Report on Learning Rules for Discrete-valued Networks
Unbiased Weight Maximization
1 Overview
A biologically plausible method for training an Artificial Neural Network (ANN) involves treating each unit as a stochastic Reinforcement Learning (RL) agent, thereby considering the network as a team of agents. Consequently, all units can learn via REINFORCE, a local learning rule modulated by a global reward signal, which aligns more closely with biologically observed forms of synaptic plasticity [1, Chapter 15]. Nevertheless, this learning method is often slow and scales poorly with network size due to inefficient structural credit assignment, since a single reward signal is broadcast to all units without considering individual contributions.
Weight Maximization [2], a proposed solution, replaces a unit’s reward signal with the norm of its outgoing weight, thereby allowing each hidden unit to maximize the norm of the outgoing weight instead of the global reward signal. In this research report, we analyze the theoretical properties of Weight Maximization and propose a variant, Unbiased Weight Maximization. This new approach provides an unbiased learning rule that increases learning speed and improves asymptotic performance. Notably, to our knowledge, this is the first learning rule for a network of Bernoulli-logistic units that is unbiased and scales well with the number of network’s units in terms of learning speed.
2 A single Bernoulli-logistic unit
We first focus on the learning rules for a single Bernoulli-logistic unit with no inputs111To generalize the learning rules to a unit with input, we can multiply the update of the bias by the input to compute the update of the weight associated with that input.: denoting the activation value of the unit by , sigmoid function as , and the scalar bias (the parameter to be learned; not to be confused with the estimation bias of an estimator) by , the distribution of is given by where . After sampling , a scalar reward is sampled from a distribution conditioned on . We are interested in learning such that the expected reward is maximized. We also denote the conditional expectation by , so .
Our goal is to compute or estimate , the gradient of the expected reward w.r.t. parameter , so as to perform gradient ascent on the expected reward.
A direct computation of the gradient gives:
| (1) | ||||
| (2) |
That is, the gradient is positive iff since is always positive. In other words, if the expected reward for firing (i.e. outputting ) is larger than the reward for not firing (i.e. outputting ), then the unit should fire more by increasing . In fact, we see that the optimal is infinitely positive if and infinitely negative if . However, is generally not known.
2.1 A multi-layer network of Bernoulli-logistic units
Before discussing the learning rules, we consider some properties of if the unit is one of the many units in a multi-layer network of Bernoulli-logistic units. In a multi-layer network, units are grouped into different layers. We call the last layer output layer and other layers hidden layers. Units on the output layer are called output units, and units on hidden layers are called hidden units. Activation values of the hidden units are passed to the next layer as inputs, and activation values of the output units are passed to the external environment and determine the reward distribution.
Therefore, if the unit is a hidden unit in a multi-layer network of Bernoulli-logistic units, is passed to units on next layer to determine their activation values by where is the weight connecting from the unit to the next layer’s unit , is the bias of the next layer’s unit , , , and is the number of next layer’s units. We call the vector outgoing weight, and the next layer’s units outgoing units.
From this, we see that can be written as some differentiable function :
| (3) | ||||
| (4) | ||||
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
where (6) uses the assumption that is independent with when conditioned on since the network has a multi-layer structure.
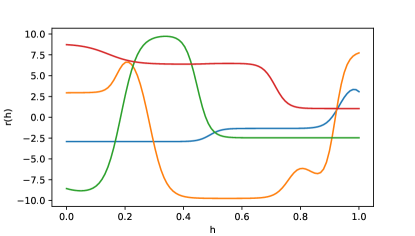
Note that for , is a differentiable function of , so gives a differentiable extension of to . We call this extension a natural extension of , which extends by allowing the unit to pass any values in instead of only to its outgoing units. Though differentiable, the natural extension can be highly non-linear, as shown in Figure 1(a). The natural extension of , which is only applicable for hidden units, is useful as it opens up the possibility of other learning rules that are not possible for output units. For example, we may have some estimates of or when training the outgoing units, which can be used to approximate by first-order Taylor approximation.
