Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Abstract
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
1 Introduction
A multi-agent control system consists of multiple decision-making entities within a shared environment, each tasked with achieving some objectives defined by a reward signal. Multi-agent reinforcement learning (MARL) offers a learning paradigm that optimizes for emergent rational behaviors within agents through interactions with the environment and one another to achieve an equilibrium [23]. In recent years, deep MARL has proven successful in numerous domains, including robotics teams [22], networking applications [38], and various social scenarios that require multi-agent interactions [3]. However, deep reinforcement learning (RL) has historically suffered from sample inefficiency, requiring a costly amount of interaction experience to learn valuable behaviors. This challenge stems largely from the high variance in existing RL algorithms paired with the data-intensive nature of deep neural networks [46]. Unfortunately, MARL applications face additional learning pathologies and complexities [36] such as exponential computational scaling with respect to the number of agents and the dynamic challenge of equilibrium computation [8].
To remedy this issue, recent MARL efforts have concentrated on the concept of centralized training and decentralized execution (CTDE) [34, 29, 53]. In CTDE, agents are trained with access to global state information while retaining autonomy, meaning the agents can make decisions based only on local information during execution. Despite the empirical improvements from CTDE, sample inefficiency remains an elusive challenge. We argue that the CTDE paradigm does not fully address the underlying limitations of RL algorithms, i.e. the sparsity and variance of its learning signals.
A natural solution to address this issue is to curate additional learning signals that supplement and enrich the RL learning process. This approach of imposing further inductive bias has proven effective in prior works at enhancing the training of control policies in single-agent RL [24]. The new objectives that are introduced range from reinforcing similarities and dissimilarities within temporal or spatial locality [30, 44] to instilling information regarding different aspects of the tasks, such as the transition dynamics [39], into the latent state space. Importantly, the main takeaway from these efforts is to learn a rich latent state space that understands and is coherent with the task dynamics and itself [35]. However, much of these techniques of representation learning has yet to be fully realized and extended to a MARL context.

 ) embed their observations and propagates their encodings through a communication block (
) embed their observations and propagates their encodings through a communication block ( ) that is subject to a communication network . Once the agents communicate, the latent state (
) that is subject to a communication network . Once the agents communicate, the latent state ( ) is computed and used as inputs for its policy (
) is computed and used as inputs for its policy ( ) and value function (
) and value function ( ). For our MA-LSO procedure, the latent states are optimized using MA-Transition Dynamics Reconstruction (MA-TDR) and MA-Self-Predictive Learning (MA-SPL). These two learning processes are outlined in Section 4 and loosely can be thought of as instilling the capability of inferring the observations and the next latent states of all agents from the current latent state.
). For our MA-LSO procedure, the latent states are optimized using MA-Transition Dynamics Reconstruction (MA-TDR) and MA-Self-Predictive Learning (MA-SPL). These two learning processes are outlined in Section 4 and loosely can be thought of as instilling the capability of inferring the observations and the next latent states of all agents from the current latent state.In this work, we propose MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization), a generalized MARL framework, outlined in Figure 2, that leverages latent space optimization (LSO) in a multi-agent setting under the CTDE framework. Specifically, we show that current state-of-the-art MARL algorithms, such as MAPPO [53], HAPPO [29], MASAC [17], and MADDPG [34] benefit from our multi-agent LSO (MA-LSO) learning process with trivial modifications. Our experiments demonstrate significant improvements in not only the sample efficiency but also in the overall performance over diverse tasks in VMAS [1] and robotic team tasks in IsaacTeams [22] over all algorithms under fixed model architectures and MARL hyperparameters setting.
Our contributions are as follows:
-
1.
We introduce a novel MARL framework, MAPO-LSO, that integrates MA-LSO, a comprehensive form of representation learning into the MARL training. MA-LSO is broken down into two parts: MA-Transition Dynamics Reconstruction and MA-Self-Predictive Learning. Hence, we provide a new perspective on the intuition behind the usage and integration of both learning processes in a multi-agent control setting.
-
2.
We study the application of pretraining, uncertainty-aware modeling techniques for agent-modeling and phasic optimization within our MAPO-LSO framework to improve learning performance, specifically in terms of convergence and stability.
-
3.
We extend and experiment using several state-of-the-art MARL algorithms on our MAPO-LSO framework on a variety of tasks with diverse nature of interactions and multi-modal data, presenting further ablation studies on design choices to showcase the improvements of our MAPO-LSO framework.
2 Related Works
Sample-Efficiency in MARL
A number of recent works have addressed the sample efficiency problem in deep MARL ranging from developing vectorized and parallelizable simulation platforms [22, 1], improving exploration strategies to collect diverse and useful samples [32], pre-training on a dataset of demonstrations [37], utilizing off-policy and/or model-based approaches [33], and learning on offline datasets [52]. While these prior efforts are not necessarily orthogonal to our efforts, the focus of this paper is on introducing a form of multi-agent representation learning that improves how much is learned from each sample by guiding the optimization of the latent state space for MARL tasks.
