Rethinking the Construction of Effective Metrics for Understanding the Mechanisms of Pretrained Language Models
Abstract
Pretrained language models are expected to effectively map input text to a set of vectors while preserving the inherent relationships within the text. Consequently, designing a white-box model to compute metrics that reflect the presence of specific internal relations in these vectors has become a common approach for post-hoc interpretability analysis of pretrained language models. However, achieving interpretability in white-box models and ensuring the rigor of metric computation becomes challenging when the source model lacks inherent interpretability. Therefore, in this paper, we discuss striking a balance in this trade-off and propose a novel line to constructing metrics for understanding the mechanisms of pretrained language models. We have specifically designed a family of metrics along this line of investigation, and the model used to compute these metrics is referred to as the tree topological probe. We conducted measurements on BERT-large by using these metrics. Based on the experimental results, we propose a speculation regarding the working mechanism of BERT-like pretrained language models, as well as a strategy for enhancing fine-tuning performance by leveraging the topological probe to improve specific submodules.111Our code is available at https://github.com/cclx/Effective_Metrics
1 Introduction
Pretrained language models consisting of stacked transformer blocks (Vaswani et al., 2017) are commonly expected to map input text to a set of vectors, such that any relationship in the text corresponds to some algebraic operation on these vectors. However, it is generally unknown whether such operations exist. Therefore, designing a white-box model that computes a metric for a given set of vectors corresponding to a text, which reflects to some extent the existence of operations extracting specific information from the vectors, is a common approach for post-hoc interpretability analysis of such models (Maudslay et al., 2020; Limisiewicz and Marecek, 2021; Chen et al., 2021; White et al., 2021; Immer et al., 2022). However, even though we may desire strong interpretability from a white-box model and metrics computed by it that rigorously reflect the ability to extract specific information from a given set of vectors, it can be challenging to achieve both of these aspects simultaneously when the source model lacks inherent interpretability. Therefore, making implicit assumptions during metric computation is common (Kornblith et al., 2019; Wang et al., 2022). A simple example is the cosine similarity of contextual embeddings. This metric is straightforward and has an intuitive geometric interpretation, making it easy to explain, but it tends to underestimate the similarity of high-frequency words (Zhou et al., 2022).
On the other hand, due to the intuition that ’if a white-box model cannot distinguish embeddings that exhibit practical differences (such as context embeddings and static embeddings), it should be considered ineffective,’ experimental validation of a white-box model’s ability to effectively distinguish between embeddings with evident practical distinctions is a common practice in research. Furthermore, if the magnitude of metrics computed by a white-box model strongly correlates with the quality of different embeddings in practical settings, researchers usually trust its effectiveness. Therefore, in practice, traditional white-box models actually classify sets of vectors from different sources.
Taking the structural probe proposed by Hewitt and Manning as an example, they perform a linear transformation on the embedding of each complete word in the text and use the square of the L2 norm of the transformed vector as a prediction for the depth of the corresponding word in the dependency tree (Hewitt and Manning, 2019). In this way, the linear transformation matrix serves as a learning parameter, and the minimum risk loss between the predicted and true depths is used as a metric. Intuitively, the smaller the metric is, the more likely the embedding contains complete syntax relations. The experimental results indeed align with this intuition, showing that contextual embeddings (such as those generated by BERT (Devlin et al., 2019)) outperform static embeddings. However, due to the unknown nature of the true deep distribution, it is challenging to deduce which geometric features within the representations influence the magnitude of structural probe measurements from the setup of structural probe. Overall, while the results of the structural probe provide an intuition that contextual embeddings, such as those generated by BERT, capture richer syntactic relations than those of the traditional embeddings, it is currently impossible to know what the geometric structure of a "good" embedding is for the metric defined by the structural probe.
In addition, to enhance the interpretability and flexibility of white-box models, it is common to include assumptions that are challenging to empirically validate. For example, Ethayarajh proposed to use anisotropy-adjusted self-similarity to measure the context-specificity of embeddings (Ethayarajh, 2019). Since the computation of this metric doesn’t require the introduction of additional human labels, it is theoretically possible to conduct further analysis, such as examining how fundamental geometric features in the representation (e.g., rank) affect anisotropy-adjusted self-similarity, or simply consider this metric as defining a new geometric feature. Overall, this is a metric that can be discussed purely at the mathematical level. However, verifying whether the measured context-specificity in this metric aligns well with context-specificity in linguistics, without the use of, or with only limited additional human labels, may be challenging. Additionally, confirming whether the model leverages the properties of anisotropy-adjusted self-similarity during actual inference tasks might also be challenging.
There appears to be a trade-off here between two types of metrics:
1. Metrics that are constrained by supervised signals with ground truth labels, which provide more practical intuition.
2. Metrics that reflect the geometric properties of the vector set itself, which provide a more formal representation.
Therefore, we propose a new line that takes traditional supervised probes as the structure of the white-box model and then self-supervises it, trying to preserve both of the abovementioned properties as much as possible. The motivation behind this idea is that any feature that is beneficial for interpretability has internal constraints. If a certain feature has no internal constraints, it must be represented by a vector set without geometric constraints, which does not contain any interpretable factors. Therefore, what is important for interpretability is the correspondence between the internal constraints of the probed features and the vector set, which can describe the geometric structure of the vector set to some extent. In the case where the internal constraints of the probed features are well defined, a probe that detects these features can naturally induce a probe that detects the internal constraints, which is self-supervised.
In summary, the contributions of this work include:
-
1.
We propose a novel self-supervised probe, referred to as the tree topological probe, to probe the hierarchical structure of sentence representations learned by pretrained language models like BERT.
-
2.
We discuss the theoretical relationship between the tree topological probe and the structural probe, with the former bounding the latter.
-
3.
We measure the metrics constructed based on the tree topological probe on BERT-large. According to the experimental results, we propose a speculation regarding the working mechanism of a BERT-like pretrained language model.
-
4.
We utilize metrics constructed by the tree topological probe to enhance BERT’s submodules during fine-tuning and observe that enhancing certain modules can improve the fine-tuning performance. We also propose a strategy for selecting submodules.
