Representation Matters:
Assessing the Importance of Subgroup Allocations
in Training Data
Abstract
Collecting more diverse and representative training data is often touted as a remedy for the disparate performance of machine learning predictors across subpopulations. However, a precise framework for understanding how dataset properties like diversity affect learning outcomes is largely lacking. By casting data collection as part of the learning process, we demonstrate that diverse representation in training data is key not only to increasing subgroup performances, but also to achieving population-level objectives. Our analysis and experiments describe how dataset compositions influence performance and provide constructive results for using trends in existing data, alongside domain knowledge, to help guide intentional, objective-aware dataset design.
1 Introduction
Datasets play a critical role in shaping the perception of performance and progress in machine learning (ML)—the way we collect, process, and analyze data affects the way we benchmark success and form new research agendas (Paullada et al., 2020; Dotan & Milli, 2020). A growing appreciation of this determinative role of datasets has sparked a concomitant concern that standard datasets used for training and evaluating ML models lack diversity along significant dimensions, for example, geography, gender, and skin type (Shankar et al., 2017; Buolamwini & Gebru, 2018). Lack of diversity in evaluation data can obfuscate disparate performance when evaluating based on aggregate accuracy (Buolamwini & Gebru, 2018). Lack of diversity in training data can limit the extent to which learned models can adequately apply to all portions of a population, a concern highlighted in recent work in the medical domain (Habib et al., 2019; Hofmanninger et al., 2020).
Our work aims to develop a general unifying perspective on the way that dataset composition affects outcomes of machine learning systems. We focus on dataset allocations: the number of datapoints from predefined subsets of the population. While we acknowledge that numerical inclusion of groups is an imperfect proxy of representation, we believe that allocations provide a useful initial mathematical abstraction for formulating relationships among diversity, data collection, and statistical risk. We discuss broader implications of our formulation in Section 5.
With the implicit assumption that the learning task is well specified and performance evaluation from data is meaningful for all groups, we ask:
-
1.
Are group allocations in training data pivotal to performance? To what extent can methods that up-weight underrepresented groups help, and when might upweighting actually hurt performance?
Taking a point of view that data collection is a critical component of the overall machine learning process, we study the effect that dataset composition has on group and population accuracies. This complements work showing that simply gathering more data can mitigate some sources of bias or unfairness in ML outcomes (Chen et al., 2018), a phenomenon which has been observed in practice as well. Indeed, in response to the Gender Shades study (Buolamwini & Gebru, 2018), companies selectively collected additional data to decrease the exposed inaccuracies of their facial recognition models for certain groups, often raising aggregate accuracy in the process (Raji & Buolamwini, 2019). Given the potential for targeted data collection efforts to repair unintended outcomes of ML systems, we next ask:
-
2.
How might we describe “optimal” dataset allocations for different learning objectives? Does the often-witnessed lack of diversity in large-scale datasets align with maximizing population accuracy?
We show that purposeful data collection efforts can proactively support intentional objectives of an ML system, and that diversity and population objectives are often aligned. Many datasets have recently been designed or amended to exhibit diversity of the underlying population (Ryu et al., 2017; Tschandl et al., 2018; Yang et al., 2020). Such endeavors are significant undertakings, as data gathering and annotation must consider consent, privacy, and power concerns in addition to inclusivity, transparency and reusability (Gebru et al., 2018; Gebru, 2020; Wilkinson et al., 2016). Given the importance of more representative and diverse datasets, and the effort required to create them, our final question asks:
-
3.
When and how can we leverage existing datasets to help inform better allocations, towards achieving diverse objectives in a subsequent dataset collection effort?
Representation bias, or systematic underrepresentation of subpopulations in data, is one of many forms of bias in ML (Suresh & Guttag, 2019). Our work provides a data-focused perspective on the design and evaluation of ML pipelines. Our main contributions are:
-
1.
We analyze the complementary roles of dataset allocation and algorithmic interventions for achieving per-group and total-population performance (Section 2). Our experiments show that while algorithmically up-weighting underrepresented groups can help, dataset composition is the most consistent determinant of performance (Section 4.2).
-
2.
We propose a scaling model that describes the impact of dataset allocations on group accuracies (Section 3). Under this model, when parameters governing the relative values of within-group data are equal for all groups, the allocation that minimizes population risk overrepresents minority groups.
-
3.
We demonstrate that our proposed scaling model captures major trends of the relationship between dataset allocations and performance (Sections 4.3 and 4.5). We evidence that a small initial sample can be used to inform subsequent data collection efforts to, for example, maximize the minimum accuracy over groups without sacrificing population accuracy (Section 4.4).
Sections 2 and 3 formalize data collection as part of the learning problem and derive results under illustrative settings. Experiments in Section 4 support these results and expose nuances inherent to real-data contexts. Section 5 synthesizes results and delineates future work.
1.1 Additional Related Work
Targeted data collection in ML. Recent research evidences that targeted data collection can be an effective way to reduce disparate performance of ML models evaluated across sub-populations (Raji & Buolamwini, 2019). Chen et al. (2018) present a formal argument that the addition of training data can lessen discriminatory outcomes while improving accuracy of learned models, and Abernethy et al. (2020) show that adaptively collecting data from the lowest-performing sub-population can increase the minimum accuracy over groups. At the same time, there are many complexities of gathering data as a solution to disparate performance across groups. Targeted data collection from specific groups can present undue burdens of surveillance or skirt consent (Paullada et al., 2020). When ML systems fail portions of their intended population due to issues of measurement and construct validity, more thorough data collection is unlikely to solve the issue without further intervention (Jacobs & Wallach, 2019).
With these complexities in mind, we study the importance of numerical representation in training datasets in achieving diverse objectives. Optimal allocation of subpopulations in statistical survey designs dates back to at least Neyman (1934), including stratified sampling methods to ensure coverage across sub-populations (Lohr, 2009). For more complex prediction systems, the field of optimal experimental design (Pukelsheim, 2006) studies what inputs are most valuable for reaching a given objective, often focusing on linear prediction functions. We consider a constrained sampling structure and directly model the impact of group allocations on subgroup performance for general model classes.
Valuing data. In economics, allocations indicate a division of goods to various entities (Cole et al., 2013). While we focus on the influence of data allocations on model accuracies across groups, there are many approaches to valuing data. Methods centering on a theory of Shapley valuations (Yona et al., 2019; Ghorbani & Zou, 2019) complement studies of the influence of individual data points on model performance to aid subsampling data (Vodrahalli et al., 2018).
Methods for handling group-imbalanced data. Importance sampling and importance weighting are standard approaches to addressing class imbalance or small groups sizes (Haixiang et al., 2017; Buda et al., 2018), though the effects of importance weighting for deep learning may vary with regularization (Byrd & Lipton, 2019). Other methods specifically address differential performance between groups. Maximizing minimum performance across groups can reduce accuracy disparities (Sagawa et al., 2020) and promote fairer sequential outcomes (Hashimoto et al., 2018). For broader classes of group-aware objectives, techniques exist to mitigate unfairness or disparate performance of black box prediction functions (Dwork et al., 2018; Kim et al., 2019). It might not be clear a priori which subsets need attention; Sohoni et al. (2020) propose a method to identify and account for hidden strata, while other methods are defined for any subsets (Hashimoto et al., 2018; Kim et al., 2019).
1.2 Notation
denotes the -dimensional simplex. denotes non-negative integers and non-negative reals.
2 Training set allocations and alternatives
We study settings in which each data instance is associated with a group , so that the training set can be expressed as where denote the features and labels of each instance. We index the discrete groups by integers , or when we specifically consider just two groups, we write . We assume that groups are disjoint and cover the entire population, with denoting the population prevalence of group , so that . Groups could represent inclusion in one of many binned demographic categories, or simply a general association with latent characteristics that are relevant to prediction.
For a given population with distribution over features, labels, and groups, we are interested in the population level risk, , of a predictor trained on dataset , as well as group specific risks. Denoting the group distributions by , defined as conditional distributions, via , the population risk decomposes as a weighted average over group risks:
| (1) |
In Section 2.2 we will assume that the loss is a separable function over data instances. While this holds for many common loss functions, some objectives do not decouple in this sense (e.g., group losses and associated classes of fairness-constrained objectives; see Dwork et al., 2018). We revisit this point in Sections 4 and 5.
2.1 Training Set Allocations
In light of the decomposition of the population-level risk as a weighted average over group risks in Eq. (1), we now consider the composition of fixed-size training sets, in terms of how many samples come from each group.
Definition 1 (Allocations).
Given a dataset of triplets, , the allocation describes the relative proportions of each group in the dataset:
| (2) |
It will be illuminating to consider not only as a property of an existing dataset, but as a parameter governing dataset construction, as captured in the following definition.
Definition 2 (Sampling from allocation ).
Given the sample size , group distributions , and allocation , such that , to sample from allocation is procedurally equivalent to independent sampling of disjoint datasets and concatenating:
| (3) | |||
For not satisfying the requirement that is integral, we could randomize the fractional allocations, or take , reducing the total number of samples to . In the following sections we will generally allow allocations with , assuming that the effect of up to fractionally assigned instances is negligible for large .
The procedure in Definition 2 suggests formalizing data collection as a component of the learning process in the following way: in addition to choosing a loss function and method for minimizing the risk, choose the relative proportions at which to sample the groups in the training set:
In Section 3, we show that when a dataset curator can design dataset allocations in the sense of Definition 2, they have the opportunity to improve accuracy of the trained model. Of course, one does not always have the opportunity to collect new data or modify the composition of an existing dataset. Section 2.2 considers methods for using fixed datasets that have groups with small training set allocation , relative to , or high risk for some groups relative to the population.
