal working distance of . The sensor is comprised of two visible-light cameras and a light projector, and produces depth maps with a resolution of . Since RGB images are not available, we captured Ensenso data with the following two configurations:
-
•
Depth configuration. We turn the camera projector on and use a low exposure time to eliminate the impact of ambient light. The raw disparity maps and pattern projected stereo pairs are collected.
-
•
Monochrome configuration. The camera projector is turned off for this configuration to capture monochrome images. We use a higher exposure time to obtain optimal contrast for objects. Only stereo pair data is saved with this configuration.
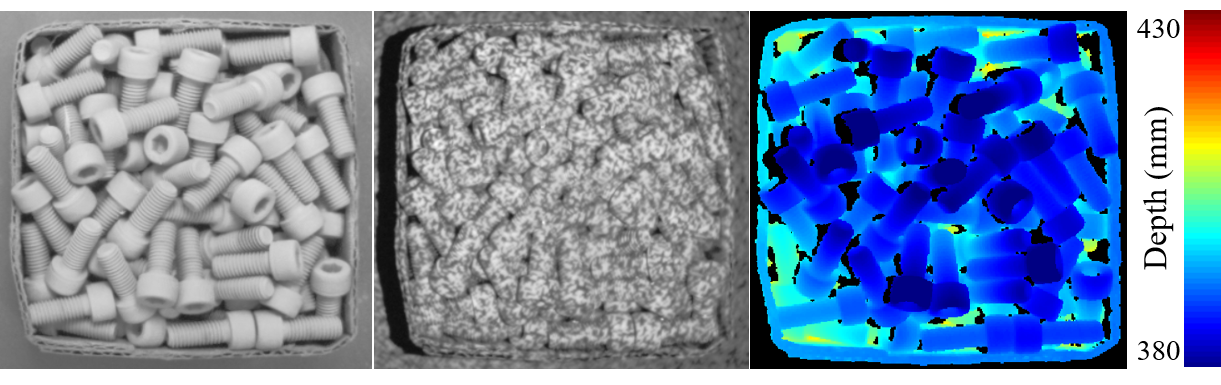
Fig. 4(a) shows the sample camera data captured with Ensenso N35 for the "ZIGZAG" object . The depth map demonstrates that the Ensenso is able to capture fine geometric details, but there is a significant amount of missing data due to surface reflection.


The Intel RealSense D415 is a compact, low cost sensor. It comes with an RGB camera and a depth camera system, comprising two IR cameras and an IR projector. We used the RealSense camera to capture the synchronized RGB images, depth maps, and pattern projected stereo pairs at resolution. The working distance is tuned to the range of . As shown in Fig. 4(b), compared to Ensenso, the depth map captured with RealSense has a higher level of completeness, but with significant degradation of depth accuracy (e.g., loss of geometric details).
III-B Data Capture Pipeline
For each of the seven objects depicted in Fig 2, we captured four bin scenarios (2 full-bin and 2 low-bin). The two active stereo cameras are mounted to an EPSON 6-Axis C4L robot arm, illustrated in Fig. 3(b). We program the robot arm to move on a view sphere around the scene, from approximately to of elevation with different camera distances. The robot end-effector stays pointing towards the center of the workstation. For full-bin scenarios, we sampled a total of 106 views for Ensenso and 125 views for RealSense. Due to the occlusion of bin wall, in low-bin data capture, the sphere elevation is limited to the range of , and there are 68 and 94 views for Ensenso and RealSense, respectively. Fig. 5 demonstrates the sampled viewpoints for these two different scenes, captured with Ensenso camera.


To determine 6D camera poses at different viewpoints, we use a two-step calibration procedure: 1) initial camera pose estimation using robot forward kinematics and the calibrated poses between end-effector and cameras; 2) pose refinement by performing iterative closest point (ICP) on calibration spheres. To acquire the transformation between robot end-effector and two cameras, we leveraged the industrial-grade accuracy of our C4L robot arm, and move the cameras to look at the same calibration pattern at different viewpoints. The 6D poses for Ensenso and RealSense camera are then estimated by solving the classic "hand-eye" calibration problem [27]. For better refinement accuracy using ICP algorithm, we placed calibration spheres around the bin (illustrated in Fig. 1(a)). The spheres are manufactured with a matte surface, so that the cameras can achieve their optimal accuracy. The average closest-point residual error was successfully reduced from 0.33 mm to 0.26mm for Ensenso data, and 1.52 mm to 0.8 mm for RealSense data.