2 Related Work
The probe is the most common approach for associating neural network representations with linguistic properties (Voita and Titov, 2020). This approach is widely used to explore part of speech knowledge (Belinkov and Glass, 2019; Voita and Titov, 2020; Pimentel et al., 2020b; Hewitt et al., 2021) and for sentence and dependency structures (Hewitt and Manning, 2019; Maudslay et al., 2020; White et al., 2021; Limisiewicz and Marecek, 2021; Chen et al., 2021). These studies demonstrate many important aspects of the linguistic information are encoded in pretrained representations. However, in some probe experiments, researchers have found that the probe precision obtained by both random representation and pretrained representation were quite close (Zhang and Bowman, 2018; Hewitt and Liang, 2019). This demonstrates that it is not sufficient to use the probe precision to measure whether the representations contain specific language information. To improve the reliability of probes, some researchers have proposed the use of control tasks in probe experiments (Hewitt and Liang, 2019). In recent research, Lovering et al. realized that inductive bias can be used to describe the ease of extracting relevant features from representations. Immer et al. further proposed a Bayesian framework for quantifying inductive bias with probes, and they used the Model Evidence Maximum instead of trivial precision.
3 Methodology
As the foundation of the white-box model proposed in this paper is built upon the traditional probe, we will begin by providing a general description of the probe based on the definition presented in Ivanova et al. (2021). Additionally, we will introduce some relevant notation for better understanding.
3.1 General Form of the Probe
Given a character set, in a formal language, the generation rules uniquely determine the properties of the language. We assume that there also exists a set of generation rules implicitly in natural language, and the language objects derived from these rules exhibit a series of features. Among these features, a subset is selected as the probed feature for which the properties represent the logical constraints of the generation rule set. Assuming there is another model that can assign a suitable representation vector to the generated language objects, the properties of are then represented by the intrinsic geometric constraints of the vector set. By studying the geometric constraints that are implicit in the vector set and that correspond to , especially when is expanded to all features of the language object, we can determine the correspondence between and . The probe is a model that investigates the relationship between the geometric constraints of the vector set and . It is composed of a function set and a metric defined on . The input of a function in is the representation vector of a language object, and the output is the predicted feature of the input language object. The distance between the predicted feature and the true feature is calculated by using the metric , and a function in that minimizes the distance is determined. Here, limits the range of geometric constraints, and limits the selection of a "good" geometry. Notably, this definition seems very similar to that of learning. Therefore, the larger the scope of is, the harder it is to discern the form of the geometric constraints, especially when is a neural network (Pimentel et al., 2020b; White et al., 2021). However, the purpose of the probe is different from that of learning. The goal of learning is to construct a model (usually a black box), which may have multiple construction methods, while the purpose of the probe is to analyze the relationship between and .
3.2 The Design Scheme for the Topological Probe
One of the goals of topology is to find homeomorphic or homotopic invariants (including invariant quantities, algebraic structures, functors, etc.) and then to characterize the intrinsic structure of a topological space with these invariants. Analogously, we can view as a geometric object and as its topology. Can we then define a concept similar to topological invariants with respect to ?
We define a feature invariant for as a set of conditions such that any element in satisfies . reflects the internal constraints of the probed feature, as well as a part of the logical constraints of . Furthermore, if is well defined, it induces a set consisting of all objects satisfying , which naturally extends the metric defined on to .
Furthermore, just as the distance measure between two points can induce a distance measure between a point and a plane, the distance measure between the predicted feature and can also be induced by (denoted as ):
| (1) |
It can be easily verified that if is a well-defined distance metric on , then should also be a well-defined distance metric on . Once we have , the supervised probe can naturally induce a self-supervised probe . We refer to as the self-supervised version of , also known as the topological probe.
Notably, the prerequisite for obtaining is that must be well-defined, so should not be a black box. Figure 1 shows an intuitive illustration.

Next, we present a specific topological probe that is based on the previously outlined design scheme and serves as a self-supervised variant of the structural probe.
3.3 The Self-supervised Tree Topological Probe
Given a sentence , it is represented by a model as a set (or sequence) of vectors, denoted as . The number of vectors in is denoted as , and we assign an index to each vector in so that the order of the indices matches the order of the corresponding tokens in the sentence. Additionally, we denote the dimension of the vectors as . For each , there exists a syntax tree , where each complete word in corresponds to a node in .
The probed feature that the structural probe defines is the depth of the nodes corresponding to complete words. Following the work in (Hewitt and Manning, 2019), we set the parameter space of for the structural probe to be all real matrices of size , where . The specific form for predicting the depth is as follows: Given
| (2) |
where is the prediction tree depth of in and is a real matrix of size . Because , there is a tree that cannot be embedded as above (Reif et al., 2019), so is usually taken as . , , form a sequence denoted as .
Moreover, we denote the true depth of as . Hence, , , also form a sequence denoted as . The metric in the structural probe is defined as follows:
| (3) |
Therefore, the structural probe is defined as , , .
Now we provide the constraints for . An important limitation of is that it is an integer sequence. Based on the characteristics of the tree structure, it is naturally determined that must satisfy the following two conditions:
(Boundary condition). If , there is exactly one minimum element in , and it is equal to ; if , at least one element in is equal to .
(Recursion condition). If we sort in ascending order to obtain the sequence , then
or
We denote the set of all sequences that conform to as . From equation 1, we can induce a metric :
| (4) |
Assuming we can construct an explicit sequence such that:
| (5) |
We can obtain an analytical expression for as follows:
| (6) |
Consider the following two examples:
-
1.
When , then .
-
2.
When , then .
It can be observed that the predicted depths for nodes further down the hierarchy can also influence the corresponding values of for nodes higher up in the hierarchy. In the examples provided, due to the change from 4.5 to 7.5, 1.8 changes from 2 to 3 at the corresponding . Therefore, using a straightforward local greedy approach may not yield an accurate calculation of , and if a simple enumeration method is employed, the computational complexity will become exponential.
However, while a local greedy approach may not always provide an exact computation of , it can still maintain a certain degree of accuracy for reasonable results of . This is because cases like the jump from 2.4 to 7.5 should be infrequent in a well-trained probe’s computed sequence of predicted depths, unless the probed representation does not encode the tree structure well and exhibits a disruption in the middle.
Before delving into that, we first introduce some notations:
-
•
denote the sequence obtained by sorting in ascending order.
