(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
11email: [email protected], 11email: [email protected], 11email: [email protected]
Rethinking Pruning for Backdoor Mitigation: An Optimization Perspective
Abstract
Deep Neural Networks (DNNs) are known to be vulnerable to backdoor attacks, posing concerning threats to their reliable deployment. Recent research reveals that backdoors can be erased from infected DNNs by pruning a specific group of neurons, while how to effectively identify and remove these backdoor-associated neurons remains an open challenge. Most of the existing defense methods rely on defined rules and focus on neuron’s local properties, ignoring the exploration and optimization of pruning policies. To address this gap, we propose an Optimized Neuron Pruning (ONP) method combined with Graph Neural Network (GNN) and Reinforcement Learning (RL) to repair backdoor models. Specifically, ONP first models the target DNN as graphs based on neuron connectivity, and then uses GNN-based RL agents to learn graph embeddings and find a suitable pruning policy. To the best of our knowledge, this is the first attempt to employ GNN and RL for optimizing pruning policies in the field of backdoor defense. Experiments show, with a small amount of clean data, ONP can effectively prune the backdoor neurons implanted by a set of backdoor attacks at the cost of negligible performance degradation, achieving a new state-of-the-art performance for backdoor mitigation.
Keywords:
Deep neural network Backdoor Defense Model Pruning1 Introduction
In recent years, Deep Neural Networks (DNNs) have demonstrated remarkable capabilities in solving real-world problems. However, the wide application of DNNs has raised concerns about their security and trustworthiness. Recent works have shown that DNNs are vulnerable to backdoor attacks[5], in which a malicious adversary injects specific triggers into the victim model through data poisoning, manipulating the training process, or directly modifying model parameters. The backdoored model performs well on clean samples but can be triggered into false predictions by the poisoned samples containing trigger patterns. As pre-trained weights and outsourced training are widely applied to cut computational costs for training DNNs, the backdoor attack is becoming an undeniable security issue. To address this issue, numerous methods have been proposed for detecting and mitigating backdoor attacks. Backdoor detection methods [27, 18, 8] identify whether a model is backdoored or a dataset is poisoned, while backdoor mitigation methods [17, 14, 29] eliminate the injected triggers from backdoored models.
Our work focuses on the task of backdoor mitigation. Recent research [29, 16] has observed a subset of neurons contributing the most to backdoor behaviors in infected DNNs. By pruning these backdoor-associate neurons, the backdoor behavior of the infected model can be effectively mitigated. Mainstream approaches, as will be further introduced in Sect. 2, concentrate on identifying these backdoor neurons using rule-based methods to obtain a clean model. However, the property of backdoor neurons varies across different attacks, models, and layers, motivating us to think about alternative approaches.
We investigate the distribution of backdoor and clean neurons, discovering that mitigating backdoor behavior often compromises clean accuracy, which inspires us to define backdoor mitigation as an optimization problem and introduce Reinforcement Learning (RL) to solve it. Moreover, we have observed that backdoor neurons and clean neurons tend to connect with neurons of the same type as themselves, motivating us to model the DNN as graphs and employ the Graph Neural Network (GNN) to leverage topological information within neuron connections. Building upon these insights, we propose Optimized Neuron Pruning (ONP), the first optimization-based pruning method that combines GNN and RL to learn from neuron connections and optimize pruning policies for backdoor mitigation.
Our experiments demonstrate that ONP can defend against a variety of attacks and outperform current state-of-the-art methods, including ANP[29], CLP[34], and RNP[16] across different datasets, revealing the potential of optimization-based pruning methods in backdoor mitigation.
In summary, our main contributions are:
-
•
We define pruning for backdoor mitigation as an optimization problem and develop a framework based on RL to optimize pruning policies for effective backdoor mitigation.
-
•
By investigating the distribution and connections of backdoor neurons, we develop a model-to-graph method for converting neuron connections into graphs to expose backdoor neurons. We further combine GNN and RL to conduct pruning on both the infected DNN and graphs.
-
•
We empirically show that ONP is competitive among existing pruning-based backdoor mitigation methods against a variety of backdoor attacks, which demonstrate the significance of optimization in enhancing backdoor mitigation performance.
2 Related Work
2.1 Backdoor Attack
Depending on trigger injection methods, backdoor attacks fall into two main categories: input-space attacks poisoning the training dataset and feature-space attacks manipulating the training process [24, 3, 33] or directly modifying model parameters [4, 22]. Input-space attacks can be further divided into static attacks using the same trigger for all samples and dynamic attacks using different triggers for different samples. Static triggers include patterns like black-white squares [5], Gaussian noise [2], adversarial perturbations [25], or more complex patterns, while dynamic attacks such as the input-aware dynamic attack [20] and WaNet [21] generate unique triggers for each input, making the defense more challenging.