2.2 Accounting for Small Group Allocations in Fixed Datasets
In classical empirical risk minimization (ERM), one learns a function from class that minimizes average prediction loss over the training instances (we also abuse notation and write ) with optional regularization :
There are many methods for addressing small group allocations in data (see Section 1.1). Of particular relevance to our work are objective functions that minimize group or population risks. In particular, one approach is to use importance weighting (IW) to re-weight training samples with respect to a target distribution defined by :
This empirical risk with instances weighted by is an unbiased estimate of the population risk, up to regularization. While unbiasedness is often desirable, IW can induce high variance of the estimator when is large for some group (Cortes et al., 2010), which happens when group is severely underrepresented in the training data relative to their population prevalence.
Alternatively, group distributionally robust optimization (GDRO) (Hu et al., 2018; Sagawa et al., 2020) minimizes the maximum empirical risk over all groups:
For losses which are continuous and convex in the parameters of , the optimal GDRO solution corresponds to the minimizer of a group-weighted objective: , though this is not in general true for nonconvex losses (see Prop. 1 of Sagawa et al., 2020, and the remark immediately thereafter).
Given the correspondence of GDRO (for convex loss functions) and IW to the optimization of group-weighted ERM objectives, we now investigate the joint roles of sample allocation and group re-weighting for estimating group-weighted risks. For prediction function , loss function , and group weights , let be the random variable defined by:
where the randomness in comes from the draws of from according to procedure (Definition 2), as well as any randomness in .
The following proposition shows that group weights and allocations play complementary roles in risk function estimation. In particular, if depends on the sampling allocations , then there are alternative group weights and allocation such that the alternative estimator has the same expected value but lower variance.
Proposition 1 (Weights and allocations).
For any loss , prediction function and group distributions , there exist weights with such that for any triplet with , if ,111We use the symbol to denote “not approximately proportional to.” The approximately part of this relation stems from finite and integer sample concerns; for example, the proposition holds if we consider to mean . there exists an alternative allocation such that
If , and if , .
Proof.
(Sketch; the full proof appears in Section A.1.) For any deterministic weighting function , there exists a vector with entries such that
for constant . For any fixed and any “target distribution" defined by , the () pair which minimizes the variance of the estimator, constrained so that , has weights with form given above. Since the original satisfy this constraint, the minimizing pair must satisfy , and . ∎
Since the estimation of risk functions is a key component of learning, Proposition 1 illuminates an interplay between the roles of sampling allocations and group-weighting schemes like IW and GDRO. When allocations and weights are jointly maximized, the optimal allocation accounts for an implicit target distribution (defined above), which may vary by objective function. The optimal weights account for per-group variability . In Section 4 we find that it can be advantageous to use IW and GDRO when some groups have small ; though the boost in accuracy is less than having an optimally allocated training set to begin with, and diminishes when all groups are appropriately represented in the training set allocation.
3 Allocating samples to minimize population-level risk
Having motivated the importance of group allocations, we now investigate the direct effects of training set allocations on group and population risks. Using a model of per-group performance as a function of allocations, we study the optimal allocations under a variety of settings.
3.1 A Per-group Power-law Scaling Model
We model the impact of allocations on performance with scaling laws that describe per-group risks as a function of the number of data points from their respective group, as well as the total number of training instances.
Assumption 1 (Group risk scaling with allocation).
The group risks scale approximately as the sum of inverse power functions on the number of samples from group and the total number of samples. That is, , , and such that for a learning procedure which returns predictor , and training set with group sizes :
| (4) |
1 is similar to the scaling law in Chen et al. (2018), but includes a term to allow for data from other groups to influence the risk evaluated on group . It additionally requires that the same exponents apply to each group, an assumption that underpins our theoretical results in Section 3. We examine the extent to which 1 holds empirically in Section 4.3, and will modify Eq. (1) to include group-dependent terms when appropriate. The following examples give intuition into the form of Eq. (1).
Example 1 (Split classifiers per group).
It is often advantageous to pool training data to learn a single classifier. In this case, model performance evaluated on group will depend on both and , as the next examples show.
Example 2 (Groups irrelevant to prediction).
When groups are irrelevant for prediction and the model class correctly accounts for this, we expect Eq. (1) to apply with .
Example 3 (Shared linear model with group-dependent intercepts).
Consider a -dimensional linear model, where two groups, , share a weight vector and features , but the intercept varies by group:
As we show in Section A.5, the ordinary least squares predictor has group risks where the arises because we need samples from group to estimate the intercept , whereas samples from both groups help us estimate .
Example 3 suggests that in some settings, we can relate and to ‘group specific’ and ‘group agnostic’ model components that affect performance for group . In general, the relationship between group sizes and group risks can be more nuanced. Data from different groups may be correlated, so that samples from groups similar to or different from have greater effect on (see Section 4.5). Eq. 1 is meant to capture the dominant effects of training set allocations on group risks and serves as our main structural assumption in the next section, where we study the allocation that minimizes the approximate population risk.
3.2 Optimal (w.r.t. Population Risk) Allocations
We now study properties of the allocation that minimizes the approximated population risk:
| (5) |
The following proposition lays the foundation for two corollaries which show that:
-
(1)
when only the population prevalences vary between groups, the allocation that minimizes the approximate population risk up-represents groups with small ;
-
(2)
for two groups with different scaling parameters , the optimal allocation of the group with is bounded by functions of , and .
Proposition 2.
The proof of Proposition 2 appears in Section A.2. Note that does not depend on , , or ; this will in general not hold if powers differ by group.
We now study the form of under illustrative settings. Corollary 1 shows that when the group scaling parameters in Eq. (1) are equal across groups, the allocation that minimizes the approximate population risk allocates samples to minority groups at higher than their population prevalences. The proof of Corollary 1 appears in Section A.3.
Corollary 1 (Many groups with equal ).
When , the allocation that minimizes in Eq. (5) satisfies for any group with .
This shows that the allocation that minimizes population risk can differ from the actual population prevalences . In fact, Corollary 1 asserts that near the allocation , the marginal returns to additional data from group are largest for groups with small , enough so as to offset the small weight in Eq. (1). This result provides evidence against the idea that small training set allocation to minority groups might comply with minimizing population risk as a result of a small relative contribution to the population risk.
Remark. A counterexample shows that does not hold for all with . Take and ; Eq. (6) gives . In general, whether group with gets up- or down-sampled depends on the distribution of across all groups.
Complementing the investigation of the role of the population proportions in Corollary 1, the next corollary shows that the optimal allocation generally depends on the relative values of between groups. Inspecting Eq. (1) shows that defines a limit of performance: if is large, the only way to make the approximate risk for group small is to make large. For two groups, we can bound the optimal allocations in terms of , and the population proportions . We let be the smaller of the two groups without loss of generality. From Eq. (6), we know that for two groups, is increasing in ; Corollary 2 gives upper and lower bounds on in terms of and . Corollary 2 is proved in Section A.4.
Corollary 2 (Unequal per-group constants).
Altogether, these results highlight key properties of training set allocations that minimize population risk. Experiments in Section 4 give further insight into the values of weights and allocations for minimizing group and population risks and apply the scaling law model in real data settings.
4 Empirical Results
Having shown the importance of training set allocations from a theoretical perspective, we now provide a complementary empirical investigation of this phenomenon. Throughout our experiments, we use a diverse collection of datasets to give as full a picture of the empirical phenomena as possible (Sections 4.1 and 1). See Appendix B for full details on each experimental setup.222Code to replicate the experiments is available at https://github.com/estherrolf/representation-matters.
The first set of experiments (Section 4.2) investigates group and population accuracies as a function of the training set allocation by sub-sampling different training set allocations for a fixed training set size. We also study the amount to which importance weighting and group distributionally robust optimization can increase group accuracies, complementing the results of Proposition 1 with an empirical perspective. The second set of experiments (Section 4.3) uses a similar subsetting procedure to examine the fit of the scaling model proposed in Section 3. The third set of experiments (Section 4.4) investigates using the estimated scaling law fits to inform future sampling practices. We simulate using a small pilot training set to inform targeted dataset augmentation through collecting additional samples. In Section 4.5, we probe a setting where we might expect the scaling law to be too simplistic, exposing the need for more nuanced modelling in such settings. In contrast to Section 2, here losses are defined over sets of data; note that AUROC is not separable over groups, and thus Eq. (1) does not apply for this metric.
4.1 Datasets
Modified CIFAR-4. To create a dataset where we can ensure class balance across groups, we modify the CIFAR-10 dataset (Krizhevsky, 2009) by subsetting to the bird, car, horse, and plane classes. We predict whether the image subject moves primarily by air (plane/bird) or land (car/horse) and group by whether the image contains an animal (bird/horse) or vehicle (car/plane); see Figure B.1. We set .
ISIC. The International Skin Imaging Collaboration dataset is a set of labeled images of skin lesions designed to aid development and standardization of imaging procedures for automatic detection of melanomas (Codella et al., 2019). For our main analysis, we follow similar preprocessing steps to (Sohoni et al., 2020), removing any images with patches. We predict whether a lesion is benign or malignant, and group instances by the approximate age of the patient of whom each photo was taken.