Representation Learning in MARL
The concept of representation learning has previously been applied in MARL applications through masked observation reconstruction [27, 43], auxiliary task-specific predictions [41], self-predictive learning in joint latent space [10], and contrastive learning on the observation embedding space [21]. In our study, our proposed MA-LSO takes a more comprehensive measure by applying two forms of representation learning that enforce consistency between the latent state space and the transition dynamics and within itself as a self-predictive representation space.
3 Preliminaries
In this work, we consider an extension of the stochastic game framework [42] called the networked Bayesian game [20, 23].
Definition 1
A networked Bayesian game is defined by a tuple .
-
•
is the set of agents.
-
•
is the global state space.
-
•
is the joint observation space, where is the observation space of agent .
-
•
is the joint action space, where is the action space of agent .
-
•
is the state transition operator, mapping the state-action space to the probability of the next states.
-
•
, is the joint reward function, where is the reward function for agent .
-
•
is the joint type/belief space, where is the belief space of agent .
-
•
is the mapping from the state to an adjacency matrix that defines the communication graph between all agents.
We optimize for the Bayes-Nash equilibrium, where each agent learns a best-response policy , by maximizing the expected ex interm return of individual agent .
| (1) |
Deep Reinforcement Learning
The field of deep RL presents general control optimization algorithms using deep neural network approximations: canonically existing in the form of Q-learning, policy gradient, and actor-critic methods [46]. With Q-learning approaches, the optimal state-value or action-value function is learned, where maps the state-action pair to its expected return following a policy . Policy gradient methods directly optimize the policy via gradient ascent over the expected return. Actor-critic methods stabilize the policy gradient by approximating the offset reinforcement with a learned Q-function under the current policy. These optimization schemes have been extended to and studied under a multi-agent context, demonstrating promising results [53].
Latent Space Optimization
Latent space optimization (LSO) is a form of representational learning that is often used in unison with generative modeling [54], where LSO leverages model-based optimization that learns an approximation of the objective function under a learned latent space [48]. In RL, LSO is often used to map various aspects of the environment model into a latent space to assist with the RL training [18]. In this work, we explore this pretense within a MARL setting.
4 Multi-agent Latent Space Optimization
Our approach, MA-LSO, optimizes a latent state representation for each agent to supplement the “sample-inefficient" MARL optimization. To achieve this goal, we employ two processes: MA-Transition Dynamics Reconstruction (MA-TDR) and MA-Self-Predictive Learning (MA-SPL). These processes draw inspiration from previous work on single-agent model-based RL [18] and representational learning methods for RL [39, 15, 16], unifying the concepts of TDR and SPL in a manner that complements one another while considering the multi-agent nature of the task.
4.1 MA-Transition Dynamics Reconstruction
MA-TDR learns an approximation of the transition dynamics of the environment by mapping the underlying “true" state to a latent state representation space , grounding to the realities of the task’s dynamics. To implement this, we make use of recurrent modeling and multi-agent predictive representation learning (MA-PRL).

Recurrent Modeling
For each agent , we maintain a recurrent state that holds information regarding its history and is realized using a recurrent neural network rnn.
From the observation , an encoder computes an embedding to be passed into a communication block to generate . The latent state space is computed using a multi-layer perceptron mlp that processes the embedding and the recurrent state .
where is a mixture of categorical distributions [19]. The purpose of this recurrent modeling is to ensure that the latent state is expressive enough such that it is sufficient to recollect information needed for decision-making from the agent’s history and can tractably perform the other auxiliary tasks posed in MA-PRL and MA-SPL.
MA-Predictive Representation Learning
In MA-PRL, we take explicit measures to ensure that the latent state contains information regarding the transition dynamics by reconstructing and inferring various aspects of the transition dynamics – namely, the observation , reward and termination – from the latent state .
Firstly, MA-PRL incorporates CURL [30], a contrastive learning framework that guides the latent state produced by to be similar to the produced by an augmented .
Next, we task each agent to maintain a belief over its own as well as the other agents’ observations, policies, rewards, and termination. These beliefs are computed as a function of their latent state . To ensure the feasibility of these beliefs, we experiment with Monte-Carlo dropout to address the inherent epistemic uncertainty [12, 28].
where is the continue signal for agent . In terms of our implementation, we adhere to the same protocols set in [19], approximating the reward using a symlog twohot distribution and the continue signal using onehot distribution. Additionally, we temporally-smoothed the reward signals with Gaussian-smoothing to ease the task of reward distribution approximation [31].
The combination of the two concepts, recurrent modeling and MA-PRL, makes up the MA-TDR process. The overall loss for MA-TDR is defined as:
| (2) |
where is the similarity measure adopted from [30], is an experience replay buffer, is Huber loss and is the stop-gradient operator. For each loss term, we append a scaling hyperparameter to each loss term to avoid dominating gradients and general performance reasons.