2.2 Backdoor Mitigation
Backdoor defense involves two primary tasks: backdoor detection and backdoor mitigation. Detection methods focuses on identifying backdoored models or poisoned datasets, while mitigation methods aims to remove the injected backdoor from the infected model with minimal degradation to its performance on clean samples. Existing backdoor mitigation approaches include fine-tuning, pruning [17], distillation [14], unlearning [32] and training-time defenses [15, 28, 9]. Recent works on pruning have demonstrated remarkable performance in backdoor mitigation. We divide these works into two basic categories: score-based methods and mask-based methods.
Score-based methods employ specific scores to measure the properties of backdoor neurons and determine the pruning policy based on each neuron’s score. Fine-Pruning (FP) [17] uses neuron activation as the score and prunes dormant neurons to mitigate backdoor behavior. Neural Cleanse (NC) [17] synthesizes the backdoor trigger and prunes neurons activated by it. Entropy Pruning (EP) [35] identifies and prunes backdoor neurons based on the entropy of their pre-activation distributions. Channel Lipschitz Pruning (CLP) [34] introduces the channel lipschitz value to evaluate each neuron’s sensitivity to input and prunes backdoor neurons with high sensitivity. Shapely Pruning [6] analyzes neuron’s marginal contribution from a game-theory perspective.
Mask-based methods create masks for each neuron, optimize the masks with a specific objective function, and prune neurons with low mask values to mitigate backdoor behavior. Adversarial Neuron Pruning (ANP) [29] uses masks to perturb neuron weights and prune neurons more sensitive to the perturbation. Reconstructive Neuron Pruning (RNP) [16] optimizes masks through an unlearning-recovering process to expose backdoor neurons.
In summary, score-based methods evaluate the computable properties of backdoor neurons, while mask-based methods optimize masks to capture complex properties. Although some advanced methods, like CLP [34], ANP [29] and RNP [16] can effectively identify backdoor neurons and reduce the Attack Success Rate (ASR) to less than 1%, the backdoor mitigation performance often comes at the cost of the Clean Accuracy (reducing more than 2%), and hyperparameters need to be tuned to make these methods well-suited for different attacks. Both score-based and mask-based methods derive pruning policies with defined rules and are determined by the neuron’s local property. In contrast, our ONP derives pruning policies through a try-and-learn process and can be considered an optimization-based method different from the rule-based methods mentioned above.
2.3 Graph Neural Network
GNN [11] and its variants are widely used in processing graph structural data across diverse domains such as social networks, chemical molecules, and recommendation systems. GNNs extend the standard image convolution to graphs to aggregate neighbor structures and capture graph topology. Previous works [31, 10] in model compression have demonstrated that GNNs can effectively extract information from DNN structures, aiding in the optimization of pruning policies. Our proposed ONP uses the Graph Attention Network (GAT) [26], an advanced GNN employing attention to better capture complex relationships between nodes, to extract information from neuron connections.
3 Preliminaries
3.1 Notations
Consider a -class classification problem on a training set , with as the sample space and as the label space. Given a subset , the standard poisoning-based backdoor attack involves injecting the trigger pattern into input samples with the poisoning function and modifying corresponding labels with the label shifting function .
Let denote the victim model with parameter . We assume as a convolutional network with layers, regarding the fully connected layer as the convolutional layer with kernels. Denote as the function of the convolutional layer and as the weight matrix of it, where , , , are the number of output and input channels, the height and width of the convolutional kernel, respectively. consists of filters , and each filter consists of kernels . The output of can be expressed as:
| (1) |
where denotes the convolution operation, denotes the concatenation operation, is the nonlinear activation function (e.g., Relu), and denotes the output channel of (also the input channel of ).
3.2 Correlation between Backdoor and Clean Neurons
Given a test set , we define the clean loss and the backdoor loss of as follows:
| (2) | ||||
| (3) |
To evaluate the impact of filters on clean accuracy and backdoor behavior, we consider pruning them and measuring the change in loss. Pruning the -th filter of the -th layer refers to setting to an all-zero matrix, thus removing the corresponding output feature map. We denote the pruned network by . For each filter, the Clean Loss Change (CLC) and Backdoor Loss Change (BLC) are defined as follows:
| (4) | ||||
| (5) |

Pruning neurons with positive BLC values mitigates the backdoor behavior by increasing backdoor loss, while pruning neurons with positive CLC values reduces clean accuracy. Note that BLC and CLC values cannot be directly used for backdoor mitigation because the impact of pruning multiple filters on loss is nonlinear and hard to compute. Fig 1 shows the distribution of BLC and CLC values across 4 blocks of ResNet18. Neurons with positive BLC values fall into the first or second quadrant and can be potential backdoor neurons. Neurons with positive CLC values fall into the first or fourth quadrant. Neurons in the first quadrant can be considered both clean and backdoor neurons, making it more challenging to find a suitable pruning policy and motivating us to develop an optimization-based pruning method.
