Review and Assessment of Digital Twin–Oriented Social Network Simulators
Abstract
The ability to faithfully represent real social networks is critical from the perspective of testing various what-if scenarios which are not feasible to be implemented in a real system as the system's state would be irreversibly changed. High fidelity simulators allow one to investigate the consequences of different actions before introducing them to the real system. For example, in the context of social systems, an accurate social network simulator can be a powerful tool used to guide policy makers, help companies plan their advertising campaigns or authorities to analyse fake news spread. In this study we explore different Social Network Simulators (SNSs) and assess to what extent they are able to mimic the real social networks. We conduct a critical review and assessment of existing Social Network Simulators under the Digital Twin-Oriented Modelling framework proposed in our previous study. We subsequently extend one of the most promising simulators from the evaluated ones, to facilitate generation of social networks of varied structural complexity levels. This extension brings us one step closer to a Digital Twin Oriented SNS (DT Oriented SNS). We also propose an approach to assess the similarity between real and simulated networks with the composite performance indexes based on both global and local structural measures, while taking runtime of the simulator as an indicator of its efficiency. We illustrate various characteristics of the proposed DT Oriented SNS using a well known Karate Club network as an example. While not considered to be of sufficient complexity, the simulator is intended as one of the first steps on a journey towards building a Digital Twin of a social network that perfectly mimics the reality.
Keywords: Social Networks; Network Dynamics; Machine learning methods
1 Introduction
Social network simulators (SNSs) aim at faithfully representing real networked systems and attempt to model the inner rules of network dynamics. They generate simulation-based networks (built with simulated data) or hybrid networks (built with both real and simulated data) to deal with the unobservability problems resulting from data sparsity, privacy concerns and lack of ground-truth [42, 64].
As proposed in our previous study Wen et al., [81], Digital Twin (DT) can be seen as a modelling paradigm that serves as an accurate reflection of reality, and this means that we can treat it as an ultimate goal of the representation and modelling of any Complex Networked System (CNS). Over the past decades, to achieve an accurate reflection of reality, variety of SNSs have been developed to embrace complexity of real world systems. Those efforts resulted in more and more realistic and complex social network simulations that, step by step, approach the desirable characteristics of a Digital Twin.
The complexity of the social network simulations results from the heterogeneity of the network components (nodes, edges and their attributes) as well as dynamically changing behaviour of those elements. Current studies have made good progress to attain a desired complexity level. They start from relatively simple simulations which are based on predetermined network statistics or connection principles about network topology, including such classical examples as Barabasi-Albert model for the scale-free network [6] or preferential attachment of nodes based on similarity, popularity or both of them [75]. Complexity of these networks increases in the structural dimension when node attributes (e.g. age, gender, geo-space, etc.) or edge attributes (e.g. direction, weight, relationship, etc.) are introduced. To incorporate theimpact of structural complexity on network simulation, social network simulators built on interaction rules have been employed due to their flexible definitions based on topology, attributes or both of them, like homophily [58, 5], triadic structure [5, 63] and geographic proximity [7].
The social network simulations get even more complex when they enable the network structure to evolve using inner rules that define how components can change over time. Studies on SNSs focus mainly on the topology change (e.g. the instantaneous social contacts [25, 67]). Only a small number of studies account for both attribute change and topology change. For example, the SNS proposed by [4] generates social networks with node attributes including features (e.g. age, gender, etc.) and preference for each feature when interacting with others, termed as social DNA (sDNA). The network topology is formed based on sDNA and evolves as sDNA changes randomly over time. However, as an example of one its existing drawbacks, the mechanisms for attributes and preferences changes need to be further studied to allow more realistic modelling.
Studies on SNSs typically focus on the social intervention analysis and conduct an optimisation of inner rules for achieving the highest possible similarity with the target network [3, 5]. The consistent network growth enabled by the iterative application of SNSs unfolds the desired network complexity at the cost of time and energy [35]. The time step in these studies is often assumed to have the same meaning with the iteration, where the networks grow linearly with time (e.g. predetermined number of added nodes or rewired edges within one iteration between time step and ) [3, 5]. However, the time truly spent on each iteration of SNS varies with the complexity of networks and computation resources [4] and the time that measures the duration of each SNS iteration can serve as an indicator of model efficiency. Current studies on SNSs take the similarity between simulated networks and the target networks as the objective of running an SNS [3, 5, 4], while none of them considers model efficiency.
In this study, we review and assess the current state-of-the-art SNSs under (i) the Digital Twin Oriented Modelling framework encompassing different complexity dimensions and (ii) the assessment framework based on similarity and efficiency, as proposed in our previous study [81]. To provide a possible pathway of extending SNSs towards a Digital Twin Oriented SNS, we build an inner rule-based SNS that enables the social network simulation to take into account structural and dynamic dimensions of complexity that builds on [4]. Both the similarity and the model efficiency are used as assessment criteria of the proposed SNS. We evaluate the similarity between a simulated and a real network using the composite performance indexes based on both global and local measures and we consider runtime of SNS as an indicator of its efficiency. We use Karate Club network as an example to primarily illustrate but also examine to what extent the proposed SNS can model the structural complexity of a real social network. The diverse network patterns simulated by SNSs and their respective similarity levels to the real network assessed by the composite performance index, given different structural complexity levels, reveal the challenges of SNS performance evaluation for the future DT Oriented SNSs.
The rest of this paper is structured as follows. Section 2 reviews the current state-of-the-art of social network simulations and offers comparison between different SNSs in the context of modelling framework proposed in [81]. Section 3 presents the methodology of building an SNS to generate desired networks. Following this, section 4 introduces the real data employed in the analysis and presents the results of the experiments. Finally, conclusions and future work are given in section 5.
2 Current state-of-the-art of Social Network Simulators
We review here and discuss the current developments in the context of SNSs from the following four perspectives: (i) modelling prerequisite – observability – that determines the observable information to be modelled and the unobservable information to be simulated; (ii) modelling generations connected with the complexity of modelling SNSs; (iii) complexity dimensions that describe the complexity of social network simulations; and (iv) assessment of SNSs concerned with the distance between the social network simulations and the target networks.
Modelling prerequiste
– observability, in the context of SNSs, is concerned with the ability of reconstructing the desired complexity of networks from a limited set of observed network components in finite time with an understanding of their dynamically changing behaviour [81]. To generate networks with desired topology and attributes, the existing SNSs simulate the unobservable (represented with a ❍) and partially observable network components (represented with a ◗) based on the observable network components (represented with a ●) and an inner rule that directs the network growth (see Table 1).
| Type | Topology | Attributes | Existing SNS | ||
| Nodes | Edges | Nodes | Edges | ||
| Simulated | ❍ | ❍ | ❍ | ❍ | [6],[20],[80],[24],[2],[3],[71], |
| [73],[69],[22],[54],[9],[10],[83], | |||||
| [59],[33],[1],[39],[32],[57],[11], | |||||
| [30],[23],[31] | |||||
| Hybrid | ● | ❍ | ● | [53],[36],[5],[74],[4],[7],[8], | |
| [72],[55] | |||||
| ● | ❍ | ● | ❍ | [49],[52],[79],[50] | |
| ● | ◗ | [75],[34],[29] | |||
| ● | ◗ | ● | [28],[76] | ||
| ● | ◗ | ◗ | [15],[18] | ||
As is shown in Table 1, the simulated networks are built with purely simulated topology and attributes, dealing with the unobservability problem of all network components for the analysis of the topological features [73, 6, 20, 80, 24, 9, 10, 83, 59, 33, 1, 39, 32, 57, 11, 30, 23, 31] and mimicking of real networked systems [2, 3, 85, 71, 86].
The hybrid networks are built with the partially observable and partially simulated network components. Some SNSs incorporate the observable nodes and node attributes while simulating the unobservable edges for a desired states of networks [53, 36, 5, 74, 4, 7, 8]. Some SNSs consider the partial observable edges and conduct link prediction for the unobservable edges [75, 34, 29, 28], while some SNSs incorporate edge attributes in this process [76, 15, 18]. In general, there is limited research that, in the simulation process, takes into account real-world attributes of both nodes and edges. There are some works that account for limited number of real node attributes [53, 36, 5, 74, 4, 7, 8, 72, 55, 49, 52, 79, 50, 28, 76] and when it comes to edges only two simulators partially consider real-world edges [15, 18]. As a result, most of the hybrid simulators take into account some of the topology information but not many consider attribute information and this points to the need for further work on SNSs, especially in the context of learning from continuously streaming data. Such advancement would bring current SNSs closer to the Digital Twin paradigm.
Modelling generations
, as proposed in [81], consider three key elements of modelling complex network dynamics, the simulation of (i) networks, (ii) processes over networks, and (iii) the interrelation between the two. There are five generations of modelling paradigms (G1, G2, G3, G4 and G5), where SNSs can be built with increasing dynamics complexity through generations and finally reach the goal of a DT in G5.
We review and discuss the above mentioned three elements in the context of the modelling generations while considering two types of heterogeneity (i) the existence of a given element (represented with a ☆) and in addition to its existence, (ii) the capability of an element to change over time (represented with a ★) (See Table 2).
| Stage | Network | Process | Interrelation | Existing SNS |
| G1 | ☆ | [6],[20],[80],[24],[2],[3], | ||
| [55],[71],[73],[75],[53], | ||||
| [36],[5],[18],[54],[49], | ||||
| [74],[79],[9],[10],[52], | ||||
| [83],[59],[33],[1],[39], | ||||
| [32],[57],[11],[30],[23], | ||||
| [31] | ||||
| ☆ | ☆ | [86],[84],[77],[78],[68], | ||
| [27] | ||||
| G2a | ☆ | ★ | [40],[14] | |
| G2b | ★ | [34],[69],[4],[7],[8],[72], | ||
| [28],[76],[45],[15],[50] | ||||
| [29],[43],[22],[13] | ||||
| ★ | ☆ | [51],[44] | ||
| G3 | ★ | ☆ | ☆ | [65] |
| ☆ | ★ | ☆ | [46],[26], [66] |
Generation 1 (G1) of models focuses on dynamic process on static networks (see Table 2 and Fig. 1). They simulate networks that are "frozen" in time, with a dynamic process taking place on the networks where parameters of this process do not change during the simulation (e.g. epidemic spreading process on static social networks with a fixed infection rate [27, 47]). Most studies focus on SNSs in G1 [6, 20, 80, 24, 2, 3, 55, 71, 73, 75, 53, 36, 5, 18, 54, 49, 52, 74, 79, 86, 84, 77, 78, 68, 27, 9, 10, 83, 59, 33, 1, 39, 32, 57, 11, 30, 23, 31, 12]. Also, many of the simulators generate static social networks without any consideration of dynamic processes [6, 20, 80, 24, 2, 3, 55, 71, 73, 75, 53, 36, 5, 18, 54, 49, 52, 74, 79].