We are now ready to discuss the five different estimates of .
2.2 REINFORCE
The gradient can be computed as:
| (9) | ||||
| (10) |
Suppose that we have an unbiased estimate of for any , denoted by , we can then estimate the gradient by:
| (11) |
which is an unbiased estimate of the gradient:
| (12) | ||||
| (13) | ||||
| (14) |
Note that the sampled (conditioned on ) is an unbiased estimate of , so is an unbiased estimate of the gradient and this becomes the REINFORCE learning rule [3].
However, if and are very close, then the expected value of is close to zero as shown by (2). Combined with the variance of , this makes the sign of almost random, and so it takes many steps of gradient ascent to reach . This is indeed the case when the unit is a hidden unit in a large network of Bernoulli-logistic units.
2.3 STE Backprop
Suppose that (i) we can extend to a differentiable function, and (ii) we have an estimate of for any ( denotes the derivative of ), denoted by ; then we can apply STE backprop [4], a common method for training Bernoulli-logistic units ( denotes the indicator function and denotes a uniformly distributed and independent variable):
| (15) | ||||
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) | ||||
| (20) |
where (15) uses the fact that has the same distribution as , and (18) uses the approximation of in STE backprop (note that the actual derivative of is zero at and does not exist at ).
Thus, the estimate of the gradient by STE backprop is given by:
| (21) |
We observe that the form of is very similar to (2). Intuitively, STE backprop is using , i.e. the estimated derivative of at , to approximate . If is a linear function and is unbiased, then and the estimate is unbiased. However, if is a non-linear function, it is possible that always has the wrong sign and thus converges to a value that minimizes instead. This is illustrated in Figure 1(b): in the second , the slope at or are both positive, so the approximated is positive. However, the true is negative, and always has a wrong sign in this case.
The reason for this approximation error is that increasing by a small amount increases the weight placed (or the probability) at and decreases the weight placed (or the probability) at by a small amount, instead of increasing by a small amount (we cannot ‘move’ on the curve ). The latter case corresponds to , i.e. the activation value of the unit is deterministic and equals . In fact, backprop applied on a deterministic ANN with sigmoid activation function gives almost the same parameter update as STE backprop applied on an ANN of Bernoulli-logistic units. In other words, STE backprop treats the network as if the hidden units are outputting expected values instead of sampled values.

2.3.1 Natural Extension
The two assumptions of having an extension and an estimate can be satisfied by using the natural extension defined in (8) if the unit is a hidden unit in a network. To estimate , we observe:
| (22) | ||||
| (23) | ||||
| (24) |
Assuming the outgoing units are also learning through adding some estimates of to its bias , we can use the change of as an estimate of and plug it in the above formula to obtain . The estimate of for outgoing units can be obtained by STE backprop if the outgoing units are hidden units, and REINFORCE (11) or direct computation (2) if the outgoing units are output units.
However, the natural extension of is not linear in most cases, so STE backprop gives a biased estimate. From the Taylor expansion of in (8), the estimation bias is in the order of , the squared norm of the outgoing weight. Note that this estimation bias accumulates across layers as is no longer an unbiased estimator of for units with hidden outgoing units.
2.4 Weight Maximization
Both the parameter updates given by REINFORCE and STE backprop are not necessarily zero when the unit is not firing. A desirable property of a learning rule is that the unit’s parameters are not updated when the unit is not firing. This can be achieved by using as a baseline in REINFORCE:
| (25) |
Note that is an unbiased estimate of conditioned on : if , then ; if , then . Thus, an unbiased estimate of the gradient is:
| (26) |
However, the above estimate cannot be computed since is not known in general. Suppose that (i) we can extend to a differentiable function, and (ii) we have an estimate of for any , denoted as , then we may approximate by , leading to the following estimate of the gradient:
| (27) |
Compared to REINFORCE, Weight Maximization replaced the global reward by the individual reward , which equals zero when the unit is not firing and equals an approximation of by when the unit is firing. Similar to STE backprop, this approximation requires to be linear, which does not hold in most cases.