III-C Ground Truth Depth Maps and Scene Model
Active stereo cameras can provide reliable depth measurements when object surfaces have the ideal diffuse reflection, also known as Lambertian reflectance. However, most industrial objects do not have this property, resulting in inaccurate or missing depth measurements. This phenomenon is more obvious for objects with glossy surfaces. As demonstrated in Fig. 6(a), due to severe specular and inter-reflections in the bin, the high-cost Ensenso camera fails to sense a large amount of depth data. To this end, some techniques have been studied to recover missing depth, such as depth completion [12] and multi-view depth fusion [10] for the bin-picking problem. In this section, we provide a method to capture the ground truth depth maps in the real world.
We captured the ground truth depth maps with the Ensenso camera, and applied a scanning spray [28] on objects to better approach ideal Lambertian surfaces, so that the Ensenso camera can achieve its optimal accuracy (). The scanning spray generates a homogeneous layer with only thickness, which is at least one order of magnitude less than expected depth accuracy. The spray is able to self-evaporate within a few hours. Therefore, we leveraged the high repeatability of our robot arm and captured the test and ground truth images with two separate scans. In the first scan, we applied the scanning spray and capture ground truth depth maps. After full evaporation, the test images were captured during the second scan. Fig. 6(b) shows the captured images after applying the scanning spray. Compared with images without the spray (Fig. 6(a)), the Ensenso sensor is able to capture more complete and less noisy depth maps on the same scene.


To evaluate depth fusion methods, for each scene, we constructed a ground truth mesh by applying TSDF fusion [29] on ground truth depth maps. To demonstrate that the reconstruction of the ground truth scene is not biased to any fusion method, we apply two methods, TSDF fusion and probabilistic fusion [10] to produce two sets of ground truth meshes, as shown in Fig. 6(a) and 6(b). We compute the mean point-to-point distance to quantitatively measure the difference between these two sets. The distance is less than 0.03 mm, indicating that our ground truth accuracy is not sensitive to different fusion methods.
III-D 3D Object Model
For each object, we provide both a manually created CAD model and a semi-automatically reconstructed model. Both models are provided with the dataset in the form of 3D meshes.
The reconstructed model is created in a manner similar to the creation of the scene model. We capture the multi-view high-quality depth maps after applying scanning spray, and use TSDF fusion for model reconstruction. For each object, we first reconstruct 2-4 partial models (depending on its geometric properties), and manually remove unnecessary parts and minor artifacts for each partial model. The partial models were then registered into a global reference frame by manual alignment and ICP refinement. Finally, we used MeshLab [30] to inpaint minor holes in the model and smooth the mesh surface. The reconstructed models are shown in Fig. 7 (first column).
III-E Ground Truth Poses
We provide ground truth object poses using the CAD object model and the high-quality scene model, described in Sec. . We perform the alignment process using MeshLab [30]. We first manually aligned object models to the scene model as an initial 6D object pose estimate. We then upsample the CAD model to a high resolution, and apply ICP to refine the object pose. Lastly, we adjust the pose manually whenever necessary to correct any in-plane translation and rotation. We repeat this process several times until a satisfactory alignment is achieved.
Lastly, for each ground truth pose, we generate a visibility score in the scene. This is done by rendering the segmentation mask of object pose via perspective projection. The visibility score, , is the fraction of the number of visible pixels over the number of pixels without any occlusion.



IV EXPERIMENTS AND BENCHMARKS
In this section, we present different benchmarks evaluating the performance of multi-view depth fusion and 6D object pose estimation on reflective objects. All experiments were performed on the full ROBI dataset.
IV-A Multi-View Depth fusion
For the performance of depth fusion, we evaluated two volumetric fusion approaches, the traditional TSDF fusion [26] and a probabilistic fusion approach from [10]. We use three metrics from [10] for the evaluation: mean point-to-point distance, outlier percentage, and scene completeness. These metrics are performed only on the surface of objects, which has a major impact on object pose estimation.
Fig. 8 shows the quantitative reconstruction results for each object with all viewpoints from different cameras. It can be seen that, for both Ensenso and RealSense data, the probabilistic fusion [10] has a much lower reconstruction error than TSDF method on all objects. Moreover, it provides a better trade-off between scene completeness and outlier percentage due to its explicit uncertainty handling. However, we can observe that the probabilistic fusion sacrifices more completeness of scene on the "Gear" object, which has both a high-gloss surface and a complex geometric shape. Fig. 8 also reveals that, when compared with Ensenso results, the reconstruction performance drops significantly on RealSense data, indicating that both methods are upper bounded by the quality of depth measurements.
IV-B 6D Object Pose Estimation
To measure the 6D pose error of the object, we used the standard Average Distance of Model Points (ADD) for non-symmetric objects and ADD-S for symmetric objects [2]. A pose hypothesis is accepted as the correct detection if its ADD or ADD-S score is less than 10% of the object diameter.
