RingCNN: Exploiting Algebraically-Sparse Ring Tensors for Energy-Efficient CNN-Based Computational Imaging ††thanks: This work was supported by the Ministry of Science and Technology, Taiwan, R.O.C., under Grant no. MOST 109-2218-E-007-034.
Abstract
In the era of artificial intelligence, convolutional neural networks (CNNs) are emerging as a powerful technique for computational imaging. They have shown superior quality for reconstructing fine textures from badly-distorted images and have potential to bring next-generation cameras and displays to our daily life. However, CNNs demand intensive computing power for generating high-resolution videos and defy conventional sparsity techniques when rendering dense details. Therefore, finding new possibilities in regular sparsity is crucial to enable large-scale deployment of CNN-based computational imaging.
In this paper, we consider a fundamental but yet well-explored approach—algebraic sparsity—for energy-efficient CNN acceleration. We propose to build CNN models based on ring algebra that defines multiplication, addition, and non-linearity for -tuples properly. Then the essential sparsity will immediately follow, e.g. -times reduction for the number of real-valued weights. We define and unify several variants of ring algebras into a modeling framework, RingCNN, and make comparisons in terms of image quality and hardware complexity. On top of that, we further devise a novel ring algebra which minimizes complexity with component-wise product and achieves the best quality using directional ReLU. Finally, we design an accelerator, eRingCNN, to accommodate to the proposed ring algebra, in particular with regular ring-convolution arrays for efficient inference and on-the-fly directional ReLU blocks for fixed-point computation. We implement two configurations, and (50% and 75% sparsity), with 40 nm technology to support advanced denoising and super-resolution at up to 4K UHD 30 fps. Layout results show that they can deliver equivalent 41 TOPS using 3.76 W and 2.22 W, respectively. Compared to the real-valued counterpart, our ring convolution engines for achieve 2.00 energy efficiency and 2.08 area efficiency with similar or even better image quality. With , the efficiency gains of energy and area are further increased to 3.84 and 3.77 with only 0.11 dB drop of peak signal-to-noise ratio (PSNR). The results show that RingCNN exhibits great architectural advantages for providing near-maximum hardware efficiencies and graceful quality degradation simultaneously.
Index Terms:
convolutional neural network, computational imaging, regular sparsity, hardware acceleratorI Introduction
Convolutional neural networks (CNNs) have demonstrated their superiority in the fields of computer vision and computational imaging. The former includes object recognition [43, 18] and detection [55]. The latter involves image denoising [49, 50], super-resolution (SR) [26, 31, 32, 47], and style transfer [24, 56]; in particular, denoising is the key to enhance low-light photography on mobile phones, and SR plays an important role for displaying lower-resolution contents on ultra-high-resolution (UHD) TVs. Although CNNs can be applied in both application fields, the computation schemes are quite different and so are their design challenges.
Recognition and detection CNNs aim to extract high-level features and usually process small images with a huge amount of parameters. In contrast, computational imaging ones need to generate low-level and high-precision details and often deal with much larger images with fewer parameters. For example, the state-of-the-art FFDNet for denoising [50] requires only 850K weights but can be used to generate 4K UHD videos at 30 fps. This will demand as high as 106 TOPS (tera operations per second) of computation, and the precision of multiplications could be at least 8-bit for representing sufficient dynamic ranges. Therefore, for computational imaging it is the intensive computation for rendering fine-textured, high-throughput, and high-precision feature maps to pose challenges for the deployment in consumer electronics.
Exploiting sparsity in computation is a promising way to reduce complexity for CNNs. Many approaches have been analyzed in detail, but most of them are discussed only for recognition and detection. The most common one is to explore natural sparsity for feature maps [3, 34] and/or filter weights [38, 16, 54]. Utilizing such sparsity, like unstructured pruning [17], will induce computation irregularity and thus significant hardware overheads. For example, the state-of-the-art SparTen [16] only delivers 0.43 TOPS/W on 45 nm technology for the dedicated designs to tame irregularity. If, instead, structured pruning [35, 40] is applied to improve regularity, model quality will then drop quickly. Thus, natural sparsity is hard to support high-throughput inference with low power consumption.
Another common approach is to explore the low-rank sparsity in over-parameterized CNNs by either decomposition [37, 30, 27] or model structuring [19, 23, 41, 12]. It aims high compression ratios and approximates weight tensors by regular but radically-changed inference structures. This low-rank approximation works well for recognition CNNs which extract high-level features. But it could quickly deteriorate the representative power of computational imaging ones for generating local details. For example, merely applying depth-wise convolution can lead to 1.2 dB of peak signal-to-noise ratio (PSNR) drop for SR networks [21]. Therefore, low-rank sparsity may not be suitable for fine-textured CNN inference.
A recent alternative for providing regular acceleration is to enforce full-rank sparsity on matrix-vector multiplications [13, 52, 53]. It partitions them into several sub-block multiplications and then replaces each one by a component-wise product between -tuples. This is equivalent to a group convolution with data reordering [53]; therefore, for restoring representative power additional pre-/post-processing is required to mix information between components or groups. CirCNN [13] equivalently applies Fourier transform on each sub-block for this purpose by forcing weight matrices to be block-circulant. ShuffleNet [52] instead performs global channel shuffling, and HadaNet [53] adopts simpler Hadamard transform. However, the applicability of this approach is unclear for computational imaging because CirCNN aims very high compression ratios (66 for AlexNet [29]), and ShuffleNet and HadaNet focus only on bottleneck convolutions.