2.4.1 Natural Extension
The two assumptions of having an extension and an estimate can be satisfied by using the natural extension defined in (8) when the unit is a hidden unit in a network. We can estimate by:
| (28) | ||||
| (29) | ||||
| (30) |
Assuming the outgoing units are also learning through adding some estimates of to its weight , we can use the change of as an estimate of and plug it in the above formula to obtain . This leads to the alternative perspective of maximizing outgoing weights in Weight Maximization [2].
However, the natural extension of is not linear in most cases, so Weight Maximization gives a biased estimate. From the Taylor expansion of in (8), the estimation bias is in the order of , the squared norm of the outgoing weight. Note that this estimation bias accumulates across layers as is no longer an unbiased estimator of for units with hidden outgoing units.
2.5 High-order Weight Maximization
Both STE backprop and Weight Maximization assume the extended to be linear. In particular, Weight Maximization uses to estimate , which is a first-order Taylor approximation. We may use -order Taylor approximation to get a better estimate (where ):
| (31) |
where denotes the -order derivative of . With this new approximation, (27) is generalized to:
| (32) |
This gives the parameter update for -order Weight Maximization, which replaces the global reward in REINFORCE by the individual reward:
| (33) |
We call the learning rule of updating by in -order Weight Maximization. Note that first-order Weight Maximization is equivalent to Weight Maximization discussed in Section 2.4.
Computing requires estimates of for . We discuss how to obtain these estimates next.
2.5.1 Natural Extension
Again, we use the natural extension of . Let first consider :
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) | ||||
| (38) | ||||
| (39) |
Thus, an unbiased estimate of is . If the outgoing units are hidden units and are trained by Weight Maximization, each unit receives a different reward that can be used to replace the global reward in the estimate. If the outgoing units are output unit, we let . Therefore, we have222For simplicity let first assume ; i.e. we ignore the approximation error of Weight Maximization applied on outgoing units. We can still use the global reward if the outgoing units are hidden units, but this leads to a higher variance.:
| (40) |
Note that is also the update to weight for outgoing unit . To simplify notation, we define the following terms:
| (41) |
| (42) |
We see that is an unbiased estimator of . Note that and . Next, consider :
| (43) | ||||
| (44) | ||||
| (45) | ||||
| (46) |
Therefore, is an unbiased estimator of . Next, consider :
| (47) | ||||
| (48) | ||||
| (49) | ||||
| (50) |
Therefore, is an unbiased estimator of . We can continue to compute an unbiased estimator of and so on in the same way. See Appendix A for the general formula of an unbiased estimator of . These estimates are then plugged in (32) to compute .
If the high-order derivatives of in (7) are bounded, i.e. there exists such that for any , for , , then
| (51) |
That is, the estimation bias is in the order of , which converges to as . The proof is based on the error bound of Taylor approximation applied on .
2.5.2 Unbounded Derivatives
Unfortunately, the high-order derivatives of are not bounded for a network of Bernoulli-logistic units. This is because of the sigmoid function in as shown in (7), and the -order derivatives of the sigmoid function are unbounded (see Fig 2). For example, estimating at by Taylor approximation results in a diverging sequence as . Denoting , the estimation bias of -order Weight Maximization applied on a network of Bernoulli-logistic units is , which is unbounded as if (see Appendix B).
In experiments, we observe that high-order Weight Maximization performs similar to low-order Weight Maximization in the beginning of training. But as the norm of outgoing weight grows large during training, the estimation bias becomes larger for a higher , and hence high-order Weight Maximization’s performance deteriorates quickly in the middle of training.
Maybe using activation functions other than the sigmoid function or using weight decay to prevent the outgoing weight’s norm from growing too large can prevent this issue. But there is another method to tackle this issue, which will be discussed next.