3.3 Neuron connections reveals backdoor neurons
-norm is widely used to evaluate the importance of each filter in model compression methods [13]. Since convolution is considered a special linear transformation, we can use the -norm of the convolutional kernel to measure the correlation between and . The -norm of a convolutional kernel can be written as:
| (6) |
where denotes a single weight of . Generally, kernels with smaller -norms produce lower activation values and have less numerical impact on the output feature map of the filter. Therefore, indicates the neuron connection strengths between the channel of and the channel of . By examining the connection strengths between consecutive convolutional layers, we have find that backdoor neurons tend to form strong connections with other backdoor neurons in the previous layer to amplify backdoor activation, while clean neurons show minimal connections with these backdoor neurons, as illustrated in Fig LABEL:fig4:a.



4 Methodology
Our proposed ONP defense is illustrated in Fig 3. Unlike other rule-based backdoor defense methods, ONP views pruning for backdoor mitigation as an optimization problem rather than a classification problem. In other words, it does not identify backdoor neurons by their properties but employs RL agents to iteratively find a nearly optimal pruning policy.
ONP draws profound inspiration from successful concepts in model compression research, such as neuron similarity [12, 7] and the joint training of GNN and RL agent[30, 10]. It first converts the infected DNN into multiple graphs to exploit the topological information within neuron connections, with each graph corresponding to a layer and each node corresponding to a specific channel. Then, ONP combines GNN and RL agents to learn pruning policies from the graphs. Each action taken by the agent results in channel-level pruning on the target DNN and changes to the graphs. The pruned DNN’s performance on clean samples and backdoor samples is used as rewards for the agent’s actions, encouraging the RL agent to continuously optimize the pruning policy for backdoor mitigation. In the following, we will explain further details on the graph construction and the RL agents.
4.1 Defense setting.
Following previous works [29, 16], we assume the defender has downloaded a backdoored model from an untrustworthy third party without knowledge of the attack or training data. We assume a small amount of clean data is available for defense. The goal of backdoor mitigation is to remove the backdoor behavior from the infected model with minimum degradation to its clean accuracy.
4.2 Graph Construction
Previous research [30, 31] on model compression has highlighted the value of topological information within DNNs for model pruning, inspiring us to explore whether connections between neurons can potentially expose backdoor neurons. To leverage the topological information, we develop a similarity-based method [12, 7] to incorporate neuron connection strengths into graphs. Consider a graph constructed for the layer , where the node set corresponds to the filters of . For the channel, we compute the connection strength , where represents the l1-norm of . Given two certain thresholds and , the edge set can be determined by the cosine similarity of neuron connections:
| (7) |
where and denote the l2-norm and the infinite norm of , respectively. Therefore, the connection strengths between neurons are transformed into edges in . Note that determines the number of edges and is used to filter dormant neurons. Part of a constructed graph is shown in Fig LABEL:fig3:b as an example, where potential backdoor nodes (neurons) are closely connected or neighboring nodes, indicating the effectiveness of our graph construction method.
Following previous work on model compression [10], we consider the distribution of model activation as the node feature, which reflects the importance of channels. Feeding images traversing the model, the average activation of the channel forms a set . Splitting the sampling interval into sub-intervals, the distribution of as well as the feature of the corresponding node in can be represented by a vector , where refers to:
| (8) |
4.3 Model Pruning with Reinforcement Learning
We employ GNN together with RL to learn from the constructed graph and find a suitable model pruning policy. In the following, we will explain the details of the RL agent.
4.3.1 Overview
ONP conducts pruning on the infected model in a layer-wise way, with each agent corresponding to a specific layer and determining the filters to be pruned. The pruning process starts from the last convolutional layer of the model, and the agents corresponding to the shallower layers work on the network pruned by the previous agents. Each agent contains a GAT [26] and is optimized by the Proximal Policy Optimization (PPO) [23] algorithm, since GAT is a spatial GNN well-suited for dynamic graphs, and PPO demonstrates faster convergence and superior performance on our task compared to other RL methods. Generally, We recommend applying ONP to a subset of deeper layers (e.g., the last two blocks for ResNet-18) to balance backdoor erasing performance and clean accuracy, as will be further discussed in Sect 5.
4.3.2 Environment states
We use the graph established in Section 2 as the environment for the agent. The agent’s action results in not only the pruning of specific neurons but also changes in the state of the environment. Once a neuron is pruned, we remove the corresponding node and edges from the constructed graph. As a result, the node embeddings learned by the GNN change accordingly to keep the RL agent informed of the current state of the DNN.
4.3.3 Action Space
The actions taken by the RL agent are directly the indices of neurons to be pruned in each step within a discrete space. The actor network contains a GAT encoding environment states into node embeddings and a multi-layer perception neural network (MLP) projecting node embeddings into logits for each neuron, followed by a softmax to convert the logits into probabilities. The behavior function is a categorical distribution determined by the probabilities:
| (9) |
To accelerate the convergence of the policy, we sample times from to get the action which determines the neurons to be pruned in each step.