-
•
represents the -th element of .
-
•
be a sequence in .
Here, we introduce a simple method for constructing from a local greedy perspective.
(Initialization). If , let ; if , let .
(Recurrence). If and , let
| (7) |
where the values of and are related if
; otherwise, .
(Alignment). Let () denote the index of in . Then, let
| (8) |
It can be shown that constructed in the above manner satisfies the following theorem:
Theorem 1.
If , , , , then
Therefore, can be considered an approximation to . Appendix A contains the proof of this theorem. In the subsequent sections of this paper, we replace with .
Additionally, an important consideration is determining the appropriate value of the minimum element for in the boundary condition. In the preceding contents, we assumed a root depth of 1 for the syntactic tree. However, in traditional structural probe (Hewitt and Manning, 2019; Maudslay et al., 2020; Limisiewicz and Marecek, 2021; Chen et al., 2021; White et al., 2021), the root depth is typically assigned as 0 due to the annotation conventions of syntactic tree datasets. From a logical perspective, these two choices may appear indistinguishable.
However, in Appendix B, we demonstrate that the choice of whether the root depth is 0 has a significant impact on the geometry defined by the tree topological probe. Furthermore, we can prove that as long as the assigned root depth is greater than 0, the optimal geometry defined by the tree topological probe remains the same to a certain extent. Therefore, in the subsequent sections of this paper, we adopt the setting where the value of the minimum element of is .
3.4 Enhancements to the Tree Topological Probe
Let the set of all language objects generated by rule be denoted as , and the cardinality of be denoted as . The structural probe induces a metric that describes the relationship between model and :
| (9) |
The tree topological probe can also induce a similar metric:
| (10) |
On the other hand, we let
| (11) |
similar to , and , inducing the following metrics:
| (12) |
Since , when is given, we have:
Furthermore, as and share the same set of probing functions , we have:
Therefore, provides us with an upper bound for the structural probe metric. Similarly, for , we also have:
Therefore, provides us with a lower bound for the structural probe metric. In summary, we have the following:
If , then there is no difference between the tree topological probe and the structural probe. On the other hand, if it is believed that a smaller is desirable, then estimating within the range becomes an interesting problem. We consider the following:
| (13) |
This leads to an intriguing linguistic distribution, the distribution of when uniformly sampling from . We suppose the density function of this distribution is denoted as , and the expectation with respect to is denoted as . Then we can approximate as follows:
| (14) |
While the analysis of is not the primary focus of this paper, in the absence of any other constraints or biases on model , we conjecture that the distribution curve of may resemble a uniform bell curve. Hence, we consider the following distribution approximation:
At this point:
| (15) |
Therefore, utilizing a self-supervised metric can approximate the unbiased optimal geometry defined by the structural probe:
| (16) |
Moreover, is an analytically tractable object, implying that the metrics induced by the tree topological probe preserve to a certain extent the two metric properties discussed in the introduction. However, there is a crucial issue that remains unresolved. Can we explicitly construct ? Currently, we have not found a straightforward method similar to constructing for approximating . However, based on the sorting inequality, we can construct a sequence that approximates based on . Let () denote . Then, let
| (17) |
In our subsequent experiments, we approximate with .
4 Experiments
In this section, delve into a range of experiments conducted on the tree topological probe, along with the underlying motivations behind them. To accommodate space limitations, we include many specific details of the experimental settings in Appendices C and D. Moreover, we focus our experiments on BERT-large and its submodules. Moreover, conducting similar experiments on other models is also straightforward (refer to Appendix F for supplementary results of experiments conducted using RoBERTa-large).
4.1 Measuring and on BERT
We denote the model consisting of the input layer and the first transformer blocks of BERT-large as . Since the input of consists of tokenized units, including special tokens [CLS], [SEP], [PAD], and [MASK], we can conduct at least four types of measurement experiments:
-
e1.
Measurement of the vector set formed by token embedding and special token embedding.
-
e2.
Measurement of the vector set formed solely by token embedding.
-
e3.
Measurement of the vector set formed by estimated embedding of complete words using token embedding and special token embedding.
-
e4.
Measurement of the vector set formed solely by estimated embedding of complete words using token embedding.
Similarly, due to space constraints, we focus on discussing e1 in this paper. The measurement results are shown in Tables 1 and 2. The precise measurement values can be found in Appendix E. Furthermore, as shown in Figure 2, we present the negative logarithm curves of three measurement values as a function of variation.