Lastly, a fundamental but less-discussed approach is to exploit algebraic sparsity. In contrast to using real numbers, CNNs can also be constructed by complex numbers [44] or quaternions [15, 39, 57]. By their nature, the number of real-valued weights can decrease two or four times, respectively. Moreover, their multiplications can be accelerated by fast algorithms. For example, the quaternion multiplication is usually expressed by a real-valued matrix and can be simplified into eight real-valued multiplications and some linear transforms [20]. Regarding activation functions, the real-valued component-wise rectified linear unit (ReLU) is mostly adopted, and its efficiency over complex-domain functions is demonstrated in [44]. Since this algebraic sparsity can reduce complexity with moderate ratios and high regularity, it is a good candidate for accelerating computational imaging. However, previous work only discusses the two traditional division algebras and thus poses strict limitations for implementation.
In this paper, we would like to lay down a more generalized framework—RingCNN—for algebraic sparsity to expand its design space for model-architecture co-optimization. Observing that division is usually not required by CNN inference, we propose to construct models by ring, a fundamental algebraic structure on -tuples with definitions of multiplication and addition. In particular, we consider a bilinear formulation for ring multiplication to have transform-based fast algorithms and thus include full-rank sparsity into this framework. For constructing CNN models, we also equip non-linearity to the rings. Then several ring variants are defined properly and compared systematically for joint quality-complexity optimization.
This algebraic generalization also brings architectural insights on ring non-linearity. We observe that conventional methods mostly adopt the component-wise ReLU for non-linearity and use the linear transforms in ring multiplication for information mixing. However, for fixed-point implementation these transforms will increase input bitwidths for the following component-wise products and bring significant hardware overheads. Inspired by this, we propose a ring with a novel directional ReLU to serve both non-linearity and information mixing. Then we can avoid the transforms before the products to eliminate the bitwidth-increasing overheads. Extensive evaluations will show that the proposed ring can achieve not only the best hardware efficiency for multiplications but also the best image quality for its compact structure for training.
Finally, we design an accelerator—eRingCNN—to utilize the proposed ring for high-throughput and energy-efficient CNN acceleration. For comparison purposes, we adopt eCNN [21], the state-of-the-art for computational imaging, as our architecture backbone. Then we devise highly-parallel ring-convolution engines for efficient inference and simply replace the real-valued counterparts in eCNN thanks to their regularity and similarity in computation. For the directional ReLU which involves two transforms, conventional MAC-based accelerators may need to perform quantization before each transform and cause up to 0.2 dB of PSNR drop. Instead, we apply an on-the-fly processing pipeline to avoid unnecessary quantization errors and facilitate fixed-point inference on 8-bit features. With 40 nm technology, we implement two sparsity settings, and , for eRingCNN to show the effectiveness.
In summary, the main contributions and findings of this paper are:
-
•
We propose a novel modeling framework, RingCNN, to thoroughly explore algebraic sparsity. The corresponding training process, including quantization, is also established for in-depth quality comparisons.
-
•
We propose a novel ring variant with a directional ReLU which achieves better image quality and area saving than complex field, quaternions, the rings alike to CirCNN and HadaNet, and all newly-discovered ones. Its image quality even outperforms unstructured weight pruning and sometimes, when , can be better than real field.
-
•
We design and implement accelerators with two configurations: eRingCNN-n2 (50% sparsity) and eRingCNN-n4 (75%). They can deliver equivalent 41 TOPS using only 3.76 W and 2.22 W, respectively, and support high-quality computational imaging at up to 4K UHD 30 fps.
-
•
Our ring convolution engines achieve near-maximum hardware efficiencies (). Layout results show that for they have 2.00 energy efficiency and 2.08 area efficiency compared to the real-valued counterpart. Those for can increase the corresponding efficiency gains to 3.84 and 3.77, respectively.
-
•
RingCNN models provide competitive image quality. Compared to the real-valued models for eCNN, those for eRingCNN-n2 even have an average PSNR gain of 0.01 dB and those for eRingCNN-n4 only drop by 0.11 dB. When serving Full-HD applications on eRingCNN, they can outperform the advanced FFDNet [50] for denoising and SRResNet [31] for SR.
II Motivation
We aim to enable next-generation computational imaging on consumer electronics by achieving high-throughput and high-quality inference with energy-efficient and cost-effective acceleration. However, computational imaging CNNs require dense model structures to generate fine-textured details. Thus before deploying any complexity-reducing method we need to examine the impact of image quality and the gain of computation complexity as a whole.
Without loss of generality, we demonstrate this quality-complexity tradeoff using the advanced model SRResNet as an example. In Fig. 1, two conventional sparsity techniques are examined. One is unstructured magnitude-based weight pruning for exploring natural sparsity. It shows graceful quality degradation when compression ratios are up to 2, 4, and 8. However, its irregular computation will erode the performance gain due to induced hardware overheads and load imbalance. For example, only 11.7% of power consumption and 5.6% of area are spent on MACs in the sparse tensor accelerator SparTen [16]. The other examined technique is depth-wise convolution (DWC) which exploits low-rank sparsity. The quality drops very quickly and even can be worse than the old-fashioned VDSR [26]. As a result, weight pruning and DWC are unfavourable for computational imaging due to the computation irregularity and the quality distortion respectively.
A more straightforward approach is to reduce the model size in a compact way, and here we consider two cases: shrinking either model depth or feature channels. For SRResNet, the depth reduction causes sharp quality loss. In contrast, the channel reduction provides a good quality-complexity tradeoff which shows a similar trend as weight pruning and performs much better than DWC. In particular, this approach maintains high computation regularity and can be accelerated by energy-efficient dense tensor accelerators, such as eCNN [21] in which 94.0% of power consumption and 72.8% of area are spent on convolutions. Therefore, the compact model configurations should also be considered before applying sparsity.
In this paper, we would like to explore the possibility of having the quality of weight pruning and the regularity of compact modeling at the same time. We will approach this goal by using ring algebra for the elementary operations in CNNs. In this way, we can achieve local sparsity and assure global regularity simultaneously. Our results, RingCNN, for SRResNet are also shown in Fig. 1 to demonstrate the effectiveness. The details of our approach will be introduced in the following.