Goodreads. Given publicly available book reviews compiled from the Goodreads database (Wan & McAuley, 2018), we predict the rating (1-5) corresponding to each review. We group instances by genre.
Mooc. The HarvardX-MITx Person-Course Dataset contains student demographic and activity data from 2013 offerings of online courses (HarvardX, 2014). We predict whether a student earned a certification in the course and we group instances by highest completed level of education.
Adult. The Adult dataset, downloaded from the UCI Machine Learning Repository (Dua & Graff, 2017) and originally taken from the 1994 Census database, has a prediction task of whether an individual’s annual income is over . We group instances by sex, codified as binary male/female, and exclude features that directly determine groups status.
| dataset | groups | target label | loss metric | main model used | |||
|---|---|---|---|---|---|---|---|
| CIFAR-4 | {animal, vehicle} | 0.1 | 10,000 | 4,000 | air/land | 0/1 loss | resnet-18 |
| ISIC | {age , age } | 0.43 | 4,092 | 2,390 | benign/malignant | 1 - AUROC | resnet-18 |
| Goodreads | {history, fantasy} | 0.38 | 50,000 | 25,000 | book rating (1-5) | loss | logistic regression |
| Mooc | {edu , edu } | 0.16 | 3,897 | 6,032 | certified | 1 - AUROC | random forest |
| Adult | {female, male} | 0.5 | 10,771 | 16,281 | income K | 0/1 loss | random forest |
4.2 Allocation-aware Objectives vs. Ideal Allocations






We first investigate (a) the change in group and population performance at different training set allocations, and (b) the extent to which optimizing the three objective functions defined in Section 2.2 decreases average and group errors.
For each dataset, we vary the training set allocations between and while fixing the training set size as (see Table 1) and evaluate the per-group and population losses on subsets of the heldout test sets. For the image classification tasks, we compare group-agnostic empirical risk minimization (ERM) to importance weighting (implemented via importance sampling (IS) batches following the findings of Buda et al. (2018)) and group distributionally robust optimization (GDRO) with group-dependent regularization as described in Sagawa et al. (2020). For the non-image datasets, we implement importance weighting (IW) by weighting instances in the loss function during training, and do not compare to GDRO, as the gradient-based algorithm of Sagawa et al. (2020) is not easily adaptable to the predictors we use for these datasets. We pick hyperparameters for each method based on cross-validation results over a coarse grid of ; for IS, IW, and GDRO, we allow the hyperparameters to vary with ; for ERM we choose a single hyperparameter setting for all values.
Figure 1 highlights the importance of at least a minimal representation of each group in order to achieve low population loss (black curves) for all objectives. For CIFAR-4, the population loss increases sharply for and , and for ISIC, when . While not as crucial for achieving low population losses for the remaining datasets, the optimal allocations (stars) do require a minimal representation of each group. The are largely consistent across the training objectives (different star colors). The population losses (black curves) are largely consistent across mid-range values of for all training objectives. The relatively shallow slopes of the black curves for near (stars) stand in contrast to the per-group losses (blue and orange curves), which can vary considerably as changes. From the perspective of model evaluation, this reinforces a well-documented need for more comprehensive reporting of performance. From the view of dataset design, this exposes an opportunity to choose allocations which optimize diverse evaluation objectives while maintaining low population loss. Experiments in Section 4.4 investigate this further.
Across the CIFAR-4 and ISIC tasks, GDRO (dotted curves) is more effective than IS (dashed curves) at reducing per-group losses. This is expected, as minimizing the largest loss of any group is the explicit objective of GDRO. Figure 1 shows that GDRO can also improve the population loss (see for CIFAR-4 and for ISIC) as a result of minimizing the worst group loss. Importance weighting (dashed curves) has little effect on performance for Mooc and Adult (random forest models), and actually increases the loss for Goodreads (multiclass logistic regression model).
For all the datasets we study, the advantages of using IS or GDRO are greatest when one group has very small training set allocation ( near or ). When allocations are optimized (stars in Figure 1), the boost that these methods give over ERM diminishes. In light of Proposition 1, these results suggest that in practice, part of the value of such methods is in compensating for sub-optimal allocations. We find, however, that explicitly optimizing the maximum per-group loss with GDRO can reduce population loss more effectively than directly accounting for allocations with IS.
Section C.2 shows that similar phenomena hold for different loss functions and models on the same dataset, though the exact can differ. In Section C.1, we show that losses of groups with small can degrade more severely when group attributes are included in the feature matrix, likely a result of the small number of samples from which to learn group-specific model components (see Example 3).
4.3 Assessing the Scaling Law Fits
| dataset | group | ||||||
|---|---|---|---|---|---|---|---|
| CIFAR-4 | 500 | animal | 1.9 (0.12) | 0.47 (9.8e-04) | 4.5e-09 (1.8e+06) | 2.0 (0.0e+00) | 1.1e-03 (8.9e-06) |
| vehicle | 1.6 (0.19) | 0.54 (2.0e-03) | 3.2e-12 (1.1e+06) | 2.0 (0.0e+00) | 1.4e-03 (2.8e-06) | ||
| ISIC | 200 | age | 0.61 (1.7e-03) | 0.20 (1.1e-03) | 1.7e-09 (1.9e+04) | 1.9 (0.0e+00) | 1.4e-15 (6.1e-04) |
| age | 0.26 (9.3e-04) | 0.13 (0.012) | 0.61 (0.044) | 0.3 (7.5e-03) | 7.5e-11 (7.2e-03) | ||
| Goodreads | 2500 | history | 0.16 (1.2e-03) | 0.074 (2.5e-03) | 2.5 (0.058) | 0.37 (2.0e-04) | 0.41 (3.0e-03) |
| fantasy | 0.62 (0.69) | 0.020 (1.2e-03) | 3.1 (0.093) | 0.39 (1.9e-04) | 7.2e-21 (0.72) | ||
| Mooc | 50 | edu | 0.08 (2.6e-05) | 0.14 (6.0e-03) | 0.73 (0.059) | 0.63 (4.8e-03) | 1.3e-15 (2.6e-04) |
| edu | 0.038 (6.2e-04) | 0.068 (6.3e-03) | 0.54 (6.5e-03) | 0.61 (9.8e-04) | 2.8e-12 (8.0e-04) | ||
| Adult | 50 | female | 0.078 (0.051) | 0.018 (3.6e-03) | 0.43 (8.3e-03) | 0.59 (1.6e-03) | 8.0e-16 (0.052) |
| male | 0.066 (2.6e-05) | 0.21 (1.2e-03) | 0.47 (6.5e-03) | 0.50 (1.1e-03) | 0.16 (5.4e-06) |
For each dataset, we combine the results in Figure 1 with extra subsetting runs where we vary both and . From the combined results, we use nonlinear least squares to estimate the parameters of modified scaling laws, where exponents can differ by group
| (7) |
The estimated parameters of Eq. (7) given in Table 2 capture different high-level phenomena across the five datasets. For CIFAR-4, for both groups, indicating that most of the group performance is explained by , the number of training instances from that group, whereas the total number of data points , has less influence. For Goodreads, both and have influence in the fitted model, though and are larger than and , respectively. For ISIC, but , suggesting other-group data has little effect on the first group, but is beneficial to the latter. For the non-image datasets (Goodreads, Mooc, and Adult), and for all groups.
These results shed light on the applicability of the assumptions made in Section 3. Figure B.2 in Section B.5 shows that the fitted curves capture the overall trends of per-group losses as a function of and . However, the assumptions of Proposition 2 and Corollaries 1 and 2 (e.g., equal for all ) are not always reflected in the empirical fits. Results in Section 3 use Eq. (1) to describe optimal allocations under different hypothetical settings; we find that allowing the scaling parameters vary by group as in Eq. (7) is more realistic in empirical settings.
The estimated models describe the overall trends (Figure B.2), but the parameter estimates are variable (Table 2), indicating that a range of parameters can fit the data, a well-known phenomenon in fitting power laws to data (Clauset et al., 2009). While we caution against absolute or prescriptive interpretations based on the estimates given in Table 2, if such interpretations are desired (Chen et al., 2018), we suggest evaluating variation due to subsetting patterns and comparing to alternative models such as log-normal and exponential fits (cf. Clauset et al., 2009).

4.4 Targeted Data Collection with Fitted Scaling Laws
We now study the use of scaling models fitted on a small pilot dataset to inform a subsequent data collection effort. Given the results of Section 4.2, we aim to collect a training set that minimizes the maximum loss on any group. This procedure goes beyond the descriptive use of the estimated scaling models in Section 4.3; important considerations for operationalizing these findings are discussed below.
We perform this experiment with the Goodreads dataset, the largest of the five we study. The pilot sample contains 2,500 instances from each group, drawn at random from the full training set. We estimate the parameters of Eq. (7) using a procedure similar to that described in Section 4.3. For a new training set of size , we suggest an allocation to minimize the maximum forecasted loss of any group:
For , the pilot sample size, we simulate collecting a new training set by drawing fresh samples from the training set with allocation . We train a model on this sample (ERM objective) and evaluate on the test set. For comparison, we also sample at (population proportions) and (equal allocation to both groups). We repeat the experiment, starting with the random instantiation of the pilot dataset, for ten trials. As a point of comparison, we also compute the results for all in a grid of resolution , and denote the allocation value in this grid that minimizes the average maximum group loss over the ten trials as .