2.6 Unbiased Weight Maximization
Let us consider Fig 1 again. All previous methods (except REINFORCE) are based on using the derivative of to approximate . STE backprop approximates it by or ; Weight Maximization approximates it by ; high-order Weight Maximization approximates it by high-order Taylor series of at . The former two methods assume the to be linear, which is not true in general; the last method may lead to a divergent Taylor series if the outgoing weight is too large. Are there any other simple methods to approximates based on ?
Fundamental theorem of calculus tells us that we can integrate over to get :
| (52) |
This can in turn be written as:
| (53) |
where is an independent and uniformly distributed random variable. Thus, if we have an unbiased estimate of for any , denoted as , we may use the following estimate instead:
| (54) |
which is an unbiased estimator of :
Proof.
| (55) | ||||
| (56) | ||||
| (57) | ||||
| (58) | ||||
| (59) | ||||
| (60) | ||||
| (61) |
The last line follows from (2). ∎
Note that is very similar to in (27) - we only replaced in (27) with , i.e. we evaluate the gradient at a random point on instead of .
We also define the individual reward , which is an unbiased estimator of conditioned on :
| (62) | ||||
| (63) | ||||
| (64) |
We call the learning rule of updating by in unbiased Weight Maximization.
2.6.1 Natural Extension
The only remaining question is how can we obtain an unbiased estimate of for any when the unit can only output . Again, let consider the natural extension of . By importance sampling, we have, for any :
| (65) |
where denotes the individual reward to the outgoing unit , which equals the global reward if the outgoing unit is an output unit, or the individual reward computed by unbiased Weight Maximization applied on the outgoing unit if the outgoing unit is a hidden unit. We denote the term in the expectation by , which is an unbiased estimator of and gives an iterative formula to compute the individual reward to all hidden units in a network.
Proof.
| (66) | ||||
| (67) |
If the outgoing units are output units, then by definition, and (67) becomes:
| (68) | ||||
| (69) | ||||
| (70) | ||||
| (71) | ||||
| (72) |
where uses the assumption that is independent with conditioned on since the network has a multi-layer structure.
If the outgoing units are hidden units, then is computed by unbiased Weight Maximization applied on the outgoing units, and by (64). So (67) becomes:
| (73) |
It suffices to show that the second term is zero since the first term is (68):
| (74) | ||||
| (75) | ||||
| (76) |
Note that the event of is not well defined since can only take binary values, and so is defined by allowing to pass any values in to outgoing units (i.e. extending to in (7)). ∎
can then be used to compute by , and can be computed to update .
Note that we can also use multiple i.i.d. or numerical integration333Analytical integration is possible iff each outgoing unit receives the same reward. to estimate to reduce variance, but it does not give a better performance in our experiments.
2.7 Relationship between different Weight Maximization
We have discussed three different forms of Weight Maximization: Weight Maximization in Section 2.4, high-order Weight Maximization in Section 2.5, and unbiased Weight Maximization in 2.6. The only difference between these algorithms is how the individual reward is computed, as shown in Table 1. This individual reward is used to replace the global reward in the REINFORCE learning rule.
Weight Maximization is equivalent to -order Weight Maximization when , as discussed previously. Weight Maximization is also equivalent to unbiased Weight Maximization if we set instead of uniformly sampling from . In other words, Weight Maximization evaluates the gradient at endpoints while unbiased Weight Maximization evaluates the gradient at a random point in .
In addition, it can be shown that if the Taylor series of converges, as , the update given by -order Weight Maximization converges to unbiased Weight Maximization that directly computes instead of estimating it with . The proof is quite long and is omitted here. From this we see that Weight Maximization can also be seen as the first-order Taylor approximation of unbiased Weight Maximization.