III Ring Algebra for Neural Networks
Deep neural networks consist of many feed-forward layers. These layers are usually defined over real field and formulated by its three elementary operations: addition , multiplication , and non-linearity . With tensor extensions, we can have a common formulation for each -th layer:
| (1) |
where , , , and represent the input feature tensor, weight tensor, bias tensor, and non-linear tensor operation respectively. Conversely, as long as we define the three operations properly, we can construct neural networks at will using other algebraic structures.
An example for using complex field is shown in Fig. 2. Each complex number can be expressed by either a complex form or an equivalent 2-tuple . Then weight storage can be reduced by a half, and arithmetic computation can be accelerated by the complex multiplication algorithm, i.e. the complexity for each complex multiplication can be reduced from four real multiplications to three. In the following, we will first consider ring algebras to generalize this idea and define proper ring multiplication for discussion. Then we will analyze their demands of hardware resources, and, finally, propose a novel ring variant with directional non-linearity to maximize hardware efficiency.

III-A Ring Algebra
A ring is a fundamental algebraic structure which is a set equipped with two binary operations and . Here we consider the set of real-valued -tuples, i.e. . For clarity, is a ring element and is its real-valued component. And we simply use the component-wise vector addition for the ring addition .
As for ring multiplication , it plays an important role for the properties of different rings. Given
| (2) |
where , we consider it has a bilinear form to have a general formulation for fast algorithms, which will be discussed in Section III-B. In particular, the components of the three ring elements are related by
| (3) |
where is a 3-D indexing tensor with only , , and as its entries. In other words, the products of input ring components in form of are distributed to output components through . With the bilinear form (3), the ring multiplication (2) will be isomorphic to a matrix-vector multiplication
| (4) |
where the matrix has entries . Without loss of generality, we will use for filter weights and for feature maps in the following.
After having definitions of and , we still need to define a unary non-linear operation for a ring to construct neural networks. A conventional choice, which is usually adopted by previous methods for full-rank or algebraic sparsity, is a component-wise ReLU
| (5) |
where is the commonly-used real-valued ReLU.
III-B Fast Ring Multiplication
Now we will integrate transform-based full-rank sparsity into this framework. For the bilinear-form ring multiplication (3), from [46] we know that its optimal general fast algorithm over real field can be expressed by the following three steps
| filter/data transform: | (6) | |||
| component-wise product: | (7) | |||
| reconstruction transform: | (8) |
where and are transform matrices for and respectively, and is for . And represents a component-wise product, i.e. for for the three -tuples , , and . If the transform matrices involve only simple coefficients, e.g. or , then they can be implemented by adders, and the component-wise product will dominate computation complexity. In particular, the number of real-valued multiplications can be reduced from the general for matrix to in (7). Therefore, the complexity of fast ring multiplication depends on how we decompose the indexing tensor or its isomorphic matrix into (6)-(8).
When is diagonalizable over real field, i.e. , this complexity can be minimized as for . The proof is given in Appendix A. In this perspective, a ring alike to HadaNet has a full-rank , i.e. , which is diagonalized by Hadamard transform. Another example is a ring equivalent to group convolution which applies component-wise products for a diagonal full-rank , and its invertible is simply the identity matrix .
In contrast, if is not diagonlizable over real field, we can instead apply the tensor rank decomposition for the indexing tensor as mentioned in [20]. However, the complexity is usually larger than in this case, and the generic rank (grank) represents the lower bound for real-valued multiplications: . For example, the rotation matrix for complex field leads to three real-valued multiplications as its while , and the circulant matrix in CirCNN also belongs to this category. The related properties of as well as and with ring dimension are as shown at the top of Table I.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x3.png)
III-C Proper Ring Multiplication
In addition to the rings at hand, we would like to search more proper variants for in-depth analysis. We make three practical assumptions to confine the scope of discussion. The first one is exclusive sub-product distribution: each input sub-product in (3) is distributed to one output component exclusively. It provides complete and non-redundant information mixing between ring components for maintaining compact model capacity. Then has full rank and can be formulated by a sign matrix and a permutation indexing matrix :
| (9) |
where , and each row or column of is a permutation of . For example, the rotation matrix for has and .
Furthermore, given the existence of a ring unity , we consider the following explicit condition:
| (C1) |
Without loss of generality, the condition on the first column of and is drawn from the permutation definition of and . The diagonal of is then derived by which states that the isomorphic matrix of is the identity matrix, and therefore if .
The second assumption is commutativity. It is not necessary for constructing neural networks, e.g. quaternions are not commutative. But it is sufficient to enable the demanded associativity for a ring, together with the exclusive sub-product distribution and an additional condition on commutative permutation. The details are discussed in Appendix B. Then, by examining the matrix form for , we have a cyclic-mapping condition for reducing candidates:
| (C2) |
Finally, the last assumption is that a smaller is preferred for saving computations and leads to this rule:
| (C3) |
In practice, for each satisfying (C1) and (C2) we ran the CP-ARLS algorithm [6] in MATLAB to evaluate for all possible and determined ring variants based on the results.
In the following, we consider moderate sparsity for computational imaging with . We searched new ring variants as mentioned above and determined their transform matrices as discussed in Section III-B. Our findings are listed in Table I where we distinguish ring symbols by indicating in the subscripts for clarity. For , only and can satisfy . For , we found, by exhaustion, that there are two such non-isomorphic permutations. After applying (C3), the minimum of them is found to be 4 and 5. The grank-4 permutation leads to two ring variants: and which are diagonalized respectively by Hadamard transform and a reflected Householder matrix where and . On the other hand, there are four grank-5 ring variants. Two of them, and , have transform matrices related to , and the other two, and , are similarly connected to . In particular, applies circular convolution as CirCNN and needs five real multiplications for complex Fourier transform. The details of isomorphic and fast algorithms are summarized in Table II.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x4.png)
III-D Hardware Efficiency
Now we can systematically examine the benefits of these rings in terms of hardware resources. For concise hardware analysis, we assume that different algebraic structures have the same bitwidths for layer inputs and parameters. Then the weight storage is directly proportional to the degrees of freedom (DoF), and the multiplier complexity can be evaluated on the same basis. Regarding the amount of filter weights, a real-valued network would require weights for an -tuple pair of input and output features. But using -tuple rings instead will only need real-valued weights to represent the matrix , i.e. DoF of is reduced from to . Therefore, the efficiency of weight storage with respect to the real-valued networks is , e.g. and for 2- and 4-tuple rings respectively. Similarly, the corresponding efficiency in terms of real-valued multiplications can be derived as . In Table I, only , , and can reach the maximum efficiency, , for full-rank .
More importantly, for practical implementation we need to consider fixed-point computation and include the bitwidths of the multiplications for precise evaluations. Fig. 3 shows such an example for the fast algorithm (6)-(8). The main overheads brought by the transforms are the increased bitwidths for and , e.g. and will transform -bit and into wider -bit and -bit . The circuit complexity of a multiplier can be approximated by the product of its input bitwidths. We further consider this factor, , for evaluating the multiplier complexity for 8-bit features and weights as shown in the rightmost column of Table I. In this case, only can reach the maximum efficiency for using identity transforms, and the other rings all suffer the corresponding overheads induced by their transforms. For example, and merely achieve efficiency which is worse than .