| 0.010.05 | |
|---|---|
| 0.050.1 | |
| 0.10.15 |
| 0.30.4 | |||
|---|---|---|---|
| 0.40.5 | |||
| 0.51.0 | |||
| 1.02.0 | |||
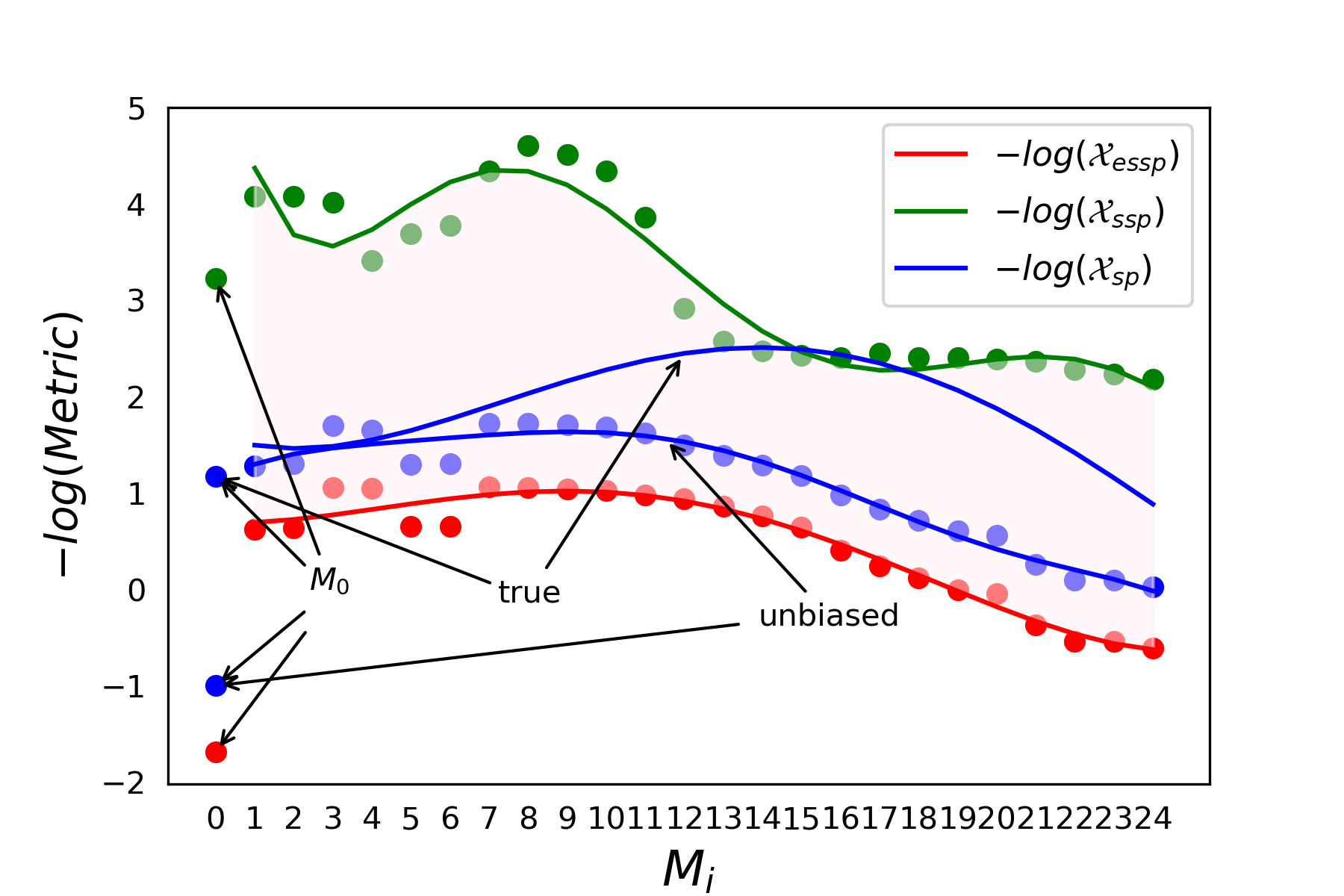
By examining the experimental results presented above, we can ascertain the following findings:
-
f1.
and indeed bound the actual , and for to , their true are very close to their .
-
f2.
serves as a good baseline model. Furthermore, using and unbiased allows for effective differentiation between embeddings generated by models consisting solely of the regular input layer and those generated by models incorporating transformer blocks.
-
f3.
For to , their true are very close to their unbiased .
-
f4.
Both the curve of and the curve of the true follow an ascending-then-descending pattern. However, the models corresponding to their highest points are different, namely, and , respectively.
-
f5.
For the curve of , its overall trend also shows an ascending-then-descending pattern but with some fluctuations in the range of to . However, the model corresponding to its highest point is consistent with , which is .
-
f6.
The true does not effectively distinguish between and .
Based on the above findings, we can confidently draw the following rigorous conclusions:
-
c1.
Based on f1, we can almost infer that for to . This implies that they memorize the preferences of the real data and minimize as much as possible to approach the theoretical boundary. Building upon f5, we can further conclude that the cost of memorizing is an increase in , which leads to a decrease in the accuracy of the embedding’s linear encoding for tree structures.
-
c2.
Based on f1, we can conclude that there exists a model where the true aligns with the determined by . This indicates that serves as a sufficiently tight condition.
-
c3.
Based on f3, we can infer that to may not capture the distributional information of the actual syntactic trees, resulting in their generated embeddings considering only the most general case for linear encoding of tree structures. This implies that the distribution curve of their parameters is uniformly bell-shaped.
-
c4.
Based on f2 and f6, we can conclude that the tree topological probe provides a more fine-grained evaluation of the ability to linearly encode tree structures in embedding vectors compared to the structural probe.
-
c5.
Based on f3, f4 and f5, we can conclude that in BERT-large, embedding generated by and its neighboring models exhibit the strongest ability to linearly encode tree structures. Moreover, they gradually start to consider the distribution of real dependency trees, resulting in the true approaching until reaching .
-
c6.
Based on f4 and f5, we can conclude that starting from , the embeddings generated by gradually lose their ability to linearly encode tree structures. The values of and for these models are generally larger compared to models before . However, they still retain some distributional information about the depth of dependency trees. This means that despite having a higher unbiased , their true is still smaller than that of before .
From the above conclusions, we can further speculate about the workings of pretrained language models such as BERT, and we identify some related open problems.
Based on c5 and c6, we can speculate that the final layer of a pretrained language model needs to consider language information at various levels, but its memory capacity is limited. Therefore, it relies on preceding submodules to filter the information. The earlier submodules in the model encode the most generic (unbiased) structures present in the language features. As the model advances, the intermediate submodules start incorporating preferences for general structures based on actual data. Once a certain stage is reached, the later submodules in the model start to loosen their encoding of generic structures. However, due to the preference information passed from the intermediate submodules, the later submodules can still outperform the earlier submodules in encoding real structures, rather than generic ones.
Based on c3 and c6, it appears that true unbiased . This suggests that for BERT, unbiased serves as a tighter upper bound for , and there exists a submodule that achieves this upper bound. Now, the question arises: Is this also the case for general pretrained models? If so, what are the underlying reasons?
4.2 Using and as Regularization Loss in Fine-tuning BERT
Let us denote the downstream task loss as . Taking as an example, using as a regularizing loss during fine-tuning refers to replacing the task loss with:
where is a regularization parameter. The purpose of this approach is to explore the potential for enhancing the fine-tuning performance by improving the submodules of BERT in their ability to linearly encode tree structures. If there exists a submodule that achieves both enhancement in linear encoding capabilities and improved fine-tuning performance, it implies that the parameter space of this submodule, which has better linear encoding abilities, overlaps with the optimization space of fine-tuning. This intersection is smaller than the optimization space of direct fine-tuning, reducing susceptibility to local optima and leading to improved fine-tuning results.