Though we include ‘Weight Maximization’ in these learning rules to emphasize their origins, it should be noted that these extensions can no longer be seen as maximizing the norm of outgoing weight as the individual rewards are computed differently compared to Weight Maximization.
| Formula for | Estimation Bias | |
|---|---|---|
| REINFORCE | 0 | |
| Weight Max | ||
| -order Weight Max | where is defined by (82) | |
| Unbiased Weight Max | 0 |
3 Experiments
To test the above algorithms, we consider the -bit multiplexer task. The input is sampled from all possible values of a binary vector of size with equal probability. The output set is , and we give a reward of if the network’s output equals the multiplexer’s output and otherwise. We consider here, so the dimension of the input space is 20. We call a single interaction of the network from receiving an input to receiving the reward an episode; the series of episodes as the network’s performance increases during training is called a run.
We used a three-layer network of Bernoulli-logistic units, with the first and the second hidden layers having units and the output layer having a single unit. The update step size for gradient ascent is chosen as , and the batch size is chosen as (i.e. we estimated the gradient for episodes and averaged them in the update). We used the Adam optimizer [5]. These hyperparameters are chosen prior to the experiments without any tuning.
The average reward in the first episodes for networks with different and learning rules is also shown in Figure 3. The learning curve (i.e. the reward of each episode throughout a run) for each is also shown in Figure 4. Note that the results are averaged over 5 independent runs, and the error bar represents the standard deviation over runs.

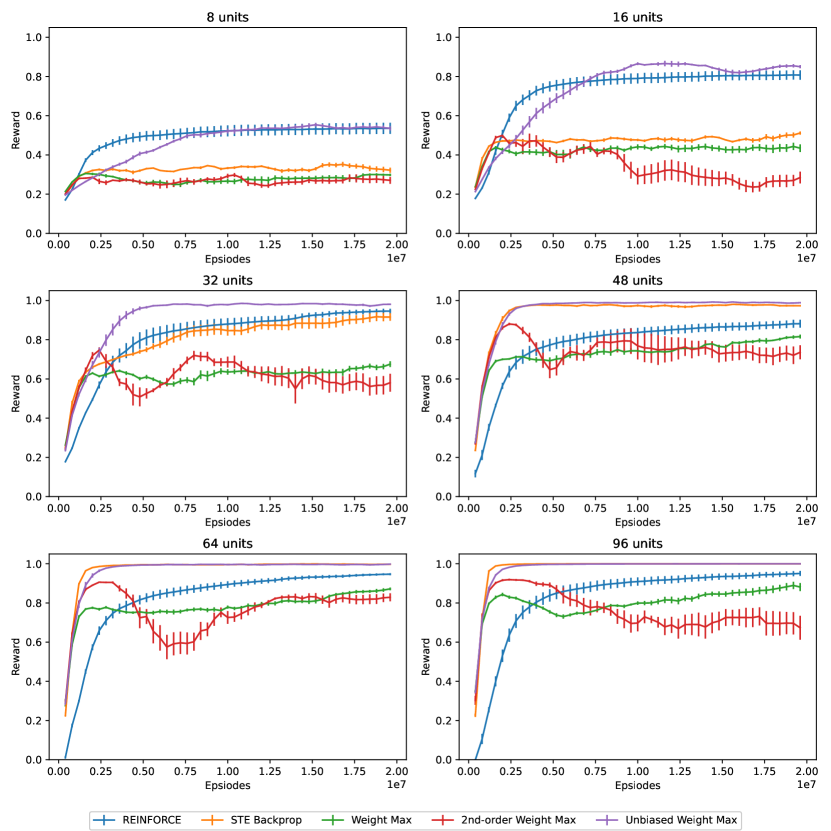
We observe that:
-
•
REINFORCE: When , REINFORCE gives the best performance in terms of both learning speed and asymptotic performance - it is easy to correlate units’ activation values with the reward when the network size is small; but as grows larger than 16, the learning curve does not change much - REINFORCE does not benefit from a larger network due to the increased noise.
-
•
STE Backprop: When is small, STE backprop has a poor asymptotic performance - when there are only a few units, the norm of weight has to be large, and so the network has a very different dynamic than an ANN with deterministic and sigmoid units, which is essentially the assumption of STE backprop. But when the network is large, the dynamic becomes similar, and so STE backprop works well when is large.
