Revelio: ML-Generated Debugging Queries for Distributed Systems
Abstract.
A major difficulty in debugging distributed systems lies in manually determining which of the many available debugging tools to use and how to query its logs. Our own study of a production debugging workflow confirms the magnitude of this burden. This paper explores whether a machine-learning model can assist developers in distributed systems debugging. We present Revelio, a debugging assistant which takes user reports and system logs as input, and outputs debugging queries that developers can use to find a bug’s root cause. The key challenges lie in (1) combining inputs of different types (e.g., natural language reports and quantitative logs) and (2) generalizing to unseen faults. Revelio addresses these by employing deep neural networks to uniformly embed diverse input sources and potential queries into a high-dimensional vector space. In addition, it exploits observations from production systems to factorize query generation into two computationally and statistically simpler learning tasks. To evaluate Revelio, we built a testbed with multiple distributed applications and debugging tools. By injecting faults and training on logs and reports from 800 Mechanical Turkers, we show that Revelio includes the most helpful query in its predicted list of top-3 relevant queries 96% of the time. Our developer study confirms the utility of Revelio.
1. Introduction
Developers often need to translate informal reports about problems provided by a user into actionable information that identifies the root cause of a bug. An ever-growing list of debugging tools aid developers in such root cause diagnosis. These tools enable a developer to log the behavior of applications running on end hosts (app, 2019; str, 2019; OpenTracing, 2019; gdb, 2018; apa, [n. d.]; dat, [n. d.]b), end host networking stacks (tcp, 2019; bpf, [n. d.]), and network infrastructure (Narayana et al., 2017; Case et al., 1990; int, 2019). Some tools also track and relate execution across multiple subsystems of a distributed system (Mace et al., 2015; Netravali and Mickens, 2019; Sigelman et al., 2010; zip, 2019). Further, each tool allows developers to query the collected logs (e.g., using BPF expressions, SQL queries, or the graphical interfaces offered by interactive dashboards (gra, [n. d.]; dat, [n. d.]a)) to hone in on interesting data.
Yet, debugging distributed systems remains difficult, largely because it typically involves multiple manual steps (Abuzaid et al., 2018): understand user reports,111We focus on user-generated reports, but note that the approach generalizes to auto-generated natural language crash reports, e.g., error messages. iteratively issue debugging queries to test hypotheses about potential root causes, and finally develop a fix. As a concrete example, consider debugging a client interaction with a web service that results in an unusually slow page load. The developer receives a user report about the slow page load and has to develop a bug fix. However, the problem could be in many possible subsystems. At the client, the browser could be executing malformed HTML. At the server, there could be an unreachable database, a program error in the application frontend, or a misconfigured forwarding table in the network.
In the example above, the developer’s difficulty is not the lack of tools; on the contrary, dozens of rich debugging frameworks exist for each subsystem (§8). Instead, the challenge lies in manually determining which debugging queries to issue, on which subsystems’ logs, and with what parameters. Further, the answer to each question can depend on vast and heterogeneous logs. Indeed, distributed systems increasingly comprise many loosely coupled subsystems (e.g., microservices (Lyft Engineering, [n. d.])), each with their own logging framework(s). As a result, developers face a significant cognitive burden to understand and correlate debugging information that exhibits heterogeneity in (1) data types (e.g., natural language user reports and error messages, numerical switch counters, RPC call graphs), (2) data sources (e.g., network infrastructure, end-host stack, application), and (3) abstraction levels (e.g., user reports, system-level logs, network-level counters).
Today, developers overcome these challenges using their hard-won intuition from debugging similar problems in the past, remembering which subsystems they investigated, and what debugging queries they issued. However, our developer survey and analysis of 4 months of debugging reports at a major SaaS company (Anon) revealed that this manual approach consumes significant developer time (§2). At Anon, moving from a user report to a root cause took developers an average of 8.5 hours, despite the fact that 94% of the faults were repeated instances of the same type (e.g., resource underprovisioning), with only the fault location varying. Prior studies of other production systems have similarly observed the time significance of root cause analysis (relative to tasks such as triaging) (Chen et al., 2019; Pham et al., 2020).
In this paper, motivated by the prevalence of large historical debugging datasets in software organizations (fbd, [n. d.]; tic, [n. d.]) and the recurring nature of faults, we ask: can a machine-learning (ML) model learn the same kind of developer intuition from past debugging experiences to accelerate root cause finding? More precisely, given debugging data collected when a report was provoked, can an ML model automatically generate a debugging query that allows the developer to extract the most informative subset of the logs? Further, is the model’s output ultimately useful: does it let the developer diagnose bugs faster than the status quo?
To answer these questions, we developed Revelio (Figure 1), whose goal is to help developers use existing debugging tools more effectively. Revelio takes as inputs user reports and system logs from existing tools, and outputs a ranked sequence of debugging queries that (when executed) elucidate the root cause. Note that Revelio is intended to be trained directly on the system logs being collected in a given deployment; we expect Revelio to be retrained if the set of tools or the data that they log changes.
Why output debugging queries? We chose to output a query sequence for several reasons. First, as evidenced by our production debugging analysis (§2.2), much developer time and effort in root cause analysis is spent selecting a subsystem to investigate, and determining how to use existing querying tools to analyze its collected logs – queries embed both of these aspects. Second, bugs can often be tackled from multiple vantage points in distributed systems, e.g., congestion between two microservices can be resolved by either moving an application VM or changing inter-service routing rules. A sequence ensures that developers can extract root cause insights from those different vantage points to
facilitate the generation of the appropriate fix. We next describe Revelio’s challenges and contributions.
1.1. Challenges and Contributions
1. Extensible model using distributed vector representations: To combine heterogeneous data sources (e.g., natural language user reports, numerical switch counters), we use neural networks that map each input to a high-dimensional distributed vector representation (Alon et al., 2019; Mikolov et al., 2013), akin to intermediate representations like SSA (Appel, 1998) in programming languages. This makes our architecture extensible: a new type of debugging data can be incorporated by learning a mapping from that data type to a high-dimensional vector.
2. Modeling queries as vectors using graph convolutional networks: Ideally, we should be able to convert queries into the same vector representation as our inputs; we could then find the relevance of a query to a particular debugging scenario by applying standard machine-learning concepts such as a similarity score between the query and input vectors. One approach is to simply assign a unique label to each query and employ a multi-label classifier to generate queries. However, this performs poorly (§6.3) because the opacity and independence of such labels fail to exploit the fact that debugging queries for a tool are all drawn from the same grammar. Instead, debugging queries are more faithfully modeled as abstract syntax trees (ASTs) in the syntax of the query language. To leverage this richer query format, we use graph convolutional networks (GCNs) (Kipf and Welling, 2016) to convert query ASTs into the same vector representation as our inputs.
3. Handling a large search space of queries using modularization: For any inputs, the search space of potential queries is massive. This is because of the presence of many (1) query templates, i.e., skeleton queries for a given subsystem with unspecified parameters, and (2) query parameters that cover the scale of production systems (e.g., every IP address in the system could be a candidate value for a parameter). To handle this large search space, we modularize our ML model into two components. The first model uses user reports and system logs to predict a query template; then the second model uses only the predicted template and system logs (not user reports), to predict numeric parameters. This is motivated by our finding that production faults typically involve recurring types (§2), and can thus be debugged using a small set of templates—one per fault type. Modularization shrinks the output space of the first model, simplifying training computationally, and the input space of the second model, making it less likely to overfit to spurious input features.
4. Generalizing to unseen faults using abstraction: To handle a large fraction of bugs in production settings, an ideal model should generalize to output useful queries for occurrences of previously seen bugs at new locations (§2). To achieve such generalization, we transform concrete switch/function ids into new, abstract ids based on rank on some metric, e.g., queue size; consequently, the ids in one setup and another need not be the same, allowing us to generalize to new fault locations. For example, if the model captures a dependence on the largest router queue (which in the training set was Router ), it can generalize during testing to a different Router with the largest router queue.

1.2. Evaluating Revelio
New distributed systems debugging testbed: While organizations running distributed systems routinely collect the described debugging data, much of it is proprietary. To address this data scarcity and evaluate Revelio, we built a testbed (§5) on top of the Mininet emulation platform (Lantz et al., 2010). Our testbed currently integrates four debugging tools—Jaeger (Uber, 2019), Marple (Narayana et al., 2017), cAdvisor (Google, 2019), and tcpdump (tcp, 2019)—and runs three industry-developed distributed applications—Reddit (red, 2016) (monolithic), Sock Shop (Weaveworks, 2017) (microservice), and Online Boutique (Google, 2019) (microservice). In addition, our testbed includes an automatic fault injector that was informed by our analysis of production bugs (§2) and generates a variety of network, system, and application errors (§5.3).
We enlisted 800 users on Amazon Mechanical Turk to interact with our testbed’s applications. Turk users, unaware of the injected faults, were asked to report their experiences under these faulty scenarios via multiple choice and free-form questions. In total, we simulated 85 different faults (per app) and collected an average of 10 user reports per fault. We paired this training data with the system logs from our testbed, and a set of debugging queries generated by us to mimic those expected in debugging reports.
Testbed evaluation, developer study: We evaluated Revelio using data from our testbed and Turk users (§6), and with a developer study (§7). Our key findings are: 1. across the set of potential queries supported by our debugging tools, for repeat occurrences of the same faults, Revelio ranks the correct (i.e., the one that most directly highlights the root cause) query in the top-k 96% (k=3), 100% (k=4), and 100% (k=5) of the time, 2. Revelio’s model successfully generalizes to output the correct query 87% (k=3), 88% (k=4), and 100% (k=5) of the time for faults that manifest in previously unseen locations, and 3. developers with access to Revelio correctly identified 90% of the root causes (compared to 60% without Revelio), and did so 72% (14 mins) faster. We additionally conducted quantitative experiments that demonstrate that each of our design choices, i.e., abstraction, GCNs, and modularization, individually has a significant (positive) effect on the query generation performance of Revelio (§6.3).