III-E Proposed Ring with Directional ReLU
The above discussions only involve linear operations of neural networks. For non-linearity, the component-wise ReLU is conventionally adopted even when we actually operate on -tuples. As a result, will have the worst model capacity, although it has the best hardware efficiency. It is because the information between different components of an -tuple is not communicated or mixed, which is the same as the discussion on group convolution in [52]. This is also the reason why we assumed the complete information mixing property for searching ring multiplications in Section III-C. In the following, we apply algebraic-architectural co-design to have the hardware advantages of while recovering the model capacity.
By examining the fast algorithm (6)-(8), we found that the information is in fact mixed by the transforms for data, , and reconstruction, . In addition, for neural networks this should be required only near non-linearity because cascaded linear operations will simply degrade to another single linear operator. Based on these two observations, we propose to mix information only before and after non-linearity and thus can adopt for linear operations to have its architectural benefits. This proposal leads to a novel algebraic function for ring non-linearity: directional ReLU , where and are two matrices for an input -tuple . It is equivalent to performing non-linearity in the directions of the row vectors of , instead of the conventional standard axes, and then turning the axes to the column vectors of . Thus the components of an -tuple are considered as a whole, not separately, for non-linearity.
The computation of and induces complexity overheads. But they are only linearly proportional to the number of output channels, unlike the bitwidth-increased products in (7) which grow quadratically. To further reduce the overhead, we consider the simple Hadamard transform in Table II and propose a novel ring with the directional ReLU as shown in Fig. 4:
| (10) |
For , another similar variant with is also possible. They have the same hardware advantages as and possess better model capacity for additional information mixing. Note that for constructing neural networks they are different from and , especially when skip connections exist or some convolutions are not followed by non-linearity.

IV RingCNN Modeling
IV-A Model Construction
We propose a unified RingCNN framework to include all the considered rings for in-depth comparisons on quality-complexity tradeoffs. By extending ring algebra to ring tensors , , and , we formulate a ring convolution (RCONV):
| (11) |
where and are indexes for output and input -tuple channels, and for feature positions, and and for weight positions. Then a real-valued convolution layer, either with non-linearity or not, can be converted into an RCONV layer as shown from Fig. 5(a) to (b). In this way, we can convert any existing real-valued model structure into an RingCNN alternative.

(a)

(b)

(c)
IV-B Model Training
An RingCNN model can be treated as a conventional real-valued CNN if we implement it in form of the matrix-vector multiplication (4). Then the Backprop algorithm can flow gradients as usual without any special treatment. For the completeness of ring algebras, we can also represent the gradients in terms of ring operations and then express Backprop using only the ring terminology. For example, we have from (4) for a training loss . Then for , , and since is symmetric for them. Similarly, the gradient equals to for and for , where and represent circular folding and quaternion conjugate of respectively. The same approach can be applied to express in ring operations.
IV-C Efficient Implementation
Dynamic fixed-point quantization. We prefer fixed-point computation for hardware implementation. It has been shown effective to apply dynamic quantization with separate per-layer Q-formats [1] for real-valued feature maps and parameters [21]. We found that this approach also works well for the RingCNN models that adopt the component-wise ReLU. But when the directional ReLU is applied, image quality is deteriorated in many cases. It is because after this non-linearity different ring components have different dynamic ranges, and using one single Q-format for them causes large saturation errors. Therefore, for the directional ReLU we propose to use component-wise Q-formats for feature maps to address this issue. In other words, there are different feature Q-formats in one layer, and each component of -tuple features follows its corresponding Q-format.
Fast algorithm. We use the fast algorithm to formulate a fast ring convolution (FRCONV):
| (12) |
where and are the ring tensors after the transforms and respectively. For minimizing overheads, we avoid redundant transform operations by applying , , and only once for each of weight, input, and output ring elements respectively. Then each RCONV layer can then be efficiently implemented in hardware by applying FRCONV to its fixed-point model as shown in Fig. 5(c). Note that for FRCONV is the same as RCONV for its identity transform matrices.
V eRingCNN Accelerator
To show the efficiency on practical applications, we further design an RingCNN accelerator, named eRingCNN, over the proposed ring . For supporting high-throughput computational imaging, we use the highly-parallel eCNN as a backbone architecture and simply replace its real-valued convolution engine by a corresponding one for RCONV. This portability of linear operations is an advantage of algebraic sparsity, but we need a new and specific design for the directional ReLU. We implement two sparsity settings for and , and the details are introduced in the following.
System diagram. Fig. 6 presents the overall architecture. In one cycle, it can compute (32/)-channel -tuple output features from (32/)-channel -tuple inputs for 42 spatial positions. For both 33 and 11 convolution engines, the number of MACs is reduced by 50% and 75% for the settings respectively. Similarly, the size of the weight memory can be reduced by the same ratios, e.g. from 1280 KB in eCNN to 640 KB for and 320 KB for . However, for simplicity the parameter compression in eCNN was not implemented; instead, we increase the size by 1.5 to 960 KB and 480 KB, respectively, to support large models. The rest architectural differences from eCNN are mainly on the designs of the RCONV engines and the novel directional ReLU.

RCONV engine. To have local sparsity while maintaining global regularity, we increase the computing granularity from real numbers to -tuple rings. Fig. 7 shows such a modification for the 33 convolution engine with . It is a channel-wise 2D computation array for 8-channel 4-tuple inputs and outputs. Each of the computing units is responsible for the 2D 33 ring convolution for the corresponding input-output pair with ring tensor weights . Thanks to , it simply computes component-wise 2D convolutions for saving complexity. Finally, a novel directional ReLU block, including dynamic quantization with component-wise Q-formats, is devised to replace their real-valued counterparts.

Directional ReLU unit. It mixes information for RCONV outputs to recover model capacity; however, the mixing demands Hadamard transforms on high-bitwidth accumulated outputs, e.g. 24-bit for . This induces two issues for conventional accelerator architectures. Firstly, the two transforms for are likely to be implemented by the same fixed-point MACs for convolutions to meet the high computation throughput. But since the weights are only and , the hardware efficiency would be low for the multipliers. Secondly and more importantly, the features before the Hadamard transforms will need to be quantized for the MACs. We found that these additional quantizations, e.g. 24-bit to 8-bit for , would cause up to 0.2 dB of PSNR drop for denoising and SR tasks.
Therefore, we propose an on-the-fly processing pipeline for this novel function, and Fig. 8 shows our implementation for . It specifically implements the butterfly structures for Hadamard transforms to optimize hardware efficiency and keeps full-precision operations to preserve image quality. In this case, the internal bitwidths are up to 33-bit, in which the component-wise Q-formats contribute 5-bit for aligning components (through the left-shifters). This circuit is the major overhead for using and also appears in the inference datapath for the non-linearity after skip or residual connections.