4.2 MA-Self-Predictive Learning
The desideratum of MA-SPL is to learn a that is sufficient to predict the expected [13, 45]. Intuitively, the learned latent state space is optimized to be consistent with itself and its own latent dynamics [47]. Moreover, we extend the concept of SPL [39] to a multi-agent setting, where now, we consider the presence of other agents in the environment and thereby enforce a structural relation [49] and consistency amongst the agents in a centralized manner.
MA-Masked Reconstruction (MA-MR)
Inspired by [27, 43], MA-MR encourages inter-predictive representation between agents’ latent space. Similar to [51], MA-MR treats the agents’ latent states as a sequence. Concretely, MA-MR utilizes a contrastive learning paradigm such that a masked joint latent state can reconstruct the joint latent state . This masking process is applied on the agent-level. Hence, if the latent state of agent is masked , the joint latent spaces of the other agents is sufficient to reconstruct . In our implementation, we adopt the framework from [43], using a self-attentive reconstruction model to process the masked latent state as shown in Figure 3.
MA-Forward Dynamics Modeling (MA-FDM)
The objective of MA-FDM is to ensure that the information contained in the current joint latent state and the joint action is sufficient to infer the next joint latent state [10]. To implement this, we define a transition head which is realized using a cross-attention head [50] that maps the joint latent state and the joint action to the next joint latent space.
MA-Inverse Dynamics Modeling (MA-IDM)
MA-IDM aims to achieve the following objective: Given the current and next joint latent state, the joint action that realized that transition from the current to the next joint latent state can be deduced. In our work, we use an inverse head which is realized using a self-attentive model that maps the current and next joint latent state to the joint action space.
The overall loss for MA-SPL is defined as:
| (3) |
MLP Heads
4.3 Integrating MA-LSO to Multi-agent Policy Optimization
Our proposed approach, MA-LSO, can easily be appended to popular MARL algorithms with minor adjustments to form MAPO-LSO. The central challenge is the use of recurrent modeling, which raises several implementation challenges for some algorithms [26] involving adjustments in the experience replay buffer and maintenance of the recurrent state. Otherwise, appending the MA-LSO learning process is trivial and can be performed concurrently with the MARL training.
On-policy MARL
In general, we define a shared replay buffer that we sample batches of transitions from to compute both MA-LSO and MARL objectives. However, for on-policy MARL algorithms that cannot learn on the offline data, we found that learning on offline data during the MA-LSO process is necessary to promote good generalization and stable learning by learning on a diverse dataset. Therefore, we ensure that we maintain both on-policy and off-policy data in such that online data is used for the MARL training but off-policy data is still available for the MA-LSO process.
Phasic Optimization
For certain MARL algorithms, notably MADDPG and MASAC, we chose to follow the training methodology outlined in [11]. This involved the utilization of target networks and delayed policy updates. These techniques are intended to mitigate the learning variance and enhance overall performance. However, despite these efforts, we still observed that the training remained too sensitive to hyperparameters, likely due to the use of a model architecture that shares parameters between the policy and value function (i.e. the encoder) and the phasic nature of learning.
To mitigate this instability, we recognized the need to incorporate a phasic regularization term inspired by the work of [6]. This regularization term constrains the policy divergence during all non-policy updates and thereby promotes a more stable learning environment. For HAPPO, we also enforce this regularization term during the sequential policy updates such that the shared encoder, which exists within the centralized critic, does not diverge from the other agents’ behaviors that are not being updated. In our study, instead of using a KL divergence, we use Huber loss to constrain the divergence of actions (i.e. of the policies) utilizing the old and new encoders.
Pre-training
The MA-LSO objective can be used as a pre-training paradigm similar to [40], where is pre-filled with an exploratory/random policy of transitions and is trained on and .
5 Experiments
For our experiments, we use the tasks in Vectorized Multi-agent Simulator (VMAS) tasks and IsaacTeams (IST) to provide a comprehensive evaluation of a diverse collection of multi-agent tasks, selecting diverse tasks from VMAS and tasks from IST as shown in Appendix A.
Experimental Setup
The scenarios parameters for VMAS and IST environments are taken from prior works [1, 2, 22]. The four MARL algorithms chosen for our experiments are MAPPO [53], HAPPO [29], MASAC [17], and MADDPG [34]; all of which are considered competitive MARL baselines. For all experiments, the MARL hyperparameters are initially tuned using a random search for the vanilla MARL algorithms (i.e. without MA-LSO), then kept fixed and trained with our MAPO-LSO method for that specific task. Further implementation details are provided in Appendix C and D. All experiments presented in this work were executed on Nvidia RTX A6000 and Intel Xeon Silver 4214R @ 2.4GHz.
5.1 Results
In this section, we evaluate the overall performance and sample efficiency of MAPO-LSO paired with popular MARL algorithms. Here, performance refers to the collective return achieved and the sample efficiency is measured by the performance with respect to the number of data samples used, meaning the better the performance at a given number of environment transitions learned on, the higher the sample efficiency. We additionally conduct further ablation studies to investigate and analyze each component of our MAPO-LSO method and study if any other improvements or degradations are realized at a more granular level.