2. Production Bugs, Debugging Workflows
| Root Cause Category | # of Tickets | # of Locations | Example Root Cause | Avg. Diagnosis Time (mins) |
| Resource underprovisioning | 17 | 11 | Load balancer is consuming all available memory and starving other co-located services | 293 |
| Component failures | 58 | 29 | 3 nodes for a service were down, leading to queued 400 ERRORs | 176 |
| Subsystem misconfigurations | 11 | 7 | Incorrect host mapping configuration in Zookeeper caused failure, and prevented cluster from servicing any events | 276 |
| Network congestion | 5 | 4 | A spike in wide-area traffic caused unusually low data transfer rates between city1 and city2 | 725 |
| Network-level misconfigurations | 18 | 10 | Instances in a region are pointing to a NAT instance with incorrectly configured security groups, leading to dropped traffic | 92 |
| Subsystem/Source-code bugs | 31 | 22 | Service returning 5xx errors due to a code change that added a condition on the availability of a parent asset ID | 1607 |
| Incorrect data exchange | 26 | 16 | 4xx errors were being raised because the noise classifier service is sending additional data with each stock request | 417 |
| One-off or unknown | 10 | 8 | 278 customer accounts were inadvertently canceled for unknown reason | 464 |
To understand the operation and limitations of debugging tools and workflows in production distributed systems, we conducted a study at a major SaaS company (Anon). Our analysis involved 7 services at Anon that collectively handle 83 million user requests per day. Across these services, we examined the debugging process through a developer survey and a manual analysis of completed debugging tickets over a 4-month time period. To develop a general taxonomy for our analysis of Anon’s data, we start with a literature survey of publicly reported bugs in production distributed systems.
2.1. Literature Survey
We surveyed many recent papers and blog posts that document or measure bugs in production settings. Our survey includes major outages in large-scale services (e.g., Dropbox (dro, [n. d.]), Kubernetes (kub, [n. d.])), bugs in cloud services (e.g., Google (Sigelman et al., 2010), Facebook (Kaldor et al., 2017), Azure (Liu et al., 2019)), and experiences with open source systems (e.g., Cassandra, HDFS (Yuan et al., 2014)). Our survey revealed the following bug categories:
-
(1)
System software and configuration faults.
-
Subsystem misconfigurations (Yuan et al., 2014; fac, [n. d.]; Liu et al., 2019): Errors in the internal configuration files for a given subsystem are common, especially given complex interoperation with other subsystems. Examples include incorrect hostname mappings that result in improper traffic routing and poorly configured values for timeouts or maximum connection limits (Liu et al., 2019).
-
(2)
Network faults.
-
Network congestion (Kaldor et al., 2017): Within data centers (Kaldor et al., 2017), queues build up at various network locations (e.g., virtual and physical switches) that connect subsystems, either due to temporarily increased application traffic (e.g., TCP incast (Chen et al., 2009)) or cross traffic.
-
Incorrect network configuration (Kaldor et al., 2017; Yuan et al., 2014; fac, [n. d.]): Network devices (e.g., firewalls, NATs, switches) between subsystems that communicate via RPCs may be incorrectly configured with forward/drop rules. This could cause unintended forwarding of packets to a destination or incorrect packet dropping.
-
-
(3)
Application logic faults.
-
Bugs within subsystems (Sigelman et al., 2010; Qin et al., 2005; Lu et al., 2008; Arora et al., 2018; Lu et al., 2005; ins, [n. d.]; kub, [n. d.]): Bugs in application logic are prevalent in practice (Netravali and Mickens, 2019; Abuzaid et al., 2018), and can result in a wide range of system effects. For example, certain bugs arise from (accidentally) inverted branch conditions that trigger seemingly inconsistent behavior: an application may traverse an incorrect branch and display incorrect content or result in a program error. In contrast, certain code changes can trigger performance degradations, e.g., if unnecessary RPC calls are generated between microservices.
-
Incorrect data exchange formats and values (Liu et al., 2019): Particularly in microservice settings as in Azure services (Liu et al., 2019), bugs can arise if the RPC formats of the sender and receiver do not match. For instance, a change in the API exposed by one microservice could result in a bug if its callers are unaware of this change. Also included in this category are certificate or credential updates that have only been partially distributed (resulting in access control errors).
-
2.2. Analysis of Debugging at Anon
Debugging workflow. Developers at Anon use a variety of state-of-the-art monitoring tools (e.g., Splunk (spl, [n. d.]), Datadog (dat, [n. d.]a), others (lig, [n. d.]; new, [n. d.]; pin, [n. d.]; ici, [n. d.])) that continuously analyze system logs, visualize that data with dashboards, and raise alerts when anomalous or potentially buggy behavior is detected. These tools raise alerts based on either manually-specified heuristics and thresholds, or standard statistical analysis techniques that compare recent data to historical baselines (e.g., for outlier detection) (lig, [n. d.]; Taylor and Letham, 2018; Xu et al., 2018; twi, [n. d.]). As user- or internally-generated reports are filed, the burden of debugging falls largely to developers. For each report, developers must (1) filter through the raised alerts (across subsystems) to determine which are worth investigating and pertain to actual bugs and the issue at hand (vs. false positives), and (2) for bugs, find the root cause. Both steps involve iteratively analyzing low-level system logs, inspecting prior debugging tickets and the current report (both written in natural language), and issuing debugging queries (using query interfaces that run atop the same logs used to raise alerts (gra, [n. d.]; Narayana et al., 2017)). Once a root cause is identified, a summary of the issue, bug, and debugging process (e.g., investigated subsystems, issued queries) is documented as a completed debugging ticket.
Analysis of historical debugging tickets. We manually analyzed all 176 debugging tickets that were created for the aforementioned services between November 2019 and February 2020. Our analysis involved manually clustering the tickets according to their root causes (as documented by Anon developers). We selected clusters based on the fault categories extracted from our literature survey (§2.1); tickets that did not fall into one of these categories were placed in a “One-off or unknown” category. Table 1 summarizes our findings, from which we make three primary observations:
-
(1)
There exists a small number of recurring categories of root causes that collectively represent the vast majority (94%) of bugs.
-
(2)
The faults in a given category often manifest at different locations in the distributed system. For example, numerous “Resource underprovisioning” tickets involve high CPU loads but pertain to different servers, e.g., gateway servers vs. storage servers for popular data shards.
-
(3)
Identifying the root cause for a fault is time consuming, taking an average of 8.5 hours (min: 14 min, max: 2.9 days) across fault categories. We found that these lengthy durations are largely a result of the error-prone nature of root cause analysis: developers at Anon must explore multiple subsystems (5 on avg.) and issue many debugging queries (8 on avg.) to find the root cause of a problem. Note that these debugging times are high even though most faults fall into recurring categories.
Takeaways. Our findings at Anon collectively show that, while debugging tools have considerably improved (primarily for improved alert-raising and richer query interfaces), post-alert debugging, or moving from alerts to root causes of faults, is largely manual and extremely time consuming. These difficulties illustrate that existing monitoring tools and anomaly detectors commonly fail to elucidate the root cause of the problem, and still require much developer effort. The focus of this paper is on automating the post-alert process for developers, i.e., ingesting diverse system logs and natural language reports, and outputting debugging queries that highlight the root cause. To the best of our knowledge, there does not exist a solution for automating such query generation. Further, we believe that ML is the appropriate tool as it is unclear how to design automated heuristics that incorporate such diverse data sources and output full-fledged debugging queries (as opposed to, say, scalar alert thresholds). Additionally, the repetitive nature of faults also makes debugging amenable to a machine learning approach.
Goals and non-goals. We note that our focus here is entirely on faults that fall into recurring categories—recall that such faults constitute the vast majority of faults at Anon, and despite their recurring nature, still take significant time to diagnose. Importantly, we do not target new fault categories and one-off faults that bear no similarity to prior ones, and instead leave debugging of those scenarios to future work.
3. Overview of Revelio

Informed by our findings at Anon, we now present an overview of Revelio’s ML-based strategy to debugging query generation. We start with the challenges associated with an ML approach, and then describe the intuition behind our corresponding solutions; §4 concretizes these insights by formally describing Revelio’s model.
At a high level, Revelio takes two inputs: (1) a user report filed by a system user, and (2) the system logs collected during the user’s interactions with the system. The two sources provide distinct perspectives into the state of the system when a fault occurs—the former from an external and the latter from an internal viewpoint. Further, the two data sources differ fundamentally: system logs are highly structured, accurate, and contextually close to a developer’s debugging options; user inputs are often noisy, unstructured (e.g., raw text), and abstract with respect to low-level system execution (e.g., a user may report that the system is slow to respond with no further information). As output, Revelio generates a ranked list of top-k debugging queries that are directly executable on the target debugging framework(s) (e.g., Jaeger (Uber, 2019)) and highlight the root cause of the fault.
3.1. Challenges
Revelio must overcome four key challenges to generate debugging queries. First, the model has to combine and relate diverse and seemingly disparate data inputs. Second, the output space of queries is highly structured, making it harder than standard multi-label classification where each label is independent (BakIr et al., 2007). This is because all debugging queries for a tool are drawn from the same language grammar, unlike opaque and independent labels. Third, the space of potential queries for a given input is large, requiring new techniques to scale to large distributed systems. Fourth, as per our study of production bugs (§2), the model must be able to generalize in a specific sense: if a fault occurs at one location during training and is debugged with a specific query, then, during testing, the model must predict the same query with a different parameter if the same fault occurs at a different location.
We now briefly describe how we handle each challenge before formally describing our model in §4
3.2. Solutions

Challenge 1: Diverse data. We handle diverse data sources by converting each into a vector and concatenating all vectors to form the system state vector. This has two benefits. First, each data source is normalized for downstream operations in the ML model. Second, the architecture is extensible: a new data source (e.g., crash reports) can be added by converting it into a vector (either learned or manually) that is then concatenated with the existing system state vector.