VI Evaluations
We show extensive evaluations for (A) ring algebras, (B) image quality on eRingCNN, and (C) hardware performance of eRingCNN. For clarity, the two sparsity configurations for eRingCNN are denoted by eRingCNN-n2 and eRingCNN-n4.
VI-A Ring Algebras
Training setting and test datasets. For quality evaluations, we use the advanced ERNets for eCNN [21] as the real-valued backbone models. Then RingCNN models are converted from them as shown from Fig. 5(a) to (b). To fairly compare RingCNNs and real-valued CNNs, we evaluate their best performance by increasing their initial learning rates as high as possible before training procedures become unstable. Note that the real-valued ERNets in this paper will therefore perform better than those in [21] because of using higher learning rates. The models are trained using the lightweight settings as summarized in Table III if not mentioned. Finally, we test denoising networks on datasets Set5 [7], Set14 [48], and CBSD68 [36], and super-resolution ones on Set5, Set14, BSD100 [36], and Urban100 [22].
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x13.png)
Quality comparison for different rings. Fig. 9 compares image quality in PSNR for the rings in Table I. When the component-wise ReLU is used, performs the worst due to the lack of information mixing. The two traditional algebra alternatives and also do not perform well, considering more real-valued multiplications are required. Between the two grank-4 variants for , the newly-discovered performs better than the HadaNet-alike . Similar results can be found for their corresponding grank-5 variants, e.g. the newly-discovered better than the CirCNN-alike . However, by using the directional ReLU, the proposed can give better quality and constantly outperform the others. Since shows inferior quality, we therefore focus on and adopt it for our implementation.

Ablation study between and . They share similar structures but have two major differences. First, multiplies input features by weights directly while does that after applying the filter transform. Second, applies Hadamard transform only when non-linearity is required, but always does that and results in a redundant structure. Therefore, can imitate by making up the differences: first training on transformed weights and then modifying model structures accordingly. Fig. 10(a) shows an example for modifying a residual block, and Fig. 10(b) illustrates typical PSNR results using two SR4 networks as examples. Training on is occasionally helpful, but structure modification improves image quality most of the time. Therefore, the compact model structure is the main reason why outperforms for computational imaging.

|

|
| (a) | (b) |
Comparison with weight pruning. We also compare image quality between the proposed algebraic sparsity and the unstructured magnitude-based weight pruning. While RingCNNs are trained directly, real-valued CNNs are first pre-trained, then pruned, and finally fine-tuned. Fig. 11 shows the comparison results, and RingCNNs over can deliver better image quality than the weight pruing for compression ratios 2, 4, and 8. In particular, the 2-tuple networks can even outperform the original (1) real-valued networks in many cases. This shows that the algebraic sparsity can serve strong prior for CNN models. As a result, not only provides more regular structures but also achieves better quality for computational imaging. A case for recognition tasks, though not the focus of this paper, is also studied in Appendix C, where convolutions and corresponding non-linear functions are implemented with , and batch normalization is remained as real-valued operations.
|
|
|


Fixed-point implementation. For comparisons in hardware efficiency, we implemented highly-parallel FRCONV engines, as depicted in Fig. 5(c) with non-linearity, for different rings. Their RTL codes are synthesized with 40 nm CMOS technology. For quality comparison, the models are quantized in 8-bit and then fine-tuned using the setting at the bottom of Table III. The quality loss due to quantization is similar for each ring, and Fig. 12 shows the comparison results. The area efficiencies are very close to the estimated 8-bit complexity in Table I because convolutions dominate the areas. The proposed can provide the smallest area and the best quality at the same time. Compared to the CirCNN-alike and HadaNet-alike , it has nearly 0.1 dB PSNR gain for the SR4 task and provides 1.8 and 1.5 area efficiencies respectively. In summary, can save area efficiently, and can recover image quality significantly.

VI-B Image Quality on eRingCNN
Training setting and model selection. To show competitive image quality, we further train models using the polishment setting in Table III with two large datasets, DIV2K [2] and Waterloo Exploration [33]. We consider two throughput targets for hardware acceleration: HD30 for Full HD 30 fps and UHD30 for 4K Ultra-HD 30 fps. For each throughput target and application scenario, we adopt the compact ERNet configuration for the real-valued eCNN in [21]. It has been optimized over model depth and width in terms of PSNR, and we build its corresponding RingCNN models with .
Floating-point models. The PSNR results are shown in Table IV. The RingCNN models show significant gains over the traditional CBM3D [11] for denoising and VDSR for SR4. Compared to the advanced FFDNet and SRResNet, the models for eRingCNN-n2 can outperform them with PSNR gains up to 0.15 dB at HD30 and have similar quality at UHD30. With 75% sparsity, the models for eRingCNN-n4 still give superior quality and only show noticeable PSNR inferiority for denoising at UHD30 due to the shallow layers.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x21.png)
Dynamic fixed-point quantization. On the top of Fig. 13, we show the effect of the 8-bit dynamic quantization which is used to save area. The quality degradation for ring tensors is around 0.11-0.12 dB of average PSNR drops, which is similar to the case of using real numbers. We also show the effect of applying sparse ring algebras (eCNNeRingCNN) at the bottom of Fig. 13. The degradation is not obvious for , and the models for eRingCNN-n2 even outperform those for eCNN by 0.01 dB on average. For , those for eRingCNN-n4 only suffer small PSNR degradation in 0.11 dB.