SNSs in Generstion 2 (G2) have two variations, one termed as G2a and the other as G2b. SNSs in G2a focus on evolving dynamic process on static networks (see Table 2 and Fig. 2). They simulate a static network where dynamic process changes its parameters over time and gets captured in snapshots (e.g. epidemic spreading processes on static social networks with a changeable infection rate [40]). There are only few studies on SNSs in G2a [14, 40, 21].

SNSs in G2b focus on dynamic process on evolving networks (see Table 2 and Fig. 3). They simulate network snapshots that describe the network topology changes over time, where the dynamic process takes place without changing its parameters (e.g. epidemic spreading process with a non-changeable infection rate on social network that evolves over time [44]). There are many studies on SNSs that model only the dynamics of network structure in this space [34, 69, 4, 7, 8, 72, 28, 76, 45, 15, 50, 29, 43, 22, 13, 51, 44, 74, 61] while few of them additionally consider the dynamic processes [51, 44].

SNSs in G3 focus on evolving dynamic processes on evolving networks with interrelations between them (See Fig. 4). They simulate networks, dynamic processes and their changes using snapshot approach (data are processed in batches), while incorporating the interactions between a network and a process. For example, the epidemic spreading across the network can leave some nodes dead and get them removed [65], while the infection rate of epidemic spreading process can also vary depending on nodes' groups (structural patterns) [46, 26]. Only few SNSs consider the interrelations between the networks and the dynamic processes, where they just study the dynamic processes with non-changeable parameters on evolving networks [65] or evolving dynamic processes on static networks [46, 26, 66]

SNSs in G4 focus on temporal dynamic processes on temporal networks with interrelations between them and the continuous acquisition of real time information (see Fig. 5). They simulate networks and the dynamic processes with instantaneous changes of network topology and parameters, while incorporating the interactions between a process and a network. SNSs in G5 further extend the SNSs in G4 by closing the feedback loop between the SNSs and the real system and can be identified as an idealised state that can be named as a Digital Twin. Currently, there are no studies on SNS in G4 and G5 and further studies are required to model such high complexity scenarios to approach a DT.