To provide a concise comparison against our method, we present much of our results in a normalized scale. This involves aggregating and scaling the results from each experiment, algorithm, and task [7, 14].
Efficacy of MAPO-LSO
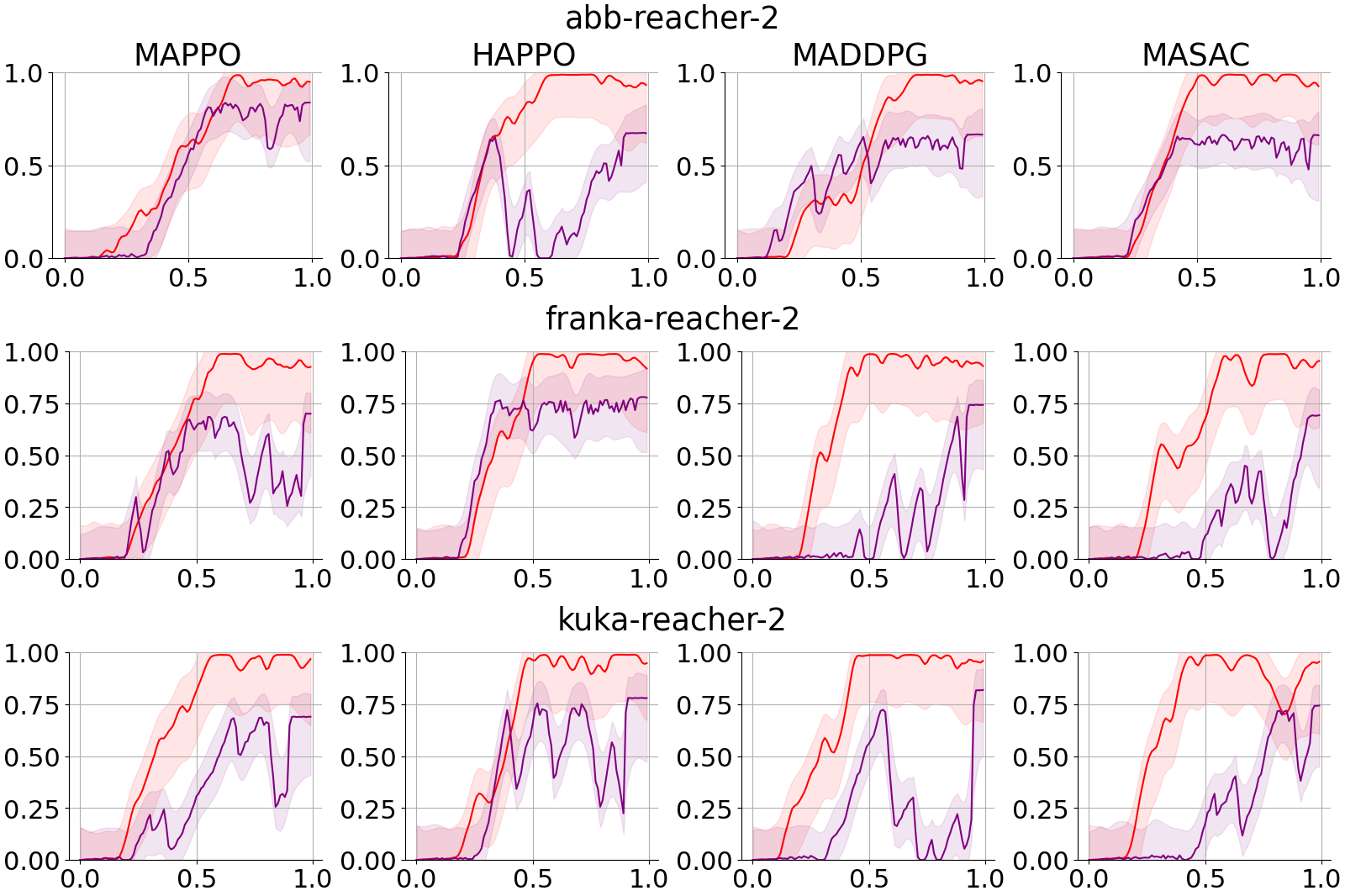
As depicted in Figure 4a, the MAPO-LSO framework demonstrates a significant improvement in the collective return, reaching a difference in convergence from the baseline without MA-LSO. Additionally, in terms of sample efficiency, our MAPO-LSO achieved the max convergence of the baseline in less samples. However, to achieve this, we discuss the design choices made that enabled this improvement.