Among the three allocation strategies we compare, minimizes the average maximum loss over groups, across (Figure 2). Since per-group losses generally decrease with the increased allocations to that group, we expect the best minmax loss over groups to be achieved when the purple and grey bars meet in Figure 2. The allocation strategy does not quite achieve this; however, it does not increase the population loss over that of the other allocation strategies. This reinforces the finding of Section 4.2 that different per-group losses can be reached for similar population losses and provides evidence that we can navigate these possible outcomes by leveraging information from a small initial sample.
While the results in Figure 2 are promising, error bars highlight the variation across trials. The variability in performance across trials for allocation baseline (which is kept constant across the ten trials) is largely consistent with that of the other allocation sampling strategies examined (standard errors in Figure 2). However, the estimation of in each trial does introduce additional variation: across the ten draws of the pilot data, the range of values for subsequent dataset size is [2e-04,0.04], for it is [1e-04,0.05], for it is [5e-05,0.14], and for it is [2e-05,0.82]. Therefore, the estimated should be leveraged with caution, especially if the subsequent sample will be much larger than the pilot sample. Further caution should be taken if there may be distribution shifts between the pilot and subsequent samples. We suggest to interpret estimated values as one signal among many that can inform a dataset design in conjunction with current and emerging practices for ethical data collection (see Section 5).
4.5 Interactions Between Groups
We now shift the focus of our analysis to explore potential between- and within- group interactions that are more nuanced than the scaling law in Eq. (1) provides for. The results highlight the need for and encourage future work extending our analysis to more complex notions of groups (e.g., intersectional, continuous, or proxy groups).
As discussed in Section 3, data from groups similar to or different from group may have greater effect on compared to data drawn at random from the entire distribution. We examine this possibility on the ISIC dataset, which is aggregated from different studies (Section B.1). We measure baseline performance of the model trained on data from all of the studies. We then remove one study at a time from the training set, retrain the model, and evaluate the change in performance for all studies in the test set.
Figure 3(a) shows the percent changes in performance due to leaving out studies from the training set. The MSK and UDA studies are comprised of 5 and 2 sub-studies, respectively; Figure 3(b) shows the results of leaving out each sub-study. Rows correspond to the study withheld from the training set and columns correspond to the study used for evaluation. Rows and columns are ordered by malignancy. For Figure 3(a) this is the same as ordering by dataset size, SONIC being the largest study.
Consistent with our modelling assumptions and results so far, accuracies evaluated on group decrease as a result of removing group from the training set (diagonal entries of Figure 3). However, additional patterns show more nuanced relationships between groups.
Positive values in the upper right regions of Figures 3(a) and 3(b) show that excluding studies with low malignancy rates can raise performance evaluated on studies with high malignancy rates. This could be partially due to differences in label distributions when removing certain studies from the training data. Importantly, this provides a counterpoint to an assumption implicit in 1, that group risks decrease in the total training set size , regardless of the groups these instances belong to. To study more nuanced interactions between pairs , future work could modify Eq. (1) by reparameterizing to directly account for .


Grouping by substudies within the UDA and MSK studies reveals that even within well defined groups, interactions between subgroups can arise. Negative off-diagonal entries in Figure 3(b) suggest strong interactions between different groups, underscoring the importance of evaluating results across hierarchies and intersections of groups when feasible.
Of the 16,965 images in the full training set, 7,401 are from the SONIC study. When evaluating on all non-SONIC instances (like the evaluation set from the rest of the paper), withholding the SONIC study from the training set (akin to the training set of the rest of the paper) leads to higher AUROC (.905) than training on all studies (0.890). This demonstrates that more data is not always better, especially if the distributional differences between the additional data and the target populations are not well accounted for.
5 Generalizations, limitations, and future work
We study the ways in which group and population performance depend on the numerical allocations of discrete groups in training sets. While focusing on discrete groups allows us to derive meaningful results, understanding similar phenomena for intersectional groups and continuous notions of inclusion is an important next step. Addressing the more nuanced relationships between the allocations of different data sources (Section 4.5) is a first step in this direction.
We find that underrepresentation of groups in training data can limit group and population accuracies. However, assuming we can easily and ethically collect more data about any group is often naive, as there may be unintended consequences of upweighting certain groups in an objective function. Naive targeted data collection attempts can present undue burdens of surveillance or skirt consent (Paullada et al., 2020). When ML systems fail to represent subpopulations due to measurement or construct validity issues, more comprehensive interventions are needed (Jacobs & Wallach, 2019).
Our results expose key properties of sub-group representation in training data from a statistical sampling perspective, complementary to current and emerging practices for ethical, contextualized data collection and curation Gebru et al. (2018); Gebru (2020); Denton et al. (2020); Abebe et al. (2021). Studying the role of numerical allocation targets within ethical and context-aware data collection practices will be an important step toward operationalizing our findings.
Representation is a broad and often ambiguous concept (Chasalow & Levy, 2021), and numerical allocation is an imperfect proxy of representation or inclusion. For example, if the data annotation process systematically misrepresents certain groups, optimizing allocations to maximize accuracy with respect to those labels would not reflect our true goals across all groups. If prediction models are tailored to majority groups and are less relevant for smaller groups, an optimized allocation might allocate more data points to smaller groups as a remedy, when in reality a better model or feature representation is preferable. True representation thus requires that each data instance measures the intended variables and their complexities in addition to numerical allocations. That said, if the optimal allocation for a certain group is well beyond that group’s population proportion, this may be cause to reflect on why that is the case. Future work could contextualize allocations as a way of auditing the limits of machine learning systems from a data-focused perspective.
By incorporating dataset collection as a design step in the learning procedure, we were able to assess and leverage the value of different data allocations toward reaching high group and population accuracies. Extending this framework to other objectives and loss functions (e.g., robustness for out-of-distribution prediction and fairness objectives) will be an important area of future work.
6 Conclusions
We demonstrate that representation in data is fundamental to training machine learning models that work for the entire population of interest. By casting dataset design as part of the learning procedure, we can formalize the characteristics that training data must satisfy in order to reach the objectives and specifications of the overall machine learning system. Empirical results bolster our theoretical findings and explore the nuances of real-data phenomena that call for domain dependent analyses in order to operationalize our general results in specific contexts. Overall, we provide insight and constructive results toward understanding, prioritizing, and leveraging conscientious data collection for successful applications of machine learning.
Acknowledgments
We thank Inioluwa Deborah Raji and Ludwig Schmidt for feedback at various stages of this work, and Andrea Bajcsy, Sara Fridovich-Keil, and Max Simchowitz for comments and suggestions during the editing of this manuscript. We thank Nimit Sohoni and Jared Dunnmon for helpful discussions regarding the ISIC dataset.
This material is based upon work supported by the NSF Graduate Research Fellowship under Grant No. DGE 1752814. ER acknowledges the support of a Google PhD Fellowship. This research is generously supported in part by ONR awards N00014-20-1-2497 and N00014-18-1-2833, NSF CPS award 1931853, and the DARPA Assured Autonomy program (FA8750-18-C-0101).
References
- Abebe et al. (2021) Abebe, R., Aruleba, K., Birhane, A., Kingsley, S., Obaido, G., Remy, S. L., and Sadagopan, S. Narratives and counternarratives on data sharing in africa. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pp. 329–341, 2021.
- Abernethy et al. (2020) Abernethy, J., Awasthi, P., Kleindessner, M., Morgenstern, J., and Zhang, J. Adaptive sampling to reduce disparate performance. arXiv preprint arXiv:2006.06879, 2020.
- Boucheron et al. (2005) Boucheron, S., Bousquet, O., and Lugosi, G. Theory of classification: A survey of some recent advances. ESAIM: Probability and Statistics, 9:323–375, 2005.
- Buda et al. (2018) Buda, M., Maki, A., and Mazurowski, M. A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Networks, 106:249–259, 2018.
- Buolamwini & Gebru (2018) Buolamwini, J. and Gebru, T. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on Fairness, Accountability and Transparency, pp. 77–91, 2018.
- Byrd & Lipton (2019) Byrd, J. and Lipton, Z. C. What is the effect of importance weighting in deep learning? In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pp. 872–881. PMLR, 2019. URL http://proceedings.mlr.press/v97/byrd19a.html.
- Chasalow & Levy (2021) Chasalow, K. and Levy, K. Representativeness in statistics, politics, and machine learning. arXiv preprint arXiv:2101.03827, 2021.
- Chawla et al. (2002) Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. SMOTE: Synthetic minority over-sampling technique. Journal of artificial intelligence research, 16:321–357, 2002.
- Chen et al. (2018) Chen, I. Y., Johansson, F. D., and Sontag, D. A. Why is my classifier discriminatory? In Bengio, S., Wallach, H. M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 3543–3554, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/1f1baa5b8edac74eb4eaa329f14a0361-Abstract.html.
- Clauset et al. (2009) Clauset, A., Shalizi, C. R., and Newman, M. E. Power-law distributions in empirical data. SIAM Review, 51(4):661–703, 2009.
- Codella et al. (2019) Codella, N., Rotemberg, V., Tschandl, P., Celebi, M. E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., et al. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (ISIC). arXiv preprint arXiv:1902.03368, 2019.
- Codella et al. (2017) Codella, N. C. F., Gutman, D., Celebi, M. E., Helba, B., Marchetti, M. A., Dusza, S. W., Kalloo, A., Liopyris, K., Mishra, N. K., Kittler, H., and Halpern, A. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (ISBI), hosted by the international skin imaging collaboration (ISIC). arXiv preprint, 2017.