Conversely, if enhancing certain submodules hinders fine-tuning or even leads to its failure, it suggests that the submodule’s parameter space, which has better linear encoding abilities, does not overlap with the optimization space of fine-tuning. This indicates that the submodule has already attained the smallest value that greatly benefits the BERT’s performance.
Based on f1, we can infer that to are not suitable as enhanced submodules. According to c5, the submodules most likely to improve fine-tuning performance after enhancement should be near . We conducted experiments on a single-sentence task called the Corpus of Linguistic Acceptability (CoLA) (Warstadt et al., 2019), which is part of The General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2019).
The test results are shown in Table 3. As predicted earlier, enhancing the submodules around to (now expanded to to ) proves to be detrimental to fine-tuning, resulting in failed performance. However, we did observe an improvement in fine-tuning performance for the sub-module near after enhancement. This gives us an intuition that if we have additional topological probes and similar metrics to and , we can explore enhancing submodules that are in the rising phase of true , away from the boundary of unbiased and , in an attempt to improve fine-tuning outcomes.
| Method | mean | std | max |
|---|---|---|---|
| DF | 63.34 | 1.71 | 66.54 |
| EH | 63.90 | 2.66 | 68.73 |
| EH | 63.90 | 1.36 | 66.04 |
| EH | 64.87 | 2.07 | 68.47 |
| EH | 0.00 | 0.00 | 0.00 |
| EH | 5.48 | 16.46 | 54.87 |
| EH | 40.43 | 26.60 | 62.52 |
5 Conclusion
Consider a thought experiment where there is a planet in a parallel universe called "Vzjgs" with a language called "Vmtprhs". Like "English", "Vmtprhs" comprises 26 letters as basic units, and there is a one-to-one correspondence between the letters of "Vmtprhs" and "English". Moreover, these two languages are isomorphic under letter permutation operations. In other words, sentences in "English" can be rearranged so that they are equivalent to sentences in "Vmtprhs", while preserving the same meaning. If there were models like BERT or GPT in the "Vzjgs" planet, perhaps called "YVJIG" and "TLG," would the pretraining process of "YVJIG" on "Vmtprhs" be the same as BERT’s pretraining on "English"?
In theory, there should be no means to differentiate between these two pretraining processes. For a blank model (without any training), extracting useful information from "Vmtprhs" and "English" would pose the same level of difficulty. However, it is true that "Vmtprhs" and "English" are distinct, with the letters of "Vmtprhs" possibly having different shapes or being the reverse order of the "English" alphabet. Therefore, we can say that they have different letter features, although this feature seems to be a mere coincidence. In natural language, there are many such features created by historical contingencies, such as slang or grammatical exceptions. Hence, when we aim to interpret the mechanisms of these black-box models by studying how language models represent language-specific features, we must consider which features are advantageous for interpretation and what we ultimately hope to gain from this research.
This paper presents a thorough exploration of a key issue, specifically examining the articulation of internal feature constraints. By enveloping the original feature within a feature space that adheres to such constraints, it is possible to effectively eliminate any unintended or accidental components. Within this explicitly defined feature space, metrics such as and can be defined. We can subsequently examine the evolution of these metrics within the model to gain a deeper understanding of the encoding strategies employed by the model for the original feature, as described in the experimental section of this paper. Once we understand the encoding strategies employed by the model, we can investigate the reasons behind their formation and the benefits they bring to the model. By conducting studies on multiple similar features, we can gain a comprehensive understanding of the inner workings of the black box.
Limitations
The main limitation of this research lies in the approximate construction of and , which leads to true surpassing near to some extent. However, this may also be due to their proximity, resulting in fluctuations within the training error. On the other hand, the proposed construction scheme for the topological probe discussed in this paper lacks sufficient mathematical formalization. One possible approach is to restate it using the language of category theory.
Acknowledgements
We thank the anonymous reviewers for their helpful comments and suggestions. This work was supported by National Natural Science Foundation of China (Nos. 62362015, 62062027 and U22A2099) and the project of Guangxi Key Laboratory of Trusted Software.
References
- Adi et al. (2017) Yossi Adi, Einat Kermany, Yonatan Belinkov, Ofer Lavi, and Yoav Goldberg. 2017. Fine-grained analysis of sentence embeddings using auxiliary prediction tasks. In 5th International Conference on Learning Representations, ICLR 2017.
- Aghajanyan et al. (2021) Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta. 2021. Better fine-tuning by reducing representational collapse. In 9th International Conference on Learning Representations, ICLR 2021.
- Aho and Ullman (1972) Alfred V. Aho and Jeffrey D. Ullman. 1972. The Theory of Parsing, Translation and Compiling, volume 1. Prentice-Hall, Englewood Cliffs, NJ.
- Alain and Bengio (2017) Guillaume Alain and Yoshua Bengio. 2017. Understanding intermediate layers using linear classifier probes. In 5th International Conference on Learning Representations, ICLR 2017, Workshop Track Proceedings.
- American Psychological Association (1983) American Psychological Association. 1983. Publications Manual. American Psychological Association, Washington, DC.
- Ando and Zhang (2005) Rie Kubota Ando and Tong Zhang. 2005. A framework for learning predictive structures from multiple tasks and unlabeled data. Journal of Machine Learning Research, 6:1817–1853.
- Andrew and Gao (2007) Galen Andrew and Jianfeng Gao. 2007. Scalable training of L1-regularized log-linear models. In Proceedings of the 24th International Conference on Machine Learning, pages 33–40.
- Belinkov and Glass (2019) Yonatan Belinkov and James R. Glass. 2019. Analysis methods in neural language processing: A survey. Trans. Assoc. Comput. Linguistics, 7:49–72.
- Cer et al. (2017) Daniel M. Cer, Mona T. Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. 2017. Semeval-2017 task 1: Semantic textual similarity - multilingual and cross-lingual focused evaluation. CoRR, abs/1708.00055.
- Chandra et al. (1981) Ashok K. Chandra, Dexter C. Kozen, and Larry J. Stockmeyer. 1981. Alternation. Journal of the Association for Computing Machinery, 28(1):114–133.
- Chen et al. (2021) Boli Chen, Yao Fu, Guangwei Xu, Pengjun Xie, Chuanqi Tan, Mosha Chen, and Liping Jing. 2021. Probing BERT in hyperbolic spaces. In 9th International Conference on Learning Representations, ICLR 2021.