Challenge 2: Predicting queries. To generate debugging queries, which can be represented as abstract syntax trees (ASTs) in the grammar of a tool’s query language, we employ a Graph Convolutional Network to convert the AST into a query vector. A vector-based representation is easier to use with the rest of the ML model relative to richer representations such as trees. During training, given pairs of query and system vectors, we find model parameters that maximize the probability that these query vectors were predicted from these system vectors. During inference, given the ML model’s parameters, we find the query that maximizes the probability of a query vector given the system vector.
Challenge 3: Scaling to large systems. Revelio has to search over a large space of queries to output the best query in response to a given input. This search space scales with the size of the distributed system. To handle this, we exploit modularity and factorize our ML model into two cascaded components. The first uses user reports and system logs to generate query templates, which are skeleton queries for a particular subsystem with all numeric parameters left unspecified (e.g., SELECT _ FROM _). The second component then predicts the corresponding parameters using only the predicted template and system logs. This approach is motivated by two ideas. First, production faults typically involve recurring types (§2), and can thus be debugged using a small number of templates (one per fault type). Second, we assume that system logs sufficiently highlight the set of potential parameter values and the relative importance of each; as per §3.1, user reports are often abstract and rarely list parameter values (e.g., switch IDs). Modularization thus shrinks the output space of the first model, simplifying training computationally, regardless of system scale. It also shrinks the input space of the second model, making it less likely to overfit to spurious inputs, which in turn improves accuracy and generalizability.
Challenge 4: Generalizing to new fault locations. Given the scale of production systems, it is infeasible to rely on training data that captures all possible locations of a given fault category. Thus, our model should generalize to different locations for fault types seen during training. To aid with such generalization, we convert concrete switch/function ids in the system logs into abstract ids based on the rank order per feature (e.g., queue depth). This allows our models to learn the relevance of a given template or the importance of a particular subsystem based on a stable property like the subsystem’s rank on a feature rather than a volatile property (e.g., switch ID); Figure 2 illustrates the utility of this approach. For example, during template prediction, the model is able to learn about the applicability of a template to the order statistics (ord, [n. d.]) of feature values across the system, rather than to the numerical or ordinal values of these features at specific subsystems. This is important because, if a given fault occurs at two different locations (both of which warrant the same template), the order statistics of feature values may be correlated, whereas the specific value assignments definitively will not. Similarly, for parameter prediction, ordering information is more robust to the addition, deletion, or restructuring of subsystems.
4. Revelio’s ML Model
| Name | Description | Example |
| Query template | SELECT QUEUE_SIZE FROM T WHERE SWITCH_ID = _ | |
| Blanks in template | ||
| = _ in the above example | ||
| Query parameters | ||
| = switch ID | ||
| User report | “Page is loading slowly” | |
| System logs | OpenTracing and Marple logs |
To enable Revelio’s prediction capabilities, we need to induce a distribution (from data)
where is a debugging query, is a user report, and refers to the system logs (Table 2 lists the variables in our model). Once the parameters of this distribution have been learned by maximum likelihood, the distribution allows us to predict the query that maximizes . The data we require for this is a set of triples . While the above formulation seems straightforward at first glance, it involves learning a probability distribution over all possible queries and across all tools, which is extremely challenging and requires a substantial amount of data. Therefore, we instead split up each query into a query template (e.g., SELECT _ FROM _) and a set of values (to fill in the blanks). This allows us to factorize the previous distribution as:
| (1) |
To simplify our training further, we make an independence assumption on by assuming that is not likely to help predict (as described in §3.2). Thus, we have:
| (2) |
We can further factorize this into a product of distributions over values for each blank in the template :
| (3) |
where is the total number of blanks in the template.
From an inference standpoint, this means we have a 2-phase query generation process: we first generate a query template and then fill in the blanks with appropriate values using the system logs (Figure 3). We next detail how we model each of the distributions ( and ), as well as our learning and inference procedures for each.
4.1. Predicting Probabilities for Query Templates ()
Assume the user report to be in the form of raw text and to be a vector obtained by concatenating ordered vectors for each feature (Figures 9 in §A) extracted from the system logs (e.g., time-windowed average, min queueing delay). Recall from §3.2 that rank ordering per feature in enables our model to learn about the order statistics of feature values across subsystems, rather than about numerical or ordinal values at specific subsystems (Figure 2). From here, a straightforward way of modeling would be to use a multi-label classifier with each template being a different label. However, as discussed in §3, query templates are structured and made up of smaller atomic components (e.g., IF, MAX, MEAN statements). In other words, the ASTs of many query templates share common subtrees. Therefore, simply treating each template as an independent output label is wasteful in terms of not sharing statistical strength.
Therefore, we adopt a different approach to modeling the output templates. In order to preserve the structural aspects in queries, we represent each template in the form of an abstract syntax tree (AST). Each node in the tree is an operator (e.g., SELECT) and the edges represent how the operators are composed together to form larger trees.
We use a Graph Convolutional Network (GCN) (Kipf and Welling, 2016) to construct a vector representation for each query template’s abstract syntax tree. The GCN updates each node’s vector representation in the AST by pooling information from all its neighbors and performs this process multiple times, allowing it to combine information from all nodes in the tree. The GCN outputs a vector for each node in the tree – we take the vector of the root node to represent the tree’s information. In parallel, we use a contextual text encoder (BERT) (Devlin et al., 2018) to convert the issue report into a vector and pass the log through a linear neural network layer to get a vector . and are concatenated and fed through a non-linear layer followed by a linear layer to get a single vector representing the system state from both internal and external viewpoints. Finally, we use both and to obtain a measure for how likely the template is applicable to the debugging scenario (i.e., the probability of given and ). We then search for a set of neural network parameters that maximize this score (S) or likelihood. The sequence of operations are summarized as:
where represents a concatenation of two or more vectors and represents indexing the output of the GCN to get the vector of the root node.
All of the above operations represent a continuous flow of information through a single deep neural network whose parameters can be trained through back-propagation and stochastic gradient descent (Goodfellow et al., 2016). We use the following maximization objective to learn the parameters:
| (4) |
Enumerating all trees is intractable, so we employ Noise Contrastive Estimation (NCE) (Gutmann and Hyvärinen, 2010) and draw negative samples to form each to approximate the objective.
4.2. Predicting Values to Fill Query Templates ()
Now that we have a method to pick a template , we need to fill in the values for each blank in .222For ease of exposition, we will assume filling in a single value, but our method can easily be used to fill in multiple values, one at a time. Each template implicitly specifies the type of subsystem (e.g., switches for a Marple query) that is relevant for the fault at hand. Thus, using the template, we first extract a list of all relevant subsystems from the system logs . For each subsystem in this list, we have a feature vector which summarizes all of its logs (e.g., avg/max queue depth, packet count; see Table 4 for a full list). We also include ranking information for each feature in (e.g., ’s rank in queue depth across all switches). Note that ranks embed the same information as ordering from §4.1; ordering is not possible here because each pertains to only a single subsystem. We use these features, along with a vector representation of the blank in the template (described below), to pick the most likely subsystem for the blank.
We feed the template (represented as an AST) through the same GCN module as in §4.1 and choose the vector representation for blank to be the output vector of its corresponding node in the tree. This allows us to represent the requirements of using the properties of its neighboring nodes in the AST. Our goal is to then pick the most suitable subsystem for the blank, and return the corresponding system identifier (e.g., IP address or port number). We use a similar set of operations to those in §4.1 to pick the most likely to fill :
where indicates the rank of subsystem in its subsystem’s logs , based on the feature of interest (e.g., rank of a switch, across all switches, based on mean queue depth). We then use an objective similar to Eq. 4 to maximize over ground truth data and learn the model parameters .
4.3. Choosing the Final Queries
Once each of the two models above have been trained, during inference, we find the combination of query template and query parameters that maximizes the probability that the resulting query would result from the given system state vector. This probability in turn is the product of the two probabilities predicted by each of our models and above.
| (5) |
We can also pick the top most relevant queries, rather than just the single most relevant one, using the ranking produced by the probabilities above. If proves to be very large, we can approximate the above computation by considering only the top few templates according to .
4.4. Implementation details
For all FFN layers in our ranking model, we use two linear layers, each with hidden size 300, along with ReLU non-linearity. The GCN also uses a hidden vector size of 300. We use the Adam optimizer (Kingma and Ba, 2014) with a learning rate of 0.0001.
5. Systems Debugging Testbed
Developing and testing Revelio requires access to an operational distributed systems environment with source code, application data, debugging data, and integrated debugging tools. Industrial systems satisfy these requirements and have large amounts of debugging data internally (fbd, [n. d.]; tic, [n. d.]). Unfortunately, to the best of our knowledge, no such environment exists for public use. While we were able to analyze debugging reports at Anon (§2), we could not access raw system logs, precluding the use of Revelio at Anon.
In this section, we describe the testbed (Figure 4) that we developed to fill this void. Our current implementation integrates multiple features to mimic realistic debugging cases. In particular, it incorporates three open-source distributed applications (red, 2016; Weaveworks, 2017; Google, 2019), four state-of-the-art systems and network debugging tools (OpenTracing, 2019; Narayana et al., 2017), and an automatic fault injection service to generate production-like debugging scenarios. Remote users can interact with the applications in our testbed using a web browser and report any performance or correctness issues they observe. The setup is structured to be compatible with most distributed applications, and can be easily extended to incorporate new tools (Kaldor et al., 2017; Fonseca et al., 2007; app, [n. d.]).

5.1. Single-Machine Emulation of Distributed Apps
Overview of applications. Our current testbed implementation considers three different distributed web applications, which involve both monolithic and microservice-based architectures: Reddit (red, 2016) (monolithic), Sock Shop (Weaveworks, 2017) (microservice-based), and Online Boutique (Google, 2019) (microservice-based). For each application, we use the publicly available source code that was provided by the corresponding industrial organization and is intended to capture the technologies and architectures that they employ in their production services. §A.1.1 provides additional details.