- Cole et al. (2013) Cole, R., Gkatzelis, V., and Goel, G. Mechanism design for fair division: Allocating divisible items without payments. In Proceedings of the Fourteenth ACM Conference on Electronic Commerce, EC ’13, pp. 251–268, New York, NY, USA, 2013. Association for Computing Machinery.
- Cortes et al. (2010) Cortes, C., Mansour, Y., and Mohri, M. Learning bounds for importance weighting. In Lafferty, J. D., Williams, C. K. I., Shawe-Taylor, J., Zemel, R. S., and Culotta, A. (eds.), Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems 2010. Vancouver, British Columbia, Canada, pp. 442–450. Curran Associates, Inc., 2010. URL https://proceedings.neurips.cc/paper/2010/hash/59c33016884a62116be975a9bb8257e3-Abstract.html.
- Denton et al. (2020) Denton, E., Hanna, A., Amironesei, R., Smart, A., Nicole, H., and Scheuerman, M. K. Bringing the people back in: Contesting benchmark machine learning datasets. arXiv preprint arXiv:2007.07399, 2020.
- Dotan & Milli (2020) Dotan, R. and Milli, S. Value-laden disciplinary shifts in machine learning. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 294–294, 2020.
- Dua & Graff (2017) Dua, D. and Graff, C. UCI machine learning repository, 2017. URL http://archive.ics.uci.edu/ml.
- Dwork et al. (2018) Dwork, C., Immorlica, N., Kalai, A. T., and Leiserson, M. Decoupled classifiers for group-fair and efficient machine learning. In Conference on Fairness, Accountability and Transparency, pp. 119–133, 2018.
- Gebru (2020) Gebru, T. Lessons from archives: Strategies for collecting sociocultural data in machine learning. In Gupta, R., Liu, Y., Tang, J., and Prakash, B. A. (eds.), KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020, pp. 3609. ACM, 2020. URL https://dl.acm.org/doi/10.1145/3394486.3409559.
- Gebru et al. (2018) Gebru, T., Morgenstern, J., Vecchione, B., Vaughan, J. W., Wallach, H., Daumé III, H., and Crawford, K. Datasheets for datasets. arXiv preprint arXiv:1803.09010, 2018.
- Ghorbani & Zou (2019) Ghorbani, A. and Zou, J. Y. Data shapley: Equitable valuation of data for machine learning. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pp. 2242–2251. PMLR, 2019. URL http://proceedings.mlr.press/v97/ghorbani19c.html.
- Habib et al. (2019) Habib, A., Karmakar, C., and Yearwood, J. Impact of ECG dataset diversity on generalization of CNN model for detecting QRS complex. IEEE Access, 7:93275–93285, 2019.
- Haixiang et al. (2017) Haixiang, G., Yijing, L., Shang, J., Mingyun, G., Yuanyue, H., and Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Systems with Applications, 73:220–239, 2017.
- HarvardX (2014) HarvardX. HarvardX Person-Course Academic Year 2013 De-Identified dataset, version 3.0, 2014. URL https://doi.org/10.7910/DVN/26147.
- Hashimoto et al. (2018) Hashimoto, T. B., Srivastava, M., Namkoong, H., and Liang, P. Fairness without demographics in repeated loss minimization. In Dy, J. G. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pp. 1934–1943. PMLR, 2018. URL http://proceedings.mlr.press/v80/hashimoto18a.html.
- Hofmanninger et al. (2020) Hofmanninger, J., Prayer, F., Pan, J., Röhrich, S., Prosch, H., and Langs, G. Automatic lung segmentation in routine imaging is primarily a data diversity problem, not a methodology problem. European Radiology Experimental, 4(1):1–13, 2020.
- Hu et al. (2018) Hu, W., Niu, G., Sato, I., and Sugiyama, M. Does distributionally robust supervised learning give robust classifiers? In Dy, J. G. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 of Proceedings of Machine Learning Research, pp. 2034–2042. PMLR, 2018. URL http://proceedings.mlr.press/v80/hu18a.html.
- Iosifidis & Ntoutsi (2018) Iosifidis, V. and Ntoutsi, E. Dealing with bias via data augmentation in supervised learning scenarios. In Proceedings of the Workshop on Bias in Information, Algorithms, pp. 24–29, 2018.
- Jacobs & Wallach (2019) Jacobs, A. Z. and Wallach, H. Measurement and fairness. arXiv preprint arXiv:1912.05511, 2019.
- Kim et al. (2019) Kim, M. P., Ghorbani, A., and Zou, J. Multiaccuracy: Black-box post-processing for fairness in classification. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pp. 247–254, 2019.
- Krizhevsky (2009) Krizhevsky, A. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009.
- Lohr (2009) Lohr, S. L. Sampling: design and analysis. Nelson Education, 2009.
- Neyman (1934) Neyman, J. On the two different aspects of the representative method: The method of stratified sampling and the method of purposive selection. Journal of the Royal Statistical Society, 97(4):558–625, 1934.
- Paullada et al. (2020) Paullada, A., Raji, I. D., Bender, E. M., Denton, E., and Hanna, A. Data and its (dis) contents: A survey of dataset development and use in machine learning research. arXiv preprint arXiv:2012.05345, 2020.
- Pukelsheim (2006) Pukelsheim, F. Optimal design of experiments. Classics in applied mathematics ; 50. Society for Industrial and Applied Mathematics, classic ed. edition, 2006.
- Raji & Buolamwini (2019) Raji, I. D. and Buolamwini, J. Actionable auditing: Investigating the impact of publicly naming biased performance results of commercial ai products. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pp. 429–435, 2019.
- Ryu et al. (2017) Ryu, H. J., Adam, H., and Mitchell, M. Inclusivefacenet: Improving face attribute detection with race and gender diversity. arXiv preprint arXiv:1712.00193, 2017.
- Sagawa et al. (2020) Sagawa, S., Koh, P. W., Hashimoto, T. B., and Liang, P. Distributionally robust neural networks. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URL https://openreview.net/forum?id=ryxGuJrFvS.
- Shankar et al. (2017) Shankar, S., Halpern, Y., Breck, E., Atwood, J., Wilson, J., and Sculley, D. No classification without representation: Assessing geodiversity issues in open data sets for the developing world. arXiv preprint arXiv:1711.08536, 2017.
- Sohoni et al. (2020) Sohoni, N., Dunnmon, J., Angus, G., Gu, A., and Ré, C. No subclass left behind: Fine-grained robustness in coarse-grained classification problems. Advances in Neural Information Processing Systems, 33, 2020.
- Suresh & Guttag (2019) Suresh, H. and Guttag, J. V. A framework for understanding unintended consequences of machine learning. arXiv preprint arXiv:1901.10002, 2019.
- Tschandl et al. (2018) Tschandl, P., Rosendahl, C., and Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Scientific Data, 5(1), 2018. URL https://doi.org/10.1038/sdata.2018.161.
- Vodrahalli et al. (2018) Vodrahalli, K., Li, K., and Malik, J. Are all training examples created equal? An empirical study. arXiv preprint arXiv:1811.12569, 2018.
- Wan & McAuley (2018) Wan, M. and McAuley, J. J. Item recommendation on monotonic behavior chains. In Pera, S., Ekstrand, M. D., Amatriain, X., and O’Donovan, J. (eds.), Proceedings of the 12th ACM Conference on Recommender Systems, RecSys 2018, Vancouver, BC, Canada, October 2-7, 2018, pp. 86–94. ACM, 2018. doi: 10.1145/3240323.3240369. URL https://doi.org/10.1145/3240323.3240369.
- Wilkinson et al. (2016) Wilkinson, M. D., Dumontier, M., Aalbersberg, I. J., Appleton, G., Axton, M., Baak, A., Blomberg, N., Boiten, J.-W., da Silva Santos, L. B., Bourne, P. E., et al. The fair guiding principles for scientific data management and stewardship. Scientific data, 3(1):1–9, 2016.
- Wright (2020) Wright, T. A general exact optimal sample allocation algorithm: With bounded cost and bounded sample sizes. Statistics & Probability Letters, pp. 108829, 2020.
- Yang et al. (2020) Yang, K., Qinami, K., Fei-Fei, L., Deng, J., and Russakovsky, O. Towards fairer datasets: Filtering and balancing the distribution of the people subtree in the imagenet hierarchy. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, pp. 547–558, 2020.
- Yona et al. (2019) Yona, G., Ghorbani, A., and Zou, J. Who’s responsible? Jointly quantifying the contribution of the learning algorithm and training data. arXiv preprint arXiv:1910.04214, 2019.
Appendix A Proofs and Derivations
A.1 Full proof of Proposition 1
Recall the random variable defined with respect to function , loss function , and group weights :
where the randomness comes from the draws of from according to procedure (Definition 2), as well as any randomness in .
See 1
Proof.
For any n, any pair induces a vector with entries , where
for constant . The vector in this sense describes an implicit ‘target distribution’ induced by the applying weights after sampling with allocation . Note that unless for all with , has at least one nonzero entry. The constant re-scales the weighted objective function with original weights so as to match the expected loss with respect to the group proportions . Stated another way, for any alternative allocation , we could pick weights (letting if ), and satisfy
Given this correspondence, we now find the pair which minimizes , subject to . Since the original pair satisfies this constraint (by construction), we must have
We first compute . By Definition 2, samples are assumed to be independent draws from distributions , so that the variance of the estimator can be written as (for convenience we assume here that , see the discussion below):
where denotes shorthand for . Now, to respect the constraint means that for any with , is a deterministic function of , since and are determined by the initial pair . Then it is sufficient to compute
The minimizer has entries . Because is unique and determines , with strict inequality unless . The optimal weights are . Note that for pair of groups , the relative weights satisfy , and thus do not depend on .