- Chicco et al. (2021) Davide Chicco, Niklas Tötsch, and Giuseppe Jurman. 2021. The matthews correlation coefficient (MCC) is more reliable than balanced accuracy, bookmaker informedness, and markedness in two-class confusion matrix evaluation. BioData Min., 14(1):13.
- Conneau et al. (2018) Alexis Conneau, Germán Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. 2018. What you can cram into a single \$&!#* vector: Probing sentence embeddings for linguistic properties. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Volume 1: Long Papers, pages 2126–2136.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
- Dolan and Brockett (2005) William B. Dolan and Chris Brockett. 2005. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing, IWP@IJCNLP 2005.
- Ethayarajh (2019) Kawin Ethayarajh. 2019. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and GPT-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, pages 55–65.
- Gabrielsson et al. (2020) Rickard Brüel Gabrielsson, Bradley J. Nelson, Anjan Dwaraknath, and Primoz Skraba. 2020. A topology layer for machine learning. In The 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020, volume 108 of Proceedings of Machine Learning Research, pages 1553–1563. PMLR.
- Gusfield (1997) Dan Gusfield. 1997. Algorithms on Strings, Trees and Sequences. Cambridge University Press, Cambridge, UK.
- Hewitt et al. (2021) John Hewitt, Kawin Ethayarajh, Percy Liang, and Christopher D. Manning. 2021. Conditional probing: measuring usable information beyond a baseline. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, pages 1626–1639.
- Hewitt and Liang (2019) John Hewitt and Percy Liang. 2019. Designing and interpreting probes with control tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, pages 2733–2743.
- Hewitt and Manning (2019) John Hewitt and Christopher D. Manning. 2019. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4129–4138.
- Hua et al. (2021) Hang Hua, Xingjian Li, Dejing Dou, Cheng-Zhong Xu, and Jiebo Luo. 2021. Noise stability regularization for improving BERT fine-tuning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, pages 3229–3241.
- Hupkes and Zuidema (2018) Dieuwke Hupkes and Willem H. Zuidema. 2018. Visualisation and ’diagnostic classifiers’ reveal how recurrent and recursive neural networks process hierarchical structure (extended abstract). In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, pages 5617–5621.
- Immer et al. (2022) Alexander Immer, Lucas Torroba Hennigen, Vincent Fortuin, and Ryan Cotterell. 2022. Probing as quantifying inductive bias. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, pages 1839–1851.
- Ivanova et al. (2021) Anna A. Ivanova, John Hewitt, and Noga Zaslavsky. 2021. Probing artificial neural networks: insights from neuroscience. CoRR, abs/2104.08197.
- Jiang et al. (2020) Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Tuo Zhao. 2020. SMART: robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, pages 2177–2190.
- Kornblith et al. (2019) Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey E. Hinton. 2019. Similarity of neural network representations revisited. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, volume 97 of Proceedings of Machine Learning Research, pages 3519–3529.
- Lee et al. (2020) Cheolhyoung Lee, Kyunghyun Cho, and Wanmo Kang. 2020. Mixout: Effective regularization to finetune large-scale pretrained language models. In 8th International Conference on Learning Representations, ICLR 2020.
- Lee et al. (2022) Seonghyeon Lee, Dongha Lee, Seongbo Jang, and Hwanjo Yu. 2022. Toward interpretable semantic textual similarity via optimal transport-based contrastive sentence learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, pages 5969–5979.
- Limisiewicz and Marecek (2021) Tomasz Limisiewicz and David Marecek. 2021. Introducing orthogonal constraint in structural probes. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, Volume 1: Long Papers, pages 428–442.
- Liu et al. (2019) Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. Linguistic knowledge and transferability of contextual representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 1073–1094.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019.
- Lovering et al. (2021) Charles Lovering, Rohan Jha, Tal Linzen, and Ellie Pavlick. 2021. Predicting inductive biases of pre-trained models. In 9th International Conference on Learning Representations, ICLR 2021.
- Marcus et al. (1993) Mitchell P. Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. 1993. Building a large annotated corpus of english: The penn treebank. Comput. Linguistics, 19(2):313–330.
- Matthews (1975) Brian W Matthews. 1975. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et Biophysica Acta (BBA)-Protein Structure, 405(2):442–451.
- Maudslay et al. (2020) Rowan Hall Maudslay, Josef Valvoda, Tiago Pimentel, Adina Williams, and Ryan Cotterell. 2020. A tale of a probe and a parser. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, pages 7389–7395.
- Pimentel and Cotterell (2021) Tiago Pimentel and Ryan Cotterell. 2021. A bayesian framework for information-theoretic probing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, pages 2869–2887.
- Pimentel et al. (2020a) Tiago Pimentel, Naomi Saphra, Adina Williams, and Ryan Cotterell. 2020a. Pareto probing: Trading off accuracy for complexity. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, pages 3138–3153.
- Pimentel et al. (2020b) Tiago Pimentel, Josef Valvoda, Rowan Hall Maudslay, Ran Zmigrod, Adina Williams, and Ryan Cotterell. 2020b. Information-theoretic probing for linguistic structure. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, pages 4609–4622.
- Rasooli and Tetreault (2015) Mohammad Sadegh Rasooli and Joel R. Tetreault. 2015. Yara parser: A fast and accurate dependency parser. Computing Research Repository, arXiv:1503.06733. Version 2.
- Reif et al. (2019) Emily Reif, Ann Yuan, Martin Wattenberg, Fernanda B. Viégas, Andy Coenen, Adam Pearce, and Been Kim. 2019. Visualizing and measuring the geometry of BERT. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, pages 8592–8600.
- Saphra and Lopez (2019) Naomi Saphra and Adam Lopez. 2019. Understanding learning dynamics of language models with SVCCA. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 3257–3267.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, pages 5998–6008.
- Voita et al. (2019) Elena Voita, Rico Sennrich, and Ivan Titov. 2019. The bottom-up evolution of representations in the transformer: A study with machine translation and language modeling objectives. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, pages 4395–4405.
- Voita and Titov (2020) Elena Voita and Ivan Titov. 2020. Information-theoretic probing with minimum description length. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, pages 183–196.
- Wang et al. (2019) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019.