Our goal is to run each application in a distributed and controlled manner, in order to scale to large workloads and deployments, consider broad sets of realistic distributed debugging faults, and ultimately generate complete debugging datasets for Revelio.
One approach would be to run each application service on VM instances in the public cloud. However, public cloud offerings typically hide inter-instance network components (e.g., switches, firewalls) from users, precluding the use of in-network debugging tools (§8).
Instead, we opt for a local emulation approach in which we run each application subsystem (or service) in a different container on the same physical machine, and specify the network infrastructure and connectivity between them. To do this, we use Containernet (Peuster et al., 2016), an extension of Mininet (Lantz et al., 2010) that can coordinate Docker (doc, 2019) containers, each running on a dedicated core; we assign a separate core for network operation (i.e., P4 switch simulation). Our testbed can be scaled up to support higher throughput by making use of additional physical machines through distributed emulation (max, [n. d.]).
As illustrated in Figure 4, for each application, we configure its subsystem/service containers into a star topology.
At the center of the topology is a router which is responsible for layer 3 faults (e.g., firewall configuration errors). Each subsystem is connected to this router via two P4 programmable switches (Bosshart et al., 2014) using Mininet. We set routing rules to ensure that all subsystems are appropriately reachable. Finally, for external reachability, a NAT is used to connect the central router to the host machine’s Internet-reachable interface.
5.2. Integrating Debugging Tools
We integrate four debugging tools into our setup:
-
Marple (Narayana et al., 2017) is a performance query language for network monitoring that uses SQL-like constructs (e.g., groupby, filter) to support queries that track 1) per-packet and per-switch queuing delays, and 2) user-defined aggregation functions across packets.
-
tcpdump (tcp, 2019) is an end-host network stack inspector which analyzes all packets flowing through the host’s network interfaces, and supports querying in the form of packet content filtering (e.g., by hostname, checksum).
-
Uber’s Jaeger (Uber, 2019) is an end-to-end distributed systems tracing system which follows the OpenTracing specification (OpenTracing, 2019). With Jaeger, developers embed tracepoints directly into their system source code to log custom state (e.g., variable values), and then aggregate tracepoint and timing information to understand how data values and control state flow across time and subsystems.
-
Google’s cAdvisor (Google, 2019) profiles the resource utilization of individual containers, logging the following every 1 second: instantaneous CPU usage, memory usage, disk read/write throughput, and cumulative number of page faults.
§A.1.2 presents more details regarding the integration and usage of each tool. We note that these tools represent only part of the state-of-the-art for network and distributed systems monitoring; our setup is amenable to others (Kaldor et al., 2017; Fonseca et al., 2007; app, [n. d.]).
5.3. Fault Injection Service
To create debugging data from realistic debugging scenarios, we created an automatic fault injection service. We note that our goal is not necessarily to match the system scale at which production faults were reported, but instead to evoke the user reports, system log patterns, and queries that correspond to the reported fault categories.
Our service is guided by our literature survey of production faults and our findings at Anon (§2). Specifically, we incorporate faults that cover all of the categories discussed in §2, and match the ratios across categories with the data from Anon (Table 1). These categories cover the observable performance (i.e., increased system response times) and functionality (i.e., missing or inconsistent page content, crashes) issues for the applications we consider. Table 10 (in §A) provides more detailed examples of the specific faults we inject. We note that our service can be easily extended to incorporate new bug types.
Injecting faults: Our fault injector operates differently per fault class. For network or system configuration faults, we use Mininet and Docker commands to bring down a subsystem, start a congestion generator, change a service’s provisioned resource values, or inject a firewall/routing rule at the router. In contrast, application logic faults require modified source code. In each container pertaining to an application’s service logic, we include a script that takes in a fault instruction and replaces the appropriate source code with a version embedding the fault, and restarts the application.
6. Evaluation
6.1. Data Collection
| Metric | Sock Shop | Online Boutique | |
|---|---|---|---|
| # of Unique Faults | 76 | 102 | 80 |
| # of Unique Queries | 118 | 320 | 269 |
| Query Vocabulary Size | 60 | 136 | 122 |
| Report Vocabulary Size | 1040 | 1327 | 1258 |
To extract system logs, user reports, and debugging queries from our testbed (§5), we conducted a large-scale data collection experiment on Amazon Mechanical Turk. For each application, we set up an EC2 instance per fault that we consider (Table 3). Each instance runs the entire testbed for that application, with the associated fault injected into it. All instances for an application were populated with the same content, which was generated using an application-provided script, e.g., Reddit content was scraped from the live site.
Our experiment supported only “master” Turk users, and each was only allowed to participate once per fault+application pair. Each user was assigned to a specific instance/fault at random, and was presented with a UI (Figure 12 in §A) that had an iframe pointing to the corresponding instance’s frontend web server. Users were asked to perform multiple tasks within each application, including loading the homepage, clicking on item pages or user profiles, adding comments, and adding items to their carts. Prior to the experiment, users were shown representative pages for each step (to ensure familiarity with the interfaces), and told about expected bug-free load times (4-5 sec in our setup).
| Marple | Jaeger | cAdvisor |
|---|---|---|
| Packet count | # of accessed variables | CPU utilization |
| Queue depth | Duration of execution | Memory utilization |
| N/A | # of exceptions thrown | Disk throughput |
For each task, users were asked to report performance and functionality issues into a form that included both multiple choice and free-form questions. During each user’s experiment, the standard system logs for each tool in our testbed (§A.1.2) were collected on the instance; Table 4 lists the collected metrics. We condense and featurize the time-series data for each metric using standard summary statistics such as min, max, average, and median. Once a user completed the experiment, their reports were paired with the associated system logs. We allowed up to 5 concurrent users per instance, and system logs reflect the interactions of all concurrent users. To complete our dataset, for each fault, we generate a debugging query with the appropriate tool that sufficiently highlights the root cause for the fault. This query is intended to represent the result of a past (successful) debugging experience. Table 3 summarizes our dataset, and Table 9 (in §A) lists example user reports.
Methodology: We divided the dataset for each application into 53% for training, 13% for validation, and 34% for testing. We further divided our testing data into two test sets, test_generalize and test_repeat. test_generalize evaluates Revelio’s ability to generalize to new locations for previously seen fault types, and includes only data for faults that have matching query templates in the training data, but different parameters. test_repeat evaluates Revelio’s ability to suggest relevant queries for repeat faults, and includes only data for faults that have matching query templates and parameters in the training data. All presented results test the best observed model from the validation set on the test sets. We evaluate Revelio primarily using two metrics: 1) rank of the correct query (i.e., the query which most directly highlights the root cause) among the ordered list of the model’s predicted queries, and 2) top-k accuracy, which we define as the presence of the correct query in the top-k predictions.
Result presentation: Results for Online Boutique are similar to the other two applications, but omitted for space; deep-dive results (§6.3) are for Reddit, but trends hold for all three.
| Ground Truth Query | Revelio’s Top-Ranked Predicted Query |
|---|---|
| stream = filter(T, switch==3) | SELECT span FROM spans WHERE name="GET_comments" |
| result = groupby(stream, [5-tuple], count); | (This Jaeger query also helps identify the Memcache failure by |
| (This Marple query highlights the lack of network traffic to/from a (failed) Memcache instance.) | honing in on the tracepoint with the corresponding ’connection failed’ error message.) |
| SELECT * FROM cpu_usage WHERE host="mn.h1" | SELECT span FROM spans WHERE name="_byID" |
| (This cAdvisor query helps to identify that a given host | (This Jaeger query also helps highlight the host’s underprovisioned |
| is consistently running at 100% CPU utilization, and is thus underprovisioned). | CPU resources by showing the ensuing high function execution times on the host.) |
| SELECT span FROM spans WHERE name="_find_rels" | stream = filter(T, switch==1) |
| (This Jaeger query helps to identify that a bug in | result = groupby(stream, [5-tuple], count); |
| a function is resulting in no queries being issued to a MongoDB database.) | (This Marple query shows the lack of network traffic between the host of a buggy function and the database.) |

6.2. Evaluating Revelio’s Queries
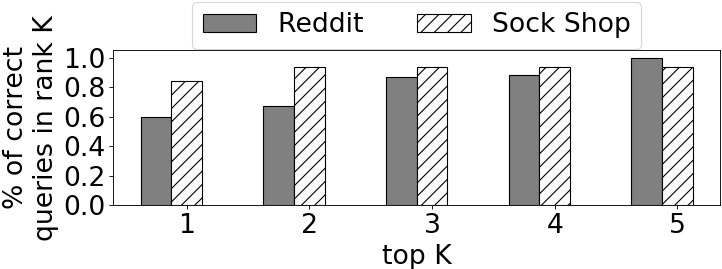
Repeat faults. For each fault in test_repeat, we measured the rank of the correct query in Revelio’s predictions. As shown in Figure 5, for 80% of the test samples for Reddit, Revelio assigns a rank of 1 to the correct query. Further, for 96% of the Reddit test cases, the correct query is within the top 3 predicted queries. Performance is similar for Sock Shop, with the correct query being in the top 3 100% of the time.
Generalizing to new fault locations. Figure 6 shows results for the more challenging scenario of new fault locations for repeat fault types (i.e., test_generalize). As shown, Revelio is still able to consistently predict the correct query: Revelio’s model assigns a rank of 1 to the correct query 60% and 85% of the time for Reddit and Sock Shop. For both applications, the correct query was always in the top-5 predictions.
Benefits of query sequences: To gain further insights into Revelio’s predicted queries, we analyzed scenarios in which the correct query was not ranked as 1. We find that in these cases, despite not matching the ground truth, Revelio’s highly ranked queries typically relate to the fault at hand, but characterize it from different vantage points.
Table 5 lists three representative examples. For instance, the first example pertains to a fault in which the Memcache subsystem is down for Reddit. The correct query is a Marple query which tracks packet counts at the switch directly connected to the failed subsystem; this query would highlight the lack of incoming/outgoing network traffic from Memcache. However, Revelio’s top-ranked query was a Jaeger query which hones in on a tracepoint that contains an error message noting the inability to connect to Memcache.