For the performance evaluation, we chose three representative pose estimators: LINE-2D [2], PPF (point pair feature) [3] and AAE (augmented autoencoder) [8]. These methods only require the object model for training. The LINE-2D and AAE are RGB-based pipelines. LINE-2D is a template-based method that builds the multi-view templates from the 3D models, and exploits the gradient response on monochrome/RGB images for detection in run-time [31]. AAE is a learning-based pose estimator. The authors used the self-supervised Augmented Autoencoders for estimating 3D rotation, and object detector (e.g., YOLO [redmon2016you]) for translation estimation. Compared with these two approaches, the method proposed by Drost et al. [3] relies on 3D point cloud data as input, and solves object poses by coupling the idea of point pair features and a dense voting scheme. This method is still one of the best performings on the 6D object pose estimation leader board (BOP) [11]. We implemented these methods based on OpenCV [32], Point Cloud Library (PCL) [33] and open-source codes provided by authors [8]. The rendering of training images was based on a toolkit from BOP [11]. Lastly, we apply the iterative closest point (ICP) algorithm for the final refinement of the object pose estimates.
As in [14, 3, 6], the performance is measured by correct detection rate (CDR). A ground truth pose will be taken into consideration only if its visibility score is larger than 0.6. Fig. 9 presents the CDR for each object using single view data. It can be seen that, due to a large number of missing depth measurements, the PPF method has an overall poor performance on both Ensenso and RealSense data. In comparison, the LINE-2D and AAE methods have significantly higher detection rates since they are less dependent on depth data (used for ICP only).
To improve the performance of pose estimation, as illustrated in [10], we can apply the depth fusion and provide high-quality depth input data for the pose estimator. We demonstrate this strategy on the Ensenso camera data with PPF pose estimator, whose performance is highly correlated to depth data. Fig. 10 shows the results on two volumetric fusion approaches, evaluated in Sec. IV-A, as well as the ground truth scene model. It can be seen that, compared with the single view result, the performance of PPF pose estimator can be greatly improved with multi-view depth fusion. And as a result of the higher reconstruction accuracy and few outliers, the probabilistic approach outperforms TSDF fusion on almost all objects. When given more accurate 3D data in the form of the ground truth meshes, the PPF pose estimator can provide close to perfect detection rates.
V CONCLUSION
This paper has presented ROBI, a new dataset for evaluating various robotic perception tasks on reflective objects. The dataset features challenging, highly reflective objects and different real-world bin scenarios which were captured using different grades of cameras with multiple viewpoints. Further, to investigate the impact of depth data quality for a given problem, we provide the ground truth depth maps captured by a high-cost depth sensor with objects coated in anti-reflective scanning spray. Initial evaluation results using the ROBI dataset indicate that the representative algorithms in both multi-view depth fusion and 6D object pose estimation have ample room for improvement. This dataset will provide researchers with the necessary benchmark data to address the severe and frequent challenges that arise in manufacturing and assembly tasks when operating with highly reflective objects.
References
- [1] A. Collet, M. Martinez, and S. S. Srinivasa, “The moped framework: Object recognition and pose estimation for manipulation,” The international journal of robotics research, vol. 30, no. 10, pp. 1284–1306, 2011.
- [2] S. Hinterstoisser, V. Lepetit, S. Ilic, S. Holzer, G. Bradski, K. Konolige, and N. Navab, “Model based training, detection and pose estimation of texture-less 3d objects in heavily cluttered scenes,” in Asian conference on computer vision, pp. 548–562, Springer, 2012.
- [3] B. Drost, M. Ulrich, N. Navab, and S. Ilic, “Model globally, match locally: Efficient and robust 3d object recognition,” in 2010 IEEE computer society conference on computer vision and pattern recognition, pp. 998–1005, Ieee, 2010.
- [4] Y. Xiang, T. Schmidt, V. Narayanan, and D. Fox, “Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes,” arXiv preprint arXiv:1711.00199, 2017.
- [5] Y. He, W. Sun, H. Huang, J. Liu, H. Fan, and J. Sun, “Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11632–11641, 2020.
- [6] M. Rad and V. Lepetit, “Bb8: A scalable, accurate, robust to partial occlusion method for predicting the 3d poses of challenging objects without using depth,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 3828–3836, 2017.
- [7] A. Doumanoglou, R. Kouskouridas, S. Malassiotis, and T.-K. Kim, “Recovering 6d object pose and predicting next-best-view in the crowd,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3583–3592, 2016.
- [8] M. Sundermeyer, Z.-C. Marton, M. Durner, M. Brucker, and R. Triebel, “Implicit 3d orientation learning for 6d object detection from rgb images,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 699–715, 2018.
- [9] B. Drost, M. Ulrich, P. Bergmann, P. Hartinger, and C. Steger, “Introducing mvtec itodd-a dataset for 3d object recognition in industry,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 2200–2208, 2017.
- [10] J. Yang, D. Li, and S. L. Waslander, “Probabilistic multi-view fusion of active stereo depth maps for robotic bin-picking,” 2021.