4.3.4 Reward
To mitigate the infected model’s backdoor behavior while preserving its performance on clean task as much as possible, we design the reward as a function of BLC and CLC computed on a limited amount of defense data:
| (10) |
where refers to , denotes the partially-pruned DNN in step, and is a manually defined coefficient. The exponential function is applied to both the CLC and BLC terms to maximize the penalty for degradation on clean performance and counteract the exponential growth of BLC as the number of pruned neurons increases.
To compute BLC, we consider reverse engineering the backdoor triggers to get the poison dataset. Following previous work [6], we use Neural Cleanse [27] for backdoor trigger synthesis on our defense data and choose the trigger with the smallest l1-norm for defense and the corresponding class as the attack label. Note that our method is also compatible with other advanced trigger synthesis methods.
4.4 Pruning Strategy for ResNet
4.4.1 Residual Connections
Residual connections are widely used in many network structures and bring channel relevance between layers. Research in model compression [13, 1] has extensively studied pruning strategies for residual networks, while the residual connection’s impact on backdoor behavior is still unexplored. To address this gap, we have conducted a simple investigation. As is shown in Fig LABEL:fig4:a, the last two residual blocks of an infected ResNet-18 model are activated by the backdoor trigger in a similar way, and the indices of the activated channels are almost the same, which proves the channel relevance exists in deep layers and holds for backdoor activation.
4.4.2 Accelerating ONP with Group-based Pruning
Following previous work[1] on model compression, we divide all layers into groups. The convolution layers within each group share the same number of output channels and are interconnected through residual connections. For ResNet, a group corresponds to a ResNet block comprising more than two residual blocks. Pruning an output channel of the whole group refers to pruning all related neurons across different layers, as is shown in Fig LABEL:fig4:b. For the model-to-graph method introduced in Sect 4.2, we use the weight matrix of the last convolutional layer to compute neuron connection strengths and construct only one graph for each group. In this way, only 1 agent is needed for a ResNet18 Block of 4 convolutional layers, cutting 75% computing costs.


Datasets Backdoor Attacks Backdoored FP ANP CLP RNP ONP (Ours) ONP/o (Ours) ASR CA ASR CA ASR CA ASR CA ASR CA ASR CA ASR CA CIFAR-10 BadNets 100.00 92.43 25.31 81.45 1.12 90.27 1.34 90.54 0.53 91.09 0.44 92.00 0.76 92.20 Trojan 100.00 92.68 62.57 82.63 1.31 90.78 2.87 91.16 2.03 91.85 0.72 92.26 0.72 92.26 Blend 99.99 92.15 76.44 83.26 0.90 90.82 1.67 91.61 0.54 91.53 1.58 91.89 0.44 91.54 CL 98.93 91.55 36.42 81.38 5.47 89.96 1.54 89.51 0.39 90.63 0.92 90.50 0.33 90.90 Dynamic 99.66 94.60 38.95 85.42 1.52 93.67 4.71 93.20 2.34 94.19 2.16 93.47 0.35 93.98 WaNet 98.81 92.12 69.74 80.53 4.79 91.06 4.14 90.58 3.02 91.60 1.76 91.34 0.88 91.75 Average 99.57 92.59 60.98 82.45 2.52 91.09 2.71 91.10 1.48 91.82 1.26 91.91 0.58 92.11 Tiny ImageNet BadNets 99.80 58.78 50.32 48.56 2.78 58.20 1.51 57.33 0.10 58.26 0.96 57.84 0.53 58.42 Trojan 99.99 59.13 93.44 49.75 8.49 57.46 1.29 58.35 0.60 58.84 0.46 57.85 0.31 58.51 Blend 99.99 57.12 83.71 51.24 0.84 56.03 0.77 56.18 0.92 56.25 2.32 56.34 0.55 56.57 CL 72.08 60.42 49.51 53.22 10.59 58.93 2.16 60.21 0.34 60.07 0.74 58.78 0.56 60.19 Dynamic 98.78 61.20 87.31 55.24 5.68 60.07 10.45 58.86 6.33 60.45 7.15 59.66 3.39 60.71 WaNet 97.53 59.56 68.72 55.23 13.54 57.38 3.76 58.43 7.64 58.69 2.52 55.83 1.41 56.39 Average 94.70 59.37 72.17 52.21 6.94 58.01 3.32 58.23 2.66 58.76 2.06 57.72 1.13 58.47
5 Experiments
5.1 Experimental Setup
5.1.1 Attack Setup.
We evaluate ONP against 6 famous attacks. These include 4 static attacks: BadNets [5], Trojan [19], Blend [2], and Clean Label [25], as well as 2 dynamic attacks: Dynamic [20] and WaNet [21]. Default settings from original papers and open-source codes are followed for most attacks, including backdoor trigger pattern and size. The backdoor label of all attacks is set to class 0, with a default poisoning rate of 10%. Attacks are performed on CIFAR-10 and Tiny ImageNet using ResNet-18. For training setups, Stochastic Gradient Descent (SGD) is utilized with an initial learning rate 0.1, weight decay 5e-4, momentum 0.9, batch size 128 for 200 epochs on CIFAR-10, and batch size 64 for 150 epochs on Tiny ImageNet. A cosine scheduler is employed to adjust the learning rate.