Similarly, in the second example, a Sock Shop subsystem is not provisioned sufficient CPU resources to handle the incoming traffic. The correct query was a cAdvisor query that explicitly tracked the container’s CPU usage, but Revelio’s top-ranked query used Jaeger to track the high residual function execution times for the microservice running in that container.
In cases where Revelio’s top-ranked query is not the correct query, Revelio most often ranked the correct query as second or third. Thus, by outputting a sequence of ranked debugging queries, Revelio can provide developers with significant context about a fault from multiple vantage points.
6.3. Understanding Revelio
| Scenario | test_repeat | test_generalize |
|---|---|---|
| User report+system logs | 1.33 (100%) | 1.97 (100%) |
| Only system logs | 1.86 (100%) | 2.29 (90.2%) |
Importance of user reports: By default, Revelio’s model accepts both natural language user reports and quantitative system logs. To understand the importance of considering user reports in query generation, we evaluated a version of Revelio that excludes user reports from its input set; note that system logs cannot be excluded as they are required for parameter prediction. As shown in Table 6, Revelio significantly benefits from having access to both inputs. For example, on test_generalize, the average rank of the correct query is 1.97 and 2.29 with and without user reports, respectively.

Multi-tool vs. single-tool models: We performed another ablation study where we compare Revelio when training and testing on logs from Marple, Jaeger, cAdvisor, and tcpdump together (multi-tool model), and in isolation (single-tool model). For each isolated tool, we prune the training, validation, test_repeat, and test_generalize sets to include only faults pertaining to that tool. As shown in Figure 7, we find that the per-tool models achieve better average ranks than the combined (default) model. The reason is that focusing on one tool allows Revelio to predict templates and parameters from a smaller space. However, our results show that Revelio pays only a small cost for operating across debugging tools: the average rank in the combined model is only 33% higher than the best per-tool model for test_repeat. This is key to Revelio’s ability to alleviate the burden of determining which tool to use for a particular scenario.
Model structure: To understand the importance of Revelio’s model structure and composition (§4), we compared it with the following variants that each modified one key design choice: 1) Revelio_monolithic uses a single model (not factorized) to output a fully formed query, 2) Revelio_no_rank_order eliminates the rank ordering of features in Revelio’s template and parameter prediction models, and 3) Revelio_classifier uses a multi-label classifier to select query templates rather than employing a GCN to construct a vector representation of each template’s AST. Table 7 lists our results which highlight three main points. First, Revelio outperforms Revelio_monolithic on both test sets, highlighting the importance of factorization in terms of simplifying (both computationally and statistically) the difficult task of query prediction, particularly for generalization. Second, by rank ordering feature values, Revelio achieves an average rank of 1.97 for test_generalize; in contrast, Revelio_no_rank_order is fundamentally unable to predict templates and parameters (and thus, queries) for repeat fault types in new (i.e., unseen during training) locations. Third, Revelio’s improved performance over Revelio_classifier illustrates the importance of using a GCN to extract semantic information about query structure (which a classifier cannot).
| Model | test_repeat | test_generalize |
|---|---|---|
| Revelio | 1.33 (100%) | 1.97 (100%) |
| Revelio_monolithic | 17.5 (15.1%) | 22.4 (18.5%) |
| Revelio_no_rank_order | 1.29 (100%) | N/A |
| Revelio_classifier | 2.41 (88.7%) | 2.69 (86.9%) |
| Removed Feature | test_repeat | test_generalize |
|---|---|---|
| Packet count | 2.14 (100%) | 7.93 (80.4%) |
| Queueing delay | 2.27 (96.1%) | 2.51 (92.4%) |
| Variable count | 1.67 (96.1%) | 3.54 (71.7%) |
| Duration of execution | 7.29 (88.2%) | 4.11 (89.1%) |
| CPU utilization | 1.65 (96.1%) | 4.37 (83.7%) |
| Memory utilization | 1.75 (100%) | 2.50 (88.0%) |
System log analysis: To understand the relative importance of each metric in the system logs, we evaluated a variety of Revelio models that were trained with each log feature removed, in turn. Table 8 lists representative results. As shown, removing the per-switch packet counts from the network logs led to the largest accuracy degradation, with a drop in average rank from 1.97 to 7.93 (for test_generalize). Importantly, removing each considered feature led to marginal degradations in Revelio’s performance, highlighting their utility.
7. Developer Study
To evaluate Revelio’s ability to accelerate end-to-end root cause diagnosis, we used our testbed (§5) to conduct a developer study. Developers were presented with the testbed’s tools and logs, both with and without Revelio, and were tasked with diagnosing the root cause of multiple high-level user reports. In summary, developers with access to Revelio were able to correctly identify 90% of the root causes (compared to 60% without Revelio), and did so 72% faster.
7.1. Study setup
Our study involved 20 PhD students and postdoctoral researchers in systems and networking. All participants brought their own laptops, but debugging tasks were performed inside a provided VM for uniformity. Prior to the study, the authors delivered a 5-hour tutorial explaining the testbed and Sock Shop UI/code base; the study only involved Sock Shop to ease the developers’ ability to become intimately familiar with the application to debug. For each tool (Marple, Jaeger, cAdvisor, tcpdump, Revelio), we described its logs, query language, and interface. Developers were given 1 hour to experiment with the testbed and resolve any questions.
During the study, developers were presented with a series of six debugging scenarios: 2 in-network faults for routing errors and congestion (targeting Marple), 2 system configuration faults for resource underprovisioning and component failures (targeting cAdvisor), and 2 application logic faults for branch condition and RPC errors (targeting Jaeger); we exclude end-host network faults due to time constraints. For each fault type, developers were randomly assigned to debug one fault using only the testbed’s tools, and one also using Revelio. Ordering of the faults and tool assignments was randomized across participants to ensure a fair comparison.
For each fault, developers were presented with 1) a user report, 2) system logs for all testbed tools collected during the faulty run, and 3) the faulty testbed code. Developers were given 30 mins to diagnose each fault and provide a short qualitative description of the root cause. For example, a routing configuration error that disconnected Cassandra could be successfully reported as “Cassandra could not receive any network packets, leading to missing page content.” When a developer believed she had found the root cause, she informed the paper authors who verified its correctness. If incorrect, the developer was told to keep debugging until a correct diagnosis was generated, or 30 mins elapsed. Developers were unrestricted in their debugging methodologies, e.g., they were not required to use queries, though most did. Without Revelio, developers had to generate any query they wished to issue on their own; with Revelio, developers could generate queries or use the 5 suggested by Revelio.
7.2. Revelio’s impact on root cause diagnosis

The results of our developer study were promising and suggest that Revelio can be an effective addition to state-of-the-art debugging frameworks in terms of accelerating root cause diagnosis. Across all of the faults, Revelio increased the fraction of developers who could correctly diagnose the faults within the given time frame from 60% to 90%. Further, as shown in Figure 8, Revelio sped up the average root cause diagnosis time by 72% (14 minutes) in cases where the developers were able to report the correct root cause.
After the study, we asked each developer qualitative questions about their experience with Revelio.
The most commonly reported benefit of Revelio was in shrinking the set of tools and queries that a developer had to consider. The primary gripe was with respect to Revelio’s UI, which is admittedly unpolished. Most importantly, the response to ”Would you prefer to use existing systems and networking debugging tools with Revelio?”, was “yes” for all 20 participants.
8. Related Work
We discuss the most closely related approaches here, and present additional related work (e.g., for triaging) in §A.2.
8.1. Debugging Tools for Distributed Systems
There exist dozens of powerful data logging and querying tools for distributed systems (Mace et al., 2015; Scott et al., 2016; Uber, 2019; Sigelman et al., 2010; Mace and Fonseca, 2018; Fonseca et al., 2007; Kaldor et al., 2017), networks (Handigol et al., 2014; Narayana et al., 2016, 2017; Scott et al., 2014; Moshref et al., [n. d.]; Tammana et al., 2015, 2016; tcp, 2019), and end-host stacks (gdb, 2018; Alpern et al., 2000; Netravali and Mickens, 2019; Feldman and Brown, 1988; Ko and Myers, 2008; Lienhard et al., 2008; Viennot et al., 2013; Agrawal et al., 1991; Gyimóthy et al., 1999; Korel and Laski, 1988; Netravali et al., 2016). Although each tool provides powerful data logging and querying capabilities from different vantage points, two limitations exist. First, these tools are not coordinated and lack context about system-wide debugging. Thus, the cognitive burden of deciding which tools to use, when, and how (e.g., parameters) falls on developers. Revelio interoperates with these tools and alleviates this burden by automatically predicting helpful debugging queries. Second, these tools ignore natural language inputs, including user reports characterizing external behavior. Our results (§6) and prior work (Potharaju et al., 2013; Govindan et al., 2016) show that these inputs can be a rich source of debugging insights.
8.2. Leveraging Natural Language Data Sources
Program debugging: NetSieve (Potharaju et al., 2013) uses NLP to parse network tickets by generating a list of keywords and using a domain-specific ontology model to extract ticket summaries from those keywords; summaries highlight potential problems and fixes. While NetSieve automates parsing, much manual effort is still required in (1) offline construction of an ontology model, and (2) determining what constitutes a keyword. In contrast, Revelio’s models learn automatically from data, with minimal manual effort, and generate queries for root cause diagnosis rather than potential fixes from a restricted set of actions. Net2Text (Birkner et al., [n. d.]) translates English queries into SQL queries, issues those queries, summarizes the results, and translates them back into natural language for easy interpretation. Revelio, on the other hand, ingests high-level user issues and system logs; the unstructured and abstract nature of this input makes Revelio’s problem harder than Net2Text’s.