- [11] T. Hodan, F. Michel, E. Brachmann, W. Kehl, A. GlentBuch, D. Kraft, B. Drost, J. Vidal, S. Ihrke, X. Zabulis, et al., “Bop: Benchmark for 6d object pose estimation,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 19–34, 2018.
- [12] S. Sajjan, M. Moore, M. Pan, G. Nagaraja, J. Lee, A. Zeng, and S. Song, “Clear grasp: 3d shape estimation of transparent objects for manipulation,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), pp. 3634–3642, IEEE, 2020.
- [13] J. Sock, G. Garcia-Hernando, and T.-K. Kim, “Active 6d multi-object pose estimation in cluttered scenarios with deep reinforcement learning,” arXiv preprint arXiv:1910.08811, 2019.
- [14] T. Hodan, P. Haluza, Š. Obdržálek, J. Matas, M. Lourakis, and X. Zabulis, “T-less: An rgb-d dataset for 6d pose estimation of texture-less objects,” in 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), pp. 880–888, IEEE, 2017.
- [15] A. Tejani, D. Tang, R. Kouskouridas, and T.-K. Kim, “Latent-class hough forests for 3d object detection and pose estimation,” in European Conference on Computer Vision, pp. 462–477, Springer, 2014.
- [16] R. Kaskman, S. Zakharov, I. Shugurov, and S. Ilic, “Homebreweddb: Rgb-d dataset for 6d pose estimation of 3d objects,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, pp. 0–0, 2019.
- [17] K. Kleeberger, C. Landgraf, and M. F. Huber, “Large-scale 6d object pose estimation dataset for industrial bin-picking,” arXiv preprint arXiv:1912.12125, 2019.
- [18] E. Brachmann, A. Krull, F. Michel, S. Gumhold, J. Shotton, and C. Rother, “Learning 6d object pose estimation using 3d object coordinates,” in European conference on computer vision, pp. 536–551, Springer, 2014.
- [19] A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5828–5839, 2017.
- [20] A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Niessner, M. Savva, S. Song, A. Zeng, and Y. Zhang, “Matterport3d: Learning from rgb-d data in indoor environments,” arXiv preprint arXiv:1709.06158, 2017.
- [21] J. Xiao, A. Owens, and A. Torralba, “Sun3d: A database of big spaces reconstructed using sfm and object labels,” in Proceedings of the IEEE international conference on computer vision, pp. 1625–1632, 2013.
- [22] Q.-Y. Zhou and V. Koltun, “Dense scene reconstruction with points of interest,” ACM Transactions on Graphics (ToG), vol. 32, no. 4, pp. 1–8, 2013.
- [23] S. Choi, Q.-Y. Zhou, S. Miller, and V. Koltun, “A large dataset of object scans,” arXiv preprint arXiv:1602.02481, 2016.
- [24] S. Weder, J. Schonberger, M. Pollefeys, and M. R. Oswald, “Routedfusion: Learning real-time depth map fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4887–4897, 2020.
- [25] G. Riegler, A. O. Ulusoy, H. Bischof, and A. Geiger, “Octnetfusion: Learning depth fusion from data,” in 2017 International Conference on 3D Vision (3DV), pp. 57–66, IEEE, 2017.
- [26] B. Curless and M. Levoy, “A volumetric method for building complex models from range images,” in Proceedings of the 23rd annual conference on Computer graphics and interactive techniques, pp. 303–312, 1996.
- [27] K. Daniilidis, “Hand-eye calibration using dual quaternions,” The International Journal of Robotics Research, vol. 18, no. 3, pp. 286–298, 1999.
- [28] “Aesub blue: Vanishing 3d scanning spray.” https://aesub.com.
- [29] R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohi, J. Shotton, S. Hodges, and A. Fitzgibbon, “Kinectfusion: Real-time dense surface mapping and tracking,” in 2011 10th IEEE International Symposium on Mixed and Augmented Reality, pp. 127–136, IEEE, 2011.
- [30] V. Scarano, R. De Chiara, U. Erra, et al., “Meshlab: an open-source mesh processing tool,” 2008.
- [31] S. Hinterstoisser, C. Cagniart, S. Ilic, P. Sturm, N. Navab, P. Fua, and V. Lepetit, “Gradient response maps for real-time detection of textureless objects,” IEEE transactions on pattern analysis and machine intelligence, vol. 34, no. 5, pp. 876–888, 2011.
- [32] G. Bradski and A. Kaehler, “Opencv,” Dr. Dobb’s journal of software tools, vol. 3, 2000.
- [33] R. B. Rusu and S. Cousins, “3d is here: Point cloud library (pcl),” in 2011 IEEE international conference on robotics and automation, pp. 1–4, IEEE, 2011.