VI-C Hardware Performance of eRingCNN
Implementation and CAD tools. We developed RTL codes in Verilog and verified the functional validity based on bit- and cycle-accurate simulations. Then the verified RTL codes were synthesized using Synopsys Design Compiler with TSMC 40 nm CMOS library. And SRAM macros were generated by ARM memory compilers. We used Synopsys IC Compiler for placement and routing and generating layouts for five well-pipelined macro circuits which constitute eRingCNN collectively. Finally, we performed time-based power consumption using Synopsys Prime-Time PX based on post-layout parasitics and dynamic signal activity waveforms from RTL simulation.
Hardware performance. We show the design configurations and layout performance in Table V. The areas of eRingCNN-n2 and eRingCNN-n4 are 33.73 and 23.36 respectively, and the corresponding power consumptions are 3.76 and 2.22 W. They mainly differ in the ring dimension, and eRingCNN-n4 uses only a half number of MACs and a half size of weight memory compared to eRingCNN-n2.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x23.png)
Area and power breakdown. The details are shown in Table VI. For eRingCNN-n2, the convolution engines contribute 57.42% of area and 86.51% of power consumption for the highly-parallel computation. And for eRingCNN-n4 their contributions go down to 45.63% and 76.56%, respectively, because of the saving of MACs. In addition, for a larger the directional ReLU uses more adders and causes wider bitwidths. Therefore, for the RCONV-33 engines it occupies only 3.4% of area for eRingCNN-n2 but up to 8.9% for eRingCNN-n4. Accordingly, the inference datapath in eRingCNN-n4 is also 0.53 larger than that in eRingCNN-n2.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x24.png)
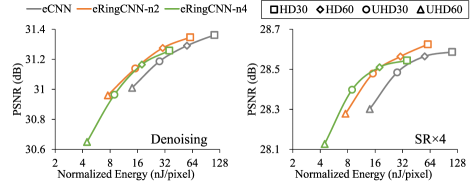
Comparison with eCNN. As shown in Fig. 14, the RCONV engines reach near-maximum hardware efficiencies . Those in eRingCNN-n2 achieve 2.08 area efficiency and 2.00 energy efficiency. And those in eRingCNN-n4 further increase the efficiency gains of area and energy to 3.77 and 3.84. The numbers for the whole accelerator are as high as 1.64 and 1.85 for eRingCNN-n2, and 2.36 and 3.12 for eRingCNN-n4. In addition, we compare their quality-energy tradeoff curves in Fig. 15. The eRingCNN accelerators show clear advantages over eCNN; in particular, the low-complexity eRingCNN-n4 is preferred when less energy is allowed to be consumed for generating one pixel. Finally, as eCNN, the eRingCNN accelerators demand only 1.93 GB/s of DRAM bandwidth for high-quality 4K UHD applications.