-
•
Weight Maximization and second-order Weight Maximization: Both learn fast in the first 1e6 episodes, but performance quickly deteriorates afterward. As the norm of weight grows large during training, estimation bias also grows large. Note that weight decay is required to make Weight Maximization work well, but we did not use weight decay in our experiments as it requires extensive tuning.
-
•
Unbiased Weight Maximization: It works well in terms of both learning speed and asymptotic performance under all . The unbiased property makes it work well when the network size is small, and the use of individual reward makes it scale well with a larger .
We have done additional experiments to understand the different learning rules better. Experiments on -order Weight Maximization for can be found in Appendix C.1. Experiments on variants of unbiased Weight Maximization with a reduced variance can be found in Appendix C.2. Experiments on comparison with continuous-valued ANNs trained by backprop can be found in Appendix C.3. Finally, experiments on the estimation bias and variance of the different estimators can be found in Appendix C.4.
4 Discussion
Both the theoretical results and experiment results of unbiased Weight Maximization are promising. Among all learning rules considered in this report, it is the only unbiased learning rule that scales well in term of performance when the network grows larger. To our knowledge, this is also the first learning rule for a network of Bernoulli-logistic units that have such property.
However, there are a few drawbacks of unbiased Weight Maximization. First, the computation cost to compute the individual reward for a layer is , where denotes the number of units on that layer and denotes the number of units on the next layer, since we have to compute the sampling ratio for each unit and each computation of sampling ratio requires . In contrast, the computation cost to compute the individual reward signal or the feedback signal for a layer is only in Weight Maximization or STE backprop; and no such computation is required for REINFORCE. Second, the computation of individual reward for unbiased Weight Maximization is too involved for biological neurons - it requires all units in a layer to coordinate together to compute the sampling ratio for individual reward signals to the upstream units. REINFORCE or Weight Maximization does not have such issue. Weight Maximization works well when the outgoing weight’s norm is small, and the efficacy of synaptic transmission in biological neurons cannot be unbounded, so Weight Maximization, which can be seen as the first-order approximation of unbiased Weight Maximization, may already be sufficient for biological neurons.
An important and fundamental question in this study is the motivation for discrete-valued ANNs in general. A continuous-valued ANNs trained by backprop can learn faster and has a better asymptotic performance than the discrete-valued ANNs trained by all learning rules considered in this report (see Appendix C.3), and so the motivation of discrete-valued ANNs remains to be explored.
In conclusion, this report analyzes different learning rules for discrete-valued ANNs and proposes two new learning rules, called high-order Weight Maximization and unbiased Weight Maximization, that extend from Weight Maximization. Possible future work includes:
-
•
Perform more experiments to understand the advantages or disadvantages of unbiased Weight Maximization (e.g. generalization error, dynamics of exploration) on standard supervised learning tasks and reinforcement learning tasks.
-
•
Generalize unbiased Weight Maximization to other discrete-valued units besides Bernoulli-logistic units, such as softmax units.
-
•
Adjust unbiased Weight Maximization to encourage exploration, e.g. adding some terms in the learning rule to encourage exploration such as the use of in [6].
-
•
Explore methods to reduce the computational cost of unbiased Weight Maximization or simplify unbiased Weight Maximization while maintaining the performance or the unbiased property.
-
•
Develop an unbiased version of STE backprop, which is straightforward using the idea of unbiased Weight Maximization since both rely on estimates of .