Program analysis and synthesis: NLP techniques have been utilized in multiple aspects of software development (Ernst, 2017). Examples include detecting operations with incompatible variable types (Haq et al., 2015) and converting natural language comments into assertions (Goffi et al., 2016). More recently, NLP has also been used in code generation by converting developer-specified requirements in natural language to structured output in the forms of regular expressions (Locascio et al., 2016), Bash programs (Lin et al., 2018), API sequences (Gu et al., 2016), and queries in domain specific languages (Desai et al., 2016). Though these projects show the potential to extract meaning from natural language debugging data, they are limited to ingesting a single stream of data from a single subsystem. In contrast, Revelio combines and extracts meaning from varied input forms to construct structured debugging queries.
9. Conclusion
Revelio employs ML to generate debugging queries from system logs and user reports to help developers find a problem’s root cause faster. Much work remains before this general vision of an ML-enhanced debugging assistant for distributed systems is ready for production use. Notably, Revelio must present a uniform interface to all debugging tools (Figure 1) and learn from logs, reports, and queries in online fashion. Further, Revelio needs to be deployed in a live environment and evaluated with real faults.
Despite this, Revelio makes significant progress towards live deployment.
In particular, we learned:
(1) a (modularized) pipeline of simple ML models is preferable to a single monolithic and complex model, (2) state-of-the-art NLP techniques such as BERT (Devlin et al., 2018) trained on news corpora can discern useful patterns from user reports, (3) GCNs serve as a universal translation layer to convert diverse query formats (e.g., Marple, Jaeger) into a common vector representation, (4) a uniform use of vector representations leads to an extensible architecture that allows easily incorporating new and diverse data sources, and (5) abstraction by ranking improves generalizability and scaling.
References
- (1)
- fac ([n. d.]) After almost 24 hours of technical difficulties, Facebook is back - Vox. https://www.vox.com/2019/3/14/18265793/facebook-app-down-outage-resolved-fixed.
- app ([n. d.]) AppDynamics Query Language - ALY310 — University — AppDynamics. https://learn.appdynamics.com/courses/appdynamics-query-language-aly310.
- bpf ([n. d.]) Berkeley Packet Filter - Wikipedia. https://en.wikipedia.org/wiki/Berkeley˙Packet˙Filter.
- dat ([n. d.]a) Cloud Monitoring as a Service — Datadog. https://www.datadoghq.com/.
- fbd ([n. d.]) Debugging Microservices: Lessons from Google, Facebook, Lyft. https://bit.ly/2tBS9By.
- grp ([n. d.]) envoy: an open source edge and service proxy, designed for cloud-native applications. https://www.envoyproxy.io/.
- gra ([n. d.]) Grafana Features — Grafana Labs. https://grafana.com/grafana/.
- env ([n. d.]) gRPC: A high performance, open-source universal RPC framework. https://redis.io/.
- ici ([n. d.]) Inspect your Entire Infrastructure. https://icinga.com/.
- ins ([n. d.]) Instapaper Outage Cause & Recovery. https://medium.com/making-instapaper/instapaper-outage-cause-recovery-3c32a7e9cc5f.
- twi ([n. d.]) Introducing practical and robust anomaly detection in a time series. https://blog.twitter.com/engineering/en˙us/a/2015/introducing-practical-and-robust-anomaly-detection-in-a-time-series.html.
- dro ([n. d.]) Kelsey Fix shares the story behind Dropbox’s largest outage ever. https://bit.ly/2S6p8az.
- apa ([n. d.]) Log Files - Apache HTTP Server. https://httpd.apache.org/docs/1.3/logs.html.
- max ([n. d.]) MaxiNet: Distributed Emulation of Software-Defined Networks. https://maxinet.github.io/.
- mys ([n. d.]) MySQL. https://www.mysql.com/.
- new ([n. d.]) New Relic — Deliver more perfect software. https://newrelic.com/.
- ord ([n. d.]) Order Statistic - Wikipedia. https://en.wikipedia.org/wiki/Order˙statistic.
- kub ([n. d.]) Our First Kubernetes Outage — Saltside Engineering. https://engineering.saltside.se/our-first-kubernetes-outage-c6b9249cfd3a.
- bas ([n. d.]) Postmortem on the read-only outage of Basecamp on November 9th, 2018. https://bit.ly/2S9pq0t.
- red ([n. d.]) Redis. https://redis.io/.
- spl ([n. d.]) SIEM, AIOps, Application Management, Log Management, Machine Learning, and Compliance — Splunk. https://www.splunk.com/.
- lig ([n. d.]) Simple Observability for Deep Systems. https://lightstep.com/.
- tic ([n. d.]) Ticketmaster Traces 100 Million Transactions per Day with Jaeger. https://bit.ly/39rTn1N.
- dat ([n. d.]b) View the SQL Server error log. https://bit.ly/372a9Tm.
- pin ([n. d.]) Website Performance and Availability Monitoring — Pingdom. https://www.pingdom.com/.
- cas (2016) Apache Cassandra. http://cassandra.apache.org/.
- red (2016) reddit. https://github.com/reddit/reddit.
- gdb (2018) GDB: The GNU Project Debugger. https://www.gnu.org/software/gdb/.
- app (2019) Application Performance Monitoring & Management — AppDynamics. https://appdynamics.com/.
- doc (2019) Enterprise Container Platform — Docker. https://docker.com/.
- hap (2019) HAProxy: The Reliable, High Performance TCP/HTTP Load Balancer. http://www.haproxy.org/.
- int (2019) INT-current-spec. https://p4.org/assets/INT-current-spec.pdf.
- rab (2019) Messaging that just works – RabbitMQ. https://www.rabbitmq.com/.
- zip (2019) OpenZipkin A distributed tracing system. https://zipkin.io/.
- pos (2019) PostgreSQL. https://www.postgresql.org/.
- pyl (2019) Pylons. http://www.pylonsproject.org/.
- str (2019) strace. https://strace.io/.
- tcp (2019) TCPDUMP/LIBPCAP public repository. https://www.tcpdump.org/.
- Abuzaid et al. (2018) Firas Abuzaid, Peter Kraft, Sahaana Suri, Edward Gan, Eric Xu, Atul Shenoy, Asvin Ananthanarayan, John Sheu, Erik Meijer, Xi Wu, and et al. 2018. DIFF: A Relational Interface for Large-Scale Data Explanation. Proc. VLDB Endow. 12, 4 (Dec. 2018), 419–432. https://doi.org/10.14778/3297753.3297761
- Agrawal et al. (1991) Hiralal Agrawal, Richard A. DeMillo, and Eugene H. Spafford. 1991. Dynamic Slicing in the Presence of Unconstrained Pointers. In Proceedings of the Symposium on Testing, Analysis, and Verification (TAV4). ACM.
- Alon et al. (2019) Uri Alon, Meital Zilberstein, Omer Levy, and Eran Yahav. 2019. code2vec: Learning distributed representations of code. Proceedings of the ACM on Programming Languages 3, POPL (2019), 1–29.
- Alpern et al. (2000) Bowen Alpern, Ton Ngo, Jong-Deok Choi, and Manu Sridharan. 2000. DejaVu: Deterministic Java Replay Debugger for JalapeÑO Java Virtual Machine. In Proceedings of OOPSLA. ACM.
- Appel (1998) Andrew W. Appel. 1998. SSA is Functional Programming. SIGPLAN Not. 33, 4 (April 1998), 17–20.
- Arora et al. (2018) Nipun Arora, Jonathan Bell, Franjo Ivančiundefined, Gail Kaiser, and Baishakhi Ray. 2018. Replay without Recording of Production Bugs for Service Oriented Applications. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering (ASE 2018). Association for Computing Machinery, New York, NY, USA, 452–463. https://doi.org/10.1145/3238147.3238186
- BakIr et al. (2007) Gökhan BakIr, Thomas Hofmann, Bernhard Schölkopf, Alexander J Smola, and Ben Taskar. 2007. Predicting structured data. MIT press.
- Birkner et al. ([n. d.]) Rüdiger Birkner, Dana Drachsler-Cohen, Laurent Vanbever, and Martin T. Vechev. [n. d.]. Net2Text: Query-Guided Summarization of Network Forwarding Behaviors.
- Bosshart et al. (2014) Pat Bosshart, Dan Daly, Glen Gibb, Martin Izzard, Nick McKeown, Jennifer Rexford, Cole Schlesinger, Dan Talayco, Amin Vahdat, George Varghese, et al. 2014. P4: Programming protocol-independent packet processors. ACM SIGCOMM Computer Communication Review 44, 3 (2014), 87–95.
- Case et al. (1990) Simple Network Management Protocol (SNMP).
- Chen et al. (2019) Junjie Chen, Xiaoting He, Qingwei Lin, Hongyu Zhang, Dan Hao, Feng Gao, Zhangwei Xu, Yingnong Dang, and Dongmei Zhang. 2019. Continuous Incident Triage for Large-Scale Online Service Systems. In Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE ’19). IEEE Press, 364–375. https://doi.org/10.1109/ASE.2019.00042
- Chen et al. (2009) Yanpei Chen, Rean Griffith, Junda Liu, Randy H. Katz, and Anthony D. Joseph. 2009. Understanding TCP Incast Throughput Collapse in Datacenter Networks. In Proceedings of the 1st ACM Workshop on Research on Enterprise Networking (WREN ’09). ACM, 73–82.
- Desai et al. (2016) Aditya Desai, Sumit Gulwani, Vineet Hingorani, Nidhi Jain, Amey Karkare, Mark Marron, Sailesh R, and Subhajit Roy. 2016. Program Synthesis Using Natural Language. In Proceedings of the 38th International Conference on Software Engineering (ICSE). ACM.
- Devlin et al. (2018) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:cs.CL/1810.04805
- Dormando (2015) Memcached-a distributed memory object caching system. https://memcached.org/.
- Ernst (2017) Michael D. Ernst. 2017. Natural Language is a Programming Language: Applying Natural Language Processing to Software Development. In 2nd Summit on Advances in Programming Languages, SNAPL 2017, May 7-10, 2017, Asilomar, CA, USA. 4:1–4:14.