Comparison with Diffy. Table VII compares the hardware performance of Diffy111We project the silicon area and power consumption of Diffy under 40 nm technology based on the scaling comparison of 65 nm in [45]: 2.35 gate density and 0.5 power consumption under the same operation speed. [34], another state-of-the-art accelerator for computational imaging, along with eCNN. Diffy applies optimization on bit-level computation which is hard to compare with eRingCNN directly; therefore, we perform comparison based on the same application target: FFDNet-level inference at Full-HD 20fps. In this case, the energy efficiencies of eRingCNN-n2 and eRingCNN-n4 over Diffy are 2.71 and 4.59 respectively by running at 167 MHz.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x27.png)
Comparison with SparTen, TIE, and CirCNN. Table VIII compares with the state-of-the-arts for different sparsity approaches: SparTen (natural) [16], TIE (low-rank) [12], and CirCNN (full-rank). Here we compare synthesis results because only such numbers are reported for SparTen and CirCNN. For comparing over different compression ratios, we consider an equivalent throughput which corresponds to the computing demand of the target uncompressed or real-valued model. With only 2-4 compression, our eRingCNN accelerators already provide competitive energy efficiencies as equivalent 19.1-28.4 TOPS/W. In contrast, SparTen merely achieves 2.7 TOPS/W due to significant overheads for handling irregularity. Although TIE is very efficient for highly-compressed fully-connected (FC) layers, it shows inefficiency for the CONV layers with lower compression ratios. Finally, CirCNN only provides 10.0 TOPS/W using as high as 66 compression. The potential of algebraic sparsity is therefore demonstrated, in particular on moderately-compressed CNNs for computational imaging.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a044211e-f737-46ef-ab01-515ec6d66d71/x28.png)
VII Related Work
Low-rank sparsity. This line of research also provides regular structure for efficient hardware acceleration. One approach is low-rank approximation, including tensor-train (TT) [37], canonical polyadic (CP) [30], and Tucker [27]. Another one is building networks using low-rank structures, such as MobileNet (v1/v2) [19, 41] and SqueezeNet [23]. However, this sparsity mainly aims to provide high compression ratios, and the effect for computational imaging need further exploration.
Natural sparsity. Exploiting such sparsity in features has been well-studied, e.g. in Cnvlutin [3], Cambricon-X [51], and Diffy [34]. And the sparsity in filter weights is usually explored by pruning [17, 35]. They can be further combined as in SCNN [38], SparTen [16], and SmartExchange [54]. However, the natural irregularity could lead to high overheads for indexing circuits and load imbalance.
Dense CNN accelerators. There are many accelerators proposed for general-purpose inference with high parallelism, such as TPU [25], DNPU [42], ShiDianNao [14], and Eyeriss (v1/v2) [8, 9]. However, the computation sparsity for computational imaging were seldom exploited.
Block-based inference flows. They eliminate huge external memory bandwidth for feature maps, and two approaches were proposed to handle the boundary features across neighboring blocks. One is feature reusing, such as fused-layer [4] and Shortcut Mining [5], and the other one is recomputing, like eCNN [21]. In this paper, we adopt the latter only for the purpose of implementation and comparison.
VIII Conclusion
This paper investigates the fundamental but seldom-explored algebraic sparsity for accelerating computational imaging CNNs. It can provide local sparsity and global regularity at the same time for energy-efficient inference. We lay down the general RingCNN framework by defining proper ring algebras and constructing corresponding CNN models. By extensive comparisons with several rings, the proposed one with the directional ReLU achieves near-maximum hardware efficiency and the best image quality simultaneously. We also design two high-performance eRingCNN accelerators for verifying practical effectiveness. They can provide high-quality computational imaging at up to 4K UHD 30 fps while consuming only 3.76 W and 2.22 W, respectively. Based on these results, we believe that RingCNN exhibits great potentials for enabling next-generation cameras and displays with energy-efficient and high-performance computational imaging.
Acknowledgment
The author would like to thank the anonymous reviewers for their feedback and suggestions. I also would like to thank Chi-Wen Weng for his help on layout implementation.
References
- [1] “Q-format,” in ARM Developer Suite—AXD and armsd Debuggers Guide. ARM Limited, 2001, ch. 4.7.9.
- [2] E. Agustsson and R. Timofte, “NTIRE 2017 challenge on single image super-resolution: Dataset and study,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017.
- [3] J. Albericio, P. Judd, T. Hetherington, T. Aamodt, N. E. Jerger, and A. Moshovos, “Cnvlutin: Ineffectual-neuron-free deep neural network computing,” in Proceedings of the 43rd Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2016.
- [4] M. Alwani, H. Chen, M. Ferdman, and P. Milder, “Fused-layer CNN accelerators,” in Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016.
- [5] A. Azizimazreah and L. Chen, “Shortcut Mining: Exploiting cross-layer shortcut reuse in DCNN accelerators,” in IEEE International Symposium on High Performance Computer Architecture (HPCA), 2019.
- [6] C. Battaglino, G. Ballard, and T. G. Kolda, “A practical randomized CP tensor decomposition,” SIAM Journal on Matrix Analysis and Applications, vol. 39, 2018.
- [7] M. Bevilacqua, A. Roumy, C. Guillemot, and M.-L. A. Morel, “Low-complexity single-image super-resolution based on nonnegative neighbor embedding,” in British Machine Vision Conference (BMVC), 2012.
- [8] Y.-H. Chen, J. Emer, and V. Sze, “Eyeriss: a spatial architecture for energy-efficient dataflow for convolutional neural networks,” in Proceedings of the 43rd Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2016.
- [9] Y.-H. Chen, T.-J. Yang, J. Emer, and V. Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,” IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, 2019.
- [10] T.-W. Chin, R. Ding, C. Zhang, and D. Marculescu, “Towards efficient model compression via learned global ranking,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [11] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-D transform-domain collaborative filtering,” IEEE Transactions on Image Processing, vol. 16, 2007.
- [12] C. Deng, F. Sun, X. Qian, J. Lin, Z. Wang, and B. Yuan, “TIE: Energy-efficient tensor train-based inference engine for deep neural network,” in Proceedings of the 46th Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2019.
- [13] C. Ding, S. Liao, Y. Wang, Z. Li, N. Liu, Y. Zhou, C. Wang, X. Qian, Y. Bai, G. Yuan, X. Ma, Y. Zhang, J. Tang, Q. Qiu, X. Lin, and B. Yuan, “CirCNN: Accelerating and compressing deep neural networks using block-circulant weight matrices,” in Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2017.
- [14] Z. Du, R. Fasthuber, T. Chen, P. Ienne, L. Li, T. Luo, X. Feng, Y. Chen, and O. Temam, “ShiDianNao: Shifting vision processing closer to the sensor,” in Proceedings of the 42nd Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2015.
- [15] C. J. Gaudet and A. S. Maida, “Deep quaternion networks,” in International Joint Conference on Neural Networks (IJCNN), 2018.
- [16] A. Gondimalla, N. Chesnut, M. Thottethodi, and T. N. Vijaykumar, “SparTen: A sparse tensor accelerator for convolutional neural networks,” in Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2019.
- [17] S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding,” in International Conference on Learning Representations (ICLR), 2016.
- [18] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [19] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv:1704.04861, 2017.
- [20] T. D. Howell and J.-C. Lafon, “The complexity of the quaternion product,” in TR 75-245. Cornell University, 1975.
- [21] C.-T. Huang, Y.-C. Ding, H.-C. Wang, C.-W. Weng, K.-P. Lin, L.-W. Wang, and L.-D. Chen, “eCNN: A block-based and highly-parallel CNN accelerator for edge inference,” in Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2019.
- [22] J.-B. Huang, A. Singh, and N. Ahuja, “Single image super-resolution from tranformed self-exemplars,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- [23] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, and K. Keutzer, “SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and 0.5MB model size,” arXiv:1602.07360, 2017.
- [24] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in European Conference on Computer Vision (ECCV), 2016.