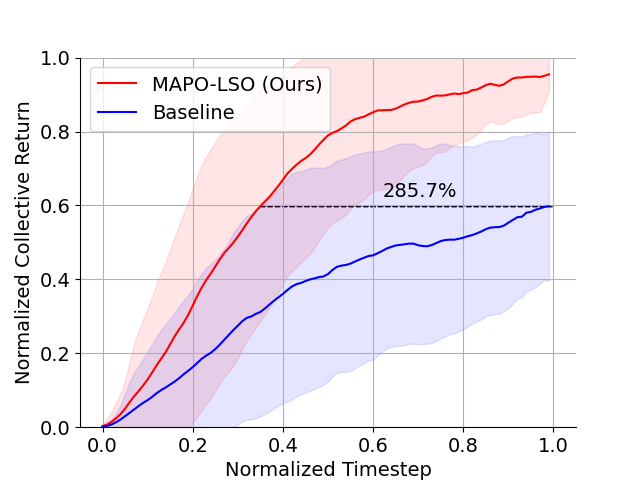


5.1.1 Design Choices in MAPO-LSO
Phasic Optimization
We confirm our hypothesis stated in Section 4.3 with Figure 4b, where we found training inefficiencies with a shared encoder between the actors and critics in the MARL algorithms (i.e. HAPPO, MADDPG and MASAC) with phasic learning. Aforementioned, this concern is not novel [6] and in our work, we addressed this issue through phasic regularization with significant improvements. Moreover, we encourage future works to explore further methodologies that can facilitate a shared encoder paradigm, as we did find that the robustness of hyperparameters can still be improved upon.

Epistemic Uncertainty Modeling
Referring to Figure 6b, the uncertainty modeling within the MA-TDR heads demonstrates improvements in the accuracy of the beliefs of observation, action, reward and continue signals, most notably having the largest impact on the accuracy of inferring the actions. Furthermore, we evaluate the imagined policies realized within each agent’s belief space by rolling out trajectories using the joint actions within the agent’s belief space. We find the uncertainty modeling does influence the behaviors learned within each agent’s belief spaces, as shown in Figure 6a, exhibiting impressive performance even using these imagined joint policies. Unsurprisingly, this uncertainty modeling also improved the expected collective return as well, as seen in Figure 4c. In future works, a further evaluation and study into the diversity and social behaviors learned within these imagined joint policies would be fruitful.
Pre-training
We study the efforts of using MA-TDR and MA-SPL objectives as a pre-training process. First, we collected a dataset of K trajectories using a random policy and pre-trained the model on the MA-LSO objectives for epochs. As shown in Figure 5, we find that the inclusion of pre-training provides an improvement of in the collective return achieved.


| case | Max Return | ||||
|---|---|---|---|---|---|
| MA-LSO | |||||
| no MA-TDR | |||||
| no MA-MR | |||||
| no MA-FDM | |||||
| no MA-IDM | |||||
| no MA-SPL | |||||
| no MA-LSO | |||||
MA-LSO Ablations
We assess the effectiveness of each component within our MA-LSO framework by conducting evaluations that include omissions of the MA-TDR and MA-SPL processes. For MA-SPL, we exclude its sub-processes individually: MA-MR, MA-FDM, and MA-IDM. A key contribution of this work is the integration of these auxiliary objectives and their symbiotic relationship, which Table 1 confirms. Hence, the results demonstrate that all of the components in our MA-LSO framework not only contribute to the demonstrated improvements but also are interdependent. Specifically, MA-SPL has the greatest impact in terms of overall performance, with MA-MR being the most important out of its sub-processes. This highlights the importance of the relational information instilled by MA-SPL and MA-MR and the consistency they endow within the latent state space between the agents.
Moreover, excluding any processes within MA-LSO results in a notable decline in the training efficiency of other processes. This suggests a form of amortization similar to that observed in multi-task applications [25], evident from optimal performance of each component is only achieved when both MA-TDR and MA-SPL are applied in unison. The interdependence of these components is underscored by the fact that the convergence of MA-TDR and MA-SPL losses deteriorates when they are separated. Specifically, without MA-SPL, the convergence of MA-TDR decreases by , while the absence of MA-TDR leads to degradation of MA-SPL subprocesses by , , and on MA-MR, MA-FDM, and MA-IDM respectively.
6 Conclusion
We introduce a generalized MARL training paradigm, MAPO-LSO, that utilizes auxiliary learning objectives to enrich the MARL learning process with multi-agent transition-dynamics reconstruction and self-predictive learning. Our approach improves its "non-LSO" counterpart in a wide variety of MARL benchmark tasks using several state-of-the-art MARL algorithms. For future directions, there remain promising avenues to study other aspects of the multi-agent nature of MARL tasks, such as ad-hoc performance and social learning, with our MAPO-LSO framework.
References
- Bettini et al. [2022] M. Bettini, R. Kortvelesy, J. Blumenkamp, and A. Prorok. Vmas: A vectorized multi-agent simulator for collective robot learning. The 16th International Symposium on Distributed Autonomous Robotic Systems, 2022.
- Bettini et al. [2023] M. Bettini, A. Prorok, and V. Moens. BenchMARL: Benchmarking Multi-Agent Reinforcement Learning. arXiv preprint arXiv:2312.01472, 2023.
- Buşoniu et al. [2010] L. Buşoniu, R. Babuška, and B. De Schutter. Multi-agent reinforcement learning: An overview. Innovations in multi-agent systems and applications-1, pages 183–221, 2010.