5.1.2 Defense Setup.
We compare ONP with 4 pruning-based backdoor mitigation methods, including Fine-Pruning [17], and state-of-the-art methods ANP [29], CLP [34] and RNP [16]. CLP is data-free and all other defenses share limited access to only 1% clean samples from the benign training data. We adapt hyperparameters for these defenses based on open-source codes to obtain best performance against different attacks. For ONP, we set hyperparameter to 5 for CIFAR-10 and 10 for Tiny ImageNet. and are adaptive adjusted to conserve 5% edges 50% nodes in each graph. The impact of these hyperparameters will be discussed in Sect. 5.3.2. ONP is applied to the last two blocks of ResNet18 for most attacks to balance backdoor elimination and clean accuracy. For Blend and WaNet, ONP is applied to all blocks, because their trigger patterns covers the whole image, thus more backdoor neurons are implanted in shallow layers. Policy of each agent is updated every 16 search episodes, and is optimized for 100 search episodes in total. Other settings follow the open-source code of PPO algorithm [23]. Backdoor trigger synthesis follows the original setup in Neural Cleanse paper[27], optimizing triggers for each class and choosing the trigger with smallest -norm for defense and assigning the corresponding class as the attack target label.
5.1.3 Evaluation Metric.
We adopt two metrics for evaluating backdoor mitigation performance: 1) Clean Accuracy (CA), which is the model’s accuracy on clean test data; 2) Attack Success Rate (ASR), which is the model’s accuracy on backdoored test data.
5.2 Main Defense Results
5.2.1 Results on CIFAR-10
Table 1 presents the defense performance of 5 pruning methods against 6 backdoor attacks on CIFAR-10 and Tiny ImageNet. On CIFAR10, the standard ONP method outperforms other defense methods by cutting the average ASR down to 1.26% with a slight drop on CA (lower than 1% on average). In comparison, FP, ANP, CLP, RNP reduce the average ASR to 60.98%, 2.52%, 2.71%, and 1.48%, respectively. ONP shows weakness against Blend, CL, and Dynamic attacks due to its reliance on the backdoor trigger synthesized by NC. The ONP/o results clearly show that ONP can be further improved by applying advanced trigger synthesis methods. Despite the limitations of trigger synthesis methods, ONP still effectively defends against static and dynamic backdoor attacks, revealing the potential of optimization-based pruning in backdoor mitigation. Among other defense methods, RNP demonstrates promising and remarkable performance in defending against most attacks, while ANP and CLP exhibit their own strengths. However, FP shows the poorest performance in most settings, indicating that pruning dormant neurons may not be an effective choice for backdoor mitigation against advanced attacks.
5.2.2 Results on Tiny ImageNet
Trigger reverse synthesis becomes more challenging on Tiny ImageNet, which further limits the performance of ONP. Despite these challenges, ONP remain competitive among state-of-the-art backdoor mitigation methods, with an average ASR reduction of 92.64% and a acceptable average CA decrease of 1.65%. RNP is also highlighted as an effective defense on Tiny ImageNet.
However, ONP/o achieves lower ASR than RNP under most settings, especially against dynamic attacks (<5% on average), which further emphasizes the effectiveness of the optimization of pruning policy.