If we consider finite sample concerns, the minimizer must satisfy integer values . In this case, efficient algorithms exist for finding the integral solution to allocating (Wright, 2020). However, the non-integer restricted solution has a closed form solution, and we will use the fact that for any group g, as defined above and its variant with the additional constraint that can differ by at most . This means that any with cannot be a minimizer of the objective function, even constrained to . Since , an equivalent statement in terms of is .
Finally, we show that if , . This follows from our definition of such that , and our constraint, such that . From these, we must have that , from which the claim and its reverse follow. ∎
A.2 Proof of Proposition 2
See 2
Proof.
Recall the decomposition of the estimated population risk:
Now we find
If , then any allocation minimizes the approximated population loss. Otherwise, will be for any group with ; what follows describes the solution for with . If any , then the objective is unbounded above, so we can restrict our constraints to . As the sum of convex functions, the objective function is convex in . It is continuously differentiable when . The KKT conditions are satisfied when
Solving this system of equations yields that the KKT conditions are satisfied when Since this is the only solution to the KKT conditions, it is the unique minimizer. ∎
A.3 Proof of Corollary 1
See 1
Proof.
Let denote the number of groups. When ,
Since by 1, we have that with subject to (a) and (b) is maximized when all are equal. Then, since ,
When , , so that
A.4 Proof of Corollary 2
See 2
Proof.
For the setting of two groups, we can express the optimal allocations as:
Rearranging,
For , it holds that . Therefore, for any and ,
From this, we derive the upper bound
and the lower bound
When ,
and when ,
∎
A.5 Additional Derivations
In Example 3, we consider the model where and denote (note: here denote the model coefficients, not allocations). We want to compute
Since the draw is independent of the data from which the ordinary least squares solution is predicted, we can write out each of these terms in terms of the dependence on , the total number of data points, as well as and (where ), the total number of datapoints for each group, from which is estimated. To do this, we’ll solve for the entries of the covariance matrix:
where is the design matrix with rows . Next, we find the block entries of the matrix . We first interrogate the term within the inverse:
where , and similarly for . We’ll now use the Schur complement to compute the desired blocks of . The Schur complement is
which we simplify to by assuming that we zero-mean the sample feature matrix before calculating the least squares solution. Using the Schur complement, the covariance matrix in block form is
Plugging in the appropriate blocks to our original equation, we get:
where the middle term cancels since . Note that is the scaled sample covariance matrix. The vectors are drawn i.i.d. from so that follows an inverse Wishart distribution with parameters . For the fresh sample ,
For the term we invoke the matrix inversion lemma. For a single row of , let denote the matrix comprised of all rows of except . Then
Letting , we rewrite the above as
Since the are independent and zero mean, From a similar argument to that given above, we derive that , so that
Putting this all together, we conclude that for ,
Appendix B Experiment Details
Section B.1 details the datasets used including preprocessing steps and any data excluded from the experiments; the remainder of Appendix B provides a detailed explanation of each experiment described in the main text. Figure 2 describes additional experiments to complement the findings of the main experiments. Code to process data and replicate the experiments detailed here is available at https://github.com/estherrolf/representation-matters.
The code repository accompanying this work can be found at https://github.com/estherrolf/representation-matters.
B.1 Dataset Descriptions
We use and modify benchmark machine learning and fairness datasets, as well as more recent datasets on image diagnosis and student performance to study the effect of training set allocations on group and population accuracies in a systematic fashion. Each of the datasets we use is described below, with download links given at the end of this section.
Modified CIFAR-4. We modify an existing machine learning benchmark dataset, CIFAR-10 Krizhevsky (2009), to instantiate binary classification tasks with binary groups, where groups are statistically independent of the labels . We take four of the ten CIFAR-10 classes: {plane, car, bird, horse}, and sort them into binary categories of {land/air, animal/vehicle} as in Fig. B.1. This instantiation balances the classes labels among the two groups , so that no matter the allocation of groups to the training set, the label distribution will remain balanced. This will eliminate class imbalance as the cause of changes in accuracy due to training set composition or up-weighting methods.
There are training and test instances of each class in the CIFAR-10 dataset, resulting in training instances of each group in our modified CIFAR-4 dataset ( instances total), and instances of each group in the test set ( instances total). By construction, the average label in the test and train sets is . Since this dataset is designed to assess the main questions of our study under a controlled setting and there is not a natural setting of population rates of animal and vehicle photos, we set the population prevalence parameter of group A (images of animals) as .

Goodreads ratings prediction. The Goodreads dataset (Wan & McAuley, 2018) contains a large corpus of book reviews and ratings, collected from public book reviews online. From the text of the reviews, we predict the numerical rating (integers 1-5) a reviewer assigns to a book. From the larger corpus, we consider reviews for two genres: history/biography (henceforth “history") and fantasy/paranormal (henceforth “fantasy"). We calculate the population prevalences from the total number of reviews in the corpus for each genre. As of the writing of this document, there are reviews for history and biography books, and for fantasy and paranormal books, so that .
After dropping entries with no valid review or rating, we have 1,985,464 reviews from the history genre, and 3,309,417 reviews from the fantasy genre, with no books assigned to both genres. To reduce dataset size and increase performance of the basic prediction task, we further reduce each dataset to only the 100 most frequently reviewed books of each genre (following a procedure similar to (Chen et al., 2018)). To instantiate the dataset we use in our analysis, we draw 62,500 review/rating pairs uniformly at random from each of these pools. The mean review for fantasy instances is 4.146, for history it is 4.103. We allocate of the data to a test set, and the remaining to the training set, with an equal number of instances of each genre in each set.
We use tf-idf vectors of the 2,000 most frequently occurring reviews from the entire dataset of 125,000 instances as features (a similar featurization to (Chen et al., 2018), with fewer total features). We note that this is a different version of the goodreads dataset from that used in (Chen et al., 2018); the updated dataset we use has more reviews, and we use different group variables.
Adult. The Adult dataset, originally extracted from the 1994 Census database, is downloaded from the UCI Machine Learning Repository (Dua & Graff, 2017). The dataset contains demographic features and the classification task is to predict whether an individual makes more than 50K per year. We drop the final-weight feature, a measure of the proportion of the population represented by that profile. There are remaining features; we one-hot encode non-binary discontinuous features including work class, education, marital status, occupation, relationship, race, and native country, resulting in feature columns.
For the main analysis, we exclude features for sex, husband, and wife as they indicate group status but do not affect predictive ability (see Section C.1), for a total of features and columns in the feature matrix. We keep the original train and test splits, with ( from group male and from group female) and ( from group male and from group female) instances respectively. We group instances based on gender (encoded as binary male/female). While the training and tests sets have roughly a male group, female group balance, we set to more adequately reflect the true proportions of men and women in the world. In the test set, the average label for the male group is , for the female group it is (for the train set, the numbers are similar; for the male group and for the female group).
Mooc dataset. The dataset we refer to as the MOOC (Massive Open Online Course) dataset is the HarvardX-MITx Person-Course Dataset (HarvardX, 2014). This dataset contains anonymized data from the 2013 academic year offerings of MITx and HarvardX edX classes. Each row in the dataset corresponds to a student-course pairing; students taking more than one course may correspond to multiple rows. We keep the following demographic, participation, and administrative features: gender, LoE_DI (highest completed level of education), final_cc_cname_DI (country), YoB, ndays_act (number of active days on the edX platform), nplay_video (number of video plays on edX), nforum_posts (number of discussion forum posts on edX), nevents (number of interactions on edX), course_id, certified (whether the student achieved a high enough grade for certification). After dropping instances without valid entries for these features, we have 25,213 instances. We one-hot encode non-binary discontinuous features including course_id, LoE_DI, and final_cc_cname_DI, resulting in an expanded 47 feature columns from the original 9 features. In Section C.1 we exclude demographic features. We partition the data into a train set of size 24,130 and a test set of size 6,032, with the same proportion of groups in each set.
We group instances by the highest level of education self-reported by the person taking the class; we bin this into those who have completed at most secondary education, and those who have completed more than secondary education. For reference, in the USA, completing secondary education corresponds to completing high school. The train and test sets contain an equal fraction of each group, about instances where the person taking the course had no recorded education higher than secondary. Of all training and test instances, those from group A (student had at most secondary education) have a certification rate, and those from group B (student had more than secondary education) have an certification rate.
ISIC skin cancer detection dataset. We download the dataset from the ISIC archive (Codella et al., 2017; Tschandl et al., 2018; Codella et al., 2019) using the repository https://github.com/GalAvineri/ISIC-Archive-Downloader to assist in downloading. To match the dataset used in Sohoni et al. (2020), we use only images added or modified prior to 2019, which gives us 23,906 instances. From this set we include only images that are explicitly labeled as benign or malignant. We additionally remove any data points from the ‘SONIC’ study, as these are all benign cases, and are easily identified via colorful dots on the images (Sohoni et al., 2020). The remaining 11,952 instances are to our knowledge identical to the “Non-patch" dataset in (Sohoni et al., 2020), up to the random splits into training/validation and test sets.