- Chen et al. [2020] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Chen et al. [2003] X. Chen, H. Fan, R. Girshick, and K. He. Improved baselines with momentum contrastive learning. arxiv 2020. arXiv preprint arXiv:2003.04297, 2003.
- Cobbe et al. [2021] K. W. Cobbe, J. Hilton, O. Klimov, and J. Schulman. Phasic policy gradient. In International Conference on Machine Learning, pages 2020–2027. PMLR, 2021.
- Colas et al. [2018] C. Colas, O. Sigaud, and P.-Y. Oudeyer. How many random seeds? statistical power analysis in deep reinforcement learning experiments. arXiv preprint arXiv:1806.08295, 2018.
- Daskalakis et al. [2023] C. Daskalakis, N. Golowich, and K. Zhang. The complexity of markov equilibrium in stochastic games. In The Thirty Sixth Annual Conference on Learning Theory, pages 4180–4234. PMLR, 2023.
- Egorov and Shpilman [2022] V. Egorov and A. Shpilman. Scalable multi-agent model-based reinforcement learning. arXiv preprint arXiv:2205.15023, 2022.
- Feng et al. [2023] M. Feng, W. Zhou, Y. Yang, and H. Li. Joint-predictive representations for multi-agent reinforcement learning. 2023.
- Fujimoto et al. [2018] S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. In International conference on machine learning, pages 1587–1596. PMLR, 2018.
- Gal and Ghahramani [2016] Y. Gal and Z. Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning, 2016.
- Givan et al. [2003] R. Givan, T. Dean, and M. Greig. Equivalence notions and model minimization in markov decision processes. Artificial Intelligence, 147(1-2):163–223, 2003.
- Gorsane et al. [2022] R. Gorsane, O. Mahjoub, R. J. de Kock, R. Dubb, S. Singh, and A. Pretorius. Towards a standardised performance evaluation protocol for cooperative marl. Advances in Neural Information Processing Systems, 35:5510–5521, 2022.
- Grill et al. [2020] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Guo et al. [2020] Z. D. Guo, B. A. Pires, B. Piot, J.-B. Grill, F. Altché, R. Munos, and M. G. Azar. Bootstrap latent-predictive representations for multitask reinforcement learning. In International Conference on Machine Learning, pages 3875–3886. PMLR, 2020.
- Haarnoja et al. [2018] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pages 1861–1870. PMLR, 2018.
- Hafner et al. [2019] D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019.
- Hafner et al. [2023] D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023.
- Harsanyi [1967] J. C. Harsanyi. Games with incomplete information played by “bayesian” players, i–iii part i. the basic model. Management science, 14(3):159–182, 1967.
- Hu et al. [2024] Z. Hu, Z. Zhang, H. Li, C. Chen, H. Ding, and Z. Wang. Attention-guided contrastive role representations for multi-agent reinforcement learning. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=LWmuPfEYhH.
- Huh and Mohapatra [2023] D. Huh and P. Mohapatra. Isaacteams: Extending gpu-based physics simulator for multi-agent learning, 2023.
- Huh and Mohapatra [2024] D. Huh and P. Mohapatra. Multi-agent reinforcement learning: A comprehensive survey, 2024.
- Jaderberg et al. [2016] M. Jaderberg, V. Mnih, W. M. Czarnecki, T. Schaul, J. Z. Leibo, D. Silver, and K. Kavukcuoglu. Reinforcement learning with unsupervised auxiliary tasks. arXiv preprint arXiv:1611.05397, 2016.
- Kalashnikov et al. [2021] D. Kalashnikov, J. Varley, Y. Chebotar, B. Swanson, R. Jonschkowski, C. Finn, S. Levine, and K. Hausman. Mt-opt: Continuous multi-task robotic reinforcement learning at scale. arXiv preprint arXiv:2104.08212, 2021.
- Kapturowski et al. [2018] S. Kapturowski, G. Ostrovski, J. Quan, R. Munos, and W. Dabney. Recurrent experience replay in distributed reinforcement learning. In International conference on learning representations, 2018.
- Kim et al. [2023] J. I. Kim, Y. J. Lee, J. Heo, J. Park, J. Kim, S. R. Lim, J. Jeong, and S. B. Kim. Sample-efficient multi-agent reinforcement learning with masked reconstruction. PloS one, 18(9):e0291545, 2023.
- Krishnan et al. [2022] R. Krishnan, P. Esposito, and M. Subedar. Bayesian-torch: Bayesian neural network layers for uncertainty estimation, Jan. 2022. URL https://doi.org/10.5281/zenodo.5908307.
- Kuba et al. [2021] J. G. Kuba, R. Chen, M. Wen, Y. Wen, F. Sun, J. Wang, and Y. Yang. Trust region policy optimisation in multi-agent reinforcement learning. arXiv preprint arXiv:2109.11251, 2021.
- Laskin et al. [2020] M. Laskin, A. Srinivas, and P. Abbeel. Curl: Contrastive unsupervised representations for reinforcement learning. In International Conference on Machine Learning, pages 5639–5650. PMLR, 2020.