5 Afterword: my view on discrete-valued ANNs
The dynamic of discrete-valued ANNs is very different than continuous-valued ANNs and may lead to a much more powerful network. For example, a restricted Boltzmann machine (RBM) with continuous-valued hidden and visible units can only model multi-variate Gaussian distribution, but an RBM with binary-valued hidden units (which becomes Bernoulli-logistic units) and continuous-valued visible units can model any distributions. Thus, by restricting the activation values of units to binary values, we can get a more powerful network paradoxically. We also observe this phenomenon in some recent advances in deep learning. The attention module in Transformers [7], which led to great success in natural language process (NLP) and underlies virtually all models in NLP nowadays, can be seen as a pseudo-discrete operation: the attention vector from a trained attention module is close to a one-hot vector, and so the network can ‘attend’ to different parts of the input in a discrete manner. Nonetheless, due to the lack of methods to train discrete-valued ANNs efficiently, we can only convert discrete operations to differentiable operations, e.g. through outputting expected values instead of sampled values as in the attention modules of Transformers, and train them by backprop. However, this may not be desirable - when being asked to think about the favorite fruit, we would not think about an apple with intensity, an orange with intensity, and a banana with intensity at the same time; we think of just one fruit at any moment! Clearly, we do not learn by making every thought differentiable. From a microscopic perspective, the output of a single biological neuron is also not differentiable as it either fires or not. Therefore, it may be better to find methods to directly train discrete operations embedded in an ANN instead of trying to design differentiable variants of them. Some discussions on the benefits of discrete-valued representation can be found in [8, 9]. To conclude, the assumption of everything being differentiable, which virtually underlies all recent advances in deep learning, should be questioned.
6 Acknowledgment
We would like to thank Andrew G. Barto, who inspired this research and provided valuable insights and comments.
Appendix A A general formula of
To obtain a general formula for an unbiased estimator of , we first define to be the set of partition of integer , with each partition represented by a tuple of the number of appearance. For example, can be partitioned into . To encode , we see that appears twice, appears once, so it is encoded into . So . Then, we define for by:
| (77) |
and . For example, for to :
| (78) | ||||
| (79) | ||||
| (80) | ||||
| (81) |
And can be expressed by (can be proved by induction; proof omitted here):
| (82) |
where and are defined in (41) and (42). Therefore, the general formula to estimate is . For example, for to (note that they are the same as the estimates derived previously):
| (83) | ||||
| (84) | ||||
| (85) | ||||
| (86) |
Appendix B A general formula of
To see that is unbounded if , it suffices to prove that for ,
| (88) |
Appendix C Additional Experiments
C.1 High-order Weight Maximization
We repeat the same experiment in Section 3 for -order Weight Maximization, with . We use . The result is shown in Figure 5.
We see that -order Weight Maximization performs worse with a larger . Manual inspection shows that the individual reward computed by high-order Weight Maximization can be very large if the outgoing weight’s norm is large. This is essentially due to the problem of approximating the sigmoid function with Taylor series evaluated , which diverges when is too large.
C.2 Variants of unbiased Weight Maximization
In unbiased Weight Maximization we estimate with , which is a Monte Carlo estimate with a single sample. An estimate with a lower variance is , where all are i.i.d. and uniformly distributed. Alternatives, we can estimate by numerical integration using the rectangle rule applied on subintervals. To test these methods, we repeat the same experiment in Section 3 with for both Monte Carlo (MC) and numerical integration (NI). We use . The result is shown in Figure 6.
We see that the learning curves are almost the same. It seems that these different methods to reduce variance do not yield observable improvement in performance despite the reduced variance. Maybe the reduction in variance is not significant enough to affect performance.
C.3 Comparison with continuous-valued ANNs
We repeat the same experiment in Section 3 for continuous-valued ANNs trained by backprop: the output unit is still a Bernoulli-logistic unit trained by REINFORCE, but all hidden units are deterministic sigmoid units trained by backprop. The architecture of the network is the same as the discrete-valued ANNs. Thus, the continuous-valued ANN considered is equivalent to the discrete-valued ANN in our experiments but with hidden units outputting expected values instead of sampled values. The average reward, similar to Figure 3 and Figure 4, is shown on Figure 7 and Figure 8.