Complexity dimensions
describe the complexity of social networks resulting from the heterogeneity of their network components (topology and attributes) and temporal dynamics of those components and their attributes. As proposed in [81], there are four complexity dimensions (i.e. structural, spatial, temporal and dynamics) that need to be considered when representing and modelling a network. The structural and the spatial complexities are concerned with the existence of network attributes and the space where the topology can be embedded respectively. The temporal and the dynamics complexities are connected with the changeable network components and their dynamics, respectively.
We review and discuss the network components and network dynamics of the social networks generated by the existing SNSs while considering two types of heterogeneity: (i) the existence of the components in a static time scale (represented with a ☆) and, in addition to its existence, (ii) the capability of the component to change over time (represented with a ★) (see Table 3).
| Stage | Topology | Attributes | Network dynamics | Existing SNS | ||
|---|---|---|---|---|---|---|
| Nodes | Edges | Nodes' | Edges' | |||
| G1/G2a | ☆ | ☆ | ☆ | [6],[20],[80],[24],[2],[3], | ||
| [85],[55],[71],[73],[86], | ||||||
| [84],[75][77],[78],[31], | ||||||
| [40],[27],[68],[21],[1],[9], | ||||||
| [83],[59],[33],[39],[10], | ||||||
| [32],[57],[11],[30],[23], | ||||||
| ☆ | ☆ | ☆ | ☆ | [53],[36],[5],[74] | ||
| ☆ | ☆ | ☆ | ☆ | [18],[54] | ||
| ☆ | ☆ | ☆ | ☆ | ☆ | [49],[52],[79],[70] | |
| G2b/G3 | ☆ | ★ | ☆ | [34],[69],[87],[51] | ||
| ☆ | ★ | ☆ | ☆ | [4],[7],[8],[72],[28],[76] | ||
| ☆ | ★ | ★ | ☆ | [4],[45] | ||
| ☆ | ★ | ★ | ☆ | [15] | ||
| ☆ | ★ | ☆ | ★ | ☆ | [13],[44] | |
| ☆ | ★ | ★ | ★ | ☆ | [50] | |
| ☆ | ★ | ★ | [29],[43],[22] | |||
As is shown in Table 3, most SNSs focus on static networks with no attributes, which are categorised as G1/G2a models and characterised with the lowest level of complexity in each dimension. They generate networks based on predetermined network statistics and connection principles about topology [6, 20, 80, 24, 2, 3, 85, 55, 71, 73, 86, 84, 75, 77, 78, 9, 10, 83, 59, 33, 1, 39, 32, 57, 11, 30, 23, 31]. Some other SNSs, with higher level of structural complexity, incorporate node attributes [53, 36, 5, 74], edge attributes [18, 54] or both of them [49, 52, 79] into the generation process of static networks. The SNSs in G2b/G3 have higher level of temporal complexity as network components are allowed to change over time, and they generally just consider the topology change [34, 69, 4, 7, 8, 72, 28, 76]. Few SNSs focus on changeable network dynamics, where the existing ones just consider topology and its changes over time, with a higher level of dynamics complexity but the lowest level of structural complexity [29, 43, 22]. To the best of our knowledge, there are no other SNSs in G4/G5 that would enable to model the desired level of complexity of network structure and its dynamics.
Assessment of SNSs
is concerned with investigating how close the generated networks are to the real systems that they attempt to model.
For SNSs, which generate simulated or hybrid networks to deal with the unobservable information, their assessment involves network statistics like density, degree distribution, shortest path, assortativity, modularity, clustering coefficient and betweenness [62]. Most SNSs employ network statistics concerned with the global network structures like degree centrality, betweenness centrality, and PageRank coefficient [3] to measure the similarity between the social network simulations and the target network. As an example, SNS proposed by [3] simulates the unobservable edges to achieve the desired betweenness centrality, PageRank, local clustering coefficient and degree distribution of the networks. There are also SNSs that simulate the missing edges for networks with partially observable edges, which can be treated as a link prediction task and evaluated considering the prediction performance with precision [56, 28], Micro Precision [16], Area Under the ROC (AUC) [56], Error Rate [17], etc. However, the above mentioned measures just focus on the states of static networks, whereas further studies are required for the measures considering network changes over time.
As an indicator of the SNSs' efficiency, the runtime of the simulation is considered by few studies [45, 4], which is proved to be influenced by the network components such as the number of simulated features and the network size.
To summarise, SNSs in the current studies can not capture enough complexity from the real world for an idealised DT modelling due to observability reasons. Though some SNSs consider real information, such as node attributes, there remains an undeveloped research space concerning how to gradually craft the increase of complexity for an improved SNS performance in one or several aspects. By increasing structural complexity, we aim to provide one of the possible pathways for extending the existing SNSs towards a DT Oriented SNS discussed in Section 3. Through experiments in Section 4, we also reveal the challenges of DT Oriented modelling by presenting the complex network patterns and, thus, the difficulties they pose to the SNS performance evaluation and SNS extension towards a DT.
3 Towards Digital Twin Oriented Social Network Simulator
To generate social networks with the desired level of complexity, we build an inner rule-based SNS referring to and extending work in [4], while enabling it to simulate social networks of increased complexity level and iterate with an optimised performance in efficiency and similarity. The two steps of building such an SNS that mimics the target network include: (i) the proposal of an inner rule-based SNS with extensible complexity in section 3.1 and (ii) an optimised iterative application of this SNS for similarity and efficiency in section 3.2 considering the observability and complexity. We have included some SNSs in the Appendix, while employing the extensible SNS initially proposed by [4] as an example in the following part of this study.
3.1 An Extensible Social Network Simulator
The inner rule-based SNS framework proposed by [4] models people as nodes, with the node attributes including features (i.e. such as age, gender, etc.) and individual preferences towards particular features termed as social-DNA (sDNA). The edges between these nodes represent relationships between people, which are connected according to preferential attachment rule based on topological and non-topological (attributes) characteristics. The edges can be directed or undirected and they are time-stamped with the iterative application of the SNS.
Based on this framework, we treat each node attribute as a tuple defined with a feature and sDNA (preference for this feature and weight of preference), while allowing their variations among individuals and changes over time. This enables the social network simulations with an extensible complexity in structural, spatial, temporal and dynamics dimensions. To implement this complexity, the detailed settings about network components and network dynamics are proposed and presented below.
Network components
include: (i) nodes (e.g. people), (ii) edges (e.g. social contact or relations), (iii) attributes including node attributes (e.g. age, gender, geo-space, etc.) and edge attributes (e.g. direction, weight, relationship, etc.). They vary in diversity and their capability to change over time.
We assume that the SNS simulates an undirected network with attributed nodes within iterations, the network formed in the iteration is represented as
| (1) |
which is composed of a fixed node set , an edge set that grows through iterations: and a node attribute set that can vary with nodes and change for each iteration.
Especially, referring to [4], the set of attributes for node is defined as
| (2) |
which includes a feature vector and the social-DNA (sDNA) defined with two vectors of the same length as . Any attribute, in this context, can be represented with a three-value tuple that is composed of feature, preference for this feature and weight of preference.
determines whether to prefer similar feature with a binary value of (prefer) or (not prefer), and represents the weight of preference for the feature with the range of .
The sDNA can be set at the level of individual nodes, groups or the whole populations in a static manner or can mutate over time. This variability of node attributes forms another source of structural complexity and requires further study.
Network dynamics
drives the network growth based on the current network topology and attributes. Referring to the previous study by [4], the edges of the undirected network are created without removal according to the ranking scores of each node pair based on the two-way evaluation between node and :
| (3) |
where , and each represents the feature-based, popularity-based and shortest-path score with the weights of , and respectively.
The feature-based score is based on the nodes' preferences and for their features and :
| (4) |
The popularity-based score incorporates the preference for nodes with higher degrees, with representing the preferential attachment parameter and represents the calculation of node degrees in the iteration:
| (5) |
The shortest path-based score is calculated based on the preference for the shortest path-length within the range between the node pair:
| (6) |
where represents node 's weight of preference for the path-length and represents the existence of the path-length between node pair and with a binary value of or .
| (7) |
where , and each represents the feature-based, popularity-based and shortest-path score with the weights of , and .
3.2 Optimisation towards a Digital Twin
A high quality SNS, in order to approach an idealised Digital Twin status, needs the optimised simulation of network components and network dynamics considering the three elements reviewed in section 2: (i) observability, (ii) complexity, and (iii) assessment of social network simulators.
Development path
of the SNS towards a DT can be divided into small steps, where with each step the complexity of a simulated social network gradually increases. Under the assumption of a fixed node set and non-attributed edges, we define a development of SNS towards a DT with increasing structural complexity and temporal complexity (see Table 4).
| Stage | Topology | Attributes | Dynamics | ||
| Nodes | Edges | Nodes' | Edges' | ||
| G1 | ☆ | ☆ | ☆ | ||
| ☆ | ☆ | ☆ | ☆ | ||
| G2 | ☆ | ★ | ☆ | ☆ | |
| ☆ | ★ | ★ | ☆ | ||
| G3 | ☆ | ★ | ★ | ★ | |
In G1, the structural complexity increases when more features are considered with a longer feature vector as part of a node attribute . The sDNA, and , represent the corresponding preference and weight of preference for respective similar features in the feature vector, composing another parts of node attribute . The sDNA also increases the structural complexity when more variability of the nodes' preferences (ranging from population-based, group-based to individual-based) is incorporated. Feature selection and the sDNA simulation is the necessary step required for an appropriate structural complexity level.
In G2, the temporal complexity increases when edges and the node attributes start to change with every simulation step, creating snapshots of evolving networks (with overall number of iterations ). This requires further study on what changes, how it changes, which network state the change leads to. In G3, the network dynamics can change with the changeable weighting factor , and for the ranking scores of node pairs, as well as the changeable mechanism that generates sDNA through various stochastic distributions.
We can simulate the unobservable networked information and remove the unnecessary steps if the increased complexity depreciates the performance of an SNS measured using criteria of similarity and efficiency. For each step ahead, we optimise the unobservable sDNA, and , with the SNS proposed in section 3.1 to achieve the maximised similarity between the , the desired and the minimised runtime for its simulation with efficiency (See equation 8).
| (8) | |||
The efficiency of SNS is measured with the runtime spent on the iterations of running the SNS. We propose the composite performance indexes to measure the similarity of social network simulations and the target network.
composite performance indexes
measure the distance between the simulated social network and the target network based on their similarity from both the global and the local perspectives [62]. As shown in equation 9, the composite performance index is calculated as the average distance between the simulated and the real networks in terms of each network measure .
| (9) |
The global perspective, concerned with the high level outcomes of interactions between the number of actors, includes measures such as node degree distribution, shortest path length distribution and the values of modularity and assortativity [62]. The local perspective, connected with interpersonal relations within subgraphs, includes measures such as the clustering coefficient distribution and the triad significance profile [62, 60, 38, 37].
We employ the 2-sample Kullback-Leibler divergence (KL divergence) to quantify their differences in distribution and the Manhattan distance to measure the differences of normalised values. Their missing values are replaced with to indicate the large gaps between the network simulations and the target network. Overall, the composite performance index of each network simulation, with values ranging from to , is calculated as the weighted average of these values. A lower value of this quality indicator means a more similar simulation compared with the target network.
Multi-objective optimisation,
towards an optimal similarity and efficiency, is required for the iterative application of DT Oriented SNS. To figure out an optimised sDNA in this process, we employ the fast elitist Non-dominated Sorting Genetic Algorithm (NSGA-2) proposed by [19] for three reasons.
First, as it is impossible to have a single solution which simultaneously optimises all objectives, NSGA-2, as a multi-objective evolutionary algorithm, enables a Pareto-optimal solution set with alternative solutions in or on Pareto-optimal front [19]. Second, NSGA-2 is characterised with low computational requirements, elitist approach, and parameter-less sharing approach [19]. Third and also the most important, NSGA-2, as a type of genetic algorithm, works best in the search of multiple parameters [48] while enabling the optimisation of sDNA based on genetics selection principles.
4 Results and Assessment
The social networks generated using the extended SNS vary with the node attributes, including the feature and the feature's preference: and . Specifically, we assume a population-based preference, where all nodes share the same preference vector and , without any change across iterations, which are calculated for an optimal level of similarity and efficiency based on a target network. The Zachary's Karate Club network [82], composed of 34 nodes with one binary attribute, is used as an illustratinve example in this experiment. For each iteration, of edges are added without removal.Ten network statistics are used in the assessment stage, including the density, assortativity, modularity, shortest path length and degree distribution in the global perspective, and the clustering coefficient and the significance profile of four types of triadic closures considering the binary node attributes.
Under the above assumptions and settings, the impact of feature selection for feature vector , concerned with the structural complexity, over the iterations is studied. This involves the benchmark SNS for networks without attributes (zero feature–based SNS), SNS for networks with one real node attribute (real feature–based SNS), SNS for networks with one unobservable node attribute that is randomly simulated as or (simulated feature–based SNS) and SNS for networks that are built with both the real and the simulated attributes (hybrid feature–based SNS). The complexity of the generated social network and the performance of the social network simulator are each presented and analysed in section 4.2 and section 4.1 respectively. Please note that all of these analyses are intended to provide insights into a discussion of how feasible and challenging the possible pathways to the development of more realistic DT oriented SNSs are likely to be and what one can expect along such a journey.
4.1 Performance of the proposed social network simulator
We measure the similarity between the simulated social networks and the target network with the composite performance indexes based on a variety of measures from both the global and the local perspectives and take the runtime of each simulation as an indicator for efficiency. Rather than proposing a performance measure or reaching final conclusions to be universally employed for SNSs, we aim to reveal the challenges of SNS performance evaluation for the future DT Oriented SNSs by discussing the diverse network patterns and the respective varying similarity levels that contribute to the composite performance index. The performance obtained based on the similarity and efficiency is shown in Fig. 6.


As we can see in Fig. 6(a), the distance between the simulated social networks and the target network topology fluctuates over the iterations. All generated networks share a similar trend of composite performance index,which firstly decreases in the first three iterations and then gradually increases. Generally all the SNSs achieve the lower values of composite performance index around the fourth iteration. The real feature–based SNS, with the introduction of one feature, achieves the lowest composite performance index among all the SNSs since the second iteration, within the shortest time. The hybrid feature-based SNS introduces a simulated feature to the real feature-based SNS, which, compared with the zero feature-based and the simulated feature-based SNSs, produces a higher composite performance index in the first three iterations and a lower composite performance index afterwards.
For each SNS, the time spent on each iteration increases as more edges are addedand more topological information is considered in the network growth, which, given the similar computation load of feature-based score with the non-changeable feature set, can be attributed to the calculation of popularity-based and shortest path score. There is little difference in runtime among the benchmark: zero feature–based SNS and other SNSs considering the small feature set that varies little.
Overall speaking, the introduction of the real feature to the SNS, with an increased structural complexity, improves the model performance in terms of similarity. In addition to the real feature, the consideration of the unobservable feature and its random simulation with the hybrid feature–based SNS do not bridge its distance with the target. Based on the SNS modelled with one real feature and an optimised population–based preference (the real feature-based SNS), we are able to approach the state of the target network while having the network growth captured in snapshots.
To better understand the contributions of the global measures and the local measures to the composite performance index, we respectively calculate the global composite performance index (Fig. 7(a)) and the local composite performance index (Fig. 7(b)), which each covers the five global measures and the five local measures of networks that respectively contribute to the of the composite performance index employed in the optimisation process.