- Wang et al. (2022) Bin Wang, C.-C. Jay Kuo, and Haizhou Li. 2022. Just rank: Rethinking evaluation with word and sentence similarities. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, pages 6060–6077.
- Warstadt et al. (2019) Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. 2019. Neural network acceptability judgments. Trans. Assoc. Comput. Linguistics, 7:625–641.
- White et al. (2021) Jennifer C. White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell. 2021. A non-linear structural probe. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, pages 132–138.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface’s transformers: State-of-the-art natural language processing. CoRR, abs/1910.03771.
- Zeng et al. (2022) Jiali Zeng, Yufan Jiang, Shuangzhi Wu, Yongjing Yin, and Mu Li. 2022. Task-guided disentangled tuning for pretrained language models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3126–3137.
- Zhang and Bowman (2018) Kelly W. Zhang and Samuel R. Bowman. 2018. Language modeling teaches you more than translation does: Lessons learned through auxiliary syntactic task analysis. In Proceedings of the Workshop: Analyzing and Interpreting Neural Networks for NLP, BlackboxNLP@EMNLP 2018, pages 359–361.
- Zhou et al. (2022) Kaitlyn Zhou, Kawin Ethayarajh, Dallas Card, and Dan Jurafsky. 2022. Problems with cosine as a measure of embedding similarity for high frequency words. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), ACL 2022, pages 401–423.
- Zhu et al. (2020) Chen Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, and Jingjing Liu. 2020. Freelb: Enhanced adversarial training for natural language understanding. In 8th International Conference on Learning Representations, ICLR 2020.
Appendix A Proof of Theorem 1
Proof.
For any sequence that is in the same order as , according to the inequality of rankings, for any permutation of , we have:
Therefore,
Since and are in the same order, we just need to prove that any sequence and in the same order as satisfies
The theorem is automatically established. Because
| (18) |
, without loss of generality, we can assume and to be ascending sequences and not equal and exist a such that when
| (19) |
and
| (20) |
Based on the recursive condition, we can infer that
| (21) |
Combined with the value condition of , we further find that
The inductive hypothesis when is
Due to the condition and the value condition of , it still holds when that
Thus, when
∎
Appendix B Analysis of Tree Depth Minimum
The minimum of is denoted as . Fixing , we let all sets (or sequences) of vectors satisfying the following conditions compose a set denoted by .
Here, . Let be and without loss of generality, and the following theorem can be obtained.
Theorem 2.
For any two different sequences and , if and . there is a one-to-one mapping between and .
Proof.
We construct such that
Here, , and when
Since
Let and when
then
After calculation,
Therefore, is well defined, and when
Therefore, is also an injective function. It is easy to prove that the inverse map of is also an injective function and satisfies the above conditions. ∎
The proof of the theorem above does not apply to the cases where or . If is greater than , then the results of the tree topological probe do not necessarily depend on the selection of , and we may set it as . However, we have not further explored whether Theorem 2 is necessarily invalid. Nevertheless, we can examine the drawbacks that arise from setting to from another perspective.
When , is projected by near the ()-dimensional sphere with a radius of ,
If , then the topology of the geometric space composed of all vectors satisfying is homeomorphic to an -dimensional open ball. This may result in probes exhibiting different preferences for the root and other nodes. However, if , the topology of the geometric space is an -dimensional annulus, which is the same for all nodes, thus avoiding the issue of preference.
Appendix C Data for Training and Evaluating Probes
To ensure the reliability and diversity of data (appropriate sentences) sources, we separated the sentences participating in the probe experiment from the training, verification and test data sets of some tasks of The General Language Understanding Evaluation (GLUE) benchmark (Wang et al., 2019).
We selected four small sample text classification tasks in GLUE with reference to (Hua et al., 2021), namely, the Corpus of Linguistic Acceptability (CoLA) (Warstadt et al., 2019), Microsoft Research Paraphrase Corpus (MRPC) (Dolan and Brockett, 2005), Recognizing Textual Entailment (RTE) (Wang et al., 2019) and Semantic Textual Similarity Benchmark (STS-B) (Cer et al., 2017), which cover the three major task types of SINGLE-SENTENCE, SIMILARITY AND PARAPHRASE and INFERENCE in GLUE. MRPC, RTE and STS-B are all double sentence tasks, and the experiment needs only BERT to represent a single sentence; thus, we consider two sentences that belong to the same group of data independently, not spliced.
After the data sets of the four tasks are processed as above, the remaining statements are merged into a raw text data set , which contains 47136 sentences. This is close to the size of the Pennsylvania tree database (Marcus et al., 1993) used by the structural probe (Hewitt and Manning, 2019); short and long sentences are evenly distributed.
Appendix D Experimental Setup for Training Probes and Fine-tuning
We use the BERT implementation of Wolf et al. and set the rank of the probe matrix to be half the embedding dimension. The probe matrix is randomly initialized following a uniform distribution .
We employ the AdamW optimizer with the warmup technique, where the initial learning rate is set to 2e-5 and the epsilon value is set to 1e-8. The training stops after 10 epochs. The training setup for fine-tuning experiments is similar to that of training probes. One notable difference is the regularization coefficient , which is dynamically determined after one epoch of training, ensuring that , without any manual tuning.
We conduct experiments on each fine-tuning method by using 10 different random seeds, and we compute the mean, the standard deviation (std), and the maximum values.
Appendix E Supplementary Chart Materials
Table 4 lists the exact measurements of , , and true for BERT-Large.
| 0.039 | 5.382 | 0.3084 | |
| 0.017 | 0.536 | 0.2644 | |
| 0.017 | 0.526 | 0.244 | |
| 0.018 | 0.348 | 0.2016 | |
| 0.033 | 0.351 | 0.1701 | |
| 0.025 | 0.52 | 0.1622 | |
| 0.023 | 0.52 | 0.1559 | |
| 0.013 | 0.345 | 0.14 | |
| 0.01 | 0.347 | 0.1424 | |
| 0.011 | 0.352 | 0.1577 | |
| 0.013 | 0.359 | 0.1415 | |
| 0.021 | 0.375 | 0.1128 | |
| 0.054 | 0.391 | 0.0975 | |
| 0.076 | 0.42 | 0.0764 | |
| 0.084 | 0.467 | 0.0651 | |
| 0.088 | 0.525 | 0.0616 | |
| 0.09 | 0.663 | 0.0656 | |
| 0.086 | 0.785 | 0.0808 | |
| 0.09 | 0.883 | 0.1155 | |
| 0.09 | 0.999 | 0.1416 | |
| 0.092 | 1.045 | 0.1615 | |
| 0.094 | 1.447 | 0.2468 | |
| 0.102 | 1.715 | 0.28634 | |
| 0.107 | 1.709 | 0.3171 | |
| 0.113 | 1.837 | 0.328 |
Appendix F Experimental data for RoBERTa-large
Figure 3 shows the negative logarithm curves of three measurement values as a function of variation in Mi for RoBERTa-Large. Table 5 lists the exact measurements of , , and true for RoBERTa-Large.