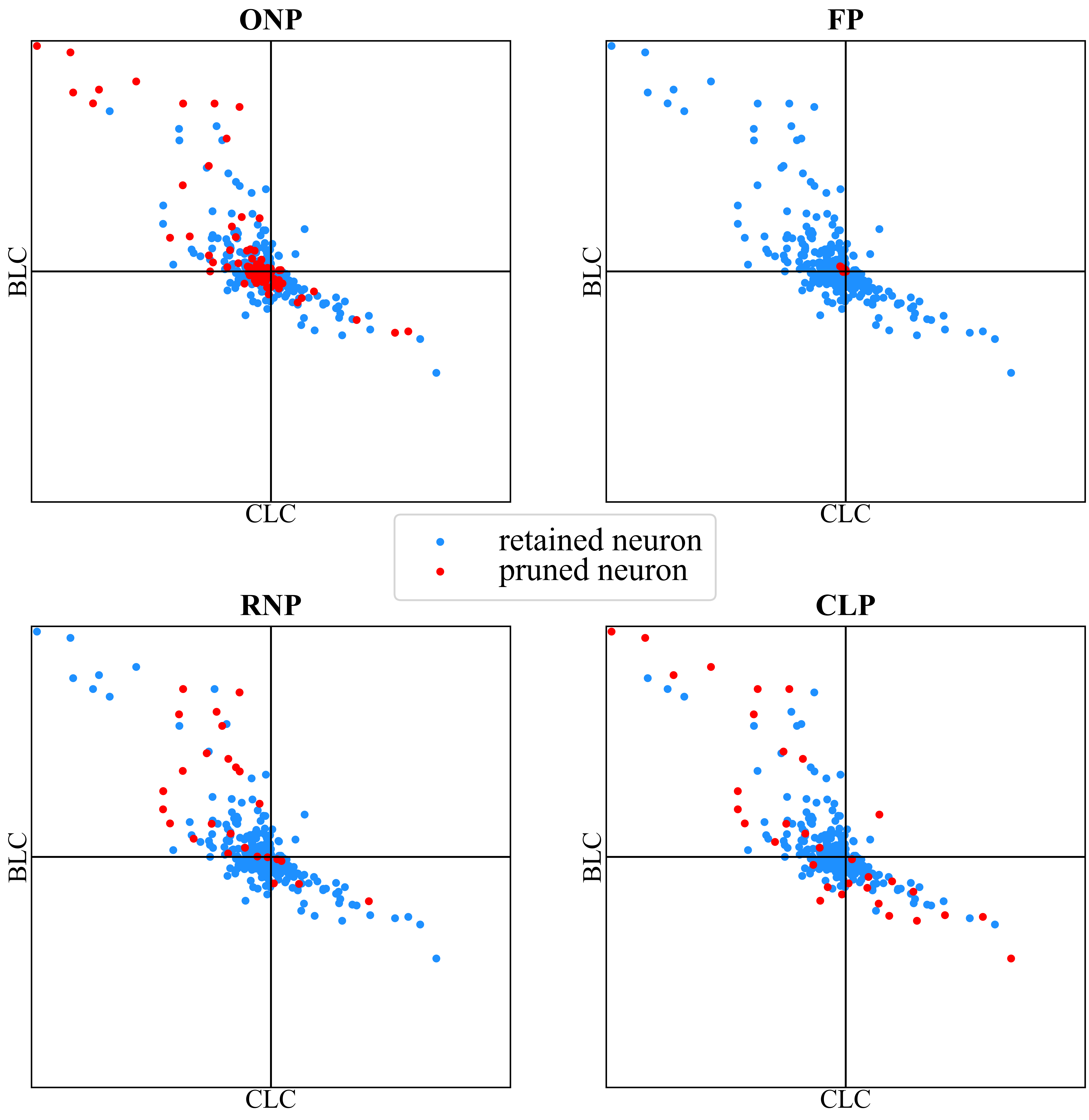
5.2.3 Analysis of Pruning Policies
We compare the pruning policies derived from different defense methods, as shown in Fig 5. For the last convolutional layer of the backdoored model, FP prunes 88 dormant neurons but does not hit any potential backdoor neurons, which is not sufficient for backdoor mitigation. RNP and CLP both prune 33 neurons and prove their effectiveness in identifying potential backdoor neurons. However, RNP doesn’t find neurons with the biggest BLC values in the second quadrant, while CLP mistakenly prunes some clean neurons in the fourth quadrant. Our ONP prunes 136 neurons, including neurons with largest BLC values for erasing the backdoor and neurons with negative CLC values for compensating for the decrease in clean accuracy. By optimizing the agent with a limited amount of clean data, ONP find the most potential backdoor neurons in the second quadrant, despite some mistakenly pruned clean neurons in the fourth quadrant. Although our ONP can be further improved to reduce the number of unnecessarily pruned neurons, it’s enough to reveal the significance of optimizing pruning policies for backdoor mitigation.
5.3 Ablation Studies
5.3.1 Impact of Defense Data Size
In this part, we evaluate the impact of defense data size on the optimization of pruning policies. We use 0.1%(50), 0.5% (250), 1% (500) and 5% (2500) images from the clean CIFAR-10 training set for defense, respectively. Results in Fig 6 show that as defense data size increases, the distribution of defense data aligns more closely to the real test set, enhancing the computed reward and further improving CA. Simultaneously, trigger synthesis quality also improves, aiding the RL agent in identifying more backdoor neurons and further reducing ASR. Generally, 1% defense data is sufficient for ONP to achieve high CA and low ASR against most attacks, making it suitable for data-limited scenarios.

5.3.2 Choice of Hyperparameters
As is mentioned in Section 3.2, the ONP hyperparameter balances the backdoor erasing performance and clean accuracy of the pruned model. A higher makes the agent more conservative and tends to avoid degradation to CA, while a lower allows for more CA reduction, enabling the agent to prune more backdoor neurons and further reduce ASR. Setting is recommended for most scenarios. and influence graph construction. filters dormant neurons with small weights to reduce search space for the agent, while conserves edges with the highest weight for neurons with similar connection strength. To alleviate the difference between layers and models, we suggest adaptive settings for and to conserve 5% edges and 50% nodes for each layer, which is proved to be effective for most scenarios.