Fig. 7(a) shows the values of composite performance index from the global perspective (composite performance index (g)) based on the average differences between simulations and target networks in density, modularity, assortativity, shortest path length distribution and degree distribution. For value-based measures, including density, modularity and assortativity, we use Manhattan distance to calculate their respective difference from the target. In contrast, the differences of distribution-based measures including the shortest path length and the degree distributions are measured with the KL divergence. Their values range from to (both for real feature SNS), and share a similar decreasing trend in the first three iterations with the composite performance index calculated from both the global and the local perspective (see Fig. 6). Generally all the SNS reach the lowest global composite performance index (g) around the fourth iteration and then deviate from the target with an increasing global composite performance index (g). The real feature-based SNS, compared with the other SNSs, achieves a lower value in the third, fourth and fifth iterations.
Fig. 7(b) shows the composite performance index from the local perspective (composite performance index (l)) based on the differences between simulations and target network in the significance profiles and the clustering coefficient. Similarly, the differences in the value-based measures including the significance profiles, and the distribution-based measures including the clustering coefficient, are respectively measured with the Manhattan distance and the KL divergence.The trend of local composite performance index (l) for each SNS is similar, with a larger value range from (for real feature SNS) to (for simulated feature SNS and hybrid feature SNS) , which decreases sharply in the first two iterations and then fluctuates around the lowest values between and . Generally all the SNSs reach their lowest composite performance index (l) around , except for the real feature-based SNS, which achieves the lowest value of . The real feature-based SNS keeps a lower composite performance index (l) than the other SNSs starting from the second iteration, similar to the trend of composite performance index calculated from both the global and the local perspective (see Fig. 6 and Fig. 7(b)).
For each SNS, with its iterative application, the global composite performance index (g) is smaller than the local composite performance index (l) in the first iteration. This indicates that the similarity between real and simulated networks, with small number of edges added, is higher when comparing networks from the global perspective than from the local perspective. Additionally, the real feature-based SNS achieves the smallest composite performance index (best performance) with the highest level of efficiency and similarity when looking at the local and global perspectives separately as well as when they are combined.
4.2 Complexity of the social network simulation
We conduct a comparative analysis of the structural complexity built up through the iterative application of zero feature–based SNS, real feature–based SNS, simulated feature–based SNS and the hybrid feature–based SNS. The network states of social network simulations and their changes across iterations are assessed based on the global and the local measures involved in the composite performance index of the optimisation process in section 3.2.
4.2.1 Global perspective
To have a better understanding of the network states and their changes across iterations from the global perspective connected with interactions over large number of actors, we conduct a comparative analysis of social network simulations from each SNS based on density, modularity, assortativity, degree distribution and shortest path length distribution.
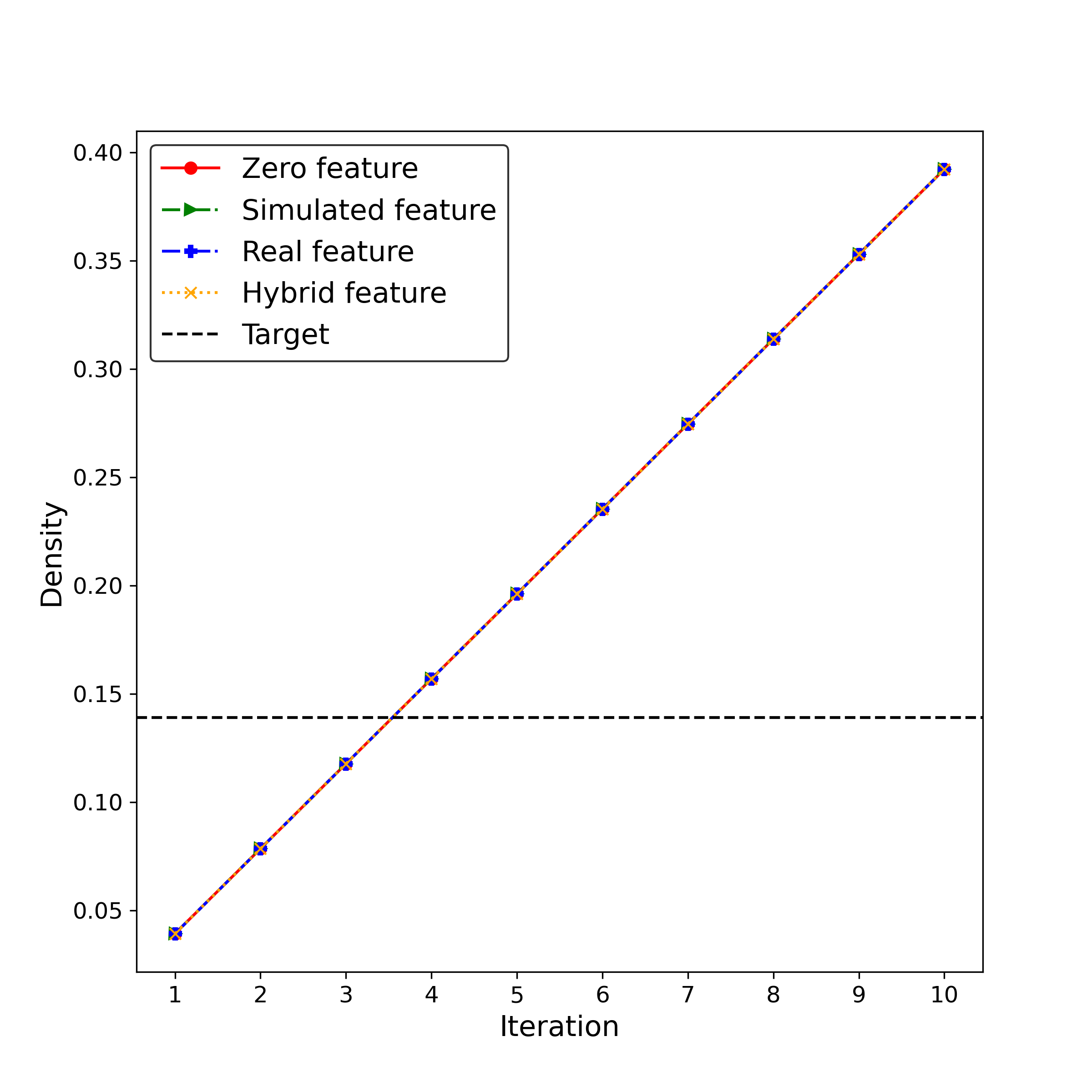
Density
of networks is calculated as a fraction of existing edges to all possible connections between all node pairs [62]. The density of networks increases with more edges added over the iterations. As is shown in Table 5, there are edges in the target network, with a network density of . In Fig. 8, all the simulated social networks share the same values of the edge number and density within each iteration under the assumed 4% edges (22 edges) to be rewired.The number of edges and the density of networks approach the values of the target network in the iteration.

| No. nodes | No. edges | Density | Modularity | Assortativity | |
|---|---|---|---|---|---|
| Target | 34 | 78 | 0.14 | 0.42 | -0.48 |
Modularity
measures the extent to which the network is clustered and how strong those clusters are. Its value is between and , where a larger value represents a strong community structure. As is shown in Fig. 9(a), the modularity of each simulated network decreases over iterations, with a convergence to the target modularity (See Table 5) in the second iteration. The real feature–based and the hybrid feature–based SNSs generally have the largest modularity over the iterations, indicating the strongest community structure for all the simulated networks. This can be caused by the binary feature, as nodes with the same feature and the same preference tend to have similar behaviours, increasing the number of connections within a community. The social network simulated by the zero feature-based SNS gets nearest to the target modularity in the second iteration.


Assortativity
measures whether the linked nodes have a similar degree (number of connections). Its value ranges between and . With a larger positive value of assortativity, nodes tend to link to other nodes with the same or similar degree, indicating a stronger assortative mixing pattern [62]. As is shown in Fig. 9(b), throughout the iterations, the assortativity of simulated networks is negative and fluctuates around . This can be caused by the weak preference for higher degrees and the strong preference for dissimilar features and shortest path lengths.The real feature-based SNS is closest to the target assortativity of (see Table 5) in the third iteration, while the other simulated networks approach the target in the third or fourth iteration.
Degree distribution
is a distribution of node degrees in a given network [62]. As shown in Table 6, the node degree of the target network fluctuates around the average value of with a standard deviation of , ranging from to . Fig. 10 shows node degree distributions of the target network and the simulated social networks over iterations. For each SNS, the range of the degree distribution generally gets larger with more edges added over the iterations. This indicates that the node degrees vary within the network and change over time, implying the diversity of network topology. The average values of the degree distribution fluctuates around with a small increase over time, which firstly approach the average node degree of the network and then deviates through iterations. The degree distributions of zero feature-based SNS (see Fig. 10(a)) and the real feature-based SNS (see Fig. 10(b)) have patterns more similar to the target network than the simulated feature-based SNS (see Fig. 10(c)) and the hybrid feature-based SNS (see Fig. 10(d)). And to quantify the level of similarity, we calculate the KL divergence based on the target degree distribution (see Fig. 11(a)).
| Average | Standard deviation | 75% quantile | 25% quantile | Maximum | Minimum | |
| Target | 4.59 | 3.82 | 5.00 | 2.00 | 17.00 | 1.00 |




As is shown in Fig. 11(a), all the simulated social networks have the same average node degree value, which increases systematically from to with the same number of edges added over the iterations. The average degree approaches the average degree of the target network in the third iteration and then deviates to higher values.
In Fig. 11(b), all the simulated networks have similar trend of KL divergence in terms of degree distribution, which firstly decreases to the lowest point at around fourth iteration and then increases. The real feature-based SNS, in the sixth iteration, reaches the lowest KL divergence among all the SNS and across all iterations. Correspondingly, the degree distribution of the simulated social network obtained using the real feature-based SNS in the fourth iteration (see Fig. 10(c)) has similar average values and quantiles as the target network, with few nodes having larger degree than nodes in the target network.