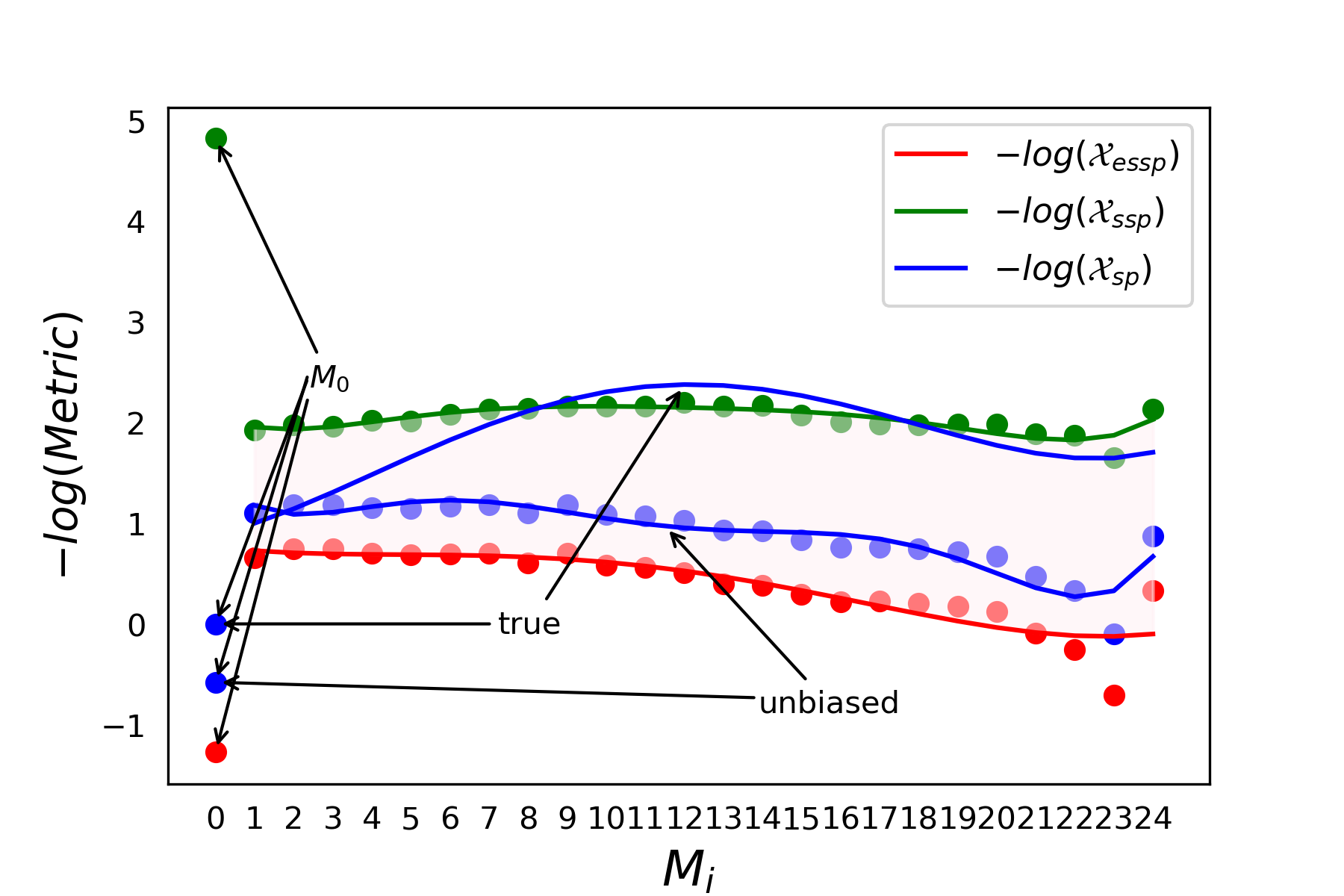
From the experimental data, it is evident that the overall pattern of evolution in the graphs for RoBERTa-Large and BERT-Large is consistent. There’s a slight initial increase followed by a decline, but the boundaries for in the case of RoBERTa-Large are much tighter, especially in the earlier modules.
| 0.008 | 3.532 | 0.991 | |
| 0.145 | 0.515 | 0.243 | |
| 0.137 | 0.469 | 0.446 | |
| 0.139 | 0.470 | 0.331 | |
| 0.131 | 0.493 | 0.257 | |
| 0.132 | 0.500 | 0.199 | |
| 0.123 | 0.494 | 0.153 | |
| 0.117 | 0.491 | 0.110 | |
| 0.117 | 0.542 | 0.109 | |
| 0.114 | 0.491 | 0.087 | |
| 0.113 | 0.555 | 0.091 | |
| 0.113 | 0.567 | 0.091 | |
| 0.110 | 0.598 | 0.094 | |
| 0.114 | 0.667 | 0.101 | |
| 0.113 | 0.675 | 0.102 | |
| 0.124 | 0.738 | 0.120 | |
| 0.133 | 0.797 | 0.136 | |
| 0.136 | 0.789 | 0.131 | |
| 0.137 | 0.807 | 0.136 | |
| 0.136 | 0.831 | 0.135 | |
| 0.136 | 0.880 | 0.145 | |
| 0.150 | 1.086 | 0.169 | |
| 0.153 | 1.277 | 0.176 | |
| 0.190 | 2.006 | 0.197 | |
| 0.117 | 0.711 | 0.201 |