As groups, we subset based on the approximate age of the patient that is the subject of the photo. Approximate age is binned to the nearest 5 years in the original dataset; we design groups as A and B . Of the group A instances in the training and test sets, are malignant; of the group B instances, are malignant. We set to match the distribution in the 11,952 data points in our preprocessed set, so that . We split 80% of the data into a train set and 20% into a test set, with the same proportion of groups in each set.
The ISIC archive is a compilation of medical images aggregated from many individual studies. Experiments detailed in Sections 4.5 and B.7 use the study from which the image originates as groups to investigate the interactions between groups when . These results also motivate our choice to exclude the SONIC study from the dataset we use for the main analysis.
Download links. Code for processing these datasets as described above can be found at https://github.com/estherrolf/representation-matters. The datasets we use (before our subsetting/preprocessing) can be downloaded at the following links:
- •
- •
- •
- •
- •
Loss metrics. For binary prediction problems, we report the the 0/1 loss when there is not significant class imbalance (modified CIFAR-4, Adult). For the ISIC and Mooc tasks, we report 1 - AUROC, where AUROC is the area under the reciever operating curve. AUROC is a standard metric for medical image prediction Sohoni et al. (2020), and for Mooc we choose this metric due to the label imbalance (low certification rates). Since AUROC is constrained to be between 0 and 1, the loss metric 1 - AUROC will also be between 0 and 1. For the Goodreads dataset, we optimize the loss (mean absolute error, MAE); in Section C.2 we compare this to minimizing the loss (mean squared error, MSE) of the predictions.
B.2 Models Details
For the neural net classifiers, we compare the empirical risk minimization (ERM) objective with an importance weighted objective, implemented via importance sampling (IS) following results in (Buda et al., 2018), and a group distributionally robust (GDRO) objective Sagawa et al. (2020). We adapt our group distributionally robust training procedure from https://github.com/kohpangwei/group_DRO, the code repository accompanying (Sagawa et al., 2020). For the non-image datasets, we choose the model class from a set of common prediction functions (Section B.3). We use implementations of these algorithms from https://scikit-learn.org, using the built in sample weight parameters to implement importance weighting (IW). Since many of the prediction functions we consider are not gradient-based, we cannot apply the algorithm from (Sagawa et al., 2020), thus we do not compare to GDRO for the non-image datasets.
| dataset name | metric | model used | objective | parameters |
| CIFAR-4 | 0/1 loss | pretrained resnet-18 (fine-tuned) | ERM | num_epochs = 20, lr = 1e-3 , wd = 1e-4, momentum = 0.9 |
| IS | num_epochs = 20, lr = 1e-3, momentum = 0.9 | |||
| wd = 1e-2 if 0.98 or 0.02; wd = 1e-3 otherwise | ||||
| GDRO | num_epochs = 20, lr = 1e-3, wd = 1e-3, momentum = 0.9, | |||
| gdro_ss = 1e-2, group_adj = 4.0 | ||||
| ISIC | 1 - AUROC | pretrained resnet-18 (fine-tuned) | ERM | num_epochs = 20, lr = 1e-3, wd = 1e-4, momentum = 0.9 |
| IS | num_epochs = 20, lr = 1e-3, wd = 1e-3, momentum = 0.9 | |||
| GDRO | num_epochs = 20, lr = 1e-3, wd = 1e-4, momentum = 0.9, | |||
| gdro_ss = 1e-1, group_adj = 1.0 | ||||
| Goodreads* | loss (MAE) | multiclass logistic regression | ERM | C = 1.0, penalty = |
| IW | C = 1.0, penalty = | |||
| Goodreads | loss (MSE) | multiclass logistic regression | ERM | |
| IW | if or ; otherwise | |||
| Mooc* (with dem. features) | 1 - AUROC | random forest classifier | ERM | num_trees = 400, max_depth = 16 |
| IW | num_trees = 400, max_depth = 16 | |||
| Mooc (no dem. features) | 1 - AUROC | random forest classifier | ERM | num_trees = 400, max_depth = 8 |
| IW | num_trees = 400, max_depth = 8 | |||
| Adult (with group features) | 0/1 loss | random forest classifier | ERM | num_trees = 200, max_depth = 16 |
| IW | num_trees = 200, max_depth = 16 | |||
| Adult* (without group features) | 0/1 loss | random forest classifier | ERM | num_trees = 400, max_depth = 16 |
| IW | num_trees = 400, max_depth = 16 |
B.3 Hyperparameter Selection
We evaluate hyperparameters for each prediction model using 5-fold cross validation on the training sets (see Section B.1), stratifying folds to maintain group proportions. We evaluate the cross-validation across a sparse grid of , allowing us to determine if hyperparameters should be set differently for different values of . Table B.3 describes the model and parameters which are chosen as a result of this process.
Image Datasets. For the results shown in Figure 1 with image datasets (CIFAR-4 and ISIC), we train a pretrained resnet-18 by running SGD with momentum for 20 epochs for each dataset. We did not find significant improvements from training for more epochs for either dataset. Sohoni et al. (2020) use a pretrained resnset-50 for the ISIC prediction task; we use a resnet-18 since we are mostly working with smaller training set sizes due to subsetting. We did not find major differences in performance for ERM for ISIC between the resnset-18 and resnet-50 for the dataset sizes we considered. We use a resnset-18 for all models for the CIFAR-4 and ISIC tasks.
In the 5-fold cross validation procedure, we search over learning rate in and weight decay in , keeping the momentum at for both the importance sampling and ERM procedures. Given these results, for GDRO, we search over group-adjustment in , gdro step size in , and weight decay in , fixing momentum at and learning rate at .
The optimal hyperparameter configurations for the coarse grid of are in Table B.3. Across values from the coarse grid, either the optimal parameters for each objective were largely consistent, or performance did not vary greatly between hyperparameter configurations for almost all dataset/objective configurations. As a result, for both the modified CIFAR and ISIC datasets, we keep the hyperparameters fixed across , with the exception of IS for CIFAR-4, where we increase weight decay for extreme (see Table B.3).
Non-Image Datasets. For the Goodreads dataset, we evaluate the following models and parameters: ridge regression model with , random forest regressor with splits determined by MSE, and with number of trees and maximum depth of trees , and a multiclass logistic regression classifier with inverse regularization strength parameter .
The multiclass logistic regression model minimized mean absolute error (MAE) over the models we considered. For ERM, the optimal regularization parameter was for all in our sparse grid. For IW, the optimal regularization value was for all other than , where the optimal for history MAE was . Since this only effected one group, and was not symmetric across , for the evaluation results, we set for all .
For the Mooc dataset, we evaluate a binary logistic regression model with penalty and inverse regularization parameter , a random forest classifier with number of tress and maximum depth of trees , and ridge regression model with , and threshold for binary classification decision . The best model across both group and population accuracies was a random forest model; the best maximum depth was for both ERM and IW, and the results were robust to the number of estimators, so we chose for both. The best hyperparameters were largely consistent for all in the sparse grid.
For the Adult dataset, we evaluate the same models and parameter configurations as the MOOC dataset. The best model across both ERM and IW was the random forest model, with optimal values given in Table B.3.
B.4 Navigating Tradeoffs
Using the selected hyperparameters from the procedure described in Section B.3, we evaluate performance on the heldout test sets (see Section B.1). For the final evaluation, we evaluate , , skipping the extremes for GDRO and IS/IW.
The training set size is determined by the smaller of the training set sizes for each group, denoted as in Table 1. This results in for the modified CIFAR-4, for ISIC, for goodreads, for Mooc, and for adult. Note that the number of test set instances ( in Table 1) does not necessarily have the proportions of instances indicated by in Table 1. For the CIFAR-4 and Goodreads dataset, the test set is constructed to have instances from group A, and instances from group B; in reporting performance, we take a weighted average over the errors from each group, as in Eq. (1). For adult, we re-weight the test set instances to reflect . For the remaining two datasets, the test set compositions align with . We assess variability in the performance of each method under each setting by examining results over 10 random seeds, which apply to both the random sampling in the subsetting procedure and the randomness in the training procedure.
B.5 Assessing scaling law fit

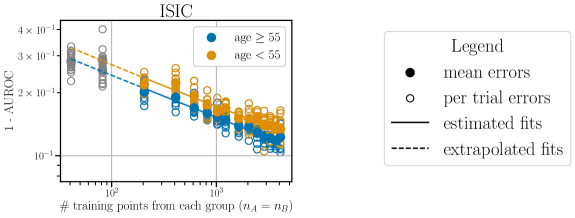



In addition to the results on the holdout set in the previous section, where we vary and keep the size of the training set fixed at , we conduct subsetting experiments to assess the affect of , as well as , on the group accuracies as in Eq. (7). Specifically, for groups A and B, we vary the relative number of data points from group A and group B, as well as the total number of datapoints . We define our subsetting grid by subsampling twice for each configuration of . First, we choose an allocation ratio of group A to group B (from options ). Then, we subsample again to fraction of the largest subset size for this allocation ratio, for an (we skip for allocation ratios ). We repeat the sampling pattern for all pairs of allocation ratio and , and again switching the roles of groups A and B in this procedure. This results in a set of 99 unique pairs, which we combine with the 25 pairs from the previous experiment, where we fix (see Figure B.3). We run ten random seeds of configuration, for a total of 1240 points from which we estimate the scaling law fits.