- [25] N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, R. Boyle, P.-l. Cantin, C. Chao, C. Clark, J. Coriell, M. Daley, M. Dau, J. Dean, B. Gelb, T. V. Ghaemmaghami, R. Gottipati, W. Gulland, R. Hagmann, C. R. Ho, D. Hogberg, J. Hu, R. Hundt, D. Hurt, J. Ibarz, A. Jaffey, A. Jaworski, A. Kaplan, H. Khaitan, D. Killebrew, A. Koch, N. Kumar, S. Lacy, J. Laudon, J. Law, D. Le, C. Leary, Z. Liu, K. Lucke, A. Lundin, G. MacKean, A. Maggiore, M. Mahony, K. Miller, R. Nagarajan, R. Narayanaswami, R. Ni, K. Nix, T. Norrie, M. Omernick, N. Penukonda, A. Phelps, J. Ross, M. Ross, A. Salek, E. Samadiani, C. Severn, G. Sizikov, M. Snelham, J. Souter, D. Steinberg, A. Swing, M. Tan, G. Thorson, B. Tian, H. Toma, E. Tuttle, V. Vasudevan, R. Walter, W. Wang, E. Wilcox, and D. H. Yoon, “In-datacenter performance analysis of a tensor processing unit,” in Proceedings of the 44th Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2017.
- [26] J. Kim, J. K. Lee, and K. M. Lee, “Accurate image super-resolution using very deep convolutional networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [27] Y.-D. Kim, E. Park, S. Yoo, T. Choi, L. Yang, and D. Shin, “Compression of deep convolutional neural networks for fast and low power mobile applications,” in International Conference on Learning Representations (ICLR), 2016.
- [28] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” 2009.
- [29] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), 2012.
- [30] V. Lebedev, Y. Ganin, M. Rakhuba, I. Oseledets, and V. Lempitsky, “Speeding-up convolutional neural networks using fine-tuned CP-decomposition,” in International Conference on Learning Representations (ICLR), 2015.
- [31] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi, “Photo-realistic single image super-resolution using a generative adversarial network,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [32] B. Lim, S. Son, H. Kim, S. Nah, and K. M. Lee, “Enhanced deep residual networks for single image super-resolution,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017.
- [33] K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and L. Zhang, “Waterloo Exploration Database: New challenges for image quality assessment models,” IEEE Transactions on Image Processing, vol. 26, 2017.
- [34] M. Mahmoud, K. Su, and A. Moshovos, “Diffy: a déjà vu-free differential deep neural network accelerator,” in Proceedings of the 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2018.
- [35] H. Mao, S. Han, J. Pool, W. Li, X. Liu, Y. Wang, and W. J. Dally, “Exploring the regularity of sparse structure in convolutional neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017.
- [36] D. Martin, C. Fowlkes, D. Tal, and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” in IEEE International Conference on Computer Vision (ICCV), 2001.
- [37] I. V. Oseledets, “Tensor-train decomposition,” SIAM Journal on Scientific Computing, 2011.
- [38] A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. Emer, S. W. Keckler, and W. J. Dally, “SCNN: An accelerator for compressed-sparse convolutional neural networks,” in Proceedings of the 44th Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2017.
- [39] T. Parcollet, M. Morchid, and G. Linarès, “Quaternion convolutional neural networks for heterogeneous image processing,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019.
- [40] A. Renda, J. Frankle, and M. Carbin, “Comparing rewinding and fine-tuning in neural network pruning,” in International Conference on Learning Representations (ICLR), 2020.
- [41] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [42] D. Shin, J. Lee, J. Lee, and H.-J. Yoo, “DNPU: An 8.1TOPS/W reconfigurable CNN-RNN processor for general-purpose deep neural networks,” in IEEE International Solid-State Circuits Conference (ISSCC), 2017.
- [43] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations (ICLR), 2015.
- [44] C. Trabelsi, O. Bilaniuk, Y. Zhang, D. Serdyuk, S. Subramanian, J. F. Santos, S. Mehri, N. Rostamzadeh, Y. Bengio, and C. J. Pal, “Deep complex networks,” in International Conference on Learning Representations (ICLR), 2018.
- [45] TSMC, 40nm Technology. [Online]. https://www.tsmc.com/english/ dedicatedFoundry/technology/logic/l_40nm, Retrieved 20 Nov 2020.
- [46] S. Winograd, Arithmetic Complexity of Computations. Cambridge University Press, 1980.
- [47] J. Yu, Y. Fan, and T. Huang, “Wide activation for efficient image and video super-resolution,” in British Machine Vision Conference (BMVC), 2019.
- [48] R. Zeyde, M. Elad, and M. Protter, “On single image scale-up using sparse-representations,” in Proceedings of the International Conference on Curves and Surfaces, 2010.
- [49] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising,” IEEE Transactions on Image Processing, vol. 26, 2017.
- [50] K. Zhang, W. Zuo, and L. Zhang, “FFDNet: Toward a fast and flexible solution for CNN-based image denoising,” IEEE Transactions on Image Processing, vol. 27, 2018.
- [51] S. Zhang, Z. Du, L. Zhang, H. Lan, S. Liu, L. Li, Q. Guo, T. Chen, and Y. Chen, “Cambricon-X: An accelerator for sparse neural networks,” in Proceedings of the 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016.
- [52] X. Zhang, X. Zhou, M. Lin, , and J. Sun, “ShuffleNet: An extremely efficient convolutional neural network for mobile devices,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [53] R. Zhao, Y. Hu, J. Dotzel, C. D. Sa, and Z. Zhang, “Building efficient deep neural networks with unitary group convolutions,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [54] Y. Zhao, X. Chen, Y. Wang, C. Li, H. You, Y. Fu, Y. Xie, Z. Wang, and Y. Lin, “SmartExchange: Trading higher-cost memory storage/access for lower-cost computation,” in Proceedings of the 47th Annual ACM/IEEE International Symposium on Computer Architecture (ISCA), 2020.
- [55] Z.-Q. Zhao, P. Zheng, S.-T. Xu, and X. Wu, “Object detection with deep learning: A review,” IEEE Transactions on Neural Networks and Learning Systems, 2019.
- [56] J.-Y. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in IEEE International Conference on Computer Vision (ICCV), 2017.
- [57] X. Zhu, Y. Xu, H. Xu, and C. Chen, “Quaternion convolutional neural networks,” in European Conference on Computer Vision (ECCV), 2018.
Appendices
A Minimal Algorithm for Diagonalizable over
Theorem A.1.
Let be the number of real-valued multiplications in a fast algorithm for an isotropic matrix . Then
-
(a)
The lower bound of is .
-
(b)
If is diagonalizable over , there exists a minimal algorithm such that .
Proof.
(b) Suppose with an invertible matrix over real field and a diagonal matrix which has entries with indeterminates . We have
| (A-1) |
and can be derived by examining for . This ring multiplication achieves the minimum complexity for . ∎
B Associativity from Commutativity
Lemma B.1.
Let be a ring with a bilinear-form multiplication, and with corresponding isomorphic matrices , , and . The the multiplication associativity of is equivalent to
Proof.
Given , it is clear because . ∎
Lemma B.2.
Let follow the exclusive sub-project distribution. Then
-
(a)
, its isomorphic matrix can be formulated by where is a signed permutation matrix.
-
(b)
For each standard-basis vector , is its isomorphic matrix: .
Proof.
(a) From (9), we equivalently have where are permutation matrices with . Then we have where . Note that from (3) can be directly derived from the indexing tensor as .
(b) Let . Then since . ∎
Theorem B.3.
The multiplication of is associative if has (i) the exclusive sub-product distribution, (ii) the commutative property of multiplication, and (iii) a commutative property of permutation matrices such that .
Proof.
Corollary B.3.1.
The multiplication of is associative if has the properties (i) and (ii) and the isomorphic matrix is diagonalizable over .
Proof.
By Lemma B.2 and (i), for we consider its isomorphic matrix which is diagonalizable: where is a diagonal matrix in form of indeterminates as . We can diagonalize each permutation matrix by setting and have . Then the commutative property of permutation matrices holds since the multiplication of diagonal matrices is commutative: . By Theorem B.3, the multiplication of is thus associative. ∎
Among the proper rings found in Section III-C, and directly have the associative property of multiplication by Corollary B.3.1 since they are diagonalizable over . The rest of them (, , , , and ) all possess the commutative property of permutation matrices and thus have the associative property as well by Theorem B.3.
C Comparison with Weight Pruning for Recognition

Recent pruning techniques for image recognition have mainly focused on structured pruning for their practical efficiency. In Fig. C-1, we compare RingCNN models to LeGR [10] which is the state-of-the-art for structured filter pruning. RingCNN models show their potential by outperforming LeGR for high computation efficiency (left) and for a wide range of compression efficiency (right). The study on hardware accelerators in this aspect will be our future work.