5.3.3 Performance Across Architectures and Datasets
We extend the evaluation of ONP to diverse settings, including VGG16 on MNIST, Pre-Activation ResNet101 on GTSRB, and ResNet34 on YouTubeFace, all attacked by BadNets. ONP is selectively applied to the last 3 convolutional layers or blocks. The defense results are shown in 2. ONP reduces the ASR down to 0.29%, 0.36%, and 0.44%, respectively, with negligible degradation to CA, proving the robustness of ONP across different layers and architectures.
5.3.4 Running Time
ONP uses RL to optimize pruning policies and needs computing loss on the defense data to obtain rewards. However, it does not perform back
Datasets MNIST GTSRB YouTubeFace CA ASR CA ASR CA ASR Backdoored 98.74 100.00 96.80 100.00 97.79 100.00 ONP 98.21 0.29 96.31 0.36 97.64 0.44
propagation on the backdoored model and only needs to train the PPO agent with fewer parameters. We record the running time of ONP on RTX 3090Ti GPU with 500 CIFAR-10 samples and a ResNet18 model attacked by BadNets. ONP is applied to the last 2 ResNet blocks, and 2 agents are optimized for a total of 200 episodes. It costs ONP 6 minutes and 27 seconds to reduce the ASR to 0.44, slower than the rule-based methods including CLP (1 second), FP (30 seconds) ANP (45 seconds) and RNP (2 minutes and 11 seconds). However, ONP achieves better backdoor mitigation performance, and the computing cost is acceptable compared to retraining the model from scratch (more than 1 hour).
6 Conclusion
In this paper, we rethink pruning for backdoor mitigation from an optimization perspective and propose ONP, the first optimization-based pruning framework for backdoor mitigation. We explore the connections between backdoor neurons and convert the DNN into graphs based on the neuron connection strength to expose backdoor neurons. We combine GNN and RL to perform pruning on both the graph and the infected model to search for the optimal pruning policy. Additionally, we investigate the impact of residual connections on backdoor activation and extend pruning strategies for residual connections from model compression to backdoor mitigation. We empirically show the effectiveness of ONP as a backdoor mitigation method and emphasize the significance of optimization for backdoor mitigation. We hope our work can offer some insights for developing more powerful backdoor defense methods in the future.
References will then be sorted and formatted in the correct style.
References
- [1] Chen, T., Ji, B., Ding, T., Fang, B., Wang, G., Zhu, Z., Liang, L., Shi, Y., Yi, S., Tu, X.: Only Train Once: A One-Shot Neural Network Training And Pruning Framework. In: Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P.S., Vaughan, J.W. (eds.) NeurIPS. vol. 34, pp. 19637–19651. Curran Associates, Inc. (2021)
- [2] Chen, X., Liu, C., Li, B., Lu, K., Song, D.: Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. CoRR abs/1712.05526 (2017)
- [3] Cheng, S., Liu, Y., Ma, S., Zhang, X.: Deep Feature Space Trojan Attack of Neural Networks by Controlled Detoxification. In: AAAI. pp. 1148–1156. AAAI Press (2021)
- [4] Garg, S., Kumar, A., Goel, V., Liang, Y.: Can Adversarial Weight Perturbations Inject Neural Backdoors. In: CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management. pp. 2029–2032. ACM (2020)
- [5] Gu, T., Dolan-Gavitt, B., Garg, S.: Badnets: Identifying vulnerabilities in the machine learning model supply chain. arXiv preprint arXiv:1708.06733 (2017)
- [6] Guan, J., Tu, Z., He, R., Tao, D.: Few-shot Backdoor Defense Using Shapley Estimation. In: CVPR. pp. 13348–13357. IEEE, New Orleans, LA, USA (Jun 2022)
- [7] He, Y., Liu, P., Wang, Z., Hu, Z., Yang, Y.: Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration. In: CVPR. pp. 4340–4349. Computer Vision Foundation / IEEE (2019)
- [8] Hu, X., Lin, X., Cogswell, M., Yao, Y., Jha, S., Chen, C.: Trigger Hunting with a Topological Prior for Trojan Detection. In: ICLR (2021)
- [9] Huang, K., Li, Y., Wu, B., Qin, Z., Ren, K.: Backdoor Defense via Decoupling the Training Process. In: ICLR. OpenReview.net (2022)
- [10] Jiang, D., Cao, Y., Yang, Q.: On the Channel Pruning using Graph Convolution Network for Convolutional Neural Network Acceleration. In: Raedt, L.D. (ed.) IJCAI. pp. 3107–3113. ijcai.org (2022)