- Feldman and Brown (1988) Stuart I. Feldman and Channing B. Brown. 1988. IGOR: A System for Program Debugging via Reversible Execution. In Proceedings of the 1988 ACM SIGPLAN and SIGOPS Workshop on Parallel and Distributed Debugging (PADD). ACM.
- Fonseca et al. (2007) Rodrigo Fonseca, George Porter, Randy H. Katz, Scott Shenker, and Ion Stoica. 2007. X-trace: A Pervasive Network Tracing Framework. In Proceedings of the 4th USENIX Conference on Networked Systems Design & Implementation (NSDI). USENIX Association.
- Goffi et al. (2016) Alberto Goffi, Alessandra Gorla, Michael D. Ernst, and Mauro Pezzè. 2016. Automatic Generation of Oracles for Exceptional Behaviors. In Proceedings of the 25th International Symposium on Software Testing and Analysis (ISSTA 2016). ACM.
- Goodfellow et al. (2016) Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 2016. Deep learning. MIT press.
- Google (2019) cAdvisor. https://github.com/google/cadvisor.
- Google (2019) Online Boutique: Sample cloud-native application with 10 microservices showcasing Kubernetes, Istio, gRPC and OpenCensus. https://github.com/GoogleCloudPlatform/microservices-demo.
- Govindan et al. (2016) Ramesh Govindan, Ina Minei, Mahesh Kallahalla, Bikash Koley, and Amin Vahdat. 2016. Evolve or Die: High-Availability Design Principles Drawn from Googles Network Infrastructure. In Proceedings of the 2016 ACM SIGCOMM Conference (SIGCOMM). ACM.
- Gu et al. (2016) Xiaodong Gu, Hongyu Zhang, Dongmei Zhang, and Sunghun Kim. 2016. Deep API learning. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. ACM, 631–642.
- Gutmann and Hyvärinen (2010) Michael Gutmann and Aapo Hyvärinen. 2010. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. 297–304.
- Gyimóthy et al. (1999) Tibor Gyimóthy, Árpád Beszédes, and Istán Forgács. 1999. An Efficient Relevant Slicing Method for Debugging. In Proceedings of the 7th European Software Engineering Conference Held Jointly with the 7th ACM SIGSOFT International Symposium on Foundations of Software Engineering (ESEC/FSE-7). Springer-Verlag, London, UK, UK.
- Handigol et al. (2014) Nikhil Handigol, Brandon Heller, Vimalkumar Jeyakumar, David Mazières, and Nick McKeown. 2014. I Know What Your Packet Did Last Hop: Using Packet Histories to Troubleshoot Networks. In Proceedings of the 11th USENIX Conference on Networked Systems Design and Implementation (NSDI). USENIX Association.
- Haq et al. (2015) Irfan Ul Haq, Juan Caballero, and Michael D. Ernst. 2015. Ayudante: Identifying Undesired Variable Interactions. In Proceedings of the 13th International Workshop on Dynamic Analysis (WODA 2015). ACM.
- Inc. (2019) mongoDB: The database for modern applications. https://www.mongodb.com/.
- Kaldor et al. (2017) Jonathan Kaldor, Jonathan Mace, Michal Bejda, Edison Gao, Wiktor Kuropatwa, Joe O’Neill, Kian Win Ong, Bill Schaller, Pingjia Shan, Brendan Viscomi, Vinod Venkataraman, Kaushik Veeraraghavan, and Yee Jiun Song. 2017. Canopy: An End-to-End Performance Tracing And Analysis System. In Proceedings of the 26th Symposium on Operating Systems Principles (SOSP). ACM.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
- Kipf and Welling (2016) Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016).
- Ko and Myers (2008) Andrew J. Ko and Brad A. Myers. 2008. Debugging Reinvented: Asking and Answering Why and Why Not Questions About Program Behavior. In Proceedings of the 30th International Conference on Software Engineering (ICSE). ACM.
- Korel and Laski (1988) Bogdan Korel and Janusz Laski. 1988. Dynamic program slicing. Information processing letters 29, 3 (1988), 155–163.
- Lantz et al. (2010) Bob Lantz, Brandon Heller, and Nick McKeown. 2010. A Network in a Laptop: Rapid Prototyping for Software-defined Networks. In Proceedings of the 9th ACM SIGCOMM Workshop on Hot Topics in Networks (Hotnets-IX). ACM.
- Lienhard et al. (2008) Adrian Lienhard, Tudor Gîrba, and Oscar Nierstrasz. 2008. Practical Object-Oriented Back-in-Time Debugging. In Proceedings of the 22Nd European Conference on Object-Oriented Programming (ECOOP). Berlin, Heidelberg.
- Lin et al. (2018) Xi Victoria Lin, Chenglong Wang, Luke Zettlemoyer, and Michael D. Ernst. 2018. NL2Bash: A Corpus and Semantic Parser for Natural Language Interface to the Linux Operating System. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, LREC 2018, Miyazaki, Japan, May 7-12, 2018.
- Liu et al. (2019) Haopeng Liu, Shan Lu, Madan Musuvathi, and Suman Nath. 2019. What Bugs Cause Production Cloud Incidents?. In Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS ’19). Association for Computing Machinery, New York, NY, USA, 155–162. https://doi.org/10.1145/3317550.3321438
- Locascio et al. (2016) Nicholas Locascio, Karthik Narasimhan, Eduardo DeLeon, Nate Kushman, and Regina Barzilay. 2016. Neural Generation of Regular Expressions from Natural Language with Minimal Domain Knowledge. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1-4, 2016.
- Lu et al. (2005) Shan Lu, Zhenmin Li, Feng Qin, Lin Tan, Pin Zhou, and Yuanyuan Zhou. 2005. Bugbench: Benchmarks for evaluating bug detection tools. In In Workshop on the Evaluation of Software Defect Detection Tools.
- Lu et al. (2008) Shan Lu, Soyeon Park, Eunsoo Seo, and Yuanyuan Zhou. 2008. Learning from Mistakes: A Comprehensive Study on Real World Concurrency Bug Characteristics. SIGOPS Oper. Syst. Rev. 42, 2 (March 2008), 329–339. https://doi.org/10.1145/1353535.1346323
- Lyft Engineering ([n. d.]) Lyft. https://eng.lyft.com/tagged/microservices.
- Mace and Fonseca (2018) Jonathan Mace and Rodrigo Fonseca. 2018. Universal Context Propagation for Distributed System Instrumentation. In Proceedings of the Thirteenth EuroSys Conference (EuroSys). ACM.
- Mace et al. (2015) Jonathan Mace, Ryan Roelke, and Rodrigo Fonseca. 2015. Pivot Tracing: Dynamic Causal Monitoring for Distributed Systems. In Proceedings of the 25th Symposium on Operating Systems Principles (SOSP). ACM.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems. 3111–3119.
- Moshref et al. ([n. d.]) Masoud Moshref, Minlan Yu, Ramesh Govindan, and Amin Vahdat. [n. d.]. Trumpet: Timely and Precise Triggers in Data Centers. In Proceedings of the 2016 ACM SIGCOMM Conference (SIGCOMM). ACM.
- Nagaraj et al. (2012) Karthik Nagaraj, Charles Killian, and Jennifer Neville. 2012. Structured Comparative Analysis of Systems Logs to Diagnose Performance Problems. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation (NSDI’12). USENIX Association, USA, 26.
- Narayana et al. (2016) Srinivas Narayana, Mina Tashmasbi Arashloo, Jennifer Rexford, and David Walker. 2016. Compiling Path Queries. In Proceedings of the 13th Usenix Conference on Networked Systems Design and Implementation (NSDI). USENIX Association.
- Narayana et al. (2017) Srinivas Narayana, Anirudh Sivaraman, Vikram Nathan, Prateesh Goyal, Venkat Arun, Mohammad Alizadeh, Vimalkumar Jeyakumar, and Changhoon Kim. 2017. Language-Directed Hardware Design for Network Performance Monitoring. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM). ACM.
- Netravali et al. (2016) Ravi Netravali, Ameesh Goyal, James Mickens, and Hari Balakrishnan. 2016. Polaris: Faster Page Loads Using Fine-grained Dependency Tracking. In Proceedings of the 13th Usenix Conference on Networked Systems Design and Implementation (NSDI). USENIX Association.
- Netravali and Mickens (2019) Ravi Netravali and James Mickens. 2019. Reverb: Speculative Debugging for Web Applications. In Proceedings of the ACM Symposium on Cloud Computing (SoCC ’19). ACM, 13.
- OpenTracing (2019) The OpenTracing project. https://opentracing.io/.
- Peuster et al. (2016) M. Peuster, H. Karl, and S. van Rossem. 2016. MeDICINE: Rapid prototyping of production-ready network services in multi-PoP environments. In 2016 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN). 148–153. https://doi.org/10.1109/NFV-SDN.2016.7919490
- Pham et al. (2020) Phuong Pham, Vivek Jain, Lukas Dauterman, Justin Ormont, and Navendu Jain. 2020. DeepTriage: Automated Transfer Assistance for Incidents in Cloud Services. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’20). Association for Computing Machinery, New York, NY, USA, 3281–3289. https://doi.org/10.1145/3394486.3403380
- Potharaju et al. (2013) Rahul Potharaju, Navendu Jain, and Cristina Nita-Rotaru. 2013. Juggling the Jigsaw: Towards Automated Problem Inference from Network Trouble Tickets. In Proceedings of the 10th USENIX Conference on Networked Systems Design and Implementation (NSDI). USENIX Association.
- Qin et al. (2005) Feng Qin, Joseph Tucek, Jagadeesan Sundaresan, and Yuanyuan Zhou. 2005. Rx: Treating Bugs as Allergies—a Safe Method to Survive Software Failures. In Proceedings of the Twentieth ACM Symposium on Operating Systems Principles (SOSP ’05). Association for Computing Machinery, New York, NY, USA, 235–248. https://doi.org/10.1145/1095810.1095833
- Scott et al. (2016) Colin Scott, Aurojit Panda, Vjekoslav Brajkovic, George Necula, Arvind Krishnamurthy, and Scott Shenker. 2016. Minimizing Faulty Executions of Distributed Systems. In Proceedings of the 13th Usenix Conference on Networked Systems Design and Implementation (NSDI). USENIX Association.