Shortest path length
between two nodes is defined as the number of edges along the shortest path between a pair of nodes [62]. As shown in Table 7, the shortest path length in the target network fluctuates around an average value of with a standard deviation of , ranging from to . Fig. 12 shows the shortest path length distributions of the target network and the simulated social networks over iterations when different SNSs were used. The shortest path lengths of simulated networks value between and as we assume no self-links exist. The shortest path length between connected nodes can not approach an upper limit at given nodes. In contrast, the shortest path length between the unconnected nodes is infinite, which is hard to be measured and visualised in a distribution. Therefore, to describe the unavailable paths between unconnected node pairs, we additionally assign these node pairs with the upper limit for shortest path length . For all SNSs, the shortest path length is distributed around the average value over in the first iteration and then converges to . This can be caused by the unavailability of paths between node pairs given a small number of edges in the first iteration.
| Average | Standard deviation | 75% quantile | 25% quantile | Maximum | Minimum | |
| Target | 2.41 | 0.93 | 3.00 | 2.00 | 5.00 | 1.00 |




As is shown in Fig. 12(a), the average values of the shortest path length for all for all the social network simulations decrease with addition of edges, approach the target and then fluctuate around , indicating small-world properties [62]. The zero feature–based SNS hits the target in the second iteration within the shortest time.
In Fig. 13(b), the KL divergence of shortest path length distribution firstly decreases to the lowest values in the third iteration and then keeps static at . The SNSs gradually get all the nodes connected and finally result in the same shortest path length distributions, between the value and , given the same number of edges (see Fig. 12). The simulated feature-based SNS achieves the lowest KL divergence in the third iteration, compared with the other SNSs across iterations.


4.2.2 Local perspective
To have a better understanding of the network states and their changes in between, we conduct a comparative analysis of the social networks obtained from running each SNS focusing on the local perspective. We focus here on the clustering coefficient distribution and the significance profiles of the four types of triads.
Clustering coefficient
describes the probability of a node's neighbours to be connected. Its value is between and [62]. As shown in Table 8, in the target network, clustering coefficient fluctuates around an average value of with a standard deviation of , ranging from to . Fig. 14 shows, for each SNS and each iteration, the clustering coefficient distribution of the simulated social networks. For all the networks, the values of the clustering coefficient start with in the first iteration and then increase over iterations, with its distribution getting closer to that of the target and then converging to the value . The clustering coefficient values of the feature-based SNSs converge slowerthan that of the zero feature-based SNS. The simulated feature–based SNS gets closest to the target in the third iteration within the shortest time.
| Average | Standard deviation | 75% quantile | 25% quantile | Maximum | Minmum | |
| Target | 0.57 | 0.34 | 1.00 | 0.33 | 1.00 | 0.00 |




As is shown in Fig. 15(a), the average values of the clustering coefficient increase over iterations, indicating a larger probability of neighbours of one node to be connected [62]. The SNSs generally approach the target network in the third iteration, except for the hybrid feature-based SNS, which reaches the target in the fifth iteration. The average clustering coefficient of the zero feature-based SNS converges to the higher bound faster than in other SNSs and keeps steady at around starting from the sixth iteration.
In Fig. 15(b), the KL divergences of the feature-based SNSs firstly decrease to the lowest values at around and then gradually increase to around . The simulated feature-based SNS achieves the lowest KL divergence in the third generation, getting closest to the target network within the shortest time.


Subgraphs significance profile
describes the similarity of subgraphs and their numbers in a given network when compared to random networks of the same size and number of edges [60]. Assuming types of subgraphs, the statistical significance of subgraph () is defined by its Z-score [60, 41]:
| (10) |
where , and represent the frequency of subgraph in the studied network, the mean value of its occurrences in the random network ensemble and the corresponding standard deviation respectively. The significance profile after normalisation is defined in equation 11, where a positive value indicates a more often occurrence of subgraph in a network than that in a set of random network ensembles.
| (11) |
We focus on the significance profile of a social structure, triadic closure, which is an interconnected three-node subgraph and can be categorised into four types considering the binary node attributes of the target network (See Fig. 16 and Table 9). The binary attribute determines whether a node (individual) belongs to the "Mr. Hi" club or the "Officer" club, while the edges represent the relations between the nodes. We respectively identify the triadic closures as triadic closure 1, triadic closure 2, triadic closure 3 and triadic closure 4 based on their node diversity considering the binary attribute (See Fig. 16).

| Type | No. nodes | No. subgraphs | Z–score | |
| "Mr. Hi" club | "Officer" club | |||
| Triadic closure 1 | 0 | 3 | 15 | 0.59 |
| Triadic closure 2 | 1 | 2 | 3 | -0.06 |
| Triadic closure 3 | 2 | 1 | 1 | -0.12 |
| Triadic closure 4 | 3 | 0 | 26 | 0.80 |
In Table 9, four types of triadic closures are identified with based on a binary node attribute that decides the number of nodes attributed with the "Mr Hi" club or the "Officer" club. There are observations for tragic closure and observations for triadic closure , more than the numbers of the other two triadic closures, which means that nodes within the same club are more likely to be connected and form a triadic closure. The significance profile of triadic closure and triadic closure is positive, contrasting with the negative values of triadic closure and triadic closure . The triadic closure and triadic appear in the target network more often than in a set of random network ensembles.




Fig. 17 shows the number of the four triadic closures in the simulated networks, which increases with addition of edges. There are more observations of triadic closure 2, 3 and 4 than triadic closure 1. The real feature-based SNS tends to have more triadic closure 1 simulated and hits the target number in the second iteration within the shortest time (see Fig. 17(a)). All the SNSs share a similar increasing trend for triadic closure 2 and 3 over iterations, with the target number reached in around the second iteration (see Fig. 17(b) and Fig. 17(c)). The real feature–based and the hybrid feature–based SNSs firstly reach the target occurrences of triadic closure 4 in the second iteration and then simulate more of them, compared with the other SNSs (see Fig. 17(d)). To better understand the significance of these triadic closures, we calculate their Z–scores (see Fig. 18).
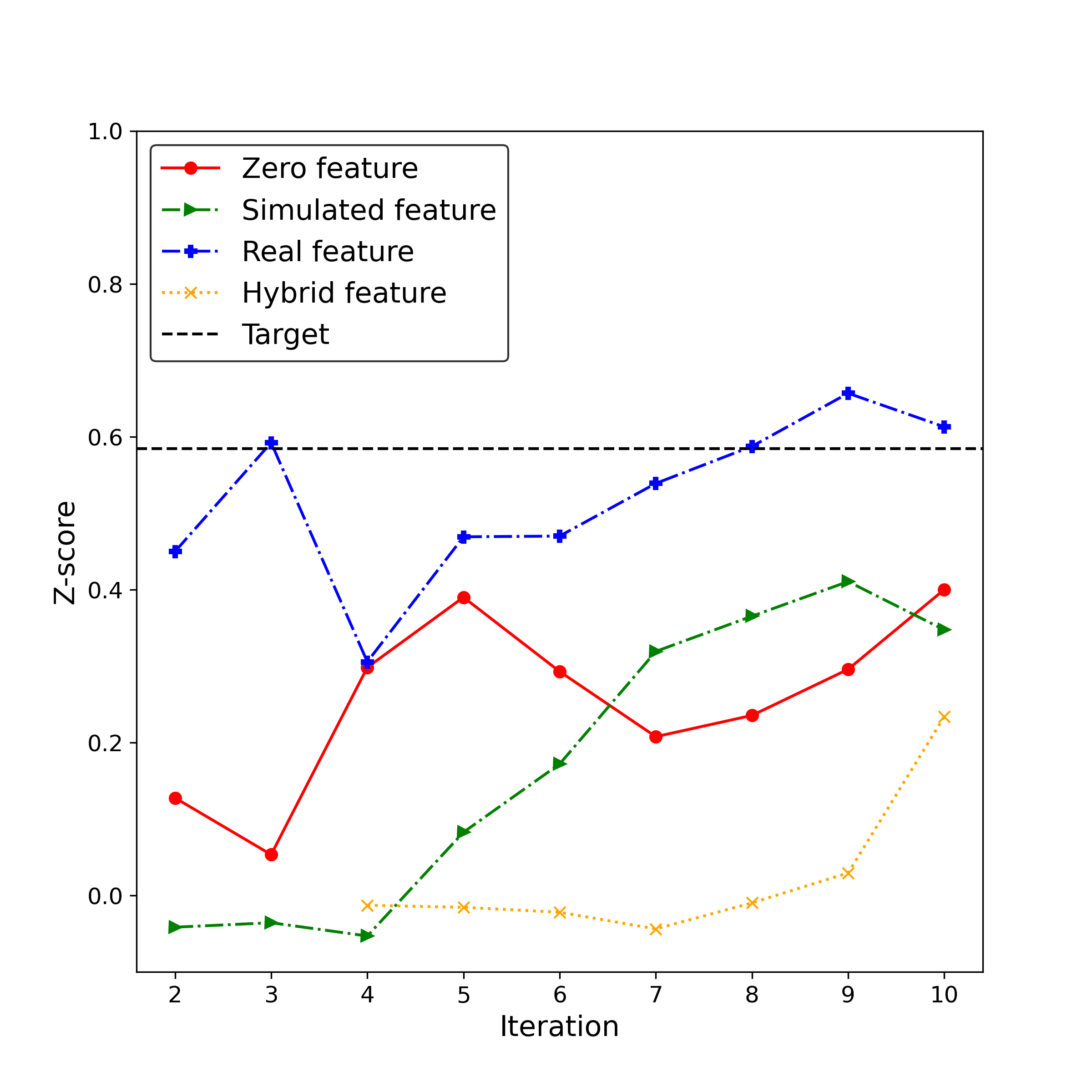