- Lee et al. [2024] V. Lee, P. Abbeel, and Y. Lee. Dreamsmooth: Improving model-based reinforcement learning via reward smoothing. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=GruDNzQ4ux.
- Li et al. [2023] J. Li, K. Kuang, B. Wang, X. Li, F. Wu, J. Xiao, and L. Chen. Two heads are better than one: A simple exploration framework for efficient multi-agent reinforcement learning. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 20038–20053. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/3fa2d2b637122007845a2fbb7c21453b-Paper-Conference.pdf.
- Liu et al. [2023] Q. Liu, J. Ye, X. Ma, J. Yang, B. Liang, and C. Zhang. Efficient multi-agent reinforcement learning by planning. In The Twelfth International Conference on Learning Representations, 2023.
- Lowe et al. [2017] R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017.
- Ni et al. [2024] T. Ni, B. Eysenbach, E. Seyedsalehi, M. Ma, C. Gehring, A. Mahajan, and P.-L. Bacon. Bridging state and history representations: Understanding self-predictive rl. arXiv preprint arXiv:2401.08898, 2024.
- Palmer [2020] G. Palmer. Independent Learning Approaches: Overcoming Multi-Agent Learning Pathologies In Team-Games. PhD thesis, University of Liverpool, 2020.
- Qiu et al. [2022] Y. Qiu, Y. Zhan, Y. Jin, J. Wang, and X. Zhang. Sample-efficient multi-agent reinforcement learning with demonstrations for flocking control. In 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), pages 1–7. IEEE, 2022.
- Qu et al. [2022] G. Qu, A. Wierman, and N. Li. Scalable reinforcement learning for multiagent networked systems. Operations Research, 70(6):3601–3628, 2022.
- Schwarzer et al. [2020] M. Schwarzer, A. Anand, R. Goel, R. D. Hjelm, A. Courville, and P. Bachman. Data-efficient reinforcement learning with self-predictive representations. arXiv preprint arXiv:2007.05929, 2020.
- Schwarzer et al. [2021] M. Schwarzer, N. Rajkumar, M. Noukhovitch, A. Anand, L. Charlin, R. D. Hjelm, P. Bachman, and A. C. Courville. Pretraining representations for data-efficient reinforcement learning. Advances in Neural Information Processing Systems, 34:12686–12699, 2021.
- Shang et al. [2021] W. Shang, L. Espeholt, A. Raichuk, and T. Salimans. Agent-centric representations for multi-agent reinforcement learning. arXiv preprint arXiv:2104.09402, 2021.
- Shapley [1953] L. S. Shapley. Stochastic games*. Proceedings of the National Academy of Sciences, 39(10):1095–1100, 1953. doi: 10.1073/pnas.39.10.1095. URL https://www.pnas.org/doi/abs/10.1073/pnas.39.10.1095.
- Song et al. [2023] H. Song, M. Feng, W. Zhou, and H. Li. Ma2cl: Masked attentive contrastive learning for multi-agent reinforcement learning. arXiv preprint arXiv:2306.02006, 2023.
- Stooke et al. [2021] A. Stooke, K. Lee, P. Abbeel, and M. Laskin. Decoupling representation learning from reinforcement learning. In International Conference on Machine Learning, pages 9870–9879. PMLR, 2021.
- Subramanian et al. [2022] J. Subramanian, A. Sinha, R. Seraj, and A. Mahajan. Approximate information state for approximate planning and reinforcement learning in partially observed systems. The Journal of Machine Learning Research, 23(1):483–565, 2022.
- Sutton and Barto [2018] R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. MIT press, 2018.
- Tang et al. [2023] Y. Tang, Z. D. Guo, P. H. Richemond, B. A. Pires, Y. Chandak, R. Munos, M. Rowland, M. G. Azar, C. Le Lan, C. Lyle, et al. Understanding self-predictive learning for reinforcement learning. In International Conference on Machine Learning, pages 33632–33656. PMLR, 2023.
- Tripp et al. [2020] A. Tripp, E. Daxberger, and J. M. Hernández-Lobato. Sample-efficient optimization in the latent space of deep generative models via weighted retraining. Advances in Neural Information Processing Systems, 33:11259–11272, 2020.
- Tseng et al. [2022] W.-C. Tseng, T.-H. J. Wang, Y.-C. Lin, and P. Isola. Offline multi-agent reinforcement learning with knowledge distillation. Advances in Neural Information Processing Systems, 35:226–237, 2022.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Wen et al. [2022] M. Wen, J. Kuba, R. Lin, W. Zhang, Y. Wen, J. Wang, and Y. Yang. Multi-agent reinforcement learning is a sequence modeling problem. Advances in Neural Information Processing Systems, 35:16509–16521, 2022.
- Yang et al. [2021] Y. Yang, X. Ma, C. Li, Z. Zheng, Q. Zhang, G. Huang, J. Yang, and Q. Zhao. Believe what you see: Implicit constraint approach for offline multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 34:10299–10312, 2021.
- Yu et al. [2022] C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu. The surprising effectiveness of ppo in cooperative multi-agent games. Advances in Neural Information Processing Systems, 35:24611–24624, 2022.