- [11] Kipf, T.N., Welling, M.: Semi-Supervised Classification with Graph Convolutional Networks. In: ICLR. OpenReview.net (2017)
- [12] Lei, W., Chen, H., Wu, Y.: Compressing deep convolutional networks using k-means based on weights distribution. In: Proceedings of the 2nd International Conference on Intelligent Information Processing. pp. 1–6 (2017)
- [13] Li, H., Kadav, A., Durdanovic, I., Samet, H., Graf, H.P.: Pruning Filters for Efficient ConvNets. In: ICLR. OpenReview.net (2017)
- [14] Li, Y., Lyu, X., Koren, N., Lyu, L., Li, B., Ma, X.: Neural Attention Distillation: Erasing Backdoor Triggers from Deep Neural Networks. In: International Conference on Learning Representations (2020)
- [15] Li, Y., Lyu, X., Koren, N., Lyu, L., Li, B., Ma, X.: Anti-Backdoor Learning: Training Clean Models on Poisoned Data. In: NeurIPS. pp. 14900–14912 (2021)
- [16] Li, Y., Lyu, X., Ma, X., Koren, N., Lyu, L., Li, B., Jiang, Y.G.: Reconstructive Neuron Pruning for Backdoor Defense. In: ICML. ICML’23, JMLR.org (2023)
- [17] Liu, K., Dolan-Gavitt, B., Garg, S.: Fine-pruning: Defending against backdooring attacks on deep neural networks. In: International symposium on research in attacks, intrusions, and defenses. pp. 273–294. Springer (2018)
- [18] Liu, Y., Lee, W.C., Tao, G., Ma, S., Aafer, Y., Zhang, X.: Abs: Scanning neural networks for back-doors by artificial brain stimulation. In: Proceedings of the 2019 ACM SIGSAC conference on computer and communications security. pp. 1265–1282 (2019)
- [19] Liu, Y., Ma, S., Aafer, Y., Lee, W.C., Zhai, J., Wang, W., Zhang, X.: Trojaning Attack on Neural Networks. In: 25th Annual Network and Distributed System Security Symposium. The Internet Society (2018)
- [20] Nguyen, T.A., Tran, A.T.: Input-Aware Dynamic Backdoor Attack. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H.T. (eds.) NeurIPS (2020)
- [21] Nguyen, T.A., Tran, A.T.: WaNet - Imperceptible Warping-based Backdoor Attack. In: ICLR. OpenReview.net (2021)
- [22] Qi, X., Xie, T., Pan, R., Zhu, J., Yang, Y., Bu, K.: Towards Practical Deployment-Stage Backdoor Attack on Deep Neural Networks. In: CVPR. pp. 13337–13347. IEEE (2022)
- [23] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal Policy Optimization Algorithms. arXiv preprint arXiv: 1707.06347 (2017)
- [24] Shafahi, A., Huang, W.R., Najibi, M., Suciu, O., Studer, C., Dumitras, T., Goldstein, T.: Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks. In: NeurIPS. pp. 6106–6116 (2018)
- [25] Turner, A., Tsipras, D., Madry, A.: Clean-label backdoor attacks. https://people.csail.mit.edu/madry/lab/ (2019)
- [26] Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y.: Graph Attention Networks. In: ICLR. OpenReview.net (2018)
- [27] Wang, B., Yao, Y., Shan, S., Li, H., Viswanath, B., Zheng, H., Zhao, B.Y.: Neural Cleanse: Identifying and Mitigating Backdoor Attacks in Neural Networks. In: 2019 IEEE Symposium on Security and Privacy (SP). pp. 707–723. IEEE Computer Society (2019)
- [28] Wang, Z., Ding, H., Zhai, J., Ma, S.: Training with More Confidence: Mitigating Injected and Natural Backdoors During Training. In: NeurIPS (2022)
- [29] Wu, D., Wang, Y.: Adversarial Neuron Pruning Purifies Backdoored Deep Models. In: NeurIPS. vol. 34, pp. 16913–16925. Curran Associates, Inc. (2021)
- [30] Yu, S., Mazaheri, A., Jannesari, A.: Auto Graph Encoder-Decoder for Neural Network Pruning. In: ICCV. pp. 6342–6352. IEEE, Montreal, QC, Canada (Oct 2021)
- [31] Yu, S., Mazaheri, A., Jannesari, A.: Topology-aware network pruning using multi-stage graph embedding and reinforcement learning. In: International conference on machine learning. pp. 25656–25667. PMLR (2022)
- [32] Zeng, Y., Chen, S., Park, W., Mao, Z., Jin, M., Jia, R.: Adversarial Unlearning of Backdoors via Implicit Hypergradient. In: ICLR. OpenReview.net (2022)
- [33] Zhao, Z., Chen, X., Xuan, Y., Dong, Y., Wang, D., Liang, K.: DEFEAT: Deep Hidden Feature Backdoor Attacks by Imperceptible Perturbation and Latent Representation Constraints. In: CVPR. pp. 15192–15201. IEEE (2022)
- [34] Zheng, R., Tang, R., Li, J., Liu, L.: Data-free backdoor removal based on channel lipschitzness. In: European Conference on Computer Vision. pp. 175–191. Springer (2022)
- [35] Zheng, R., Tang, R., Li, J., Liu, L.: Pre-activation Distributions Expose Backdoor Neurons. In: NeurIPS (2022)