As shown in Fig. 18, the positive/negative Z–score indicates a more/less frequent occurrence of triadic closures in comparison to random networks. There are missing Z–scores for the networks simulated by the hybrid feature-based SNS in the first two iterations. This is caused by the unavailability of triadic closures when only small number of edges are added.
The zero feature–based, the real feature–based and the simulated feature-based SNSs achieve a generally positive Z–score for triadic closure 1 over the iterations, while the hybrid feature–based SNS produces negative ones (close to zero) (see Fig. 18(a)). The zero feature–based, the simulated feature–based and the hybrid feature–based SNSs achieve a positive Z–score for triadic closure 2, deviating from the negative target, while the real feature–based SNS fluctuates around the target over the first five iterations (see Fig. 18(b)). All the SNSs generally enable a positive Z–score for triadic closure 2 and 4, except for the simulated feature–based SNS, which produces negative values in the first iteration (see Fig. 18(c) and Fig. 18(d)).
The real feature–based SNS, compared with the other SNSs, attains a higher value of Z–score for the triadic closure 1 and the triadic closure 4, and a generally lower Z–score for the triadic closure 2 and the triadic closure 3. The real feature–based SNS gets closest to the target Z–scores, which, for triadic closure 1, 2, 3 and 4, is reached in the seventh, third, first and fifth iteration respectively (See Fig. 18).
4.2.3 A brief summary
To conclude the analysis, from a global perspective, the density, the modularity and the average node degrees increase with more edges added over the iterations for each SNS. This indicates a denser network and a stronger community structure and it is the expected result as the number of nodes remains static and only number of edges increases over the iterations. The average shortest path lengths decrease when more nodes get connected, and stabilise at a value that is smaller than , showing small-world properties. From a local perspective, the average clustering coefficient and number of triadic closures increase with edge addition over iterations, indicating more interpersonal connections within the subgraphs of the simulated networks.
Among all the SNSs and across iterations, the real feature–based SNS gets closest to the target when considering modularity, assortativity, degree distribution, and subgraph significance profiles. The simulated feature–based SNS gets closest to the target clustering coefficient distribution and the shortest path length distribution. Generally all the network measures for all the social network simulators approach their target values and then deviate from them as the number of edges exceeds the number of edges of the target network. The SNS that achieves the closest distance to the target network measure (as measured through KL divergence) varies from case to case and requires different numbers of iterations. Real feature-based SNS can generally achieve a higher level of similarity with the target value of each measure through a smaller number of iterations within a shorter time and this indicates that including different features in the simulation process leads to different network patterns, which may respectively deviate from that of the real networks to a different extent. The trade-offs between the similarity levels considering multiple network measures pose a challenge to the performance evaluation of SNSs and their extension towards a DT. Current studies on network simulators generally employ a single network measure or combine a few to evaluate the similarity between the simulated and real social networks. The selection and combination of various features in the SNS extension and the selection and combination of multiple network measures for SNS performance evaluation in a systemic way remains a research gap and requires further study.
5 Conclusions
In this paper, we firstly review the current state-of-the-art of the Social Network Simulators under the modelling and assessment framework proposed in our previous study [81] and identify research gaps in the space of social network modelling. To progress the field further and achieve a simulator that can better model real networks, we extend one of the promising SNS proposed by [4] towards a Digital Twin Oriented SNS by proposing one possible pathway of increasing structural complexity, which is to include informative features that are simulated or observed in the real world.With this SNS, each node attribute is composed of a node feature and a social DNA (the node's preference for a similar feature and the corresponding weight of preference).
We test different settings of sDNA in DT Oriented SNS to see which one results in social network that is closest to the target network. We propose to assess the similarity between target and simulated networks using metrics calculated at both global and local levels while taking the runtime of SNS as an indicator of efficiency. This DT Oriented SNS also serves as a tool to analyse the complexity of social network simulations built up over iterations. As an illustrative example, we conduct experiments and assessments of this DT Oriented SNS with the Karate Club network, which results show the possibility of optimisation and assessment of DT Oriented SNS towards a Digital Twin.
Literature review revealed that the majority of existing SNSs focus on generating purely simulated networks, while only a small proportion of SNSs aim to model real nodes and node attributes with/without observable information about edges. Under this constraint, we review and discuss the modelling social networks through generations towards the ultimate goal of a DT. Current SNSs generally focus on static networks or dynamic networks. Few SNSs consider networks, the dynamic process on the network and their interrelations. The interrelated social networks and dynamic processes, with the continuous acquisition of real-time information and feedback, also remain a research gap and require further study. We also discuss the complexity of social network simulations from the perspective of four dimensions and review the current ways of assessing SNSs. Most SNSs simulate social networks composed of fixed nodes and edges, while some SNSs incorporate network attributes and slow changes in network topologies. Current SNSs consider the global level similarity between the social network simulation and the target network as an indicator of its performance, where neither the local level similarity nor the efficiency is incorporated.
In the experiment, we extend an SNS towards a DT Oriented SNS to help illustrate the possible pathways and the challenges of developing a DT Oriented SNS. The extension of an SNS towards a DT Oriented SNS incorporates different levels of structural complexity and involves experiments on the benchmark, zero feature-based SNS, and its extensions, including simulated feature-based SNS, real feature-based SNS and the hybrid feature-based SNS concerned about both the real and the simulated features. We calculate the composite performance index of different networks by combining the results of various network measures. For a deeper understanding of the composite performance index that changes over iterations, we also conduct a comparative analysis of these SNSs to see the complexity of their social network simulations over iterations. The experimental results show that among all the SNSs, the real feature-based SNS, with an appropriately increased structural complexity, has the best performance in the efficiency and similarity from both the local and the global perspective. To be more specific with each measure, real feature-based SNS can also get closer to the target value through a smaller number of iterations. However, this conclusion holds for the experiments presented in this study, considering the pathway of SNS extension, the information employed in network simulation and the way we calculate the composite performance index. We need to develop a more systematic approach to developing DT Oriented SNS and propose referable SNS evaluation metrics for further study. And as SNSs add more edges over the iterations, the runtime of SNSs increases, and a stronger community structure and an assortative mixing pattern emerge, with more triadic closures as more neighbouring nodes get connected. Overall, all the measures involved in the composite performance index approach their target values and then deviate from them as the simulated network exceeds the target network's density. However, different similarity levels achieved by SNSs considering different network measures reveal the challenge of an accurate SNS performance evaluation given the specific requirements of social network simulations. This is a research gap to be addressed in our future study.
The DT Oriented SNSs can be extended with structural variations and temporal changes to approach a DT of the real systems. There is a requirement for a future study on the sDNA that varies across groups or individuals. Further research is also required on the network topology that changes over time and the process dimension that simultaneously interacts with the network dimension. Specific SNS performance evaluation criteria, considering various SNS complexity levels, also require further study. More generally, this study serves as a starting point of our future work on exploring the complexities of the real systems.