- Scott et al. (2014) Colin Scott, Andreas Wundsam, Barath Raghavan, Aurojit Panda, Andrew Or, Jefferson Lai, Eugene Huang, Zhi Liu, Ahmed El-Hassany, Sam Whitlock, H.B. Acharya, Kyriakos Zarifis, and Scott Shenker. 2014. Troubleshooting Blackbox SDN Control Software with Minimal Causal Sequences. In Proceedings of the 2014 ACM Conference on SIGCOMM (SIGCOMM). ACM.
- Sigelman et al. (2010) Benjamin H Sigelman, Luiz Andre Barroso, Mike Burrows, Pat Stephenson, Manoj Plakal, Donald Beaver, Saul Jaspan, and Chandan Shanbhag. 2010. Dapper, a large-scale distributed systems tracing infrastructure. Technical Report. Technical report, Google.
- Tammana et al. (2015) Praveen Tammana, Rachit Agarwal, and Myungjin Lee. 2015. CherryPick: Tracing Packet Trajectory in Software-defined Datacenter Networks. In Proceedings of the 1st ACM SIGCOMM Symposium on Software Defined Networking Research (SOSR). ACM.
- Tammana et al. (2016) Praveen Tammana, Rachit Agarwal, and Myungjin Lee. 2016. Simplifying Datacenter Network Debugging with Pathdump. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI). USENIX Association.
- Taylor and Letham (2018) Sean J Taylor and Benjamin Letham. 2018. Forecasting at scale. The American Statistician 72, 1 (2018), 37–45.
- Uber (2019) Jaeger. https://www.jaegertracing.io/docs/1.14/.
- Viennot et al. (2013) Nicolas Viennot, Siddharth Nair, and Jason Nieh. 2013. Transparent Mutable Replay for Multicore Debugging and Patch Validation. In Proceedings of ASPLOS.
- Weaveworks (2017) Sock Shop: A Microservices Demo Application. https://microservices-demo.github.io/.
- Xu et al. (2018) Haowen Xu, Wenxiao Chen, Nengwen Zhao, Zeyan Li, Jiahao Bu, Zhihan Li, Ying Liu, Youjian Zhao, Dan Pei, Yang Feng, et al. 2018. Unsupervised anomaly detection via variational auto-encoder for seasonal kpis in web applications. In Proceedings of the 2018 World Wide Web Conference. 187–196.
- Yuan et al. (2014) Ding Yuan, Yu Luo, Xin Zhuang, Guilherme Renna Rodrigues, Xu Zhao, Yongle Zhang, Pranay U. Jain, and Michael Stumm. 2014. Simple Testing Can Prevent Most Critical Failures: An Analysis of Production Failures in Distributed Data-Intensive Systems. In Proceedings of the 11th USENIX Conference on Operating Systems Design and Implementation (OSDI’14). USENIX Association, USA, 249–265.
Appendix A Appendix
A.1. Additional Testbed Details
A.1.1. Overview of Applications
Reddit: Reddit is a popular discussion website whose three-tier backend architecture is representative of many distributed applications that utilize the monolithic architectural paradigm. In the front-end tier, HAProxy (hap, 2019) load balances traffic across web servers. The application tier, implemented using the Pylons framework for Python (pyl, 2019), embeds the core application program logic and accesses data objects from the storage tier. The storage tier consists of three data stores: PostgreSQL (pos, 2019) is mainly used as a key/value store for objects such as accounts and comments; Cassandra (cas, 2016) is used as a key/value store for precomputed objects such as comment trees; and Memcache (Dormando, 2015) is used for caching throughout the system. Reddit also uses the RabbitMQ message broker (rab, 2019) to manage asynchronous writes to the storage layer.
Sock Shop: Developed by Weaveworks, Sock Shop is an e-commerce application that employs a microservice-based backend architecture. Sock Shop incorporates 14 different microservices, including a user-facing Node.js frontend microservice, a shopping cart management microservice, a catalog microservice, and so on. Each microservice includes an application server whose logic is implemented in one of a variety of programming languages (e.g., Java, Go), and select microservices additionally operate an individually-managed datastore. For instance, separate MongoDB database instances (Inc., 2019) are used for cart information, processed order transactions, and user profiles, while catalog information is stored in a MySQL database (mys, [n. d.]). As with Reddit, RabbitMQ manages inter-microservice communication.
Online Boutique: Online Boutique is another microservice-based e-commerce platform from Google that includes 10 distinct microservices that are implemented in Python, Go, C#, Java, and JavaScript. Microservices include a frontend HTTP server (implemented in Go), a payment microservice, a cart microservice, and an ad microservice. Each microservice operates its own datastore, e.g., the cart microservice stores a user’s to-be-purchased items in Redis (red, [n. d.]). Microservices communicate using the gRPC framework (grp, [n. d.]).
A.1.2. Overview of Debugging Tools
Marple: Marple is a performance query language for network monitoring that uses SQL-like constructs (e.g., groupby, filter). To operate, Marple assigns each network switch and packet a unique ID, and supports queries that track 1) per-packet and per-switch queuing delays, and 2) user-defined aggregation functions across packets. In our implementation, switches log queue depths that each arriving packet encounters, and the packet’s 5-tuple (src/dest ip addresses, src/dest ports, and protocol). This is sufficient to track queueing information and high-level statistics such as packet counts. We write queries in Marple to capture and track these values, and then use Marple’s compiler to generate P4 programs (Bosshart et al., 2014) that can run directly on our emulated switches. Switches stream query results to a data collection server running on the same host machine for further analysis.
tcpdump: tcpdump is an end-host network stack inspector which analyzes all incoming and outgoing packets across all of the host’s network interfaces. tcpdump’s command line interface supports querying in the form of packet content filtering (e.g., by hostname, packet type, checksum, etc.), which can be applied at runtime or offline. In our implementation, tcpdump is configured to collect all network packet information in a pcap file, and filters are applied offline.
Jaeger: Uber’s Jaeger framework is an end-to-end distributed systems tracing system which, like its predecessors Dapper (Sigelman et al., 2010) and Zipkin (zip, 2019), implements distributed tracing according to the OpenTracing specification (OpenTracing, 2019). With Jaeger, developers embed tracepoints directly into their system source code (or RPC monitoring proxies (env, [n. d.])) and specify custom state (e.g., variable values) to log at each one.
By aggregating tracepoint and timing information, Jaeger provides distributed context propagation so developers can understand how data values and control state flows across time and subsystems. We modified each application’s source code (application tier for Reddit, and each microservice frontent for Sock Shop and Online Boutique) to include tracepoints for each function accessed during HTTP response generation. As per the examples provided by OpenTracing (OpenTracing, 2019), at each tracepoint, we log the accessed variables, function execution duration, and any thrown exceptions. During execution, all tracepoint information is sent to a Jaeger aggregation server running on the same host machine for subsequent querying.
cAdvisor: Google’s cAdvisor framework profiles the resource utilization of individual containers. To do so, cAdvisor runs in a dedicated container, which coordinates with a Docker daemon running on the same machine to get a listing of all active containers to profile (and the process ids that each owns). With this information, caAvisor uses the Linux cgroups kernel feature to extract resource utilization information for each container. We use cAdvisor’s default configuration, in which the following values are reported every 1 second: instantaneous CPU usage, memory usage, and disk read/write throughput, and cumulative number of page faults. Resource usage information collected by cAdvisor is dynamically sent to a custom logging server running on the same host machine for subsequent querying.
A.2. Additional Related Work
DeepCT (Chen et al., 2019) uses a GRU (Gated Recurrent Unit) and attention-based model to leverage discussions between team members to accurately triage an incident. It incrementally learns knowledge from the discussions to better triage the incident. DeepTriage (Pham et al., 2020) leverages both textual and contextual data from incident reports. The textual data contains information like the incident title, summary and the initial discussion entries and the contextual data includes information about the service, severity of the incident, etc. The authors also identify that only few discussion items correspond to triaging and several of the subsequent discussion is on root cause analysis and logging troubleshooting steps which indicates that identifying the root cause requires several manual steps and is time consuming. While triaging identifies the team to detect root cause, it doesn’t provide any hints as to the specific metrics and their relation to the subsystems to help developers.
DISTALYZER (Nagaraj et al., 2012) leverages logs printed by distributed systems to identify the strongest association between performance and specific components. These log snippets are returned to the developer to identify the root cause of the incident. Due to the presence of several components in a distributed system and a bug can manifest itself in logs across different components, it is hard to find the most useful log by association alone and developer has to still sieve through all the logs.
A.3. Diagrams Illustrating Model Operation/Insights


A.4. Diagrams for Testbed and Dataset


| User report text |
|---|
| there is nothing on the page, it is empty, nothing to click on |
| ‘you broke reddit’ with the cartoon showed up |
| Page took forever to load. Sat at the gray screen for almost a minute, entirely too long.. |
| I clicked to expand for comments, and page went away and defaulted to a grey screen.. No Page |
| ‘Funny 500 Page Message 8’ message below that. Blank otherwise. . Page does not include any usernames |
| Fault Type | Number of Faults | Example |
|---|---|---|
| Resource underprovisioning | 15 | Reducting the CPU quota |
| for the docker container running PostgreSQL | ||
| Component failures | 15 | Take down container for a given microservice |
| Subsystem misconfigurations | 12 | Incorrectly configure hostname of a database |
| Network congestion | 13 | Generate significant network |
| cross-traffic between hosts for different microservice | ||
| Network-level misconfigurations | 16 | Incorrect firewall rules at routers to drop |
| or forward packets on an incorrect interface | ||
| Subsystem/Source-code bugs | 16 | Negated if condition resulting in different execution path |
| Incorrect data exchange | 15 | Alter function signature within |
| a microservice, triggering argument violations |