We observe that continuous-valued ANNs trained by backprop has a better performance in term of both learning speed and asymptotic performance than discrete-valued ANNs, though the difference narrows for a larger network. This is likely because units in discrete-valued ANNs can only communicate by binary values, which constraints the amount of information passed between units, e.g. a unit can only express if there is an edge but not the probability that there is an edge. As the network size increases, more binary units can detect the same edge, and the average value of these units can estimate the probability that there is an edge, so the difference in performance narrows.
More experiments can be conducted to evaluate and compare discrete-valued ANNs and continuous-valued ANNs on other aspects besides learning speed and network capacity, such as generalization error in supervised learning tasks and dynamics of exploration in reinforcement learning tasks.
C.4 Estimation bias and variance of the estimators
All learning rules discussed can be seen as using different estimators to estimate the gradient of expected reward w.r.t. bias of the unit . To evaluate the quality of estimators, we compute their estimation bias and variance on some randomly selected distributions.
We consider a five-layered network of Bernoulli-logistic units. The first hidden layer and the output layer have a single unit; the other hidden layers have four units. The weight and bias of these units are all uniformly sampled from where . The task considered has no inputs, and the rewards for the two binary outputs are uniformly sampled from . Then we apply the estimators to estimate w.r.t. bias of the unit on the first layer. The estimation bias and variance of the different estimators can be analytically computed as the network’s size is small.
The estimation bias and variance for a network with different parameter range are shown in Figure 9 and Figure 10. We observe that when the is small, the estimation bias of -order Weight Maximization is lower for a higher - at that range, the Taylor series of sigmoid function converges. However, when is large, the Taylor series diverges, and so the estimation bias is larger for a higher . As for variance, we observe that REINFORCE has a steady variance regardless of , since the variance of REINFORCE is bounded by the square of expected rewards. Unbiased Weight Maximization’s variance increases fastest with , since the sampling ratio in unbiased Weight Maximization can be huge when the weight is large. Nonetheless, the large variance of unbiased Weight Maximization seems to have not much impact on the learning curve. This may be explained by the fact that those huge sampling ratios only occur with a probability close to zero and so may never be encountered during training. The relationship between variance and learning speed deserves further investigation.






References
- [1] Richard S Sutton and Andrew G Barto “Reinforcement learning: An introduction” MIT press, 2018
- [2] Stephen Chung “Learning by competition of self-interested reinforcement learning agents” In Proceedings of the AAAI Conference on Artificial Intelligence 36.6, 2022, pp. 6384–6393
- [3] Ronald J Williams “Simple statistical gradient-following algorithms for connectionist reinforcement learning” In Machine learning 8.3-4 Springer, 1992, pp. 229–256
- [4] Yoshua Bengio, Nicholas Léonard and Aaron Courville “Estimating or propagating gradients through stochastic neurons for conditional computation” In arXiv preprint arXiv:1308.3432, 2013
- [5] Diederik P Kingma and Jimmy Ba “Adam: A method for stochastic optimization” In arXiv preprint arXiv:1412.6980, 2014
- [6] Andrew G Barto “Learning by statistical cooperation of self-interested neuron-like computing elements” In Human Neurobiology 4.4, 1985, pp. 229–256
- [7] Ashish Vaswani et al. “Attention is all you need” In Advances in neural information processing systems 30, 2017
- [8] Lorenzo Ferrone and Fabio Massimo Zanzotto “Symbolic, distributed, and distributional representations for natural language processing in the era of deep learning: A survey” In Frontiers in Robotics and AI Frontiers, 2020, pp. 153
- [9] Ruben Cartuyvels, Graham Spinks and Marie-Francine Moens “Discrete and continuous representations and processing in deep learning: looking forward” In AI Open 2 Elsevier, 2021, pp. 143–159
- [10] Ali A Minai and Ronald D Williams “On the derivatives of the sigmoid” In Neural Networks 6.6 Elsevier, 1993, pp. 845–853
- [11] Horst Alzer “Sharp bounds for the Bernoulli numbers” In Archiv der Mathematik 74.3 Springer, 2000, pp. 207–211