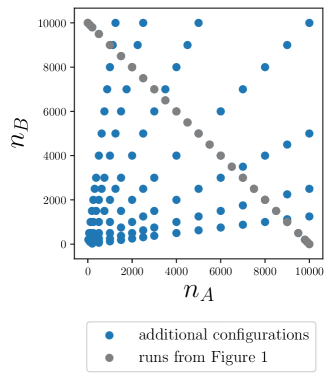
Since our main point of comparison is across training set sizes and allocations, rather than optimizing hyperparameters for each new sample size, we use the same hyperparameter configurations as for first set of experiments (ERM rows in Table B.3). For the neural net classifiers, we decrease the number of epochs when the total training set size increases, so as to keep nearly the same number of gradient steps per training procedure. Specifically, we set the number of epochs as the nearest integer to , where the first set of experiments corresponds to those in Figure 1.
Together with the results from the previous experiment shown in Figure 1, we use these values of and the accuracies evaluated on groups and to estimate the parameters of the scaling laws in Eq. (7). We use the nonlinear least squares implementation of scipy.optimize.curve_fit. The estimated parameters are given in Table 2. The standard deviations reported in Table 2 are the estimated standard deviations resulting from the nonlinear least squares fits. Figure B.2 plots the fitted model over a subset of the data used to fit it, showing that the modified scaling model in Eq. (7) can express the trends in per-group losses as a function of and .
The parameter estimates sometimes have large standard deviations; we also found the parameter estimates to vary with , the minimum number of points required to include a data point in the fitting procedure, as well as the overall subsetting design. When seeking exact and robust estimates of the parameters in Eq. (7), we suggest following the experimental procedures outlined in Clauset et al. (2009), and additionally accounting for potential variation due to sampling patterns.
B.6 Pilot Sample Experiment
In this experiment, we take a small random sample from the Goodreads training set to instantiate a “pilot sample" from which to estimate scaling law parameters and suggest an at which to sample a larger training sample in a subsequent sampling effort. The pilot sample contains total instances, with . With the pilot sample, we conduct a series of subsetting pairs for , similar to the procedure outlined in Section B.5, using relative allocations in and . For each subset configuration, we sample 5 random seeds. From these results, we estimate the scaling parameters of Eq. (7) according to the performance of each subset configuration on the heldout evaluation set. We set the minimum number of points from which to fit the scaling parameters to .
Next, we use these estimated fits to extrapolate predicted per-group losses with more data points. For a given sample size, we suggest the that would minimize the the maximum of the estimated per-group losses. We use the training data held separate from the pilot sample to sample a training set at allocation, and evaluate performance on the original held out evaluation set. We follow the same procedure, sampling the new training set from and at .
As a point of comparison we also compute the results for all in a grid of resolution ; i.e., and denote the allocation value in this grid that minimizes the average maximum group loss over trials as . The best allocation possible (up to the 0.01 grid resolution) were: 0.01 for , 0.06 for , 0.03 for , and 0.07 for . The baseline helps contextualize performance of other allocation strategies with the optimal-in-hindsight . Furthermore, the variability across trials due to subsetting around is largely consistent with that of the other allocation sampling strategies examined.
We repeat this entire procedure (starting with generation of the pilot sample) for 10 random seeds, and the results are reported in Figure 2. Since we have enough training data in the Goodreads dataset outside of the pilot sample to simulate gathering larger datasets of up to , we simulate collecting a new training dataset of size , which are the size of the pilot training dataset, respectively.
The error bars in Figure 2 are similarly large for all three allocation strategies we compare. The allocation when is an exception, indicating that high variation in may be an issue when is large relative to the pilot training sample size.
B.7 Interactions Between Groups
While the main experiments exclude the SONIC study from the ISIC dataset, consistent with the ‘non-patch’ dataset in Sohoni et al. (2020), this experiment utilizes the larger corpus of labeled images from the ISIC repository. The difference is the inclusion of the SONIC sub-study. This larger dataset has 21,203 instances after subsetting to precisely benign/malignant cases. The number of data instances coming from each dataset are given by the grey bars (black annotated numbers) in Figure 4; purple bars denote the number of malignant instances. Note the logarithmic scale.
We separate 16,965 images to the training set and the remaining 4,238 to the test set, with equal ratios of each sub-study represented in the train and test sets. The train and test splits differ for the study and sub-study analysis, accounting for differing values in corresponding cells of Figure 3(a) and Figure 3(b), particularly apparent when evaluating on JID Editorial Images, the study with the smallest number of data instances (see Figure 4). We choose hyperparameters based off a 5 fold cross-validation procedure on the 16,965 training instances, searching over the same hyperparameter options as in Section B.3, ultimately using 20 epochs, momentum 0.9, weight decay 0.001 and learning rate 0.001 to tune the resnet-18 model (with ERM objective). For each of the 5 studies, and 10 sub-studies that comprise the larger datasets, we retrain the resnet-18 model on the training set with that sub-study excluded from the training data, and compare to performance of the model trained on the entire training set. As in Section B.5, we keep the number of gradient steps for each training process roughly equal. We run 10 random seeds for all conditions and report the differences in the mean performance metrics across groups.

Appendix C Supplementary Experiments
In this appendix we detail additional experiments to supplement the findings of Section 4. These experiments investigate the robustness of our findings to different problem formulations and data pre-processing.
C.1 The Effects of Including Groups as Features or Not
Here we compare models that use group or demographic information as features, and models that do not. We examine differences in group performance across and the effect of importance weighting in both cases.
| dataset | group | ||||||
|---|---|---|---|---|---|---|---|
| Mooc (with dem. features) | 50 | edu | 0.08 (2.6e-05) | 0.14 (6.0e-03) | 0.73 (0.059) | 0.63 (4.8e-03) | 1.3e-15 (2.6e-04) |
| edu | 0.038 (6.2e-04) | 0.068 (6.3e-03) | 0.54 (6.5e-03) | 0.61 (9.8e-04) | 2.8e-12 (8.0e-04) | ||
| Mooc (without dem. features) | 50 | edu | 0.41 (0.86) | 1.0 (0.26) | 0.6 (0.028) | 0.56 (3.5e-03) | 0.029 (1.4e-06) |
| edu | 0.029 (1.3e-03) | 0.055 (0.011) | 0.33 (2.2e-03) | 0.54 (9.5e-04) | 1.9e-14 (1.5e-03) | ||
| Adult (with group features) | 50 | female | 0.036 (3.2e-06) | 0.14 (2.5e-03) | 0.23 (3.3e-03) | 0.47 (2.3e-03) | 0.055 (2.1e-05) |
| male | 0.12 (6.8e-05) | 0.24 (5.8e-04) | 0.3 (6.2e-03) | 0.47 (2.7e-03) | 0.16 (3.5e-06) | ||
| Adult (without group features) | 50 | female | 0.078 (0.051) | 0.018 (3.6e-03) | 0.43 (8.3e-03) | 0.59 (1.6e-03) | 8.0e-16 (0.052) |
| male | 0.066 (2.6e-05) | 0.21 (1.2e-03) | 0.47 (6.5e-03) | 0.50 (1.1e-03) | 0.16 (5.4e-06) |




For Mooc, we compare the model used in the main analysis with removing all demographic information including education level, which we group data instances by. There are five remaining features: number of active days, number of video plays, number of forum posts, and number of events, and course-id, which we one-hot encode. The random forest model is still the best performing of those we considered, though the optimal hyperparameters after a 5 fold cross validation search shifted to and . For the Adult dataset, we add back in the features for sex, wife, and husband. This results in 13 unique features, and after one-hot encoding, 103 feature columns. After running a 5 fold cross validation search with the new feature matrix, the optimal model and parameters were and .
Figure 1 compares the results of after excluding (left column) and including (right column) this information in the training feature matrix. Models with the group features excluded generally exhibit less degradation in performance for near 0 or 1. The negative impacts of IW are lessened slightly when the models do not incorporate groups as features.
The different scaling law fits are shown in Table 4. For the Adult task without group features, the estimated exponent and scaling constant on group-agnostic data, and , are larger than than for the model with demographic features. For the Mooc task, the effect is the reverse. In all settings, the fitted parameters show that influences group errors more than , so long as is at least (the region for which we estimate the fit).
In the main analysis, we include demographic features for the Mooc certification prediction task, as this increases accuracy of the “edu secondary group," and exclude gender features from the Adult income prediction, as it does not not greatly impact performance for near 0.5, and improves performance for more extreme settings of (Figure 1). For the other three datasets we study, there is no singular feature corresponding to the group that we can hold out in a similar fashion.
C.2 Trends across models and performance metrics
Figure 2 contrasts the trade offs we can navigate with different allocations and re-weighting schemes for different models and accuracy metrics. The left hand side of Figure 2 shows the result of the model fitting and evaluation procedure to minimize loss (MAE) of the Goodreads predictions (same as the results shown in Figure 1). The right hand side shows the result of the same model fitting and evaluation procedure applied to minimizing the loss (MSE), where ridge regression is the best performing model of those we consider. The ridge model evaluated with MSE exhibits similar trends across values as the multiclass logistic regression model evaluated on MAE. The value that minimizes population loss is similar for both methods – near to , though on opposite sides of . The degradation in population loss for close to 0 or 1 is also apparent for the ridge model, and the range of for which importance weighting (IW) increases per-group and population losses compared to empirical risk minimization (ERM) is similar across models.