Acknowledgements
This work was supported by the Australian Research Council, Dynamics and Control of Complex Social Networks under Grant DP190101087.
Appendix
In this appendix, we list some extensible SNSs found through the review of literature and websites (http://caagt.ugent.be/CaGe/index.html; https://hog.grinvin.org/). The Table 10 below includes the names, references and links to the code for these SNSs while briefly describing their functions.
| SNS | Study | Link to the code | Description |
|---|---|---|---|
| VirtualSoc | [4] | https://github.com/AkandaAshraf/VirtualSoc | Dynamic Social Network Simulation Data with Ground Truth Labels and Features |
| Hashkat | docs.hashkat.org | A dynamic network simulor designed to model the growth of and information propagation through an online social network. | |
| Minibaum | [9] | http://caagt.ugent.be/minibaum/ | A generator for connected cubic graphs, but can be restricted to generating only graphs that have a fixed minimal girth or are bipartite |
| snarkhunter | [10] | http://caagt.ugent.be/cubic/ | A generator for connected cubic graphs and snarks. |
| GenHypohamiltonian | [83] | http://caagt.ugent.be/hypoham/ | A generator for hypohamiltonian and almost hypohamiltonian graphs |
| Genreg | [59] | http://www.mathe2.uni-bayreuth.de/markus/reggraphs.html | A very fast structure generator for regular graphs |
| MOLGEN | [33] | http://www.molgen.de/?src=documents/molgen4.html | A structure generator for molecular graphs. |
| alternating | [1] | https://github.com/nvcleemp/alternating | A generator for alternating planar graphs |
| CographGeneration | [39] | https://github.com/atilaajones/CographGeneration | A generator for cographs |
| CriticalPfreeGraph | [32] | http://caagt.ugent.be/criticalpfree/ | A generator for k-critical graphs without long induced paths |
| nauty and Traces | [57] | https://pallini.di.uniroma1.it/ | A generator for automorphism groups of graphs and digraphs. It can also produce a canonical labelling. |
| plantri and fullgen | [11] | https://users.cecs.anu.edu.au/~bdm/plantri/ | A generator for planar graph. |
| Buckygen | [30] | http://caagt.ugent.be/buckygen/ | A generator for all nonisomorphic fullerenes |
| perihamiltonian | [23] | https://github.com/nvcleemp/perihamiltonian | A generator for perihamiltonian graphs with a given connectivity. |
| GenerateUHG | [31] | http://caagt.ugent.be/uhg/ | A generator for graphs with a given number k of hamiltonian cycles (which is especially efficient for small values of k) |
References
- Althöfer et al., [2015] Althöfer, I., Haugland, J. K., Scherer, K., Schneider, F., and Van Cleemput, N. (2015). Alternating plane graphs. ARS MATHEMATICA CONTEMPORANEA, 8(2):337–363.
- Amati et al., [2018] Amati, V., Lomi, A., and Mira, A. (2018). Social network modeling. Annual Review of Statistics and Its Application, 5:343–369.
- Arora and Ventresca, [2017] Arora, V. and Ventresca, M. (2017). Action-based modeling of complex networks. Scientific reports, 7(1):1–10.
- Ashraf et al., [2019] Ashraf, A. W.-U., Budka, M., and Musial, K. (2019). Simulation and augmentation of social networks for building deep learning models. arXiv preprint arXiv:1905.09087.
- Asikainen et al., [2020] Asikainen, A., Iñiguez, G., Ureña-Carrión, J., Kaski, K., and Kivelä, M. (2020). Cumulative effects of triadic closure and homophily in social networks. Science Advances, 6(19):eaax7310.
- Barabási and Albert, [1999] Barabási, A.-L. and Albert, R. (1999). Emergence of scaling in random networks. science, 286(5439):509–512.
- Block et al., [2020] Block, P., Hoffman, M., Raabe, I. J., Dowd, J. B., Rahal, C., Kashyap, R., and Mills, M. C. (2020). Social network-based distancing strategies to flatten the covid-19 curve in a post-lockdown world. Nature Human Behaviour, 4(6):588–596.
- Boda et al., [2020] Boda, Z., Elmer, T., Vörös, A., and Stadtfeld, C. (2020). Short-term and long-term effects of a social network intervention on friendships among university students. Scientific reports, 10(1):1–12.
- Brinkmann, [1996] Brinkmann, G. (1996). Fast generation of cubic graphs. Journal of Graph Theory, 23(2):139–149.
- Brinkmann and Goedgebeur, [2017] Brinkmann, G. and Goedgebeur, J. (2017). Generation of cubic graphs and snarks with large girth. Journal of Graph Theory, 86(2):255–272.
- Brinkmann et al., [2007] Brinkmann, G., McKay, B. D., et al. (2007). Fast generation of planar graphs. MATCH Commun. Math. Comput. Chem, 58(2):323–357.
- Bródka et al., [2020] Bródka, P., Musial, K., and Jankowski, J. (2020). Interacting spreading processes in multilayer networks: a systematic review. IEEE Access, 8:10316–10341.
- Budka et al., [2013] Budka, M., Juszczyszyn, K., Musial, K., and Musial, A. (2013). Molecular model of dynamic social network based on e-mail communication. Social Network Analysis and Mining, 3(3):543–563.
- Carchiolo et al., [2021] Carchiolo, V., Longheu, A., Malgeri, M., Mangioni, G., and Previti, M. (2021). Mutual influence of users credibility and news spreading in online social networks. Future Internet, 13(5):107.
- Chen and Li, [2018] Chen, H. and Li, J. (2018). Exploiting structural and temporal evolution in dynamic link prediction. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, pages 427–436.
- Chen et al., [2020] Chen, H., Yin, H., Sun, X., Chen, T., Gabrys, B., and Musial, K. (2020). Multi-level graph convolutional networks for cross-platform anchor link prediction. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1503–1511.
- Chen et al., [2021] Chen, J., Wang, X., and Xu, X. (2021). Gc-lstm: graph convolution embedded lstm for dynamic network link prediction. Applied Intelligence, pages 1–16.
- Dai et al., [2017] Dai, C., Chen, L., Li, B., and Li, Y. (2017). Link prediction in multi-relational networks based on relational similarity. Information Sciences, 394:198–216.
- Deb, [2002] Deb, K. (2002). A fast elitist non-dominated sorting genetic algorithm for multi-objective optimization: Nsga-2. IEEE Trans. Evol. Comput., 6(2):182–197.
- Doye, [2002] Doye, J. P. (2002). Network topology of a potential energy landscape: A static scale-free network. Physical review letters, 88(23):238701.
- Eletreby et al., [2020] Eletreby, R., Zhuang, Y., Carley, K. M., Yağan, O., and Poor, H. V. (2020). The effects of evolutionary adaptations on spreading processes in complex networks. Proceedings of the National Academy of Sciences, 117(11):5664–5670.
- Elhesha et al., [2019] Elhesha, R., Sarkar, A., Cinaglia, P., Boucher, C., and Kahveci, T. (2019). Co-evolving patterns in temporal networks of varying evolution. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, pages 494–503.
- Fabrici et al., [2021] Fabrici, I., Madaras, T., Timková, M., Van Cleemput, N., and Zamfirescu, C. T. (2021). Non-hamiltonian graphs in which every edge-contracted subgraph is hamiltonian. Applied Mathematics and Computation, 392:125714.
- Fortunato et al., [2006] Fortunato, S., Flammini, A., and Menczer, F. (2006). Scale-free network growth by ranking. Physical review letters, 96(21):218701.
- Fox et al., [2016] Fox, E. W., Short, M. B., Schoenberg, F. P., Coronges, K. D., and Bertozzi, A. L. (2016). Modeling e-mail networks and inferring leadership using self-exciting point processes. Journal of the American Statistical Association, 111(514):564–584.
- Fu et al., [2019] Fu, G., Chen, F., Liu, J., and Han, J. (2019). Analysis of competitive information diffusion in a group-based population over social networks. Physica A: Statistical Mechanics and its Applications, 525:409–419.
- Ganesh et al., [2005] Ganesh, A., Massoulié, L., and Towsley, D. (2005). The effect of network topology on the spread of epidemics. In Proceedings IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies., volume 2, pages 1455–1466. IEEE.
- Gao et al., [2017] Gao, F., Musial, K., and Gabrys, B. (2017). A community bridge boosting social network link prediction model. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, pages 683–689.
- Gao and Musial-Gabrys, [2016] Gao, F. and Musial-Gabrys, K. (2016). Hybrid structure-based link prediction model. In 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), pages 1221–1228. IEEE.
- Goedgebeur and McKay, [2015] Goedgebeur, J. and McKay, B. D. (2015). Recursive generation of ipr fullerenes. Journal of Mathematical Chemistry, 53(8):1702–1724.
- Goedgebeur et al., [2020] Goedgebeur, J., Meersman, B., and Zamfirescu, C. (2020). Graphs with few hamiltonian cycles. Mathematics of Computation, 89(322):965–991.
- Goedgebeur and Schaudt, [2018] Goedgebeur, J. and Schaudt, O. (2018). Exhaustive generation of k-critical-free graphs. Journal of Graph Theory, 87(2):188–207.
- Gugisch et al., [2015] Gugisch, R., Kerber, A., Kohnert, A., Laue, R., Meringer, M., Rücker, C., and Wassermann, A. (2015). Molgen 5.0, a molecular structure generator. In Advances in mathematical chemistry and applications, pages 113–138. Elsevier.
- Güneş et al., [2016] Güneş, İ., Gündüz-Öğüdücü, Ş., and Çataltepe, Z. (2016). Link prediction using time series of neighborhood-based node similarity scores. Data Mining and Knowledge Discovery, 30(1):147–180.
- Hiesinger, [2021] Hiesinger, P. R. (2021). The Self-Assembling Brain: How Neural Networks Grow Smarter. Princeton University Press.
- Hunter et al., [2008] Hunter, D. R., Goodreau, S. M., and Handcock, M. S. (2008). Goodness of fit of social network models. Journal of the american statistical association, 103(481):248–258.