- Zhou et al. [2023] L. Zhou, M. Poli, W. Xu, S. Massaroli, and S. Ermon. Deep latent state space models for time-series generation. In International Conference on Machine Learning, pages 42625–42643. PMLR, 2023.
Appendix A MARL Environments
A.1 Vectorized Multi-Agent Environments

A.2 IsaacTeams





Appendix B Implementation of MARL Algorithms
MAPPO
Multi-Agent Proximal Policy Optimization (MAPPO) [53] is a CTDE extension of the Proximal Policy Optimization (PPO) algorithm that employs decentralized policies with centralized value functions. In our implementation, we follow the original paper’s implementation but with a centralized critic shared between all agents.
HAPPO
Heterogenous-Agent Proximal Policy Optimization [29] refines MAPPO, imposing a random-order sequential-update scheme to ensure monotonic improvements unrestricted to the assumption of homogeneity of agents. Our implementation follows the original work, but the main differences stem largely from the shared encoder between the policy and value function. To ensure more stable learning, largely due to the shared encoder, we update the value function upon each agent update and reduce the learning rate of the encoder.
MADDPG
Similar to MAPPO, Multi-Agent Deep Deterministic Policy Gradient (MADDPG) [34] is a CTDE extension of the Deep Deterministic Policy Gradient (DDPG) algorithm. The main difference in our implementation follows [11], including delayed policy updates, target policy smoothing, clipped double learning, stochastic actors and a shared critic between all agents.
MASAC
Multi-Agent Soft Actor Critic is a CTDE extension of the Soft Actor Critic (SAC) algorithm [17]. Our implementation is similar to our MADDPG implementation with adjustments for auto-tuned entropy maximization.
Appendix C Model Architecture
For all algorithms, we follow the same model architecture we described below.
Encoder
The encoder is responsible for embedding the input data and follows the DreamerV3 encoder architecture [19] that most matches the 12M parameter model. For multi-modal data, we process the different modality of data separately, i.e. images with a CNN and structured data with a MLP, and aggregate the embeddings with a sum operator. We define a separate encoder for each agent.
Communication Block
The communication block propagates the embeddings between agents dependent on the communication graph to produce the latent space. We modeled this component after MAMBA’s communication block [9], although we opted to have a smaller model. For partial communication graphs, we mask the embeddings of the unconnected agents. The policy of each agent uses their own latent state to compute their actions, and the centralized critic concatenates the latent state of all agents to compute the value for all agents.
MA-TDR
MA-SPL
Appendix D Hyperparameters
For each task, we initially ran random search over the following hyperparameters and followed up with further tuning using qualitative examinations over these runs.
| Name | Value |
|---|---|
| learning rate | [1e-3, 5e-4, 1e-4, 5e-5, 1e-5, 1e-6] |
| entropy coef. | [1e-5, 1e-3, 3e-4] |
| clip coef. | [0.05, 0.1, 0.15, 0.2, 0.3, 0.5] |
| discount factor | 0.99 |
| num. of updates | 30 |
| target KL | [0.01, None] |
| gradient norm | [0.5, 1.0, None] |
| -return | 0.95 |
| Name | Value |
|---|---|
| learning rate | [1e-3, 5e-4, 1e-4, 5e-5, 1e-5, 1e-6] |
| exploration noise | [0.01, 0.1, 0.5] |
| learning starts | [t, 2t] |
| smoothing noise | [0.1, 0.2, 0.5] |
| smoothing noise clip | [0.01, 0.1] |
| num. of updates | 50 |
| policy update frequency | 2 |
| gradient norm | [0.5, 1.0, None] |
| target network update | 0.005 |
| target network frequency | 2 |
| Name | Value |
|---|---|
| learning rate | [1e-3, 5e-4, 1e-4, 5e-5, 1e-5, 1e-6] |
| learning starts | [t, 2t] |
| num. of updates | 50 |
| policy update frequency | 2 |
| gradient norm | [0.5, 1.0, None] |
| target network update | 0.005 |
| target network frequency | 2 |
| Name | Value |
|---|---|
| [1e-3,0.1,0.5,1] | |
| [1e-3,0.1,0.5,1] | |
| [1e-3,0.1,0.5,1] | |
| [1e-3,0.1,0.5,1] | |
| [1e-3,0.1,0.5,1] | |
| dropout | [0, 0.1, 0.2, 0.5, 0.8] |
| Name | Value |
|---|---|
| [1e-3,0.1,0.5,1] | |
| [1e-3,0.1,0.5,1] | |
| [1e-3,0.1,0.5,1] |
Appendix E Full Results: Efficiacy of MAPO-LSO




Appendix F Full Results: Phasic Optimization For HAPPO/MADDPG/MASAC




Appendix G Full Results: Pretraining Experiments




Appendix H Full Results: Uncertainty Modeling Experiments



Appendix I Full Results: MAPO-LSO Abalations