- [37] Jia, M., Gabrys, B., and Musial, K. (2021a). Directed closure coefficient and its patterns. Plos one, 16(6):e0253822.
- [38] Jia, M., Gabrys, B., and Musial, K. (2021b). Measuring quadrangle formation in complex networks. IEEE Transactions on Network Science and Engineering.
- Jones et al., [2018] Jones, Á. A., Protti, F., and Del-Vecchio, R. R. (2018). Cograph generation with linear delay. Theoretical Computer Science, 713:1–10.
- Jovanovski et al., [2021] Jovanovski, P., Tomovski, I., and Kocarev, L. (2021). Modeling the spread of multiple contagions on multilayer networks. Physica A: Statistical Mechanics and its Applications, 563:125410.
- Juszczyszyn et al., [2008] Juszczyszyn, K., Kazienko, P., Musial, K., and Gabrys, B. (2008). Temporal changes in connection patterns of an email-based social network. In 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, volume 3, pages 9–12. IEEE.
- Kavak et al., [2019] Kavak, H., Kim, J.-S., Crooks, A., Pfoser, D., Wenk, C., and Züfle, A. (2019). Location-based social simulation.
- Kendrick et al., [2018] Kendrick, L., Musial, K., and Gabrys, B. (2018). Change point detection in social networks—critical review with experiments. Computer Science Review, 29:1–13.
- Kim et al., [2020] Kim, J.-S., Jin, H., Kavak, H., Rouly, O. C., Crooks, A., Pfoser, D., Wenk, C., and Züfle, A. (2020). Location-based social network data generation based on patterns of life. In 2020 21st IEEE International Conference on Mobile Data Management (MDM), pages 158–167. IEEE.
- Kim et al., [2019] Kim, J.-S., Kavak, H., Manzoor, U., and Züfle, A. (2019). Advancing simulation experimentation capabilities with runtime interventions. In 2019 Spring Simulation Conference (SpringSim), pages 1–11. IEEE.
- Koprulu et al., [2019] Koprulu, I., Kim, Y., and Shroff, N. B. (2019). Battle of opinions over evolving social networks. IEEE/ACM Transactions on Networking, 27(2):532–545.
- Król et al., [2015] Król, D., Fay, D., and Gabryś, B. (2015). Propagation phenomena in real world networks. Springer.
- Lambora et al., [2019] Lambora, A., Gupta, K., and Chopra, K. (2019). Genetic algorithm-a literature review. In 2019 international conference on machine learning, big data, cloud and parallel computing (COMITCon), pages 380–384. IEEE.
- Lancichinetti and Fortunato, [2009] Lancichinetti, A. and Fortunato, S. (2009). Benchmarks for testing community detection algorithms on directed and weighted graphs with overlapping communities. Physical Review E, 80(1):016118.
- Lin et al., [2008] Lin, Y.-R., Chi, Y., Zhu, S., Sundaram, H., and Tseng, B. L. (2008). Facetnet: a framework for analyzing communities and their evolutions in dynamic networks. In Proceedings of the 17th international conference on World Wide Web, pages 685–694.
- [51] Liu, F., Li, X., and Zhu, G. (2020a). Using the contact network model and metropolis-hastings sampling to reconstruct the covid-19 spread on the “diamond princess”. Science bulletin, 65(15):1297–1305.
- [52] Liu, X., Song, W., Musial, K., Zhao, X., Zuo, W., and Yang, B. (2020b). Semi-supervised stochastic blockmodel for structure analysis of signed networks. Knowledge-Based Systems, 195:105714.
- Liu et al., [2021] Liu, X., Yang, B., Song, W., Musial, K., Zuo, W., Chen, H., and Yin, H. (2021). A block-based generative model for attributed network embedding. World Wide Web, 24(5):1439–1464.
- Lou et al., [2020] Lou, Y., Wang, L., Tsang, K.-F., and Chen, G. (2020). Towards optimal robustness of network controllability: An empirical necessary condition. IEEE Transactions on Circuits and Systems I: Regular Papers, 67(9):3163–3174.
- Lü et al., [2009] Lü, L., Jin, C.-H., and Zhou, T. (2009). Similarity index based on local paths for link prediction of complex networks. Physical Review E, 80(4):046122.
- Lü and Zhou, [2011] Lü, L. and Zhou, T. (2011). Link prediction in complex networks: A survey. Physica A: statistical mechanics and its applications, 390(6):1150–1170.
- McKay and Piperno, [2014] McKay, B. D. and Piperno, A. (2014). Practical graph isomorphism, ii. Journal of symbolic computation, 60:94–112.
- McPherson et al., [2001] McPherson, M., Smith-Lovin, L., and Cook, J. M. (2001). Birds of a feather: Homophily in social networks. Annual review of sociology, 27(1):415–444.
- Meringer, [1999] Meringer, M. (1999). Fast generation of regular graphs and construction of cages. Journal of Graph Theory, 30(2):137–146.
- Milo et al., [2004] Milo, R., Itzkovitz, S., Kashtan, N., Levitt, R., Shen-Orr, S., Ayzenshtat, I., Sheffer, M., and Alon, U. (2004). Superfamilies of evolved and designed networks. Science, 303(5663):1538–1542.
- [61] Musial, K., Budka, M., and Juszczyszyn, K. (2013a). Creation and growth of online social network. World Wide Web, 16(4):421–447.
- [62] Musial, K., Gabrys, B., and Buczko, M. (2013b). What kind of network are you? using local and global characteristics in network categorisation tasks. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, pages 1366–1373.
- Musial et al., [2012] Musial, K., Juszczyszyn, K., and Budka, M. (2012). Triad transition probabilities characterize complex networks. Awareness Magazine.
- Musiał and Kazienko, [2013] Musiał, K. and Kazienko, P. (2013). Social networks on the internet. World Wide Web, 16(1):31–72.
- Newman, [2005] Newman, M. E. (2005). Threshold effects for two pathogens spreading on a network. Physical review letters, 95(10):108701.
- Pan et al., [2018] Pan, C., Yang, L.-X., Yang, X., Wu, Y., and Tang, Y. Y. (2018). An effective rumor-containing strategy. Physica A: Statistical Mechanics and its Applications, 500:80–91.
- Passino and Heard, [2021] Passino, F. S. and Heard, N. A. (2021). Mutually exciting point process graphs for modelling dynamic networks. arXiv preprint arXiv:2102.06527.
- Pastor-Satorras and Vespignani, [2001] Pastor-Satorras, R. and Vespignani, A. (2001). Epidemic spreading in scale-free networks. Physical review letters, 86(14):3200.
- Petri and Barrat, [2018] Petri, G. and Barrat, A. (2018). Simplicial activity driven model. Physical review letters, 121(22):228301.
- Scatà et al., [2016] Scatà, M., Di Stefano, A., Liò, P., and La Corte, A. (2016). The impact of heterogeneity and awareness in modeling epidemic spreading on multiplex networks. Scientific reports, 6(1):1–13.
- Seaton and Hackett, [2004] Seaton, K. A. and Hackett, L. M. (2004). Stations, trains and small-world networks. Physica A: Statistical Mechanics and its Applications, 339(3-4):635–644.
- Shi et al., [2020] Shi, L., Zhang, L., and Lu, Y. (2020). Evaluating social network-based weight loss interventions in chinese population: An agent-based simulation. Plos one, 15(8):e0236716.
- Solomonoff and Rapoport, [1951] Solomonoff, R. and Rapoport, A. (1951). Connectivity of random nets. The bulletin of mathematical biophysics, 13(2):107–117.
- Verhoeven et al., [2020] Verhoeven, D., Musial, K., Palmer, S., Taylor, S., Abidi, S., Zemaityte, V., and Simpson, L. (2020). Controlling for openness in the male-dominated collaborative networks of the global film industry. PloS one, 15(6):e0234460.
- Wahid-Ul-Ashraf et al., [2019] Wahid-Ul-Ashraf, A., Budka, M., and Musial, K. (2019). How to predict social relationships—physics-inspired approach to link prediction. Physica A: Statistical Mechanics and its Applications, 523:1110–1129.
- Wang et al., [2007] Wang, C., Satuluri, V., and Parthasarathy, S. (2007). Local probabilistic models for link prediction. In Seventh IEEE international conference on data mining (ICDM 2007), pages 322–331. IEEE.
- [77] Wang, W., Zhang, J., Zhao, S., and Zhang, Y. (2019a). Simulation of asset pricing in information networks. Physica A: Statistical Mechanics and its Applications, 513:620–634.
- Wang et al., [2021] Wang, W., Zhao, S., and Zhang, J. (2021). Multi-asset pricing modeling using holding-based networks in energy markets. Finance Research Letters, page 102483.
- [79] Wang, Y., Jin, D., Musial, K., and Dang, J. (2019b). Community detection in social networks considering topic correlations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 321–328.
- Watts and Strogatz, [1998] Watts, D. J. and Strogatz, S. H. (1998). Collective dynamics of ‘small-world’networks. nature, 393(6684):440–442.
- Wen et al., [2022] Wen, J., Gabrys, B., and Musial, K. (2022). Toward digital twin oriented modeling of complex networked systems and their dynamics: A comprehensive survey. IEEE Access, 10:66886–66923.
- Zachary, [1977] Zachary, W. W. (1977). An information flow model for conflict and fission in small groups. Journal of anthropological research, 33(4):452–473.
- Zamfirescu and Goedgebeur, [2019] Zamfirescu, C. T. and Goedgebeur, J. (2019). On almost hypohamiltonian graphs. Discrete Mathematics & Theoretical Computer Science, 21.
- Zhang, [2018] Zhang, J. (2018). Influence of individual rationality on continuous double auction markets with networked traders. Physica A: Statistical Mechanics and its Applications, 495:353–392.
- [85] Zhang, J., Wen, J., and Chen, J. (2021a). Modeling market fluctuations under investor sentiment with a hawkes-contact process. The European Journal of Finance, pages 1–16.
- [86] Zhang, J., Xu, Y., and Houser, D. (2021b). Vulnerability of scale-free cryptocurrency networks to double-spending attacks. The European Journal of Finance, pages 1–15.
- Zhu et al., [2019] Zhu, P., Wang, X., Li, S., Guo, Y., and Wang, Z. (2019). Investigation of epidemic spreading process on multiplex networks by incorporating fatal properties. Applied mathematics and computation, 359:512–524.